
SEO + AJAX: как им ужиться?
Почему это важноСегодня в сети все чаще можно встретить не только отдельные страницы, свёрстанные при помощи технологии AJAX, но и целые сайты, использующие этот способ вывода контента. Это продиктовано тем, что AJAX набрал большую популярность среди web-разработчиков как более современный и совершенный путь решения сложных задач динамического вывода контента и его визуализации.
Однако, несмотря на свою прогрессивность, данная технология весьма нелюбима в профессиональной среде SEO-специалистов из-за ряда особенностей, о которых мы поговорим ниже. Хотим не просто обозначить те проблемы, которые могут возникнуть у AJAX-сайтов в контексте продвижения, но и расскажем о поиске компромиссных путей их решения.
Причины популярности технологии AJAX среди разработчиковОдной из основных тенденций в разработке юзер-ориентированых сайтов, является их физическое ускорение. Во внимание берётся всё: время загрузки страницы, элементов на ней, скорость реакции на взаимодействие, совершаемое пользователем. При этом любая технология, которая позволяет качественно ускорить любую из составляющих сайта или отдельных его страниц, сразу после появления взлетает на пик популярности у веб-разработчиков. Это объясняется весьма просто: умея создавать более быстрые и удобные для пользователей сайты, вы получаете преимущество перед конкурентами.
Во внимание берётся всё: время загрузки страницы, элементов на ней, скорость реакции на взаимодействие, совершаемое пользователем. При этом любая технология, которая позволяет качественно ускорить любую из составляющих сайта или отдельных его страниц, сразу после появления взлетает на пик популярности у веб-разработчиков. Это объясняется весьма просто: умея создавать более быстрые и удобные для пользователей сайты, вы получаете преимущество перед конкурентами.
AJAX как раз и является одной из технологий, внедрение которой можно назвать прорывом в сайтостроении. Ключевая особенность AJAX в том, что он позволяет сделать интерфейсы сайта асинхронными, т.е. уйти от классической модели работы «запрос – ответ – запрос», когда браузер не может выполнять никаких операций, пока не получит ответ от сервера. В итоге пользователь вынужден ждать пока «прогрузится» интерфейс.
AJAX же позволяет динамически изменять содержание страницы без полной перезагрузки, т.е. пользователю нет необходимости ждать, пока сайт «замер» в ожидании ответа от сервера.
Однако у любой медали есть две стороны. Предоставляя определенные преимущества, AJAX накладывает и ряд ограничений, с которыми нужно считаться.
Плюсы и минусы использования AJAX для формирования страницОсновные плюсы, на которые может рассчитывать владелец ресурса, продиктованы особенностью самой технологии.
Плюсы использования:
- Экономичность. Ввиду того, что при запросе AJAX-страницы серверу нет необходимости заново «перегружать» весь контент и повторно генерировать всю страницу, а только часть ее (ту, которая изменяется/подгружается AJAX-скриптом), происходит значительная экономия web-трафика и снижается количество запросов-обращений на сервер.
- Снижение серверной нагрузки. Данное преимущество вытекает из первого, когда за счет снижения количества запросов, посылаемых на сервер, снижается и нагрузка. Это особенно актуально на крупных сайтах, где количество генерируемых запросов пользователями может стать серьезной проблемой, ставящей под угрозу работоспособность.
- Ускорение загрузки страницы. Отсутствие необходимости в перезагрузке страницы, позволяет добиться того, что конечный пользователь, значительно быстрее увидит результат своего взаимодействия с интернет-ресурсом.


В то же время AJAX может в буквальном смысле «похоронить» всю работу SEO-специалиста при некорректном использовании. Поэтому о минусах использования данной технологии говорят обычно именно оптимизаторы.
Минусы использования:
- Страницы сайта не индексируются поисковыми системами. Это одна из основных проблем использования AJAX. Особенно она актуальна, если принимается решение о реализации динамической подгрузки содержимого на уже оптимизированных сайтах. Некорректное использование может привести к тому, что проиндексированные страницы, которые и создают трафик, просто исчезнут из результатов поиска.
- Искажение данных статистики. Так как поисковые системы перестают «видеть» AJAX-страницы, данные от счетчиков, установленных на них, передаются некорректно. Для крупных ресурсов, особенно работающих в нише e-commerce, это такая же большая потеря, как и исчезновение посадочных страниц из выдачи.
Из-за этих существенных минусов долгое время AJAX был неким «табу» среди оптимизаторов. Однако сегодня есть достаточно простое и логичное решение, которое может убрать негативный эффект от использования данной технологии и прийти к разумному компромиссу между SEO-специалистом, владельцем сайта, разработчиком и конечным пользователем. То есть, в полной мере использовать вышеперечисленные плюсы AJAXи избавиться от недостатков.
Однако сегодня есть достаточно простое и логичное решение, которое может убрать негативный эффект от использования данной технологии и прийти к разумному компромиссу между SEO-специалистом, владельцем сайта, разработчиком и конечным пользователем. То есть, в полной мере использовать вышеперечисленные плюсы AJAXи избавиться от недостатков.
Как показать поисковику, где находится контент страницы на AJAX?
Основной проблемой AJAX является то, что поисковая система не может проиндексировать содержимое динамической страницы. Но для выполнения SEO-задач необходимо каким-то образом предоставить поисковому роботу возможность увидеть этот контент.
На данный момент существует несколько вариантов, как это сделать:
1. Использование HIJAX (устаревший способ)
Это решение подразумевает использование специальной технологии под названием HIJAX (названа разработчиком, который ее придумал). Суть ее заключалется в том, что одновременно с вызовом AJAX-функции происходит переход по статической ссылке с параметром. Таким образом пользователь получает страницу с динамическим содержимым, а робот, игнорирующий вызов функции, попадает на статическую html-страницу. Выглядит это примерно так:
Таким образом пользователь получает страницу с динамическим содержимым, а робот, игнорирующий вызов функции, попадает на статическую html-страницу. Выглядит это примерно так:
foo 32
Где, =»ajax.html?foo=32″ – это статическая ссылка для поискового бота, а ‘ajax.html#foo=32′ – это параметр для вызова AJAX-кода.
В данном случае статическая страница – это «html-слепок» (копия) динамической страницы, которую видит пользователь.
Данное решение, хоть и остается рабочим и эффективным на сегодняшний день, уже несколько устарело. С развитием технологий сайтостроения и все большей популярностью исполняемых Java-скриптов поисковые системы пришли к тому, что необходимо предоставить веб-мастерам более простые и эффективные пути решения проблемы.
2. Использование знака «!» как указателя для поисковой системы в URL-адресе (актуальный способ)
Более современный способ, позволяющий роботу поисковой системы просканировать и проиндексировать содержимое AJAX-страницы, упростил жизнь веб-мастерам и разработчикам, позволив избежать модифицирования всех ссылок на динамическое содержимое по методу HIJAX.
