
Настройка Robots.txt. Подробное руководство
Почти каждый проект, который приходит к нам на аудит либо продвижение, имеет некорректный файл robots.txt, а часто он вовсе отсутствует. Так происходит, потому что при создании файла все руководствуются своей фантазией, а не правилами. Давайте разберем, как правильно составить этот файл, чтобы поисковые роботы эффективно с ним работали.
Зачем нужна настройка robots.txt?
Robots.txt — это файл, размещенный в корневом каталоге сайта, который сообщает роботам поисковых систем, к каким разделам и страницам сайта они могут получить доступ, а к каким нет.
Настройка robots.txt — важная часть SEO-работ по повышению позиций сайта в выдаче поисковых систем, правильно настроенный robots также увеличивает производительность сайта. Отсутствие Robots.txt не остановит поисковые системы сканировать и индексировать сайт, но если этого файла у вас нет, у вас могут появиться две проблемы:
-
Поисковый робот будет считывать весь сайт, что «подорвет» краулинговый бюджет.

Без файла robots, поисковик получит доступ к черновым и скрытым страницам, к сотням страниц, используемых для администрирования CMS. Он их проиндексирует, а когда дело дойдет до нужных страниц, на которых представлен непосредственный контент для посетителей, «закончится» краулинговый бюджет.
-
В индекс может попасть страница входа на сайт, другие ресурсы администратора, поэтому злоумышленник сможет легко их отследить и провести ddos атаку или взломать сайт.
Как поисковые роботы видят сайт с robots.txt и без него:
Синтаксис robots.txt
Прежде чем начать разбирать синтаксис и настраивать robots.txt, посмотрим на то, как должен выглядеть «идеальный файл»:
Но не стоит сразу же его применять. Для каждого сайта чаще всего необходимы свои настройки, так как у всех у нас разная структура сайта, разные CMS. Разберем каждую директиву по порядку.
Для каждого сайта чаще всего необходимы свои настройки, так как у всех у нас разная структура сайта, разные CMS. Разберем каждую директиву по порядку.
Читайте также Медленные сайты убивают продажи — как это исправить
User-agent
User-agent — определяет поискового робота, который обязан следовать описанным в файле инструкциям. Если необходимо обратиться сразу ко всем, то используется значок *. Также можно обратиться к определенному поисковому роботу. Например, Яндекс и Google:
Disallow
С помощью этой директивы, робот понимает какие файлы и папки индексировать запрещено. Если вы хотите, чтобы весь ваш сайт был открыт для индексации оставьте значение Disallow пустым. Чтобы скрыть весь контент на сайте после Disallow поставьте “/”.
Мы можем запретить доступ к определенной папке, файлу или расширению файла. В нашем примере, мы обращаемся ко всем поисковым роботам, закрываем доступ к папке bitrix, search и расширению pdf.
В нашем примере, мы обращаемся ко всем поисковым роботам, закрываем доступ к папке bitrix, search и расширению pdf.
Allow
Allow принудительно открывает для индексирования страницы и разделы сайта. На примере выше мы обращаемся к поисковому роботу Google, закрываем доступ к папке bitrix, search и расширению pdf. Но в папке bitrix мы принудительно открываем 3 папки для индексирования: components, js, tools.
Host — зеркало сайта
Зеркало сайта — это дубликат основного сайта. Зеркала используются для самых разных целей: смена адреса, безопасность, снижение нагрузки на сервер и т. д.
Host — одно из самых важных правил. Если прописано данное правило, то робот поймет, какое из зеркал сайта стоит учитывать для индексации. Данная директива необходима для роботов Яндекса и Mail.ru. Другие роботы это правило будут игнорировать. Host прописывается только один раз!
Для протоколов «https://» и «http://», синтаксис в файле robots.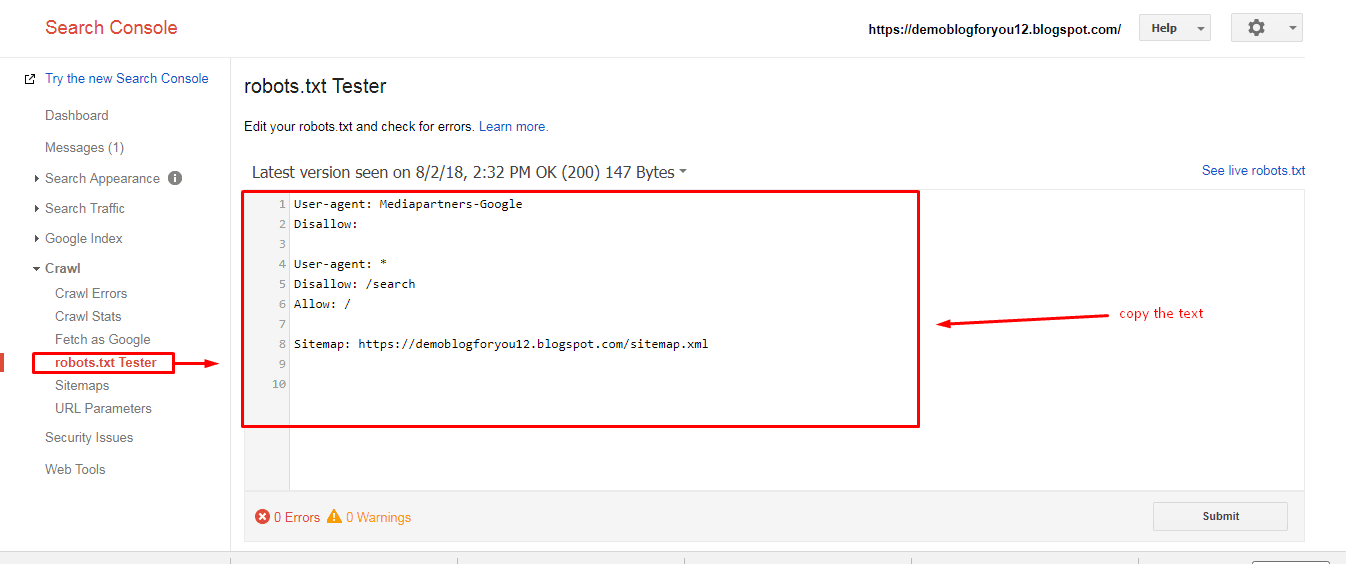 txt будет разный.
txt будет разный.
Sitemap — карта сайта
Карта сайта — это форма навигации по сайту, которая используется для информирования поисковых систем о новых страницах. С помощью директивы sitemap, мы «насильно» показываем роботу, где расположена карта.
Символы в robots.txt
Символы, применяемые в файле: «/, *, $, #».
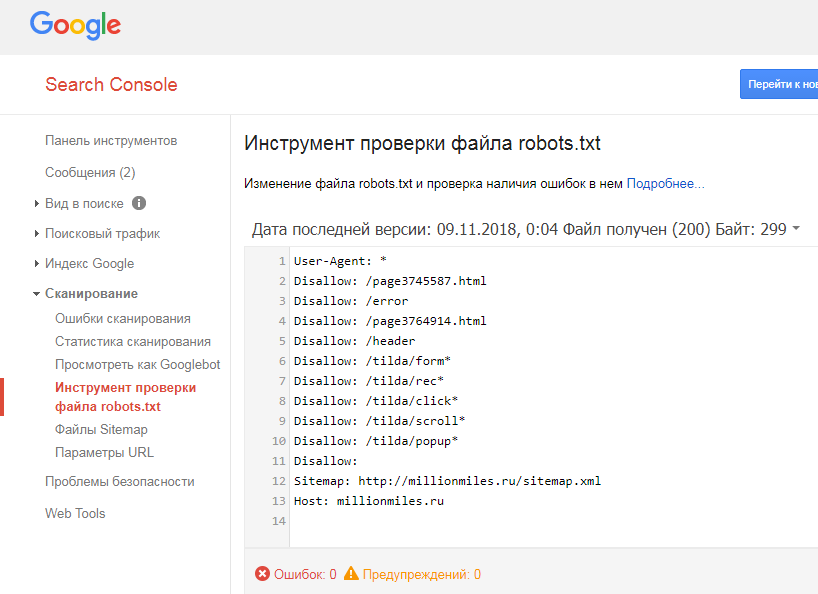
Проверка работоспособности после настройки robots.txt
После того как вы разместили Robots.txt на своем сайте, вам необходимо добавить и проверить его в вебмастере Яндекса и Google.
Проверка Яндекса:
- Перейдите по ссылке.
- Выберите: Настройка индексирования — Анализ robots.txt.
Проверка Google:
- Перейдите по ссылке.
- Выберите: Сканирование — Инструмент проверки файла robots.txt.
Таким образом вы сможете проверить свой robots.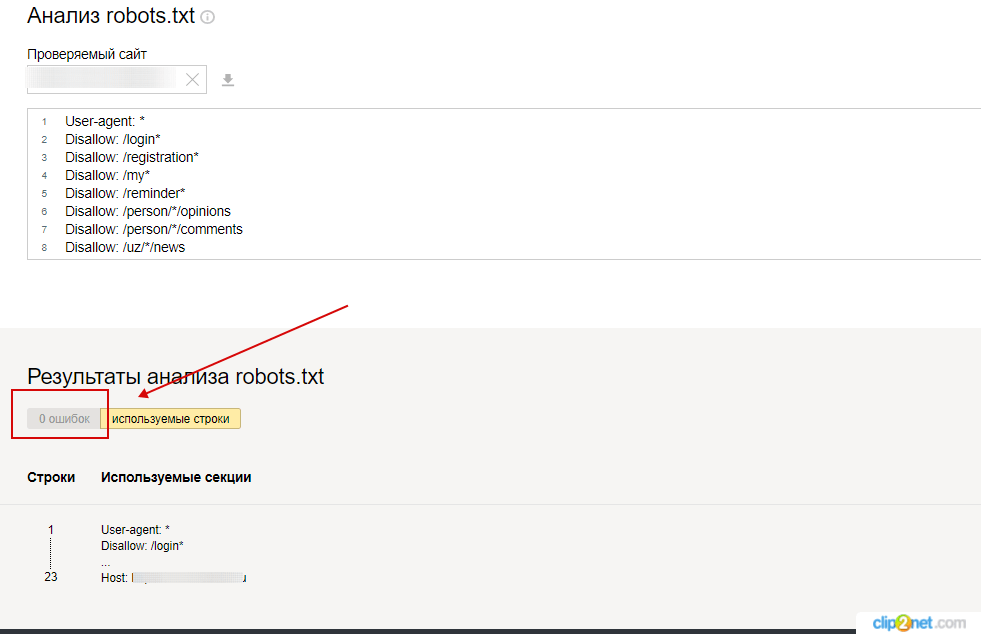 txt на ошибки и внести необходимые настройки, если потребуется.
txt на ошибки и внести необходимые настройки, если потребуется.
В заключение приведу 6 главных рекомендаций по работе с файлом Robots.txt:
- Содержимое файла необходимо писать прописными буквами.
- В директиве Disallow нужно указывать только один файл или директорию.
- Строка «User-agent» не должна быть пустой.
- User-agent всегда должна идти перед Disallow.
- Не стоит забывать прописывать слэш, если нужно запретить индексацию директории.
- Перед загрузкой файла на сервер, обязательно нужно проверить его на наличие синтаксических и орфографических ошибок.
Успехов вам!
Видеообзор 3 методов создания и настройки файла Robots.txt
-
Хотите, чтобы ваш сайт реально продавал? Готовы работать вместе с нами? Оформите заявку
Как настроить и добавить robots.
 txt на сайт
txt на сайтПоисковые системы ранжируют страницы согласно заданным параметрам. Если не прописать условия ранжирования с помощью специальных инструментов, в топ выдачи попадут ненужные страницы, а нужные — останутся в тени. Чтобы этого избежать, необходимо настроить robots.txt.
Что такое файл robots.txt, для чего он нужен и за что отвечает
Robots.txt — простой, но важный файл для SEO-продвижения. Он содержит команды и инструкции по индексации сайта.
Правильный robots.txt позволит закрыть от индексации, например, технические страницы. Это нужно для того, чтобы оптимизировать сайт под поисковые системы и повысить его позиции в выдаче.
Как создать и добавить robots.txt на сайт
Если у вашего сайта нет robots.txt, то он считается полностью открытым для индексирования.
Robots.txt сайта yandex.ru
Создаем файл в блокноте или любой текстовой программе — подойдет Word, NotePad и т. д. Главное, чтобы вы сохранили файл в формате “.txt” и назвали его “robots”.
Разрешили сканировать все, что начинается с “/catalog”, запретили доступ к разделам “about”, “info”, “album1”
Исключать из индексации нужно те страницы, которые не содержат полезной и релевантной для целевой аудитории информации:
- страницы авторизации и регистрации;
- результаты поиска;
- служебные разделы;
- страницы фильтров;
- PDF-документы;
- разрабатываемые страницы;
- формы заказа, корзина и т. д.
Файл загрузите в корень сайта через панель администратора.
Затем установить галочку в строке «Включить robots.txt» и внести в поле необходимые правила, нажать «Применить». Проверьте, открывается ли файл по адресу ваш_домен/robots.txt.
Как настроить файл robots.txt вручную
Для этого не нужно быть программистом или верстальщиком — достаточно разобраться, за что отвечает каждый параметр, который мы будем вносить в файл.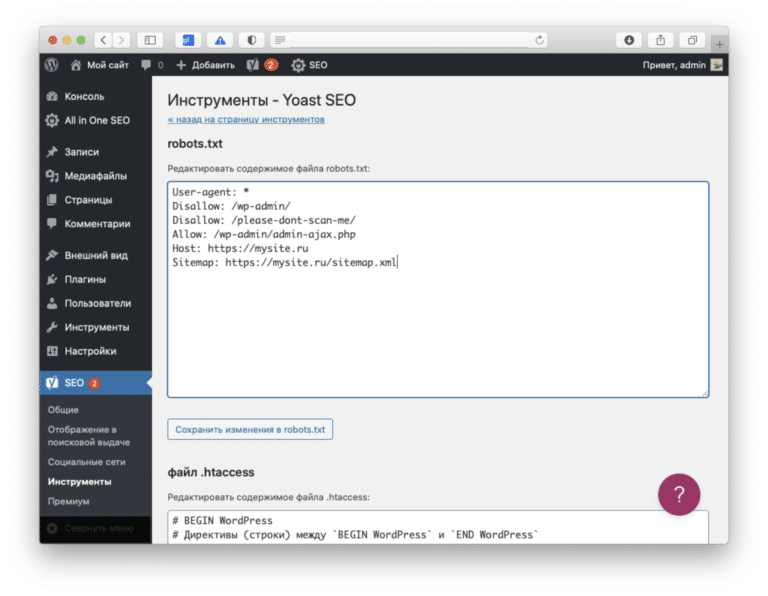
- User-agent. С этой директивы должен начинаться каждый robots.txt. Она показывает, для бота какой поисковой системы предназначается инструкция.
User-agent: YandexBot — для Яндекса,
User-agent: Googlebot — для Гугла,
User-Agent: * — общий для всех роботов.
https://vk.com/robots.txt предназначается для всех роботов поисковых систем
- Allow. Эта директива показывает, какие страницы может индексировать робот поисковых систем.
Например, в этом файле Яндексу разрешается индексировать весь сайт:
User-Agent: YandexBot
Allow: /
- Disallow. Полная противоположность предыдущей директивы — закрывает те страницы, которые запрещается индексировать.
Директивы в файле robots.txt на сайте apple.com
- Sitemap. Этот параметр показывает, где находится карта сайта в формате XML, если такая у вас есть. Добавляется данная строчка в конец файла. Прописывается так:
Sitemap: http://www. вашсайт.ru/sitemap.xml
вашсайт.ru/sitemap.xml
- Clean Param. Закрывает от индексации страницы с дублирующимся контентом. Это нужно для того, чтобы снизить нагрузку на сервер, — так робот поисковой системы не будет раз за разом перезагружать дублирующуюся информацию. Например, у вас есть три страницы с одинаковым содержанием, которые отличаются только параметром “get=”. Он нужен, чтобы понять, с какого сайта к вам пришел пользователь. В этом случае URL страниц разные, но все они ведут на одну и ту же страницу. Чтобы робот не индексировал всё как дубли, прописываем:
Clean-param: option /index.php
Готовые шаблоны файлов: где взять и как редактировать
Если нет желания или времени прописывать директивы вручную, можно воспользоваться сервисами для создания готовых файлов robots.txt для сайта. Однако, у этого способа есть свои плюсы и минусы.
Экономия времени — если у вас много сайтов, не придется для каждого вручную прописывать параметры
Директивы будут настроены однотипно, в них не учитываются особенности именно вашего сайта
Рассмотрим самые популярные сервисы:
- CY-PR. Интерфейс довольно простой — все, что требуется сделать, выбрать нужные поля и задать ваши значения. Готовый файл нужно перенести в корень сайта.
