
Справочник по ошибкам анализа robots.txt
- Ошибки
- Предупреждения
- Ошибки проверки URL
Перечень ошибок, возникающих при анализе файла robots.txt.
| Ошибка | Расширение Яндекса | Описание |
|---|---|---|
| Правило начинается не с символа / и не с символа * | Да | Правило может начинаться только с символа / или *. |
| Найдено несколько правил вида User-agent: * | Нет | Допускается только одно правило такого типа. |
| Превышен допустимый размер robots.txt | Да | Количество правил в файле превышает 2048. |
Перед правилом нет директивы User-agent. | Нет | Правило должно всегда следовать за директивой User-agent. Возможно, файл содержит пустую строку после User-agent. |
| Слишком длинное правило | Да | Правило превышает допустимую длину (1024 символа). |
| Некорректный формат URL файла Sitemap | Да | В качестве URL файла Sitemap должен быть указан полный адрес, включая протокол. Например, https://www.example.com/sitemap.xml |
| Некорректный формат директивы Clean-param | Да | В директиве Clean-param указывается один или несколько параметров, которые робот будет игнорировать, и префикс пути. Параметры перечисляются через символ & и отделяются от префикса пути пробелом. |
Перечень предупреждений, возникающих при анализе файла robots.txt.
| Предупреждение | Расширение Яндекса | Описание |
|---|---|---|
| Возможно, был использован недопустимый символ | Да | Обнаружен спецсимвол, отличный от * и $. |
| Обнаружена неизвестная директива | Да | Обнаружена директива, не описанная в правилах использования robots.txt. Возможно, эта директива используется роботами других поисковых систем. |
| Синтаксическая ошибка | Да | Строка не может быть интерпретирована как директива robots.txt. |
| Неизвестная ошибка | Да | При анализе файла возникла неизвестная ошибка. Обратитесь в службу поддержки. |

Перечень ошибок проверки URL в инструменте Анализ robots.txt.
| Ошибка | Описание |
|---|---|
| Синтаксическая ошибка | Ошибка синтаксиса URL. |
| Этот URL не принадлежит вашему домену | Заданный URL не принадлежит сайту, для которого производится анализ файла. Возможно, вы указали адрес одного из зеркал вашего сайта или допустили ошибку в написании имени домена. |
Проверка файла robots.txt | REG.RU
Файл robots.txt — это инструкция для поисковых роботов.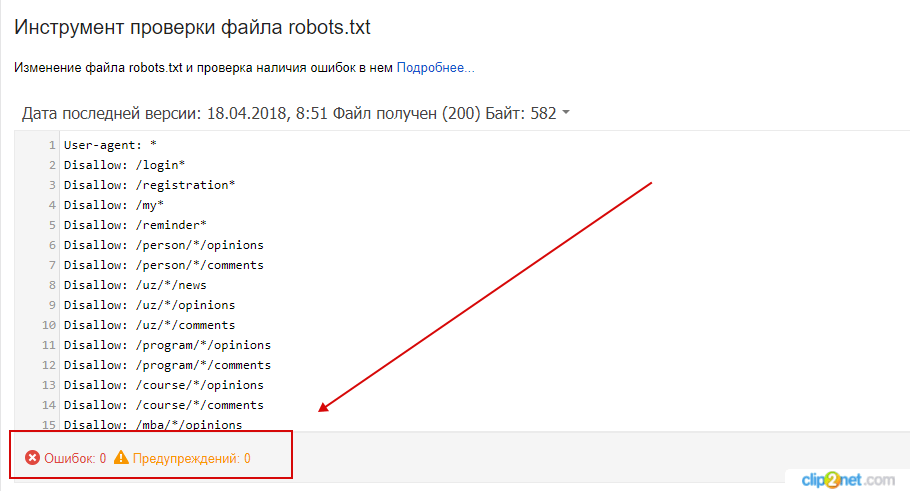 В ней указывается, какие разделы и страницы сайта могут посещать роботы, а какие должны пропускать. В фокусе этой статьи — проверка robots.txt. Мы рассмотрим советы по созданию файла для начинающих веб-разработчиков, а также разберем, как делать анализ robots.txt с помощью стандартных инструментов Яндекс и Google.
В ней указывается, какие разделы и страницы сайта могут посещать роботы, а какие должны пропускать. В фокусе этой статьи — проверка robots.txt. Мы рассмотрим советы по созданию файла для начинающих веб-разработчиков, а также разберем, как делать анализ robots.txt с помощью стандартных инструментов Яндекс и Google.
