
что это, как работает и ранжирует сайты, плюсы и минусы
MatrixNet (Матрикснет) – это алгоритм машинного обучения, разработанный поисковой системой Яндекс для построения формулы ранжирования сайтов с учетом их авторитетности и формирования результатов выдачи. Внедрен алгоритм в 2009 году.
Особенностью данного метода машинного обучения является то, что это самообучающаяся система, учитывающая любые изменения факторов ранжирования и, как итог, вносящая коррективы в принципы своей работы.
Как работает Матрикснет?
Как ранжируются сайты с помощью Матрикснет?
Плюсы и минусы Матрикснет
Заключение
Как работает Матрикснет?
В компании Яндекс есть большой штат людей, которые лично смотрят сайты, попадающие в индекс, и дают им оценки. Таких сотрудников называют асессорами. Они смотрят поисковый запрос и сайт, найденный по нему, после чего оценивают, насколько он удобный для пользователей, релевантный и так далее.
- Ресурс отвечает всем критериям, его контент релевантный запросу.
- Контент релевантный запросу.
- Контент сайта удовлетворяет ожидания посетителей.
- Контент веб-ресурса частично отвечает запросу пользователя.
- Контент нерелевантный запросу или материалы являются спамом.
Выписка учебных оценок должна быть максимально правильной, чтобы затем алгоритм MatrixNet имел возможность объективно и корректно оценивать и ранжировать другие сайты, которые еще не успели оценить асессоры или которые они вообще не оценят.
База данных поисковой системы регулярно пополняется новыми страницами или наоборот из нее удаляются несуществующие и ненужные документы. Но для корректного обновления индекса машине нужно прописать правила, по которым она будет работать.
Ранее релевантные страницы включали в индекс исключительно аналитики, но в наши дни сайты создаются немыслимыми темпами и люди просто бы не успевали проверять все страницы, которые находят роботы, если бы не был создан алгоритм машинного обучения.
Как ранжируются сайты с помощью Матрикснет?
Поисковику ежедневно приходится обрабатывать миллионы запросов, находить огромные объемы информации, определять релевантность и упорядочивать их так, чтобы выше всех остальных в результатах выдачи отображались самые полезные страницы.
Для проверки параметров каждой страницы по отдельности требуется огромное количество серверов, способных обработать информацию максимально быстро. В ином случае потребуется немыслимое количество времени. Такой поиск пользователям не нужен, потому что результата им придется ждать несколько дней, а то и недель. Ни тот, ни другой вариант не подходит для решения проблемы.
Благодаря алгоритму MatrixNet Яндекс способен проверять сотни факторов ранжирования чрезвычайно быстро, при этом нет необходимости привлекать дополнительные вычислительные мощности.
Поиск обеспечивает одновременной работой нескольких тысяч серверов. Каждый отдельно взятый сервер отвечает за свою часть индекса и составляет рейтинг самых полезных результатов, где оказываются страницы с наиболее релевантным запросам пользователей контентом.
Затем множество списков объединяются в один общий, после чего документы, находящиеся в данном списке, выставляются по своему рейтингу с применением сложнейшей формулы ранжирования, составленной алгоритмом на основе не одной сотни факторов и их комбинаций: поведение пользователей, ссылочный профиль и многое другое.
Вот таким образом Яндекс определяет самые релевантные страницы и выставляет их сверху результатов выдачи, благодаря чему интернет-пользователь быстро находит информацию, отвечающую его вопросу в поиске.
При этом машинное обучение не стоит на месте. В процессе любой выдачи MatrixNet чему-то обучается, что позволяет ему в последующие разы выдавать для интернет-пользователей все более релевантную информацию.
Если объяснить по простому. То чтобы экономить свои ресурсы и быстро ранжировать документы, применяется Матрикснет. Сложные формулы ранжирования не могут работать на больших объемах данных. Поэтому чтобы определить самые релевантные результаты. Поисковая система сначала определяет 1000 результатов, по первоначальным данным, так называемым FastRank — быстрые ранги. Это самые легкие факторы ранжирования, которые уже записаны к документам и поисковой системе не составляет труда определить эти результаты.
Поисковая система сначала определяет 1000 результатов, по первоначальным данным, так называемым FastRank — быстрые ранги. Это самые легкие факторы ранжирования, которые уже записаны к документам и поисковой системе не составляет труда определить эти результаты.
На втором этапе из этих 1000 результатов, поиск уже определяет и рассчитывает лучших 100 документ, по наиболее весомым и сложным факторам. А из этих 100 документов, уже выводит 30 результатов по другим еще более сложным факторам.
И к 30 лучшим результатам поиска уже применяется сложная формула Матрикснет и расставляет их в приоритете полезности для людей.
Формула эта постоянна меняется в зависимости от запроса. А обучается и подстраивается эта формула, благодаря оценкам асессоров.
Плюсы и минусы Матрикснет
В отличие от программ, используемых другими поисковыми машинами, MatrixNet от Яндекса способен формировать сложные формулы ранжирования с изобилием коэффициентов в них, влияющих на расчет авторитетности сайта. Вот почему вебмастеру, продвигающему свой проект, важно знать, как поисковик относится к ресурсу:
Вот почему вебмастеру, продвигающему свой проект, важно знать, как поисковик относится к ресурсу:
- алгоритмом рассматриваются географические, демографические и социальные критерии;
- для пользователя в приоритете выдача результатов, отвечающих его интересам;
- если сайт посвящен узкой тематике, расчет его значимости может производиться по другой формуле;
- формула регулярно дополняется новыми величинами и изменяется в зависимости от внедрения новых или усовершенствования старых факторов.
Но есть у данного машинного обучения и побочные эффекты. К недостаткам Матрикснет можно отнести то, что иногда алгоритм может хорошо оценить сайт с кривым контентом и он появится в выдаче.
Можно отметить и трудности в раскрутке молодых веб-ресурсов. Расчет авторитетности сайта очень сильно зависит от того, как давно был создан сайт. Еще один минус – в выдачу иногда попадают одностраничные или мелкие проекты без текстового контента, тогда пользователям труднее отыскать реально полезную информацию.
