
Поисковый индекс — Википедия с видео // WIKI 2
Поиско́вый и́ндекс — структура данных, которая содержит информацию о документах и используется в поисковых системах. Индекси́рование[⇨], совершаемое поисковой машиной, — процесс сбора, сортировки и хранения данных с целью обеспечить быстрый и точный поиск информации. Создание индекса включает междисциплинарные понятия из лингвистики, когнитивной психологии, математики, информатики и физики. Веб-индексированием называют процесс индексирования в контексте поисковых машин, разработанных, чтобы искать веб-страницы в Интернете.
Популярные поисковые машины сосредотачиваются на полнотекстовой индексации документов, написанных на естественных языках[1][⇨]. Мультимедийные документы, такие как видео и аудио[2] и графика[3][4], также могут участвовать в поиске.
Метапоисковые машины используют индексы других поисковых сервисов и не хранят локальный индекс, в то время как поисковые машины, основанные на кешированных страницах, долго хранят как индекс, так и текстовые корпусы. В отличие от полнотекстовых индексов, частично-текстовые сервисы ограничивают глубину индексации, чтобы уменьшить размер индекса. Большие сервисы, как правило, выполняют индексацию в заданном временно́м интервале из-за необходимого времени и затрат на обработку, в то время как поисковые машины, основанные на агентах, строят индекс в масштабе реального времени.
Энциклопедичный YouTube
1/5
Просмотров:381
20 122
1 736
121 966
1 915
✪ 012. Модели специализированного поиска и поисковый индекс — Евгений Соколов
✪ Книги скачать Список 200 сайтов библиотек поисковых Книг
✪ [Коллоквиум]: Эффективные алгоритмы нахождения ближайших соседей
✪ Dennis Hong: My 7 species of robot
✪ 1. ИНФОПОИСК 2. Лингвистика. Основы обработки текстов | Технострим
Содержание
Индексация
Цель использования индекса — повышение скорости поиска релевантных документов по поисковому запросу. Без индекса поисковая машина должна была бы сканировать каждый документ в корпусе, что потребовало бы большого количества времени и вычислительной мощности. Например, в то время, как индекс 10 000 документов может быть опрошен в пределах миллисекунд, последовательный просмотр каждого слова в 10 000 больших документов мог бы занять часы. Дополнительная память, выделяемая для хранения индекса, и увеличение времени, требуемое для обновления индекса, компенсируется уменьшением времени на поиск информации.
Факторы, влияющие на проектирование поисковых систем
При разработке поисковой системы необходимо учитывать следующие факторы:
- Факторы слияния
- Как данные входят в индекс? Как слова и подчиненные функции добавляются в индекс во время текстового корпусного обхода? И могут ли несколько поисковых роботов работать асинхронно? Поисковый робот должен сначала проверить, обновляет он старое содержание или добавляет новое. Слияние индекса
- Методы хранения
- Как хранить индексируемые данные? То есть определяют вид хранимой информации: сжатый или отфильтрованный.
- Размер индекса
- Сколько памяти компьютера необходимо, чтобы поддерживать индекс.
- Скорость поиска
- Как быстро можно найти слово в инвертированном индексе. Важным для информатики является сравнение скорости нахождения записи в структуре данных и скорости обновления/удаления индекса.
- Хранение
- Как хранится индекс в течение длительного времени[6].
- Отказоустойчивость
- Для поисковой службы важно быть надежной. Вопросы отказоустойчивости включают проблему повреждения индекса, определяя, можно ли отдельно рассматривать некорректные данные, связанные с плохими аппаратными средствами, секционированием и схемами на основе хеш-функций и композитного секционирования [7], а также репликации.
Индексные структуры данных
Архитектура поисковой системы различается по способам индексирования и по методам хранения индексов, удовлетворяя факторы[⇨]. Индексы бывают следующих типов:
- Суффиксное дерево
- Образно структурировано как дерево, поддерживает линейное время поиска. Построено на хранении суффиксов слов. Деревья поддерживают расширенное хеширование, которое важно для индексации поисковой системы[8]. Используется для поиска по шаблону в последовательностях ДНК и кластеризации. Основным недостатком является то, что хранение слова в дереве может потребовать пространство за пределами необходимого для хранения самого слова[9]. Альтернативное представление — суффиксный массив. Считается, что он требуют меньше виртуальной памяти и поддерживает блочно-сортирующее сжатие данных.
- Инвертированный индекс
- Хранилище списка вхождений каждого критерия поиска[10], обычно в форме хеш-таблиц или бинарного дерева[11][12].
- Индекс цитирования
- Хранилище цитат или гиперссылок между документами для поддержки анализа цитирования, предмет библиометрии.
- N-грамма
- Хранилище последовательностей длин данных для поддержки других типов поиска или анализа текста[13].
- Матрица термов документа
- Используется в латентно-семантическом анализе (ЛСА), хранит вхождения слов в документах в двумерной разреженной матрице.
Проблемы параллельного индексирования
Одной из основных задач при проектировании поисковых систем является управление последовательными вычислительными процессами. Существует ситуации, в которых возможно создание состояния гонки и когерентных отказов. Например, новый документ добавлен к корпусу, и индекс должен быть обновлен, но в то же время индекс должен продолжать отвечать на поисковые запросы. Это коллизия между двумя конкурирующими задачами. Считается, что авторы являются производителями информации, а поисковый робот — потребителем этой информации, захватывая текст и сохраняя его в кэше (или корпусе). Прямой индекс является потребителем информации, произведенной корпусом, а инвертированный индекс — потребителем информации, произведенной прямым индексом. Это обычно упоминается как
модель производителя-потребителя. Индексатор является производителем доступной для поиска информации, а пользователи, которые её ищут, — потребителями. Проблема усиливается при распределенном хранении и распределенной обработке. Чтобы масштабировать большие объемы индексированной информации, поисковая система может основываться на архитектуре распределенных вычислений, при этом поисковая система состоит из нескольких машин, работающих согласованно. Это увеличивает вероятность нелогичности и делает сложнее поддержку полностью синхронизируемой, распределенной, параллельной архитектурыПрямой индекс
Прямой индекс хранит список слов для каждого документа. Ниже приведена упрощенная форма прямого индекса:
| Документ | Слова |
|---|---|
| Документ 1 | наша, Таня, громко, плачет |
| Документ 2 | уронила, в, речку, мячик |
| Документ 3 | тише, Танечка, не, плачь, |
| Документ 4 | не, утонет, в, речке, мяч |
Необходимость разработки прямого индекса объясняется тем, что лучше сразу сохранять слова за документами, поскольку их в дальнейшем анализируют для создания поискового индекса. Формирование прямого индекса включает асинхронную системную обработку, которая частично обходит узкое место обновления инвертированного индекса[15]. Прямой индекс сортируют, чтобы преобразовать в инвертированный. Прямой индекс по сути представляет собой список пар, состоящих из документов и слов, отсортированный по документам. Преобразование прямого индекса к инвертированному является только вопросом сортировки пар по словам. В этом отношении инвертированный индекс — отсортированный по словам прямой индекс.
Инвертированный индекс
Многие поисковые системы используют инвертированный индекс при оценке поискового запроса, чтобы быстро определить местоположение документов, содержащих слова из запроса, а затем ранжировать эти документы по релевантности. Поскольку инвертированный индекс хранит список документов, содержащих каждое слово, поисковая система может использовать прямой доступ, чтобы найти документы, связанные с каждым словом в запросе, и быстро получить их. Ниже приведено упрощенное представление инвертированного индекса:
| Слово | Документы |
|---|---|
| в | Документ 2, Документ 4 |
| громко | Документ 1 |
| мяч | Документ 2, Документ 4 |
| наша | Документ 1 |
| не | Документ 3, Документ 4 |
| плакать | Документ 1, Документ 3 |
| речка | Документ 2, Документ 4 |
| Таня | Документ 1, Документ 3 |
| тише | Документ 3 |
| уронить | Документ 2 |
| утонуть | Документ 4 |
Инвертированный индекс может только определить, существует ли слово в пределах конкретного документа, так как не хранит никакой информации относительно частоты и позиции слова, и поэтому его считают логическим индексом. Инвертированный индекс определяет, какие документы соответствуют запросу, но не оценивает соответствующие документы. В некоторых случаях индекс включает дополнительную информацию, такую как частота каждого слова в каждом документе или позиция слова в документе
[16]. Информация о позиции слова позволяет поисковому алгоритму идентифицировать близость слова, чтобы поддерживать поиск фраз. Частота может использоваться, чтобы помочь в ранжировании документов по запросу. Такие темы в центре внимания исследований информационного поиска.Инвертированный индекс представлен разреженной матрицей, так как не все слова присутствуют в каждом документе. Индекс подобен матрице термов документа, используемом в ЛСА. Инвертированный индекс можно считать формой хеш-таблицы. В некоторых случаях индекс представлен в форме двоичного дерева, которая требует дополнительной памяти, но может уменьшить время поиска. В больших индексах архитектура, как правило, представлена распределенной хеш-таблицей[17].
Слияние индекса
Инвертированный индекс заполняется путём слияния или восстановления. Архитектура может быть спроектирована так, чтобы поддерживать инкрементную индексацию[18][19]
После синтаксического анализа индексатор добавляет указанный документ в список документов для соответствующих слов. В более крупной поисковой системе процесс нахождения каждого слова для инвертированного индекса может быть слишком трудоемким, поэтому его, как правило, разделяют на две части:
- разработка прямого индекса,
- сортировка прямого индекса в инвертированный индекс.
Инвертированный индекс называется так из-за того, что он является инверсией прямого индекса.
Сжатие
Создание и поддержка крупномасштабного поискового индекса требует значительной памяти и выполнения задач обработки. Многие поисковые системы используют ту или иную форму сжатия, чтобы уменьшить размер индексов на диске[6]. Рассмотрим следующий сценарий для полнотекстового механизма поиска в Интернете:
- Требуется 8 битов (1 байт) для хранения одного символа. Некоторые кодировки используют 2 байта на символ[20].
- Среднее число символов в любом слове на странице примем за 5.
Учитывая этот сценарий, несжатый индекс для 2 миллиардов веб-страниц должен был бы хранить 500 миллиардов записей слов. 1 байт за символ или 5 байт за слово — потребовалось бы 2500 гигабайт одного только пространства памяти. Это больше, чем среднее свободное пространство на диске 2 персональных компьютеров. Для отказоустойчивой распределенной архитектуры требуется еще больше памяти. В зависимости от выбранного метода сжатия индекс может быть уменьшен до части такого размера. Компромисс времени и вычислительной мощности, требуемой для выполнения сжатия и распаковки.
Примечательно, что крупномасштабные проекты поисковых систем включают затраты на хранение, а также на электроэнергию для осуществления хранения.
Синтаксический анализ документа
Синтаксический анализ (или парсинг) документа предполагает разбор документа на компоненты (слова) для вставки в прямой и инвертированный индексы. Найденные слова называют токенами (англ. token), и в контексте индексации поисковых систем и обработки естественного языка парсинг часто называют токенизацией (то есть разбиением на токены). Синтаксический анализ иногда называют частеречной разметкой, морфологическим анализом, контент-анализом, текстовым анализом, анализом текста, генерацией согласования, сегментацией речи, лексическим анализом. Термины «индексация», «парсинг» и «токенизация» взаимозаменяемы в корпоративном сленге.
Обработка естественного языка постоянно исследуется и улучшается. Токенизация имеет проблемы с извлечением необходимой информации из документов для индексации, чтобы поддерживать качественный поиск. Токенизация для индексации включает в себя несколько технологий, реализация которых может быть коммерческой тайной.
Проблемы при обработке естественного языка
- Неоднозначность границ слова
- На первый взгляд может показаться, что токенизация является простой задачей, но это не так, особенно при разработке многоязычного индексатора. В цифровой форме тексты некоторых языков, таких, как китайский или японский, представляют сложную задачу, так как слова четко не разделены пробелом. Цель токенизации в том, чтобы распознать слова, которые будут искать пользователи. Специфичная для каждого языка логика используется, чтобы правильно распознать границы слов, что необходимо для разработки синтаксического анализатора для каждого поддерживаемого языка (или для групп языков с похожими границами и синтаксисом).
- Неоднозначность языка
- Для более точного ранжирования документов поисковые системы могут учитывать дополнительную информацию о слове, например, к какому языку или части речи оно относится. Эти методы зависят от языка, поскольку синтаксис между языками различается. При токенизации некоторые поисковые системы пытаются автоматически определить язык документа.
