Bad Quality Яндекс Вебмастер — сайт выпал из поиска Яндекса, как узнать проиндексирована ли страница
Команда AskUsers
2021-04-12 • 4 мин читать
Читать позже
Бывает, что на сайте резко снижается поисковый трафик. Разбираясь, почему сайт пропал из поиска, можно обнаружить, что страницы вылетели из индекса Яндекса, Google или двух поисковых систем одновременно. Выпадение из индекса может быть связано с техническими проблемами, вирусами, контентом низкого качества или с комплексом причин.
Поможем вашему бизнесу оптимизировать расходы на маркетинг и увеличить прибыль!
Узнать больше о продуктах
Проверка исключения сайта из выдачи
Сначала нужно убедиться, что проблема действительно в том, что документ или весь сайт выпал из поиска Яндекса или Google.
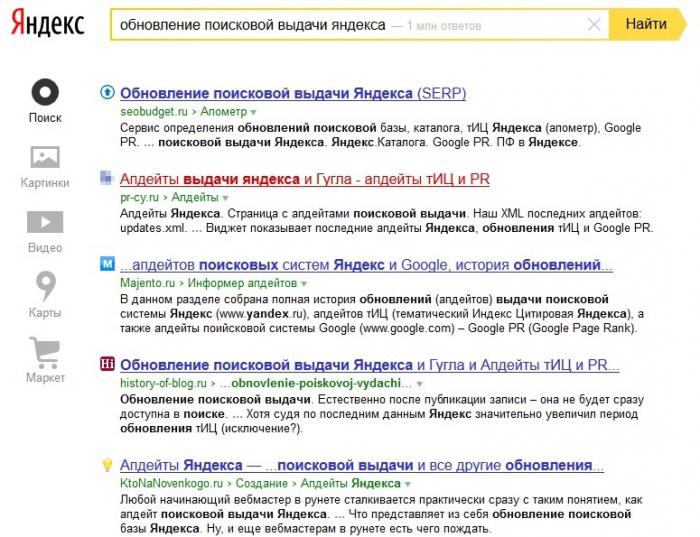
Как проверить индексацию страницы Яндексом? Нужно воспользоваться оператором site:URL. Эту комбинацию вводят в поисковую строку. Если вы не нашли документ в выдаче поисковика, то страницы нет в поисковой базе. Если она не на первой строке, то позиции понижены.
Узнать, проиндексирована ли страница в Yandex, можно в панели Яндекс.Вебмастер. Если поисковая система удалила документ из базы, это будет отображено в разделе «Сводка». Чтобы узнать причины, откройте вкладку «Исключенные страницы». Там может быть указано, что страничка не является канонической, с нее идет редирект или она является недостаточно качественной (Bad Quality).
Также на странице «Сводка» нужно проверить, не наложен ли фильтр на весь проект. Из-за фильтра резко падают позиции по целевым запросам в поисковой системе, может произойти выпадение страниц из индекса. Такое также может случиться, если, например, сайт заражен вирусами.
Аналогично можно посмотреть индексацию в Google Search Console («Покрытие» — «Исключено»).
Что нужно сделать, если сайт все-таки исключен из поиска?
Когда страницы сайта выпадают из индекса, причины не всегда очевидны. Нужно провести несколько проверок. От результатов будет зависеть, что нужно делать.
Устранение запрещенных методов продвижения
К санкциям могут привести устаревшие и «черные» методы SEO-продвижения:
Переоптимизация текстов (переспам). Такой контент может быть признан низкокачественным. Не появилась ли на документе соответствующая пометка, нужно проверять в Вебмастере.
Клоакинг, когда роботам ПС и посетителям показывается разный контент. Относится к «черному» SEO.
Дорвеи.
Невидимый текст.
Аффилированные сайты (в коммерческих тематиках).
От этих и подобных методов придется отказаться в пользу «белого» продвижения.
Проверка ссылок на сайт
Большое количество ссылок с ресурсов низкого качества, с сайтов сомнительных тематик могут привести к фильтрам поисковых систем.
Если вы не покупали такие ссылки, возможно, это работа недобросовестных конкурентов. В Google Search Console можно отклонить ненужные ссылки. В Яндексе такой опции нет, но можно обратиться в техподдержку поисковика и объяснить, что произошло.
