Настройка представления сайта в результатах поиска
Сниппет — это блок информации о странице сайта, которая отображается в результатах поиска. Сниппет состоит из заголовка и описания страницы, а также может содержать дополнительную информацию о сайте.
Сниппет формируется автоматически. В некоторых случаях сниппет может содержать дополнительную информацию. Это позволяет повысить информативность сниппета и предоставить пользователю дополнительные знания о сайте и компании. Подробно о формировании и отображении сниппета.
К следующему разделу
Чтобы ваш вопрос быстрее попал к нужному специалисту, уточните тему:
Адресный сниппетБыстрые ссылкиФавиконкаПартнерские программы и разметкаЗаголовок и описание сайтаНавигационные цепочкиСсылки на сайт в поисковых подсказкахИсправление запроса, содержащего адрес сайта
Подробнее об адресном сниппете и других видах отображения информации об организации на сервисах Яндекса см. в разделе Информация об организации.
Если вы видите неправильный адрес не в адресном сниппете, а в описании страницы, выберите в списке пункт «Заголовок и описание сайта» и опишите ситуацию как можно подробнее, а также покажите ее на скриншотах.
Уточните ваш вопрос об адресном сниппете:
Вопрос о метке «Адреса на карте»У сайта не отображается адресный сниппетКак изменить телефон или адрес в сниппете?Другой вопрос об адресном сниппете
Метка «Адреса на карте» отображается, если у организации есть два и более адресов в одном регионе. При нажатии на метку можно увидеть адреса организации на Яндекс Картах. В этом случае в сниппете не отображаются адрес и номер телефона.
Если у вашей организации один адрес, но в сниппете отображается метка «Адреса на карте», проверьте информацию в Яндекс Бизнесе. Чтобы задать вопрос об изменении информации в Бизнесе, воспользуйтесь специальной формой.
Адресный сниппет отображается, если сайт входит в Топ 30 результатов поиска Яндекса. Также учитывается информация об организации, опубликованная в Яндекс Бизнесе:
Также учитывается информация об организации, опубликованная в Яндекс Бизнесе:
указана главная страница сайта (например, http://example.com).
адрес сайта указан так же, как в Вебмастере — с префиксом www или без него, с протоколом HTTP или HTTPS;
указана полная контактная информация об организации (город, улица, номер дома).
Условия выполнены, но адресный сниппет не отображается
Чтобы изменить контактную информацию в адресном сниппете, отредактируйте данные в карточке организации на Яндекс Картах:
Найдите организацию на Яндекс Картах и нажмите ссылку Исправить.
В открывшейся форме укажите корректные данные об организации.
Обычно данные в адресном сниппете обновляются в течение недели после изменения карточки организации.
Если у вас есть вопрос о редактировании карточки организации в Бизнесе, задайте его через специальную форму.
Рекомендуем ознакомиться с информацией о формировании быстрых ссылок и возможном управлении ими в сервисе Яндекс Вебмастер.
Если у вас остались вопросы о быстрых ссылках, заполните форму ниже:
Подробную информацию о фавиконке вы можете найти в разделах:
- Рекомендации по формату и размеру фавиконки
- Как установить фавиконку
- Как изменить или удалить фавиконку
Если у вас остались вопросы, уточните тему:
Фавиконка не появляется для моего сайтаУ сайта пропала фавиконкаВ поиске отображается некорректная или старая фавиконкаТеоретический вопрос про индексирование фавиконок
Если все требования по размещению фавиконки выполнены, то для индексирования и появления ее в результатах поиска необходимо около двух недель.
Прошло больше двух недель, фавиконка не появилась
Фавиконка может пропасть из поиска, если в случае последнего обновления, она не попала в базу. Такая ситуация возможна, если в момент обхода специальным роботом фавиконка, сайт или его хостинг были недоступны.
Такая ситуация возможна, если в момент обхода специальным роботом фавиконка, сайт или его хостинг были недоступны.
Также, проверьте, правильно ли размещена фавиконка. Если она прописана корректно, дождитесь следующего обновления базы фавиконок, это занимает около двух недель.
Прошло больше двух недель, фавиконка не появилась
Такая ситуация возникает, если:
У сайта по разным адресам расположены разные фавиконки. Если сайт доступен по адресам с префиксом www и без него, по протоколам HTTPS и HTTP, проверьте, что фавиконка везде одинаковая или именно та, которая должна индексироваться для каждого из сайтов.
Сайт временно недоступен. В таком случае может скачаться фавиконка хостинга со страницы-заглушки сайта.
Если эти причины устранены и выполнены рекомендации по размещению фавиконки, то после обхода роботом изменения появятся в результатах поиска в течение двух недель.
Рекомендации не помогли, прошло больше двух недель
Яндекс поддерживает только перечисленные в разделе Какие данные можно передать примеры партнерских программ и разметку, представленную в разделе Семантическая разметка страниц (Schema. org, Open Graph, JSON-LD и микроформаты).
org, Open Graph, JSON-LD и микроформаты).
Как часто формируется разметкаПартнерская программа «Кулинарные рецепты»Разметка навигационных цепочекВзаимодействие микроразметки для товаров и партнерской программы «Товары и цены»Не нашлось подходящей разметкиОшибка в валидаторе микроразметкиДругой вопрос о партнерской программе или разметке
Разметка формируется в течение двух недель. Если Яндекс не поддерживает какой-то из видов разметки на странице или в разметке ошибки, то просто пропускает ее.
Рецептные сниппеты формируются только для сайтов, тематика которых связана с едой и ее приготовлением.
Яндекс не поддерживает разметку навигационных цепочек, поэтому в валидаторе могут появиться ошибки. На проверку разметки эти ошибки не влияют.
Следует отличать микроразметку для товаров и саму программу Товары и цены. Если на сайте подключена программа «Товары и цены» и прописана микроразметка, приоритет отдается сниппетам программы.
Робот Яндекса сможет проиндексировать информацию с сайта и без разметки, на показ страниц в поиске это не повлияет. Чтобы задать желаемое описание страницы в результатах поиска, используйте метатег description.
Чтобы задать желаемое описание страницы в результатах поиска, используйте метатег description.
Подробное описание возможных ошибок см. в разделе Валидатор микроразметки.
Не удалось исправить ошибку
Данная форма обратной связи предназначена для вопросов о партнерских программах Яндекса и разметке. Если вы сомневаетесь, стоит ли использовать ту или иную партнерскую программу, которую предоставляют другие сервисы (не Яндекс), то мы никак не можем прокомментировать ее возможное влияние на состояние вашего сайта в поиске.
Подробную информацию о формировании и изменении заголовка и описания сайта см. в разделе Сниппет.
Рекомендации не помогли
Уточните свой вопрос:
В результатах поиска у главной страницы нет описания и заголовка или появилась надпись «Найден по ссылке»Другой вопрос о заголовке и описании сайта
Ознакомьтесь с информацией о навигационных цепочках и их формировании.
