
Что такое индексация — самый полный гайд
Часто происходит путаница в терминологии: под индексацией иногда подразумевают сканирование сайта или совокупность и сканирования и индексации. В этом нет большой ошибки, часто путаницу вносят сами мануалы поисковых систем. Иногда в текстах Яндекса и Гугла можно увидеть использование термина индексация в разных контекстах, например:
Индексация сайта простыми словами
Так что же такое индексация: если кратко, то индексация (или индексирование, indexing) — один из процессов работы поисковых систем по построению поисковой базы в результате которого содержимое страниц попадает в индекс поисковой системы.
Для большей ясности приведу терминологию, а потом опишу все процессы.
Терминология
Планировщик (Scheduler) — программа, которая выстраивает маршрут обхода интернета роботами исходя из характеристик страниц, таких как частота обновления документов, востребованность этих страниц, цитируемость.
Crawler, Spider (Паук) Googlebot, YandexBot. Робот, ответственный за обход и скачивание страниц из интернета в порядке очередности, который задается планировщиком. Подразделяются на:
- Основной робот, обходящий контент в порядке общей очереди.
- Быстрый робот (быстроробот или быстробот). Робот, который использует свежий индекс, на основе группы заданных хабовых страниц с важной, часто обновляемой информацией, например, с новостями популярных СМИ.
Сканирование (Crawling) — процесс загрузки страниц краулером в результате чего они попадают в хранилище, в виде сохраненных копий.
Краулинговый спрос: это то, как часто и в каком объеме робот бы хотел сканировать конкретные страницы.
Краулинговый лимит: ограничения скорости сканирования на стороне сайта, связанные с производительностью сайта или заданным вручную ограничением.
Краулинговый бюджет — это совокупность краулингового спроса и доступной скорости сканирования сайта (краулингового лимита). Простыми словами — это то сколько робот хочет и может скачать страниц.
Простыми словами — это то сколько робот хочет и может скачать страниц.
Сохраненная копия — необработанная копия документа на момент последнего сканирования.
Поисковый индекс — информация со страниц, приведенная в удобный для работы поисковых алгоритмов формат. Список всех терминов и словопозиций где и на каких страницах они упоминаются. Информация хранится в базе в виде инвертированного индекса. Схематический пример:
Поисковая база — это совокупность поискового индекса, сохраненных страниц и служебной информации о документах, таких как заголовки, типы и кодировка документов, коды ответов страниц, мета теги и др.
Как происходит сканирование сайта
Так как ресурсы поисковых систем не безграничны, планировщик составляет очередь обхода страниц, исходя критериев их полезности, востребованности, популярности и др. Каждый сайт получает свой краулинговый бюджет исходя из скоростных характеристик сайта и таких критериев как:
Каждый сайт получает свой краулинговый бюджет исходя из скоростных характеристик сайта и таких критериев как:
- Доля полезных/мусорных страниц на сайте, дубликаты
- Спамные и малополезные страницы
- Наличие бесконечной генерации страниц, например, некорректной фасетной навигации
- Популярность страниц
- Насколько актуальные версии страниц сайта, содержащиеся в поисковой базе
Робот в постоянном режиме скачивает страницы и помещает их в хранилище, заменяя старые версии. Мы можем увидеть их в виде сохраненных копий. Далее уже происходит индексация страниц.
Как проходит индексация сайта
Индексацию можно условно разбить на следующие процессы:
- Загрузка и разбор страницы по элементам: текст, мета-теги, микроразметка, изображения, видео и другой контент и служебные данные.
- Анализ страницы по определенным параметрам, например: разрешена ли она к индексации, сканированию, является ли неглавной копией другой страницы, содержит ли страница малополезный, спамный контент и др.

- Если страница успешно прошла все проверки, она добавляется в индекс.

Как проходит индексация сайта в Яндексе
У Google обновление поисковой базы — непрерывный процесс. В Яндексе обновление происходит во время Апдейтов, примерно раз в три дня. О том что произошло обновление можно узнать по уведомлениям в Яндекс.Вебмастере
Как проверить индексацию
Есть разные способы для проверки статуса индексации сайтов и отдельных его страниц:
- Вебмастер Яндекса
- Панель Google Search Console
- API панели для вебмастеров Yandex/Google
- SEO-сервисы, например Rush Analytics
- Плагины и расширения для браузеров
- Поисковые операторы ПС
- GA/Метрика
- Серверные логи
Выбор сервиса зависит от поисковой системы, а также задачи: узнать сколько страниц всего в индексе, получить список проиндексированных страниц или проверить статус индексации конкретной страницы или списка страниц.
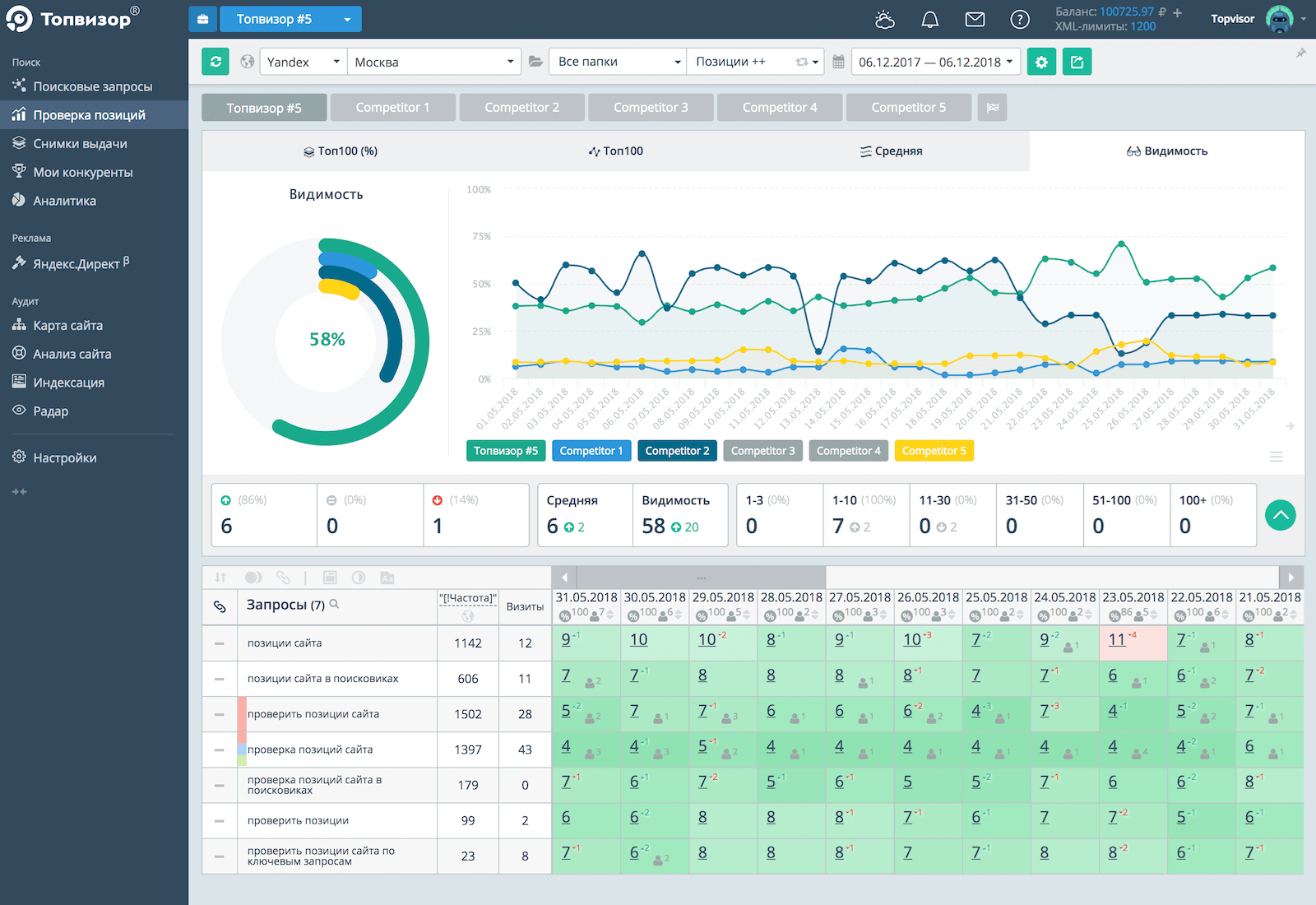
Как узнать сколько страниц проиндексировано на сайте
Расширения для браузера
Быстрые способы проверить статус индексации сайта — расширения и букмарклеты для браузера, например RDS-бар
Сервисы для анализа сайтов
Так же можно проверить с помощью сервисов, таких как pr-cy.ru
Яндекс.Вебмастер и Google Search Console
Если есть доступы к панелям вебмастеров, можно получить количество проиндексированных страниц в панелях вебмастеров:
Яндекс Вебмастер — http://webmaster.yandex.ru/
Google Search Console — https://search.google.com/search-console/
С помощью специализированных программ для SEO, например Allsubmitter, Netpeak Checker

Пример проверки числа проиндексированных страниц в Netpeak Checker.