- Различные форматы файлов
- Для того, чтобы правильно определить, какие байты представляют символы документа, формат файла должен быть правильно обработан. Поисковые системы, которые поддерживают различные форматы файлов, должны правильно открывать документ, получать доступ к документу и токенизировать его символы.
- Ошибки памяти
- Качество данных естественного языка не всегда может быть совершенным. Уязвимость существует из-за неизвестного количества документов, в частности, в Интернете, которые не подчиняются соответствующему протоколу файла. Двоичные символы могут быть ошибочно закодированы в различных частях документа. Без распознавания этих символов и соответствующей обработки может ухудшиться качество индекса или индексирования.
Токенизация
В отличие от большинства людей, компьютеры не понимают структуру документа естественного языка и не могут автоматически распознавать слова и предложения. Для компьютера документ — это только последовательность байтов. Компьютер не «знает», что символ пробела является разделителем слов в документе. Человек должен запрограммировать компьютер так, чтобы определить, что является отдельным словом, называемым токеном. Такую программу обычно называют токенизатором или синтаксическим анализатором (парсером), а также лексическим анализатором[21]. Некоторые поисковые системы и другое ПО для обработки естественного языка поддерживают специализированные программы, удобные для осуществления синтаксического анализа, например, YACC или Лекс[22].
Во время токенизации синтаксический анализатор определяет последовательность символов, которые представляют слова и другие элементы, например, пунктуация, представленная числовыми кодами, некоторые из которых являются непечатаемыми управляющими символами. Синтаксический анализатор может распознать некоторые объекты, например, адреса электронной почты, телефонные номера и URL. При распознавании каждого токена могут быть сохранены некоторые характеристики, например, язык или кодировка, часть речи, позиция, число предложения, позиция в предложении, длина и номер строки[21].
Распознавание языка
Если поисковая система поддерживает несколько языков, то первым шагом во время токенизации будет определение языка каждого документа, поскольку многие последующие шаги зависят от этого (например, стемминг и определение части речи). Распознавание языка — это процесс, при котором компьютерная программа пытается автоматически определить или классифицировать язык документа. Автоматическое распознавание языка является предметом исследований в обработке естественного языка[23].
Анализ формата документа
Если поисковая система поддерживает множество форматов документов, то документы должны быть подготовлены для токенизации. Проблема состоит в том, что некоторые форматы документов содержат информацию о форматировании в дополнение к текстовому содержанию. Например, документы HTML содержат HTML-теги[24]. Если бы поисковая система игнорировала различие между содержанием и разметкой текста, то посторонняя информация включалась бы в индекс, что привело бы к плохим результатам поиска. Анализ формата — выявление и обработка языка разметки, встроенного в документ. Анализ формата также упоминается как структурный анализ, разделение тегов, текстовая нормализация.
Задача анализа формата осложняется тонкостями различных форматов файлов. Некоторые форматы файлов защищаются правом интеллектуальной собственности, о них мало информации, а другие — наоборот, хорошо документированы. Распространенные, хорошо задокументированные форматы файлов, которые поддерживают поисковые системы[25][26]:
Некоторые поисковики поддерживают файлы, которые хранятся в сжатом или зашифрованном формате[27][28][29]. При работе со сжатым форматом индексатор сначала распаковывает документ. Этот шаг может привести к получению одного или нескольких файлов, каждый из которых должен быть индексирован отдельно. Бывают следующие поддерживаемые форматы сжатого файла:
Анализ формата может включать методы повышения качества, чтобы избежать включения ненужной информации в индекс. Контент может управлять информацией о форматировании, чтобы включать дополнительные сведения. Примеры злоупотребления форматированием документа в случае веб-спама:
- Включение сотен или тысяч слов в раздел, который скрыт от представления на мониторе, но является видимым индексатору, при помощи тегов форматирования (например, в скрытый тег div в HTML можно включить использование CSS или JavaScript).
- Установка цвета шрифта слов таким же, как цвет фона, что делает невидимыми слова для человека при просмотре документа, но слова остаются видимыми для индексатора.
Распознавание раздела
Некоторые поисковые системы включают распознавание раздела, определяют основные части документа до токенизации. Не все документы в корпусе читаются как правильно написанная книга, разделенная на главы и страницы. Некоторые документы в Интернете, такие как новостные рассылки и корпоративные отчеты, содержат ошибочное содержание и боковые блоки, в которых нет основного материала. Например, эта статья отображает в левом меню ссылки на другие веб-страницы. Некоторые форматы файлов, как HTML или PDF, допускают содержание, которое будет отображаться в колонках. Хотя содержимое документа представлено на экране в различных областях, исходный текст хранит эту информацию последовательно. Слова, которые появляются последовательно в исходном тексте, индексируются последовательно, несмотря на то, что предложения и абзацы отображаются в различных частях монитора. Если поисковые системы индексируют весь контент, как будто это основное содержание документа, то качество индекса и поиска может ухудшиться. Отмечают две основные проблемы:
- Содержание в различных разделах рассматривают как связанное с индексом, хотя в действительности это не так.
- Дополнительное содержание «боковой панели» включено в индекс, но оно не способствует реальной значимости документа, поэтому индекс заполнен плохим представлением о документе.
Для анализа раздела может потребоваться, чтобы поисковая система реализовала логику визуализации каждого документа, то есть абстрактное представление самого документа, и затем проиндексировала представление вместо документа. Например, иногда для вывода контента на страницу в Интернете используют JavaScript. Если поисковая система «не видит» JavaScript, то индексация страниц происходит некорректно, поскольку часть контента не индексируется. Учитывая, что некоторые поисковые системы не беспокоятся о проблемах с визуализацией, веб-разработчики стараются не представлять контент через JavaScript или используют тег NoScript, чтобы убедиться, что веб-страница индексируется должным образом[30]. В то же время этот факт можно использовать, чтобы «заставить» индексатор поисковой системы «видеть» различное скрытое содержание.
Индексация метатегов
Определенные документы часто содержат встроенные метаданные, такие как автор, ключевые слова, описание и язык. В HTML-страницах метатеги содержат ключевые слова, которые также включены в индекс. В более ранних технологиях поиска в Интернете индексировались ключевые слова в метатегах для прямого индекса, а полный текст документа не анализировался. В то время еще не было полнотекстовой индексации, и аппаратное обеспечение компьютера было не в состоянии поддерживать такую технологию. Язык разметки HTML первоначально включал поддержку метатегов для того, чтобы правильно и легко индексировать, без использования токенизации[31].
В процессе развития Интернета в 1990-х, многие корпорации создали корпоративные веб-сайты. Ключевые слова, используемые для описания веб-страниц стали больше ориентироваться на маркетинг и разрабатывались, чтобы управлять продажами, помещая веб-страницу в начало страницы результатов поиска для определенных поисковых запросов. Факт, что эти ключевые слова были определены субъективно, приводил к спаму, что вынудило поисковые системы принять полнотекстовую индексацию. Разработчики поисковой системы могли поместить много «маркетинговых ключевых слов» в содержание веб-страницы до того, как наполнят её интересной и полезной информацией. Однако целью проектирования веб-сайтов являлось привлечение клиентов, поэтому разработчики были заинтересованы в том, чтобы включить больше полезного контента на сайт, чтобы сохранить посетителей. В этом смысле полнотекстовая индексация была более объективной и увеличила качество результатов поисковой системы, что содействовало исследованиям технологий полнотекстовой индексации.
В локальном поиске решения могут включать метатеги, чтобы обеспечить поиск по авторам, так как поисковая система индексирует контент из различных файлов, содержание которых не очевидно. Локальный поиск больше находится под контролем пользователя, в то время как механизмы интернет-поиска должны больше фокусироваться на полнотекстовом индексе.
См. также
Примечания
- ↑ Clarke,Cormack, 1995.
- ↑ Rice,Bailey.
- ↑ Jacobs,Finkelstein,Salesin, 2006.
- ↑ Lee.
- ↑ Brown, 1996.
- ↑ 1 2 Cutting,Pedersen, 1990.
- ↑ mysql.
- ↑ trie.
- ↑ Gusfield, 1997.
- ↑ inverted index.
- ↑ Foster, 1965.
- ↑ Landauer, 1963.
- ↑ 5-gram.
- ↑ Dean,Ghemawat, 2004.
- ↑ Brin,Page, 2006.
- ↑ Grossman,Frieder,Goharian, 2002.
- ↑ Tang,Sandhya, 2004.
- ↑ Tomasic, 1994.
- ↑ Luk,Lam, 2007.
- ↑ unicode.
- ↑ 1 2 Tokenization Guidelines, 2011.
- ↑ Lex&Yacc, 1992.
- ↑ Automated language recognition, 2009.
- ↑ html, 2011.
- ↑ formats files.
- ↑ Типы файлов Google/Yandex.
- ↑ Программы индексации и поиска файлов.
- ↑ Индексирование архивов.
- ↑ Служба индексирования windows.
- ↑ JS indexing.
- ↑ Lee Hypertext, 1995.
Литература
- Charles E. Jacobs, Adam Finkelstein, David H. Salesin. Fast Multiresolution Image Querying (англ.) // Department of Computer Science and Engineering. — University of Washington, Seattle, Washington 98195, 2006.
- Cutting, D., Pedersen, J. Optimizations for dynamic inverted index maintenance (англ.) / Jean-Luc Vidick. — NY, USA: ACM New York, 1990. — P. 405-411. — ISBN 0-89791-408-2.
- Eric W. Brown. Execution Performance Issues in Full-Text Information Retrieval. — University of Massachusetts Amherst: Computer Science Department, 1996. — 179 с. — (Technical Report 95-81).
- Dan Gusfield. Algorithms on Strings, Trees and Sequences: Computer Science and Computational Biology. — USA: Cambridge University Press, 1997. — 326 с. — ISBN 0-521-58519-8.
- Caxton Croxford Foster. Information retrieval: information storage and retrieval using AVL trees (англ.) // ACM ’65 Proceedings of the 1965 20th national conference. — NY, USA, 1965. — P. 192-205. — doi:10.1145/800197.806043.
- Landauer, W. I. The balanced tree and its utilization in information retrieval (англ.) // IEEE Trans. on Electronic Computers. — USA, 1963. — No. 6. — P. 12.
- Jeffrey Dean, Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters (англ.). — Google, Inc, 2004.
- Sergey Brin, Lawrence Page. The Anatomy of a Large-Scale Hypertextual Web Search Engine (англ.). — Stanford University, Stanford: Computer Science Department, 2006.
- Grossman, Frieder, Goharian. IR Basics of Inverted Index (англ.). — 2002.
- Tang Hunqiang, Sandhya Dwarkadas. Hybrid Global Local Indexing for Efficient Peer to Peer Information Retrieval (англ.). — University of Rochester: Computer Science Department, 2004.
- Anthony Tomasic. Incremental Updates of Inverted Lists for Text Document Retrieval (англ.) : Conference Proceeding. — Stanford University, 1994.
- Robert W.P. Luk, Wai Lam. Efficient in-memory extensible inverted file (англ.) // Information Systems. — 2007. — No. 32 (5). — P. 733-754. — doi:10.1016/j.is.2006.06.001.
- Radim Řehůřek, Milan Kolkus. Language Identification on the Web: Extending the Dictionary Method (англ.) // Lecture Notes in Computer Science Volume. — Mexico, 2009. — No. 5449. — P. 357-368. — ISBN 978-3-642-00382-0. (недоступная ссылка)
- Scoping SIG, Tokenization Taskforce PCI Security Standards Council. Info Supplement:PCI DSS Tokenization Guidelines. — 2011. — С. 23.
- Б. Лоусон, Р. Шарп. Изучаем HTML5 = Introducing HTML5. — Питер, 2011. — 272 с. — (Библиотека специалиста). — 2000 экз. — ISBN 978-5-459-00269-0, 978-0321687296.
- T. Berners-Lee. Hypertext Markup Language - 2.0 (англ.). — Network Working Group, 1995.
- Levine JR, Mason T, Brown D. Lex & Yacc. — Sebastopol: O’Reilly & Associates, 1992. — P. 387. — ISBN 1565920007.
Ссылки
 Эта страница в последний раз была отредактирована 14 апреля 2020 в 16:41.
