Парсим сайты и превращаем их в данные
Парсите содержимое сайтов в данные
Запускайте парсеры в облаке
или на вашем компьютере
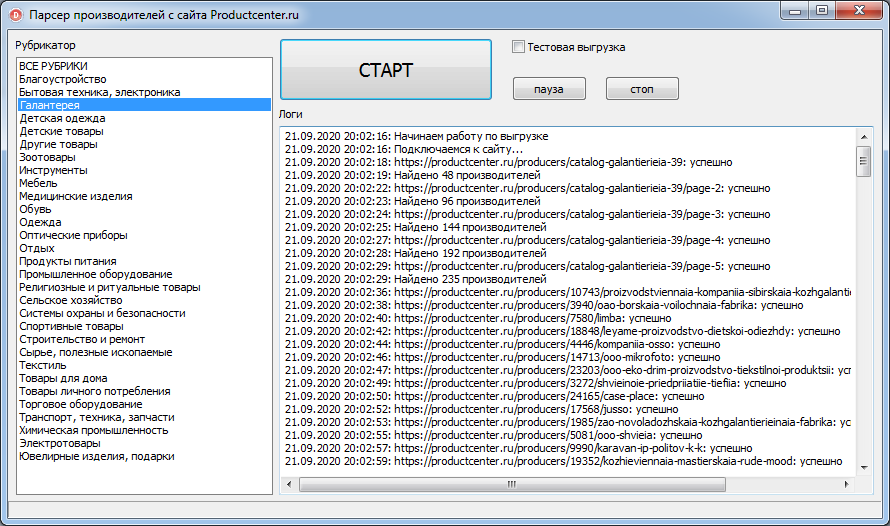
КАТАЛОГ БЕСПЛАТНЫХ ПАРСЕРОВ
Парсите страницы сайтов в структуры данных
Что такое Диггернаут и что такое диггер?
Диггернаут — это облачный сервис для парсинга сайтов, сбора информации и других ETL (Extract, Transform, Load) задач. Если ваш бизнес лежит в плоскости торговли и ваш поставщик не предоставляет вам данные в нужном вам формате, например в csv или excel, мы можем вам помочь избежать ручной работы, сэкономив ваши время и деньги!
Все, что вам нужно сделать — создать парсер (диггер), крошечного робота, который будет парсить сайты по вашему запросу, извлекать данные, нормализовать и обрабатывать их, сохранять массивы данных в облаке, откуда вы сможете скачать их в любом из доступных форматов (например, CSV, XML, XLSX, JSON) или забрать в автоматическом режиме через наш API.
Какую информацию может добывать Диггернаут?
- Цены и другую информацию о товарах, отзывы и рейтинги с сайтов ритейлеров.
- Данные о различных событиях по всему миру.
- Новости и заголовки с сайтов различных новостных агентств и агрегаторов.
- Данные для статистических исследований из различных источников.
- Открытые данные из государственных и муниципальных источников. Полицейские сводки, документы по судопроизводству, росреест, госзакупки и другие.
- Лицензии и разрешения, выданные государственными структурами.
- Мнения людей и их комментарии по определенной проблематике на форумах и в соцсетях.
- Информация, помогающая в оценке недвижимости.

- Или что-то иное, что можно добыть с помощью парсинга.
Должен ли я быть экспертом в программировании?
Если вы никогда не сталкивались с программированием, вы можете использовать наш специальный инструмент для построения конфигурации парсера (диггера) — Excavator. Он имеет графическую оболочку и позволяет работать с сервисом людям, не имеющих теоретических познаний в программировании. Вам нужно лишь выделить данные, которые нужно забрать и разместить их в структуре данных, которую создаст для вас парсер. Для более простого освоения этого инструмента, мы создали серию видео уроков, с которыми вы можете ознакомиться в документации.
Если вы программист или веб-разработчик, знаете что такое HTML/CSS и готовы к изучению нового, для вас мы приготовили мета-язык, освоив который вы сможете решать очень сложные задачи, которые невозможно решить с помощью конфигуратора Excavator.
