
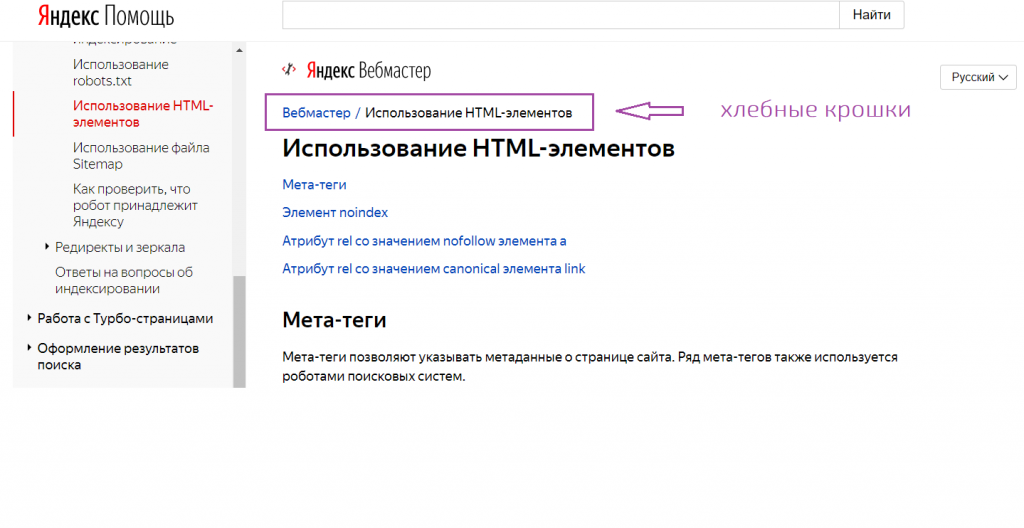
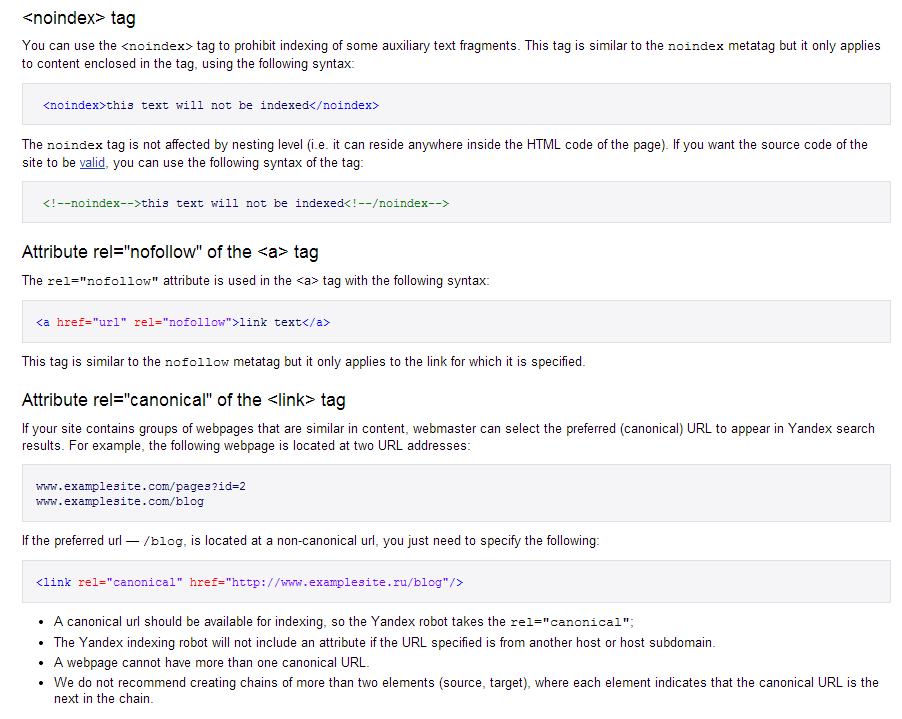
Пагинация и SEO: нужно ли закрывать постраничную навигацию от индексации
Привет, друзья. Тут недавно в Фейсбуке возникло обсуждение на тему постраничной навигации (пагинации) с целью сформировать какую-то единую точку зрения на то, что делать с такими страницами на сайте: как правильно их оформлять, открыть их для индексации или лучше закрывать. Если открывать, то что при этом надо учесть, уникализировать заголовки или оптимизировать каждую страницу. И вообще полезно ли держать эти страницы открытыми? А если закрывать, то каким именно способом: robots.txt, meta robots, canonical…
Вопросов очень много и, к сожалению, к единому мнению мы так и не пришли. Многое зависит от конкретной ситуации, от технических возможностей и материальных вложений в доработки.
Я же хочу рассмотреть все возможные варианты, их плюсы и минусы, а также предостеречь вас от очевидных ошибок, в которых разногласий быть не может.
Итак, пагинация – это постраничная навигация на страницах каталогов или категорий (смотря о каком типе сайта речь), и возникает она в том случае, когда все товары или другие элементы не помешаются на одной странице, и чтобы посмотреть следующий список элементов, приходится переходить на вторую страницу и далее. Уверен, каждый из вас это видел: пагинация есть на страницах поисковых систем, в интернет-магазинах, досках объявлений и т. д.
Уверен, каждый из вас это видел: пагинация есть на страницах поисковых систем, в интернет-магазинах, досках объявлений и т. д.
Вот пример блока со страницами навигации на моем блоге:
Пользователи к этому привыкли и не видят проблем в такой навигации, а вот для вебмастера не все так однозначно, потому что, если визуально это выглядит всегда одинаково, внутри может работать совершенно по-разному, следовательно, и поисковые роботы могут воспринимать это тоже по-разному.
Как сделать пагинацию, мы обсуждать с вами не будем, потому что каждый движок (CMS) имеет такой функционал и везде он похож, так что подразумеваем, что вы сейчас решаете вопрос, что делать с уже существующими страницами пагинации, чтобы это не вредило, а помогало в SEO. Тем не менее, упомяну мой пост как сделать пагинацию для WordPress без плагинов – этим методом я пользуюсь для моего блога и по сей день.
Вот какие у нас есть варианты и соответствующие требования:
- Оставить страницы пагинации для индексации:
- Факты:
- Уникализировать title,
- Не дублировать seo-текст с первой страницы,
- Не дублировать главную страницу категории со страницей page/1/.

- Вопросы:
- Надо ли использовать атрибуты next/prev?
- Надо ли уникализировать h2?
- Что делать с description для пагинации?
- Факты:
- Закрыть пагинацию от поисковых систем:
- Способы:
- Закрыть в robots.txt,
- Закрыть мета-тегом robots,
- Использовать canonical.
- Вопросы:
- А может лучше использовать X-Robots Tag?
- Можно ли использовать несколько методов одновременно?
- Надо ли уникализировать закрытые от индексации страницы?
- Способы:
- Другие вопросы, связанные с пагинацией:
- На что влияет кнопка «Показать еще» и AJAX подгрузка контента?
- Важно ли наличие ЧПУ для страниц пагинации?
- Можно ли продвигать страницы пагинации?
- Сколько товаров выводить на странице?
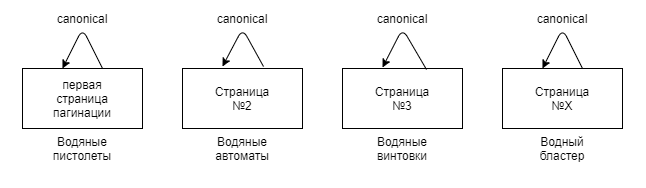
Как видите, вариантов много, вопросов тоже достаточно. Я предлагаю все это подробно разобрать, в результате чего вы сможете выбрать подходящий для себя вариант. А если не сможете, то я обязательно поделюсь вариантом, который предпочитаю лично я.
А если не сможете, то я обязательно поделюсь вариантом, который предпочитаю лично я.
Очень часто страницы пагинации становятся причиной появления дублей title у сайта. А это, как известно, нарушение, и не приветствуется поисковыми системами. Выявить наличие или отсутствие дублей заголовков вы можете любой программой-краулером, например, ComparseR. Хотя если страницы пагинации у вас закрыты от индексации, вы не увидите дубликатов при стандартных настройках программы, но их не увидит и робот ПС.
В последнее время проблем с дублями все меньше, потому что большинство свежих версий движков из коробки уникализируют заголовки, но, если у вас старая версия, провериться все же стоит.
Давайте разберем каждый из вариантов и ответим на вопрос: оставлять или закрывать страницы пагинации для индексации.
Оставить страницы пагинации в индексе
Лично мне нравится такой вариант больше всех, и я использую его на своих личных проектах.
И если мы решили оставить страницы пагинации, нам надо выполнить несколько важных условий:
- Надо уникализировать заголовок title у всех страниц пагинации. Первая страница, она же главная страница категории, будет иметь какой-то оптимизированный заголовок, например: «Купить холодильник в Краснодаре недорого – интернет-магазин Холодос». Тогда для всех последующих страниц, начиная со второй и далее, заголовок будет с приставкой « – страница X», вот так: «Купить холодильник в Краснодаре недорого – интернет-магазин Холодос – страница 2».
- Описанный выше вариант самый простой и распространенный. Но его можно модифицировать, чтобы стало еще лучше и красивее. Например, подставлять в title пагинаций не весь title целиком, а брать только название категории (часто это переменная, которая подставляется в h2), вот так: «Холодильники – страница 2». Я называю это деоптимизацией title. Это нужно, чтобы страницы пагинации никак не мешали первой странице категории, поэтому делаем заголовок неоптимизированным, менее релевантным.
- Если вдруг у нас есть в категории какое-то описание или seo текст, он не должен дублироваться, то есть его нельзя повторять на всех страницах, он должен оставаться только на главной странице категории.
- Нельзя допускать дублирования главной страницы категории по адресам типа
site.ru/category/holodolnikиsite.ru/category/holodolnik/page/1(илиsite.ru/category/holodolnik?page=1в зависимости от технических особенностей движка). Это решается 301 редиректом со страниц page/1 (page=1 и т.п.) на url без них.
 Первая страница, она же главная страница категории, будет иметь какой-то оптимизированный заголовок, например: «Купить холодильник в Краснодаре недорого – интернет-магазин Холодос». Тогда для всех последующих страниц, начиная со второй и далее, заголовок будет с приставкой « – страница X», вот так: «Купить холодильник в Краснодаре недорого – интернет-магазин Холодос – страница 2».
