
Что такое robots.txt ✔️ Блог Webpromo
20.10.2022
Редакция: Оля Сомова. Автор: Ольга Сомова
Результаты поисковой выдачи содержат релевантные ресурсы в ответ на пользовательский запрос. Перед тем как дать информацию, поисковые роботы сканируют сайт и отправляют в индекс. Как управлять Google ботами? В статье разбираем, что такое robots.txt, из чего он состоит и какие инструменты для составления файла существуют? Зачем нужен файл robots.txt?
Содержание:
- Как поисковые боты сканируют страницы?
- Что такое robots.txt?
- Структура файла robots.txt
- ТОП-6 ошибок в robots.txt
- Пример robots.txt
- Создание и валидация robots.txt
- Сервисы и инструменты для проверки robots.txt
- Что исключать из индекса с помощью robots.txt?
- Выводы
Читайте также: Веб-архив.
Поисковые роботы — это системные алгоритмы, которые проверяют доступные страницы в интернете. Google индексирует информацию, которую вы публикуете. Можно ли управлять ботами? Есть возможность направить системных ботов. Для этого необходимо создать файл robots.txt и показать, какие страницы стоит индексировать, а какие нет.
Как поисковые боты сканируют страницы?
Работа поисковых ботов заключается в поиске нового контента, которые они добавляют в поисковый индекс. Их также называют алгоритмами, краулерами. Боты переходят по ссылкам на страницах в интернете и сканируют содержащую информацию. Когда пользователь вводит запрос в строку, релевантные результаты извлекаются из индекса и ранжируются согласно рейтингу.
Задача поисковых роботов — предоставить пользователям лучшие варианты ответов на их запросы. Почему это важно? Понимание того, как боты находят, индексируют и ранжируют контент, поможет повлиять на позиции сайта в органических результатах поисковой выдачи. Более высокие позиции привлекают больше трафика, кликов и конверсий соответственно.
Более высокие позиции привлекают больше трафика, кликов и конверсий соответственно.
Как поисковики сканируют страницу? Рассмотрим самую популярную поисковую систему в мире Google, доля рынка которой составляет 92%.
Google содержит индекс, где находится больше триллиона веб-страниц. Поэтому система всегда сможет найти любую ссылку, ресурс и т.д. Алгоритмы начинают индексировать с URL-адреса. Далее Googlebot сканирует и обрабатывает страницы согласно прописанному алгоритму и после этого отправляет в цифровую библиотеку под названием поисковый индекс.
Существует понятие, как краулинговый бюджет. Это ограниченное количество страниц, которое боты могут проиндексировать за один раз, и определяется в индивидуальном порядке. Поэтому важно исключать ненужные данные и указывать, что именно необходимо отправить в индекс. Robots.txt это файл, с помощью которого это можно реализовать.
Что такое robots.txt?
Отвечая на вопрос, что такое robots.txt это инструкция, хранящийся в формате текста на сервере. Текст robots.txt это команды, созданные из латинских символов. С помощью этой информации поисковые роботы понимают, какие страницы можно индексировать. Если не прописывать robots.txt, система будет индексировать все страницы, включая дубли или другой «мусор». Каждая строка robots.txt несет одну команду в форме директивы.
Текст robots.txt это команды, созданные из латинских символов. С помощью этой информации поисковые роботы понимают, какие страницы можно индексировать. Если не прописывать robots.txt, система будет индексировать все страницы, включая дубли или другой «мусор». Каждая строка robots.txt несет одну команду в форме директивы.
Читайте также: Рейтинг популярных поисковых систем в мире и Украине за 2022. Сравниваем результаты прошлого и текущего года
Robots.txt можно редактировать по необходимости, чтобы закрыть отдельные страницы от индексации. Чаще это лендинги под временные акции и распродажи, версии для печати, системные файлы и каталоги, пустые страницы.
Важно! 500 кб — максимальный размер файла robots.txt, установленный Google.
При обработке robots.txt, роботы получают 3 правила для индексирования:
- Полный доступ дает разрешение для сканирования всего сайта.

- Частичный доступ позволяет сканировать отдельные элементы.
- При полном запрете Googlebot не сможет ничего просканировать.