Проверка индексации сайтов в Яндекс:
Проверка индексации сайтов в Google:
Пример проверки индексации сайтов в Яндекс и Google в Allsubmitter.
Как выгрузить список проиндексированных страниц сайта в Яндексе и Google
Яндекс Вебмастер: Отчет индексирование -> Страницы в поиске -> Все страницы
Внизу страницы ссылки на скачивание файла — cуществует ограничение в 50 000 страниц.Google Search Console: в отчете Покрытие — выбираем нужные типы страниц.
Переходим в нужный отчет и скачиваем список страниц в удобном формате. Google отдает только 1 000 страниц.
Google отдает только 1 000 страниц.
Поисковые операторы Яндекса
Запрос для поиска страниц в пределах одного домена — url:www.site.ru/* | url:site.ru/* | url:site.ru | url:www.site.ru.
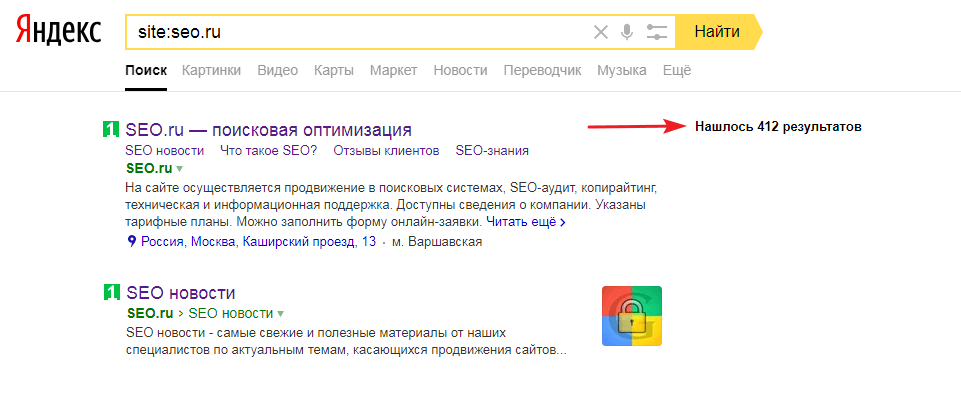
Запрос для поиска с учетом всех поддоменов — site:site.ru
Ограничение: можно получить только 1000 результатов. Нужны специальные инструменты чтобы скопировать список страниц SERP: расширения браузера, букмарклеты или программы для парсинга выдачи.
Поисковые операторы Google
Запрос для поиска страниц в пределах одного сайта — site:site.ru
Получение списка страниц входа из систем веб-аналитики
Списки страниц входа из органики Яндекса в системах аналитики Яндекс.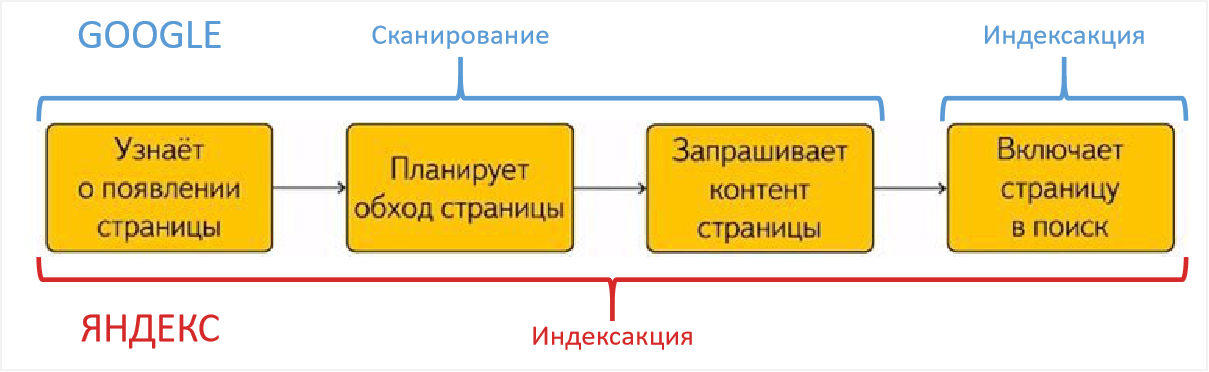 Метрика и Google.Analytics. Страницы по которым идут переходы с органической выдачи с большой вероятностью индексируются, но для точности рекомендуется проверять индексацию собранных страниц — индекс не статичен и страницы могут выпадать из индекса.
Метрика и Google.Analytics. Страницы по которым идут переходы с органической выдачи с большой вероятностью индексируются, но для точности рекомендуется проверять индексацию собранных страниц — индекс не статичен и страницы могут выпадать из индекса.
Список страниц по которым сайт показывается в выдаче в Яндекс.Вебмастере
Для выгрузки большого списка страниц из Яндекс.Вебмастера потребуется специальный скрипт.
Плагин для API Google Webmasters: Google Search Analytics for Sheets
Отображает страницы по которым были показы сайта в выдаче.
Преимущества выгрузки списка страниц через API в том что можно получить десятки тысяч страниц, которые с большой вероятностью проиндексированы, в отличие от веб-интерфейса где установлено ограничение по выгрузкам в 1000 страниц.
Серверные логи сайта
Получить список страниц которые посещает робот можно из логов, например с помощью программы SEO Log File Analyser от создателей Screaming Frog.
Как проверить индексацию конкретной страницы в Яндексе и Google
Сервис Яндекс.Вебмастер: Индексирование -> Проверить статус URL
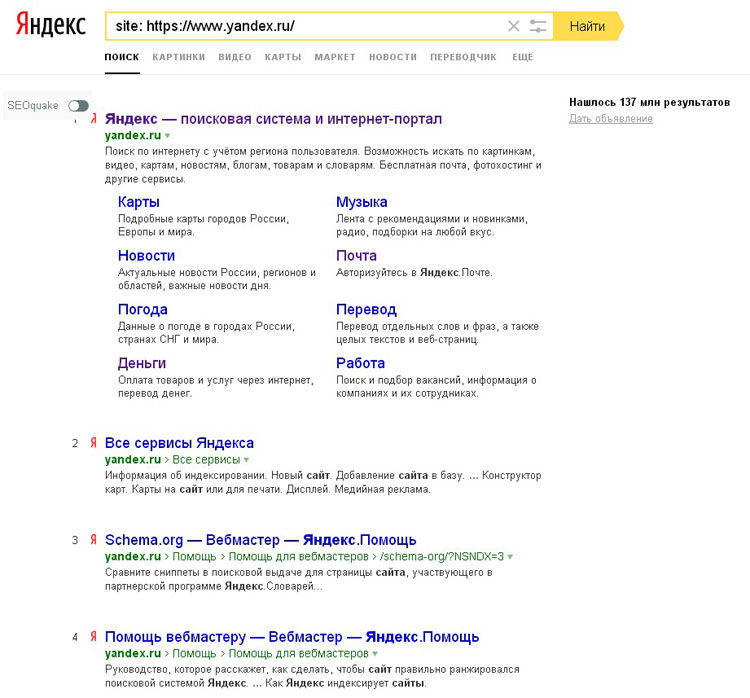
Проверка с помощью оператора пример запроса url:https://site.com/page/
Сервис Google Search Console: инструмент “Покрытие”: Нужно ввести в указанной на скрине строке поиска URL-адрес своего сайта и откроется отчет о статусе страницы.
Проверка с помощью оператора: пример запроса site:https://habr.com/ru/news/t/468361/
После отмены оператора info остался оператор site, но он выдает не всегда точные данные, можно сократить список результатов с помощью указания уникального текста проверяемой страницы.
Как массово проверить индексацию списка страниц
Для проверки можно использовать SEO-сервисы, например Rush Analytics.
Это позволяет массово проверить индексацию до десятков-сотен тысяч страниц
Как проверить разрешена индексация/сканирование страницы в Robots.txt
В Яндексе
Проверить доступна ли роботам страница или содержит запрет можно через. Инструменты -> Анализ robots.txt
В Google
Инструмент проверки файла robots.txt
Важно: если файл robots.txt отдает 404 ошибку, боты считают что разрешено сканирование всего сайта без ограничений. Если файл отдает ошибку 5хх, то Googlebot считает это полным запретом на сканирование сайта, но если ошибка отдается более 30 дней — считает что разрешено сканировать весь сайт без ограничений. Яндекс любые серверные ошибки считает отсутствием файла robots. txt и отсутствием ограничений на обход и индексацию сайта.
txt и отсутствием ограничений на обход и индексацию сайта.
