Управление robots.txt
Заказать сайт
Искать везде
- Искать везде
- CMS
- Интернет-магазин 2.0
- Интернет-магазин 1.0
- Onicon
- Maliver
- Rekmala
- Кабинет и почта
- CRM
- Интеграции CMS.
 S3
S3
 S3
S3Главная / Редактирование сайта / Как мне настроить сайт? / Настройки SEO / SEO-панель сайта / Управление robots.txt
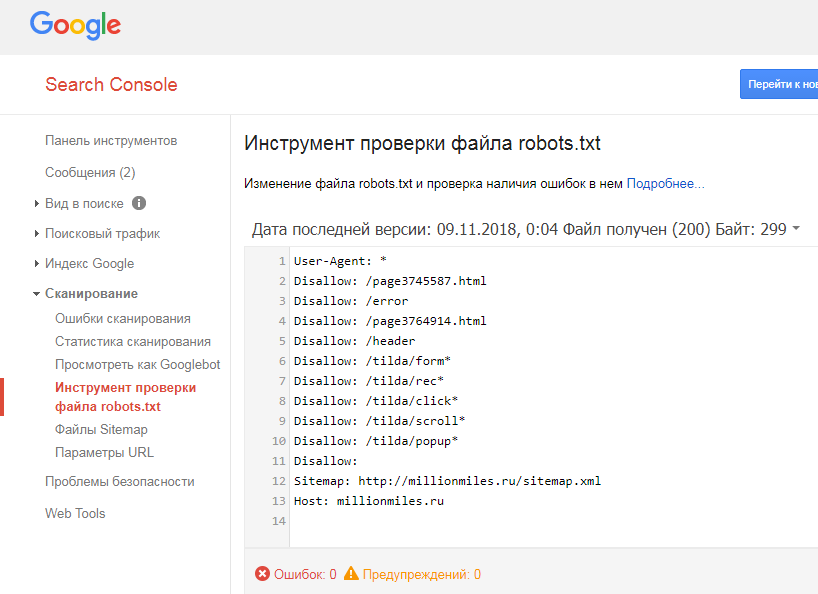
Robots.txt — файл ограничения доступа поисковых роботов к содержимому http-сервера (Вашего сайта). В файле можно указать параметры индексирования сайта как для всех роботов сразу, так и для каждой поисковой системы по отдельности.
В данном разделе вы можете посмотреть текущий статус индексации сайта, текущее значение файла.
Также система управления сайта допускает возможность редактирования файла robots.txt.
Обратите внимание!
- Для редактирования robots.txt Вам могут потребоваться расширенные права доступа.
Шаг 1
Для того чтобы внести правки в файл robots. txt, вы можете в меню “Настройки” выбрать пункт “Robots.txt”.
txt, вы можете в меню “Настройки” выбрать пункт “Robots.txt”.
Или же перейти по ссылке “Изменить” в строке «Установить собственное содержание robots.txt:» раздела “SEO панель”.
Шаг 2
Откроется страница с содержимым robots.txt. Внесите все необходимые изменения (подробную информацию по работе с файлом robots.txt вы можете также прочитать тут).
Шаг 3
После внесения изменений, нажмите на кнопку “Сохранить изменения”.
Обратите внимание!
- Если в разделе SEO индексация сайта запрещена, то изменения robots.txt не вступят в силу.
- Правильность заполнения robots.txt можно проверить с помощью сервиса от Яндекс — Анализ robots.txt.
- Подробную информацию по работе с файлом robots.txt вы можете также прочитать тут.
Была ли статья вам полезна?
Да
Нет
Укажите, пожалуйста, почему?
- Рекомендации не помогли
- Нет ответа на мой вопрос
- Содержание статьи не соответствует заголовку
- Другая причина
Комментарий
Читайте также
- Использование robots. txt Подробнее
- Анализ robots.txt Подробнее
 txt Подробнее
txt ПодробнееЧто такое Robots.txt? | Глоссарий Интернет-маркетинга
Что такое Robots.txt?
Robots.txt — это текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем.
После создания файла robots.txt, его нужно поместить в корневой каталог сайта. Поисковый робот всегда обращается к файлу по URL /robots.txt.
