
Команды поиска для Google и Yandex чтобы найти пользовательские данные и файлы
Специальные команды для расширенного поиска скрытых файлов, камер и документов в интернете. Как пользоваться командами в поисковой строке Google и Yandex.
В статье
Любой пользователь Интернета когда-нибудь сталкивается с вопросами технического характера.
Знание некоторых моментов основных языков программирования попросту необходимо, чтобы не запутаться в системе символов, нередко всплывающих на э
Тем более, если нужно найти конкретный тип фала, например, с расширением «.txt». Поисковые машины типа Google и Яндекса работают с алгоритмом, выявляющим текст запроса в проиндексированных страницах множества ресурсов. Список из миллиона ресурсов нередко выдаваемый поисковиком, конечно же, не подойдет для такой поистине кропотливой работы.
Сделать поиск в Сети более успешным нам помогут специальные команды, их еще называют служебными. Они используются продвинутыми пользователями, помогая отыскивать в мировой паутине самые труднодоступные файлы. Именно такие команды способствуют решению большинства вопросов, возникающих к поисковым системам.
Именно такие команды способствуют решению большинства вопросов, возникающих к поисковым системам.
Теперь перейдем непосредственно к служебным командам, которые следует вводит перед запросом в поисковых системах Google и Яндекс. Обратите внимание, что они разные и некоторых их них начинаются с символов «-» или «:».
Продвинутая работа с поиском Google
- -allinlinks выражение — ищем по названиям ссылок, а не на страницах;;
- -allintext выражение — ищем по тексту страницы, а не в названии;
- -allintittle выражение — ищем в заголовке страницы;
- -allinurl: адрес_сайта — ищем похожую на введенную страницу;
- cache: адрес_сайта — нередко страницы удаляют, поэтому данную команду полезно использовать при поиске проиндексированной копии;
- filetype: имя.расширение — ищем файлы с конкретным расширением, например, «.ppt», «.pdf», «.xls», «.doc»;
- info: адрес_сайта — ищем дополнительные варианты запроса поисковой системы по параметрам: обратных ссылок, похожим страницам и страницам, имеющим точно такую же ссылку.
 Такой же результат даст ввод в строку поиска адреса интересующей нас страницы;
Такой же результат даст ввод в строку поиска адреса интересующей нас страницы; - intext:значение
- intitle:значение — а данная команда способствует поиску именно в заголовке страницы, но обратите внимание, что не между параметром и командой не должно быть пробелов. В противном случае Google выведет ссылки на первые полосы русскоязычных газет;
- inurl:имя_сайта — ищем в адресе страницы;
- link:имя_сайта — ищем страницы, ссылающиеся на интересующий нас сайт;
- related:имя_сайта — ищем страницы, похожие на интересующую нас. Эта команда так же подойдет тем, кто хочет узнать категорию собственного сайта в Google;
- site:имя_сайта — ищем исключительно на интересующем нас сайте;
- -filetype:расширение значение — отклонить при поиске файлы конкретного расширения.
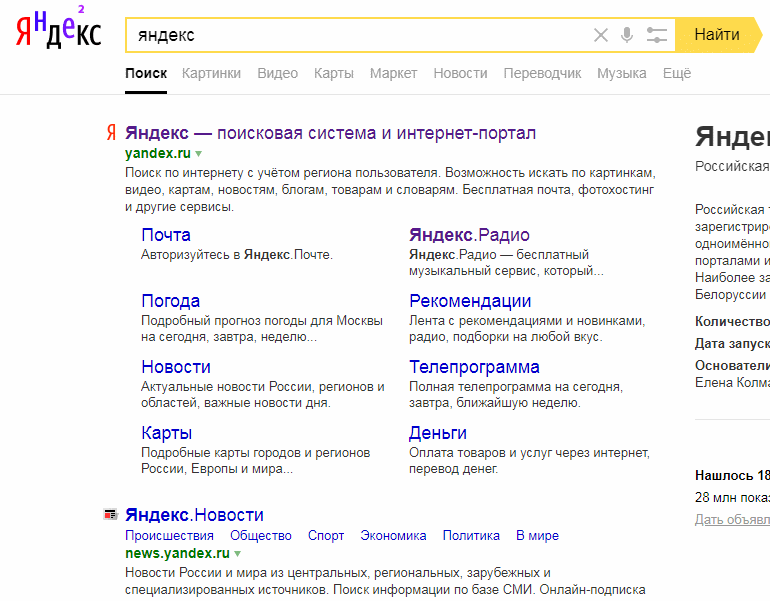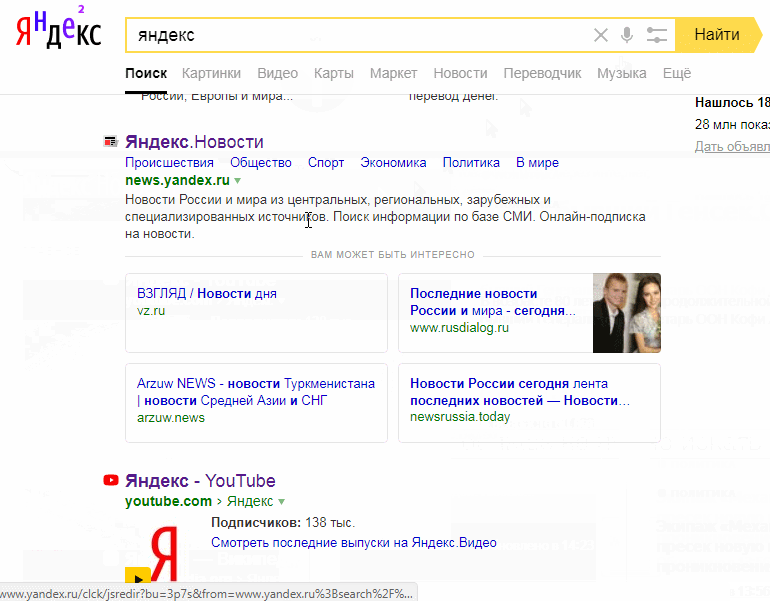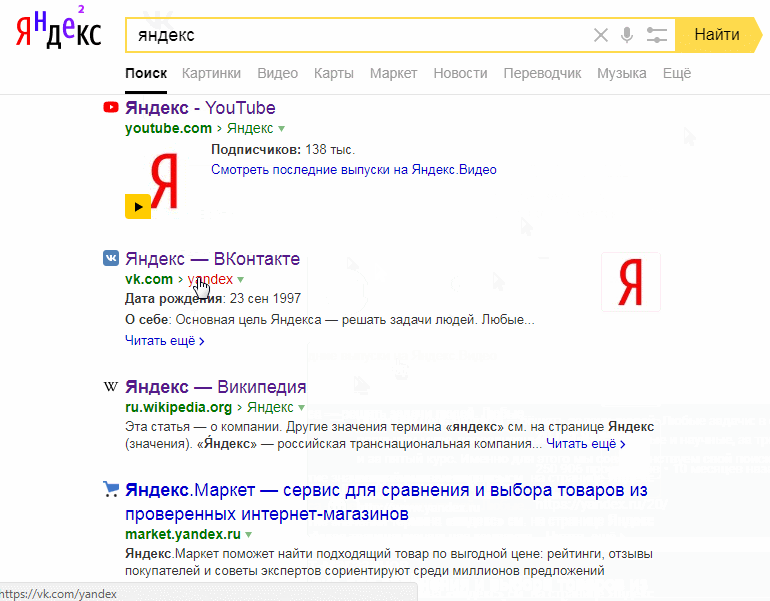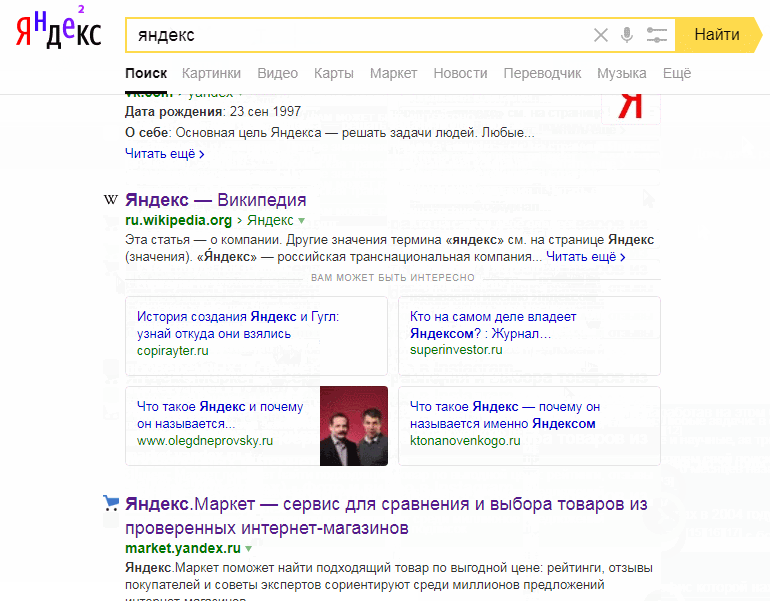 Такой же результат даст ввод в строку поиска адреса интересующей нас страницы;
Такой же результат даст ввод в строку поиска адреса интересующей нас страницы;
Продвинутая работа с поиском Яндекс
- $title выражение — ищем в заголовке страницы;
- $anchor выражение — ищем в ссылках;
- #keywords=выражение — ищем по ключевым словам;
- #abstract=выражение — ищем по описанию веб-страницы;
