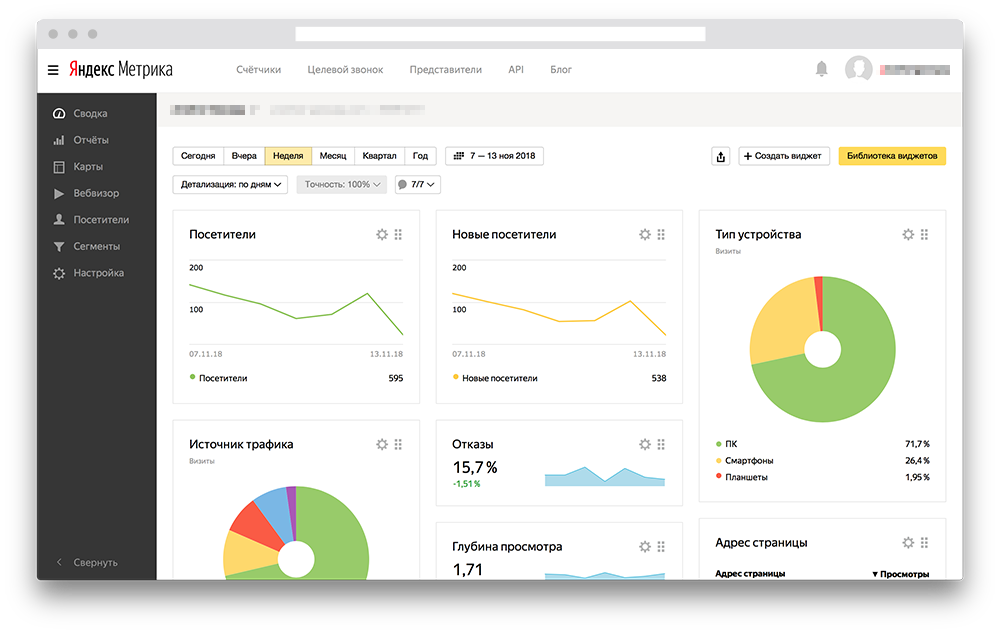
Полезная статистика от Яндекс.Музыка
Статистика Яндекс.Музыка
Вы наверняка знаете про сервис Яндекс.Музыка. Это стриминговая платформа позволяющая прослушивать трэки, альбомы и составлять персональные трэклисты. Мы еще в 2017 году рассказывали, что такое Яндекс.Музыка. На сегодняшний день многие пользуются данным сервисом для прослушивания трэков, поэтому большинство читателей понимает как он работает. В этой статье мы расскажем про одну из новых удобных функций сервиса, которая будет интересна как молодым артистам, так и опытным. Это позволит вам лучше понимать текущую ситуацию на музыкальном рынке, понимать спрос целевой аудитории на конкретного исполнителя.
В любом деле важно получать актуальную информацию о рынке, на котором вы работаете. Важно получить точный портрет целевой аудитории, выявить регион с наибольшим спросом на вашу музыку, отследить как влияет сезонность. Если совсем упрощать, то летом хочется слушать веселую танцевальную музыку, осенью многие погружаются в минор.
Можем рассмотреть, как работает статистика Яндекс.Музыка на примере Люси Чеботиной. Люся Чеботина является автором и исполнителем песен, а также видеоблогером. В 18-летнем возрасте она участвовала в украинском вокальном проекте «Голос страны-5», потом – в некоторых иных музыкальных шоу: «Главная сцена», болливудский проект талантов «Dil Hai Hindustani», «Новоя волна-2017». За спиной у артистки большое количество синглов и один полноценный альбом, который был выпущен на лейбле Zhara Music в октябре 2019 года. На YouTube можно найти ее клипы и видео живых выступлений на различных музыкальных фестивалях.
Чтобы получить статистику через сервис Яндекс.Музыка по Люси Чеботиной достаточно зайти раздел Инфо ее профиля артиста.
При проведении анализа и оценки популярности исполнителя надо учитывать, что статистика касается только прослушиваний через сервисы Яндекс. Статистика с других стриминговых площадок не учитывается. Однако это уже дает возможность любому пользователю посмотреть открытую статистику по всем популярным артистам в любое время.