После того, как сайт загружен на хостинг и прописаны DNS, роботы поисковых систем получают возможность для обхода сайта и индексации его страниц. Отсутствие файла robots.txt может служить поводом для возникновения проблем со скоростью обхода сайта и присутствия мусора в индексе. А неправильная настройка приводит к исключению из индекса важных частей ресурса или присутствию в выдаче ненужных страниц. Это способствует трудностям с продвижением сайта.
Функции robots.txt
Основная задача этого файла — информирование роботов индексации. Главные указания или директивы robots.txt — это:
- «Allow» (отвечает за разрешение индексации определенного раздела или файла).
- «Disallow» (соответственно, запрещает индексацию),
- «User-agent» (определяет, к каким именно роботам относятся разрешительные и запрещающие директивы).
Но следует знать, что указания robots.txt носят рекомендательный характер. Это значит, что при определенных условиях робот может проигнорировать их.
Символы в robots.txt
Символы, которые чаще всего используют в данном файле — «/, *, $, #».
С помощью «/» можно показать, что нужно закрыть от индексации. Например, если поставить один слеш в правиле Disallow, то он будет означать запрет на сканирование всего сайта. Применив два знака, запрещают сканирование отдельного раздела, например: /tovary/. Такая запись говорит, что запрещена индексация всего содержимого папки tovary. Но если прописать /tovary, то запрет распространится на все ссылки на сайте, которые будут начинаться на /tovary.
Такая запись говорит, что запрещена индексация всего содержимого папки tovary. Но если прописать /tovary, то запрет распространится на все ссылки на сайте, которые будут начинаться на /tovary.
Звездочка «*» имеет значение любой последовательности символов в файле. Ее ставят после каждого правила.
Эта запись говорит, что все роботы не должны индексировать любые файлы с расширением .gif в папке /catalog/
Знак доллара «$» нужен для ограничения знака «*». Если нужно запретить все содержимое папки catalog, но при этом нельзя запретить url-адреса, которые содержат /catalog, то запись в индексном файле будет такой:
Решетка «#» используется для комментариев, которые веб-мастер оставляет для себя или других веб-мастеров. Робот не будет их учитывать при сканировании сайта.
Требования к файлу robots.txt
Веб-мастер всегда должен помнить, что отсутствие в корневом каталоге сайта файла robots. txt или его неправильная настройка потенциально угрожают посещаемости сайта и доступности в поиске.
txt или его неправильная настройка потенциально угрожают посещаемости сайта и доступности в поиске.
По стандартам, в файле robots.txt запрещено использование кириллических символов. Поэтому для работы с кириллическими доменами нужно применять Punycode. При этом кодировка адресов страниц должна соответствовать кодировке применяемой структуры сайта.
См. также
Индексация
Ранжирование
Уровень вложенности
Анкор
Disavow
Все, что вам нужно знать
Если на вашем веб-сайте есть страницы, проиндексированные Google, но не сканируемые, вы получите сообщение «Проиндексировано, но заблокировано Robots.txt» в своей консоли поиска Google (GSC).
Хотя Google может просматривать эти страницы, он не будет показывать их как часть страниц результатов поисковой системы по их целевым ключевым словам.
В этом случае вы упустите возможность получить органический трафик для этих страниц.
Это особенно важно для страниц, генерирующих тысячи органических посетителей в месяц только для того, чтобы столкнуться с этой проблемой.
На данный момент у вас, вероятно, есть много вопросов об этом сообщении об ошибке. Почему вы его получили? Как это произошло? И, что более важно, как вы можете исправить это и восстановить трафик, если это произошло со страницей, которая уже хорошо ранжируется.
Этот пост ответит на все эти вопросы и покажет, как избежать повторения этой проблемы на вашем сайте.
Как узнать, есть ли на вашем сайте эта проблема
Обычно вы должны получать электронное письмо от Google, информирующее вас о «проблеме индексации» на вашем сайте. Вот как выглядит письмо:
В письме не будут указаны точные затронутые страницы или URL-адреса. Вам нужно будет войти в консоль поиска Google, чтобы узнать это самостоятельно.
Если вы не получили электронное письмо, лучше все же просмотреть его, чтобы убедиться, что ваш сайт находится в отличной форме.
После входа в GSC перейдите к отчету о покрытии индекса, нажав «Покрытие» в разделе «Индекс». Затем на следующей странице прокрутите вниз, чтобы увидеть проблемы, о которых сообщает GSC.