Зачем нужен robots.txt
Поисковые роботы — это программы, которые сканируют содержимое сайтов и заносят их в базы поисковиков Яндекс, Google и других систем. Этот процесс называется индексацией.
robots.txt содержит информацию о том, какие разделы нельзя посещать поисковым роботам. Это нужно для того, чтобы в выдачу не попадало лишнее: служебные и временные файлы, формы авторизации и т. п. В поисковой выдаче должен быть только уникальный контент и элементы, необходимые для корректного отображения страниц (изображения, CSS- и JS-код).
Если на сайте нет robots.txt, роботы заходят на каждую страницу. Это занимает много времени и уменьшает шанс того, что все нужные страницы будут проиндексированы корректно.
Если же файл есть в корневой папке сайта на хостинге, роботы сначала обращаются к прописанным в нём правилам. Они узнают, куда нельзя заходить, а какие страницы/разделы обязательно нужно посетить. И только после этого начинают обход сайта по инструкции.
Веб-разработчикам следует создать файл, если его нет, и наполнить его правильными директивами (командами) для поисковых роботов. Ниже кратко рассмотрим основные директивы для robots.txt.
Основные директивы robots.txt
Структура файла robots.txt выглядит так:
- Директива User-agent. Обозначает, для каких поисковых роботов предназначены правила в документе. Здесь можно указать все поисковые системы (для этого используется символ «*») или конкретных роботов (Yandex, Googlebot и другие).
- Директива Disallow (запрет индексации). Указывает, какие разделы не должны сканировать роботы. Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение).
 Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.
Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами. - Директива Allow (разрешение). Указывает, какие разделы или файлы должны просканировать поисковые роботы. Здесь не нужно указывать все разделы сайта: все, что не запрещено к обходу, индексируется автоматически. Поэтому следует задавать только исключения из правила Disallow.
- Sitemap (карта сайта). Полная ссылка на файл в формате .xml. Sitemap содержит список всех страниц, доступных для индексации, а также время и частоту их обновления.
 Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.
Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.Пример простого файла robots.txt (после # указаны пояснительные комментарии к директивам):
User-agent: * # правила ниже предназначены для всех поисковых роботов Disallow: /wp-admin # запрет индексации служебной папки со всеми вложениями Disallow: /*? # запрет индексации результатов поиска на сайте Allow: /wp-admin/admin-ajax.php # разрешение индексации JS-скрипты темы WordPress Allow: /*.jpg # разрешение индексации всех файлов формата .
 jpg
Sitemap: http://site.ru/sitemap.xml # адрес карты сайта, где вместо site.ru — домен сайта
jpg
Sitemap: http://site.ru/sitemap.xml # адрес карты сайта, где вместо site.ru — домен сайтаСоветы по созданию robots.txt
Для того чтобы файл читался поисковыми программами корректно, он должен быть составлен по определенным правилам. Даже детали (регистр, абзацы, написание) играют важную роль. Рассмотрим несколько основных советов по оформлению текстового документа.
Группируйте директивы
Если требуется задать различные правила для отдельных поисковых роботов, в файле нужно сделать несколько блоков (групп) с правилами и разделить их пустой строкой. Это необходимо, чтобы не возникало путаницы и каждому роботу не нужно было сканировать весь документ в поисках подходящих инструкций. Если правила сгруппированы и разделены пустой строкой, робот находит нужную строку User-agent и следует директивам. Пример:
User-agent: Yandex # правила только для ПС Яндекс Disallow: # раздел, файл или формат файлов Allow: # раздел, файл или формат файлов # пустая строка User-agent: Googlebot # правила только для ПС Google Disallow: # раздел, файл или формат файлов Allow: # раздел, файл или формат файлов Sitemap: # адрес файла
Учитывайте регистр в названии файла
Для некоторых поисковых систем не имеет значение, какими буквами (прописными или строчными) будет обозначено название файла robots. txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
Не указывайте несколько каталогов в одной директиве
Для каждого раздела/файла нужно указывать отдельную директиву Disallow. Это значит, что нельзя писать Disallow: /cgi-bin/ /authors/ /css/ (указаны три папки в одной строке). Для каждой нужно прописывать свою директиву Disallow:
Disallow: /cgi-bin/ Disallow: /authors/ Disallow: /css/
Убирайте лишние директивы
Часть директив robots.txt считается устаревшими и необязательными: Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующегося контента). Вы можете удалить эти директивы, чтобы не «засорять» файл.