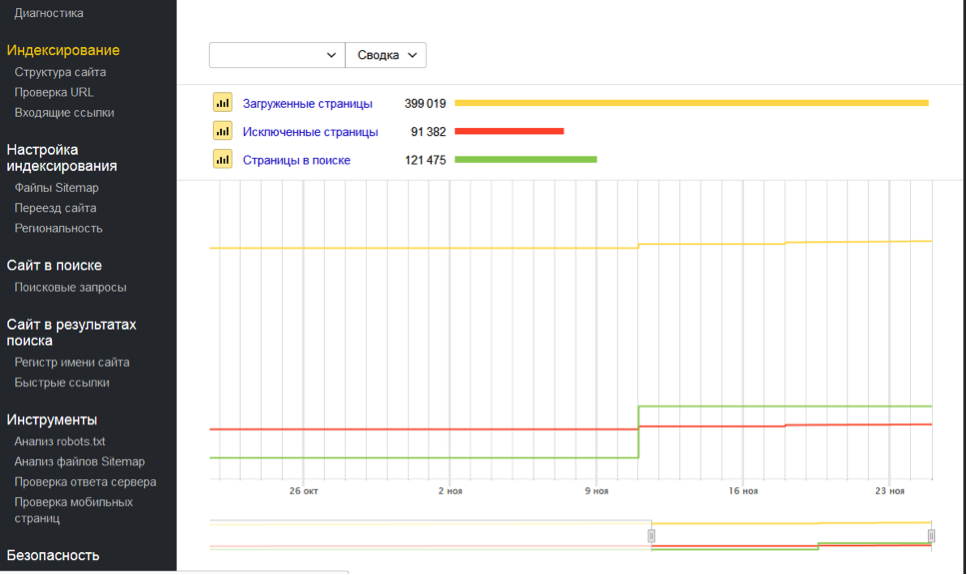
Как узнать динамику числа проиндексированных страниц
С помощью специализированных сервисов, например: https://be1.ru/
С помощью Яндекс Вебмастера: в разделе Индексирование -> Страницы в поиске.
С помощью Google Search Console: в отчете Покрытие.
Почему число проиндексированных страниц может отличаться в разных сервисах
Нужно понимать что проиндексированные страницы и страницы в поиске это разные сущности. Не все проиндексированные страницы будут включены в поиск и не все страницы в поиске будут показываться через операторы поиска — операторы лишь выводят результаты пустого поиск по сайту а не список всех страниц. Но этого в большинстве случаев достаточно чтобы оценить порядок числа проиндексированных страниц сайта.
Запрет индексации страниц
Запрет индексации с помощью Meta Noindex/X-Robots-Tag
Для гарантированного исключения попадания страниц в индекс можно использовать атрибут Noindex Мета Тега Robots или HTTP-заголовка X-Robots-Tag. Подробнее про этот атрибут можно прочитать тут.
Важно: Использование запрета индексации в через Meta/X-Robots-Tag Noindex вместе с запретом в Robots.txt
При добавлении директивы Noindex в мета-тег Robots и http-заголовок X-Robots-Tag, чтобы ее прочитать, робот должен просканировать страницу, поэтому она должна быть разрешена в файле Robots.txt. Следовательно для точечного запрета индексации страниц иногда требуется снять запрет в robots.txt или добавить директиву Allow, чтобы робот смог переобойти эти страницы.
Несмотря на вышеописанное, запрет в robots.txt в большинстве случаев все таки приведет к тому, что страницы не будут индексироваться, но его нельзя использовать для закрытия персональных данных или страниц с конфиденциальной информацией.
Как запретить индексацию страницы в robots.txt
Стоит сразу упомянуть что запрет в robots.txt не является надежным методом закрытия страниц от индексации.
В файле robots.txt указываются основные директивы для запрета или разрешения обхода/индексации отдельных страниц или разделов сайта.
Важно: Многие ошибочно считают что директива Disallow в Robots.txt служит для запрета индексации страниц, это не совсем так. Основная цель файла Robots.txt — управление трафиком поисковых роботов на сайте, а не индексацией / переиндексацией и разные поисковые системы по разному интерпретируют запрет.
Многие вебмастера не понимают почему после запрета страницы в robots.txt она продолжает находиться в индексе и приносить трафик. Запрет посещения и обновления страницы роботом не означает, что он обязан удалить уже присутствующую в индексе страницу. К тому же для индексации не всегда обязательно физически сканировать страницу, информацию о ней можно собирать из различных источников, например, из анкоров входящих ссылок.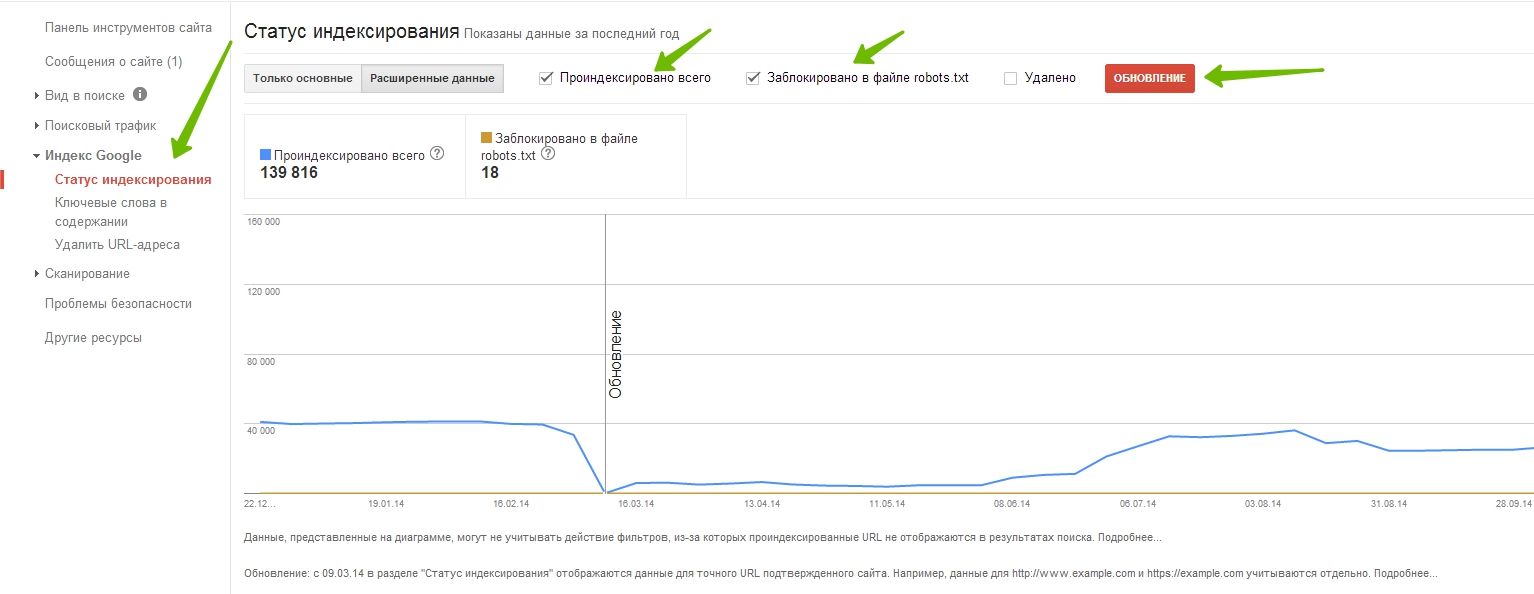
Почему заблокированные в robots.txt страницы отображаются в выдаче
В Яндексе и Google различается механизм обработки директив файла Robots.txt. Для Google директива Disallow в robots.txt запрещает лишь обход страниц, но не их индексацию из-за чего часто появляются страницы со статусом:
Для запрета индексации в Google через файл Robots.txt ранее использовалась незадокументированная директива Noindex в Robots.txt, но с сентября 2019 года Google перестал поддерживать ее.
На данный момент для надежного запрета индексации страниц в Google рекомендуется использовать атрибут Noindex Мета Тега Robots и HTTP-заголовка X-Robots-Tag.
Яндекс же, наоборот, воспринимает запрет в Robots.txt Disallow: как сигнал к запрету и сканирования и индексирования сайта и после добавления директивы Disallow: страницы будут удалены из индекса.
Использование атрибута canonical для запрета индексации дубликатов
Для консолидации дубликатов или похожих страниц страниц используется атрибут canonical, который указывает поисковикам по какому адресу рекомендуется индексировать страницу. Yandex» search_bot
Yandex» search_bot
Запрет сканирования, индексации с помощью кодов ответа сервера 3хх/4хх
Чтобы гарантированно запретить роботам скачивать страницы, можно отдавать ботам при сканировании страниц коды:
- 301 редирект: особенно подходит для запрета дубликатов и склейки их с основными страницами;
- 403 Forbidden: доступ запрещен;
- 404 Not Found: не найдено;
- 410 Gone: удалено;
Удаление страниц из индекса
Удаление страниц или каталогов через Search Console
Инструмент не запрещает страницы к индексации или сканированию — он лишь временно скрывает страницы из поисковой выдачи. Рекомендуется использовать только для экстренного удаления страниц, случайно попавших в выдачу, после этого уже физически удалить их или запретить сканирование/индексацию.