Заключение
Машинное обучение MatrixNet постоянно самообучается помимо того, что ей помогают асессоры. Аналитики предоставляют для алгоритма список релевантных, по их мнению, веб-сайтов, после чего он изучает их и затем самостоятельно выбирает тематические ресурсы.
Несмотря на то, что система еще несовершенна, поиск информации в Яндексе для рядовых пользователей за последние годы сделал огромный шаг вперед, стал удобнее, быстрее и, самое главное, точнее. И большой прогресс наблюдается именно после реализации Матрикснет.
что это такое и как работет
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем
Заказывайте честное и прозрачное продвижение
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
MatrixNet (Матрикснет) – это алгоритм машинного обучения, который учитывает критерии авторитетности сайта при формировании выдачи.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
Матрикснет — это не просто алгоритм ранжирования. Это самообучающаяся система, которая учитывает все изменения. И если меняются, например, поведенческие факторы — система это учитывает, принимает к сведению и корректирует методы своей работы.
Принцип работы MatrixNet
В Яндексе есть должность асессора – человека, который в ручном режиме просматривает и оценивает веб-ресурсы. Суть их работы в следующем: используя связку «поисковой запрос + сайт», специалист дает ответ поисковой запрос. В частности, существует несколько вариантов оценки:
- Сайт соответствует всем критериям, контент релевантен запросу.
- Контент сайта релевантен запросу.
- Контент сайта соответствует ожиданию аудитории.

- Контент частично релевантен запросу.
- Контент не релевантен запросу, либо это спам.

Асессоры работают приблизительно по такой системе оценок. Однако везде есть субъективность.
Выборка учебных оценок должна быть корректной и достаточной, чтобы алгоритм машинного обучения смог самостоятельно выставлять рейтинг другим веб-ресурсам, не участвовавших в «учебной программе».
Как происходит сортировка сайтов в поисковой выдаче
Каждый день поисковая система обрабатывает огромное количество запросов. В ответ на каждый она отсортировывает выдачу в соответствии с алгоритмом ранжирования. Все данные: реакция пользователей, модель их поведения — остался ли на предложенном сайте, сколько провел времени и т. д. — анализируются. А затем учитываются системой Matrixnet.
С каждой выдачей алгоритм чему-то учится и выдает все более релевантный запросу контент.
Преимущества и недостатки Матрикснет
В отличие аналогичных программ, Matrixnet может образовывать длинные и сложные формулы ранжирования. Оптимизатор должен понимать, как его сайт воспринимается поисковой системой.
Оптимизатор должен понимать, как его сайт воспринимается поисковой системой.
- Алгоритм учитывает демографические, социальные, географические показатели.
- Для каждого пользователя приоритет выдачи составляется с учетом его интересов.
- Формула расчета постоянно изменяется — добавляются новые показатели в виде коэффициентов
Есть и недостатки. Например, в выдаче может оказаться сайт с неправильно оформленным контентом.
И продвигать молодой сайт сложнее. Возраст домена сильно влияет на расчет авторитетности.
Вместо действительно интересных пользователю порталов в выдаче могут оказаться одностраничники, или небольшие сайты без текстовых материалов.
Алгоритм Матрикснет постоянно совершенствуется. Ассесор предоставляет выборку порталов, которые релевантны определенным запросам. Алгоритм анализирует их, и дальше в состоянии сам отбирать тематические порталы. Процесс поиска информации в Яндексе стал более удобным и эффективным после введения MatrixNet.
Процесс поиска информации в Яндексе стал более удобным и эффективным после введения MatrixNet.
Яндекс открывает технологию машинного обучения MatrixNet для исследователей CERN
Эта статья была опубликована 21 января 2013 года
История
Мартин Брайант
История
Мартин Брайант
Основатель
Мартин Брайант является основателем Big Revolution, где он помогает технологическим компаниям совершенствовать свои предложения и позиционирование, а также разрабатывает высококачественные продукты. (показать все)
Мартин Брайант — основатель Big Revolution, где он помогает технологическим компаниям совершенствовать свои предложения и позиционирование, а также разрабатывает для них высококачественный и привлекательный контент. Ранее он занимал несколько должностей в TNW, в том числе главного редактора. Он покинул компанию в апреле 2016 года в пользу новых пастбищ.
(показать все)
Мартин Брайант — основатель Big Revolution, где он помогает технологическим компаниям совершенствовать свои предложения и позиционирование, а также разрабатывает для них высококачественный и привлекательный контент. Ранее он занимал несколько должностей в TNW, в том числе главного редактора. Он покинул компанию в апреле 2016 года в пользу новых пастбищ.
Российский интернет-гигант «Яндекс» сегодня объявляет о расширении своего партнерства с европейской организацией ядерных исследований CERN. Соглашение позволит физикам ЦЕРН фильтровать большие наборы данных, чтобы находить чрезвычайно редкие события, используя технологию машинного обучения.
ЦЕРН будет использовать MatrixNet, поисковую технологию Яндекса, которая «обучается» улучшать результаты поиска на основе широкого спектра динамических факторов, связанных с веб-страницами, которые соответствуют любому конкретному запросу.
Яндекс начал сотрудничество с ЦЕРН в 2011 году, предложив исследовательской организации вычислительные ресурсы. В апреле прошлого года он запустил инструмент поиска для использования с данными Большого адронного коллайдера. В настоящее время Яндексу необходимо предоставить персонал для помощи CERN в его использовании. Однако разработка удобного интерфейса, который позволит физикам использовать его самостоятельно, продолжается.
Присоединяйтесь к TNW в Валенсии!
Сердце технологий приближается к сердцу Средиземноморья
Подробнее
Хотя ЦЕРН в настоящее время использует MatrixNet для работы с данными Большого адронного коллайдера, в частности, с анализом распада B-мезона (ничего страшного, если вы не знаете, что это такое, хотя Шелдон из «Теории большого взрыва», вероятно, издеваются над вами), Яндекс говорит, что сделка поможет улучшить качество MatrixNet для всех его пользователей благодаря опыту работы с обширными наборами данных, полученными в результате исследований Большого адронного коллайдера.