Эта страница в последний раз была отредактирована 14 апреля 2020 в 16:41.Алгоритмы поиска, обратный индекс — Часть 1 / Хабр
C этой статьи я начинаю цикл статей по SEO, в которых будет теория, практика и советы. Начнем естественно с азов. В материале вкратце описываются алгоритмы, по которым современные поисковые системы осуществляют поиск, как проходит индексация, какие математические модели используются при поиске документов.
Что вы узнаете?
Алгоритмы поиска. Что представляет из себя индексация, инвертированный индекс. Математические модели, используемые современными поисковыми системами.
Алгоритмы поиска
- Прямой поиск — последовательный перебор всех данных;
- Инвертированных индексов — список слов (индекс-файл) документированные в алфавитном порядке с указание позиции и других параметров вхождения слова документа.
Обратный индекс
Как вы наверное догадались поисковиками используется алгоритм инвертированных индексов, т. к. использование прямого поиска гораздо более ресурсоемко. Восстановление из обратного индекса произойдет с потерями (падежи, дефисы, запятые, и т. п.). Поэтому также хранится прямой индекс документа для отображения сниппета (фрагмент найденного текста документа отображаемый в поиске).
Документ
Жил-был поп,
Толоконный лоб.
Пошел поп по базару
Посмотреть кой-какого товару.
Обратный индекс документа
базар (3,4)
был (1,2)
жил (1,1)
какой (1,1)
кой (4,2)
лоб (2,1)
поп (1,3) (3,2)
Параметры указаны самые примитивные и только для примера — строка, позиция в строке. В параметрах также хранятся падежи слов, и принадлежность к пассажу.
Математическая модель
При поиске используется 3 типа математических моделей, вот они:
- Булевские (логические) — есть слово — найден, нет — не найден;
- Векторные (используются всеми ПС) — вес слова = TF * IDF;
TF — частота слова в документе
IDF — редкость слова в коллекции (корпус слов) - Вероятностная — подбор выдачи в ручную (с помощью асессоров) — самостоятельное определение релевантности страниц.
Главное
Релевантность — степень отношения к делу. Продвигайте только релевантные документы.
Как работают поисковые системы Сегалович И.В.
П.С. Продолжение следует…
Что должен знать о поиске каждый разработчик / Блог компании Alconost / Хабр
Хотите внедрить или доработать функцию поиска? Вам сюда.
Спросите разработчика: «Как бы вы реализовали функцию поиска в своем продукте?» или «Как создать поисковую систему?». Вероятно, в ответ вы услышите что-нибудь такое: «Ну, мы просто запустим кластер Elasticsearch: с поиском сегодня всё просто».
Но так ли это? Во многих современных продуктах по-прежнему не лучшим образом реализован поиск. Настоящий специалист по поисковым системам скажет вам, что лишь немногие разработчики глубоко понимают, как работает поиск, а ведь это знание часто необходимо для улучшения качества поиска.
Есть множество программных пакетов с открытым исходным кодом, проведено немало исследований, однако лишь немногие избранные понимают, как нужно делать функциональный поиск. Как ни забавно, но если поискать в Интернете связанную с реализацией поиска информацию, вы не найдете актуальных и содержательных обзоров.
Цель статьи
Этот текст можно считать собранием ценных идей и ресурсов, которые могут помочь в создании функции поиска. Статья, безусловно, не претендует на исчерпывающую полноту, однако я надеюсь, что ваши отзывы помогут ее доработать (оставляйте замечания в комментариях или свяжитесь со мной).
Основываясь на опыте работы с универсальными решениями и узкоспециализированными проектами самого разного масштаба (в компаниях Google, Airbnb и нескольких стартапах), я расскажу о некоторых популярных подходах, алгоритмах, методах и инструментах.
Недооценка и непонимание масштабов и сложности задачи поиска могут привести к тому, что у пользователей останутся плохие впечатления, разработчики потратят время впустую, а продукт провалится.
Переведено в Alconost
Если вам не терпится перейти к практике или вы многое по этой теме уже знаете, возможно, стоит сразу перескочить в раздел инструментов и сервисов.
Немного общих размышлений
Статья длинная. Однако большая часть материала в ней опирается на четыре основных принципа:
Поиск — очень неоднородная задача:
- Запросы бывают самые разные, а задача поиска сильно зависит от потребностей продукта.
- В сети Facebook — это поиск по графу людей.
- На сервисе YouTube — поиск отдельных видео.
- Оба эти случая сильно отличаются от поиска на сервисе Kayak: планирование авиаперелетов — очень трудоемкая задача.
- Далее — Карты Google, для которых важно «понимать» геопространственные данные.
- Pinterest — здесь можно найти фото завтрака, который вы в один прекрасный день все-таки приготовите.
Большое значение имеют качество, показатели и организация работы:
- Здесь нет никаких чудесных средств (как тот же PageRank), нет и волшебной формулы ранжирования, которая сделает все красиво. Обработка запросов — это постоянно меняющийся набор методов и процессов, которые занимаются различными аспектами задачи и улучшают работу системы — как правило, постепенно и непрерывно.
- ️ Иными словами, поиск — это не просто создание ПО, которое занимается ранжированием или выборкой (это обсудим ниже) по определенному набору данных. Обычно поисковые системы — это постоянно развивающийся конвейер налаженных компонентов, которые с течением времени меняются, а вместе составляют связанную систему.
- Так, в частности, ключ к созданию успешного поиска — это встраивание процессов оценки и подстройки в сам продукт и в цикл разработки. Архитектор поисковой системы должен думать о процессах и показателях, а не только о технологиях.
В первую очередь — существующие технологии:
- Как и в случае многих других технических задач, не нужно изобретать велосипед: по возможности используйте существующие сервисы или инструменты с открытым кодом. Если есть SaaS (например, Algolia или управляемый Elasticsearch), который соответствует заданным ограничениям и вписывается в бюджет, — используйте его. На начальном этапе такое решение будет, скорее всего, самым оптимальным, даже если потом придется настраивать и улучшать его — или даже искать замену.
️ Подробно ознакомьтесь с тем, что покупаете:
- Даже если вы используете существующее ПО с открытым кодом или коммерческое решение, у вас должно быть некоторое представление о сложности задачи поиска и о том, где могут быть подводные камни.
Теория. Задача поиска
У каждого продукта — свой поиск. Выбор решения зависит от множества технических характеристик и требований. Полезно определить ключевые параметры конкретной задачи поиска:
- Размер: насколько большим будет корпус данных (полный набор документов, по которому нужно искать)? Тысячи, миллионы, миллиарды документов?
- Носитель информации: поиск будет по тексту, изображениями, связям на графах или геопространственным данным?
- Контроль и качество корпуса данных: находятся ли источники документов под вашим контролем — или вы получаете их от третьего лица (вероятного конкурента)? Документы полностью готовы к индексированию или их нужно подчистить и отобрать?
- Скорость индексирования: индексирование нужно в реальном времени или хватит построения индексов в пакетном режиме?
- Язык запросов: запросы будут структурированные — или нужно понимать и неструктурированные?
- Структура запросов: запросы будет текстовые, в форме изображений, звуков? Может, это почтовые адреса, идентификационные записи, лица людей?
- Учет контекста: зависят ли результаты поиска от того, кем является пользователь, какая у него история работы с продуктом, где он находится, какое у него сейчас время суток и т. д.?
- Подсказки: нужна ли поддержка неполных запросов?
- Задержка: какие требования к задержкам в работе сервиса? 100 миллисекунд или 100 секунд?
- Контроль доступа: сервис полностью открытый — или пользователи должны видеть ограниченное подмножество документов?
- Соблюдение нормативов: есть ли ограничения со стороны законодательства или организации?
- Интернационализация: нужна ли поддержка документов с многоязычными кодировками или «Юникодом»? (Подсказка: всегда используйте UTF-8, а если не используете, вы должны точно знать, что и зачем делаете.) Понадобится ли поддерживать многоязычный корпус? А многоязычные запросы?
Если продумать перечисленные вопросы заранее, это поможет сделать важный выбор в проектировании и создании отдельных компонентов поисковой системы.
Конвейер индексации в работе.
Теория. Поисковый конвейер
Пришло время пройтись по списку подзадач в построении поисковой системы, которые обычно решаются отдельными подсистемами, образующими конвейер: иными словами, каждая подсистема получает выходные данные предыдущих подсистем и выдает входные данные для последующих подсистем.
Это приводит нас к важному свойству всей экосистемы: изменив работу какой-либо подсистемы, нужно оценить, как это повлияет на следующие за ней подсистемы, и, возможно, изменить их поведение тоже.
Рассмотрим самые важные практические задачи, которые придется решать.
Выбор индекса
Берем набор документов (например, весь Интернет, все сообщения сети Twitter или фото на сервисе Instagram), выбираем потенциально меньшее подмножество документов, которые есть смысл рассматривать как результаты поиска и включаем в индекс только их, отбрасывая остальные. Это почти не зависит от выбора документов для показа пользователю и нужно для того, чтобы индекс был компактным. Не подойти для индекса могут, например, следующие классы документов.
Спам
Поисковый спам самых разных форм и размеров — это объемная тема, которая сама по себе достойна отдельного руководства. Здесь — хороший обзор таксономии интернет-спама.
Нежелательные документы
При некоторых ограничениях области поиска может потребоваться фильтрация: придется отбросить порнографию, незаконные материалы и т. д. Соответствующие методы похожи на фильтрацию спама, но могут включать в себя и специальные эвристические алгоритмы.
Копии
В том числе почти копии и избыточные документы. Здесь могут помочь хеширование с чувствительностью к местоположению, мера сходства, методы кластеризации и даже данные кликов. Здесь — хороший обзор таких методов.
Малополезные документы
Определение полезности зависит от области работы поиска, поэтому порекомендовать конкретные подходы трудно. Пригодиться могут следующие соображения. Вероятно, для документов можно будет построить функцию полезности. Можно попробовать эвристику; или, например, изображение, содержащее только черные пиксели — как образец бесполезного документа. Полезность можно оценить, опираясь на поведение пользователя.
Построение индекса
В большинстве поисковых систем выборка документов выполняется посредством обращенного индекса, который часто называется просто индексом.
- Индекс — это сопоставление поисковых терминов документам. Поисковым термином может быть слово, характеристика изображения или любое иное производное документа, пригодное для сопоставления запросов и документов. Список документов для данного термина называется предметным указателем (posting list). Его можно сортировать по показателям, например, по качеству документа.
- Выясните, нужно ли индексировать данные в реальном времени. ️ Многие компании с объемными корпусами документов, используя пакетный подход к индексированию, впоследствии приходят к тому, что этот подход не отвечает потребностям продукта: пользователи ожидают, что результаты поиска будут актуальными.
- В текстовых документах при извлечении терминов обычно используются методы обработки естественного языка (NLP), такие как список стоп-слов, выделение основы слов, а также извлечение объектов; для изображений и видео используются методы компьютерного зрения и т. д.
- Кроме того, с документов собираются метаданные и статистическая информация, например, ссылки на другие документы (что используется в известном ранжирующем сигнале PageRank), темы, количество вхождений термина, размер документа, упомянутые сущности и т. д. Эта информация может быть позже использована в построении ранжирующего сигнала или для кластеризации документов. В более крупных системах может быть несколько индексов, например, для документов разных типов.
- Форматы индексов. Фактическая структура и компоновка индекса — сложная тема, поскольку индекс можно оптимизировать по-разному. Например, есть методы сжатия предметных указателей, можно использовать отображение данных через mmap() или LSM-дерево для постоянно обновляемого индекса.
Анализ запросов и выборка документов
Самые популярные поисковые системы принимают неструктурированные запросы. Это означает, что система должна извлечь структуру из самого запроса. В случае обращенного индекса извлекать поисковые термины нужно с помощью методов NLP.
Извлеченные термины могут использоваться для выборки соответствующих документов. К сожалению, в большинстве случаев запросы сформулированы не очень хорошо, поэтому необходимо дополнительно расширять и переписывать их, например, следующим образом:
Ранжирование
Дается список документов (полученных на предыдущем шаге), их сигналы и обработанный запрос и формируется оптимальный порядок этих документов (что и называется ранжированием).
Первоначально большинство используемых моделей ранжирования представляли собой подстроенные вручную взвешенные сочетания всех сигналов документов. Наборы сигналов могут включать в себя PageRank, данные кликов, сведения об актуальности и другое.