- #image значение — ищем изображение с конкретным наименованием;
- #hint=выражение — ищем в описаниях картинок;
- #url адрес_сайта — ищем только по заданному сайту;
- #link адрес_сайта — ищем ссылки на конкретный ресурс;
- #mime имя.расширение — ищем файлы с конкретным расширением;
- host=»www.host.ru» — ищем на конкретном сайте, учитывая его зеркала;
- rhost=»ru.url.*» или rhost=»ru.url.www» — ищем хост, но его имя записывается наоборот – сначала домен верхнего уровня, потом второго и т.д. При указании «.*» поиск осуществляется по всем поддоменам конкретного домена, за исключением домена ru.
- lang=»язык» — ищем на страницах с конкретным языком, например, русский (ru), английский (en), немецкий (de) и т.д.;
- like=»адрес_страницы» — ищем страницы, похожие на интересующую;
- domain=»домен» — ищем по странице, размещенной в каталоге конкретного домена;
- date=»ГГГГ{*|ММ{*|ДД}}» — ищем по страницам, с использованием параметра даты, удовлетворяющего требованиям пользователя;
- cat=(ID региона) или cat=(ID темы) — ищем по ресурсам, зарегистрированным в Яндекс.Каталоге, при условии совпадения заданных региона и тематической рубрики.

Как Яндекс перепридумал поиск для разработчиков / Хабр
У вас бывало, что открываешь поиск, ищешь что-то по программированию и не находишь ответ? Тогда эта история для вас.
Меня зовут Алексей Степанов, я руковожу службой исследований машинного обучения поиска Яндекса. Сегодня я расскажу непростую историю. Она про проблему, до решения которой у нас слишком долго не доходили руки. Из поста вы узнаете, почему стандартная метрика качества поиска не учитывала интересы разработчиков и как мы её улучшили. Расскажу про новую нейросеть CS YATI, обученную понимать таких же айтишников, как и мы. Ну и про грабли на нашем пути тоже расскажу, куда без них.
Из поста вы узнаете, почему стандартная метрика качества поиска не учитывала интересы разработчиков и как мы её улучшили. Расскажу про новую нейросеть CS YATI, обученную понимать таких же айтишников, как и мы. Ну и про грабли на нашем пути тоже расскажу, куда без них.
Этот пост основан на моём докладе с Data Fest 2022, но не во всём (мой коллега Максим Хурсанов @Maxim2207 существенно расширил историю).
К нам в команду поиска регулярно прилетают жалобы от коллег на качество ранжирования по тем или иным запросам, специфичным для разработчиков. Например, выдача по запросу [C++ list find] ещё недавно выглядела вот так:
Слова все нужные, а ответа нетОднако у нас были продуктовые метрики, которые говорили: ребята, успокойтесь, у вас всё хорошо, вы как минимум не хуже коллег по индустрии. В результате у нас сложилось противоречие. С одной стороны, метрики говорили, что с качеством всё хорошо. А с другой, мы сами пользовались поиском в работе и сами регулярно были недовольны результатами. В один прекрасный день нам надоело это терпеть, и мы решили наконец-то разобраться.
В один прекрасный день нам надоело это терпеть, и мы решили наконец-то разобраться.
Исправляем метрики
Метрики — это инструмент, с помощью которого мы ставим задачи и контролируем качество их исполнения. Невозможно что-то улучшить в такой сложной системе, как ранжирование, если у вас нет корректных метрик для измерения изменений. Поэтому наша история начинается именно с них.
Больше года назад мы собрались небольшой компанией разработчиков в переговорке, заказали пиццу, начали вводить в поиск реальные запросы пользователей по программированию и оценивать результаты, ориентируясь на свой опыт и знания в предметной области.