Изображение предоставлено: Йоханнес Саймон / Getty Images
rep.estimators.matrixnet — документация REP (воспроизводимая экспериментальная платформа) 0.6.7
"""
:class:`MatrixNetClassifier` и :class:`MatrixNetRegressor` — это оболочки для веб-сервиса MatrixNet — проприетарный BDT.
разработан в Яндексе. Думайте об этом как о конкретном алгоритме Boosted Decision Tree, который доступен как услуга.
На данный момент MatrixMet доступен только для **пользователей CERN**.
Чтобы использовать MatrixNet, сначала приобретите токен::
* Перейдите на https://yandex-apps.cern.ch/ (войдите под своей учетной записью CERN)
* Нажмите «Добавить токен» на левой панели.
* Выберите сервис `MatrixNet` и нажмите `Создать токен`
* Создайте файл `~/.rep-matrixnet.config.json` со следующим содержимым
(при создании объекта-обертки можно указать собственный путь к файлу конфигурации)::
{
"url": "https://ml. cern.yandex.net/v1",
"токен": "<ваш_токен>"
}
"""
from __future__ import Division, print_function, absolute_import
импортировать контекстную библиотеку
импортировать хеш-библиотеку
импортировать json
импортировать номера
импорт ОС
импортный шутил
импортировать временный файл
время импорта
из abc импортировать ABCMeta
из коллекций импортировать defaultdict
из копии импортировать глубокую копию
из лога импортировать getLogger
импортировать numpy
импортировать панд
из шести импортных BytesIO
из sklearn.utils импортировать check_random_state
из ._matrixnetapplier импортировать MatrixNetApplier
из ._mnkit импортировать MatrixNetClient
из .interface импорта Классификатор, Регрессор
из .utils импортировать check_inputs, score_to_proba, remove_first_line
из ..utils импортировать take_last
__author__ = 'Татьяна Лихоманенко, Алексей Рогожников'
__all__ = ['MatrixNetBase', 'MatrixNetClassifier', 'MatrixNetRegressor']
регистратор = getLogger (__ имя__)
РАЗМЕР = 1000
SYNC_SLEEP_TIME = 10
DEFAULT_CONFIG_PATH = "$HOME/. rep-matrixnet.config.json"
@contextlib.contextmanager
определение make_temp_directory():
temp_dir = tempfile.mkdtemp()
выход temp_dir
Shutil.rmtree(temp_dir) [документы]класс MatrixNetBase(объект):
"""Базовый класс для MatrixNetClassifier и MatrixNetRegressor.
Это оболочка вокруг технологии **MatrixNet (специально BDT)**, разработанной в **Яндексе**,
который доступен для сотрудников CERN, использующих авторизацию.
Обученный оценщик загружается и хранится на вашем компьютере, поэтому вы можете использовать его в любое время.
:param features: функции, используемые в обучении
Особенности :type: list[str] или None
:param str api_config_file: путь к файлу с удаленной конфигурацией API в формате json::
{"url": "https://ml.cern.yandex.net/v1", "токен": "<ваш_токен>"}
:param int iterations: количество построенных деревьев (по умолчанию=100)
:param float Regularization: номер регуляризации (по умолчанию = 0,01)
:param intervals: количество бинов для дискретизации функций или dict с границами
список для каждой функции для ее дискретизации (по умолчанию = 8)
:тип интервалы: int или dict(str, list)
:param int max_features_per_iteration: depth (по умолчанию = 6, поддерживает 1 <= . . <= 6)
:param float features_sample_rate_per_iteration: выборка обучающих признаков (по умолчанию = 1.0)
:param float training_fraction: укладка обучающих строк (по умолчанию = 0,5)
:param auto_stop: значение ошибки для предварительной остановки обучения
:type auto_stop: нет или с плавающей запятой
:param bool sync: синхронное или асинхронное обучение на сервере
:param random_state: состояние псевдослучайного генератора
:type random_state: None или int или RandomState
"""
__metaclass__ = ABCMeta
_model_type = Нет
def __init__(self, api_config_file=DEFAULT_CONFIG_PATH,
итерации = 100, регуляризация = 0,01, интервалы = 8,
max_features_per_iteration=6, features_sample_rate_per_iteration=1,0,
training_fraction=0,5, auto_stop=Нет, sync=True, random_state=42):
self.api_config_file = API_config_file
self.iterations = итерации
саморегуляция = регуляризация
self.intervals = интервалы
self. auto_stop = авто_стоп
self.max_features_per_iteration = max_features_per_iteration
self.features_sample_rate_per_iteration = features_sample_rate_per_iteration
self.training_fraction = тренировочная_фракция
self.sync = синхронизировать
self.random_state = случайное_состояние
self._initialisation_before_fit()
def _initialisation_before_fit(я):
self.formula_mx = Нет
self.mn_cls = Нет
self._api = Нет
self._feature_importances = Нет
self._pool_hash = Нет
self._fit_status = Ложь
def _configure_api (я, config_file_path):
config_file_path = os.path.expandvars(config_file_path)
с open(config_file_path, 'r') как conf_file:
config = json.load(conf_file)
self._api = MatrixNetClient(config['url'], token=config['token'])
если self.mn_cls не None:
self.mn_cls.requests_kwargs['заголовки']['X-Yacern-Token'] = self._api.auth_token
защита __getstate__(я):
результат = глубокая копия (self. __dict__)
если '_api' в результате:
результат результата['_api']
если результат['mn_cls'] не равен None:
результат['mn_cls'].requests_kwargs['заголовки']['X-Yacern-Token'] = ""
вернуть результат
def __convert_borders (я, границы, функции):
"""
конвертировать границы объектов в правильный формат для отправки на сервер
"""
convert_borders = ""
для i функция в enumerate(features):
если нет в границах:
Продолжать
для границы в границах [функция]:
convert_borders += "{}\t{}\t0\n".format(i, граница)
вернуть convert_borders
def _md5 (я, имя файла):
"""
вычислить хэш md5 для файла
"""