Теперь для того, чтобы указать поисковому боту на то, что AJAX-страница имеет статический «html-слепок», достаточно добавить в URL восклицательный знак. Выглядит это следующим образом:
http://www.example.com/#stranica – стандартная «ссылка» на AJAX-страницу
http://www.example.com/#!stranica – модифицированный формат «ссылки» на AJAX-страницу
В таком случае как только робот встретит в URL-адресе #!, он запросит у сервера «html-слепок» страницы, который сможет проиндексировать. В то же время пользователю будет показана AJAX-страница.
Единственным условием является то, что «html-слепок» страницы должен быть доступен для поискового бота по URL-адресу, где #!, заменен на ?_escaped_fragment_=.
http://www.example.com/#!stranica – «ссылка» на AJAX-страницу
http://www.example.com/?_escaped_fragment_=stranica – ссылка на html-версию страницы
При использовании данного способа в кэше поисковой системы будет храниться html-версия страницы, доступная по «уродливому», как его называет Google, URL-адресу с ?_escaped_fragment_=, но на выдаче вид ссылки на сайт будет сохранен, то есть в нем будет стоять #!

Такой способ решения проблем рекомендован для применения системой Yandex, о чем можно прочесть в официальном руководстве данной поисковой системы.
Некоторые дополнительные особенности
Использование технологии AJAX подразумевает некоторые дополнительные особенности, которые нужно учитывать при разработке нового сайта и при обновлении архитектуры уже существующего. К ним можно отнести следующие:
1. ЧПУ-адреса страниц. В стандартном виде, как было описано в примере выше, адреса страниц все равно получаются не очень красивыми, хоть Googleи называет их prettyURL. То есть, в них все равно будут присутствовать символы #!. Однако эту проблему можно обойти, присвоив стандартные статические ЧПУ (человекопонятные URL-адреса) страницам, использующим AJAX. Единственное, что нужно учесть: при этом способ имплементации «html-слепка» будет отличаться.
Для страницы вида:
http://www.example.com/stranica
«html-слепок» должен находиться по адресу:
http://www. example.com/stranica?_escaped_fragment_=
example.com/stranica?_escaped_fragment_=
Т.е. значение параметра будет пустым, но в код самой страницы (в теге <head>) необходимо добавить строку:
В «html-слепке» данного тега быть недолжно, иначе он не проиндексируется.
Подобная имплементация будет актуальна и для сайтов, полностью построенных на AJAX, где то же самое придется проделать с главной страницей и любыми другими статическими URL.
2. Формирование файла Sitemap.xml. Поисковая система Yandex в своем руководстве «Помощь Вебмастеру» говорит следующее: «Ссылки, содержащие
«Подводные камни» при использовании AJAX
Несмотря на кажущуюся понятность и простоту предложенных методов оптимизации AJAX-страниц, под которой подразумевается их доступность поисковым ботам, есть несколько моментов, о которых стоит задуматься перед внедрением технологии, особенно на работающих сайтах.
К ним можно отнести следующие:
- Непрогнозируемые последствия для ранжирования. Если нужно, например, для тысячи однотипных товаров поменять URL-адреса, организовав их вывод посредством AJAX, то даже при настройке постраничных 301 редиректов, ресурс может сильно «качнуть» в поисковой выдаче. Вероятность таких последствий непрогнозируемая, так как планируемые изменения не идут в разрез с требованиями поисковых систем. Но на примере ряда сайтов, можно утверждать, что проблемы вполне вероятны. В данном случае можно рекомендовать только постепенное внедрение, разбитое на несколько итераций.
- Неясный механизм расчета скорости загрузки страницы. Данный параметр является косвенным фактором ранжирования сайта поисковыми системами, однако его влияние достаточно велико. В случае с AJAX-страницами не ясно, на основании загрузки какой из версий производится расчет скорости загрузки – версии для пользователей или html-версии для поискового робота, а значит, на данный параметр сложнее повлиять. Единственной рекомендацией тут может быть следующая: делать максимально быстрыми обе версии.
 Единственной рекомендацией тут может быть следующая: делать максимально быстрыми обе версии.
Единственной рекомендацией тут может быть следующая: делать максимально быстрыми обе версии.Вывод
Сегодня использование AJAX уже не является табу для поисковой оптимизации. Более того, при правильном подходе вы можете использовать данную технологию так же эффективно, как и простой html, но при этом получить ряд дополнительных преимуществ, которые дает AJAX.Основной плюс – это возможность строить более быстрые и удобные пользовательские интерфейсы.
Однако стоит помнить, что SEOшники не зря настороженно относятся к данной технологии. При некорректном использовании, без соблюдения требований поисковых систем, AJAX может привести к плачевным последствиям в виде серьезных потерь органического трафика и в ранжировании. Прежде чем «выкатывать» какую-либо из AJAX-разработок на основной домен, стоит удостовериться в том, сделана ли она в соответствии с одним из двух рассмотренных в статье способов. А также проверить, как поисковые боты «видят» данное изменение, например, при помощи инструмента «Посмотреть как Googlebot».
Оба описанных в данной статье способа решения возможных проблем являются рабочими – их использование протестировано на реальных проектах и доказало свою эффективность. Но начиная с октября 2015 года, поисковая система Google не рекомендует использовать описанные в этой статье технологии индексирования AJAXстраниц, о чем было официально написано в блоге GoogleWebmasterCenterBlog. Вместо этого, система предлагает следовать принципам «ProgressiveEnhancement» при создании сайтов, что позволит роботам Google лучше интерпретировать динамический контент – в текущий момент система в состоянии самостоятельно распознать его без дополнительной настройки, интерпретируя .jsи .css. Несмотря на это, описанные нами механизмы полностью поддерживаются поисковой системой и остаются стабильно рабочими до сегодняшнего дня.
что это такое и его влияние на SEO
AJAX – это технология, позволяющая обращаться
к серверу и не перезагружать при этом страницу. Обычно используется для
динамической подгрузки содержимого странички, к примеру в
интернет-магазинах или на маркетплейсах. С ее помощью пользоваться
ресурсом становится удобнее, вырастает скорость взаимодействия.
Аббревиатура расшифровывается как Asynchronous JavaScript and XML, из
названия очевидно, что для работы технологии необходим JS.
Обычно используется для
динамической подгрузки содержимого странички, к примеру в
интернет-магазинах или на маркетплейсах. С ее помощью пользоваться
ресурсом становится удобнее, вырастает скорость взаимодействия.
Аббревиатура расшифровывается как Asynchronous JavaScript and XML, из
названия очевидно, что для работы технологии необходим JS.
Идеи, отдаленно напоминающие
AJAX, использовались в веб-разработке еще в 90-х годах. К ним можно
отнести Remote Scripting – инструмент Microsoft для удаленного вызова
серверных процедур с помощью клиентского скрипта. Механизм был придуман
еще в 1998 году, а тег iframe, позволяющий встраивать один HTML-документ
в другой, появился даже раньше – в 1996-м. Но эти способы не давали тех
широких возможностей, которые обеспечила разработчикам технология AJAX.