Ускоренное удаление из индекса страниц в Яндексе
На сайт должны быть подтверждены права. Можно удалить только страницы, которые недоступны для робота: запрещенные в robots.txt или отдавать код 3хх, 4хх.
Можно удалить только страницы, которые недоступны для робота: запрещенные в robots.txt или отдавать код 3хх, 4хх.
Для удаления из индекса Яндекса страниц чужого сайта можно воспользоваться формой — https://webmaster.yandex.ru/tools/del-url/.
Требования к URL-адресам такие же: запрет в robots.txt или коды ответа 301, 403, 404, 410 и т.п.
Как добавить страницы в индекс Яндекса или Google
Роботы постоянно ходят по ссылкам на сайтах. Для ускорения добавления существуют инструменты:
- Sitemap.xml. Добавьте и регулярно обновляйте актуальный список страниц в сайтмапах сайта.
- В Яндексе: инструменты -> переобход страниц
- В Google: Проверка URL -> Запросить индексирование
Как проверить обход / сканирование сайта поисковыми системами
Яндекс:
Общее количество загруженных (просканированных) Яндексом страниц можно увидеть на главной странице вебмастера.
Динамику обхода страниц можно увидеть на странице Индексирование -> Статистика обхода.
Google: отчет: статистика сканирования сайта.
Также можно проверить обход сайта всеми поисковыми роботами с помощью анализа серверных логов сайта (Access logs). Например, через программу SEO Log File Analyser.
Как часто происходит индексация сайта
Поисковые боты постоянно равномерно загружают страницы сайта, далее выкладывая их в обновленный индекс: Google обновляет индекс в постоянном режиме, Яндекс во время апдейтов поисковой базы, примерно раз в три дня.
Частота сканирования и переиндексации каждого отдельного сайта различается, и зависит от факторов:
- объем контента/страниц сайта
- краулинговый спрос поисковой системы для текущего сайта
- настройки скорости сканирования в вебмастерах
- скорость работы сайта
Как улучшить и ускорить индексацию сайта
Рекомендации для увеличения охвата страниц индексом поисковых систем:
- качественный уникальный контент, востребованный пользователями;
- все основные страницы должны быть в валидных сайтмапах sitemap. xml;
- оптимизация вложенности страниц;
- оптимизация краулингового спроса/бюджета;
- хорошая скорость сайта;
- закрывать лишние страницы, чтобы не тратить на них ресурсы роботов;
- внутренняя перелинковка;
- создание ротарора на сайте (Ловец ботов).
 xml;
xml;Как ограничить скорость сканирования сайта
Обычно если требуется ограничить нагрузку, которую создают роботы, то у сайта большие проблемы и это негативно скажется на его индексации. Боты стараются быть “хорошими” юзерами и сканируют сайт равномерно, стараясь не перегружать сервера.
То что сайт от этого испытывает проблемы с нагрузкой, в 90% случаев может быть сигналом к смене хостинга/сервера или оптимизации производительности CMS. Но в случае крайней необходимости все таки можно задать рекомендуемую скорость сканирования сайта.
Для ограничения скорости обхода сайта можно воспользоваться инструментами Яндекс.Вебмастер и Google
Яндекс GoogleGoogle:
В старой версии консоли можно было временно ограничить максимальную скорость сканирования сайта
В обновленной консоли такой возможности нет, но можно отправить сообщение о проблеме с активностью GoogleBot’а на сайте — https://www. google.com/webmasters/tools/googlebot-report
google.com/webmasters/tools/googlebot-report
Хочешь увеличить продажи из органики?
За 3 дня составим набор точечных рекомендаций по вашему сайту, как за 1 месяц сделать рост на 30-50%
Адрес вашего сайта
Номер вашего телефона
Нажимая на кнопку, вы даете согласие на обработку ваших персональных данных, согласно политике конфиденциальности
почему страницы сайта плохо индексируются в Гугл
Очень типичная ситуация, что Google плохо индексирует сайт, особенно, интернет магазины. В этой статье я подробно разбираю причины плохой индексации в Google, способы проверки и решения проблем индексации страниц в поисковой системе Гугл.
Очень важно, чтобы ваш сайт был зарегистрирован в сервисе Google Search Console. Это сервис для аналитики, который показывает как сайт ведет себя в поисковой системе Google и без него сделать какой-то анализ просто невозможно.
Содержание:
- 1 Проверка индексации страниц
- 2 Индексация молодого сайта
- 3 Размер сайта
- 4 URL-адреса недоступны для индексирования
- 5 Наличие ошибок переадресации
- 6 Проблемы на стороне хостинга
- 7 Проиндексировано, несмотря на блокировку в файле robots. txt
 txt
txtПроверка индексации страниц
Если ваш сайт зарегистрирован на данном сервисе, то вы просто берете url страницы, которую хотите проверить и, используя инструмент «Проверка URL», получаете данные, введя url в поле и нажав Enter.
В данном примере видно, что url есть в индексе, а значит все нормально. Если бы урла не было в индексе, то, соответственно, сервис бы написал, что URL нет в индексе.
Индексация молодого сайта
Если у вас молодой сайт и вы совсем недавно его запустили, то абсолютно нормально, что он долгое время не будет сразу индексироваться.
Сайт может и до месяца не индексироваться, такая особенность Google. Есть, конечно, способы как ускорить индексацию, например, закупить ссылок на сайт. Но в общем для молодого сайта долгая индексация это нормально.
Но, если ваш сайт уже имеет какой-то возраст, историю, а у него все равно наблюдаются проблемы с индексацией, то здесь нужно смотреть уже более детально.
Размер сайта
Если на вашем сайте несколько сотен тысяч страниц или даже более, то у него действительно могут быть проблемы с индексацией.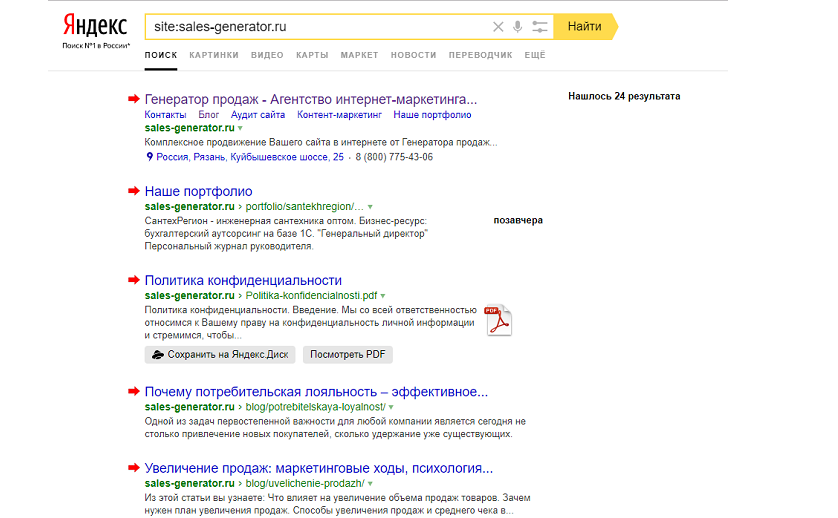 Потому что на каждый сайт поисковая система Google выделяет определенный лимит по сканированию и индексированию страниц, так называемый краулинговый бюджет. И если у вас очень много страниц, то бюджета может просто не хватить на индексирование всех страниц.
Потому что на каждый сайт поисковая система Google выделяет определенный лимит по сканированию и индексированию страниц, так называемый краулинговый бюджет. И если у вас очень много страниц, то бюджета может просто не хватить на индексирование всех страниц.
В данной ситуации поможет файл sitemap.xml, который лучше разбить на несколько файлов (категории, товары, служебные страницы и любые другие группы). Если у вас обновился ассортимент, вы добавили много новых товаров, соответственно, автоматически обновился файл sitemap. Вы просто загружаете новый файл через инструмент «Файлы Sitemap» и нажимаете «Отправить». Дальше идет сканирование этого файла.
Если же у вас сайт небольшой (несколько тысяч страниц или даже несколько десятков тысяч страниц), но все равно есть проблемы с индексацией, то нужно смотреть сам сайт. Возможно, есть какие-то технические проблемы, недоработки:
- страницы или раздел сайта могут быть закрыты в файле robots.txt;
- на странице есть мета-тег noindex;
- на страницу поставлен тег canonical, который ведет на какую-то другую страницу;
- страницы имеют 400 или 404 код ответа сервера и т. д.
