
какие бывают и 3 способа избавится от них
Словосочетания «дубликаты страниц» или «дубликат контента» запали в сердца многих веб-мастеров и SEO-оптимизаторов
Из многочисленных проблем в SEO, дубли страниц на сайте одна из проблем, которую решить проще всего.
Словосочетания «дубли страниц» или «дубликат контента» запали в сердца многих веб-мастеров и SEO-оптимизаторов. Но правда в том, что не каждый дубликат контента является негативным фактором при оптимизации сайта, а вернее сказать, существуют разные типы дубликатов и они не равны!
Почему нужно обратить внимание на дубли страниц?
Дубли страниц с точки зрения поисковых систем
- Они не знают какую страницу следует индексировать, а какую страницу выкидывать из индекса. Вследствие чего, не редки такие случаи, когда то одна страница влетает в поиск, а остальные вылетают, то наоборот. Как следствие, позиции для этой страницы могут существенно изменятся.
- Они не знают какой странице передавать траст и вес, а вернее сказать, они не могут определить, каким образом эти параметры должны передаваться, для каждой страницы, в отдельности или только для одной из них.


Дубли страниц с точки зрения владельца сайта
- Поисковые системы крайне редко ставят в выдачу две страницы с одинаковым содержимым (дубли страницы на сайте), поэтому они вынуждены самостоятельно выбирать, какую из страниц нужно показывать в результатах поиска. Это разбавляет видимость каждого из документов. Как следствие потеря трафика.
- На разные адреса страниц могут быть ссылки внутри сайта или из внешних источников, а поскольку ссылочный вес является одним из факторов ранжирования, то очевидна потеря «веса» остальных страниц.
О неуникальном контенте
Поскольку контент является ключевым элементом хорошего SEO, многие пытались манипулировать результатом поисковой выдачи с помощью старого доброго метода “копировать и вставить”, т.е. забирали контент на свой сайт с других сайтов. Поисковые системы, как правило, наказывают за такой метод, поэтому он должен использоваться с осторожностью, а лучше не использоваться вовсе.
Но, если вы создали не уникальный контент на сайте, не сходите с ума! Ниже мы рассмотрим, как поисковые системы относятся к дубликату контента, и я поделюсь несколькими советами, которые вы можете применить, чтобы убедиться, что содержание вашего сайта свежее и уникальное.
Чтобы лучше понимать как, например, Google обрабатывает дублированный контент, вам нужно ознакомится с их мануалом https://support.google.com/webmasters/answer/66359?hl=ru Если вы боитесь получить фильтр за дублированный контент, позвольте я вас успокою и приведу цитату из данной справки
Наличие на сайте повторяющегося контента не является основанием для принятия каких-либо мер по отношению к нему. Такие меры применяются только в том случае, если это сделано с целью ввести пользователей в заблуждение или манипулировать результатами поиска.
Вот и все, Google сообщает, что сайт не попадет под фильтр за дублированный контент, если вы не вводите пользователей в заблуждение. Но, если на сайте присутствуют дубли, то нужно разобраться, что это за дубли и решить эту проблему. Существует несколько типов дублированного контента:
- Полный дубль – два разных URL’а имеют одинаковый контент
- Частичный дубль – контент на разных страницах имеет мало отличий друг от друга
- Дубли с других доменов – полный или частичный дубль с другими сайтами (доменами).

Дублированный контент может получится в связи с разными ситуациями. Неправильная структура сайта, которая порождает полные или частичные дубли на разных страницах, лицензионное соглашение выбранной CMS, которое может находиться на разных сайта, шаблонные страницы, такие как публичная оферта, тексты законов и так далее.
Каждая из этих проблем имеет свои пути решения. Прежде чем приступить к решению этой проблемы, рассмотрим последствия наличие дублей страниц для сайта.
Последствия дублированного контента
Если вы разместили на сайте кусок дублированного контента по недосмотру или другим случайным причинам, то поисковые алгоритмы могут просто зафильтровать эту часть текста и отобразят в ТОП лучшие, по их мнению материалы.
Иногда они могут отобразить в ТОП и ваш сайт, даже с не уникальном контентом. Пользователи хотят видеть вверху результатов поиска, сайты с лучшим контентом и поисковые алгоритмы оценивая страницы сайтов, так или иначе могут подмешивать в выдачу страницы состоящие из частично неуникального контента.
- Краулинговый бюджет. У каждого сайта есть так называемый краулинговый бюджет. Это количество страниц, которые поисковый робот обходит при очередном посещении сайта. При большом количестве дублей контента (фильтра, сортировки в интернет-магазинах, доступные по разным адресам) поисковый алгоритм заходит на эти URL’ы и как только заканчивается краулинговый бюджет, он покидает сайт, из-за большого количества дублей не доиндексировав сайт.
- Потеря ссылочного веса. На внутренних страницах сайта может быть хороший ссылочный вес, но поисковые алгоритмы могут выкинуть из индекса эти страницы.
- Неправильные страницы в выдаче. Никто точно не знает, как работаю поисковые алгоритмы. Поэтому в поисковую выдачу они могут поставить совсем не ту страницу которую следовало бы из пула дубликатов.
Почему появляются дубли страниц?
Существует несколько основных путей появления таких станиц:
1.
Параметры URL, такие как фильтра, UTM-метки и прочее создают дубль страницы.
Например, адрес этой страницы : https://ex-pl.com/blog/dubli-stranits-na-sajte-kakie-byvayut-dubli-i-kak-ot-nikh-izbavitsya , но она также доступна по следующим адресам:
- https://ex-pl.com/index.php?option=com_content&Itemid=682&catid=11&id=102&lang=ru&view=article;
- https://ex-pl.com/blog/dubli-stranits-na-sajte-kakie-byvayut-dubli-i-kak-ot-nikh-izbavitsya?utm
Однако в первом случае происходит 301 редирект, во-втором, в коде страницы есть тег rel=canonical, но об этом ниже.
2. Домен с www и без www, с http и(или) https
Если ваш сайт доступен по двум адресам «site.ru» и «www.site.ru», один и тот же контент представлен на обоих версиях сайта, т.е. каждая страница сайта имеет полный дубликат. Такая же ситуация и с http:// и https:// если сайт доступен по обоим протоколам, то у каждой страницы также есть свой дубликат.
3. Неуникальный контент
Контент страницы состоит не только из обычного текста или записей в блогах, сюда же можно отнести и графику, и документы в docx, pdf, итд, а также и характеристики и описания продуктов или товаров, если мы говорим о интернет-магазинах. Если множество разных интернет-магазинов продают один и тот же товар и для описания товара используют данные производителя, то такой контент, наверняка, будет использован на множестве других сайтов.
Как найти дубли страниц на сайте?
Существует несколько методов поиска дублей страниц.
Google WebMaster
В Google Search Console вы можете посмотреть, у каких страниц есть повторяющиеся заголовки, проверить эти страницы и сделать вывод о том, являются ли эти страницы дублями.
Программа Xenu Link Sleuth
Xenu Link Sleuth – одна из необходимых программ для любого SEO-оптимизатора, которая помогает провести технический аудит сайта и выявить одинаковые заголовки (titles).
Просто просканируйте сайт этой программой, отсортируйте результаты в алфавитном порядке по заголовку и вы увидите одинаковые заголовки.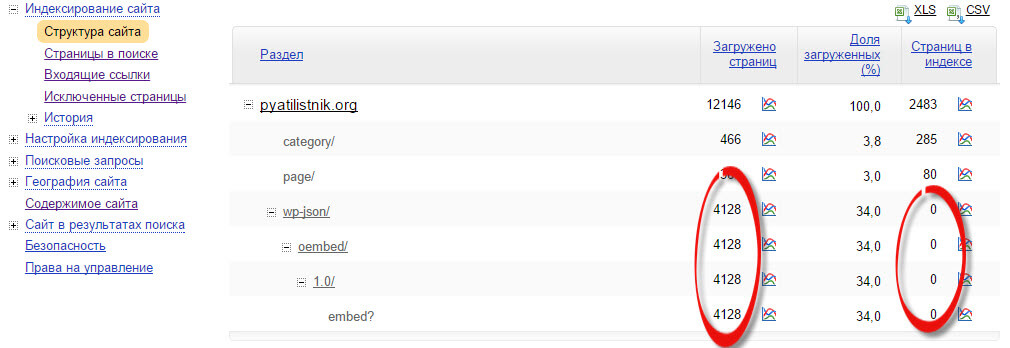 Скорее всего страницы с одинаковыми заголовками являются дубликатами.
Скорее всего страницы с одинаковыми заголовками являются дубликатами.
Воспользоваться операторами в поисковой системе
В поисковых системах можно произвести поиск не только в глобальной сети, но и на одном отдельно взятом сайте. Например, для того, чтобы в Google найти дубликаты на сайте, нужно сделать специальный запрос, который выглядит следующим образом: site:test.ru -site:test.ru/&.
- site:test.ru – вывод всех проиндексированных страниц
- site:mysite.com/& — вывод страниц участвующих в поиске
Как бороться с дублями страниц на сайте
Наличие не уникального контента на сайте, как в пределах сайта, так и в пределах интернета, не самое полезное явление для поисковых алгоритмов и пользователей сайта. Проще говоря, дублированный контент может негативно сказаться на продвижении сайта, поэтому, желательно от него избавиться. Есть несколько путей решения данной проблемы:
Использование 301 редиректов. Это один из подходов для того, чтобы избавиться от дубликатов. Если один из дублей страниц внутри сайта имеет наибольший ссылочный вес, то решением является сделать 301 редирект из пула дубликатов именно на эту страницу.
Если один из дублей страниц внутри сайта имеет наибольший ссылочный вес, то решением является сделать 301 редирект из пула дубликатов именно на эту страницу.
Использование файла robots.txt. Еще один выход это использование директив в файле robots.txt, который позволит запретить индексировать дубликаты страниц. В зависимости от ситуации, такое решение может быть не самым лучшим, т.к. директивы в файле robots.txt имеют рекомендательный характер.
Использование rel=“canonical”. Если вы хотите избавиться от дублированного контента, использование rel=“canonical” прекрасный выбор. Данный тег сообщает поисковым алгоритмам, какая страница из пула дубликатов является главной. Этот тег используется в <head></head> и выглядит следующим образом:
<link href="https://ex-pl.com/blog/kak-perejti-na-https-gotovyj-kejs" rel="canonical" />
Хотя дубликаты контента являются проблемой и могут помешать в поисковом продвижении сайта, они не так уж и страшны. Если вы намеренно не пытаетесь манипулировать поисковой выдачей, то поисковые системы, как правило, не наказывают вас. Но, как и говорилось выше, существуют и другие негативные последствия за дублированный контент. Я рекомендую избавиться от дублированного контента, это первый шаг к улучшению позиций сайта.
Но, как и говорилось выше, существуют и другие негативные последствия за дублированный контент. Я рекомендую избавиться от дублированного контента, это первый шаг к улучшению позиций сайта.
Что такое дубли страниц, как их найти и как с ними бороться
Дубли на сайте — это страницы, которые повторяют контент друг друга частично или полностью.
Условно внутренние дубли на сайте можно разделить на 3 типа:
- Полные дубли — полностью одинаковые страницы со 100-процентно совпадающим контентом и метатегами, доступные по разным адресам.
- Частичные дубли — страницы, контент которых дублируется частично. Например, страницы пагинации в интернет-магазине: метатеги, заголовки и текст одинаковые, но список товаров меняется.
- Семантические дубли — страницы, которые наполнены разным контентом, но оптимизированы под одни и те же либо похожие запросы.
Какие негативные последствия могут принести дубли страниц
Наличие дублей на сайте в большинстве случаев некритично для пользователей. Но с точки зрения поисковой оптимизации есть следующие негативные последствия:
Но с точки зрения поисковой оптимизации есть следующие негативные последствия:
-
Помехи качественному ранжированию, так как поисковые системы не могут однозначно определить, какой URL релевантен запросу. Как результат, в выдаче может отображаться не та страница, на которой проводились работы. Или релевантная страница в выдаче будет постоянно изменяться вместе с занимаемой позицией.
-
Нецелевое расходование краулингового бюджета и снижение скорости индексации значимых страниц, так как значительная часть краулингового бюджета поисковых систем будет тратиться на переиндексацию нецелевых страниц при наличии большого количества дублей.
-
Потеря потенциальной ссылочной массы на продвигаемые страницы. Естественные внешние ссылки могут быть установлены на страницы-дубли, в то время как продвигаемая страница естественных ссылок получать не будет.

Причин появления дублей страниц не очень много. Для удобства разделим дубли на три группы — полные, частичные, семантические — и рассмотрим причины появления для каждой.
Полные дубли
Передача кода ответа 200 страницами неглавных зеркал.
Например, у сайта с главным зеркалом https://site-example.info есть 3 неглавных зеркала:
http://site-example.info;
http://www.site-example.info;
Если с неглавных зеркал не был настроен 301-й редирект на главное, их страницы могут быть проиндексированы и признаны дублями главного зеркала.
Решение: настроить прямые редиректы со всех страниц неглавных зеркал на соответствующие страницы главного зеркала.
https://www.site-example.info/
301 →
https://site-example.info/
http://site-example.info/catalog/
301 →
https://site-example.info/catalog/.
Передача кода ответа 200 страницами с указанием index.php, index.html, index.htm в конце URL:
https://site-example.info/index.php,
https://site-example.info/index.html и другие.
Решение: настроить прямые 301 редиректы со всех страниц с указанными окончаниями в URL на страницы без них:
https://site-example.info/index.php → https://site-example.info/,
https://site-example.info/catalog/index.html → https://site-example.info/catalog/.