Если вы не хотите тратить свое время на освоение конфигуратора Excavator или мета-языка и хотите просто получать данные, обратитесь к нам и мы создадим для вас парсер в кратчайшие сроки.
БЕСПЛАТНАЯ РЕГИСТРАЦИЯ
Люди спрашивают, Диггернаут отвечает
ЗАЧЕМ МНЕ НУЖЕН ДИГГЕРНАУТ?
Если вы собираете данные для вашего бизнеса вручную, то наверняка вы тратите на это часы или даже дни, или даже нанимаете людей, которые это делают. С Диггернаутом, вы соберете информацию за минуты. Это сэкономит ваше время и деньги.
ОДИН ДИГГЕР ДЛЯ СБОРА ИНФОРМАЦИИ С РАЗНЫХ САЙТОВ?
Диггер не ограничен одной страницей, он может собирать данные с множественных страниц одного сайта, или даже с разных сайтов. Другими словами, диггер может переходить с одной страницы на другую без всяких проблем.
Другими словами, диггер может переходить с одной страницы на другую без всяких проблем.
МОГУ ЛИ Я ЗАПУСКАТЬ ДИГГЕР У СЕБЯ НА КОМПЬЮТЕРЕ? ДОЛЖЕН ЛИ Я БУДУ ПЛАТИТЬ ЗА ЭТО?
Вы можете скомпилировать ваш диггер и запускать на своем компьютере или сервере так часто и много, как вам требуется. Вам не нужно оплачивать подписку, чтобы использовать скомпилированный диггер.
НА ЧЕМ НАПИСАН ДИГГЕРНАУТ?
Мы используем Golang как язык программирования для наших сервисов. Это позволяет нам держать наши цены на достаточно низком уровне, поскольку по сравнению со многими другими языками программирования, Golang намного эффективнее в этом случае.
У ВАС ЕСТЬ ПРОБНЫЙ ПЕРИОД?
Мы предлагаем бесплатную регистрацию с бесплатным планом, это лучше пробного периода, поскольку вы можете пользоваться вашим бесплатным аккаунтом вечно, пока вам хватает ресурсов.
МОГУ ЛИ Я ИЗВЛЕКАТЬ ТЕКСТ ИЗ КАРТИНОК?
Да, мы предоставляем функционал OCR, однако эта функция доступна только в облаке и не доступна в скомпилированных диггерах.
Интегрировано с
Zapier
Zapier автоматически перемещает данные между вашими веб-приложениями.
Zapier | ИспользованиеTableau
Tableau — Business Intelligence платформа, лидер рынка платформ для бизнес-аналитики.
Tableau | ИспользованиеruCaptcha
Еще один сервис с помощью которого вы сможете обходить капчи любой сложности.
rucaptcha | ИспользованиеAnti-captcha
С помощью сервиса Anti-captcha вы можете обходить капчи любой сложности.
DeathByCaptcha
С помощью сервиса Death by Captcha вы можете обходить капчи любой сложности.
Deathbycaptcha | ИспользованиеASocks
ASocks предлагает быстрые, легитимные, безлимитные резидентские прокси-сервера.
Proxy-Seller
Proxy-Sellers предоставляют прокси из более чем 100 сетей и 300 различных подсетей.
Proxy-Seller | ИспользованиеBlazing SEO
Инфраструктура поддерживает миллиарды скраперов каждый месяц.
Blazing SEO | ИспользованиеКак спарсить любой сайт? / Хабр
Меня зовут Даниил Охлопков, и я расскажу про свой подход к написанию скриптов, извлекающих данные из интернета: с чего начать, куда смотреть и что использовать.
Написав тонну парсеров, я придумал алгоритм действий, который не только минимизирует затраченное время на разработку, но и увеличивает их живучесть, робастность, масштабируемость.