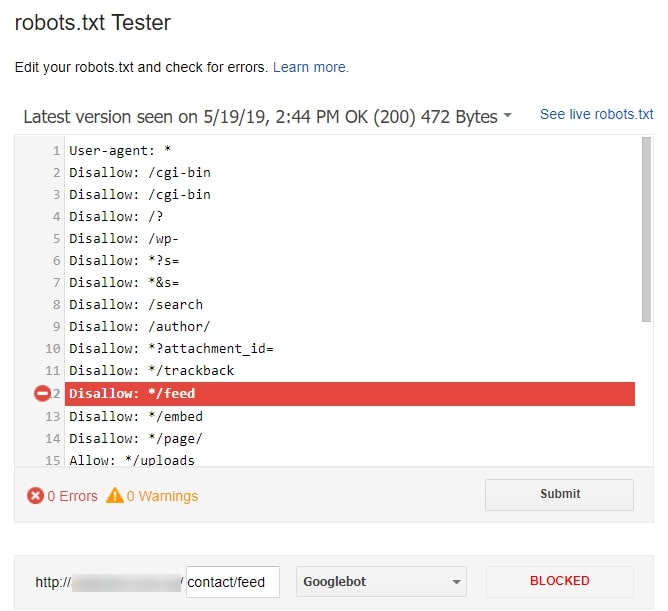
Как проверить robots.txt онлайн
Чтобы убедиться в том, что файл составлен грамотно, можно использовать веб-инструменты Яндекс, Google или онлайн-сервисы (PR-CY, Website Planet и т. п.). В Яндекс и Google есть собственные правила для проверки robots.
Яндекс.Вебмастер
Если вы впервые пользуетесь сервисом Яндекс.Вебмастер, сначала добавьте свой сайт и подтвердите права на него. После этого вы получите доступ к инструментам для анализа SEO-показателей сайта и продвижения в ПС Яндекс.
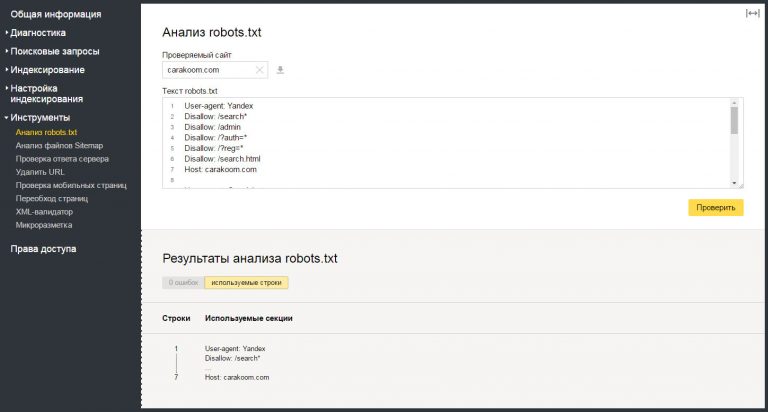
Чтобы проверить robots.txt с помощью валидатора Яндекс:
- 1.
Зайдите в личный кабинет Яндекс.Вебмастер.
- 2.
Выберите в левом меню раздел Инструменты → Анализ robots.txt
. - 3.
Содержимое нужного файла подставиться автоматически. Если по какой-то причине этого не произошло, скопируйте код, вставьте его в поле и нажмите Проверить:
 org/HowToStep»>
4.
org/HowToStep»>
4.Ниже будут указаны результаты проверки. Если в директивах есть ошибки, сервис покажет, какую строку нужно поправить, и опишет проблему:
Google Search Console
Чтобы сделать проверку с помощью Google:
- 1.
Перейдите на страницу инструмента проверки.
- 2.
Если на открывшейся странице отображается неактуальная версия robots.txt, нажмите кнопку
- 3.
Через несколько минут вы можете обновить страницу. В поле будут отображаться актуальные директивы. Предупреждения/ошибки (если система найдет их) будут перечислены под кодом.
Проверка robots.txt Google не выявила ошибок
Обратите внимание: правки, которые вы вносите в сервисе проверки, не будут автоматически применяться в robots. txt. Вам нужно внести исправленный код вручную на хостинге или в административной панели CMS и сохранить изменения.
txt. Вам нужно внести исправленный код вручную на хостинге или в административной панели CMS и сохранить изменения.
Помогла ли вам статья?
Да
3
раза уже
помогла
🤖 Анализ и тестирование файлов robots.txt в больших масштабах — Python
Несмотря на крошечный размер, файлы robots.txt содержат важные инструкции. которые могут заблокировать основные разделы вашего сайта, что они и должны делать. Только иногда вы можете совершить ошибку, заблокировав не тот раздел.
Поэтому очень важно проверить, доступны ли определенные страницы (или группы страниц). заблокирован для определенного user-agent определенным файлом robots.txt. В идеале вы хотел бы запустить ту же проверку для всех возможных пользовательских агентов. Даже больше в идеале вы хотите иметь возможность запускать проверку большого количества страниц с помощью все возможные комбинации с пользовательскими агентами.
