
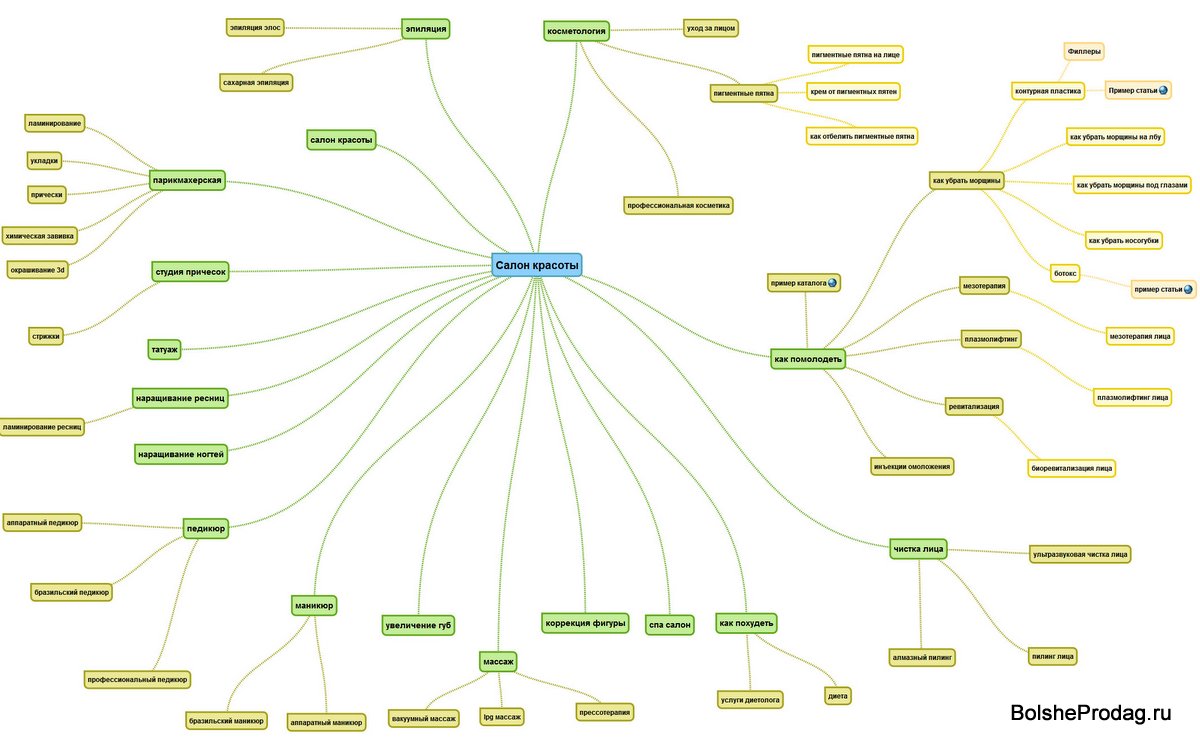
Как сделать работу с семантическим ядром понятной для клиента? — SEO на vc.ru
Работа с семантическим ядром – это не всегда сложные экселевские таблицы с непонятными формулировками. Все может быть гораздо проще и понятнее. Рассказываем в статье, как сделать работу с семантическим ядром прозрачной и полезной для всех сторон, а бизнесу – пользоваться этой информацией. Бонус: обзор лучших инструментов для работы с семантическим ядром.
3423 просмотров
Для кого статья?
- Для оптимизаторов и аналитиков, работающих с семантическим ядром.
- Для руководителей бизнеса и маркетологов, которые заинтересованы в эффективном сотрудничестве с SEO-агентствами.
Материал подготовлен на базе выступления на Optimization-2020 Артема Багненко, ведущего SEO-специалиста в ITECH.group
В чем проблема?
Семантическое ядро – основа продвижения сайта, потому что именно оно и содержит в себе ту информацию/коммерческое предложение, ради которого пользователи заходят на сайт.
Корень проблемы лежит в том, что SEO-специалисту не хватает ориентированности на бизнес клиента!
1. Делайте семантику для клиента, а не только для оптимизатора
Классический подход в сборе семантики выглядит так:
- собираем основные запросы и «хвосты» из различных источников;
- затем кластеризуем;
- определяем преобладание коммерческого интента;
- проектируем по частотности/уровню агрегированности;
- и получаем результаты в виде таблицы Google или Excel.


Чего в этом подходе не хватает клиенту, почему он воспринимает результат без понимания, а то и скептически? При таком формировании семантического ядра отсутствует ориентация на бизнес!
Вы можете обеспечить клиенту трафик на страницы, но бизнесу нужен не просто трафик, а его конвертация в деньги. И никто лучше самого бизнеса не подскажет вам, какие товарные категории маржинальны, куда выгоднее направить трафик.
Для этого необходимо представлять клиенту семантику на языке бизнеса, показывать ему, какой рост трафика возможен по каким категориям, и дать ему наглядную отчетность по всей воронке, начиная от стандартных SEO-показателей, таких как позиции и трафик, заканчивая маржинальностью и другими важными для бизнеса позициями.
Недостаточно собрать семантику запросов, приоритезировать, посадить на какие-то страницы и пытаться эти страницы продвигать. Необходимо понимать цели бизнеса и полностью погрузиться в проект клиента, что увеличивает количество направлений работы с семантическим ядром (выделены на картинке ниже).
2. Ориентируйте работу с семантическим ядром под задачи бизнеса
Каждый из пунктов, выделенных выше на картинке, разберем подробнее:
Товарные категории и их маржинальность
Что касается товарных категорий, то здесь необходима внимательная связь с клиентом, так как только через него вы сможете понять: какие категории маржинальны, на какие делать фокус. Маржинальность страниц, на которые ведут запросы, определяет, что выгоднее продвигать бизнесу.
Интенты
Интенты страниц — еще одна проблема. Много лет существует тенденция смотреть результаты поисковой выдачи, делать анализ сайтов конкурентов и использовать похожие типы страниц. При этом по-прежнему в SEO не все смотрят на интенты, какого типа страницы нужны пользователям, и из-за этого теряют способ повышения релевантности страниц.
Типы страниц
Семантику необходимо разбивать под типы страниц — будь то листинги, детальная карточка товара или главная страница.