В 2005 году глава компании Adaptive Path Джесси Джеймс Гарретт написал
книгу о принципе, который на тот момент использовали почтовые клиенты,
дал ему название AJAX и подробно описал его работу. С тех пор технология
стала инструментом широкого использования: она дает возможность
работать с интернет-страницей как с обычным приложением, не обновляя ее.
Это удобно и для владельца сайта, и для пользователя.
С тех пор технология
стала инструментом широкого использования: она дает возможность
работать с интернет-страницей как с обычным приложением, не обновляя ее.
Это удобно и для владельца сайта, и для пользователя.
Узнать, что на сайте используется AJAX, можно даже по его внешнему виду. Если ресурс позволяет подгрузить новую информацию без обновления страницы и генерирует какой-то контент динамически, значит, он работает по этой технологии.
Этапы. Понять, что такое AJAX и как он функционирует, поможет алгоритм действий – четкий список этапов его работы:
- пользователь совершает на странице действие, которое вызывает AJAX. Обычно это нажатие кнопки «Узнать больше», «Загрузить еще» и других похожих;
- запрос отправляется на сервер, с ним передаются необходимые сведения;
- сервер обращается к базе данных, получает необходимую информацию, отправляет эти сведения браузеру;
- тот расшифровывает ответ с помощью JavaScript и выводит новую информацию пользователю.

Обмен данными. Он происходит за счет объекта XMLHttpRequest,
своеобразного буфера между сервером и браузером. К серверной части
обращается POST- или GET-запрос. Первый используется для больших объемов
данных, второй обращается к конкретному документу на сервере и передает
как аргумент ссылку на страницу. После того как сервер получит запрос,
он формирует ответ в формате XML или JSON.
- XML сразу переводится в HTML;
- в случае с JSON браузер запускает полученный код, создается объект JavaScript;
- иногда ответ – простой текст, тогда он сразу же выводится на странице без лишних преобразований.
Благодаря асинхронной передаче данных, которую использует AJAX, пользователь может спокойно работать с сайтом, пока происходит обмен данными, у него не возникнет ощущения, что страница зависла.
Преимущества технологии AJAXСнижение нагрузки.
Благодаря тому, что пользователь не обновляет страницу, нагрузка на
сайт серьезно снижается.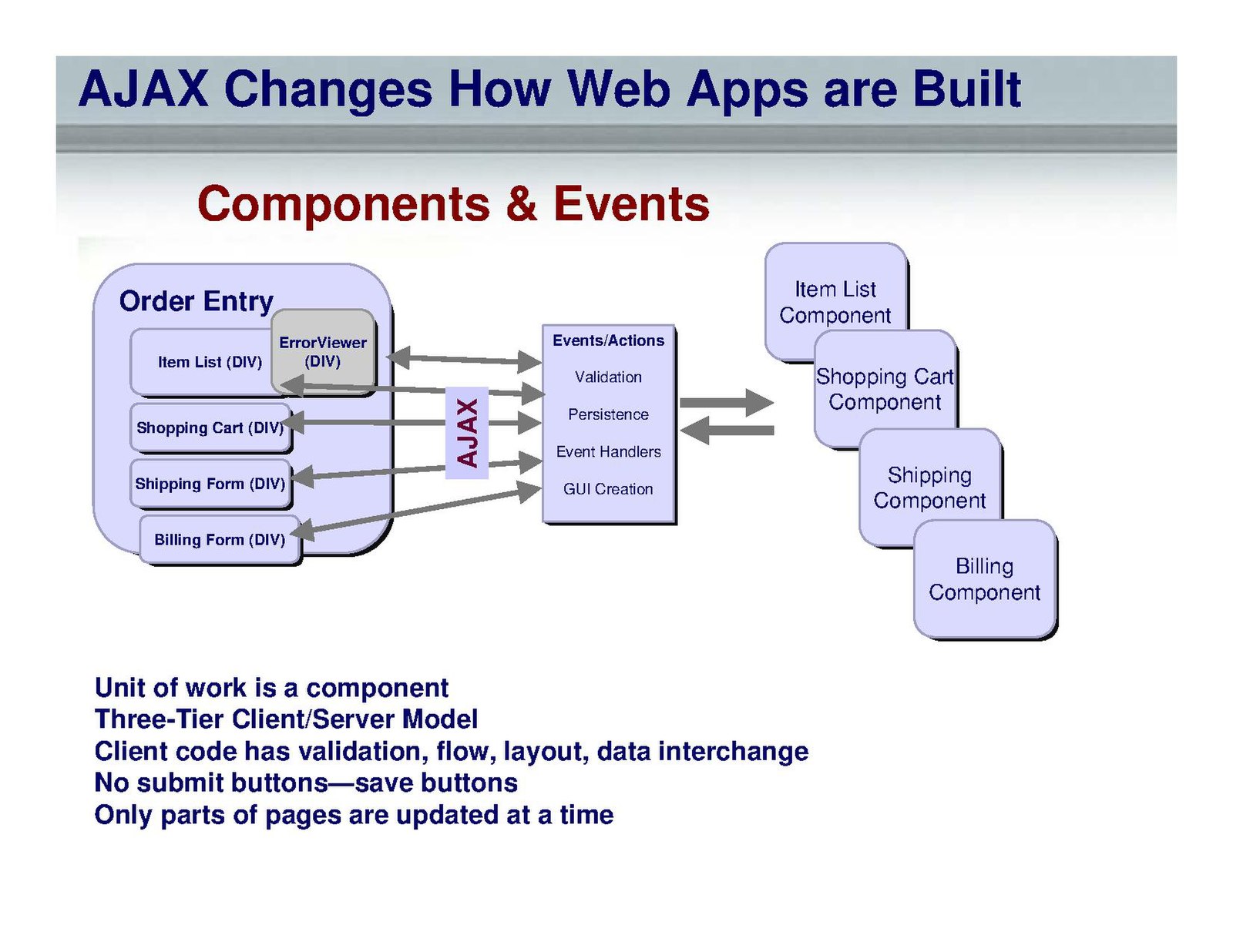 Иногда человек может выполнить целый комплекс
действий, и это не потребует перезагрузки: к серверу обращаются только
за конкретными данными, а не за огромным количеством сведений сразу.
Иногда человек может выполнить целый комплекс
действий, и это не потребует перезагрузки: к серверу обращаются только
за конкретными данными, а не за огромным количеством сведений сразу.
Увеличение скорости. Взаимодействовать с AJAX намного быстрее, чем обновлять всю страницу. Когда пользователь только заходит на сайт, ему подгружается только часть информации, остальную он получает динамически, а подгрузить условные 50 товаров намного быстрее, чем 500. Вдобавок пользователь быстро видит результат действий: для получения новой информации не нужно ждать, пока обновится страница.
Уменьшение информационного трафика. В связи с этими
особенностями объем передаваемых данных между пользователем и сервером
значительно сокращается, что полезно и с точки зрения скорости, и для
удобства посетителя. Например, вопрос трафика актуален для пользователей
мобильных устройств.
