
Файл robots txt для сайта на WordPress, Joomla, OpenCart, Bitrix
СОДЕРЖАНИЕ
Файл robots.txt для сайта
Где находится robots.txt на сайте?
Директивы robots.txt
Правило Disallow
Правило Allow
User-agent
Sitemap
Host
Crawl delay
Clean param
Самые частые вопросы
Как в robots.txt запретить индексацию?
Как в robots.txt указать главное зеркало?
Простейший пример правильного robots.txt
Закрытый от индексации сайт – как выглядит robots.txt?
Как указать главное зеркало для сайта на https robots.txt?
Наиболее частые ошибки в robots.txt
Онлайн-проверка файла robots.txt
Готовые решения для самых популярных CMS
robots.txt для WordPress
robots.txt для Joomla
robots.txt Wix
robots.txt для Opencart
robots.txt для Битрикс (Bitrix)
robots.txt для Modx
Выводы
Файл robots.txt для сайта
Robots.txt для сайта – это индексный текстовый файл в кодировке UTF-8.
Индексным его назвали потому, что в нем прописываются рекомендации для поисковых роботов – какие страницы нужно просканировать, а какие не нужно.
Если кодировка файла отличается от UTF-8, то поисковые роботы могут неправильно воспринимать находящуюся в нем информацию.
Файл действителен для протоколов http, https, ftp, а также имеет «силу» только в пределах хоста/протокола/номера порта, на котором размещен.
Где находится robots.txt на сайте?
У файла robots.txt может быть только одно расположение – корневой каталог на хостинге. Выглядит это примерно вот так: http://vash-site.xyz/robots.txt
Директивы файла robots txt для сайта
Обязательными составляющими файла robots.txt для сайта являются правило Disallow и инструкция User-agent. Есть и второстепенные правила.
Правило Disallow
Disallow – это правило, с помощью которого поисковому роботу сообщается информация о том, какие страницы сканировать нет смысла. И сразу же несколько конкретных примеров применения этого правила:
Пример 1 — разрешено индексировать весь сайт:

Пример 2 — полностью запретить индексацию сайта:

Продвижение сайтов в таком случае будет бесполезно. Применение этого примера актуально в том случае, если сайт «закрыт» на доработку (например, неправильно функционирует). В этом случае сайту в поисковой выдаче не место, поэтому его нужно через файл robots txt закрыть от индексации. Разумеется, после того, как сайт будет доработан, запрет на индексирование надо снять, но об этом забывают.
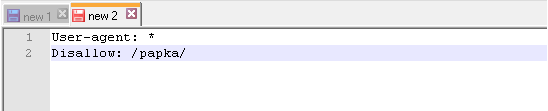
Пример 3 – запрещено сканирование всех документов, находящихся в папке /papka/:
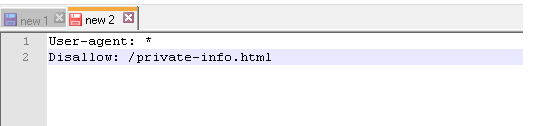
Пример 4 – запретить индексацию страницы с конкретным URL:
Пример 5 – запрещено индексировать конкретный файл (в данном случае – изображение):

Пример 6 – как в robots txt закрыть от индексации файлы конкретного расширения (в данном случае — .gif):

Звездочка перед .gif$ сообщает, что имя файла может быть любым, а знак $ сообщает о конце строки. Т.е. такая «маска» запрещает сканирование вообще всех GIF-файлов.
Правило Allow в robots txt
Правило Allow все делает с точностью до наоборот – разрешает индексирование файла/папки/страницы.
И сразу же конкретный пример:
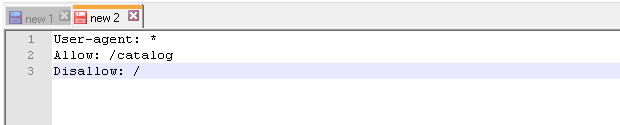
Мы с вами уже знаем, что с помощью директивы Disallow: / мы можем закрыть сайт от индексации robots txt. В то же время у нас есть правило Allow: /catalog, которое разрешает сканирование папки /catalog. Поэтому комбинацию этих двух правил поисковые роботы будут воспринимать как «запрещено сканировать сайт, за исключением папки /catalog»
Сортировка правил и директив Allow и Disallow производится по возрастанию длины префикса URL и применяется последовательно. Если для одной и той же страницы подходит несколько правил, то робот выбирает последнее подходящее из списка.
Рассмотрим 2 ситуации с двумя правилами, которые противоречат друг другу — одно правило запрещает индексировать папки /content, а другое – разрешает.
В данном случае будет приоритетнее директива Allow, т.к. оно находится ниже по списку:

А вот здесь приоритетным является директива Disallow по тем же причинам (ниже по списку):

User-agent в robots txt
User-agent — правило, являющееся «обращением» к поисковому роботу, мол, «список рекомендаций специально для вас» (к слову, списков в robots.txt может быть несколько – для разных поисковых роботов от Google и Яндекс).
Например, в данном случае мы говорим «Эй, Googlebot, иди сюда, тут для тебя специально подготовленный список рекомендаций», а он такой «ОК, специально для меня – значит специально для меня» и другие списки сканировать не будет.
Правильный robots txt для Google (Googlebot)

Примерно та же история и с поисковым ботом Яндекса. Забегая вперед, список рекомендаций для Яндекса почти в 100% случаев немного отличается от списка для других поисковых роботов (чем – расскажем чуть позже). Но суть та же: «Эй, Яндекс, для тебя отдельный список» — «ОК, сейчас изучим его».

И последний вариант – рекомендации для всех поисковых роботов (кроме тех, у которых отдельные списки). Через «звездочку» было решено сделать по одной простой причине – чтоб не перечислять «поименно» все 300 с чем-то роботов.

Т.е. если в одном и том же robots.txt есть 3 списка с User-agent: *, User-agent: Googlebot и User-agent: Yandex, это значит, первый является «одним для всех», за исключением Googlebot и Яндекс, т.к. для них есть «личные» списки.
Sitemap
Правило Sitemap — расположение файла с XML-картой сайта, в которой содержатся адреса всех страниц, являющихся обязательными к сканированию. Как правило, указывается адрес вида http://site.ua/sitemap.xml.
Т.е. каждый раз поисковый робот будет просматривать карту сайта на предмет появления новых адресов, а затем переходить по ним для дальнейшего сканирования, дабы освежить информацию о сайте в базах данных поисковой системы.
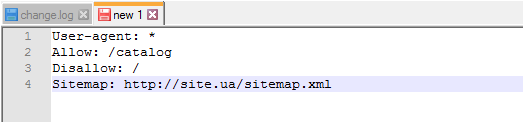
Правило Sitemap должно быть вписано в Robots.txt следующим образом:
Директива Host
Межсекционная директива Host в файле robots.txt так же является обязательной. Она необходима для поискового робота Яндекса — сообщает ему, какое из зеркал сайта нужно учитывать при индексировании. Именно поэтому для Яндекса формируется отдельный список правил, т.к. Google и остальные поисковые системы директиву Host не понимают. Поэтому если у вашего сайта есть копии или же сайт может открываться под разными URL адресами, то добавьте директиву host в файл robots txt, чтобы страницы сайта правильно индексировались.
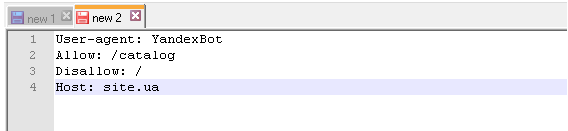
«Зеркалом сайта» принято называть либо точную, либо почти точную «копию» сайта, которая доступна по другому адресу.
Адрес основного зеркала обязательно должно быть указано следующим образом:
— для сайтов, работающих по http — Host: site.ua или Host: http://site.ua (т.е. http:// пишется по желанию)
— для сайтов, работающих по https – Host: https://site.ua (т.е. https:// прописывается в обязательном порядке)
Пример директивы host в robots txt для сайта на протоколе HTTPS:

