
Что такое микроразметка и для чего она нужна
Микроразметка – это разметка страницы сайта с дополнительными тегами и атрибутами, которая помогает поисковикам более четко понимать содержание страниц интернет-ресурса. А это, в свою очередь, позволяет более корректно отображать контент в поисковой выдаче. Так, микроразметка карточки товара позволит поисковым роботам понять, где указана цена на товар, где представлено его описание, а где – фотография.
Использование семантической разметки улучшает представление сниппета вашего ресурса в результатах поиска. С помощью такого сниппета пользователь сможет сразу понять, та ли эта страница, которая ему необходима, и получить важную информацию о товарах/услугах, даже еще не заходя на ваш сайт. То есть микроразметка позволяет сделать сайт более клиентоориентированным не только с точки зрения поисковиков, но и интернет-пользователей.
Как сделать микроразметку? Она выполняется добавлением в HTML-код страницы определенных тегов, в которых размещаются необходимые сведения. Существует несколько языков синтаксической разметки, с помощью которых можно задать микроразметку сайта. Среди популярных словарей — RDFa, микроформаты, Open Graph, Schema.org. Специалисты компаний Google и Яндекс советуют использовать стандарт Schema.org.
Schema.org: возможности и особенности
Schema.org — это стандарт семантической разметки данных, который представили поисковики Google, Bing и Yahoo! летом 2011 года. Чуть позже о поддержке данного стандарта объявил и Яндекс. Обычная HTML-разметка показывает браузеру, как отображать данные, но ничего не говорит о смысловом содержании контента, тогда как микроразметка делает страницу максимально понятной для поисковой системы.
Стандарт представляет собой несколько сотен классов, описывающих различные сущности и их свойства.
Какие атрибуты используются в Sсhema.org
Начнем с атрибута itemscope. При его добавлении мы сообщаем, что HTML-код, содержащийся в блоке <div>…</div>, описывает определенную сущность.
Представим страницу, посвященную книге «Бойцовский клуб»:
<div>
<h2>Бойцовский клуб<h2>
<span>Автор: Чак Паланик<span>
<span>Жанр: роман, контркультура <span>
Добавляем атрибут itemscope:
<div itemscope>
<h2>Бойцовский клуб<h2>
<span>Автор: Чак Паланик<span>
<span>Жанр: роман, контркультура <span>
</div>
После этого становится понятно, какая часть страницы посвящена книге. Другими словами, мы сообщили поисковику о какой-то сущности. Далее нам необходимо указать тип сущности. Для этого используется атрибут itemtype, который добавляется сразу после itemscope.
Другими словами, мы сообщили поисковику о какой-то сущности. Далее нам необходимо указать тип сущности. Для этого используется атрибут itemtype, который добавляется сразу после itemscope.
<div itemscope itemtype=https://schema.org/Book>
<h2>Бойцовский клуб<h2>
<span>Автор: Чак Паланик<span>
<span>Жанр: роман, контркультура<span>
</div>
Таким образом, мы указали, что сущность, о которой идет речь, представляет собой книгу.
Если вы захотите также сообщить дополнительные сведения о книге, вам понадобится атрибут itemprop, который отмечает свойства сущности. Например:
<span>Автор: <span itemprop=author>Чак Паланик</span>
Особенности микроразметки карточки товара
Schema.org описывает большое количество разных типов сущностей, для каждой из которых разработан определенный перечень свойств. Так, если вы делаете микроразметку карточки товара, то вам необходимо выбирать сущность Product, дополнив ее необходимыми свойствами. Причем, обязательными характеристиками при микроразметке товаров будут название, цена и валюта продажи. Все остальные пункты можно пропустить.
Так, если вы делаете микроразметку карточки товара, то вам необходимо выбирать сущность Product, дополнив ее необходимыми свойствами. Причем, обязательными характеристиками при микроразметке товаров будут название, цена и валюта продажи. Все остальные пункты можно пропустить.
Если ваша страница посвящена не одной, а нескольким сущностям, то каждую сущность необходимо размечать отдельно. Пример кода микроразметки товара представлен на изображении ниже.
Как много контента стоит размечать? Чем больше, тем лучше. Однако речь идет о видимом контенте, размечать скрытые элементы страницы необходимости нет. К примеру, на странице “О компании” явно стоит разметить блок с контактными данными, а на главной — выделить логотип.
Как проверить корректность микроразметки
Чтобы веб-мастерам не пришлось несколько раз переделывать разметку, поисковые системы разработали валидаторы микроразметки, которые позволяют понять, смогут ли поисковики извлечь из внедренной разметки необходимые данные.
Сейчас валидатор позволяет проверить все самые распространенные форматы микроразметки: schema.org, микроформаты,OpenGraph, RDFa, microdata. У Яндекса этот инструмент находится в вебмастере. Аналогичный инструмент от Google называется Structured Data Testing Tool.
|
|
Статью подготовил Дмитрий Медведев, ведущий спикер Webcom Academy. |
Поделиться с друзьями:
Для чего нужна микроразметка и как её добавить на сайт
05 мая 2022 SEO-продвижение
Микроразметка — это специальные теги и атрибуты в веб-верстке, использующиеся для лучшего понимания информации на страницах сайта поисковыми роботами. Ее использование помогает получить качественные переходы на сайт, тем самым увеличив трафик без лишних затрат бюджета.
В первую очередь, микроразметка сайта удобна для пользователя — тем, что кратко передает содержание нужной страницы. Например, если у вас интернет-магазин, пользователь может увидеть цену товара, ключевые характеристики и отзывы покупателей. Если есть точка в офлайне, в микроразметке можно увидеть ее время работы, адрес и контактные данные. Если вы публикуете статьи, то разметка отображает выходные данные и автора каждого материала.
Кроме того, использование микроразметки делает сайт более привлекательным визуально в поисковой выдаче. Красивый сниппет хорош с точки зрения кликабельности, что увеличивает позицию в выдаче (но это происходит не сразу, а в соответствии с реакцией пользователей) и увеличивает посещаемость сайта. Не факт, что это сработает сразу, но если делать эту работу качественно, а параллельно совершенствовать контент, верстку и ассортимент, то можно добиться более чем положительного эффекта, так как это работает и на людей, и на поисковики.
Если вы используете микроразметку, то необходимо делать это со всем контентом сайта. Для интернет-магазина это, в первую очередь, каталог товаров, отдельные позиции и категории, а также статьи на сайте. Любые структурированные данные должны соответствовать контенту конкретной веб-страницы, в код которой они добавлены, и не должны описывать скрытую от посетителей информацию.
«Микроразметку используем всегда на любых типах проектов (коммерция или информационные порталы). Трудностей на практике бывает мало. Чаще всего, программист при внедрении правок может задать уточняющие вопросы, если возникнут сложности. В Яндексе сейчас, микроразметка никак не влияет на основные показатели (в первую очередь CTR). CTR увеличивается ненамного только после загрузки YML-файла, который улучшает представление сниппета в поиске (имеется ввиду картинка товара, цена и иногда регион доставки — подставляется автоматически самим Яндексом). Также в сниппет автоматически добавляется рейтинг магазина из Яндекс.
Маркета. В Google ситуация иначе. Микроразметка напрямую влияет на отображение в поисковой выдаче. Конкретно, разметка хлебных крошек, информация о продуктах (цены, отзывы, рейтинг и т.п.), информация о разделах (диапазон цен). По ситуации применяются эмодзи (в хлебных крошках или в теге title и/или мета-тегах description). Также периодически нужна разметка о событиях. Именно эта разметка показывается на выдаче и влияет на CTR, что способствует повышению средней позиции (по всем ранжируемым ключевым фразам) и соотвественно трафику.»

Айрат Рахимзянов, Автор телеграм-канала «SEO-секретики»
Составляющие микроразметки сайтаМикроразметка сайта состоит из тегов и атрибутов, отвечающих за конкретное содержимое: некоторые из них видны посетителям, некоторые нужны для поисковых роботов. Если брать во внимание ассортимент интернет-магазина, то в сниппет можно вставить описание и фото товара, отзывы о нем, информацию о наличии в продаже.
В микроразметке существует несколько словарей, то есть наборов атрибутов. Поговорим о наиболее распространенных и широко используемых в современном интернете.
Cловарь Schema.org создавался сразу несколькими поисковиками для предоставления основной информации об объекте (в том числе товаре) без необходимости заходить на сайт. В нем есть три основных атрибута (itemscope — указывает на сам объект, itemtype — на его тип, itemprop — на свойства, если речь идет о товарах, то это могут быть, например, цена и описание).
Читайте также: Микроразметка Schema.org на платформе ADVANTSHOP.
Open GraphИзначально этот словарь был разработан Facebook* для корректного отображения веб-страниц в соцсетях, но сейчас его поддерживают и мессенджеры, в том числе популярный ныне на российском рынке Telegram. У него также есть ряд атрибутов:
У него также есть ряд атрибутов:
«og:locale» — местоположение сайта и язык контента
«og:type» — тип отображаемого контента (обзор, статья и т.д.)
«og:title» — метатег title
«og:description» — метатег description
«og:url» — адрес веб-страницы
«og:image» — изображение в тексте статьи, обзора, описания и т.д.
«og:site_name» — название сайта.
Пример разметки Open Graph в интернет-магазине
Читайте также: Микроразметка «Протокол Open Graph».
МикроформатыЭто специальный вариант разметки, помогающий поисковым ботам понимать контент. Основная их задача — рассказать о содержащихся данных. Для интернет-магазина важны такие данные, как адрес и контакты, описания товаров и отзывы.
Для работы с информацией сайта интернет-магазина подходит формат hCard, который поддерживают и Google, и Яндекс.Он структурирует географические координаты и контактные данные сайта, которые автоматически передаются в справочники поисковиков, в том числе при изменении.
Синтаксисы микроразметкиПод синтаксисом микроразметки понимается способ применения словаря. Унифицированного стандарта синтаксиса нет, но есть несколько наиболее часто используемых.
MicrodataТак называемые микроданные состоят из нескольких элементов (вспомним атрибуты itemscope, itemtype и itemprop в Schema.org). Размечаются обычно те данные, которые уже доступны пользователю, но иногда для разметки необходимы и метаданные.
Пример микроразметки schema.org в формате Microdata
RDFaЭтот синтаксис был разработан еще 2004 году для разметки HTML-кода с целью структурирования данных. Сейчас из-за относительной сложности реализации он используется заметно реже, чем раньше, а Google отдает предпочтение JSON-LD или Microdata.
Сейчас из-за относительной сложности реализации он используется заметно реже, чем раньше, а Google отдает предпочтение JSON-LD или Microdata.
Пример микроразметки schema.org в формате RDFa
JSON-LDЭто актуальный и популярный синтаксис, существующий с 2010 года и внедряющийся в тег script. Он состоит из пар ключей и значений, понятных как пользователю, так и поисковому боту.
Пример микроразметки schema.org в формате JSON-LD
Реализация микроразметкиСтатьиДля публикуемых на сайте статей (у интернет-магазина это может быть блог или советы экспертов) используются следующие атрибуты.
headline – название материала
datePublished – дата публикации
image – изображение
articleBody – основной текст статьи
author – автор
publisher – название ресурса, на котором статья была опубликована
Хлебные крошкиТак называется система навигации на сайте, демонстрирующая структуру и вложенность страниц. Можно сделать линейную цепочку навигации либо систему с возможностью вернуться назад на главную страницу или в каталог товаров. Хлебные крошки повышают уникальность сниппета, появляясь в поисковой выдаче.
Можно сделать линейную цепочку навигации либо систему с возможностью вернуться назад на главную страницу или в каталог товаров. Хлебные крошки повышают уникальность сниппета, появляясь в поисковой выдаче.
Для разметки хлебных крошек используются следующие теги:
itemscope — указание на описываемый объект
itemtype — указание на тип объекта. Если элемент относится к хлебным крошкам, то в Schema.Org он будет выглядеть так:
itemtype=https://schema.org/BreadcrumbList
itemprop=»itemListElement» — указывает на принадлежность элемента к списку
itemprop=»item» —указывает на ссылку
itemprop=»name» — указывает на название хлебной крошки.
meta itemprop=»position» content=»%number%» — указывает на позицию элемента в цепочке навигации.
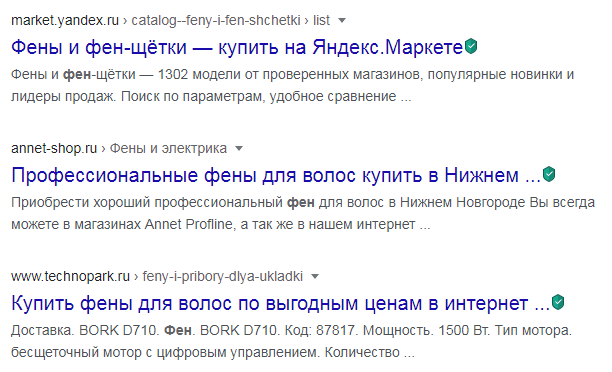
Микроразметка товаров в интернет-магазинеGoogle и Яндекс рекомендуют устанавливать микроразметку на разделы и страницы с ассортиментом товаров для интернет-магазина: поисковые боты могут использовать эти данные для сниппета, что, в свою очередь, побуждает пользователя перейти по ссылке.
Для товаров достаточно атрибутов name (название), description (описание), image (изображение), price (цена) и priceCurrency (валюта). Если вы хотите добавить в сниппет отзывы, необходимо поле AggregateRating.
«При оптимизации любого сайта обязательно проверяется наличие микроразметки. Внедрить её на сайт не так сложно, к тому же у поисковиков есть свои инструменты для проверки структурированных данных, а в Google даже есть инструмент, который поможет добавить разметку на страницу сайта. Для интернет-магазинов пригодится микроразметка товаров. Для этого в словаре семантической разметки schema.org есть типы данных Product и Offer. После добавления такой микроразметки, сниппет страницы товара, помимо заголовка и описания, будет содержать цену, рейтинг, наличие, изображение, информацию об акциях и доставке. Микроразметка необходима для формирования расширенного сниппета, который будет включать в себя больше информации о содержимом страницы и, соответственно, получать больше кликов.
Увеличение CTR положительно влияет на ранжирование и посещаемость сайта.»
 Увеличение CTR положительно влияет на ранжирование и посещаемость сайта.»
Увеличение CTR положительно влияет на ранжирование и посещаемость сайта.»Полина Карлова, AdClients, старший менеджер
Проверка микроразметки на ошибкиГотовую разметку нужно проверить ее на ошибки — только правильно структурированные данные доступны поисковым роботам. В Google это делается на странице валидатора, которая отображает малейшие ошибки в отчете и тем самым дает возможность их исправить.
Для проверки в Яндексе используется валидатор в вебмастере, где проблемы и несоответствия отмечаются красным с комментариями. Соответственно, все ошибки также можно отследить и исправить.
«Основная сложность при микрокразметке связана непосредственно с внедрением на сайт. Оптимальным является вариант, когда уже на этапе разработки сайта программист в курсе того, что на страницах того или иного типа требуется определенная микроразметка, поскольку если что-то на сайте сделано не так, как канонически это должно быть с учетом CMS, то микроразметку потребуется делать вручную.
 »
»Анастасия Шестова, руководитель направления поискового продвижения, ИнтерЛабс
Подведем кратко итоги. Микроразметка нужна, чтобы сделать сниппеты более заметными. Это может влиять на ранжирование, но не напрямую, а через поисковое поведение пользователей. Размечаться должен весь контент, без ошибок: все атрибуты должны быть прописаны правильно. Однако валидаторы поисковых систем способны проверять код разметки, тем самым помогая исправлять ошибки. Главное — не забывать это делать.
*Instagram и Facebook принадлежат компании Meta, чья деятельность запрещена на территории России с 21 марта 2022 года.
Создание своего интернет-магазина — процесс довольно трудоемкий. Если вам нужна помощь в выполнении какой-то задачи — мы подскажем, где найти исполнителей.
Наши партнеры приготовили для вас специальные предложения, которые помогут вам решить любую задачу в создании своего онлайн-проекта:
-Настроить интернет-магазин «под ключ».
-Настроить визуальное оформление магазина.
-Запустить контекстную рекламу.
-Настроить SEO для вашего сайта.
И много других задач.
Чтобы заказать нужную вам услугу перейдите по ссылке и выберите подходящего исполнителя.
Делегируя задачи профессионалам, вы сможете реализовать ваш проект за короткие сроки.
Создать аккаунт на AdvantShop
На платформе вы сможете быстро создать интернет-магазин, лендинг или автоворонку.
Воспользоваться консультацией специалиста
Ответим на любые ваши вопросы и поможем выйти на маркетплейсы.
СвязатьсяДля чего нужна микроразметка, как её добавить на сайт?
Содержание:
- Что такое структурированная разметка
- Зачем нужна такая разметка
- Как микроразметка влияет на SEO-показатели
- Работает ли разметка на мобильных устройствах
- Разметка Schema.org для голосового поиска
- Как устроена разметка Schema. org
- Пример оформления структурной разметки
- Основные виды разметки Schema.org
- Разметка контента
- Как подключить Schema.org к своему сайту
- Ручная разметка
- Мастер разметки Google
- Плагины для CMS
- Как понять, что разметка работает правильно
- Заключение
 org
orgSchema.org — это созданная поисковиками семантическая разметка данных, которая не только позволяет создать привлекательный сниппет, но и значительно улучшает взаимодействие поискового робота с сайтом. Поговорим о том, зачем вообще нужны микроданные, в чем заключается результат их внедрения и как применить микроразметку для своего ресурса.
Что такое структурированная разметка
Структурированная микроразметка имеет множество синонимов. Также ее называют микроразметкой, разметкой структурированных данных или вовсе сокращают до микроданных. Фактически микроразметка представляет собой комплекс необходимых тегов и атрибутов, которые позволяют предоставить поисковым системам нужную информацию о вашем сайте. Благодаря микроразметке поисковые роботы понимают, какая именно информация размещена на его страницах. Для того, чтобы правильно внедрить эти значения на свой сайт, необходимо пользоваться соответствующим словарем, в котором будут перечислены все соответствующие значения. Микроразметка Schema и есть такой словарь, наиболее востребованный и подробный на сегодняшний день.
Благодаря микроразметке поисковые роботы понимают, какая именно информация размещена на его страницах. Для того, чтобы правильно внедрить эти значения на свой сайт, необходимо пользоваться соответствующим словарем, в котором будут перечислены все соответствующие значения. Микроразметка Schema и есть такой словарь, наиболее востребованный и подробный на сегодняшний день.
Этот словарь был разработан крупными поисковиками, чтобы улучшить собственные результаты выдачи. Благодаря Schema можно уточнить для поисковых роботов значение буквально каждого элемента на странице.
Зачем нужна такая разметка
Поисковые машины все еще могут совершать ошибки, несмотря на то, что алгоритмы совершенствуются каждый день. Для того, чтобы улучшить отображение в выдаче, обеспечить правильное описание представленных на сайте товаров или услуг, а также улучшить отображение других блоков, используется микроразметка.
Для чего еще нужна микроразметка:
- В первую очередь, ваш кропотливый ручной труд будет вознагражден улучшением SEO-показателей;
- Кроме того, внедрение микроразметки позволит быстрее попасть в расширенные результаты поиска, которые представляют собой сниппеты или карточки, привлекая повышенное внимание потенциальных клиентов;
- Если вы публикуете товар или услугу с рейтингом, рядом со ссылкой будут отображены специальные звездочки, которые позволят потенциальному клиенту еще до посещения сайта удостовериться в вашей компетентности. Для ресторанного бизнеса возможно отображение кнопки бронирования столика. Дополнительные возможности по увеличению конверсии доступны и для других товаров и услуг;
- В результате применение разметки позволяет значительно выделить ваш ресурс на фоне конкурентов, а также повысит конверсию.
Помимо плюсов для вашего развития, внедрение микроразметки позволяет снизить количество ошибок со стороны поисковика. Иными словами, снизится количество нерелевантных переходов.
Как микроразметка влияет на SEO-показатели
Внедрение микроразметки — одна из важнейших обязанностей SEO-специалиста, так как ее наличие влияет на показатели весьма значительно. Почему важно своевременно добавить микроразметку:
- Правильное внедрение микроразметки позволяет не только улучшить позиции сайта в выдаче, но и сделать представление результатов в выдаче более привлекательным, а переходы — релевантными;
- Если пользователь видит в результате поиска не ссылку, а контент, который его интересует, вероятность перехода по ссылке увеличивается;
- Количество переходов повышает уровень ретенции: количество отказов снижается;
- Наличие сниппета позволяет заказать товар или услугу, не заходя на сайт, что также увеличивает число ваших клиентов.