Рекомендации не помогли
Рекомендации не помогли
Прочитать об автоматическом исправлении поисковых запросов можно в Справке Поиска.
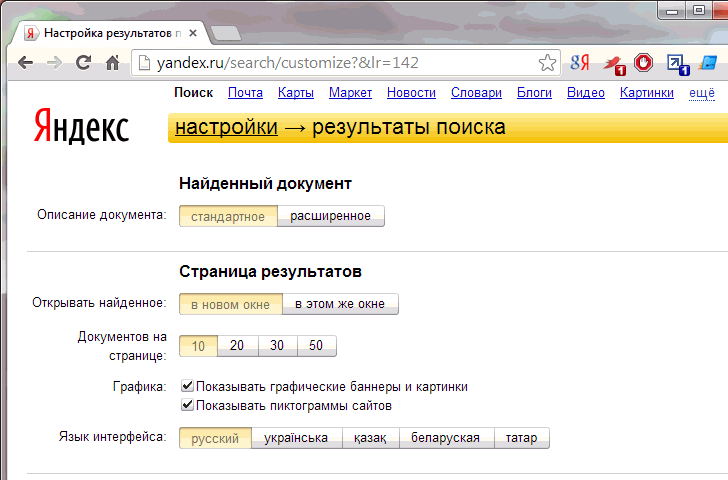
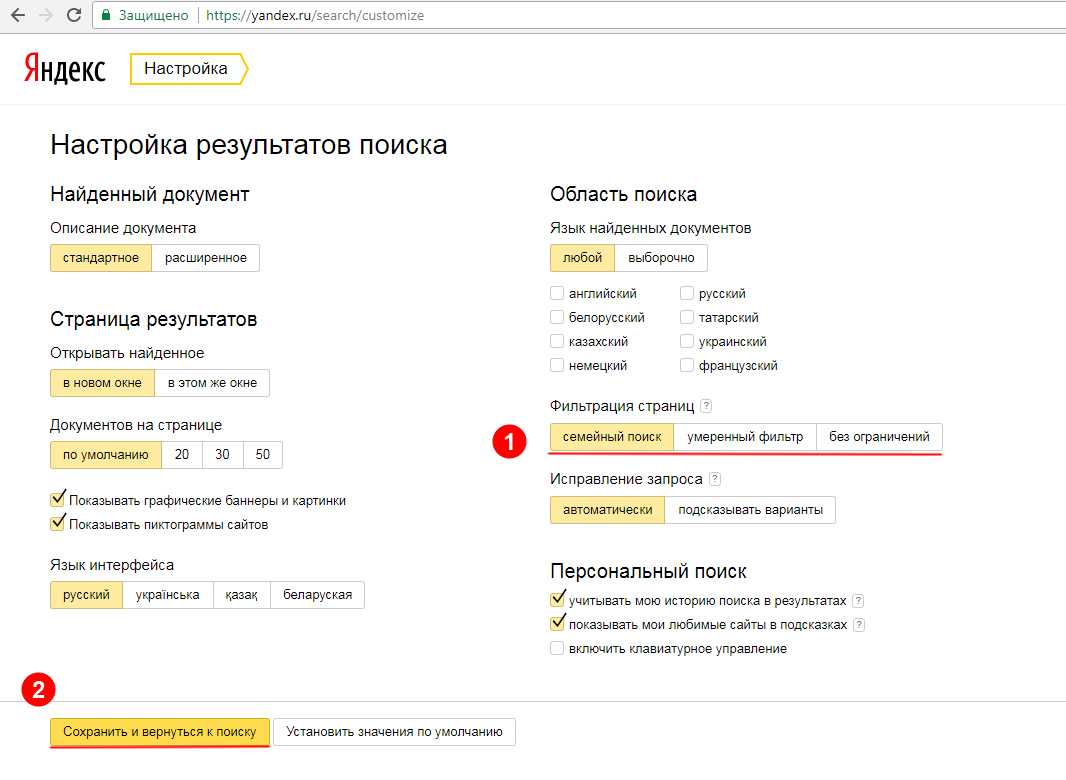
1.4.8. Настройка результатов поиска. Яндекс для всех
1.4.8. Настройка результатов поиска
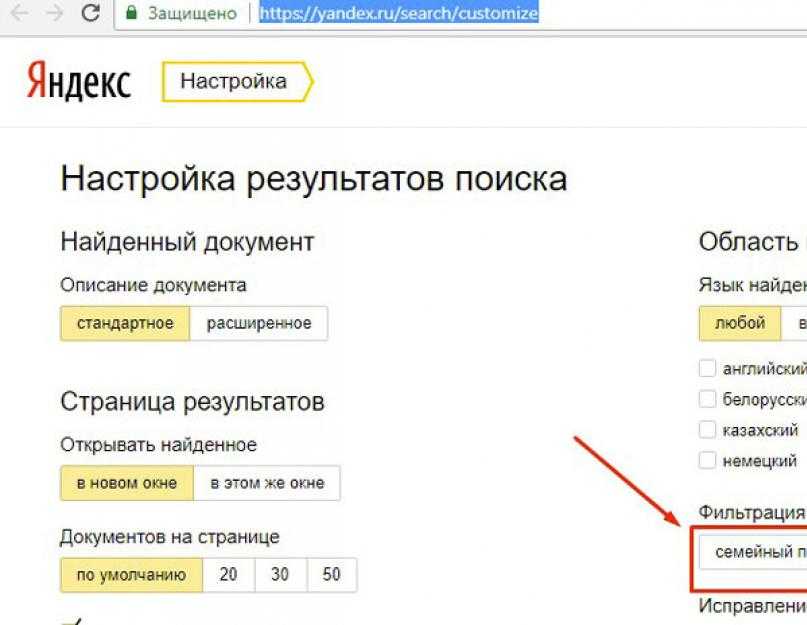
Хотя мы еще не рассматривали процесс формирования результатов поиска, определить, в каком виде они будут выводиться, можно уже сейчас. Ссылка на настройку страницы результатов находится в том же блоке страницы настроек, что и настройка отдельных страниц Яндекса.
Цель выполнения таких настроек — сделать результаты поиска максимально удобными. А понятие «удобство» у каждого свое. Кому-то хотелось бы видеть максимальную информацию о найденном документе, другому достаточно самого минимума. Для одного на странице достаточно показывать десяток первых результатов, а другому хотелось бы просматривать сотню.
На странице все настройки разделены на 4 блока:
? найденный документ;
? страница результатов;
? область поиска;
? дополнительно.
Информация о найденном документе
Первый блок относится к выводу информации о найденном документе. Все изменения, вносимые вами, немедленно отображаются на примере в правой части страницы. Что можно изменить?
? Полноту выводимой информации о документе — в число настраиваемых параметров входят адрес страницы (URL), размер документа, дата его создания или обновления, сведения о соответствии найденного документа запросу, ссылка на похожие документы, количество найденных фрагментов.