Чтобы преобразовать файл robots. txt в удобный для чтения формат, вы можете использовать
txt в удобный для чтения формат, вы можете использовать robotstxt_to_df() , чтобы получить его в DataFrame.
импортировать рекламные инструменты как рекламу
amazon = adv.robotstxt_to_df('https://www.amazon.com/robots.txt')
Амазонка
директива | содержание | etag | robotstxt_last_modified | robotstxt_url | дата_загрузки | |
|---|---|---|---|---|---|---|
0 | Агент пользователя | * | «а850165д925дб701988даф7еад7492д3» | 28.10.2021 17:51:39+00:00 | https://www.amazon.com/robots.txt | 2022-02-11 19:33:03.200689+00:00 |
1 | Запретить | /exec/obidos/аккаунт-доступ-логин | «а850165д925дб701988даф7еад7492д3» | 28. | https://www.amazon.com/robots.txt | 2022-02-11 19:33:03.200689+00:00 |
2 | Запретить | /exec/obidos/change-style | «а850165д925db701988daf7ead7492d3» | 28.10.2021 17:51:39+00:00 | https://www.amazon.com/robots.txt | 2022-02-11 19:33:03.200689+00:00 |
3 | Запретить | /exec/obidos/flex-вход | «а850165д925дб701988даф7еад7492д3» | 28.10.2021 17:51:39+00:00 | https://www.amazon.com/robots.txt | 2022-02-11 19:33:03.200689+00:00 |
4 | Запретить | /exec/obidos/handle-buy-box | «а850165д925дб701988даф7еад7492д3» | 28.10.2021 17:51:39+00:00 | https://www. | 2022-02-11 19:33:03.200689+00:00 |
… | … | … | … | … | … | … |
146 | Запретить | /hp/video/mystuff | «а850165д925дб701988даф7еад7492д3» | 28.10.2021 17:51:39+00:00 | https://www.amazon.com/robots.txt | 11 февраля 2022 г. 19:33:03.200689+00:00 |
147 | Запретить | /gp/видео/профили | «а850165д925дб701988даф7еад7492д3» | 28.10.2021 17:51:39+00:00 | https://www.amazon.com/robots.txt | 2022-02-11 19:33:03.200689+00:00 |
148 | Запретить | /hp/video/профили | «а850165д925дб701988даф7еад7492д3» | 28. | https://www.amazon.com/robots.txt | 2022-02-11 19:33:03.200689+00:00 |
149 | Агент пользователя | ЭтаоСпайдер | «а850165д925дб701988даф7еад7492д3» | 28.10.2021 17:51:39+00:00 | https://www.amazon.com/robots.txt | 2022-02-11 19:33:03.200689+00:00 |
150 | Запретить | / | «а850165д925дб701988даф7еад7492д3» | 28.10.2021 17:51:39+00:00 | https://www.amazon.com/robots.txt | 2022-02-11 19:33:03.200689+00:00 |
 10.2021 17:51:39+00:00
10.2021 17:51:39+00:00
 10.2021 17:51:39+00:00
10.2021 17:51:39+00:00Возвращенный DataFrame содержит столбцы для директив, их содержимое, URL файла robots.txt, а также дату его загрузки.
директива : Основные команды. Разрешить, Запретить, Карта сайта, Задержка сканирования, Пользователь-агент и так далее.
содержание : Детали каждой из директив.
robotstxt_last_modified : Дата последней публикации файла robots.txt модифицировано, если указано (согласно заголовку ответа Last-modified).
etag : Тег сущности заголовка ответа, если он предоставлен.
robotstxt_url : URL-адрес файла robots.txt.
download_date : Дата и время загрузки файла.

Кроме того, вы можете предоставить список URL-адресов роботов, если хотите скачать их все за один раз. Это может быть интересно, если:
Вы анализируете отрасль и хотите следить за множеством различных сайты.
Вы анализируете веб-сайт со множеством поддоменов и хотите получить все файлы robots вместе.
Вы пытаетесь понять компанию, у которой много веб-сайтов под разными названиями. домены и поддомены.