Гибкие возможности. Настроить
AJAX можно не только для отображения оставшегося текста или списка
товаров.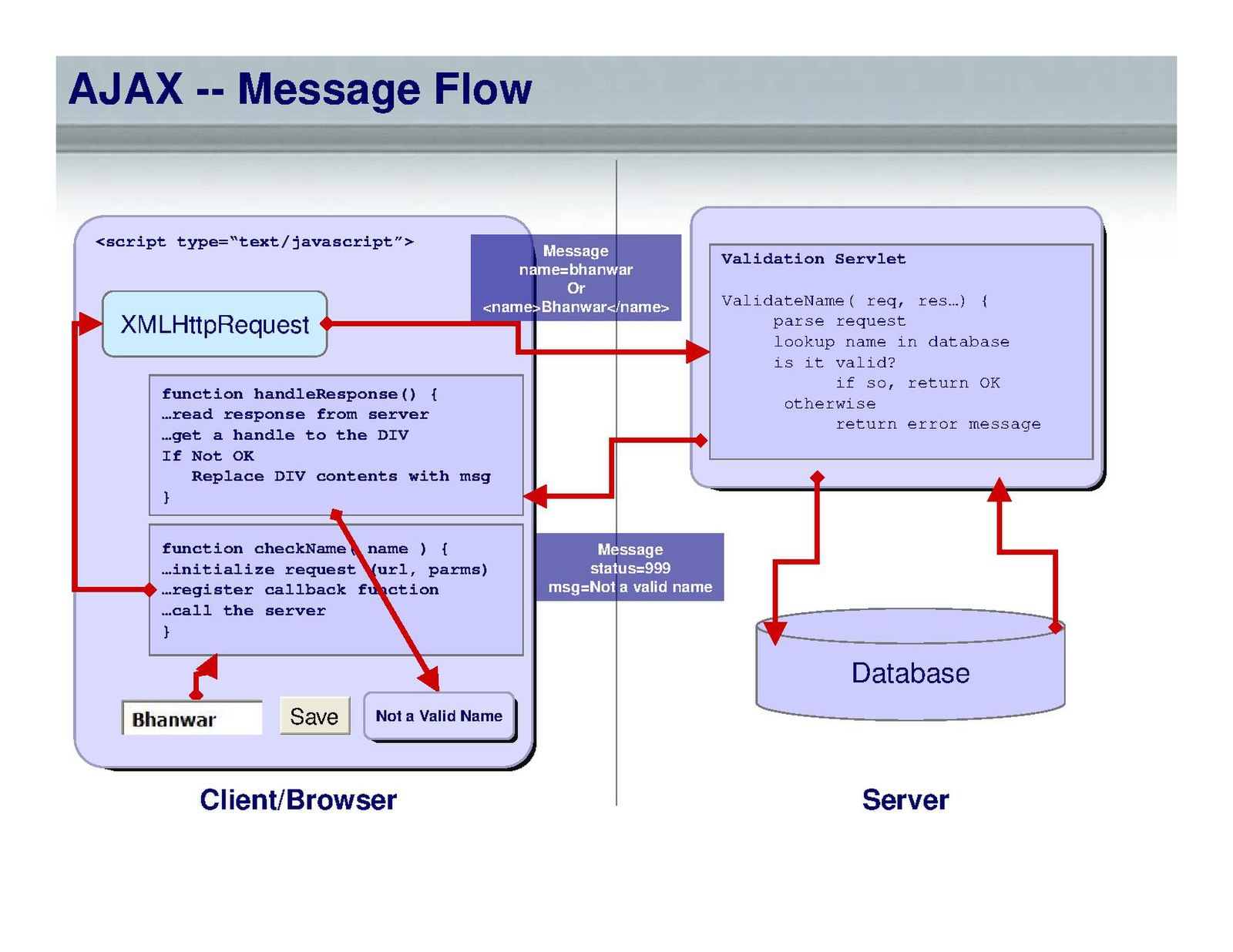 С помощью технологии создаются формы и опросы с быстрым
получением результатов, она же упрощает регистрацию на сервисах: можно
ввести логин и сразу узнать, свободен ли он. Онлайн-банкинги динамически
отслеживают цифры номера карты, которые ввел пользователь, и в режиме
реального времени вычисляют, какой платежной системой он пользуется.
Используют AJAX и поисковые системы: если ввести часть запроса,
поисковая строка показывает возможные варианты его продолжения. Это тоже
реализуется с помощью AJAX. Для пользователя такая система крайне
удобна.
С помощью технологии создаются формы и опросы с быстрым
получением результатов, она же упрощает регистрацию на сервисах: можно
ввести логин и сразу узнать, свободен ли он. Онлайн-банкинги динамически
отслеживают цифры номера карты, которые ввел пользователь, и в режиме
реального времени вычисляют, какой платежной системой он пользуется.
Используют AJAX и поисковые системы: если ввести часть запроса,
поисковая строка показывает возможные варианты его продолжения. Это тоже
реализуется с помощью AJAX. Для пользователя такая система крайне
удобна.
Ни одна система не лишена недочетов и недостатков, и в случае с технологией динамической подгрузки основная сложность – оптимизация и связанные с ней факторы. Существует и еще несколько минусов.
Снижение безопасности. Исходный код открыт в браузере, злоумышленники могут этим воспользоваться, поэтому AJAX упрекают в возможном уменьшении защищенности сайта.
Отсутствие интеграции. Если подгружать новую информацию, перелистывая страницы, можно в любой
момент вернуться назад с помощью специальной кнопки в браузере или
установить на определенный контент закладку. Интеграции с этими
возможностями браузера у AJAX нет, потому что подгруженная информация не
кешируется и не остается в истории посещений. Правда, в случае с
кнопкой «Назад» проблему можно решить, составив специальный скрипт.
Если подгружать новую информацию, перелистывая страницы, можно в любой
момент вернуться назад с помощью специальной кнопки в браузере или
установить на определенный контент закладку. Интеграции с этими
возможностями браузера у AJAX нет, потому что подгруженная информация не
кешируется и не остается в истории посещений. Правда, в случае с
кнопкой «Назад» проблему можно решить, составив специальный скрипт.
Искажение статистики. AJAX серьезно мешает составлять достоверную статистику посещений. Пользователь листает страницы, но переход не регистрируется, так как это происходит динамически, без обновления страничек, поэтому количество просмотров занижается. Этот недостаток несущественен, если сайт не слишком большой, но для проектов с высоким трафиком разница с реальной посещаемостью может быть огромной.
Необходимость в JavaScript. Без включенного в браузере JavaScript технология просто не будет
работать. JS поддерживают все современные браузеры, но, если
пользователь решил отключить его выполнение, он не сможет нормально
пользоваться сайтом. Это мешает и поисковым системам: из-за того что
часть содержимого показывается только при выполнении запроса, поисковик
не может ее проиндексировать.
Это мешает и поисковым системам: из-за того что
часть содержимого показывается только при выполнении запроса, поисковик
не может ее проиндексировать.