Передача кода ответа 200 страницами со множественными слешами «/» в конце URL либо со множественными слешами в качестве разделителя уровня вложенности страницы:
https://site-example.![]() info/catalog///////,
info/catalog///////,
https://site-example.info/catalog///category///subcategory/.
Решение: настроить прямые 301 редиректы по правилу замены множественных слешей на одинарный:
https://site-example.info/catalog/////// 301 → https://site-example.info/catalog/,
https://site-example.info/catalog///category///subcategory/ 301 → https://site-example.info/catalog/category/subcategory/.
Передача кода ответа 200 несуществующими страницами (отсутствие корректной передачи кода ответа 404):
https://site-example.info/catalog/category/qwerty123123/,
https://site-example.info/catalog/category/471-13-2/ и другие.
Решение: настроить корректную передачу кода ответа 404 несуществующими страницами.
Написание URL в разных регистрах:
https://site-example. info/catalog/,
info/catalog/,
https://site-example.info/Catalog/,
https://site-example.info/CATALOG/.
Решение: заменить все внутренние ссылки страницами с URL в нижнем регистре (при наличии таких ссылок) и настроить прямые 301 редиректы со страниц с другим типом написания URL.
Страницы с UTM-метками в URL:
http://site-example.info/catalog?utm_source=test&utm_medium=cpc,
http://site-example.info/catalog?utm_medium=target,
http://site-example.info/catalog?sort=price и другие.
Решение: указать поисковым системам на параметры в URL, которые не изменяют содержимое страниц.
Для ПС «Яндекс»: используя директиву Clean-param в файле robots.txt. Например:
User-agent: Yandex,
Clean-param: utm_campaign&utm_content&utm_medium&utm_source.
Для ПС Google: в разделе «Параметры URL», в GSC установить значение «Нет, параметр не влияет на содержимое страницы».
Страницы с одинаковым контентом, но доступные по разным адресам.
Наиболее яркий пример таких страниц — размещение одного товара в разных категориях:
https://site-example.info/category_14/product_page/,
https://site-example.info/category_14/product_page/,
https://site-example.info/category_256/product_page/.
Решение: настроить работу сайта таким образом, чтобы при размещении товара в дополнительных категориях адрес страницы самого товара не изменялся и был привязан только к одной категории.
Частичные дубли
Дублирование контента на страницах пагинации:
https://site-example. info/catalog/category/,
info/catalog/category/,
https://site-example.info/catalog/category/page_2/.
Решение: уникализировать страницы пагинации, чтобы они не мешали ранжированию основной страницы раздела.
-
Уникализировать метатеги title и description, добавив в них информацию о странице: «title_страницы_каталога — страница {номер_страницы_пагинации}».
-
Разместить основной заголовок <h2> на страницах пагинации с помощью тега <div>.
-
Скрыть текстовый блок со страниц пагинации.
Альтернативным решением является создание отдельной страницы, на которой будут отображаться все товары/материалы, и последующее закрытие от индексации страниц пагинации.
Однако в случае наличия большого количества товаров подобная реализация может быть неприемлемой — скорость загрузки такой страницы будет значительно медленнее, чем у страницы с небольшим количеством товаров.
Дублирование контента на страницах фильтрации каталога:
https://site-example.info/catalog/category/,
https://site-example.info/catalog/category/filter_color-black/.
Решение: уникализировать страницы фильтрации, чтобы они не мешали ранжированию основной страницы раздела и позволяли получать поисковый трафик по запросам с вхождением значения примененного фильтра.
-
Уникализировать заголовок h2, тег title и метатег description, включив в них информацию о параметре фильтрации.
-
При необходимости — разместить текстовый блок с уникальным текстом.
Дублирование контента на страницах каталога с измененной сортировкой (при наличии статичных страниц сортировки):
https://site-example. info/catalog/category/sort-price-low/
info/catalog/category/sort-price-low/
.
Решение: поскольку страницы с измененной сортировкой не являются значимыми для продвижения, рекомендуем закрыть их от индексации, разместив в коде тег <meta name="robots" content="noindex" />.
Дублирование контента в версиях страниц для печати.
Например: https://site-example.info/print.html.
Решение: установить на таких страницах тег <link rel="canonical" href="ссылка_на_основную_страницу" />.
Семантические дубли страниц
Семантическое дублирование страниц может происходить только при одновременной оптимизации нескольких страниц под одинаковые или похожие запросы.
В таком случае необходимо определить более подходящую страницу — ту, что отличается лучшей технической оптимизацией, лучше ранжируется поисковыми системами и более посещаема. Затем установить с дублирующих страниц прямой 301 редирект.
Затем установить с дублирующих страниц прямой 301 редирект.
Дублированные страницы в рамках одного сайта можно найти несколькими методами. Мы рекомендуем использовать их все для получения более качественных результатов:
- Проверка через сервис «Я.Вебмастер».
Если дубли страниц уже просканированы ПС «Яндекс», значительная часть из них будет исключена из индекса по причине дублирования. Такие страницы легко увидеть в разделе «Индексирование — страницы в поиске», вкладка «Исключенные страницы».
- Проверка через сервис Google Search Console.
Аналогично панели «Яндекс.Вебмастер» в GSC можно увидеть список страниц, исключенных по причине дублирования. Переходим в раздел «Покрытие» на вкладку «Исключено», причина: «Страница является копией. Канонический вариант не выбран пользователем».
Отметим, что сервис Google Search Console может предоставить данные только по 1 тыс. исключенных страниц.
исключенных страниц.
- Использование программ для сканирования сайта, например Screaming Frog SEO Spider Tool или Netpeak Spider.
После сканирования сайта необходимо проверить страницы на предмет дублирования тегов title, description, keywords и h2. Отсутствие перечисленных тегов также может стать сигналом существования дублей.
Метод позволяет обнаружить только полные дубли страниц.
- Использование сервисов для проверки позиций сайта. Рекомендуем для поиска семантических дублей.
После проведения проверки необходимо проанализировать каждую группу запросов на предмет наличия страниц, которые ранжируются по каждому запросу из группы.
Если по одной группе запросов ранжируются разные страницы, необходимо провести ручную проверку этих страниц на предмет сходства контента.
Если релевантные страницы по одному запросу периодически изменяются, рекомендуем проверить эти страницы.
Наличие дублей на сайте — серьезная ошибка, которая может значительно ухудшить качество индексации и ранжирования сайта, особенно если дублей много. Исправление этой ошибки критически важно для обеспечения хороших результатов в продвижении сайта любой тематики и с любым количеством страниц.
Важно отметить, что мы рекомендуем проверять сайт на наличие дублей не только при первоначальном аудите, но и в рамках регулярных проверок технического состояния сайта.
Дубли страниц сайта — поиск и устранение дубликатов страниц
Алексей Думчев
20 Октября 2014 г, 15:05
1074
Чем опасны дубли страниц
Во всех поисковых системах дублированные страниц негативно влияют на продвижение, так как поисковики видят несколько полностью релевантных страниц для одного и того же запроса, и в результаты органической выдачи будут добавляться постоянно разные страницы. Известно, что из-за дубликатов позиции проседают на 10-30 пунктов буквально за 2-3 недели. Чтобы избежать этого, советуем хотя бы 1 раз в месяц проверять контент и мета-теги. Как найти дубли страниц сайта — читайте в этой статье.
Чтобы избежать этого, советуем хотя бы 1 раз в месяц проверять контент и мета-теги. Как найти дубли страниц сайта — читайте в этой статье.
Поиск дубликатов страниц
1. Фразы в кавычках
Простой и доступный способ найти дубли страниц в Яндексе, хотя далеко не самый эффективный.
— выделяем 5-7 слов без знаков препинаний и заглавных букв;;
— включаем расширенный поиск по сайту;
— ставим весь текст в кавычки и копируем в адресную строку Яндекса.
В результатах выдачи получаем страницы, где есть точное вхождение данной фразы. Если есть 2 или более страниц — верный сигнал того, что у нас есть дублированный контент.
2. Сервер для проверки уникальности текста
На наш взгляд, наиболее эффективный способ поиска дублированного контента. Копируем текст и заливаем его на проверку уникальности в любой автоматический сервер. На выходе имеем полную картину о дубликатах.
— какие именно куски текста имеют дубликаты;
— адреса одинаковых страниц;
Чтобы не попасть под различные фильтры поисковых систем, делаем такую проверку для продвигаемых страниц ежемесячно. Для небольшого сайта поиск дубликатов таким образом занимает не много времени, но позволяет избежать неприятностей.
Для небольшого сайта поиск дубликатов таким образом занимает не много времени, но позволяет избежать неприятностей.
3. Программы-пауки
Бесплатные программы-пауки, которые определяют на каждой странице (даже те, которые не в индексе) мета-теги и теги h2.Вбиваем УРЛ сайта, и программа начинает парсить данные. В зависимости от количества страниц, процесс занимает до нескольких часов. В результатах получаем таблицу с множеством столбцов. Нас интересуют только мета-теги: title, description, keyword, тег h2 и адреса страниц:
Проверяем глазами – на одинаковые значения и устраняем ошибки. Этот способ хорош тем, что позволяет найти не только дублированный контент, но и одинаковые мета-теги. А как говорилось в предыдущих статьях, за идентичные мета-теги вырастает вероятность наложения фильтра, особенно это касается Google.
Читаем статью: продвижение cайта в Google.
4. Гугл Вебмастер: оптимизация HTML
Полезный инструмент для поиска дублей находится в панели Гугл-вебмастер. Заходим в панель для веб-мастеров Google и переходим в раздел – “Вид в поиске”, там выбираем вкладку – “Оптимизация HTML”. Гугл сообщает нам о дубликатах мета-тегов и предоставляет рекомендации по их устранению.
Заходим в панель для веб-мастеров Google и переходим в раздел – “Вид в поиске”, там выбираем вкладку – “Оптимизация HTML”. Гугл сообщает нам о дубликатах мета-тегов и предоставляет рекомендации по их устранению.
5. Ручная проверка выдачи
Длительный и затруднительный способ, который требует много внимания. Но если есть желания и силы, то можно и воспользоваться. Данный метод позволяет найти дубли страниц, которые существуют из-за технических проблем с сайтом. Например, распространенная ошибка — сайт доступен по адресам www. site.com ww.site.com site.com. Довольно редко, но вероятность есть.
Как убрать дубли страниц
1. Если дублируется контент, то достаточно переписать текст, через некоторое время поисковики проиндексируют сайт, и дублированный контент исчезнет из основного поиска.
2. При наличие одинаковых мета-тегов, находим причину (возможно, происходит автоматическая генерация) и устраняем неполадки.
3. Если дубли страниц образуются вследствие действия фильтров, то закрываем подобные страницы в файле robots.txt. Особенно характерно для интернет-магазинов.
Если дубли страниц образуются вследствие действия фильтров, то закрываем подобные страницы в файле robots.txt. Особенно характерно для интернет-магазинов.
Читаем статью: как увеличить продажи интернет-магазина
А теперь рассмотрим типичные дубли для наиболее популярных CMS: Joomla и Openstat.
Joomla — дубли страниц
Для любых версий этой CMS наиболее характерны 2 типа дубликатов. Давайте рассмотрим подробнее, как убрать дубли страниц Joomla.
1. Дубли главной страницы
В следствии технических ошибок сайта, на Joomla появляются дубликаты или полу-дубликаты главной страницы. Обязательно проверяем “морду” любым из предложенных способов и устраняем проблемы. Чаще всего необходимо закрыть дубли в файле robots.txt
2. Дубли модуля статей
Для Joomla существуют много модулей для статей, которые дублируют контент новых статей на одну страницу – Статьи. То есть на одной страницы мы получаем сразу все материалы. В более современных версиях такого уже не встретишь.
В более современных версиях такого уже не встретишь.
Чтобы устранить проблему – просто закрываем общую страницу статей от индексации.
Дубли страниц Opencart
Для данного CMS характерно наличие множества фильтров, которые создают дублированный контент. Чтобы решить проблему – закрываем все подобные фильтры от индикации.
Дублированные страницы – характерная проблема абсолютно для всех сайтов без исключения. Используйте вышеприведенные методы для поиска дубликатов, ежемесячно делайте мониторинг сайта и устраняйте проблемы, тогда степень доверия поисковых система к вашему ресурсу останется на высоком уровне.
Оцените статью:
Поделиться:
Дублированный контент в SEO – как его найти и исправить
7 скрытых типов дублированного контента
(и как защититься от каждого из них)
Дублированный контент – большая тема в сфере SEO. Когда мы слышим об этом, в основном в контексте штрафов Google; но этот потенциальный побочный эффект дублирования контента не только преувеличен (Google почти никогда не наказывает сайты за дублирование контента как такового), но и вряд ли является самым серьезным последствием проблемы. 3 гораздо более вероятные проблемы, которые могут быть вызваны дублированием страницы SEO, это следующие:
3 гораздо более вероятные проблемы, которые могут быть вызваны дублированием страницы SEO, это следующие:
- Расходование краулингового бюджета. Если дублирование контента происходит внутри вашего сайта, это гарантированно приведет к тому, что часть вашего краулингового бюджета (то есть количество ваших страниц, просматриваемых поисковыми системами в единицу времени) будет потрачена впустую. Это означает, что важные страницы вашего сайта будут сканироваться реже.
- Разведение сока Link. Как для внешнего, так и для внутреннего дублирования контента разбавление ссылочного веса является одним из самых больших недостатков SEO. Со временем оба URL-адреса могут создавать обратные ссылки, указывающие на них, и если один из них не имеет канонической ссылки (или перенаправления 301), указывающей на исходную часть, ценные ссылки, которые помогли бы исходному рейтингу страницы выше, распределяются между обоими. URL-адреса.