Crawl delay

Clean param
С помощью директивы Clean-param можно бороться с get-параметрами, чтобы не происходило дублирование контента, т.к. один и тот же контент бывает доступен по разным динамическим ссылкам (это те, которые со знаками вопроса). Динамические ссылки могут генерироваться сайтом в том случае, когда используются различные сортировки, применяются идентификаторы сессий и т.д.
Например, один и тот же контент может быть доступен по трем адресам:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_2&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
В таком случае директива Clean-param оформляется вот так:
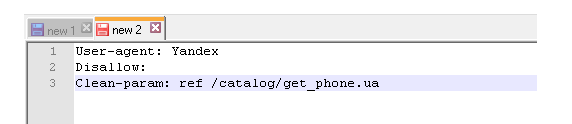
Т.е. после двоеточия прописывается атрибут ref, указывающий на источник ссылки, и только потом указывается ее «хвост» (в данном случае — /catalog/get_phone.ua).
Самые частые вопросы
Как в robots.txt запретить индексацию?
Для этих целей придумано правило Disallow: т.е. копируем ссылку на документ/файл, который нужно закрыть от индексации, вставляем ее после двоеточия:
User-agent: *
Disallow: http://your-site.xyz/privance.html
Disallow: http://your-site.xyz/foord.doc
Disallow: http://your-site.xyz/barcode.jpg
А затем удаляете адрес домена (в данном случае удалить надо вот эту часть — http://your-site.xyz). После удаления у нас останется ровно то, что и должно остаться:
User-agent: *
Disallow: /privance.html
Disallow: /foord.doc
Disallow: /barcode.jpg
Ну а если требуется закрыть от индексирования все файлы с определенным расширением, то правила будут выглядеть следующим образом:
User-agent: *
Disallow: /*.html
Disallow: /*.doc
Disallow: /*.jpg
Как в robots.txt указать главное зеркало?
Для этих целей придумана директива Host. Т.е. если адреса http://your-site.xyz и http://yoursite.com являются «зеркалами» одного и того же сайта, то одно из них необходимо указать в директиве Host. Пусть основным зеркалом будет http://your-site.xyz. В этом случае правильными вариантами будут следующие:
— если сайт работает по https-протоколу, то нужно делать только так:
User-agent: Yandex
Disallow: /privance.html
Disallow: /foord.doc
Disallow: /barcode.jpg
Host: https://your-site.xyz
— если сайт работает по http-протоколу, то оба приведенных ниже варианта будут верными:
User-agent: Yandex
Disallow: /privance.html
Disallow: /foord.doc
Disallow: /barcode.jpg
Host: http://your-site.xyz
User-agent: Yandex
Disallow: /privance.html
Disallow: /foord.doc
Disallow: /barcode.jpg
Host: your-site.xyz
Однако, следует помнить, директива Host является рекомендацией, а не правилом. Т.е. не исключено, что в Host будет указан один домен, а Яндекс посчитает за основное зеркало другой, если у него в панели вебмастера введены соответствующие настройки.
Простейший пример правильного robots.txt
В таком виде файл robots.txt можно разместить практически на любом сайте (с мельчайшими корректировками).
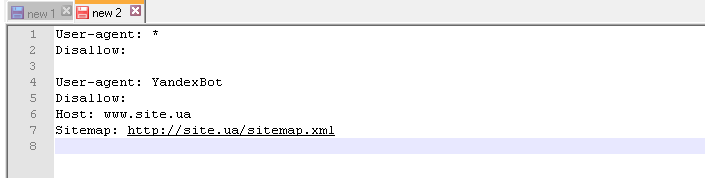
Давайте теперь разберем, что тут есть.
- Здесь 2 списка правил – один «персонально» для Яндекса, другой – для всех остальных поисковых роботов.
- Правило Disallow: пустое, а значит никаких запретов на сканирование нет.
- В списке для Яндекса присутствует директива Host с указанием основного зеркала, а также, ссылка на карту сайта.
НО… Это НЕ значит, что нужно оформлять robots.txt именно так. Правила должны быть прописаны строго индивидуально для каждого сайта. Например, нет смысла индексировать «технические» страницы (страницы ввода логина-пароля, либо тестовые страницы, на которых отрабатывается новый дизайн сайта, и т.д.). Правила, кстати, зависят еще и от используемой CMS.
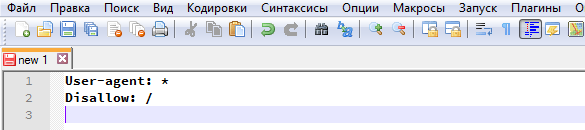
Закрытый от индексации сайт – как выглядит robots.txt?
Даем сразу же готовый код, который позволит запретить индексацию сайта независимо от CMS:
Как указать главное зеркало для сайта на https robots.txt?
Очень просто:
Host: https://your-site.xyz
ВАЖНО!!! Для https-сайтов протокол должен указываться строго обязательно!

Наиболее частые ошибки в robots.txt
Специально для Вас мы приготовили подборку самых распространенных ошибок, допускаемых в robots.txt. Почти все эти ошибки объединяет одно – они допускаются по невнимательности.
1. Перепутанные инструкции:

Правильный вариант:

2. В один Disallow вставляется куча папок:

В такой записи робот может запутаться. Какую папку нельзя индексировать? Первую? Последнюю? Или все? Или как? Или что? Одна папка = одно правило Disallow и никак иначе.