• Адрес страницы в неявном виде присутствует в заголовке документа, но чтобы его увидеть, необходимо подвести к нему указатель мыши. Но адрес документа можно получить и в явном виде, если включить в результат вывод адреса документа.
Примечание
В заголовок документа подставляется его название, данное автором и заключенное в теги <title>. Если автор не дал своему документу названия, вместо него будет подставлен адрес страницы.
• Дата документа — на мой взгляд, это довольно «скользкий» параметр. Он вполне адекватен документам в форматах офисных программ (MS Word, Excel), в формате PDF, но применительно к веб-страницам дату можно рассматривать лишь в отношении статических страниц.
• Соответствие запросу — эта информация отражает, насколько точно найденный документ соответствует искомому поисковому выражению. Возможны три варианта:
? если все слова запроса есть в тексте страницы, статус соответствия не отображается;
? если Яндекс считает, что страница соответствует запросу не полностью, но полностью подходящих результатов недостаточно, ссылка на эту страницу также будет включена в число результатов, но с отметкой «нестрогое соответствие»;
? отметка «найден по ссылке» говорит о том, что на самой странице искомых слов запроса не найдено, но страница обнаружена по ссылке и, возможно, также будет представлять интерес.
 Пользователю предоставляется возможность выбрать, какое количество найденных фрагментов будет отображаться в результате поиска. Допустимый диапазон выбора — от одного до пяти.
Пользователю предоставляется возможность выбрать, какое количество найденных фрагментов будет отображаться в результате поиска. Допустимый диапазон выбора — от одного до пяти.? Отображение описания документа — выбор этого параметра означает, что, помимо названия и части текста, содержащего слова запроса, будет приведено описание документа, данное его автором. У этого параметра возможны три варианта:
• если нет фрагментов — описание будет отображено в том случае, если в тексте документа не будет найдено предложение, содержащее слова запроса, которое могло бы быть взято в качестве аннотации;
• всегда — описание будет приведено в любом случае;
• никогда — какой бы ни был результат поиска, авторское описание выводиться не будет.
? Выделение найденных слов — сформированный результат содержит заголовок документа, его описание и фрагменты текста. Искомые слова при стандартных настройках будут выделены полужирным шрифтом и в описании, и во фрагментах. Вы можете отключить выделение поисковых слов в любой или в обоих частях результата поиска.
В результатах поиска присутствуют и иные сведения и ссылки, но они не настраиваются, поэтому о них мы поговорим при рассмотрении собственно результатов.
Настройка страницы вывода результатов поиска
Настройки, относящиеся к этому блоку, не оказывают влияния на отбор и отображение каждого отдельного результата. Все, что здесь можно настроить, имеет отношение только к самой странице.
Обычно поисковая форма, в которую вводится запрос, расположена в верхней части страницы. Но ее можно продублировать и в нижней части. Зачем? Допустим, среди результатов не окажется документа, отвечающего вашему пониманию релевантности запросу. Тогда вместо того, чтобы прокручивать страницу вверх, вы можете в нижней форме ввести новый запрос. Небольшое изменение структуры страницы избавит вас от лишних движений мыши.
Допустим, среди полученных результатов есть несколько документов, которые вы бы хотели изучить более подробно. Для этого вы щелкаете на ссылке и попадаете на нужную страницу. Но в каком окне она будет открыта? В Google по умолчанию ссылка открывается в окне результатов поиска. В Яндексе по умолчанию каждая ссылка открывается в новом окне. Вы можете настроить переход к документу так, как вам покажется более удобно. Документ может открываться:
Но в каком окне она будет открыта? В Google по умолчанию ссылка открывается в окне результатов поиска. В Яндексе по умолчанию каждая ссылка открывается в новом окне. Вы можете настроить переход к документу так, как вам покажется более удобно. Документ может открываться:
? в том же окне;
? в новом окне;
? в общем новом окне.
Последний вариант говорит о том, что первый документ будет открыт в новом окне, каждый последующий будет открываться в нем же. Конечно, можно обойтись и без изменения настроек, для чего придется использовать клавиатуру и мышь. Чтобы открыть документ в новом окне, достаточно подвести к ссылке указатель мыши щелкнуть на ней правой кнопкой и в открывшемся контекстном меню выбрать пункт Открыть в новом окне. Этого же результата в Internet Explorer можно добиться, если при нажатой клавише <Shift> щелкнуть на ссылке левой кнопкой мыши.
Следующий параметр, характеризующий страницу выдачи результатов, поможет вам настроить количество выводимых на нее документов. Первоначальное значение равно 10. Это довольно удобно, поскольку страница получается не очень большая и не требует долгого прокручивания для просмотра. Кроме того, размер страницы не получится большим, что удобно для работающих в Интернете через обычный модем. С другой стороны, при большом количестве полученных результатов для их просмотра вам придется выполнять переход от страницы к странице, подгружая их взамен просмотренных. При хорошем соединении (ADSL, XDSL, локальная сеть) вполне допустимо увеличить количество выводимых результатов на странице. В настройках вы можете назначить этому параметру значение от 10 до 50.
Первоначальное значение равно 10. Это довольно удобно, поскольку страница получается не очень большая и не требует долгого прокручивания для просмотра. Кроме того, размер страницы не получится большим, что удобно для работающих в Интернете через обычный модем. С другой стороны, при большом количестве полученных результатов для их просмотра вам придется выполнять переход от страницы к странице, подгружая их взамен просмотренных. При хорошем соединении (ADSL, XDSL, локальная сеть) вполне допустимо увеличить количество выводимых результатов на странице. В настройках вы можете назначить этому параметру значение от 10 до 50.
Для людей, экономящих трафик, либо работающих через медленные соединения, полезно обратить внимание на настройки, связанные с отображением графики на странице результатов. С помощью настроек вы сможете отключить вывод графических баннеров и блока картинок, а также пиктограмм сайтов на первой странице результатов.
Область поиска
В этом блоке всего два параметра, доступных для настройки. Первый определяет, на каком языке должны быть документы, попадающие в результат поиска. У вас есть возможность получения в результате поиска любых документов вне зависимости от языка. Во втором случае вы можете ограничить область поиска документами, относящимися к одному из доступных для фильтрации языков — русскому, белорусскому, украинскому, английскому, немецкому или французскому.
Первый определяет, на каком языке должны быть документы, попадающие в результат поиска. У вас есть возможность получения в результате поиска любых документов вне зависимости от языка. Во втором случае вы можете ограничить область поиска документами, относящимися к одному из доступных для фильтрации языков — русскому, белорусскому, украинскому, английскому, немецкому или французскому.
Второй параметр позволяет включить фильтр, соответствующий так называемому семейному поиску, исключающему, по возможности, вывод результатов, не предназначенных для несовершеннолетних.