Первая страница, она же главная страница категории, будет иметь какой-то оптимизированный заголовок, например: «Купить холодильник в Краснодаре недорого – интернет-магазин Холодос». Тогда для всех последующих страниц, начиная со второй и далее, заголовок будет с приставкой « – страница X», вот так: «Купить холодильник в Краснодаре недорого – интернет-магазин Холодос – страница 2».
Это действия, которые необходимо сделать если вы решили оставлять страницы пагинации в индексе.
Но есть и менее очевидные вещи, которые находятся под вопросом:
- Надо ли менять h2 на страницах пагинации? Вопрос интересный, но лично я этого не делаю, я дублирую на всех страницах навигации один и тот же заголовок (в отличие от дублирования title — это не есть нарушение). И в целом очень редко встречаю сайты, где в h2 добавляется приставка «- страница X». Это не хорошо и не плохо, можете делать так, как вам нравится.
- Надо ли использовать атрибуты <link rel=»prev» href=». ..»/> и <link rel=»next» href=»…»/>? Раньше Google поддерживал эти теги и рекомендовал их использовать для страниц пагинации, но весной 2019 года внезапно сообщили, мол: «Мы упразднили атрибуты rel=prev/next, потому что исследования показали, что пользователи любят одностраничный контент».
Spring cleaning!
As we evaluated our indexing signals, we decided to retire rel=prev/next.
Studies show that users love single-page content, aim for that when possible, but multi-part is also fine for Google Search. Know and do what’s best for *your* users!— Google Webmasters (@googlewmc) March 21, 2019
Это заявление не запрещает использовать данные директивы, но и поисковик их учитывать больше не будет.
Учитывая, что сама публикация, к которой оставлен данный комментарий, датирована 2015 годом и вопрос об next и prev там поднимался не раз, вряд ли что-то изменится когда-либо.
Что касается Яндекса, то он никогда и не поддерживал атрибуты next и prev, о чем свидетельствует комментарий Платона от 2018 года: Поэтому целенаправленно настраивать данные атрибуты не нужно, но и удалять, если ваш движок их выводит, нет смысла. - Последнее, с чем осталось разобраться, если мы решили оставить страницы пагинации открытыми для индексации – надо ли уникализировать метатег description? Лично я вообще удаляю этот метатег со страниц пагинации, чтобы его не было в коде. Как вариант – можно оставить его пустым. Еще один вариант – добавлять в него приставку «- страница X», как для title. Выбирайте то, что вам больше нравится, любой из этих вариантов приемлемый.
 ..»/> и <link rel=»next» href=»…»/>? Раньше Google поддерживал эти теги и рекомендовал их использовать для страниц пагинации, но весной 2019 года внезапно сообщили, мол: «Мы упразднили атрибуты rel=prev/next, потому что исследования показали, что пользователи любят одностраничный контент».
..»/> и <link rel=»next» href=»…»/>? Раньше Google поддерживал эти теги и рекомендовал их использовать для страниц пагинации, но весной 2019 года внезапно сообщили, мол: «Мы упразднили атрибуты rel=prev/next, потому что исследования показали, что пользователи любят одностраничный контент». Поэтому целенаправленно настраивать данные атрибуты не нужно, но и удалять, если ваш движок их выводит, нет смысла.
Поэтому целенаправленно настраивать данные атрибуты не нужно, но и удалять, если ваш движок их выводит, нет смысла.Теперь я объясню, почему я выбираю для себя вариант держать пагинацию открытой для поисковиков.
Чтобы не оставлять страницы товаров, которые находятся не на первой странице каталога, без ссылочных связей и не портить индексацию. Конечно, ссылки на товары могут встречаться в других категориях или фильтрах, появляться в перелинковке в блоке похожих товаров, но, как правило, это неконтролируемый процесс, поэтому какие-то товары могут остаться не у дел. Если оставить пагинацию открытой, то поисковый робот всегда сможет добраться до всех страниц и до всех товаров, которые у нас есть, так что вероятность, что товары будут выпадать из индекса из-за недостатка ссылочного веса, снижается.
Если оставить пагинацию открытой, то поисковый робот всегда сможет добраться до всех страниц и до всех товаров, которые у нас есть, так что вероятность, что товары будут выпадать из индекса из-за недостатка ссылочного веса, снижается.
У меня есть отдельная большая публикация о перелинковке для интернет-магазинов, где подробно разобраны все способы перелинковки товаров, seo-фильтров и категорий. Разумеется, с наглядными примерами, скриншотами и сопутствующими материалами. Если вы владелец интернет-магазина или занимаетесь продвижением ИМ, настоятельно рекомендую прочитать мой пост.
Закрыть от индексации страницы пагинации
Данный вариант не плохой, сторонников его использования не меньше, чем первого (это как iOS vs. Android, Canon vs. Nikon и т. д.), поэтому и единого мнения на счет пагинации никогда не будет, в каждом методе есть свои преимущества.
И если вы решили закрыть страницы пагинации, у вас есть несколько способов:
- Закрыть индексацию страниц через robots. txt. Например, директивой
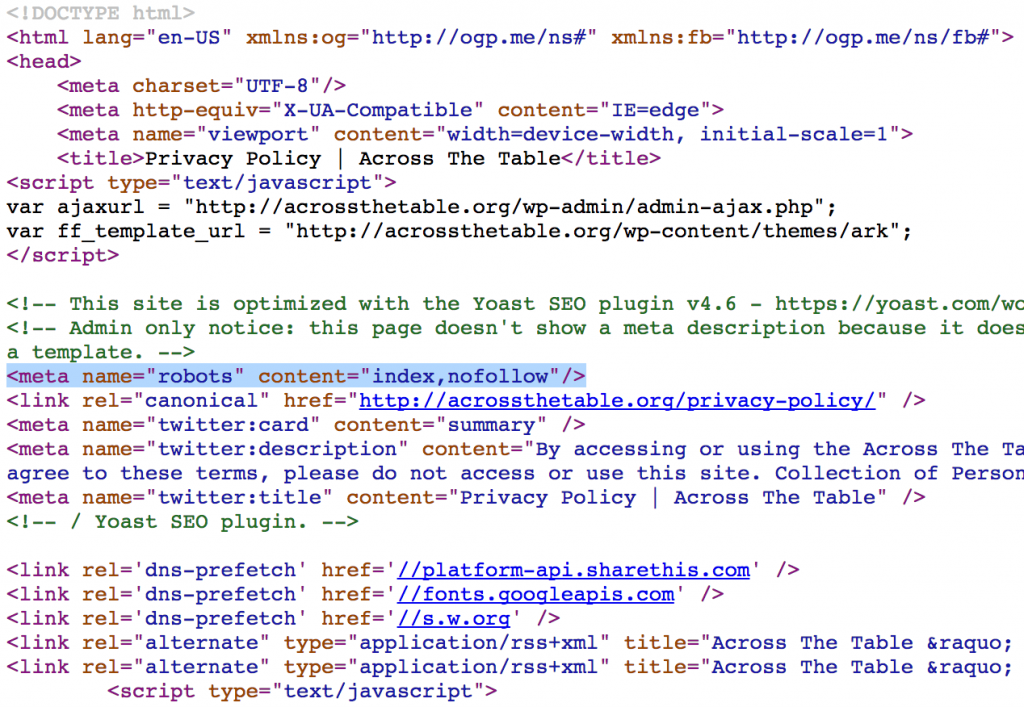
Disallow: */page/илиDisallow: /*page=(в зависимости от технической реализации в CMS). Это самый плохой способ избавиться от пагинаций, и я не рекомендую вам его использовать. Потому что тогда робот точно не будет заходить на закрытые страницы, карточки товаров в глубине каталога будут плохо индексироваться, а при всем при этом ссылки на страницы пагинации могут появляться в выдаче Google (он показывает в выдаче даже закрытые страницы, но с пометкой, что они закрыты). - Закрыть страницы при помощи <meta name=»robots» content=»noindex» />. Этот метод также закроет страницы от поисковиков, как и предыдущий, только Google уже не будет выводить ссылки на такие страницы, то есть все будет чисто. Но проблема с тем, что товары из глубины каталога будут страдать останется. Можно использовать сочетание директив
content="noindex,follow"при которых робот не будет добавлять страницы в индекс, но будет переходить по ссылкам, содержащимся на данных страницах, но проблему с товарами из глубины каталога это не решает. - Использовать rel=»canonical» с указанием главной страницы категории для страниц пагинации. Это самый лучший вариант избавиться от пагинации в индексе. Если мы будем использовать канонический адрес, например,
<link rel="canonical" href="https://site.ru/category/holodolnik"/>на всех страницах пагинации, то поисковики будут заходить на все страницы, будут обходить ссылки на этих страницах, при этом сами страницы пагинации в индекс не попадут.
 txt. Например, директивой
txt. Например, директивой 
Вариант с использованием canonical является единственным приемлемым среди сторонников избавления от лишних страниц пагинации. Этим же вариантом чаще всего пользуются и ребята в нашей студии при работе с клиентскими сайтами.
У Яндекса есть публикация в блоге для вебмастеров от 29 декабря 2015 года «Несколько советов интернет-магазинам по настройкам индексирования» и в ней раздел «Что делать со страницами пагинации товаров», где рекомендуется использовать каноникал:
Если в какой-либо категории на вашем сайте находится большое количество товаров, могут появиться страницы пагинации (порядковой нумерации страниц), на которых собраны все товары данной категории.
Например, страница сайт.рф/ромашки/1 — каноническая, с неё начинается каталог, а страницы вида сайт.рф/ромашки/2 и сайт.рф/ромашки/3 — неканонические, в поиск их можно не включать. Это не только предотвратит возможное дублирование контента, но и позволит указать роботу, какая именно страница должна находиться в выдаче по запросам. При этом ссылки на товары, которые находятся на неканонических страницах, также будут известны индексирующему роботу.
 Если на такие страницы нет трафика из поисковых систем и их контент во многом идентичен, то советую настраивать атрибут rel=»canonical» тега <link> на подобных страницах и делать страницы второй, третьей и дальнейшей нумерации неканоническими, а в качестве канонического (главного) адреса указывать первую страницу каталога, только она будет участвовать в результатах поиска.