Мы надеемся, что статья была для вас полезной. Вы можете сами попробовать возможности Яндекс. Музыки на примере Люси по ссылке.
Музыки на примере Люси по ссылке.
Связаться с нами через мессенджеры:
Анализируем историю прослушивания в «Яндекс.Музыке» / Хабр
Вот уже почти год я пользуюсь сервисом Яндекс Музыка и меня все устраивает. Но есть в этом сервисе одна интересная страница — история. Она хранит все треки, которые были прослушаны, в хронологическом порядке. И мне, конечно, захотелось скачать ее и проанализировать, что я там наслушал за все время.
Начав разбираться с этой страницей, я сразу же столкнулся с проблемой. Сервис не загружает все треки сразу, а только по мере скроллинга. Скачивать сниффер и разбираться в трафике мне не хотелось, да и навыков у меня в этом деле на тот момент не было. Поэтому я решил пойти более простым путем эмулирования браузера с помощью selenium.
Скрипт был написан. Но работал он очень нестабильно и долго. Но загрузить историю у него всё-таки получилось. После просто анализа я оставил скрипт без доработок, пока через какое-то время мне снова не захотелось загрузить историю. Надеясь на лучшее, я запустил его. И, конечно же, он выдал ошибку. Тогда я понял, что пора сделать все по-человечески.
Надеясь на лучшее, я запустил его. И, конечно же, он выдал ошибку. Тогда я понял, что пора сделать все по-человечески.
Для анализа трафика я выбрал для себя Fiddler из-за более мощного интерфейса для http трафика в отличие от wireshark. Запустив сниффер, я ожидал увидеть запросы к api с токеном. Но нет. Наша цель оказалась по адресу music.yandex.ru/handlers/library.jsx. И запросы к ней требовали полноценной авторизации на сайте. С нее и начнем.
Авторизация
Здесь ничего сложного. Заходим на passport.yandex.ru/auth, находим параметры для запросов и делаем два запроса для авторизации.
auth_page = self.get('/auth').text
csrf_token, process_uuid = self.find_auth_data(auth_page)
auth_login = self.post(
'/registration-validations/auth/multi_step/start',
data={'csrf_token': csrf_token,
'process_uuid': process_uuid,
'login': self.login}
).json()
auth_password = self.post(
'/registration-validations/auth/multi_step/commit_password',
data={'csrf_token': csrf_token,
'track_id': auth_login['track_id'],