Файл «Проиндексирован, хотя и заблокирован robots.txt» помечен как «Действителен с предупреждением». Это означает, что в самом URL-адресе нет ничего плохого, но поисковые системы не будут отображать страницы в результатах поиска.
Почему на вашем сайте возникла эта проблема (и как ее исправить)?
Прежде чем вы начнете думать о решении, вы должны сначала знать, какие страницы должны быть проиндексированы и , которые должны отображаться в результатах поиска.
Возможно, URL-адреса, которые вы видите в GSC с ошибкой «Проиндексировано, но заблокировано robots.txt», не предназначены для привлечения органического трафика на ваш сайт. Например, целевые страницы для ваших платных рекламных кампаний. Поэтому исправление страниц может не стоить вашего времени и усилий.
Ниже приведены причины, по которым на некоторых ваших страницах возникает эта проблема, и следует ли ее исправлять:
Запретить правило в файле robots.txt
и Метатег Noindex в HTML страницы Наиболее распространенная причина этой проблемы происходит, когда вы или кто-либо, управляющий вашим сайтом, включает правило Disallow для этого конкретного URL-адреса в файле robots. txt вашего сайта и добавляет метатег noindex к тому же URL-адресу.
txt вашего сайта и добавляет метатег noindex к тому же URL-адресу.
Во-первых, владельцы сайтов используют файл robots.txt для информирования поисковых роботов о том, как обрабатывать URL-адреса вашего сайта. В этом случае вы добавили правило запрета на страницы и папки вашего сайта в robots.txt вашего сайта.
Вот что вы можете увидеть, открыв файл robots.txt своего сайта:
User-agent: * Disallow: /
В приведенном выше примере эта строка кода запрещает всем поисковым роботам (*) сканировать ваш страницы сайта (Disallow) включают вашу домашнюю страницу (/). В результате все поисковые системы не будут ни сканировать, ни индексировать страницы вашего сайта.
Вы можете отредактировать robots.txt, чтобы выделить поисковые роботы (Googlebot, msnbot, magpie-crawler и т. д.) и указать, какие страницы вы не хотите трогать поисковые роботы (/page1, /page2, /page3, и т. д.).
Однако, если у вас нет root-доступа к вашему серверу, вы можете запретить роботам поисковых систем индексировать страницы вашего сайта с помощью тега noindex.
Этот метод имеет тот же эффект, что и правило запрета в файле robots.txt. Однако вместо того, чтобы перечислять различные страницы и папки на вашем сайте в файле robots.txt, которые вы хотите предотвратить от появления в поисковой выдаче, вам нужно ввести метатег noindex на каждой странице вашего сайта, которую вы не хотите для отображения в результатах поиска.
Это гораздо более трудоемкий процесс, чем предыдущий метод, но он дает вам более детальный контроль над тем, какой URL блокировать. Это также означает, что с вашей стороны меньше вероятность ошибки.
Исправление: Опять же, проблема в GSC возникает, когда страницы вашего сайта имеют правило запрета на файл robots.txt и тег noindex.
Чтобы поисковые системы знали, индексировать страницу или нет, они должны иметь возможность сканировать ее с вашего сайта. Но если вы запретите поисковым системам делать это через файл robots.txt, они не будут знать, что делать с этой страницей.
Используя robots. txt и тег noindex, чтобы дополнять друг друга, а не конкурировать друг с другом, ваш сайт будет иметь более четкие и прямые правила, которым роботы поисковых систем должны следовать при обработке своих страниц.
txt и тег noindex, чтобы дополнять друг друга, а не конкурировать друг с другом, ваш сайт будет иметь более четкие и прямые правила, которым роботы поисковых систем должны следовать при обработке своих страниц.
Для этого необходимо отредактировать файл robots.txt. Для владельцев сайтов WordPress наиболее удобным является использование SEO-плагинов с редактором robots.txt, таким как Yoast SEO или Rank Math.
Если файл robots.txt недоступен для записи с вашей стороны, вы должны обратиться к своему хостинг-провайдеру, чтобы изменить права доступа к своим файлам и папкам.
Другой способ — войти в FTP-клиент или в файловый менеджер вашего хостинг-провайдера. Это предпочтительный метод среди разработчиков, потому что они имеют полный контроль над тем, как редактировать файл, среди прочего.