Работает ли разметка на мобильных устройствах
Не только работает, но и выглядит подчас даже привлекательнее, чем на стационарных компьютерах. Сегодня практически все мы чаще пользуемся смартфонами, чем компьютерами, поэтому для мобильных устройств создаются новые типы сниппетов, которые позволяют взаимодействовать с сайтом, не посещая его.
В особенности это важно для тех типов бизнесов, которые зависят от заказов, а не от посещений сайта. Так, возможность заказать товар или услугу, не переходя на сайт, увеличивает вероятность совершения этого действия пользователем. Таким образом, вы получите больше заказов.
Разметка Schema.org для голосового поиска
В последнее время люди стали чаще пользоваться возможностями голосовых ассистентов. Голосовой поиск используют не только на смартфонах, но и на умных колонках, станциях, автомобильных системах. В данном случае наличие микроразметки дополнительно упрощает взаимодействие пользователя с вашим сайтом.
Так, поисковый бот при отсутствии микроразметки часто не может точно распознать, что именно ему необходимо озвучить. В особенности часто это происходит с различными алгоритмами и пошаговыми руководствами. Если же каждый шаг будет снабжен микроразметкой, поисковый бот сможет ориентироваться и озвучить необходимую информацию, а пользователю не потребуется отвлекаться на телефон.
Как устроена разметка Schema.org
Микроразметка представляет собой определенный комплекс классов, предназначенных для HTML-страниц. Каждый класс относится только к определенному виду контента.
Какие есть примеры использования таких классов:
- Основной класс Thing в коде прописывается через атрибут itemscope. Дополнительно этот класс делится на Event, Organisation и другие аналогичные классы. Каждый из них относится к уникальному виду контента и прописывается в коде через атрибуты itemtipe, itemtope;
- Если вам нужно, например, предоставить описание кинокартины, необходимо использовать соответствующий тег Movie, который располагается в категории Creative Work. Соответствующие атрибуты есть для каждой детали: имени режиссера, актерского состава, постера, длительности, жанра и так далее.
 Соответствующие атрибуты есть для каждой детали: имени режиссера, актерского состава, постера, длительности, жанра и так далее.
Соответствующие атрибуты есть для каждой детали: имени режиссера, актерского состава, постера, длительности, жанра и так далее.Пример оформления структурной разметки
Микроразметку необходимо формировать в соответствии с актуальностью для конкретной структуры. В самом начале всегда располагается основной класс Thing, который располагается во главе каждого из ваших объектов. Затем необходимо указать соответствующую категорию, а после дополнительные атрибуты для каждого типа контента. Набор тегов будет зависеть исключительно от ниши, которую вы занимаете.
Например, для любого вида бизнеса микроразметка может выглядеть так:
- Thing
- Organisation
- LocalBusiness
- Dentist
- Name
- Address
- Logo
- Review
- Dentist
- LocalBusiness
- Organisation
Не забывайте соблюдать иерархию. Это позволит поисковикам лучше взаимодействовать с вашим ресурсом.
Это позволит поисковикам лучше взаимодействовать с вашим ресурсом.
Основные виды разметки Schema.org
Для того, чтобы понять, как сделать микроразметку, необходимо ознакомиться с тем, как необходимые атрибуты будут выглядеть непосредственно в коде сайта. Ниже приведем пример разметки и объясним, как она выглядит со стороны поискового робота.
<div>
<p>Название категории товаров</p>
<p>Название бренда</p>
<p>Страна производитель</p>
<p>Цвет товара</p>
<p>Состояние товара</p>
</div>
Здесь поисковик увидит только текст, и в поисковой выдаче отобразит ссылку без дополнительных атрибутов. Если добавить к этой разметке дополнительные элементы, робот сможет распознать и предоставить пользователю больше информации:
<div itemscope itemtype="https://schema.org/Product">
<p itemprop="category">Название категории товаров</p>
<p itemprop="brand">Название бренда</p>
<p itemprop="countryOfOrigin">Страна производитель</p>
<p itemprop="color">Цвет товара</p>
<p itemprop="itemCondition">Состояние товара</p>
</div>
Разметка контента
Существует два основных вида контента: некоммерческий и коммерческий. Атрибуты микроразметки для таких видов необходимо искать в различных категориях. Так, для некоммерческого контента используется категория Creative Work. Какие виды контента могут быть дополнены расширенной микроразметкой:
Атрибуты микроразметки для таких видов необходимо искать в различных категориях. Так, для некоммерческого контента используется категория Creative Work. Какие виды контента могут быть дополнены расширенной микроразметкой:
- Статья. В качестве статьи может выступать как общий информационный текст, так и полноценное профессиональное исследование. Кроме того, под это понятие также подпадают новости, для которых есть отдельные теги. При помощи разметки Schema можно указать автора, дату публикации и другие важные атрибуты;
- Книга встречается в словаре значительно реже. Для любых печатных изданий предусмотрены такие атрибуты как количество страниц, синопсис, автор и прочие важные данные;
- Курс в контексте образовательного мероприятия. Используя теги из словаря Schema, можно предоставить информацию о дате и месте проведения, дисциплине и так далее;
- Подкаст: теги позволяют указать абсолютно всю важную информацию, включая тематику, авторов, длительность и так далее.
Для коммерческих ресурсов есть такие виды разметки:
- Страница ЧаВо или FAQ. Этот раздел значительно улучшает показатели SEO, поэтому имеет смысл использовать для него разметку. В словаре есть отдельный специальный тег;
- Отзывы на товары: соответствующий тег позволяет увидеть оценку товара уже в поисковой выдаче;
- Непосредственно товары: используется соответствующий тег Product;
- Хлебные крошки: весь путь пользователя от страницы, с которой он начал знакомство с вашим ресурсом, до страницы, на которой он находится в конкретный момент. Обычно это выглядит как «категория/подкатегория/страница товара/и так далее». Для оформления существуют специальные теги.
Кроме того, в словаре также можно найти теги и для других видов контента.
Как подключить Schema.org к своему сайту
Способов подключения несколько. Результат в каждом случае будет одинаковым, разница заключается лишь в процессе реализации. Рассмотрим основные способы, которые используются чаще всего.
Ручная разметка
Все атрибуты и теги можно прописать вручную, так как структурная разметка является частью разметки HTML. Для крупных сайтов такой способ нецелесообразен, так как придется вводить слишком много данных. Если же бизнес небольшой или вы хотите пока только протестировать работу микроразметки, чтобы убедиться в необходимости внедрения тегов, можно попробовать ввести некоторые значения вручную.
Мастер разметки Google
Один из наиболее удобных инструментов (ссылка на сервис: https://www.google.com/webmasters/markup-helper/), снабженный визуальным редактором, который позволит правильно использовать разметку даже в том случае, если у вас нет необходимых навыков. Алгоритм работы прост:
- Зайти на официальный сайт сервиса;
- Выбрать категорию, которая определит тип контента;
- Вставить ссылку на страницу;
- Перейти в редактор;
- Выделить область, для которой необходима разметка, указать необходимый тег.
Плагины для CMS
Если ваш сайт создан при помощи конструктора, вы можете использовать соответствующий плагин.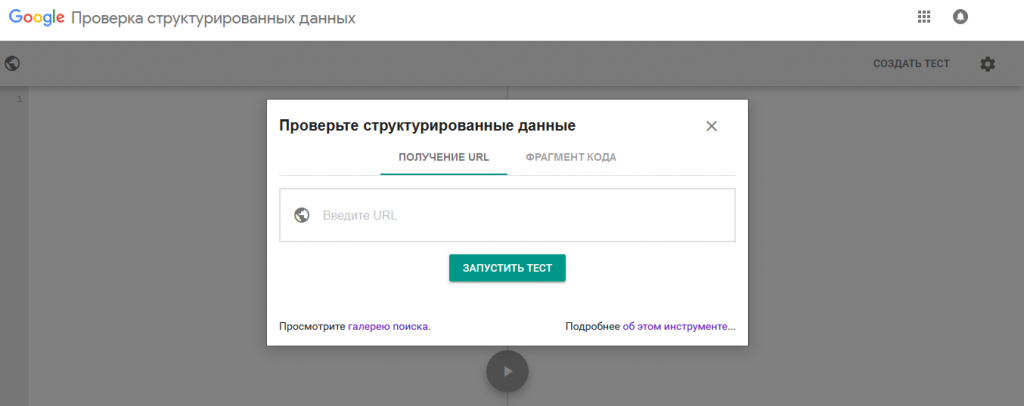 Например:
Например:
- Google Structured Data для Joomla;
- Shema для WordPress: обратите внимание, это дополнение платное, но также в общем поиске можно найти и бесплатный вариант;
- Для 1С-Битрикс также используется одноименное официальное приложение.
Как понять, что разметка работает правильно
Перед тем, как закончить работу с микроразметкой, желательно прогнать его через валидатор Schema. Это инструмент, который позволяет проверить микроразметку и убедиться, что она соответствует правилам. Так вы сможете до публикации проверить корректность введенных данных и избавиться от допущенных ошибок. Проверить можно отдельную часть кода, а также страницу целиком.
Заключение
Знакомство с Schema.org — важный этап в жизни любого SEO-специалиста. Узнав, как работает этот словарь, вы сможете оптимизировать ресурс таким образом, что заявок станет значительно больше. Кроме того, пользователям будет значительно проще взаимодействовать с сайтом. Однако помните о том, что во всем важна мера. Не стоит создавать путаницу, вводя слишком много тегов. До того, как приступить к работе впервые, имеет смысл ознакомиться с руководством, созданным Google для работы с этим словарем.
Не стоит создавать путаницу, вводя слишком много тегов. До того, как приступить к работе впервые, имеет смысл ознакомиться с руководством, созданным Google для работы с этим словарем.
Читайте также: Что такое бэклинки сайта и для чего нужны
Для чего нужна микроразметка сайта, как проверить правильность ее внедрения и как она влияет на позиции сайта
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Микроразметка — это структурные элементы сайта, позволяющие роботам подробнее изучить содержание указанного ресурса.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
В этой статье разберем следующие вопросы:
- Понятие микроразметки.
- Зачем нужна микроразметка.
- Какие существуют языки микроразметки и с каким работать лучше.
- Как внедрить микроразметку и какие инструменты существуют.

Надеемся, эта статья будет полезной, и после прочтения вы повысите уровень своих знаний. Это чек-лист, преподающий основы микроразметки.
Что такое микроразметка сайта
Объясним на примере.
Допустим, мы зашли в ресторан поужинать. Смотрим в меню — выбираем блюдо из известных продуктов. В крайнем случае спрашиваем официанта: “Из чего это приготовлено?” — и исходя из ответов уже делаем заказ. То есть собираем всю информацию о блюде — что это, подходит ли мне, безопасно ли и т.д. Если находим нужную информацию, то делаем заказ.
То же самое с поиском. Когда пользователь вводит запрос в поисковую строку, роботы, как и официанты, выдают сниппеты с объяснением содержания в них. Микроразметка помогает структурировать сниппет и, как следствие, наиболее полно рассказать роботу о сайте. Внедряем микроразметку — помогаем поисковой системе рассказать покупателю, о чем ссылка и что он увидит после перехода.
Так, можно указать роботу, что на странице является, например, заголовком, основной фотографией, описанием товара, ценой, временем работы, телефоном. Для каждого основного вида данных есть свой тег разметки.
Так выглядит сниппет с микроразметкой:
2 основные причины, для чего нужна микроразметка сайта
Если вы еще не внедрили микроразметку на своем ресурсе, то поторопитесь с этим. И вот 2 причины поторопиться это сделать:
- во-первых, так удобнее пользователю. Если HTML-код помогает оформить данные, то микроразметка помогает подробно объяснить, что именно мы имели в виду. Не только рассказать о ресурсе, но и показать часть его содержимого. Разметка помогает оптимизировать поиск, сделать этот процесс менее времязатратным;
- во-вторых, это полезно с коммерческой точки зрения. Когда покупатель видит в поисковой выдаче множество ответов на свой вопрос, то ему легче выбрать сайт, который предоставляет всю информацию о себе именно в выдаче. Соответственно, больше шансов, что он перейдет по показанной ссылке.

Влияет ли наличие микроразметки на выдачу? Только косвенно — микроразметка стимулирует пользователей заходить на сайт, из-за чего он поднимается по поисковой выдаче. Чем больше важной информации в сниппете, тем он понятнее пользователю -> больше вероятность перехода.
Виды микроразметки сайта
- Schema.org — язык роботов поисковых систем Яндекс и Google. Отметим, что его также понимают Bing и Yahoo, и другие роботы менее известных поисковых систем. Schema.org — самый распространенный язык микроразметки. несколько лет назад его приняли за всеобщий стандарт разметки данных. Узнать подробнее про Schema.org…
- OpenGraph — способ разметки информации, используемый роботами социальных сетей. Разработала его Facebook, но подхватили Вконтакте, Twitter, Google+, LinkedIn и все остальные. Используется для отображения превью в новостной ленте пользователя. Также этот язык понимает Яндекс.Видео. Узнать подробнее про OpenGraph…
- JSON-LD — способ описания содержания страницы с помощью языка связанных данных. Описанная таким образом информация видна для роботов, но скрыта от людей. Чтобы было понятно: этот язык различает Яндекс.Почта, но оставляет без внимания поисковой робот Яндекса. Может быть использован в качестве дополнения к Schema.org (кстати, структурированные таким образом данные выглядят красивее). Узнать подробнее о JSON-LD…
- Микроформаты — альтернативный способ разметки гипертекста через атрибут “class”. Например, задаем тег<div class=”adr”></div>, то есть сообщаем роботу о том, что внутри <div>помещен адрес.
 Описанная таким образом информация видна для роботов, но скрыта от людей. Чтобы было понятно: этот язык различает Яндекс.Почта, но оставляет без внимания поисковой робот Яндекса. Может быть использован в качестве дополнения к Schema.org (кстати, структурированные таким образом данные выглядят красивее). Узнать подробнее о JSON-LD…
Описанная таким образом информация видна для роботов, но скрыта от людей. Чтобы было понятно: этот язык различает Яндекс.Почта, но оставляет без внимания поисковой робот Яндекса. Может быть использован в качестве дополнения к Schema.org (кстати, структурированные таким образом данные выглядят красивее). Узнать подробнее о JSON-LD…Какой язык внедрять? Влияет ли наличие микроразметки на позиции сайта в поисковой выдаче? Администрации поисковых систем отрицают эту зависимость, но, при этом, рекомендуют использовать schema.org. Конструкторы сайтов содержат модуль для работы с OpenGraph. При этом вопрос об оптимальном выборе остается открытым.
Как внедрить микроразметку на сайт
Читайте статью “Введение в schema.org”. Статья раскрывает основные принципы синтаксиса этого языка, и это дает реальную возможность начать использовать его. Если хотите научиться делать микроразметку руками, то начните с изучения этого материала.
Если хотите научиться делать микроразметку руками, то начните с изучения этого материала.
Кроме этого существует несколько инструментов для автоматизации процесса внедрения микроразметки:
- Schema App — набор платных инструментов, позволяющих использовать язык Schema.org без их изучения.
- Microdata Generator Using Schema.org + JSON-LD — инструменты, позволяющие структурировать информацию по принципам Schema.org.
- Разные плагины и расширения для разных языков и платформ, на которых строится сайт — как самописных на PHP, Javascript, Python, так и созданных на WordPress, Joomlah, Drupal.
Больше информации — в помощи вебмастеру, от Яндекса.
Как проверить наличие микроразметки на сайте
- Проверяйте наличие микроразметки в Валидаторе Яндекса.
Введите URL искомой страницы и узнайте, применена ли там микроразметка. Кстати, таким же образом можно посмотреть сценарий микроразметки на сайте конкурентов. Например, если хотите сниппет, похожий на конкретный сайт, то введите его URL в данное поле — и подсмотрите 🙂
- Другой вариант — использовать Structured Data Testing Tool от Google.

Работайте в нем по аналогии с Валидатором — введите адрес в строку и нажмите “запустить тест”.
В чем разница? Валидатор Яндекса отображает при анализе конкретные элементы и их свойства (без контекста). Structured Data Tool от Google показывает весь код, и элементы микроразметки видны в контексте всего кода страницы.
Проверка микроразметки сайта
При выдаче робот системы может игнорировать микроразметку. Это происходит либо из-за системного сбоя, либо из-за ошибки в разметке. Истинную причину можно легко установить — при помощи Валидатора и Structured Data Testing Tool.
Вставьте фрагмент HTML-кода в поле под надписью.
После проверки оба инструмента покажут, как роботы отображают поисковой сниппет исходя из кода.
Надеемся, статья была полезна. В ней собрали информацию о микроразметке, позволяющую сразу же начать ее внедрение.
На сайте компании SEMANTICA вы можете заказать продвижение интернет-магазина детской одежды. Оставьте заявку, и мы вам перезвоним в ближайшее время.
Оставьте заявку, и мы вам перезвоним в ближайшее время.
Что такое микроразметка и для чего она нужна на сайте в блоге FireSeo
Микроразметка сайта – пожалуй, известный всем SEO-шникам набор структурных элементов ресурса, помогающий выделить особо важную информацию на сайте и дать правильно понять поисковикам подробную информацию о ресурсе. Расскажем подробнее о микроразметке для сайта и дадим исчерпывающую информацию о том, для чего она нужна, и как грамотно ее подготовить.
Содержание:
- Что такое микроразметка
- Для чего нужна микроразметка
- Виды микроразметки
- Как сделать микроразметку на сайте
Что такое микроразметка
«Микроразметка на сайте что это» – отвечаем подробно на вопрос. Чтобы точнее понять, что такое микроразметка сайта, представим хорошо знакомый случай из жизни. Вы впервые пришли в недавно открывшийся ресторан на набережной «Алые паруса» и совсем не знаете меню заведения, из каких ингредиентов готовят блюда, понравятся ли вам и прочее. Как вы поступаете в таком случае? Просматриваете перечень кулинарных позиций и задаете конкретные вопросы официанту. Получив нужную информацию, уже выбираете приглянувшееся вашим вкусовым предпочтениям и делаете заказ.
Чтобы точнее понять, что такое микроразметка сайта, представим хорошо знакомый случай из жизни. Вы впервые пришли в недавно открывшийся ресторан на набережной «Алые паруса» и совсем не знаете меню заведения, из каких ингредиентов готовят блюда, понравятся ли вам и прочее. Как вы поступаете в таком случае? Просматриваете перечень кулинарных позиций и задаете конкретные вопросы официанту. Получив нужную информацию, уже выбираете приглянувшееся вашим вкусовым предпочтениям и делаете заказ.
Аналогичная история происходит и с семантической разметкой сайта, которая и призвана облегчить процесс поиска пользователю и главное – предоставить понятную и структурированную информацию поисковому роботу.
Приведем конкретный пример. Пользователь ищет через поиск Яндекса, в какое агентство обратиться за разработкой и продвижением сайта. Вот так выглядит ресурс с микроразметкой:
Микроразметка что это такое наглядно с рейтингом:
Как настроить на Яндекс и Google читайте в нашей статье здесь – https://fireseo. ru/blog/mikrorazmetka-yandeks-i-google-kak-nastroit-schema-org/
ru/blog/mikrorazmetka-yandeks-i-google-kak-nastroit-schema-org/
Для чего нужна микроразметка
Если на вашем ресурсе до сих пор не внедрена микроразметка, скорее исправьте эту ситуацию.
Подпишитесь на авторский телеграм-канал про предпринимательство в России.
Микроразметка на сайте необходима:
- Для удобства пользователя
Микроразметка страницы подробно объясняет часть содержимого вашего сайта и помогает в оптимизации поиска. С семантической микроразметкой пользователь тратит меньше времени, чтобы найти нужный продукт в сети.
- Коммерческая польза
В результатах выдачи поисковой системы пользователь видит уйму предложений по своему запросу и теряется в выборе – какой из представленных ресурсов точнее отвечает его задаче? Микроразметка как раз помогает в этом процессе – главная информация о сайте показана уже в самой выдаче, до перехода на сайт компании.
Виды микроразметки
- разметка schema org
Отвечаем на вопрос массы пользователей и начинающих SEO-специалистов «schema org что это?».