Уровень агрегированности по запросу
Уровень агрегированности по запросу важен для расставления приоритетов, особенно для молодых проектов, где это — основной способ понять, куда лучше заходить по запросам и по каким.
Понимание семантики клиентом
И, конечно, нужно понимание со стороны клиента, которому необходимо объяснять, какую выгоду он получит в результате проделанной вами работы. Как говорили выше — не всегда клиенту понятны эксельки — нужно объяснять, что за выгоду вы ему даете.
3. Разбивайте семантику в понятной клиенту форме
Приведем примеры разбивки семантики на примере кейса в спортивной нише.
Разбивка семантики по категориям
Вот пример базовой разбивки небольшой семантики в тематике «спортивные очки» по категориям (видам) на основе общей частотности тэга.
Здесь мы видим, что в нише спортивных очков преобладают очки для плавания, далее идут спортивные солнцезащитные очки, и все остальные имеют довольно маленькую долю. Становится понятно, какие категории дают больше трафика, какие меньше.
Становится понятно, какие категории дают больше трафика, какие меньше.
Как понять, с какими трафикообразующими категориями работать в первую очередь? Тут SEO-специалист не может принять правильное решение без взаимодействия с клиентом! Когда у вас уже есть понимание, какая категория сколько трафика приносит, необходимо общаться с клиентом для расстановки приоритетов. Только клиент скажет вам, что, например, «для плавания» не самая маржинальная категория, а вот «лыжные» — наиболее маржинальная. И тогда можно будет понять, что выгоднее: попасть в топ по большому спросу с менее маржинальным товаром, или выводить в топ более маржинальный товар с меньшим спросом. Без погруженности в бизнес правильный выбор сделать не получится!
Разбивка по сайтам в SERP (Search Engine Results Page, или результаты поисковой выдачи)
Другой пример — анализ позиций различных сайтов в SERP (анализ видимости) в той же тематике и ее семантике.
Здесь две цели на выбор: либо отобрать сайты для дальнейшего анализа, либо оценить емкость тематики и ее лидеров для составления стратегии продвижения.
— Отбор сайтов полезен, если нужно сделать перекластеризацию, текстовый анализ и т.п. Для решения подобных задач не подходит ориентир на сайты, которые занимают место в топе не по причине хороших текстов или LSI, а по другим факторам — размер и т.п. Поэтому анализируем и исключаем сайты типа Яндекс.Маркет, Озон, Goods.ru, которые не дадут релевантной информации.
— Оценивая емкость тематики, важно сразу выявить лидеров и снимать их позиции. Потому что даже при небольшой семантике на 7-10 тысяч запросов будет огромное количество сайтов. Снять позиции по всему пулу запросов по каждому сайту нереально. Так мы получаем оценочные доли лидеров тематики и можем смотреть референсы, из которых стоит выбрать какие элементы, которые позволяют этим сайтам держаться в топе.
Разбивка по брендам
Базовая разбивка по брендам также очень важна, особенно если SЕO-специалист работает с e-commerce.
Разбивка по выдаче в блоке контекстной рекламы
Сложно добиться успеха в продвижении, не обеспечивая себе максимальное покрытие во всем поисковом пространстве и не понимая, с кем вы в нем конкурируете.
Полезно понимать, какие сайты часто встречаются в контекстной рекламе, так как контекст активно присутствует в SERP. Данный анализ покажет, как в выдачу заходят конкуренты и откуда они получают трафик.
6 лучших инструментов для работы с информацией в SERP
Чем больше информации с SERP мы сможем получить, тем качественнее будет тэгирование. Для автоматизации работы используйте инструменты, которые могут дать максимум необходимой информации в одном месте. Про каждый инструмент подробно пишем ниже.
Rush Analytics предоставляет понятную кластеризацию: мы видим силу связей, степень совпадений, количество главных страниц по каждому кластеру, подсветки, кто является лидерами тематики. Отдельно показываются запросы, которые не попали в кластеры. Имеется достаточно гибкая настройка, также можно получить релевантные страницы своего домена, что тоже очень полезно для дальнейшей работы в Google Data Studio.
Отдельно показываются запросы, которые не попали в кластеры. Имеется достаточно гибкая настройка, также можно получить релевантные страницы своего домена, что тоже очень полезно для дальнейшей работы в Google Data Studio.
Пиксель Тулс дает чуть менее гибкую настройку кластеризации. Это связано с тем, что у сервиса есть большое количество других инструментов помимо кластеризатора, в которых можно получить дополнительную информацию (правда, за отдельные лимиты). Здесь также мы получаем вменяемые кластеры, позиции, главные страницы, хоть меньшее количество настроек на входе может искажать информацию.
Keys.so — лучший инструмент по полноте информации, но не лучший кластеризатор. Вы получите очень много информации по SERP (степень агрегированности, коммерция), сможете выделить топонимы из семантики. Для кластеризации лучше использовать другие сервисы.
Just-magic очень хорошо кластеризует семантику, в том числе большие объемы. Здесь есть разделение по тематике, что упрощает тэгирование: по тематике запроса можно понять, к какой категории относится запрос. Особенно это удобно на этапе разработки сайта, когда еще нет URL’ов, к которым можно привязать и промаркировать семантику. Инструмент также снимает позиции и частотность.
Особенно это удобно на этапе разработки сайта, когда еще нет URL’ов, к которым можно привязать и промаркировать семантику. Инструмент также снимает позиции и частотность.
Аrsenkin.ru особенно хорошо работает на маленьких анализах. Здесь гибкая настройка на вход, как soft, так и hard кластеризация работает качественно. На выходе получаем также такую полезную информацию как позиции, частотность, геозависимость, но относительно слабое место — сила связей.
Searchlab от Лаборатории поисковой аналитики — один из наиболее полных инструментов. Он делает качественную кластеризацию, показывает степень совпадения запросов, количество главных страниц по кластеру, подсветки. Также он дает возможность работать с теми запросами, которые не вошли в кластеры, с учетом связей. Это очень полезная функция, так как, например, при большой семантике на 30-50 тысяч запросов при кластеризации очень большая часть реально важных для сайта запросов попадает в некластеризованные. Другие инструменты не дают возможности глубоко поработать с ними. Searchlab дает информацию о силе связей у некластеризованных запросов и возможность распределить эти запросы по другим кластерам. Плюс он позволяет бесплатно провести перекластеризацию с другими параметрами.