Сложности с индексированием. Проблемы с SEO-продвижением – существенный недостаток технологии. Из-за того что часть контента доступна только после вызова AJAX, она не индексируется поисковиками: робот просто ее не замечает. В результате страдают показатели ранжирования и, следовательно, позиции.
Как снизить влияние AJAX на ранжированиеНедостатки вовсе не значат, что пользоваться AJAX не стоит или нельзя. Наоборот, это удобно и для пользователей, и для владельцев сайтов. Но, чтобы минимизировать негативное влияние на SEO и статистику, стоит работать с технологией по определенным правилам.
- Ключевую часть, которая особенно важна для индексирования, лучше сделать статической и размещать в самом начале страницы.
- Еще один прием – кеширование динамических страниц, что позволяет отображать их в качестве статических.
- Вызывать AJAX лучше не событием onClick, а якорем.
- Иметь на сайте sitemap.xml практически обязательно, это ускоряет и облегчает индексацию.
.jpg)
Как переписать ссылки. Динамическую подгрузку контента лучше дублировать ссылками. Так у пользователей, отключивших JavaScript, и поисковых роботов содержимое будет отображаться корректно.
- URL-адреса динамических страниц содержат в себе символ #. Их следует переписать, добавив после каждого восклицательный знак. Вот так: «#!».
- После этого нужно прописать для каждой такой страницы HTML-версию, доступную по определенному адресу. Адреса создаются с помощью замены сочетаний «#!» на «?_escaped_fragment_=».
- На каждой странице AJAX следует прописать метатег ‘ meta name=»fragment» content=»!» ‘.
Обязательно
сверяйте сохраненные версии сайта с его AJAX-версиями, чтобы убедиться,
что все страницы отображаются нормально и без ошибок. Правильное
использование технологии поможет обеспечить пользователям комфорт при
работе с сайтом и одновременно не потерять позиции в поисковой выдаче.
как отдельным страницам попасть в выдачу
При создании сайта или приложения на Ajax игнорируется одна из основных сущностей интернета — веб-страница с отдельным URL. Вся информация на странице подгружается скриптом без обновления URL, то есть фактически поисковым системам нечего добавлять в индекс, кроме главной страницы. Это просто ад для поискового продвижения.
Та же проблема существует для одностраничных лендингов, созданных не на Ajax.
Конечно, напрашивается вопрос…
Зачем вообще создавать сайты на Javascript и Ajax?
Проекты на Javascript и Ajax проще в разработке. Они обеспечивают удобное и быстрое взаимодействие с пользователем благодаря использованию асинхронных запросов. Коды таких сайтов значительно короче из-за возможности повторного использования компонентов. Кроме того, в плюсы запишу быструю загрузку страниц и отсутствие ожидания связи с сервером.
Но вот с поисковой оптимизацией у таких сайтов настоящая беда, и чтобы исправить это придется запомнить несколько новых терминов 🙂
Что такое shebang/hashbang и причем тут SEO?
Shebang/hashbang — последовательность из символов #! в URL, которая позволяет поисковым системам сканировать и индексировать сайты и приложения, полностью созданные с помощью Ajax.
Суть метода: для каждой Ajax-страницы, которую необходимо проиндексировать, на сервере разместить HTML-версию.
По шагам:
1. При запросе Ajax-страницы должен формироваться URL http://site.com/#!/hello-world. Включение восклицательного знака позволит узнать о наличии HTML-версии документа, а не просто якоря — закладки с уникальным именем на той же странице, как в случае с использованием простого #. Пример простой якорной ссылки можно увидеть на странице «Как настроить расширенную электронную торговлю с помощью Google Tag Manager». Клик по ссылкам из блока ниже позволит перейти к нужной части статьи на той же странице:
2. Поисковый робот автоматически заменяет #! на ?_escaped_fragment_= и, соответственно, обращается к странице http://site.com/?_escaped_fragment_=hello-world — именно эта страница должна быть HTML копией Ajax-страницы сайта.
3. Ссылки на страницы с #! необходимо поместить в карту сайта. Это ускорит индексацию страниц.
Это ускорит индексацию страниц.
4. Чтобы сообщить роботу об HTML-версии главной страницы, в код следует включить метатег <meta name=»fragment» content=»!»>. Этот метатег нужно использовать на каждой Ajax-странице.
Важно! В HTML-версии документа метатег размещать не следует: в этом случае страница не будет проиндексирована, потому что при наличии метатега на странице, поисковый робот делает обращение к серверу в поисках соответствующей страницы с фрагментом URL: ?_escaped_fragment_=. Саму страницу c метатегом он не индексирует.
5. Ссылка в результатах поиска направит пользователя на Ajax-версию страницы.
6. В файле robots.txt должны быть открыты все Javascript-файлы, а также файлы, отвечающие за обработку Ajax. Это очень важно для индексации.
Например:
На сайте maxcar.bg с помощью технологии hashbang реализована фильтрация в категориях сайта. Например:
В результате страницы попадают в индекс Google:
Как ускорить индексацию с помощью функции window.
 history.pushState() в HTML5
history.pushState() в HTML5Это небольшая Javascript-функция в HTML5 History API. Кроме передачи других параметров, она позволяет изменить URL и Title, который отображается в браузере пользователя. Важно уточнить, что обращения к серверу или к новой странице при этом не происходит, что положительно влияет на скорость загрузки страниц.
Даже на сайте-одностраничнике можно создать любое количество таких URL и поместить их в XML-карту сайта, отправив ее на индексацию. Таким образом мы получим сколько угодно страниц с разным контентом.
У такого метода есть недостатки. Если в браузере отключен Javascript, пользователь не сможет увидеть содержимое страниц. Кроме того, у поисковых систем все еще могут возникать трудности при сканировании сайта с использованием Javascript, особенно если в реализации допущены ошибки.
Вот что пишет справка Google:
Многие веб-мастера уже оценили преимущества Ajax для повышения привлекательности сайтов за счет создания динамических страниц, которые выступают в роли функциональных веб-приложений. Но, как и Flash, Ajax может затруднить индексирование сайтов поисковыми системами, если эта технология реализована с ошибками. В основном Ajax вызывает две проблемы при использовании поисковых систем. Роботы поисковых систем должны «видеть» ваше содержание. Необходимо также убедиться, что они распознают правила навигации и следуют им.
Но, как и Flash, Ajax может затруднить индексирование сайтов поисковыми системами, если эта технология реализована с ошибками. В основном Ajax вызывает две проблемы при использовании поисковых систем. Роботы поисковых систем должны «видеть» ваше содержание. Необходимо также убедиться, что они распознают правила навигации и следуют им.
Робот Googlebot хорошо подходит в тех случаях, когда нужно понять структуру HTML-ссылок, но он может допускать ошибки на тех сайтах, где для навигации применяется Javascript. Мы работаем над совершенствованием системы распознавания Javascript, но если вы хотите создать сайт, который смогут сканировать Google и другие поисковые системы, то ссылки на содержание лучше всего предоставлять на языке HTML.
То, что ранее выглядело как http://site.com/#page1, при применении функции push.State() будет выглядеть как http://site.com/page1.