Чтобы жизнь медом не казалась, многие подобные сигналы, например, PageRank и сформированные статистическими языковыми моделями сигналы, содержат параметры, которые значительно влияют на работу сигнала. И они тоже требуют ручной подстройки.
В последнее время все более популярным становится обучение ранжированию — основанные на сигналах дифференциальные подходы с учителем. Среди популярных LtR в качестве примера можно привести McRank и LambdaRank от Microsoft, а также Матрикснет от «Яндекса».
Также в области семантического поиска и ранжирования сейчас набирает популярность новый подход на основе векторных пространств. Задумка в том, чтобы обучить отдельные низкоразмерные векторные представления документа, а затем построить модель, которая будет отображать запросы в это векторное пространство.
В таком случае при выборке нужно просто найти несколько документов, которые по некоторому показателю находятся ближе всего к вектору запроса (например, по евклидову расстоянию). Это расстояние и будет рангом. Если хорошо построить отображение и документов, и запросов, то документы будут выбираться не по наличию какого-либо простого шаблона (например, слова), а по тому, насколько близки документы к запросу по смыслу.
Управление конвейером индексации
Обычно, чтобы сохранять актуальность поискового индекса и функции поиска, все рассмотренные части конвейера должны быть под постоянным контролем.
Управление поисковым конвейером может оказаться сложной задачей, поскольку вся система состоит из множества подвижных частей. Ведь конвейер — это не только перемещение данных: с течением времени меняются также код модулей, форматы и допущения, включенные в данные.
Конвейер можно запускать в «пакетном» режиме, на регулярной, нерегулярной основе (если не нужно индексировать в реальном времени), в потоковом режиме (если без индексирования в реальном времени не обойтись) или по определенным триггерам.
Некоторые сложные поисковые системы (например, Google) используют конвейеры в несколько уровней — на разных временных масштабах: например, часто изменяющаяся страница (тот же cnn.com) индексируется чаще, чем статическая страница, которая не менялась годами.
Обслуживающие системы
Конечная цель поисковой системы — принимать запросы и посредством индекса возвращать соответствующим образом ранжированные результаты. Вопрос обслуживающих систем может быть очень сложным и включать в себя множество технических подробностей, но я все-таки упомяну несколько ключевых аспектов этой части поисковых систем.
- Скорость работы. Пользователи замечают задержки в системе, с которой они работают. ️ Компания Google провела обширное исследование и выяснила, что если задержка ответа увеличивается на 300 мс (100 → 400 мс), то количество поисковых запросов падает на 0,6%. Они рекомендуют добиться того, чтобы на большинстве запросов задержка была не более 200 мс. Есть хорошая статья по этой теме. А теперь сложная часть: система может собирать документы со многих компьютеров, объединять их в список, который может оказаться очень длинным, а затем сортировать его в порядке ранжирования. И если вам это кажется недостаточно сложным, то учтите, что ранжирование может зависеть от запросов, поэтому при сортировке система не просто сравнивает два числа, а выполняет более сложные вычисления.
- Кэширование результатов. Если нужно добиться хорошей производительности, часто без этого никак. ️ Но и с кэшем все не так-то просто. Индекс уже обновился, какие-то результаты попали в черный список — а кэш при этом может показать устаревшую выдачу. Очистка кэша — тоже та еще головоломка: система поиска, вполне вероятно, не сможет справиться со всем потоком запросов, имея пустой («холодный») кэш, поэтому прежде чем получать запросы, кэш нужно подготовить — «разогреть». В общем, кэш усложняет функциональный разрез системы, а выбор его размера и алгоритма замещения — сложная задача.
- Уровень работоспособности. Часто определяется как соотношение «время работы / (время работы + время простоя)». Если индекс находится в распределенном состоянии, то для выдачи результатов поиска системе обычно приходится запрашивать у каждого сегмента его часть общего результата. ️ А это значит, что если один сегмент недоступен, то не работает вся система. Чем больше машин задействовано в обслуживании индекса, тем выше вероятность того, что одна из них перестанет работать и остановит всю систему.
- Управление несколькими индексами. Индексы больших систем могут разделяться просто на куски (сегменты), а также по типу носителя и ритму индексации (актуальные и долгосрочные индексы). Результаты их выдачи могут объединяться.
- Слияние результатов данных разного типа. Например, Google показывает результаты из карт, новостей и т. д.
Оценка человеком. Да, такая работа в поисковых системах все еще нужна.
Качество, оценка и доработка
Итак, вы запустили собственный конвейер индексации и поисковые серверы; все работает хорошо. К сожалению, запуск инфраструктуры — лишь начало пути к хорошему поиску.
Далее нужно будет создать набор процессов непрерывной оценки и повышения качества поиска. Это на самом деле и есть основная часть работы — и самая сложная задача, которую придется решать.
Что такое качество? Во-первых, нужно определить (и заставить своего начальника или руководителя проекта согласиться), что значит «качество» в конкретном случае:
- Удовлетворенность пользователей, о которой они сообщают самостоятельно (пользовательский интерфейс учитывается).
- Субъективная релевантность возвращаемых результатов (пользовательский интерфейс не учитывается).
- Удовлетворенность по сравнению с предложениями конкурентов.
- Удовлетворенность по сравнению с работой предыдущей версии поиска (например, на прошлой неделе).
- Приверженность пользователей.
Поговорим о показателях. Некоторые из следующих понятий бывает сложно оценить количественно. И в то же время было бы невероятно полезно одним числом — показателем качества — выразить, насколько хорошо работает поисковая система.
Непрерывный расчет такого показателя для своей системы (а также для конкурентов) позволяет отследить прогресс и показать начальнику, насколько хорошо вы делаете свою работу. Вот несколько классических методов количественной оценки качества, которые помогут построить собственную волшебную формулу оценки качества:
Оценка человеком. Может возникнуть ощущение, что показатели качества — это результат статистических расчетов, однако их нельзя получить автоматически. В конечном итоге показатели должны отражать субъективную человеческую оценку, и именно здесь вступает в игру человеческий фактор.
Построение поисковой системы без оценки результатов человеком — это, вероятно, самая распространенная причина плохой работы поиска.
Обычно на первых порах разработчики сами вручную оценивают результаты. Чуть позже привлекаются оценщики, которые для просмотра возвращаемых результатов поиска и отправки своей оценки качества обычно используют специальные инструменты.
Разработчик может использовать полученные таким образом сигналы, чтобы скорректировать курс разработки, принять решение о запуске и даже передать эти данные на этап выбора индекса и в системы выборки и ранжирования.
Вот несколько иных видов «человеческой» оценки, которые могут выполняться в поисковой системе:
- Основная пользовательская оценка: пользователь оценивает общую удовлетворенность от использования.
- Сравнительная оценка: сравнение с другими результатами поиска (которые получены от предыдущих версий системы или от конкурентов).
- Оценка выборки: качество выборки и результат анализа запроса часто оцениваются с помощью собранных вручную наборов «запрос — документ». Пользователю показывается запрос и список выбранных по нему документов, в котором можно отметить документы, имеющие отношение к запросу и не относящиеся к нему. Полученные пары (запрос + соответствующие документы) называются «тестовой выборкой» и представляют собой в высшей степени полезные данные. Например, с их помощью разработчик может настроить автоматические регрессионные тесты функции выборки. Получаемый в результате сигнал выбора также можно вернуть в виде контрольных данных на повторную весовую обработку терминов и в другие модели перезаписи.
- Оценка ранжирования: оценщикам дается запрос и два документа, из которых нужно выбрать тот, что лучше соответствует запросу. Таким образом можно частично упорядочить документы по данному запросу. И такой порядок позже можно сравнить с выдачей системы ранжирования. Обычно показатели качества ранжирования — это MAP и nDCG.
Оценочные наборы данных
Об оценочных наборах данных, таких как упомянутые выше тестовые выборки, следует начинать думать на ранних этапах проектирования поиска. Как их собирать и обновлять? Как внедрять в рабочий конвейер оценки? Насколько они репрезентативны?
Эксперименты в реальном времени. После того как поисковая система заманит достаточно пользователей, на части трафика можно начинать экспериментировать в реальном времени. Суть в том, чтобы для группы людей включить некоторую оптимизацию, а затем сравнить результат с «контрольной» группой — аналогичной выборкой пользователей, у которых ничего не изменялось. Оцениваемый в таком исследовании показатель зависит от продукта: это могут быть клики по результатам поиска, клики по рекламе и т. д.
Периодичность оценки. Скорость совершенствования поиска напрямую связана с тем, насколько быстро можно проворачивать описанный выше цикл измерения и доработки. Нужно с самого начала задаться вопросом: «Как быстро мы можем измерять и повышать производительность?».
Сколько понадобится времени, чтобы внести изменения и дождаться результатов: дни, часы, минуты или секунды? ️ Кроме прочего, процедура запуска оценки должна быть максимально простой и не должна отнимать слишком много времени.
Как все это сделать НА ПРАКТИКЕ?
Эта статья не задумывалась как руководство. Тем не менее, я кратко опишу, как я сам подошел бы к разработке функции поиска сегодня:
- Как уже говорилось, если можете себе позволить — просто купите один из предлагаемых на рынке SaaS (ниже — пару хороших вариантов). Но есть несколько условий:
- У вас «подключенная» система (сервис или приложение подключены к Интернету).
- Выбранное решение должно поддерживать необходимую функциональность «из коробки». Эта статья дает неплохое представление о том, какие функции могут понадобиться. К примеру, я бы подумал о следующих требованиях: поддержка носителей, по которым вы будете искать; поддержка индексирования в режиме реального времени; универсальность обрабатываемых запросов, в том числе учет контекста.
- У вас должно хватить бюджета на оплату обслуживания в течение следующих 12 месяцев — с учетом размера корпуса и ожидаемого числа запросов в секунду.
- Сервис должен выдерживать ожидаемый трафик в пределах требований к задержкам. Если поисковые запросы будут идти из приложения, убедитесь, что там, где находятся ваши пользователи, доступ к сервису достаточно быстрый.
2. Если размещение на сервере не отвечает требованиям проекта или на это нет средств, возможный выбор в этом случае — библиотека или инструмент с открытым кодом. На данный момент для «подключенных» приложений и веб-сайтов я бы выбрал Elasticsearch. Для встроенных систем некоторые инструменты перечислены ниже.
3. Перед загрузкой данных в поисковый индекс вы скорее всего захотите выбрать собственно индекс, а также подчистить документы (например, извлечь нужный текст из HTML-страниц), что уменьшит размер индекса и упростит получение хорошей выдачи. Если корпус влазит на одну машину, просто напишите для этого пару скриптов. Если нет — я бы использовал Spark.
Инструментов много не бывает.
SaaS
Algolia — проприетарный SaaS, который индексирует веб-сайт клиента и дает API для поиска по его страницам. У них есть API для отправки документов клиента, поддержка контекстно-зависимых запросов, да и работает их система очень быстро. Если внедрять сегодня веб-поиск, сначала я бы использовал Algolia (если это по карману) — так можно было бы выиграть время на создание собственного аналогичного поиска.
- Различные провайдеры Elasticsearch: AWS (️Elasticsearch Cloud), ️elastic.co и решение от компании ️ Qbox.
- ️Поиск Azure — решение от Microsoft. Доступ через REST API, может масштабироваться и обрабатывать миллиарды документов. Есть интерфейс запросов Lucene, который упрощает переход с решений на основе соответствующей библиотеки (см. ниже).
- ️Swiftype — корпоративный SaaS, который индексирует внутренние сервисы компании, такие как Salesforce, G Suite, Dropbox и сайт интрасети.
Инструменты и библиотеки
Lucene — самая популярная библиотека информационного поиска. Умеет анализировать запросы, делать ранжирование и выборку по индексу. Любой из компонентов можно заменить на альтернативную реализацию. Есть также порт на C — Lucy.
- Solr — полноценный поисковый сервер на основе библиотек Lucene. Входит в экосистему инструментов Hadoop.
- Hadoop — наиболее широко используемая система MapReduce с открытым кодом, первоначально разработанная как инфраструктура конвейера индексации для сервера Solr. Постепенно сдает свои позиции фреймворку пакетной обработки данных Spark, который используется для индексирования. ️EMR — проприетарная реализация MapReduce на платформе AWS.