Searchlab дает информацию о силе связей у некластеризованных запросов и возможность распределить эти запросы по другим кластерам. Плюс он позволяет бесплатно провести перекластеризацию с другими параметрами.
Также инструмент показывает лидеров тематики, предоставляет возможность получить релевантные страницы своего домена. Здесь очень гибкий функционал: можно использовать hard и soft кластеризацию, не ограничиваться ТОП-10, а брать ТОП-30, чтобы получить больше корреляций. Searchlab определяет информационность запроса, тематику, интенты, то есть дает практически всю нужную информацию.
У Searchlab есть очень полезная функция «исключение сайтов». Выше мы говорили об отсеве маркетплейсов, агрегаторов и т.п., которые обычному сайту ну никак не конкуренты. В этом инструменте мы можем их исключить и определить, какие сайты нам нужны для сравнения. Сама работа кластеризатора похожа на Rush Analytics, он дает чуть больше возможностей настроек на входе. В целом я возлагаю на него большие надежды и ставлю оценку 9 из 10.

Итоги обзора и оценки инструментов по 10-ти бальной шкале
При сравнении инструментов учитывайте, что невозможно найти универсальный сервис, «волшебную кнопку», которая даст полностью все данные о SERP. Пока что все равно приходится использовать несколько решений, чтобы получить всю полноту информации.
Как SEO-специалисту и клиенту общаться эффективно и взаимовыгодно?
Для налаживания взаимодействия можно использовать дашборды Google Data Studio, созданные на основе данных из облачных инструментов.
Ранее в нашем блоге мы уже рассказывали о необходимости использовать для отчетов не тяжелые для восприятия таблицы и выгрузки, а наглядные кастомные отчеты. Достаточно простой дашборд (на рисунке), собранный в Google Data Studio, сделает процесс общения и сотрудничества с клиентом реально удобным. На таких дашбордах наглядно представлена вся информация по работе.
Здесь показаны запросы по категориям, и по каждому сразу виден коммерческий интент, позиции по Яндексу и Google, URL’ы и т. п. Клиент сразу действительно понимает, чем вы занимаетесь, и видит, какие его запросы как ранжируются, какие категории доминируют в семантике.
п. Клиент сразу действительно понимает, чем вы занимаетесь, и видит, какие его запросы как ранжируются, какие категории доминируют в семантике.
Часто случается, что оптимизатор чего-то не знает, потому что не погружен в бизнес, а клиент, получив и поняв всю полноту данных, дает великолепные инсайты. Работая с клиентом, проще тэгировать семантику и расставлять ее по страницам.
Клиенты, не имеющие представления, как вы работаете с семантикой, рано или поздно захотят найти такого подрядчика, который даст им ответы на вопросы. Давая развернутую информацию и понятные дашборды, вы даете космический рост LTV.
Google Data Studio — простой в освоении инструмент с интуитивно понятным интерфейсом. С ним могут работать как оптимизаторы, так и аналитики. Кто из них будет составлять дашборды для клиента, зависит от конкретного проекта и степени вовлеченности специалиста в него.
Загружаем в инструмент семантику и данные и даем возможность клиенту самому смотреть разрезы по маржинальности, по брендам, по деньгам и так далее. Фактически клиент получает аналитический инструмент его собственной ниши, ради которого он нанимает себе целый отдел маркетинга.
Фактически клиент получает аналитический инструмент его собственной ниши, ради которого он нанимает себе целый отдел маркетинга.
Выводы:
- Для эффективной работы SEO-специалисту необходимо погружаться в бизнес клиента и ориентироваться на его приоритеты, а не только на трафик.
- Тэгирование семантики необходимо для продвижения нужных бизнесу маржинальных товаров и категорий. Также необходимо обращать внимание на интенты страниц.
- Идеального инструмента для работы с семантикой пока нет, но некоторые облачные сервисы во многом приблизились к этой цели.
- Отчеты для бизнеса должны формироваться не в виде тяжелых для восприятия таблиц и массивов данных, а в формате дашбордов и виджетов, где сам клиент может смотреть срезы сравнения по тем или иным категориям.
- Взаимопонимание с клиентом позволяет оптимизировать сайт в нужном направлении и давать бизнесу тот результат, в котором он нуждается. Понятная отчетность повышает профессиональную ценность оптимизатора для клиента.
 Понятная отчетность повышает профессиональную ценность оптимизатора для клиента.
Понятная отчетность повышает профессиональную ценность оптимизатора для клиента.Материал подготовлен на базе выступления на Optimization-2020 Артема Багненко, ведущего SEO-специалиста в ITECH.group
Основные ошибки при работе с семантическим ядром: топ-5
72465 58 1
| SEO | – Читать 17 минут |
Прочитать позже
Михаил Ахромушкин
Руководитель отдела поискового продвижения Ingate
Если семантическое ядро составлено некорректно, сайт не завоюет высокие позиции в выдаче поисковых систем по желаемым ключевым словам, трафик не вырастет, затраты на продвижение не оправдаются.Как не свести на нет все усилия и сделать продвижение эффективным, расскажет Михаил Ахромушкин из Ingate.
Содержание
Ошибка #1: Использование искусственной семантики
Ошибка #2: Постраничная проработка страниц ресурса без учета общего семантического ядра
Ошибка #3: Использование ограниченного числа запросов для одной страницы
Ошибка #4: Составление семантического ядра без учета особенностей и тематики сайта
Ошибка #5: Объединение коммерческих и информационных запросов для одной страницы
Итог: Краткий чек-лист по работе с семантическим ядром сайта
 Многие начинающие специалисты копируют подходы без глубокого понимания принципов работы.
Многие начинающие специалисты копируют подходы без глубокого понимания принципов работы.Как итог: снижаются позиции сайта в выдаче и трафик по большому числу запросов. Чтобы этого избежать, врага надо знать в лицо. Поэтому рассмотрим основные ошибки при работе с семантическим ядром подробнее.
Краткая сводка: 5 ошибок при работе с семантическим ядром
Неконтролируемое использование искусственной семантики.
Проработка страниц сайта без учета общего семантического ядра.
Ограниченное количество запросов для страницы.
Составление семантического ядра без учета тематики сайта.
Использование коммерческих и информационных запросов на одной странице.
Теперь подробнее о каждом пункте.
Ошибка #1:
Использование искусственной семантики
 Ее часто называют мусорной.