В этом случае вы просто предоставляете список URL-адресов вместо одного.
robots_urls = ['https://www.google.com/robots.txt',
'https://twitter.com/robots.txt',
'https://facebook.com/robots.txt']
googtwfb = adv.robotstxt_to_df(robots_urls)
# Сколько строк в каждом файле robots?
googtwfb.groupby('robotstxt_url')['директива'].count()
robotstxt_url https://facebook.com/robots.txt 541 https://twitter.com/robots.txt 108 https://www.google.com/robots.txt 289 Имя: директива, dtype: int64
# Показать первые пять строк каждого из файлов robots:
googtwfb.groupby('robotstxt_url').head()
директива | содержание | robotstxt_last_modified | robotstxt_url | дата_загрузки | |
|---|---|---|---|---|---|
0 | Агент пользователя | * | 2022-02-07 22:30:00+00:00 | https://www. | 2022-02-11 19:52:13.375724+00:00 |
1 | Запретить | /поиск | 2022-02-07 22:30:00+00:00 | https://www.google.com/robots.txt | 2022-02-11 19:52:13.375724+00:00 |
2 | Разрешить | /поиск/о | 2022-02-07 22:30:00+00:00 | https://www.google.com/robots.txt | 2022-02-11 19:52:13.375724+00:00 |
3 | Разрешить | /поиск/статический | 2022-02-07 22:30:00+00:00 | https://www.google.com/robots.txt | 2022-02-11 19:52:13.375724+00:00 |
4 | Разрешить | /search/howsearchworks | 2022-02-07 22:30:00+00:00 | https://www. | 2022-02-11 19:52:13.375724+00:00 |
289 | комментарий | Робот поисковой системы Google | НаТ | https://twitter.com/robots.txt | 2022-02-11 19:52:13.461815+00:00 |
290 | комментарий | НаТ | https://twitter.com/robots.txt | 2022-02-11 19:52:13.461815+00:00 | |
291 | Агент пользователя | Гуглбот | НаТ | https://twitter.com/robots.txt | 2022-02-11 19:52:13.461815+00:00 |
292 | Разрешить | /?_escaped_fragment_ | НаТ | https://twitter.com/robots.txt | 2022-02-11 19:52:13.461815+00:00 |
293 | Разрешить | /*?язык= | НаТ | https://twitter. | 2022-02-11 19:52:13.461815+00:00 |
397 | комментарий | Примечание. Сбор данных на Facebook с помощью автоматизированных средств | НаТ | https://facebook.com/robots.txt | 2022-02-11 19:52:13.474456+00:00 |
398 | комментарий | запрещено, если у вас нет письменного разрешения от Facebook | НаТ | https://facebook.com/robots.txt | 2022-02-11 19:52:13.474456+00:00 |
399 | комментарий | и может проводиться только для ограниченной цели, указанной в указанном | НаТ | https://facebook.com/robots.txt | 2022-02-11 19:52:13.474456+00:00 |
400 | комментарий | разрешение. | НаТ | https://facebook.com/robots.txt | 2022-02-11 19:52:13.474456+00:00 |
401 | комментарий | См.: http://www.facebook.com/apps/site_scraping_tos_terms.php | НаТ | https://facebook.com/robots.txt | 2022-02-11 19:52:13.474456+00:00 |
 google.com/robots.txt
google.com/robots.txt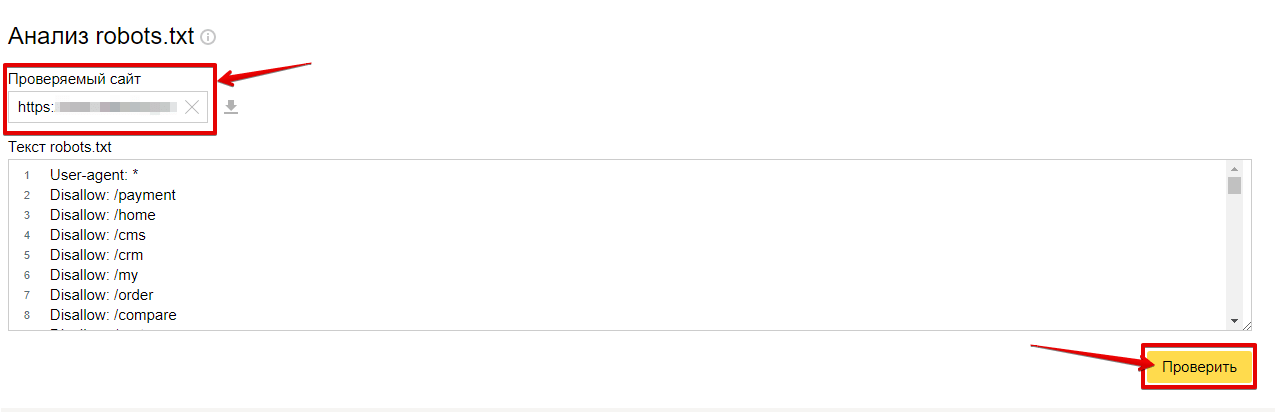 google.com/robots.txt
google.com/robots.txt com/robots.txt
com/robots.txt
Массовая
robots.txt Тестер Этот тестер предназначен для работы в больших масштабах. robotstxt_test() функция запускает тест для заданного файла robots.txt, проверяя, какой из
при условии, что пользовательские агенты могут получить, какой из предоставленных URL-адресов, путей или шаблонов.