Это особый язык поисковиков Google и Яндекс, его понимают и роботы других поисковых систем вроде Yahoo, Bing и прочие.
schema org – популярнейший язык микроразметки рейтинга, микроразметки товаров
микроразметки product, микроразметки отзывов и прочего содержимого сайта. В 2011 году этот тип микроразметки приняли за стандарт известные поисковые системы.
О требованиях микроразметки статей по schema.org от Google и Яндекс читайте здесь.
- itemprop что это – атрибут, используемых для дополнения свойств микроданных к элементу сайта. Название такого свойства назначается itemprop, а значение свойства уже определяется содержимым HTML-элемента. Например, текстом, расположенным внутри элемента.
Как выглядит:
itemprop="<свойство>"
Свойства определяется словарём данных на Schema.org
- JSON-LD
Это метод описания содержания страницы посредством языка связанных данных. Такая информация видна для роботов поисковых систем, но скрыта от обычных пользователей.
Наглядный пример такого типа микроразметки:
- разметка OpenGraph
Этот способ разметки информации используется в SMM (соцсети) – Facebook, ВКонтакте, Twitter, Google+, LinkedIn и прочие. Такая микроразметка нужна для публикации привлекательного и понятного превью в новостной ленты пользователей. С помощью такой микроразметки привлечете больше целевых переходов 🙂
- Микроформаты
Другой метод разметки гипертекста с помощью атрибута “class”. К примеру, назначаем тег
<div class=”adr”></div>
, что значит – сообщаем роботу о том, что внутри <div>помещен адрес.
Какой вид микроразметки SEO внедрять? Зависит ли от наличия микроразметки места, которые займет ваш сайт в результатах выдачи? Эксперты отрицают такие зависимости, но советуют применять микроразметку schema.org. Но вы можете выбрать ту, которая удобнее и практичнее для вас.
Как сделать микроразметку на сайте
Если решились внедрить микроразметку schema. org, то ознакомьтесь подробнее с руководством в статье “Введение в schema.org”. Этот материал рассказывает об основных принципах синтаксиса этого языка основные принципы синтаксиса этого языка. С помощью таких понятных рекомендаций сможете действительно грамотно внедрить эту микроразметку на свой ресурс.
org, то ознакомьтесь подробнее с руководством в статье “Введение в schema.org”. Этот материал рассказывает об основных принципах синтаксиса этого языка основные принципы синтаксиса этого языка. С помощью таких понятных рекомендаций сможете действительно грамотно внедрить эту микроразметку на свой ресурс.
Также вы можете более подробно рассмотреть создание микроразметки на сайте в нашей статье
Еще есть масса инструментов, которые автоматизируют процесс внедрения микроразметки на сайт:
Schema App — платный сервис. Здесь есть набор инструментов, с помощью которых сможете использовать язык Schema.org, не вникая с головой в их суть ☺
Microdata Generator Using Schema.org + JSON-LD – инструменты, помогающие в структурировании информацию по принципам Schema.org.
Довольно много информации изложено в помощи вебмастеру от Яндекса. Знакомьтесь с материалами и применяйте на практике возможности, которые улучшают позиции вашего сайта в поиске, и облегчат понимание ресурса роботами. Но самое главное – привлекут больше целевых пользователей на ваш ресурс с помощью грамотного и детального представления сжатой информации о сайте и конкретно вашем предложении.
Но самое главное – привлекут больше целевых пользователей на ваш ресурс с помощью грамотного и детального представления сжатой информации о сайте и конкретно вашем предложении.
Теперь вы знаете, зачем нужна микроразметка, какими видами она представлена и как ее внедрить. Не отставайте от конкурентов, дерзайте! ☺
Подпишитесь на рассылку FireSEO
и получайте подборки статей, полезных сервисов, анонсы и бонусы. Присоединяйтесь!
Настоящим подтверждаю, что я ознакомлен и согласен с условиями политики конфиденциальности на отправку данных.
что это такое, зачем нужна, и как ее внедрить – примеры реализации
Сайт разработали, все подогнали, но поисковые роботы не интересуются им. Почему так? Видимо, дело в отсутствии или ошибках микроразметки страниц…
Из этой статьи вы узнаете, что она собой представляет, зачем ее добавлять и какие виды в целом использовать.
Что такое микроразметка сайта?
В 2011 году был анонсирован стандарт schema. org. Инициатива создания принадлежала трем гигантам: Google, Microsoft, Yahoo. Чуть позднее и разработчики оценили это нововведение и поддержали внедрение микроразметки. Итак, что это?
org. Инициатива создания принадлежала трем гигантам: Google, Microsoft, Yahoo. Чуть позднее и разработчики оценили это нововведение и поддержали внедрение микроразметки. Итак, что это?
Микроразметка — это разметка данных на странице. Она имеет вид тегов и атрибутов, которые вставляются в код страницы. Не требуется формировать отдельные файлы для микроразметки. Этим объясняется относительная доступность использования инструмента.
Зачем нужна микроразметка?
Разметка помогает ботам лучше понять содержимое сайта, что впоследствии хорошо отражается на сканировании ресурса и его ранжировании. К примеру, на странице «О компании» или «Контакты» целесообразно выделить микроразметкой блок с телефонами и электронной почтой. Если пользователь введет запрос «телефон компании Х», поисковый бот сразу покажет ему эту страницу.
Смысл микроразметки сайта состоит в том, чтобы разместить элементы на странице тегами. Тем самым вы выделяете их для поисковиков. Существует немало словарей микроразметки, и детально мы изучим их чуть ниже.
Словари микроразметки
Мы перешли к самому интересному. Рассмотрим конкретные словари микроразметки сайта. Словарь представляет собой комплект разных атрибутов для данных. Ознакомимся с наиболее популярными на сегодняшний день.
Schema.org
Поддерживается с 2011 года «Гуглом» и всеми остальными поисковиками-гигантами. Словарь считают международным и он регулярно обновляется. Благодаря schema.org веб-мастерам удается составлять крутые сниппеты с основными данными страницы.
Данные описываются по древовидной структуре. Доступны сотни классов, позволяющие описывать различные объекты страницы. Для каждого предназначены стандартные атрибуты:
Как будет выглядеть участок кода с атрибутами schema.org:
Microformats.org
Этот словарь создали еще в 2007 году. В него входят различные виды объектов с описаниями их свойств. Как раз microformats.org помогает создавать описания товаров, мероприятий, компаний и прочие сущности с уникальными характеристиками. Из всех видов микроформатов самым используемым считается hCard. Он предназначен для описания контактов людей и компаний. То есть вы можете указать имя, дату рождения, адрес, фотографию, местоположение и прочие данные.
Из всех видов микроформатов самым используемым считается hCard. Он предназначен для описания контактов людей и компаний. То есть вы можете указать имя, дату рождения, адрес, фотографию, местоположение и прочие данные.
Сам участок с внедренным кодом выглядит следующим образом:
Open Graph
Этот словарь тоже распространенный и применяется для корректного показа публикаций в «Фейсбуке». С ним в посте будут заголовок, изображение и описание.
Пример микроразметки в коде:
Синтаксис микроразметки
К текущему году появилась значительная путаница из нескольких словарей, где применяется разный синтаксис. Например, для schema.org возможно несколько вариантов синтаксиса — от микроданных до JSON-LD. Разберемся подробнее в основных.
Microdata
Первое появление синтаксиса было в HTML-5. Он позволил поисковикам эффективнее сканировать данные на странице и использовать их в результатах выдачи. Разметка выполняется прямо в HTML-коде.
Вот пример разметки статьи посредством синтаксиса:
RDFa и RDFa Lite
Этот синтаксис создали эксперты World Wide WEb Consortium, чтобы привести в адекватную структуру данные на странице. Он имеет схожесть с Microdata, поскольку тоже размечается прямо в коде HTML. Применяют RDFa нечасто. Его считают непростым в реализации.
А вот и пример:
JSON-LD
Один из актуальных синтаксисов. От остальных отличается методом добавления на сайт: не в код, а в тег < script >. JSON-LD имеет вид комплекса пар «ключ-значение». Его легко понять не только поисковику, но и пользователю.
Допустим, требуется разместить статью посредством синтаксиса:
Как добавить микроразметку на сайт?
Можно воспользоваться любым из трех вариантов:
- Самостоятельно собрать код. Вы прописываете теги и атрибуты вручную.
- Использовать онлайн-инструменты. Как Schema-generator.
- Задействовать предварительно добавленный плагин или расширение в системе управления сайта — WordPress, Joomla и проч.

Не стоит сразу размечать все данные. Начните с ключевого: товаров, отзывов для онлайн-магазина или анонса с датами для сайта услуг.
На заметку. Поисковики предупреждают: если на странице нет какого-либо элемента, то и в микроразметке ему не место. В противном случае сайт попадет под ручные санкции. Кроме того, не используются совершенно не подходящие странице типы микроразметки. Это тоже грозит санкциями.
Популярные типы микроразметки
Присутствие микроразметки на странице уже стало подтвержденным условием ранжирования веб-ресурса. Разработчики Google рекомендуют как раз JSON-LD.
BreadcrumbList
Представляет собой микроразметку хлебных крошек страниц. Очень распространенная ошибка веб-мастеров — делать отдельную разметку для каждой хк. В целом размещение в сниппете хлебных крошек позволяет сделать его более привлекательным, чем при наличии невзрачной ссылки. Пример:
Organization
Общая разметка контактов на сайте, подходящая для контактных данных и разных видов ресурсов. Organization можно применять и отдельно, и внутри разметки Website. Обязательно размечайте все контактные данные!
Organization можно применять и отдельно, и внутри разметки Website. Обязательно размечайте все контактные данные!
Product
Эта микроразметка одна из наиболее востребованных. Она предназначена для страниц с товаром. Помогает добавить все главные данные о продукте: картинку, характеристики, стоимость, отзывы и остальное. Если все настроить верно, у вас получится существенно улучшить сниппет товара и тем самым повысить кликабельность.
Теперь немного о том, что размечать.
Review и additionalProperty — множественные данные. Если на ресурсе несколько отзывов и множество характеристик, блоки в разметке дублируются.
Какие возможные проблемы поджидают? В ходе разметки товара могут появиться предупреждения в инструменте проверки от Google. В целом это не скажется на итоговом результате, но для большей надежности можете заполнять все следующим образом:
Event
Микроразметка сайта позволяет разметить мероприятия. Например, спортивные, детские, социальные и любые другие. Подтипов у микроразметки страниц очень много, так что можете выбрать любой необходимый.
Подтипов у микроразметки страниц очень много, так что можете выбрать любой необходимый.
Внедряется микроразметка просто. Вы или делаете скрипт с информацией со страницы мероприятия и интегрируете в код этой самой страницы, или размечаете имеющийся код с помощью Microdata.
FAQ
Эта микроразметка Google позволяет увеличить сниппет путем вывода 2–4 популярных вопросов по теме запроса. Чтобы настроить FAQ, нужно писать вопросы и ответы из средне- и низкочастотных запросов. Если речь об оптимизации онлайн-магазина, задействуйте автогенерацию ответов. Выглядит она в сниппете так:
AggregateRating
Этот тип микроразметки страницы дает возможность добавлять рейтинги заведений, магазинов и проч. Как правило, применяется в качестве части чего-то более масштабного, как Product. За счет добавления микроразметки вы делаете расширенный сниппет, примерно вот такой:
Он смотрится привлекательнее обычного, поэтому с большой вероятностью приведет дополнительный трафик на сайт и мотивирует заказать товар или услугу.
Как проверить микроразметку на сайте?
Чтобы убедиться в правильном составлении кода, используйте валидаторы Google. И в одном, и во втором инструменте доступна вставка ссылки на страницу или фрагмент кода с синтаксисом разметки. Если ошибок нет в обоих валидаторах, можно смело внедрять код на сайт.
Посмотрим способ проверки микроразметки через валидатор микроразметки от Google. Выглядит он так:
Здесь вы можете проверить микроразметку на определенной странице веб-ресурса:
А также проверить нужную часть кода:
Если микроразметка страницы в порядке, вы увидите следующее:
В случае присутствия ошибок будет такое:
Вывод
Правильное внедрение микроразметки на сайте позволяет значительно улучшить результаты SEO-продвижения. Согласитесь, ведь информативный и привлекательный сниппет мотивирует кликнуть по нем куда быстрее, чем неприметный и непонятный.
Но пока она все же остается недооцененной, так как кажется сложной и запутанной. На самом деле разобраться можно, если хорошо погрузиться в тему. Да и разбираться в принципе необязательно. Можно найти хороших специалистов, которые досконально проработают микроразметку страниц сайта и помогут улучшить показатели ресурса. Следовательно — и поднять продажи товаров или услуг.
На самом деле разобраться можно, если хорошо погрузиться в тему. Да и разбираться в принципе необязательно. Можно найти хороших специалистов, которые досконально проработают микроразметку страниц сайта и помогут улучшить показатели ресурса. Следовательно — и поднять продажи товаров или услуг.
У вас остались вопросы?
Оставьте ваши контактные данные. Наш менеджер свяжется и проконсультирует вас.
Полезность
Проголосовали 2
Как вам статья?
Что такое микроданные SEO? — SEO Design Chicago
Вы только что завели блог или создали веб-сайт и хотите увеличить посещаемость и улучшить свой рейтинг. Итак, что нужно сделать? Вот ваш ответ: микроданные SEO. Часто вы будете слышать о поисковой оптимизации и ее невероятной маркетинговой стратегии по увеличению количества кликов на веб-сайте (что правда), но о чем вы не слышите, так это о технических данных, которые в нее входят. SEO с микроданными — это золотой билет для каждого человека, который хочет, чтобы его контент отображался в SERP (странице результатов поисковой системы). По данным Google, 53% потребителей в США сказали, что они изучают продукты с помощью поисковой системы, прежде чем принять решение о покупке поэтому доверие к поисковой системе необходимо для роста бизнеса. Микроданные обычно используются разработчиками веб-сайтов и включают кодирование HTML и CSS. Но в этой статье мы обсудим, как каждый может извлечь выгоду из этой сложной маркетинговой стратегии, и узнаем о различиях между микроданными, схемой и структурированными данными.
По данным Google, 53% потребителей в США сказали, что они изучают продукты с помощью поисковой системы, прежде чем принять решение о покупке поэтому доверие к поисковой системе необходимо для роста бизнеса. Микроданные обычно используются разработчиками веб-сайтов и включают кодирование HTML и CSS. Но в этой статье мы обсудим, как каждый может извлечь выгоду из этой сложной маркетинговой стратегии, и узнаем о различиях между микроданными, схемой и структурированными данными.
Содержание
Что такое микроданные? Начнем с определения микроданных. Это словоблудие немного расплывчато, но, по сути, эта стратегия SEO включает в себя объяснение поисковым системам, какие элементы находятся на странице. Если это звучит запутанно, не волнуйтесь. Мы разберем это дальше и изложим это с точки зрения непрофессионала. Микроданные — это помеченный закодированный язык, который помогает поисковым системам, таким как Google, Yahoo! или Bing, понять, что находится на веб-сайте, с помощью фрагментов кода, размещенных в коде веб-сайта. Причина использования микроданных — простая концепция: семантический поиск. Поисковые системы должны знать контекст того, почему вы ищете то, что ищете, чтобы предоставить лучший и наиболее подходящий контент. Давайте рассмотрим пример упрощенных микроданных.
Причина использования микроданных — простая концепция: семантический поиск. Поисковые системы должны знать контекст того, почему вы ищете то, что ищете, чтобы предоставить лучший и наиболее подходящий контент. Давайте рассмотрим пример упрощенных микроданных.
Технический жаргон для кодирования SEO и разработки веб-сайтов может сбивать с толку людей, незнакомых со специальностью, поэтому давайте рассмотрим пример того, как микроданные будут выглядеть без использования HTML-кода, однако мы об этом позже в этой статье. А пока давайте посмотрим на микроданные так, как это может понять каждый. Поисковик видит это: Апельсины здоровы. Поисковая система не будет знать, о чем вы говорите: об апельсине, фруктах, апельсине, цвете или апельсине, полосе. Чтобы правильно продвигать веб-сайт, поисковые системы требуют, чтобы вы были более конкретными с вашим контентом. Вот тут-то и появляются микроданные. Когда вы включаете микроданные (код, определяющий вашу статью) в свой заголовок и информацию, поисковая система теперь будет знать, что вы говорите о фруктах. Затем он может рекламировать ваш контент всем, кто ищет этот конкретный контент.
Затем он может рекламировать ваш контент всем, кто ищет этот конкретный контент.
Поисковые системы предназначены для цифрового сканирования веб-сайта, чтения его кода и последующего продвижения его на своем сайте для доступа людей. Микроданные делают работу поисковой системы в сотни раз проще, потому что информация, которую они ищут, предоставляется в более конкретном, удобном для компьютера виде. Основы SEO-маркетинга подскажут вам, как использовать сильные ключевые слова на вашем веб-сайте, чтобы поисковые системы могли помечать их как важные и релевантные. Микроданные делают то же самое, но в усиленном виде, потому что используют язык, понятный компьютеру.
Где следует использовать микроданные? Теперь, когда мы знаем, что такое микроданные, давайте узнаем, как мы можем включить их в наш контент. Если у вас есть блог или веб-сайт, вы можете использовать микроданные именно здесь. Вы можете легко вставить код в любое из этих существующих имен:
Вы можете легко вставить код в любое из этих существующих имен:
- Заголовок
- Автор
- Изображение
- Дата публикации
- Дата последнего изменения
- Сам формат
Использование микроданных особенно успешен в SEO-маркетинге B2B. Внедряя метатеги в заголовок своей страницы, вы предоставляете более подробную информацию о своем веб-сайте, которую поисковая система будет отображать, когда они появятся на странице результатов.
Микроданные и метаданные Метаданные — еще одно сбивающее с толку расплывчатое слово, которое, как вам может показаться, вы не знаете, но на самом деле вы, вероятно, уже знакомы с ним. Это форма структурированных данных, используемых поисковиками веб-сайтов, которые могут включать в себя: заголовки, URL-адреса веб-сайтов и краткие описания страниц. Обычно это то, что отображается вам, когда вы находитесь в Google или Bing, и содержит удобные ключевые слова, которые используются для SEO. Итак, в чем разница между микроданными и метаданными? Микроданные обычно используются для поисковых систем, а метаданные — для людей с помощью поисковых систем. Микроданные включают код HTML и CSS, тогда как метаданные используют слова для описания веб-сайта. Оба, однако, жизненно важны для SEO-маркетинга.
Итак, в чем разница между микроданными и метаданными? Микроданные обычно используются для поисковых систем, а метаданные — для людей с помощью поисковых систем. Микроданные включают код HTML и CSS, тогда как метаданные используют слова для описания веб-сайта. Оба, однако, жизненно важны для SEO-маркетинга.
По мере того, как мы углубляемся в микроданные, терминология становится немного более точной и запутанной, но оставайтесь со мной. Если микроданные — это язык кодирования, предназначенный для использования на HTML-страницах, будет ли он работать для всех веб-страниц? Этот вопрос приводит к ответу: разметка схемы. Микроданные — это тип языка, и для любого языка они могут различаться в зависимости от того, кто их использует. Чтобы противодействовать этому и упростить для поисковых систем чтение всего кода, Google, Microsoft, Yahoo и Яндекс объединились для создания универсальных структурированных данных, которые были бы доступны не только для их поисковых систем, но и для использования в Интернете. разработчиков и создателей контента. Разметка Schema — это особый язык кодирования, понятный поисковым системам и используемый на веб-сайтах для понимания содержимого. Разметка схемы — это особый тип микроданных, которые можно найти на Schema.org.
разработчиков и создателей контента. Разметка Schema — это особый язык кодирования, понятный поисковым системам и используемый на веб-сайтах для понимания содержимого. Разметка схемы — это особый тип микроданных, которые можно найти на Schema.org.