Структура файла robots.txt
Robots.txt это текстовый файл, который прописывается в блокноте, любом текстовом редакторе (Notepad++, Sublime). Его добавляют в корневую часть сайта. Такие кодовые инструкции для роботов задаются с помощью директив с различными параметрами.
Структура robots.txt это:
- user-agent — название робота, который должен просканировать данную страницу
- allow/disallow — директивы (команды) для выполнения роботами
Что такое robots.txt и из чего он состоит? Разберем директивы robots.tx по отдельности.
User-agent
Указывает робота, для которого будут актуальны описанные правила robots.txt. К популярным относятся:
- Googlebot — основной бот Google.
- Googlebot-Image — бот картинок.
- Googlebot-Mobile — индексатор мобильной версии.
- Googlebot-Video — робот для сканирования видео.

Готовый текстовый документ robots.txt следует загрузить в корневую папку с названием сайта, где находится файл index.html и файлы движка.
Поисковая система каждый раз при сканировании будет обращаться к robots.txt. Это дает ей информацию и понимание, что можно индексировать, что нет.
Директива allow/disallow
Команда robots.txt разрешает или запрещает сканирование. Для каждого отдельного раздела, папки или URL нужно прописывать правила с помощью знака «/». Например:
- Для запрета папки сайта указываем такую последовательность в robots.txt это:
Disallow: /folder/ - Для запрета только одного файла (в данном случае изображения):
Disallow: /folder/img.jpg
Директива sitemap
Директива Sitemap в robots.txt это направление ботам, где найти карту сайта в формате XML, что поможет им быстрее ориентироваться в структуре ресурса.
Читайте также: Как проверить индексацию сайта в Google и что делать, если страниц нет в выдаче?
Директива Clean-param
Правило robots.txt это запрет для индексации информации, которая содержит динамические параметры. Это страницы с одинаковым контентом — дубли, приводящие к понижению позиции сайта в выдаче.
Директива Crawl-delay
Команда robots.txt подходит для крупных сайтов с большим количеством страниц, что может влиять на скорость загрузки. Каждый раз когда роботы заходят на сайт, это также дает дополнительную нагрузку.
Чтобы снизить давление на сервер, следует использовать в robots.txt директиву Crawl-delay, которая ограничивает количество сканирований. Время в секундах — это параметр, который указывает роботам, сколько раз за определенный период следует сканировать сайт.
ТОП-6 ошибок в robots.txt
Ошибки в robots.txt это нарушения, которые приводят к последствиям. Как отмечает Google, у поисковых роботов гибкие алгоритмы, поэтому небольшие недочеты в robots.![]()
- Неправильное расположение robots.txt. Где находится robots.txt? Напомним, что robots.txt это файл, который должен быть расположен в корневой папке. В обратном случае роботы не смогут его найти.
- Ошибка названия. Всегда название следует писать с маленькой буквы — robots.txt.
- Перечисление папок через запятую. Каждое новое правило пишется с новой строки. При перечислении правил через запятую директива robots.txt не сработает.
- Отсутствие ссылки на файл sitemap.xml. С помощью него роботы получают информацию о структуре сайта и его главных разделах, которые Google сканируют в первую очередь. Данный пункт robots.txt особенно важен для SEO-продвижения сайта.
- Пустые команды в robots.txt это папки и файлы для индексирования или закрытия от индексации, которые нужно не забывать прописывать. Многие специалисты оставляют открытые (пустые) allow/disallow.
- Отсутствие проверок robots.txt. Если вы закрываете отдельные страницы, следует периодически проверять установленные правила. Для этого используйте валидатор.
 Многие специалисты оставляют открытые (пустые) allow/disallow.
Многие специалисты оставляют открытые (пустые) allow/disallow.
Пример robots.txt
Приводим пример что такое robots.txt:
Создание и валидация robots.txt
Как сделать robots.txt? Потребуется обычный текстовый редактор, встроенный блокнот на компьютере или любой другой сервис. Robots.txt пишется вручную.
Чтобы знать, как правильно составить robots.txt, воспользуйтесь онлайн-генераторами. Это сервисы, с помощью которых можно автоматически быстро сгенерировать robots.txt. Такой способ подойдет для тех, кто имеет несколько сайтов. После автоматической генерации, robots.txt необходимо проверить вручную правильность его написания, чтобы избежать ошибок.