Проверка работы хостинга
Сайт может выпасть из поисковой базы Яндекса и Google из-за перебоев в работе хостинга. Нужно добиться стабильной работы (например, переехать к другому хостеру) и воспользоваться опцией «переобход» в Яндексе, чтобы поисковик смог заново проиндексировать страницы.
Проверка сайта на вирусы
Вирусы на сайте — фатальная проблема, которая может привести не только к падению позиций, фильтрам, но и к бану. Чтобы вылечить зараженный сайт, нужно найти вредоносный код и удалить его. Для профилактики вирусов и взлома важно пользоваться антивирусами, регулярно сканировать файлы, повысить безопасность сайта.
Обращение в службу поддержки
Если ПС не индексирует сайт, документы выпадают из базы или при проверке позиций выясняется, что они сильно просели, возможно, виноваты технические проблемы. Если определить конкретную причину не получилось, нужно написать в техподдержку хостинга. Специалисты проверят, есть ли на сайте технические проблемы и предложат варианты решения.
Если определить конкретную причину не получилось, нужно написать в техподдержку хостинга. Специалисты проверят, есть ли на сайте технические проблемы и предложат варианты решения.
Читайте на AskUsers
Парсинг (автоматизированный сбор информации) в рунете считается чем-то неоднозначным. При этом парсерами пользуются и небольшие стартапы, и серьезные компании. Рассказываем, что такое парсинг и как правильно парсить.
Каждый год поисковые системы меняют правила. То, что работало в SEO еще три года назад, сейчас может не подействовать. Мы подготовили для вас руководство по внутренней SEO-оптимизации в 2021 году.
Закажи юзабилити-тестирование прямо сейчас
Заказать услугу
Понравилась статья? Жмите лайк или подписывайтесь на рассылку.
А также, поделитесь статьей с друзьями в соцсети.
Подписаться 1
Команда AskUsers
Google Search Console и Яндекс.
 Вебмастер. SEO-трилогия, часть 3
Вебмастер. SEO-трилогия, часть 3В первой части я рассказал про базовую настройку сайта для поискового продвижения, во второй – про оптимизацию контента на сайте. Теперь самое время залезть в настройки двух сервисов, которые имеют самое прямое отношение к продвижению сайтов. Посмотрим, как наши сайты выглядят со стороны поисковых ботов. Какие страницы индексируются, как смотреть историю поисковых запросов и многое другое.
Что это за сервисы?
У Google и Яндекс есть два сервиса, которые позволяют мониторить сайт и отслеживать динамику изменений на нем. И это не Яндекс.Метрика или Google Analytics – эти двое наиболее известны. В отличие от них, Google Search Console и Яндекс.Вебмастер стоят чуть в стороне, хотя они столь же полезны и нужны.
Вот, например, ваш сайт подключен к этим сервисам? Если да, то отлично. Если нет, то почему не подключен? Не знали про эти сервисы? Или знали, но по какой-то причине не стали их подключать?
Отслеживать количество посещений на сайте – это одна сторона аналитики сайта. Другая – знать, что происходит со страницами, какие из них уже попали в поисковую базу, а какие еще нет. И если не попали, то почему? Именно для этого и нужны Google Search Console и Яндекс.Вебмастер. Как к ним подключиться, я рассказал во второй части трилогии. Сейчас заглянем в их настройки поглубже.
Другая – знать, что происходит со страницами, какие из них уже попали в поисковую базу, а какие еще нет. И если не попали, то почему? Именно для этого и нужны Google Search Console и Яндекс.Вебмастер. Как к ним подключиться, я рассказал во второй части трилогии. Сейчас заглянем в их настройки поглубже.
Что есть такого интересного в этом сервисе, на что стоит обратить внимание? Пройдемся по интерфейсу и посмотрим, какие функции здесь есть. Основные пункты – на скриншоте ниже, все они расположены на левой колонке.
Обзор
Это стартовая страница, аналог главной страницы консоли сайта WordPress. Здесь собрана сводная информация по наиболее значимым показателям. О них ниже и чуть подробнее.