Schema.org — это веб-сайт, который помогает как создателям контента, так и разработчикам веб-сайтов понимать и использовать разметку схемы для своих веб-сайтов. Их веб-сайт работает как руководство по интеграции определенного кода, который распознают поисковые системы. Schema.org использует три разных типа кода:
- JSON-LD
- Микроданные
- RDFa
Эти коды работают как тип языка, который понимают поисковые системы. Использование разметки схемы на schema.org используется для точного определения:
- Статьи
- События
- Продукты
- People
- Организации
- Местные предприятия
- Обзоры
- Рецепты
- Условия медицинских работ. это не так. Вот пример того, как вы можете использовать веб-сайт Schema, чтобы помочь вам с вашим конкретным контентом. Пример разметки Local Business Schema:
Находясь на Schema.org, используйте панель поиска в правом верхнем углу веб-сайта. Допустим, мы являемся владельцем местной пекарни и хотим использовать Schema.org для организации данных вашего веб-сайта. Когда мы вводим «бизнес» в строку поиска, первая всплывающая ссылка — «Местный бизнес». Если вы нажмете на вкладку «Местный бизнес», вы найдете весь набор структурированных данных, необходимых для обогащения фрагментов вашего веб-сайта. Это то, что вы будете использовать в качестве руководства при вводе данных на свой веб-сайт.
Что такое структурированные данные?Теперь мы подошли к последней части микроданных. Мы начали с того, что узнали все об использовании микроданных и о том, как они полезны для SEO. Мы узнали о схеме и ее важной роли в том, чтобы помочь поисковой системе понять контент.
Как структурированные данные влияют на SEO? Теперь мы подошли к структурированным данным: луку, объединяющему их все вместе. Согласно Руководству Google по разработке структурированных данных, структурированные данные — это стандартизированный формат для предоставления информации о странице и классификации содержимого страницы. Другими словами, если микроданные и разметка схемы — это язык, понятный поисковой системе, то структурированные данные — это организационная система, которую она использует для их чтения. Использование структурированных данных на вашем веб-сайте дает несколько преимуществ, включая улучшение SEO.Думайте о структурированных данных и поисковых системах, как о попытке найти одежду в грязной комнате. Вы входите и ищете зеленый свитер. Но если в вашей комнате беспорядок, вы с меньшей вероятностью найдете этот зеленый свитер и с большей вероятностью выберете что-то другое из-за разочарования. Поисковые системы тоже это сделают. Маркировка вашего веб-сайта правильной информацией, такой как рейтинги, часы работы, адреса и номера телефонов, — это именно тот тип расширенных фрагментов, которые поисковые системы любят, потому что они организованы.
Как SEO Design Chicago может помочь вам в SEO Ваш веб-сайт и контент всегда будут иметь более высокий рейтинг, если у вас есть подробные, систематизированные данные, которые дают контекст вашему веб-сайту. Как мы обсуждали ранее, ключевые слова, хотя и являются важными факторами для SEO, нуждаются в контекстных данных, чтобы отличать их от других. Оглядываясь назад на пример, который мы использовали ранее, ваш веб-сайт может быть посвящен апельсинам, но если вы не разместите код, который идентифицирует апельсин как объект, цвет или музыку, Google не поймет, что вы имеете в виду. Ключевые слова, контекстные микроданные и структурированные данные являются ключом к правильному SEO.Мы понимаем, что входит в создание, продвижение и отслеживание веб-сайта, и здесь, в SEO Design Chicago, мы хотим упростить вам задачу. Мы можем помочь вам с разработкой веб-сайта, внедрением стратегий SEO и использованием Google Analytics для отслеживания вашего успеха. Свяжитесь с нами сегодня с вашими вопросами и потребностями цифрового маркетинга!
Часто задаваемые вопросы о микроданных SEO:- Важна ли схема для SEO?
- Что является примером микроданных?
- Как добавить микроразметку на веб-сайт?
- Какие существуют типы схемы в SEO?
- Что такое JSON-LD?
Что такое микроданные и как они могут помочь моему SEO-рейтингу?
Если вы хорошо разбираетесь в поисковой оптимизации, то знаете, что существуют разные методы, позволяющие найти ваш сайт в поисковых системах.
Многим маркетологам удобнее всего использовать SEO на странице: создавать контент для ключевых слов, а затем оптимизировать этот контент (например, добавлять теги заголовков, альтернативный текст и т. д.) для сканирования в поисковых системах.Но техническое SEO — то, что обычно ложится на плечи разработчика, — может пугать маркетолога, поскольку оно имеет дело с кодом и структурированными данными за кулисами.
Итак, мы расскажем о преимуществах микроданных в вашей стратегии SEO и дадим вам язык, необходимый для разговора с вашей командой разработчиков.
Что такое микроданные и метаданные?
Метаданные, пожалуй, более привычная стратегия для SEO-маркетологов. Но хотя это также форма структурированных данных, у нее есть некоторые отличия.
Метаданные . Мы можем думать о метаданных, как о том, что сообщает пользователям, выполняющим поиск, о содержании страницы. Например, в метаописании может быть сказано: «В этом сообщении в блоге вы узнаете о пяти инструментах, которые помогут повысить эффективность вашего сервера данных».
Некоторые распространенные теги метаданных включают заголовок, краткий URL-адрес и описание страницы. Это в основном для пользы искателя, намекая на то, что он собирается прочитать.Микроданные . Мы можем думать о микроданных, как о том, что сообщает поисковым системам, какие элементы страницы это . Другими словами, микроданные присваивают ярлыки отдельным фрагментам контента. И тогда поисковая система выделит эти куски в поиске. Например, мы можем использовать микроданные, чтобы сказать: «Привет, Google, следующий текст — имя автора» или «Следующий фрагмент информации — звездный рейтинг». Это похоже на обращение напрямую к Google или Bing, но в конечном итоге это приносит пользу искателю.
Статья по теме: Как голосовой поиск повлияет на SEO?
Как микроданные улучшают SEO?
Значимость метаданных снижается для ранжирования. Другими словами, то, что вы включаете описание страницы с ключевыми словами, не означает, что ваша страница будет иметь более высокий рейтинг.
Но, с другой стороны, микроданные предпочитают поисковые системы, потому что они облегчают сканирование вашего сайта. Он говорит им: «Вот что нужно выделить и что важно в моем произведении!» Подумайте об этом, как об организации вашего загроможденного инвентаря в магазине по разным помеченным корзинам. Это, в свою очередь, помогает Google создавать более удобный и удобный интерфейс для пользователей, осуществляющих поиск.
Например, в некоторых поисковых запросах автор будет самым важным фактором. Но при поиске с другим намерением обзор или звездный рейтинг будут иметь приоритет.
Как метаданные, так и микроданные улучшают поиск, но есть свидетельства того, что микроданные действительно могут улучшить ваш рейтинг, а не только рейтинг кликов.
Статья по теме: 5 Передовой опыт SEO для корпоративных веб-сайтов
Где следует использовать микроданные?
Существует так много применений микроданных, что трудно рассмотреть их все. Но для вашего блога и веб-сайта — особенно если вы B2B — вы можете предоставить поисковым системам помеченную страницу для сканирования, что поможет им лучше индексировать вас при поиске.
А это означает больше трафика и, в конечном счете, лучший бизнес для вас.В частности, вы можете попросить свою команду разработчиков идентифицировать эти фрагменты с помощью языка схемы:
- Изображение
- Автор
- Дата публикации
- Дата последнего изменения
- Заголовок
- Формат (например, блог)
Микроданные особенно полезны для событий. Ticketmaster здесь определил разные даты билетов, что отлично подходит для людей, которые ищут быстрый доступ к билетным мероприятиям. Google также оказывает влияние на ранжирование веб-сайтов, которые идентифицируют элементы страницы с помощью микроданных.
Чтобы получить более широкий список, посетите Schema.org и узнайте больше о возможностях их языка. Самое замечательное, что все основные поисковые системы будут придерживаться этого языка.
Есть также свидетельства того, что добавление микроданных — как и многих видов структурированных данных — поможет связать результаты вашего поиска с Google+, а также представить ваш контент в многообещающих «расширенных фрагментах», которым Google отдает предпочтение при поиске для всех виды ключевых слов.
Могу ли я самостоятельно внедрить микроданные для SEO?
Реализация языка не слишком сложна. Подобно добавлению метатегов в заголовок вашей страницы, вы оборачиваете диапазон контента фрагментом кода на языке схемы.
Если это вам знакомо, перейдите на Schema.org и начните поиск тегов, которые вы можете использовать. Затем вы можете протестировать свой код с помощью инструмента тестирования структурированных данных Google, по сути, увидев свой веб-сайт глазами Google.
Как правило, если у вас есть базовые знания HTML/CSS, вы можете легко выучить язык самостоятельно. Если это страшно или чуждо, вместо этого сотрудничайте со своим разработчиком. Вы также можете сотрудничать с SEO-агентством, чтобы помочь с внутренними, внешними и техническими стратегиями SEO.
https://www.ironpaper.com/articles/2015-critical-seo-statistics-and-trends/
Источники:
https://search.google.com/structured-data/testing -tool/u/0/
https://schema.
org/docs/gs.htmlКак использование микроданных может улучшить SEO вашего веб-сайта
Подпишитесь на Entrepreneur за 5 долларов США
Подписывайся
По Эй Джей Кумар
Мнения, выраженные участниками Entrepreneur , являются их собственными.
Прошлым летом поисковые гиганты Google, Bing и Yahoo объявили о редком сотрудничестве, направленном на поддержку использования тегов микроданных для получения более релевантных и подробных результатов поиска. Это дает владельцам бизнеса и другим издателям веб-сайтов еще одну возможность улучшить свою поисковую оптимизацию (SEO), внеся несколько изменений в свои веб-сайты.
Хотя поначалу микроданные могут звучать как иностранный язык, не бойтесь. Чтобы помочь вам начать, вот краткое описание того, что такое микроданные, как их используют поисковые системы и почему они могут принести пользу вашему веб-сайту.
Что такое микроданные?
По сути, микроданные — это один из трех кодовых языков, предназначенных для предоставления программам-паукам поисковых систем информации о содержании веб-сайтов. Чтобы понять, как это работает на практике, рассмотрим следующий пример, предоставленный веб-сайтом Schema.org со списками микроданных:«Обычно теги HTML сообщают браузеру, как отображать информацию, содержащуюся в теге. Например,
указывает браузеру отображать текстовую строку «Аватар» в формате «заголовок 1». Однако тег HTML не не давать никакой информации о том, что означает эта текстовая строка, и это может затруднить поисковым системам разумное отображение релевантного контента для пользователя».
В этом случае можно добавить элементы микроданных, также называемые «тегами схемы», чтобы уточнить, что рассматриваемый «Аватар» — это фильм, а не графическое изображение, предназначенное для представления человека в Интернете.
Связано: Как создать SEO команду с нуля
Зачем использовать микроданные для разметки ваших страниц?
Интеграция микроданных в код вашего веб-сайта дает ряд потенциальных преимуществ. Во-первых, микроданные могут дать поисковым роботам больше информации о типе информации на веб-сайте и о том, как сайт должен быть проиндексирован и ранжирован. Например, добавление микроданных для разметки HTML-кода на веб-странице, связанной с фильмом «Аватар», сообщит поисковым роботам о ранжировании страницы в отношении сайтов с фильмами, а не сайтов с графическим дизайном.Еще одним преимуществом микроданных является создание «расширенных фрагментов», которые отображают больше информации на страницах результатов поиска, чем традиционные списки. Например, поиск в Google с использованием тегов микроданных для «рецепта тыквенного супа» дает следующие результаты, включая изображения, отзывы и время приготовления.
Если бы вы искали новый рецепт супа из тыквы, скорее всего, вы бы скорее нажали на один из них, чем на традиционный список, который отображает только название сайта, мета-описание и URL-адрес.
Связано с: Три шага по оптимизации вашего веб-сайта для обновления Google «Свежесть»
Кому следует использовать теги микроданных?
Партнерство Google, Bing и Yahoo значительно расширило набор опций в библиотеке тегов микроданных. К наиболее популярным типам микроданных относятся:- Творческие работы: CreativeWork, Book, Movie, MusicRecording, Recipe, TVSeries
- Встроенные нетекстовые объекты: AudioObject, ImageObject, VideoObject
- Событие
- Организация
- Лицо
- Место, Местный Бизнес, Ресторан
- Продукт, Предложение, Совокупное Предложение
- Обзор, Совокупный Рейтинг
Малые местные предприятия, такие как рестораны и интернет-магазины, и магазины включение микроданных. Но это может быть полезно для любого бизнеса, у которого есть проблемы с получением трафика через результаты поиска. Теги микроданных могут помочь вашему сайту более точно индексироваться и ранжироваться, а полученные расширенные фрагменты могут помочь вашему сайту выделиться среди других на странице результатов и привлечь к вам больше трафика.
Как начать работу с тегами микроданных?
Чтобы понять, как будет выглядеть ваш готовый размеченный код, рассмотрите следующую вымышленную HTML-страницу для примера «Аватар»:
Режиссер: Джеймс Кэмерон (родился 16 августа 1954 г.)В этом примере тег микроданных «фильм» был добавлен в раздел «div», указывающий, что информация в этой текстовой области сайта относится к фильму. Тег «itemscope» сообщает поисковым системам, что весь контент в этом конкретном разделе «div» относится к определенному «типу элемента» (в данном случае «кино»).
Для получения дополнительной информации о том, как интегрировать микроданные в HTML-код вашего сайта, попробуйте прочитать «Руководство по началу работы» на Schema.org. После завершения кодирования рассмотрите возможность запуска вашего веб-сайта с помощью «Инструмента тестирования расширенных фрагментов» Google, чтобы убедиться, что ваши микроданные анализируются правильно и обеспечивают максимальную пользу для ваших страниц.
Связано с этим: Руководство по выживанию из шести шагов для обновлений поисковой системы
Когда ресторан ее родителей сгорел, бренд острых соусов этого основателя первого поколения восстал из пепла, чтобы бросить вызов корпоративным гигантам
Не достигает цели? Вот как узнать, следует ли вам изменить тактику или стратегию.
Вы можете создать свой собственный вирусный пост LinkedIn с помощью этого веселого инструмента
Эта пара потеряла все, когда рынок жилья рухнул. Но проявление «волшебства» помогло им запустить метафизический бренд с 10 магазинами.
4 Скрытые опасности удаленной работы
Лучшие поставщики программного обеспечения и технологий в индустрии франчайзинга
Этот 18-летний студент хотел, чтобы он лучше следил за своей школьной работой.
Итак, он создал приложение — и бизнес.
Новости бизнеса
ФРС снова повысила процентные ставки. Вот что это значит для вашего кошелька.
Эмили Релла
Новости бизнеса
Это основные страны, в которые переезжают американцы, с разбивкой по возрастным группам
Габриэль Биенаш
Развитие бизнеса
Почему простота имеет решающее значение для бизнеса SaaS (и как сохранить простоту)
Скотт Салкин
Читать далее
IPUMS USA: FAQ
Общая информация о проекте
Что такое IPUMS USA?
Что ждет IPUMS в будущем?
Добавляет ли IPUMS USA ценность данным?
Начало работы
С чего начать новому пользователю?
Как получить доступ к данным IPUMS USA?
Основные понятия
Что такое микроданные?
Что такое «переменные-указатели»?
Что такое «общая» и «подробная» версии переменных?
Что такое «гири»?
Что означает слово «вселенная» в описаниях переменных?
Что такое «флаги качества данных»?
Получение данных
Как получить данные?
В каком формате представлены данные?
Сколько времени занимает извлечение данных?
Что делать, если образцы слишком велики для меня?
Как работает «выбор образца» на веб-сайте IPUMS USA?
Что означают «добавить в корзину» и «в корзину»?
Почему я не могу открыть файл данных?
Есть ли предпочтительный статистический пакет для использования IPUMS?
Могу ли я анализировать данные IPUMS USA без статистического пакета?
Можно ли получить исходные данные?
Как уникально идентифицируется запись?
Использование данных IPUMS
Существуют ли сложные аспекты данных IPUMS, о которых следует особенно помнить?
Как решить, какую выборку использовать за тот или иной год?
Вы говорите, что IPUMS является национальным представителем; Является ли он также репрезентативным для меньших областей?
Каковы основные ограничения данных?
Могу ли я найти конкретных лиц в данных IPUMS?
Как цитировать IPUMS USA?
Могу ли я использовать IPUMS для генеалогии?
Использование страницы переменных
Меню страницы переменных
Сведения о странице переменных
Использование системы извлечения данных
Ваша корзина данных
Почему некоторые переменные в моей корзине данных выбраны заранее?
Что такое «Тип»?
Извлечь страницу запроса
Извлечение определения: структура данных
Вариант извлечения: настройка размеров выборки
Вариант извлечения: выберите дела
Опция извлечения: прикрепить характеристики
Опция извлечения: выберите флаги качества данных
Вариант извлечения: опишите свое извлечение
Опция извлечения: скорректировать денежные значенияОбщая информация о проекте
Что такое IPUMS USA? [наверх]
Интегрированная серия микроданных общественного пользования (IPUMS USA) состоит из более чем пятидесяти высокоточных выборок американского населения, взятых из пятнадцати федеральных переписей и обследований американского сообщества с 2000 г.
по настоящее время. Некоторые из этих образцов существуют годами, а другие были созданы специально для этой базы данных. Эти выборки, основанные на всех сохранившихся переписях с 1850 по 2010 год, а также выборки ACS/PRCS с 2000 года по настоящее время, в совокупности составляют наш самый богатый источник количественной информации о долгосрочных изменениях в американском населении. Однако, поскольку разные исследователи создавали эти образцы в разное время, они использовали самые разные макеты записей, схемы кодирования и документацию. Это усложняет попытки использовать их для изучения изменений с течением времени. IPUMS присваивает единые коды всем образцам и приводит соответствующую документацию в согласованную форму, чтобы облегчить анализ социальных и экономических изменений.IPUMS не является набором скомпилированных статистических данных; он состоит из микроданных. Каждая запись представляет собой человека со всеми характеристиками, закодированными числовым кодом. В большинстве выборок люди организованы в домохозяйства, что позволяет изучать характеристики людей в контексте их семей или других сожителей.
Поскольку данные представляют собой отдельных лиц, а не таблицы, исследователи должны использовать статистический пакет для анализа миллионов записей в базе данных. Система извлечения данных позволяет пользователям выбирать только те образцы и переменные, которые им необходимы.IPUMS International — крупнейшая в мире коллекция общедоступных данных переписи населения на индивидуальном уровне. IPUMS International объединяет образцы переписей населения со всего мира, проведенные с 1960 года. Ученые, интересующиеся только Соединенными Штатами, лучше обслуживаются с помощью IPUMS USA, оптимизированного для исследований в США.
IPUMS CPS представляет собой интегрированный набор данных мартовского текущего обследования населения (CPS), начиная с 1962 года и продолжающегося до настоящего времени. Этот гармонизированный набор данных также совместим с данными десятилетних переписей населения США, которые являются частью IPUMS USA. Исследователи могут воспользоваться относительно большим размером выборки IPUMS USA с десятилетними интервалами и заполнить информацию за промежуточные годы, используя IPUMS CPS.
Что ждет IPUMS в будущем? [наверх]
IPUMS USA финансируется до 2023 г. за счет нескольких грантов Национальных институтов здравоохранения. Мы всегда работаем над улучшением этих важных ресурсов данных и метаданных, предоставляем пользователям новые инновационные способы использования данных IPUMS USA и, конечно же, добавляем больше данных.
У нас есть все основания рассчитывать на продолжение проекта в течение многих лет, но нам придется обеспечить дополнительное финансирование, поскольку наши текущие гранты истекают. Чтобы добиться успеха, нам нужно иметь большое количество пользователей и опубликованных работ, на которые мы можем указать. Пожалуйста, сообщите нам, если у вас есть какие-либо презентации или публикации с использованием данных IPUMS.
Добавляет ли IPUMS USA ценность данным? [наверх]
Данные IPUMS интегрируются во времени и между образцами путем присвоения единых кодов переменным. Этот процесс сам по себе повышает ценность данных, полностью документируя все коды и компилируя всю документацию по переменным в веб-формате с гиперссылками.
Но мы делаем и многое другое:IPUMS создает согласованный набор сконструированных переменных по семейным взаимоотношениям для всех выборок. Переменные-указатели указывают местонахождение в домохозяйстве матери, отца и супруга каждого человека.
Данные IPUMS также включают гармонизированные переменные доходов и занятий. Бюро переписи реорганизовало свои системы классификации занятий и отраслей почти в каждой переписи, проводимой с 1850 года. Хотя IPUMS сохраняет первоначальные коды занятий и отраслей, для долгосрочного анализа были созданы различные переменные занятий и отраслей. Дополнительную информацию об этих переменных можно найти на странице Переменные профессии и отрасли.
Начало работы
С чего начать новому пользователю? [наверх]
Документация является естественной отправной точкой для новых пользователей IPUMS USA. Во-первых, Руководство пользователя содержит обзор базы данных и подробную документацию по доступным переменным и примерам.