импортировать рекламные инструменты как рекламу
adv.robotstxt_test(
robotstxt_url='https://www.amazon.com/robots.txt',
user_agents=['Googlebot', 'baiduspider', 'Bingbot'],
urls=['/', '/hello', '/some-page. html'])
В результате вы получаете DataFrame со строкой для каждой комбинации (пользовательский агент, URL), указывающий, может ли этот конкретный пользовательский агент получить указанный URL.
Некоторые причины, по которым вы можете это сделать:
SEO-аудит: особенно для крупных веб-сайтов с множеством шаблонов URL и правила для разных юзер-агентов.
Разработчик или владелец сайта собирается внести большие изменения
Интерес к стратегиям некоторых компаний
Пользовательские агенты
На самом деле есть только две группы пользовательских агентов, о которых вам нужно беспокоиться о:
Пользовательские агенты, перечисленные в файле robots.txt: для каждого из них вам необходимо проверить, заблокированы ли они для получения определенного URL-адреса (или узор).
*все остальные пользовательские агенты:*включает в себя все другие пользовательские агенты, поэтому проверка применимых к нему правил должна позаботиться обо всем остальном.
robots.txt Подход к тестированию
Получите интересующий вас файл robots.txt
Извлечь из него пользовательские агенты
Укажите URL-адреса, которые вы хотите протестировать
Запустить функцию
robotstxt_test()
fb_robots = adv.robotstxt_to_df('https://www.facebook.com/robots.txt')
fb_robots
директива | содержание | robotstxt_url | дата_загрузки | |
|---|---|---|---|---|
0 | комментарий | Примечание: Сбор данных на Facebook с помощью автоматизированных средств | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 |
1 | комментарий | запрещено, если у вас нет письменного разрешения от Facebook | https://www. | 2022-02-12 00:48:58.951053+00:00 |
2 | комментарий | и может проводиться только для ограниченной цели, указанной в указанном | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 |
3 | комментарий | разрешение. | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 |
4 | комментарий | См.: http://www.facebook.com/apps/site_scraping_tos_terms.php | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 |
… | … | … | … | … |
536 | Разрешить | /ajax/pagelet/generic. | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 |
537 | Разрешить | /карьера/ | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 |
538 | Разрешить | /проверка безопасности/ | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 |
539 | Агент пользователя | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 | |
540 | Запретить | / | https://www.facebook.com/robots.txt | 2022-02-12 00:48:58.951053+00:00 |
Теперь, когда мы загрузили файл, мы можем легко извлечь список
пользовательские агенты, которые он содержит.
fb_useragents = (fb_robots
[fb_robots['директива']=='Агент пользователя']
['контент'].drop_duplicates()
.составлять список())
fb_useragents
['Applebot', 'байдуспайдер', 'Бингбот', «Дискорбот», 'facebookexternalhit', 'гуглбот', 'Googlebot-Изображение', 'ia_archiver', 'LinkedInBot', мснбот, «Навербот», 'Pinterestbot', 'сезнамбот', 'Хлеб', 'теома', 'ТелеграмБот', «Твиттербот», 'Яндекс', 'Йети', '*']
Довольно длинный список!
В качестве небольшого и быстрого теста мне интересно проверить домашнюю страницу, случайный страница профиля (/bbc), страницы групп и хэштегов.
urls_to_test = ['/', '/bbc', '/groups', '/хэштег/']
fb_test = robotstxt_test('https://www.facebook.com/robots.txt',
fb_useragents, urls_to_test)
fb_test
robotstxt_url | пользователь_агент | url_path | can_fetch | |
|---|---|---|---|---|
0 | https://www. | * | / | Ложь |
1 | https://www.facebook.com/robots.txt | * | /ББК | Ложь |
2 | https://www.facebook.com/robots.txt | * | /группы | Ложь |
3 | https://www.facebook.com/robots.txt | * | /хэштег/ | Ложь |
4 | https://www.facebook.com/robots.txt | Эпплбот | / | Правда |
… | … | … | … | |
75 | https://www.facebook.com/robots.txt | сезнамбот | /хэштег/ | Правда |
76 | https://www. | теома | / | Правда |
77 | https://www.facebook.com/robots.txt | теома | /ББК | Правда |
78 | https://www.facebook.com/robots.txt | теома | /группы | Правда |
79 | https://www.facebook.com/robots.txt | теома | /хэштег/ | Правда |
Для двадцати пользовательских агентов и четырех URL-адресов каждый мы получили в общей сложности восемьдесят тестовых Результаты. Сразу видно, что все юзер-агенты, не указанные в списке (обозначаются * не может получить ни один из предоставленных URL-адресов).