'password': self. password}
).json()
password}
).json() password}
).json()
password}
).json()И вот мы авторизовались.
Загрузка истории
Дальше переходим на music.yandex.ru/user/<user>/history, где тоже забираем пару параметров, который нам пригодятся при получении информации о треках. Теперь можно загружать историю. Id треков мы получаем по адресу music.yandex.ru/handlers/library.jsx с параметрами {'owner': <user>, 'filter': 'history', 'likeFilter': 'favorite', 'lang': 'ru', 'external-domain': 'music.yandex.ru', 'overembed': 'false', 'ncrnd': '0.9546193023464256'}. Интерес у меня вызвал тут параметр ncrnd. При запросах Яндекс присваивает этому параметру всегда разные значения, но с одинаковым все тоже работает. Обратно мы получаем историю в виде id треков и Подробную информацию о первых десятках треков. Из подробной информации треков можно сохранить много интересных данных для последующего анализа. Например год выхода, длительность трека и жанр. Информацию об остальных треках получаем c  yandex.ru/handlers/track-entries.jsx
yandex.ru/handlers/track-entries.jsx
Для анализа используем стандартные инструменты в виде pandas и matplotlib.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('statistics.csv')
df.head(3)| № | artist | artist_id | album | album_id | track | track_id | duration_sec | year | genre |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Coldplay | 671 | Viva La Vida — Prospekt’s March Edition | 51399 | Death And All His Friends | 475739 | 383 | 2008 | rock |
| 1 | Coldplay | 671 | Hypnotised | 4175645 | Hypnotised | 34046075 | 355 | 2017 | rock |
| 2 | Coldplay | 671 | Yellow | 49292 | No More Keeping My Feet On The Ground | 468945 | 271 | 2000 | rock |
Меняем питоновские None на NaN и выбрасываем их.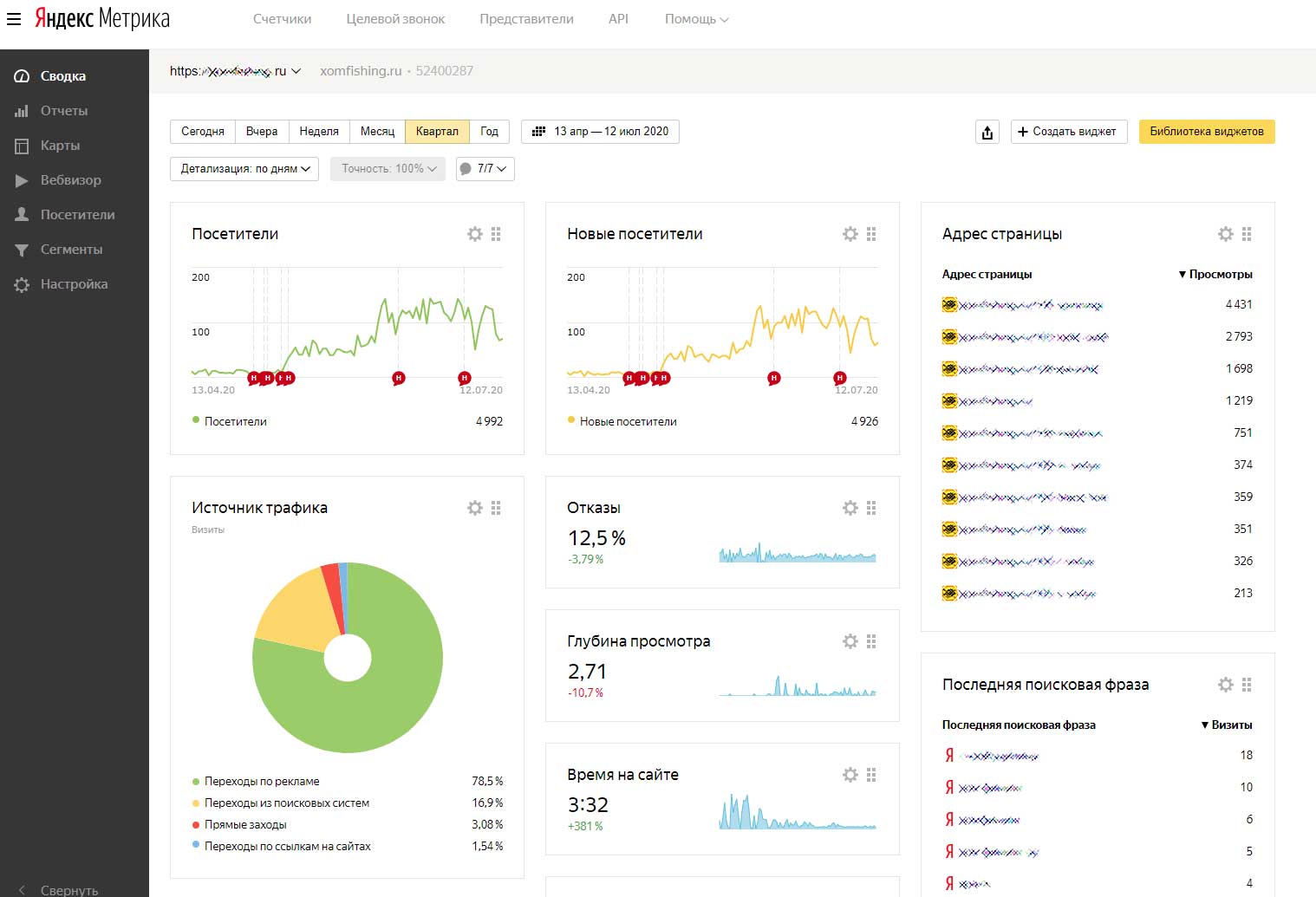
df = df.replace('None', pd.np.nan).dropna()Начнем с простого. Посмотрим время, которое мы потратили на прослушивание всех треков
duration_sec = df['duration_sec'].astype('int64').sum()
ss = duration_sec % 60
m = duration_sec // 60
mm = m % 60
h = m // 60
hh = h % 60
f'{h // 24} {hh}:{mm}:{ss}''15 15:30:14'
Но тут можно поспорить насчет точности этой цифры, тк не понятно какую часть трека нужно прослушать, чтобы яндекс добавил ее в историю.