Ее часто называют мусорной.Иными словами, искусственная семантика включает большое число запросов с множеством вариантов расстановки слов (например, «купить кухню» и «кухню купить»), которые реальные пользователи никогда не вводят в поисковую строку.
Например, «*название раздела* купить», «*название подкатегории* в Москве», «*название тега* недорого» и т. д.
Способы получения искусственной семантики:
Использование сервисов, программ генерации ключевых фраз. Например, PromoTools.ru.
Применение функции «СЦЕПИТЬ» в Microsoft Excel (для сцепки названий категорий с транзакционными словами).
Недостатки искусственной семантики:
Не используются поисковые подсказки, необходимые для привлечения дополнительного трафика на сайт из органической выдачи. При составлении искусственной семантики невозможно предугадать возможные комбинации, которые пользователи вводят в поисковую строку.
При составлении искусственной семантики невозможно предугадать возможные комбинации, которые пользователи вводят в поисковую строку.
Не учитывается последовательность слов и их формы. Как следствие, выбираются запросы, имеющие неоптимальную форму — т. е. с меньшим спросом, например, «купить кухни» с чистым спросом 20 000 против «кухню купить» с чистым спросом 200 000. А позиции сайта отслеживаются по ключевым словам с минимальным, а не максимальным спросом.
Теряется большое число запросов за счет отсутствия анализа конкурентов или поверхностного изучения тематики продвигаемого сайта.
Невозможно корректно распределить запросы на группы для дальнейшего продвижения.
В результате искусственная семантика приводит к:
формированию большого числа «запросов-пустышек» (поисковых фраз, по которым в реальности переходит меньше пользователей, чем это показывают статистические прогнозы)
потере большого количества запросов, которые задают реальные пользователи
и, как следствие, отсутствию трафика на сайт из поисковой системы.

По запросу «игрушки в москве» в топ-5 выдачи Яндекса преобладают главные страницы сайтов.
По запросу «купить игрушки» в топ-5 выдачи Яндекса преобладают внутренние страницы сайтов с каталогом товаров.
Искусственную семантику не следует использовать для развитых сайтов, которые уже имеют базовую оптимизацию, так как возникают высокие риски снижения трафика на значительное число страниц.
Однако полностью отказываться от этого способа составления семантического ядра не стоит. Он может быть применим для новых сайтов или разделов ресурса, когда необходимо в короткие сроки и при минимальных трудозатратах создать большое число страниц и сформировать структуру подкатегорий или тегов.
Как правильно работать с искусственной семантикой?
Формируйте список синонимов, а также альтернативных написаний названия категории, тега, подкатегории. Например, «игрушки для детей» и «детские игрушки».
Используйте кластеризацию по методу подобия топов: группируйте ключевые слова на основе анализа выдачи поисковых систем. Это позволит избежать ошибки продвижения разных запросов на одной странице. Выполнить кластеризацию можно в различных сервисах, например, JustMagic или с помощью API Serpstat.
С помощью асессорской оценки сайтов и анализа конкурентов в топ-10 оценивайте посадочные страницы и на основании полученных данных формируйте структуру сайта.
Как собрать семантическое ядро самостоятельно с помощью Serpstat
| Читать! |
Ошибка #2:
Постраничная проработка страниц ресурса без учета общего семантического ядра
Эта проблема связана преимущественно с большим числом синонимов или аналогичных написаний запросов, которые невозможно учесть без мощного лингвистического анализа.
Например, по ряду тематик для Яндекса слова «купить» и «заказать» равноценны, хотя с точки зрения логики и лингвистического анализа — это разные леммы. Поэтому необходимо работать с учетом общего семантического ядра и на основание этого формировать посадочные страницы, а также структуру сайта.
Основные недостатки постраничной проработки страниц без учета общего семантического ядра:
Подбор семантики в отрыве от системных проблем ресурса. Например, страница не ранжируется в выдаче по запросу «купить» из-за отсутствия определенного функционала, недостаточного ассортимента и других факторов, которые влияют на ранжирование этой леммы.
Крайне низкий порог заимствования фич, используемых конкурентами (например, создание большого числа одностраничных поддоменов для продвижения по высокочастотным запросам или применение технологии параллакс-скроллинг, которая позволяет использовать для продвижения страницы с якорями и отдавать разный контент в рамках одной страницы).
Как правильно прорабатывать страницы ресурса?
Осуществляйте парсинг семантического ядра в тематике.
Распределяйте большинство запросов по посадочным страницам сайта (для каждой группы запросов нужна релевантная страница с отдельным URL).
Проводите асессорскую оценку, анализируйте конкурентов в топ-10, собирайте дополнительную информацию по типам запросов (информационные, коммерческие), их частотности, сезонности для дальнейшей аналитики и выведения сайта в топ поисковой выдачи.
Как собрать семантическое ядро, чтобы полностью охватить тематику
| Читать! |
Ошибка #3:
Использование ограниченного числа запросов для одной страницы
Существует множество сайтов, которые ранжируются в топ-3 и топ-5 по двумстам-тремстам запросам различной частотности. С помощью Serpstat посмотрим, по какому числу запросов ранжируется одна страница сайта интернет-магазина Wildberries.ru.
На примере мы еще раз доказали, что одна страница сайта может эффективно продвигаться (а в данном случае она занимает 1-е место в выдаче поисковых систем) по большому числу запросов: В Яндексе (по региону Москва) по 615 ключевым фразам, в Google (по России в целом) по 522-м.
Как создать структуру сайта на основе семантики
| Читать! |
Недостатки этого метода:
Ограниченное семантическое ядро.
Отсутствие оптимизации страницы под все запросы, которые могут ранжироваться на эту посадочную страницу.
Продвижение сайта по высококонкурентным запросам, по которым ресурс маловероятно попадет в топ выдачи.
Создание большого числа страниц, по которым пользователи не переходят из поисковых систем, способствует ухудшению хостовых и кликовых поведенческих факторов ранжирования.
Следствием работы с ограниченным количеством запросов для одной страницы является минимальный объем трафика на сайт. Данный подход приемлем только при продвижении незначительного числа ключевых слов с отчетностью за позиции.
Как правильно подбирать запросы для продвижения?
Проанализируйте сайты конкурентов, находящиеся в топе выдачи поисковых систем.