Неверный формат URL-адреса
URL-адреса на вашем сайте, которые на самом деле не являются «страницами» в самом строгом смысле, могут получить сообщение «Проиндексировано, хотя и заблокировано robots. txt».
txt».
Например, https://example.com?s=what+is+seo — это страница на сайте, которая показывает результаты поиска по запросу «что такое SEO». Этот URL-адрес распространен среди сайтов WordPress, где функция поиска включена для всего сайта.
Исправление: Обычно нет необходимости решать эту проблему, при условии, что URL-адрес безвреден и не сильно влияет на ваш поисковый трафик.
Страницы, которые вы не хотите индексировать, имеют внутренние ссылки
Даже если у вас есть тег noindex на странице, которую вы не хотите индексировать, Google может рассматривать их как предложения, а не как правила. Это очевидно, когда вы ссылаетесь на страницы с директивой noindex или правилом запрета на страницах вашего сайта, которые поисковые системы сканируют и индексируют.
Таким образом, вы можете увидеть эти страницы в поисковой выдаче, даже если вы этого не хотите.
Исправление : Вы должны удалить ссылки, указывающие на эту конкретную страницу, и вместо этого вести их на аналогичную страницу.
Чтобы сделать это, вы должны определить его внутренние ссылки, запустив SEO-аудит с помощью такого инструмента, как Screaming Frog (бесплатно для веб-сайтов с 500 URL-адресами) или инструментов для веб-мастеров Ahrefs (намного лучшая бесплатная альтернатива), чтобы определить, какие страницы ссылаются на ваш заблокированный сайт. страницы.
С помощью Ahrefs перейдите в «Отчеты» > «Внутренние страницы» после проведения аудита. Найдите страницы, которые вы заблокировали от поисковых роботов и не проиндексировали, и посмотрите, какие страницы ссылаются на них, в столбце «Количество внутренних ссылок».
Отсюда редактируйте ссылки с этих страниц по одной. Или вы можете заменить их ссылкой на свою страницу с тегом noindex.
Указание на цепочку перенаправлений
Если ссылка на вашем сайте указывает на бесконечный поток перенаправлений, робот Googlebot прекратит переход по каждой ссылке, прежде чем найдет фактический URL-адрес страницы.
Эти цепочки перенаправлений также могут вызывать проблемы с дублированным содержимым, которые в дальнейшем могут привести к более серьезным проблемам с поисковой оптимизацией. Единственный способ решить эту проблему — указать предпочтительную и каноническую страницу с помощью канонического тега, чтобы Google знал, какую страницу из многих следует сканировать и индексировать.
Единственный способ решить эту проблему — указать предпочтительную и каноническую страницу с помощью канонического тега, чтобы Google знал, какую страницу из многих следует сканировать и индексировать.
Также учтите, что ссылка на перенаправление вместо канонической страницы израсходует ваш краулинговый бюджет. Если ссылка перенаправления указывает на несколько перенаправлений, вы не сможете использовать краулинговый бюджет на важных страницах вашего сайта. К тому времени, когда он доберется до самых важных страниц, Google не сможет должным образом просканировать и проиндексировать их через некоторое время.
Исправление: Удалите ссылки перенаправления с вашего сайта и вместо этого ссылайтесь на каноническую страницу.
Снова воспользовавшись Инструментами для веб-мастеров Ahrefs, вы сможете просмотреть свои ссылки перенаправления на странице Инструменты > Обозреватель ссылок. Затем отфильтруйте результаты, чтобы показывать только ссылки перенаправления на вашем сайте.
По результатам определите, какие ссылки образуют бесконечную цепочку переадресации. Затем разорвите цепочку, найдя правильную страницу, на которую должна ссылаться каждая страница, ссылающаяся на переадресацию.
Что делать после устранения этой проблемы
После того как вы внедрили приведенные выше решения для важных страниц с проблемой «Проиндексировано, но заблокировано Robots.txt», вам необходимо проверить изменения, чтобы Google Search Console мог пометить их как решено.
Вернувшись к отчету о покрытии индексов в GSC, нажмите на ссылки с исправленной проблемой. На следующем экране нажмите кнопку «Подтвердить исправление».
Это попросит Google проверить, устранена ли проблема на странице.