Если на такие страницы нет трафика из поисковых систем и их контент во многом идентичен, то советую настраивать атрибут rel=»canonical» тега <link> на подобных страницах и делать страницы второй, третьей и дальнейшей нумерации неканоническими, а в качестве канонического (главного) адреса указывать первую страницу каталога, только она будет участвовать в результатах поиска.Но не стоит забывать, что указание канонической страницы – это не строго правило, а лишь рекомендация для поискового робота. Если страницы полные дубли друг друга, то склейка неканонической страницы с канонической произойдет, а если есть различия, то поисковик сможет поступать так, как посчитает нужным, и результат будет непредсказуемым.
Так что в последнее время появляется все больше вопросов, когда неканонические страницы попадают в индекс и ранжируются. Подтверждением тому служит пост Яндекса «Неканонические страницы в Поиске»:
Часто на сайтах присутствуют страницы с разными URL, но с одинаковым или очень похожим содержанием. С помощью атрибута rel=«canonical» вебмастера могут указать, какая страница является «канонической» — предпочтительной для индексации и появления в результатах поиска. Остальные, неканонические версии как правило в поиск не попадают.
Наши исследования показывают, что страницы, размеченные как неканонические могут быть полезны, а их наличие в поиске может влиять на качество и полноту ответа на запрос пользователя.
…
В результате сайт не находится по запросу-цитате, соответствующей тексту за пределами первой странице. Поэтому теперь в поиске неканонические страницы будут появляться чаще.
Они будут показаны в том случае, если они более релевантны запросу и их контент существенно отличался от канонической версии во время сканирования роботом.

Несмотря на это, использование каноникала для страниц пагинации остается самым приемлемым вариантом для исключения их из индекса.
Есть и еще один метод закрыть страницы от индексации, который я не указал в своем списке выше – это заголовок X-Robots Tag. По результатам он полностью идентичен использованию метатега robots и имеет аналогичные директивы: noindex, nofollow, nosnippet и т. д., однако робот узнает о правилах не в момент посещения страницы и изучения ее кода, а на уровне ответа сервера, когда только идет обращение к url-адресу. Данный метод самый сложный в реализации и отслеживании, поэтому практически никто им не пользуется для решения задач, типа нашей.
Можно ли использовать несколько методов одновременно?
Нельзя! Каждый из перечисленных выше методов – robots.txt, meta robots, canonical, x-robots – исключают использование друг друга, а срабатывать будет более строгое правило.
Вот, что написано об этом в Google:
Метатеги robots и HTTP-заголовки X-Robots-Tag обнаруживаются при сканировании URL.
 Если сканирование страницы запрещено файлом robots.txt, то директивы, касающиеся индексирования или показа контента, будут проигнорированы. Чтобы обеспечить обязательное выполнение директив, не следует запрещать сканирование URL, для которых они заданы.
Если сканирование страницы запрещено файлом robots.txt, то директивы, касающиеся индексирования или показа контента, будут проигнорированы. Чтобы обеспечить обязательное выполнение директив, не следует запрещать сканирование URL, для которых они заданы.По аналогии: Если в коде одновременно будут meta robots noindex и canonical, то страница просто не будет индексироваться и дело до учета канонического адреса страницы не дойдет, так как meta robots – это правило, а canonical – всего лишь рекомендация.
Надо ли уникализировать закрытые от индексации страницы?
Не надо. В этом просто нет смысла. Если у страниц, которые вы запретили к индексации дублируются title заголовки, то нет смысла делать их уникальными, робот все равно не проиндексирует страницы, а значит не возникнет и проблем.
Если вы будете уникализировать страницы, которые хотите склеить с помощью canonical, то они станут еще более отличные друг от друга и вероятность того, что они не будут склеены, повышается. Так что не надо этого делать.
Так что не надо этого делать.
Пагинация на JS, кнопка «Показать еще» и AJAX подгрузка контента
Замена классической системы навигации с перечнем страниц 1, 2, 3 … N встречается часто, вместо нее может быть одна кнопка «Показать еще», «Еще товары», «Следующая страница» и т. д. Согласен, что это довольно удобно с точки зрения юзабилити, особенно при работе с мобильных устройств. Кроме того, скорость отдачи контента выше, ведь приходится загружать только блок с карточками товаров вместо перезагрузки все страницы, как это происходит при классической пагинации.
Не зря крупные сайты типа Яндекс.Маркета и других используют такую систему:
Но обратите внимание, что кроме кнопки «Еще» дублируется и классическая навигация по страницам.
Вот что сам Яндекс говорит на этот счет:
Часто вместо пагинации сайты используют динамическую прокрутку, когда для посетителя, пролиставшего каталог до определённого момента, с помощью JavaScripts загружаются другие товары в данной категории.
 В такой ситуации необходимо проследить, чтобы весь контент таких страниц отдавался индексирующему роботу (например, с помощью инструмента в Яндекс.Вебмастере), либо чтобы роботу становилась доступна статическая пагинация товаров.
В такой ситуации необходимо проследить, чтобы весь контент таких страниц отдавался индексирующему роботу (например, с помощью инструмента в Яндекс.Вебмастере), либо чтобы роботу становилась доступна статическая пагинация товаров.То есть необходимо совмещать приятное (кнопка «Показать еще» для пользователя) и полезное (постраничная навигация для робота). Если же по какой-то причине классическая пагинация не вписывается в дизайн вашего сайта или есть другие причины ее не показывать, есть решение – оставить классическую пагинацию в коде страницы, а с помощью стилей “display:none” скрыть ее в дизайне. И все будут довольны 🙂
Важно ли наличие ЧПУ для страниц пагинации?
Нет. Не важно. На этот счет можно не заморачиваться и оставить все как есть, принципиальной разницы между:
site.ru/category/holodolnik/page/2site.ru/category/holodolnik/?page=2site.ru/category/holodolnik/?PAGEN_1=2 и т. д.
д.
Нет никакой! Главное, чтобы и робот, и посетитель понимали, что это пагинация.
Можно ли продвигать страницы пагинации?
Технически можно, но вот нужно ли? В сети было несколько кейсов на этот счет, когда бралась какая-то категория магазина, кластер запросов для посадки на одну страницу был слишком большой и его разбивали на несколько кластеров и вели на страницы пагинации этой категории.
Мое мнение – это из разряда каких-то извращений или «а смотрите, как я могу!». Во-первых, технические заморочки, чтобы обеспечить на страницах навигации настройку уникальных title, h2 и seo-текста. Во-вторых, чем плохи подкатегории, тегирование и seo-фильтры? Ничем не хуже, они даже лучше, так как более предсказуемы по содержанию и лучше отвечают на запросы пользователя, который попадает на главную страницу подкатегории/фильтра, а не на энную страницу общей категории.
Сколько товаров выводить на странице?
Вопрос и относится, и не относится к теме одновременно. Главным аргументом в данном вопросе будут результаты проведения коммерческого аудита сайта и сравнение с конкурентами. Можно изучить конкурентов по своим ВЧ-запросам из топа и посмотреть, сколько товаров на странице выводят они. Чтобы сильно долго не думать, можно взять медианное значение.
Главным аргументом в данном вопросе будут результаты проведения коммерческого аудита сайта и сравнение с конкурентами. Можно изучить конкурентов по своим ВЧ-запросам из топа и посмотреть, сколько товаров на странице выводят они. Чтобы сильно долго не думать, можно взять медианное значение.
Все вышесказанное относится не только к интернет-магазинам, на примере которых я вам рассказывал, но и к каталогам, доскам объявлений, агрегаторам, порталам и т. д., даже к информационным сайтам. Везде, где есть пагинация – данная информация будет применима!
На этом все, друзья. Если у вас остались какие-то вопросы, задавайте их в комментариях.
До связи!
Тег Canonical в 2021 году — Что изменилось в Google
Ваш браузер не поддерживает HTML5 аудио. Вот взамен ссылка на аудио
1X
Длительность: 8:34
В очередном аудиоподкасте №295 Николай Шмичков рассказал про тег Canonical в 2021 году — что изменилось в Google.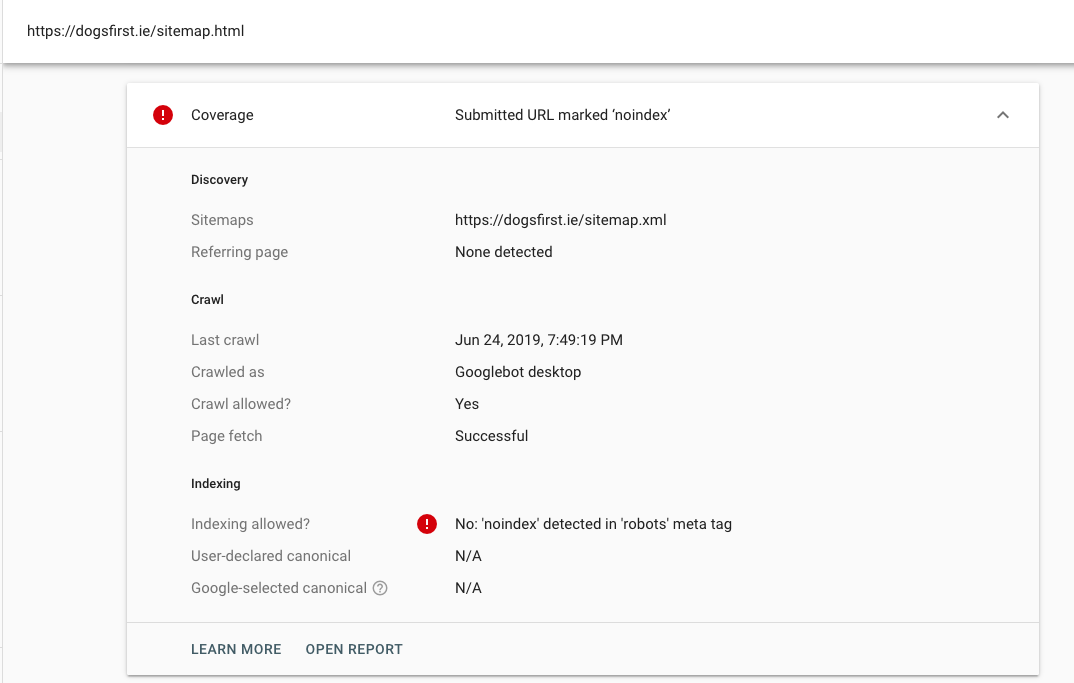
Полная текстовая версия выступления:
“Всем привет!