Посмотрим, кому разрешено, а кому нет доступа к домашней странице.
fb_test.query('url_path== "/"')
robotstxt_url | пользователь_агент | url_path | can_fetch | |
|---|---|---|---|---|
0 | https://www.facebook.com/robots.txt | * | / | Ложь |
4 | https://www.facebook.com/robots.txt | Эпплбот | / | Правда |
8 | https://www.facebook.com/robots.txt | Бингбот | / | Правда |
12 | https://www.facebook.com/robots.txt | Дискордбот | / | Ложь |
16 | https://www. | Гуглбот | / | Правда |
20 | https://www.facebook.com/robots.txt | Googlebot-изображение | / | Правда |
24 | https://www.facebook.com/robots.txt | LinkedInBot | / | Ложь |
28 | https://www.facebook.com/robots.txt | Навербот | / | Правда |
32 | https://www.facebook.com/robots.txt | Pinterestbot | / | Ложь |
36 | https://www.facebook.com/robots.txt | Хлеб | / | Правда |
40 | https://www. | TelegramBot | / | Ложь |
44 | https://www.facebook.com/robots.txt | Твиттербот | / | Правда |
48 | https://www.facebook.com/robots.txt | Яндекс | / | Правда |
52 | https://www.facebook.com/robots.txt | Йети | / | Правда |
56 | https://www.facebook.com/robots.txt | байдуспайдер | / | Правда |
60 | https://www.facebook.com/robots.txt | facebookexternalhit | / | Ложь |
64 | https://www. | ia_archiver | / | Ложь |
68 | https://www.facebook.com/robots.txt | msnbot | / | Правда |
72 | https://www.facebook.com/robots.txt | сезнамбот | / | Правда |
76 | https://www.facebook.com/robots.txt | теома | / | Правда |
Я оставлю это вам, чтобы выяснить, почему LinkedIn и Pinterest запрещены. сканировать домашнюю страницу, но Google и Apple, потому что я понятия не имею!
- robotstxt_test( robotstxt_url , user_agents , URL )[источник]
Учитывая
robotstxt_url, проверьте, какой изuser_agentsявляется разрешено получать, какой изURL-адресов.Все комбинации
user_agentsиURL-адресабудут проверено, и результаты возвращаются в одном кадре данных.>>> robotstxt_test('https://facebook.com/robots.txt', ... user_agents=['*', 'Googlebot', 'Applebot'], ... urls=['/', '/bbc', '/groups', '/hashtag/']) robotstxt_url user_agent url_path can_fetch 0 https://facebook.com/robots.txt * / Ложь 1 https://facebook.com/robots.txt * /bbc Ложь 2 https://facebook.com/robots.txt * /groups Ложь 3 https://facebook.com/robots.txt * /хэштег/ Ложь 4 https://facebook.com/robots.txt Applebot/True 5 https://facebook.com/robots.txt Applebot/bbc Правда 6 https://facebook.com/robots.txt Applebot/группы Правда 7 https://facebook.com/robots.txt Applebot /hashtag/ Ложь 8 https://facebook.com/robots.txt Googlebot / True 9https://facebook.com/robots.txt Googlebot/bbc Правда 10 https://facebook.com/robots.txt Googlebot /groups Верно 11 https://facebook.com/robots.txt Googlebot /hashtag/ Ложь- Параметры
robotstxt_url ( url ) — URL файла robotx.
txtuser_agents ( str , список ) — Один или несколько пользовательских агентов
URL-адреса ( str , list ) — Один или несколько путей (относительных) или URL-адресов (абсолютных) к чек
- Возврат DataFrame robotstxt_test_df
- robotstxt_to_df( robotstxt_url , output_file=None )[источник]
Загрузить содержимое
robotstxt_urlв DataFrameВы также можете использовать его для загрузки нескольких файлов robots, передав список URL-адреса.