 Интерфейс довольно простой — все, что требуется сделать, выбрать нужные поля и задать ваши значения. Готовый файл нужно перенести в корень сайта.
Интерфейс довольно простой — все, что требуется сделать, выбрать нужные поля и задать ваши значения. Готовый файл нужно перенести в корень сайта.Интерфейс CY-PR
- Seo-auditor. Выбираете нужные поля и вводите ваши значения. Можно указать зеркало сайта, запретить скачивание сайта программами и адаптировать robots.txt под движок WordPress.
Интерфейс Seo-auditor
- IKSWEB. Еще один генератор с более разнообразной адаптацией настроек под CMS сайта — доступны WordPress, 1C-Bitrix, Blogger, uCoz и многие другие.
Интерфейс IKSWEB
После создания файла вы можете его редактировать под себя. Для этого достаточно открыть файл в блокноте и внести необходимые изменения в директивы. Не забудьте загрузить обновленный документ в корень сайта.
Как исправить ошибки при проверке robots.txt
В первой части статьи мы писали, как проверить корректную работу файла. Рассмотрим, как исправить ошибки, которые могут возникнуть.
Чек-лист для настройки файла robots.
 txt
txt- Файл имеет расширение “.txt” и называется “robots”.
- Файл загружен в корень сайта.
- Файл начинается с директивы User-agent и содержит не более 2 048 правил.
- Каждое правило длиной не более 1 024 символа.
- Файл содержит только одну директиву типа “User-agent: *”.
- После каждой директивы проставлено двоеточие, а затем прописан параметр.
- Файл успешно прошел проверку на сервисе, ошибок не обнаружено.
Перейти ко всем материалам блога
Как создать и правильно настроить файла robots.txt для индексации сайта
Привет, я руководитель SEO-отдела в компании TRINET.Group. Если на сайте падает трафик, возможно, запрещена индексация для поисковых систем. Причина в файле robots.txt. Если вовремя обнаружить проблему и настроить его работу правильно, индексация веб-страниц восстановится.
В этом видео я рассказываю, как robots. txt влияет на индексацию
txt влияет на индексацию
В этой статье рассмотрим:
Что такое robots.txt?
Как его правильно настроить?
Какие сервисы использовать для проверок robots.txt?
Почему не стоит запрещать пагинацию?
Что такое robots.txt
Справка: robots.txt — это файл в корневом каталоге, который отвечает за то, чтобы сайт был открыт для индексации и сканирования страницы или ее элементов поисковыми системами.
Пример файла robots.txt
Прежде чем зайти на сайт, поисковая система обращается к файлу robots.txt и индексирует директивы — правила, которые запрещают индексацию страниц. Например, указан «User-agent» — обязательная директива, где указано, для какого робота указаны правила. Если стоит «*» (звездочка), это означает руководство для всех роботов. Можно создать персональные правила для ботов Яндекса (User-agent: Yandex) или Google (User-agent: Googlebot).
Читайте также: Разница SEO-продвижения в «Яндекс» и Google: почему отличаются позиции в поисковиках
Файл передает один из трех вариантов разрешений:
Частичный допуск — сканирование отдельных элементов. Запрещает индексацию данных, которые нельзя допускать в выдачу — формы с личными данными пользователей, дублированные страницы, неуникальные изображения и др.
Полный доступ — разрешено сканировать все.
Полный запрет — нельзя сканировать ничего. Часто такое ограничение применяется при размещении нового сайта, чтобы он был закрыт для посещения, пока ведется его разработка, наполнение и проверка работы.
Часто разработчики при запуске нового сайта забывают обновить этот файл и открыть сайт для индексации. И почему-то делают это по пятницам, не предупреждая никого. Таким образом, страницы нового сайта автоматически будут закрыты на выходные, трафик и продажи упадут. Страницы могут вылетать из индекса — обычно до 2 недель.
Страницы могут вылетать из индекса — обычно до 2 недель.
Если это быстро заметить, после исправления robots.txt индексация восстановится и позиции могут вернуться обратно. Если до открытия индексации пройдет больше недели, могут быть более негативные последствия.
Читайте также: SEO-специалист: кто это, его задачи, умения и навыки
Файл robots.txt необходим, и его важно корректно настраивать. Например, вам не нужно, чтобы поисковая система просканировала какие-то дублированные изображения или вы хотите скрыть от посетителей раздел, предназначенный только для сотрудников.
Главное предназначение robots.txt в SEO — закрытие дублей. Например, есть технические дубли страниц сортировки, фильтрации, UTM-метки, которые генерирует система управления сайтом CMS. От таких страниц в индексе необходимо избавиться, закрыть их от индексации.
Как создать robots.txt и настроить его работу
Это обычный текстовый файл, который создается в блокноте. Указываются User-agent с помощью значка «звездочка» и ниже прописываются правила.
Указываются User-agent с помощью значка «звездочка» и ниже прописываются правила.
Существует несколько способов, как создать robots.txt:
Самый простой метод — посмотреть стандартные правила для CMS сайта. Обычно туда включены рекомендации, что именно нужно закрыть от индексации. Эту информацию можно найти в интернете, например для Bitrix или WordPress. С помощью специальных плагинов и модулей редактирование возможно даже с административной панели CMS.
Инструменты в Яндекс.Вебмастер и в Google Search Console позволят вам осуществить проверку ваших директив, чтобы избежать ошибок.
Если сайт новый, за исходник можно взять стандарт и потом проверить в инструментах через валидатор. Он сканирует robots.txt на содержание ошибок. В него можно добавить страницу сайта и посмотреть, какие элементы открыты, а какие закрыты.
Справка: Файл robots.txt создается через блокнот и сохраняется в формате «.
 txt». Учитывайте ограничение по размеру до 32 Кб на индексацию поисковой системой Яндекс.
txt». Учитывайте ограничение по размеру до 32 Кб на индексацию поисковой системой Яндекс.Для формирования файла в CMS есть свои плагины. Классический вариант размещения — публикация через файловый менеджер или FTP-соединение с перезаписыванием файла. Обязательно проверьте результат. Возможно кэширование результатов — в таком случае обновите кэш браузера. Если хочется внедрить изменения и узнать, как будет работать страница, закроется ли она от индексации, не запретили ли лишнего, используйте сервисы проверки от Яндекса.
Читайте также: Актуальный сборник статей по SEO 2021 — статьи о продвижении и оптимизации сайтов
Основные директивы robots.txt
Инструкции для поисковых роботов указываются с помощью символов и текста. Важно разобраться, какие директивы за что отвечают. Есть стандартные формулировки правил. Вот несколько примеров директив:
Disallow — запрет сканирования.
Ставится двоеточие и внутри знаков «/» пишется название раздела, который нельзя сканировать. Disallow: /admin/ — будет запрещена индексация содержимого указанного раздела.Allow — разрешающая директива. По умолчанию все, что не запрещено, то разрешено.
«$» — указывает на конец строки, например Disallow: /poly/$, папку индексировать нельзя, а ее содержимое можно.
Sitemap — указывает путь к карте сайта для ускорения индексации.
 Ставится двоеточие и внутри знаков «/» пишется название раздела, который нельзя сканировать. Disallow: /admin/ — будет запрещена индексация содержимого указанного раздела.
Ставится двоеточие и внутри знаков «/» пишется название раздела, который нельзя сканировать. Disallow: /admin/ — будет запрещена индексация содержимого указанного раздела.C помощью специальных платных программ можно удобно изучать каждую страницу на предмет доступности для индексации.
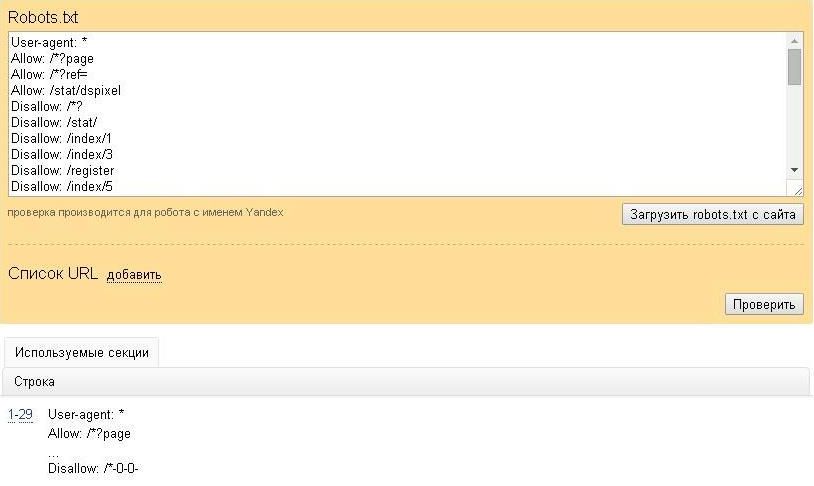
Пример проверки в Яндекс Вебмастер
Screaming Frog.
Netpeak Spider.
Почему не стоит запрещать пагинацию
Справка: пагинация — это разделение контента на сайте на отдельные страницы. Часто применяется в каталогах интернет-магазинов.
Пример страниц пагинации
Например, в одном из листингов представлены кольца — 1000 видов. Если разместить все в одном разделе, скорость загрузки страницы будет крайне низкой. Чтобы не выводить 1000 позиций в одном листинге, его разбивают на подстраницы для удобства клиентов и поисковых роботов.
Если разместить все в одном разделе, скорость загрузки страницы будет крайне низкой. Чтобы не выводить 1000 позиций в одном листинге, его разбивают на подстраницы для удобства клиентов и поисковых роботов.
Мы не рекомендуем закрывать пагинацию от поисковых роботов, чтобы ссылки на товары появлялись в выдаче и разделы сайта быстро индексировались. Поисковые системы должны просканировать все товары и узнать обо всем ассортименте.
Если правильно настраивать robots.txt и проверять его настройки, проблем с индексацией из-за этого файла не возникнет. Если обнаружены неполадки, рекомендуем обратиться к специалистам либо разобраться в вопросе самостоятельно.
Workspace.LIVE — мы в Телеграме
Новости в мире диджитал, ответы экспертов на злободневные темы, опросы, статьи и многое другое. Подписывайтесь: https://t.me/workspace
▷ Що таке файл Robots.txt — як створити та налаштувати правила в файлі Robots.txt, приклади використання
Що таке Robots.
 txt?
txt?Robots.txt — текстовий файл, в якому вказуються правила сканування сайту для пошукових систем. Файл знаходиться в кореневій папці і є звичайним текстовим документом в форматі .txt.
Пошукові системи спочатку сканують вміст файлу Robots.txt і тільки потім інші сторінки сайту. Якщо файл Robots.txt відсутня – пошуковим системам дозволено сканувати всі сторінки сайту.
Содержание- Що таке Robots.txt?
- Для чого потрібен файл Robots.txt
- Як створити текстовий файл Robots.txt
- Вимоги до файлу Robots.txt
- Обмеження документа Robots.txt
- Позначення і види директив
- У якому порядку виконуються правила
- Приклади використання файлу Robots.txt
- Найбільш поширені помилки
- Довідкові матеріали
Для чого потрібен файл Robots.txt
- Вказати пошуковим системам правила сканування і індексації сторінок сайту. Для кожного пошукача можна задати як різні правила, так і однакові.
- Вказати пошуковим системам посилання на xml-карту сайту, щоб роботи могли без проблем її знайти і просканувати.

Основним завданням robots.txt є управління доступу до сторінок сайту пошуковим системам і іншим роботам. На сайті може перебувати конфіденційна інформація, наприклад, особисті дані користувачів або внутрішні документи компанії. Завдяки директивам в файлі Robots.txt можна заборонити до них доступ пошуковим системам і їх не знайдуть.
Варто пам’ятати про те, що пошукові системи враховують правила в файлі Robots.txt по-різному. Для Google вміст файлу є рекомендацією по скануванню сайту, а для Яндекса – прямий директивою.
Тобто, якщо сторінка закрита в файлі Robots.txt, вона все одно може потрапити в індекс пошукової системи Google, адже для нього це рекомендації по скануванню, а не індексації.
Щоб не допустити індексації певних сторінок сайту потрібно використовувати метатег robots або X-Robots-Tag.
Яндекс сприймає вміст файлу Robots.txt як директиви і завжди їх виконує.
Тут потрібна картинка, що Яндекс кориться вимогам, а Google ухиляється. Треба намалювати.
Як створити текстовий файл Robots.txt
- Створіть текстовий документ у форматі .txt.
- Поставте йому ім’я robots.txt.
- Вкажіть вміст файлу.
- Додайте його в кореневий каталог сайту, щоб він був доступний за адресою /robots.txt.
- Перевірте коректність файлу через інструмент Яндекса или Google.
Файл Robots.txt повинен обов’язково знаходитися за адресою robots.txt. Якщо він буде розміщений по іншому url-адресою, пошукова система буде його ігнорувати і вважати, що все дозволено для сканування і індексації.
Вірно:
https://inweb.ua/robots.txt
Невірно:
https://inweb.ua/robots.txt
https://inweb.ua/ua/robots.txt
https://inweb.ua/robot.txt
Для популярних CMS є плагіни для редагування файлу Robots.txt:
- WordPress – Clearfy Pro .
- Opencart – редактор Robots.txt .
- Bitrix – є можливість редагувати через адміністративну панель за замовчуванням. Маркетинг & gt; Пошукова оптимізація & gt; Налаштування robots.txt.
 Маркетинг & gt; Пошукова оптимізація & gt; Налаштування robots.txt.
Маркетинг & gt; Пошукова оптимізація & gt; Налаштування robots.txt.За допомогою зазначених модулів можна легко змінювати директиви через адміністративну панель, без використання ftp.
Вимоги до файлу Robots.txt
Щоб пошукові системи виявили і слідували директивам необхідно дотримуватись наступних правил:
- Розмір файлу не перевищує 500кб;
- Це TXT-файл з назвою robots – robots.txt;
- Файл розміщений в кореневому каталозі сайту;
- Файл доступний для роботів – код відповіді сервера – 200. Перевірити можна за допомогою сервісу або інструментів Google Search Console і Яндекс Вебмастера.
- Якщо файл не відповідає вимогам – сайт вважається відкритим для сканування і індексації.
Якщо ж пошукова система, при запиті файлу /robots.txt, отримала код відповіді сервера відмінний від 200 – сканування сайту припиниться. Це може істотно погіршити швидкість сканування сайту.
Обмеження документа Robots.txt
- Не всі пошукові системи обробляють директиви у файлі Robots. txt однаково. У кожної є своя інтерпретація. При складанні правил слід на це звертати увагу.
- Кожна директива повинна починатися з нового рядка.
- У кожної пошукової системи є кілька роботів, які сканують сайти. Деякі з них інтерпретують правила robots.txt інакше.
- У файлі Robots.txt дозволяється використовувати тільки латинські літери. Якщо у вас кириличні url-адреси або домен – необхідно використовувати punycode.
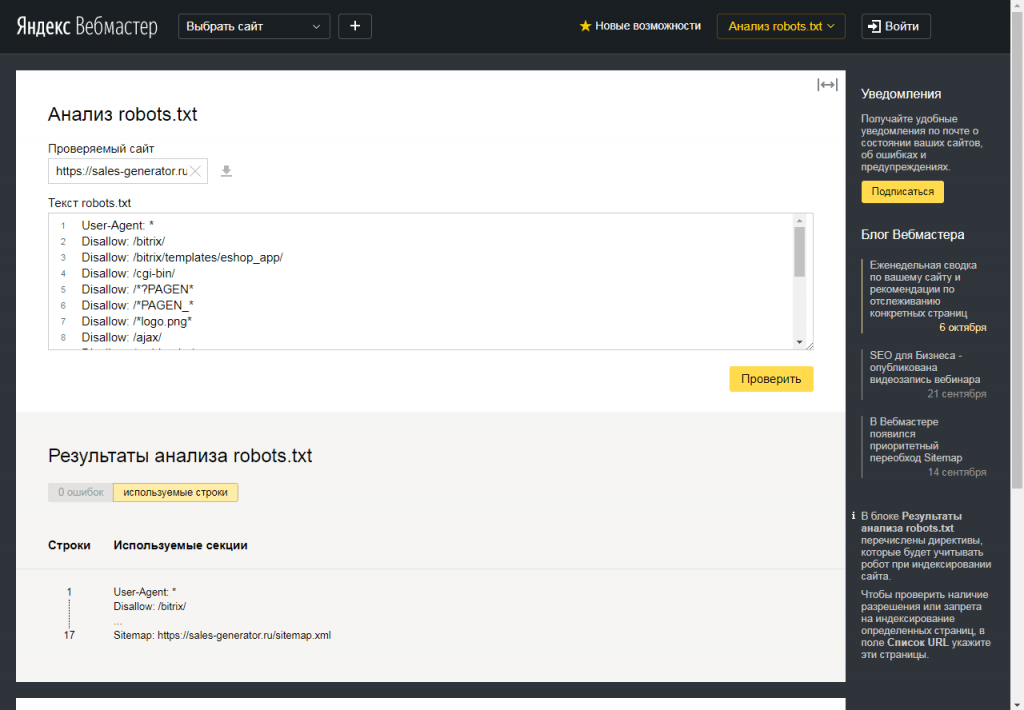 txt однаково. У кожної є своя інтерпретація. При складанні правил слід на це звертати увагу.
txt однаково. У кожної є своя інтерпретація. При складанні правил слід на це звертати увагу.Розглянемо на прикладі, як Robots.txt використовує систему кодування:
Вірно:
User-agent: *
Disallow: /корзина
Sitemap: сайт.рф/sitemap.xml
Не вірно:
User-agent: *
Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0
Sitemap:http://xn--80aswg.xn--p1ai/sitemap.xml
Позначення і види директив
Нижче розглянемо які є директиви у файлі Robots.txt
- User-agent — вказівка пошукового бота, до якого застосовуються правила. Щоб вибрати всіх роботів – вкажіть “*”. Директива є обов’язковою для використання, без вказівки User-gent не можна використовувати будь-які правила.