TL;DR
Чтобы спарсить данные с вебсайта, пробуйте подходы именно в таком порядке:
Найдите официальное API,
Найдите XHR запросы в консоли разработчика вашего браузера,
Найдите сырые JSON в html странице,
Отрендерите код страницы через автоматизацию браузера,
Если ничего не подошло — пишите парсеры HTML кода.
Совет профессионалов: не начинайте с BS4/Scrapy
BeautifulSoup4 и Scrapy — популярные инструменты парсинга HTML страниц (и не только!) для Python.
Крутые вебсайты с крутыми продактами делают тонну A/B тестов, чтобы повышать конверсии, вовлеченности и другие бизнес-метрики. Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Приходим к выводу, что не надо извлекать данные из HTML тегов раньше времени: разметка страницы может сильно поменяться, а CSS-селекторы и XPath могут не помочь. Используйте другие методы, о которых ниже. ⬇️
Используйте официальный API
👀 Ого? Это не очевидно 🤔? Конечно, очевидно! Но сколько раз было: сидите пилите парсер сайта, а потом БАЦ — нашли поддержку древней RSS-ленты, обширный sitemap.xml или другие интерфейсы для разработчиков. Становится обидно, что поленились и потратили время не туда. Даже если API платный, иногда дешевле договориться с владельцами сайта, чем тратить время на разработку и поддержку.
Sitemap.xml — список страниц сайта, которые точно нужно проиндексировать гуглу. Полезно, если нужно найти все объекты на сайте. Пример: http://techcrunch.com/sitemap.xml
RSS-лента — API, который выдает вам последние посты или новости с сайта. Было раньше популярно, сейчас все реже, но где-то еще есть! Пример: https://habr.com/ru/rss/hubs/all/
Поищите XHR запросы в консоли разработчика
Кабина моего самолетаВсе современные вебсайты (но не в дарк вебе, лол) используют Javascript, чтобы догружать данные с бекенда. Это позволяет сайтам открываться плавно и скачивать контент постепенно после получения структуры страницы (HTML, скелетон страницы).
Обычно, эти данные запрашиваются джаваскриптом через простые GET/POST запросы. А значит, можно подсмотреть эти запросы, их параметры и заголовки — а потом повторить их у себя в коде! Это делается через консоль разработчика вашего браузера (developer tools).
В итоге, даже не имея официального API, можно воспользоваться красивым и удобным закрытым API. ☺️
☺️
Даже если фронт поменяется полностью, этот API с большой вероятностью будет работать. Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Алгорим действий такой:
Открывайте вебстраницу, которую хотите спарсить
Правой кнопкой -> Inspect (или открыть dev tools как на скрине выше)
Открывайте вкладку Network и кликайте на фильтр XHR запросов
Обновляйте страницу, чтобы в логах стали появляться запросы
Найдите запрос, который запрашивает данные, которые вам нужны
Копируйте запрос как cURL и переносите его в свой язык программирования для дальнейшей автоматизации.
Вы заметите, что иногда эти XHR запросы включают в себя огромные строки — токены, куки, сессии, которые генерируются фронтендом или бекендом. Не тратьте время на ревёрс фронта, чтобы научить свой парсер генерировать их тоже.
Не тратьте время на ревёрс фронта, чтобы научить свой парсер генерировать их тоже.
Вместо этого попробуйте просто скопипастить и захардкодить их в своем парсере: очень часто эти строчки валидны 7-30 дней, что может быть окей для ваших задач, а иногда и вообще несколько лет. Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Поищите JSON в HTML коде страницы
Как было удобно с XHR запросами, да? Ощущение, что ты используешь официальное API. 🤗 Приходит много данных, ты все сохраняешь в базу. Ты счастлив. Ты бог парсинга.
Но тут надо парсить другой сайт, а там нет нужных GET/POST запросов! Ну вот нет и все. И ты думаешь: неужели расчехлять XPath/CSS-selectors? 🙅♀️ Нет! 🙅♂️
Чтобы страница хорошо проиндексировалась поисковиками, необходимо, чтобы в HTML коде уже содержалась вся полезная информация: поисковики не рендерят Javascript, довольствуясь только HTML. А значит, где-то в коде должны быть все данные.