>>> robotstxt_to_df('https://www.twitter.com/robots.txt') содержание директивы robotstxt_url download_date 0 Пользователь-агент * https://www.twitter.com/robots.txt 2020-09-27 21:57:23.702814+00:00 1 Запретить / https://www.twitter.com/robots.txt 2020-09-27 21:57:23.702814+00:00>>> robotstxt_to_df(['https://www.
google.com/robots.txt',
... 'https://www.twitter.com/robots.txt'])
содержание директивы robotstxt_last_modified robotstxt_url download_date
0 User-agent * 2021-01-11 21:00:00+00:00 https://www.google.com/robots.txt 2021-01-16 14:08:50.087985+00:00
1 Disallow /search 11-01-2021 21:00:00+00:00 https://www.google.com/robots.txt 16-01-2021 14:08:50.087985+00:00
2 Разрешить /search/about 11-01-2021 21:00:00+00:00 https://www.google.com/robots.txt 16-01-2021 14:08:50.087985+00:00
3 Разрешить /search/static 11-01-2021 21:00:00+00:00 https://www.google.com/robots.txt 16-01-2021 14:08:50.087985+00:00
4 Разрешить /search/howsearchworks 11-01-2021 21:00:00+00:00 https://www.google.com/robots.txt 16-01-2021 14:08:50.087985+00:00
283 User-agent facebookexternalhit 11.01.2021 21:00:00+00:00 https://www.google.com/robots.txt 16-01-2021 14:08:50.087985+00:00
284 Разрешить /imgres 2021-01-11 21:00:00+00:00 https://www.google.com/robots.txt 2021-01-16 14:08:50.087985+00:00
285 Карта сайта https://www. google.com/sitemap.xml 11-01-2021 21:00:00+00:00 https://www.google.com/robots.txt 16-01-2021 14:08 :50.087985+00:00
286 User-agent * NaT https://www.twitter.com/robots.txt 2021-01-16 14:08:50.468588+00:00
287 Disallow / NaT https://www.twitter.com/robots.txt 2021-01-16 14:08:50.468588+00:00
В исследовательских целях и если вы хотите скачать более ~500 файлов, вам возможно, вы захотите использовать
output_fileдля сохранения результатов по мере их загрузки. Расширение файла должно быть «.jl», к нему добавляются файлы robots. файл, как только они будут загружены, на случай, если вы потеряете соединение или может ваше терпение!>>> robotstxt_to_df(['https://example.com/robots.txt', ... 'https://example.com/robots.txt', ... 'https://example.com/robots.txt'], ... output_file='robots_output_file.jl')
Чтобы открыть файл как DataFrame:
>>> импортировать панд как pd >>> robotsfiles_df = pd.read_json('robots_output_file.jl', lines=True)- Параметры
robotstxt_url ( url ) — Один или несколько URL-адресов файлов robots.
txtoutput_file ( str ) — Необязательный путь к файлу для сохранения файлов robots.txt, в основном полезно для загрузки > 500 файлов. файлы добавляются, как только они загружаются. Поддерживаются только расширения «.jl».
- Возвращает DataFrame robotstxt_df
DataFrame, содержащий директивы, их содержание, URL и время загрузки
Делайте это правильно
# robots.txt
#
# Этот файл предназначен для предотвращения сканирования и индексирования определенных частей
# вашего сайта поисковыми роботами и поисковыми роботами, управляемыми такими сайтами, как Yahoo!
# и Гугл. Сообщая этим «роботам», куда не следует заходить на вашем сайте,
# вы экономите пропускную способность и ресурсы сервера.
#
# Этот файл будет игнорироваться, если только он не находится в корневом каталоге вашего хоста:
# Используется: http://example. com/robots.txt
# Игнорируется: http://example.com/ site/robots.txt
#
# Для получения дополнительной информации о стандарте robots.txt см.:
# http://www.robotstxt.org/wc/robots.html
#
# Проверка синтаксиса , см.:
# http://www.sxw.org.uk/computing/robots/check.html
#
# Предотвращение блокировки параметров URL с помощью robots.txt
# Вместо этого используйте Инструменты Google для веб-мастеров > Сканирование > Параметры URL
# Карта сайта
Карта сайта: http://www.example.com/sitemap.xml
# Настройка сканеров
Агент пользователя: *
# Каталоги
Запретить: /404/
Запретить: /app/
Запретить: /cgi-bin/
Запретить: /downloader3 9000 admin/
Запретить: /ошибки/
Запретить: /includes/
#Запретить: /js/
Запретить: /lib/
Запретить: /magento/
#Запретить: /media/
Запретить: /media/captcha/
3
33 : /media/catalog/
#Disallow: /media/css/
#Disallow: /media/css_secure/
Disallow: /media/customer/
Disallow: /media/dhl/
Disallow: /media /загружаемый/
Запретить: /media/import/
#Запретить: /media/js/
Запретить: /media/pdf/
Запретить: /media/sales/
Запретить: /media/tmp/
Запретить: /media/wysiwyg/
Запретить: /media/xmlconnect/
Запретить: / pkginfo/
Disallow: /report/
Disallow: /scripts/
Disallow: /shell/
#Disallow: /skin/
Disallow: /stats/
Disallow: /var/
#s 900 ( чистые URL-адреса)
Запретить: /index.