Сегодня говорим про каноникализацию.
Canonical — это особый тег, который используется для отметки одинакового контента на сайте.
Но есть одно но: Google не считает Canonical директивой.
А чем считает — я расскажу подробно в этом подкасте.
Совсем недавно Google на своем YouTube-канале Webmasters выпустил ролик Canonicalization: SEO Mythbusting с разоблачением сео-мифов по теме каноникализации.
Что главное нужно знать?
Каноникализация — это не группировка, не объединение страниц, общих по тематике.
Canonical должен быть обязательно идентичным или почти идентичным.
Например, можно считать Canonical, когда отличается title и description у статьи, но абсолютно повторяется контент.
Такое часто встречается, когда генерируют конкретные страницы под город.
Если контент практически повторяется, Canonical в этом случае актуален.
Из-за этого среди специалистов бытует миф, что Canonical — это директива.
Директива — это инструкция, которой должен четко следовать поисковик.
Когда, например, вы делаете тег noindex, это конкретная директива, вы запрещаете индексировать конкретную страницу либо конкретный блок контента.
Google не считает Canonical директивой, а воспринимает ее лишь как подсказку, а не как конкретные указания для поисковой системы.
Поэтому он попросту может проигнорировать и вообще выбрать не ту страницу, которую вы считаете главной в поиске.
Поэтому каноникализация может сработать некачественно, если вы сделали Canonical один контент, который немного отличается от другого, и это может не сработать.
С Canonical может возникнуть такая ситуация: поисковик по умолчанию может выбрать не то, что вы хотите.
Если же происходят дубликаты в результатах поиска, Google использует Canonical-тег и свои системы оценки.
Дубликация происходит без участия человека, и поисковик выполняет эту функцию автоматически.
Google может заменить эту каноническую страницу, которую указал владелец сайта, на ту, которую посчитает сам подходящей для пользователей.
И он, конечно, учтет поведенческий фактор конкретной страницы.
Google может принять предпочтительную каноническую страницу, даже если она имеет небольшое количество уникального контента, которого нет на других страницах.
Если уникального контента много, то Google не распознает ее как дубликат.
В таком случае Canonical использовать не имеет смысла.
Делаем выводы: раньше, когда тег Canonical ставился сам на себя, то есть self-Canonical на всех страницах, это была как директива защиты, чтобы поисковик не склеил страницы между собой.
Теперь по факту это делать необязательно.
С помощью Canonical можно показывать абсолютно повторяющиеся страницы, чтобы поисковик не выбрал страницу, не являющуюся основной.
Он может, конечно, выбрать ту, которую посчитает нужным.
Как можно улучшить этот показатель?
Во-первых, внутренней перелинковкой на страницу, которая является главной в Canonical.
Должно быть как можно больше внутренних ссылок на внутренние страницы, которые являются, например, той же пагинацией.
Странно, но от пагинации многие сейчас уходят, делают автоматическую внутреннюю подгрузку, фильтрацию и т.п.
Но Google сам использует пагинацию, поэтому она все еще актуальна.
То есть каноникализация — это не редирект.
И раньше при помощи Canonical делали передачу веса, а сейчас этот трюк не сработает.
Если детально обратиться к теме каноникализации, главное, что нужно знать: это сигнал для поиска Google, а не директива.
И в качестве редиректа Canonical мы однозначно использовать не советуем.
Редирект 301 прекрасно подходит для передачи веса, междоменный Canonical с этой задачей справляется отвратительно.
Сейчас актуален отказ от этого метода.
В старых статьях и роликах я говорил про междоменный Canonical, но Google таким образом не учтет ваш переезд.
Таким образом часто делаются сайты, допустим, посвященные прокачке аккаунтов в Warcraft, каждый новый сайт создается на новом домене, мы сейчас этого делать не рекомендуем.
Делайте просто редирект и создавайте полноценный сайт.
Канонические теги предназначены исключительно для рекомендации поисковикам, какая страничка является основной, если есть дубли.
Google может признать Canonical даже ту страницу, которая является неканонической, при условии если вы не уникализировали контент.
Поэтому если вы хотите делать сайты четко под каждый город, мы рекомендуем на каждой странице не просто уникализировать текстовый контент, но и обязательно делать заголовки и визуально разный контент.
И, конечно, уделять внимание текстовым блокам, которые посвящены конкретному городу.
Например, можно указать конкретный адрес доставки в этом городе, филиалы, представительства, которые можно посетить.
Таким образом можно создавать поддомены.
Допустим, интернет-магазины вообще не переживают по поводу Canonical, потому что у них уникализацией контента выступает товарная матрица.
И если вы хотите заточить товарную матрицу под конкретный город, можно сделать сортировку за счет наличия, которая постоянно будет меняться, и, конечно, указывать адреса доставки в ближайших магазинах и сервисы службы доставки, которые действуют в конкретном городе, список складов.
Если у вас их нет, для уникализации есть другие трюки.
Если вас интересует эта тема — напишите в комментариях.”
Если у тебя есть вопросы, мы с радостью ответим в нашей группе в телеграмме — https://t.me/seoquick_com_ua
Пагинация для SEO — пошаговое руководство
Вы наверняка замечали, что сверху или снизу страницы сайта находится порядковая нумерация. Другое ее название – классическая пагинация. Если рассматривать функционирование интернет-площадки, то неправильная работа с этим структурным элементом может спровоцировать существенные проблемы с последующей индексацией содержимого. Чтобы понять, насколько важен такой момент для внутренней оптимизации, необходимо рассмотреть главные нюансы работы со структурной деталью.
Проблемы, возникающие из-за пагинации
-
Количество посещения страницы. Поисковые роботы, сканируя ресурс, будут проверять число и глубину составляющих, которые зависят от траста и частоты обновления контента.
-
Дубликаты. Содержание страниц может быть похожим, а иногда и идентичным. Это связано со структурой размещения данных. Также вы видите, что на каждом элементе встречаются одинаковые теги «metadescription» и «title». Это приводит к тому, что поисковики затрудняются в определении релевантных составляющих для удовлетворения запроса.

Как правило, практически все интернет-ресурсы обладают подобным функционалом, из-за чего и возникает проблема с его настройкой – весьма актуальная задача для SEO-оптимизаторов и веб-мастеров. А все по той причине, что неканонические страницы по сути являются частичными дублями, поскольку они копируют содержание главной, не включая список товаров.
Как устранить затруднения?
SEO-специалисты разработали четыре варианта решения проблем.
Использование noindex с целью удаления постраничной нумерации
Метод пользуется популярностью по причине высокой скорости его реализации. Суть применения: из индекса исключаются все страницы, кроме первой. Реализовать его можно, используя стандартный метатег: <meta name=»robots» content=»noindex, follow» /> (вставляется в раздел <head> на все составляющие, кроме выбранной посадочной фигуры). Результат: обеспечивается полное сканирование каталога, который представлен на первом листе.
Особенности метода: текст описания главного каталога лучше размещать в первом разделе. Также не забудьте проверить URL – он не должен дублироваться.
Преимущества варианта:
-
один из простых способов;
-
превосходно подходит для Яндекса;
-
отличный вариант исключить категорию из индекса, если нет основания добавления ее в систему.

Однако здесь есть и недостатки:
Последнее можно исправить применением xml-карты.
«Просмотр всего» и rel=“canonical”
Рекомендуется использовать для Google. Способ заключается в создании новой категории, которая подразумевает вывод всех изделий, представленных в галерее. На остальных разделах с нумерацией проставляется rel=“canonical”, что отправляет на просмотр всего ассортимента. В секцию <head> помещается <link rel=»canonical» href=»http://site.com/catalog/view-all.html» />. Поисковые системы воспринимают каждый раздел в качестве части общего просмотра. «Фишка» в том, что это наиболее предпочтительный вариант для Google.
Нюансы: такая категория должна загружаться не дольше трех секунд. Поэтому подобный тип идеально подойдет для каталогов, у которых не больше 20 составляющих пагинации. Также нужно учитывать, что на стандартных CMS реализация предельно сложная, и без опытного специалиста в такой ситуации не обойтись.
Rel=“prev”/“next”
Метод подойдет исключительно для поисковика Google. Его реализация непростая, поэтому нужно учитывать все тонкости и быть предельно осторожными во время применения. Вставляя rel=»prev»/»next», вы формируете цепочку между всеми разделами. Начинать нужно с первого, добавляя в секцию <head> :<linkrel=»next» href=»http://site.com/page2.html»>.
Особенность в том, что для каждой следующей страницы необходимо указывать атрибуты предыдущего и следующего компонента. Например, вторая категория будет выглядеть таким образом: <linkrel=»prev» href=»http://site.com/page1.html»>, <linkrel=»next» href=»http://site.com/page3.html»>. Третья имеет следующий вид: <link rel=»prev» href=»http://site.com/page2.html»>, <link rel=»next» href=»http://site.com/page4.html»>. С применением rel=»prev»/»next» Google устранит разбиение и объединит все разделы в единый на индексе. Пользователи увидят его в первую очередь, ведь он будет принят за релевантный.
Особенности: rel=»prev» и rel=»next» – не директивы, а вспомогательные структуры. Значениями при таких условиях могут выступать абсолютные и относительные rel=»prev» и rel=»next». Ссылаясь в документе на <base>, относительные пути будут основываться на базовом (существующем) URL. Google может обнаружить большие ошибки, являющиеся причиной того, что система проведет индексирование на основе собственного алгоритма. Чтобы избежать дублирования, обязательно проверяйте адреса.
Преимущества вышеописанного метода:
Недостатки:
Javascript прокрутка и AJAX
Сталкивались ли вы с проблемой прокрутки посадочной страницы к нижней части экрана, чтобы рассмотреть представленную продукцию? При этом изображения изделий медленно загружались. Такой способ поможет закрыть вопрос с юзабилити, если применить его правильно. Автоматическая загрузка позиций сменится простой кнопкой «Показать n число товаров».