3. Название файла допускается только одно — robots.txt, причем все буквы маленькие. Имена Robots.txt, ROBOTS.TXT и т.п. не допускаются.
4. Правило User-agent запрещено оставлять пустым. Либо указываем имя поискового робота (например, для Яндекса), либо ставим звездочку (для всех остальных).
5. Мусор в файле (лишние слэши, звездочки и т.д.).
6. Добавление в файл полных адресов скрываемых страниц, причем иногда даже без правила Disallow.
Неправильно:
http://mega-site.academy/serrot.html
Тоже неправильно:
Disallow: http://mega-site.academy/serrot.html
Правильно:
Disallow: /serrot.html
Онлайн-проверка файла robots.txt
Существует несколько способов проверки файла robots.txt на соответствие общепринятому в интернете стандарту.
Способ 1. Зарегистрироваться в панелях веб-мастера Яндекс и Google. Единственный минус – придется покопаться, чтоб разобраться с функционалом. Далее вносятся рекомендованные изменения и готовый файл закачивается на хостинг.
Способ 2. Воспользоваться онлайн-сервисами:
— https://services.sl-team.ru/other/robots/
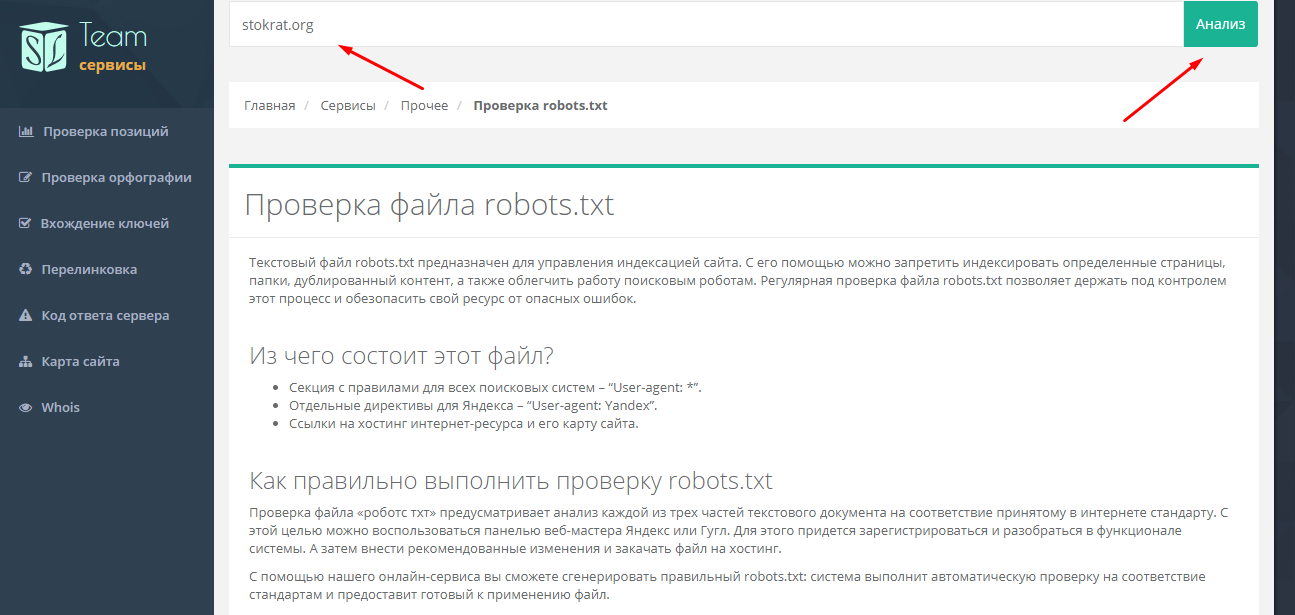
— https://technicalseo.com/seo-tools/robots-txt/
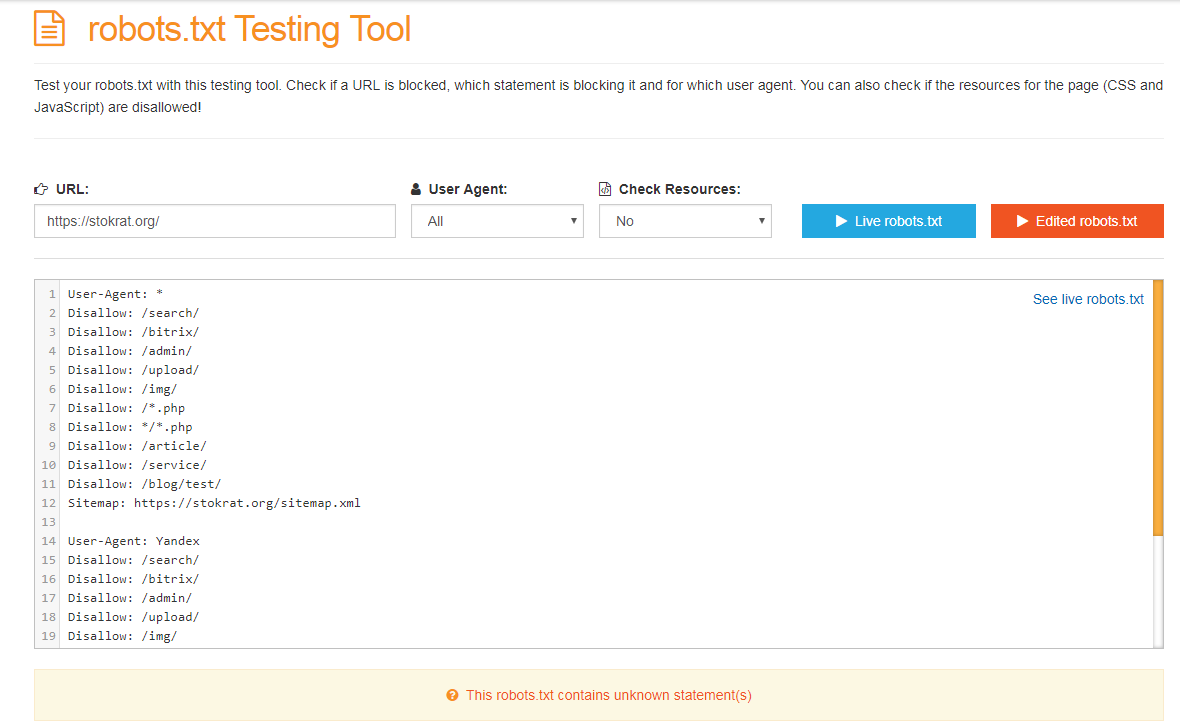
— http://tools.seochat.com/tools/robots-txt-validator/
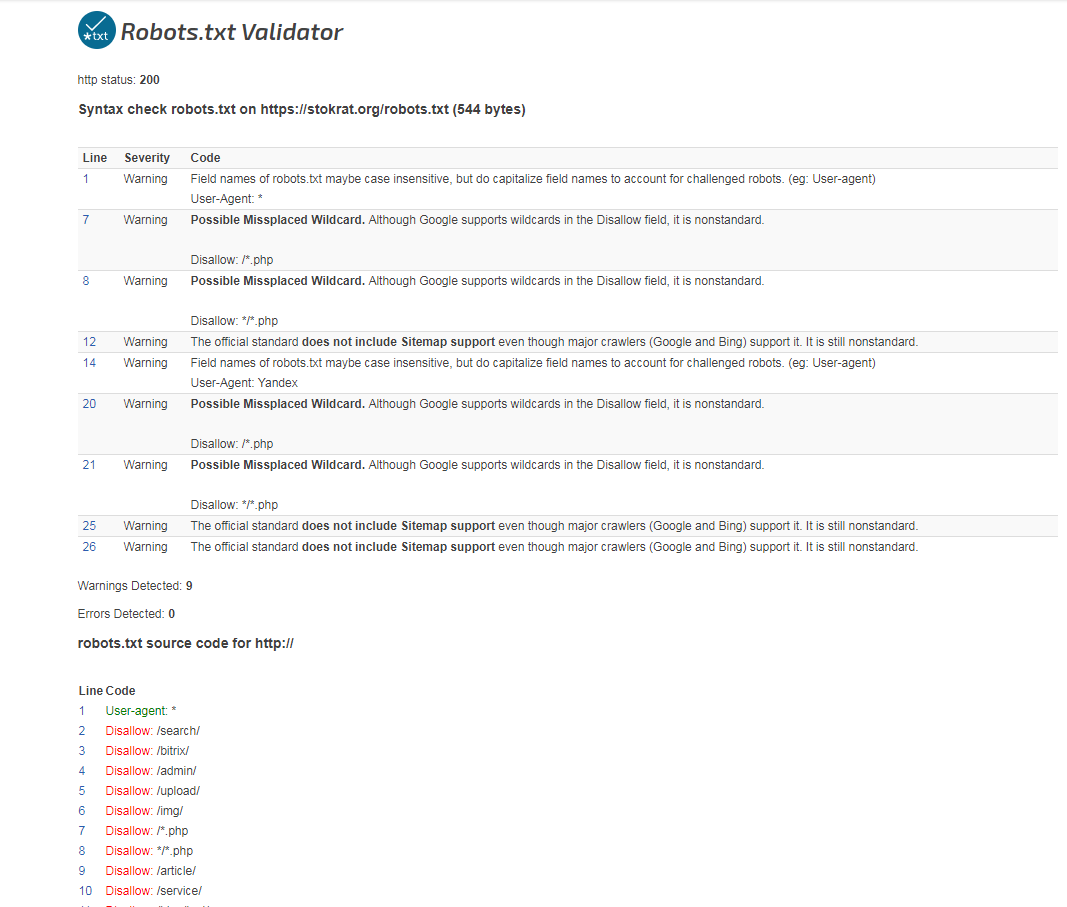
Итак, robots.txt сформирован. Осталось только проверить его на ошибки. Лучше всего использовать для этого инструменты, предлагаемые самими поисковыми системами.
Google Вебмастерс (Search Console Google): заходим в аккаунт, если в нем сайт не подтвержден – подтверждаем, далее переходим на Сканирование -> Инструмент проверки файла robots.txt.
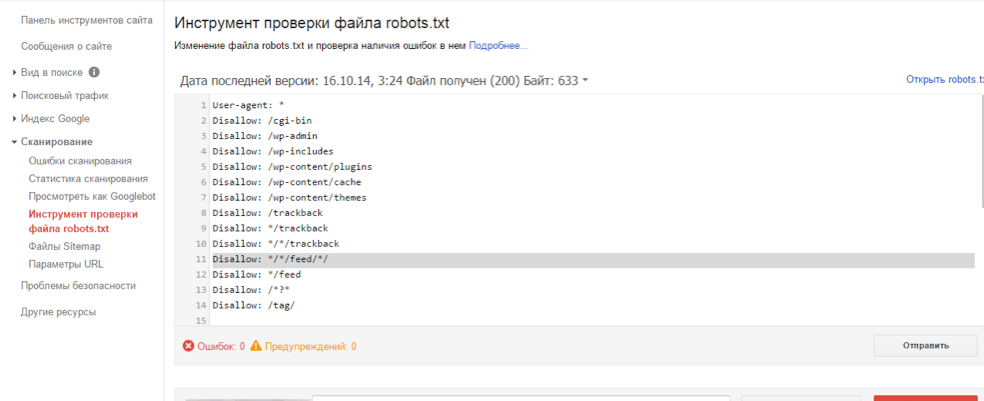
Здесь можно:
- моментально обнаружить все ошибки и потенциально возможные проблемы,
- сразу же «на месте» внести поправки и проверить на ошибки еще раз (чтоб не перезагружать файл на сайт по 20 раз)
- проверить правильность запретов и разрешений индексирования страниц.
Яндекс Вебмастер (прямая ссылка — http://webmaster.yandex.ru/robots.xml).
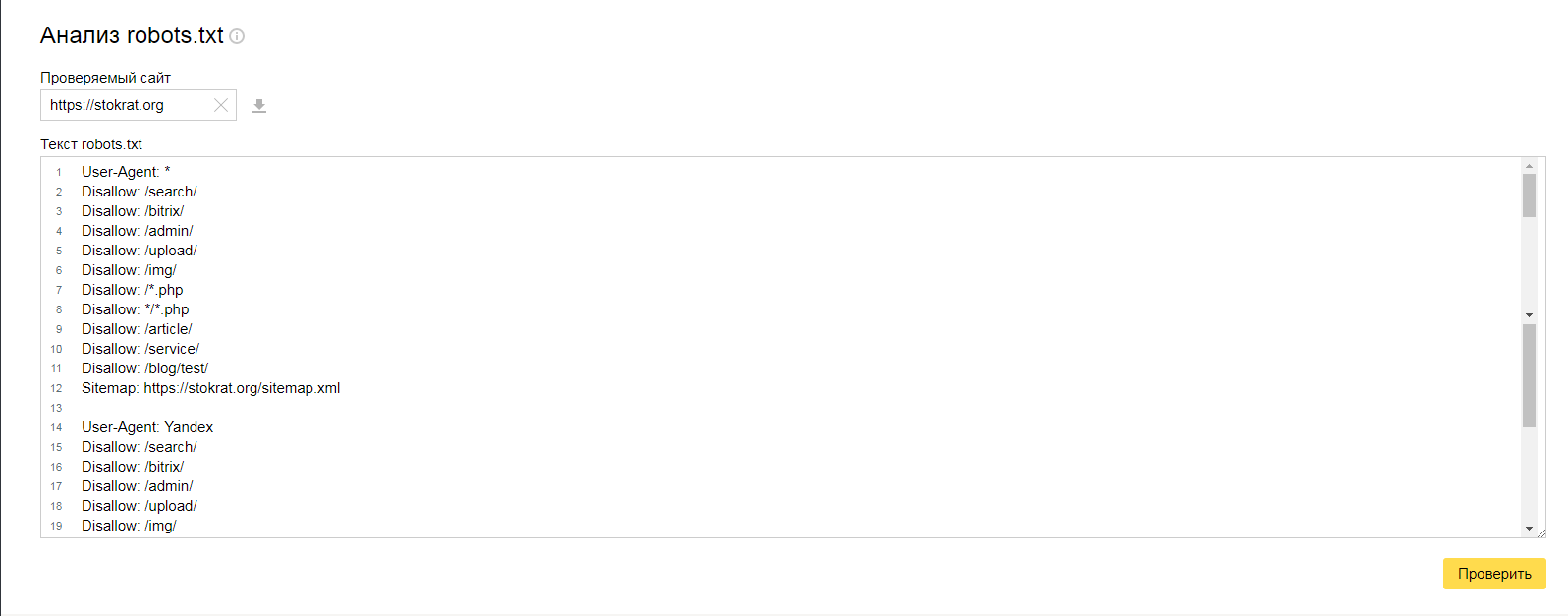
Является аналогом предыдущего, за исключением:
- авторизация не обязательна;
- подтверждение прав на сайт не обязательно;
- доступна массовая проверка страниц на доступность;
- можно убедиться, что все правила правильно восприняты Яндексом.
Готовые решения для самых популярных CMS
Правильный robots.txt для WordPress
User-agent: *
Disallow: /cgi-bin # классика жанра
Disallow: /? # любые параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search # поиск
Disallow: /author/ # архив автора
Disallow: *?attachment_id= # страница вложения. Вообще-то на ней редирект…
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */page/ # все виды пагинации
Allow: */uploads # открываем uploads
Allow: /*/*.js # внутри /wp- (/*/ — для приоритета)
Allow: /*/*.css # внутри /wp- (/*/ — для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.svg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.pdf # файлы в плагинах, cache папке и т.д.
#Disallow: /wp/ # когда WP установлен в подкаталог wp
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap2.xml # еще один файл
#Sitemap: http://site.ru/sitemap.xml.gz # сжатая версия (.gz)
Host: www.site.ru # для Яндекса и Mail.RU. (межсекционная)
# Версия кода: 1.0
# Не забудьте поменять `site.ru` на ваш сайт.
Давайте разберем код файла robots txt для WordPress CMS:
User-agent: *
Здесь мы указываем, что все правила актуальны для всех поисковых роботов (за исключением тех, для кого составлены «персональные» списки). Если список составляется для какого-то конкретного робота, то * меняется на имя робота:
User-agent: Yandex
User-agent: Googlebot
Allow: */uploads
Здесь мы осознанно даем добро на индексирование ссылок, в которых содержится /uploads. В данном случае это правило является обязательным, т.к. в движке WordPress есть директория /wp-content/uploads (в которой вполне могут содержаться картинки, либо другой «открытый» контент), индексирование которой запрещено правилом Disallow: /wp-. Поэтому с помощью Allow: */uploads мы делаем исключение из правила Disallow: /wp-.
В остальном просто идут запреты на индексирование:
Disallow: /cgi-bin – запрет на индексирование скриптов
Disallow: /feed – запрет на сканирование RSS-фида
Disallow: /trackback – запрет сканирования уведомлений
Disallow: ?s= или Disallow: *?s= — запрет на индексирование страниц внутреннего поиска сайта
Disallow: */page/ — запрет индексирования всех видов пагинации
Правило Sitemap: http://site.ru/sitemap.xml указывает Яндекс-роботу путь к файлу с xml-картой. Путь должен быть прописан полностью. Если таких файлов несколько – прописываем несколько Sitemap-правил (1 файл = 1 правило).
В строке Host: site.ru мы специально для Яндекса прописали основное зеркало сайта. Оно указывается для того, чтоб остальные зеркала индексировались одинаково. Пустая строка перед Host: является обязательной.
Где находится robots txt WordPress вы все наверное знаете — так как и в другие CMS, данный файл должен находится в корневом каталоге сайта.
Файл robots.txt для Joomla
Joomla — почти самый популярный движок у вебмастеров, т.к. не смотря на широчайшие возможности и множества готовых решений, он поставляется бесплатно. Однако, штатный robots.txt всегда имеет смысл подправить, т.к. для индексирования открыто слишком много «мусора», но картинки закрыты (это плохо).
Вот так выглядит правильный robots.txt для Joomla :
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /images/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
robots.txt Wix
Платформа Wix автоматически генерирует файлы robots.txt персонально для каждого сайта Wix. Т.е. к Вашему домену добавляете /robots.txt (например: www.domain.com/robots.txt) и можете спокойно изучить содержимое файла robots.txt, находящегося на Вашем сайте.
Отредактировать robots.txt нельзя. Однако с помощью noindex можно закрыть какие-то конкретные страницы от индексирования.
robots.txt для Opencart
Стандартный файл robots.txt для OpenCart:
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Disallow: /index.php?route=product/manufacturer
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/category
User-agent: Yandex
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*route=product/search
Disallow: /*?page=
Disallow: /*&page=
Clean-param: tracking
Clean-param: filter_name
Clean-param: filter_sub_category
Clean-param: filter_description
Disallow: /wishlist
Disallow: /login
Disallow: /index.php?route=product/manufacturer
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/category
Host: Vash_domen
Sitemap: http://Vash_domen/sitemap.xml
robots.txt для Битрикс (Bitrix)