Дополнительно
Помимо результатов поиска, на странице может быть выведена и дополнительная информация. Например, статистика слов, включенных в поисковое выражение. Если вы включите этот параметр, то перед списком результатов будет выведена строка с данными, сколько раз каждое из слов встречалось Яндексом среди всех проиндексированных им страниц. Числа приблизительные хотя бы потому, что в базу Яндекса постоянно добавляются новые страницы.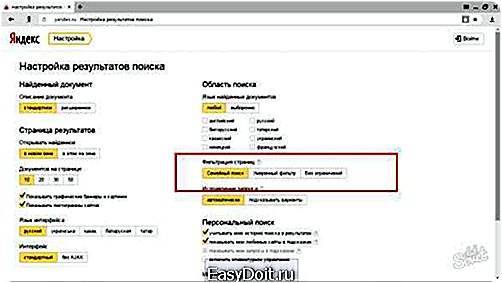
Возможно, вас интересуют результаты обработки вашего запроса не только поисковой системой Яндекс. В этом случае вы можете в настройках поставить флажок предлагать искать другими поисковыми системами. В результате в самом низу страницы будет добавлена строка со ссылками на поисковые системы Google, MSN, Yahoo! Rambler, Апорт! с уже подготовленными запросами. Щелкнув на ссылке, вы передадите в выбранную поисковую систему свой запрос и перейдете на страницу результатов поиска.
Данный текст является ознакомительным фрагментом.
Обработка результатов запроса
Обработка результатов запроса
mysql_resultПолучение определенного поля результата.Синтаксис:int mysql_result(int result, int row [, mixed field])Функция возвращает значение поля field в строке результата с номером row.
Настройка поиска
Настройка поиска Параметры поиска, принятые в системе по умолчанию, позволяют находить файлы точно и быстро. Однако при необходимости вы можете изменить некоторые параметры системы поиска, сместив баланс «глубина – точность – быстрота поиска» в одну или другую
Факторы, влияющие на ранжирование результатов поиска в поисковых машинах
Факторы, влияющие на ранжирование результатов поиска в поисковых машинах Поисковая машина выстраивает сайты в результатах поиска в соответствии с их релевантностью введенному запросу, то есть по соответствию сайта некоему «эталону», который она должна показать
Печать результатов
Печать результатов
После обработки результатов в соответствующем редакторе распечатайте файл для будущих исследований. Шрифт должен быть Courier New в формате Portrait. Программа OrCAD позволяет вам получить также и распечатку схемы. Мы возвратимся к этой теме после исследования
Шрифт должен быть Courier New в формате Portrait. Программа OrCAD позволяет вам получить также и распечатку схемы. Мы возвратимся к этой теме после исследования
Просмотр результатов
Просмотр результатов Если вы ведете деловую переписку (точнее, рассылку, то есть отправляете свои письма большому количеству адресатов одновременно), то желательно не делать ошибок в адресах и именах тех, кому вы пишете ваши обращения.Для этого и существует группа
Буфер результатов слишком мал
Буфер результатов слишком мал Когда мы рассказывали о функции door_call, мы отметили, что если буфер результатов оказывается слишком мал, библиотека дверей осуществляет автоматическое выделение нового буфера. Сейчас мы покажем это на примере. В листинге 15.4 приведен текст
12.
 4.3. Кэширование результатов операций
4.3. Кэширование результатов операций12.4.3. Кэширование результатов операций Иногда можно получить оба преимущества (низкую задержку и хорошую пропускную способность) путем вычисления дорогостоящих результатов по мере необходимости и их кэширования для последующего использования. Выше было сказано, что в
12.4.3. Кэширование результатов операций
12.4.3. Кэширование результатов операций Иногда можно получить оба преимущества (низкую задержку и хорошую пропускную способность) путем вычисления дорогостоящих результатов по мере необходимости и их кэширования для последующего использования. Выше было сказано, что в
Хранение лучших результатов
Хранение лучших результатов
Теперь игроку может указывать свое имя при достижении хорошего результата. Но нужно как-то сохранять это имя и достигнутый результат. Эту информацию будем хранить в той же папке, где и саму программу. Значит, наша программа должна
Эту информацию будем хранить в той же папке, где и саму программу. Значит, наша программа должна
3.5. Настройка поиска
3.5. Настройка поиска Если вы часто пользуетесь стандартным механизмом поиска операционной системы, то вам могут быть интересны некоторые уникальные возможности его
11.1.2. Сохранение результатов сортировки
11.1.2. Сохранение результатов сортировки Чтобы сохранить результаты сортировки, укажите опцию -o и выходной файл. Можно также воспользоваться традиционным методом переадресации с помощью оператора >. В следующем примере результаты сортировки сохраняются в файле results.out$
Сохранение результатов
Сохранение результатов
Результаты анализа своего почерка и написания буквы можно сохранять. Для этого нажмите кнопку «Сохранить как…», расположенную в нижнем правом углу окна «Результат», и задайте путь для сохранения в любой папке на вашем компьютере. Файл будет
Для этого нажмите кнопку «Сохранить как…», расположенную в нижнем правом углу окна «Результат», и задайте путь для сохранения в любой папке на вашем компьютере. Файл будет
Просмотр результатов
Просмотр результатов Результаты выполнения всех заданий из задачника Programming Taskbook заносятся в специальный файл результатов results.abc, который должен находиться в том каталоге, из которого запускаются программы с заданиями.Данный файл автоматически создается в рабочем
Сохранение результатов поиска
Сохранение результатов поиска При необходимости регулярно выполнять один и тот же поисковый запрос сохраните его условия, после чего вы сможете многократно повторять поиск, просто открыв сохраненный запрос.Последовательность действий для сохранения поискового
результатов поиска Google · PyPI
Этот пакет Python предназначен для извлечения и анализа результатов поиска из Google, Bing, Baidu, Yandex, Yahoo, Home Depot, eBay и других, используя SerpApi.
Предоставляются следующие услуги:
- API поиска
- API поиска в архиве
- API учетной записи
- API определения местоположения (только Google)
SerpApi предоставляет конструктор скриптов, который поможет вам быстро приступить к работе.
Установка
Python 3.7+
pip установить результаты поиска Google
Ссылка на страницу пакета python
Быстрый старт
из serpapi import GoogleSearch
поиск = GoogleПоиск({
«к»: «кофе»,
"местоположение": "Остин, Техас",
"api_key": "<ваш секретный ключ API>"
})
результат = search.get_dict()
В этом примере выполняется поиск «кофе» с использованием вашего секретного ключа API.
Сервис SerpApi (бэкэнд)
- Ищет Google с помощью поиска: q=»coffee»
- Разбирает беспорядочные HTML-ответы
- Возвращает стандартный ответ JSON Класс поиска Google
- Форматирует запрос
- Выполняет HTTP-запрос GET к службе SerpApi
- Разбирает ответ JSON в словарь
И вуаля. ..
..
Кроме того, вы можете выполнить поиск:
- Bing, используя BingSearch class
- Baidu с использованием BaiduSearch класса
- Yahoo с использованием класса YahooSearch
- DuckDuckGo с использованием DuckDuckGoSearch класса
- eBay с использованием EbaySearch класса
- Яндекс с использованием класса YandexSearch
- HomeDepot с использованием класса HomeDepotSearch
- GoogleScholar с использованием класса GoogleScholarSearch
- Youtube с использованием класса YoutubeSearch
- Walmart с использованием WalmartSearch
- Apple App Store с использованием класса AppleAppStoreSearch
- Naver использует класс NaverSearch
См. игровую площадку, чтобы сгенерировать код.