Еще один вариант как создать robots.txt это использовать готовые шаблоны. В интернете есть большое количество файлов для популярных CMS, например WordPress. Шаблон включает стандартные директивы, что упрощает процесс написания, нет необходимости создавать robots.txt с нуля.
Шаблон включает стандартные директивы, что упрощает процесс написания, нет необходимости создавать robots.txt с нуля.
Учитывайте, что для написания robots.txt важно владеть базовыми знаниями синтаксиса.
Как мы указывали выше в статье, проверить robots.txt можно несколькими способами. Обнаружить ошибки поможет Google Search Console, который показывает, какие страницы не прошли индексацию.
Сервисы и инструменты проверки robots.txt
Важно проверять правильность написания robots.txt, чтобы сайт корректно сканировался роботами и попадал в поисковый индекс. Для этого советуем использовать дополнительные сервисы:
Google Search Console — главный инструмент для проверки robots.txt, если говорить о системе Google. Сервис включает отдельный раздел как настроить robots.txt. Если ваш сайт еще не подключен, тогда следует зарегистрироваться и добавить его. Google Search Console выводит на экран результат проверки robots.txt, где указано количество ошибок и предостережений.
Seositecheckup — сторонний инструмент для проверки robots.txt на ошибки.
Также можно проверить доступность robots.txt через браузер. Для этого к домену необходимо дописать /robots.txt. Следует провести проверку в нескольких браузерах.
Читайте также: Как Google ранжирует сайты? Ключевые слова как фактор
Что исключать из индекса с помощью robots.txt?
Robots.txt это возможность управлять поисковыми алгоритмами и направить их на главные страницы сайта, которые будут видеть пользователи. Правильный robots.txt не должен содержать следующие пункты:
- Дубли страниц. Каждая из них имеет индивидуальный URL с уникальным контентом;
- Страницы с неуникальным контентом;
- Данные с показателями сессий;
- Файлы, связанные с системой CMS и управлением сайтом (шаблоны, темы, панель администратора).
Исключать с помощью robots.txt это значит закрыть все, что не приносит пользу, а также то, что еще находится на стадии доработки или разработки, дублируется, нерелевантные страницы.
Выводы
Googlebot периодически сканирует и индексирует сайт, чтобы определить его позицию в поисковой выдаче. Алгоритмы знают, что такое robots.txt и считывают правила, указанные в файле. Текстовый документ robots.txt включает директивы или команды, с помощью которых роботы определяют какие страницы доступны для индексации.
Существует несколько вариантов, как создать robots.txt для сайта. Важно также понимать, где находится robots.txt и как его настроить. Не забываем делать проверки на ошибки через сервисы.
Правильный файл robots.txt для wordpress за 5 минут
Что такое Robots.txt и зачем он нужен
Robots.txt — это файл с инструкциями и директивами для роботов поисковых систем, который создан в текстовом формате. Он указывает на то, какие папки и страницы сайта можно индексировать, а какие нет. Рекомендуется к использованию всеми поисковыми системами для улучшения индексирования ресурса.
При каждом сканировании сайта, поисковые роботы обращаются первым делом к Robots. Поэтому можно назвать файл одним из важных факторов ранжирования при продвижении. Большую роль играет то, что Robots не только запрещает и разрешает сканирование страниц, но и содержит ссылку на файл Sitemap. Он в свою очередь сообщает поисковым роботам структуру сайта со ссылками на имеющиеся страницы ресурса.
Поэтому можно назвать файл одним из важных факторов ранжирования при продвижении. Большую роль играет то, что Robots не только запрещает и разрешает сканирование страниц, но и содержит ссылку на файл Sitemap. Он в свою очередь сообщает поисковым роботам структуру сайта со ссылками на имеющиеся страницы ресурса.
Благодаря файлу вы можете:
- убрать дубли страниц;
- закрыть неуникальный контент;
- обозначить главное зеркало сайта;
- задать частоту и скорость загрузки страницы роботами;
- скрыть служебные папки.
Правильное заполнение директив показывает поисковым системам, что вы следите за чистотой на сайте. При некорректно созданном файле, ваш сайт вообще может выпасть из поиска, поэтому первым делом seo-специалист проверяет Robots.txt.