Заключение
В отличие от других проблем, обнаруженных Google Search Console, «Проиндексирован, но заблокирован robots.txt» может показаться каплей в море. Однако эти падения могут накапливаться в потоке проблем для всего вашего сайта, что не позволит ему генерировать органический трафик.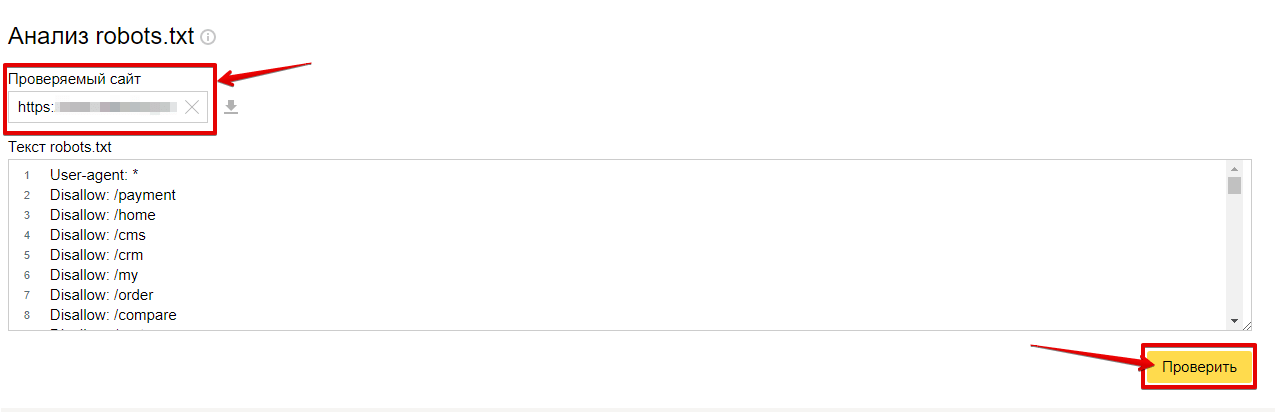
Следуя приведенным выше рекомендациям по устранению проблемы с наиболее важными страницами, вы можете предотвратить потерю ценного трафика на своем веб-сайте, оптимизировав свой веб-сайт для правильного сканирования и индексирования Google.
«Заблокировано robots.txt» и «Проиндексировано, но заблокировано robots.txt»: различия и как их исправить Статусы Search Console. Они указывают на то, что затронутые страницы не сканировались, поскольку вы заблокировали их в файле robots.txt.
Однако разница между этими двумя проблемами заключается в следующем:
- С «Заблокировано robots.txt» ваши URL-адреса не будут отображаться в Google,
- В свою очередь, с параметром «Проиндексировано, хотя и заблокировано robots.txt» вы можете увидеть уязвимые URL-адреса в результатах поиска, даже если они заблокированы директивой Disallow в файле robots.txt. Другими словами, «Проиндексировано, хотя и заблокировано robots.txt» означает, что Google не сканировал ваш URL, но тем не менее проиндексировал его.

Поскольку устранение этих проблем лежит в основе создания эффективной стратегии сканирования и индексации вашего веб-сайта, давайте проанализируем, когда и как их следует решать.
Какое отношение индексация имеет к robots.txt?
Хотя взаимосвязь между файлом robots.txt и процессом индексирования может сбивать с толку, позвольте мне помочь вам глубже разобраться в этой теме. Это облегчит понимание окончательного решения.
Как работают обнаружение, сканирование и индексирование?
Прежде чем страница будет проиндексирована, сканеры поисковых систем должны сначала обнаружить и просканировать ее.
На этапе обнаружения сканер узнает, что данный URL-адрес существует. Во время сканирования Googlebot посещает этот URL-адрес и собирает информацию о его содержании. Только после этого URL попадает в индекс и его можно найти среди других результатов поиска.
Псст. Процесс не всегда такой гладкий, но вы можете узнать, как помочь ему, прочитав наши статьи:
- Как исправить статус «Обнаружено – в настоящее время не проиндексировано» в GSC и
- Как исправить статус «Просканировано — пока не проиндексировано» в GSC.

Что такое robots.txt?