Сводка
- Результаты поиска Google на Python
- Установка
- Быстрый старт
- Резюме
- Возможности API поиска Google
- Как установить ключ SERP API
- Пример по спецификации
- API местоположения
- API поиска в архиве
- API учетной записи
- Поиск Bing
- Поиск Baidu
- Поиск Яндекс
- Поиск Yahoo
- Поиск на Ebay
- Поиск Домашний склад
- Поиск на Ютубе
- Поиск в Google Scholar
- Общий поиск с SerpApiClient
- Поиск в Google Картинках
- Поиск в Новостях Google
- Поиск в Google Покупках
- Поиск Google по местоположению
- Пакетный асинхронный поиск
- Объект Python в результате
- Разбиение на страницы Python с использованием итератора
- Управление ошибками
- Журнал изменений
- Заключение
Возможности Google Search API
Исходный код.
параметров = {
«к»: «кофе»,
"location": "Запрошенное местоположение",
"device": "рабочий стол|мобильный|планшет",
"hl": "Язык пользовательского интерфейса Google",
"gl": "Страна Google",
"safe": "Флаг безопасного поиска",
"num": "Количество результатов",
"start": "Смещение страницы",
"api_key": "Ваш API-ключ SERP",
# Чтобы соответствовать
"tbm": "нвс|ищ|магазин",
# Для поиска
"tbs": "настраивается как критерии поиска",
# разрешить асинхронный запрос
"асинхронный": "правда|ложь",
# Выходной формат
"выход": "json|html"
}
# определяем поисковый поиск
поиск = Поиск в Google (параметры)
# переопределить существующий параметр
search.params_dict["location"] = "Портленд"
# формат поиска возвращается как необработанный html
html_results = search.get_html()
# анализ результатов
# как словарь python
dict_results = поиск.get_dict()
# как JSON с использованием пакета json
json_results = search.get_json()
# как динамический объект Python
object_result = search. get_object()
get_object()
 get_object()
get_object()
Ссылка на полную документацию
См. ниже дополнительные практические примеры.
Как установить ключ API SERP
Вы можете получить ключ API здесь, если у вас его еще нет: https://serpapi.com/users/sign_up
SerpApi api_key можно установить глобально:
GoogleSearch.SERP_API_KEY = "Ваш закрытый ключ"
Для каждого поиска можно указать SerpApi api_key :
query = GoogleSearch({"q": "coffee", "serp_api_key": "Ваш закрытый ключ"})
Пример по спецификации
Мы любим настоящий открытый исходный код, непрерывную интеграцию и разработку через тестирование (TDD). Мы используем RSpec для круглосуточного тестирования нашей инфраструктуры для достижения наилучшего качества обслуживания (QoS).
Каталог test/ содержит спецификации/примеры.
Установите свой ключ API.
export API_KEY="ваш секретный ключ"
Провести тест
Сделать тест
API местоположения
из serpapi import GoogleSearch
поиск = Поиск в Google({})
location_list = search. get_location("Остин", 3)
распечатать (список_местоположений)
 get_location("Остин", 3)
распечатать (список_местоположений)
get_location("Остин", 3)
распечатать (список_местоположений)
Это печатает первые 3 местоположения, соответствующие Остину (Техас, Техас, Рочестер).
[ { 'canonical_name': 'Остин, Техас, Техас, США',
'код_страны': 'США',
'google_id': 200635,
'google_parent_id': 21176,
'gps': [-97.7430608, 30.267153],
«идентификатор»: «585069bdee19ad271e9bc072»,
'ключи': ['Остин', 'Техас', 'Техас', 'Юнайтед', 'Штаты'],
'имя': 'Остин, Техас',
«досягаемость»: 5560000,
'target_type': 'Регион прямого доступа к памяти'},
...]
API архива поиска
Результаты поиска сохраняются во временном кэше. Предыдущий поиск можно получить из кэша бесплатно.
из serpapi импорт GoogleSearch
search = GoogleSearch({"q": "Кофе", "location": "Остин, Техас"})
search_result = search.get_dictionary()
утверждать search_result.get("ошибка") == Нет
search_id = search_result.get("search_metadata"). get("id")
печать (search_id)
 get("id")
печать (search_id)
get("id")
печать (search_id)
Теперь давайте извлечем предыдущий поиск из архива.
archived_search_result = GoogleSearch({}).get_search_archive(search_id, 'json')
print(archived_search_result.get("search_metadata").get("id"))
Распечатывает результат поиска из архива.
API аккаунта
из serpapi import GoogleSearch
поиск = Поиск в Google({})
аккаунт = search.get_account()
Распечатывает информацию о вашей учетной записи.
Поиск Bing
из импорта serpapi BingSearch
search = BingSearch({"q": "Кофе", "location": "Остин, Техас"})
данные = search.get_dict()
Этот код печатает результаты поиска Bing для кофе в виде словаря.
https://serpapi.com/bing-search-api
Поиск Baidu
из импорта serpapi BaiduSearch
search = BaiduSearch({"q": "Кофе"})
данные = search.get_dict()
Этот код печатает результаты поиска Baidu по запросу кофе в виде словаря. https://serpapi.com/baidu-search-api
https://serpapi.com/baidu-search-api
Поиск Яндекс
от serpapi импорт ЯндексПоиск
search = YandexSearch({"text": "Кофе"})
данные = search.get_dict()
Этот код выводит результаты поиска кофе в Яндексе в виде словаря.
https://serpapi.com/yandex-search-api
Поиск Yahoo
из импорта serpapi YahooSearch
поиск = YahooSearch({"p": "Кофе"})
данные = search.get_dict()
Этот код печатает результаты поиска Yahoo для кофе в виде словаря.
https://serpapi.com/yahoo-search-api
Поиск на eBay
из импорта serpapi EbaySearch
search = EbaySearch({"_nkw": "Кофе"})
данные = search.get_dict()
Этот код печатает результаты поиска кофе на eBay в виде словаря.
https://serpapi.com/ebay-search-api
Поиск Home Depot
от serpapi import HomeDepotSearch
search = HomeDepotSearch({"q": "стул"})
данные = search.get_dict()
Этот код печатает результаты поиска Home Depot для стула в виде словаря.
https://serpapi.com/home-depot-search-api
Поиск на Youtube
от serpapi import HomeDepotSearch
search = YoutubeSearch({"q": "стул"})
данные = search.get_dict()
Этот код выводит результаты поиска на Youtube для стула в виде словаря.
https://serpapi.com/youtube-search-api
Поиск в Google Scholar
из serpapi import GoogleScholarSearch
search = GoogleScholarSearch({"q": "Кофе"})
данные = search.get_dict()
Этот код печатает результаты поиска Google Scholar.