Скриншот страницы оценки эффективности представления в поиске.Под номером 1 на скриншоте строка, где можно выбрать период показа данных. По умолчанию там стоит за 3 месяца, обратите внимание.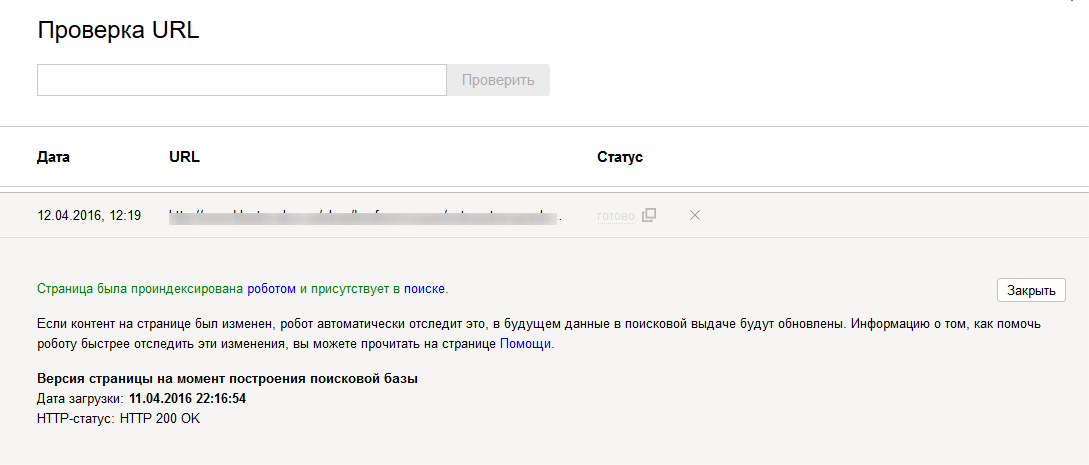 Ниже на цветных блоках видно количество кликов за этот период, показов, средний CTR сайта и средняя позиция. CTR – это процент показов, которые привели к кликам. Чем больше, тем лучше. А средняя позиция – это такой относительный показатель по месту в поисковой выдаче, то есть на каком месте находится ваш сайт. Но с учетом наивысшей позиции, когда-либо занятой сайтом.
Ниже на цветных блоках видно количество кликов за этот период, показов, средний CTR сайта и средняя позиция. CTR – это процент показов, которые привели к кликам. Чем больше, тем лучше. А средняя позиция – это такой относительный показатель по месту в поисковой выдаче, то есть на каком месте находится ваш сайт. Но с учетом наивысшей позиции, когда-либо занятой сайтом.
Под номером 2 можно более детально посмотреть статистику по поисковым запросам, которые ведут на ваш сайт. На вкладке Страницы видно топ страниц сайта по кликам и показам. И вот здесь уже можно смотреть детали индексации. Например, если перейти на вкладку Страницы и напротив нужной нажать на иконку лупы «Проверить URL», то откроется новая страница с подробными сведениями.
Скриншот раздела эффективности показа страниц в поиске.Будет видно, есть ли эта страница в индексе Google. И если на ней есть изменения, то можно вручную отправить на переиндексацию. Тут же видно, оптимизирована ли страница для мобильных устройств. Эти данные можно получить и с главной страницы. Для этого нужно зайти в пункт «Проверка URL» и ввести нужный адрес.
Эти данные можно получить и с главной страницы. Для этого нужно зайти в пункт «Проверка URL» и ввести нужный адрес.
Покрытие
Скриншот отчетов по ошибкам на страницах сайта.Здесь все оформлено в цветах, поэтому максимально наглядно. Красный – страницы, которые в поиск не попали. Почему? Нужно разбираться. Чуть ниже на странице нажимаем на строку с ошибкой и смотрим детали. Оранжевый – страница в поиск попала, но есть предупреждение. Тоже смотрим, в чем причина. Зеленый – самый классный пункт и цвет. Все отлично, эти страницы проиндексированы роботом и есть в поисковой базе Google. Серый цвет – эти страницы исключены из поиска. Возможно, это сделано прямым запретом через файл robots.txt.
Файлы Sitemap
Здесь можно указать путь к файлу карты сайта. В ней есть полный перечень всех страниц и постов. И этот самый перечень и попадает в поисковую базу. Если на сайте стоит плагин Yoast SEO, то карта сайта находится по адресу /sitemap_index.xml – допишите эту строку после имени сайта.