Страница «Переменные» — это основной инструмент для изучения содержимого IPUMS USA. На странице переменных щелчок по имени переменной вызывает ее документацию. Он содержит описание переменной и обсуждение вопросов сопоставимости во времени. На странице переменных также есть прямые ссылки на страницу кодов для каждой переменной. На странице кодов показана структура кодирования и метки для переменной, а также наличие категорий в выборках. Эти категории могут предложить типы исследования, возможные с данной выборкой. Ссылки в нижней части описания каждой переменной ведут к исходному тексту вопросника и инструкциям, относящимся к вопросу переписи для каждой выборки. Нажмите кнопку «Учебник» на странице переменных, чтобы узнать, как сделать выписку, или просмотрите раздел часто задаваемых вопросов на странице переменных.
На странице «Выборки» описаны характеристики выборок в рядах данных и переписях, на основе которых они были получены.
Если вы уже зарегистрированы для использования IPUMS USA, вы можете нажать «создать выписку» и использовать систему доступа к данным.
Для начала пользователи могут ознакомиться с нашими инструкциями для системы извлечения (pdf).Как получить доступ к данным IPUMS USA? [наверх]
Доступ к документации свободный без ограничений; однако пользователи должны зарегистрироваться, прежде чем извлекать данные с веб-сайта.
Данные IPUMS USA также доступны для онлайн-анализа через систему онлайн-анализа данных IPUMS.
Основные концепции
Что такое микроданные? [наверх]
Микроданные переписи состоят из отдельных записей, содержащих информацию, собранную о лицах и домохозяйствах. Единицей наблюдения является человек. Ответы каждого человека на разные вопросы переписи записываются в отдельные переменные.
Микроданные отличаются от более привычных «сводных» или «совокупных» данных. Обобщенные данные представляют собой собранную статистику, например, таблицу семейного положения по полу для какой-либо местности. В данных IPUMS такой табличной или сводной статистики нет.
Микроданные по своей природе являются гибкими. Нет необходимости полагаться на опубликованную статистику переписи, которая собирала данные определенным образом, если вообще нужно. Пользователи могут генерировать свою собственную статистику из данных любым способом, включая многомерный анализ на индивидуальном уровне.
См. изображение данных IPUMS здесь. Все данные IPUMS представлены в этом общем формате.
Что такое «переменные-указатели»? [наверх]
«Указательные» переменные IPUMS указывают местонахождение в домашнем хозяйстве матери, отца и супруга каждого человека. Почти во всех выборках указывается родство каждого лица с главой домохозяйства, но гораздо труднее связать отдельных лиц с лицами, не являющимися главой (например, внуки с детьми, зятья с дочерьми или неродственные лица с каждым домохозяйством). Другой). Мы разработали сложный базовый алгоритм для создания таких соединений и настраиваем его по мере необходимости с учетом особенностей конкретных образцов.
Переменные-указатели называются MOMLOC, POPLOC и SPLOC в системе IPUMS, а сопутствующие переменные указывают основные правила, по которым была сделана конкретная ссылка.Переменные-указатели упрощают построение переменных индивидуального уровня, представляющих характеристики совместно проживающих лиц, таких как профессия супруга, возраст матери или уровень образования отца. Вам необходимо включить в свою выписку переменные серийного номера и идентификатора человека (SERIAL и PERNUM), а также сами переменные-указатели, чтобы выполнить эти манипуляции с данными.
Что такое «общая» и «подробная» версии переменных? [сверху]
Большинство переменных в IPUMS имеют составную структуру кодирования, где первая цифра в значительной степени сравнима между выборками, а вторая и последующие цифры предоставляют все больше деталей, доступных в одних выборках, а не в других. Для некоторых часто запрашиваемых переменных составная структура кодирования формально распознается в нашей системе путем выделения отдельных «общих» и «подробных» версий переменной.
Например, исследователи могут получить доступ к сопоставимой на международном уровне однозначной общей версии «статуса занятости» или могут использовать полностью подробную трехзначную версию, если их исследование требует более точных различий. Два набора кодов полностью согласуются друг с другом; один просто предоставляет больше категорий, в то время как другой проще в использовании и, как правило, более сопоставим по выборкам.Обе версии переменных имеют соответствующие синтаксические метки. В извлечениях данных к подробной версии переменной добавляется буква «D» в конце ее мнемоники (например, для «статуса занятости» EMPSTAT является общим, а EMPSTATD — подробным).
Общая и подробная версии переменной соответствуют одному и тому же описанию в системе документации. Коды и частоты каждой версии можно просмотреть отдельно на соответствующей странице переменных кодов.
Что такое «весы»? [наверх]
Все наборы данных в образцах IPUMS; каждый выборочный случай представляет от 20 до 1000 человек в общей численности населения за данный год.
Переменные «веса» указывают, сколько человек в совокупности представлено каждым случаем выборки. Многие выборки IPUMS являются невзвешенными или «плоскими», что означает, что каждый человек в данных выборки представляет одинаковое количество людей в совокупности. Например, в 1% невзвешенной выборке 2000 года вес для всех случаев выборки зафиксирован на уровне 100; каждый случай представляет 100 человек в популяции. Но многие выборки в IPUMS являются «взвешенными», что означает, что некоторые выборочные случаи представляют больше людей в популяции, чем другие. Лица и домохозяйства с одними характеристиками представлены в выборках чрезмерно, а другие недопредставлены. Весовые переменные позволяют исследователям создавать точные оценки населения, используя взвешенные выборки. См. переменную PERWT или Что такое IPUMS? страница со списком взвешенных образцов IPUMS USA.Чтобы получить репрезентативную статистику из взвешенных выборок, пользователи должны применять веса выборки. Выполните одну из следующих процедур:
1.
Для анализа на уровне человека с использованием взвешенной выборки примените переменную PERWT. PERWT дает совокупность, представленную каждым человеком в выборке; в образцах 1850–1930 гг. точность выше, чем в образцах 1940 г. и позже.2. Для анализа на уровне домохозяйств с использованием взвешенной выборки взвесьте домохозяйства с помощью переменной HHWT. HHWT дает количество домохозяйств в общей совокупности, представленной каждым домохозяйством в выборке; больше точности доступно в 1850-19на 30 образцов больше, чем у образцов 1940-го года выпуска. Если вы используете прямоугольную выборку, выберите только одного человека (например, PERNUM = 1) для представления этого домохозяйства.
3. Для анализа с использованием переменных линии отбора проб за 1940 и 1950 годы примените переменную SLWT. SLWT дает количество людей в общей популяции, представленных каждым человеком из линии выборки. (Для других выборок SLWT содержит PERWT, поэтому применение SLWT к данным за другие годы не изменит результаты для этих лет.
)Даже невзвешенные выборки имеют значения HHWT и PERWT, но каждая запись в этих выборках получает одинаковый вес. Это позволяет применять весовые переменные в объединенных экстрактах, которые содержат как взвешенные, так и невзвешенные образцы. В противном случае использование весов в невзвешенных выборках необязательно.
Что означает «вселенная» в описаниях переменных? [наверх]
Вселенная — это население, которому грозит опасность получить ответ на рассматриваемую переменную. В большинстве случаев это домохозяйства или лица, которым был задан вопрос переписи, что отражено в переписном листе. Например, детям обычно не задают вопросы о трудоустройстве, а мужчинам и детям не задают вопросов о фертильности. Случаи, которые находятся за пределами юниверса для переменной, помечены «NIU» на странице кодов. Различия во множестве переменных в выборках являются распространенной проблемой сопоставимости данных.
Вселенные не всегда будут полностью свободны от очевидно ошибочных случаев.
Некоторые люди или домохозяйства, которые не должны были отвечать на вопрос, ответили, а некоторые, которые должны были ответить, могут быть включены в категорию «NIU» (не во вселенной). Но до тех пор, пока мы не выполним всестороннее редактирование и распределение данных в будущем, мы не знаем, ошибочна ли рассматриваемая переменная или переменные, определяющие совокупность (например, возраст или статус занятости), неверны.Что такое «флаги качества данных»? [наверх]
Многие переменные в IPUMS были отредактированы из-за отсутствующих, неразборчивых и несовместимых значений. Флаги качества данных указывают, какие значения редактируются или распределяются. Дополнительную информацию о философии и процедурах, используемых для редактирования и размещения данных IPUMS, можно найти на странице «Введение в редактирование и размещение данных».
Каждый флаг качества данных соответствует одной или нескольким переменным IPUMS, и коды для каждого флага различаются в зависимости от выборки.
Флаги качества данных можно включить в извлечение, установив флажки на шаге «Установить параметры переменных» в системе извлечения.Получение данных
Как получить данные? [наверх]
Все данные IPUMS доставляются через нашу систему извлечения данных. Пользователи выбирают интересующие их переменные и образцы, а система создает заказную выписку, содержащую только эту информацию. Для начала пользователи могут ознакомиться с нашими инструкциями для системы извлечения данных (pdf) и инструкциями по открытию извлечения IPUMS на вашем компьютере.
Данные генерируются на нашем сервере. Система отправляет сообщение электронной почты пользователю, когда извлечение завершено. Пользователь должен загрузить выдержку и проанализировать ее на своем локальном компьютере. Доступ к документации находится в свободном доступе без ограничений; однако пользователи должны зарегистрироваться, прежде чем извлекать данные с веб-сайта.
В каком формате данные? [top]
IPUMS создает данные ASCII с фиксированным столбцом.
Данные полностью числовые. По умолчанию система извлечения прямоугольизирует данные: то есть она помещает информацию о домохозяйствах в записи о лицах и не сохраняет домохозяйства как отдельные записи. Никакая информация не теряется, и именно этот формат предпочитает большинство исследователей; однако система извлечения включает в себя возможность выбора иерархических данных или данных только о домашнем хозяйстве.В дополнение к файлу данных ASCII система создает файл синтаксиса статистического пакета для сопровождения каждого извлечения. Файл синтаксиса предназначен для чтения данных ASCII с применением соответствующих меток переменных и значений. Поддерживаются SPSS, SAS и Stata. Вы должны загрузить файл синтаксиса с извлечением, иначе вы не сможете прочитать данные. Файл синтаксиса требует незначительного редактирования, чтобы определить расположение файла данных на локальном компьютере.
Файл кодовой книги также создается с каждым извлечением. Он записывает характеристики вашей выписки и должен быть загружен для ведения учета.
Все файлы данных создаются в сжатом формате gzip. Вы должны распаковать файл, чтобы проанализировать его. Большинство утилит сжатия данных будут работать с файлами.
Сколько времени занимает извлечение данных? [наверх]
Время, необходимое для создания выписки, зависит от количества и размера запрошенных образцов, от того, выполняется ли отбор случаев, и от нагрузки на наш сервер. Экстракты могут занимать от нескольких минут до часа и более. Система отправляет электронное письмо, когда выписка завершена, поэтому нет необходимости оставаться активным на сайте IPUMS, пока делается выписка.
Что делать, если образцы слишком велики для меня? [наверх]
Можно делать очень большие выборки. Выдержки, превышающие определенный размер, не допускаются
наш сервер. Если у вас есть законная причина делать очень большие выписки, напишите нам, чтобы запросить более высокий порог.Грубо говоря, количество записей, умноженное на количество столбцов запрошенных данных, дает
размер файла вашего извлечения в байтах. Количество записей в каждом образце указано на странице образцов. Среди текущих образцов база данных полного подсчета 1880 г., 1980-2000 десятилетних выборок, а многолетние выборки ACS особенно велики.Экран «запрос на извлечение» прогнозирует размер вашего файла данных. Если он слишком велик для ваших целей,
— это несколько вещей, которые вы можете сделать.1) Выберите меньше переменных и/или выборок. В частности, запрос повторных весов (REPWT и REPWTP) резко увеличит размер вашего экстракта, поэтому мы рекомендуем вам выбирать их, только если вы собираетесь использовать их для этого экстракта.
2) Используйте функцию «Выбрать дела» на странице извлечения, чтобы включить только определенные типы людей.
или домохозяйства, которые вы хотите включить в свои данные. Инструкции можно найти здесь. (Примечание: предполагаемый размер файла не включает в свой расчет выбор случая, поэтому это число не изменится.)3) Используйте функцию «Настроить размеры выборки», чтобы получить меньшие случайные подмножества некоторых или всех выборок в
ваша выписка. Веса выборки в данных будут скорректированы соответствующим образом. Инструкции можно найти здесь.Как работает «выбор образца» на веб-сайте IPUMS USA? [наверх]
Когда пользователь впервые входит в систему документации переменных, по умолчанию выбираются все образцы. Каждая переменная в системе будет отображаться на всех соответствующих экранах.
Пользователи могут фильтровать отображаемую информацию, выбирая только интересующие их образцы. В списках переменных появятся только переменные, доступные в одном из выбранных образцов. Интегрированные описания переменных и кодовые страницы также будут отфильтрованы, чтобы отображать только текст и столбцы, соответствующие выбранным образцам. Выбранные семплы можно изменить в любой момент сеанса. Выборки не сохраняются за пределами текущего сеанса.
Когда пользователь входит в систему извлечения после выбора образцов, этот выбор переносится в систему извлечения данных.
Что означает «добавить в корзину» и «в корзину»? [top]
Подобно корзине для покупок на коммерческих веб-сайтах, ваша корзина данных содержит переменные и образцы, которые вы хотите включить в свой настраиваемый экстракт.
Вы можете помещать переменные в корзину данных (и удалять их из нее) во время просмотра системы документации, щелкая значки в столбце «Добавить в корзину», как описано в разделе часто задаваемых вопросов по выбору переменных. Когда вы просматриваете свою корзину данных, значки отображаются в столбце «В корзине» и работают так же.Почему я не могу открыть файл данных? [наверх]
Возможны два объяснения:
1) Данные, созданные системой извлечения, сжаты gzip (файл имеет расширение .gz). Вы должны использовать утилиту сжатия данных, чтобы распаковать файл, прежде чем вы сможете его проанализировать.
2) Вы не можете открыть файл данных напрямую с помощью статистического пакета. Это простой файл ASCII, а не системный файл в формате какого-либо статистического пакета. Однако система извлечения создает файл синтаксиса (настройки) для чтения файла ASCII в ваш статистический пакет. Вы должны загрузить файл синтаксиса вместе с файлом данных с нашего сервера, открыть файл синтаксиса с вашим статистическим пакетом и отредактировать путь в файле синтаксиса, чтобы он указывал на расположение данных на вашем локальном компьютере.
Теперь вы готовы прочитать данные.Существует ли предпочтительный статистический пакет для использования IPUMS? [наверх]
IPUMS поддерживает SPSS, SAS и Stata. Система не создает файлы данных в этих форматах, но создает файлы синтаксиса, с помощью которых можно читать данные ASCII.
Могу ли я анализировать данные IPUMS USA без статистического пакета? [наверх]
Онлайн-система анализа данных IPUMS позволяет пользователям анализировать все образцы IPUMS USA в режиме онлайн. Система выполняет широкий спектр операций с данными на основе спецификаций, сделанных пользователем, от простых операций, таких как составление таблиц, до расширенного статистического анализа. Примеры и скриншоты доступны на нашей странице с краткими инструкциями.
Могу ли я получить исходные данные? [вверх]
За все годы переписи с 1850 по 1950 год (за исключением 1890 года, который был уничтожен пожаром) исходные графики населения рукописей хранятся на микрофильмах в Национальном архиве в Вашингтоне, округ Колумбия.
расписания внутри барабанов организованы географически: в алфавитном порядке по штатам, внутри штатов в алфавитном порядке по округам и внутри округов в числовом порядке по переписным округам. Для переписи и АСГ лет с 1960, графики переписи существуют в полностью машиночитаемой форме.Основным источником большей части документации IPUMS является документация, предоставленная для каждого отдельного образца микроданных общего пользования. Все они должны быть доступны через Межуниверситетский консорциум политических и социальных исследований (ICPSR), P.O. Box 1248, Ann Arbor, MI, 48106.
Как однозначно идентифицируется запись? [наверх]
Уникальный идентификатор каждой записи домохозяйства в IPUMS составляют три переменные: YEAR, DATANUM и SERIAL (год, номер набора данных и порядковый номер домохозяйства).
Четыре переменные составляют уникальный идентификатор для каждой записи о человеке в IPUMS: YEAR, DATANUM, SERIAL и PERNUM (год, номер набора данных, серийный номер домохозяйства и серийный номер человека).
Использование данных IPUMS
Существуют ли сложные аспекты данных IPUMS, о которых следует особенно помнить? [наверх]
Некоторые выборки взвешены: каждый человек не представляет одинаковое количество людей в совокупности. Важно использовать весовые переменные при анализе этих образцов. См. переменную PERWT для списка взвешенных выборок IPUMS USA. Для других образцов использование гирь необязательно.
Для пользователей, интересующихся выборками ACS за 2000-2004 гг., эти выборки не включают лиц в групповых помещениях.
Важно изучить документацию по используемым вами переменным. Коды и метки для переменных категорий не рассказывают всей истории. Другими словами, синтаксических меток недостаточно. Есть две вещи, на которые стоит обратить особое внимание. Вселенная для переменной — населения, рискующего ответить на вопрос, — может незначительно или заметно различаться в разных выборках. Кроме того, прочитайте обсуждение сопоставимости переменных для интересующих вас образцов.
Там должны быть упомянуты важные вопросы сопоставимости. Если переменная имеет особое значение в вашем исследовании (например, это ваша зависимая переменная), вы также можете прочитать текст перечисления, связанный с ней. Этот текст напрямую связан с переменной, поэтому его достаточно легко вызвать.По умолчанию система извлечения упорядочивает данные: она помещает информацию о домашнем хозяйстве в записи о лицах и удаляет отдельные записи о домашнем хозяйстве. Это может исказить результаты анализа на уровне домохозяйств. Количество наблюдений будет увеличено до количества записей о людях. Вы можете либо выбрать первого человека в каждом домохозяйстве (PERNUM), либо выбрать «иерархическое» поле в системе извлечения, чтобы получить правильное количество наблюдений за домохозяйством. Функция прямоугольной формы также исключает любые свободные домохозяйства, которые в других случаях доступны в некоторых выборках. Несмотря на эти сложности, подавляющее большинство исследователей предпочитают прямоугольный формат, поэтому наша система выводит его по умолчанию.
Как мне решить, какую выборку использовать за тот или иной год? [наверх]
В некоторые годы доступны несколько образцов IPUMS USA. Какой образец использовать, зависит от ваших исследовательских вопросов; как правило, решение предполагает обмен меньшей точностью некоторых переменных на более подробную информацию о других переменных. Помимо очевидного различия между выборками из США и Пуэрто-Рико, есть четыре основных параметра, по которым выборки различаются:
1) Плотность
В данных за 1880 и 1980-2000 годы доступны несколько плотностей. Выборки с более низкой плотностью меньше по размеру и, следовательно, с ними быстрее работать, но они могут не содержать столько географических деталей, как выборки с более высокой плотностью. Кроме того, пользователи, которые хотят изучать небольшие подгруппы населения, должны использовать выборки с более высокой плотностью, которые будут содержать больше интересных случаев.2) Передискретизация
Выборки 1860–1870 и 1900–1910 годов содержат избыточные выборки расовых и этнических меньшинств. (Хотя технически это не избыточная выборка, 3% выборка домохозяйств, в которых есть пожилые люди, также доступна в 19 странах.90.) Эти дополнительные выборки дают большее количество случаев меньшинства; исследователи, заинтересованные в таких подгруппах, должны рассмотреть возможность их использования.3) Гири
В 1990 и 2000 годах доступны как взвешенные, так и невзвешенные образцы. (Также можно выбрать невзвешенные подвыборки данных за 1940 и 1950 гг.) Невзвешенные выборки могут содержать меньше случаев из малонаселенных районов, но с ними легче работать для статистического анализа, который не принимает веса. Дополнительные сведения см. в разделе «Веса выборки» во введении к IPUMS.4) Переменные
В 1970-2000 годах многие выборки содержат разные наборы переменных. Это особенно важно при использовании данных 1970 г.; многие переменные появляются только в образцах «Формы 1», тогда как другие появляются только в образцах «Формы 2»; информация о характеристиках соседства доступна в одних выборках, но не в других. В другие годы в выборках различаются в основном географические идентификаторы: например, некоторые выборки не включают идентификаторы городских районов, в то время как другие в некоторых случаях не включают идентификацию штата.Более подробную информацию о каждом образце можно найти на нашей странице образцов и в разделе Руководства пользователя, посвященном образцам дизайна. В течение нескольких лет также доступны оригинальные кодовые книги, описывающие различные образцы.