1. Папки /bitrix и /cgi-bin должны быть закрыты, т.к. это чисто технический «хлам», который незачем светить в поисковой выдаче.
Disallow: /bitrix
Disallow: /cgi-bin
2. Папка /search тоже не представляет интереса ни для пользователей, ни для поисковых систем. Да и образование дублей никому не нужно. Поэтому тоже ее закрываем.
3. Про формы PHP-аутентификации и авторизации на сайте тоже забывать нельзя – закрываем.
Disallow: /auth/
Disallow: /auth.php
4. Материалы для печати (например, счета на оплату) тоже нет смысла светить в поисковой выдаче. Закрываем.
Disallow: /*?print=
Disallow: /*&print=
5. Один из жирных плюсов «Битрикса» в том, что он фиксирует всю историю сайта – кто когда залогинился, кто когда сменил пароль, и прочую конфиденциальную информацию, утечка которой не допустима. Поэтому закрываем:
Disallow: /*register=yes
Disallow: /*forgot_password=yes
Disallow: /*change_password=yes
Disallow: /*login=yes
Disallow: /*logout=yes
Disallow: /*auth=yes
6. Back-адреса тоже нет смысла индексировать. Эти адреса могут образовываться, например, при просмотре фотоальбома, когда Вы сначала листаете его «вперед», а потом – «назад». В эти моменты в адресной строке вполне может появиться что-то типа матерного ругательства: ?back_url_ =%2Fbitrix%2F%2F. Ценность таких адресов равна нулю, поэтому их тоже закрываем от индексирования. Ну а в качестве бонуса – избавляемся от потенциальных «дублей» в поисковой выдаче.
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
7. Папку /upload необходимо закрывать строго по обстоятельствам. Если там хранятся фотографии и видеоматериалы, размещенные на страницах, то ее скрывать не нужно, чтоб не срезать дополнительный трафик. Ну а если что-то конфиденциальное – однозначно закрываем:
Готовый файл robots.txt для Битрикс:
User-agent: *
Allow: /map/
Allow: /search/map.php
Allow: /bitrix/templates/
Disallow: */index.php
Disallow: /*action=
Disallow: /*print=
Disallow: /*/gallery/*order=
Disallow: /*/search/
Disallow: /*/slide_show/
Disallow: /*?utm_source=
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*arrFilter=
Disallow: /*auth=
Disallow: /*back_url_admin=
Disallow: /*BACK_URL=
Disallow: /*back_url=
Disallow: /*backurl=
Disallow: /*bitrix_*=
Disallow: /*bitrix_include_areas=
Disallow: /*building_directory=
Disallow: /*bxajaxid=
Disallow: /*change_password=
Disallow: /*clear_cache_session=
Disallow: /*clear_cache=
Disallow: /*count=
Disallow: /*COURSE_ID=
Disallow: /*forgot_password=
Disallow: /*ID=
Disallow: /*index.php$
Disallow: /*login=
Disallow: /*logout=
Disallow: /*modern-repair/$
Disallow: /*MUL_MODE=
Disallow: /*ORDER_BY
Disallow: /*PAGE_NAME=
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGEN_
Disallow: /*print_course=
Disallow: /*print=
Disallow: /*q=
Disallow: /*register=
Disallow: /*register=yes
Disallow: /*set_filter=
Disallow: /*show_all=
Disallow: /*show_include_exec_time=
Disallow: /*show_page_exec_time=
Disallow: /*show_sql_stat=
Disallow: /*SHOWALL_
Disallow: /*sort=
Disallow: /*sphrase_id=
Disallow: /*tags=
Disallow: /access.log
Disallow: /admin
Disallow: /api
Disallow: /auth
Disallow: /auth.php
Disallow: /auto
Disallow: /bitrix
Disallow: /bitrix/
Disallow: /cgi-bin
Disallow: /club/$
Disallow: /club/forum/search/
Disallow: /club/gallery/tags/
Disallow: /club/group/search/
Disallow: /club/log/
Disallow: /club/messages/
Disallow: /club/search/
Disallow: /communication/blog/search.php
Disallow: /communication/forum/search/
Disallow: /communication/forum/user/
Disallow: /content/board/my/
Disallow: /content/links/my/
Disallow: /error
Disallow: /e-store/affiliates/
Disallow: /e-store/paid/detail.php
Disallow: /examples/download/download_private/
Disallow: /examples/my-components/
Disallow: /include
Disallow: /personal
Disallow: /search
Disallow: /temp
Disallow: /tmp
Disallow: /upload
Disallow: /*/*ELEMENT_CODE=
Disallow: /*/*SECTION_CODE=
Disallow: /*/*IBLOCK_CODE
Disallow: /*/*ELEMENT_ID=
Disallow: /*/*SECTION_ID=
Disallow: /*/*IBLOCK_ID=
Disallow: /*/*CODE=
Disallow: /*/*ID=
Disallow: /*/*IBLOCK_EXTERNAL_ID=
Disallow: /*/*SECTION_CODE_PATH=
Disallow: /*/*EXTERNAL_ID=
Disallow: /*/*IBLOCK_TYPE_ID=
Disallow: /*/*SITE_DIR=
Disallow: /*/*SERVER_NAME=
Sitemap: http://site.ru/sitemap_index.xml
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для Modx и Modx Revo
CMS Modx Revo тоже не лишена проблемы дублей. Однако, она не так сильно обострена, как в Битриксе. Теперь о ее решении.
- Включаем ЧПУ в настройках сайта.
- закрываем от индексации:
Disallow: /index.php # т.к. это дубль главной страницы сайта
Disallow: /*? # разом решаем проблему с дублями для всех страниц
Готовый файл robots.txt для Modx и Modx Revo:
User-agent: *
Disallow: /*?
Disallow: /*?id=
Disallow: /assets
Disallow: /assets/cache
Disallow: /assets/components
Disallow: /assets/docs
Disallow: /assets/export
Disallow: /assets/import
Disallow: /assets/modules
Disallow: /assets/plugins
Disallow: /assets/snippets
Disallow: /connectors
Disallow: /core
Disallow: /index.php
Disallow: /install
Disallow: /manager
Disallow: /profile
Disallow: /search
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
Выводы
Без преувеличения файл robots.txt можно назвать «поводырём для поисковых роботов Яндекс и Гугл» (разумеется, если он составлен правильно). Если файл robots txt отсутствует, то его нужно обязательно создать и загрузить на хостинг Вашего сайта. Справка Disallow правил описаны выше в этой статьей и вы можете смело их использоваться в своих целях.
Еще раз резюмируем правила/директивы/инструкции для robots.txt:
- User-agent — указывает, для какого именно поискового робота создан список правил.
- Disallow – «рекомендую вот это не индексировать».
- Sitemap – указывает расположение XML-карты сайта со всеми URL, которые нужно проиндексировать. В большинстве случаев карта расположена по адресу http://[ваш_сайт]/sitemap.xml.
- Crawl-delay — директива, указывающая период (в секундах), через который будет загружена страница сайта.
- Host – показывает Яндексу основное зеркало сайта.
- Allow – «рекомендую вот это проиндексировать, не смотря на то, что это противоречит одному из Disallow-правил».
- Clean-param — помогает в борьбе с get-параметрами, применяется для снижения рисков образования страниц-дублей.
Знаки при составлении robots.txt:
- Знак «$» для «звездочки» является «ограничителем».
- После слэша «/» указывается наименование файла/папки/расширения, которую нужно скрыть (в случае с Disallow) или открыть (в случае с Allow) для индексирования.
- Знаком «*» обозначается «любое количество любых символов».