- Elasticsearch — также работает на библиотеках Lucene (здесь можно сравнить Elasticsearch и Solr). В последнее время этому решению уделяется все больше внимания, поэтому когда речь заходит о поиске, на ум сразу же приходит ES, и не без причины: у сервиса хорошая поддержка, функциональный API, его можно интегрировать в Hadoop, он хорошо масштабируется. Есть версия с открытым кодом и версия Enterprise. ES можно использовать как SaaS: он умеет масштабироваться на миллиарды документов, однако реализовать такое масштабирование может быть очень сложно, поэтому обычно используется ряд корпусов меньшего размера.
- Xapian — библиотека информационного поиска на C++: относительно компактная, хороша для встраивания в классические и мобильные приложения.
- Sphinx — сервер полнотекстового поиска. Использует SQL-подобный язык запросов. Может работать как подсистема хранилища для MySQL или применяться как библиотека.
- Nutch — модуль веб-поиска. Может применяться в связке с сервером Solr. Используется в проекте Common Crawl.
- Lunr — компактная встраиваемая поисковая библиотека для веб-приложений на стороне клиента.
- SearchKit — библиотека компонентов веб-интерфейса для использования вместе с сервисом Elasticsearch.
- Norch — поисковая библиотека для Node.js на основе LevelDB.
- Whoosh — быстрая полнофункциональная поисковая библиотека, использует чистый Python.
- У проекта OpenStreetMap есть собственный набор поискового ПО.
Наборы данных
Несколько интересных и полезных наборов данных, которые помогут построить поисковую систему или оценить ее качество:
Литература
- Modern Information Retrieval («Современный информационный поиск»), авторы R. Baeza-Yates и B. Ribeiro-Neto — хорошее, основательное учебное пособие по теме и отличный обзор для новичков.
- Information Retrieval («Информационный поиск»), авторы S. Büttcher, C. Clarke и G. Cormack — еще один учебник с широким охватом, но чуть более актуальный. Охватывает обучение ранжированию и неплохо излагает теорию оценки поисковых систем. Может также послужить хорошим обзором.
- Learning to Rank («Обучение ранжированию»), автор Tie-Yan Liu — лучшее теоретическое рассмотрение LtR. Практики не очень много. Если кто-то хочет построить LtR-систему — стоит ознакомиться.
- Managing Gigabytes («Управление гигабайтами») — книга опубликована в 1999 г., но по-прежнему остается исчерпывающим источником для тех, кто приступает к созданию эффективного индекса значительных размеров.
- Text Retrieval and Search Engines («Поиск текста и поисковые системы») — массовый открытый онлайн-курс на платформе Coursera. Достойный внимания обзор основных тем.
- Indexing the World Wide Web: The Journey So Far («Индексирование Интернета: где мы сейчас», здесь — в формате PDF) — обзор веб-поиска по состоянию на 2012 г., авторы Ankit Jain и Abhishek Das из компании Google.
- Why Writing Your Own Search Engine is Hard («Почему написать собственную поисковую систему — сложно?») — классическая статья 2004 г., автор Анна Паттерсон.
- https://github.com/harpribot/awesome-information-retrieval — список связанных с поисковыми системами ресурсов, который ведет Harshal Priyadarshi.
- Отличный блог о всяком разном в информационном поиске, автор — Daniel Tunkelang.
- Пару десятков хороших слайдов об оценке поисковой системы.
Это была моя скромная попытка сделать хоть сколь-нибудь полезную «карту» для тех, кто начинает разрабатывать поисковую систему. Если я пропустил что-то важное — пишите.
О переводчике
Перевод статьи выполнен в Alconost.
Alconost занимается локализацией игр, приложений и сайтов на 68 языков. Переводчики-носители языка, лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджеры проектов 24/7, любые форматы строковых ресурсов.
Мы также делаем рекламные и обучающие видеоролики — для сайтов, продающие, имиджевые, рекламные, обучающие, тизеры, эксплейнеры, трейлеры для Google Play и App Store.
Подробнее: https://alconost.com
Построение индекса для поисковой машины / Хабр
Полное содержание и список моих статей по поисковой машине будет обновлятся здесь.В предыдущих статьях я рассказывал про работу поисковой машины, вот и дошел до сложного технически момента. Напомню что разделяют 2 типа индексов – прямой и обратный. Прямой – сопоставление документу списка слов в нем встреченного. Обратный – слову сопоставляется список документов, в которых оно есть. Логично, что для быстрого поиска лучше всего подходит обратный индекс. Интересный вопрос и про то, в каком порядке в списке хранить документы.
На предыдущем шаге DataFlow от модуля-индексатора мы получили кусочек данных в виде прямого индекса, ссылочной информации и информации о страницах. Обычно у меня он составляет около 200-300mb и содержит примерно 100 тысяч страниц. Со временем я отказался от стратегии хранения цельного прямого индекса, и храню только все эти кусочки + полный обратный индекс в нескольких версиях, чтобы можно было откатиться назад.
Устройство обратного индекса с виду, простое, – храним файл, в нем в начале таблица адресов начала данных по каждому слову, потом собственно данные. Это я утрировано. Так получается самый выгодный для оптимизации скорости поиска формат — не надо прыгать по страницам — как писали Брин и Пейдж, — 1 seek, 1 read. На каждой итерации перестроения, я использую 20-50 кусочков информации описанных выше, очевидно загрузить всю инфу из них в память я не могу, тем более что там полезно хранить еще кучу служебных данных об индексе.
Чтобы решить и эту, и много других проблем связанных с ограничениями ФС, диска, параллельным доступом к нескольким спискам страниц, я разбил весь индекс на 256 частей. В часть I попадают списки страниц для слов WORD_ID%256=I
Таким образом делим индекс на примерно равные части. Кроме того вся обработка на очередной итерации перестроения индекса связана только в рамках одной части. Т.е. из 20-50 кусков БД по 200-300 Mb необходимо загрузить только те данные, которые связаны со словами, попадающими в обрабатываемую часть.
Итого: делаем 256 повторений одной и той же процедуры:
- читаем нужные данные из входных кусков БД, предварительно загрузив всю информацию о словах, страницах и Url страниц. В памяти сортируем, делаем списки правильной структуры. Упаковываем инфу о странице и добавляем ее ID, HASH и другие данные.
- открываем баррель (я обозвал так куски индекса) обратного индекса «крайней версии» для чтения. Открываем пустой баррель «новой версии» индекса для записи.
- Для каждого слова по порядку сливаем 2 списка – один построенный сортированный в памяти, а другой читаемый и уже отсортированный в файле.
- Закрываем, дописываем все что надо, радуемся.
На практике естественно оказалось, что тот список, который уже хранится в «предыдущей версии» индекса оказывается отсортированным при новой итерации только тогда, когда никакая внешняя информация о страницах не менялась, а это очевидно не так.
Ведь пока мы копили инфу для индекса, могли пересчитаться данные о PR, метрики страниц, тематичность сайтов, и тд. И как следствие, изменится коэффициенты для сортировки. Вопрос нужно ли вообще сортировать списки по подобным параметрам, до сих пор открыт. По слухам гугл сортирует страницы в списках по PR, но очевидно тогда надо уметь быстро отбрасывать шелуху при поиске – которую специально накачали PR, но тематичности недостаточно.
Я использую совмещенный коэффициент, построенный из общей информации о слове на странице (кол-во встреч; место встречи – title, meta, ссылки, текст; выделение, форматирование), из метрик тематичности (пока что они развиты у меня весьма слабо), из PR, из пословного PR (PR по каждому слову у меня тоже есть) и некоторых других.
Причем очевидно, что при высокочастотных запросах, нам реально нужны дай бог первая 1000-2000 результатов в списке, для верности будем считать 262 тысячи. Т.к. все популярные ответы очевидно попадут в них, а дальше на них можно запускать уже функцию ранжирования которая как следует их отсортирует.
При низкочастотных запросах, когда нам реально нужны 2-3-10 результатов, без полного прохождения индекса не обойтись, однако и общая длина списка страниц редко когда будет больше 100 тысяч.
В целом если мы сможем гарантировать что первые N тысяч страниц в списке будут лучшими из остальных пары миллионов, то задача решена, а гарантировать это довольно просто эвристическими методами. Тогда для корректного перестроения каждого барреля:
- запоминаем какие PR сильно изменились при пересчете
- грузим первые N тысяч из списка+немного из остатка по критериям PR, метрики страницы и другой эвристике
- туда же грузим из входных данных нужную порцию о словах текущего барреля
- только для выделенных страниц уже обновляем все данные на корректные, новые – PR, метрики
- сортируем сотню тысяч результатов, вместо пары десятков миллионов и уже в памяти
- пишем отсортированное, а остальное просто копируем из предыдущего индекса удаляя дубли
Ну и конечно надо иметь функцию «обновить целиком» когда раз в месяц-полгода, к примеру, индекс будет перестраиваться весь самым простым прямым алгоритмом
Понятно, что даже такой объем работы в применении к 3 миллионам средне употребляемых слов и цифр дается нелегко, но зато по сравнению с полным перестроением выигрыш существенен: ведь не надо сортировать на диске, не надо грузить внешние метрики, PR и другие параметры – их ведь тоже нельзя кэшировать все в памяти.
Забавно что итеративный способ перестроения дает в разы большую производительность чем простейшее построение обратного индекса из прямого. Некоторые поисковики конечно умудряются это делать достаточно быстро на довольно мощном железе, однако это все равно не лучший подход хоть и самый корректный. Просто количество длинных вставок в обратный индекс сводит все плюсы на нет, да и в известных мне структурах хранения страдает либо скорость вставки либо скорость последовательного чтения.
Как работают поисковые системы — сниппеты, алгоритм обратного поиска, индексация страниц и особенности работы Яндекса
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Занимаясь SEO или, иначе говоря, поисковой оптимизацией, как на профессиональном уровне (продвигая за деньги коммерческие проекты), так и на любительском уровне (самостоятельная раскрутка сайта описанная мною тут), вы обязательно столкнетесь с тем, что необходимо знать принципы работы поисковиков в России и интернете в целом для того, чтобы успешно оптимизировать под них свой или чужой сайт.

Врага, как говорится, надо знать в лицо, хотя, конечно же, они (для рунета это Яндекс и лидер мирового поиска Google.ru, про которого мы говорили здесь) для нас вовсе не враги, а скорее партнеры, ибо их доля трафика является в большинстве случаев превалирующей и основной. Есть, конечно же, исключения, но они только подтверждают данное правило.
Что такое сниппет и принципы работы поисковиков
Но тут сначала нужно будет разобраться, а что такое сниппет, для чего он нужен и почему его содержимое так важно для оптимизатора? В результатах поиска располагается сразу под ссылкой на найденный документ (текст которой берется из метатега TITLE, о важности которого я здесь уже писал):
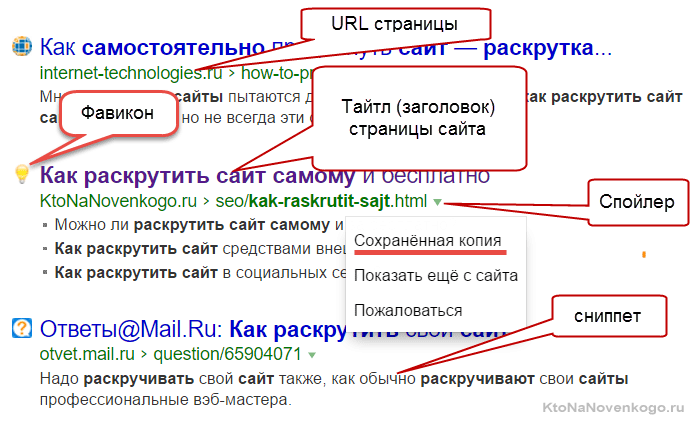
В качестве сниппета используются обычно куски текста из этого документа. Идеальный вариант призван предоставить пользователю возможность составить мнение о содержимом страницы, не переходя на нее (но это, если он получился удачным, а это не всегда так).
Сниппет формируется автоматически и какие-именно фрагменты текста будут использоваться в нем решает алгоритм (что это?), и, что важно, для разных запросов у одной и той же вебстраницы будут разные сниппеты.
Но есть вероятность, что именно содержимое тега Description иногда может быть использовано (особенно в Google) в качестве сниппета. Конечно же, это еще будет зависеть и от того поискового запроса, в выдаче которого он показывается.