md5 = hashlib.md5()
с открытым (имя файла, 'rb') как file_d:
для чанка в iter(lambda: file_d.read(128 * md5.block_size), b''):
md5.update(чанк)
вернуть md5.hexdigest()
def _save_df_to_file(self, df, labels, sample_weight, outfile):
"""
сохранить DataFrame для отправки на сервер
"""
заголовок = Истина
режим = 'ш'
для строки в диапазоне (0, len (df), CHUNKSIZE):
df_ef = df. iloc[строка: строка + CHUNKSIZE, :].copy()
df_ef['is_signal'] = метки[строка: строка + CHUNKSIZE]
df_ef['вес'] = sample_weight[строка: строка + CHUNKSIZE]
df_ef.to_csv(outfile, sep='\t', index=False, header=header, mode=mode)
заголовок = Ложь
режим = 'а'
def _upload_training_to_bucket(self, X, y, sample_weight):
с make_temp_directory() как temp_dir:
data_local = os.path.join (temp_dir, 'data.csv')
self._save_df_to_file(X, y, sample_weight, data_local)
self._pool_hash = self._md5 (data_local)
self._configure_api(self.api_config_file)
mn_bucket = self._api.bucket (bucket_id = self._pool_hash)
если 'data.csv' не в наборе (mn_bucket.ls()):
mn_bucket.upload (data_local)
вернуть mn_bucket
def _train_formula (я, mn_bucket, функции):
"""
подготовить параметры и вызвать _train_sync
"""
если self. random_state равно None:
семя = нет
elif isinstance (self.random_state, int):
семя = self.random_state
еще:
seed = check_random_state(self.random_state).randint(0, 10000)
mn_options = {'итерации': int(self.iterations),
'регуляризация': float(self.regularization),
'max_features_per_iteration': int(self.max_features_per_iteration),
'features_sample_rate_per_iteration': поплавок (self.features_sample_rate_per_iteration),
'training_fraction': поплавок (self.training_fraction),
«семя»: нет,
«интервалы»: нет,
'auto_stop': нет,
'train_type': self._model_type}
если семя не None:
mn_options['seed'] = int(seed)
если isinstance (self.intervals, numbers.Number):
mn_options['интервалы'] = int(self.intervals)
еще:
assert set(self. intervals.keys()) == set(features), 'интервалы должны содержать границы для всех признаков'
с make_temp_directory() как temp_dir:
borders_local = os.path.join (temp_dir, 'границы')
с open(borders_local, "w") как file_b:
file_b.write(self.__convert_borders(self.intervals, features))
суффикс = '.{}.baseline'.format (self._md5 (borders_local))
borders_name = borders_local + суффикс
os.rename (borders_local, borders_name)
если borders_name не в наборе (mn_bucket.ls()):
mn_bucket.upload(имя_границы)
mn_options['интервалы'] = 'границы' + суффикс
если self.auto_stop не None:
mn_options['auto_stop'] = float(self.auto_stop)
дескриптор = {
'мн_параметры': мн_параметры,
'мн_версия': 1,
«поля»: список (функции),
'дополнительный': {},
}
self._configure_api(self. api_config_file)
self.mn_cls = self._api.classifier(
параметры = дескриптор,
description="Классификатор, представленный REP",
ведро_id = mn_bucket.bucket_id,
)
self.mn_cls.upload()
self._fit_status = Истина
[документы] def training_status(self):
"""
Проверить, закончилось ли обучение на сервере
:rtype: бул
"""
self._configure_api(self.api_config_file)
утверждать, что self._fit_status и self.mn_cls не равны None, 'Вызвать подгонку до'
печать (я.mn_cls)
assert self.mn_cls.get_status() != 'сбой', 'Ошибка оценщика, запустить функцию повторной отправки, идентификатор задания {}'.format(
self.mn_cls.classifier_id)
если self.mn_cls.get_status() == 'завершено':
self._download_formula()
self._download_features()
вернуть Истина
еще:
вернуть Ложь
[документы] определение синхронизации (самостоятельно):
"""
Синхронизировать асинхронное обучение: дождитесь окончания процесса обучения на сервере
"""
assert self. _fit_status, 'Подходит, модель не обучена'
если self.formula_mx не равно None и self._feature_importances не равно None:
возвращаться
пока не self.training_status():
время.сон (SYNC_SLEEP_TIME)
утверждать (self.formula_mx не равно None и self._feature_importances не равно None), \
"Классификатор не был подогнан, сначала позвоните "подходит""
деф _download_formula (я):
"""
Скачать формулу с сервера
"""
если self.formula_mx не None:
возвращаться
с tempfile.NamedTemporaryFile() в качестве внешнего файла:
self._configure_api(self.api_config_file)
self.mn_cls.save_formula(outfile.name)
с открытым (outfile.name, 'rb') как файл_формулы:
self.formula_mx = файл_формулы.read()
утверждать len(self.formula_mx) > 0, "Формула пуста"
защита _download_features (я):
если self. _feature_importances не None:
возвращаться
с tempfile.NamedTemporaryFile() в качестве внешнего файла:
self.mn_cls.save_stats(outfile.name)
статистика = json.loads(open(outfile.name).read())['факторы']
важности = defaultdict (список)
столбцы = ["имя", "эффект", "информация", "эффективность"]
для данных в статистике:
для ключа в столбцах:
важности [ключ]. добавить (данные [ключ])
df = pandas.DataFrame (важность)
df_result = {'эффект': df['эффект'].values / max(df['эффект']),
'информация': df['info'].values / max(df['info']),
'эффективность': df['эффективность'].values / max(df['эффективность'])}
self._feature_importances = pandas.DataFrame (df_result, index = df ['имя']. значения)
[документы] def get_feature_importances(self):
"""
Получить важность характеристик: `эффект`, `эффективность`, `информационные` характеристики
:rtype: pandas. DataFrame с `index=self.features`
"""
самосинхронизировать()
вернуть self._feature_importances
@имущество
определение feature_importances_(я):
"""Sklearn-способ вернуть важность функции.
Это возвращается как numpy.array, столбец «эффект» используется среди важностей MatrixNet.