В любой непонятной ситуации заказывай пиццуИтак, нам нужно было выяснить, какая из поисковых систем лучше отвечает на специфичные запросы про разработку. Что значит «лучше отвечает»? Предположили, что это означает более полезный документ (так мы называем страницы в интернете) в топ-1 результатов выдачи. Мы взяли около 30 программистских запросов и документы в топ-1 Яндекса и Google. Перемешали, чтобы никто не знал, какие ответы откуда. Участникам нужно было сказать, какой из двух документов лучше решает задачу из запроса, или отметить, что они одинаково полезны. Три десятка попарных оценок показали, что Яндекс как минимум не выигрывает. Статистически значимой такую выборку, конечно, не назвать, но этого было достаточно, чтобы начать копать по-крупному.
Перемешали, чтобы никто не знал, какие ответы откуда. Участникам нужно было сказать, какой из двух документов лучше решает задачу из запроса, или отметить, что они одинаково полезны. Три десятка попарных оценок показали, что Яндекс как минимум не выигрывает. Статистически значимой такую выборку, конечно, не назвать, но этого было достаточно, чтобы начать копать по-крупному.
Мы решили отмасштабировать встречу в переговорке с пиццей на всю компанию: писали посты в этушку (это такие внутренние блоги), выступили с призывом на хурале (еженедельной встрече всех сотрудников). Придумали процесс, в котором участники не только выбирали лучший ответ, но ещё и обсуждали свой выбор с другими разработчиками, если их мнения разошлись. Более того, взяли за привычку каждую пятницу созваниваться с разработчиками из других компаний. Так нам удалось за несколько недель собрать уже не 30, а 1500 попарных оценок! К сожалению, выводы остались теми же: мы отвечаем существенно хуже, чем говорят нам метрики.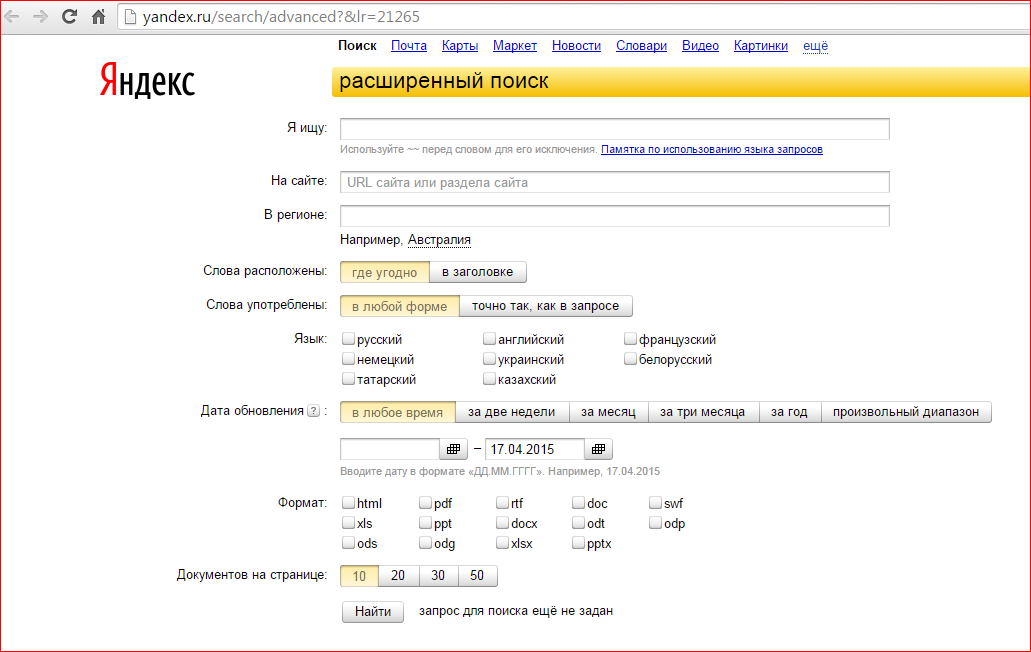 Почему? Чтобы понять причину, нужно немного рассказать, как именно оцениваются результаты поиска.
Почему? Чтобы понять причину, нужно немного рассказать, как именно оцениваются результаты поиска.
С оценкой качества поиска нам помогают асессоры. Это специалисты, которые умеют отвечать на сложные смысловые вопросы и делают это лучше, чем любой ML-алгоритм. В том числе они оценивают, насколько веб-документ полезен по запросу. И наш процесс разметки не гарантировал, что на вопрос, связанный с программированием, будет отвечать асессор с опытом в программировании. Главная причина в том, что мы таких асессоров-программистов просто не наняли в достаточном количестве.
Представьте, что вас просят оценить пользу от документа на китайском языке. Как вы будете это делать, не зная язык? Правильно, искать иероглифы из запроса в тексте документа. В ряде случаев это нормальная стратегия, но далеко не всегда. К примеру, просим неспециалиста, который никогда не программировал, оценить ответ по запросу [C++ find_if]. Он видит, что в документе вполне себе есть и C++, и find, и даже if. Этот документ будет отмечен как хороший.
Этот документ будет отмечен как хороший.
На самом деле среди асессоров мог найтись тот, кто разбирается в программировании. Вот только каждое задание проходит через нескольких асессоров. Если вердикт асессора с опытом не совпадал с ответами других для этого же задания, то оценка просто усреднялась и качество разметки падало.
Как решить эту проблему? Нанять больше людей с опытом в программировании размечать запросы. Так мы и поступили. Непросто найти специалистов, которые смогут разобраться в специфических запросах и прочитать код на веб-страницах. Для этого мы проверили более тысячи кандидатов и наняли сотню лучших. Но оно того стоило: оценки новых асессоров не только были согласованы друг с другом, но и коррелировали с оценками яндексоидов! Метрика, построенная на новых оценках, на порядок лучше подсвечивала проблемы ранжирования. А это значило, что мы наконец-то починили «компас» и теперь знали, куда двигаться. Дальше наш взор устремился на модель, которая и отвечает за ранжирование документов.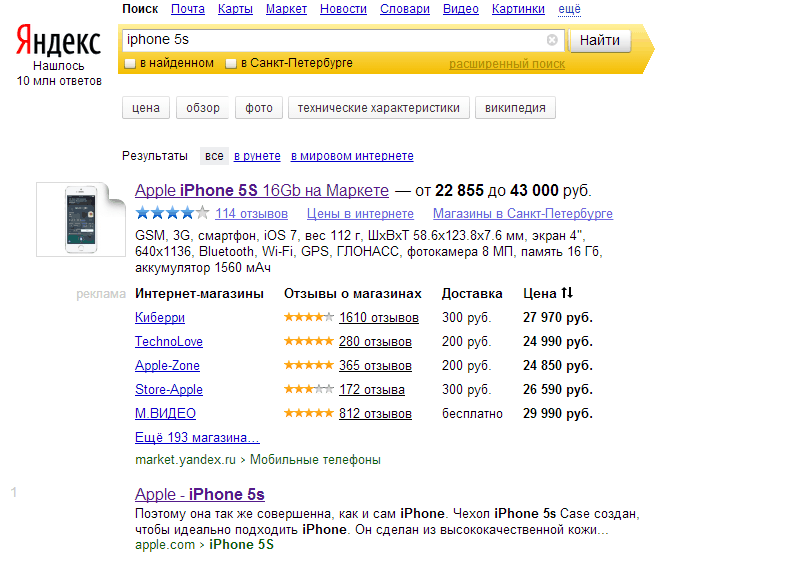
Улучшаем ранжирование
Задача поиска в интернете довольно сложная. У нас есть сотни миллиардов документов. Нам надо найти среди них десять наиболее релевантных всего за сотню миллисекунд. Поэтому большинство документов отсеиваются простыми, но зато очень быстрыми алгоритмами. А вот дальше начинается самое интересное.