Вы говорите, что IPUMS является национальным представителем; Является ли он также репрезентативным для меньших областей? [наверх]
Данные IPUMS USA можно считать репрезентативными для географических областей всех размеров, если применяются надлежащие веса. Стандартные ошибки статистики, основанной на меньших географических районах, будут больше, чем ошибки, основанные на национальных данных, но это связано только с уменьшенным размером выборки, а не с тем фактом, что анализируется небольшая территория.
Каковы основные ограничения данных? [наверх]
Данные полностью состоят из записей отдельных лиц и домохозяйств, полученных в результате переписи населения. Нет макроэкономической, деловой или совокупной статистики. Мы не предоставляем опубликованную статистику переписей населения.
IPUMS полностью состоит из выборочных данных с плотностью выборки от 1 до 5 процентов национального населения. Некоторые подгруппы могут быть слишком малы для изучения выборочных данных.
Поскольку данные общедоступны, были приняты меры для обеспечения конфиденциальности. Имена и другая идентифицирующая информация скрыты. Что наиболее важно для многих исследователей, географическая информация обычно ограничена, иногда сильно.
Могу ли я найти конкретных лиц в данных IPUMS? [наверх]
Нет. Были предприняты различные шаги для обеспечения конфиденциальности данных. Самое главное, что современные образцы не содержат имен или адресов. Данные являются только образцами, поэтому нет никакой гарантии, что какой-либо конкретный человек будет в наборе данных.
Как цитировать IPUMS USA? [наверх]
См. страницу цитирования IPUMS USA.
Любые публикации, исследовательские отчеты, презентации или учебные материалы, в которых используются данные или документация, должны быть добавлены в нашу библиографию. Дальнейшее финансирование IPUMS зависит от нашей способности показать нашим спонсорским агентствам, что исследователи используют данные в продуктивных целях.
Могу ли я использовать IPUMS для генеалогии? [наверх]
Вы можете работать с данными IPUMS, но вы должны знать о его серьезных ограничениях для генеалогических целей. Только 1850-1880 и 1920 образцов содержат имена людей. Более того, выборки 1850–1870 и 1920 годов составляют 1 из 100 выборок населения, а это означает, что существует 1-процентный шанс найти в данных любого конкретного человека.
Система извлечения данных не подходит для генеалогических исследований. Система не является поисковой системой. Вы не можете искать какое-либо конкретное имя в данных, и система не будет отбирать дела на основе имени.
Если вы хотите попытать счастья с данными, вы также должны знать, если вы еще этого не сделали, что данные являются «сырыми» (т. е. это просто строки чисел со встроенными именами и адресами). Каждая линия представляет человека или домохозяйство. Для интерпретации чисел требуется кодовая книга IPUMS. Большинство программ, особенно текстовые процессоры, не в состоянии работать с такими большими файлами. SPSS или SAS — наиболее часто используемые программы для работы с данными.
Данные для полной переписи 1880 года доступны на двух веб-сайтах, которые содержат программы для поиска данных по имени (Ancestry.com и FamilySearch.org). Эти сайты также помогают специалистам по генеалогии искать другие базы данных исторических переписей и гораздо лучше подходят для генеалогических исследований, чем IPUMS.Использование страницы переменных
Меню страницы переменных [наверх]
Используйте меню «Переменные» для просмотра или поиска переменных:
Домохозяйство: переменные домохозяйства по группам
Человек: переменные человека по группе
A-Z: интегрированные переменные по буквам
Поиск: отображать только те переменные, которые содержат указанный текст в определенных поляхИспользуйте ссылки в правой части меню, чтобы:
Select Samples: ограничить отображение переменной информации выбранными образцами
Параметры и справка: изменить способ отображения списка переменных или получить справку для этой страницыСведения о странице переменных [наверх]
Меню
Страница переменных позволяет просматривать переменные, ограничивая и контролируя способ отображения информации.Меню «Переменные» предназначено для просмотра переменных. Вы также можете искать переменные, указав критерии поиска для определенных полей метаданных переменных. Система вернет список переменных, которые включают любое из условий поиска, которые вы укажете.
Когда вы «Выбираете образцы», вы ограничиваете список переменных, чтобы отображались только те переменные, которые доступны по крайней мере в одном из этих образцов. Но эффект выбора образцов распространяется на все описания переменных и кодовые страницы, к которым вы можете получить доступ через систему переменных. При просмотре переменных в любом контексте будет отображаться только информация, относящаяся к выбранным вами образцам. Вы можете изменить свой выбор образцов в любой момент.
Выбор образцов является хорошей практикой при изучении IPUMS, поскольку объем информации может быть громоздким. С другой стороны, иногда нужно увидеть все, чтобы определить, какие виды исследований возможны с использованием базы данных.
Последним выбором являются «Параметры» и «Справка». Элемент «Параметры отображения» открывает экран, который предлагает ряд вариантов отображения списка переменных. Каждый выбор имеет выбор по умолчанию.
Просмотр одной группы / Просмотр всех групп
Переключение между просмотром одной группы переменных за раз и просмотром всех групп переменных на одном экране. Если у вас не выбрано ограниченное количество образцов, ваш браузер может медленно отображать все группы. Представление по умолчанию — это одна группа за раз.Показать сведения о доступности / Показать сводку о доступности
Переключение между отображением полной матрицы доступности для конкретной выборки и представлением, в котором отображается только общее количество выборок, содержащих каждую переменную. В обоих представлениях отображаются или суммируются только образцы, выбранные пользователем в разделе «Выбрать образцы». Представление по умолчанию — это подробная информация о доступности.Просмотреть доступные переменные / Просмотреть все переменные
Переключение между представлением, в котором отображаются только переменные, присутствующие в одном из выбранных вами образцов, и представлением, в котором отображаются все переменные, даже если они недоступны. Представление по умолчанию должно отображать только доступные переменные.Образцы отображаются в хронологическом порядке / Образцы. . . в обратном хронологическом порядке
Отображение столбцов примеров, указывающих доступность переменных, в хронологическом порядке (от самых старых к самым новым) или в обратном хронологическом порядке (от новых к самым старым). По умолчанию используется обратный хронологический порядок (от нового к старому).Список переменных
Когда вы просматриваете переменные, они отображаются в списке, содержащем несколько столбцов. Имя переменной связано с описанием переменной, которое включает подробные обсуждения сопоставимости, юниверсы и текст перечисления.
Коды переменных и связанные с ними метки доступны напрямую с помощью ссылок «коды». Столбец «тип» указывает, является ли это переменной человека или домохозяйства. В некоторых контекстах, например в алфавитном представлении, эти два типа объединяются.В области справа от столбца «коды» находится столбец для каждого образца, который пользователь выбрал в «Выборе образцов». По умолчанию выбираются наиболее часто запрашиваемые образцы за каждый год. Четырехзначный год и краткий идентификатор образца идентифицируют каждый образец в верхней части каждого столбца. Наведите указатель мыши на год, чтобы увидеть полное название образца. Если переменная доступна в данном образце, в этом столбце печатается «x».
В столбце с надписью «Добавить в корзину» каждая переменная отмечена желтым кружком со знаком «+» слева. Нажмите на эти кружки, чтобы добавить их в корзину данных (они станут зелеными, когда вы наведете на них курсор, чтобы показать, что вы можете их выбрать). После того, как вы щелкнете по ним, эти значки изменятся на установленный флажок, указывая на то, что переменная находится в вашей корзине данных.
Чтобы удалить переменную из корзины данных, просто установите флажок.Использование системы извлечения данных
Ваша корзина данных [наверх]
Вы должны войти в систему, чтобы использовать систему извлечения данных. Если вы не зарегистрированы, вы должны подать заявку на доступ.
В правом верхнем углу страницы переменных находится сводка вашей корзины данных. В этом поле отображается количество выбранных вами переменных и выборок. Щелкнув желтый кружок рядом с заданной переменной, вы поместите ее в корзину данных. Вы можете просмотреть свою корзину данных в любое время, нажав «Просмотр корзины».
В вашей корзине данных перечислены переменные, предварительно выбранные системой извлечения, а также любые переменные, выбранные вами при просмотре документации. Как и на странице выбора переменных, вы можете удалить переменные из своей выписки на этом этапе, установив флажок рядом с переменной в столбце «Добавить в корзину». Если вы выбрали переменную, но впоследствии изменили свой выбор образцов таким образом, что эта переменная больше недоступна, это обозначается значком «i».
Корзина данных также включает тип записи, ссылки на кодовые страницы и доступность образцов для переменных и образцов в вашей корзине.
Предусмотрены кнопки для возврата к списку переменных, чтобы сделать дополнительные выборки или изменить выбранные образцы. Если вы вернетесь к списку переменных, нажмите «Просмотр корзины» еще раз, чтобы вернуться в корзину данных.
Если вы удовлетворены выбором данных, нажмите «ПРОВЕРИТЬ: Создать извлечение данных», чтобы завершить запрос на извлечение.
Почему некоторые переменные в моей корзине данных выбраны заранее? [top]
Некоторые переменные появляются в вашей корзине данных, даже если вы их не выбирали, и они не учитываются в постоянно обновляемом количестве переменных в вашей корзине данных.
Эти переменные важны по разным причинам. В IPUMS USA есть четыре переменные — YEAR, DATANUM, SERIAL и PERNUM — которые однозначно определяют каждое наблюдение в базе данных IPUMS USA.
Статус групповых кварталов (GQ) включен, поскольку он является важной частью получения согласованных определений домохозяйств во времени. И две весовые переменные в домохозяйстве (HHWT) и человеке (PERWT) необходимы для получения репрезентативной статистики из выборочных данных.Если вы не уверены, что вам не понадобится ни одна из этих переменных, мы рекомендуем вам не удалять их из вашей корзины данных.
Что такое «Тип»? [наверх]
Колонка «Тип» на страницах выбора переменных и в вашей корзине данных указывает тип записи переменной. Переменные с буквой «P» взяты из личных записей, а переменные с буквой «H» взяты из записей домохозяйств. Данные на уровне домохозяйства относятся к каждому члену домохозяйства и идентичны в записи о каждом человеке в домохозяйстве в прямоугольном файле данных.
Извлечь страницу запроса [сверху]
Когда вы нажимаете «Создать извлечение данных» в корзине данных, вы попадаете на страницу запроса на извлечение.
Все из
действия на этой странице необязательны. При желании вы можете просто нажать кнопку «Отправить» и создать свой Извлечение данных
. Вам будет предложено войти в систему, если вы еще этого не сделали.На этой странице приводится сводка ваших данных и предоставляется ряд параметров для их настройки. Ссылка
вверху расширяется, чтобы показать выбранные вами образцы. Если какие-либо образцы имеют связанные с ними примечания,
на панели образцов появится сообщение, предлагающее просмотреть эту информацию. Нажмите на
соответствующие ссылки, чтобы вернуться к страницам просмотра переменных и выбора образцов, чтобы изменить свой выбор.
Вы возвращаетесь на страницу запроса извлечения через корзину данных, где можете просмотреть матрицу доступности для
выбора и легко удалить переменные, сняв с них отметку. Если вы выбрали переменную, имеющую как общую, так и подробную версии, на этом экране она отображается как две переменные. Вы можете отменить выбор любых версий, которые вам не нужны.Отдельная ссылка позволяет вам выбрать предпочтительную структуру данных для вашей выписки:
прямоугольные, иерархические или только для домашних хозяйств. Прямоугольный формат используется по умолчанию.В другой строке на странице оценивается размер вашего извлечения. Если предполагаемый размер слишком велик, нажмите кнопку Ссылка
для уменьшения размера извлечения. Два метода уменьшения размера экстрактов
включает кнопки параметров в нижней половине страницы запроса на извлечение.При подаче выписки будет задержка от минут до часов, в зависимости от размера
работы. Вам не нужно ждать на нашем сайте, пока работа будет завершена. Наша система отправит вам
по электронной почте, когда ваша выписка будет готова.Все данные создаются в сжатом формате gzip, и вы должны распаковать данные перед их чтением. Большинство программ для сжатия не имеет проблем с файлами. Система создает данные только в фиксированном формате столбца ASCII, но при каждом извлечении она создает командные файлы SAS, SPSS и STATA для чтения данных в один из этих статистических пакетов.
Система также создает файл кодовой книги, в котором описывается содержимое вашего извлечения. Помните об этом, прежде чем читать его с пакетом статистических программ.Определения каждой выписки останутся на нашем сервере на неопределенный срок, но файлы данных подлежат
удаление через три дня. Однако экран, на котором вы загружаете выдержки, имеет функцию, которая позволяет вам
пересмотреть старые выписки. Когда вы нажмете «пересмотреть», все ваши выборки для этого отрывка будут загружены в
, после чего вы можете отредактировать или перегенерировать его. Обратите внимание, однако, что каждый последующий выпуск данных может
создают трудности для воссоздания старых выписок, поскольку коды могут измениться.Извлечь определение: структура данных [наверх]
На шаге 1 процедуры извлечения вы определяете некоторые общие характеристики желаемого извлечения.
Выберите предпочтительную файловую структуру для выписки: прямоугольная (только записи о лицах, при этом вся запрашиваемая информация о домохозяйстве прикреплена к соответствующим членам домохозяйства), иерархическая (записи о домохозяйствах, за которыми следуют записи о лицах) или только домохозяйства (записи о домохозяйствах без каких-либо записей о лицах).
; используйте это только в том случае, если вас интересуют прежде всего характеристики жилых единиц). По умолчанию система использует прямоугольный формат, который чаще всего выбирают исследователи. Обратите внимание, что свободные единицы жилья недоступны в прямоугольных данных, поэтому выберите один из других вариантов, если вам нужны данные для них.Параметр извлечения: настройка размеров выборки [наверх]
Этот шаг не является обязательным. В верхней части экрана система извлечения вычисляет ожидаемый размер извлечения данных после его распаковки. (Обратите внимание, что прогнозируемый размер извлечения не учитывает какой-либо выбор наблюдения, который вы могли реализовать на шаге 2. Если вы использовали выбор наблюдения, размер извлечения, вероятно, будет меньше, чем размер, указанный на этом экране.)
Если это слишком большой, или если вы хотите управлять размерами отдельных выборок в своей выписке, щелкните ссылку «настроить размеры выборки» в нижней части экрана, чтобы использовать инструмент размера выборки.
В инструменте размера выборки образцы, которые вы включили в свою выписку, перечислены в первом столбце. В следующих трех столбцах (помеченных как «Полные выборки IPUMS») вы увидите количество записей о домохозяйствах и личных данных (в тысячах) с плотностью выборки (процент от общей численности населения, включенный в выборку). Это случаи, которые вы получите, если перейдете к следующему шагу без внесения изменений.В следующих трех столбцах (помеченных как «Настроить размеры выборки») вы можете ввести число в любую ячейку, чтобы настроить размеры выборки, а затем подтвердить свой выбор, нажав кнопку «Рассчитать» в нижней части экрана, нажав кнопку « Tab» или щелкнув любое другое место на экране. Две другие ячейки будут рассчитаны автоматически в соответствии с вашей записью, а общее количество записей и общий предполагаемый размер извлечения будут скорректированы внизу.
Например, вы можете изменить плотность 5-процентной выборки 2000 года с 5,0 до 2,5 процентов, сократив выборку вдвое, и количество записей о домохозяйствах и личных данных также будет автоматически разделено пополам.
Или вы можете ввести число в первой строке («Все образцы»), чтобы применить один и тот же выбор ко всем без исключения образцам в вашем экстракте. Например, вы можете ввести «1,0» в столбце плотности, чтобы дать каждой выборке плотность 1 процент, или ввести «50» в столбце домохозяйств, чтобы получить 50 000 домохозяйств для каждой выборки.
Минимальное количество случаев для любой выборки составляет 10 000 домохозяйств. Если для вашей записи потребуется больше случаев, чем доступно в данной выборке, инструмент укажет число из полной выборки. В любой момент вы можете отменить свой выбор и вернуться к полному размеру для каждого образца, нажав кнопку «Сбросить выбор» в нижней части экрана.
Единицей выборки для инструмента размера выборки является домохозяйство. Система выполнит систематическую выборку каждого N-го домохозяйства — после случайного запуска — с надлежащей плотностью, чтобы получить запрошенное вами количество случаев. Веса в вашем экстракте автоматически корректируются, чтобы отразить новую плотность образца, поэтому ваш меньший экстракт по-прежнему будет давать примерно те же результаты, что и полный экстракт.
Ваша выдержка должна включать соответствующую переменную веса (PERWT и, возможно, HHWT) для расчета новых весов в вашем статистическом пакете.Из-за случайной ошибки выборки точность оценок из меньшей выборки по сравнению с оценками из полного набора данных зависит от размера запрашиваемой выборки. В то время как оценки небольшой выборки, вероятно, будут в пределах 1 или 2 процентов от оценки полной выборки даже при минимальном размере выборки (10 000 домохозяйств), оценки для небольших географических районов или небольших подгрупп населения могут быть еще дальше. Используйте эту функцию с осторожностью.
Также обратите внимание, что незанятые домохозяйства уменьшают количество домохозяйств в индивидуальной выборке. Доля вакансий существует в следующие годы: эти нормы вакансий также влияют на количество записей о сотрудниках, рассчитанных в индивидуальной выборке на самом низком уровне; количество человек уменьшится на количество вакансий.
Вы должны знать, что система выписок предназначена для создания запрошенного количества дел в иерархической выписке, в которую записи о домохозяйствах и отдельных лицах включаются отдельно.
Если вы запросили прямоугольную выписку (которая используется по умолчанию), вы, скорее всего, получите меньше дел. Это связано с тем, что многие выборки содержат вакантные единицы жилья, отобранные программой выборки, но исключенные из прямоугольных выборок, поскольку в них отсутствуют записи о лицах. Чем выше доля вакантных квартир, тем в большей степени количество домохозяйств, которые вы получаете в прямоугольной выписке, будет меньше, чем указано на сайте. Пользователи могут соответствующим образом скорректировать запрошенные ими размеры домохозяйств. В следующие годы есть пустующие жилые единицы: 1860 г. (2 процента свободных), 1870 г. (1,5 процента), 1970 (7 процентов для образцов из США, 10 процентов для образцов из Пуэрто-Рико), 1980 год (8 процентов для США, 12 процентов для Пуэрто-Рико), 1990 год (12 процентов для США, 10 процентов для Пуэрто-Рико), 2000 год (8 процентов для США). , 10 процентов для Пуэрто-Рико), ACS с 2000 г. (6-7 процентов) и PRCS с 2005 г. (10-14 процентов). Все остальные образцы не имеют свободных единиц.Вариант извлечения: выберите дела [наверх]
Функция «выбрать случаи» позволяет пользователям ограничить набор данных, чтобы он содержал только записи с определенными значениями для выбранных переменных, например, лица в возрасте 65 лет и старше. Несколько переменных могут использоваться в комбинации во время выбора случая. Выборки для нескольких переменных являются аддитивными, каждая из которых неявно связана логическим «И» для целей обработки. Вы можете выполнять выбор случая только для общей или подробной версии переменной, но не для обеих одновременно.
Однако простое извлечение выбранных случаев может быть слишком грубым, поскольку вам могут понадобиться лица, которые совместно проживали с выбранным вами населением. Соответственно, функция выбора случая также позволяет включить всех проживающих в домохозяйстве с лицом с выбранными характеристиками.
Пользователи должны быть осторожны с функцией выбора случая.
Можно выбрать конкретную переменную категорию (например, полигамный брак), которая не существует во всех выборках в вашей выписке, тем самым непреднамеренно исключив эти выборки из вашего набора данных.Вариант извлечения: Прикрепить характеристики [наверх]
Система извлечения данных может добавить характеристику матери, отца или супруга в качестве новой переменной в запись о человеке. Также можно добавить характеристики главы домохозяйства. Например, используя переменную «Профессия», можно создать новую переменную «Профессия матери». Все лица в выписке, проживающие в домохозяйстве со своей матерью, получат значение этой новой переменной. Лица без матери, присутствующей в домашнем хозяйстве, получат недостающую сумму. Система извлечения автоматически генерирует уникальное имя для новой переменной.