"""
вернуть numpy.array(self.get_feature_importances()['effect'].ix[self.features])
[документы] def get_iterations(self):
"""
Возвращает количество уже построенных деревьев во время обучения
:return: целое или None
"""
self._configure_api(self.api_config_file)
если self.mn_cls не None:
вернуть self.mn_cls.get_iterations()
еще:
return None
[документы] def resubmit(self):
"""
Повторно отправить процесс обучения на сервер в случае сбоя задания.
"""
если self.mn_cls не None:
self. _configure_api(self.api_config_file)
self.mn_cls.resubmit()
[документы] класс MatrixNetClassifier (MatrixNetBase, Classifier):
__doc__ = 'Модель классификации MatrixNet. \n' + remove_first_line(MatrixNetBase.__doc__)
def __init__(self, features=None, api_config_file=DEFAULT_CONFIG_PATH,
итерации = 100, регуляризация = 0,01, интервалы = 8,
max_features_per_iteration=6, features_sample_rate_per_iteration=1,0,
training_fraction=0,5, auto_stop=Нет, sync=True, random_state=42):
MatrixNetBase.__init__(self, api_config_file=api_config_file,
итерации=итерации, регуляризация=регуляризация, интервалы=интервалы,
max_features_per_iteration=max_features_per_iteration,
features_sample_rate_per_iteration=features_sample_rate_per_iteration,
training_fraction=training_fraction, auto_stop=auto_stop,
sync=синхронизация, random_state=random_state)
Классификатор. __init__(self, features=features)
self._model_type = 'классификация'
защита _set_classes_special (я, у):
self._set_classes(y)
assert self.n_classes_ == 2, "Поддержка только 2 классов (данные содержат {})".format(self.n_classes_)
[документы] def fit(self, X, y, sample_weight=None):
self._initialisation_before_fit()
X, y, sample_weight = check_inputs(X, y, sample_weight=sample_weight, allow_none_weights=False)
self._set_classes_special(y)
X = self._get_features(X)
mn_bucket = self._upload_training_to_bucket (X, y, sample_weight)
self._train_formula (mn_bucket, список (X.columns))
если self.sync:
самосинхронизировать()
вернуть себя
fit.__doc__ = Классификатор.fit.__doc__
[документы] def predict_proba(self, X):
вернуть take_last (self.staged_predict_proba (X, шаг = 100000))
Predict_proba. __doc__ = Classifier.predict_proba.__doc__
[документы] def staged_predict_proba(self, X, step=10):
"""
Прогнозировать вероятности данных для каждой метки класса на каждом этапе.
:param pandas.DataFrame X: данные формы [n_samples, n_features]
:param int step: шаг возвращаемых итераций (по умолчанию 10).
:возврат: итератор
"""
самосинхронизировать()
X = self._get_features(X)
данные = X.astype (с плавающей запятой)
данные = pandas.DataFrame(данные)
mx = MatrixNetApplier (BytesIO (self.formula_mx))
для этапа прогнозирование в enumerate(mx.staged_apply(data)):
если этап % шаг == 0:
доходность score_to_proba(прогноз)
если этап % шаг != 0:
доходность score_to_proba(прогноз)
[документы] класс MatrixNetRegressor (MatrixNetBase, регрессор):
__doc__ = 'MatrixNet для регрессионной модели. \n' + remove_first_line(MatrixNetBase. __doc__)
def __init__(self, features=None, api_config_file=DEFAULT_CONFIG_PATH,
итерации = 100, регуляризация = 0,01, интервалы = 8,
max_features_per_iteration=6, features_sample_rate_per_iteration=1,0,
training_fraction=0,5, auto_stop=Нет, sync=True, random_state=42):
MatrixNetBase.__init__(self, api_config_file=api_config_file,
итерации=итерации, регуляризация=регуляризация, интервалы=интервалы,
max_features_per_iteration=max_features_per_iteration,
features_sample_rate_per_iteration=features_sample_rate_per_iteration,
training_fraction=training_fraction, auto_stop=auto_stop, sync=sync,
random_state = случайное_состояние)
Регрессор.__init__(self, features=features)
self._model_type = 'регрессия'
[документы] def fit(self, X, y, sample_weight=None):
self. _initialisation_before_fit()
X, y, sample_weight = check_inputs(X, y, sample_weight=sample_weight, allow_none_weights=False)
X = self._get_features(X)
mn_bucket = self._upload_training_to_bucket (X, y, sample_weight)
self._train_formula (mn_bucket, список (X.columns))
если self.sync:
самосинхронизировать()
вернуть себя
fit.__doc__ = Классификатор.fit.__doc__
[документы] определение предсказать(я, X):
вернуть take_last (self.staged_predict (X, шаг = 100000))
прогноз.__doc__ = Классификатор.predict.__doc__
[документы] def staged_predict(self, X, step=10):
"""
Прогнозировать вероятности данных для каждой метки класса на каждом этапе.
:param pandas.DataFrame X: данные формы [n_samples, n_features]
:param int step: шаг возвращаемых итераций (по умолчанию 10).
:возврат: итератор
"""
самосинхронизировать()
X = self.
 rep-matrixnet.config.json"
@contextlib.contextmanager
определение make_temp_directory():
temp_dir = tempfile.mkdtemp()
выход temp_dir
Shutil.rmtree(temp_dir)
rep-matrixnet.config.json"
@contextlib.contextmanager
определение make_temp_directory():
temp_dir = tempfile.mkdtemp()
выход temp_dir
Shutil.rmtree(temp_dir) . <= 6)
:param float features_sample_rate_per_iteration: выборка обучающих признаков (по умолчанию = 1.0)
:param float training_fraction: укладка обучающих строк (по умолчанию = 0,5)
:param auto_stop: значение ошибки для предварительной остановки обучения
:type auto_stop: нет или с плавающей запятой
:param bool sync: синхронное или асинхронное обучение на сервере
:param random_state: состояние псевдослучайного генератора
:type random_state: None или int или RandomState
"""
__metaclass__ = ABCMeta
_model_type = Нет
def __init__(self, api_config_file=DEFAULT_CONFIG_PATH,
итерации = 100, регуляризация = 0,01, интервалы = 8,
max_features_per_iteration=6, features_sample_rate_per_iteration=1,0,
training_fraction=0,5, auto_stop=Нет, sync=True, random_state=42):
self.api_config_file = API_config_file
self.iterations = итерации
саморегуляция = регуляризация
self.intervals = интервалы
self.