Посмотрите, по каким запросам успешно ранжируются конкретные страницы, и с учетом этого составьте семантическое ядро для продвижения вашего ресурса.
Хотите с помощью Serpstat собрать качественную семантику?
Активируйте триал и протестируйте платформу бесплатно в течение 7 дней!
| Зарегистрироваться! |
Ошибка #4:
Составление семантического ядра без учета особенностей и тематики сайта
Например, сайт, занимающийся продажей женских сумок в розницу, продвигается по запросу «женские сумки оптом» только потому, что по этому запросу эффективно ранжируется сайт конкурента (при этом конкурент занимается продажей женских сумок и в розницу, и оптом).
В итоге продвижение по этому запросу не принесет результата, так как на сайте данная услуга не представлена. Или страница оптимизирована под запросы, содержащие слово «цена», при условии, что на сайте в принципе не указаны цены. Продвижение по таким ключевым словам также не приведет к повышению позиций в выдаче.
Недостатки этого метода составления семантического ядра:
Сайт, который продвигается по запросам, не учитывающим его особенности и тематику сайта, не будет ранжироваться в поисковых системах. Это связано с тем, что коммерческие и поведенческие факторы имеют большое значение в формуле ранжирования.Посетители сайта будут плохо конвертироваться в клиентов, если ресурс не закрывает их потребности. А проведение только текстовой оптимизации и оптимизации важных зон (title, h2 и пр.) не принесет значимого результата.
Как правильно составлять семантическое ядро?
Все запросы должны строго соответствовать тематике сайта и наличию на нем определенного контента.
Ассортимент товаров на сайте не должен уступать ассортименту конкурентов в топе, если вы продвигаете ресурс по аналогичным запросам. В противном случае продвижение не принесет реальной пользы и будет сводиться к попыткам обмануть поисковые системы.
Как собрать максимально полное семантическое ядро и провести точечную SEO-аналитику + документ с готовой семантикой
| Читать! |
Ошибка #5:
Объединение коммерческих и информационных запросов для одной страницы
Еще одна ошибка при работе с семантическим ядром сайта — продвижение одной страницы одновременно и по информационным, и по коммерческим запросам. Например, по запросам «канализация для дачи» (информационный) и «канализация для дачи цена» (коммерческий).
Недостаток данного метода:
Коммерческие и информационные запросы имеют разные факторы ранжирования, которые зачастую противоречат друг другу. Как следствие, страница может попасть в выдачу либо только по информационным запросам, либо только по коммерческим.
Как следствие, страница может попасть в выдачу либо только по информационным запросам, либо только по коммерческим.
Как избежать этой ошибки?
Изначально правильно сгруппируйте запросы по типам страниц в выдаче. Разводите информационные и коммерческие запросы на разные страницы и проводите их оптимизацию исходя из результатов поисковой выдачи.Зачастую нельзя сразу определить, к какой группе относится тот или иной запрос. Например, по запросу «смартфоны » выдача коммерческая, а по запросу «смартфон» — информационная.
Лучший способ проверить, можно ли продвигать запросы на одной странице, — сравнить страницы, находящиеся по ним в топе. Если в топ-10 по «запросу №1» и в топ-10 по «запросу №2» находятся одинаковые страницы, эти ключевые фразы можно продвигать на одной странице.
Как правильно собирать ключевые фразы для SEO: пошаговая инструкция
| Читать! |
Как итог:
Краткий чек-лист по работе с семантическим ядром сайта
Не подбирайте запросы, некорректные с точки зрения русского языка, например, «цветы букеты доставка Москва», «цена ремонт отделка» и другие.
При составлении семантического ядра не игнорируйте существующее ранжирование сайта по запросам: их изменение или удаление из текстов и метатегов может негативно сказаться на числе переходов на сайт, а как следствие, и на позициях в выдаче.
Не выбирайте слишком общие запросы. Продвижение по ним может быть неэффективным, так как высока вероятность перехода на сайт нецелевых посетителей.
При составлении семантического ядра учитывайте реальные запросы пользователей. В результате использования метода искусственной семантики могут сформироваться «запросы-пустышки», что приведет к отсутствию трафика из поисковой системы.
Прорабатывайте каждую страницу ресурса с учетом общего семантического ядра, включающего не только сами запросы, но и их синонимы.
Составляйте семантическое ядро с учетом особенностей сайта, его тематики, наличия определенного контента и функциональных элементов.
Группируйте запросы по типам страниц в выдаче: коммерческие и информационные запросы должны вести на разные страницы.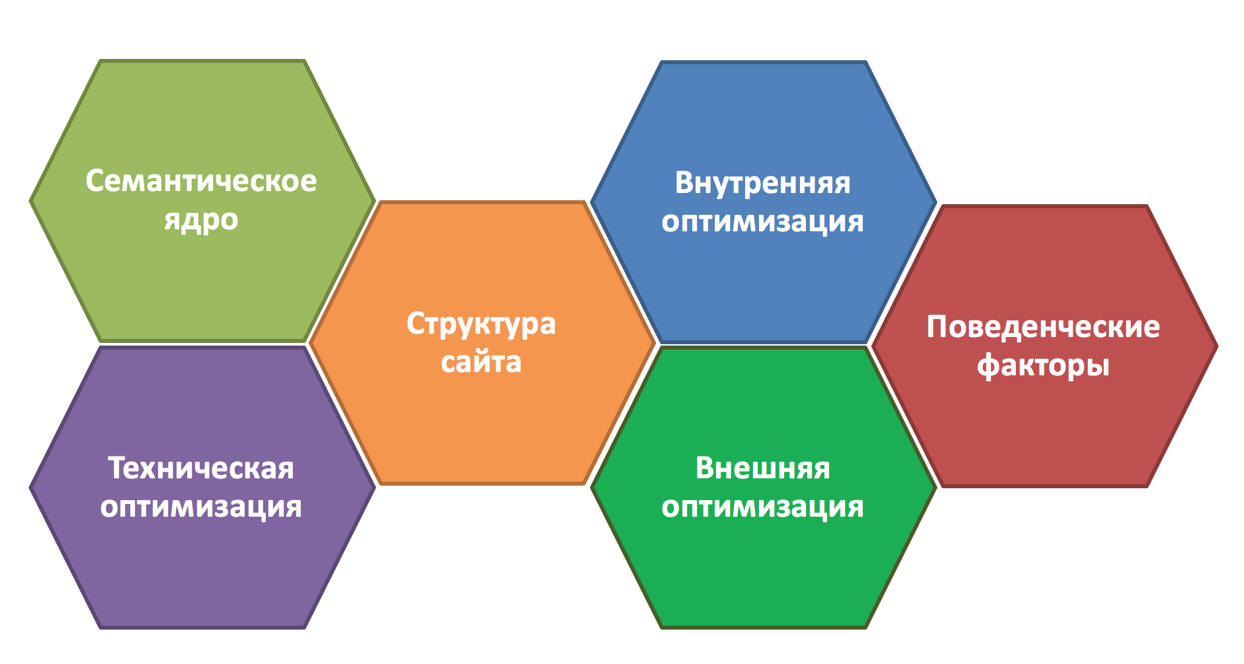
Следуя моим рекомендациям, вы сделаете семантическое ядро мощным инструментом для эффективного продвижения ресурса и получите еще больше целевого трафика на сайт.