А значит, где-то в коде должны быть все данные.
Современные SSR-движки (server-side-rendering) оставляют внизу страницы JSON со всеми данные, добавленный бекендом при генерации страницы. Стоп, это же и есть ответ API, который нам нужен! 😱😱😱
Вот несколько примеров, где такой клад может быть зарыт (не баньте, плиз):
Красивый JSON на главной странице Habr.com. Почти официальный API! Надеюсь, меня не забанят.И наш любимый (у парсеров) Linkedin!Алгоритм действий такой:
В dev tools берете самый первый запрос, где браузер запрашивает HTML страницу (не код текущий уже отрендеренной страницы, а именно ответ GET запроса).
Внизу ищите длинную длинную строчку с данными.
Если нашли — повторяете у себя в парсере этот GET запрос страницы (без рендеринга headless браузерами). Просто
requests.get.Вырезаете JSON из HTML любыми костылямии (я использую
html.find("={")).
Отрендерите JS через Headless Browsers
Если XHR запросы требуют актуальных tokens, sessions, cookies.
Если коротко, то есть инструменты, которые позволяют управлять браузером: открывать страницы, вводить текст, скроллить, кликать. Конечно же, это все было сделано для того, чтобы автоматизировать тесты веб интерфейса. I’m something of a web QA myself.
После того, как вы открыли страницу, чуть подождали (пока JS сделает все свои 100500 запросов), можно смотреть на HTML страницу опять и поискать там тот заветный JSON со всеми данными.
driver.get(url_to_open) html = driver.page_source
Selenoid — open-source remote Selenium cluster
Для масштабируемости и простоты, я советую использовать удалённые браузерные кластеры (remote Selenium grid).
Недавно я нашел офигенный опенсорсный микросервис Selenoid, который по факту позволяет вам запускать браузеры не у себя на компе, а на удаленном сервере, подключаясь к нему по API.
Вот так я подключаюсь к Selenoid из своего кода: по факту нужно просто указать адрес запущенного Selenoid, но я еще зачем-то передаю кучу параметров бразеру, вдруг вы тоже захотите. На выходе этой функции у меня обычный Selenium driver, который я использую также, как если бы я запускал браузер локально (через файлик chromedriver).
def get_selenoid_driver(
enable_vnc=False, browser_name="firefox"
):
capabilities = {
"browserName": browser_name,
"version": "",
"enableVNC": enable_vnc,
"enableVideo": False,
"screenResolution": "1280x1024x24",
"sessionTimeout": "3m",
# Someone used these params too, let's have them as well
"goog:chromeOptions": {"excludeSwitches": ["enable-automation"]},
"prefs": {
"credentials_enable_service": False,
"profile. password_manager_enabled": False
},
}
driver = webdriver.Remote(
command_executor=SELENOID_URL,
desired_capabilities=capabilities,
)
driver.implicitly_wait(10) # wait for the page load no matter what
if enable_vnc:
print(f"You can view VNC here: {SELENOID_WEB_URL}")
return driver password_manager_enabled": False
},
}
driver = webdriver.Remote(
command_executor=SELENOID_URL,
desired_capabilities=capabilities,
)
driver.implicitly_wait(10) # wait for the page load no matter what
if enable_vnc:
print(f"You can view VNC here: {SELENOID_WEB_URL}")
return driver
password_manager_enabled": False
},
}
driver = webdriver.Remote(
command_executor=SELENOID_URL,
desired_capabilities=capabilities,
)
driver.implicitly_wait(10) # wait for the page load no matter what
if enable_vnc:
print(f"You can view VNC here: {SELENOID_WEB_URL}")
return driverЗаметьте фложок enableVNC
Парсите HTML теги
Если случилось чудо и у сайта нет ни официального API, ни вкусных XHR запросов, ни жирного JSON внизу HTML, если рендеринг браузерами вам тоже не помог, то остается последний, самый нудный и неблагодарный метод. Да, это взять и начать парсить HTML разметку страницы. То есть, например, из <a href="https://okhlopkov.com">Cool website</a> достать ссылку. Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Мой единственный совет: постараться минимизировать число фильтров и условий, чтобы меньше переобучаться на текущей структуре HTML страницы, которая может измениться в следующем A/B тесте.