. <= 6)
:param float features_sample_rate_per_iteration: выборка обучающих признаков (по умолчанию = 1.0)
:param float training_fraction: укладка обучающих строк (по умолчанию = 0,5)
:param auto_stop: значение ошибки для предварительной остановки обучения
:type auto_stop: нет или с плавающей запятой
:param bool sync: синхронное или асинхронное обучение на сервере
:param random_state: состояние псевдослучайного генератора
:type random_state: None или int или RandomState
"""
__metaclass__ = ABCMeta
_model_type = Нет
def __init__(self, api_config_file=DEFAULT_CONFIG_PATH,
итерации = 100, регуляризация = 0,01, интервалы = 8,
max_features_per_iteration=6, features_sample_rate_per_iteration=1,0,
training_fraction=0,5, auto_stop=Нет, sync=True, random_state=42):
self.api_config_file = API_config_file
self.iterations = итерации
саморегуляция = регуляризация
self.intervals = интервалы
self. auto_stop = авто_стоп
self.max_features_per_iteration = max_features_per_iteration
self.features_sample_rate_per_iteration = features_sample_rate_per_iteration
self.training_fraction = тренировочная_фракция
self.sync = синхронизировать
self.random_state = случайное_состояние
self._initialisation_before_fit()
def _initialisation_before_fit(я):
self.formula_mx = Нет
self.mn_cls = Нет
self._api = Нет
self._feature_importances = Нет
self._pool_hash = Нет
self._fit_status = Ложь
def _configure_api (я, config_file_path):
config_file_path = os.path.expandvars(config_file_path)
с open(config_file_path, 'r') как conf_file:
config = json.load(conf_file)
self._api = MatrixNetClient(config['url'], token=config['token'])
если self.mn_cls не None:
self.mn_cls.requests_kwargs['заголовки']['X-Yacern-Token'] = self._api.auth_token
защита __getstate__(я):
результат = глубокая копия (self.
auto_stop = авто_стоп
self.max_features_per_iteration = max_features_per_iteration
self.features_sample_rate_per_iteration = features_sample_rate_per_iteration
self.training_fraction = тренировочная_фракция
self.sync = синхронизировать
self.random_state = случайное_состояние
self._initialisation_before_fit()
def _initialisation_before_fit(я):
self.formula_mx = Нет
self.mn_cls = Нет
self._api = Нет
self._feature_importances = Нет
self._pool_hash = Нет
self._fit_status = Ложь
def _configure_api (я, config_file_path):
config_file_path = os.path.expandvars(config_file_path)
с open(config_file_path, 'r') как conf_file:
config = json.load(conf_file)
self._api = MatrixNetClient(config['url'], token=config['token'])
если self.mn_cls не None:
self.mn_cls.requests_kwargs['заголовки']['X-Yacern-Token'] = self._api.auth_token
защита __getstate__(я):
результат = глубокая копия (self. __dict__)
если '_api' в результате:
результат результата['_api']
если результат['mn_cls'] не равен None:
результат['mn_cls'].requests_kwargs['заголовки']['X-Yacern-Token'] = ""
вернуть результат
def __convert_borders (я, границы, функции):
"""
конвертировать границы объектов в правильный формат для отправки на сервер
"""
convert_borders = ""
для i функция в enumerate(features):
если нет в границах:
Продолжать
для границы в границах [функция]:
convert_borders += "{}\t{}\t0\n".format(i, граница)
вернуть convert_borders
def _md5 (я, имя файла):
"""
вычислить хэш md5 для файла
"""
md5 = hashlib.md5()
с открытым (имя файла, 'rb') как file_d:
для чанка в iter(lambda: file_d.read(128 * md5.block_size), b''):
md5.update(чанк)
вернуть md5.hexdigest()
def _save_df_to_file(self, df, labels, sample_weight, outfile):
"""
сохранить DataFrame для отправки на сервер
"""
заголовок = Истина
режим = 'ш'
для строки в диапазоне (0, len (df), CHUNKSIZE):
df_ef = df.
__dict__)
если '_api' в результате:
результат результата['_api']
если результат['mn_cls'] не равен None:
результат['mn_cls'].requests_kwargs['заголовки']['X-Yacern-Token'] = ""
вернуть результат
def __convert_borders (я, границы, функции):
"""
конвертировать границы объектов в правильный формат для отправки на сервер
"""
convert_borders = ""
для i функция в enumerate(features):
если нет в границах:
Продолжать
для границы в границах [функция]:
convert_borders += "{}\t{}\t0\n".format(i, граница)
вернуть convert_borders
def _md5 (я, имя файла):
"""
вычислить хэш md5 для файла
"""
md5 = hashlib.md5()
с открытым (имя файла, 'rb') как file_d:
для чанка в iter(lambda: file_d.read(128 * md5.block_size), b''):
md5.update(чанк)
вернуть md5.hexdigest()
def _save_df_to_file(self, df, labels, sample_weight, outfile):
"""
сохранить DataFrame для отправки на сервер
"""
заголовок = Истина
режим = 'ш'
для строки в диапазоне (0, len (df), CHUNKSIZE):
df_ef = df. iloc[строка: строка + CHUNKSIZE, :].copy()
df_ef['is_signal'] = метки[строка: строка + CHUNKSIZE]
df_ef['вес'] = sample_weight[строка: строка + CHUNKSIZE]
df_ef.to_csv(outfile, sep='\t', index=False, header=header, mode=mode)
заголовок = Ложь
режим = 'а'
def _upload_training_to_bucket(self, X, y, sample_weight):
с make_temp_directory() как temp_dir:
data_local = os.path.join (temp_dir, 'data.csv')
self._save_df_to_file(X, y, sample_weight, data_local)
self._pool_hash = self._md5 (data_local)
self._configure_api(self.api_config_file)
mn_bucket = self._api.bucket (bucket_id = self._pool_hash)
если 'data.csv' не в наборе (mn_bucket.ls()):
mn_bucket.upload (data_local)
вернуть mn_bucket
def _train_formula (я, mn_bucket, функции):
"""
подготовить параметры и вызвать _train_sync
"""
если self.