- Знаком «#» отделяются какие-либо комментарии или примечания, оставленные вэб-мастером для себя, либо для кого-то другого. Поисковые роботы их не читают.
stokrat.org
Создание robots.txt онлайн
Запрет индексации для следующих ботов:
Для всех
Яндекс
Google
Mail.ru
Рабмлер
Бинг
Yahoo
Основной домен сайта:
Таймаут между переходами робота по страницам:
1 секунда5 секунд10 секунд60 секунд
| Запрет индексации разделов, страниц: | Пример: /contacts/ /category1/ /category2/ /page.html |
Готовый robots.txt:
Сохраните данные в файл «robots.txt» и скопируйте в конревую папку сайта.
Для чего предназначен инструмент «Генератор robots.txt»
Сервис cy-pr.com представляет вам инструмент «Генератор robots.txt», с помощью которого можно в режиме онлайн за несколько секунд создать файл robots.txt, а также установить запрет на индексацию страниц сайта определенными поисковыми системами.
Что такое robots.txt
Robots.txt – это файл, который расположен в корне сайта и в котором содержатся указания для поисковых ботов. Заходя на любой ресурс, роботы начинают с ним знакомство с файла robots.txt – своеобразной «инструкции по применению». Издатель указывает в данном файле, как роботу необходимо взаимодействовать с ресурсом. Например, здесь может содержаться запрет индексации некоторых страниц или рекомендация о соблюдении временного интервала между сохранением документов с веб-сервера.
Возможности инструмента
Веб-мастер может установить запрет на индексацию роботами поисковых систем Яндекс, Google, Mail.ru, Рамблер, Bing или Yahoo!, а также задать тайм-аут между переходами поискового робота по страницам ресурса и запретить индексацию избранных страниц сайта. Кроме этого, в специальной строке можно указать поисковым роботам путь к карте сайта (sitemap.xml).
После того, как вы заполните все поля инструмента и нажмете кнопку «Создать», система автоматически сгенерирует файл для поисковых ботов, который вы должны будете разместить в корневой зоне вашего сайта.
Обратите внимание, что файл robots.txt нельзя применять для скрытия страницы из результатов поиска, потому что на нее могут ссылаться иные ресурсы, и поисковые роботы так или иначе ее проиндексируют. Напоминаем, что для блокировки страницы в результатах поисковой выдачи используется специальный тег «noindex» или устанавливается пароль.
Стоит также отметить, что с помощью инструмента «Генератор robots.txt» вы создадите файл исключительно рекомендательного характера. Само собой, боты «прислушиваются» к указаниям, оставленным для них веб-мастерами в файле robots.txt, но иногда игнорируют их. Почему так происходит? Потому, что каждый поисковый робот имеет свои настройки, согласно которым он интерпретирует информацию, полученную из файла robots.txt.
www.cy-pr.com
Создать Robots.txt онлайн — автоматическая генерация
Автоматическая генерация robots.txt подходит лишь для базового создания файла. Для тонкой настройки нужен анализ структуры сайта и директорий, которые необходимо скрыть от поисковых систем во избежании дублей в индексе и исключения попадания в поисковую базу лишней информации.
Онлайн-генератор Robots.txt — поля заполняйте последовательно:
Откройте текстовый редактор, вставьте в него полученный результат и сохраните файл под именем robots.txt
После этого разместите файл в корневой директории вашего сайта. Файл должен быть доступен по ссылке http://ваш-сайт.com/robots.txt
Пояснения к атрибутам для файла Robots.txt
Директива «User-agent» — указывает для бота какой поисковой системы действуют расположенные ниже предписания. Файл Robots.txt можно создавать как с едиными для всех поисковых роботов указаниями, так и с отдельными предписаниями для каждого бота.
Директива «Disallow» — данная директива указывает какие каталоги и фалы запрещено индексировать поисковикам. Если вы создаете отдельные предписания для каждого поискового бота, то для каждого такого предписания создаются отдельные правила «Disallow». Этой директивой можно запретить индексировать сайт полностью (Disallow: /) или запрещать индексирование отдельных каталогов. В случае запрета индексации отдельных директорий количество предписаний «Disallow» может быть неограниченным.
Директива «Host» определяет главное зеркало сайта. Сайт может быть доступен по 2-м адресам: «с WWW» и «без WWW». Если файл Robots.txt отсутствует на сервере или в нем не заполнена запись «Host», роботы поисковых систем определяют главное зеркало для сайта по своему усмотрению, но если вы хотите сделать это самостоятельно вам следует указать это правило в директиве «Host».
Директива «Sitemap» указывает по какому пути находится файл Sitemap.xml (карта сайта). Этот файл существенно облегчает и ускоряет индексацию сайта роботами поисковых систем. Особенно важен файл Sitemap.xml для сайтов с большим количеством страниц и сложной структурой (высокий уровень вложенности).
Совет SEO-специалиста: Файл Robots.txt очень важен при продвижении сайта, т.к. он указывает поисковым системам Ваши пожелания по индексации/запрету_индексации разделов Вашего сайта. Поисковики не гарантируют соблюдение предписаний в robots.txt, но учитывают их при индексации. Для сайтов, созданных на популярных CMS, обычно есть готовые варианты файлов robots.txt, но если Вы делали доработки функционала, то может потребоваться его ручная корректировка.
mediasova.com
Как создать файл robots.txt для сайта
Здравствуйте, уважаемые читатели. Не так давно я написал статью о создании карты сайта. Карта сайта, значительно упрощает индексацию вашего блога. Карта сайта должна быть в обязательном порядке у каждого сайта и блога. Но также на каждом сайте и блоге должен быть файл robots.txt. Файл robots.txt содержит свод инструкций для поисковых роботов. Можно сказать, — правила поведения поисковых роботов на вашем блоге. А также в данном файле содержится путь к карте сайта вашего блога. И, по сути, при правильно составленном файле robots.txt поисковый робот не тратит драгоценное время на поиск карты сайта и индексацию не нужных файлов.
Что же из себя представляет файл robots.txt?
robots.txt – это текстовый файл, может быть создан в обычном «блокноте», расположенный в корне вашего блога, содержащий инструкции для поисковых роботов.
Эти инструкции ограничивают поисковых роботов от беспорядочной индексации всех файлов вашего бога, и нацеливают на индексацию именно тех страниц, которым следует попасть в поисковую выдачу.
С помощью данного файла, вы можете запретить индексацию файлов движка WordPress. Или, скажем, секретного раздела вашего блога. Вы можете указать путь к карте Вашего блога и главное зеркало вашего блога. Здесь я имею ввиду, ваше доменное имя с www и без www.
Индексация сайта с robots.txt и без