На этой же странице видно, когда карта сайта последний раз обновлялась и сколько в ней есть адресов.
Ссылки
Итак, смотрим, сколько есть внутренних и внешних ссылок. Внутренние – это ссылки внутри сайта на свои же страницы. Внешние – совсем другое дело. Их еще называют обратными ссылками. Это когда на каком-то сайте стоит ссылка на ваш. Очень важная штука. По возможности нужно обзаводиться такими ссылками. Они увеличивают трафик на ваш сайт и как следствие поднимают его позиции в поиске.
Но здесь важный момент – обратные ссылки должны стоять на подходящих ресурсах. Из вашей же тематики, в идеале. Потому что когда на ваш сайт ссылается какой-то сомнительный форум с не совсем адекватным контентом (каждый у себя в голове представьте свой вариант), то мало хорошего от такой ссылки. Если же их будет несколько, то еще хуже. И так далее. Google анализирует ссылки и делает свои выводы. Ссылка на другом сайте НКО с большой посещаемостью будет лучшим вариантом.
Краткое заключение по Google Search Console
Пунктом меню в Google Search Console не в пример меньше, чем в Яндекс. Вебмастере (сейчас сами увидите). При этом все, что нужно, делается, настраивается и мониторится. В первую очередь, рекомендую «скормить» сервису карту сайта, проверить страницы на мобильную адаптацию и отсутствие ошибок. Затем уже можно отслеживать динамику показа страниц и кликов. А там можно и оптимизацией заняться, по итогам тех отчетов, что выдаст сервис примерно через пару-тройку недель работы.
Вебмастере (сейчас сами увидите). При этом все, что нужно, делается, настраивается и мониторится. В первую очередь, рекомендую «скормить» сервису карту сайта, проверить страницы на мобильную адаптацию и отсутствие ошибок. Затем уже можно отслеживать динамику показа страниц и кликов. А там можно и оптимизацией заняться, по итогам тех отчетов, что выдаст сервис примерно через пару-тройку недель работы.
Но это работа постоянная, а не просто «поставил и забыл». Нужно смотреть динамику страниц, проверять отсутствие ошибок, вручную отправлять новые и измененные страницы на переиндексацию. Ну, это чтобы не ждать, пока до них вновь доберется поисковый робот.
Яндекс.Вебмастер
Изображение: скриншот главной страницы сайта webmaster.yandex.ru.Чего-чего, а пунктов меню в левой колонке в Вебмастере гораздо больше, чем в его аналоге от Google. Сейчас пройдемся по ним. Многие понятны уже из своего названия, на некоторых нужно будет остановиться подробнее.
Скриншот главной страницы кабинета Яндекс. Вебмастер.
Вебмастер.Индексирование
Внутри есть подпункт «Страницы в поиске», который показывает страницы, как находящиеся в поиске Яндекс, так и исключенные из него. Первым делом можно заглянуть сюда и посмотреть, что тут делается. В соседнем подразделе «Проверить статус URL» можно вручную проверить отдельно взятую страницу. Если в результатах проверки есть «Страница обходится роботом и находится в поиске», то отлично, это и нужно. Там же можно нажать «отслеживать страницу», после чего она появится в разделе «Мониторинг важных страниц».
Скриншот мониторинга важных страниц в кабинете Яндекс.Вебмастер.Здесь видно более подробное описание работы по индексации страниц. В колонке URL видно ссылку на страницу, ее заголовок и описание. Справа в колонках видно дату последнего изменения на странице, когда ее последний раз обходил робот и какой ответ был получен. Если код 200, то все отлично. Недавно созданные страницы не сразу попадают в поисковую базу, нужно немного времени. На скриншоте выше это первая строка. Этой страницы еще нет в поисковой базе. Но робот на ней был, все считал и дело свое сделал. Скоро появится.
Этой страницы еще нет в поисковой базе. Но робот на ней был, все считал и дело свое сделал. Скоро появится.
В этом же разделе в пункте «Файлы Sitemap» можно добавить карту сайта. Дальше – по аналогии с сервисом Google, принцип работы такой же. В пункте «Обход по счетчикам» можно подключить Яндекс.Метрику и связать два сервиса.