Функция прикрепленных характеристик использует созданные IPUMS семейные взаимосвязи «переменные-указатели», которые идентифицируют совместно проживающих матерей, отцов и супругов для каждого человека.
Переменные-указатели идентифицируют социальных матерей и отцов, а не строго биологических родителей.Параметр извлечения: выбор флагов качества данных [наверх]
Вы можете включить флаги качества данных для определенных переменных, установив флажки рядом с именем переменной. Если установить флажок в верхней части столбца «Включить флаги», будут выбраны все флаги качества данных, доступные для выбранных вами переменных и выборок.
Опция извлечения: опишите вашу выписку [наверх]
Вы можете описать свою выписку для дальнейшего использования. Наша система отобразит описание на странице
, где вы загружаете свою выписку данных.Параметр извлечения: настроить денежные значения [наверх]
IPUMS создает скорректированные версии денежных переменных для подмножества переменных. Эти новые скорректированные переменные содержат значения, которые были скорректированы до постоянных долларов во времени с использованием индекса цен, такого как ИПЦ-U.
Для получения дополнительной информации о конкретных индексах, доступных через IPUMS, см. документацию по функции скорректированных денежных значений.При выборе скорректированной версии переменной IPUMS для включения в извлечение как исходная переменная IPUMS, так и скорректированная версия переменной доставляются пользователю в его настроенном извлечении данных.
Что такое разметка схемы в SEO? SEO-оптимизация микроданных.
5967
Как сделать – 7 минут чтения Читать позже
Микроданные Schema.org позволяют структурировать общую информацию с веб-страницы и предоставлять ее поисковым системам. Код микроданных создает расширенный фрагмент, который привлекает внимание пользователей и появляется в результатах поиска.
Что такое микроданные Schema.org?
Это форма, которая включает структуру сайта и важные данные со страниц ресурсов.
Он используется для создания информативного сниппета в результатах поиска и продвижения сайта на первые позиции. Кликабельность таких сниппетов значительно выше, чем у обычного образца за счет расширенного привлекательного предварительного просмотра страницы.Словарь Schema.org официально подтвержден основными поисковыми системами: Google, Bing и Yahoo. Вот так страница с подразумеваемыми микроданными выглядит в результатах поиска:
В представленном образце сниппет включает описание, рейтинг и хлебные крошки. Если пользователь введет «рецепт клубничного чизкейка», скорее всего, он выберет этот сайт из списка результатов, так как он выглядит информативно и удобно. Что касается поисковых систем, то они лучше распознают тип объекта, его атрибуты и характеристики благодаря микроданным.
Вы можете проверить, есть ли у вас какие-либо проблемы, связанные с разметкой, с помощью инструмента аудита сайта Serpstat, просто создайте проект и перейдите к отчету «Все проблемы», который содержит список ошибок:
Расширенный SEO-аудит: Полное руководство по всем этапам анализа [Инфографика]
Подробнее Персональная демонстрация
Наши специалисты свяжутся с вами и обсудят варианты дальнейшей работы.
Это может быть личная демонстрация, пробный период, подробные обучающие статьи, записи вебинаров и индивидуальные советы от специалиста Serpstat. Наша цель — сделать так, чтобы вы чувствовали себя комфортно при использовании Serpstat.Schema.org на практике
Веб-страницы с микроданными выглядят более привлекательно в результатах поиска и эффективно индексируются. Сегодня Schema.org считается основным словарем микроданных. Он включает в себя сотни записей; каждый из них описывает объект, услугу, товар, видео и т. д.
Этот список постоянно расширяется. Представители самых популярных поисковых систем не перестают его улучшать.
Как внедрить Schema.org на свой сайт
Для описания объекта с помощью микроданных требуются теги и атрибуты. Три переменные следующие:
- itemscope — служит для указания описания объекта, входящего в состав страницы;
- itemtype — тип объекта из официального словаря;
- itemprop — свойства объекта для описания.
Вот как это выглядит на самом деле:
Код передает данные о продукте, его рейтинге и информацию о продавце, включая цену.
Словарь объектов на сайте имеет вид структуры:
Цепочка начинается с «Вещь», которая включает «Действие», продолжается «ДостичьДействия», «ИгнорироватьДействие» и т. д. Метатеги, которые отмечают объекты и их атрибуты, используется для описания этих элементов в схеме микроданных.
Вот пример размещения видеоданных:
Код может содержать следующие метатеги:
- — открывает и закрывает описание;
- — описывает атрибуты словами;
- <ссылка> , включая атрибут href — ссылка с «каноническим» атрибутом, невидимым пользователям;
- с атрибутом date time — отмечает дату и время в заданном формате «год-месяц-день», «час-минута», «час-минута-секунда»;
- — отмечает ссылку, которую видят пользователи;
- — используется для текста, который не отображается пользователям.
Для генерации кода необходимо выбрать нужный объект из списка и определить его атрибуты. Составив код, вы можете проверить его с помощью валидатора Google.
Самый трудоемкий этап процесса разметки — установка параметров для обеих поисковых систем. В этих сервисах не должно быть ошибок, чтобы обеспечить правильную оценку данных.
Микроданные должны быть включены в код каждой страницы, на которой будет реализован семантический словарь. Для автоматизации разметки можно использовать плагины.
Например, есть плагин Schema для WordPress, который генерирует автоматическую разметку. Однако он сам выбирает атрибуты. Если вы предпочитаете указывать определенные свойства объекта, вам следует создать код разметки вручную.
Использование Schema.org предоставляет следующие варианты описания:
Разметка продуктов, услуг и данных.
Хлебные крошки Schema.
org. Эти микроданные отображают структуру сайта, раздела или страницы в сниппете.Отзывы покупателей и пользователей.
Контактная информация определенного лица или компании.
Рейтинг Schema.org. Указывает рейтинг товара, услуги или другого объекта с помощью звездочек.
Показ офисов, компаний, продавцов и любых других мест.
Вывод
Schema.org используется для формирования информативных фрагментов и указания определенной информации на страницах сайта для поисковых систем. Такой способ представления данных упрощает ранжирование и повышает надежность сайта в глазах потенциальных пользователей. Описания с метатегами и атрибутами должны присутствовать на каждой странице вашего источника.
Дополнительно можно организовать хлебные крошки Schema.org, разметку рейтинга, контактов, отзывов и других свойств, которые могут описывать продукт или компанию.
Чтобы проверить точность разметки, используйте валидатор Google.
Они позволяют просматривать код уже готовых или созданных вручную микроданных. Поисковые системы не смогут оценить и отобразить необходимые данные, если в коде есть ошибки. Узнайте, как получить максимальную отдачу от Serpstat
Хотите получить личную демонстрацию, пробный период или множество успешных вариантов использования?
Отправьте заявку и наш специалист свяжется с Вами 😉
Оцените статью по пятибалльной шкале
Статью уже оценили 2 человека в среднем 3 из 5
Нашли ошибку? Выберите его и нажмите Ctrl + Enter, чтобы сообщить нам
Рекомендуемые сообщения
How-to
Валерия Лохтенко
Как найти и исправить ошибку 404 на вашем сайте
How-to
3
Deny0s проверить ссылки доноров на наличие кодов ответов сервераHow-to
Stacy Mine
Как проверить сайты-доноры на наличие фильтров и вредоносного ПО
Кейсы, лайфхаки, исследования и полезные статьи
Нет времени следить за новостями? Без проблем! Наш редактор подберет статьи, которые обязательно помогут вам в работе.
Присоединяйтесь к нашему уютному сообществу 🙂Нажимая на кнопку, вы соглашаетесь с нашей политикой конфиденциальности.
Поделитесь этой статьей с друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылки.
Сообщить об ошибке
Отменить
Схема и микроданные: обзор
Act-On
Корпоративный
Первый веб-сайт был опубликован в августе 1991 года. Сегодня почти миллиард веб-сайтов онлайн, и их сложность (не говоря уже о сложности экосистемы) они составляют) только продолжает расти. Существуют сотни продвинутых языков программирования , , которые делают одно и то же: общаются с компьютером. С сотнями языков, которые нужно понимать, вы можете себе представить, что компьютеры, системы и люди должны идти в ногу со временем. Настало время, когда сообразительные люди из Yahoo, Bing и Google поняли, что необходима определенная структура и организация, иначе ситуация может выйти из-под контроля.
Метаданные: карточный каталог для поисковых систем Это стало чем-то вроде Дикого Дикого Запада.«Метаданные» — это информация, которая сообщает, о чем данные; т. е. данные о данных. Помните старые картотеки в библиотеках? Каталог карточек содержит карточки, которые стандартизированным образом рассказывают обо всех книгах в библиотеке. Карточки содержат такие данные, как название, автор и дата публикации. Эти данные используются для создания уникального номера вызова на основе десятичной системы счисления Дьюи. Это набор стандартов, используемых для индексации каждой книги в библиотеке, чтобы гарантировать, что книги по одному и тому же предмету можно найти рядом друг с другом в предсказуемом порядке. Система Дьюи используется с 1876 года!
Что такое схема?В контексте Интернета и в упрощенном виде «схема» — это способ структурирования и организации метаданных. В середине 2011 года три крупнейшие поисковые системы объединились в беспрецедентном сотрудничестве: Google, Bing и Yahoo инициировали создание набора стандартов для метаданных веб-сайтов.
Не прошло и года, как к ним присоединился лидер российского поиска Яндекс.Поисковые системы создали Schema.org с целью определения и поощрения принятия согласованной структуры (и аналогичных словарей), которую веб-мастера и другие лица могли бы использовать для разметки содержимого веб-сайта. В результате поисковые системы (и другие системы) смогут легче и точнее понять, о чем сайт, и информацию будет легче найти.
Как работает схемаКак отмечается на веб-сайте Schema.org о своих общих словарях: «Эти словари охватывают сущности, отношения между сущностями и действиями и могут быть легко расширены с помощью хорошо документированной модели расширения. Более 10 миллионов сайтов используют Schema.org для разметки своих веб-страниц и сообщений электронной почты».
Люди, места и вещи представлены на странице, и схема действует, чтобы последовательно определять их во всей сети. Простые элементы, такие как местоположение и контактная информация, а также сложные элементы, такие как рейтинги, оптимизированы и соответствуют языку Schema.
org. Вот пример того, как структурированные данные отображаются читателю, просматривающему результаты поиска фильмов: …и вот как сайт отображает часть той же информации для поисковых систем:Вот еще один пример из фильма, иллюстрирующий, как схема может помочь поисковой системе понять, о чем сайт. Слово «аватар» может означать многое: онлайн-представление человека, известный фильм или телесериал, не связанный с ним. Это также бренд лосьона после бритья, снятого с производства. Если вы коллекционируете старинные мужские ароматы и ищете Coty’s Avatar, схема на этой странице сообщает поисковой системе, что это именно та страница, на которую нужно вернуться, а не одна из самых популярных страниц о фильме.
Метаданные имеют значение. Он используется за кулисами в HTML-коде сайта, по всему сайту для определения его содержимого и контекста. Для поисковых систем эта информация является топливом, которое заставляет поисковую систему работать. Без контекста и понимания поисковая система все еще может работать, но она не может точно анализировать веб-сайт.
Это означает, что он не может квалифицировать, как этот сайт может ответить на вопрос пользователя, что, в свою очередь, означает, что он может с меньшей вероятностью вернуть этот сайт.Вы когда-нибудь задумывались, как эти маленькие синие ссылки появляются в результатах поиска Google, как вторая запись здесь?
Или почему у одних результатов есть оценки, а у других, например, нет? Или почему некоторые результаты отображаются на страницах результатов поиска развернутыми, а другие нет? Это магия схемы и микроданных.
Типы схемИспользуются многие типы схем; тысячи существуют и продолжают разрабатываться. Это может быть немного запутанным, чтобы ориентироваться в ландшафте.
Во-первых, начните с правильного типа схемы для ваших нужд. Чтобы определить наилучший тип схемы для реализации, важно понимать все ваши варианты и доступные типы схемы. Давайте посмотрим на самое основное:
- Вещь – Определение «вещь» может состоять из любого количества общих элементов. Сюда входят, например, специальные микроданные для изображений, текстовые описания и альтернативные имена. Это наиболее общий тип элемента схемы.
- Событие — Событие, которое может произойти в указанное время и в указанном месте, может использовать определенные данные схемы для обмена информацией, такой как продолжительность времени, даты окончания, рейтинги, организация вечеринки и многое другое.
- Человек – 9Данные схемы 0008 для определения элементов лица, включая адрес, принадлежность, адрес, дату рождения и смерть. Реальные или вымышленные данные схемы доступны для определения характеристик человека в форме микроданных.
- Место — Физическое местоположение может быть определено с помощью микроданных, таких как информация об имуществе, адрес, коды магазинов, глобальный номер местоположения, долгота и широта, а также URL-адрес карты местоположения. Эти элементы метаданных помогают определить, где находится компания.
- Продукт — Схема, доступная для определения продуктов, таких как названия товаров, рейтинги продуктов, предложения, размер продукта, тип товара и многое другое. Микроданные, которые помогают лучше понять продукт и услугу, которую компания может продавать онлайн или офлайн.
- Организация — Микроданные, определяющие элементы организации, включая адрес, обслуживаемую территорию, награды, информацию о бренде, контактных лиц, адреса электронной почты, налоговые номера, телефон, издательство (если применимо) и многое другое.
- Обзор — Определить все элементы страницы, на которых обсуждаются элементы для обзора. От обзора продукта, услуги или объекта до элементов обзора, таких как автор, персонаж, цитирование и рейтинг контента, определяются с помощью схемы обзора.
Вот где в игру вступают общие словари. Словари микроданных предоставляют семантику или значение элемента.
Google дает хорошее определение микроданным: «Микроданные — это спецификация для встраивания машиночитаемых данных в HTML-документы. Микроданные состоят из пар имя-значение (известных как элементы), определенных в соответствии со словарем».
Вот примеры распространенных пар имя-значение в одном словаре:
Schema.org предоставляет примеры в четырех форматах: без разметки, микроданные, RDFa и JSON-LD. Для разработчиков и веб-мастеров это невероятно полезный ресурс.
Внедрение схемыНадеемся, что если вы дочитали до этого места, то понимаете типы схем и то, что они могут предложить поисковым системам. Теперь настало время реализовать схему. С чего начать?
Определение возможностей схем, используемых на вашем сайте, — это двухсторонний процесс. Во-первых, вам нужно определить фактическую схему, которую вы хотите протестировать. Если вы пытаетесь добавить данные о местоположении или, возможно, предоставить данные о событиях, выберите элемент для реализации.
 это не так. Вот пример того, как вы можете использовать веб-сайт Schema, чтобы помочь вам с вашим конкретным контентом. Пример разметки Local Business Schema:
это не так. Вот пример того, как вы можете использовать веб-сайт Schema, чтобы помочь вам с вашим конкретным контентом. Пример разметки Local Business Schema:  Теперь мы подошли к структурированным данным: луку, объединяющему их все вместе. Согласно Руководству Google по разработке структурированных данных, структурированные данные — это стандартизированный формат для предоставления информации о странице и классификации содержимого страницы. Другими словами, если микроданные и разметка схемы — это язык, понятный поисковой системе, то структурированные данные — это организационная система, которую она использует для их чтения. Использование структурированных данных на вашем веб-сайте дает несколько преимуществ, включая улучшение SEO.
Теперь мы подошли к структурированным данным: луку, объединяющему их все вместе. Согласно Руководству Google по разработке структурированных данных, структурированные данные — это стандартизированный формат для предоставления информации о странице и классификации содержимого страницы. Другими словами, если микроданные и разметка схемы — это язык, понятный поисковой системе, то структурированные данные — это организационная система, которую она использует для их чтения. Использование структурированных данных на вашем веб-сайте дает несколько преимуществ, включая улучшение SEO. Ваш веб-сайт и контент всегда будут иметь более высокий рейтинг, если у вас есть подробные, систематизированные данные, которые дают контекст вашему веб-сайту. Как мы обсуждали ранее, ключевые слова, хотя и являются важными факторами для SEO, нуждаются в контекстных данных, чтобы отличать их от других. Оглядываясь назад на пример, который мы использовали ранее, ваш веб-сайт может быть посвящен апельсинам, но если вы не разместите код, который идентифицирует апельсин как объект, цвет или музыку, Google не поймет, что вы имеете в виду. Ключевые слова, контекстные микроданные и структурированные данные являются ключом к правильному SEO.
Ваш веб-сайт и контент всегда будут иметь более высокий рейтинг, если у вас есть подробные, систематизированные данные, которые дают контекст вашему веб-сайту. Как мы обсуждали ранее, ключевые слова, хотя и являются важными факторами для SEO, нуждаются в контекстных данных, чтобы отличать их от других. Оглядываясь назад на пример, который мы использовали ранее, ваш веб-сайт может быть посвящен апельсинам, но если вы не разместите код, который идентифицирует апельсин как объект, цвет или музыку, Google не поймет, что вы имеете в виду. Ключевые слова, контекстные микроданные и структурированные данные являются ключом к правильному SEO. Многим маркетологам удобнее всего использовать SEO на странице: создавать контент для ключевых слов, а затем оптимизировать этот контент (например, добавлять теги заголовков, альтернативный текст и т. д.) для сканирования в поисковых системах.
Многим маркетологам удобнее всего использовать SEO на странице: создавать контент для ключевых слов, а затем оптимизировать этот контент (например, добавлять теги заголовков, альтернативный текст и т. д.) для сканирования в поисковых системах.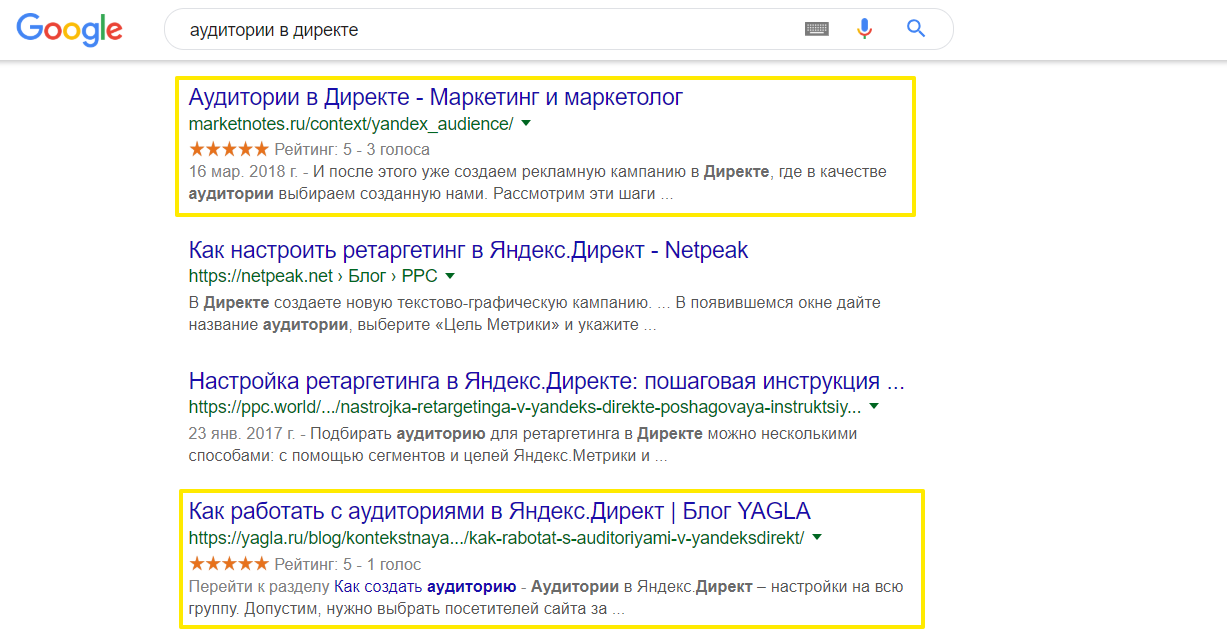 Некоторые распространенные теги метаданных включают заголовок, краткий URL-адрес и описание страницы. Это в основном для пользы искателя, намекая на то, что он собирается прочитать.
Некоторые распространенные теги метаданных включают заголовок, краткий URL-адрес и описание страницы. Это в основном для пользы искателя, намекая на то, что он собирается прочитать.
 А это означает больше трафика и, в конечном счете, лучший бизнес для вас.