- Только одна из страниц ранжируется по целевым ключевым словам. Когда Google находит дублированный контент или скопированные экземпляры контента, он обычно показывает только один из них в ответ на поисковые запросы — и нет никакой гарантии, что это будет тот, который вы хотите ранжировать.
 Когда Google находит дублированный контент или скопированные экземпляры контента, он обычно показывает только один из них в ответ на поисковые запросы — и нет никакой гарантии, что это будет тот, который вы хотите ранжировать.
Когда Google находит дублированный контент или скопированные экземпляры контента, он обычно показывает только один из них в ответ на поисковые запросы — и нет никакой гарантии, что это будет тот, который вы хотите ранжировать.Но все эти сценарии можно предотвратить, если знать, где может скрываться дублирующийся контент, как его обнаружить и что делать с дублирующимся контентом. В этой статье я собираюсь в первую очередь рассказать о том, что такое дублированный контент, а также о 7 распространенных типах дублирования контента, а затем разобраться с дублированным контентом.
1. Вычищенный контент
Вычищенный контент — это неоригинальный контент на сайте, который был скопирован с другого сайта без разрешения. Как я уже говорил ранее, Google не всегда может отличить оригинальный контент от дубликата, поэтому задача владельца сайта часто заключается в том, чтобы следить за парсерами и знать, что делать, если их контент будет украден.
Увы, это не всегда легко и просто. Но вот небольшая хитрость, которую использую лично я.
Но вот небольшая хитрость, которую использую лично я.
Если вы отслеживаете, как вашим контентом делятся и ссылаются на него в Интернете (а если у вас есть блог, вам действительно следует это делать) с помощью приложения для социальных сетей/веб-мониторинга, такого как Awario, вы можете поразить двух зайцев одним выстрелом. В своем инструменте мониторинга вы обычно используете URL-адрес и заголовок вашего сообщения в качестве ключевых слов в своем предупреждении. Чтобы также искать очищенные версии вашего контента, все, что вам нужно сделать, это добавить еще одно ключевое слово — отрывок из вашего сообщения. В идеале оно должно быть довольно длинным, например, предложение или два. Окружите фрагмент двойными кавычками, чтобы убедиться, что вы ищете точное совпадение. Это будет выглядеть так:
С этой настройкой приложение будет искать как упоминания вашей исходной статьи (такие как общие ресурсы, ссылки и т. д.), так и потенциальный очищенный или скопированный контент версий, найденных на других сайтах.
Если вы обнаружите дублирующийся контент веб-сайта, рекомендуется сначала связаться с веб-мастером и попросить его удалить фрагмент (или поставить каноническую ссылку на оригинал, если это вам подходит). Если это неэффективно, вы можете сообщить о парсере, используя отчет Google о нарушении авторских прав.
2. Синдицированный контент
Синдицированный контент — это контент, повторно опубликованный на другом веб-сайте с разрешения автора оригинального материала. Это то, к чему обычно относится дублированный контент, поэтому, хотя это законный способ представить ваш контент новой аудитории, важно установить правила для издателей, с которыми вы работаете, чтобы убедиться, что синдикация не превращает дублирующую страницу SEO. в проблему SEO.
В идеале издатель должен использовать тег ‘rel=canonical’ в статье, чтобы указать, что ваш сайт является исходным источником контента, избегая штрафа за дублирование контента. Другой вариант — использовать тег noindex для синдицированного контента. Всегда лучше проверять это вручную всякий раз, когда синдицированный фрагмент вашего контента публикуется на другом сайте.
Всегда лучше проверять это вручную всякий раз, когда синдицированный фрагмент вашего контента публикуется на другом сайте.
3. Страницы HTTP и HTTPS
Одной из наиболее распространенных проблем внутреннего дублирования являются идентичные URL-адреса HTTP и HTTPS на сайте, даже если оба содержат одинаковый исходный контент. Эти проблемы возникают, когда переход на HTTPS осуществляется без должного внимания, которого требует процесс. Два наиболее распространенных сценария, когда это происходит:
1. Часть вашего сайта использует протокол HTTPS и использует относительные URL-адреса. Часто справедливо использовать одну безопасную страницу или каталог (например, страницы входа и корзины покупок) на HTTP-сайте. Однако важно помнить, что на этих страницах могут быть внутренние ссылки, указывающие на относительные URL-адреса, а не на абсолютные URL-адреса:
- Абсолютный URL: /rank-tracker/
- Относительный URL: /rank-tracker/
Относительные URL-адреса не содержат информации о протоколе; вместо этого они используют тот же протокол, что и родительская страница, на которой они находятся. Если поисковый бот найдет подобную внутреннюю ссылку и решит перейти по ней, он перейдет на URL-адрес HTTPS. Затем он может продолжить сканирование, перейдя по более относительным внутренним ссылкам, и даже может просканировать весь веб-сайт в безопасном формате и, таким образом, проиндексировать две полностью идентичные версии страниц вашего сайта. В этом сценарии вы захотите использовать абсолютные URL-адреса вместо относительных URL-адресов во внутренних ссылках. Если на вашем сайте уже есть повторяющиеся страницы HTTP и HTTPS, лучшим решением будет постоянное перенаправление защищенных страниц на правильные версии HTTP.
Если поисковый бот найдет подобную внутреннюю ссылку и решит перейти по ней, он перейдет на URL-адрес HTTPS. Затем он может продолжить сканирование, перейдя по более относительным внутренним ссылкам, и даже может просканировать весь веб-сайт в безопасном формате и, таким образом, проиндексировать две полностью идентичные версии страниц вашего сайта. В этом сценарии вы захотите использовать абсолютные URL-адреса вместо относительных URL-адресов во внутренних ссылках. Если на вашем сайте уже есть повторяющиеся страницы HTTP и HTTPS, лучшим решением будет постоянное перенаправление защищенных страниц на правильные версии HTTP.
2. Вы перевели весь сайт на HTTPS, но его HTTP-версия по-прежнему доступна. Это может произойти, если есть обратные ссылки с других сайтов, указывающие на HTTP-страницы, или потому, что некоторые внутренние ссылки на вашем сайте все еще содержат старый протокол, а незащищенные страницы не перенаправляют посетителей на защищенные. Чтобы избежать разбавления ссылочного веса и траты краулингового бюджета, используйте переадресацию 301 на всех своих HTTP-страницах и убедитесь, что все внутренние ссылки на вашем сайте указаны через относительные URL-адреса.
Вы можете быстро проверить, есть ли на вашем сайте проблема с дублированием HTTP/HTTPS, в WebSite Auditor SEO PowerSuite. Все, что вам нужно сделать, это создать проект для вашего сайта; когда приложение закончит сканирование, нажмите «Проблемы с версиями сайта HTTP/HTTPS» в аудите вашего сайта, чтобы увидеть, где вы находитесь.
4. WWW- и не-WWW-страницы
Одной из самых старых причин дублирования содержания в книге является доступность как WWW-, так и не-WWW-версий сайта. Как и в случае с HTTPS, вызывающим дублирование внутреннего контента, этот дублированный контент обычно можно исправить, внедрив переадресацию 301. Возможно, еще лучше указать предпочитаемый домен в Google Search Console.
Чтобы проверить, есть ли случаи такого дублирования на вашем сайте, просмотрите Фиксированные версии с www и без www (в разделе Перенаправления ) в вашем проекте WebSite Auditor.
5. Динамически генерируемые параметры URL
Динамически генерируемые параметры часто используются для хранения определенной информации о пользователях (например, идентификаторов сеансов) или для отображения немного отличающейся версии той же страницы (например, с настройками сортировки или фильтрации). сделанный). В результате URL-адреса выглядят следующим образом:
сделанный). В результате URL-адреса выглядят следующим образом:
- URL-адрес 1: /rank-tracker.html?newuser=true
- URL-адрес 2: /rank-tracker.html?order=desc
Хотя эти страницы, как правило, содержат одинаковый (или очень похожий) контент, Google может сканировать обе страницы. Часто динамические параметры создают не две, а десятки разных версий URL, что может привести к напрасному расходованию краулингового бюджета.
Чтобы проверить, не является ли это проблемой на вашем сайте, перейдите в свой проект WebSite Auditor и нажмите Проект восстановления . На шаге 1 установите флажок Включить экспертные параметры. На следующем шаге выберите Googlebot , чтобы в опции Следовать инструкциям robots.txt для… .
Затем перейдите на вкладку Параметры URL и снимите флажок Игнорировать параметры URL .
Эта настройка позволит вам сканировать ваш сайт, как это делает Google (следуя инструкциям robots. txt для робота Googlebot), и обрабатывать URL-адреса с уникальными параметрами как отдельные страницы. Нажмите Далее и выполните следующие шаги, как обычно, чтобы начать сканирование. Когда WebSite Auditor завершит сканирование, переключитесь на панель мониторинга Pages и отсортируйте результаты по столбцу Page, щелкнув его заголовок. Это должно позволить вам легко обнаруживать дубликаты страниц или скопированный контент с параметрами в URL-адресе.
txt для робота Googlebot), и обрабатывать URL-адреса с уникальными параметрами как отдельные страницы. Нажмите Далее и выполните следующие шаги, как обычно, чтобы начать сканирование. Когда WebSite Auditor завершит сканирование, переключитесь на панель мониторинга Pages и отсортируйте результаты по столбцу Page, щелкнув его заголовок. Это должно позволить вам легко обнаруживать дубликаты страниц или скопированный контент с параметрами в URL-адресе.
Если вы обнаружите такие проблемы на своем сайте, обязательно используйте инструмент обработки параметров в Google Search Console. Таким образом, вы будете сообщать Google, какие параметры нужно игнорировать при сканировании.
6. Похожий контент
Когда говорят о дублировании контента, часто имеют в виду полностью идентичный контент. Однако фрагменты очень похожего контента также подпадают под определение дублированного контента Google:
«Если у вас много похожих страниц, рассмотрите возможность расширения каждой страницы или объединения страниц в одну. Например, если у вас есть туристический сайт с отдельные страницы для двух городов, но одна и та же информация на обеих страницах, вы можете либо объединить страницы в одну страницу об обоих городах, либо расширить каждую страницу, чтобы она содержала уникальный контент о каждом городе».
Например, если у вас есть туристический сайт с отдельные страницы для двух городов, но одна и та же информация на обеих страницах, вы можете либо объединить страницы в одну страницу об обоих городах, либо расширить каждую страницу, чтобы она содержала уникальный контент о каждом городе».
Такие проблемы могут часто возникать на сайтах электронной коммерции, где описания похожих продуктов отличаются лишь несколькими характеристиками. Чтобы решить эту проблему и избежать проблем с ранжированием в поисковых системах, постарайтесь сделать страницы продуктов разнообразными во всех областях, кроме описания: отзывы пользователей — отличный способ добиться этого. В блогах аналогичные проблемы с контентом могут возникнуть, когда вы берете старый контент, добавляете некоторые обновления и переделываете его в новый пост. В этом случае лучшим решением будет использование канонической ссылки (или перенаправления 301) на старую статью.
7. Страницы для печати
Если несколько страниц вашего сайта имеют версии для печати, доступные через отдельные URL-адреса, Google будет легко найти и просканировать их по внутренним ссылкам. Очевидно, что содержимое самой страницы и ее версии для печати будет идентичным — таким образом, вы снова потратите свой краулинговый бюджет.
Очевидно, что содержимое самой страницы и ее версии для печати будет идентичным — таким образом, вы снова потратите свой краулинговый бюджет.
Если вы предлагаете страницы для печати посетителям вашего сайта, лучше закрыть их от роботов поисковых систем с помощью тега noindex. Если все они хранятся в одном каталоге, например https://www.link-assistant.com/news/print, вы также можете добавить правило запрета для всего каталога в файле robots.txt.
Заключительные мысли
Конкретный дублированный контент SEO может быть проблемой для тех, кто работает с SEO, так как он разбавляет ссылочный вес ваших страниц (т. е. ранжирование) и истощает краулинговый бюджет, препятствуя сканированию и индексированию новых страниц. Помните, что вашими лучшими инструментами для борьбы с этой проблемой являются канонические теги, переадресация 301 и robots.txt, а также включение проверок дублированного контента в процедуру аудита вашего сайта для улучшения индексации и рейтинга.
Какие случаи дублирования контента вы видели на своем собственном сайте и какие методы вы используете для предотвращения дублирования? Я с нетерпением жду ваших мыслей и вопросов в комментариях ниже.
Автор: Евгений Хутарнюк
Руководитель отдела SEO в SEO PowerSuite
5 мифов и 5 фактов о том, как это влияет на SEO
Слышали ли вы о дублированном контенте?
Возможно, этот термин наполняет вас ужасом. В конце концов, вы, наверное, слышали ужасные истории о том, как поисковые системы, такие как Google, наказывают веб-сайты, если они дублируют хотя бы заголовок или фразу. Дублированный контент должен быть одной из худших ошибок SEO, которую вы можете совершить, верно?
Не волнуйтесь, это не так.
На самом деле, большинство людей, которые распространяют эти слухи, мало (или вообще не понимают) того, что означает дублированный контент и как он влияет на SEO.
Ниже я расскажу вам, что такое дублированный контент и как он на самом деле влияет на ранжирование в поиске. Попутно развею несколько распространенных мифов.
Что такое дублированный контент? Дублированный контент — это контент, который появляется более чем в одном месте или URL-адресе в Интернете. Это означает, что если одна и та же информация доступна по нескольким URL-адресам, это может считаться дублирующимся контентом.
Это означает, что если одна и та же информация доступна по нескольким URL-адресам, это может считаться дублирующимся контентом.