Robots.txt — это файл, который можно использовать для управления тем, как робот Googlebot сканирует ваш веб-сайт. Всякий раз, когда вы добавляете в него директиву Disallow, робот Googlebot знает, что не может посещать страницы, к которым применяется эта директива.
Но robots.txt не управляет индексацией.
Подробные инструкции по изменению и управлению файлом см. в нашем руководстве robots.txt.
Что вызывает сообщение «Проиндексировано, но заблокировано robots.txt» в Google Search Console?
Иногда Google решает проиндексировать обнаруженную страницу, несмотря на то, что не может ее просканировать и понять ее содержание.
В этом сценарии Google обычно мотивирован множеством ссылок, ведущих на страницу, заблокированную robots.txt.
Ссылки преобразуются в оценку PageRank. Google вычисляет его, чтобы оценить, насколько важна данная страница. Алгоритм PageRank учитывает как внутренних, так и внешних ссылок.
Когда в ваших ссылках беспорядок и Google видит, что запрещенная страница имеет высокое значение PageRank, он может решить, что страница достаточно значима, чтобы поместить ее в индекс.
Однако в индексе будет храниться только пустой URL-адрес без информации о содержимом, так как содержимое не было просканировано.
Почему «Проиндексировано, но заблокировано robots.txt» плохо для SEO?
Статус «Проиндексирован, но заблокирован robots.txt» — серьезная проблема. Это может показаться относительно безобидным, но это может саботировать вашу поисковую оптимизацию двумя важными способами.
Плохое отображение в поиске
Если вы заблокировали данную страницу по ошибке, то «Проиндексирована, но заблокирована robots.txt» не означает, что вам повезло, и Google исправил вашу ошибку.
Страницы, проиндексированные без сканирования, не будут выглядеть привлекательно в результатах поиска. Google не сможет отобразить:
- Тег заголовка (вместо этого он автоматически сгенерирует заголовок из URL-адреса или информации, предоставленной страницами, которые ссылаются на вашу страницу),
- Мета-описание,
- Любая дополнительная информация в виде расширенных результатов.

Без этих элементов пользователи не будут знать, чего ожидать после входа на страницу, и могут выбрать конкурирующие веб-сайты, резко снизив ваш CTR.
Вот пример — один из собственных продуктов Google:
Google Jamboard заблокирован от сканирования, но с почти 20000 ссылок с других веб-сайтов (по данным Ahrefs) Google все еще проиндексировал его.
Пока страница ранжируется, она отображается без какой-либо дополнительной информации. Это потому, что Google не смог просканировать его и собрать какую-либо информацию для отображения. Он показывает только URL-адрес и основной заголовок, основанный на том, что Google нашел на других веб-сайтах, которые ссылаются на Jamboard.
Чтобы узнать, есть ли на вашей странице та же проблема и есть ли «Индексировано, хотя и заблокировано robots.txt», перейдите в консоль поиска Google и проверьте ее в инструменте проверки URL.
Нежелательный трафик
Если вы намеренно использовали директиву Disallow в файле robots. txt для определенной страницы, вы не хотите, чтобы пользователи могли найти эту страницу в Google. Предположим, например, что вы все еще работаете над содержанием этой страницы, и оно еще не готово для всеобщего просмотра.
txt для определенной страницы, вы не хотите, чтобы пользователи могли найти эту страницу в Google. Предположим, например, что вы все еще работаете над содержанием этой страницы, и оно еще не готово для всеобщего просмотра.
Но если страница будет проиндексирована, пользователи смогут найти ее, зайти на нее и сформировать отрицательное мнение о вашем сайте.
Как исправить «Проиндексировано, но заблокировано robots.txt?»
Во-первых, найдите статус «Проиндексировано, но заблокировано robots.txt» в нижней части отчета об индексировании страниц в вашей консоли поиска Google.
Там вы можете увидеть таблицу «Улучшить внешний вид страницы».
Нажав на статус, вы увидите список затронутых URL-адресов и диаграмму, показывающую, как их количество менялось с течением времени.
Список можно фильтровать по URL-адресу или URL-пути. Если у вас есть много URL-адресов, затронутых этой проблемой, и вы хотите просмотреть только некоторые части своего веб-сайта, используйте символ пирамиды с правой стороны.
Прежде чем приступить к устранению неполадок, подумайте, действительно ли URL-адреса в списке должны быть проиндексированы. Содержат ли они контент, который может быть полезен вашим посетителям?