Поиск Walmart
от serpapi import WalmartSearch
поиск = WalmartSearch({"запрос": "стул"})
данные = search.get_dict()
Этот код выводит результаты поиска Walmart.
Поиск на Youtube
от serpapi import YoutubeSearch
search = YoutubeSearch({"search_query": "стул"})
данные = search.get_dict()
Этот код выводит результаты поиска на Youtube.
Поиск в Apple App Store
из serpapi import AppleAppStoreSearch
search = AppleAppStoreSearch({"термин": "Кофе"})
данные = search. get_dict()
 get_dict()
get_dict()
Этот код выводит результаты поиска в Apple App Store.
из импорта serpapi NaverSearch
поиск = NaverSearch({"запрос": "стул"})
данные = search.get_dict()
Этот код выводит результаты поиска Naver.
Общий поиск с помощью SerpApiClient
из импорта serpapi SerpApiClient
query = {"q": "Кофе", "location": "Остин, Техас", "engine": "google"}
поиск = SerpApiClient(запрос)
данные = search.get_dict()
Этот класс обеспечивает взаимодействие с любой поисковой системой, поддерживаемой SerpApi.com
Поиск в картинках Google
из serpapi импорт GoogleSearch
search = GoogleSearch({"q": "coffe", "tbm": "isch"})
для image_result в search.get_dict()['images_results']:
ссылка = image_result["оригинал"]
пытаться:
print("ссылка: " + ссылка)
# wget.download(ссылка, '.')
кроме:
проходить
Этот код печатает все ссылки на изображения,
и загружает изображения, если вы раскомментируете строку с помощью wget (инструмент Linux/OS X для загрузки файлов).
Это руководство охватывает больше информации по этой теме. https://github.com/serpapi/showcase-serpapi-tensorflow-keras-image-training
Поиск в Новостях Google
из serpapi import GoogleSearch
поиск = GoogleПоиск({
"q": "кофе", # поиск поиск
"tbm": "nws", # новости
"tbs": "qdr:d", # последние 24 часа
"число": 10
})
для смещения в [0,1,2]:
search.params_dict["начало"] = смещение * 10
данные = search.get_dict()
для news_result в data['news_results']:
print(str(news_result['position'] + offset * 10) + "-" + news_result['title'])
Этот скрипт печатает первые 3 страницы заголовков новостей за последние 24 часа.
Поиск в Google Покупках
из serpapi import GoogleSearch
поиск = GoogleПоиск({
"q": "кофе", # поиск поиск
"tbm": "магазин", # новости
"tbs": "p_ord:rv", # за последние 24 часа
"число": 100
})
данные = search.get_dict()
для shopping_result в data['shopping_results']:
print(shopping_result['position']) + "-" + shopping_result['title'])
Этот скрипт выводит все результаты покупок, упорядоченные по порядку просмотра.
Поиск Google по местоположению
С помощью SerpApi мы можем создать поиск Google из любой точки мира. Этот код ищет лучшую кофейню для заданных городов.
из serpapi импорт GoogleSearch
для города в ["Нью-Йорк", "Париж", "Берлин"]:
location = GoogleSearch({}).get_location(город, 1)[0]["canonical_name"]
поиск = GoogleПоиск({
"q": "лучшая кофейня", # search search
"местоположение": местоположение,
"число": 1,
"старт": 0
})
данные = search.get_dict()
top_result = данные["organic_results"][0]["title"]
Пакетный асинхронный поиск
Мы предлагаем два способа повысить эффективность поиска благодаря async параметр.
- Блокирование — async=false — более интенсивное вычисление, поскольку для поиска необходимо поддерживать множество подключений. (по умолчанию)
- Неблокирующий — async=true — способ обработки больших пакетов запросов (рекомендуется)
# Операционная система
импорт ОС
# библиотека регулярных выражений
импортировать повторно
# безопасная очередь (называется Queue в python2)
из очереди импорта Очередь
# Полезность времени
время импорта
# Поиск SerpApi
из serpapi импортировать GoogleSearch
# поиск в магазине
search_queue = Очередь()
# Поиск SerpApi
поиск = GoogleПоиск({
"местоположение": "Остин, Техас",
"асинхронный": правда,
"api_key": os. getenv("API_KEY")
})
# цикл по списку компаний
для компании в ['amd', 'nvidia', 'intel']:
print("выполнить асинхронный поиск: q = " + компания)
search.params_dict["q"] = компания
результат = search.get_dict()
если в результате "ошибка":
print("ой ошибка: ", результат["ошибка"])
продолжать
print("Добавить поиск в очередь, где id: ", результат['search_metadata'])
# добавляем поиск в search_queue
search_queue.put(результат)
print("Подождите, пока все статусы поиска не будут закешированы или не будут выполнены успешно")
# Создать обычный поиск
пока не search_queue.empty():
результат = search_queue.get()
search_id = результат['search_metadata']['id']
# получить поиск из архива - блокировщик
print(search_id + ": получить поиск из архива")
search_archived = search.get_search_archive(search_id)
print(search_id + ": статус = " +
search_archived['search_metadata']['status'])
# Проверь состояние
если re.search('Кэширование|Успех',
search_archived['search_metadata']['status']):
print(search_id + ": поиск выполняется с помощью q = " +
search_archived['параметры_поиска']['q'])
еще:
# запросим search_queue
print(search_id + ": запросить поиск")
search_queue. put(результат)
# подождите 1с
время сна(1)
print('все поиски завершены')
 getenv("API_KEY")
})
# цикл по списку компаний
для компании в ['amd', 'nvidia', 'intel']:
print("выполнить асинхронный поиск: q = " + компания)
search.params_dict["q"] = компания
результат = search.get_dict()
если в результате "ошибка":
print("ой ошибка: ", результат["ошибка"])
продолжать
print("Добавить поиск в очередь, где id: ", результат['search_metadata'])
# добавляем поиск в search_queue
search_queue.put(результат)
print("Подождите, пока все статусы поиска не будут закешированы или не будут выполнены успешно")
# Создать обычный поиск
пока не search_queue.empty():
результат = search_queue.get()
search_id = результат['search_metadata']['id']
# получить поиск из архива - блокировщик
print(search_id + ": получить поиск из архива")
search_archived = search.get_search_archive(search_id)
print(search_id + ": статус = " +
search_archived['search_metadata']['status'])
# Проверь состояние
если re.search('Кэширование|Успех',
search_archived['search_metadata']['status']):
print(search_id + ": поиск выполняется с помощью q = " +
search_archived['параметры_поиска']['q'])
еще:
# запросим search_queue
print(search_id + ": запросить поиск")
search_queue.