Чтобы быть в курсе всех новостей нашего блога подписывайтесь на рассылку Serpstat. У вас есть целых 11 причин, чтобы это сделать 😉
А также вступайте в чат любителей Серпстатить и подписывайтесь на наш канал в Telegram.
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
7 дней бесплатноОцените статью по 5-бальной шкале
4.2 из 5 на основе 111 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Используйте лучшие SEO инструменты
Проверка обратных ссылок
Быстрая проверка обратных ссылок вашего сайта и конкурентов
API для SEO
Получите быстро большие объемы данных используя SЕО API
Анализ конкурентов
Сделайте полный анализ сайтов конкурентов для SEO и PPC
Мониторинг позиций
Отслеживайте изменение ранжирования запросов используя мониторинг позиций ключей
Рекомендуемые статьи
SEOЮлия ГончаренкоКакие страницы сайта нужно оптимизировать в первую очередь?
SEOАнастасия СотулаЧто мы знаем о метриках оценки качества поиска в machine-learned ranking [MLR]
SEO +1Александр ШараевскийКак убедиться, что собранная семантика полностью охватывает тематику
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
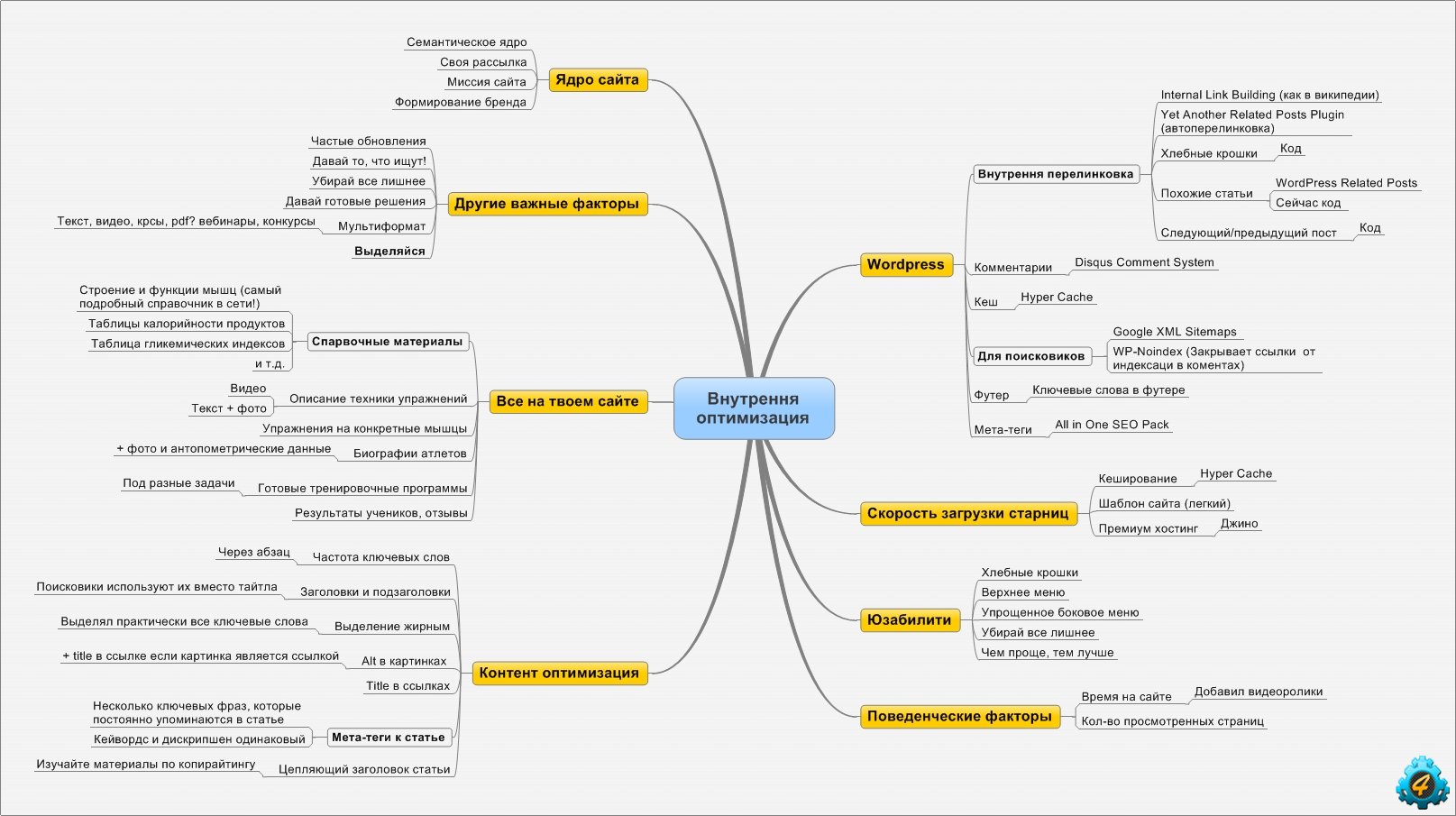
Семантическое ядро (интеграция AI LLM) получает инструменты VS Code, поддержку Python — Visual Studio Magazine
Новости
Семантическое ядро (интеграция AI LLM) получает инструменты VS Code, поддержку Python /2023
Microsoft была занята обновлением своего недавно открытого внутреннего инкубационного проекта под названием Semantic Kernel, SDK, который позволяет разработчикам смешивать обычные языки программирования с последними подсказками ИИ в Large Language Model (LLM).