iloc[строка: строка + CHUNKSIZE, :].copy()
df_ef['is_signal'] = метки[строка: строка + CHUNKSIZE]
df_ef['вес'] = sample_weight[строка: строка + CHUNKSIZE]
df_ef.to_csv(outfile, sep='\t', index=False, header=header, mode=mode)
заголовок = Ложь
режим = 'а'
def _upload_training_to_bucket(self, X, y, sample_weight):
с make_temp_directory() как temp_dir:
data_local = os.path.join (temp_dir, 'data.csv')
self._save_df_to_file(X, y, sample_weight, data_local)
self._pool_hash = self._md5 (data_local)
self._configure_api(self.api_config_file)
mn_bucket = self._api.bucket (bucket_id = self._pool_hash)
если 'data.csv' не в наборе (mn_bucket.ls()):
mn_bucket.upload (data_local)
вернуть mn_bucket
def _train_formula (я, mn_bucket, функции):
"""
подготовить параметры и вызвать _train_sync
"""
если self. random_state равно None:
семя = нет
elif isinstance (self.random_state, int):
семя = self.random_state
еще:
seed = check_random_state(self.random_state).randint(0, 10000)
mn_options = {'итерации': int(self.iterations),
'регуляризация': float(self.regularization),
'max_features_per_iteration': int(self.max_features_per_iteration),
'features_sample_rate_per_iteration': поплавок (self.features_sample_rate_per_iteration),
'training_fraction': поплавок (self.training_fraction),
«семя»: нет,
«интервалы»: нет,
'auto_stop': нет,
'train_type': self._model_type}
если семя не None:
mn_options['seed'] = int(seed)
если isinstance (self.intervals, numbers.Number):
mn_options['интервалы'] = int(self.intervals)
еще:
assert set(self.
random_state равно None:
семя = нет
elif isinstance (self.random_state, int):
семя = self.random_state
еще:
seed = check_random_state(self.random_state).randint(0, 10000)
mn_options = {'итерации': int(self.iterations),
'регуляризация': float(self.regularization),
'max_features_per_iteration': int(self.max_features_per_iteration),
'features_sample_rate_per_iteration': поплавок (self.features_sample_rate_per_iteration),
'training_fraction': поплавок (self.training_fraction),
«семя»: нет,
«интервалы»: нет,
'auto_stop': нет,
'train_type': self._model_type}
если семя не None:
mn_options['seed'] = int(seed)
если isinstance (self.intervals, numbers.Number):
mn_options['интервалы'] = int(self.intervals)
еще:
assert set(self. intervals.keys()) == set(features), 'интервалы должны содержать границы для всех признаков'
с make_temp_directory() как temp_dir:
borders_local = os.path.join (temp_dir, 'границы')
с open(borders_local, "w") как file_b:
file_b.write(self.__convert_borders(self.intervals, features))
суффикс = '.{}.baseline'.format (self._md5 (borders_local))
borders_name = borders_local + суффикс
os.rename (borders_local, borders_name)
если borders_name не в наборе (mn_bucket.ls()):
mn_bucket.upload(имя_границы)
mn_options['интервалы'] = 'границы' + суффикс
если self.auto_stop не None:
mn_options['auto_stop'] = float(self.auto_stop)
дескриптор = {
'мн_параметры': мн_параметры,
'мн_версия': 1,
«поля»: список (функции),
'дополнительный': {},
}
self._configure_api(self.
intervals.keys()) == set(features), 'интервалы должны содержать границы для всех признаков'
с make_temp_directory() как temp_dir:
borders_local = os.path.join (temp_dir, 'границы')
с open(borders_local, "w") как file_b:
file_b.write(self.__convert_borders(self.intervals, features))
суффикс = '.{}.baseline'.format (self._md5 (borders_local))
borders_name = borders_local + суффикс
os.rename (borders_local, borders_name)
если borders_name не в наборе (mn_bucket.ls()):
mn_bucket.upload(имя_границы)
mn_options['интервалы'] = 'границы' + суффикс
если self.auto_stop не None:
mn_options['auto_stop'] = float(self.auto_stop)
дескриптор = {
'мн_параметры': мн_параметры,
'мн_версия': 1,
«поля»: список (функции),
'дополнительный': {},
}
self._configure_api(self. api_config_file)
self.mn_cls = self._api.classifier(
параметры = дескриптор,
description="Классификатор, представленный REP",
ведро_id = mn_bucket.bucket_id,
)
self.mn_cls.upload()
self._fit_status = Истина
api_config_file)
self.mn_cls = self._api.classifier(
параметры = дескриптор,
description="Классификатор, представленный REP",
ведро_id = mn_bucket.bucket_id,
)
self.mn_cls.upload()
self._fit_status = Истина _fit_status, 'Подходит, модель не обучена'
если self.formula_mx не равно None и self._feature_importances не равно None:
возвращаться
пока не self.training_status():
время.сон (SYNC_SLEEP_TIME)
утверждать (self.formula_mx не равно None и self._feature_importances не равно None), \
"Классификатор не был подогнан, сначала позвоните "подходит""
_fit_status, 'Подходит, модель не обучена'