Применение параметра: используйте rel=»prev»/»next», пагинативные элементы будут содержать атрибуты, которые никак не отразятся на изменении контента (сортировке, количестве продукции, переменных, или сессионных). Однако в результате получаются дубли. Решение – сочетать rel=»prev»/»next» и rel=”canonical”. Во-первых, разделы с нумерацией должны использовать представленный параметр rel=»prev»/»next». Во-вторых, к каждому URL создается (прописывается) канонический компонент без этого атрибута.
Однако в результате получаются дубли. Решение – сочетать rel=»prev»/»next» и rel=”canonical”. Во-первых, разделы с нумерацией должны использовать представленный параметр rel=»prev»/»next». Во-вторых, к каждому URL создается (прописывается) канонический компонент без этого атрибута.
Использование фильтров в сочетании с rel=“prev”/“next” выглядит следующим образом (описание рекомендованного алгоритма на примере создания страницы для выдачи брендовых изделий):
-
на основной категории говорите твердое «нет» rel=”canonical”, чтобы не испортить уникальность содержания;
-
каждому бренду присвойте оригинальные цепные связи на основе rel=“prev”/“next”;
-
для каждого фильтра создайте оригинальные title, descriprion, описание и уникальный текст.
Рекомендации по поводу решения проблемы
Если вы сделаете неправильную оптимизацию, то в результате это может привести к вреду для самого ресурса – важные странички не проиндексируются или же покажутся некачественными для поисковых систем. Не хотите терять целевой трафик? Тогда предельно важно осуществить правильную оптимизацию.
Не хотите терять целевой трафик? Тогда предельно важно осуществить правильную оптимизацию.
-
Если вы владеете соответствующими навыками и техническими возможностями для создания категории «Смотреть все», то воспользуйтесь этим вариантом. Все составляющие будут быстро загружаться из-за небольшого размера. К тому же Google дает лучшие рекомендации по поводу этого метода, а Яндекс адекватно реагирует на директиву rel=”canonical”.
-
В 70% случаев будет рационально сочетать rel=”next/prev” и метатег robots=”noindex, follow”. Если первый понимает только Google, то второй ясен и Яндексу.
-
Везде необходимо разместить директиву для роботов-поисковиков в виде метатега. Такая директива способствует тому, чтобы страничка не добавлялась в индекс поисковиков, но при этом робот может переходить по всем имеющимся ссылкам.
-
В секцию <head> помещается <meta name=»robots» content=»noindex, follow» />.
Помимо этого, требуется везде внести теги «prev» и «next», которые указывают на предыдущую и следующую странички соответственно. Таким образом, роботу легче воспринимать структуру пронумерованных разделов, за счет чего улучшается сканирование присутствующих товаров или статей.
 Помимо этого, требуется везде внести теги «prev» и «next», которые указывают на предыдущую и следующую странички соответственно. Таким образом, роботу легче воспринимать структуру пронумерованных разделов, за счет чего улучшается сканирование присутствующих товаров или статей.
Помимо этого, требуется везде внести теги «prev» и «next», которые указывают на предыдущую и следующую странички соответственно. Таким образом, роботу легче воспринимать структуру пронумерованных разделов, за счет чего улучшается сканирование присутствующих товаров или статей.ВАЖНО! Учтите, что URL главной не должен быть представлен в виде http://site.com/page1.html. Вместо него должен существовать вот такой: http://site.com/page.html. Другими словами, когда пользователь нажимает на цифру 1 в списке выбора страничек, переход будет осуществляться непосредственно на главную в виде http://site.com/page.html. Обратите внимание, что при размещении текста на категории следует скрыть его на остальных страницах.
Если вы попадаете в ситуацию, когда генерируется огромное количество дублей, тогда можно применить способ с закрытием страничек для индексации роботами поисковых систем.
Как выяснить, что пагинация настроена неправильно?
Главный признак, указывающий на возможные ошибки в настройке пагинации, – наличие дублей метаданных в числе проиндексированных поисковыми системами страничек. Наиболее простым способом проверки считается просмотр проиндексированных разделов в Google с помощью оператора site: (к примеру, site:example.com). Он продемонстрирует все страницы для домена example.com. Однако если ваш сайт отличается большим количеством страниц, лучше всего воспользоваться специальными сервисами для проверки по типу Screaming Frog Seo Spider. Здесь необходимо отыскать дубликаты по title и посмотреть на их URL, чтобы определить пагинацию.
Наиболее простым способом проверки считается просмотр проиндексированных разделов в Google с помощью оператора site: (к примеру, site:example.com). Он продемонстрирует все страницы для домена example.com. Однако если ваш сайт отличается большим количеством страниц, лучше всего воспользоваться специальными сервисами для проверки по типу Screaming Frog Seo Spider. Здесь необходимо отыскать дубликаты по title и посмотреть на их URL, чтобы определить пагинацию.
Заключение
Нужно понимать, что как таковой единой стратегии по оптимизации страниц пагинации не существует. Каждый SEO-специалист выбирает тот вариант, который считает наиболее действенным. Поэтому необходимо анализировать конкурентов, подмечать используемые ими тактики, которые могут быть эффективны и для вашей ниши. Так вы найдете решения, которые пригодны для внедрения в ваш проект. Однако помните, что работа с настройкой и продвижением сайта – кропотливое и сложное дело, требующее значительного практического опыта и теоретических знаний. Если вы не обладаете ни тем, ни другим, а от интернет-ресурса зависит ваш бизнес, лучше не рисковать, пытаясь сделать все самостоятельно.
Если вы не обладаете ни тем, ни другим, а от интернет-ресурса зависит ваш бизнес, лучше не рисковать, пытаясь сделать все самостоятельно.
Во-первых, вам придется не только выучить, но и понять целый словарь профессиональной терминологии, которой пользуются специалисты. Во-вторых, никто не даст гарантии, что вы все делаете правильно. Вам придется пойти по методу проб и ошибок, а собственное дело – не лучший вариант для «тренировочного манекена».
В подобной ситуации наиболее разумным решением станет обращение к профессионалам из UMI. Так вы сможете быть уверенными в успешном результате и освободить себе время для других дел.
Когда использовать Rel Canonical или Noindex …или и то, и другое
Во время встречи в рабочее время Google SEO Джона Мюллера из Google спросили, какой тег rel canonical или noindex является лучшим подходом для работы с дублирующимся и неполноценным контентом на сайте электронной коммерции. . Джон Мюллер обсудил оба варианта, а затем предложил третий способ решения этой проблемы.
Директива Noindex
Метатег noindex является директивой, которая означает, что Google должен подчиняться метатегу и исключать веб-страницу из результатов поиска.
Все, что делает тег noindex, — это удаляет эту страницу из результатов поиска Google.
В официальной документации Google указано:
«Вы можете предотвратить появление страницы или другого ресурса в поиске Google, включив метатег noindex или заголовок в ответ HTTP. Когда робот Googlebot в следующий раз просканирует эту страницу и увидит тег или заголовок, робот Googlebot полностью исключит эту страницу из результатов поиска Google, независимо от того, ссылаются ли на нее другие сайты».
Rel Canonical
Тег rel=canonical является подсказкой, а не директивой. Это дает Google предложение, для которого URL вы хотите показать в результатах поиска.
Это полезно, когда есть несколько похожих страниц, особенно когда CMS для покупок создает несколько страниц для одного и того же продукта, и обычно единственное различие заключается в чем-то тривиальном, например, в цвете товара.
Официальная каноническая документация Google объясняет проблему следующим образом:
«Канонический URL-адрес — это URL-адрес страницы, которая, по мнению Google, является наиболее репрезентативной из набора повторяющихся страниц на вашем сайте. Например, если у вас есть URL-адреса одной и той же страницы (example.com?dress=1234 и example.com/dresses/1234), Google выбирает один из них как канонический».
rel canonical — полезное решение, потому что оно может объединить все сигналы ссылок и релевантности на главную страницу, которые издатель хочет видеть в результатах поиска.
Но поскольку Google воспринимает тег rel canonical как подсказку, нет никакой гарантии, что Google будет ему подчиняться, и алгоритм Google может решить показать какую-то другую страницу в результатах поиска.
Rel Canonical Versus Noindex
Человек, задавший вопрос, хотел уточнить, лучше ли использовать noindex или канонизацию.
Путаница не является неразумной, потому что дело может быть возбуждено с использованием любого решения.
Вот вопрос:
«У нас есть веб-сайт… интернет-магазин с большим количеством вариантов продуктов, которые иногда имеют неполный контент или дублируют контент.
Итак… я составил список всех URL-адресов, которые мы хотим сохранить или которые мы хотим проиндексировать… а затем я составил список всех URL-адресов, которые мы не хотим индексировать.
Чем больше я над этим работал, тем больше задавал себе этот вопрос, канонизация или неиндексация?
Я не знаю, что из этого лучше.
Мюллер ответил:
«… Я думаю, что общий вопрос о том, следует ли мне использовать noindex или rel canonical для другой страницы, — это то, на что, вероятно, нет абсолютного ответа.
Так что это как-то навскидку. Это похоже на то, что если вы боретесь с этим, вы не единственный человек, который такой, о, какой из них я должен использовать?
Обычно это также означает, что обе эти опции могут быть приемлемыми.
Так что обычно я обращаю внимание на ваши предпочтения.
И если вы действительно не хотите, чтобы этот контент вообще отображался в поиске, я бы использовал noindex.
Если вы предпочитаете, я действительно хочу, чтобы все было объединено на одной странице, и если будут отображаться отдельные, как и все, но большинство из них должны быть объединены, тогда я бы использовал rel canonical.
И, в конечном счете, эффект аналогичен тому, что страница, которую вы просматриваете, скорее всего, не будет отображаться в поиске.
А вот с noindex точно не показывается.
А с рел каноническим скорее не показывается.

Третий способ борьбы с повторяющимися и тонкими страницами
Затем Мюллер предложил издателю использовать как noindex, так и rel canonical, чтобы извлечь выгоду из обоих.
Мюллер сказал:
«…можно и то, и другое.
И еще кое-что… если внешние ссылки, например, ведут на эту страницу, то наличие их обеих помогает нам хорошо понять, вы не хотите, чтобы эта страница индексировалась, но вы также указали другую.
Так что, возможно, мы можем просто передать некоторые сигналы.

Объединение Rel Canonical и Noindex не является часто обсуждаемым решением. Но, по словам Джона Мюллера, это действенный способ борьбы с дублирующимся и неполноценным контентом.