Работа robots.txt
Данный скриншот, наглядно показывает, как файл robots.txt запрещает индексацию определённых папок на сайте. Без файла, роботу доступно всё на вашем сайте.
Основные директивы файла robots.txt
Для того чтобы разобраться с инструкциями, которые содержит файл robots.txt нужно разобраться с основными командами (директивы).
User-agent – данная команда обозначает доступ роботам к вашему сайту. Используя эту директиву можно создать инструкции индивидуально под каждого робота.
Пример:
User-agent: Yandex – правила для робота Яндекс
User-agent: * — правила для всех роботов
Disallow и Allow – директивы запрета и разрешения. С помощью директивы Disallow запрещается индексация а с помощью Allow разрешается.
Пример запрета:
User-agent: *
Disallow: / — запрет ко всему сайта.
User-agent: Yandex
Disallow: /admin – запрет роботу Яндекса к страницам лежащим в папке admin.
Пример разрешения:
User-agent: *
Allow: /photo
Disallow: / — запрет ко всему сайту, кроме страниц находящихся в папке photo.
Примечание! директива Disallow: без параметра разрешает всё, а директива Allow: без параметра запрещает всё. И директивы Allow без Disallow не должно быть.
Sitemap – указывает путь к карте сайта в формате xml.
Пример:
Sitemap: https://1zaicev.ru/sitemap.xml.gz
Sitemap: https://1zaicev.ru/sitemap.xml
Host – директива определяет главное зеркало Вашего блога. Считается, что данная директива прописывается только для роботов Яндекса. Данную директиву следует указывать в самом конце файла robots.txt.
Пример:
User-agent: Yandex
Disallow: /wp-includes
Host: 1zaicev.ru
Примечание! адрес главного зеркала указывается без указания протокола передачи гипертекста (http://).
Как создать robots.txt
Теперь, когда мы познакомились с основными командами файла robots.txt можно приступать к созданию нашего файла. Для того чтобы создать свой файл robots.txt с вашими индивидуальными настройками, вам необходимо знать структуру вашего блога.
Мы рассмотрим создание стандартного (универсального) файла robots.txt для блога на WordPress. Вы всегда сможете дополнить его своими настройками.
Итак, приступаем. Нам понадобится обычный «блокнот», который есть в каждой операционной системе Windows. Или TextEdit в MacOS.
Открываем новый документ и вставляем в него вот эти команды:
User-agent: * Disallow: Sitemap: https://1zaicev.ru/sitemap.xml.gz Sitemap: https://1zaicev.ru/sitemap.xml User-agent: Yandex Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /xmlrpc.php Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-content/languages Disallow: /category/*/* Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: /tag/ Disallow: /feed/ Disallow: */*/feed/*/ Disallow: */feed Disallow: */*/feed Disallow: /?feed= Disallow: /*?* Disallow: /?s= Host: 1zaicev.ru
Не забудьте заменить параметры директив Sitemap и Host на свои.
Важно! при написании команд, допускается лишь один пробел. Между директивой и параметром. Ни в коем случае не делайте пробелов после параметра или просто где попало.
Пример: Disallow:<пробел>/feed/<Enter>
Данный пример файла robots.txt универсален и подходит под любой блог на WordPress с ЧПУ адресами url. О том что такое ЧПУ читайте здесь. Если же Вы не настраивали ЧПУ, рекомендую из предложенного файла удалить Disallow: /*?* Disallow: /?s=
Теперь нужно сохранить файл с именем robots.txt.