Исследование, проведенное Raven, показало, что до 29 процентов страниц содержат дублированный контент.
Что на самом деле считается дублирующимся контентом? Это полная веб-страница или может быть несколько строк текста?
Вот определение дублированного контента Google:
Другими словами, дублированный контент может включать что угодно, от описания продукта до целой страницы, если он появляется в разных местах вашего сайта.
Вот пример. Допустим, вы продавец, продающий белые джинсы, и URL-адрес выглядит так: 9.0003
«https://yourcooljeanshop.com/jeans/white-jeans.html»
Может быть, вы запускаете распродажу, и товар теперь тоже доступен по этой ссылке:
«https://yourcooljeanshop.com/clearance/ Jeans/white-jeans.html»
Вы размещаете одно и то же описание продукта и изображение по двум разным URL-адресам, поэтому технически это дублирующийся контент.
По данным Google, дублированный контент не повлияет на ваш SEO-рейтинг. Они специально говорят:
«Дублирующийся контент на сайте не является основанием для действий на этом сайте, за исключением случаев, когда создается впечатление, что цель дублированного контента состоит в том, чтобы ввести в заблуждение и манипулировать результатами поисковых систем. Если на вашем сайте возникают проблемы с дублированием контента, а вы не следуете советам, перечисленным в этом документе, мы проделаем хорошую работу, выбрав версию контента для отображения в наших результатах поиска».
Однако по возможности следует ограничивать дублированный контент.
Почему? Что ж, поисковые системы, такие как Google, не знают, какой URL показывать первым в результатах поиска. Они попытаются определить, какой результат наиболее релевантен конкретному поисковому запросу, но есть вероятность, что они ошибутся.
Если Google поймет «неправильно», ваша целевая аудитория может не увидеть ваш контент. Или они не будут взаимодействовать с вашим контентом, потому что страница, которую показывает им Google, не отвечает их поисковым запросам.
Это подводит меня к следующему пункту: пользовательский опыт или UX.
UX имеет решающее значение. На самом деле, улучшения UX имеют средний ROI 9900 процентов.
Это означает, что улучшение UX за счет уменьшения дублирования контента стоит затраченных усилий.
Стремление избежать дублирования контента помогает мне обеспечить наилучший UX, к чему мы все стремимся как маркетологи, верно?
5 мифов о дублирующемся контентеТо, что вы должны ограничивать дублированный контент, не означает, что все плохо. Чтобы помочь вам лучше понять, как этот тип контента действительно влияет на SEO, позвольте мне развеять пять самых распространенных мифов.
1. Дублирующийся контент вредит вашему поисковому рейтингу Хотя дублированный контент может в некоторых случаях влиять на ваш поисковый рейтинг, этот тип контента оказывает гораздо меньшее влияние на ваш поисковый рейтинг, чем вы думаете.![]()
Помните, Google учитывает множество факторов при сканировании, индексировании и ранжировании страниц. Убедитесь, что вы создаете репутацию создателя уникального и ценного контента, чтобы Google с большей вероятностью просканировал вашу страницу и ранжировал ее выше, чем дубликаты страниц.
Все еще беспокоитесь о ранжировании своей страницы? Убедитесь, что вы выделили свой новый пост в социальных сетях. Ваша аудитория может помочь продвигать вашу страницу с помощью кликов, лайков, ссылок и репостов, чтобы обеспечить видимость и охват, которых она заслуживает.
2. Любой дублированный контент наказываетсяGoogle не имеет привычки наказывать дублированный контент. Серьезно.
Единственное исключение? Обманчивое поведение. Согласно Руководству Google для веб-мастеров, если вы дублируете контент только для того, чтобы манипулировать поисковыми системами, они удалят оскорбительные страницы или понизят ваш поисковый рейтинг.
Однако для большинства маркетологов дублированный контент не является поводом для беспокойства.![]() Если вы публикуете посты с качественным контентом и избегаете плохих тактик SEO, таких как наполнение ключевыми словами, вам не грозят штрафы за дублированный контент.
Если вы публикуете посты с качественным контентом и избегаете плохих тактик SEO, таких как наполнение ключевыми словами, вам не грозят штрафы за дублированный контент.
Все еще не уверены? Посмотрите этот SEO-чат с участием Джона Мюллера из Google и перейдите примерно к 28 минутам:
По словам Мюллера, некоторый дублированный контент на веб-сайте не имеет большого значения.
3. Парсеры навредят вашему сайтуНекоторые блоггеры презирают скребки. Я понимаю, почему. Сама идея о том, что бот «счищает» или извлекает данные с вашего сайта, кажется довольно тревожной, по крайней мере, на первый взгляд.
Но разве я ненавижу скребки? Нет. Скрейперы не помогают вашему сайту, но и не вредят ему.
Скрейперы не помогают вашему сайту, но и не вредят ему.
Вам действительно не стоит беспокоиться об этом маленьком блоге без оригинального содержания и без посетителей. Google один раз взглянет на эту страницу и поймет, что она неактуальна, поэтому это не повредит вашему рейтингу.
Однако, если очищенная версия имеет более высокий ранг, чем оригинал, обратитесь к хосту сайта и запросите удаление контента. Или отправьте запрос в Google на удаление страницы в соответствии с Законом об авторском праве в цифровую эпоху, выполнив действия по устранению юридических неполадок Google:
Как насчет отклонения ссылок на ваш веб-сайт из скопированных версий? Это рискованно, на самом деле.
Google рекомендует отклонять ссылки только в том случае, если у вас есть большое количество «спамовых» ссылок, указывающих на ваш сайт, и вы столкнулись с ручными мерами в отношении вашего сайта. Это означает, что доверяйте Google делать свою работу и сосредоточьтесь на создании уникального, привлекательного контента для повышения вашего рейтинга.
Гостевые посты — отличный способ получить больше трафика и повысить свой авторитет как лидера отрасли. Просто будьте осторожны, чтобы не давать слишком много ссылок из ваших гостевых постов — 52% гостевых постов имеют больше исходящих ссылок, чем входящих , и наше недавнее исследование показало, что это на самом деле вредно для SEO.
Тем не менее, если вы решите опубликовать гостевой пост, есть шанс, что ваша обычная аудитория не увидит ваши гостевые посты, поэтому вы можете опубликовать этот контент в своем собственном блоге. Однако не повредит ли повторная публикация гостевого поста рейтингу?
Не совсем так.
Я публиковал гостевые посты на некоторых отличных сайтах, и некоторые из них действительно поощряют авторов повторно публиковать контент в своих собственных блогах через несколько недель. Однако вы можете добавить к сообщению небольшой HTML-тег, чтобы отличить оригинальную (каноническую) версию статьи от переизданной.
Вот тег: rel= «канонический» . Если вы повторно публикуете гостевой пост, скажем, из «Основного блога», ваш тег может выглядеть так:
Тег помогает Google идентифицировать исходное сообщение и ранжировать его соответствующим образом.
5. Google может определить создателя оригинального контентаОбычно поисковые системы, такие как Google, не могут идентифицировать создателя исходного контента или URL-адрес.
Это одна из основных проблем с дублирующимся контентом. Это означает, что есть шанс, что кто-то может украсть ваш контент, опубликовать его в своем собственном блоге и назвать себя автором.
Это плагиат. Если это произойдет с вами, воспользуйтесь описанным выше средством устранения юридических неполадок или обратитесь к юристу за дополнительной консультацией по урегулированию нарушений авторских прав.
Google очень серьезно относится к плагиату. Если это случится с вами, вы будете думать о юристах, а не о поисковых системах.
5 фактов о дублирующемся контентеИтак, мы развеяли несколько давних SEO-мифов о дублирующемся контенте. Впрочем, что правда? Давайте взглянем.
1. Используйте переадресацию 301, чтобы избежать штрафов за дублирование контента0011 — так что нужно быть осторожным при использовании этой стратегии.Сведите к минимуму дублирование контента, перенаправляя старый или устаревший URL-адрес на новую версию. Вот когда это полезно.
- Недавно вы перенесли свой веб-сайт на новый домен.
- После слияния двух веб-сайтов вы пытаетесь перенаправить устаревшие URL-адреса.
- На вашей домашней странице несколько URL-адресов, и вы хотите выбрать «канонический».
- После смены сайта вы удалили страницу.
Например, если вы настроили постоянную переадресацию, ваш HTML-код может выглядеть примерно так:
301 переадресация — это простой способ удалить надоедливое дублирование контента с вашего сайта.
В этом руководстве вы узнаете, как настроить переадресацию 301 в WordPress, или вы можете внести изменения непосредственно в HTML, используя приведенный выше код.
2. Дублированный контент влияет на ссылочный вес«Ссылочный вес» относится к тому, как определенные ссылки передают авторитет и ценность с одной страницы на другую. Если вы пытаетесь создать ссылочный капитал, вот почему дублированный контент представляет собой проблему.
Поисковые системы не хотят показывать несколько страниц с одинаковым содержанием, поэтому они должны решить, какая страница подходит лучше всего. Видимость падает для каждой дублирующейся страницы, что снижает доступность вашей ссылки.
Ссылки имеют значение. По данным Backlinko, топовый результат в Google имеет в 3,8 раза больше ссылок, чем позиции со второй по десятую.
Что еще хуже, внешние сайты могут ссылаться на дублирующую страницу, а не на ваше «предпочтительное» местоположение. Если разные сайты ссылаются на разные версии одной и той же страницы, вы снижаете ценность этих внешних ссылок.
Если разные сайты ссылаются на разные версии одной и той же страницы, вы снижаете ценность этих внешних ссылок.
Дублированный контент вредит вашим кампаниям по созданию ссылок. Вы можете избежать этой дилеммы, добавив канонический тег или перенаправив дубликаты страниц в нужное место.
3. Вариации URL-адресов могут вызывать проблемы с дублированием контентаНезначительные вариации URL-адресов, хотя и довольно безобидные, вызывают дублирование контента. Варианты URL возникают, например, из:
- кода аналитики
- отслеживания кликов
- версий страниц для печати
- идентификаторы сеансов
Например, «https://theurltag/green» может иметь то же содержание, что и «https://theurltag/print/green», хотя один из них является просто версией для печати.
Чтобы определить и исправить варианты URL, воспользуйтесь Google Search Console.
Вы можете установить предпочитаемый домен и настроить параметры, чтобы Google знал, какие параметры URL сканировать, а какие игнорировать.
4. Google рекомендует свести к минимуму повторение стандартных шаблоновКогда мы говорим о «стандартном» содержании, мы обычно имеем в виду повторяющиеся утверждения, такие как уведомления об авторских правах или правовые оговорки.
Когда эти стандартизированные блоки текста появляются в основной части контента, Google может считать их дубликатами.
У Google есть рекомендации по работе со стандартными операторами. Например, если вы используете заявления об отказе от ответственности, вы можете написать очень короткие правовые заявления для каждой статьи и включить ссылку на полную юридическую политику.
Вот пример из The Reformed Broker, где они ссылаются на главную страницу раскрытия информации:
В противном случае убедитесь, что вы используете исходный язык, где это возможно, чтобы избежать возможных проблем с дублированием.
Ваша CMS или система управления контентом могут создавать дубликаты контента, о которых вы даже не подозреваете.
Например, одна статья может появиться на главной странице и в поисковой категории, например, «https://pretendsite.com/article-a» совпадает с «https://pretendsite.com/article-category/». статья-а».
Как это исправить? Понимая все тонкости вашей CMS. Как только вы научитесь обнаруживать дублированный контент, у вас появится несколько вариантов.
- Вы можете включить тег canonical, если это полезно.
- Или вы можете использовать тег «Noindex», чтобы запретить Google индексировать страницу (особенно полезно для страниц, пригодных для печати).
- Кроме того, вы можете немного переписать содержимое, чтобы сохранить его исходным.
Если вы не знаете, как получить максимальную отдачу от вашей CMS или найти дублирующийся контент, свяжитесь с нами, и я посмотрю, чем могу помочь.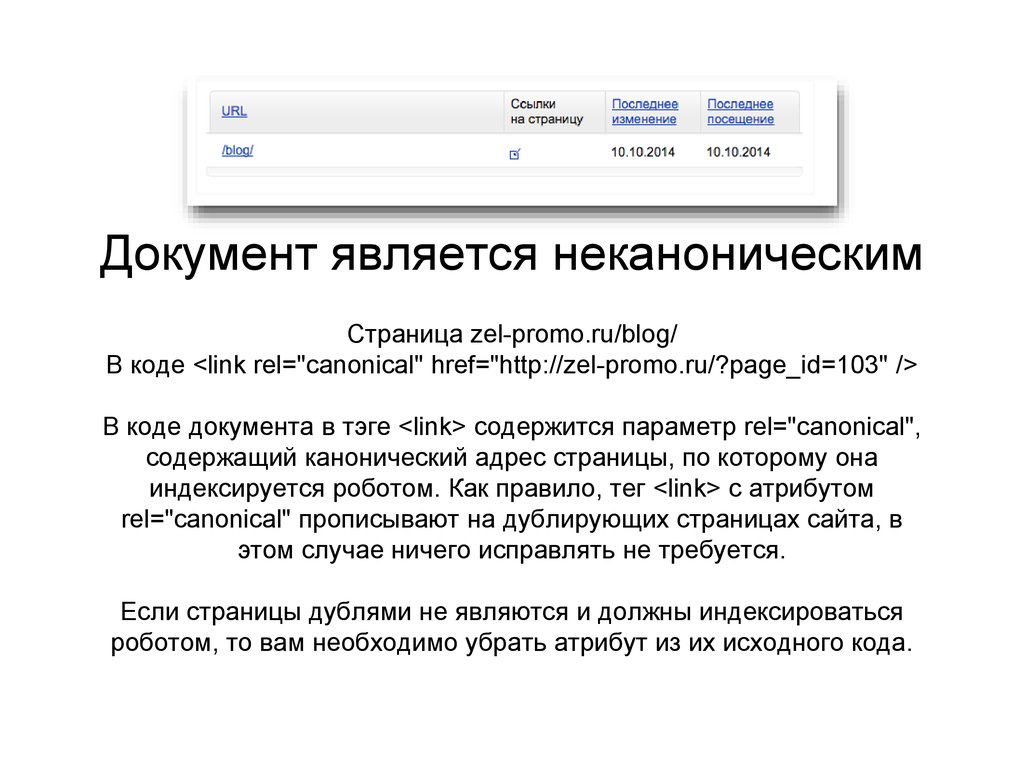
Надеюсь, теперь вы понимаете, что такое дублированный контент и как он на самом деле влияет на поисковую оптимизацию. Тем не менее, вот краткий обзор основных моментов, которые мы исследовали.