Теперь посмотрим на распределение треков по году выпуска.
plt.rcParams['figure.figsize'] = [15, 5] plt.hist(df['year'].sort_values(), bins=len(df['year'].unique())) plt.xticks(rotation='vertical') plt.show()
Тут то же не все так однозначно, тк у разнообразных сборников “Best Hits” будет стоять более поздний год.
Остальные статистики будут строиться по очень схожему принципу. Приведу пример самых прослушиваемых треков
df.groupby(['track_id', 'artist','track'])['track_id'].
 count().sort_values(ascending=False).head()
count().sort_values(ascending=False).head()| track_id | artist | track | |
|---|---|---|---|
| 170252 | Linkin Park | What I’ve Done | 32 |
| 28472574 | Coldplay | Up&Up | 31 |
| 3656360 | Coldplay | Charlie Brown | 31 |
| 178529 | Linkin Park | Numb | 29 |
| 289675 | Thirty Seconds to Mars | ATTACK | 27 |
и самых прослушиваемых треков исполнителя
artist_name = 'Coldplay'
df.groupby([
'artist_id', 'track_id', 'artist', 'track'
])['artist_id'].count().sort_values(ascending=False)[:,:,artist_name].head(5)| artist_id | track_id | track | |
|---|---|---|---|
| 671 | 28472574 | Up&Up | 31 |
| 3656360 | Charlie Brown | ||
| 340302 | Fix You | 26 | |
| 26285334 | A Head Full of Dreams | 26 | |
| 376949 | Yellow | 23 |
Полный код можно найти тут
Яндекс Метрика — О данных, конфиденциальности и файлах cookie
Поиск
- Российская Федерация
ПОДЕЛИТЬСЯ ПАСПОРТОМ ДАННЫХ В СОЦИАЛЬНЫХ СЕТЯХ
- Юридическая информация: https://yandex. com/legal/cookies_policy_eng/?lang=ru
- Свяжитесь с оператором веб-сайта, используя эту услугу напрямую
- Последнее обновление: 11 апреля 2022 г.
 com/legal/cookies_policy_eng/?lang=ru
com/legal/cookies_policy_eng/?lang=ruСобирает или получает ли этот поставщик ваши личные или конфиденциальные данные?
при посещении сайта с установленной Яндекс Метрикой
ДаЕсли персональные данные используются данным сервисом
Как долго хранятся ваши данные
после использования сервиса на и закрытия сайта?
1 месяц или менееДелится ли этот поставщик вашими данными с другими третьими сторонами
после сбора или получения данных?
Откуда мы знаем?
В СОТРУДНИЧЕСТВЕ С ФОНД СИДН
Cookiedatabase.org был создан в сотрудничестве между Complianz и Фондом SIDN для создания более прозрачного веб-интерфейса для всех. Информация, как показано ниже, собрана из общедоступной информации, такой как Заявление о конфиденциальности или этикетка конфиденциальности от поставщика. Его модерирует сообщество профессионалов в области информационных технологий и права.
Его модерирует сообщество профессионалов в области информационных технологий и права.
- Фонд СИДН
- 21 июля 2021 г.
- Совокупные данные
Эта служба хранит и получает сводные данные?
- Данные наблюдений за поведением
- Личные данные
Эта служба хранит и получает личные данные?
- Данные наблюдений за поведением
- Конфиденциальные данные
Эта служба хранит и получает конфиденциальные личные данные?
- Неизвестно
- Общие данные
Кто-нибудь имеет доступ к вашим данным, кроме самого сервиса?
- партнеры
- Правовые основания
На каких правовых основаниях эта служба обрабатывает ваши данные?
- Согласие
- Контракт
- Удержание
Как долго ваши данные хранятся и обрабатываются этой службой?