Где находится robots.txt WordPress
Расположение файла может быть разным. Для того, чтобы узнать, есть ли он на сайте в принципе, можно добавить к адресу главной страницы /robots.txt.
В WordPress, как и во многих других CMS, файл находится в корневой папке, поэтому даже если вам открылись директивы выше, редактировать их можно только из файлов на хостинге.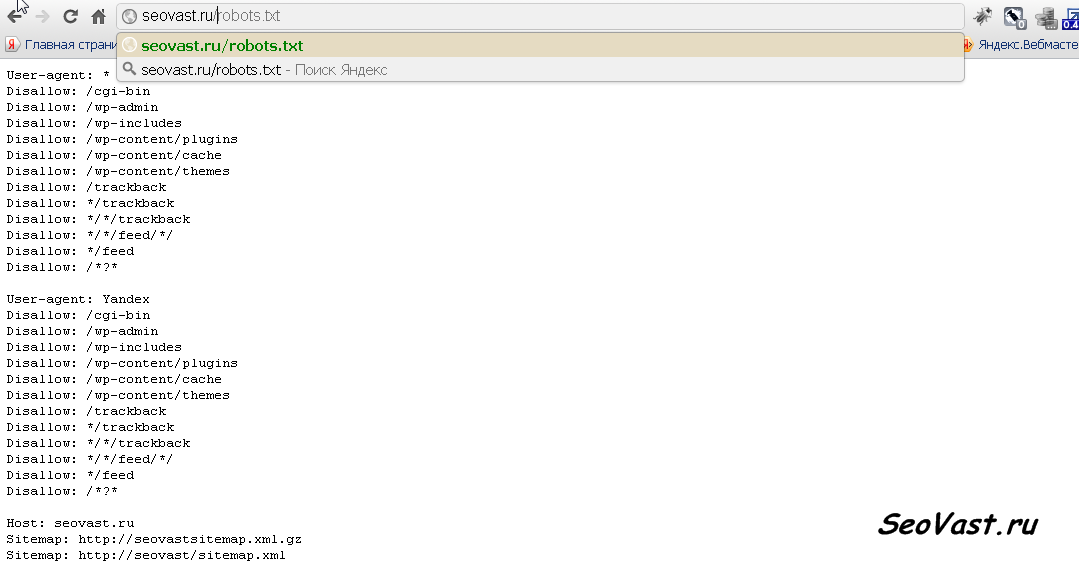 Для этого нужно войти в корневую папку сайта.
Для этого нужно войти в корневую папку сайта.
При отсутствии Robots.txt, создайте его заново.
Как создать файл robots.txt для WordPress
Чтобы создать правильный robots вручную, нужно понимать значение директив и команд. Начать следует с создания документа txt:
- Откройте блокнот на рабочем столе.
- Нажмите “Сохранить”.
- Дайте название сохраняемому файлу robots (не нужно давать свои названия, это стандартное исключение).
- Не меняйте расширение txt.
- Сохраните.
Мы сохранили пустой документ, поэтому далее вам нужно разобраться в значении директив:
- Allow — разрешает сканирование;
- User-agent — указывает для какой поисковой системы составлены директивы;
- Disallow — запрещает сканирование;
- Sitemap — путь с адресом карты сайта;
- Host — главное зеркало;
- Crawl-delay — ограничение времени сканирования;
- Clean-param — убирает дублирующийся контент с других линков.

Считается, что последние три команды уже устарели, но как показывает практика, в работе сайта бывают различные нюансы, поэтому будет не лишним в некоторых случаях прописать эти команды. Поисковые системы всё равно учтут их значения.
После того, как вы внесли нужные вам директивы, сохраните файл и перезалейте его в корень WordPress. Также вы можете создать robots.txt с помощью плагина. Скачайте Yoast SEO, AIOSEO или любой другой плагин, установите его. Войдите во вкладку Инструменты — Редакторы файлов — Создать файл robots.txt — Сохранить изменения. В этом случае файл будет создан с минимальным количеством директив автоматом.
Как редактировать robots.txt на WordPress?
Редактирование может осуществляться через FTP, плагин.
Редактирование через плагин AIOSEO
Войдите в меню плагина — Инструменты — Редактор Robots.txt.