Даниил Охлопков — Data Lead @ Runa Capital
Подписывайтесь на мой Телеграм канал, где я рассказываю свои истории из парсинга и сливаю датасеты.
Надеюсь, что-то из этого было полезно! Я считаю, что в парсинге важно, с чего ты начинаешь. С чего начать — я рассказал, а дальше ваш ход 😉
Online Web Scraper Tool — Очистка веб-сайтов с помощью GrabzIt
Очистить данные из Интернета, независимо от того, как они хранятся, легко с помощью онлайн-инструмента Web Scraper от GrabzIt. Каждый созданный вами скрап будет использовать наш онлайн-мастер и следовать этим трем простым шагам.
Определение целевых веб-сайтов
Определите, с каких сайтов, разделов сайтов или файлов вы хотите извлечь данные. Затем запланируйте, когда вы хотите это сделать.
Затем запланируйте, когда вы хотите это сделать.
Укажите данные для очистки
Определите, какие части веб-страниц или файлов следует удалить. Затем укажите, как эти данные должны быть сохранены.
Пакет очищенных данных
Определите, в каких форматах файлов должны храниться данные. Наконец, укажите, как вы хотите, чтобы данные очистки передавались вам.
Для кого предназначен Web Scraper?
Этот парсер создан для того, чтобы им мог пользоваться каждый! Вам не нужно быть программистом, чтобы использовать его. Хотя, если вы опытный пользователь, у нас есть много дополнительных функций и для вас.
Веб-скребок поставляется с отличным онлайн-мастером, который использует простой интерфейс «укажи и щелкни» для автоматического создания инструкций, определяющих, какой контент нужно очистить. Это означает, что вам не нужно писать код или очень мало! Но мы не хотим останавливаться на достигнутом и всегда стараемся улучшить наш парсер, чтобы он был самым простым в Интернете.
На самом деле, чтобы выполнять общие задачи очистки, такие как; превращая веб-сайты в PDF, извлекая все ссылки или изображения проще. Мы создали серию готовых шаблонов. Итак, прежде чем вы начнете писать парсер, вы можете проверить, написали ли мы уже парсер или большую его часть для вас!
Какие типы данных можно очищать?
Существует множество причин для извлечения данных с веб-сайтов, в том числе получение цен на продукцию ваших конкурентов. Извлечение моментальных снимков последней финансовой информации в определенный момент времени или получение контактной информации из онлайн-телефонной книги.
Наш онлайн-инструмент для парсинга веб-страниц упрощает извлечение этой информации без необходимости использовать расширение для Chrome или обычное расширение для браузера. Со специальными функциями для автоматической обработки разбивки на страницы веб-страницы и множественных кликов на одной веб-странице.
Web Scraper также может собирать данные с любой части веб-страницы. Будь то содержимое элемента HTML, такого как div или span, значение CSS или атрибут элемента HTML. Любые метаданные или текст веб-страницы, хранящиеся в виде изображения, XML, JSON или PDF. Он также использует машинное обучение для автоматического понимания концепций. Например, это предложение, говорящее что-то положительное или отрицательное.
Будь то содержимое элемента HTML, такого как div или span, значение CSS или атрибут элемента HTML. Любые метаданные или текст веб-страницы, хранящиеся в виде изображения, XML, JSON или PDF. Он также использует машинное обучение для автоматического понимания концепций. Например, это предложение, говорящее что-то положительное или отрицательное.