 д.
д.То есть могут быть какие-то такие технические ошибки, которые не дают страницам или разделам индексироваться. Все это как раз можно проверить через инструмент сервиса Google Search Console.
Но даже в случае проверки, которая показала, что все нормально, нужно воспользоваться еще инструментом «Покрытие».
Сперва необходимо зайти в разделы «Ошибка» и «Без ошибок, есть предупреждения». Это поможет узнать, какие ошибки есть на указанных страницах, а еще как их можно устранить. Давайте узнаем какие ошибки индексации считаются самыми распространенными, а также о том, как их исправить наиболее простыми способами.
URL-адреса недоступны для индексирования
Зачастую, это не одна ошибка, а целая группа проблем. Она появляется, если пользователь дает команду Google осуществить индексацию выбранного URL, однако сама причина не имеет доступа к обходу поисковыми роботами. Наиболее ярким примером такого случая является следующий:
В первую очередь необходимо понять, нужно ли добиться того, чтоб искомая страница показывалась в поисковике.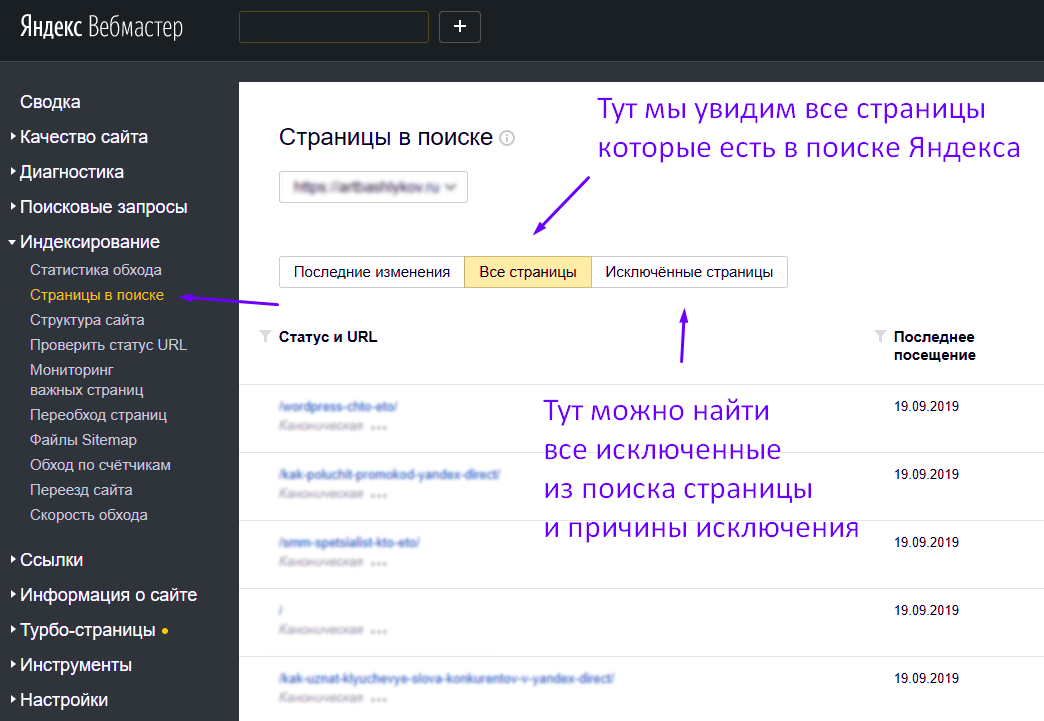 Если за пример взять страницу, URL-адрес которой не индексируется, то следует прекратить попытки обхода. Эти попытки ни к чему не приведут, так как поисковик не сможет отправить нужный адрес в индекс.
Если за пример взять страницу, URL-адрес которой не индексируется, то следует прекратить попытки обхода. Эти попытки ни к чему не приведут, так как поисковик не сможет отправить нужный адрес в индекс.
Обычно, такие ошибки появляются из-за того, что в карту сайта случайным образом бы добавлен нежелательный URL. Если это так, то решение проблемы достигается путем редактирования файла Sitemap.xml. Для этого достаточно удалить из файла URL-адрес, который вызывает проблемы.
Если пользователю нужно, чтобы искомый адрес показывалась в поисковике, необходимо более подробно разобраться в том, из-за чего именно он не индексируется. Обычно, это происходит из-за следующих причин:
- Существует директива noindex, которая и не дает доступ к индексированию необходимой страницы. Чтобы решить проблему, необходимо удалить тег директивы из HTML-кода неиндексируемого адреса.
- Адрес не индексируется в файле в robots.txt. Чтобы устранить ошибки, нужно воспользоваться особым инструментом поисковика и заняться проверкой файла robots. txt. Данные инструменты позволят найти все директивы, которые запрещают индексирование, после чего-либо удалить их, либо исправить показанные ошибки.
- Ошибка 404 (адрес не найден). Такое случается в двух случаях: когда страница была удалена самим владельцем, или в случае изменения начального URL. Решением проблемы является восстановление исходного кода или настройка 301-редиректа на существующем адресе.
- Soft 404 (ложная ошибка). Это случается довольно редко, когда сама адрес существует (сервер подтверждает его существование), но поисковик решил, что URL работает с ошибкой 404. Чаще всего такое происходит в случаях, когда на странице долгое время отсутствует контент (или же он слишком незначительный). Еще одним случаем появления такой ошибки является манипуляция с редиректами. Решение проблемы весьма простое – необходимо заняться поиском «неудачного» контента или же удалить нерелевантные редиректы.
- Ошибка 401 (неавторизованный запрос). Данная неисправность появляется, когда поисковик не получает доступ к искомой странице из-за отсутствия авторизации. Для решения проблемы необходимо отменить авторизацию или ручным способом дать боту поисковика возможность взаимодействия с искомой страницей.
- Ошибка 403. Ее появление означает, что поисковик пытается войти на сервер, однако бот не может получить доступ к контенту, находящемуся на странице. Исправить ошибку можно, разрешив доступ к адресу анонимным пользователям.
 txt. Данные инструменты позволят найти все директивы, которые запрещают индексирование, после чего-либо удалить их, либо исправить показанные ошибки.
txt. Данные инструменты позволят найти все директивы, которые запрещают индексирование, после чего-либо удалить их, либо исправить показанные ошибки. Для решения проблемы необходимо отменить авторизацию или ручным способом дать боту поисковика возможность взаимодействия с искомой страницей.
Для решения проблемы необходимо отменить авторизацию или ручным способом дать боту поисковика возможность взаимодействия с искомой страницей.Наличие ошибок переадресации
Это происходит не только при ошибке 404 (то есть из-за перенаправления на страницу, не являющуюся релевантной), но и по многим другим причинам, возникающим при переадресации.
Например, страница не попадает в индекс из-за слишком частых перенаправлений или же неработающих URL-адресов при переадресациях. Решить проблему можно отладкой неправильно работающих 301- и 302-редиректов.
Проблемы на стороне хостинга
Часто проблемы возникают не из-за пользователя, а из-за проблем в хостинге. Наиболее часто встречается ошибка 5хх. Она появляется в случае, когда поисковик не может получить доступ к серверу. Это может произойти из-за поломки сервера, истечения срока ожидания или отсутствия доступа во время того, когда бот поисковика занимался обходом сайта.
Это может произойти из-за поломки сервера, истечения срока ожидания или отсутствия доступа во время того, когда бот поисковика занимался обходом сайта.
Решить проблему можно несколькими способами, но наиболее легкий из них – воспользоваться инструментом «Проверка URL-адреса». Если есть какие-либо неполадки в работе, то инструмент сможет их отобразить. Если проблем с сервером нет, то следует внимательно изучить то, какие предложения дает сам поисковик. В последнюю очередь стоит связаться с хостинг-провайдером.
Давайте перейдем к разделу «Без ошибок, есть предупреждения». Существуют случаи, когда поисковик может проиндексировать адрес сайта, но не может быть на 100% уверен, что в индексации была необходимость. Во время подобных ситуаций страницы будут помечен как физически существующие, но с предупреждением.
Обычно, такие страницы приносят ее больше проблем из-за того, что владелец сайта предоставил общий доступ тем документам, которые таковыми быть не должны. Именно по этой причине все URL-адреса, которые так или иначе получили желтую категорию, должны быть под контролем владельца сайта.
Именно по этой причине все URL-адреса, которые так или иначе получили желтую категорию, должны быть под контролем владельца сайта.
Проиндексировано, несмотря на блокировку в файле robots.txt
Данная ошибка считается одной из самых распространенных. Из-за нее все страницы, находящиеся на сайте, со стопроцентной вероятностью попадают в желтую категорию индексирования. На эту ошибку часто попадаются начинающие веб-мастера, а также специалисты, которые убеждены, что файл robots.txt является самым лучшим механизмом для того, чтобы страницы не попали в индекс поисковика.