Но содержимое тега Description может выводиться, например, при совпадении ключевых слов запроса и слов, употребленных вами в дескрипшине или в случае, когда алгоритм сам еще не нашел на вашем сайте фрагменты текста для всех запросов, по которым ваша страница попадает в выдачу Яндекса или Гугла.
Поэтому не ленимся и заполняем содержимое тега Description для каждой статьи. В WordPress это можно сделать, если вы используете описанный тут плагин All in One SEO Pack (а его использовать я вам настоятельно рекомендую).
Если вы фанат Джумлы, то можете воспользоваться этим материалом — Настройка мета-данных в Joomla (мета-теги DESCRIPTION, KEYWORDS, TITLE и ROBOTS).
Но сниппет нельзя получить из обратного индекса, т.к. там хранится информация только об использованных на странице словах и их положении в тексте. Вот именно для создания сниппетов одного и того же документа в разных поисковых выдачах (по разным запросам) наши любимые Яндекс и Гугл, кроме обратного индекса (нужного непосредственно для ведения поиска — о нем читайте ниже), сохраняют еще и прямой индекс, т.е. копию веб-страницы.
Сохраняя копию документа у себя в базе им потом довольно удобно нарезать из них нужные сниппеты, не обращаясь при этом к оригиналу.
Т.о. получается, что поисковики хранят в своей базе и прямой, и обратный индекс веб-страницы. Кстати, на формирование сниппетов можно косвенно влиять, оптимизируя текст веб-станицы таким образом, чтобы алгоритм выбирал в качестве оного именно тот фрагмент текста, который вы задумали. Но об этом поговорим уже в другой статье рубрики Продвижение сайтов (SEO и SMO)
Как работают поисковые системы в общих чертах
Суть оптимизации заключается в том, чтобы «помочь» алгоритмам поисковиков поднять страницы тех сайтов, которые вы продвигаете, на максимально высокую позицию в выдаче по тем или иным запросам.
Слово «помочь» в предыдущем предложении я взял в кавычки, т.к. своими оптимизаторскими действия мы не совсем помогаем, а зачастую и вовсе мешаем алгоритму сделать полностью релевантную запросу выдачу (о загадочных словах релевантность, ранжирование и прочих можно почитать здесь).
Но это хлеб оптимизаторов, и пока алгоритмы поиска не станут совершенными, будут существовать возможности за счет внутренней и внешней оптимизации улучшить их позиции в выдаче Яндекса и Google.
Но прежде, чем переходить к изучению методов оптимизации, нужно будет хотя бы поверхностно разобраться в принципах работы поисковиков, чтобы все дальнейшие действия делать осознано и понимая зачем это нужно и как на это отреагируют те, кого мы пытаемся чуток обмануть.
Ясное дело, что понять всю логику их работы от и до у нас не получится, ибо многая информация не подлежит разглашению, но нам, на первых порах, будет достаточно и понимания основополагающих принципов. Итак, приступим.
Как же все-таки работают поисковые системы? Как ни странно, но логика работы у них всех, в принципе, одинаковая и заключается в следующем: собирается информация обо всех вебстраницах в сети, до которых они могут дотянуться, после чего эти данные хитрым образом обрабатываются для того, чтобы по ним удобно было бы вести поиск. Вот, собственно, и все, на этом статью можно считать завершенной, но все же добавим немного конкретики.
Во-первых, уточним, что документом называют то, что мы обычно называем страницей сайта. При этом он должен иметь свой уникальный адрес (URL, о котором мы с вами беседовали тут) и, что примечательно, хеш-ссылки не будут приводить к появлению нового документа (о том, что такое хеш-ссылки читайте здесь).
Во-вторых, стоит остановиться на алгоритмах (способах) поиска информации в собранной базе документов.
Алгоритмы прямых и обратных индексов
Очевидно, что метод простого перебора всех страниц, хранящихся в базе данных, не будет являться оптимальным. Этот метод называется алгоритмом прямого поиска и при том, что этот метод позволяет наверняка найти нужную информацию не пропустив ничего важного, он совершенно не подходит для работы с большими объемами данных, ибо поиск будет занимать слишком много времени.
Поэтому для эффективной работы с большими объемами данных был разработан алгоритм обратных (инвертированных) индексов. И, что примечательно, именно он используется всеми крупными поисковыми системами в мире. Поэтому на нем мы остановимся подробнее и рассмотрим принципы его работы.
При использовании алгоритма обратных индексов происходит преобразование документов в текстовые файлы, содержащие список всех имеющихся в них слов.
Слова в таких списках (индекс-файлах) располагаются в алфавитном порядке и рядом с каждым из них указаны в виде координат те места в вебстранице, где это слово встречается. Кроме позиции в документе для каждого слова приводятся еще и другие параметры, определяющие его значение.
Если вы вспомните, то во многих книгах (в основном технических или научных) на последних страницах приводится список слов, используемых в данной книге, с указанием номеров страниц, где они встречаются. Конечно же, этот список не включает вообще всех слов, используемых в книге, но тем не менее может служить примером построения индекс-файла с помощью инвертированных индексов.
Обращаю ваше внимание, что поисковики ищут информацию не в интернете, а в обратных индексах обработанных ими вебстраниц сети. Хотя и прямые индексы (оригинальный текст) они тоже сохраняют, т.к. он в последствии понадобится для составления сниппетов, но об этом мы уже говорили в начале этой публикации.
Алгоритм обратных индексов используется всеми системами, т.к. он позволяет ускорить процесс, но при этом будут неизбежны потери информации за счет искажений внесенных преобразованием документа в индекс-файл. Для удобства хранения файлы обратных индексов обычно хитрым способом сжимаются.
Математическая модель используемая для ранжирования
Для того, чтобы осуществлять поиск по обратным индексам, используется математическая модель, позволяющая упростить процесс обнаружения нужных вебстраниц (по введенному пользователем запросу) и процесс определения релевантности всех найденных документов этому запросу. Чем больше он соответствует данному запросу (чем он релевантнее), тем выше он должен стоять в поисковой выдаче.
Значит основная задача, выполняемая математической моделью — это поиск страниц в своей базе обратных индексов соответствующих данному запросу и их последующая сортировка в порядке убывания релевантности данному запросу.
Использование простой логической модели, когда документ будет являться найденным, если в нем встречается искомая фраза, нам не подойдет, в силу огромного количества таких вебстраниц, выдаваемых на рассмотрение пользователю.
Поисковая система должна не только предоставить список всех веб-страниц, на которых встречаются слова из запроса. Она должна предоставить этот список в такой форме, когда в самом начале будут находиться наиболее соответствующие запросу пользователя документы (осуществить сортировку по релевантности). Эта задача не тривиальна и по умолчанию не может быть выполнена идеально.
Кстати, неидеальностью любой математической модели и пользуются оптимизаторы, влияя теми или иными способами на ранжирование документов в выдаче (в пользу продвигаемого ими сайта, естественно). Матмодель, используемая всеми поисковиками, относится к классу векторных. В ней используется такое понятие, как вес документа по отношению к заданному пользователем запросу.
В базовой векторной модели вес документа по заданному запросу высчитывается исходя из двух основных параметров: частоты, с которой в нем встречается данное слово (TF — term frequency) и тем, насколько редко это слово встречается во всех других страницах коллекции (IDF — inverse document frequency).
Под коллекцией имеется в виду вся совокупность страниц, известных поисковой системе. Умножив эти два параметра друг на друга, мы получим вес документа по заданному запросу.
Естественно, что различные поисковики, кроме параметров TF и IDF, используют множество различных коэффициентов для расчета веса, но суть остается прежней: вес страницы будет тем больше, чем чаще слово из поискового запроса встречается в ней (до определенных пределов, после которых документ может быть признан спамом) и чем реже встречается это слово во всех остальных документах проиндексированных этой системой.
Оценка качества работы формулы асессорами
Таким образом получается, что формирование выдач по тем или иным запросам осуществляется полностью по формуле без участия человека. Но никакая формула не будет работать идеально, особенно на первых порах, поэтому нужно осуществлять контроль за работой математической модели.
Для этих целей используются специально обученные люди — асессоры, которые просматривают выдачу (конкретно той поисковой системы, которая их наняла) по различным запросам и оценивают качество работы текущей формулы.
Все внесенные ими замечания учитываются людьми, отвечающими за настройку матмодели. В ее формулу вносятся изменения или дополнения, в результате чего качество работы поисковика повышается. Получается, что асессоры выполняют роль такой своеобразной обратной связи между разработчиками алгоритма и его пользователями, которая необходима для улучшения качества.
Основными критериями в оценке качества работы формулы являются:
- Точность выдачи поисковой системы — процент релевантных документов (соответствующих запросу). Чем меньше не относящихся к теме запроса вебстраниц (например, дорвеев) будет присутствовать, тем лучше
- Полнота поисковой выдачи — процентное отношение соответствующих заданному запросу (релевантных) вебстраниц к общему числу релевантных документов, имеющихся во всей коллекции. Т.е. получается так, что во всей базе документов, которые известны поиску вебстраниц соответствующих заданному запросу будет больше, чем показано в поисковой выдаче. В этом случае можно говорить о неполноте выдаче. Возможно, что часть релевантных страниц попала под фильтр и была, например, принята за дорвеи или же еще какой-нибудь шлак.
- Актуальность выдачи — степень соответствия реальной вебстраницы на сайте в интернете тому, что о нем написано в результатах поиска. Например, документ может уже не существовать или быть сильно измененным, но при этом в выдаче по заданному запросу он будет присутствовать, несмотря на его физическое отсутствие по указанному адресу или же на его текущее не соответствие данному запросу. Актуальность выдачи зависит от частоты сканирования поисковыми роботами документов из своей коллекции.
Как Яндекс и Гугл собирают свою коллекцию
Несмотря на кажущуюся простоту индексации веб-страниц тут есть масса нюансов, которые нужно знать, а в последствии и использовать при оптимизации (SEO) своих или же заказных сайтов. Индексация сети (сбор коллекции) осуществляется специально предназначенной для этого программой, называемой поисковым роботом (ботом).
Робот получает первоначальный список адресов, которые он должен будет посетить, скопировать содержимое этих страниц и отдать это содержимое на дальнейшую переработку алгоритму (он преобразует их в обратные индексы).
Робот может ходить не только по заранее данному ему списку, но и переходить по ссылкам с этих страниц и индексировать находящиеся по этим ссылкам документы. Т.о. робот ведет себя точно так же, как и обычный пользователь, переходящий по ссылкам.
Поэтому получается, что с помощью робота можно проиндексировать все то, что доступно обычно пользователю, использующему браузер для серфинга (поисковики индексируют документы прямой видимости, которые может увидеть любой пользователь интернета).
Есть ряд особенностей, связанных с индексацией документов в сети (напомню, что мы уже обсуждали здесь запрет индексации через robots txt).
Первой особенностью можно считать то, что кроме обратного индекса, который создается из оригинального документа скачанного из сети, поисковая система сохраняет еще и его копию, иначе говоря, поисковики хранят еще и прямой индекс. Зачем это нужно? Я уже упоминал чуть ранее, что это нужно для составления различных сниппетов в зависимости от введенного запроса.
Сколько страниц одного сайта Яндекс показывает в выдаче и индексирует
Обращаю ваше внимание на такую особенность работы Яндекса, как наличие в выдаче по заданному запросу всего лишь одного документа с каждого сайта. Такого, чтобы в выдаче присутствовали на разных позициях две страницы с одного и того же ресурса, быть не могло до недавнего времени.
Это было одно из основополагающих правил Яндекса. Если даже на одном сайте найдется сотня релевантных заданному запросу страниц, в выдаче будет присутствовать только один (самый релевантный).
Яндекс заинтересован в том, чтобы пользователь получал разнообразную информацию, а не пролистывал несколько страниц поисковой выдачи со страницами одного и того же сайта, который этому пользователю оказался не интересен по тем или иным причинам.
Однако, спешу поправиться, ибо когда дописал эту статью узнал новость, что оказывается Яндекс стал допускать отображение в выдаче второго документа с того же ресурса, в качестве исключения, если эта страница окажется «очень хороша и уместна» (иначе говоря сильно релевантна запросу).
Что примечательно, эти дополнительные результаты с того же самого сайта тоже нумеруются, следовательно, из-за этого из топа выпадут некоторые ресурсы, занимающие более низкие позиции. Вот пример новой выдачи Яндекса:
Поисковики стремятся равномерно индексировать все вебсайты, но зачастую это бывает не просто из-за совершенно разного количества страниц на них (у кого-то десять, а у кого-то десять миллионов). Как быть в этом случае?