Но, в конечном счете, именно издатель должен решить, основываясь на желаемом результате, важно ли объединение ссылок и сигналов релевантности и является ли первостепенным обеспечение того, чтобы страница не отображалась в поиске.
Цитаты
Официальная документация Google по Noindex
Блокирование поискового индексирования с помощью noindex
Официальная документация Google по Rel Canonical
Объединение повторяющихся URL-адресов
Что лучше: NoIndex или Rel Canonical?
Смотреть в 16:49 минутную отметку
Категория Новости SEO
Когда канонизировать, не индексировать или ничего не делать с похожим контентом
Представьте себе свой контент так, как вы сами его себе представляете. У вас есть какой-то багаж, от которого вы могли бы избавиться? Вы носите с собой что-то, что хотите сохранить, но, возможно, хотите перепрофилировать или увидеть по-другому?
У вас есть какой-то багаж, от которого вы могли бы избавиться? Вы носите с собой что-то, что хотите сохранить, но, возможно, хотите перепрофилировать или увидеть по-другому?
То же самое и с контентом веб-сайта. Мы все, вероятно, сидели вместе, как группа умов, думая о контенте, который мы хотели бы отрезать от нашего веб-сайта, но понимаем, что он все еще нужен, будь то конкретный потенциальный клиент, внутренняя команда и т. д.
Хотя мы ищем способы максимально уменьшить размеры наших веб-сайтов для целей управления контентом, мы также хотим сделать то же самое, чтобы успокоить сканирующих роботов поисковых систем.
Мы хотим, чтобы их ежедневное посещение наших веб-сайтов было быстрым и лаконичным.
Надеюсь, это покажет им, кто мы такие, чем мы занимаемся и, в конечном счете, — если у нас должен быть контент, который нельзя удалить, — как мы его помечаем для них.
К счастью, сканеры поисковых систем хотят понять наш контент так же, как мы хотим этого от них. Нам даны шансы канонизировать контент и неиндексируемый контент.
Нам даны шансы канонизировать контент и неиндексируемый контент.
Однако имейте в виду, что неправильное выполнение этого действия может привести к тому, что важные элементы веб-сайта будут неправильно поняты роботами поисковых систем или вообще не прочитаны.
Канонизировать?Снимок экрана, сделанный автором, июль 2022 г.
Канонические теги — отличный способ проинструктировать поисковые системы: «Да, мы знаем, что этот контент не такой уж уникальный или ценный, но мы должны его иметь».
Это также может быть отличным способом показать ценность контента из другого домена или наоборот.
Тем не менее, пришло время показать сканирующим ботам, как вы воспринимаете контент веб-сайта.
Для использования вы должны поместить этот тег в раздел заголовка исходного кода.
Тег canonical может быть отличным способом борьбы с контентом, который, как вы знаете, дублируется или похож, но он должен существовать для нужд пользователей на сайте или медленной команды обслуживания сайта.
Если вы считаете, что этот тег идеально подходит для вашего веб-сайта, просмотрите свой веб-сайт и обратитесь к разделам сайта, которые имеют отдельные URL-адреса, но имеют схожее содержание (например, текст, изображение, заголовки, элементы заголовка и т. д.).
Средства аудита веб-сайтов, такие как Screaming Frog и раздел Semrush Site Audit, позволяют быстро выявить сходство контента.
Если вы считаете, что могут быть какие-то другие виновники похожего контента, вы можете глубже изучить его с помощью таких инструментов, как средство проверки похожих страниц и Siteliner, которые проверят ваш сайт на наличие похожего контента.
Теперь, когда вы хорошо чувствуете случаи сходства, вам нужно понять, заслуживает ли это отсутствие уникальности канонизации. Вот несколько примеров и решений:
Пример 1: Ваш веб-сайт существует как в HTTP-, так и в HTTPS-версиях страниц сайта, или ваш веб-сайт существует в обеих версиях www. и без www. версии страницы.
Решение: Ставьте канонический тег на версию страницы с наибольшим количеством ссылок, внутренних ссылок и т.д., пока не сможете перенаправить все дублирующиеся страницы один к одному.
Пример 2: Вы продаете товары, которые очень похожи, если на этих страницах нет уникальной копии, но есть небольшие различия в названии, изображении, цене и т. д. Если вы канонически указываете определенные страницы продукта на родительский продукт страница?
Решение: Здесь мой совет — ничего не делать. Эти страницы достаточно уникальны, чтобы их можно было проиндексировать. У них есть уникальные имена, которые их отличают, и это может помочь вам с экземплярами ключевых слов с длинным хвостом.
Пример 3: Вы продаете футболки, но у вас есть страница для каждого цвета и каждой рубашки.
Решение: Canonical пометьте страницы цвета для ссылки на родительскую страницу рубашки. Каждая страница — это не конкретный продукт, а очень похожая вариация.
Каждая страница — это не конкретный продукт, а очень похожая вариация.
Как и в примере, представленном выше, я хотел объяснить, что иногда немного похожий контент может быть уместным для индексации.
Что, если бы это были рубашки с дочерними страницами для разных типов рубашек, таких как рубашки с длинными рукавами, майки и т. д.? Теперь это становится другим продуктом, а не просто вариацией. Как уже упоминалось ранее, это может быть успешным для поиска в Интернете с длинным хвостом.
Вот отличный пример: сайт по продаже автомобилей, на котором есть страницы, посвященные маркам автомобилей, связанным с ними моделям и вариациям этих моделей (2Dr, 4Dr, V8, V6, роскошная версия и т. д.). Первоначальная мысль об этом сайте заключается в том, что все варианты просто почти дублируют типовые страницы.
Вы можете подумать, зачем нам раздражать поисковые системы этим почти дублирующимся контентом, когда мы можем канонизировать эти страницы, чтобы они указывали на типовую страницу как на репрезентативную?
Мы двигались в этом направлении, но беспокойство по поводу того, смогут ли эти страницы быть успешными, заставило нас перейти к канонической маркировке каждой соответствующей страницы модели.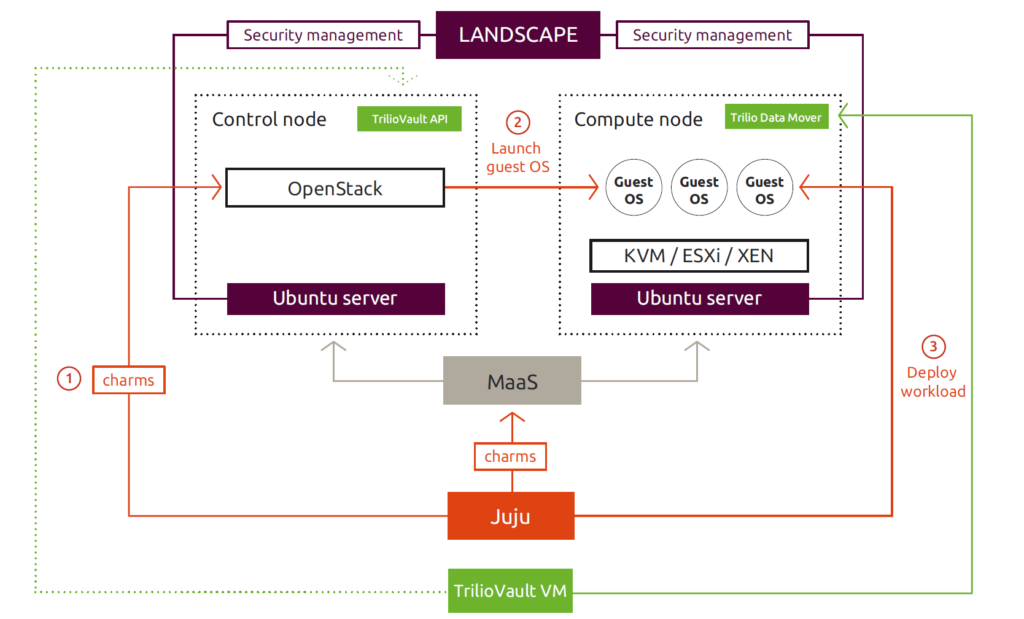
Предположим, вы канонически помечаете страницу родительской модели. Даже если вы покажете поисковым системам важность/иерархию контента, они все равно могут ранжировать канонизированную страницу, если поиск относительно специфичен.
Итак, что мы увидели?
Мы обнаружили, что органический трафик увеличился как на дочерние, так и на родительские страницы. По моему мнению, когда вы отдаете должное дочерним страницам, родительская страница выглядит более авторитетной, поскольку у нее есть много дочерних страниц, которым теперь возвращается «кредит».
Ежемесячный трафик всех этих страниц вместе вырос в пять раз.
С сентября этого года, когда мы пересмотрели канонические теги, органический трафик на эту область сайта увеличился в 5 раз в месяц: 754 страницы обеспечивают органический трафик по сравнению со 154, признанными ранее в предыдущем году.
Скриншот автора с Semrush, июль 2022 г.
Не совершайте этих ошибок канонизации- Установка канонических тегов, которые выдерживают перенаправление до разрешения на финальную страницу, может оказать большую медвежью услугу. Это замедлит поисковые системы, поскольку вынуждает их пытаться понять важность контента, но теперь они пропускают URL-адреса.
- Точно так же, если вы указываете каноническим тегам целевые URL-адреса, которые являются страницами с ошибкой 404, то вы, по сути, указываете им на стену.
- Каноническая пометка неверной версии страницы (например, www./без www., HTTP/HTTPS). Мы обсудили обнаружение с помощью инструментов сканирования веб-сайтов того, что у вас может быть непреднамеренное дублирование веб-сайтов. Не ошибитесь, указывая важность страницы на более слабую версию страницы.
 Это замедлит поисковые системы, поскольку вынуждает их пытаться понять важность контента, но теперь они пропускают URL-адреса.
Это замедлит поисковые системы, поскольку вынуждает их пытаться понять важность контента, но теперь они пропускают URL-адреса.Вы также можете использовать тег метатега robots noindex, чтобы полностью исключить похожий или повторяющийся контент.
Размещение тега noindex в разделе head вашего исходного кода остановит поисковые системы от индексации этих страниц.
Осторожно: хотя тег метатега robots noindex — это быстрый способ удалить дублированный контент из рейтинга, он может быть опасен для вашего органического трафика, если вы не используете его должным образом.