Если вы уже настроили ранее файл robots.txt, то импортируйте его в плагин. Если вы хотите создать новый, тогда система оповещения предупредить вас о наличии уже созданного файла. Его придется либо импортировать, либо удалить. Иногда стоит проигнорировать уведомления и оставить старый роботс до создания нового корректного файла.
Его придется либо импортировать, либо удалить. Иногда стоит проигнорировать уведомления и оставить старый роботс до создания нового корректного файла.
После входа в редактор Robots.txt плагина AIOSEO, перетяните галочку Custom Robots.txt на включение.
Перед вами откроется предварительный просмотр, где вы сможете вносить свои изменения. Плагин уже создаст базовый файл с закрытыми папками админки, темы и прочей информацией, которая не будет полезна людям.
AIOSEO содержит конструктор правил, поэтому путем выбора страниц вы можете легко задать нужные правила сканирования.
Также вы можете добавить новое правила для другой поисковой системы.
Сохраняйте изменения и проверяйте правильность созданного файла.
Редактирование через FTP
FTP позволяет управлять сайтом через удаленный веб-сервер. Благодаря ему можно вносить изменения в любые файлы сайта не имея физического доступа к серверу. Самыми частыми FTP-клиентами считаются FileZilla, Free FTP, Cyberduck, WinSCP.
Настройте FTP для доступа к учетной записи хостинга. Войдите в панель и найдите папку под названием Robots.txt. Можно создать новый файл и перезалить его, либо редактировать уже имеющийся.
Стандартный Robots.txt для WordPress
По умолчанию роботс выглядит так:
Должны быть закрыты административная часть сайта, за исключением admin-ajax.php, которая относится к данной директиве. К сожалению даже для базового Robots.txt на сегодня этого мало, поэтому рекомендуется также закрыть доступ к таким директивам и параметрам как:
- /xmlrpc.php;
- /wp-json;
- author;
- customize_autosaved;
- p&preview;
- s;
- customize_theme.
Базовый файл лучше разделить для двух поисковых систем Гугл и Яндекс, либо для всех поисковых систем User-agent: *, и отдельно для Яндекса User-agent: Yandex.
Строка Disallow: /*? указывает на запрет сканирования UTM-меток, CRM, коллтрекинг и т.д. При копировании кода с нашей страницы не забудьте изменить путь Sitemap.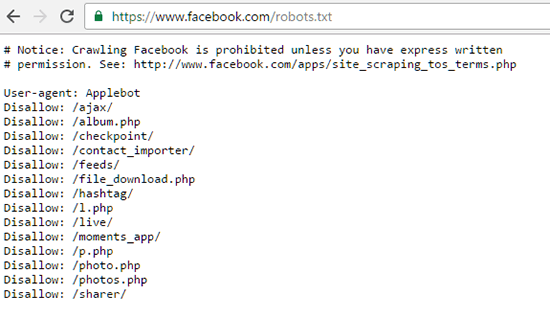
Расширенный Robots.txt для WordPress
Поскольку WordPress использует кастомную авторизацию, следует закрыть в Robots.txt страницы входа, регистрации и восстановления данных:
- Disallow: /login
- Disallow: /register
- Disallow: /reset-password
Регулярно следите за выдачей и страницами в Яндекс.Вебмастер. Лишние и ненужные страницы нужно убирать из поисковой выдачи, чтобы у роботов было больше шансов просканировать полезные страницы. В связи с этим следует запретить:
- страницы пагинации;
- записи;
- рубрики;
- архивы;
- комментарии к записям;
- скрипты;
- стили.
Директива clean-param
Clean-param прописывается только для Яндекс роботов, поскольку Гуглом она не учитывается. Данная директива сообщает роботам об одинаковых урлах, но с разными динамическими параметрами. Такое часто встречается у тех, кто пользуется контекстной рекламой, сортировкой товаров и т.д. Задача Clean-param в роботс — объяснить поисковым роботам Яндекс, что на сайте есть GET-параметры, что позволит не индексировать и не учитывать дубли страниц.
Чтобы настроить директиву clean-param в Robots.txt для WordPress откройте ее через FTP или плагин (там же где и отредактировать сам файл роботс). Директива может быть прописана в любом месте, но помните что регистр букв играет большую роль. Если вам надо обозначить несколько параметров, то используйте амбассадором &.