Информация о сайте
Если ваш/а бизнес/деятельность/работа имеют региональную привязку, то стоит задать регион сайта. Это можно сделать в разделе «Региональность» здесь же в Вебмастере либо в карточке организации в Яндекс.Справочнике.
Другой подраздел здесь – «Оригинальные тексты». Написали новый текст (авторский, конечно), затем закинули его сначала сюда, а потом уже опубликовали на сайте. Этим вы говорите Яндексу, что текст изначально ваш. Если его будут перепечатывать другие ресурсы, то Яндекс будет это учитывать при индексации их страниц с вашим текстом.
Турбо-страницы
Яндекс.Вебмастер может отслеживать трафик с турбо-страниц. Их можно подключить по инструкции Яндекса, а можно воспользоваться плагином Теплицы социальных технологий. Важный момент – турбо-страницы работают по своему, скажем так, шаблону. Если у вашего сайта адаптивный дизайн и скорость загрузки на мобильных устройствах хорошая, то турбо-страницы можно и не использовать. Иначе многие элементы интерфейса с вашего сайта пропадут в режиме турбо-страниц.
Их можно подключить по инструкции Яндекса, а можно воспользоваться плагином Теплицы социальных технологий. Важный момент – турбо-страницы работают по своему, скажем так, шаблону. Если у вашего сайта адаптивный дизайн и скорость загрузки на мобильных устройствах хорошая, то турбо-страницы можно и не использовать. Иначе многие элементы интерфейса с вашего сайта пропадут в режиме турбо-страниц.
Инструменты
Здесь можно проверить на ошибки файл robots.txt, сделать запрос на удаление страниц из поиска, проверить страницы на мобильную адаптацию. Все нужное, полезное. Всем рекомендую пользоваться.
Краткое заключение по Яндекс.Вебмастеру
К чему сводится текущая работа в сервисе? Добавляете важные страницы в список отслеживаемых и регулярно смотрите, что там с ними делается. Вышел новый пост или изменилась страница – отправьте ее на переобход роботу. На главной странице сервиса есть блок с уведомлениями об ошибках. Поэтому смотрим, чтобы там все было чисто и без ошибок. Это такой базовый набор, который помогает держать сайт в тонусе.
Это такой базовый набор, который помогает держать сайт в тонусе.
Дальше – дело за контентом. Пишете оригинальные тексты, добавляете свои фотографии и смотрите, как вся эта красота индексируется.
Итог по двум сервисам
Если у вас подключена статистика посещений, то это, безусловно, хорошо. Но для полной картины можно подключить еще и оба сервиса мониторинга. Если вы работаете преимущественно на зарубежную аудиторию, то вполне можно обойтись только Google Search Console. Если же ваши читатели пользуются и Яндексом, то тогда точно лучше подключить оба сервиса.
Да, вначале могут вылезти ошибки и предупреждения. Но это все поправимое. После этого, глядишь, и сайт начнет подниматься в результатах поиска. Оно же все взаимосвязано. Поисковые алгоритмы меняются день ото дня и нужно быть в курсе событий. А лучший способ для этого – смотреть на сайт глазами поисковых роботов. Как это делать, вы теперь знаете.
sql — Как работает индексация базы данных?
Зачем это нужно?
Когда данные хранятся на дисковых запоминающих устройствах, они хранятся в виде блоков данных. Доступ к этим блокам осуществляется полностью, что делает их операцией доступа к атомарному диску. Дисковые блоки структурированы почти так же, как связанные списки; оба содержат раздел для данных, указатель на местоположение следующего узла (или блока), и оба не должны храниться непрерывно.
Доступ к этим блокам осуществляется полностью, что делает их операцией доступа к атомарному диску. Дисковые блоки структурированы почти так же, как связанные списки; оба содержат раздел для данных, указатель на местоположение следующего узла (или блока), и оба не должны храниться непрерывно.