Это помогает разработчикам внедрять в свои приложения передовые технологии искусственного интеллекта, в том числе чрезвычайно популярные системы генеративного искусственного интеллекта, такие как ChatGPT и GPT-4 от партнера Microsoft OpenAI. По словам Microsoft, SDK предоставляет возможности шаблонов, цепочек и планирования для более быстрого и простого создания приложений, ориентированных на ИИ.
По словам Microsoft, SDK предоставляет возможности шаблонов, цепочек и планирования для более быстрого и простого создания приложений, ориентированных на ИИ.
Улучшение подсказок, связанное с новой дисциплиной «оперативной разработки», которая может платить до 335 000 долларов в год, является одним из четырех ключевых преимуществ, которые Microsoft перечисляет для проекта с открытым исходным кодом:
- Быстрая интеграция: SK предназначен для встраивания в любое приложение, что упрощает тестирование и запуск LLM AI.
- Расширяемость: С помощью SK вы можете подключаться к внешним источникам данных и службам, предоставляя их приложениям возможность использовать обработку естественного языка в сочетании с оперативной информацией.
- Улучшенные подсказки: шаблонные подсказки SK позволяют быстро разрабатывать семантические функции с полезными абстракциями и механизмами, чтобы раскрыть потенциал LLM AI.
- Новый, но знакомый: Родной код всегда доступен для вас в качестве первоклассного партнера в ваших стремительных инженерных поисках. Вы получаете лучшее из обоих миров.
После открытия исходного кода Semantic Kernel в прошлом месяце компания на прошлой неделе объявила о выпуске Semantic Kernel Tools, расширения для Visual Studio Code, а на этой неделе объявила, что оно доступно в версии Python.
Инструменты семантического ядра
Это расширение VS Code, которое теперь доступно на рынке редакторов кода, предназначено для того, чтобы помочь разработчикам писать навыки для семантического ядра. Microsoft «Что такое навыки?» документация описывает навык как область знаний, доступную ядру как единую функцию или даже как группу функций, связанных с навыком. Функция может быть подсказкой LLM AI, собственным кодом или их комбинацией. Например, навык суммирования может использовать подсказки LLM AI для создания сводок текста или речи.
В списке инструментов Semantic Kernel Tools на рынке объясняется, как создать семантический навык и выполнить семантическую функцию, а также приведены рекомендации по устранению неполадок и другие рекомендации. Как совершенно новый инструмент, на момент написания этой статьи он был загружен всего 424 раза, дебютировав 11 апреля и обновившись в понедельник.
[Щелкните изображение, чтобы увеличить его.] Инструменты семантического ядра (источник: Microsoft).Microsoft заявила, что упрощенный процесс разработки, обеспечиваемый инструментами, может помочь программистам быстрее и эффективнее создавать и тестировать новые навыки, позволяя им сосредоточиться на творческих аспектах своих проектов, а не погружаться в технические детали.
«Благодаря возможности создавать собственные навыки разработчики могут адаптировать свои проекты для удовлетворения конкретных потребностей и целей», — говорится в сообщении компании. «Будь то чат и диалоговое взаимодействие, генерация или преобразование кода, ответы на вопросы или любой другой предполагаемый вариант использования, инструменты семантического ядра обеспечивают гибкость и мощность, необходимые для создания инновационных и эффективных проектов.
«Мы считаем, что инструменты семантического ядра представляют собой значительный шаг вперед в развитии технологий ИИ. Предоставляя удобную и доступную среду разработки, мы надеемся дать разработчикам возможность создавать приложения и сервисы на основе ИИ нового поколения».
Семантическое ядро теперь доступно в версии Python
Когда семантическое ядро дебютировало, оно работало только с проектами C#, хотя поддержка Python была в предварительной версии. На этой неделе эта поддержка Python перешла от экспериментального предварительного просмотра к официальному выпуску, доступному на GitHub.
«Python широко используется в ИИ и машинном обучении, что делает его отличным выбором для изучения и интеграции ИИ», — заявили в Microsoft. «В результате SK получает множество алгоритмов, функций и библиотек ИИ, таких как TensorFlow, PyTorch, Scikit-learn, Pandas, Keras, NLTK, Caffe и т. д. Кроме того, разработчики SK могут легко извлечь выгоду из предварительно обученных моделей от HuggingFace, Легкие преимущества графического процессора и облачных вычислений. Наконец, есть много хороших вариантов визуализации, которые впервые были предложены сообществом специалистов по данным, что позволяет пользователям строить диаграммы, гистограммы и графики».
Наконец, есть много хороших вариантов визуализации, которые впервые были предложены сообществом специалистов по данным, что позволяет пользователям строить диаграммы, гистограммы и графики».
В том же объявлении также есть короткие вопросы и ответы с Дэвисом Лукато, главным архитектором программного обеспечения в Microsoft, который помог создать семантическое ядро. Лукато, когда его спросили, что делает Python отличным языком для приложений, ориентированных на ИИ, ответил:
По моему скромному мнению, Python — это Мона Лиза среди языков программирования. Python элегантно сочетает в себе красоту и мощь в таком идеальном сочетании, что неудивительно, что такие итальянцы, как я, так нежно его любят. Традиционное кодирование требует от людей владения синтаксисом компьютерного языка, который может ощущаться как говорящая машина. С другой стороны, Python всегда читался близко к обычному письменному языку. А Python с SK идет еще дальше, дополняя обычный код естественным языком плавным и мощным способом.
 В результате разработчики ИИ смогут двигаться быстрее, писать меньше кода и наслаждаться SK в Моне Лизе языков программирования.
В результате разработчики ИИ смогут двигаться быстрее, писать меньше кода и наслаждаться SK в Моне Лизе языков программирования. Microsoft заявила, что добавила официальную поддержку Python в ответ на отзывы сообщества, и ранее указывала, что такие отзывы могут побудить к поддержке других языков программирования, включая собственный TypeScript.
Об авторе
Дэвид Рамел — редактор и писатель Converge360.
Обмен сообщениями Azure: какой вариант использовать, почему и как
Что должен сделать облачный разработчик Azure для обмена сообщениями в этом модном новом приложении? От сообщений до событий, от потоков до публикации и подписки — варианты кажутся огромными.