Функция window.history.pushState() использует три параметра: data, title, url. Внедрение данной функции происходит следующим образом:
- Перед тем как приступить к внедрению функции, необходимо удостовериться, что сайт работает и с отключенным в браузере Javascript — контент должен отображаться даже в таком случае.
- Контент, который меняется на странице, должен размещаться на серверной части. При переходе по ссылкам должна подгружаться только контентная часть, а не HTML-страница целиком.
- Javascript должен перехватывать и записывать в параметр URL клики по любым внутренним ссылкам (элементы навигации и так далее), если они есть.
- Учитывая атрибуты ссылки, по которой кликнул пользователь (возможно, на href), Javascript / Ajax загружает соответствующий контент на страницу.
- При этом, если использовать привычные для поисковиков ссылки вида <a target=»_blank» href=”site.ru/page1”> и обрабатывать клики с помощью данной функции, можно значительно улучшить скорость загрузки без какого-либо негативного влияния на SEO.

Посмотреть, как это реализовано, можно на сайте html5.gingerhost.com.
Хорошо, допустим, разобрались.
Что делать, если сайт на Angular JS и React?
Чтобы ускорить индексацию сайтов на Angular JS и React, необходимо использовать один из описанных ниже методов:
- Вместо того, чтобы постоянно отдавать HTML-версию страницы с помощью ?_escaped_fragment_=, отдавать HTML-версию только при запросе поисковым роботом. Список ботов Google можно посмотреть здесь.
- Предоставлять сайт поисковым системам без предварительного рендеринга. Используйте функцию HTML5 History API для обновления URL-адреса в браузере без использования #!, создайте файл sitemap.xml со всеми каноническими URL-адресами и добавьте его в Google Search Console.
- Использовать ?_escaped_fragment_= без использования #!. Для этого необходимо добавить в код <meta name=»fragment» content=»!»>, не меняя при этом URL. Поисковые системы при наличии данного метатега будут искать соответствующую HTML-версию страницы на сервере.
 Список ботов Google можно посмотреть здесь.
Список ботов Google можно посмотреть здесь.Посмотрите результат.
Выводы
- Используйте последовательность из символов #! в URL для сайтов на Ajax, Javascript для улучшения индексации.
- Используйте Javascript-функции pushState() для лендингов, Ajax и Javascript-сайтов.
- Внедряйте методы для улучшения индексации сайтов на AngularJS и React.
Повлияет ли контент, загруженный AJAX, на SEO / поисковые системы?
интересно, влияет ли контент, динамически загружаемый AJAX, на SEO / способность поисковых систем индексировать страницу?
я думаю о том, чтобы сделать постоянно загружающуюся страницу, что-то вроде панели мониторинга Tumblr, где контент автоматически загружается по мере того, как пользователь прокручивает вниз.
Поделиться Источник Jiew Meng 21 июня 2010 в 10:58
7 ответов
- Повлияет ли PHP включенный html контент на мой seo?
Сегодня я покупаю небольшую систему CMS. С помощью этого CMS я могу превратить свой статический сайт в редактируемую страницу. Я должен вырезать контент, который хочу сделать редактируемым, и вставить его в админку. Скрипт сгенерирует новый html с этим содержимым. Чем я должен включить этот html в…
- Получает ли загруженный контент AJAX «document.ready»?
Вчера у меня была проблема, когда обработчик событий .on(‘click’) , который я назначал, работал неправильно. Оказывается, это потому, что я пытался применить этот .on(‘click’) до того, как этот элемент существовал в DOM, потому что он загружался через AJAX и, следовательно, еще не существовал,…
9
Год спустя. ..
..
Некоторое время назад Google выпустила спецификации для создания контента XHR, который может быть проиндексирован поисковыми системами. Он включает в себя сопряжение содержимого в ваших асинхронных запросах с синхронными запросами, за которыми может следовать искатель.
http:/ / code.google.com / web/ajaxcrawling/
Понятия не имею, поддерживают ли эту спецификацию другие поисковые гиганты или даже Google. Если у кого-то есть какие-то знания о практичности этого метода, я хотел бы услышать об их опыте..
Правка: на сегодняшний день, 14 октября 2015 года, Google устарела от своей схемы обхода AJAX :
В 2009 году мы предложили сделать AJAX страницы ползучими. Тогда наши системы не могли визуализировать и понимать страницы, которые используют JavaScript для представления контента пользователям. … времена изменились. Сегодня, пока вы не блокируете Googlebot от обхода ваших файлов JavaScript или CSS, мы, как правило, можем визуализировать и понимать ваши веб-страницы, как современные браузеры.

H/T: @mark-bembnowski
Поделиться Jon z 27 июля 2011 в 16:07
Поделиться haoqiang 08 декабря 2015 в 02:57
2
Если у вас есть какой-то контент, загруженный запросом Ajax, то он загружается только агентами пользователей, которые запускают код Javascript.
Поисковые роботы обычно не поддерживают Javascript (или вообще не поддерживают).
Таким образом, есть вероятность, что ваш контент, загруженный запросом Ajax, не будет замечен поисковыми системами, а это значит, что он не будет проиндексирован ; что не совсем хорошо для вашего сайта.
Поделиться Pascal MARTIN 21 июня 2010 в 11:02
- JavaScript загруженный внешний контент SEO
Интересно, как лучше всего индексировать загруженный контент JavaScript поисковыми системами? Я знаю, что поисковые системы не выполняют JavaScript, но я больше думаю о прогрессивном зачаровании.
Я создаю адаптивный веб-сайт, и на главной странице у меня будет несколько разделов о наиболее… - SEO и ajax ссылка на загруженный контент
Мне нужна помощь, чтобы лучше понять SEO с загруженным контентом ajax. Здесь контекст: У меня есть single.php, где контент динамически генерируется (с базой данных php и xml) для каждого отдельного сообщения. Я загружаю контейнер этого single.php внутри моей страницы index.php через ajax. Вот…
 Я создаю адаптивный веб-сайт, и на главной странице у меня будет несколько разделов о наиболее…
Я создаю адаптивный веб-сайт, и на главной странице у меня будет несколько разделов о наиболее…
2
Короткий ответ: это зависит.
Вот почему — скажем, у вас есть какой — то контент, который вы хотите проиндексировать, — в этом случае загрузка его с помощью ajax гарантирует, что он этого не сделает. Поэтому этот контент должен загружаться нормально.
С другой стороны, скажем, у вас есть какой-то контент, который вы хотите индексировать, но по той или иной причине вы не хотите его показывать (я знаю, что это не рекомендуется и не очень приятно конечному пользователю в любом случае, но есть допустимые варианты использования), вы можете загрузить этот контент нормально, а затем скрыть или даже заменить его с помощью javascript.
Что касается вашего случая, когда у вас есть контент «constantly loading» — вы можете убедиться, что он проиндексирован, предоставив ссылки на поисковые агенты пользователей с поддержкой engines/non-js. Например, у вас может быть какой-то контент типа twitter, а в конце его-кнопка «Еще», которая ссылается на контент, начиная с последнего отображаемого элемента. Вы можете скрыть кнопку с помощью javascript, чтобы обычные пользователи никогда не знали, что она там есть, но искатели все равно проиндексируют этот контент (нажав на ссылку).