В прошлом этот тег использовался для отсеивания крупных сайтов, чтобы представить только критически важные для поиска страницы сайта, чтобы затраты на сканирование сайта были максимально эффективными.
Однако вы хотите, чтобы поисковые системы видели все релевантное содержимое сайта, чтобы понимать таксономию сайта и иерархию страниц.
Однако, если этот тег вас не слишком пугает, вы можете использовать его, чтобы позволить поисковым системам сканировать и индексировать только то, что вы считаете свежим, уникальным контентом.
Вот несколько вариантов решения проблемы отсутствия индексации:
Пример 1: Чтобы помочь своим клиентам, вы можете предоставить документацию от производителя, даже если они уже размещают ее на своем веб-сайте.
Решение: Продолжайте предоставлять документацию, чтобы помочь вашим клиентам на месте, но не индексируйте эти страницы.
Они уже принадлежат производителю и проиндексированы им, у которого, вероятно, гораздо больше полномочий в домене, чем у вас.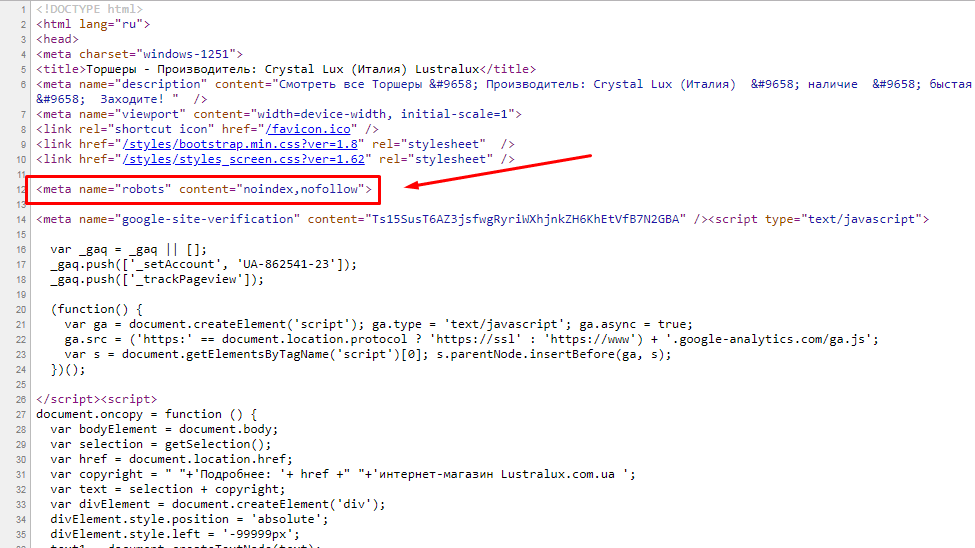 Другими словами, вы, скорее всего, не будете рейтинговым веб-сайтом для этого контента.
Другими словами, вы, скорее всего, не будете рейтинговым веб-сайтом для этого контента.
Пример 2: Вы предлагаете несколько разных, но похожих товаров. Единственная разница — это цвет, размер, количество и т. д. Мы не хотим тратить деньги на сканирование.
Решение: Решить с помощью канонических тегов. Поиск с длинным хвостом может привлечь квалифицированный трафик, поскольку данная страница по-прежнему будет проиндексирована и сможет занимать высокие позиции.
Пример 3: У вас есть много старых продуктов, которые вы больше не продаете и которые больше не являются вашим основным направлением.
Решение: Этот идеальный сценарий, вероятно, можно найти в аудите контента или продаж. Если продукты мало приносят компании пользы, рассмотрите возможность выхода на пенсию.
Рассмотрите возможность канонического указания этих страниц на страницы соответствующих категорий или перенаправления их на страницы соответствующих категорий. Эти страницы имеют возраст/доверие, могут иметь ссылки и могут иметь рейтинг.
Эти страницы имеют возраст/доверие, могут иметь ссылки и могут иметь рейтинг.
Что касается нашего веб-сайта, мы знаем, что хотим сделать все возможное для поисковых систем.
Мы не хотим тратить их время на сканирование и не хотим создавать впечатление, что большей части нашего контента не хватает уникальности.
В приведенном ниже примере, чтобы уменьшить раздувание несколько похожего содержимого страницы продукта из обзоров поисковых систем, теги meta robots noindex были помещены на дочерние страницы вариантов продукта во время перехода/перезапуска домена.
На приведенном ниже графике показано общее количество ключевых слов, перешедших из одного домена в другой.
После удаления метатегов robots noindex общее количество терминов ранжирования выросло на 50%.
Скриншот автора с Semrush, июль 2022 г.
- Не размещайте тег метатега robots noindex на странице со значением входящей ссылки. Если это так, вы должны навсегда перенаправить рассматриваемую страницу на другую соответствующую страницу сайта. Размещение тега устранит ценный ссылочный вес, который у вас есть.
- Если вы не индексируете страницу, которая включена в основную часть, нижний колонтитул или вспомогательную навигацию, убедитесь, что указана директива не «noindex, nofollow», а «noindex, follow», чтобы поисковые системы, сканирующие сайт, могли по-прежнему переходить по ссылкам на неиндексируемой странице.
Иногда трудно расстаться с содержанием веб-сайта.
Канонические и мета-теги robots noindex — отличный способ сохранить функциональность веб-сайта для всех пользователей, а также инструктировать поисковые системы.
В конце концов, будьте осторожны с тегами! Легко потерять присутствие в поиске, если вы не полностью понимаете процесс тегирования.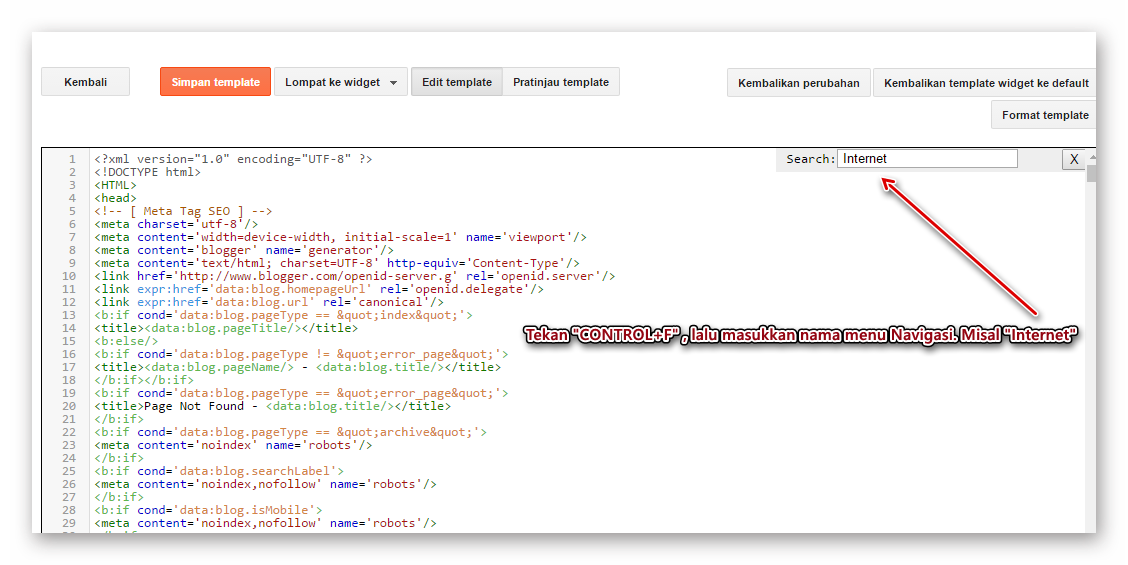
Дополнительные ресурсы:
- Когда использовать Rel Canonical или Noindex… или оба
- Что происходит, когда Google выбирает неправильный канонический URL?
- Продвинутое техническое SEO: полное руководство
Рекомендуемое изображение: Джек Фрог/Shutterstock
Категория SEO Техническое SEO
Канонический и без индекса? Используйте вместе | SEO Форум
Ваш браузер не поддерживает JavaScript. В результате ваши впечатления от просмотра будут уменьшены, и вы будете переведены в режим только для чтения .
Загрузите браузер, поддерживающий JavaScript, или включите его, если он отключен (например, NoScript).
- SEO-тактика
- Средний и продвинутый SEO
- Канонический и безиндексный? Использовать вместе
 org/ListItem»> Дом
org/ListItem»> ДомЭта тема была удалена. Его могут видеть только пользователи с правами управления вопросами.
-
Для дубликатов страниц, созданных с помощью функции «печать»,
semoz говорит, что лучше использовать noindex (http://www.
seomoz.org/blog/complete-guide-to-rel-canonical-how-to-and -почему бы и нет), и JohnMu говорит, что лучше использовать канонический http://www.google.com/support/forum/p/Webmasters/thread?tid=6c18b666a552585d&hl=en
Что вы думаете?
-
Я работаю над удалением низкокачественных страниц из каталога, в то же время разрешая поиску и индексированию нескольких высококачественных страниц в том же каталоге. Для этого я поместил тег robots noindex на страницы низкого качества, которые мы не хотим индексировать.
Эти теги noindex были реализованы вчера, но страницы низкого качества никуда не делись. Я даже использовал «Просмотреть как Googlebot», чтобы принудительно просканировать несколько страниц низкого качества.
Может быть, мне нужно дать им несколько дней, чтобы они исчезли, но это заставило меня задуматься: «Почему Google игнорирует тег robots noindex?» Потом я придумал теорию. Я заметил, что мы включаем канонический тег по умолчанию на каждую страницу нашего сайта, включая те, которые я хочу запретить индексировать. Я никогда не использовал тег noindex в сочетании с каноническим тегом, поэтому, возможно, канонический тег сбивает с толку поисковых роботов SE.Я провел небольшое исследование и нашел цитату сотрудника Google JohnMu в следующей статье: http://www.seroundtable.com/archives/020151.html Это не точное совпадение с моей ситуацией, потому что наш канонический тег указывает сам на себя, а не чем другой URL. Но похоже, что использовать их вместе — плохая идея.