Финальное решение о релевантности каждого документа принимает модель на базе нашей опенсорсной технологии градиентного бустинга CatBoost. На вход модели подаются разные факторы о запросе и документе, на выходе получаем предсказание релевантности документов. Факторов исторически очень много. Но с 2020 года можно однозначно выделить самый главный — тот, что выдаёт текстовая нейросеть YATI. Это огромная сеть с архитектурой Transformer, для работы которой требуются наши суперкомпьютеры. Мой коллега Саша Готманов уже подробно рассказывал о ней на Хабре. Самое главное, что тут надо знать: технология YATI стала самым большим прорывом в истории поиска с момента внедрения Матрикснета в 2009-м. Если убрать все-все остальные факторы, то качество поиска хоть и ухудшится, но не фатально. Ни один другой фактор в одиночку удержать качество не сможет.
Если убрать все-все остальные факторы, то качество поиска хоть и ухудшится, но не фатально. Ни один другой фактор в одиночку удержать качество не сможет.
Итак, у нас есть модели YATI и CatBoost — два ключевых компонента, от которых зависит качество поиска. Давайте улучшим их для нашей задачи!
Мы решили обучить отдельный трансформер на базе YATI, который будет в первую очередь хорошо решать задачи по программированию. Недолго думая, назвали его CS YATI (Computer Science). Почему отдельный, а не в рамках универсального YATI? Запросов, связанных с программированием, в общем потоке очень мало. Поэтому мы можем позволить себе применять более мощную модель с бóльшим числом параметров. Кроме того, мы можем итеративно обновлять и обучать её без риска что-то поломать в основной модели.
Начали с того, что скормили трансформеру огромное число текстов, связанных с программированием. Так наша новая модель выучила все специализированные словечки и лексику из области компьютерных наук.
Дальше мы собрали поисковые логи программистских запросов и документов, на которые пользователи кликали по этим запросам. И обучили CS YATI именно на них. Правда, не без хитростей.
У нас была проблема: размер документов по программированию часто довольно большой. Это значит, что наша большая модель может отрабатывать на них непростительно долго. Но при этом резать тексты и терять информацию очень не хотелось. Хотелось, наоборот, выжать из неё как можно больше качества при сохранении производительности.
Мы поисследовали различные способы оптимизации модели и пришли к следующему трюку. Вместо того чтобы сокращать число слоёв нейросети, мы стали итеративно уменьшать длину входа каждого слоя. Само по себе это ухудшает качество. Но вся соль в том, что при этом и потребление ресурсов падает, а значит, мы можем подавать больше информации на вход. В результате тонкая оптимизация позволила не только не просадить качество, но и повысить его за счёт увеличения входной информации в полтора раза.
Однако некоторые документы по программированию все равно имеют слишком большой объём. Можно было бы просто брать начало текста, но это слишком грубый способ, снижающий качество. Мы начали выбирать из документов N наиболее релевантных предложений по данному запросу и уже их передавали в трансформер. Причём мера релевантности тоже оптимизировалась под программистские тексты. Финально мы зафайнтюнили CS YATI, ориентируясь на оценки асессоров с опытом в программировании.
Итак, мы создали нейросетевую модель CS YATI, которая может похвастаться пониманием языка программистов и умеет угадывать их выбор в поиске. Осталось придумать, как это всё внедрить в текущий процесс, применить на каждом запросе и не лечь под нагрузкой. Взгляните на схему:
Выглядит логично. Применяем дополнительную нагрузку в виде CS YATI не всегда, а только для узкого среза программистских запросов. Но есть нюанс: кто будет классифицировать каждый запрос перед развилкой?
Решили, что и тут без CS YATI не обойтись.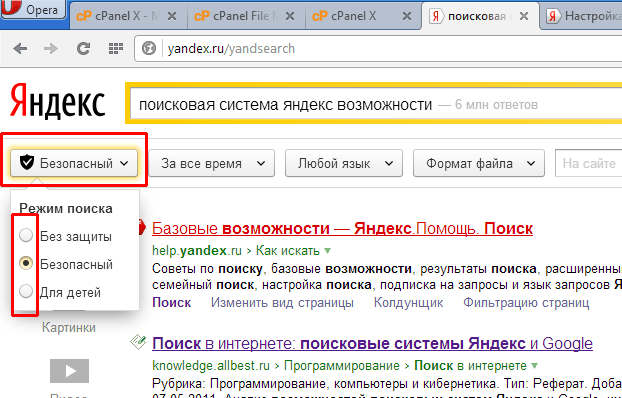 Благодаря тем же самым асессорам-программистам мы собрали датасет и с его помощью обучили CS YATI работать ещё и в режиме классификатора запросов — отличать программистские от всех остальных. Но главную проблему это всё равно никак не решало: модель была слишком тяжёлой, чтобы применять её на каждом запросе.
Благодаря тем же самым асессорам-программистам мы собрали датасет и с его помощью обучили CS YATI работать ещё и в режиме классификатора запросов — отличать программистские от всех остальных. Но главную проблему это всё равно никак не решало: модель была слишком тяжёлой, чтобы применять её на каждом запросе.
Мы воспользовались уже хорошо зарекомендовавшим себя способом — дистилляцией. Специалисты сразу поймут, о чём я, но для всех остальных скажу: дистилляция — это обучение более лёгкой нейросети «подражать» поведению более тяжёлой. Мы взяли лёгкую DSSM-подобную сеть и обучили её на результатах работы нашего трансформера CS YATI. Понятно, что качество классификации немного просело, но при этом мы сэкономили огромные вычислительные ресурсы и смогли внедрить модель в продакшен.
Схема стала выглядеть так:
Внимательный читатель в этот момент может спросить: если у нас появилась специальная версия YATI, то, может быть, нужна и специальная версия CatBoost, которая будет учитывать специфику? Мы тоже сначала посчитали это хорошей идеей. Но давайте обо всём по порядку.