если self.formula_mx не равно None и self._feature_importances не равно None:
возвращаться
пока не self.training_status():
время.сон (SYNC_SLEEP_TIME)
утверждать (self.formula_mx не равно None и self._feature_importances не равно None), \
"Классификатор не был подогнан, сначала позвоните "подходит"" _feature_importances не None:
возвращаться
с tempfile.NamedTemporaryFile() в качестве внешнего файла:
self.mn_cls.save_stats(outfile.name)
статистика = json.loads(open(outfile.name).read())['факторы']
важности = defaultdict (список)
столбцы = ["имя", "эффект", "информация", "эффективность"]
для данных в статистике:
для ключа в столбцах:
важности [ключ]. добавить (данные [ключ])
df = pandas.DataFrame (важность)
df_result = {'эффект': df['эффект'].values / max(df['эффект']),
'информация': df['info'].values / max(df['info']),
'эффективность': df['эффективность'].values / max(df['эффективность'])}
self._feature_importances = pandas.DataFrame (df_result, index = df ['имя']. значения)
_feature_importances не None:
возвращаться
с tempfile.NamedTemporaryFile() в качестве внешнего файла:
self.mn_cls.save_stats(outfile.name)
статистика = json.loads(open(outfile.name).read())['факторы']
важности = defaultdict (список)
столбцы = ["имя", "эффект", "информация", "эффективность"]
для данных в статистике:
для ключа в столбцах:
важности [ключ]. добавить (данные [ключ])
df = pandas.DataFrame (важность)
df_result = {'эффект': df['эффект'].values / max(df['эффект']),
'информация': df['info'].values / max(df['info']),
'эффективность': df['эффективность'].values / max(df['эффективность'])}
self._feature_importances = pandas.DataFrame (df_result, index = df ['имя']. значения) DataFrame с `index=self.features`
"""
самосинхронизировать()
вернуть self._feature_importances
DataFrame с `index=self.features`
"""
самосинхронизировать()
вернуть self._feature_importances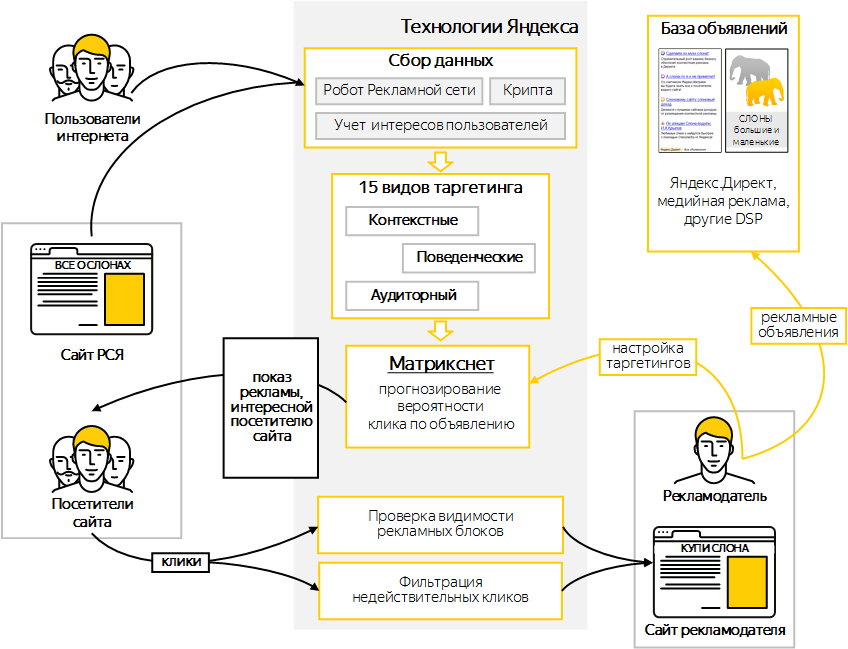 _configure_api(self.api_config_file)
self.mn_cls.resubmit()
_configure_api(self.api_config_file)
self.mn_cls.resubmit() __init__(self, features=features)
self._model_type = 'классификация'
защита _set_classes_special (я, у):
self._set_classes(y)
assert self.n_classes_ == 2, "Поддержка только 2 классов (данные содержат {})".format(self.n_classes_)
__init__(self, features=features)
self._model_type = 'классификация'
защита _set_classes_special (я, у):
self._set_classes(y)
assert self.n_classes_ == 2, "Поддержка только 2 классов (данные содержат {})".format(self.n_classes_) __doc__ = Classifier.predict_proba.__doc__
__doc__ = Classifier.predict_proba.__doc__ __doc__)
def __init__(self, features=None, api_config_file=DEFAULT_CONFIG_PATH,
итерации = 100, регуляризация = 0,01, интервалы = 8,
max_features_per_iteration=6, features_sample_rate_per_iteration=1,0,
training_fraction=0,5, auto_stop=Нет, sync=True, random_state=42):
MatrixNetBase.__init__(self, api_config_file=api_config_file,
итерации=итерации, регуляризация=регуляризация, интервалы=интервалы,
max_features_per_iteration=max_features_per_iteration,
features_sample_rate_per_iteration=features_sample_rate_per_iteration,
training_fraction=training_fraction, auto_stop=auto_stop, sync=sync,
random_state = случайное_состояние)
Регрессор.__init__(self, features=features)
self._model_type = 'регрессия'
__doc__)
def __init__(self, features=None, api_config_file=DEFAULT_CONFIG_PATH,
итерации = 100, регуляризация = 0,01, интервалы = 8,
max_features_per_iteration=6, features_sample_rate_per_iteration=1,0,
training_fraction=0,5, auto_stop=Нет, sync=True, random_state=42):
MatrixNetBase.__init__(self, api_config_file=api_config_file,
итерации=итерации, регуляризация=регуляризация, интервалы=интервалы,
max_features_per_iteration=max_features_per_iteration,
features_sample_rate_per_iteration=features_sample_rate_per_iteration,
training_fraction=training_fraction, auto_stop=auto_stop, sync=sync,
random_state = случайное_состояние)
Регрессор.__init__(self, features=features)
self._model_type = 'регрессия' _initialisation_before_fit()
X, y, sample_weight = check_inputs(X, y, sample_weight=sample_weight, allow_none_weights=False)
X = self._get_features(X)
mn_bucket = self._upload_training_to_bucket (X, y, sample_weight)
self._train_formula (mn_bucket, список (X.columns))
если self.sync:
самосинхронизировать()
вернуть себя
_initialisation_before_fit()
X, y, sample_weight = check_inputs(X, y, sample_weight=sample_weight, allow_none_weights=False)
X = self._get_features(X)
mn_bucket = self._upload_training_to_bucket (X, y, sample_weight)
self._train_formula (mn_bucket, список (X.columns))
если self.sync:
самосинхронизировать()
вернуть себя