Конечно, если вам нужен загрузчик изображений, то в качестве онлайн-скребка HTML любые изображения, которые вы хотите, могут быть загружены автоматически.
Как работает Web Scraper?
Одна из вещей, которая делает сервис GrabzIt уникальным, заключается в том, что это онлайн-инструмент. Это означает, что вам не нужно загружать какое-либо программное обеспечение, чтобы начать парсинг.
Тем не менее, он делает это, оставаясь очень сложным инструментом для извлечения данных. Он просматривает Интернет с помощью специального веб-браузера, который позволяет парсеру очищать как динамические, так и статические веб-страницы, например контент, созданный с помощью JavaScript или AJAX.
Кроме того, чтобы ускорить извлечение веб-данных, чтобы вы могли как можно быстрее получить результаты очистки. Каждая очистка использует несколько экземпляров браузера, каждый с другим прокси-сервером и пользовательским агентом, чтобы избежать блокировки. Это позволяет одновременно очищать несколько частей целевого веб-сайта.
Парсер GrabzIt очень интерактивен. Таким образом, он позволяет вам щелкать ссылки и кнопки, отправлять формы, набирать текст, бесконечно прокручивать и многое другое. Разрешение парсингу выполнять те же действия, что и пользователю-человеку. После того, как вы выбрали элемент, некоторые веб-скрейперы настаивают на создании сложных регулярных выражений для извлечения именно той части данных, которая вас интересует. Вместо этого мы позволяем вам использовать шаблоны, а затем мы создаем регулярное выражение в фоновом режиме, чтобы очищать данные для вас.
В качестве сборщика данных Grabz предоставляет средства для очистки данных. Это позволяет устранить любые несоответствия до того, как данные будут возвращены вам. Затем, после создания парсинга, его можно настроить для выполнения запланированного парсинга. Начинайте, когда хотите, и повторяйте, когда хотите.
Затем, после создания парсинга, его можно настроить для выполнения запланированного парсинга. Начинайте, когда хотите, и повторяйте, когда хотите.
Ваши данные доступны в режиме реального времени и могут быть выведены в нескольких различных форматах, чтобы вы могли максимально легко интегрировать их в свое приложение. Эти форматы включают Excel, XML, CSV, JSON, HTML и SQL для MySQL или SQL Server.
Но как вы взаимодействуете с этими данными? Вы можете отправить его вам или в место по вашему выбору. Или вы можете использовать опцию Callback URL, которая позволяет вам использовать наш API и автоматизировать весь процесс очистки. Тем более, что вы можете настроить запуск парсинга по регулярному расписанию, что означает, что у вас всегда будет самая свежая информация!
Многие веб-сайты хранят похожий контент на многих страницах, поэтому для получения всех данных, которые вам нужны, Web Scraper GrabzIt может переходить по ссылкам и искать контент, соответствующий вашим инструкциям по очистке, в любом месте веб-сайта.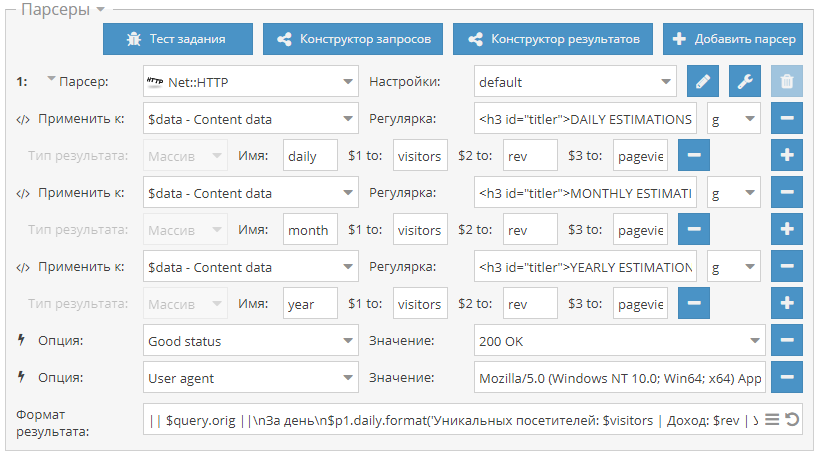 В качестве альтернативы вы можете указать точные веб-страницы, которые хотите очистить, или просто указать подраздел сайта для очистки. Мы даже предоставляем ежемесячное бесплатное пособие по очистке веб-страниц, так что вы можете попробовать прямо сейчас, не рискуя!