Проверка работы файла robots.txt
После того, как вы создали файл robots.txt, загрузили его и убедились в его отображении, следует проверить его доступность с точки зрения поисковиков. Сделать это можно и Яндекс.Вебмастере и Google Search Console. Проверим работу файла robots.txt в Яндекс.Вебмастере:
- Авторизуйтесь;
- Выберите нужный сайт;
- Инструменты;
- Анализ robots.txt.
Перед вами откроется окошко с уже имеющимся файлом или загрузите свой. Нажмите кнопку “Проверить”. Также проверить правильность robots.txt можно перейдя по ссылке https://webmaster.yandex.ru/tools/server-response/. Здесь можно вставить фрагмент кода или ссылку на файл.
Если все директивы отдают ответом 200 ОК, то все работает корректно. При наличии ошибок, они будут подсвечиваться красным.
Как создать файл robots.txt (4 основных шага)
Содержание
Файл robots.txt делает роботов поисковых систем более эффективными при анализе SEO вашего сайта. Хорошая метафора заключается в том, что файл robots.txt помогает указать Google, куда вы хотите, чтобы они направлялись, как указатель к вашему контенту. Эта статья покажет вам, как создавать файлы robots.txt для оптимизации SEO вашего сайта и увеличения трафика. Исторически сложилось так, что сайты robots.txt имеют немного лучший SEO и веб-трафик, чем сайты, не использующие файлы robots.txt.
1. Создайте файл
Начните с создания файла .txt с помощью блокнота или любого текстового редактора, сохранив новый файл как «роботы» в нижнем регистре.
2. Добавьте строки текста в файл
Введите следующие две строки текста в файл robots.txt, который вы только что сохранили:
User-agent: *
Disallow:
сайт, что эта строка текста относится ко всем из них.
3. Используйте линии запрета для управления поиском бота
Используя строки запрета для ограничения частей вашего сайта, которые боты Google могут сканировать, вы можете сделать SEO более эффективным, вырезав любые страницы, на которых вы не хотите, чтобы они фокусировались, оставив их для прямого доступа. к вашему контенту. Примером строки запрета может быть:
Запретить: /database/
Вырезание раздела базы данных вашего сайта и упрощение поиска по вашему сайту.
4. Сохраните файл robots.txt на своем веб-сайте
Последний шаг — сохранить только что созданный файл robots.txt в корневой каталог вашего веб-сайта. Перейдите в корневую директорию сервера хостинга веб-сайта и сохраните там файл robots.txt.
Структура и содержимое файла robots.txt
Файл robots.txt состоит из двух элементов. Во-первых, вы должны назвать пользовательский агент. После этого вы даете команды, какие каталоги на вашем сайте следует читать или игнорировать. Файл sitemap.xml вашего сайта может храниться в файле robots.txt, чтобы сканер обращался ко всему сайту. Ниже приведена правильная структура файла robots.txt:
- Команда, которая обращается к боту, идет первой.
Агент пользователя:
- После агента пользователя: вы можете назвать каждого бота отдельно или использовать звездочку *, чтобы включить всех ботов.
- Далее идет командная строка. Запретить: это для предотвращения доступа ботов к определенным областям. В то время как команда Разрешить: разрешает доступ к перечисленным областям.
 В то время как команда Разрешить: разрешает доступ к перечисленным областям.
В то время как команда Разрешить: разрешает доступ к перечисленным областям.Ниже приведены несколько примеров файлов robots.txt:
Образец 1:
Агент пользователя: seobot
Disallow: /nothere/
В этом примере бот с именем «seobot» не будет сканировать папку http://www.test.com/nothere/ и все последующие подкаталоги.
Образец 2:
Агент пользователя: *
Разрешить: /
В этом примере все агенты пользователя могут получить доступ ко всему сайту. Однако боты все равно будут искать по всему сайту, если нет команды disallow, поэтому команда Allow:/ не нужна.
Образец 3:
Агент пользователя: seobot
ПОСЛЕДНИЕ ПОСТЫ
Ошибка 502 Bad Gateway является довольно распространенной, но раздражающей проблемой для большинства пользователей Интернета. Это один из кодов состояния HTTP, указывающих на наличие …
. SMTP-сервер может сбивать с толку, но вы должны научиться использовать его для своего бизнеса. Вместо использования переносного SMTP-сервера или стороннего почтового клиента…
Запретить: /directory2/
Запретить: /directory3/
В этом примере имя бота ‘seobot’ сообщает, что он не может просматривать каталоги 2 и 3. Обратите внимание, что каждая команда Disallow: должна располагаться на отдельной строке.