getenv("API_KEY")
})
# цикл по списку компаний
для компании в ['amd', 'nvidia', 'intel']:
print("выполнить асинхронный поиск: q = " + компания)
search.params_dict["q"] = компания
результат = search.get_dict()
если в результате "ошибка":
print("ой ошибка: ", результат["ошибка"])
продолжать
print("Добавить поиск в очередь, где id: ", результат['search_metadata'])
# добавляем поиск в search_queue
search_queue.put(результат)
print("Подождите, пока все статусы поиска не будут закешированы или не будут выполнены успешно")
# Создать обычный поиск
пока не search_queue.empty():
результат = search_queue.get()
search_id = результат['search_metadata']['id']
# получить поиск из архива - блокировщик
print(search_id + ": получить поиск из архива")
search_archived = search.get_search_archive(search_id)
print(search_id + ": статус = " +
search_archived['search_metadata']['status'])
# Проверь состояние
если re.search('Кэширование|Успех',
search_archived['search_metadata']['status']):
print(search_id + ": поиск выполняется с помощью q = " +
search_archived['параметры_поиска']['q'])
еще:
# запросим search_queue
print(search_id + ": запросить поиск")
search_queue. put(результат)
# подождите 1с
время сна(1)
print('все поиски завершены')
put(результат)
# подождите 1с
время сна(1)
print('все поиски завершены')
Этот код показывает, как выполнять поиск асинхронно. Параметры поиска должны иметь значение {async: True}. Это указывает на то, что клиент не должен ждать завершения поиска. Текущий поток, выполняющий поиск, теперь неблокируется, что позволяет ему выполнять тысячи поисков за секунды. Серверная часть SerpApi выполнит всю работу по обработке. Фактический результат поиска откладывается до более позднего вызова из архива поиска с использованием get_search_archive(search_id). В этом примере неблокирующие поиски сохраняются в очереди: search_queue. Цикл через search_queue позволяет получать отдельные результаты поиска. Этот процесс можно легко сделать многопоточным, чтобы разрешить большое количество одновременных поисковых запросов. Для простоты в этом примере результаты поиска исследуются только по одному (однопоточное).
См. пример.
Объект Python в результате
Результаты поиска могут быть автоматически заключены в динамически генерируемый объект Python. Это решение предлагает более динамичный, полностью ориентированный объектно-ориентированный подход к программированию по сравнению с обычной структурой данных Dictionary/JSON.
Это решение предлагает более динамичный, полностью ориентированный объектно-ориентированный подход к программированию по сравнению с обычной структурой данных Dictionary/JSON.
из serpapi импорт GoogleSearch
search = GoogleSearch({"q": "Кофе", "location": "Остин, Техас"})
г = search.get_object ()
утвердить тип (r.organic_results), список
утверждать r.organic_results[0].title
утверждать r.search_metadata.id
утверждать r.search_metadata.google_url
утверждать r.search_parameters.q, "Кофе"
утверждать r.search_parameters.engine, "google"
Разбиение на страницы с использованием итератора
Давайте соберем ссылки на нескольких страницах результатов поиска.
# чтобы получить 2 страницы
начало = 0
конец = 40
размер_страницы = 10
# основные параметры поиска
параметр = {
«к»: «кока-кола»,
"ТБМ": "НВС",
"api_key": os.getenv("API_KEY"),
# необязательный параметр пагинации
# метод пагинации может напрямую принимать аргументы
"старт": старт,
"конец": конец,
"число": размер_страницы
}
# как доказательство концепции
# URL собирает
URL-адреса = []
# инициализируем поиск
поиск = Поиск в Google(параметр)
# создаем генератор Python, используя параметр
страницы = search. pagination()
# или установить пользовательский параметр
страницы = search.pagination (начало, конец, размер_страницы)
# получить один результат поиска за итерацию
# использование базового цикла for для Python
# который вызывает итератор Python под капотом.
для страницы на страницах:
print(f"Текущая страница: {page['serpapi_pagination']['current']}")
для news_result на странице["news_results"]:
print(f"Title: {news_result['title']}\nLink: {news_result['link']}\n")
urls.append(news_result['ссылка'])
# проверяем, соответствует ли общее количество страниц ожидаемому
# примечание: точное число, если переменная зависит от серверной части поисковой системы
если len(urls) == (конец - начало):
print("Все результаты поиска совпадают!")
если len(urls) == len(set(urls)):
print("Все результаты поиска уникальны!")
 pagination()
# или установить пользовательский параметр
страницы = search.pagination (начало, конец, размер_страницы)
# получить один результат поиска за итерацию
# использование базового цикла for для Python
# который вызывает итератор Python под капотом.
для страницы на страницах:
print(f"Текущая страница: {page['serpapi_pagination']['current']}")
для news_result на странице["news_results"]:
print(f"Title: {news_result['title']}\nLink: {news_result['link']}\n")
urls.append(news_result['ссылка'])
# проверяем, соответствует ли общее количество страниц ожидаемому
# примечание: точное число, если переменная зависит от серверной части поисковой системы
если len(urls) == (конец - начало):
print("Все результаты поиска совпадают!")
если len(urls) == len(set(urls)):
print("Все результаты поиска уникальны!")
pagination()
# или установить пользовательский параметр
страницы = search.pagination (начало, конец, размер_страницы)
# получить один результат поиска за итерацию
# использование базового цикла for для Python
# который вызывает итератор Python под капотом.
для страницы на страницах:
print(f"Текущая страница: {page['serpapi_pagination']['current']}")
для news_result на странице["news_results"]:
print(f"Title: {news_result['title']}\nLink: {news_result['link']}\n")
urls.append(news_result['ссылка'])
# проверяем, соответствует ли общее количество страниц ожидаемому
# примечание: точное число, если переменная зависит от серверной части поисковой системы
если len(urls) == (конец - начало):
print("Все результаты поиска совпадают!")
если len(urls) == len(set(urls)):
print("Все результаты поиска уникальны!")
Примеры извлечения ссылок с разбиением на страницы: тестовый файл, интерактивная среда разработки
Управление ошибками
SerpApi упрощает управление ошибками.
- ошибка внутренней службы или сбой поиска
- ошибка клиента
Если это внутренняя ошибка, в ответе сервера возвращается простое сообщение об ошибке в виде строки.
из serpapi импорт GoogleSearch
search = GoogleSearch({"q": "Кофе", "location": "Остин, Техас", "api_key": ""})
данные = search.get_json()
утверждать данные["ошибка"] == Нет
В некоторых случаях в объекте данных доступны дополнительные сведения.
Если это ошибка клиента, возникает исключение SerpApiClientException.