В качестве альтернативы вы можете указать точные веб-страницы, которые хотите очистить, или просто указать подраздел сайта для очистки. Мы даже предоставляем ежемесячное бесплатное пособие по очистке веб-страниц, так что вы можете попробовать прямо сейчас, не рискуя!
Начать парсинг
Собрать данные с любого веб-сайта в 1 клик
Недавно выпущенная версия 5.7!
добавить в Хром Это бесплатноData Miner — это расширение Google Chrome и расширение браузера Edge, которое помогает вам сканировать и очищать данные с веб-страниц. и в файл CSV или электронную таблицу Excel.
Data Miner — это расширение Google Chrome и расширение браузера Edge, которое помогает вам сканировать и очищать данные с веб-страниц и в файл CSV или электронную таблицу Excel.
Простой в использовании инструмент для автоматизации извлечения данных
Интуитивно понятный пользовательский интерфейс и рабочий процесс
Data Miner имеет интуитивно понятный пользовательский интерфейс, который поможет вам выполнять расширенное извлечение данных и сканирование веб-страниц.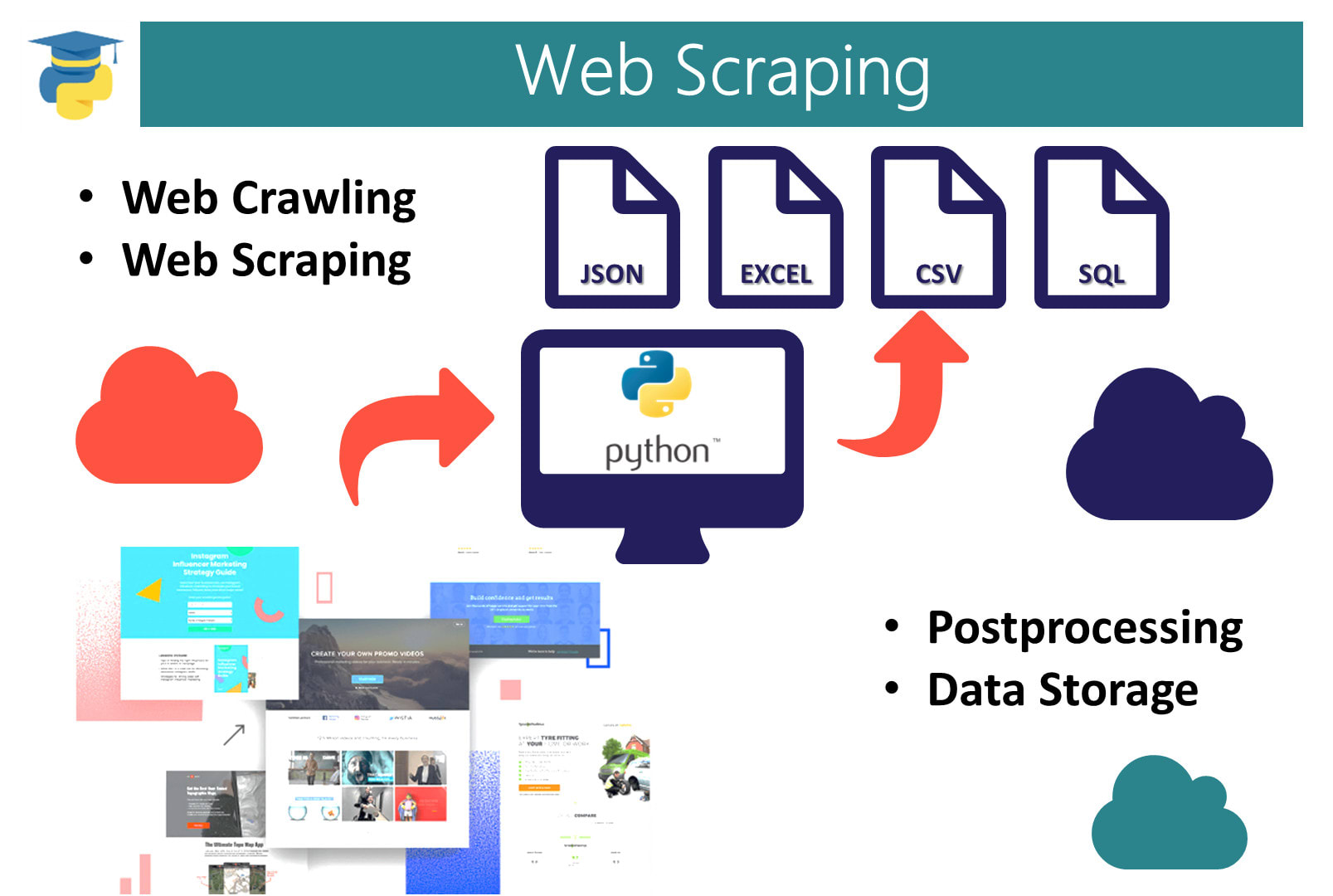
Всего несколькими щелчками мыши вы можете запустить любое из более чем 60 000 правил извлечения данных в инструменте или создать свое собственное. настраиваемые правила извлечения, чтобы получать с веб-страницы только те данные, которые вам нужны.
Одна страница или многостраничный автоматизированный парсинг
Data Miner может очищать одну страницу или сканировать сайт и извлекать данные с нескольких страниц, такие как результаты поиска, сведения о продуктах. и цены, контактная информация, электронная почта, номера телефонов и многое другое. Затем Data Miner преобразует извлеченные данные в чистый Формат файла CSV или Microsoft Excel для загрузки.