Если вы хотите, чтобы страница была проиндексирована
Если страница была запрещена в robots.txt по ошибке, вам необходимо изменить файл.
После удаления директивы Disallow, блокирующей сканирование вашего URL-адреса, робот Googlebot, скорее всего, просканирует его при следующем посещении вашего веб-сайта.
Если вы хотите, чтобы страница была деиндексирована
Если страница содержит информацию, которую вы не хотите показывать пользователям, посещающим вас через поисковую систему, вы должны указать Google, что вы не хотите, чтобы страница была проиндексирована.
Robots.txt не следует использовать для управления индексацией. Этот файл блокирует сканирование Googlebot. Вместо этого используйте тег noindex.
Google всегда учитывает noindex, когда находит его на странице. Используя его, вы можете гарантировать, что Google не покажет вашу страницу в результатах поиска.
Используя его, вы можете гарантировать, что Google не покажет вашу страницу в результатах поиска.
Вы можете найти подробные инструкции по его реализации на своих страницах в нашем руководстве по тегу noindex.
Не забудьте разрешить Google просканировать вашу страницу, чтобы обнаружить этот тег HTML. Это часть содержимого страницы.
Если вы добавите тег noindex, но оставите страницу заблокированной в файле robots.txt, Google не обнаружит этот тег. И страница останется «Проиндексирована, но заблокирована robots.txt».
Когда Google просканирует страницу и увидит тег noindex, она будет удалена из индекса. Консоль поиска Google отобразит другой статус индексации при проверке этого URL-адреса.
Имейте в виду, что если вы хотите скрыть какую-либо страницу от Google и ее пользователей, всегда будет самым безопасным выбором реализовать HTTP-аутентификацию на вашем сервере. Таким образом, только пользователи, которые вошли в систему, могут получить к нему доступ.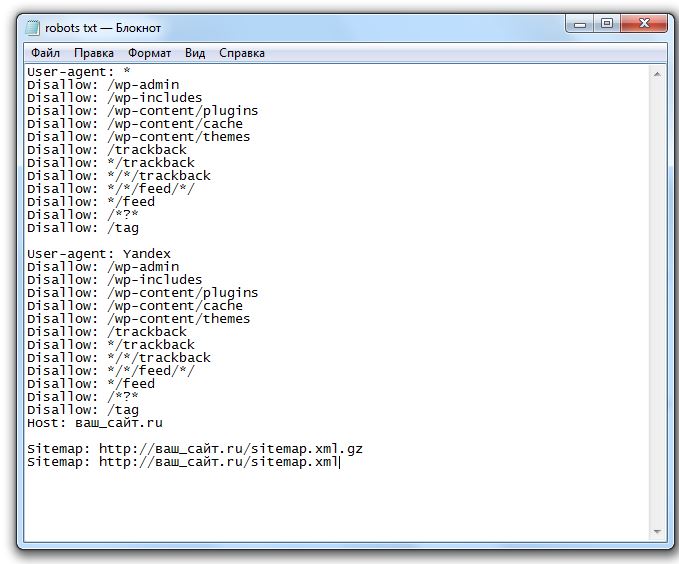 Это необходимо, например, если вы хотите защитить конфиденциальные данные.
Это необходимо, например, если вы хотите защитить конфиденциальные данные.
Если вам нужно долгосрочное решение
Приведенные выше решения помогут вам на некоторое время решить проблему «Проиндексирован, хотя и заблокирован robots.txt». Однако возможно, что в будущем он появится и на других страницах.
Такой статус указывает на то, что вашему веб-сайту может потребоваться тщательная проверка внутренних ссылок или проверка обратных ссылок.
Что означает «Заблокировано robots.txt» в Google Search Console?
«Заблокировано robots.txt» означает, что Google не просканировал ваш URL-адрес, потому что вы заблокировали его с помощью директивы Disallow в robots.txt. Это также означает, что URL-адрес не был проиндексирован.
Помните, что робот Googlebot не может сканировать некоторые URL-адреса, особенно если ваш сайт становится больше. Некоторые из них не актуальны для поисковых систем по разным причинам.
Решение о том, какие страницы вашего веб-сайта следует и не следует сканировать, является обязательным шагом в создании надежной стратегии индексации вашего веб-сайта.