Журнал изменений
10.03.2023 @ 2.4.2
- Изменить подробное описание на README.md
22.12.2021 @ 2.4.1
- добавить еще поисковую систему
- ютуб
- Волмарт
- apple_app_store
- навер
- поднять SerpApiClientException вместо необработанной строки, чтобы следовать рекомендациям Python 3.5+
- добавить больше модульных тестов ошибок для serp_api_client
26. 07.2021 @ 2.4.0
07.2021 @ 2.4.0
- добавить поддержку размера страницы, используя числовой параметр
- добавить поисковую систему YouTube
05.06.2021 @ 2.3.0
- добавить поддержку нумерации страниц
2021-04-28 @ 2.2.0
- добавить метод get_response для предоставления необработанных запросов. Объект ответа
04.04.2021 @ 2.1.0
- Добавить поисковую систему домашнего склада
- get_object() возвращает динамический объект Python
26.10.2020 @ 2.0.0
- Уменьшить имя класса до
Search - Добавить get_raw_json
30.06.2020 @ 1.8.3
- упростить импорт
- улучшить пакет для Python 3.5+
- добавить поддержку Python 3.5 и 3.6
25.03.2020 @ 1.8
- добавить поддержку Яндекс, Yahoo, Ebay
- очищающий тест
10.11.2019 @ 1.7.1
- увеличить приоритет параметра двигателя по сравнению со значением двигателя, установленным в классе
12. 09.2019 @ 1.7
09.2019 @ 1.7
- Изменить пространство имен «из библиотеки». вместо этого: «из serpapi импортировать GoogleSearch»
- Поддержка Bing и Baidu
25.06.2019 @ 1.6
- Поддерживается новая поисковая система: Baidu и Bing
Заключение
SerpApi поддерживает все основные поисковые системы. Google имеет расширенную поддержку всех основных доступных сервисов: изображения, новости, покупки и многое другое. Чтобы включить тип поиска, поле tbm (для соответствия) должно быть установлено на:
- исх: API изображений Google.
- nws: API Новостей Google. Магазин
- : Google Shopping API.
- любой другой сервис Google должен работать из коробки.
- (без параметра tbm): обычный поиск в Google.
Поле tbs позволяет еще больше настроить поиск.
Полная документация доступна здесь.
Утечка Яндекса: Список факторов, определяющих рейтинг в поиске
Как и любая другая утечка данных, Яндекс находится в очень тяжелом положении. Случилось так, что бывший сотрудник якобы слил Репозиторий исходных кодов Яндекса , часть которого содержала более 1900 факторов, используемых поисковыми системами для ранжирования сайтов в результатах поиска.
Случилось так, что бывший сотрудник якобы слил Репозиторий исходных кодов Яндекса , часть которого содержала более 1900 факторов, используемых поисковыми системами для ранжирования сайтов в результатах поиска.
Хотя очевидно, что Яндекс — это не Google, впервые в наше время позволяет взглянуть на внутренние механизмы и факторы ранжирования значимой и мощной поисковой системы.
Исходный код Яндекса просочился в сеть. Вот что мы узналиПо крайней мере, по состоянию на июль 2022 года эта утечка выявила Яндекс 1922 просочившихся фактора ранжирования используемых в его алгоритме поиска. Взлом Яндекса, пожалуй, самый интересный и многообещающий прорыв в SEO за последние годы.
Интернет и SEO-сообщества не заставили себя долго ждать использования таких ценных данных, так как не каждый день нам предоставляется возможность увидеть, как работает поисковая система. Они даже зашли так далеко, что создали обозреватель факторов ранжирования в поиске Яндекса.
Digipeak предлагает вам список интересных поисковых факторов Яндекса, оптимизированных для всех видов: техническое SEO, оптимизация контента, практики социальных сетей, EEAT и многое другое!
Утечка Яндекса будет переведена с русского на несколько языков. Мы также предоставляем ниже список ресурсов от людей, которые удивительным образом проанализировали просочившиеся факторы ранжирования поиска Яндекса, а также англоязычную версию исходного кода Яндекса с прикрепленными описаниями. Все, что вам нужно сделать, это щелкнуть ссылку, указанную выше, и ввести «Описание:» после нажатия Ctrl + F . Приятного чтения исходного кода и приведенных ниже факторов:
- Возраст ссылок является фактором ранжирования.
- Наш совет: (Не избавляйтесь от старых ссылок, перенаправляйте)
- Трафик и % органического трафика являются факторами ранжирования.
- Числа в URL плохо влияют на ранжирование.

- Наш совет: Возможно, не для перечисленных запросов и контрольных списков, Google может ранжировать их по-разному.
- Большое количество косых черт в URL плохо влияет на ранжирование.
- Наш совет: Целостность URL имеет ключевое значение. Меньше вложенности = лучший URL
- Жесткая пессимизация равна PageRank=0.
- Наш совет: (Это технический термин, противоположный оптимизации. Страницы с грязным и некачественным кодом могут иметь более низкий рейтинг.)
- Надежность хоста является фактором ранжирования.
- Наш совет: (Всегда проверяйте свои серверы и хосты и выполняйте домашнее задание перед выбором хоста.)
- Для Википедии существует отдельный фактор ранжирования. Трафик из Википедии является фактором ранжирования.
- Средняя позиция домена по всем запросам является фактором ранжирования.
 Трафик из Википедии является фактором ранжирования.
Трафик из Википедии является фактором ранжирования. - Наш совет: (Гармоничный EEAT для веб-страниц домена может быть полезен.)
- Глубина сканирования является фактором ранжирования.
- Наш совет: Держите важные страницы ближе к главной странице.
- Лучшие страницы : 1 клик с главной страницы.
- Важные страницы : менее 3 кликов.
- Фактор ранжирования страниц-сирот.
- Наш совет: Вы можете легко найти их с помощью Screaming Frog или других сканеров.
- Обратные ссылки с главных страниц важнее, чем с внутренних страниц.
- Количество поисковых запросов на вашем сайте/адресе является фактором ранжирования.

- Наш совет: Чем больше, тем лучше!
- Если ваш URL будет последним для поисковой сессии (пользователи найдут то, что им нужно). Положительное влияние на рейтинг.
- Наш совет: EEAT является ключевым и живым!
- Фактор ранжирования закладок.
- Наш совет: Чем больше пользователей добавляют в закладки URL-адрес, тем большую ценность он имеет.
- Специальные факторы ранжирования для коротких видеороликов в социальных сетях (tiktok, шорты, ролики).
- Карты на веб-странице (например, Google Maps) являются фактором ранжирования.
- Наш совет: Если у вас есть физический адрес, всегда указывайте живую карту.
- Ключевые слова в URL являются фактором ранжирования.
- Наш совет: От 1 до 2 Ключевые слова оптимальны, избегайте их переполнения !
- Отрицательный рейтинг для неработающих встроенных видео на странице.

- Наш совет: Всегда проводите аудит на наличие неработающих ссылок и неработающих встроенных элементов.
- Если анкоры ваших обратных ссылок содержат слова из ключевых слов, это хорошо для SEO.
- Рейтинг качества текстов на домене является фактором ранжирования.
- Наш совет: Страницы с некачественным контентом влияют на весь домен.
- Количество рекламы на странице является фактором ранжирования.
- Наш совет: Меньше = лучше.
- Длинные документы.
- Наш совет: (чем длиннее документ, тем больше значение коэффициента).
Как динамичное агентство цифрового маркетинга с профессиональной командой, мы всегда стремимся оптимизировать наши знания и восприятие наших практик, а также уникальную возможность, такую как Утечка Яндекса даст большинству SEO-специалистов значительное преимущество.