Data Miner поставляется с богатым набором функций, которые помогут вам извлечь любой текст на странице, которую вы видите в своем браузере. Это
может автоматически нажимать на кнопки и ссылки, переходить на подстраницы, открывать всплывающие окна и собирать из них данные.
Новые возможности Data Miner 5.0
Быстрый и простой сбор данных
Сотрите одним щелчком мыши.
Использование
50 000+
бесплатные готовые запросы, сделанные для
15 000+
популярные сайты.
Упрощенный рабочий процесс
Сканирование URL-адресов, разбиение на страницы и сбор одной страницы в одном месте.
Кодирование не требуется
Новый инструмент Easy Finder помогает находить селекторы CSS и создавать собственные рецепты
Безопасное веб-сканирование и парсинг
Безопасное и надежное использование
Data Miner ведет себя так, как если бы вы сами нажимали на страницу в своем браузере.
Соскоблить без забот
Data Miner — это не бот.
Вас не заблокируют.
Сохраняйте конфиденциальность ваших данных
Data Miner никогда не продает ваши данные.
Data Miner никогда не разглашает ваши данные.
Data Miner — самый мощный парсер около
Парсинг в один клик
Используйте один из 50 000 общедоступных запросов на извлечение для извлечения данных одним щелчком мыши.
Пользовательский сбор данныхСоздавайте собственные запросы на извлечение для извлечения любых данных с любого сайта.
Автоматизация очисткиЗапуск массовых операций очистки на основе списка URL-адресов.
Быстросъемные скобы для стола Извлечь основные данные таблицы
правой кнопкой мыши на странице.
Автоматически переходить на следующую страницу и очищать с помощью автоматического разбиения на страницы.
Автоматизация заполнения форм Data Miner может автоматически заполнять формы для вас, используя предварительно заполненный CSV.