Дублированный контент по-прежнему вреден для SEO?
Что ж, Google не наказывает за дублированный контент, но иногда это может сбить с толку поисковые системы и помешать правильному ранжированию вашей страницы. Вы должны сосредоточиться на регулярном написании оригинального контента.
Как вы проверяете дублированный контент?
Вы можете использовать Google для проверки URL-адресов, ведущих к дублирующемуся контенту, или вы можете использовать бесплатную онлайн-проверку дублированного контента. Не забудьте также проверить, создает ли ваша CMS дублированный контент, чтобы вы могли предпринять шаги, чтобы смягчить влияние SEO, где это возможно.
Не забудьте также проверить, создает ли ваша CMS дублированный контент, чтобы вы могли предпринять шаги, чтобы смягчить влияние SEO, где это возможно.
Какое количество дублированного содержимого допустимо?
Технически не существует ограничений на количество дублированного контента, которое вы можете иметь. Тем не менее, все же стоит свести к минимуму количество дублированного контента, который вы используете, или, по крайней мере, попытаться смягчить его влияние на SEO или рейтинг вашего сайта.
Является ли дублирование содержимого незаконным?
В сети огромное количество дублированного контента. Однако другой компании запрещено копировать ваш исходный контент, публиковать его на своем веб-сайте и претендовать на авторство создания контента. Всегда принимайте меры против нарушений авторских прав.
Вывод: дублированный контент Вопреки тому, во что верят многие маркетологи, дублированный контент не является серьезной проблемой, если только вы не используете его злонамеренно.
Google не будет наказывать вас низким рейтингом в поиске только потому, что то здесь, то там встречается дублированный контент. Тем не менее, все же стоит выявить дублированный контент и удалить его.
Избегайте шаблонных повторений, по возможности используйте переадресацию 301 и проверяйте, не создает ли ваша CMS дублированный контент без необходимости.
Нужна помощь в обнаружении дублированного контента во время следующего SEO-аудита? Ознакомьтесь с моими консультационными услугами, чтобы увидеть, как я могу помочь.
Были ли вы ранее наказаны за дублированный контент? Или у вас есть истории с повторяющимся контентом, которыми вы хотите поделиться?
Узнайте, как мое агентство может привлечь огромное количество трафика на ваш сайт
- SEO — разблокируйте огромные объемы SEO-трафика. Смотрите реальные результаты.
- Контент-маркетинг — наша команда создает эпический контент, которым будут делиться, получать ссылки и привлекать трафик.
- Платные медиа — эффективные платные стратегии с четкой рентабельностью инвестиций.

Закажите звонок
Полное руководство по дублированию контента и поисковой оптимизации
Дублированный контент бывает разных видов и разной степени злонамеренности. Некоторые не так уж и плохи, но другие типы просто противны и являются настоящим врагом SEO!
В этом руководстве мы рассмотрим как внешние, так и внутренние проблемы дублирования содержимого. Мы рассмотрим, что такое дублированный контент на самом деле, каковы причины, как найти его на вашем собственном веб-сайте, а затем как вы можете это исправить. Все с большим гарниром кинометафор.
Содержание:
- Что такое дублированный контент?
- Почему дублированный контент вреден для SEO?
- Существует ли штраф за дублирование контента?
- Каковы причины дублирования контента?
- Как определить дублирующийся контент на вашем сайте
- Как бороться с дублирующимся контентом
- Технические исправления проблем с дублированием содержимого
- Рекомендации по предотвращению дублирования контента
- Сообщите о проблемах с дублированным содержимым
Мы все любим фильмы, верно? Ну, почти все мы. И большинство из нас видели классику на протяжении многих лет.
И большинство из нас видели классику на протяжении многих лет.
Но сталкивались ли вы когда-нибудь с фильмами продюсерской компании The Asylum? Нет?
За прошедшие годы они выпустили несколько абсолютных жемчужин.
- Трансформеры
- Пираты острова сокровищ
- Терминаторы
- Атлантический край
- День независимых
- Охотники за привидениями
Некоторые из этих названий звучат знакомо, не так ли? Это потому, что они специализируются на грабежах популярных фильмов. Это не единственная производственная компания, которая делает это — некоторые также создают плакаты и другие рекламные материалы, предназначенные для того, чтобы обмануть потребителя, заставив его думать, что он покупает оригинальный товар.
У моей мамы даже есть несколько из них, и она каждый раз сбивается с толку.
Эти производственные компании часто попадают в беду, но рентабельность инвестиций должна быть довольно приличной, потому что они продолжают их вытеснять.
«Какое это имеет отношение к SEO и аудиту?» Я слышу, как ты плачешь. Что ж, это немного похоже на некоторые аспекты дублированного контента — в частности, внешний дублированный контент, который может доставить вам неприятности.
Незначительный, я знаю.
Позвольте мне принять мои интересы.
Я обнаружил, что клиенты могут быстро понять идею внешнего дублированного контента и понять, почему это плохо (отсюда ссылка на The Asylum), но им трудно понять внутренние проблемы дублирования и то, как это может повлиять на их успех в поисковой оптимизации.
Итак, давайте продолжим — с более тонкими ссылками на мир кино.
Что такое дублированный контент?
Звучит примерно так, и если вы читаете это, то, вероятно, имеете представление о том, что такое дублированный контент. Однако в духе ясности…
Дублированный контент — это когда у вас есть блок контента на одной веб-странице, который идентичен или почти идентичен другой веб-странице в прекрасном Интернете.
Дублирование содержимого почти неизбежно. Это случается, и это естественно, но это не значит, что вы не должны следить за этим и максимально смягчать его. Google не идеален, знаете ли.
Существует два типа дублированного или почти дублирующегося содержимого, о которых вам необходимо знать.
Внутренний дублированный контент
Внутренний дублированный контент — это когда на ВАШЕМ сайте есть более одной страницы, идентичной или почти идентичной одной (или нескольким) другим страницам на вашем сайте.
Внешнее дублированное содержимое
Внешнее дублированное содержимое (часто называемое междоменными дубликатами) — это когда на вашем сайте есть страница, которая дублируется на одном (или нескольких) других доменах. Эти сайты могут принадлежать вам, но во многих случаях это не так.
Почему дублированный контент вреден для SEO?
Несмотря на то, что для Google не существует такого понятия, как штраф за дублирование контента (см. раздел ниже, где я определенно опровергаю этот миф). Например, навсегда.
раздел ниже, где я определенно опровергаю этот миф). Например, навсегда.
Так почему же это плохо для SEO?
Google не хочет, чтобы в результатах поиска было много похожих страниц. Поэтому они применяют фильтр к страницам, которые содержат дублированный или почти дублирующийся контент, и возвращают только ту страницу, которую они считают канонической или «истинной» версией. Но это не значит, что Google всегда понимает это правильно.
Кроме того, вы можете обнаружить, что некоторые из страниц, которые по существу дублируются, являются теми, которые вы хотите отображать в результатах поиска, и если Google отфильтровывает их, вы оставляете трафик на столе.
Это плохо для SEO, потому что вы можете потерять трафик и, в свою очередь, доход.
“ Слава означает финансовый успех, а финансовый успех означает безопасность. ”
Стив Маккуин
Существует ли штраф за дублирование контента?
Давайте развенчаем этот SEO-миф прямо здесь и сейчас (хотя его развенчивали уже много раз).
Он все еще возвращается, как Джейсон в фильмах «Пятница 13-е».
Нет такой вещи, как штраф за дублирование контента, когда речь идет о контенте на вашем сайте.
Давайте перейдем прямо к прекрасному парню, Джону Мюллеру, за подтверждением этого.
«С таким дублирующимся контентом [Джон имел в виду дублированный контент верхнего и нижнего колонтитула] не так уж много отрицательной оценки, связанной с ним. Дело в том, что если мы находим одинаковую информацию на нескольких страницах в Интернете, и кто-то ищет именно эту часть информации, то мы пытаемся найти наиболее подходящую страницу.
Если у вас есть одинаковый контент на нескольких страницах, мы не будем показывать все эти страницы. Мы попробуем выбрать один из них и показать его. Так что это не значит, что с этим связан какой-то негативный сигнал. Во многих случаях это нормально, что у вас есть некоторое количество общего контента на некоторых страницах».
Джон Мюллер, Google SEO Office Hours, 2021
Что насчет страниц продуктов?
«Очень распространенный случай, например, с электронной коммерцией. Если у вас есть продукт, и кто-то другой продает тот же продукт, или на веб-сайте, возможно, у вас есть нижний колонтитул, который вы используете на всех своих страницах, и иногда это довольно большой нижний колонтитул. Технически это дублированный контент, но мы можем с этим справиться. Так что это не должно быть проблемой».
Если у вас есть продукт, и кто-то другой продает тот же продукт, или на веб-сайте, возможно, у вас есть нижний колонтитул, который вы используете на всех своих страницах, и иногда это довольно большой нижний колонтитул. Технически это дублированный контент, но мы можем с этим справиться. Так что это не должно быть проблемой».
Джон Мюллер, Google SEO Office Hours, 2021
Ну вот. Это не должно быть проблемой.
Значит, соскребать и копировать содержимое можно?
Воровать (в основном) плохо. В основном? На самом деле, нет ничего нового, но есть огромная разница между воровством и тем, что Остин Клеон называет «кради как художник».
«Нет ничего оригинального. Воруйте из любого места, которое резонирует с вдохновением или подпитывает ваше воображение. Поглотите старые фильмы, новые фильмы, музыку, книги, картины, фотографии, стихи, сны, случайные разговоры, архитектуру, мосты, дорожные знаки, деревья, облака, водоемы, свет и тени. Выбирайте для кражи только то, что говорит непосредственно с вашей душой. Если вы сделаете это, ваша работа (и кража) будет подлинной. Подлинность бесценна; оригинальности не существует».
Если вы сделаете это, ваша работа (и кража) будет подлинной. Подлинность бесценна; оригинальности не существует».
Джим Джармуш, журнал MovieMaker, 2004
Скопированный контент, с другой стороны, является просто кражей, а не ремиксом. Не использовать другой контент в качестве трамплина. Таким образом, ему не место в результатах поиска Google.
Вот что сказал сотрудник Google Андрей Липатцев, когда пытался различать разные типы дублированного контента:
«Вы правильно поняли, что штрафов за дублирование контента нет… Я бы не стал говорить о штрафах за дублирование контента в целях спама, потому что тогда речь идет не о дублированном контенте, а о создании очень часто автоматизированным способом контента, который не столько дублируется, сколько быстро извлекается из нескольких мест, а затем, возможно, тем или иным образом монетизируется…»
Андрей Липатцев, Google Duplicate Content Q&A, 2016
Есть. Является. Дубликат. Содержание. Пенальти.
Содержание. Пенальти.
Каковы причины дублирования контента?
А теперь вопрос. Есть грузы. Давайте совершим небольшое путешествие по некоторым наиболее распространенным из них, с которыми вы, вероятно, столкнетесь при аудите сайтов. Я разбил их на два основных раздела: во-первых, то, что мы считаем «настоящим» дублирующимся контентом, а во-вторых, дубликаты URL-адресов, которые, как правило, связаны с техническими проблемами.
Дублированный контент
Настоящим дублирующимся контентом является то, что один и тот же или похожий контент появляется на нескольких страницах. Вот некоторые из наиболее распространенных примеров.
Сменные фильтры
Аааааааа. Это может быть сложно разгадать, и оно чаще всего встречается на сайтах электронной коммерции.
Если вы управляете сайтом электронной коммерции или когда-либо работали с ним, вы поймете важность фильтров. Они помогают пользователям перемещаться по категориям и просматривать только интересующие товары.
Они имеют решающее значение для сайтов электронной коммерции.
Однако самое неприятное — это когда сайт не принимает во внимание тот факт, что фильтры могут создавать множество индексируемых дубликатов страниц.
Как выглядят такие повторяющиеся URL-адреса?
https://tomranks.com/category будет вашей главной страницей категории.
Но по мере того, как пользователь начинает переходить по ссылкам, могут начать появляться такие страницы:
https://tomranks.com/category/?brand=niceguy
выглядеть так:
https://tomranks.com/category/?brand=nice?seo=no?prduct=3423424
Легко увидеть, как это может расти в геометрической прогрессии, и вы можете закончить с большим количеством индексируемых страниц, которые вы знаете, что нужно делать с.
Дополнительная литература:
- 7 реализаций фильтрации продуктов, которые делают Macy лучшим
Индексируемые страницы поиска
Это еще одна форма дублированного контента, с которой я регулярно сталкиваюсь. Такой дублированный контент создается, когда у вас есть функция поиска, которая создает новую страницу и служит для нее кодом состояния 200.