Наприклад:
User-agent: * # правила для всіх.
User-agent: Googlebot # правила тільки для Google.
User-agent: Yandex # правила тільки для Яндекса
. - Disallow — директива, яка забороняє сканування певних сторінок або розділів.
Наприклад:
Disallow: / order / # закриває всі сторінки, які починаються з / order /.
Disallow: / * sort-order # закриває всі сторінки, які містять фрагмент “sort-order”.
Disallow: / secretiki / # закриває всі сторінки, які починаються з / secretiki /. - Sitemap — вказівка посилання на xml-карту сайту. Якщо xml-карт сайту кілька – можна вказати їх все.
Наприклад:
Sitemap: https://inweb.ua/sitemap.xml
Sitemap: https://inweb.ua/sitemap-images.xml - Allow — дозволяє відкрити для робота сторінку або групу сторінок.
Наприклад:
Disallow: /category/
Allo: /category/phones/
Ми закриваємо всі сторінки, які починаються з / category /, але відкриваємо /category/phones/ - Clean-param — повідомляє Яндексу, що в адресі є параметри і мітки, необов’язкові при скануванні. Працює тільки з роботами в Yandex.
- Crawl-delay — з 22 лютого 2018 року не враховується. Раніше враховувалася тільки пошуковою системою Яндекс і впливала на затримку між зверненнями до сайту.
- Host — вказівка головного дзеркала для Яндекса. Не враховується з 12 березня 2018 року. Тепер все пошукові системи ігнорують цю директиву.
- Спецсимволи:* – позначає будь-яку кількість символів.
Наприклад:
Disallow: * # забороняє сканування всього сайту.
Disallow: * limit # Забороняє сканування всіх сторінок, які містять “limit”.
Disallow: / order / * / success / # забороняє сканування всіх сторінок, які починаються з / order /, потім містять будь-яку кількість символів, а потім / success /. - $ – позначає кінець рядка.
Наприклад:
Disallow: /*order$ #забороняє сканування всіх сторінок, які закінчуються на order.
 Працює тільки з роботами в Yandex.
Працює тільки з роботами в Yandex.У якому порядку виконуються правила
Yandex і Google обробляє директиви Allow і Disallow не по порядку, в якому вони вказані, а спочатку сортує їх від короткого правила до довгого, а потім обробляє останнім відповідне правило:
User-agent: *
Allow: */uploads
Disallow: /wp-
Буде прочитана як:
User-agent: *
Disallow: /wp-
Allow: */uploads
Таким чином, якщо перевіряється посилання виду: /wp-content/uploads/file.![]() jpg, правило “Disallow: / wp-” посилання заборонить, а наступне правило “Allow: * / uploads” її дозволить і посилання буде доступна для сканування.
jpg, правило “Disallow: / wp-” посилання заборонить, а наступне правило “Allow: * / uploads” її дозволить і посилання буде доступна для сканування.
У разі, якщо директиви рівнозначні або суперечать один одному:
User-agent: *
Disallow: /admin
Allow: /admin
Пріоритет віддається директиві Allow.
Приклади використання файлу Robots.txt
Приклад №1 – повністю закрити сайт від індексації.
User-agent: *
Disallow: /
Приклад №2 – блокуємо доступ до папки для Google, іншим пошуковим системам відкриваємо.
User-agent: *
Disallow:
User-agent: Googlebot
Disallow: /papka/
Приклад №3 – сайт повністю відкритий для індексації.
User-agent: *
Disallow:
Приклад №4 – закриваємо всі сторінки сайту, які містять фрагмент url-адреси “secret”.
User-agent: *
Disallow: *secret
Приклад №5 – закриємо повністю сайт для Яндекса, а для Google відкриємо тільки папку /for-google/
User-agent: Yandex
Disallow: /
User-agent: Googlebot
Disallow: /
Allow: /for-google/
Найбільш поширені помилки
Розглянемо найбільш поширені помилки, які допускають SEO-фахівці при складанні директив.
- Відсутність на самому початку директиви зірочки. Варто пам’ятати, що обов’язково потрібно додавати * перед фрагментом url-адреси, якщо директива містить фрагмент, який знаходиться не на початку url-адреси.
Наприклад, потрібно закрити від сканування url-адреса
https://inweb.ua/catalog/cateogory/?sort=name
Невірно: Disallow: ?sort=
Вірно: Disallow: /*sort= - Директива, крім неякісних url-адрес, забороняє сканування якісних сторінок. При написанні директив варто вказувати їх максимально чітко, щоб навіть теоретично якісні url-адреси не потрапили під заборону.
Невірно: Disallow: *sort
Вірно: Disallow: /*?sort=
У першому випадку, випадково можуть бути сторінки виду:
https://inweb.ua/kak-zakryt-ot-indeksacii-sortirovki/ Адже, теоретично, деякі сторінки можуть містити в url-адресу фрагмент “sort”. - Сторінки одночасно закриті в файлі Robots.txt і через метатег robots.Еслі неякісний документ закритий від сканування в файлі Robots.txt і від індексування через метатег robots – сторінка ніколи не випаде з індексу, оскільки робот пошукової системи Google не побачить noindex, адже не може її просканувати.
- Використання кириличних символів. Варто завжди пам’ятати, що кирилиця не розпізнає пошуковими системами в файлі Robots.txt, обов’язково потрібно замінити на punycode. Посилання на конвертер.
Довідкові матеріали
- Довідка Яндекс по Robots.txt.
- Довідка Google по Robots.txt.
- Види пошукових роботів Google.
- Види пошукових роботів Яндекс.
- Інструмент перевірки файлу Robots.txt.
Тест на знання файлу Robots.txt
Коли-небудь настане день і знамення олдові «Термінатора» стане реальністю – роботи заполонять світ і візьмуть верх над людством. І тільки вправні знавці машин зможуть лавірувати в смертельній сутичці. Як добре ви вмієте спілкуватися з роботами? Чи зможете очолити повстання проти машин? Давайте перевіримо!
Настройка robots.txt для SEO [АйТи бубен]
Файл robots.txt или индексный файл — обычный текстовый документ в кодировке UTF-8, действует для протоколов http, https, а также FTP.
robots.txt — файл ограничения доступа к содержимому роботам на Методы и структура протокола HTTP- сервере. Файл должен находиться в корне сайта (т.е. иметь путь относительно имени сайта /robots.txt). При наличии нескольких субдоменов файл должен располагаться в корневом каталоге каждого из них. Данный файл дополняет стандарт Sitemaps, который служит прямо противоположной цели: облегчать роботам доступ к содержимому.
Обязательно ли использовать на сайте файл robots.txt? Использование файла добровольно. Когда робот Googlebot посещает сайт, сначала он пытается найти файл robots.txt. Отсутствие файла robots.txt, метатегов robots или HTTP-заголовков X-Robots-Tag обычно не влияет на нормальное сканирование и индексирование сайта.
Стандарт был принят консорциумом 30 января 1994 года в списке рассылки robots-request@nexor.co.uk и с тех пор используется большинством известных поисковых машин.
Файл robots.txt используется для частичного управления индексированием сайта поисковыми роботами. Этот файл состоит из набора инструкций для поисковых машин, при помощи которых можно задать файлы, страницы или каталоги сайта, которые не должны индексироваться. Файл robots.txt может использоваться для указания расположения файла и может показать, что именно нужно, в первую очередь, проиндексировать поисковому роботу.
Этот файл состоит из набора инструкций для поисковых машин, при помощи которых можно задать файлы, страницы или каталоги сайта, которые не должны индексироваться. Файл robots.txt может использоваться для указания расположения файла и может показать, что именно нужно, в первую очередь, проиндексировать поисковому роботу.
Файл состоит из записей. Записи разделяются одной или более пустых строк (признак конца строки: символы CR, CR+LF, LF). Каждая запись содержит непустые строки следующего вида:
<поле>:<необязательный пробел><значение><необязательный пробел>
где поле — это либо User-agent, либо Disallow.
Сравнение производится методом простого поиска подстроки. Например, запись Disallow: /about запретит доступ как к разделу http://example.com/about/, так и к файлу http://example.com/about.php, а запись Disallow: /about/ — только к разделу http://example.com/about/.
На сайте может быть только один файл «/robots.txt». Например, не следует помещать файл robots. txt в пользовательские поддиректории – все равно роботы не будут их там искать. Что такое ссылка URL -ы чувствительны к регистру, и название файла «/robots.txt» должно быть написано полностью в нижнем регистре.
txt в пользовательские поддиректории – все равно роботы не будут их там искать. Что такое ссылка URL -ы чувствительны к регистру, и название файла «/robots.txt» должно быть написано полностью в нижнем регистре.
Запрет доступа всех роботов ко всему сайту в файле robots.txt — это и есть закрытие от индексирования сайта
User-agent: * Disallow: /
Но директивы которые прописываются в robots.txt это рекомендации поисковому роботу, а не строгие правила. Известны случаи когда сайт закрытый в robots.txt попадал в индекс.
Поэтому добавляем в мета-тег в раздел head.
<meta name="robots" content="noindex, nofollow"/>
Вот теперь мы точно закрыли сайт от индексирования! Удачно вам выпасть из индекса!
User-agent: googlebot Disallow: /private/
robots.txt для DokuWiki и Яндекса
Разрешить доступ всех роботов ко всему сайту
- robots.txt
User-agent: * Allow: /
Официальное руководство Google рекомендует:
Для временной приостановки сканирования всех URL следует отобразить для них код ответа HTTP 503 (в том числе и для файла robots.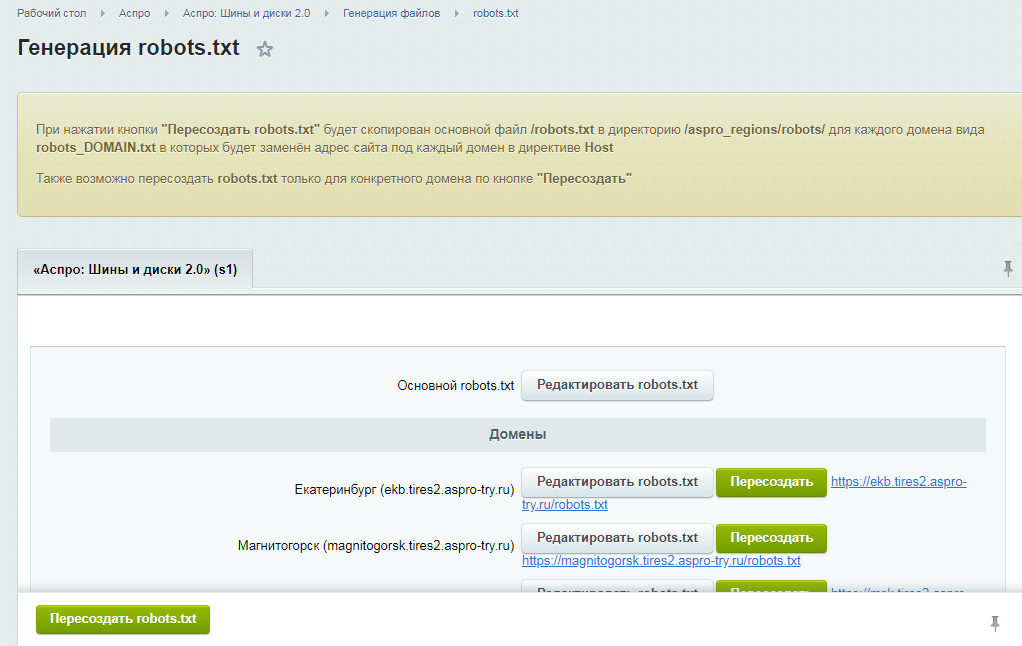 txt). Робот Google будет периодически пытаться получить доступ к файлу robots.txt до тех пор, пока он не станет вновь доступен. Не рекомендуется запрещать сканирование путем внесения изменений в файл robots.txt.
txt). Робот Google будет периодически пытаться получить доступ к файлу robots.txt до тех пор, пока он не станет вновь доступен. Не рекомендуется запрещать сканирование путем внесения изменений в файл robots.txt.
Для проверки синтаксиса и структуры файла robots.txt существует ряд специализированных онлайн-служб.
Служба Яндекса (выполняет только проверку синтаксиса) (рус.)
Google webmasters tools (позволяет проверить разрешения для каждой отдельной страницы) (рус.)
Существует специализированная поисковая система BotSeer, которая позволяет осуществлять поиск по файлам robots.txt.
Он достаточно сложный и лучше его использовать в образовательных целях. Я обычно использую более простой вариант robots.txt.
Не забудьте заменить your_domen на имя вашего домена
- robots.txt
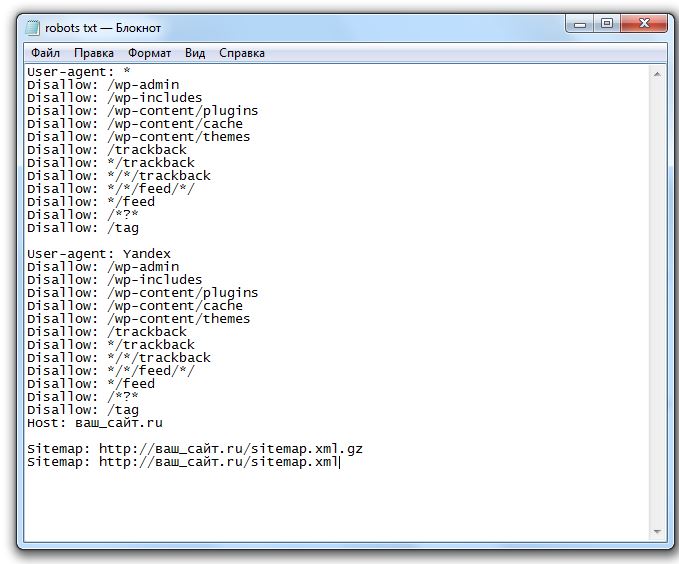
User-agent: * Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /wp-admin Disallow: /shop Disallow: /?s= Disallow: /cgi-bin Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */feed Disallow: */feed/* Disallow: /*?* Allow: /wp-content/uploads/ Allow: /wp-content/*.
js$
Allow: /wp-content/*.css$
Allow: /wp-includes/*.js$
Allow: /wp-includes/*.css$
Allow: /wp-content/themes/*.css
Allow: /wp-content/plugins/*.css
Allow: /wp-content/uploads/*.css
Allow: /wp-content/themes/*.js
Allow: /wp-content/plugins/*.js
Allow: /wp-content/uploads/*.js
Allow: /wp-includes/css/
Allow: /wp-includes/js/
Allow: /wp-includes/images/
Allow: /wp-content/uploads/
Allow: /wp-admin/admin-ajax.php
User-agent: Yandex
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /wp-admin
Disallow: /shop/
Disallow: /?s=
Disallow: /cgi-bin
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */feed
Disallow: */feed/*
Disallow: /*?*
Allow: /wp-content/uploads/
Allow: /wp-content/*.js$
Allow: /wp-content/*.css$
Allow: /wp-includes/*.js$
Allow: /wp-includes/*.css$
Allow: /wp-content/themes/*.css
Allow: /wp-content/plugins/*.css
Allow: /wp-content/uploads/*.css
Allow: /wp-content/themes/*.js
Allow: /wp-content/plugins/*.js
Allow: /wp-content/uploads/*. js
Allow: /wp-includes/css/
Allow: /wp-includes/js/
Allow: /wp-includes/images/
Allow: /wp-content/uploads/
Allow: /wp-admin/admin-ajax.php
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
Host: https://your_domen/
Sitemap: https://your_domen/sitemap_index.xml
 js$
Allow: /wp-content/*.css$
Allow: /wp-includes/*.js$
Allow: /wp-includes/*.css$
Allow: /wp-content/themes/*.css
Allow: /wp-content/plugins/*.css
Allow: /wp-content/uploads/*.css
Allow: /wp-content/themes/*.js
Allow: /wp-content/plugins/*.js
Allow: /wp-content/uploads/*.js
Allow: /wp-includes/css/
Allow: /wp-includes/js/
Allow: /wp-includes/images/
Allow: /wp-content/uploads/
Allow: /wp-admin/admin-ajax.php
User-agent: Yandex
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /wp-admin
Disallow: /shop/
Disallow: /?s=
Disallow: /cgi-bin
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */feed
Disallow: */feed/*
Disallow: /*?*
Allow: /wp-content/uploads/
Allow: /wp-content/*.js$
Allow: /wp-content/*.css$
Allow: /wp-includes/*.js$
Allow: /wp-includes/*.css$
Allow: /wp-content/themes/*.css
Allow: /wp-content/plugins/*.css
Allow: /wp-content/uploads/*.css
Allow: /wp-content/themes/*.js
Allow: /wp-content/plugins/*.js
Allow: /wp-content/uploads/*.