Поделиться Ramuns Usovs 21 июня 2010 в 11:12
1
Искатели не запускают JavaScript, так что нет, ваш контент не будет виден им. Вы должны предоставить альтернативный метод доступа к этому контенту, если хотите, чтобы он был проиндексирован.
Вы должны придерживаться того, что называется «graceful degradation» и «progressive enhancement». В основном это означает, что ваш сайт должен функционировать, а контент должен быть доступен, когда вы начинаете отключать некоторые технологии.
В основном это означает, что ваш сайт должен функционировать, а контент должен быть доступен, когда вы начинаете отключать некоторые технологии.
Создайте свой сайт с классической навигацией, а затем «ajaxify» его. Таким образом, он не только правильно индексируется поисковыми системами, но и удобен для пользователей, которые просматривают его с мобильных устройств / с отключенным JS / и т. д.
Поделиться Victor Stanciu 21 июня 2010 в 11:01
Поделиться ars265 24 июля 2012 в 14:50
1
Принятый ответ на этот вопрос уже не является точным. Поскольку этот пост все еще отображается в результатах поиска, я подытожу последние факты:
Где-то в 2009 году Google выпустила свое предложение по ползучести AJAX. Вскоре после этого другие поисковые системы добавили поддержку этой схемы. На сегодняшний день, 14 октября 2015 года, Google устарела от своей схемы обхода AJAX :
На сегодняшний день, 14 октября 2015 года, Google устарела от своей схемы обхода AJAX :
В 2009 году мы сделали предложение сделать AJAX страниц ползучими. Тогда наши системы не могли визуализировать и понимать страницы, которые используют JavaScript для представления контента пользователям. … времена изменились. Сегодня, пока вы не блокируете Googlebot от обхода ваших файлов JavaScript или CSS, мы, как правило, можем визуализировать и понимать ваши веб-страницы, как современные браузеры.
Поделиться Mark Bembnowski 15 октября 2015 в 01:28
Похожие вопросы:
Скрытый контент div, учитывают ли поисковые системы этот контент или игнорируют его?
Возможный Дубликат : jQuery и SEO (скрытые div’s) Что делать, если я добавлю скрытый тег div внутри него какой-то текст контента, будут ли поисковые системы заглядывать в этот div? Пример:. ..
..
Прогрессивный рендеринг и SEO
На веб-сайте, над которым я работаю, есть типичная страница продукта электронной коммерции, верхняя часть которой содержит название, изображения и цены, а нижняя часть страницы имеет раздел вкладок…
Просматривает ли Google контент, загруженный через функцию загрузки jQuery?
Если у меня есть файл test1.html , содержащий некоторую информацию и test2.html , когда я использую .load(test1.html) Будут ли поисковые системы читать контент, загруженный с test1.html ?
Повлияет ли PHP включенный html контент на мой seo?
Сегодня я покупаю небольшую систему CMS. С помощью этого CMS я могу превратить свой статический сайт в редактируемую страницу. Я должен вырезать контент, который хочу сделать редактируемым, и…
Получает ли загруженный контент AJAX «document.ready»?
Вчера у меня была проблема, когда обработчик событий .on(‘click’) , который я назначал, работал неправильно. Оказывается, это потому, что я пытался применить этот .on(‘click’) до того, как этот…
Оказывается, это потому, что я пытался применить этот .on(‘click’) до того, как этот…
JavaScript загруженный внешний контент SEO
Интересно, как лучше всего индексировать загруженный контент JavaScript поисковыми системами? Я знаю, что поисковые системы не выполняют JavaScript, но я больше думаю о прогрессивном зачаровании. Я…
SEO и ajax ссылка на загруженный контент
Мне нужна помощь, чтобы лучше понять SEO с загруженным контентом ajax. Здесь контекст: У меня есть single.php, где контент динамически генерируется (с базой данных php и xml) для каждого отдельного…
Если я удалю базу данных mySQL на phpmyadmin, повлияет ли это на контент, загруженный на мой сервер ftp?
Если я удалю базу данных mySQL на phpmyadmin, повлияет ли это на контент, загруженный на мой сервер ftp? Связаны ли каким-то образом mySQL таблиц и FTP контента? Я использую wordpress для настройки…
Могут ли поисковые системы индексировать отдельные страницы в веб-приложении на базе JavaScript?
Веб-приложение, которое я создаю, имеет интерфейс с питанием JavaScript и извлекает данные с сервера с помощью AJAX. Все находятся на одном и том же page, но данные после хэштега в URL используются…
Все находятся на одном и том же page, но данные после хэштега в URL используются…
Как мне построить SEO дружественный сайт Ionic 5, который может генерировать HTML, а поисковые системы могут сканировать этот html
Мы разрабатываем веб — сайт в Ionic 5- Angular. Мы хотим, чтобы веб-сайт был SEO дружественным, чтобы поисковые системы могли легко сканировать веб-сайт. Обычно, если мы делаем вид источника ионного…
Индексирование сайта с динамической подгрузкой данных
Руководитель SEO-отдела агентства Nimax Олег Белов написал для «Нетологии» колонку о том, что делать сайтам с динамической подгрузкой данных, чтобы попадать в поисковики.
Последние годы разработчики сайтов уделяют больше внимания удобству интерфейсов: всё должно быть быстро, удобно и понятно. Но технологии, которые помогают создавать такие проекты, не всегда «дружат» с поисковыми системами. Иногда современные сайты либо отсутствуют в поиске «Яндекса» или Google, либо плохо ранжируются. Часто так бывает у сайтов с динамической подгрузкой данных. Давайте разберёмся, в чём сложность их индексации и как решить этот вопрос.
Часто так бывает у сайтов с динамической подгрузкой данных. Давайте разберёмся, в чём сложность их индексации и как решить этот вопрос.
Что такое динамическая подгрузка данных
Под динамической подгрузкой данных понимается, как правило, использование технологии AJAX. Это подход для создания интерактивных интерфейсов. Он строит взаимодействие пользователя и веб-сервера по сценарию:
Пользователь нажимает на кнопку, ссылку или другой элемент страницы.
Элемент обрабатывается JavaScript’ом, после запрос уходит на сервер, чтобы получить данные.
Сервер возвращает информацию, скрипт добавляет информацию на страницу без ее перезагрузки.
Таким образом, AJAX позволяет добавлять или обновлять контент на странице без её перезагрузки. Технология применяется в одностраничных сайтах-приложения (mail.google.com/ и yandex.ru/maps/), в различных интерактивных проектах (rambler-co. ru), а также на обычных сайтах для подгрузки информации в новостных блоках, листингах и других элементах на страницах (комментарии на livejournal.com/).
ru), а также на обычных сайтах для подгрузки информации в новостных блоках, листингах и других элементах на страницах (комментарии на livejournal.com/).