Сохранение robots.txt
Загрузка файла robots.txt на сервер
Лучшим способом для такого рода манипуляций является FTP соединение. О том как настроить FTP соединение для TotolCommander читайте здесь. Или же Вы можете использовать файловый менеджер на Вашем хостинге.
Я воспользуюсь FTP соединением на TotolCommander.
Сеть > Соединится с FTP сервером.

FTP-соединение
Выбрать нужное соединение и нажимаем кнопку «Соединиться».

Выбор FTP-соединения
Открываем корень блога и копируем наш файл robots.txt, нажав клавишу F5.

Копирование robots.txt на сервер
Вот теперь Ваш файл robots.txt будет исполнять надлежащие ему функции. Но я всё же рекомендую провести анализ robots.txt, чтобы удостоверится в отсутствии ошибок.
Анализ robots.txt
Для этого Вам потребуется войти в кабинет вебмастера Яндекс или Google. Рассмотрим примере Яндекс. Здесь можно провести анализ даже не подтверждая прав на сайт. Вам достаточно иметь почтовый ящик на Яндекс.
Открываем кабинет Яндекс.вебмастер.

Яндекс.вебмастер
На главной странице кабинета вебмастер, открываем ссылку «Проверить robots.txt».

Проверка robots.txt
Для анализа потребуется ввести url адрес вашего блога и нажать кнопку «Загрузить robots.txt с сайта». Как только файл будет загружен нажимаем кнопку «Проверить».

Анализ robots.txt
Отсутствие предупреждающих записей, свидетельствует о правильности создания файла robots.txt.
Теперь следует проверить ссылки Ваших материалов, дабы убедится, что Вы не запретили индексацию чего то нужного.
Для этого нажимаем на ссылку «Список URL добавить». Вводим ссылки Ваших материалов. И нажимаем кнопку «Проверить»

Добавление url
Ниже будет представлен результат. Где ясно и понятно какие материалы разрешены для показа поисковым роботам, а какие запрещены.