Другие инструкции, которые может использовать файл robots.txt
Выше мы упомянули несколько командных инструкций. Вот описательный список инструкций;
- User-agent: Используется для присвоения имен ботам, которым вы хотите отдавать команды. Использование *, чтобы позволить всем агентам следовать командам.
- Disallow: запрещает ботам доступ к каким-либо каталогам, расположенным по указанному пути к файлу. / косая черта относится ко всем страницам сайта, поэтому Disallow: / предотвратит доступ ботов к любой странице.
- Разрешить: по умолчанию каждая страница на сайте помечена как разрешенная. Однако его можно использовать для предоставления доступа к определенным путям к файлам, даже если они ранее были заблокированы командой Disallow:. Эта функция полезна, если вы хотите заблокировать доступ к поддомену и получить доступ к определенной странице в этом заблокированном поддомене.
- Карта сайта: используется для предоставления местоположения вашей карты сайта ботам поисковых систем.
Как файл robots.txt влияет на поисковую оптимизацию?
При правильном использовании файл robots.txt может существенно повлиять на поисковую оптимизацию (SEO). Крайне важно не ограничивать ботов поисковых систем слишком сильно с помощью команды disallow. Если они слишком ограничены, это отрицательно скажется на рейтинге ваших веб-страниц. Прежде чем сохранять файл в корневой каталог, обязательно проверьте его на наличие ошибок. Если есть ошибка, это может означать, что важные области вашего сайта не включены или включены области, которые должны быть проигнорированы.
У Google есть удобный инструмент для проверки правильности работы файла robots.txt. Используйте консоль поиска Google, так как она перечислит все заблокированные страницы из ваших инструкций по запрету под заголовками «текущее состояние» и «ошибки сканирования». поисковые системы, которые его посещают.
Преимущества использования файла robots.txt на вашем веб-сайте
Поисковые роботы, индексирующие веб-сайты в Интернете, имеют заранее установленное количество страниц, которые они могут сканировать, известное как краулинговый бюджет. Основное преимущество файла robots.txt заключается в том, что он позволяет заблокировать их в различных частях сайта и сосредоточиться на более дружественных к SEO разделах. Например, если на вашем сайте продаются футболки разных цветов и размеров, у каждой из них есть действительный URL-адрес для сканирования ботом. Заблокировав их, бот может сосредоточиться на основных важных страницах и пропустить разделы с несколькими цветами и размерами, если вы запретите эту область. Поэтому, если вы создадите файл robots.txt для своего сайта, вы сможете воспользоваться этими преимуществами.
Недостатки использования файла robots.txt
Поисковые системы не обязаны следовать командам, содержащимся в файле robots. txt. Так что в будущем файл robots.txt может полностью игнорироваться. Другим недостатком является то, что даже если вы запретите раздел своего сайта, он будет проиндексирован в результатах поиска независимо от файла robots.txt, если будет найдено достаточно ссылок на этот раздел. Это означает, что результат Google для этой страницы будет выглядеть пустым, потому что ботам не разрешено просматривать ее, но они знают, что она есть. Файл robots.txt также не обеспечивает никакой защиты от других людей, хотя настоятельно рекомендуется использовать защиту паролем на веб-сервере. Если вы беспокоитесь об этом, вы не можете создать файл robots.txt для своего сайта.
Завершение файла robots.txt
Мы объяснили, как создать файл robots.txt. В целом, файл robots.txt легко создать и внедрить, и он может помочь повысить удобство SEO, а также увеличить веб-трафик для вашего сайта. Тот факт, что поисковые системы могут полностью игнорировать этот файл в будущем, не умаляет преимуществ реализации файла сегодня. Тот факт, что крошечный файл может помочь направить поисковые системы в определенные области вашего сайта, является слишком большой возможностью, чтобы его игнорировать. Надеюсь, вам понравилось читать эту статью, и вы узнали кое-что о файлах robots.txt и о том, как их использовать. Если вы хотите узнать, что такое файл robots.txt, у нас есть более подробная статья о нем.