js$
Allow: /wp-content/*.css$
Allow: /wp-includes/*.js$
Allow: /wp-includes/*.css$
Allow: /wp-content/themes/*.css
Allow: /wp-content/plugins/*.css
Allow: /wp-content/uploads/*.css
Allow: /wp-content/themes/*.js
Allow: /wp-content/plugins/*.js
Allow: /wp-content/uploads/*.js
Allow: /wp-includes/css/
Allow: /wp-includes/js/
Allow: /wp-includes/images/
Allow: /wp-content/uploads/
Allow: /wp-admin/admin-ajax.php
User-agent: Yandex
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /wp-admin
Disallow: /shop/
Disallow: /?s=
Disallow: /cgi-bin
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */feed
Disallow: */feed/*
Disallow: /*?*
Allow: /wp-content/uploads/
Allow: /wp-content/*.js$
Allow: /wp-content/*.css$
Allow: /wp-includes/*.js$
Allow: /wp-includes/*.css$
Allow: /wp-content/themes/*.css
Allow: /wp-content/plugins/*.css
Allow: /wp-content/uploads/*.css
Allow: /wp-content/themes/*.js
Allow: /wp-content/plugins/*.js
Allow: /wp-content/uploads/*. js
Allow: /wp-includes/css/
Allow: /wp-includes/js/
Allow: /wp-includes/images/
Allow: /wp-content/uploads/
Allow: /wp-admin/admin-ajax.php
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
Host: https://your_domen/
Sitemap: https://your_domen/sitemap_index.xml
js
Allow: /wp-includes/css/
Allow: /wp-includes/js/
Allow: /wp-includes/images/
Allow: /wp-content/uploads/
Allow: /wp-admin/admin-ajax.php
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
Host: https://your_domen/
Sitemap: https://your_domen/sitemap_index.xmlИспользуешь WordPress? Я тебе рекомендую использовать этот супер-мега-функциональный плагин в том числе и для создания robots.txt
Директива host уже не нужна! 12 марта 2018 года Яндекс в своем блоге для вебмастеров анонсировал скорое прекращение поддержки директивы Host, а уже 20 марта констатировал сей факт, сопроводив его новыми подробными инструкциями по переезду с помощью 301-го редиректа.
Яндекс наконец-то хоть как-то унифицирует свою деятельность, а то достал своими заморочками.
- robots.txt
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ Disallow: /xmlrpc.
php
Disallow: /readme.html
Disallow: /*?
Disallow: /?s=
Allow: /*.css
Allow: /*.js
Sitemap: https://catsplanet.club/sitemap_index.xml
 php
Disallow: /readme.html
Disallow: /*?
Disallow: /?s=
Allow: /*.css
Allow: /*.js
Sitemap: https://catsplanet.club/sitemap_index.xml
php
Disallow: /readme.html
Disallow: /*?
Disallow: /?s=
Allow: /*.css
Allow: /*.js
Sitemap: https://catsplanet.club/sitemap_index.xmlУправление файлами robots.txt — Commerce | Dynamics 365
Обратная связь
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 3 мин
Важно!
Dynamics 365 Retail теперь называется Dynamics 365 Commerce — это универсальное многоканальное решение для электронной коммерции, магазинов и центров обработки вызовов. Дополнительные сведения об этих изменениях см. в разделе Microsoft Dynamics 365 Commerce.
Дополнительные сведения об этих изменениях см. в разделе Microsoft Dynamics 365 Commerce.
В этой статье описано, как управлять файлами robots.txt в Microsoft Dynamics 365 Commerce.
Стандарт исключения роботов, или robots.txt, является стандартом, который веб-сайты используют для связи с веб-роботами. Он инструктирует веб-роботов о любых областях веб-сайта, которые не должны быть посещены. Роботы часто используются поисковыми системами для индексирования веб-сайтов.
Чтобы исключить роботов с сервера, вы создаете файл на сервере. В этом файле указывается политика доступа для роботов. Файл должен быть доступен через HTTP по локальному URL-адресу /robots.txt. Файл robots.txt помогает поисковым системам индексировать содержимое вашего сайта.
Dynamics 365 Commerce позволяет загружать файл robots.txt для вашего домена. Для каждого домена в вашей среде Commerce вы можете загрузить один файл robots.txt и связать его с этим доменом.
Для получения дополнительной информации о файле robots.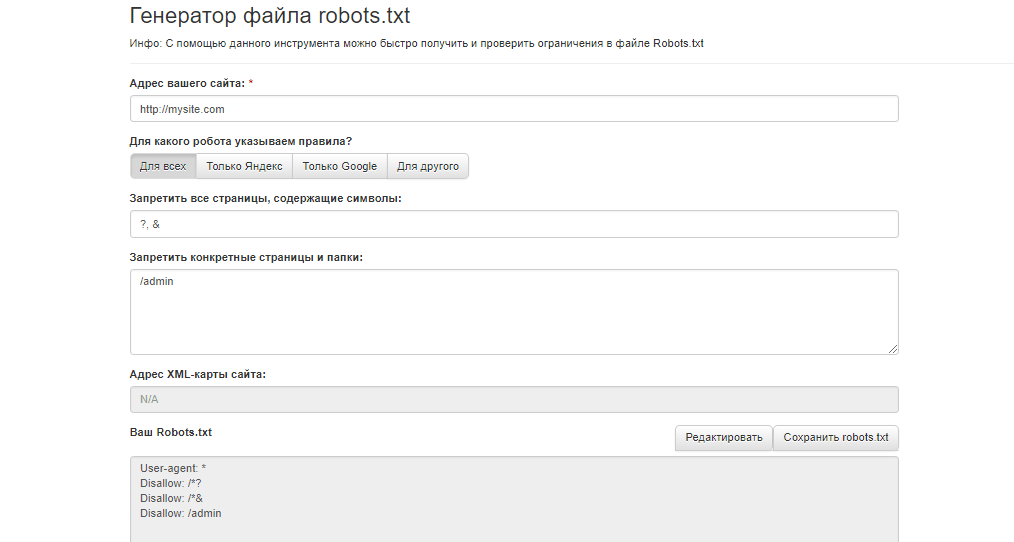 txt см. страницы о веб-роботах.
txt см. страницы о веб-роботах.
Отправка файла robots.txt
После того, как вы создали и отредактировали свой файл robots.txt в соответствии со стандартом исключения роботов, убедитесь, что файл доступен на компьютере, где вы будете использовать инструменты авторизации Commerce. Файл должен называться robots.txt. Для достижения наилучших результатов он должен быть в формате, который указан в стандарте. Каждый клиент Commerce несет ответственность за проверку и обслуживание содержимого своего файла robots.txt. Чтобы отправить файл robots.txt, вы должны войти в Commerce как системный администратор.
Чтобы отправить файл robots.txt в Commerce, выполните следующие действия.
- Войдите в Commerce в качестве системного администратора.
- В левой области переходов выберите Настройки клиента (рядом с символом шестеренки), чтобы развернуть его.
- В разделе Настройки клиента выберите Robots.txt. Список всех доменов, связанных с вашей средой, отображается в основной части окна.
- Выберите Управление, чтобы отправить файл robots.txt для домена в вашей среде.
- В меню справа выберите кнопку Отправить (стрелка вверх) рядом с доменом, который связан с файлом robots.txt. Появляется диалоговое окно браузера файлов.
- В диалоговом окне найдите и выберите файл robots.txt, который вы хотите отправить для связанного домена, а затем выберите Открыть для завершения отправки.
 Список всех доменов, связанных с вашей средой, отображается в основной части окна.
Список всех доменов, связанных с вашей средой, отображается в основной части окна.Примечание
Во время отправки Commerce проверяет, что файл является текстовым файлом, но он не проверяет содержимое файла.
Загрузка файла robots.txt
Чтобы загрузить файл robots.txt в Commerce, выполните следующие действия.
- Войдите в Commerce в качестве системного администратора.
- В левой области переходов выберите Настройки клиента (рядом с символом шестеренки), чтобы развернуть его.
- В разделе Настройки клиента выберите Robots.txt. Список всех доменов, связанных с вашей средой, отображается в основной части окна.
- Выберите Управление, чтобы загрузить файл robots.txt для домена в вашей среде.
- В меню справа выберите кнопку Загрузить (стрелка вниз) рядом с доменом, который связан с файлом robots.txt. Появляется диалоговое окно браузера файлов.
- В диалоговом окне перейдите в нужное место на локальном диске, подтвердите или введите имя файла, а затем выберите Сохранить для завершения загрузки.

Примечание
Эта процедура может быть использована для загрузки только файлов robots.txt, которые ранее были загружены через инструменты разработки Commerce.
Удаление файла robots.txt
Чтобы удалить файл robots.txt в Commerce, выполните следующие действия.
- Войдите в Commerce в качестве системного администратора.
- В левой области переходов выберите Настройки клиента (рядом с символом шестеренки), чтобы развернуть его.
- В разделе Настройки клиента выберите Robots.txt. Список всех доменов, связанных с вашей средой, отображается в основной части окна.
- Выберите Управление, чтобы удалить файл robots.txt для домена в вашей среде.
- В меню справа выберите кнопку Удалить (символ корзины) рядом с доменом, который связан с файлом robots.txt. Отображается окно браузера файлов.
- В окне браузера фалов найдите и выберите файл robots.txt, который вы хотите удалить для домена, а затем выберите Открыть. Появляется окно предупреждающих сообщений.
- В поле сообщения выберите Удалить, чтобы подтвердить удаление файла robots.txt.

Примечание
Эта процедура может быть использована для удаления только файлов robots.txt, которые ранее были загружены через инструменты разработки Commerce.
Дополнительные ресурсы
Настройка доменного имени
Развертывание нового клиента электронной коммерции
Создание сайта электронной коммерции
Связывание сайта Dynamics 365 Commerce с интернет-каналом
Пакетная отправка перенаправлений URL-адресов
Настройка клиента B2C в модуле Commerce
Настройка специальных страниц для входа пользователей
Настройка нескольких клиентов B2C в среде Commerce
Добавление поддержки сети доставки контента (CDN)
Включение обнаружения магазинов на основе местоположения
Примечание
Каковы ваши предпочтения в отношении языка документации? Пройдите краткий опрос (обратите внимание, что этот опрос представлен на английском языке).
Опрос займет около семи минут. Личные данные не собираются (заявление о конфиденциальности).
Обратная связь
Отправить и просмотреть отзыв по
Этот продукт Эта страница
Просмотреть все отзывы по странице
Robots.txt — полное руководство
26 сен
26 сен
Содержание
- Определение
- Зачем вам нужен Robots.txt
- Вот некоторые вещи, которые robots.txt будет и не будет делать:
- Понимание синтаксиса robots.txt
- Результаты инструкций Robots.txt
- Полное разрешение
- Полный запрет
- Условное разрешение
- Может ли робот по-прежнему сканировать и игнорировать мой файл robots. txt?
- Могу ли я заблокировать только плохих роботов?
- Каковы лучшие методы SEO при использовании robots.txt?
- Основные правила robots.txt
- Формат и расположение
- Как тогда убедиться, что файл robots.txt не отображает конфиденциальные данные в результатах поиска?
- Не приводит ли перечисление страниц или каталогов в файле robots.txt к непреднамеренному доступу?
- Можете ли вы оптимизировать файл robots.txt для SEO?
- Какие страницы вы можете исключить из индексации?
- Noindex и NoFollow
- Директива noindex
- Директива nofollow
- Генерация robots.txt
- Проверка файла robots.txt
- Как добавить robots.txt на ваш сайт WordPress
- Как отредактировать файл robots.txt на Wix
- Как отредактировать файл robots.txt на Shopify
 txt?
txt?
Определение
Robots.txt — это файл в текстовой форме, который указывает поисковым роботам индексировать или не индексировать определенные страницы. Он также известен как привратник для всего вашего сайта. Первая цель сканеров ботов — найти и прочитать файл robots.txt, прежде чем получить доступ к вашей карте сайта или любым страницам или папкам.
Он также известен как привратник для всего вашего сайта. Первая цель сканеров ботов — найти и прочитать файл robots.txt, прежде чем получить доступ к вашей карте сайта или любым страницам или папкам.
С помощью robots.txt вы можете более конкретно:
- Регулировать, как роботы поисковых систем сканируют ваш сайт
- Предоставить определенный доступ
- Помогите поисковым роботам проиндексировать содержимое страницы
- Показать, как предоставлять контент пользователям
Robots.txt является частью протокола исключения роботов (R.E.P), состоящего из директив уровня сайта/страницы/URL. Хотя роботы поисковых систем все еще могут сканировать весь ваш сайт, вы должны помочь им решить, стоят ли определенные страницы времени и усилий.
Зачем вам нужен Robots.txt
Для правильной работы вашего сайта не требуется файл robots.txt. Основная причина, по которой вам нужен файл robots.txt, заключается в том, что когда боты сканируют вашу страницу, они запрашивают разрешение на сканирование, чтобы они могли попытаться получить информацию о странице для индексации.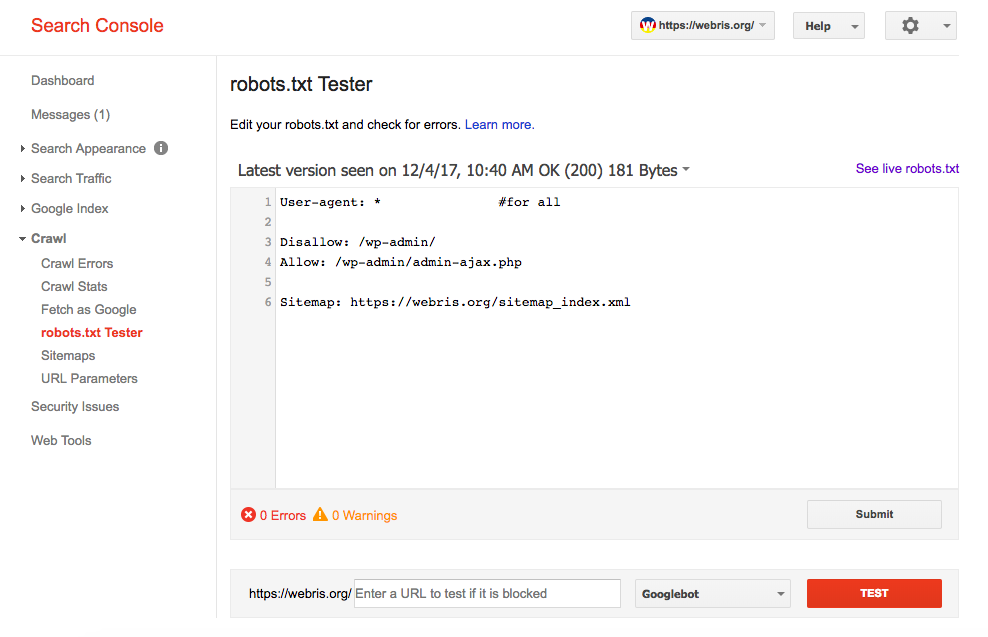 Кроме того, веб-сайт без файла robots.txt в основном просит поисковые роботы проиндексировать сайт по своему усмотрению. Важно понимать, что боты все равно будут сканировать ваш сайт без файла robots.txt.
Кроме того, веб-сайт без файла robots.txt в основном просит поисковые роботы проиндексировать сайт по своему усмотрению. Важно понимать, что боты все равно будут сканировать ваш сайт без файла robots.txt.