Результат анализа файла robots.txt
Здесь же вы можете вносить изменения в robots.txt и экспериментировать до получения нужного вам результата. Но помните, файл расположенный на вашем блоге при этом не меняется. Для этого вам потребуется полученный здесь результат скопировать в блокнот, сохранить как robots.txt и скопировать на Вас блог.
Кстати, если вам интересно как выглядит файл robots.txt на чьём-то блоге, вы может с лёгкостью его посмотреть. Для этого к адресу сайта нужно просто добавить /robots.txt
Пример:
https://1zaicev.ru/robots.txt
Вот теперь ваш robots.txt готов. И помните не откладывайте в долгий ящик создание файла robots.txt, от этого будет зависеть индексация вашего блога.
Если же вы хотите создать правильный robots.txt и при этом быть уверенным, что в индекс поисковых систем попадут только нужные страницы, то это можно сделать и автоматически с помощью плагина Clearfy.
На этом у меня всё. Всем желаю успехов. Если будут вопросы или дополнения пишите в комментариях.
До скорой встречи.
С уважением, Максим Зайцев.
1zaicev.ru
Создать robots.txt онлайн
Чтобы активировать PRO версию программы достаточно только нажать и поделиться страницей через социальные сети выше.
Robots.txt является обыкновенным текстовым файлом, располагающимся в корне вашего сайта, просмотреть и отредактировать его можно используя любой текстовый редактор. В данном файлике записаны инструкции, которыми должны руководствоваться поисковые машины (роботы). Собственно, отсюда и пошло название этого документа. Инструкции эти указывают поисковику, что подлежит индексированию, а что трогать не нужно. Наверное, каждый вебмастер хотел бы, чтобы созданный им сайт как можно быстрее был проиндексирован поисковой системой, причем чтобы этот процесс прошел правильно и без ошибок. Поэтому, нужно понимать, что без грамотно составленного файла robots.txt это маловероятно, следовательно, нужно позаботиться о его создании. Конечно же вы можете самостоятельно написать данный файл, к тому же примеров в сети очень много. Но, намного правильнее и быстрее будет воспользоваться нашим инструментом создания robots.txt – это самый эффективный способ. Все что от Вас требуется это заполнить форму на нашем сайте и все. В результате вы получите уже готовый текст, который нужно просто вставить в документ и сохранить в корне вашего сайта под именем Robots.txt. При этом у вас есть возможность полностью запретить индексирование своего сайта, хотя вряд ли это кому-то понадобится. Здесь вам нужно будет указать местонахождение карты вашего сайта, а если у вас ее нету, то можно просто не заполнять данное поле. Далее вы можете выбрать поисковые системы, которым дадите право проводить индексирование страниц вашего ресурса. Рекомендуется выбирать все, это даст наиболее положительный эффект в плане посещаемости сайта. В перечне присутствуют все основные поисковые машины. Далее вам предлагается указать те страницы, которые вы бы не хотели видеть в индексе поисковиков. На этом все, ваш файлик готов, можете выкладывать его к себе на сайт.Есть ли какие-то отличия Robots.txt для Яндекса в сравнении с файлами для других роботов?
На самом деле каждая поисковая машина использует разные методы индексирования, и вообще работают они по-разному. Каждый поисковик имеет свои методики ранжирования, присвоения сайтам определенного места в своем списке. Однако, практически все они одинаково индексируют и понимают файл Robots.txt. Практика свидетельствует, что один файл Robots.txt подходит абсолютно ко всем поисковым системам и с ним не возникает никаких проблем.Есть ли возможность проверить существующий файл Robots.txt?
Если вы сами писали данный файл, или использовали другой генератор, и сомневаетесь в его работоспособности, то можете проверить его с помощью специального сервиса на нашем сайте. Если в ходе такой проверки обнаружатся те или иные проблемы, то вы с легкостью сможете сгенерировать новый файлик воспользовавшись нашим инструментом. Специалисты всегда рекомендуют проверять самодельные файлы Robots.txt с помощью уже проверенных генераторов, чтобы избежать возможных проблем в будущем.sitespy.ru
Делаем правильный файл Robots.txt для WordPress
Приветствую вас, друзья. Сегодня я покажу как сделать правильный файл Robots.txt для WordPress блога. Файл Robots является ключевым элементом внутренней оптимизации сайта, так как выступает в роли гида-проводника для поисковых систем, посещающих ваш ресурс – показывает, что нужно включать в поисковый индекс, а что нет.
Содержание:
Само название файла robots.txt подсказываем нам, что он предназначен для роботов, а не для людей. В статье о том, как работают поисковые системы, я описывал алгоритм их работы, если не читали, рекомендую ознакомиться.
Зачем нужен файл robots.txt
Представьте себе, что ваш сайт – это дом. В каждом доме есть разные служебные помещения, типа котельной, кладовки, погреба, в некоторых комнатах есть потаенные уголки (сейф). Все эти тайные пространства гостям видеть не нужно, они предназначены только для хозяев.
Аналогичным образом, каждый сайт имеет свои служебные помещения (разделы), а поисковые роботы – это гости. Так вот, задача правильного robots.txt – закрыть на ключик все служебные разделы сайта и пригласить поисковые системы только в те блоки, которые созданы для внешнего мира.
Примерами таких служебных зон являются – админка сайта, папки с темами оформления, скриптами и т.д.
Вторая функция этого файла – это избавление поисковой выдачи от дублированного контента. Если говорить о WordPress, то, часто, мы можем по разным URL находить одни и те же статьи или их части. Допустим, анонсы статей в разделах с архивами и рубриках идентичны друг другу (только комбинации разные), а страница автора обычного блога на 100% копирует весь контент.
Поисковики интернета могут просто запутаться во всем многообразии таких страниц и неверно понять – что нужно показывать в поисковой выдаче. Закрыв одни разделы, и открыв другие, мы дадим однозначную рекомендацию роботам по правильной индексации сайта, и в поиске окажутся те страницы, которые мы задумывали для пользователей.
Если у вас нет правильно настроенного файла Robots.txt, то возможны 2 варианта:
1. В выдачу попадет каша из всевозможных страниц с сомнительной релевантностью и низкой уникальностью.
2. Поисковик посчитает кашей весь ваш сайт и наложит на него санкции, удалив из выдачи весь сайт или отдельные его части.
Есть у него еще пара функций, о них я расскажу по ходу.
Принцип работы файла robots
Работа файла строится всего на 3-х элементах:
- Выбор поискового робота
- Запрет на индексацию разделов
- Разрешение индексации разделов
1. Как указать поискового робота
С помощью директивы User-agent прописывается имя робота, для которого будут действовать следующие за ней правила. Она используется вот в таком формате:
User-agent: * # для всех роботов
User-agent: имя робота # для конкретного робота
После символа «#» пишутся комментарии, в обработке они не участвуют.
Таким образом, для разных поисковых систем и роботов могут быть заданы разные правила.
Основные роботы, на которые стоит ориентироваться – это yandex и googlebot, они представляют соответствующие поисковики.
2. Как запретить индексацию в Robots.txt
Запрет индексации осуществляется в помощью директивы Disallow. После нее прописывается раздел или элемент сайта, который не должен попадать в поиск. Указывать можно как конкретные папки и документы, так и разделы с определенными признаками.
Если после этой директивы не указать ничего, то робот посчитает, что запретов нет.
Disallow: #запретов нет
Для запрета файлов указываем путь относительного домена.
Disallow: /zapretniy.php #запрет к индексации файла zapretniy.php
Запрет разделов осуществляется аналогичным образом.
Disallow: /razdel-sajta #запрет к индексации всех страниц, начинающихся с /razdel-sajta
Если нам нужно запретить разные разделы и страницы, содержащие одинаковые признаки, то используем символ «*». Звездочка означает, что на ее месте могут быть любые символы (любые разделы, любой степени вложенности).
Disallow: */*test #будут закрыты все страницы, в адресе которых содержится test
Обратите внимание, что на конце правила звездочка не ставится, считается, что она там есть всегда. Отменить ее можно с помощью знака «$»
Disallow: */*test$ #запрет к индексации всех страниц, оканчивающихся на test
Выражения можно комбинировать, например:
Disallow: /test/*.pdf$ #закрывает все pdf файлы в разделе /test/ и его подразделах.
3. Как разрешить индексацию в Robots.txt
По-умолчанию, все разделы сайта открыты для поисковых роботов. Директива, разрешающая индексацию нужна в тех случаях, когда вам необходимо открыть какой-либо кусочек из блока закрытого директивой disallow.
Для открытия служит директива Allow. К ней применяются те же самые атрибуты. Пример работы может выглядеть вот так:
User-agent: * # для всех роботов Disallow: /razdel-sajta #запрет к индексации всех страниц, начинающихся с /razdel-sajta Allow: *.pdf$ #разрешает индексировать pdf файлы, даже в разделе /razdel-sajta
Теорию мы изучили, переходим к практике.
Как создать и проверить Robots.txt
Проверить, что содержит ваш файл на данный момент можно в сервисе Яндекса – Проверка Robots.txt. Введете там адрес своего сайта, и он покажет всю информацию.
Если у вас такого файла нет, то необходимо срочного его создать. Открываете текстовый редактор (блокнот, notepad++, akelpad и т.д.), создаете файл с названием robots, заполняете его нужными директивами и сохраняете с txt расширением (ниже я расскажу, как выглядит правильный robots.txt для WordPress).
Дальше, помещаем файл в корневую папку вашего сайта (рядом с index.php) с помощью файлового менеджера вашего хостинга или ftp клиента, например, filezilla (как пользоваться).
Если у вас WordPress и установлен All in One SEO Pack, то в нем все делается прямо из админки, в этой статье я рассказывал как.
Robots.txt для WordPress
Под особенности каждой CMS должен создаваться свой правильный файл, так как конфигурация системы отличается и везде свои служебные папки и документы.
Мой файл robots.txt имеет следующий вид:
User-agent: * Disallow: /wp-admin Disallow: /wp-content Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: /xmlrpc.php Disallow: */feed Disallow: */author Allow: /wp-content/themes/папка_вашей_темы/ Allow: /wp-content/plugins/ Allow: /wp-includes/js/ User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/ host: biznessystem.ru Sitemap: https://biznessystem.ru/sitemap.xml
Первый блок действует для всех роботов, так как в строке User-agent стоит «*». Со 2 по 9 строки закрывают служебные разделы самого вордпресс. 10 – удаляет из индекса страницы RSS ленты. 11 – закрывает от индексации авторские страницы.
По последним требованиям поисковиков, необходимо открыть доступ к стилям и скриптам. Для этих целей в 12, 13 и 14 строках прописываем разрешение на индексирование папки с шаблоном сайта, плагинами и Java скриптами.
Дальше у меня идет 2 блока, открывающих доступ к папке с картинками роботам YandexImages и Googlebot-Image. Можно их не выделять отдельно, а разрешающую директиву для папки с картинками перенести выше на 15 строку, чтобы все роботы имели доступ к изображениям сайта.
Если бы я не использовал All-in-One-Seo-Pack, то добавил бы правило, закрывающее архивы (Disallow: */20) и метки (Disallow: */tag).
При использовании стандартного поиска по сайту от WordPress, стоит поставить директиву, закрывающую страницы поиска (Disallow: *?s=). А лучше, настройте Яндекс поиск по сайту, как это сделано на моем блоге.
Обратите внимание на 2 правила:
1. Все директивы для одного робота идут подряд без пропуска строк.
2. Блоки для разных роботов обязательно разделяются пустой строкой.
В самом конце есть директивы, которые мы ранее не рассматривали – это host и sitemap. Обе эти директивы называют межсекционными (можно ставить вне блоков).
Host – указывает главное зеркало ресурса (с 2018 года отменена и больше не используется). Обязательно стоит указать какой домен является главным для вашего сайта – с www или без www. Если у сайта есть еще зеркала, то в их файлах тоже нужно прописать главное. Данную директиву понимает только Яндекс.
Sitemap – это директива, в которой прописывается путь к XML карте вашего сайта. Ее понимают и Гугл и Яндекс.
Дополнения и заблуждения
1. Некоторые вебмастера делают отдельный блок для Яндекса, полностью дублируя общий и добавляя директиву host. Якобы, иначе yandex может не понять. Это лишнее. Мой файл robots.txt известен поисковику давно, и он в нем прекрасно ориентируется, полностью отрабатывая все указания.
2. Можно заменить несколько строк, начинающихся с wp- одной директивой Disallow: /wp-, я не стал такого делать, так как боюсь – вдруг у меня есть статьи, начинающиеся с wp-, если вы уверены, что ваш блог такого не содержит, смело сокращайте код.
3. Переиндексация файла robots.txt проходит не мгновенно, поэтому, ваши изменения поисковики могут заметить лишь спустя пару месяцев.
4. Гугл рекомендует открывать доступ своим ботам к файлам темы оформления и скриптам сайта, пугая вебмастеров возможными санкциями за несоблюдение этого правила. Я провел эксперимент, где оценивал, насколько сильно влияет это требование на позиции сайта в поиске – подробности и результаты эксперимента тут.
Резюме
Правильный файл Robots.txt для WordPress является почти шаблонным документом и его вид одинаков для 99% проектов, созданных на этом движке. Максимум, что требуется для вебмастера – это внести индивидуальные правила для используемого шаблона.
biznessystem.ru