Но давайте обо всём по порядку.
Мы сделали отдельный CS CatBoost, который, подобно CS YATI, будет обучен ранжировать запросы и документы по программированию. А ещё он будет независим от основного компонента CatBoost — значит, мы сможем обновлять и экспериментировать с ним без оглядки на остальную часть поиска. Для его обучения мы использовали уже собранные нами оценки асессоров-программистов. Звучит хорошо, не правда ли?
Но у такого решения были и минусы. Однажды мы на этом попались. В апреле наши коллеги выпустили в опенсорс технологию YDB и очень громко пошумели об этом (в том числе на Хабре). Настолько, что пользователи пошли в поиск и стали вводить там запрос [YDB]. Наша быстрая нейросетка IS CS QUERY DSSM корректно определяла его как программистский. Дальше правильно отрабатывал трансформер CS YATI. А вот CS-версия CatBoost не показывала ни одной новости о событии.
Чтобы осознать суть беды, нужно добавить немного контекста. В поиске есть особые запросы, которые мы называем «свежими». Это запросы, ответы на которые появились в интернете совсем недавно — от нескольких минут до нескольких дней назад. Чтобы правильно отвечать на них, недостаточно быстро индексировать интернет. Необходимо обучать модель на примерах запросов, по которым пользователи хотят видеть свежие документы, и на самих свежих документах, которые хорошо на такие запросы отвечают. Если этого не делать, то модель на подобных документах будет вести себя неадекватно. Свежие ответы либо вовсе пропадут из топа выдачи, либо будут нерелевантными.
Это запросы, ответы на которые появились в интернете совсем недавно — от нескольких минут до нескольких дней назад. Чтобы правильно отвечать на них, недостаточно быстро индексировать интернет. Необходимо обучать модель на примерах запросов, по которым пользователи хотят видеть свежие документы, и на самих свежих документах, которые хорошо на такие запросы отвечают. Если этого не делать, то модель на подобных документах будет вести себя неадекватно. Свежие ответы либо вовсе пропадут из топа выдачи, либо будут нерелевантными.
Мы проверили, что основная версия CatBoost, которая специально обучается на свежих запросах, хорошо справлялась с запросом [YDB]. А в обучении CS CatBoost свежих запросов не было, это и приводило к проблеме. Решение с отдельной версией CatBoost для CS, которое вначале нам показалось простым, привело к тому, что мы сломали ранжирование свежих программистских запросов. Усложнять ими обучение CS CatBoost мы не хотели, и решили, что самый простой способ — объединить две модели в одну. Сейчас это так и работает в проде.
Сейчас это так и работает в проде.
Окей, у нас есть новые метрики, новый CS YATI, обновлённый CatBoost. Что ещё можно было сделать для улучшения качества ранжирования? Например, убедиться, что в данных для обучения моделей ранжирования есть всё, что нужно.
В последнее время я часто читаю новые посты по машинному обучению в телеграме. Часть постов мне потом хотелось перечитать, я шёл в поиск и… не находил их. На самом деле это логично, потому что посты из веб-версии мессенджера плохо оптимизированы для поисковых систем. Начали думать, что же мы можем сделать на своей стороне, чтобы помочь похожим на нас пользователям.
Мы собрались с командой и посмотрели, как асессоры оценивают посты в телеграме. Обнаружили, что в обучающей выборке таких постов почти не было. Мы решили это исправить: намайнили и разметили асессорами-программистами больше документов из телеграма.
Дообучение сработало. Наш поиск научился находить полезные посты в телеграме. Не просто каналы, а конкретные посты из каналов!
Итак, мы починили метрики, улучшили ранжирование и долили новые данные. Но на этом мы не остановились.
Но на этом мы не остановились.
Добавляем быстрые ответы и сниппеты
Цель поиска — не просто ранжировать ссылки, а помогать людям быстро решать свои задачи. Поэтому, помимо работы над ранжированием, мы развиваем и другие форматы. Например, совершенствуем быстрые ответы. Это такие специальные блоки, в которых поиск сразу приводит краткий ответ на запрос. По нашим подсчётам, они экономят пользователям десятки тысяч часов в сутки.
Мы улучшили в поиске быстрые ответы для сайтов, популярных среди разработчиков. Например, теперь там можно встретить ответы на вопросы со Stack Overflow. Поначалу это был просто наиболее рейтинговый ответ с платформы, который выводился в блоке справа. Отзывы коллег помогли усовершенствовать его: появился выбор из нескольких ответов, число оценок, комментариев и даже сам вопрос.
Расширенным стал не только быстрый ответ, но и сниппет в результатах поиска.
Ещё один интересный пример: мы доработали сниппет Гитхаба. Теперь прямо в выдаче можно увидеть рейтинг проекта, число форков и даже дату последнего коммита. Это поможет быстрее сделать правильный выбор.
Это поможет быстрее сделать правильный выбор.
А вот, например, новый сниппет, который помогает быстро найти команду для установки пакетов из npm, brew, pip, Pub и nuget — или сразу получить основную информацию о пакете.
Мы продолжим развивать быстрые ответы, а также добавлять сниппеты и для других сайтов тоже.
Выученные уроки
Если метрика говорит, что мы у пользователей самые лучшие, то стоит проверить эту метрику.
На скорую руку можно только прод поломать (ну или свежие CS-запросы).
Если сделали новую метрику и по ней выиграли, то это не значит, что продукт некуда улучшать. Реальную обратную связь можно получить только от пользователей. Попробуйте наш поиск для запросов по программированию и присылайте фидбэк. Теперь поделиться отзывом просто: внизу выдачи появился пункт «Сообщить об ошибке». Вместе мы можем упростить жизнь огромному числу разработчиков. Спасибо!
Добавить Fergun Discord Bot | Список ботов Discord №1
Утилитарный бот с множеством полезных и мощных команд, таких как перевод, поиск изображений, обратный поиск изображений, OCR, TTS и многое другое!
Fergun — это служебный бот с множеством полезных и мощных команд, таких как перевод, поиск изображений, обратный поиск изображений, OCR, TTS и многое другое!