Build 2023 Dev Conference to Details Semantic Kernel (интеграция AI LLM)
На фоне ежедневной шумихи о продвинутом ИИ Microsoft посвятит две сессии на конференции разработчиков Build 2023 на следующей неделе своему предложению семантического ядра с открытым исходным кодом, которое помогает разработчикам использовать большие языковые модели (LLM) ИИ в своих приложениях.
.
NET 8 Preview 4 ускоряет собственный AOT, Blazor ‘Streaming Rendering’Четвертая предварительная версия Microsoft .NET 8 продолжает улучшать встроенную компиляцию Ahead-of-Time (AOT), в то время как Blazor получает потоковую визуализацию компонентов.
Visual Studio 2022 v17.6 выпущена
Microsoft объявила об общедоступной версии Visual Studio 2022 v17.6, которая содержит множество новых функций, улучшений и исправлений ошибок во флагманской среде IDE.
Принято для чата GitHub Copilot? С чего начать и что можно сделать
Итак, вас наконец исключили из списка ожидания чата GitHub Copilot. Что теперь?

 NET 8 Preview 4 ускоряет собственный AOT, Blazor ‘Streaming Rendering’
NET 8 Preview 4 ускоряет собственный AOT, Blazor ‘Streaming Rendering’
Самые популярные
Microsoft Semantic Kernel обеспечивает интеграцию LLM с обычными программами
Домашняя страница InfoQ Новости Microsoft Semantic Kernel обеспечивает интеграцию LLM с обычными программами
ИИ, машинное обучение и инженерия данных
Этот пункт в Японский
Закладки 31 марта 2023 г. 2
мин читать
2
мин читать
по
Серхио Де Симоне
Напишите для InfoQ
Присоединяйтесь к сообществу экспертов. Увеличьте свою видимость.Развивайте свою карьеру.Подробнее
Корпорация Майкрософт разработала Semantic Kernel (SK) с открытым исходным кодом, упрощенный SDK, позволяющий интегрировать большие языковые модели (LLM) с обычными программами, которые могут использовать шаблоны подсказок, векторизованную память, интеллектуальное планирование и другие возможности.
Семантическое ядро предназначено для поддержки и инкапсуляции нескольких шаблонов проектирования из последних исследований в области искусственного интеллекта, чтобы разработчики могли наполнять свои приложения сложными навыками, такими как создание цепочек подсказок, рекурсивное рассуждение, суммирование, обучение с нулевым/несколько выстрелов, контекстуальная память, долгосрочная память.
 память терминов, вложения, семантическое индексирование, планирование и доступ к внешним хранилищам знаний, а также к вашим собственным данным.
память терминов, вложения, семантическое индексирование, планирование и доступ к внешним хранилищам знаний, а также к вашим собственным данным.Шаблоны подсказок — это механизм, используемый для определения и составления функций ИИ с использованием обычного текста. Для создания подсказок разработчики могут вставлять выражения в подсказки с помощью фигурных скобок. Например, вот как можно вызвать внешнюю функцию, передав ей аргумент:
Сегодня в {{$city}} погода {{weather.getForecast $city}}.
Вложения позволяют сопоставить каждое слово в словаре с точкой в многомерном пространстве, которая представляет его значение и отношения между словами. Это важно для таких решений, как анализ настроений, классификация документов и системы рекомендаций.
В SK встраивания используются для создания семантической памяти , которая имитирует то, как человеческий мозг хранит и извлекает знания о мире на основе расстояния, существующего между понятиями. Разработчики могут либо использовать предварительно обученные модели встраивания, либо обучать свои собственные, используя такие методы, как Word2Vec, GloVe и FastText.
Разработчики могут либо использовать предварительно обученные модели встраивания, либо обучать свои собственные, используя такие методы, как Word2Vec, GloVe и FastText.
Еще одна ключевая возможность, предоставляемая SK «из коробки», — интеллектуальное планирование, которое заключается в работе в обратном направлении от заданной пользователем цели. Таким образом, планировщик строит обратную последовательность шагов, на каждом шаге используя предварительно определенный навык, доступный в библиотеке навыков. Если необходимый навык отсутствует, планировщик может предложить разработчику создать этот навык или даже помочь ему написать недостающий навык.
На более низком уровне абстракции навык — это просто контейнер для функции или набора функций. В SK есть три категории навыков: основные навыки, семантические навыки (подсказки LLM) и собственные навыки, которые реализуются с помощью собственного кода. Microsoft также предоставляет ряд примеров навыков для разработчиков, чтобы научиться их создавать, включая чат, кодирование, классификацию, навыки обобщения и другие.
Если вы заинтересованы в опробовании Microsoft Semantic Kernel, хорошим местом для начала является любое из примеров приложений, которые оно включает, а также официальная записная книжка «Приступая к работе», которая познакомит вас с основным синтаксисом для создания семантических функций, вложений, и так далее.
Об авторе
Sergio De Simone Показать ещеПоказать меньшеОцените эту статью
Принятие
Автор связался с
Вдохновлен этим контентом? Пишите для InfoQ.
Написание статьи для InfoQ открыло для меня много дверей и расширило возможности карьерного роста . Я смог глубоко пообщаться с экспертами и лидерами мнений, чтобы узнать больше о темах, которые я освещал. И я также могу распространять свои знания среди более широкого технического сообщества и понимать, как технологии используются в реальном мире.
Вивиан Ху Редактор новостей DevOps @InfoQ; Директор по продуктам @Second State
Запись для InfoQ
Вдохновлен этим контентом? Пишите для InfoQ.
Я открыл для себя программу InfoQ для участников в начале этого года и с тех пор наслаждаюсь ею! Система взаимного рецензирования InfoQ не только предоставила мне платформу для обмена опытом с глобальным сообществом разработчиков программного обеспечения, но и значительно улучшила мои навыки письма.0141 . Если вы ищете место, где можно поделиться своим опытом в области программного обеспечения, начните вносить свой вклад в InfoQ.
Огеневведе Эмени Автор статей @InfoQ; Разработчик программного обеспечения, генеральный директор @Pact
Запись для InfoQ
Вдохновлен этим контентом? Пишите для InfoQ.
Я начал писать новости для очереди InfoQ .NET, чтобы не отставать от технологий, но получил от этого гораздо больше.