Яндекс выходит из этого положения ограничением количества документов, которое он сможет загнать в индекс с одного сайта.
Для проектов с доменным именем второго уровня, например, KTONANOVENKOGO.RU, максимальное количество страниц, которое может быть проиндексировано зеркалом рунета, находится в диапазоне от ста до ста пятидесяти тысяч (конкретное число зависит от отношения к данному проекту).
Для ресурсов с доменным именем третьего уровня — от десяти до тридцати тысяч страниц (документов).
Если у вас сайт с доменом второго уровня (подробности про домены ищите тут), а вам нужно будет загнать в индекс, например, миллион вебстраниц, то единственным выходом из этой ситуации будет создание множества поддоменов (Создание поддоменов (субдоменов)).
Поддомены для домена второго уровня могут выглядеть так: JOOMLA.KTONANOVENKOGO.RU. Количество поддоменов для второго уровня, которое может проиндексировать Яндекс, составляет где-то чуть более 200 (иногда вроде бы и до тысячи), поэтому таким нехитрым способом вы сможете загнать в индекс зеркала рунета несколько миллионов вебстраниц.
Как Яндекс относится к сайтам в не русскоязычных доменных зонах
В связи с тем, что Яндекс до недавнего времени искал только по русскоязычной части интернета, то и индексировал он в основном русскоязычные проекты.
Поэтому, если вы создаете сайт не в доменных зонах, которые он по умолчанию относит к русскоязычным (RU, SU и UA), то ждать быстрой индексации не стоит, т.к. он, скорее всего, его найдет не ранее чем через месяц. Но уже последующая индексация будет происходить с той же частотой, что и в русскоязычных доменных зонах.
Т.е. доменная зона влияет лишь на время, которое пройдет до начала индексации, но не будет влиять в дальнейшем на ее частоту. Кстати, от чего зависит эта частота?
Логика работы поисковых систем по переиндексации страниц сводится примерно к следующему:
- найдя и проиндексировав новую страницу, робот заходит на нее на следующий день
- сравнив содержимое с тем, что было вчера, и не найдя отличий, робот придет на нее еще раз только через три дня
- если и в этот раз на ней ничего не изменится, то он придет уже через неделю и т.д.
Т.о. со временем частота прихода робота на эту страницу сравняется с частотой ее обновления или будет сопоставима с ней. Причем, время повторного захода робота может измеряться для разных сайтов как в минутах, так и в годах.
Такие вот они умные поисковые системы, составляя индивидуальный график посещения для различных страниц различных ресурсов. Можно, правда, принудить поисковики переиндексировать страничку по нашему желанию, даже если на ней ничего не изменилось, но об этом в другой статье.
Продолжим изучать принципы работы поиска в следующей статье, где мы рассмотрим проблемы, с которыми сталкиваются поисковики, рассмотрим нюансы работы с морфологией русского языка и узнаем некоторые подробности по запросам пользователей — читайте ее здесь. Ну, и многое другое, конечно же, так или иначе помогающее раскрутить сайт.
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Использую для заработка
Как работает поисковой индекс? — Студопедия
Поисковые каталоги
Поисковые каталоги служат для тематического поиска.
Информация на этих серверах структурирована по темам и подтемам. Имея намерение осветить какую-то узкую тему, нетрудно найти список веб- страниц, ей посвященных.
Каталог ресурсов в Интернете или каталог интернет-ресурсов или про- сто интернет-каталог — структурированный набор ссылок на сайты с кратким их описанием.
Каталог в котором ссылки на сайты внутри категорий сортируются по популярности сайтов называется рейтинг (или топ).
Поисковые индексы
Поисковые индексы работают как алфавитные указатели. Клиент зада- ет слово или группу слов, характеризующих его область поиска, — и получает список ссылок на веб-страницы, содержащие указанные термины. Первой поисковой системой для Всемирной паутины был «Wandex»,
уже не существующий индекс, разработанный Мэтью Грэйем из Массачусетского технологического института в 1993.
Как работает поисковой индекс?
Поисковые индексы автоматически, при помощи специальных про- грамм (веб-пауков), сканируют страницы Интернета и индексируют их, то есть заносят в свою огромную базу данных.
Поисковый робот ( «веб-паук») — программа, являющаяся составной частью поисковой системы и предназначенная для обхода страниц Интернета с целью занесения информации о них (ключевые слова) в базу поисковика. По своей сути паук больше всего напоминает обычный браузер. Он сканирует содержимое страницы, забрасывает его на сервер поисковой системы, которой принадлежит и отправляется по ссылкам на следующие страницы.
В ответ на запрос, где найти нужную информацию, поисковый сервер возвращает список гиперссылок, ведущих веб-страницам, на которых нужная информация имеется или упоминается. Обширность списка может быть лю- бой, в зависимости от содержания запроса.
Поисковая система Yandex
Yandex является пожалуй наилучшей поисковой системой в россий- ском Интернете. Эта база данных содержит около 200 000 серверов и до 30 миллионов документов, которые система просматривает в течение несколь- ких секунд. На примере этой системы покажем как осуществляется поиск информации.
Поиск информации задается введением ключевого слова в специаль- ную рамку и нажатием кнопки «Найти», справа от рамки (рис. 1).
 |
Рисунок 1 – Строка поиска Yandex
Результаты поиска появляются в течение нескольких секунд, причем ранжированные по значимости – наиболее важные документы размещаются в начале списка. При этом ранг найденного документа определяется тем, в ка- ком месте документа находится ключевое слово (в заглавии документа важ- нее, чем в любом другом месте) и числом упоминаний ключевого слова (чем больше упоминаний, тем ранг выше) (рис. 2).
Рисунок 2 – результаты поиска по запросу
Таким образом, сайты, расположенные на первых местах в списке, яв- ляются ведущими не с содержательной точки зрения, а практически, по от- ношению к частоте упоминания ключевого слова. В связи с этим, не следует ограничиваться просмотром первого десятка предложенных поисковой си- стемой сайтов.
Содержательную часть сайта можно косвенно оценить по краткому его описанию, размещаемому поисковой системой под адресом сайта. Некоторые недобросовестные авторы сайтов, для того, чтобы повысить вероятность по- явления своей веб-страницы на первых местах поисковой системы, умыш- ленно включают в документ бессмысленные повторы ключевого слова. Но как только поисковая система обнаруживает такой «замусоренный» доку- мент, она автоматически исключает его из своей базы данных.
Даже ранжированный список документов, предлагаемый поисковой си- стемой в ответ на ключевую фразу или слово, может оказаться практически необозримым. В связи с этим в Yandex (как и других мощных Поисковых Системах) предоставлена возможность в рамках первого списка, выбрать до- кументы, которые точнее отражают цель поиска, то есть уточнить или улуч- шить результаты поиска. Для этого можно воспользоваться флажком в найденном, который расположен под строкой поиска (см. рис. 2). Данным параметром можно пользоваться не один раз, с каждым разом вводя в строку поиска уточняющие ключевые слова (рис. 3).

Рисунок 3 – улучшение результатов поиска с помощью флажка в найденном
Поиск по рубрикатору поисковой системы
Поисковые каталоги представляют собой систематизированную кол- лекцию (подборку) ссылок на другие ресурсы Интернета. Ссылки организо- ваны в виде тематического рубрикатора, представляющего собой иерархиче- скую структуру, перемещаясь по которой, можно найти нужную информа- цию.
Приведем в качестве примера структуру поискового интернет-каталога Yandex.
В верхней строке меню, которая расположена над строкой поиска в пункте ещѐ(рис. 4) необходимо выбрать команду Каталог. В результате ок- но браузера примет следующий вид (рис. 5).
 |
Рисунок 4 – Выбор Интернет-каталога Yandex
 |
Рисунок 5 – внешний вид каталога Yandex
Это каталог общего назначения, так как в нем представлены ссылки на ресурсы Интернета практически по всем возможным направлениям: Развле- чения, СМИ, Отдых, Дом, Культура, Учеба и т.д.
Каждая тема включает множество подразделов, а они, в свою очередь, содержат рубрики и т. д.
Предположим, вы готовите мероприятие ко Дню победы и хотите найти в Интернете слова известной военной песни Булата Окуджавы «Вы слышите, грохочут сапоги». Поиск можно организовать следующим образом:
Yandex > Каталог > Культура > Музыка > Авторская песня
Такой способ поиска является достаточно быстрым и эффективным. В конце вам предлагается достаточно ограниченное число ссылок, среди кото- рых есть ссылки на сайты с песнями известных бардов. Остается только найти на сайте архив с текстами песен Б. Окуджавы и выбрать в нем нужный текст. Для ускорения поиска вы можете воспользоваться строкой поиска и флажком только в этой рубрике (рис. 6).
Рисунок 6 – Поиск по каталогу
Поисковый индекс — это… Что такое Поисковый индекс?
Индексирование, совершаемое поисковой машиной — процесс сбора, сортировки и сохранения данных с целью облегчить быстрый и точный поиск информации. Дизайн индекса включает междисциплинарные понятия из лингвистики, когнитивной психологии, математики информатики и физики. Альтернативное название для этого процесса в контексте поисковых машин, разработанных, чтобы искать веб-страницы в Интернете, является индексацией Сети.
Популярные движки сосредотачиваются на полнотекстовой индексации в онлайне, документов естественного языка[1]. Мультимедийные документы, такие как видео и аудио[2] и графика[3][4] также могут участвовать в поиске.
Метапоисковые машины переиспользуют индексы других поисковых сервисов и не хранят локальный индекс, в то время как основанные на скешированных страницах поисковые машины надолго хранят как индекс, так и корпусы. В отличие от полнотекстовых индексов, частично-текстовые сервисы ограничивают глубину индексации, чтобы уменьшить размер индекса. Большие сервисы, как правило, выполняют индексацию в предопределенных временных рамках из-за необходимого времени и обработки затрат, в то время как поисковые машины, основанные на агентах, строят индекс в масштабе реального времени.
Индексация
Цель использования индекса — в повышении скорости поиска релевантных документов по поисковому запросу. Без индекса поисковая машина должна была бы сканировать каждый документ в корпусе, что потребовало бы большого количества времени и вычислительной мощности. Например, в то время, как индекс 10 000 документов может быть опрошен в пределах миллисекунд, последовательный просмотр каждого слова в 10 000 больших документов мог бы занять часы. Дополнительное хранилище, требуемое для хранения индекса, а также значительное увеличение времени, требуемого для его обновления, являются компромиссом за экономию времени при поиске информации.
Факторы, учитываемые при дизайне индекса
Примечания
- ↑ Clarke, C., Cormack, G.: Dynamic Inverted Indexes for a Distributed Full-Text Retrieval System. TechRep MT-95-01, University of Waterloo, February 1995.
- ↑ Stephen V. Rice, Stephen M. Bailey. Searching for Sounds. Comparisonics Corporation. May 2004. Verified Dec 2006
- ↑ Charles E. Jacobs, Adam Finkelstein, David H. Salesin. Fast Multiresolution Image Querying. Department of Computer Science and Engineering, University of Washington. 1995. Verified Dec 2006
- ↑ Lee, James. Software Learns to Tag Photos. MIT Technology Review. November 09, 2006. Pg 1-2. Verified Dec 2006. Commercial external link
Ссылки
Руководство по сканированию, индексированию и ранжированию
Индекс
Поисковые системы превратились в системы ответов. И очень сложные.
Их работа — обнаруживать, интерпретировать и систематизировать контент в Интернете; чтобы показать пользователям результаты, соответствующие им и их потребностям.
Чтобы ваш контент был виден как можно большему количеству пользователей, вы должны сначала понять, как сделать его видимым.
Видимость — самый важный аспект SEO; «нулевой момент» , когда все начинается.Если поисковая система не индексирует ваш веб-сайт, она не может показать его среди результатов поиска.
Но как работают поисковые системы? Они выполняют три функции: сканирование, индексирование и ранжирование.
- Сканирование : — это анализ веб-страниц в Интернете. Поисковая система сканирует код и содержимое каждого найденного URL.
- Индексирование : — это сбор содержимого, обнаруженного в процессе сканирования. Если страница находится в этом списке, это означает, что поисковая система проиндексировала ее, и она может появиться среди результатов поиска по связанным запросам.