- Переводите текст с более чем 140 языков и на них с помощью надежного модуля перевода на базе популярных переводчиков из Google Translate, Microsoft Translator и Yandex Translate
- Поиск изображений от Google, DuckDuckGo и Brave
- Обратный поиск изображений из Bing и Яндекс
- Выполнять распознавание изображений с помощью Bing и Yandex
- Преобразование текста в речь с помощью Google и Microsoft Azure
- Перевести текст несколько раз, используя разные переводчики для плохих переводов
- Получить полные определения слов с Dictionary. com
- Получите комплексные решения ваших проблем с помощью Wolfram Alpha
- Получайте вдохновляющие цитаты от InspiroBot
- Поиск или получение случайных определений из Городского словаря
- Поиск и получение статей из Википедии
- Поиск и получение музыкальных текстов от
GeniusMusixmatch - Поиск видео на YouTube
- Получить информацию о пользователе и сервере/глобальном/стандартном аватаре
- Создание изображений цветов
- 2 поддерживаемых языка (английский и испанский)
- Поддержка локализованного вывода (например, локализованных результатов) в большинстве команд
- И скоро будет больше™️
 com
com| Команда | Описание |
|---|---|
| Команды поиска изображений | |
| /имг гугл | Ищет изображения в Google Images и отображает их в пагинаторе. |
| /img уткакго | Ищет изображения из DuckDuckGo и отображает их в пагинаторе.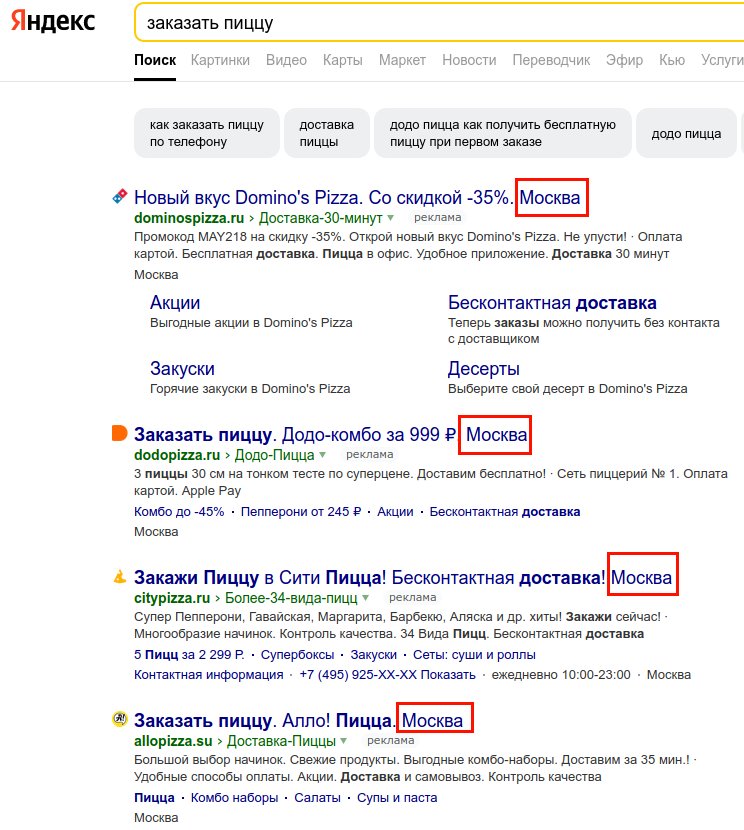 |
| /img Храбрый | Ищет изображения из Brave и отображает их в пагинаторе. |
| /изображение реверс | Обратный поиск изображения. |
| Служебные команды | |
| /аватар | Отображает аватар пользователя. |
| /плохой переводчик | Пропускает текст через несколько разных переводчиков. |
| /цвет | Отображает цвет. |
| /помощь | Информация о Фергуне 2. |
| /пинг | Отправляет время отклика бота. |
| /скажем | Что-то говорит. |
| /перевод | Переводит текст. |
| /пользователь | Получает информацию о пользователе. |
| / Википедия | Поиск статей в Википедии. |
| /вольфрам | О чем-то спрашивает Вольфрама|Альфу. |
| /youtube | Отправляет пагинатор, содержащий видео с YouTube. |
| Команды оптического распознавания символов | |
| /окр Бинг | Выполняет распознавание изображения с помощью визуального поиска Bing. |
| /ocr яндекс | Выполняет распознавание изображения с помощью Яндекс. |
| Команды TTS | |
| /tts гугл | Преобразует текст в синтезированную речь с помощью Google. |
| /ттс майкрософт | Преобразует текст в синтезированную речь с помощью Microsoft Azure. |
| Команды городского словаря | |
| /городской поиск | Поиск определений термина в Городском словаре. |
| /городской случайный | Получает случайные определения из городского словаря. |
| /городские слова дня | Получает слова дня в городском словаре. |
| Другие команды | |
| /командная статистика | Отображает статистику использования команды. |
| /инспиробот | Отправляет вдохновляющую цитату. |
| /пригласить | Пригласить Фергана на свой сервер. |
| /слова | Получить текст песни. |
| /статистика | Отправляет статистику бота. |
Все секреты рентгена Search
Что делает поисковик?
Google, Bing и все другие поисковые системы постоянно сканируют все сайты и страницы в Интернете. для создания огромных индексов. Мы можем найти эти страницы, выполнив поиск по этим индексам. Этот также объясняет, почему каждая поисковая система показывает несколько разные результаты, даже если мы используем одни и те же условия поиска.
Сила поисковых систем
Когда мы просто пишем условия поиска, мы на самом деле не в полной мере используем эти впечатляющие поисковые системы, мы на самом деле можем пойти дальше с использованием команд и операторов, используемых Google и другими поисковыми системами
позволяет нам глубже и лучше фильтровать огромное количество данных, доступных в Интернете.
Что такое рентгеновский поиск?
Поиск, в котором используются поисковые операторы, называется «рентгеновским поиском».
и само название дает нам хорошее представление о его поисковых возможностях, которые выходят за рамки обычных результатов, которые мы обычно видим.Это может показаться сложным, но на самом деле это не так.
| Поисковые системы в Интернете |
|---|
| Bing (Microsoft) |
| Yahoo |
| Baidu | Яндекс |
| DuckDuckGo |
Ask. com com |
Результаты разных поисковых систем не всегда совпадают… 900 03
Логические операторы
Простейшими операторами поиска являются логические операторы, и их использование очень интуитивно понятно. Многие из нас знают, как использовать оператор И, оператор ИЛИ, а также оператор НЕ.
Когда мы строим строку поиска с помощью этих операторов, мы воссоздаем удобочитаемое предложение, представляющее условие фильтрации, которое объединяет список слов, терминов или ключевых слов в определенном порядке. Итак, мы можем искать:
(«веб-разработчик» ИЛИ «веб-разработка» ИЛИ «веб-приложение») И HTML И CSS И (Javascript ИЛИ AJAX) И (Dreamweaver ИЛИ «dream weaver») И «asp.net» И SQL НЕ Recruiter
Конечно, действуют некоторые правила. Рассмотрим подробно всех операторов:
Оператор И
В случае с Google и в некоторых других случаях оператор AND является излишним, поскольку последовательность ключевых слов неявно указывает на последовательность AND.