На самом деле это далеко не так:
Если добавить директивы в этот файл, это не значит, что страницы будут полностью запрещены для индексирования. Владельцы сайтов используют этот файл для уменьшения перегрузки сайта.
Для стопроцентного исключения желаемых адресов в индекс поисковика используются другие механизмы. Запрет в файле robots.txt используется в роли рекомендации. Этот файл не сможет отсканировать адрес, который отклоняется в robots. txt во время процедуры обхода сайта. Однако, если на эту страницу ведут несколько других ссылок, то она вполне может проиндексироваться.
txt во время процедуры обхода сайта. Однако, если на эту страницу ведут несколько других ссылок, то она вполне может проиндексироваться.
Именно отсюда вытекает следующий момент: адреса могут индексироваться в неполной версии, так как роботы могут отсканировать лишь определенную часть документа, доступ к которому закрыт.
Решается данная проблема довольно просто. Нужно понять, какие URL-адреса относятся к желтой категории, а затем сделать вывод, стоит ли их блокировать. Если пользователь убежден, что данный адрес не должен находиться в индексе, то необходимо ограничить доступ ботов к поисковикам, используя мета-тег noindex или X-Robots-Tag. Страницы, не приносящие никакой пользы, лучше вообще удалить.
Теперь перейдем к разделу «Исключено». Консоль поисковика уведомляет пользователей обо всех адресах, которые полностью отсутствуют в индексе, однако работают на сайте. Такие адреса обычно и отображаются в блоке «Исключено».
Преимущественно, адреса попадают в этот блок по желанию вебмастера.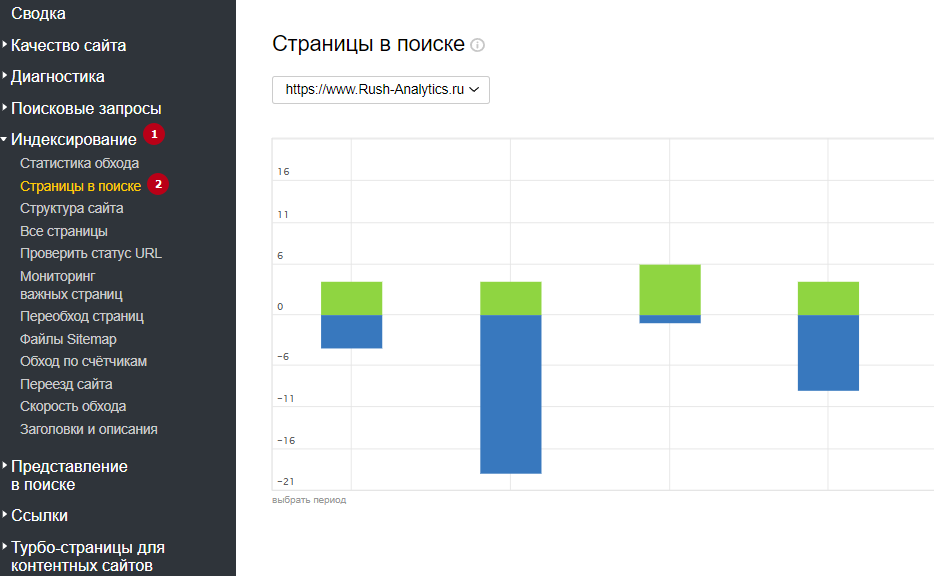 Надо понимать, что это никак не зависит от технических проблем, связанных с работой сайта. Чаще всего такое происходит в следующих ситуациях:
Надо понимать, что это никак не зависит от технических проблем, связанных с работой сайта. Чаще всего такое происходит в следующих ситуациях:
- Адрес нельзя обойти из-за директивы noindex
- Есть директивы, запрещающие индексирование, в файле robots.txt
- Выбранный адрес — это дубль
Зачастую происходит попадание адресов в блок из-за следующих ошибок:
- Адрес не индексируется из-за наличия ошибки 401/ ошибки 404/ ошибки 403/ ошибки 404
- Наличие редиректа, настроенного с ошибками
- Страница неканоническая (то есть поисковик выбрал канонический вариант не таким, каким его указал вебмастер)
Кроме этого, в разделе «Исключено» особое внимание уделите пункту «Страница просканирована, но не проиндексирована». Если среди страниц встречаются те, которые вы хотите чтобы были проиндексированы, значит проблема внутренняя, а именно с контентом этих страниц.
Это могут быть, например, дубли страниц (полный или частичный повтор контента). Таким дублями могут быть карточки товаров, которые мало отличаются по контенту и сильно дублируют друг друга. В этом случае необходимо уникализировать эти карточки.
Таким дублями могут быть карточки товаров, которые мало отличаются по контенту и сильно дублируют друг друга. В этом случае необходимо уникализировать эти карточки.
Проблемы могут иметь страницы со слабым, нерелевантным контентом. Например, на странице есть только коротенький текст и больше ничего нет. Естественно, Google определяет такую страницу как малоинформативную, неполезную.
Такую страницу он не индексирует и помещает ее в Исключения. Эти страницы необходимо исправить, доработать в соответствии с топом и отправить обратно на переиндексацию. Для этого нужно будет опять ввести url исправленной страницы в инструменте «Проверка URL».
Сервис выдаст ответ, что URL нет в индексе. Далее нажимаем «Запросить индексирование» и ваш запрос вновь будет отправлен на индексирование. Нужно будет подождать пока страница переиндексируется и, если страница верно исправлена, то она появится в индексе.
Подводя итог вышесказанному, можно сказать, что необходимо отслеживать все страницы, попавшие в блок «Исключено». Благодаря этому можно вовремя замечать все недоработки и своими силами исправить имеющиеся ошибки.
Благодаря этому можно вовремя замечать все недоработки и своими силами исправить имеющиеся ошибки.
0 0 голоса
Рейтинг статьи
Руководство по поисковым системам: сканирование, индексирование и ранжирование
Поисковые системы сканируют Интернет, сохраняя и индексируя страницы в базе данных, а также предоставляют поисковые интерфейсы, чтобы мы могли получить доступ к обширной базе знаний человечества, называемой Интернетом.
Google стал глаголом и синонимом поиска в Интернете. Тем не менее поисковые системы в Интернете существовали до Google, и у неоспоримого лидера поискового маркетинга есть конкуренты по всему миру.
Bing от Microsoft вступил в борьбу, и пока российский Яндекс и чешский Seznam испытывают на себе давление со стороны Google, у Baidu такие же сильные позиции в Китае, как у Google в Западном полушарии.
Обзор: Что такое поисковая система?
Поисковые системы — это ворота, через которые вы проходите во всемирную паутину. Это человеко-машинный интерфейс, если считать Интернет машиной. Поисковая система — это интерфейс, который позволяет вам ориентироваться в Интернете, находить ответы на свои вопросы и, во все большей степени, находить товары или услуги для покупки.
Это человеко-машинный интерфейс, если считать Интернет машиной. Поисковая система — это интерфейс, который позволяет вам ориентироваться в Интернете, находить ответы на свои вопросы и, во все большей степени, находить товары или услуги для покупки.
В будущем поисковая система может стать вашим голосовым личным помощником, управляемым искусственным интеллектом, который поможет вам организовывать не только информацию, но и встречи, путешествия, покупки и ваше здоровье.
Поисковая система построена вокруг запроса, также называемого ключевым словом или поисковым термином, и страницы результатов поисковой системы или SERP для тех, кто в курсе. Высокая концентрация кликов в верхней части результатов поиска. На это есть несколько причин.
В интерфейсе может отображаться только ограниченное количество результатов, и когда результат предлагается в качестве первого, многие люди нажимают на него, вместо того чтобы читать другие. Кроме того, люди склонны доверять рейтингам. Если поисковая система помещает страницу на первую позицию, они предполагают, что она, вероятно, лучшая.
Если поисковая система помещает страницу на первую позицию, они предполагают, что она, вероятно, лучшая.
Это создало экономическую модель платной поисковой рекламы в верхней части поисковой выдачи и целую индустрию поисковых маркетологов, работающих над ранжированием веб-страниц как можно выше в этих результатах поиска. Эту работу выполняют наши дорогие друзья, SEO-специалисты, которые, если вы интересуетесь поисковыми системами, вероятно, знаете, что это аббревиатура от Search Engine Optimization.
Как работают поисковые системы?
Поисковая система — это очень сложное программное обеспечение, управляющее огромными объемами данных и обрабатывающее их с помощью продвинутых алгоритмов, включающих в себя все больше и больше искусственного интеллекта (ИИ).
Основными функциями поисковой системы являются следующие:
- Просматривание веб-страниц
- Сохранение веб-страниц в базе данных
- Индексирование контента
- Предоставление интерфейса поиска веб
Один из Основная функция поисковой системы — «сканирование» Интернета.