В связи с тем, что несколько записей могут быть отсортированы только по одному полю, мы можем заявить, что для поиска по неотсортированному полю требуется линейный поиск, для которого требуется (N+1)/2
N — количество блоков, охватываемых таблицей. Если это поле является неключевым (т. е. не содержит уникальных записей), то во всем табличном пространстве необходимо искать N обращений к блокам. Принимая во внимание, что с отсортированным полем может использоваться двоичный поиск, который имеет log2 N доступов к блокам. Кроме того, поскольку данные сортируются по неключевому полю, в остальной части таблицы нет необходимости искать повторяющиеся значения, как только будет найдено более высокое значение. Таким образом, прирост производительности существенный.
Таким образом, прирост производительности существенный.
Что такое индексация?
Индексация — это способ сортировки ряда записей по нескольким полям. Создание индекса для поля в таблице создает другую структуру данных, которая содержит значение поля и указатель на запись, к которой оно относится. Затем эта структура индекса сортируется, что позволяет выполнять в ней двоичный поиск.
Недостатком индексации является то, что для этих индексов требуется дополнительное место на диске, поскольку индексы хранятся вместе в таблице с использованием механизма MyISAM, этот файл может быстро достичь пределов размера базовой файловой системы, если в одной таблице много полей. индексируются.
Как это работает?
Во-первых, давайте наметим примерную схему таблицы базы данных;
Имя поля Тип данных Размер на диске id (первичный ключ) Unsigned INT 4 байта firstName Char(50) 50 байт фамилия Char(50) 50 байт адрес электронной почты Char(100) 100 байт
Примечание : вместо varchar использовался char, чтобы обеспечить точный размер значения на диске. Этот образец базы данных содержит пять миллионов строк и не индексируется. Теперь будет проанализирована производительность нескольких запросов. Это запрос с использованием
Этот образец базы данных содержит пять миллионов строк и не индексируется. Теперь будет проанализирована производительность нескольких запросов. Это запрос с использованием
Пример 1 — отсортированные и несортированные поля
Учитывая нашу базу данных r = 5 000 000 записей фиксированного размера, что дает длину записи R = 204 байт 90 используя движок MyISAM, который использует размер блока по умолчанию записей на блок диска. Общее количество блоков, необходимых для хранения таблицы, равно B = 1024 байт. Фактор блокировки таблицы будет равен 9.0009 bfr = (B/R) = 1024/204 = 5 N = (r/bfr) = 5000000/5 = 1 000 000 блоков.
Линейный поиск по полю id потребует в среднем N/2 = 500 000 обращений к блокам, чтобы найти значение, учитывая, что поле id является ключевым полем.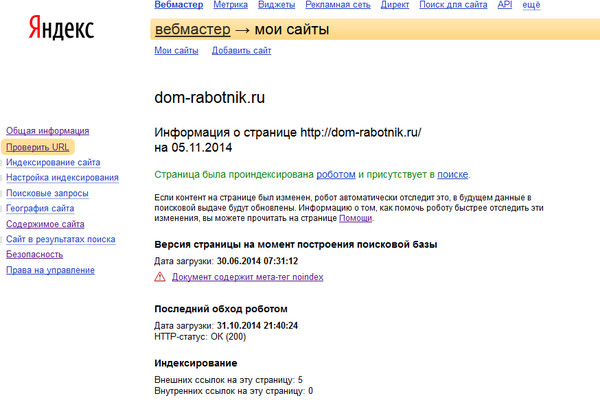
log2 1000000 = 19,93 = 20 обращений к блоку. Мгновенно мы можем видеть, что это резкое улучшение. Теперь поле firstName не является ни отсортированным, ни ключевым полем, поэтому бинарный поиск невозможен, а значения не уникальны, и поэтому таблица потребует поиска до конца для точного N = 1 000 000 обращений к блоку. Именно эту ситуацию и призвана исправить индексация.
Учитывая, что запись индекса содержит только индексированное поле и указатель на исходную запись, само собой разумеется, что она будет меньше, чем запись с несколькими полями, на которую она указывает. Таким образом, для самого индекса требуется меньше дисковых блоков, чем для исходной таблицы, что, следовательно, требует меньшего количества обращений к блокам для итерации. Схема для индекса на
Имя поля Тип данных Размер на диске firstName Char(50) 50 байт (указатель записи) Специальные 4 байта
Примечание : указатели в MySQL имеют длину 2, 3, 4 или 5 байтов в зависимости от размера таблицы.