Расположение файла robots.txt также важно, поскольку все боты будут искать www.123.com/robots.txt. Если там ничего не найдут, то будут считать, что на сайте нет файла robots.txt и все проиндексируют. Файл должен быть текстовым файлом ASCII или UTF-8. Также важно отметить, что правила чувствительны к регистру.
Вот некоторые вещи, которые robots.txt будет и не будет делать:
- Файл может контролировать доступ поисковых роботов к определенным областям вашего веб-сайта. Вы должны быть очень осторожны при настройке robots.txt, так как можно заблокировать индексацию всего веб-сайта.
- Предотвращает индексацию дублированного контента и его появление в результатах поиска.
- В этом файле указывается задержка обхода, чтобы предотвратить перегрузку серверов, когда сканеры загружают несколько фрагментов содержимого одновременно.
Вот некоторые роботы Google, которые могут время от времени сканировать ваш сайт:
| Веб-краулер | Строка агента пользователя |
| Новости Googlebot | Googlebot-Новости |
| Googlebot Изображения | Googlebot-Изображение/1.0 |
| Робот Googlebot Видео | Googlebot-Видео/1.0 |
| Google Mobile (рекомендуемый телефон) | SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (совместимый; Googlebot-Mobile/2.1; +http://www .google.com/bot.html) |
| Смартфон Google | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, как Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (совместимо; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile AdSense | (совместимо; Mediapartners-Google/2. 1; +http://www.google.com/bot.html) 1; +http://www.google.com/bot.html) |
| Гугл Адсенс | Медиапартнеры-Google |
| Google AdsBot (качество целевой страницы PPC) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Сканер приложений Google (извлечение ресурсов для мобильных устройств) | AdsBot-Google-Mobile-Apps |
Список дополнительных ботов можно найти здесь.
- Файлы помогают указать расположение карт сайта.
- Это также предотвращает индексацию различных файлов на веб-сайте ботами поисковых систем, таких как изображения и PDF-файлы.
Когда бот хочет посетить ваш сайт (например, www.123.com), он сначала проверяет www.123.com/robots.txt и находит:
User-agent: *
Disallow: /
Если вы удалили прямую черту из Diswally, как в примере ниже,
Пользовательский агент: *
DESSINGE:
БОТ на сайте.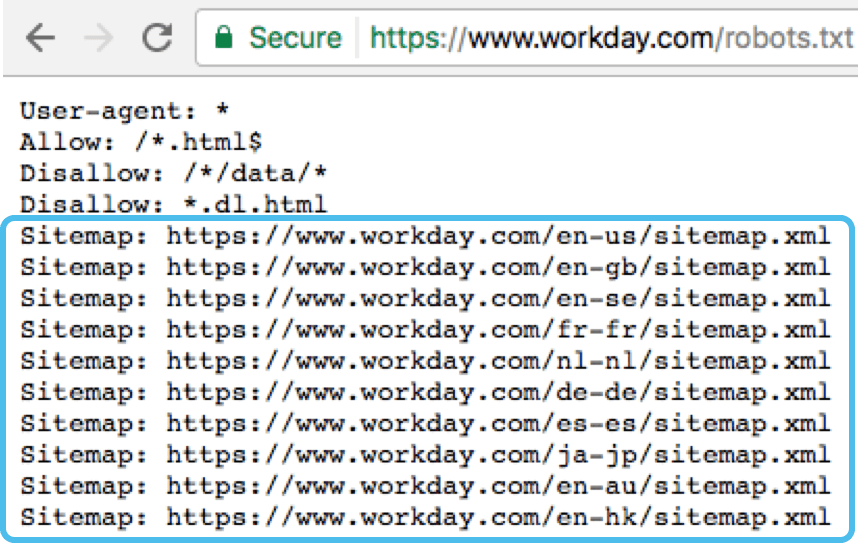 Вот почему важно понимать синтаксис файла robots.txt.
Вот почему важно понимать синтаксис файла robots.txt.
Понимание синтаксиса robots.txt
Синтаксис robots.txt можно рассматривать как «язык» файлов robots.txt. В файле robots.txt вы, скорее всего, встретите 5 распространенных терминов. Это:
- User-agent: Конкретный поисковый робот, которому вы даете инструкции по сканированию (обычно это поисковая система). Список большинства пользовательских агентов можно найти здесь.
- Disallow: Команда, используемая для указания пользовательскому агенту не сканировать определенный URL-адрес. Для каждого URL разрешена только одна строка «Disallow:».
- A llow (применимо только для робота Googlebot): Команда сообщает роботу Googlebot, что он может получить доступ к странице или вложенной папке, даже если ее родительская страница или вложенная папка могут быть запрещены.
- Crawl-delay: Количество миллисекунд, в течение которых сканер должен ждать перед загрузкой и сканированием содержимого страницы. Обратите внимание, что Googlebot не подтверждает эту команду, но скорость сканирования можно установить в Google Search Console.
- Карта сайта: Используется для вызова местоположения любой карты сайта в формате XML, связанной с URL-адресом. Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.
 Обратите внимание, что Googlebot не подтверждает эту команду, но скорость сканирования можно установить в Google Search Console.
Обратите внимание, что Googlebot не подтверждает эту команду, но скорость сканирования можно установить в Google Search Console.
Результаты инструкций robots.txt
Вы ожидаете три результата при вводе инструкций robots.txt:
- Полное разрешение
- Полный запрет
- Условное разрешение
Давайте рассмотрим каждую из них ниже.
Полное разрешение
Этот результат означает, что все содержимое вашего веб-сайта может быть просканировано. Файлы robots.txt предназначены для блокировки сканирования ботами поисковых систем, поэтому эта команда может быть очень важной.
Такой результат может означать, что на вашем веб-сайте вообще нет файла robots. txt. Даже если у вас его нет, поисковые роботы все равно будут искать его на вашем сайте. Если они этого не получат, то будут сканировать все части вашего сайта.
txt. Даже если у вас его нет, поисковые роботы все равно будут искать его на вашем сайте. Если они этого не получат, то будут сканировать все части вашего сайта.
Другой вариант в этом случае — создать файл robots.txt, но оставить его пустым. Когда паук начнет ползать, он идентифицирует и даже прочитает файл robots.txt. Поскольку он ничего там не найдет, он продолжит сканирование остальной части сайта.
Если у вас есть файл robots.txt, и у него есть следующие две строки в нем,
Пользовательский агент:*
DISLEANG:
, найдите файл robots.txt и прочитайте его. Он доберется до второй строки, а затем продолжит сканирование остальной части сайта.
Полный запрет
Здесь содержимое не будет сканироваться и индексироваться. Эта команда выдается этой строкой:
User-agent:*
Disallow:/
Когда мы говорим об отсутствии контента, мы имеем в виду, что ничто с веб-сайта (контент, страницы и т. д.) не может быть просканировано. Это никогда не бывает хорошей идеей.
д.) не может быть просканировано. Это никогда не бывает хорошей идеей.
Условное разрешение
Это означает, что сканировать можно только определенный контент на веб-сайте.
Условное разрешение имеет следующий формат:
User-agent:*
Disallow:/
User-agent: Mediapartner-Google
Allow:/
Полный синтаксис robots.txt можно найти здесь.
Обратите внимание, что заблокированные страницы все еще могут быть проиндексированы, даже если вы запретили URL-адрес, как показано на изображении ниже:
Вы можете получить электронное письмо от поисковых систем о том, что ваш URL-адрес был проиндексирован, как показано на снимке экрана выше. Если ваш запрещенный URL-адрес связан с другими сайтами, например якорным текстом в ссылках, он будет проиндексирован. Решение этой проблемы состоит в том, чтобы 1) защитить файлы на сервере паролем, 2) использовать метатег noindex или 3) полностью удалить страницу.
Может ли робот сканировать и игнорировать мой файл robots.txt?
Да. возможно, что робот может обойти robots.txt. Это связано с тем, что Google использует другие факторы, такие как внешняя информация и входящие ссылки, чтобы определить, следует ли индексировать страницу или нет. Если вы не хотите, чтобы страница вообще индексировалась, используйте метатег noindex robots. Другой вариант — использовать HTTP-заголовок X-Robots-Tag.
Могу ли я заблокировать только плохих роботов?
Теоретически можно заблокировать плохих роботов, но на практике это может быть сложно. Давайте рассмотрим несколько способов сделать это:
- Вы можете заблокировать плохого робота, исключив его. Однако вам необходимо знать имя, которое конкретный робот сканирует в поле User-Agent. Затем вам нужно добавить в файл robots.txt раздел, исключающий неверный робот.
- Конфигурация сервера. Это будет работать только в том случае, если плохой робот работает с одного IP-адреса. Конфигурация сервера или сетевой брандмауэр заблокируют доступ вредоносного робота к вашему веб-серверу.
- Использование расширенных конфигураций правил брандмауэра. Они автоматически блокируют доступ к различным IP-адресам, на которых существуют копии вредоносного робота. Хорошим примером ботов, работающих с разными IP-адресами, являются захваченные компьютеры, которые могут даже быть частью более крупного ботнета (узнайте больше о ботнете здесь).
 Конфигурация сервера или сетевой брандмауэр заблокируют доступ вредоносного робота к вашему веб-серверу.
Конфигурация сервера или сетевой брандмауэр заблокируют доступ вредоносного робота к вашему веб-серверу.
Если плохой робот работает с одного IP-адреса, вы можете заблокировать его доступ к вашему веб-серверу с помощью конфигурации сервера или сетевого брандмауэра.
Если копии робота работают с несколькими разными IP-адресами, то их становится сложнее заблокировать. Наилучший вариант в этом случае — использовать расширенные конфигурации правил брандмауэра, которые автоматически блокируют доступ к IP-адресам, которые осуществляют много подключений; к сожалению, это может повлиять и на доступ хороших ботов.
Каковы лучшие методы SEO при использовании robots.txt?
В этот момент вам может быть интересно, как ориентироваться в этих очень сложных водах robots.txt. Рассмотрим это подробнее:
- Убедитесь, что вы не блокируете какой-либо контент или разделы вашего сайта, которые вы хотите просканировать.
- Используйте механизм блокировки, отличный от robots.txt, если вы хотите, чтобы ссылочный вес передавался со страницы с robots.txt (что означает, что она практически заблокирована) к месту назначения ссылки.
- Не используйте robots.txt, чтобы предотвратить появление конфиденциальных данных, таких как личная информация пользователя, в результатах поиска. Это может позволить другим страницам ссылаться на страницы, содержащие личную информацию пользователя, что может привести к индексации страницы. В данном случае файл robots.txt был обойден. Другие варианты, которые вы можете изучить здесь, — это защита паролем или мета-директива noindex.
- Нет необходимости указывать директивы для каждого сканера поисковой системы, поскольку большинство пользовательских агентов, если они принадлежат одной и той же поисковой системе, следуют одним и тем же правилам. Google использует Googlebot для поисковых систем и Googlebot Image для поиска изображений. Единственное преимущество знания того, как указать каждый поисковый робот, заключается в том, что вы можете точно настроить, как будет сканироваться контент на вашем сайте.
- Если вы изменили файл robots.txt и хотите, чтобы Google обновил его быстрее, отправьте его непосредственно в Google. Чтобы узнать, как это сделать, нажмите здесь. Важно отметить, что поисковые системы кешируют содержимое robots.txt и обновляют кешированный контент не реже одного раза в день.

Основные рекомендации по robots.txt
Теперь, когда у вас есть общее представление о поисковой оптимизации применительно к robots.txt, о чем следует помнить при использовании robots. txt? В этом разделе мы рассмотрим некоторые рекомендации, которым необходимо следовать при использовании robots.txt, хотя на самом деле важно прочитать весь синтаксис.
txt? В этом разделе мы рассмотрим некоторые рекомендации, которым необходимо следовать при использовании robots.txt, хотя на самом деле важно прочитать весь синтаксис.
Формат и расположение
Текстовый редактор, который вы выбрали для создания файла robots.txt, должен иметь возможность создавать стандартные текстовые файлы ASCII или UTF-8. Использование текстового процессора не является хорошей идеей, так как могут быть добавлены некоторые символы, которые могут повлиять на сканирование.
Хотя для создания файла robots.txt можно использовать практически любой текстовый редактор, настоятельно рекомендуется использовать этот инструмент, поскольку он позволяет проводить тестирование на вашем сайте.
Вот дополнительные рекомендации по формату и местоположению:
- Создаваемый файл должен называться robots.txt, поскольку он чувствителен к регистру. Заглавные буквы не используются.
- На всем сайте может быть только один файл robots. txt.
- Файл robots.txt находится только в одном месте: в корне хоста веб-сайта, к которому он применим. Обратите внимание, что его нельзя поместить в подкаталог. Если ваш веб-сайт http://www.123.com/, то расположение файла robots.txt — http://www.123.com/robots.txt, а не http://www.123.com/pages/. robots.txt. Обратите внимание, что файл robots.txt может применяться к поддоменам (http://website.123.com/robots.txt) и даже к нестандартным портам, таким как http://www.123.com: 8181/robots.txt. .
 txt.
txt.
Как упоминалось выше, файл robots.txt — не лучший способ предотвратить индексацию конфиденциальной личной информации. Это серьезная проблема, особенно сейчас, когда недавно был введен GDPR. Конфиденциальность данных не должна быть нарушена. Период.
Как в таком случае убедиться, что файл robots.txt не отображает конфиденциальные данные в результатах поиска?
Использование отдельного подкаталога, который не указан в Интернете, предотвратит распространение конфиденциальных материалов. Вы можете убедиться, что он «не включен в список», используя конфигурацию сервера. Просто сохраните все файлы, которые вы не хотите, чтобы robot.txt посещал и индексировал в этом подкаталоге.
Вы можете убедиться, что он «не включен в список», используя конфигурацию сервера. Просто сохраните все файлы, которые вы не хотите, чтобы robot.txt посещал и индексировал в этом подкаталоге.
Не приводит ли список страниц или каталогов в файле robots.txt к непреднамеренному доступу?
Как упоминалось выше, размещение всех файлов, которые вы не хотите индексировать, в отдельный подкаталог, а затем удаление его из списка с помощью конфигураций сервера должно гарантировать, что они не будут отображаться в результатах поиска. Единственный список, который вы затем сделаете в файле robots.txt, — это имя каталога. Единственный способ получить доступ к этим файлам — это прямая ссылка на один из файлов.
Here is an example:
Instead of
User-Agent:*
Disallow:/foo.html
Disallow:/bar.html
Используйте
User-Agent:*
Disallow:/norobots/
Затем вам нужно создать каталог «norobots», который включает foo. html и bar.html Обратите внимание, что в конфигурации вашего сервера должно быть четко указано, что не нужно создавать список каталогов для каталога «norobots».
html и bar.html Обратите внимание, что в конфигурации вашего сервера должно быть четко указано, что не нужно создавать список каталогов для каталога «norobots».
Это может быть не очень безопасный подход, потому что человек или бот, атакующий ваш сайт, все еще может видеть, что у вас есть каталог «norobots», даже если они не могут просматривать файлы внутри каталога. Однако кто-то может опубликовать ссылку на эти файлы на своем веб-сайте или, что еще хуже, ссылка может появиться в общедоступном файле журнала (например, в журнале веб-сервера в качестве реферера). Также возможна неправильная конфигурация сервера, что приводит к отображению списка каталогов.
Что это значит? Robots.txt не может помочь вам с контролем доступа по той простой причине, что он для этого не предназначен. Хороший пример — знак «Вход запрещен». Есть люди, которые все равно нарушат инструкцию.
Если есть файлы, доступ к которым должен иметь только авторизованный пользователь, конфигурация сервера поможет с аутентификацией. Если вы используете CMS (систему управления контентом), у вас есть элементы управления доступом к отдельным страницам и коллекции ресурсов.
Можете ли вы оптимизировать файл robots.txt для SEO?
Абсолютно. Лучшее руководство по оптимизации robots.txt — это контент сайта. Небольшое напоминание: Robots.txt никогда не следует использовать для блокировки страниц от сканирования ботами поисковых систем. Используйте его только для блокировки разделов вашего сайта, недоступных для публики, например, страницы входа, такие как wp-admin.
Это строка запрета для страницы входа Нила Пателя на один из его веб-сайтов:
Пользовательский агент:*
DISLAING:/WP-ADMIN/
Разрешить: /WP-ADMIN/ADMIN-AJAX.PHP
Вы можете использовать эту линию. ваш логин от индексации.
Если есть определенные страницы, которые вы не хотите индексировать, используйте ту же команду, что и выше. Пример:
User-agent:*
Disallow:/page/
Укажите страницу, которую вы не хотите индексировать, после косой черты и закройте ее другой косой чертой. Например:
User-agent:*
Disallow:/page/thank-you/
Какие страницы вы можете исключить из индексации?