Этот термин происходит от того факта, что поисковая система перемещается от страницы к странице в Интернете для сбора данных. Он просматривал весь контент и определял все ссылки, а затем начинал посещать каждую из этих ссылок — движение изображалось как паук, ползающий по всемирной паутине.На заре интернет-поиска от вас требовалось представить свой веб-сайт поисковым системам, чтобы они могли найти ваши страницы. Сегодня веб-сканирование Google настолько эффективно, что находит ваш сайт вскоре после того, как на него указывает ссылка с другой страницы.
Хранение веб-страниц
Поисковая система собирает информацию с найденных страниц и сохраняет их в агрегированном виде в базе данных. Ранние поисковые системы сохраняли только части страницы или просто метаинформацию (информацию об информации), скрытую в заголовке страницы. Сегодня нормой является сбор полного объема контента. Поисковые системы действительно хранят большие данные, пытаясь охватить весь Интернет.
Индексирование содержимого
Поисковая система выполняет процесс индексации веб-сайта для создания легкодоступного индекса содержимого. Он использует технику, известную как инвертированный индекс, в которой он классифицирует веб-страницы по доступным для поиска записям, таким как ключевые слова, темы или сущности. Это позволит ему находить и отображать релевантные данные намного быстрее, чем если бы ему приходилось выполнять поиск по всему контенту при каждом запросе.
Интерфейс поиска
Интерфейс поиска позволяет поисковым системам вводить и интерпретировать запросы по ключевым словам и отображать страницу результатов поиска с результатами инвертированного индекса. Интерфейс поиска состоит из поля запроса, которое представляет собой форму, в которой вы вводите поиск по ключевому слову и нажимаете кнопку, чтобы перейти на страницу результатов, показывающую ваш контент или ссылки на контент и обеспечивающую наиболее релевантные результаты, которые может найти поисковая система.
.Google изначально был только окном поиска с двумя кнопками. Нажатие кнопки «Поиск в Google» откроет страницу результатов поиска, а нажатие кнопки «Мне повезет» приведет вас к первому результату в списке. Источник изображения: Автор
Что такое поисковая оптимизация?
Верхние позиции в результатах поиска стали главной целью из-за того, что пользователи поисковых систем ленивы, нажимают на первый результат и доверяют алгоритму, чтобы обеспечить лучший результат в верхней части страницы. Рейтинги поисковых систем стали прайм-таймом в Интернете — местом, где пользователи выполняли поиск по ключевому слову, имеющему отношение к вашему бизнесу.
Индустрия SEO возникла задолго до того, как поисковые системы нашли свою экономическую модель с платным поиском. Специалисты по поисковой оптимизации будут исследовать, тестировать и узнавать, как улучшить веб-страницы, чтобы занимать первые позиции по наиболее релевантным ключевым словам.
SEO основывается на трех столпах: архитектуре, контенте и авторитете.
Архитектура охватывает технические аспекты вашего веб-сайта, то есть время отклика, структуру страниц и ссылок, компоненты заголовков и метатеги.Параметр «Контент» охватывает ключевые слова и контент веб-сайта. SEO-специалисты проведут исследование, чтобы найти лучшие ключевые слова для ранжирования, а затем создадут или закажут контент, который хорошо структурирован для этих ключевых слов. Измерение авторитета касается того, как ваш сайт воспринимается извне, силы бренда и ссылок, указывающих на сайт.
Существуют инструменты для каждого из трех столпов SEO, а также инструменты для мониторинга и измерения рыночных сил и эффективности. Источник изображения: Author
Анализ поисковых систем охватывает различные подходы, показанные на рисунке выше: сканирование сайта, исследование ключевых слов, оптимизация контента, анализ обратных ссылок, мониторинг рейтинга, а также различные подходы к анализу тенденций рынка и конкурентному анализу. Чтобы узнать больше об инструментах SEO, ознакомьтесь с обзорами The Ascent некоторых ведущих программных решений для SEO на рынке.
7 альтернатив Google для пользователей, чтобы найти ваш контент
Хотя Google считается ведущей поисковой системой в мире, он не единственный игрок на рынке и имеет множество конкурентов по всему миру. Давайте посмотрим, кто они ниже:
- Bing: Поисковая система Microsoft во многих аспектах является последователем, но она опирается на отличные технологии и амбиции. Это также заполнение с белой маркировкой для различных поисковых свойств по всему миру.
- DuckDuckGo: Небольшая поисковая система в США, которая не отслеживает пользователей и не фильтрует результаты поиска.
- Baidu: Китайская поисковая система, созданная Робином Ли, человеком, создавшим алгоритм Rankdex, вдохновивший Google. Baidu — ведущая поисковая система в Китае.
- Яндекс: Яндекс, что означает «Еще один индекс», был создан в России и в основном охватывает Россию и страны бывшего Советского Союза. Единственным другим дополнением является Турция, где Яндексу удалось конкурировать с Google.
- Naver: Южнокорейская поисковая система, доминирующая на местном рынке.
- Yahoo!: Yahoo! раньше был самой важной точкой входа в Интернет. Он использовал Google в качестве резерва, но был превзойден своим бывшим поставщиком услуг. Яху! Япония отличается от Yahoo! и главная поисковая система на этом рынке.
- Кол-во: Французская поисковая система, стремящаяся привлечь пользователей удобным пользовательским интерфейсом и защитой конфиденциальности, аналогичной DuckDuckGo. Тем не менее, Qwant остается на низком уровне проникновения.
Шагните через ворота поисковой системы к знаниям
Поисковые системы являются одними из самых совершенных технических решений, которые видел мир, и являются краеугольным камнем бизнеса Google, Yandex, Baidu и Microsoft. Они позволяют пользователям в любой точке мира получить доступ к большему количеству информации, чем кто-либо мог себе представить.
Ожидается, что со временем характер поиска будет развиваться в сторону более естественных интерфейсов, таких как голос и изображения, но сегодня он по-прежнему в основном основан на ключевых словах и тексте.
Маркетинг в поисковых системах с его двойным измерением SEO и платного поиска является одним из самых доминирующих и мощных каналов цифрового маркетинга. Поиск предоставляет поистине волшебное решение для доступа к огромным объемам данных, доступных в Интернете, и способствовал созданию экономической модели для Интернета. Просто погуглите, чтобы узнать больше.
Предупреждение: самая большая карта с кэшбэком, которую мы когда-либо видели, теперь имеет 0% годовых в начале почти до 2025 года
Если вы используете неправильную кредитную или дебетовую карту, это может стоить вам серьезных денег. Нашим экспертам нравится этот лучший выбор, который предлагает 0% годовых в начале в течение 15 месяцев, безумную ставку кэшбэка до 5%, и все это каким-то образом без годовой платы.
На самом деле, эта карта настолько хороша, что наши специалисты даже используют ее лично. Нажмите здесь, чтобы бесплатно прочитать наш полный обзор и подать заявку всего за 2 минуты.
Прочитайте наш бесплатный обзор
Что такое поисковый индекс и как он работает?
Представьте, что вы вводите поисковый запрос в Google и все ждете и ждете, пока ваши результаты медленно появятся на экране. Вы, вероятно, нажмете кнопку обновления или переключитесь на другой веб-сайт. В эпоху стремительного интернета никому не хочется тратить время на ожидание поискового запроса.
Этот сценарий является гипотетическим, поскольку поисковые системы в настоящее время работают очень быстро . В течение нескольких секунд они отображают результаты вашего поиска после того, как вы ввели поисковый запрос. Чтобы сделать вашу работу как пользователя такой гладкой, поисковые системы используют так называемые поисковые индексы для возврата результатов по запросу.
Несмотря на то, что мы привыкли получать быстрые результаты в Google и других популярных поисковых системах, часто внутренний поиск по сайту не дает результатов так же быстро.
Без поискового индекса поисковый запрос потребляет ресурсы сервера и замедляет работу сайта. Вот почему поисковый индекс является жизненно важной частью любого хорошего варианта поиска по сайту.Содержание
Что такое поисковый индекс?
Индекс поиска помогает пользователям быстро находить информацию на веб-сайте. Он предназначен для сопоставления поисковых запросов с документами или URL-адресами, которые могут отображаться в результатах.
Звучит сложно? Вот более простой способ описать это:
Возможно, вы уже сталкивались с указателем на более традиционном носителе: книги . Многие большие (научные) книги имеют указатель, который поможет вам найти нужную информацию за считанные секунды.
Обычно в конце книги находится указатель, который включает список ключевых слов, организованных в алфавитном порядке. Каждое ключевое слово указывает на страницу, на которой можно найти полезную информацию о ключевом слове.