Такой дублированный контент создается, когда у вас есть функция поиска, которая создает новую страницу и служит для нее кодом состояния 200.
Обычно это выглядит примерно так:
https://markupwahlberg.com/?search=onedecentfilm
Проблема здесь в том, что большинство страниц результатов поиска очень похожи, а количество поисковых запросов (и, следовательно, страниц) потенциально бесконечен!
Стандартное содержимое
Стандартное содержимое относится к содержимому, которое появляется на большинстве, если не на всех, страницах вашего сайта. Чаще всего это содержимое верхнего и нижнего колонтитула.
Вот несколько примеров. Если вы ведете блог, у вас будет одна и та же биография для писателей на многих страницах.
Почти каждый сайт в Интернете имеет дублированный контент на каждой странице сайта, потому что навигационный контент располагается на многих страницах.
Как упоминалось ранее в этом руководстве, вы почти наверняка можете предположить, что Google может работать с этим контентом и понимает, что это необходимо для хорошего взаимодействия с пользователем.
Мой совет — не беспокойтесь о дублирующемся контенте.
Содержание описания продукта
Дублирование на страницах товаров очень распространено. В течение многих лет большинство сайтов электронной коммерции использовали описания продуктов, которые предоставляет производитель.
На это есть несколько причин:
- Так проще
- На сайтах часто есть сотни, если не тысячи товаров, и написать для них уникальный контент — адская задача
- Они не знают, как расставить приоритеты, для каких продуктов они должны написать уникальную копию
- Иногда конкуренция настолько жесткая, что окупаемость инвестиций невелика
Вопрос о том, стоит ли иметь дело с дублирующимся контентом такого рода, зависит не только от простых ответов «да» или «нет». Это зависит от вашей вертикали, уровня конкуренции, вашего бюджета и того, что еще вам нужно сделать на сайте, чтобы повысить рентабельность инвестиций.
Давайте вернемся к тому, что сказал наш старый Джон Мюллер несколько лет назад:
«Дольше не обязательно лучше. Так что вопрос действительно в том, есть ли у вас что-то полезное для пользователя? Актуально ли это для людей, которые ищут? Тогда, может быть, мы попытаемся это показать».
Так что вопрос действительно в том, есть ли у вас что-то полезное для пользователя? Актуально ли это для людей, которые ищут? Тогда, может быть, мы попытаемся это показать».
Джон Мюллер, Google SEO Office Hours, 2015
Вращающийся контент
Вращающийся контент? Люди все еще делают это? Ответ один колоссальный Стив Остин «черт возьми!».
Работает? Не так много. Google намного умнее, чем это в настоящее время.
По большому счету 😉
Если вы никогда не сталкивались с генерируемым контентом, он берет существующий контент и прогоняет его через какое-то программное обеспечение, чтобы добавить синонимы и заменить текст. Не то, чтобы я когда-либо делал это. Я до сих пор вижу, что он используется в описаниях продуктов по сей день, хотя и не так часто, поскольку контент не часто появляется в Google.
Что Google может сказать по этому поводу?
«искусственное переписывание контента часто связано с созданием контента, когда вы просто делаете контент уникальным, но на самом деле вы не пишете что-то уникальное. Затем это часто приводит к низкому качеству контента на этих страницах. Таким образом, искусственное переписывание таких вещей, как замена синонимов и попытка сделать их уникальными, вероятно, более контрпродуктивно, чем на самом деле помогает вашему веб-сайту».
Затем это часто приводит к низкому качеству контента на этих страницах. Таким образом, искусственное переписывание таких вещей, как замена синонимов и попытка сделать их уникальными, вероятно, более контрпродуктивно, чем на самом деле помогает вашему веб-сайту».
Джон Мюллер, Google SEO Office Hours, 2015
Тем не менее, я экспериментировал с программным обеспечением ИИ, которое в последнее время стало дешевле и доступнее, и в некоторых случаях есть возможность использовать его.
Страницы-заполнители
Страницы-заполнители — это обычно страницы, добавляемые в домен перед запуском сайта. Они часто используются для сбора информации по электронной почте перед запуском продукта или, по крайней мере, для привлечения интереса к продукту или сайту.
За прошедшие годы я видел несколько из них, где они размещались на одном URL-адресе, но никогда не удалялись, и часто они содержали много дублированного контента.
Это может выглядеть примерно так:
https://johnwayneyb77/launch
Сайт начинает работать, и содержимое этого URL-адреса очень похоже на содержание готовой домашней страницы, но стартовая страница забывается и остается индексируемым. У вас будет еще больше проблем, если запуск продукта прошел хорошо и принес кучу ссылок из прессы, потому что ваш продукт просто потрясающий.
У вас будет еще больше проблем, если запуск продукта прошел хорошо и принес кучу ссылок из прессы, потому что ваш продукт просто потрясающий.
Целевые страницы PPC
SEO и PPC разные. Мы знаем это, верно?
Иногда страницы сайта, над которым вы работаете, хороши для SEO, но не всегда хороши для PPC. В Boom мы часто создаем специальные целевые страницы для команды PPC, чтобы мы могли размещать на них тот контент, который помогает их конверсиям.
Я может и не PPCer (пробовал 10 лет назад, и просто попал в яму отчаяния, просто это была не моя сумка), но я прекрасно понимаю, что парням часто нужно что-то другое для их трафик, чтобы приземлиться.
Но…
Это часто означает, что содержимое дублируется или почти дублируется. Всегда будьте в курсе того, над чем работают другие команды и есть ли у них созданные страницы, которые могут оказаться неприятными для вашего SEO.
Контент для разных стран/диалектов
Классика. У вас есть веб-сайт. Вы находитесь в Великобритании, но продаете по всему миру. В США, в Европу (хотя сейчас это немного сложнее) и еще кучу всего.
Вы находитесь в Великобритании, но продаете по всему миру. В США, в Европу (хотя сейчас это немного сложнее) и еще кучу всего.
Сейчас не время говорить о международном SEO или о том, почему кажется таким сложным не только объяснить, как работает hreflang, но и правильно реализовать его — я уверен, что мы рассмотрим это позже.
Пока я просто скажу, что если это не реализовано правильно, вы можете столкнуться с некоторыми проблемами дублирования контента. Хотя контент *должен* быть другим (да, я видел британский контент на множестве международных страниц, которые не были переведены, и это никогда не переставало кипеть у меня в крови), вы видите дублирующиеся теги заголовков, метаописания и описания продуктов. . Все. . Время.
Синдикация контента
Если вы не слышали о синдикации контента до того, как вы просто работаете с влиятельными лицами, другими цифровыми издателями и партнерами по распространению контента, чтобы добиться большего охвата вашего контента или ваших продуктов и услуг.
Привлечение дополнительного внимания может быть полезным для вашего бренда или бизнеса, но за это приходится платить.
Ага, вы уже догадались — дублированный контент.
Часто другие сайты, с которыми вы работаете, публикуют ваш контент. Слово за слово. Даже если у вас был контент на вашем сайте до того, как он был синдицирован, у вас все равно могут возникнуть проблемы. Часто Google больше доверяет многим из этих сайтов, и их контент может быть проиндексирован вместо вашего. Грр.
https://arnoldshwarzenggerisatwin.com/amazingballscontent — это контент, который вы создали на своем сайте.
Но вы синдицировали его на другие сайты…
https://dannydevitoisatwin.com/amazingballscontent
И..
https://eddiemurphyisatwinortriplet.com/amazingballscontent
Non-www против www и http против https
Можно подумать, что большинство людей уже разобрались с этим, но я до сих пор сталкиваюсь с ним довольно регулярно. Часто из-за неправильной настройки редиректов.
Часто из-за неправильной настройки редиректов.
В то время как Google и другие поисковые системы обычно могут понять это, это быстрое решение, поэтому вы также можете обратиться к нему.
Это когда у вас есть как версия вашего сайта с www, так и версия вашего сайта без www, живая и доступная для поисковых систем..
Вот так:
https://spamelaanderson.com
AND
https://www.spamelaanderson.com
То же самое относится к вашим безопасным и незащищенным версиям URL-адресов:
http: //spamelaanderson.com
И
https://spamelaanderson.com
См. также: 3
https://spamelaanderson.com
И
https://www.spamelaanderson.com
- www или не www: что правильно с точки зрения SEO
- Выбор между URL-адресами с www и без www — HTTP
- WWW против не-WWW — что лучше для WordPress SEO?
Параметры и варианты URL
Повторяющееся содержимое также может быть случайно создано с помощью вариантов URL. Это включает (но не ограничивается) отслеживание кликов, код аналитики, идентификаторы сеансов и версии страниц для печати. Хотя Google довольно хорошо справляется с сортировкой, вам все равно нужно найти и, возможно, исправить такое дублирование.
Это включает (но не ограничивается) отслеживание кликов, код аналитики, идентификаторы сеансов и версии страниц для печати. Хотя Google довольно хорошо справляется с сортировкой, вам все равно нужно найти и, возможно, исправить такое дублирование.
Вот несколько примеров, наполненных очень веселыми каламбурами из фильмов.
Идентификаторы сеансов
https://alttagpacino/serp-ico?SessID=243432
То же, что и:
https://alttagpacino/serp-ico 91 версии 9000 страницы
https://glennclosetag/print/cookiesfortune
То же, что:
https://glennclosetag/cookiesfortune
Дальнейшее чтение:
- Как избежать ловушек SEO параметров URL | Халлам
Причуды CRM
Я рассказал о причудах CRM в недавней публикации на Sitebulb, так что нет особого смысла вдаваться здесь в подробности. Но некоторые CMS создают проблемы с дублированием контента из коробки. Удобно, да?
Удобно, да?
Один из самых обсуждаемых — Shopify.
«Очень важно отметить, что, хотя Shopify создает дублированный контент, для консолидации требуется несколько шагов. В приведенных ниже примерах Shopify правильно использует канонический тег, чтобы указать, какой должна быть страница ранжирования. Это помогает Google объединить эти повторяющиеся URL-адреса в один.
Однако лучше не полагаться на канонические теги, поскольку они являются подсказками, а не директивами. По возможности старайтесь полностью удалять дублированный контент».
Крис Лонг, Как исправить Shopify Дублированный контент
Дополнительная литература:
- Как проводить аудит веб-сайтов на разных платформах CMS
- Shopify SEO-аудит — как исправить распространенные проблемы SEO в Shopify
Несогласованная внутренняя связь
Все мы люди. Мы все делаем ошибки. Одна распространенная человеческая ошибка = проблема с дублированием — это когда мы создаем внутренние ссылки. Вы должны убедиться, что все на сайте последовательны, когда они ссылаются, и они ссылаются на страницы, которые вы хотите проиндексировать и ранжировать. Что они не создают дубликаты случайно.
Вы должны убедиться, что все на сайте последовательны, когда они ссылаются, и они ссылаются на страницы, которые вы хотите проиндексировать и ранжировать. Что они не создают дубликаты случайно.
И не только люди. Инструменты, которые мы используем, также могут вызывать эти проблемы. У некоторых CMS есть свои особенности (как я уже рассказывал на Sitebulb). Убедитесь, что используемая вами технология не вызывает подобных проблем с дублированием контента.
Что я имею в виду? Давайте посмотрим на некоторые примеры.
Страница, которую вы хотите ранжировать:
https://sigourneydreamweaver.com/alien
Возможные проблемы с внутренними ссылками, которые могут привести к дублированию контента, если он связан следующим образом:
https://sigourneydreamweaver.com /Alien
https://sigourneydreamweaver.com/ALIEN
https://sigourneydreamweaver.com/alien/
«Вот оно, чувак. Игра окончена, чувак. Игра закончена!»
Private Hudson
Дополнительная литература:
- Внутренние ссылки для SEO: лучшие практики, стратегии, аксиомы
Несколько индексных страниц
Иногда ваш сервер может быть неправильно настроен, и это может привести к появлению нескольких версий любой данной страницы. Следите за этими маленькими мошенниками, когда вы проверяете сайты. Обычно их довольно легко обнаружить после сканирования вашего сайта — они выглядят так:
Следите за этими маленькими мошенниками, когда вы проверяете сайты. Обычно их довольно легко обнаружить после сканирования вашего сайта — они выглядят так:
https://charliechaplink.com/index.php
https://charliechaplink.com/index.asp
https://charliechaplink.com/index.html
https://charliechaplink.com/idex.aspx
Как определить дублированный контент на вашем веб-сайте
Теперь вы знаете, как на вашем сайте может появиться дублированный контент, и вам захочется узнать, как все это найти, верно?
Не волнуйтесь; Дядя Уэйн прикроет твою спину. Давайте совершим краткий обзор некоторых инструментов, которые помогут вам определить все места, где вы можете найти дублированный контент.
Siteliner
Если вы только начинаете находить и устранять проблемы с дублированием контента, то Siteliner — отличное место для начала. Созданная теми же людьми, что и Copyscape (подробнее об этом ниже), это бесплатная программа для проверки сайта, которая покрывает дублированный контент.
Созданная теми же людьми, что и Copyscape (подробнее об этом ниже), это бесплатная программа для проверки сайта, которая покрывает дублированный контент.
Будет только отчет на 250 страницах, а что вы ожидали бесплатно?
Copyscape
Ах, добрый старый верный. Copyscape существует уже много лет и является дешевым способом поиска дублирующегося контента как на вашем сайте, так и на других сайтах, которые могли удалить ваш контент. Есть бесплатная версия, но платная версия (через кредиты) настолько дешевая, что вы можете купить премиум-версию.
Sitebulb
Было бы неправильно, если бы я не упомянул Sitebulb здесь по нескольким причинам.