- Преднамеренное дублирование контента. Что это значит? Иногда вы намеренно создаете дублированный контент для достижения определенной цели. Хорошим примером является версия определенной веб-страницы для печати. Вы можете использовать robots.txt, чтобы заблокировать индексацию печатной версии идентичного контента.
- страниц благодарности. Причина, по которой вы хотите заблокировать эту страницу от индексации, проста: предполагается, что это последний шаг в воронке продаж. К тому времени, когда ваши посетители попадают на эту страницу, они должны пройти всю воронку продаж. Если эта страница будет проиндексирована, это означает, что вы можете упустить лидов или получить ложные лиды.
Команда для блокировки такой страницы:
Disallow:/thank-you/
Noindex и NoFollow
Как мы уже говорили в этой статье, использование robots.txt не является 100% гарантией того, что ваша страница не будет проиндексирована. Давайте рассмотрим два способа убедиться, что ваша заблокированная страница действительно не проиндексирована.
Директива noindex
Работает в сочетании с командой disallow. Используйте оба в своей директиве, например:
Disallow:/thank-you/
Noindex:/thank-you/
Директива nofollow
Это специально указывает ботам Google не сканировать ссылки на странице. Это не часть файла robots.txt. Чтобы использовать команду nofollow для блокировки сканирования и индексации страниц, вам необходимо найти исходный код конкретной страницы, которую вы не хотите индексировать.
Вставьте это между открывающим и закрывающим тегами заголовка:
Вы можете использовать как «nofollow», так и «noindex» одновременно. Используйте следующую строку кода:
Создание robots.txt
с использованием
robots. необходимые форматы и синтаксис, которые необходимо понимать и соблюдать, можно использовать инструменты, упрощающие процесс. Хороший пример — наш бесплатный генератор robots.txt.
Этот инструмент позволяет вам выбрать тип результата, который вам нужен на вашем веб-сайте, а также файл или каталоги, которые вы хотите добавить. Вы даже можете протестировать свой файл и посмотреть, как обстоят дела у ваших конкурентов.
Проверка файла robots.txt
Вам необходимо протестировать файл robots. txt, чтобы убедиться, что он работает должным образом.
Используйте тестер Google robots.txt.
Для этого войдите в свою учетную запись веб-мастера.
- Затем выберите свой ресурс. В данном случае это ваш сайт.
- Нажмите «сканировать» на левой боковой панели.
- Нажмите «тестер robots.txt».
- Замените любой существующий код новым файлом robots.txt.
- Нажмите «Проверить».
Вы должны увидеть текстовое поле «разрешено», если файл действителен. Для получения дополнительной информации ознакомьтесь с этим подробным руководством по тестированию Google robots.txt.
Если ваш файл действителен, пришло время загрузить его в корневой каталог или сохранить как другой файл robots.txt.
Как добавить robots.txt на ваш сайт WordPress
Чтобы добавить файл robots.txt в ваш файл WordPress, мы рассмотрим плагин и параметры FTP.
Для опции плагина вы можете использовать плагин, такой как All in One SEO Pack
Для этого войдите в свою панель управления WordPress
Прокрутите вниз до тех пор, пока не дойдете до «Плагинов»
Нажмите «Добавить новый»
Перейти на «Поиск плагинов»
Тип «Все в одном пакете SEO»
. Установите его. и активируйте
В разделе «Общие настройки» плагина All in One SEO вы можете настроить правила noindex и nofollow, которые будут включены в файл robots.txt.
Вы можете указать, какие URL-адреса должны быть NOINDEX, NOFOLLOW. Если оставить их неотмеченными, по умолчанию будет проиндексировано:
Чтобы создать расширенные правила в файле robots.txt, щелкните диспетчер функций, а затем нажмите кнопку активации сразу под файлом robots.txt.
Robots.txt теперь отображается сразу под диспетчером функций. Нажмите здесь. Вы увидите раздел «Создать файл robots.txt».
Существует раздел построителя правил, который позволяет вам выбирать и заполнять правила, которые вы хотите для своего сайта, в зависимости от того, что вы хотите не индексировать.
Завершив создание правила, нажмите «Добавить правило».
Правило будет указано в созданной папке robots.txt.
Вы увидите сообщение о том, что «Параметры «Все в одном»» обновлены.
Другой метод, который вы можете использовать, — это загрузить файл robots.txt непосредственно на FTP-клиент (протокол передачи файлов), например FileZilla.
Создав файл robots.txt, вы можете найти и заменить его. Ваш файл robots.txt будет находиться в папке: «/applications/[ИМЯ ПАПКИ]/public_html».
Как редактировать файл robots.txt на Wix
Wix создает файл robots.txt для веб-сайтов, использующих платформу веб-строительства. Чтобы просмотреть его, добавьте «/robots.txt» в свой домен. Файлы, добавленные в robots.txt, связаны со структурой сайтов Wix, например, ссылки noflashhtml, которые не влияют на ценность SEO вашего сайта на базе Wix.
Вы не можете редактировать файл robots.txt, если ваш сайт работает на Wix. Вы можете использовать только другие параметры, такие как добавление «тега noindex» к страницам, которые вы не хотите индексировать.
Чтобы создать тег noindex для определенной страницы:
- Нажмите Меню сайта
- Нажмите на параметр Настройка для этой конкретной страницы
- Выберите Тег SEO (Google)
- Включить Скрыть эту страницу из результатов поиска
Как редактировать файл robots.txt на Shopify
Как и в случае с Wix, Shopify автоматически добавляет на ваш сайт нередактируемый файл robots. txt. Если вы не хотите, чтобы некоторые страницы индексировались, вам нужно добавить «тег noindex» или отменить публикацию страницы. Вы также можете добавить метатеги в раздел заголовков страниц, которые вы не хотите индексировать. Вот что вы должны добавить в свой заголовок:
Shopify создал подробное руководство о том, как скрыть страницы от поисковых систем, за которыми вы можете следить.
Другой вариант — загрузить приложение под названием Sitemap & NoIndex Manager от Orbis Labs. Вы можете просто проверить параметры noindex или nofollow для каждой страницы на вашем сайте Shopify:
Как правильно настроить robots.txt для вашего сайта
Если у вас есть веб-сайт, вы, вероятно, слышали о файле robots.txt (или «стандарте исключения роботов»). Есть у вас или нет, пришло время узнать об этом, потому что этот простой текстовый файл является важной частью вашего сайта. Это может показаться незначительным, но вы можете быть удивлены тем, насколько это важно.
Давайте посмотрим, что такое файл robots.txt, для чего он нужен и как его правильно настроить для вашего сайта.
Что такое файл robots.txt?
Чтобы понять, как работает файл robots.txt, вам нужно немного узнать о поисковых системах. Короткая версия заключается в том, что они рассылают «краулеров», то есть программы, которые рыщут в Интернете в поисках информации. Затем они сохраняют часть этой информации, чтобы позже направить людей к ней.
Эти поисковые роботы, также известные как «боты» или «пауки», находят страницы на миллиардах веб-сайтов. Поисковые системы дают им указания, куда идти, но отдельные веб-сайты также могут общаться с ботами и сообщать им, какие страницы им следует просматривать.
В большинстве случаев они на самом деле делают обратное и говорят им, на какие страницы им не следует смотреть. Такие вещи, как административные страницы, серверные порталы, страницы категорий и тегов и другие вещи, которые владельцы сайтов не хотят отображать в поисковых системах. Эти страницы по-прежнему видны пользователям и доступны всем, у кого есть на это разрешение (часто всем).
Но, говоря этим паукам не индексировать некоторые страницы, файл robots.txt делает всем одолжение. Если бы вы искали «MakeUseOf» в поисковой системе, хотели бы вы, чтобы наши административные страницы отображались высоко в рейтинге? Нет. Это никому не принесет пользы, поэтому мы просим поисковые системы не отображать их. Его также можно использовать, чтобы поисковые системы не проверяли страницы, которые могут не помочь им классифицировать ваш сайт в результатах поиска.
Короче говоря, файл robots.txt указывает поисковым роботам, что делать.
Могут ли сканеры игнорировать robots.txt?
Игнорируют ли сканеры файлы robots.txt? Да. На самом деле, многие поисковые роботы делают игнорируют его. Однако, как правило, эти сканеры не принадлежат авторитетным поисковым системам. Они исходят от спамеров, сборщиков электронной почты и других типов автоматических ботов, которые бродят по Интернету. Важно помнить об этом: использование стандарта исключения роботов для указания ботам держаться подальше не является эффективной мерой безопасности . На самом деле, некоторые боты могут начинают со страниц, на которые вы запрещаете им заходить.
Однако поисковые системы будут действовать так, как указано в файле robots.txt, если он правильно отформатирован.
Как написать файл robots.txt
Стандартный файл исключения роботов состоит из нескольких частей. Я разобью их здесь по отдельности.
Декларация пользовательского агента
Прежде чем указывать боту, какие страницы ему не следует просматривать, необходимо указать, с каким ботом вы разговариваете. В большинстве случаев вы будете использовать простое объявление, означающее «все боты». Это выглядит так:
Указанный язык: разметка не существует'Генерация кода не удалась!!'
Звездочка означает «все боты». Однако вы можете указать страницы для определенных ботов. Для этого вам нужно знать имя бота, для которого вы разрабатываете рекомендации. Это может выглядеть так:
Указанный язык: разметка не существует'Генерация кода не удалась!!'
И так далее. Если вы обнаружите бота, который вообще не хочет сканировать ваш сайт, вы также можете указать это.
Чтобы найти имена пользовательских агентов, посетите useragentstring.com [Больше не доступно].
Запрет страниц
Это основная часть вашего файла исключения роботов. С помощью простого объявления вы говорите боту или группе ботов не сканировать определенные страницы. Синтаксис прост. Вот как вы можете запретить доступ ко всему в каталоге «admin» вашего сайта:
Указанный язык: разметка не существует'Генерация кода не удалась!!'
Эта строка не позволит ботам сканировать yoursite.com/admin, yoursite.com/admin/login, yoursite.com/admin/files/secret.html и все остальное, что попадает в каталог admin.
Чтобы запретить одну страницу, просто укажите ее в строке запрета:
Указанный язык: разметка не существует'Генерация кода не удалась!!'
Теперь страница «исключение» не будет прорисовываться, а все остальное в «общей» папке будет.
Чтобы включить несколько каталогов или страниц, просто перечислите их в следующих строках:
Указанный язык: разметка не существует'Генерация кода не удалась!!'
Эти четыре строки будут применяться к любому пользовательскому агенту, который вы указали в верхней части раздела.
Если вы хотите, чтобы боты не просматривали какие-либо страницы вашего сайта, используйте этот код:
.Указанный язык: разметка не существует'Генерация кода не удалась!!'
Установка разных стандартов для ботов
Как мы видели выше, вы можете указать определенные страницы для разных ботов. Объединив два предыдущих элемента, вот как это выглядит:
Указанный язык: разметка не существует'Генерация кода не удалась!!'
Разделы «admin» и «private» будут невидимы в Google и Bing, но Google увидит «секретный» каталог, а Bing — нет.
Вы можете указать общие правила для всех ботов с помощью пользовательского агента звездочки, а затем также дать конкретные инструкции ботам в последующих разделах.
Собираем все вместе
Обладая вышеуказанными знаниями, вы можете написать полный файл robots.txt. Просто запустите свой любимый текстовый редактор (мы фанаты Sublime) и начните сообщать ботам, что они не приветствуются в определенных частях вашего сайта.
Если вы хотите увидеть пример файла robots.txt, просто перейдите на любой сайт и добавьте «/robots.txt» в конец. Вот часть файла robots.txt Giant Bicycles:
.Как видите, есть довольно много страниц, которые они не хотят показывать в поисковых системах. Они также включили несколько вещей, о которых мы еще не говорили. Давайте посмотрим, что еще вы можете сделать в своем файле исключения роботов.
Поиск вашей карты сайта
Если ваш файл robots.txt сообщает ботам, где , а не , ваша карта сайта делает обратное и помогает им найти то, что они ищут. И хотя поисковые системы, вероятно, уже знают, где находится ваша карта сайта, не помешает сообщить им об этом еще раз.
Объявление местоположения карты сайта простое:
Указанный язык: разметка не существует'Генерация кода не удалась!!'
Вот и все.
В нашем собственном файле robots.txt это выглядит так:
Указанный язык: разметка не существует'Генерация кода не удалась!!'
Вот и все.
Установка задержки сканирования
Директива задержки сканирования сообщает определенным поисковым системам, как часто они могут индексировать страницу на вашем сайте. Он измеряется в секундах, хотя некоторые поисковые системы интерпретируют его несколько иначе. Некоторые считают, что задержка сканирования в 5 – это указание им ждать пять секунд после каждого сканирования, чтобы начать следующее. Другие интерпретируют это как указание сканировать только одну страницу каждые пять секунд.
Почему вы говорите краулеру не ползать как можно больше? Для сохранения пропускной способности. Если ваш сервер не справляется с трафиком, вы можете установить задержку сканирования. В общем, большинству людей не нужно беспокоиться об этом. Однако крупные сайты с высокой посещаемостью могут захотеть немного поэкспериментировать.
Вот как можно установить задержку сканирования в восемь секунд:
Указанный язык: разметка не существует'Генерация кода не удалась!!'
Вот и все. Не все поисковые системы будут подчиняться вашей директиве. Но спросить не помешает. Как и в случае с запрещенными страницами, вы можете установить разные задержки сканирования для определенных поисковых систем.
Загрузка файла robots.txt
После того, как вы настроите все инструкции в своем файле, вы можете загрузить его на свой сайт. Убедитесь, что это обычный текстовый файл с именем robots.txt. Затем загрузите его на свой сайт, чтобы его можно было найти по адресу yoursite.com/robots.txt.
Если вы используете систему управления контентом, такую как WordPress, вам, вероятно, потребуется сделать это особым образом. Поскольку в каждой системе управления контентом он разный, вам необходимо обратиться к документации по вашей системе.
Некоторые системы также могут иметь онлайн-интерфейсы для загрузки вашего файла. Для этого просто скопируйте и вставьте файл, созданный на предыдущих шагах.
Не забудьте обновить файл
Последний совет, который я дам, — время от времени просматривать файл исключения роботов. Ваш сайт меняется, и вам может потребоваться внести некоторые коррективы. Если вы заметили странные изменения в трафике вашей поисковой системы, рекомендуется также проверить файл. Также возможно, что стандартная нотация может измениться в будущем. Как и все остальное на вашем сайте, его стоит проверять время от времени.
Какие страницы вашего сайта исключаются для поисковых роботов? Вы заметили разницу в трафике поисковых систем? Поделитесь своими советами и комментариями ниже!
Как отредактировать файл robots.txt с помощью Rank Math SEO » Rank Math Это можно легко отредактировать с помощью плагина Rank Math SEO. Если вы еще не используете Rank Math на своем веб-сайте, узнайте больше и начните работу здесь.
В этом руководстве мы покажем вам, как редактировать файл robots. txt с помощью Rank Math.
Содержание
1 Почему Robots.txt важен?
Прежде чем приступить к редактированию файла robots.txt, попробуем понять его важность.
Когда сканеры поисковых систем или любые боты попадают на ваш сайт, они сначала ищут наличие файла robots.txt, так как он содержит важные инструкции о том, как поисковые системы должны сканировать ваш сайт.
Хотя большинство ботов выполнит ваш запрос, некоторые вредоносные боты и боты для очистки электронной почты вряд ли будут следовать инструкциям из файла robots.txt. Но при этом эти плохие боты в большинстве случаев практически не имеют объема трафика, и, следовательно, таких ботов можно безопасно игнорировать.
2 Как редактировать файл robots.
txt с помощью Rank Math?Rank Math позволяет редактировать файл robots.txt прямо в панели управления WordPress путем создания виртуального файла. Если вы предпочитаете редактировать файл robots.txt с помощью Rank Math, вам необходимо удалить фактический файл robots.txt (если он есть) из корневой папки вашего веб-сайта с помощью FTP-клиента.
Теперь, чтобы отредактировать файл robots.txt с помощью Rank Math, вы можете выполнить следующие шаги.
2.1 Перейдите к редактированию robots.txt
Для начала войдите на свой веб-сайт WordPress и убедитесь, что вы переключились на расширенный режим с панели инструментов Rank Math.
Перейдите к файлу robots.txt в Rank Math, который находится в разделе Панель управления WordPress > Rank Math > Общие настройки > Изменить robots.txt , как показано ниже:
по умолчанию, Rank Math автоматически добавит набор правил (
включая вашу карту сайта ) в файл robots. txt. Но вы всегда можете добавить/отредактировать код по своему усмотрению из доступной текстовой области.Если вы не уверены в правилах, доступных для использования с вашим файлом robots.txt, подождите, так как мы вскоре обсудим их в этой статье.