Например, у вас может быть книга о животных с несколькими сотнями страниц. Вы хотите найти информацию о «кошках». В указателе вы бы искали ключевое слово «кошка» и читали страницы, которые упоминаются (стр. 17, 89, 203-205).
Индекс поиска очень похож на индекс книги. Позволяет пользователю быстро найти полезную информацию по ключевому слову. Конечно, индекс веб-поиска имеет много технологических преимуществ по сравнению с индексом в книге и предлагает отличные инструменты, помогающие посетителям веб-сайтов быстрее получать то, что они хотят.
Как создаются поисковые индексы?
Индексы для книг традиционно создаются автором(ами) и редакторами, а также профессионалами, специализирующимися на индексировании, так называемыми индексаторами. Анализируя содержание книги, они определяют ключевые слова и следят за тем, чтобы они указывали на наиболее релевантные страницы книги.
Программное обеспечение автоматизирует процесс индексации.
Поисковый индекс для веб-сайтов создается сканерами , также известными как веб-сканеры и веб-пауки. Проще говоря, сканер посещает страницы веб-сайта и собирает содержимое с веб-сайта. Затем эти данные преобразуются в индекс.Возвращаясь к нашему примеру, если вы ищете «кошка» в Google, вам будет представлено несколько страниц и URL-адресов, релевантных вашему ключевому слову «кошка». В то время как книжный индекс является статическим, поскольку содержание книги не меняется, поисковый индекс является динамическим, поскольку веб-сайты постоянно создаются и обновляются.
Кроме того, количество условий поиска в индексе книги является фиксированным. Веб-поиск пытается включить все ключевые слова и поддерживает запросы с комбинированными условиями поиска. Например, вы можете искать «видео с кошками», и индекс поиска предложит соответствующие результаты.
Как результаты поиска возвращаются из индекса?
Когда пользователь вводит поисковый запрос, поисковая система находит документы, содержащие поисковый запрос.
Результаты возвращаются из индекса с title , короткое выделение контента , возможно изображение и ссылка на URL страницы .Некоторые CMS предлагают встроенные средства поиска, которые посещают собственную базу данных CMS. Поскольку база данных не организована как индекс, результаты будут отображаться медленнее, чем при поиске по сайту на основе индекса.
Как поисковый индекс может улучшить ваш веб-сайт
Поисковые системы автоматически собирают содержимое вашего веб-сайта . Благодаря алгоритму ваши результаты поиска имеют приоритет. Некоторым результатам будет придан больший вес, поэтому они будут отображаться перед другими страницами на странице результатов. Индекс помогает поисковым системам быстрее находить релевантные результаты.
При выборе службы поиска по сайту вы можете улучшить результаты поиска с помощью различных функций.
Начните бесплатную 14-дневную пробную версию с AddSearch.
Управление результатами и корректировка рейтинга
Существуют три основные функции для управления рейтингом и его корректировки в AddSearch: разделы сайта, закрепленные результаты и рекламные акции.
Области сайта: С помощью функции области сайта вы можете выбрать, какие области вашей веб-страницы вы хотите повысить, а какой контент вы хотите сделать менее важным. Например, вы можете захотеть, чтобы ваши статьи поддержки показывались перед любыми статьями блога, если ваш пользователь с большей вероятностью найдет соответствующую информацию в «поддержке». Вы также можете вообще исключить определенные страницы из результатов поиска, например целевые страницы или страницы авторов. Эта функция влияет только на внутренний поиск по сайту, но не на ваш поиск в Google.
Закрепленные результаты: Вы можете закрепить определенный контент, чтобы он отображался в верхней части страницы результатов. Сначала вы выбираете ключевое слово, а затем выбираете страницу, которая должна отображаться первой.
Можно закрепить несколько страниц и соответственно упорядочить их. Эта функция отображается как обычный результат, поэтому ваши пользователи не будут знать, что они смотрят на закрепленный результат.Рекламные акции: Подобно закрепленному результату, рекламная акция будет отображаться первой на странице результатов. Акции могут быть выбраны для нескольких ключевых слов и страниц. Кроме того, вы можете использовать несколько элементов дизайна, таких как цвет фона, чтобы сделать продвижение визуально привлекательным для вашего посетителя. Акции могут быть временными, например, для специального рождественского предложения.
Персонализация
Вы можете персонализировать результаты для каждого посетителя сайта.
Благодаря персонализации пользователи могут видеть результаты поиска на основе своих предпочтений и истории просмотров.Все пользователи приходят на веб-сайт с разными целями, и, хотя кажется, что они выполняют поиск по одному и тому же ключевому слову, ожидаемые результаты могут сильно различаться. Например, если посетитель сайта, который, как известно, является вегетарианцем, ищет «рецепт пасты», результаты поиска могут сразу же дать информацию о вегетарианском соусе, в то время как вы порекомендуете мясоеду болоньезе.
Пользовательские результаты более релевантны, а более качественные результаты поиска повышают удобство работы пользователей на вашем веб-сайте, повышают их удовлетворенность и, как следствие, увеличивают число конверсий. На персонализацию может влиять что угодно, от определенного просмотра страницы до предпочтительных параметров поиска, информации об учетной записи или истории покупок.
AddSearch также предоставляет владельцам сайтов рекомендации по настройке параметров персонализации, чтобы убедиться, что опыт удовлетворяет потребности каждого пользователя.
Если вы заинтересованы в этом, вы можете связаться с нашим отделом продаж.Пользовательский интерфейс поиска и API
Если вы хотите настроить свой пользовательский интерфейс для более продвинутого и персонализированного дизайна для поиска по сайту, вы можете использовать AddSearch для сканирования вашего сайта и предоставления поискового индекса, но кодируйте свой собственный дизайн. Этот индивидуальный подход отлично подходит для оформления страницы результатов поиска в соответствии с уникальными потребностями и желаниями вашего посетителя.
Одним из вариантов является предоставление индексирующего API для сканера. С помощью этого метода результаты могут постоянно обновляться новым поступающим контентом. Это решение имеет смысл, если на вашем веб-сайте есть прямые трансляции или постоянно обновляемый контент (например, новостные сайты или видеоплатформы).
Analytics
С помощью Analytics вы можете увидеть, что ищут ваши пользователи, и дать им именно то, что они хотят.
 Этот термин происходит от того факта, что поисковая система перемещается от страницы к странице в Интернете для сбора данных. Он просматривал весь контент и определял все ссылки, а затем начинал посещать каждую из этих ссылок — движение изображалось как паук, ползающий по всемирной паутине.
Этот термин происходит от того факта, что поисковая система перемещается от страницы к странице в Интернете для сбора данных. Он просматривал весь контент и определял все ссылки, а затем начинал посещать каждую из этих ссылок — движение изображалось как паук, ползающий по всемирной паутине.
 .
. Архитектура охватывает технические аспекты вашего веб-сайта, то есть время отклика, структуру страниц и ссылок, компоненты заголовков и метатеги.
Архитектура охватывает технические аспекты вашего веб-сайта, то есть время отклика, структуру страниц и ссылок, компоненты заголовков и метатеги.



 Без поискового индекса поисковый запрос потребляет ресурсы сервера и замедляет работу сайта. Вот почему поисковый индекс является жизненно важной частью любого хорошего варианта поиска по сайту.
Без поискового индекса поисковый запрос потребляет ресурсы сервера и замедляет работу сайта. Вот почему поисковый индекс является жизненно важной частью любого хорошего варианта поиска по сайту.
 Поисковый индекс для веб-сайтов создается сканерами , также известными как веб-сканеры и веб-пауки. Проще говоря, сканер посещает страницы веб-сайта и собирает содержимое с веб-сайта. Затем эти данные преобразуются в индекс.
Поисковый индекс для веб-сайтов создается сканерами , также известными как веб-сканеры и веб-пауки. Проще говоря, сканер посещает страницы веб-сайта и собирает содержимое с веб-сайта. Затем эти данные преобразуются в индекс. Результаты возвращаются из индекса с title , короткое выделение контента , возможно изображение и ссылка на URL страницы .
Результаты возвращаются из индекса с title , короткое выделение контента , возможно изображение и ссылка на URL страницы .
 Можно закрепить несколько страниц и соответственно упорядочить их. Эта функция отображается как обычный результат, поэтому ваши пользователи не будут знать, что они смотрят на закрепленный результат.
Можно закрепить несколько страниц и соответственно упорядочить их. Эта функция отображается как обычный результат, поэтому ваши пользователи не будут знать, что они смотрят на закрепленный результат. Благодаря персонализации пользователи могут видеть результаты поиска на основе своих предпочтений и истории просмотров.
Благодаря персонализации пользователи могут видеть результаты поиска на основе своих предпочтений и истории просмотров. Если вы заинтересованы в этом, вы можете связаться с нашим отделом продаж.
Если вы заинтересованы в этом, вы можете связаться с нашим отделом продаж.