Таким образом, ключевое слово1 И ключевое слово2 в поиске Google можно упростить до ключевого слова1 ключевого слова2
ИЛИ оператора
. Логический оператор ИЛИ задает альтернативы для использования в качестве синонимов при поиске.
Например, запрос: (HR ИЛИ «человеческие ресурсы») может использоваться для поиска людей в этой профессиональной области, независимо от того, каким из двух способов они написали свою роль.
Примечание: Трубка | Вместо 9 можно также использовать оператор .0321 ИЛИ
НЕ оператор
Как и следовало ожидать, оператор NOT используется для исключения термина или фразы из результатов поиска.
В случае с Google X-Ray эквивалентным оператором исключения является знак минус (-) .
Итак, поставьте минус — перед любым термином (включая операторы), чтобы исключить этот термин из результатов.
Например, для поиска людей, которые работают с Java, но не являются рекрутерами, ищущими экспертов по Java, вы можете использовать следующую строку: Java-рекрутер
Поиск по фразе (с использованием
двойных кавычек « … » )Помещая набор слов в двойные кавычки » » , вы говорите Google рассматривать точные слова именно в таком порядке без каких-либо изменений. Google уже использует порядок и тот факт, что слова вместе, как очень сильный индикатор, и отклоняются от него только по уважительной причине, поэтому кавычки обычно излишни.
Например: «Менеджер проектов»
Google использует синонимы автоматически. Обычно это приветствуется, но иногда Google выручает слишком много и дает вам синоним, когда вы на самом деле этого не хотите. Заключая этот термин или ключевое слово в кавычки, вы говорите Google, что это слово (или предложение) должно соответствовать именно тому, как вы его ввели.
Обычно это приветствуется, но иногда Google выручает слишком много и дает вам синоним, когда вы на самом деле этого не хотите. Заключая этот термин или ключевое слово в кавычки, вы говорите Google, что это слово (или предложение) должно соответствовать именно тому, как вы его ввели.
Однако важно отметить, что, настаивая на поиске по фразе, вы можете упустить дополнительные хорошие результаты.
Например, при поиске «разработчик Java» (с кавычками) будут пропущены все страницы, которые относятся к разработчику программного обеспечения Java. потому что ключевые слова не соответствуют указанному порядку.
Оператор подстановочных знаков. Заполните пропуски звездочкой
* * или подстановочный знак — очень мощный, но не очень известный оператор.
Если вы включаете * в запрос, это говорит Google попытаться рассматривать звездочку как заполнитель для любого неизвестного термина (терминов), а затем найти лучшие совпадения.
Таким образом, звездочка * действует как подстановочный знак и соответствует любому слову или фразе.
Обратите внимание, что оператор * работает только с целыми словами, а не с частями слов.
Например, Chief * Officer будет соответствовать всем «Chief Executive Officer», «Chief Technical Officer», «Chief Operation Officer» и так далее.
Селектор источников рентгеновского излучения, используемый в Jobin.cloud
Групповые операторы — круглые скобки
( )Круглые скобки используются так же, как и в алгебре, а именно для группировки операторов и управления порядком их выполнения.
Лондон (резюме ИЛИ резюме ИЛИ биографические данные) «Java Developer»
Иногда они просто используются для повышения удобочитаемости логической строки.
Любопытство: Знаете ли вы, что булева алгебра является основой любой компьютерной схемы, электроники и всех языков программирования?
Булевы операторы (И, ИЛИ, НЕ), которые мы используем для построения простых «логических строк», — это лишь поверхностная часть обширной ветви «Математического логического анализа»
.
Узнайте больше о булевой алгебре в Википедии
Эксклюзивный поиск по сайту,
Сайт:Использование сайта : оператор ограничивает ваши результаты поиска исключительно внутри указанного вами сайта или домена.
Например,
site:linkedin.com «рекрутинговый маркетинг»
будет искать страницы, содержащие «рекрутинговый маркетинг», которые находятся исключительно в LinkedIn.
Вы даже можете сделать еще один шаг и указать, какие страницы нужного сайта:
Например,
сайт:linkedin.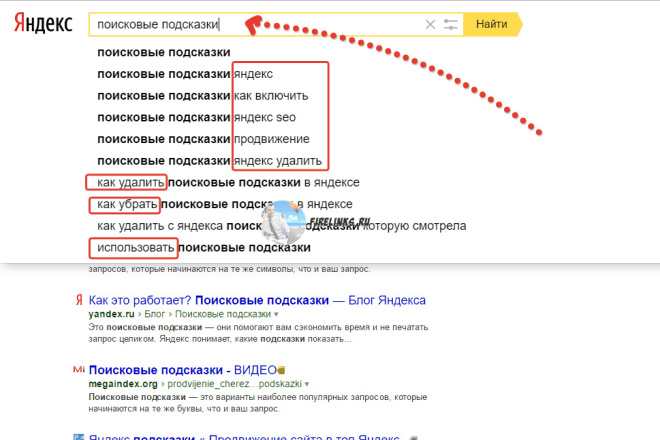 com/jobs «инженер-программист»
com/jobs «инженер-программист»
будет искать «инженер-программист» исключительно на странице вакансий LinkedIn.
Операторы позиционного поиска
Существуют специальные поисковые операторы, которые позволяют вам искать термины, найденные в определенных местах интернет-страницы.
В этом контексте мы имеем в виду поиск не только в теле страницы, но и в других позициях, таких как URL-адрес и заголовок HTML.
intitle:
Поиск одного слова или фразы только в заголовке страницы. Используйте кавычки для точного соответствия или фраз.
allintitle:
Поиск в заголовке страницы для каждого отдельного термина, следующего за «allintitle:». То же, что несколько intitle:’s.
inurl:
Найдите одно слово или фразу (в кавычках) в URL-адресе документа. Может сочетаться с другими терминами.
Может сочетаться с другими терминами.
allinurl:
Найдите в URL каждый отдельный термин, следующий за «allinurl:». То же, что несколько inurl:’s.
intext:
Поиск отдельного слова или фразы (в кавычках), но только в теле/тексте документа.
allintext:
Поиск в основном тексте каждого отдельного термина, следующего за «allintext:». То же, что несколько intexts:’s.
Поиск формата загруженного файла —
тип файла:тип файла: [ x ] будет соответствовать определенному файлу, который соответствует указанному расширению типа файла [x]. Общие примеры расширений типов файлов включают PDF, DOC, XLS, PPT и TXT.
тип файла: pdf
Этот оператор будет искать страницы с загруженными pdf-файлами. Это особенно полезно для рекрутеров, которые ищут резюме или CV, которые были загружены в Интернет.
Это особенно полезно для рекрутеров, которые ищут резюме или CV, которые были загружены в Интернет.
Рентгеновские или внутренние поиски?