2.3 Сохраните изменения
Сохраните изменения, нажав Сохранить изменения после внесения необходимых изменений в файл.
Предостережение : Будьте осторожны при внесении любых серьезных или незначительных изменений на свой веб-сайт с помощью файла robots.txt. Хотя эти изменения могут улучшить ваш поисковый трафик, они также могут принести больше вреда, чем пользы, если вы не будете осторожны.
3 Правила robots.txt
Теперь, когда мы знаем, как редактировать robots.txt с помощью Rank Math, давайте углубимся в правила, которые вы можете добавить в свой файл robots.txt.
Правило (или директива) в файле robots.txt — это просто инструкция для сканера, какие страницы индексировать. Это простой способ сказать: « Эй, поисковый робот, ты должен сканировать эти страницы, но не страницы из этих директив » и так далее.
Когда дело доходит до добавления правил в файл robots.txt, следует придерживаться некоторых общих рекомендаций:
- В файле robots.txt может быть одна или несколько групп, и каждая группа состоит из нескольких правил.
- Каждая группа начинается с агента пользователя, а затем указывает, к каким каталогам или файлам агент имеет доступ, а к каким нет.
- По умолчанию предполагается, что пользовательский агент может сканировать любую страницу на вашем веб-сайте, если вы специально не заблокируете доступ с помощью запрещающего правила.
- Правила чувствительны к регистру.
-
#символ отмечает начало комментария.
А теперь давайте рассмотрим различные правила ( или директивы ), которые можно использовать в robots.txt: группа нацелена. Полный список пользовательских агентов Google и пользовательских агентов Bing доступен здесь. Запретить Правило относится к каталогу или странице на вашем веб-сайте, которую вы не хотите, чтобы пользовательский агент сканировал . Разрешить Правило относится к каталогу или странице на вашем веб-сайте, которую вы хотите, чтобы пользовательский агент просканировал . Карта сайта Правило указывает карту сайта веб-сайта и должно быть введено как полный URL-адрес. Хотя это необязательно, это хорошая практика.
Обратите внимание: любая строка в файле robots.txt, не соответствующая приведенным выше директивам, полностью игнорируется. И все директивы, кроме карты сайта, будут принимать подстановочный знак * в качестве префикса, суффикса или всей строки. $ – это еще один подстановочный знак, который используется как Google, так и Bing, и указывает на конец URL-адреса.
4 Примеры правил robots.
txtНесмотря на то, что в robots.txt разрешено лишь несколько правил, все же легче допустить ошибку. Таким образом, у нас есть несколько примеров правил robots.txt, которые вы можете использовать прямо сейчас.
4.1 Запрет сканирования всего веб-сайта
Это правило запрещает всем ботам сканировать весь ваш веб-сайт. Здесь / представляет собой корень каталога веб-сайта и все страницы, от которых отходят ответвления. Таким образом, он включает в себя домашнюю страницу вашего веб-сайта и все страницы, на которые есть ссылки с нее.
Мы не рекомендуем использовать это правило на действующем веб-сайте, так как сканеры поисковых систем не будут сканировать и индексировать ваш веб-сайт. Но, тем не менее, это правило находит свое применение на сайтах разработки и промежуточных версиях, где вы не хотите, чтобы поисковые роботы получали доступ и индексировали содержимое сайта.
Агент пользователя: * Запретить: /
4.2 Запретить сканирование всего веб-сайта для определенного бота
Вместо блокировки доступа ко всем поисковым роботам, если вы хотите защитить доступ к вашему веб-сайту от определенных поисковых роботов, замените подстановочный знак в агенте пользователя на название сканеров. Например, следующее правило заблокирует доступ к рекламному роботу Google.
Агент пользователя: AdsBot-Google Disallow: /
И, если вы хотите явно указать, что другие боты могут сканировать ваш сайт, то используйте следующую группу правил.
Агент пользователя: AdsBot-Google Запретить: / Пользовательский агент: * Разрешить: /
4.3 Rank Math Default Robots.txt Rules
Rank Math по умолчанию включает в файл robots.txt следующие правила. Если вы когда-нибудь удалите эти правила из файла robots.txt, но позже захотите добавить их, вы можете скопировать и вставить следующие правила. Не забудьте заменить yoursite.com с вашим доменным именем.
Агент пользователя: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php Карта сайта: yoursite.com/sitemap_index.xml
4.4 Запретить доступ к определенному каталогу
Чтобы заблокировать доступ к определенным каталогам на вашем веб-сайте, вы можете включить относительный путь каталога в правило запрета. Например, если вы хотите заблокировать доступ к страницам каналов на своем веб-сайте, вы можете включить правило следующим образом.
Агент пользователя: * Запретить: */канал/
4.5 Запрет сканирования файлов определенного типа
Если вы хотите запретить сканерам поисковых систем доступ к определенным типам файлов, вы можете использовать следующее правило. Но учтите, Google не рекомендует блокировать файлы CSS и JS, так как это помешает рендерингу страницы для Google, и это потенциально может повлиять на ваш поисковый трафик.
Агент пользователя: * Disallow: /*.pdf$
Заключение — отредактируйте файл robots.txt и проверьте
Вот и все! Мы надеемся, что руководство помогло вам отредактировать файл robots.txt с помощью Rank Math. Но обратите внимание, вы также можете вручную создать и отредактировать файл robots.txt, и, если вы предпочитаете такой способ, вы можете просто загрузить файл в корневую папку своего веб-сайта (на своем сервере) и отредактировать его — если вы Если вы не знаете, куда загрузить файл, вы всегда можете обратиться за помощью к своему веб-хостингу.
После того, как вы отредактировали файл robots.txt, вы всегда можете попробовать смоделировать сканирование страниц вашего сайта с помощью ботов Google и проверить, могут ли они получить доступ к странице или нет, с помощью тестера robots.txt.
Если у вас все еще есть какие-либо вопросы об редактировании файла robots.txt с помощью Rank Math или возникли проблемы при редактировании, вы всегда можете связаться с нашей специальной службой поддержки, и мы доступны 24/7, 365 дней в неделю. год…
Полное руководство по WordPress robots.txt (и как его использовать для SEO)
Вордпресс Расширенный
30 августа 2022 г.
Уилл М.
8 минут Чтение
Чтобы обеспечить высокий рейтинг вашего сайта на страницах результатов поиска (SERP), вам необходимо упростить поисковым роботам доступ к наиболее важным страницам. Наличие хорошо структурированной robots.txt поможет направить этих ботов на страницы, которые вы хотите проиндексировать (и избежать остальных).
Скачать Ultimate WordPress Cheat Sheet
В этой статье мы рассмотрим:
- Что такое файл robots.txt и почему он важен
- Где находится файл WordPress robots.txt .
- Как создать файл robots.txt .
- Какие правила включить в ваш WordPress robots.txt файл.
- Как протестировать файл robots.txt и отправить его в Google Search Console.
К концу нашего обсуждения у вас будет все необходимое для настройки идеального файла robots.txt для вашего веб-сайта WordPress. Давайте погрузимся!
Что представляет собой файл WordPress
robots.txt (и зачем он вам нужен) Когда вы создаете новый веб-сайт, поисковые системы отправляют своих миньонов (или ботов), чтобы «просканировать» его и составить карту всех содержащихся на нем страниц. Таким образом, они будут знать, какие страницы отображать в качестве результатов, когда кто-то ищет связанные ключевые слова. На базовом уровне это достаточно просто.
Проблема в том, что современные веб-сайты содержат гораздо элементов больше, чем просто страницы. WordPress позволяет вам, например, устанавливать плагины, которые часто поставляются со своими собственными каталогами. Однако вы не хотите, чтобы они отображались в результатах вашей поисковой системы, поскольку они не относятся к релевантному контенту.
Файл robots.txt предоставляет набор инструкций для роботов поисковых систем. Он говорит им: «Эй, вы можете посмотреть сюда, но не заходите в те комнаты вон там!» Этот файл может быть настолько подробным, насколько вы хотите, и его довольно легко создать, даже если вы не технический мастер.
На практике поисковые системы будут сканировать ваш веб-сайт, даже если у вас не настроен файл robots.txt . Однако не создавать его неэффективно. Без этого файла вы предоставляете ботам индексировать весь ваш контент, и они настолько тщательны, что могут в конечном итоге показать части вашего сайта, к которым вы не хотите, чтобы другие люди имели доступ.
Что еще более важно, без файла robots.txt у вас будет множество ботов, сканирующих весь ваш сайт. Это может негативно сказаться на его производительности. Даже если удар незначителен, скорость страницы всегда должна быть в верхней части списка ваших приоритетов. В конце концов, мало что люди ненавидят так сильно, как медленные веб-сайты.
Где находится файл robots.txt WordPress
Когда вы создаете веб-сайт WordPress, он автоматически устанавливает виртуальный файл robots.txt , расположенный в главной папке вашего сервера. Например, если ваш сайт расположен по адресу yourfakewebsite.com , вы сможете посетить адрес yourfakewebsite.com/robots.txt, и увидеть такой файл:
User-agent: * Запретить: /wp-admin/ Запретить: /wp-includes/
Это пример очень простого файла robots. txt . Говоря человеческим языком, часть сразу после User-agent: объявляет, к каким ботам применяются приведенные ниже правила. Звездочка означает, что правила универсальны и применяются ко всем ботам. В этом случае файл сообщает этим ботам, что они не могут войти в ваши каталоги wp-admin и wp-includes . Это имеет определенный смысл, поскольку эти две папки содержат много конфиденциальных файлов.
Однако вы можете добавить дополнительные правила в свой собственный файл. Прежде чем вы сможете это сделать, вам нужно понять, что это виртуальный файл . Обычно расположение WordPress robots.txt находится в корневом каталоге , который часто называется public_html или www (или назван в честь вашего веб-сайта):
Однако файл robots.txt WordPress устанавливает для вас по умолчанию, вообще недоступен из любого каталога. Он работает, но если вы хотите внести в него изменения, вам нужно создать собственный файл и загрузить его в корневую папку 9Папка 0246 в качестве замены.
Через минуту мы рассмотрим несколько способов создания нового файла robots.txt для WordPress. А пока давайте поговорим о том, как определить, какие правила должны включать ваши правила.
Какие правила включить в ваш WordPress
файл robots.txtВ последнем разделе вы видели пример созданного WordPress файла robots.txt . Он включал только два коротких правила, но большинство веб-сайтов устанавливали больше. Давайте посмотрим на два разных robots.txt и расскажите о том, что каждый из них делает по-своему.
Вот наш первый WordPress robots.txt пример:
User-agent: * Разрешать: / # Запрещенные подкаталоги Запретить: /checkout/ Запретить: /изображения/ Disallow: /forum/
Это универсальный файл robots. txt для веб-сайта с форумом. Поисковые системы часто индексируют каждую тему на форуме. Однако в зависимости от того, для чего предназначен ваш форум, вы можете запретить его. Таким образом, Google не будет индексировать сотни тредов о пользователях, ведущих светскую беседу. Вы также можете настроить правила, указывающие на определенные подфорумы, которых следует избегать, и позволить поисковым системам сканировать остальные.
Вы также заметите строку Allow: / в верхней части файла. Эта строка сообщает ботам, что они могут сканировать все страницы вашего веб-сайта, кроме исключений, указанных ниже. Кроме того, вы заметите, что мы установили эти правила как универсальные (со звездочкой), как это делает виртуальный файл robots.txt WordPress.
Теперь давайте проверим другой пример WordPress robots.txt :
User-agent: * Запретить: /wp-admin/ Запретить: /wp-includes/ Агент пользователя: Bingbot Запретить: /
В этом файле мы устанавливаем те же правила, что и WordPress по умолчанию. Однако мы также добавили новый набор правил, которые блокируют сканирование нашего веб-сайта поисковым роботом Bing. Bingbot, как вы можете догадаться, — это имя этого бота.
Вы можете довольно точно определить, какие боты поисковых систем получают доступ к вашему сайту, а какие нет. На практике, конечно, Bingbot довольно мягок (даже если он не так крут, как Googlebot). Однако существует вредоносных ботов.
Плохая новость заключается в том, что они не всегда следуют инструкциям вашего файла robots.txt (в конце концов, они бунтари). Стоит иметь в виду, что, хотя большинство ботов будут следовать инструкциям, которые вы предоставляете в этом файле, вы не принуждаете их к этому. Вы просто хорошо просите.
Если вы почитаете эту тему, вы найдете множество предложений о том, что разрешить и что заблокировать на вашем веб-сайте WordPress. Однако, по нашему опыту, чем меньше правил, тем лучше. Вот пример того, что мы рекомендуем вашему первому robots. txt файл должен выглядеть так:
User-Agent: * Разрешить: /wp-content/uploads/ Disallow: /wp-content/plugins/
Традиционно WordPress любит блокировать доступ к каталогам wp-admin и wp-includes . Однако это больше не считается лучшей практикой. Кроме того, если вы добавляете метаданные к своим изображениям для целей поисковой оптимизации (SEO), нет смысла запрещать ботам сканировать эту информацию. Вместо этого два приведенных выше правила охватывают то, что потребуется большинству основных сайтов.
Однако то, что вы включите в свой файл robots.txt , будет зависеть от вашего конкретного сайта и потребностей. Так что не стесняйтесь проводить дополнительные исследования самостоятельно!
Как создать файл WordPress
robots. txt (3 метода)После того, как вы решили, что будет в вашем файле robots.txt , все, что осталось, — это создать его. Вы можете редактировать robots.txt в WordPress либо с помощью плагина, либо вручную. В этом разделе мы научим вас, как использовать два популярных плагина для выполнения работы, и обсудим, как создать и загрузить файл самостоятельно. Давайте приступим!
1. Используйте Yoast SEO
Yoast SEO вряд ли нуждается в представлении. Это самый популярный SEO-плагин для WordPress, который позволяет оптимизировать ваши сообщения и страницы, чтобы лучше использовать ключевые слова. Помимо этого, он также поможет вам повысить читабельность вашего контента, а это значит, что больше людей смогут им наслаждаться.
Лично мы являемся поклонниками Yoast SEO из-за простоты использования. Это в равной степени относится и к созданию файла robots.txt 9.файл 0246. После установки и активации плагина перейдите на вкладку SEO > Инструменты на панели инструментов и найдите параметр с надписью Редактор файлов:
. Нажав на эту ссылку, вы перейдете на новую страницу, где вы можете отредактируйте файл .htaccess , не выходя из панели управления. Также есть удобная кнопка с надписью Создать файл robots.txt , которая делает именно то, что вы ожидаете:
После того, как вы нажмете на эту кнопку, на вкладке отобразится новый редактор, в котором вы можете изменить свои robots.txt напрямую. Имейте в виду, что Yoast SEO устанавливает свои собственные правила по умолчанию, которые переопределяют существующий виртуальный файл robots.txt .
Всякий раз, когда вы добавляете или удаляете правила, не забудьте нажать кнопку Сохранить изменения в robots.txt , чтобы они сохранялись:
Это достаточно просто! Теперь давайте посмотрим, как другой популярный плагин делает то же самое.
2. С помощью плагина All-in-One SEO Pack
All-in-One SEO Pack — еще одно громкое имя, когда речь заходит о WordPress SEO. Он включает в себя большинство функций Yoast SEO, но некоторые люди предпочитают его, потому что это более легкий плагин. До 9 0245 robots.txt идет, создать файл с этим плагином так же просто.
После настройки плагина перейдите на страницу All in One SEO > Feature Manager на панели управления. Внутри вы найдете опцию под названием Robots.txt с заметной кнопкой Активировать прямо под ней. Нажмите на это:
Теперь новая вкладка Robots.txt появится в вашем меню All in One SEO . Если вы нажмете на нее, вы увидите варианты добавления новых правил в ваш файл, сохранения внесенных изменений или полного удаления:
Обратите внимание, что вы не можете вносить изменения в файл robots.txt напрямую с помощью этого плагина. Сам файл неактивен, в отличие от Yoast SEO, который позволяет вам вводить все, что вы хотите:
В любом случае добавлять новые правила просто, поэтому не позволяйте этому небольшому недостатку обескуражить вас. Что еще более важно, All in One SEO Pack также включает в себя функцию, которая может помочь вам заблокировать «плохих» ботов, доступ к которой вы можете получить на вкладке All in One SEO :
Это все, что вам нужно сделать, если вы решите использовать это метод. Однако давайте поговорим о том, как создать robots.txt вручную, если вы не хотите устанавливать дополнительный плагин только для выполнения этой задачи.
3. Создайте и загрузите свой файл WordPress
robots.txt через FTPСоздание файла txt не может быть проще. Все, что вам нужно сделать, это открыть ваш любимый текстовый редактор (например, Блокнот или TextEdit) и ввести несколько строк. Затем вы можете сохранить файл, используя любое имя и тип файла txt . Это буквально занимает несколько секунд, поэтому имеет смысл отредактировать robots.txt в WordPress без использования плагина.