- Они платят мне миллион долларов каждый раз, когда я их где-то упоминаю
- Это хорошо подходит для выявления дублированного контента, и это действительно инструмент, который я использую
- У Патрика на меня такое дерьмо, что я не хочу, чтобы мир увидел
Хотите узнать, как использовать Sitebulb для поиска дублирующегося контента? Конечно, вы делаете. Нажмите на эту тяжелую ссылку с якорным текстом, чтобы получить вкусности.
Нажмите на эту тяжелую ссылку с якорным текстом, чтобы получить вкусности.
Кричащая лягушка
Нравятся лягушки больше, чем лампочки? С нами все в порядке. Нам нравятся ребята из Screaming Frog, и мы знаем, что многие из вас, ребята, используют старую Frog в течение многих лет (но дайте нам шанс, если хотите, с нашей супер-бесплатной пробной версией), и это может помочь вам определить, что надоедливый дублированный контент.
Если вы хотите узнать, как это сделать, вы можете щелкнуть эту текстовую ссылку без привязки здесь (даже я не такой уж хороший).
Botify
При работе с сайтами электронной коммерции ребята из Boom будут использовать Botify и Sitebulb для проверки дублирующегося контента. Несмотря на то, что в настоящее время это немного дорого, у него есть отличная функциональность для того, чтобы найти то, что вам нужно.
Пример сайта с небольшим дублированием:
Пример Пример. это сказал Марлон Брандо — или Барри Адамс, я не помню), так что никогда не забывайте, что у вас есть Google под рукой.
это сказал Марлон Брандо — или Барри Адамс, я не помню), так что никогда не забывайте, что у вас есть Google под рукой.
Думаю, у них в индексе много страниц Интернета. Конечно, я где-то это слышал.
Если вам нужно провести выборочную проверку перед запуском инструментов, вы всегда можете взять фрагмент своего сайта и добавить к нему цитаты, чтобы узнать, что предлагает Google.
Простой.
Что делать с дублирующимся контентом
Ух ты, ты продвинулся так далеко? Я тронут.
Теперь вы знаете, что такое дублированный контент, что его вызывает и как найти проблемы с дублирующимся контентом. Держу пари, вы хотите знать, как это исправить?
Придержи лошадей, Джон Уэйн. Прежде чем мы перейдем к исправлениям технической реализации, нам нужно посмотреть, как вы справляетесь с этим — это то, что приводит вас к применению правильного технического исправления.
Также стоит отметить, что иногда лучше просто ничего не делать. Это облегчает жизнь, верно?
Возможно, у вас есть небольшой сайт с несколькими проблемами, и Google уже выяснил ваши проблемы с дублирующимся контентом. Это все здорово, вам не нужно исправлять то, что Google выяснил сам. Тем не менее, всегда стоит следить за обнаруженными проблемами. Гугл может быть забывчивым.
Это все здорово, вам не нужно исправлять то, что Google выяснил сам. Тем не менее, всегда стоит следить за обнаруженными проблемами. Гугл может быть забывчивым.
Хотя я бы не рекомендовал просто оставлять задачи. Рассмотрим основные доступные вам варианты.
У вас должна быть трилогия, верно?
Вот 3 основные области, о которых вам нужно подумать, когда вы решаете, как вы будете справляться с обнаруженными вами проблемами с дублирующимся контентом.
Объединить
Иногда лучшим вариантом является объединение содержимого. Вы берете существующие страницы с дублирующимся контентом и размещаете их на одном URL-адресе (и перенаправляете остальные на эту страницу с помощью переадресации 301).
Консолидация часто является хорошим выбором, если URL-адреса содержат внешние ссылки. Вы объедините сигналы ранжирования на одной странице.
Вот несколько примеров, когда это может быть лучшим способом действий.
Точные дубликаты страниц — это может быть что-то вроде не-www против www и http против https, упомянутых ранее в статье.
Семантически похожие страницы — один из самых распространенных типов семантически похожих страниц либо родом из старых времен «одно ключевое слово — одна страница». Если контент довольно старый, есть шанс, что какой-то SEO просто нашел и заменил некоторые слова, а остальная часть контента в значительной степени дублируется. Опять же, если страницы старые, то на них могут быть ссылки, указывающие на них. Просто убедитесь, что вы поняли, какую версию лучше всего сохранить.
Консолидация также может работать немного по-другому. Используя канонические файлы (которых мы вскоре коснемся), вы можете консолидировать сигналы для Google, а не объединять фактический контент.
Вот несколько примеров, когда этот тип консолидации может быть лучшим способом действий.
Целевые страницы PPC — хотя их можно легко настроить для индексации, вы также можете объединить сигналы, чтобы сообщить Google, что содержимое этих страниц очень похоже на то, что находится на главной целевой странице.
URL-адреса параметров — как вы уже знаете из руководства, эти страницы могут быть проблематичными. Объединение сигналов — это простой способ убедиться, что Google знает, что они являются дублирующимся контентом, и вы хотите, чтобы они обрабатывались соответствующим образом.
Страницы фильтров — продукты на сайте могут получать и получают внешние ссылки, поэтому консолидация сигналов часто является лучшим способом дублирования контента, вызванного фильтрами, необходимыми для пользователей на сайте электронной коммерции.
Удалить
В других случаях может потребоваться полностью удалить страницу. Вы хотите, чтобы это исчезло. Он не представляет никакой ценности для пользователей или поисковых систем. Уберите оттуда этих плохих парней.
Когда вы должны просто полностью отказаться от страницы? Вот вам пара примеров.
Сокращенный контент — Не знаю, слышали ли вы это, но некоторым SEO-специалистам нравится заниматься какой-нибудь хитростью. Особенно в те дни, когда мы еще не стали маяками маркетинговой индустрии, которыми мы являемся сейчас. Если на вашем сайте есть контент, скопированный с других сайтов, избавьтесь от него. Google знает, что вы сделали. Пришло время очистить и убить эти страницы.
Особенно в те дни, когда мы еще не стали маяками маркетинговой индустрии, которыми мы являемся сейчас. Если на вашем сайте есть контент, скопированный с других сайтов, избавьтесь от него. Google знает, что вы сделали. Пришло время очистить и убить эти страницы.
Просроченные продукты — ладно, это немного необычно, но всегда полезно иметь примеры из реальной жизни. У нас был клиент с несколькими тысячами продуктов с истекшим сроком годности, которые никогда не возвращались.
Есть много способов справиться с просроченными продуктами. Это только один.
Большинство страниц на сайте этого клиента по-прежнему получали показы и трафик, поэтому на них были формы для захвата электронной почты. Проблема заключалась в том, что их серверная часть замедляла работу их продавцов.
Нехорошо.
Многие из них были почти дубликатами. Таким образом, после извлечения всех данных мы перенаправили некоторые из них, но там, где у нас были некоторые, которые почти не получали показов, И нам некуда было их перенаправить, мы просто убивали их ответом 410 «Ушел». Все оказалось набухшим.
Все оказалось набухшим.
Сделать уникальным
Наконец, у нас есть возможность сделать эти дубликаты уникальными. Если у страниц есть реальная причина для существования (т. е. они имеют объем поиска и полезны для пользователя), то вам придется засучить рукава и немного поработать над ними.
На самом деле важные страницы местоположения — если у вас есть несколько офисов или обычных магазинов, то у вас, вероятно, есть контактные страницы для каждого из них. Также есть большая вероятность, что они являются почти дубликатами и могут появиться в результатах поиска, если на них есть уникальный контент. Я бы рекомендовал сделать их уникальными следующими способами.
- Уникальные теги заголовков
- Уникальные метаописания
- Схема проезда к месту с указанием местных достопримечательностей
- Уникальная копия
- Подробная информация о команде и услугах, уникальных для этого места
Варианты продуктов, которые имеют объемы поиска — никогда не будет времени, когда вы захотите проиндексировать все варианты страницы продукта — а индексируемые фильтры создают множество уникального контента, который бессмысленен.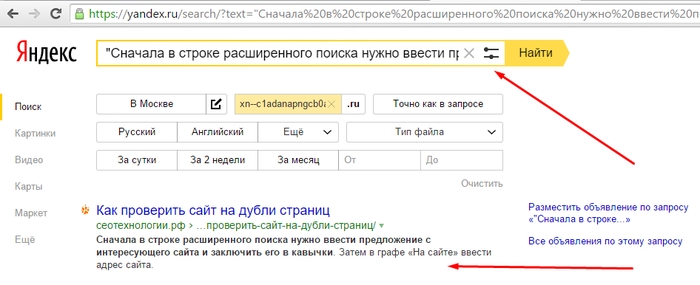
Но это не значит, что вы не хотите, чтобы *некоторые* из них были проиндексированы.
Хотите пример?
С удовольствием обязуюсь.
Бум работает с компанией, которая продает бытовую технику. На их старом сайте были фильтры, создававшие уникальные страницы — буквально сотни тысяч. Дублированный контент выходит из наших ушей. Но некоторые фильтры приводили к страницам с приличным объемом поиска вокруг них. Поэтому, когда мы переделали их сайт в WordPress, мы также создали плагин, который позволил нам полностью контролировать страницы фильтров.
По умолчанию страницы фильтра канонизируются обратно на родительскую страницу. Но когда мы указываем, что страница должна быть уникальной, создается действительный URL-адрес (в отличие от обычного WordPress).
Оттуда мы можем создать:
- Уникальный тег заголовка
- Уникальное метаописание
- Уникальный заголовок h2
- Уникальный контент, который находится выше и/или ниже продуктов
Сейчас мы работаем с 1400 из них!
Технические исправления проблем с дублирующимся содержимым
Теперь, когда вы потратили некоторое время на изучение имеющихся проблем и способов их устранения, вам нужно знать, КАК вы делаете эти исправления.
Вот краткий обзор некоторых технических реализаций, которые могут быть выполнены, чтобы избавить вас от кошмаров дублированного контента.
Канонизация
Тег canonical — иногда также называемый rel canonical — был введен в феврале 2009 года, кстати, примерно в то время, когда я как следует занялся SEO. Мне, как новичку, потребовалось некоторое время, чтобы прийти в себя. На самом деле, это довольно простая концепция.
Канонический тег — это способ сообщить поисковым системам, какую страницу вы хотите рассматривать как основную копию любой данной страницы.
Есть два типа канонических; давайте быстро взглянем на них.
Канонизация вашего сайта
Вы можете использовать тег canonical на своем сайте, чтобы сообщить Google, что создаваемые страницы являются точными или почти дубликатами более сильной и важной страницы. По сути, вы говорите: «Окей, Google, я знаю, что эта страница очень похожа на другую страницу, и я хочу, чтобы вы проиндексировали и ранжировали именно эту страницу, пожалуйста, продолжайте».![]()
Междоменная канонизация
Второй тип канонического — междоменный канонический. Это используется, когда один и тот же контент публикуется более чем в одном домене. Он используется, чтобы сообщить Google, какой контент вы хотели бы проиндексировать и ранжировать.
Перенаправления
Я довольно подробно рассказал о перенаправлениях в недавнем руководстве по перенаправлениям, поэтому загляните туда, если хотите узнать больше.
Мета-роботы noindex
В отличие от rel=canonical, noindex является директивой, а не предложением. Google может игнорировать канонические символы, если посчитает, что вы внедрили их неправильно или по ошибке. Когда дело доходит до noindex, Google будет делать именно то, что вы ему скажете. Так что используйте с осторожностью.
Также рекомендуется не переключаться между index и noindex, потому что это может запутать Google.
«В целом, я думаю, что эти колебания между индексированными и неиндексированными могут немного сбить нас с толку.
Потому что, если мы увидим страницу, которая не индексируется в течение длительного периода времени, мы предположим, что это что-то вроде страницы 404, и нам не нужно сканировать ее так часто.
Так что, вероятно, происходит то, что мы видим эти страницы как неиндексированные и решаем не сканировать их так часто, независимо от того, что вы отправляете в файле карты сайта.
Так что здесь… колебание метаданных noindex здесь контрпродуктивно, если вы действительно хотите, чтобы эти страницы время от времени индексировались».
Джон Мюллер, Google рассказывает, как метатег Noindex может вызывать проблемы
Быстрый совет. Никогда не смешивайте Noindex и Rel=Canonical на одной странице. Google посылает смешанные сигналы. Смешанные сигналы никогда не бывают хорошими. Никогда не пересекайте ручьи. Не верите мне? Давайте проверим у Джона.
«Отсюда и совет, что не следует смешивать noindex и rel=canonical: для нас это очень противоречивая информация. Обычно мы выбираем rel=canonical и используем его вместо noindex, но каждый раз, когда вы полагаетесь на интерпретацию компьютерным скриптом, вы уменьшаете вес своего ввода 🙂 (и SEO в значительной степени заключается в том, чтобы сообщать компьютерным скриптам ваши предпочтения)».
Обычно мы выбираем rel=canonical и используем его вместо noindex, но каждый раз, когда вы полагаетесь на интерпретацию компьютерным скриптом, вы уменьшаете вес своего ввода 🙂 (и SEO в значительной степени заключается в том, чтобы сообщать компьютерным скриптам ваши предпочтения)».
Джон Мюллер, Reddit r/TechSEO, 2018
«Эгон: не переходи ручьи.
Питер: Почему?
Эгон: Было бы плохо.
Питер: Я не совсем понимаю, что такое хорошо/плохо. Что вы имеете в виду под «плохим»?
Эгон: Попробуй представить, что вся жизнь, какой ты ее знаешь, мгновенно останавливается, а каждая молекула в твоем теле взрывается со скоростью света.
Рэймонд: Полная инверсия протонов.
Питер: Это плохо. Хорошо. Хорошо, важный совет по безопасности, спасибо, Эгон.