Часто задаваемые вопросы
Нужен ли мне файл robots.txt для моего сайта WordPress?
Нет, файл robots.txt использовать не нужно. Тем не менее, это может помочь вашему сайту стать более оптимизированным для SEO и увеличить посещаемость сайта.
Где сохранить файл robots.txt?
Файл robots. txt всегда следует сохранять в корневом каталоге вашего домена. В нашем предыдущем примере вы должны найти файл robots.txt по адресу https://www.test.com/robots.txt. Имя файла чувствительно к регистру и всегда должно быть строчным; в противном случае это не сработает.
Как включить карту сайта в robots.txt?
Вы должны включить файл sitemap.xml в файл robots.txt, так как это считается хорошей практикой. Вы можете использовать команду sitemap: для ссылки на вашу карту сайта. В файле robots.txt можно указать несколько файлов Sitemap. Не забудьте также отправить карту сайта через консоль поиска Google и инструменты Bing для веб-мастеров.
Как найти файл robots.txt вашего сайта?
Если на вашем сайте уже есть файл robots.txt, вы можете найти его по адресу https://www.yourdomain.com/ robots.txt. Если вы перейдете по своему URL-адресу и увидите текст блокнота, значит, у вас уже есть рабочий файл robots.txt, который вы можете отредактировать, если хотите.
Можно ли создать файл robots.txt?
Да, многие веб-сайты генерируют для вас файлы robots.txt. Тем не менее, это всего несколько строк текста, и любой может создать свой собственный за несколько минут, следуя нашему простому руководству robots.txt, представленному выше.
Комплект приложений NetSuite — SEO и Robots.txt
Файл robots.txt — это первый файл, который поисковая система запрашивает при индексации вашего сайта. Этот файл позволяет указать поисковым системам, какие страницы вашего сайта не индексировать. Когда вы впервые настраиваете свой сайт, важно иметь файл robots.txt , прежде чем вы начнете работу. Это особенно важно, если у вас многогранная навигация. Многогранная навигация может привести к большому количеству URL-адресов страниц, которые для поисковых систем будут иметь одинаковое содержание. Поскольку дублированный контент негативно влияет на ваш рейтинг в поисковых системах, вам следует использовать robots. для управления тем, что индексируется, и предотвращения индексации поисковой системой страниц, которые кажутся одинаковыми. Сведения о создании файла txt robots.txt при использовании фасетной навигации см. в разделе Robots.txt с категориями и фасетами.
Важно: протестируйте файл robots.txt
Перед запуском сайта крайне важно протестировать файл robots.txt , чтобы убедиться, как ведут себя различные URL-адреса. Лучшим инструментом для выполнения этого теста является инструмент тестирования роботов в инструментах Google для веб-мастеров.
https://www.google.com/webmasters/tools/robots-testing-tool
Как создать файл robots.txt
Файл robots.txt представляет собой текстовый файл. Вы можете использовать любой текстовый редактор для создания файла.
Общие команды robots.txt
В следующих примерах файлов robots.txt представлены некоторые часто используемые методы запрета/разрешения индексирования.
Разрешить всем поисковым роботам сканировать весь контент:
Агент пользователя: *
Запретить:
Заблокировать все поисковые роботы от всего контента:
Агент пользователя: *
Запретить: /
Заблокировать определенный поисковый робот от всего контента:
Агент пользователя: Googlebot
Запретить: /
Заблокировать определенный поисковый робот из определенного аспекта и всех его значений:
Агент пользователя: Googlebot
Запретить: /facet/*
Заблокировать всех поисковых роботов из определенного аспекта, независимо от порядка их появления:
Агент пользователя: *
Запретить: */facet/*
Разрешить всем поисковым роботам сканировать определенное значение фасета внутри фасета, независимо от порядка его появления:
Агент пользователя: *
Запретить: */facet/*
Разрешить: */facet/facet-value-1
Разрешить всем поисковым роботам сканировать определенное значение фасета в фасете, только если этот фасет появляется первым:
Агент пользователя: *
Запретить: /facet/*
Разрешить: /facet/facet-value-1
Запретить всем поисковым роботам добавлять товары в корзину, следуя ссылкам «Добавить в корзину»:
Агент пользователя: * Запретить: /additemtocart.