А это означает больше трафика и, в конечном счете, лучший бизнес для вас.
 org/docs/gs.html
org/docs/gs.html

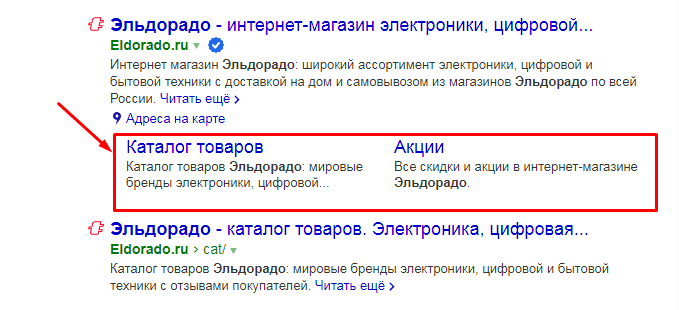

 Итак, он создал приложение — и бизнес.
Итак, он создал приложение — и бизнес. по настоящее время. Некоторые из этих образцов существуют годами, а другие были созданы специально для этой базы данных. Эти выборки, основанные на всех сохранившихся переписях с 1850 по 2010 год, а также выборки ACS/PRCS с 2000 года по настоящее время, в совокупности составляют наш самый богатый источник количественной информации о долгосрочных изменениях в американском населении. Однако, поскольку разные исследователи создавали эти образцы в разное время, они использовали самые разные макеты записей, схемы кодирования и документацию. Это усложняет попытки использовать их для изучения изменений с течением времени. IPUMS присваивает единые коды всем образцам и приводит соответствующую документацию в согласованную форму, чтобы облегчить анализ социальных и экономических изменений.
по настоящее время. Некоторые из этих образцов существуют годами, а другие были созданы специально для этой базы данных. Эти выборки, основанные на всех сохранившихся переписях с 1850 по 2010 год, а также выборки ACS/PRCS с 2000 года по настоящее время, в совокупности составляют наш самый богатый источник количественной информации о долгосрочных изменениях в американском населении. Однако, поскольку разные исследователи создавали эти образцы в разное время, они использовали самые разные макеты записей, схемы кодирования и документацию. Это усложняет попытки использовать их для изучения изменений с течением времени. IPUMS присваивает единые коды всем образцам и приводит соответствующую документацию в согласованную форму, чтобы облегчить анализ социальных и экономических изменений. Поскольку данные представляют собой отдельных лиц, а не таблицы, исследователи должны использовать статистический пакет для анализа миллионов записей в базе данных. Система извлечения данных позволяет пользователям выбирать только те образцы и переменные, которые им необходимы.
Поскольку данные представляют собой отдельных лиц, а не таблицы, исследователи должны использовать статистический пакет для анализа миллионов записей в базе данных. Система извлечения данных позволяет пользователям выбирать только те образцы и переменные, которые им необходимы.
 Но мы делаем и многое другое:
Но мы делаем и многое другое:
 Для начала пользователи могут ознакомиться с нашими инструкциями для системы извлечения (pdf).
Для начала пользователи могут ознакомиться с нашими инструкциями для системы извлечения (pdf).
-4.png) Переменные-указатели называются MOMLOC, POPLOC и SPLOC в системе IPUMS, а сопутствующие переменные указывают основные правила, по которым была сделана конкретная ссылка.
Переменные-указатели называются MOMLOC, POPLOC и SPLOC в системе IPUMS, а сопутствующие переменные указывают основные правила, по которым была сделана конкретная ссылка. Например, исследователи могут получить доступ к сопоставимой на международном уровне однозначной общей версии «статуса занятости» или могут использовать полностью подробную трехзначную версию, если их исследование требует более точных различий. Два набора кодов полностью согласуются друг с другом; один просто предоставляет больше категорий, в то время как другой проще в использовании и, как правило, более сопоставим по выборкам.
Например, исследователи могут получить доступ к сопоставимой на международном уровне однозначной общей версии «статуса занятости» или могут использовать полностью подробную трехзначную версию, если их исследование требует более точных различий. Два набора кодов полностью согласуются друг с другом; один просто предоставляет больше категорий, в то время как другой проще в использовании и, как правило, более сопоставим по выборкам. Переменные «веса» указывают, сколько человек в совокупности представлено каждым случаем выборки. Многие выборки IPUMS являются невзвешенными или «плоскими», что означает, что каждый человек в данных выборки представляет одинаковое количество людей в совокупности. Например, в 1% невзвешенной выборке 2000 года вес для всех случаев выборки зафиксирован на уровне 100; каждый случай представляет 100 человек в популяции. Но многие выборки в IPUMS являются «взвешенными», что означает, что некоторые выборочные случаи представляют больше людей в популяции, чем другие. Лица и домохозяйства с одними характеристиками представлены в выборках чрезмерно, а другие недопредставлены. Весовые переменные позволяют исследователям создавать точные оценки населения, используя взвешенные выборки. См. переменную PERWT или Что такое IPUMS? страница со списком взвешенных образцов IPUMS USA.
Переменные «веса» указывают, сколько человек в совокупности представлено каждым случаем выборки. Многие выборки IPUMS являются невзвешенными или «плоскими», что означает, что каждый человек в данных выборки представляет одинаковое количество людей в совокупности. Например, в 1% невзвешенной выборке 2000 года вес для всех случаев выборки зафиксирован на уровне 100; каждый случай представляет 100 человек в популяции. Но многие выборки в IPUMS являются «взвешенными», что означает, что некоторые выборочные случаи представляют больше людей в популяции, чем другие. Лица и домохозяйства с одними характеристиками представлены в выборках чрезмерно, а другие недопредставлены. Весовые переменные позволяют исследователям создавать точные оценки населения, используя взвешенные выборки. См. переменную PERWT или Что такое IPUMS? страница со списком взвешенных образцов IPUMS USA. Для анализа на уровне человека с использованием взвешенной выборки примените переменную PERWT. PERWT дает совокупность, представленную каждым человеком в выборке; в образцах 1850–1930 гг. точность выше, чем в образцах 1940 г. и позже.
Для анализа на уровне человека с использованием взвешенной выборки примените переменную PERWT. PERWT дает совокупность, представленную каждым человеком в выборке; в образцах 1850–1930 гг. точность выше, чем в образцах 1940 г. и позже. )
) Некоторые люди или домохозяйства, которые не должны были отвечать на вопрос, ответили, а некоторые, которые должны были ответить, могут быть включены в категорию «NIU» (не во вселенной). Но до тех пор, пока мы не выполним всестороннее редактирование и распределение данных в будущем, мы не знаем, ошибочна ли рассматриваемая переменная или переменные, определяющие совокупность (например, возраст или статус занятости), неверны.
Некоторые люди или домохозяйства, которые не должны были отвечать на вопрос, ответили, а некоторые, которые должны были ответить, могут быть включены в категорию «NIU» (не во вселенной). Но до тех пор, пока мы не выполним всестороннее редактирование и распределение данных в будущем, мы не знаем, ошибочна ли рассматриваемая переменная или переменные, определяющие совокупность (например, возраст или статус занятости), неверны. Флаги качества данных можно включить в извлечение, установив флажки на шаге «Установить параметры переменных» в системе извлечения.
Флаги качества данных можно включить в извлечение, установив флажки на шаге «Установить параметры переменных» в системе извлечения. Данные полностью числовые. По умолчанию система извлечения прямоугольизирует данные: то есть она помещает информацию о домохозяйствах в записи о лицах и не сохраняет домохозяйства как отдельные записи. Никакая информация не теряется, и именно этот формат предпочитает большинство исследователей; однако система извлечения включает в себя возможность выбора иерархических данных или данных только о домашнем хозяйстве.
Данные полностью числовые. По умолчанию система извлечения прямоугольизирует данные: то есть она помещает информацию о домохозяйствах в записи о лицах и не сохраняет домохозяйства как отдельные записи. Никакая информация не теряется, и именно этот формат предпочитает большинство исследователей; однако система извлечения включает в себя возможность выбора иерархических данных или данных только о домашнем хозяйстве.
 Количество записей в каждом образце указано на странице образцов. Среди текущих образцов база данных полного подсчета 1880 г., 1980-2000 десятилетних выборок, а многолетние выборки ACS особенно велики.
Количество записей в каждом образце указано на странице образцов. Среди текущих образцов база данных полного подсчета 1880 г., 1980-2000 десятилетних выборок, а многолетние выборки ACS особенно велики. Веса выборки в данных будут скорректированы соответствующим образом. Инструкции можно найти здесь.
Веса выборки в данных будут скорректированы соответствующим образом. Инструкции можно найти здесь. Вы можете помещать переменные в корзину данных (и удалять их из нее) во время просмотра системы документации, щелкая значки в столбце «Добавить в корзину», как описано в разделе часто задаваемых вопросов по выбору переменных. Когда вы просматриваете свою корзину данных, значки отображаются в столбце «В корзине» и работают так же.
Вы можете помещать переменные в корзину данных (и удалять их из нее) во время просмотра системы документации, щелкая значки в столбце «Добавить в корзину», как описано в разделе часто задаваемых вопросов по выбору переменных. Когда вы просматриваете свою корзину данных, значки отображаются в столбце «В корзине» и работают так же. Теперь вы готовы прочитать данные.
Теперь вы готовы прочитать данные. расписания внутри барабанов организованы географически: в алфавитном порядке по штатам, внутри штатов в алфавитном порядке по округам и внутри округов в числовом порядке по переписным округам. Для переписи и АСГ лет с 1960, графики переписи существуют в полностью машиночитаемой форме.
расписания внутри барабанов организованы географически: в алфавитном порядке по штатам, внутри штатов в алфавитном порядке по округам и внутри округов в числовом порядке по переписным округам. Для переписи и АСГ лет с 1960, графики переписи существуют в полностью машиночитаемой форме.
 Там должны быть упомянуты важные вопросы сопоставимости. Если переменная имеет особое значение в вашем исследовании (например, это ваша зависимая переменная), вы также можете прочитать текст перечисления, связанный с ней. Этот текст напрямую связан с переменной, поэтому его достаточно легко вызвать.
Там должны быть упомянуты важные вопросы сопоставимости. Если переменная имеет особое значение в вашем исследовании (например, это ваша зависимая переменная), вы также можете прочитать текст перечисления, связанный с ней. Этот текст напрямую связан с переменной, поэтому его достаточно легко вызвать.
 (Хотя технически это не избыточная выборка, 3% выборка домохозяйств, в которых есть пожилые люди, также доступна в 19 странах.90.) Эти дополнительные выборки дают большее количество случаев меньшинства; исследователи, заинтересованные в таких подгруппах, должны рассмотреть возможность их использования.
(Хотя технически это не избыточная выборка, 3% выборка домохозяйств, в которых есть пожилые люди, также доступна в 19 странах.90.) Эти дополнительные выборки дают большее количество случаев меньшинства; исследователи, заинтересованные в таких подгруппах, должны рассмотреть возможность их использования. В другие годы в выборках различаются в основном географические идентификаторы: например, некоторые выборки не включают идентификаторы городских районов, в то время как другие в некоторых случаях не включают идентификацию штата.
В другие годы в выборках различаются в основном географические идентификаторы: например, некоторые выборки не включают идентификаторы городских районов, в то время как другие в некоторых случаях не включают идентификацию штата.




 Коды переменных и связанные с ними метки доступны напрямую с помощью ссылок «коды». Столбец «тип» указывает, является ли это переменной человека или домохозяйства. В некоторых контекстах, например в алфавитном представлении, эти два типа объединяются.
Коды переменных и связанные с ними метки доступны напрямую с помощью ссылок «коды». Столбец «тип» указывает, является ли это переменной человека или домохозяйства. В некоторых контекстах, например в алфавитном представлении, эти два типа объединяются. Чтобы удалить переменную из корзины данных, просто установите флажок.
Чтобы удалить переменную из корзины данных, просто установите флажок.
 Статус групповых кварталов (GQ) включен, поскольку он является важной частью получения согласованных определений домохозяйств во времени. И две весовые переменные в домохозяйстве (HHWT) и человеке (PERWT) необходимы для получения репрезентативной статистики из выборочных данных.
Статус групповых кварталов (GQ) включен, поскольку он является важной частью получения согласованных определений домохозяйств во времени. И две весовые переменные в домохозяйстве (HHWT) и человеке (PERWT) необходимы для получения репрезентативной статистики из выборочных данных. Все из
Все из 
 Система также создает файл кодовой книги, в котором описывается содержимое вашего извлечения. Помните об этом, прежде чем читать его с пакетом статистических программ.
Система также создает файл кодовой книги, в котором описывается содержимое вашего извлечения. Помните об этом, прежде чем читать его с пакетом статистических программ. ; используйте это только в том случае, если вас интересуют прежде всего характеристики жилых единиц). По умолчанию система использует прямоугольный формат, который чаще всего выбирают исследователи. Обратите внимание, что свободные единицы жилья недоступны в прямоугольных данных, поэтому выберите один из других вариантов, если вам нужны данные для них.
; используйте это только в том случае, если вас интересуют прежде всего характеристики жилых единиц). По умолчанию система использует прямоугольный формат, который чаще всего выбирают исследователи. Обратите внимание, что свободные единицы жилья недоступны в прямоугольных данных, поэтому выберите один из других вариантов, если вам нужны данные для них. В инструменте размера выборки образцы, которые вы включили в свою выписку, перечислены в первом столбце. В следующих трех столбцах (помеченных как «Полные выборки IPUMS») вы увидите количество записей о домохозяйствах и личных данных (в тысячах) с плотностью выборки (процент от общей численности населения, включенный в выборку). Это случаи, которые вы получите, если перейдете к следующему шагу без внесения изменений.
В инструменте размера выборки образцы, которые вы включили в свою выписку, перечислены в первом столбце. В следующих трех столбцах (помеченных как «Полные выборки IPUMS») вы увидите количество записей о домохозяйствах и личных данных (в тысячах) с плотностью выборки (процент от общей численности населения, включенный в выборку). Это случаи, которые вы получите, если перейдете к следующему шагу без внесения изменений.
 Ваша выдержка должна включать соответствующую переменную веса (PERWT и, возможно, HHWT) для расчета новых весов в вашем статистическом пакете.
Ваша выдержка должна включать соответствующую переменную веса (PERWT и, возможно, HHWT) для расчета новых весов в вашем статистическом пакете. Если вы запросили прямоугольную выписку (которая используется по умолчанию), вы, скорее всего, получите меньше дел. Это связано с тем, что многие выборки содержат вакантные единицы жилья, отобранные программой выборки, но исключенные из прямоугольных выборок, поскольку в них отсутствуют записи о лицах. Чем выше доля вакантных квартир, тем в большей степени количество домохозяйств, которые вы получаете в прямоугольной выписке, будет меньше, чем указано на сайте. Пользователи могут соответствующим образом скорректировать запрошенные ими размеры домохозяйств. В следующие годы есть пустующие жилые единицы: 1860 г. (2 процента свободных), 1870 г. (1,5 процента), 1970 (7 процентов для образцов из США, 10 процентов для образцов из Пуэрто-Рико), 1980 год (8 процентов для США, 12 процентов для Пуэрто-Рико), 1990 год (12 процентов для США, 10 процентов для Пуэрто-Рико), 2000 год (8 процентов для США). , 10 процентов для Пуэрто-Рико), ACS с 2000 г. (6-7 процентов) и PRCS с 2005 г. (10-14 процентов).
Если вы запросили прямоугольную выписку (которая используется по умолчанию), вы, скорее всего, получите меньше дел. Это связано с тем, что многие выборки содержат вакантные единицы жилья, отобранные программой выборки, но исключенные из прямоугольных выборок, поскольку в них отсутствуют записи о лицах. Чем выше доля вакантных квартир, тем в большей степени количество домохозяйств, которые вы получаете в прямоугольной выписке, будет меньше, чем указано на сайте. Пользователи могут соответствующим образом скорректировать запрошенные ими размеры домохозяйств. В следующие годы есть пустующие жилые единицы: 1860 г. (2 процента свободных), 1870 г. (1,5 процента), 1970 (7 процентов для образцов из США, 10 процентов для образцов из Пуэрто-Рико), 1980 год (8 процентов для США, 12 процентов для Пуэрто-Рико), 1990 год (12 процентов для США, 10 процентов для Пуэрто-Рико), 2000 год (8 процентов для США). , 10 процентов для Пуэрто-Рико), ACS с 2000 г. (6-7 процентов) и PRCS с 2005 г. (10-14 процентов). Все остальные образцы не имеют свободных единиц.
Все остальные образцы не имеют свободных единиц. Можно выбрать конкретную переменную категорию (например, полигамный брак), которая не существует во всех выборках в вашей выписке, тем самым непреднамеренно исключив эти выборки из вашего набора данных.
Можно выбрать конкретную переменную категорию (например, полигамный брак), которая не существует во всех выборках в вашей выписке, тем самым непреднамеренно исключив эти выборки из вашего набора данных.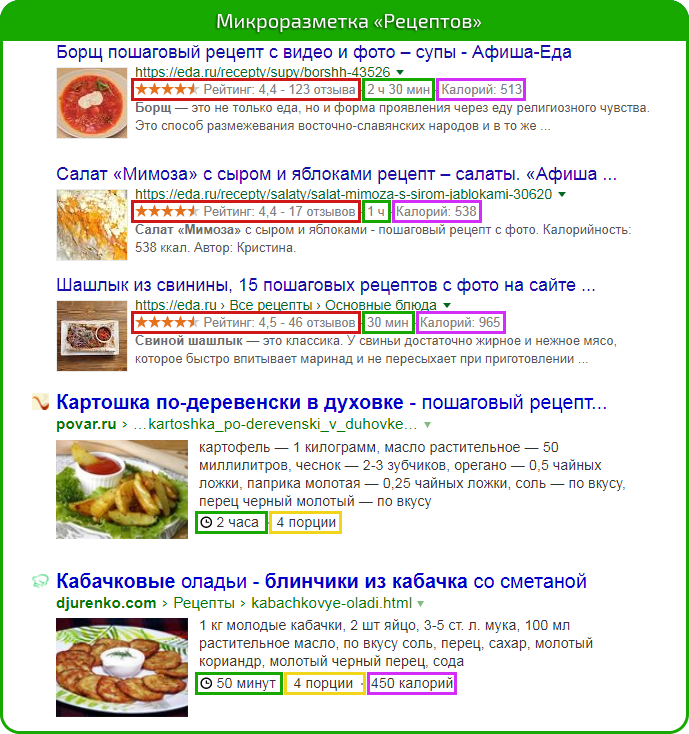 Переменные-указатели идентифицируют социальных матерей и отцов, а не строго биологических родителей.
Переменные-указатели идентифицируют социальных матерей и отцов, а не строго биологических родителей. Для получения дополнительной информации о конкретных индексах, доступных через IPUMS, см. документацию по функции скорректированных денежных значений.
Для получения дополнительной информации о конкретных индексах, доступных через IPUMS, см. документацию по функции скорректированных денежных значений. Он используется для создания информативного сниппета в результатах поиска и продвижения сайта на первые позиции. Кликабельность таких сниппетов значительно выше, чем у обычного образца за счет расширенного привлекательного предварительного просмотра страницы.
Он используется для создания информативного сниппета в результатах поиска и продвижения сайта на первые позиции. Кликабельность таких сниппетов значительно выше, чем у обычного образца за счет расширенного привлекательного предварительного просмотра страницы. Это может быть личная демонстрация, пробный период, подробные обучающие статьи, записи вебинаров и индивидуальные советы от специалиста Serpstat. Наша цель — сделать так, чтобы вы чувствовали себя комфортно при использовании Serpstat.
Это может быть личная демонстрация, пробный период, подробные обучающие статьи, записи вебинаров и индивидуальные советы от специалиста Serpstat. Наша цель — сделать так, чтобы вы чувствовали себя комфортно при использовании Serpstat.

 org. Эти микроданные отображают структуру сайта, раздела или страницы в сниппете.
org. Эти микроданные отображают структуру сайта, раздела или страницы в сниппете. Они позволяют просматривать код уже готовых или созданных вручную микроданных. Поисковые системы не смогут оценить и отобразить необходимые данные, если в коде есть ошибки.
Они позволяют просматривать код уже готовых или созданных вручную микроданных. Поисковые системы не смогут оценить и отобразить необходимые данные, если в коде есть ошибки.  Присоединяйтесь к нашему уютному сообществу 🙂
Присоединяйтесь к нашему уютному сообществу 🙂 Это стало чем-то вроде Дикого Дикого Запада.
Это стало чем-то вроде Дикого Дикого Запада.