Охотники за привидениями
Обработка параметров в Google Search Console
Да, это все еще актуально для тех, кто помнит старый не очень полезный GSC.
Он просто спрятан.
Эта функция в Google Search Console позволяет вам указать Google, как именно вы хотите, чтобы он обрабатывал различные параметры на вашем сайте. Как это работает — это совсем другое руководство — и кто знает, скоро ли Google откажется от него, поэтому позвольте мне просто отправить вас к другим хорошим руководствам.
- Как использовать параметры URL в Google Search Console — Seer Interactive
- Как использовать параметры URL в инструменте Google Search Console — ShoutMeLoud
- SEO-руководство по обработке параметров URL — журнал поисковой системы
Рекомендации по предотвращению дублирования содержимого
Согласованность
Как и во многих других вещах в жизни, согласованность имеет решающее значение. Особенно, когда вы работаете над сайтами приличного размера.
Создавайте рабочие процессы и рекомендации для всех, кто работает над сайтом, и следите за их соблюдением. Процессы и руководство должны быть предоставлены для следующего (как минимум).
- Добавление уникальных тегов заголовков и оптимизация
- Создание уникальных метаописаний и способы оптимизации
- Создание уникальных тегов h2 и способы оптимизации
- На какие версии страниц ссылаться (с косой чертой в конце и без)
Канонические ссылки на самих себя для защиты от парсеров
Помимо других технических причин, быстрый способ борьбы с ленивыми парсерами, копирующими ваш контент, заключается в добавлении канонических ссылок на каждую страницу вашего сайта. В то время как Google довольно хорошо разбирается в подобных вещах, это легко реализовать на большинстве сайтов, поэтому вы также можете включить его. Это сообщит Google, что вы являетесь первоначальным источником контента.
Хотя это зависит от сайта, стоит отметить, что ваш собственный сайт также может извлечь выгоду из канонических ссылок на себя.
Многие из ваших URL-адресов могут иметь идентификатор сеанса или параметры отслеживания. Они будут иметь тот же контент, что и исходный URL. Используя самоссылающиеся канонические ссылки для такого рода дублированного контента, вы немедленно даете Google намек на то, что знаете, что они дублируются.
Они будут иметь тот же контент, что и исходный URL. Используя самоссылающиеся канонические ссылки для такого рода дублированного контента, вы немедленно даете Google намек на то, что знаете, что они дублируются.
Вот как это будет выглядеть:
https://jonathanpryceperlink.com?grrtrackingmakeduplicate
Имея каноническую ссылку на себя, Google увидит в качестве исходного URL-адреса следующее:
https://jonathanpryceperlink.com
Уникальный контент продукта
Но, но Уэйн, так много. Да, я понимаю твою боль. Сайты электронной коммерции часто имеют тысячи продуктов. У кого есть время, чтобы написать весь этот контент? У кого есть бюджет, чтобы нанять штатного копирайтера? Некоторые делают, но далеко не все.
Есть несколько способов обойти это.
Возьмите свои лучшие продукты и перепишите описания с учетом конверсии, и посмотрите, что получится. Отслеживайте изменения в Google Search Console и смотрите, как они работают. Вам не обязательно делать их все за один раз.
Вам не обязательно делать их все за один раз.
Как вы решаете, над чем работать? Возьмите те, которые уже работают хорошо, убедитесь, что это продукты с хорошей наценкой, а также добавьте в уравнение объем поиска. Вставьте все это в таблицы Excel или Google и поиграйте с данными.
Что насчет ИИ? Ну, я недавно немного возился с этим. Становится лучше и доступнее. Я бы не советовал полностью избавляться от человеческой стороны (пожалуйста, не надо), но она может стать достойным трамплином для создания уникального масштабного контента.
Хотите несколько примеров? Конечно. Вот так.
Давайте придерживаться сайта бытовой техники. Все они были сгенерированы из менее чем 200 символов текста подсказки:
———————
Холодильник с морозильной камерой в американском стиле — отличный выбор. если вы ищете холодильник с морозильной камерой, который предлагает много места, а также некоторые дополнительные функции, такие как лед и вода. Внутри холодильника вы найдете несколько прочных полок, в том числе…
Внутри холодильника вы найдете несколько прочных полок, в том числе…
———————
Холодильник с морозильной камерой американского типа изготовлен из качественных материалов, рассчитанных на долгий срок службы. Очень большая вместимость предоставит вам много места для любимых блюд вашей семьи. У вас не возникнет проблем с поиском идеального холодильника с морозильной камерой в американском стиле благодаря…
———————
созданный в соответствии с вашими потребностями. Они бывают разных размеров и могут быть найдены в конструкции морозильной камеры «бок о бок» или «верхнее дно». Большинство моделей будут включать в себя дополнительные функции, такие как диспенсеры для льда и воды, чтобы…
———————
Идеально? Неа. Попасть туда? Да. Наблюдайте за этим пространством.
Вот несколько инструментов, которые вы можете попробовать:
- Нейронный текст
- CopyAI
- Копировальная мастерская
- Conversion. ai
 ai
aiПросто ради смеха, я увидел, как хорошо некоторые из них могут описать Sitebulb.
Sitebulb — единственный поисковый робот для веб-сайтов, который анализирует данные с точки зрения SEO, предоставляя вашим клиентам действенные аудиты веб-сайтов. Он предназначен для SEO-консультантов и агентств, которые хотят тратить меньше времени на ручную проверку и больше времени на прибыльные задачи.
Sitebulb — это сканер веб-сайтов, который сканирует ваш сайт так же, как поисковый робот, находя все мертвые ссылки и страницы, на которые нет ссылок на других страницах. Sitebulb также собирает информацию о спине сети…
«Любая достаточно продвинутая технология неотличима от магии».
Артур К. Кларк, три закона Кларка
Хорошо, теперь вы там. Вы знаете, какие повторяющиеся проблемы могут возникнуть на сайте и как вы можете их исправить. Теперь вам просто нужно их исправить.
Теперь на вашем пути только два препятствия.
Убедить клиента и заставить разработчиков внедрить исправления.
Сообщите о проблемах с дублирующимся контентом
Как вы, возможно, знаете из других моих сообщений Sitebulb, я заинтересован в том, чтобы на самом деле реализовывать дерьмо. Аудит ничего не стоит, если что-то не реализовано. Аудит — это самое простое. SEO-специалисты знают свое дело. Но они не обязательно знают, как сообщить об этом клиентам. Они не знают, как убедить разработчиков внедрить исправления, даже если клиент дал согласие.
Итак, давайте посмотрим, как это сделать. Клиенты и разработчики — очень разные звери.
Как сообщать клиентам о проблемах с дублированием контента
Говорите проще и глупее (KISS)
Да, они были веселой группой, но я сейчас не об этом, так что уберите свой длинный язык и театральный грим.
KISS — это аббревиатура от «будь проще и глупее», которая была популяризирована ВМС США в 1960 году. На нее в основном ссылаются, когда речь идет о дизайнерских работах, но она также применима и для получения поддержки от клиентов.
Клиенты заняты; клиенты часто не так много знают о SEO. Так что не тратьте время на обсуждение всех технических деталей. Вам нужно быстро донести свою точку зрения; слишком глубокое копание в данных приведет к тому, что клиент потеряет интерес и перейдет к тому, о чем будет его следующая встреча или какое важное решение он должен принять в этот день.
Чем меньше, тем лучше.
Покажите, как это может вписаться в более широкие цели компании
Это то, что заботит клиента. «Как это поможет моим бизнес-целям?» Электронная таблица и разговоры о пагинации, параметрах URL и истории скейпинга не приведут к тому, что ваши рекомендации будут подписаны. Перед презентацией вам нужно знать, каковы эти цели. Зная их, вы можете адаптировать свои рекомендации.
Это не каждый раз одно и то же, поверь мне.
Знайте, что движет их лодкой
Скорее всего, вы будете пытаться получить разрешение на исправление дублированного контента на раннем этапе отношений с клиентом. В Boom аудит — это одно из первых дел, которые мы берем на себя. Какие бы стратегии и тактики ни появились позже, они основаны на прочном фундаменте.
В Boom аудит — это одно из первых дел, которые мы берем на себя. Какие бы стратегии и тактики ни появились позже, они основаны на прочном фундаменте.
Это означает, что вы не будете знать их так хорошо. Так что найдите время, чтобы узнать. Поговорите с другими, кто имел с ними дело. Если у вас есть доступ к другим людям в команде, расспросите их (осторожно), чтобы узнать, что помогает получить одобрение.
Им нравятся данные? Аналогии? Как им нравятся вещи, которые им преподносят?
Зная это, вы повысите шансы на то, что они одобрят ваши рекомендации.
Как сообщать разработчикам о проблемах с дублирующимся контентом
Изучите жаргон разработчиков
Знаете ли вы, что означает скрам? Вы знаете, что значит работать agile? Вы знаете, что такое стори-пойнтинг?
Если нет, то самое время начать учиться. У команд разработчиков совершенно другой способ работы, чем у маркетинговых команд. Они берегут свое время. Работа происходит спринтами. Когда вы знаете, как на самом деле, э-э, работает команда, с которой вы собираетесь работать, вы можете увидеть, как ваши рекомендации будут соответствовать ей.
Когда вы знаете, как на самом деле, э-э, работает команда, с которой вы собираетесь работать, вы можете увидеть, как ваши рекомендации будут соответствовать ей.
Возможность корректировать свою работу помогает выполнять рекомендации, это помогает им выполняться так, как вы хотите, и это, безусловно, ускоряет их выполнение.
Разделение проблем
Не существует универсального решения для устранения проблем с дублированием содержимого. Вы, наверное, поняли это сами, если дочитали эту статью до конца. Но команда разработчиков может не знать об этом. Так что вам нужно не только объяснить, почему это важно, но и объяснить им это.
Я не имею в виду снисходительное «это идет сюда» и «если вы нажмете эту кнопку, произойдет волшебство». Я говорю о том, чтобы принять каждое исправление и объяснить, почему это может потребоваться сделать именно так. Разработчики любят находить элегантные решения проблем. Но иногда вам нужно решать разные проблемы по-разному.
Понять их технический стек
Я уже рассказывал об этом в своем посте о различиях и особенностях различных CMS. Если вы хотите, чтобы ваши рекомендации были реализованы, найдите время, чтобы узнать, что они используют. Некоторые CMS просто не имеют возможности развертывать определенные исправления. Некоторые CMS ограничены в возможностях команды разработчиков.
Если вы хотите, чтобы ваши рекомендации были реализованы, найдите время, чтобы узнать, что они используют. Некоторые CMS просто не имеют возможности развертывать определенные исправления. Некоторые CMS ограничены в возможностях команды разработчиков.
Если вы заранее знаете эти ограничения, вы можете быть уверены, что не требуете невозможного.
Понимание шкалы Андерсона-Алдерсона
Что-что?
Это взято из поста Майка Кинга (также известного как ipullrank) на сайте Search Engine Land еще в 2017 году. Он демонстрирует сверхъестественный способ понять, как заставить разработчиков выполнять рекомендации по SEO, и вдобавок содержит отсылки к поп-культуре. Перфик.
Эм, «что?» Я слышу, как ты плачешь.
Давайте разберемся.
В статье Майк обсуждает двух вымышленных персонажей, Томаса Андерсона из фильма «Матрица» и Эллиота Алдерсона из телешоу «Мистер Робот».
Как указывает Майк в статье, Томас Андерсон немного ренегат, независимый сотрудник.
«У вас проблема, мистер Андерсон. Ты думаешь, что ты особенный. Вы считаете, что каким-то образом правила к вам неприменимы».
Босс Томаса Андерсона, Матрица
Майк излагает это более красноречиво, чем я когда-либо мог, и я не хочу перефразировать.
«Разработчики Anderson — это тип сотрудников, которые живут на своих условиях и делают что-то только тогда, когда им хочется. Это индивидуалисты, которые будут спорить с вами о достоинствах руководств по стилю кода, о том, почему они полностью убрали метатеги из своей собственной CMS и почему они никогда не будут внедрять AMP — между тем, ни одна строка их кода не подтверждается. против спецификаций, которые им дороги.
Они также являются разработчиками, которые закатывают глаза на ваши рекомендации или говорят о том, что они знают обо всех «SEO-оптимизациях», которые вы представляете, у них просто не было времени их сделать. Конечно, мистер Андерссссон.
Майк Кинг, Как заставить разработчиков реализовать рекомендации по SEO
С другой стороны, у вас есть сторона Олдерсона, основанная на персонаже, которого Рами Малек, который вскоре станет Фредди Меркьюри, сыграл в «Мистере Роботе». Еще раз процитирую Майка.
Еще раз процитирую Майка.
«Олдерсон относится к тому типу людей, которые приходят в офис в 2 часа ночи, чтобы починить сломанные вещи, и даже заходят так далеко, что в ту же ночь прыгают на самолете компании, чтобы разобраться в последнем крахе сети.
Разработчики типа Алдерсона жаждут немедленно реализовать ваши рекомендации. Это не потому, что они обязательно заботятся о рейтинге, а потому, что они заботятся о том, чтобы быть хорошими в том, что они делают.
Этот тип разработчика внимателен и позвонит вам по телефону. если не знаешь о чем говоришь. Так что не приходите с рекомендациями по асинхронному JavaScript, не понимая, как он работает».
Майк Кинг, Как заставить разработчиков реализовать рекомендации по SEO
Я предлагаю вам пойти и прочитать эту статью, так как это потерянная жемчужина в мире статей о SEO, но она сводится к этому. Если вы хотите, чтобы ваши рекомендации были реализованы разработчиками с наименьшими затратами, вам нужно знать, что они за разработчик.