- Рейтинг : — это порядок, в котором проиндексированные результаты появляются на странице результатов (SERP). Список идет от наиболее актуального к наименее значимому.
Ползание
Сканирование — это процесс, посредством которого поисковая система просматривает контент во всемирной паутине: старые и новые веб-сайты, статьи, описания продуктов, изображения, ссылки и т. Д.
Поисковые системыиспользуют сканеры (также называемые ботами или пауками), которые с помощью определенных алгоритмов решают, какие веб-сайты сканировать и как часто, распределяя так называемый краул-бюджет .
Сканер обнаруживает новый контент, идентифицируя и записывая каждую ссылку, которую он находит на отсканированных страницах, а затем помещает их в список URL-адресов, которые должны быть просканированы.
Это действие критически важно для SEO, потому что именно в этот момент поисковая система определяет количество и качество соединений страницы, как входящих, так и исходящих.
Хотите узнать больше о сканировании? Узнайте, как работают сканеры поисковых систем, прочитав нашу статью.
Индексирование
После извлечения содержимого страницы поисковый робот помещает его в индекс посещенных страниц и систематизирует всю информацию.Затем информация используется для измерения релевантности страницы по сравнению с аналогичными.
Рейтинг
В то время как два предыдущих действия являются «закулисной» работой поисковых систем, ранжирование является наиболее очевидным.
SERP — это место, где консультант по SEO может показать своим клиентам результаты своей работы. Как только пользователь вводит ключевое слово в строке поиска, поисковая система будет искать в своем индексе страницы, соответствующие поисковому запросу.
Затем этим страницам присваивается оценка, рассчитанная на основе 200 различных факторов ранжирования.
Если вы проделали хорошую работу в области SEO, страница, сообщение в блоге или описание продукта, над которыми вы работали, получили бы лучшее позиционирование, чем ваши конкуренты.
Рейтинговые факторы
Процесс ранжирования страницы включает в себя различные аспекты.
Не говоря уже о технических аспектах, такая «система ответов», как Google, постоянно учится предоставлять информацию наилучшим образом, сопоставляя различные факторы:
- Типология веб-сайтов : простой рейтинг, сделанный поисковой системой, чтобы отличить поисковый запрос от другого;
- Контекст: относится к каждому поисковому запросу;
- Время: Важность одного фактора зависит от запроса;
- Макет: SERP будет показывать разные результаты в зависимости от цели поиска.
Типология веб-сайтов
Как только пользователь набирает запрос, первое, что делает поисковая машина, — это классифицирует его, чтобы получить наилучшую типологию для этого запроса.
Например:
- Сайты «Ваши деньги, ваша жизнь» (YMYL);
- Сайты местных предприятий;
- сайтов для взрослых;
- Новостные сайты.
- и т. Д.
Это постоянно меняющийся рейтинг, но он помогает определить, к какому «месту» относится запрос.
Контекст
Поисковая система также учитывает контекст. Он извлекает любую релевантную информацию от пользователя, который вводит запрос, понимая социальные, исторические и экологические факторы в игре и предоставляя наиболее полезный ответ. Этими факторами являются, например, позиция, время, тип запроса.
Время
Еще один аспект, который вы должны учитывать, — это соотношение между «весом», придаваемым запросу, временем его выполнения и временем индексации контента.
Это потому, что каждый поисковый запрос имеет разное намерение, и поисковая система это знает.
По этой причине результаты, скажем, «Первая мировая война» в большей степени зависят от источника, в то время как для «фильмы уже вышли» поисковая система отдает приоритет свежести контента.
Формат результатов
Выбор показа графа знаний, а не видео или связанных результатов, зависит от запроса.
Если исследуемый контент — это в основном видео, именно видео Google будет показывать в поисковой выдаче.
Если вместо этого целью поиска является тема с большим количеством релевантных запросов, появляется поле «Люди также ищут».
И это также относится к другим элементам поисковой выдачи, таким как темы и связанные поисковые запросы.
.Как работает индексирование | Учебник Chartio
Что делает индексирование?
Индексирование — это способ упорядочить неупорядоченную таблицу, чтобы максимально повысить эффективность запроса при поиске.
Когда таблица не проиндексирована, порядок строк, скорее всего, не будет определен запросом как оптимизированный каким-либо образом, и поэтому вашему запросу придется выполнять линейный поиск по строкам. Другими словами, запросы должны будут перебирать каждую строку, чтобы найти строки, соответствующие условиям.Как вы понимаете, это может занять много времени. Просматривать каждую строку не очень эффективно.
Например, приведенная ниже таблица представляет собой полностью неупорядоченную таблицу в вымышленном источнике данных.
| company_id | шт. | unit_cost |
|---|---|---|
| 10 | 12 | 1,15 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1,31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1,15 |
| 16 | 12 | 1,31 |
| 10 | 12 | 1,15 |
| 12 | 24 | 1.3 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 14 | 12 | 1,95 |
| 21 | 18 | 1,36 |
| 12 | 12 | 1.05 |
| 20 | 6 | 1.31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1,15 |
| 14 | 24 | 1.05 |
Если бы мы выполнили следующий запрос:
ВЫБРАТЬ
Идентификатор компании,
единицы,
себестоимость единицы продукции
ИЗ
index_test
ГДЕ
company_id = 18
База данных должна будет выполнить поиск по всем 17 строкам в том порядке, в котором они появляются в таблице, сверху вниз, по одной.Таким образом, чтобы найти все возможные экземпляры company_id номер 18, база данных должна просмотреть всю таблицу на предмет всех появлений 18 в столбце company_id .
Это будет занимать все больше и больше времени по мере увеличения размера таблицы. По мере увеличения сложности данных в конечном итоге может произойти то, что таблица с миллиардом строк будет соединена с другой таблицей с миллиардом строк; теперь запрос должен перебирать в два раза большее количество строк, что требует вдвое больше времени.
Вы можете видеть, насколько это становится проблематичным в нашем постоянно насыщенном данными мире. Таблицы увеличиваются в размере, а время поиска увеличивается.
Запрос к неиндексированной таблице, если он представлен визуально, будет выглядеть так:
Индексирование настраивает столбец, в котором находятся условия поиска, в отсортированном порядке, что помогает оптимизировать производительность запроса.
С индексом в столбце company_id таблица, по сути, «выглядела бы» так:
| company_id | шт. | unit_cost |
|---|---|---|
| 10 | 12 | 1.15 |
| 10 | 12 | 1,15 |
| 11 | 24 | 1,15 |
| 11 | 24 | 1,15 |
| 12 | 12 | 1.05 |
| 12 | 24 | 1,3 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1,31 |
| 14 | 12 | 1,95 |
| 14 | 24 | 1.05 |
| 16 | 12 | 1,31 |
| 18 | 18 | 1,34 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1,35 |
| 18 | 18 | 1,34 |
| 20 | 6 | 1,31 |
| 21 | 18 | 1,36 |
Теперь база данных может искать company_id number 18 и возвращать все запрашиваемые столбцы для этой строки, а затем переходить к следующей строке.Если номер comapny_id следующей строки также равен 18, то он вернет все столбцы, запрошенные в запросе. Если в следующей строке company_id равен 20, запрос знает, что нужно прекратить поиск, и запрос завершится.
Как работает индексирование?
На самом деле таблица базы данных не переупорядочивается каждый раз при изменении условий запроса, чтобы оптимизировать производительность запроса: это было бы нереально. На самом деле происходит то, что индекс заставляет базу данных создавать структуру данных.Тип структуры данных, скорее всего, является B-деревом. Несмотря на то, что B-Tree имеет множество преимуществ, главное преимущество для наших целей состоит в том, что его можно сортировать. Когда структура данных отсортирована по порядку, это делает наш поиск более эффективным по очевидным причинам, которые мы указали выше.
Когда индекс создает структуру данных для определенного столбца, важно отметить, что никакой другой столбец не сохраняется в структуре данных. Наша структура данных для таблицы выше будет содержать только числа company_id .Единицы и unit_cost не будет храниться в структуре данных.
Как база данных узнает, какие еще поля в таблице нужно возвращать?
Индексы базы данных также будут хранить указатели, которые представляют собой просто справочную информацию для размещения дополнительной информации в памяти. В основном индекс содержит company_id и домашний адрес этой конкретной строки на диске памяти. Фактически индекс будет выглядеть так:
| company_id | указатель |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
С этим индексом запрос может искать только те строки в столбце company_id , которые имеют 18, а затем с помощью указателя может перейти в таблицу, чтобы найти конкретную строку, в которой находится этот указатель.Затем запрос может перейти в таблицу, чтобы получить поля для столбцов, запрошенных для строк, которые соответствуют условиям.
Если бы поиск был представлен визуально, это выглядело бы так:
Резюме
- Индексирование добавляет структуру данных со столбцами для условий поиска и указателем
- Указатель — это адрес на диске памяти строки с остальной информацией
- Структура данных индекса отсортирована для повышения эффективности запросов
- Запрос ищет определенную строку в индексе; индекс относится к указателю, который найдет остальную информацию.
- Индекс уменьшает количество строк, в которых должен выполнять поиск запрос, с 17 до 4.
java — Как вы читаете индекс в Lucene, чтобы выполнить поиск?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
- Реклама Обратитесь к разработчикам и технологам со всего мира
- О компании
Создание индекса — Как работают поисковые системы в Интернете
Как только пауки завершили задачу поиска информации на веб-страницах (и мы должны отметить, что это задача, которая на самом деле никогда не завершается — постоянно меняющаяся природа сети означает, что пауки всегда ползают), поисковая машина должны хранить информацию таким образом, чтобы она была полезной. Есть два ключевых компонента, которые делают собранные данные доступными для пользователей:
- Информация , хранящаяся в данных
- Метод , с помощью которого информация индексируется
В простейшем случае поисковая машина может просто сохранить слово и URL-адрес, по которому оно было найдено.На самом деле это сделало бы механизм ограниченного использования, поскольку не было бы способа определить, было ли слово использовано на странице важным или тривиальным образом, использовалось ли слово один или несколько раз или страница содержит ссылки на другие страницы, содержащие это слово. Другими словами, не было бы способа создать список с рейтингом , который пытается представить наиболее полезные страницы в верхней части списка результатов поиска.
Объявление
Для получения более полезных результатов большинство поисковых систем хранят больше, чем просто слово и URL.Механизм может хранить количество раз, когда слово появляется на странице. Механизм может присвоить вес каждой записи, с увеличивающимися значениями, назначаемыми словам, по мере их появления в верхней части документа, в подзаголовках, в ссылках, в метатегах или в заголовке страницы. Каждая коммерческая поисковая система имеет свою формулу для присвоения веса словам в своем индексе. Это одна из причин, по которой поиск одного и того же слова в разных поисковых системах дает разные списки со страницами, представленными в разном порядке.
Независимо от точной комбинации дополнительных частей информации, хранимых поисковой системой, данные будут закодированы для экономии места для хранения. Например, в исходном документе Google описывается использование 2 байтов по 8 бит каждый для хранения информации о весе — написано ли слово с заглавной буквы, размер шрифта, положение и другая информация, помогающая ранжировать попадание. Каждый фактор может занимать 2 или 3 бита в 2-байтовой группе (8 бит = 1 байт).В результате большой объем информации можно хранить в очень компактной форме. После сжатия информация готова к индексации.
Индекс имеет единственную цель: он позволяет как можно быстрее находить информацию. Существует несколько способов построения индекса, но один из наиболее эффективных — это создание хэш-таблицы . При хешировании формула применяется для добавления числового значения к каждому слову. Формула предназначена для равномерного распределения записей по заранее определенному количеству подразделений.Это числовое распределение отличается от распределения слов по алфавиту, и это ключ к эффективности хеш-таблицы.
В английском языке одни буквы начинаются со многих слов, а другие — с меньшего. Вы обнаружите, например, что раздел «M» в словаре намного толще, чем раздел «X». Это неравенство означает, что поиск слова, начинающегося с очень «популярной» буквы, может занять гораздо больше времени, чем поиск слова, начинающегося с менее популярной.Хеширование выравнивает разницу и сокращает среднее время, необходимое для поиска записи. Он также отделяет индекс от фактической записи. Хэш-таблица содержит хешированное число вместе с указателем на фактические данные, которые можно отсортировать любым способом, позволяющим их хранить наиболее эффективно. Комбинация эффективной индексации и эффективного хранения позволяет быстро получать результаты, даже когда пользователь создает сложный поиск.
.