Пример 2 — индексация
Для нашей выборки базы данных r = 5 000 000 записей с длиной записи индекса R = 54 байт и используя размер блока по умолчанию B = 1024 байт. Коэффициент блокировки индекса будет равен bfr = (B/R) = 1024/54 = 18 записей на блок диска. Общее количество блоков, необходимых для хранения индекса, равно N = (r/bfr) = 5000000/18 = 277 778 блоков.
Теперь поиск с использованием поля firstName может использовать индекс для повышения производительности. Это позволяет выполнять бинарный поиск индекса со средним значением log2 277778 = 18,08 = 19. блокировать доступ. Чтобы найти адрес фактической записи, для чтения которой требуется еще один доступ к блоку, в результате чего общее количество обращений к блоку достигает 19 + 1 = 20 , что далеко от 1 000 000 обращений к блоку, необходимых для поиска совпадения firstName в неиндексированная таблица.
Когда следует использовать?
Учитывая, что для создания индекса требуется дополнительное место на диске (277 778 дополнительных блоков по сравнению с приведенным выше примером, увеличение примерно на 28%), и слишком большое количество индексов может вызвать проблемы, возникающие из-за ограничений размера файловой системы, необходимо тщательно подумать, чтобы выберите правильные поля для индексации.
Поскольку индексы используются только для ускорения поиска совпадающего поля в записях, само собой разумеется, что индексирование полей, используемых только для вывода, было бы просто пустой тратой дискового пространства и времени обработки при выполнении операции вставки или удаления, и поэтому следует избегать. Кроме того, учитывая природу бинарного поиска, важна кардинальность или уникальность данных. Индексирование поля с кардинальностью 2 разделит данные пополам, тогда как кардинальность 1000 вернет примерно 1000 записей. При таком малом количестве элементов эффективность снижается до линейной сортировки, и оптимизатор запросов будет избегать использования индекса, если количество элементов меньше 30% от номера записи, что фактически делает индекс пустой тратой места.
Стратегия поиска — советы по исследованию
Определение основных понятий
Разбейте тему на понятия (предметы). Эти концепции сформируют строительные блоки вашей поисковой стратегии.
Почему?
- Базы данных не любят предложения!
- Длинные фразы или предложения запутают базу данных и приведут к неудовлетворительным или НЕТ результатам.
- Выберите слова, которые обозначают основные моменты вашей темы.
Пример вопроса:
Советы: -4 910405 90
Мозговой штурм по ключевым словам
Используемые вами условия поиска (ключевые слова) чрезвычайно важны!
- Ключевые слова — это условия поиска, которые вы вводите в базу данных для описания каждого из ваших понятий.

- При поиске в базе данных вы обычно ищете слова в заголовке и аннотации, а не в полном тексте статьи.
- Заголовок и аннотация написаны автором статьи.
- База данных будет сопоставлять ваши ключевые слова со словами автора в заголовке и аннотации и предоставлять только те результаты, которые соответствует тому, что вы вводите.

Проблема:
Базы данных ищут точные слова и фразы, которые вы вводите, поэтому, если автор использует другое слово (синоним) для описания концепции, вы не увидите эту статью в своих результатах.
Решение:
Для каждого понятия определите альтернативные ключевые слова.
- Спросите себя: «Какими другими словами автор мог бы описать эту концепцию?»
- Будьте осторожны с фразами. Если вы выполняете поиск по фразе, подумайте об альтернативных способах описания фразы и выполните поиск по ней. Пример: мытье рук или мытье рук или гигиена рук.
- Не знаком с темой? Проблемы с подбором синонимов? Просмотрите эти ресурсы (словари, учебники, энциклопедии) для получения справочной информации.
 Пример: мытье рук или мытье рук или гигиена рук.
Пример: мытье рук или мытье рук или гигиена рук.
Создайте основной список альтернативных слов для каждого из ваших понятий.