Как исправить «Заблокировано robots.txt?»
Во-первых, перейдите к таблице «Почему страницы не индексируются» под диаграммой в отчете об индексации страниц, чтобы разобраться с проблемами «Блокировано robots.txt.
Решение этой проблемы требует другого подхода в зависимости от того, заблокировали ли вы свою страницу по ошибке или намеренно.
Позвольте мне рассказать вам, как действовать в этих двух ситуациях:
Когда вы использовали директиву Disallow по ошибке
В этом случае, если вы хотите исправить «Заблокировано robots.txt», удалите блокировку директивы Disallow сканирование заданной страницы.
Благодаря этому робот Googlebot, скорее всего, просканирует ваш URL-адрес при следующем сканировании вашего веб-сайта. Без дальнейших проблем с этим URL Google также проиндексирует его.
Если у вас много URL-адресов, затронутых этой проблемой, попробуйте отфильтровать их в GSC. Нажмите на статус и перейдите к символу перевернутой пирамиды над списком URL-адресов.
Вы можете отфильтровать все затронутые страницы по URL-адресу (или только части пути URL-адреса) и дате последнего обхода.
Если вы видите сообщение «Заблокировано robots.txt», это может также означать, что вы намеренно заблокировали весь каталог, но непреднамеренно включили страницу, которую хотите просканировать. Чтобы устранить эту проблему:
- Включите в директиву Disallow как можно больше фрагментов пути URL, чтобы избежать потенциальных ошибок или
- Используйте директиву Allow, чтобы разрешить ботам сканировать определенный URL-адрес в запрещенном каталоге.
При изменении файла robots.txt я предлагаю вам проверить свои директивы с помощью тестера robots.txt в Google Search Console. Инструмент загружает файл robots.txt для вашего веб-сайта и помогает вам проверить, правильно ли ваш файл robots.txt блокирует доступ к заданным URL-адресам.
Тестер robots.txt также позволяет проверить, как ваши директивы влияют на конкретный URL-адрес в домене для данного агента пользователя, например, Googlebot. Благодаря этому вы можете поэкспериментировать с применением различных директив и посмотреть, заблокирован или принят URL-адрес.
Благодаря этому вы можете поэкспериментировать с применением различных директив и посмотреть, заблокирован или принят URL-адрес.
Однако вы должны помнить, что инструмент не будет автоматически изменять ваш файл robots.txt. Поэтому, когда вы закончите тестирование директив, вам нужно вручную внести все изменения в свой файл.
Дополнительно я рекомендую использовать расширение Robots Exclusion Checker в Google Chrome. При просмотре любого домена инструмент позволяет обнаружить страницы, заблокированные файлом robots.txt. Он работает в режиме реального времени, поэтому поможет вам быстро реагировать, проверять и работать с заблокированными URL-адресами в вашем домене.
Посмотрите мою ветку в Твиттере, чтобы узнать, как я использую этот инструмент выше.
Что делать, если вы продолжаете блокировать важные страницы в robots.txt? Вы можете значительно ухудшить свою видимость в результатах поиска.
Когда вы намеренно использовали директиву Disallow
Вы можете игнорировать статус «Заблокировано robots. txt» в Google Search Console, если вы не запрещаете какие-либо ценные URL-адреса в файле robots.txt.
txt» в Google Search Console, если вы не запрещаете какие-либо ценные URL-адреса в файле robots.txt.
Помните, что запретить ботам сканировать низкокачественный или дублирующийся контент — это совершенно нормально.
Принятие решения о том, какие страницы должны и не должны сканировать боты, имеет решающее значение для:
- создания стратегии сканирования для вашего веб-сайта и
- Значительно поможет вам оптимизировать и сэкономить краулинговый бюджет.
СЛЕДУЮЩИЕ ШАГИ
Вот что вы можете сделать сейчас:
- Свяжитесь с нами.
- Получите от нас индивидуальный план решения ваших проблем.
- Раскройте потенциал сканирования и индексирования вашего веб-сайта!
Все еще не уверены, стоит ли писать нам? Обратитесь за услугами по оптимизации краулингового бюджета, чтобы улучшить сканирование вашего веб-сайта.
Ключевые выводы
- Директива Disallow в файле robots.txt запрещает Google сканировать вашу страницу, но не индексировать ее.