Мы знаем, что некоторые сайты, такие как LinkedIn или Facebook и многие другие, имеют собственные внутренние возможности поиска.
В большинстве случаев эти возможности поиска хорошо сегментированы и работают в определенных областях. Например, в LinkedIn вы можете искать профили с определенной ролью или в определенной компании.
Это очень эффективно, потому что они могут читать напрямую из внутренних баз данных, но покрытие часто ограничено из-за ограничений производительности.
Ограничения внутреннего поиска
Этот ограниченный охват поиска заметен даже на веб-сайтах, предназначенных для выполнения поиска, таких как LinkedIn, который ограничивает поиск профилями исключительно в нашей сети,
и взимать плату за расширение возможностей поиска.
Однако даже при более высокой коммерческой подписке доступ к общему списку существующих профилей, хотя и очень обширный, все же остается ограниченным.
С Facebook ограничения на внутренний поиск еще больше, и все знают, насколько плохи результаты поиска, если смотреть за пределами вашего круга друзей. То же самое касается Twitter и некоторых других.
Преимущества рентгена Поиск
С Google и другими поисковыми системами ситуация с технической точки зрения совершенно иная, со своими плюсами и минусами.
Большим преимуществом рентгеновского поиска является то, что результаты основаны на содержании каждой страницы.
применяются ко всем доступным страницам, сканируемым поисковыми роботами.
Это значит, что
вы можете получить доступ ко всем опубликованным профилям, даже к тем, к которым внутренний поиск не дал бы вам доступа,
например, профили за пределами вашей сети LinkedIn.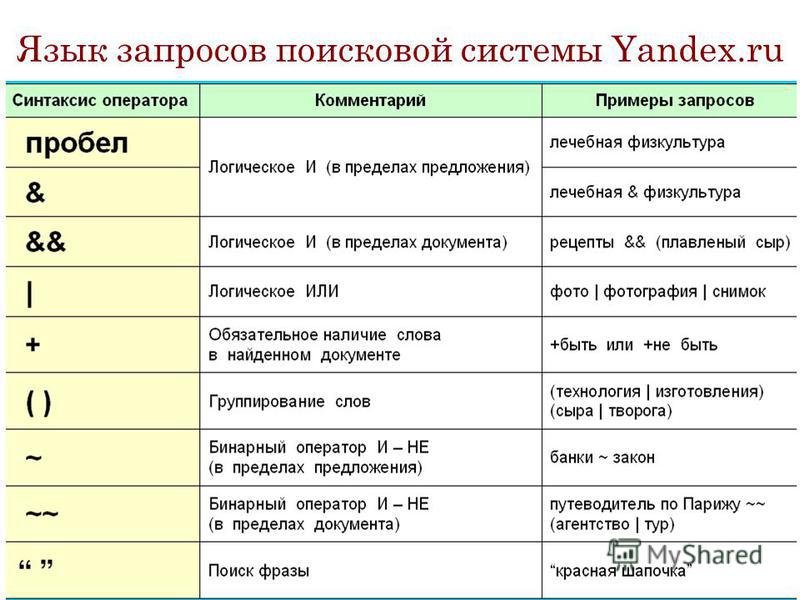
Ограничения рентгеновского поиска
Поиски, сделанные с помощью рентгеновского снимка, охватывают любой контент, найденный в Интернете, а также позволяют указать больше полей и критериев, включая веб-сайт, который вы хотите сканировать, и все другие удобные команды, которые мы перечислили до сих пор. Излишне говорить, что это очень мощно, но есть небольшая проблема.
Рентгеновские лучи не могут с абсолютной точностью определить контекст, в котором термин использовался на странице.
Это означает, что при поиске разработчиков Java в Лос-Анджелесе вы также можете найти людей, чьи профили содержат информацию о событии, произошедшем в Лос-Анджелесе. Это может привести либо к неожиданной полезной информации, либо к нежелательному беспорядку.Рентгеновский датчик приближения —
ВОКРУГ (n) К счастью, рентгеновский поиск может выиграть от усовершенствованных операторов поиска, которые могут точно определить контекст внутри страницы. Они называются «операторами близости», и наиболее известным из них является оператор AROUND (n).
Они называются «операторами близости», и наиболее известным из них является оператор AROUND (n).
Используя оператор AROUND(n) и «якорь» на странице профиля, становится возможным выполнять поиск, сосредоточив внимание на разделах, которые имеют отношение к нашему контексту.
ключевое слово1 ВОКРУГ(n) ключевое слово2
Это ограничивает результаты документами, в которых ключевое слово1 встречается в пределах определенного числа n слов из ключевого слова2.
Например, (Директор ВОКРУГ(5) Microsoft) найдет профили, в которых слово «Директор» находится в пределах 5 слов или менее от «Microsoft», находя такие профили, как: «Директор по персоналу в Microsoft», а также «Директор по социальному маркетингу в Microsoft» и т. д.
Использование операторов близости особенно полезно при поиске общих слов, которые имеют отношение к вашему поиску только в непосредственной близости. Иногда один из двух терминов является просто «якорем» или ключевым словом, которое просто необходимо, чтобы второе ключевое слово было релевантным для нас.
тогда как второе ключевое слово является фактическим ключевым словом, которое мы ищем.
Иногда один из двух терминов является просто «якорем» или ключевым словом, которое просто необходимо, чтобы второе ключевое слово было релевантным для нас.
тогда как второе ключевое слово является фактическим ключевым словом, которое мы ищем.
Заключение
Как это часто бывает, явного победителя нет, и наилучшие результаты дает комбинация обоих подходов.
Для труднодоступных критериев, где необходим более широкий доступ к данным, лучше всего подходят рентгеновские снимки, но если результатов много (и нужный фильтр присутствует), то предпочтительнее более контекстно-точный фильтр от внутренних поисков.
Но не волнуйтесь, это не выбор между одним или другим, Jobin.cloud позволяет вам легко сделать и то, и другое, причем бесплатно!
А поскольку вы объединяете данные из обоих источников, вам даже не нужно беспокоиться о дублировании данных благодаря встроенной системе очистки и устранения дубликатов данных.
Есть еще…
Список продвинутых операторов рентгена продолжается, но кажется, что общая политика состоит в том, чтобы удалить лишнее. и пусть «мозг Google» (ИИ, который Google использует для интерпретации запросов без использования поисковых операторов) развивается и делает некоторые старые операторы устаревшими.
Эти ненадежные или устаревшие операторы не были перечислены выше, но если вам интересно, то вот они:
#..#
Используйте (..) с числами с обеих сторон, чтобы найти любое целое число в этом диапазоне чисел.
объявление 2015..2017
Это будет искать объявления с 2015 по 2017 год
$ и €
Поиск цен со знаком доллара ($) или знака евро (€). Вы можете комбинировать валюты и (.