Используйте этот список при поиске в базах данных. Помимо синонимов, проявите творческий подход и придумайте:
- Родственные слова
- Варианты написания (особенно американское и британское, например анестезия или анестезия)
- Акронимы (также расшифруйте фразу)
- Брендовые и непатентованные названия лекарственных средств
- Варианты множественного и единственного числа
- Более узкие термины
- Более широкие термины
Вот начало списка для нашего исследовательского вопроса —
Увеличивает ли потребление безалкогольных напитков риск ожирения у детей?
| Концепция 1 | Концепция 2 | Концепция 3 |
| Ребенок | Сода | Ожирение |
| Дети | Безалкогольный напиток | Избыточный вес |
| Подросток | Поп | Масса тела |
| Несовершеннолетний | Напитки с сахаром | Индекс массы тела |
| Напитки | ИМТ | |
| Кола |
Выберите базу данных
Выберите базы данных, соответствующие тематике выбранной вами темы.
- Базы данных могут быть междисциплинарными или специализироваться на конкретных предметных областях. Существуют базы данных медсестер, базы данных по образованию, базы данных по психологии и т. д.
- Поиск более чем в одной базе данных для всестороннего поиска по теме. Хотя могут быть некоторые совпадения, каждая база данных содержит разные журналы и дает разные результаты.
- Ознакомьтесь с руководством по библиотеке вашей программы для получения списка соответствующих баз данных.
Совет:
Библиотекари также являются отличным ресурсом, чтобы спросить, не застряли ли вы в какой базе данных для поиска по вашей теме!
Соедините ключевые слова вместе
То, как вы связываете условия поиска, может изменить результат поиска.
- Базе данных нужны инструкции — скажите ей, что делать!
- Базы данных используют логические операторы И, ИЛИ, НЕ для объединения условий поиска.
- Большинство баз данных автоматически используют AND. Это извлекает только статьи, которые содержат все ключевых слов.
Дополнительную информацию см. на вкладке Логические операторы.
Исследовательский поиск
Исследуйте базу данных и посмотрите, что там.
Помните, что ваши первоначальные поиски — это предположение о том, как автор описал тему в заголовке и аннотации. Вы пытаетесь сопоставить свои ключевые слова с их словами.
1. Выполните поиск в базе данных, используя разные ключевые слова из вашего списка.
2. Просмотрите результаты поиска. В большинстве баз данных вам нужно будет щелкнуть заголовок, чтобы прочитать аннотацию.
3. Ищите соответствующие статьи.
4. Ищите предметные заголовки. Большинство баз данных назначают предметные заголовки для каждой статьи. Они обозначают основные темы статьи. Если для одного из ваших понятий есть соответствующий предметный заголовок, используйте его для поиска вместо ключевых слов! Для получения дополнительной информации нажмите на вкладку Тематический поиск.
5. Пересмотреть, Пересмотреть, Пересмотреть . Первоначальный поиск часто можно улучшить. Оцените свои результаты, а затем повторите поиск, используя альтернативные ключевые слова или соответствующие тематические заголовки, найденные в ваших первоначальных результатах.
Настройка поиска:
1. Как правило, начинайте с широкого поиска. Забросьте широкую сеть и исследуйте свои результаты. После того, как вы определили лучшие ключевые слова/тематические рубрики, начните ограничивать поиск.
- Начните только с двух концепций. Расставьте приоритеты в ваших концепциях и начните с двух самых важных концепций.
- Сначала не используйте ограничители (ограничения по дате, рецензирование и т. д.). Дополнительную информацию см. на вкладке Использование ограничителей.
2. Большинство баз данных имеют несколько окон поиска в верхней части страницы.
- Введите каждое из ваших основных понятий отдельно.
- Если вы не видите отдельные поля поиска, щелкните параметр «Расширенный поиск» (PubMed).
Вот пример того, как настроить поиск по ключевым словам, используя наш пример поиска.
1 . Введите ключевых слова .
Первое окно поиска:
Ожирение
Второе окно поиска:
«безалкогольные напитки»
Обратите внимание: этот термин заключен в кавычки. См. вкладку «Подсказки по ключевым словам» для получения дополнительной информации о поиске по фразе, а также об усечении.
2 . Нажмите кнопку поиска .
Уточнить поиск
Поиск — это процесс проб и ошибок. Вероятно, вы будете пересматривать и уточнять результаты поиска несколько раз в зависимости от результатов каждого поиска. Используйте инструменты базы данных для уточнения результатов поиска.