Кто-нибудь использовал или видел теги canonical и noindex вместе в дикой природе? Может ли кто-нибудь подтвердить или опровергнуть эту теорию о том, что канонический код снижает эффективность мета-тега robots?
 seomoz.org/blog/complete-guide-to-rel-canonical-how-to-and -почему бы и нет)
seomoz.org/blog/complete-guide-to-rel-canonical-how-to-and -почему бы и нет) Может быть, мне нужно дать им несколько дней, чтобы они исчезли, но это заставило меня задуматься: «Почему Google игнорирует тег robots noindex?» Потом я придумал теорию. Я заметил, что мы включаем канонический тег по умолчанию на каждую страницу нашего сайта, включая те, которые я хочу запретить индексировать. Я никогда не использовал тег noindex в сочетании с каноническим тегом, поэтому, возможно, канонический тег сбивает с толку поисковых роботов SE.
Может быть, мне нужно дать им несколько дней, чтобы они исчезли, но это заставило меня задуматься: «Почему Google игнорирует тег robots noindex?» Потом я придумал теорию. Я заметил, что мы включаем канонический тег по умолчанию на каждую страницу нашего сайта, включая те, которые я хочу запретить индексировать. Я никогда не использовал тег noindex в сочетании с каноническим тегом, поэтому, возможно, канонический тег сбивает с толку поисковых роботов SE. org/Comment»>
org/Comment»> Я согласен с рассуждениями Линдси, но мне не ясно ее высказывание по этому поводу: «Если на печатных страницах вашего веб-сайта есть ссылка на исходную страницу, вы также можете использовать метатег robots ‘noindex’. индекса, и любое значение ссылки будет передано обратно в исходную каноническую веб-версию страницы».
Если вы добавите тег «noindex» на страницу печати, поисковые системы будут игнорировать страницу, которая ДОЛЖНА оставить им только каноническую версию страницы. Вы требуете, чтобы поисковая система сделала некоторые предположения, чего мы хотим избежать. Используя тег canonical, мы явно сообщаем поисковой системе правильную версию страницы для индексации.
Судя по приведенной выше цитате, Линдсей предлагает использовать тег «noindex» и «канонический». Основное внимание в ее статье уделяется тому, что существуют превосходные методы канонизации веб-страниц без использования канонического тега, поэтому мне непонятна логика.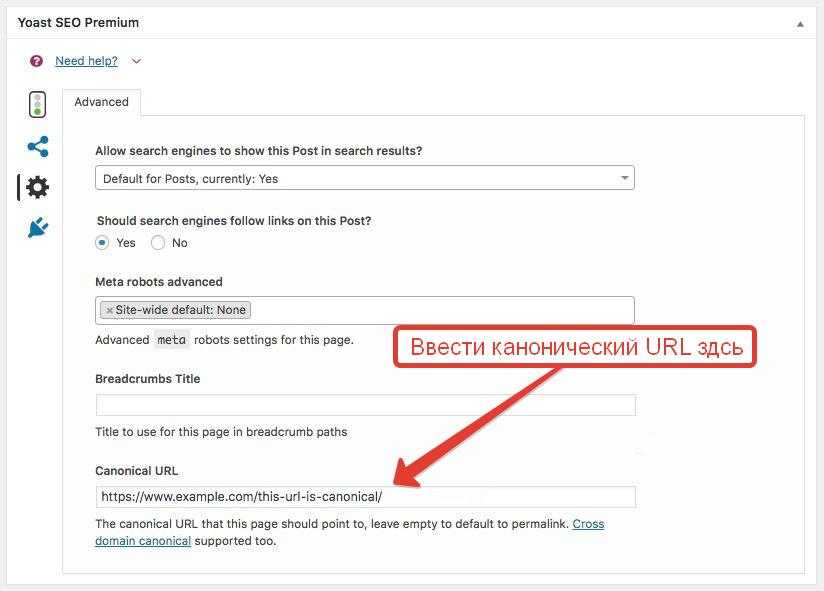
В настоящее время я использую тег canonical в таких ситуациях. Я хотел бы попросить Линдси дать дополнительные разъяснения по поводу использования тега «noindex» в этом случае. Последний комментарий в блоге был вопросом, заданным в мае, на который так и не ответили, поэтому похоже, что она не слишком часто посещает сайт.
У вас есть животрепещущий вопрос по SEO?
Подпишитесь на Moz Pro, чтобы получить полный доступ к вопросам и ответам, отвечать на вопросы и задавать свои.
Начать бесплатную пробную версию
Есть вопрос?
Просмотр вопросов
Посмотреть Все вопросыНовые (нет ответов)ОбсуждениеОтветыПоддержка продуктаБез ответа
От Все времяПоследние 30 днейПоследние 7 днейПоследние 24 часа
Сортировка по Последние вопросыНедавняя активностьБольше всего лайковБольшинство ответовМеньше всего ответовСамые старые вопросы
С категорией All CategoriesAffiliate MarketingAlgorithm UpdatesAPIBrandingCommunityCompetitive ResearchContent DevelopmentConversion Rate OptimizationDigital MarketingFeature RequestsGetting StartedImage & Video OptimizationIndustry EventsIndustry NewsIntermediate & Advanced SEOInternational SEOJobs and OpportunitiesKeyword ExplorerKeyword ResearchLink BuildingLink ExplorerLocal ListingsLocal SEOLocal Website OptimizationMoz BarMoz LocalMoz NewsMoz ProMoz ToolsOn-Page OptimizationOther SEO ToolsPaid Search MarketingProduct SupportReporting & AnalyticsResearch & TrendsReviews and RatingsSearch BehaviorSEO ТактикаТренды поисковой выдачиСоциальные сетиТехническое SEOВеб-дизайнБелое/черное SEO
Связанные вопросы
 schema.org/ItemList» data-nextstart=»» data-set=»»>
schema.org/ItemList» data-nextstart=»» data-set=»»>Здравствуйте, команда Moz! Я хотел бы внедрить AMP для своего отдельного сообщения в блоге, а не для всего блога. Является ли это возможным? если да то как? Примечание. Я уже использую GTM для своего веб-сайта abcd.com, но я хотел бы использовать его только для своего сообщения в блоге, а мой блог выглядит так: abcd.com/blog…………..let мне уточнить, что означает пост в блоге — abcd.com/blog/my-favorite-dress Спасибо!
Средний и продвинутый SEO | | Джонни12345
0
 org/ListItem»> Прокси-серверы и SEO
org/ListItem»> Прокси-серверы и SEO Влияет ли размещение блога на прокси-сервер (указанный на основной сайт) на SEO? т.е. может ли Google сказать? А если могут, то какая разница? Мои серверщики не будут использовать PHP на своих серверах, но нам нужен блог на WordPress. Поэтому предлагаемое ими решение состоит в том, что они размещают блог на прокси-сервере и указывают его в подпапке ourdomain.com/blog на нашем сайте. Таким образом, во всех смыслах и целях он размещен в одном и том же месте. Они уверяют меня, что это нормальная практика, и указывают, что изображения нашего (основного сайта) уже получены из CDN. Очевидно, мы будем иметь дело с тем, что Google не увидит две отдельные версии одного и того же сайта. Но помимо этого, есть ли какой-либо негативный эффект, от которого мы можем пострадать с точки зрения SEO?
Средний и продвинутый SEO | | абистин2
0
 org/ListItem»> Использование hreflang для международных страниц — как вы это делаете?
org/ListItem»> Использование hreflang для международных страниц — как вы это делаете? Мой клиент пытается добиться глобального присутствия в избранных странах, а затем отслеживать трафик со своих международных страниц в Google Analytics.
Содержание международных страниц почти такое же, как и для страниц США, но форма и некоторые другие детали отличаются из-за того, как необходимо настроить лицензирование продукта.
Я не хочу рисковать потерей рейтинга существующих страниц в США из-за таких проблем, как дублирование контента и т. д.
Как лучше всего подойти к этому? Это мой первый набег на это, и я просматривал темы MOZ, но ряд разговоров проходит мимо меня, поэтому предложения должны быть довольно простыми 🙂
Это случай добавления кода hreflang на каждую страницу и создания разных URL-адресов для отслеживания. Например:
Например:
URL-адрес для США : https://company.com/en-US/products/product-name/
URL-адрес для Канады : https://company.com/en-ca/products/product-name/
URL для контента на немецком языке : https://company.com/de/products/product-name /
URL для остального мира : https://company.com/en/products/product-name /
Средний и продвинутый SEO | | Каро-О
1
Привет Есть ли у кого-нибудь отличные примеры сайта электронной коммерции с отличным контентом на страницах категорий или страницах со списком продуктов? Спасибо!
Средний и продвинутый SEO | | БеккиКи
1
 org/ListItem»> Изменение 301 или использование 302 после перезапуска?
org/ListItem»> Изменение 301 или использование 302 после перезапуска? Мы делаем перезапуск и меняем почти каждый URL. Поскольку список перенаправлений > 5000, у нас могут быть некоторые ошибки, которые мы захотим исправить позже (например, иметь 301 в каталоге, но позже найти одну страницу, которая лучше соответствует своей цели). Могу ли я позже поменять 301 и получат ли его Seachengine? Могу ли я использовать 302 в течение недели или двух, пока я не буду уверен в своих редиректах, и только потом использовать правильные 301?
Средний и продвинутый SEO | | набухона
0
 org/ListItem»> Теги блога создают чрезмерное дублирование контента… должны ли мы использовать rel canonicals или переадресацию 301?
org/ListItem»> Теги блога создают чрезмерное дублирование контента… должны ли мы использовать rel canonicals или переадресацию 301? У нас возникла проблема с блогом нашего клиента, который создает слишком много дублированного контента с помощью тегов блога. Дублированные веб-страницы из тегов не представляют абсолютно никакой ценности (мы даже не видим тег). Должны ли мы просто перенаправить 301 страницу с тегами или использовать каноническую ссылку?
Средний и продвинутый SEO | | VanguardСвязи
0
У меня есть вопрос об использовании hreflang. Например, в стране один у меня есть
web.one/BlueWidget web.one/YellowWidgetВ стране (и языке) два У меня есть web.two/Widget Другими словами, в стране два нет различия между желтым и синим. Лучше всего использовать web.one/BlueWidget two» href=»http://web.two/Widget» />web.one/YellowWidget
Например, в стране один у меня есть
web.one/BlueWidget web.one/YellowWidgetВ стране (и языке) два У меня есть web.two/Widget Другими словами, в стране два нет различия между желтым и синим. Лучше всего использовать web.one/BlueWidget two» href=»http://web.two/Widget» />web.one/YellowWidget
Средний и продвинутый SEO | | Пикабо
0