Вот краткий пример одного из таких файлов:
Для целей этого руководства мы сохранили этот файл непосредственно на нашем компьютере. После того, как вы создали и сохранили свой собственный файл, вам нужно будет подключиться к вашему веб-сайту через FTP. Если вы не знаете, как это сделать, у нас есть руководство, как это сделать с помощью удобного для начинающих клиента FileZilla.
После подключения к сайту перейдите в папку public_html . Затем все, что вам нужно сделать, это загрузить robots.txt с вашего компьютера на сервер. Вы можете сделать это, щелкнув файл правой кнопкой мыши в локальном навигаторе вашего FTP-клиента или просто перетащив его на место:
Загрузка файла займет всего несколько секунд. Как видите, этот метод почти так же прост, как использование плагина.
Как протестировать файл robots.txt WordPress и отправить его в Google Search Console
После создания и загрузки файла WordPress robots.txt вы можете использовать Google Search Console, чтобы проверить его на наличие ошибок. Search Console — это набор инструментов, которые предлагает Google, чтобы помочь вам отслеживать, как ваш контент отображается в результатах поиска. Одним из таких инструментов является robots.txt Checker, который можно использовать, войдя в консоль и перейдя на вкладку robots.txt Tester :
Внутри вы найдете поле редактора, в которое вы можете добавить свой WordPress robots.txt код файла и нажмите кнопку Отправить прямо под ним. Консоль поиска Google спросит, хотите ли вы использовать этот новый код или извлечь файл со своего веб-сайта. Нажмите на вариант с надписью Попросить Google обновить , чтобы отправить его вручную:
Теперь платформа проверит ваш файл на наличие ошибок. Если они есть, он укажет на них для вас. Тем не менее, вы уже видели не один пример WordPress robots.txt , поэтому велики шансы, что ваш вариант идеален!
Заключение
Чтобы повысить узнаваемость вашего сайта, вам необходимо убедиться, что роботы поисковых систем сканируют наиболее релевантную информацию. Как мы видели, хорошо настроенный файл WordPress robots. txt позволит вам точно указать, как эти боты взаимодействуют с вашим сайтом. Таким образом, они смогут предоставить поисковикам более актуальный и полезный контент.
У вас есть вопросы о том, как редактировать robots.txt в WordPress? Дайте нам знать в комментариях ниже!
Узнайте больше о WordPress SEO
WordPress Советы по SEO
Как создать карту сайта в WordPress
Как добавить разметку схемы WordPress
Как добавить мета-описание и мета-заголовок в WordPress
Как настроить AMP (ускоренные мобильные страницы) в WordPress
Как запретить поисковым системам индексировать ваш сайт WordPress
Как добавить хлебные крошки в WordPress
Уилл Моррис — штатный писатель WordCandy. Когда он не пишет о WordPress, он любит выступать со своими стендап-комедиями на местных каналах.
Подробнее от Уилла М.
Важность файла robots.txt для SEO
Ваш файл robots.txt сообщает поисковым системам, какие страницы вашего веб-сайта открывать и индексировать, а какие нет. Например, если вы укажете в файле Robots.txt, что вы не хотите, чтобы поисковые системы имели доступ к вашей странице благодарности, эта страница не сможет отображаться в результатах поиска, а веб-пользователи t быть в состоянии найти его. Предотвращение доступа поисковых систем к определенным страницам вашего сайта важно как для конфиденциальности вашего сайта, так и для вашего SEO.
В этой статье объясняется, почему это так, и вы узнаете, как настроить хороший файл Robots.txt.
How Robots.txt Work Поисковые системы рассылают крошечные программы, называемые «пауками» или «роботами», для поиска на вашем сайте и возвращают информацию поисковым системам, чтобы страницы вашего сайта могли быть проиндексированы в результатах поиска и найдены пользователями сети. Ваш файл Robots.txt предписывает этим программам не искать страницы на вашем сайте, которые вы указываете с помощью команды «запретить». Например, следующая команда Robots. txt:
User-agent: *
Disallow: /thankyou
…заблокирует для всех роботов поисковых систем посещение следующей страницы на вашем сайте:
http://www.yoursite.com/thankyou
Обратите внимание, что перед disallow, у вас есть команда:
User-agent: *
Часть «User-agent:» указывает, какого робота вы хотите заблокировать, и может также читаться следующим образом:
User-agent: Googlebot
Эта команда заблокирует только роботов Google, в то время как другие роботы по-прежнему будут иметь доступ к странице:
http://www.yoursite.com/thankyou
Однако, используя символ «*», вы указываете, что команды под ним относятся ко всем роботам. Ваш файл robots.txt будет находиться в главном каталоге вашего сайта. Например:
http://www.yoursite.com/robots.txt
Почему некоторые страницы необходимо заблокировать
Файл robots. txt. Во-первых, если на вашем сайте есть страница, которая является дубликатом другой страницы, вы не хотите, чтобы роботы индексировали ее, потому что это приведет к дублированию контента, что может повредить вашему SEO. Вторая причина — если у вас есть страница на вашем сайте, к которой вы не хотите, чтобы пользователи могли получить доступ, если они не предпримут определенного действия. Например, если у вас есть страница благодарности, на которой пользователи получают доступ к определенной информации благодаря тому, что они предоставили вам свой адрес электронной почты, вы, вероятно, не хотите, чтобы люди могли найти эту страницу, выполнив поиск Google. Другой раз, когда вы захотите заблокировать страницы или файлы, — это когда вы хотите защитить личные файлы на своем сайте, такие как ваш cgi-bin, и не допустить использования пропускной способности из-за того, что роботы индексируют ваши файлы изображений:
User-agent: *
Disallow: /images/
Disallow: /cgi-bin/
Во всех этих случаях вам необходимо включить команду в файл Robots. txt, которая сообщает поисковым роботам не заходить на эту страницу, не индексировать ее в результатах поиска и не отправлять на нее посетителей. Давайте посмотрим, как вы можете создать файл Robots.txt, который сделает это возможным.
Настроив бесплатную учетную запись Google Webmaster Tools, вы можете легко создать файл Robots.txt, выбрав параметр «Доступ для сканера» в разделе «Конфигурация сайта» в строке меню. . Оказавшись там, вы можете выбрать «сгенерировать robots.txt» и настроить простой файл Robots.txt.
Как видите, вы выбираете опцию «блокировать» в разделе «действие», а затем указываете роботов, которых хотите заблокировать, в разделе «User-agent». Затем вы просто вводите каталоги, которые хотите заблокировать, в разделе «каталоги и файлы». При этом убедитесь, что часть URL «http://www.yoursite.com» отключена. Например, если вы хотите заблокировать следующие страницы:
http://www.yoursite.com/thank-you
http://www. yoursite.com/free-stuff
http://www. yoursite.com/private
Введите следующее в поле «Каталоги и файлы» в инструментах Google для веб-мастеров:
/thank-you
/free-stuff
/private
», вы получите файл Robots.txt следующего вида:
User-agent: *
Disallow: /private
Disallow: /thank-you
Disallow: /free-stuff
Allow: /
Обратите внимание, что у вас есть команда «Разрешить» по умолчанию, которая полезна, если вы хотите сделать исключение и разрешить роботу доступ к странице, которую вы заблокировали с помощью такой команды.
User-agent: *
Disallow: /images/
Поместив команду:
Allow: /Googlebot
… под командой disallow, вы разрешите ТОЛЬКО роботу Googlebot доступ к каталогу изображений вашего сайт. Указав, какие страницы и файлы вы хотите заблокировать, нажмите «Загрузить», чтобы загрузить файл Robots.txt.
Установка файла Robots.txtПолучив файл Robots.txt, вы можете загрузить его в главный каталог (www) в области ЧПУ вашего веб-сайта. Вы можете сделать это с помощью FTP-программы, такой как Filezilla. Другой вариант — нанять веб-программиста для создания и установки вашего файла robots.txt, сообщив ему, какие страницы вы хотите заблокировать. Если вы выберете этот вариант, хороший веб-программист сможет выполнить работу менее чем за час.
ЗаключениеВажно обновить файл Robots.txt, если вы добавляете на сайт страницы, файлы или каталоги, которые вы не хотите индексировать поисковыми системами или к которым должны иметь доступ веб-пользователи. Это обеспечит безопасность вашего веб-сайта и наилучшие результаты при поисковой оптимизации.
Спасибо, что прочитали. Продолжайте свое путешествие по обучению на нашем сайте SEOSiteCheckUp.com. Не забудьте воспользоваться нашими бесплатными инструментами SEO!
Присоединяйтесь к нашим ежедневным обсуждениям на Facebook!
Как использовать robots.
txt для разрешения или запрета всегоНа первый взгляд, файл robots.txt может показаться чем-то, предназначенным только для самых искушенных в тексте среди нас. Но на самом деле научиться пользоваться файлом robots.txt может и должен освоить каждый.
И если вы заинтересованы в точном контроле над тем, какие области вашего веб-сайта разрешены для роботов поисковых систем (а какие вы можете запретить), то этот ресурс вам нужен.
В этом руководстве мы рассмотрим основные основы, в том числе:
- Что такое файл robots.txt
- Когда использовать файл robots.txt
- Как создать файл robots.txt
- Зачем и как реализовать файл robots.txt «Запретить все» (или «Разрешить все»)
Проще говоря, robots.txt — это специальный текстовый файл, расположенный в корневом домене вашего сайта и используемый для связи с роботами поисковых систем. В текстовом файле указывается, к каким веб-страницам/папкам на данном веб-сайте им разрешен доступ.
Возможно, вы захотите заблокировать URL-адреса в robots.txt, чтобы поисковые системы не индексировали определенные веб-страницы, к которым вы не хотите, чтобы онлайн-пользователи имели доступ. Например, файл robots.txt «Запретить» может запретить доступ к веб-страницам, содержащим специальные предложения с истекшим сроком действия, невыпущенные продукты или частный контент только для внутреннего пользования.
Когда дело доходит до решения проблем с дублированием контента или других подобных проблем, использование файла robots.txt для запрета доступа также может поддержать ваши усилия по SEO.
Как именно работает файл robots.txt? Когда робот поисковой системы начинает сканировать ваш веб-сайт, он сначала проверяет наличие файла robots.txt. Если он существует, робот поисковой системы может «понимать», к каким страницам ему не разрешен доступ, и будет просматривать только разрешенные страницы.
Когда использовать файл robots.txt Основной причиной использования файла robots. txt является запрет поисковым системам (Google, Bing и т. д.) индексировать определенные веб-страницы или контент.
Эти типы файлов могут быть идеальным вариантом, если вы хотите:
- Управлять обходным трафиком (если вы обеспокоены тем, что ваш сервер перегружен)
- Убедитесь, что некоторые части вашего веб-сайта остаются закрытыми (например, страницы администратора или страницы «песочницы», принадлежащие команде разработчиков)
- Избегайте проблем с индексацией
- Заблокировать URL-адрес
- Предотвращение включения дублированного контента в результаты поиска (и негативного влияния на SEO)
- Запретить поисковым системам индексировать определенные файлы, например PDF-файлы или изображения
- Удалить медиафайлы из SERP (страниц результатов поисковой системы)
- Запускайте платную рекламу или ссылки, требующие выполнения определенных требований для роботов
Как видите, существует множество причин для использования файла robots. txt. Однако, если вы хотите, чтобы поисковые системы имели доступ к вашему веб-сайту и индексировали его целиком, вам не нужен файл robots.txt.
Во-первых, давайте удостоверимся, что для вашего веб-сайта не существует файла robots.txt. В строке URL вашего веб-браузера добавьте «/robots.txt» в конце имени вашего домена (например, www.example.com/robots.txt ).
Если отображается пустая страница, у вас нет файла robots.txt. Но если появится файл со списком инструкций, то там это один.
2. Если вы создаете новый файл robots.txt, определите свою общую цель.Одно из наиболее значительных преимуществ файлов robots.txt заключается в том, что они упрощают разрешение или запрет нескольких страниц одновременно, не требуя ручного доступа к коду каждой страницы.
Существует три основных параметра для файлов robots. txt, каждый из которых имеет определенный результат:
- Полное разрешение: Роботам поисковых систем разрешено сканирование весь контент (обратите внимание, что, поскольку по умолчанию разрешены все URL-адреса, полное разрешение, как правило, не требуется)
- Полный запрет: Роботам поисковых систем не разрешено сканировать любой контент (вы хотите запретить поисковым роботам Google доступ к любой части вашего сайта)
- Условное разрешение: Файл устанавливает правила для заблокированного контента, который открыт для поисковых роботов (вы хотите запретить определенные URL-адреса, но не весь веб-сайт)
Как только вы определите желаемую цель, вы готовы настроить файл.
3. Используйте файл robots.txt, чтобы заблокировать выбранные URL-адреса.При создании файла robots.txt вы будете работать с двумя ключевыми элементами:
- user-agent — это конкретный робот поисковой системы, к которому применяется блок URL.
- Строка disallow относится к URL-адресам или файлам, которые вы хотите заблокировать от робота поисковой системы.
Эти строки содержат одну запись в файле robots.txt, что означает, что один файл robots.txt может содержать несколько записей.
Вы можете использовать строку user-agent, чтобы назвать конкретный бот поисковой системы (например, Googlebot Google), или вы можете использовать звездочку (*), чтобы указать, что блокировка должна применяться ко всем поисковым системам: User-agent : *
Тогда в строке запрета будет ломаться именно то, что доступ ограничен. Косая черта ( Disallow: / ) блокирует весь сайт. Или вы можете использовать косую черту, за которой следует конкретная страница, изображение, тип файла или каталог. Например, Disallow: /bad-directory/ заблокирует каталог веб-сайта и его содержимое, а Disallow: /secret.html заблокирует веб-страницу.
Соберите все вместе, и вы можете получить запись, которая выглядит примерно так:
User-agent: *
Disallow: /bad-directory/
Каждый URL-адрес, который вы хотите разрешить или запретить, должен располагаться на отдельной строке. Если вы включаете несколько URL-адресов в одну строку, вы можете столкнуться с проблемами, когда сканеры не могут их разделить.
Вы можете найти множество примеров записей в этом ресурсе от Google, если вы хотите увидеть другие потенциальные варианты.
4. Сохраните файл robots.txt.После того, как вы закончите свои записи, вам нужно правильно сохранить файл.
Вот как:
- Скопируйте его в текстовый файл или файл блокнота, а затем сохраните как «robots.txt». Используйте только строчные буквы.
- Сохраните файл в каталоге верхнего уровня вашего веб-сайта. Убедитесь, что он размещен в корневом домене и его имя соответствует «robots.txt».
- Добавьте файл в каталог верхнего уровня кода вашего веб-сайта, чтобы его можно было легко сканировать и индексировать.
- Убедитесь, что ваш код имеет правильную структуру (User-agent -> Disallow/Allow -> Host -> Sitemap). Таким образом, роботы поисковых систем будут обращаться к страницам в правильном порядке.
- Вам нужно настроить отдельные файлы для разных субдоменов. Например, для «blog.domain.com» и «domain.com» требуются отдельные файлы.
Наконец, запустите быстрый тест в Google Search Console, чтобы убедиться, что ваш файл robots.txt работает должным образом.
- Откройте инструмент «Тестер», затем выполните быстрое сканирование, чтобы увидеть, не обнаружены ли какие-либо ошибки или предупреждающие сообщения.
- Если все выглядит хорошо, введите URL для проверки в поле внизу страницы.
- Выберите пользовательский агент, который вы хотите протестировать (из раскрывающегося меню).
- Нажмите «ТЕСТ».
- После этого кнопка «ТЕСТ» будет выглядеть как «ПРИНЯТО» или «БЛОКИРОВАНО», что говорит о том, заблокирован ли доступ к этому файлу для сканера.
- При необходимости вы можете отредактировать файл и повторно протестировать его. Не забывайте, что любые изменения, сделанные в инструменте, должны быть скопированы в код вашего сайта и сохранены там.
Теперь вы знаете, как использовать robots.txt, чтобы запретить или разрешить доступ, но когда этого следует избегать?
Согласно Google, robots.txt не должен быть вашим методом блокировки URL-адресов без рифмы или причины. Этот метод блокировки не заменяет надлежащую разработку и структуру веб-сайта и, безусловно, не является приемлемой заменой мер безопасности. Google предлагает несколько причин для использования различных методов блокировки поисковых роботов, чтобы вы могли решить, какой из них лучше всего соответствует вашим потребностям.
Усовершенствуйте свою SEO-стратегию и дизайн веб-сайта с помощью V Digital Services Вы узнали, что в некоторых ситуациях файл robots.txt может быть невероятно полезен. Однако есть также несколько сценариев, которые не требуют файла robots.