- 1 месяц или менее
- Расположение
Где хранятся и обрабатываются ваши данные?
- Данные обрабатываются в странах без надлежащего уровня защиты данных
- Цель
Для чего или каких целей обрабатываются ваши данные?
- Статистика
Известные файлы cookie
В СОТРУДНИЧЕСТВЕ С COMPLIANZ. IO
IO
Файлы cookie и другие технологии отслеживания, как показано ниже, анонимно собираются cookiedatabase.org путем синхронизации отсканированных файлов cookie на более чем 350 000 веб-сайтов, на которых установлено Complianz. Complianz — это полнофункциональный пакет конфиденциальности для WordPress.
Российский Яндекс проводит IPO Nasdaq на сумму до 1,1 миллиарда долларов публичное размещение, которое воспользуется спросом на интернет-акции, поступающие на биржи США.
Голландская материнская компания компании, Yandex NV, в понедельник подала в Комиссию по ценным бумагам и биржам США заявку на IPO 52,2 млн акций класса А, которые будут проданы по цене от 20 до 22 долларов каждая.
Заявка была подана всего через несколько часов после того, как LinkedIn, социальная сеть для профессионалов бизнеса, опубликовала подробности своего плана IPO, рассчитывая привлечь до 274,4 миллиона долларов.
IPO Яндекса состоялось всего через шесть месяцев после размещения в Лондоне российской интернет-инвестиционной компании Mail. ru Group MAILRq.L на сумму 1 млрд долларов и через несколько дней после того, как акции Renren Inc RENN.N, одной из крупнейших социальных сетей Китая, выросли почти на 30 процентов в своем дебюте на Нью-Йоркской фондовой бирже после привлечения 743,4 миллиона долларов.
ru Group MAILRq.L на сумму 1 млрд долларов и через несколько дней после того, как акции Renren Inc RENN.N, одной из крупнейших социальных сетей Китая, выросли почти на 30 процентов в своем дебюте на Нью-Йоркской фондовой бирже после привлечения 743,4 миллиона долларов.
Яндекс.ру, запущенный в 1997 году, в прошлом году генерировал 64% всего поискового трафика в России, согласно данным документа.
Помимо Mail.ru, которому принадлежит 2,38% акций гиганта социальной сети Facebook, список основных конкурентов Яндекса возглавляет глобальный поисковый гигант Google GOOG.Oi. Google представила русскоязычную поисковую систему в 2001 году и открыла свой первый российский офис в 2006 году, но по-прежнему уступает Яндексу в России с долей рынка около 22 процентов, говорится в заявлении Яндекса со ссылкой на статистику другой российской интернет-компании Liveinternet. RU.
В обычно обширном списке факторов риска, связанных с инвестированием в IPO, Яндекс предупредил, что он может быть подвержен «агрессивному применению противоречивых или двусмысленных законов или правил», включая налоговые правила и лицензионные требования. Он также заявил, что может потребоваться провести двойной листинг в России и столкнуться с агрессивными попытками поглощения со стороны «хорошо финансируемых финансовых групп с хорошими связями и так называемых «олигархов», которым он, возможно, не сможет помешать.
Он также заявил, что может потребоваться провести двойной листинг в России и столкнуться с агрессивными попытками поглощения со стороны «хорошо финансируемых финансовых групп с хорошими связями и так называемых «олигархов», которым он, возможно, не сможет помешать.
Яндекс, чья американская база находится в Пало-Альто, штат Калифорния, планирует использовать выручку от IPO для инвестиций в технологическую инфраструктуру, особенно в новые серверы и центры обработки данных, а также для возможных приобретений или инвестиций в технологии, команды и предприятия.
Основатели Аркадий Волож и Илья Сегалович планируют продать 4,1 млн и 820 000 акций соответственно, немного сократив свои доли до 20 и 4 процентов. Крупнейший акционер Яндекса, Baring Vostok Private Equity Funds, планирует продать 6,2 миллиона акций, но его общее количество голосов фактически увеличится примерно на 1 процентный пункт до 26 процентов.
Оператор поисковой системы планирует разместить свои акции на Nasdaq под символом «YNDX».