В качестве альтернативной технологии можно использовать WebSocket, при котором обмен данными между браузером и сервером происходит в режиме реального времени. Технология применяется в сервисах с live-контентом ,например, в социальных сетях, где ленты и диалоги между пользователями регулярно обновляются без перезагрузки страниц. Но задачи индексации контента с использованием WebSocket не возникает, поэтому далее речь пойдет именно об AJAX технологии.
В чём сложность индексации AJAX-контента
Необходимое условие для индексации страниц сайта — наличие контента в коде в формате HTML. Особенность динамически подгружаемого контента в том, что в HTML-виде его в коде нет, он подгружается отдельно через JavaScript. Это приводит к двум проблемам:
Поисковый робот не видит контент, потому что его нет в HTML-коде. Из-за этого страницы могут не индексироваться.
Поисковые системы могут индексировать только главную страницу. Так получается, если разработчик использует символ «#» после доменного имени в URL-адресах: http://site.ru/#page-1 или http://site.ru/#page-2. Если адреса на сайте выглядят так, то в индекс поисковых систем будет попадать только главная страница.
Как решить проблему
Чтобы подготовить к продвижению сайт с динамической подгрузкой контента, используют схему сканирования AJAX.
1. Необходимо, чтобы поисковый робот понял, что сайт поддерживает схему сканирования AJAX. Реализация зависит от организации URL-адресов на сайте.
Если адреса на сайте формируются с помощью «#», нужно заменить их на «#!» (хэшбэнг). То есть http://site.ru/#url → http://site.ru/#!url.
Если адреса имеют обычные ЧПУ без хэша, добавьте на динамические страницы мета-тег:
При выполнении условий выше, робот будет запрашивать варианты страниц с параметром «?_escaped_fragment_=», по которым ему нужно отдавать HTML-снимки (HTML-копии страниц со всем контентом, загруженным после выполнения JavaScript). Чтобы создать HTML-снимки страниц обычно используют headless браузеры на стороне сервера. Например, PhantomJS или HtmlUnit.
Подробнее для разработчиков:
Когда робот попадёт на страницу с «#!» в URL-адресе или с мета-тегом , он запросит страницу с параметром «?_escaped_fragment_=»:
В итоге поисковый робот будет получать HTML-снимки всех страниц, которые и будут добавлены в индекс. Сайт будет участвовать в поиске на общих основаниях. В индексе поисковых систем при этом хранятся адреса без параметра «?_escaped_fragment_=».
Рекомендации для разработчиков:
Что делают поисковики для индексации динамического контента
В октябре 2015 года Google отозвал рекомендации по сканированию сайтов на AJAX. Теперь, если для Googlebot нет ограничений по чтению файлов JS и CSS, он отрисовывает и загружает контент в том же варианте, каким его видят пользователи у себя в браузере. Это значит, что сайты, использующие динамически подгружаемый контент, должны корректно индексироваться в Google, если роботу открыты служебные файлы.
Чтобы проверить, как выглядят страницы сайта для поискового робота Google, можно воспользоваться сервисом Search Console. В разделе «Сканирование» нужно выбрать «Посмотреть как Googlebot», ввести в соответствующую строку адрес страницы и нажать кнопку «Получить и отобразить». После обработки получить результат: посмотреть, как бот видит страницу и какие компоненты JS или CSS ему недоступны.
Вкладка «Сканирование»
Вкладка «Отображение»
В ноябре 2015 года Яндекс объявил о тестировании подобной технологии — использовании JS и CSS при сканировании сайтов.
Полезное почитать:
Нужно ли следовать новым рекомендациям Google?
Пока только Google способен индексировать сайты без получения полной HTML-копии страниц. Яндекс только тестирует такую возможность. Для всех остальных поисковых систем вариант остаётся прежний. Поэтому отказываться от HTML-копий страниц будет некорректным решением.
Индексирование страниц с подстановкой параметра «?_escaped_fragment_=» (когда происходит обращение к полной HTML-версии страницы) по-прежнему поддерживается и в Google. Если вы используете на сайте AJAX для подгрузки контента, ваш сайт будет по-прежнему корректно индексироваться в Google, если роботу отдаются страницы с «?_escaped_fragment_=».
Как использовать AJAX для нужд SEO
Динамическая подгрузка данных полезна, когда нужно, наоборот, скрыть часть контента. В каких случаях может возникнуть такая потребность?
Какая-то часть контента дублируется на многих страницах сайта. Например, условия оплаты и доставки на карточках товара в интернет-магазине.
Выводимый контент берется с других сайтов. Например, отзывы о товарах с Яндекс.Маркета — безусловно полезны для пользователей, но могут негативно восприниматься поисковыми системами, как наличие неуникального контента.
Скрытие части навигационных элементов на страницах. Может использоваться, например, для перераспределения статического веса между страницами сайта.
Как решить эти задачи
Для решения, конечно, можно использовать тег noindex, но он подходит только для Яндекса, другие поисковые системы его не воспринимают. В таком случае, вы можете подгружать дублирующийся контент динамически. Но остается проблема с Google’ом, т.к. он умеет исполнять JS-скрипты, а значит, контент все же проиндексируется. Для того, чтобы этого не произошло, ограничьте в фале robots.txt индексацию JS-файла, отвечающего за подгрузку контента. Это позволит скрыть нужную часть контента от поисковых роботов.
Итого
AJAX — полезная технология, позволяющая улучшать взаимодействие пользователя с сайтом и ускорять загрузку контента. У многих SEO-оптимизаторов сложился стереотип, что подружить сайты, использующие AJAX с SEO невозможно. Это не так, поисковые системы постепенно идут к индексации сайтов с динамическим контентом собственными силами, а также предлагают вебмастерам и оптимизаторам варианты специальных технических настроек, позволяющих решать проблемы.
Мнение автора и редакции может не совпадать. Хотите написать колонку для «Нетологии»? Читайте наши условия публикации.
AJAX | SEO-глоссарий | SEO-портал
AJAX (Asynchronous JavaScript and XML — асинхронный JavaScript и XML) — технология, реализующая обмен данных между сервером и браузером без перезагрузки веб-страницы.
Грамотное применение технологии AJAX на сайтах позволяет:
- ускорить обмен данными между браузером и сервером,
- исключить дублирование страниц,
- уменьшить объем загружаемого трафика,
- снизить нагрузку на сервер.
Таким образом, AJAX целесообразно применять в целях ускорения работы сайта, улучшения его удобства к использованию (юзабилити), а также для исключения возможных проблем с дублированием страниц при SEO-оптимизации.
В качестве отличного примера применения AJAX можно привести веб-страницу со списком товаров и с модулем фильтрации товаров по многочисленным параметрам. В результате применения фильтра на странице отображаются необходимые товары, при этом страница не перезагружается и её исходный URL-адрес не меняется.
что это такое и зачем он нужен на сайте
AJAX Asynchronous JavaScript & XML – специальная технология взаимодействия с сервером, которая не требует выполнения перезагрузки. Она позволяет повысить скорость загрузки страниц веб–ресурса, поскольку нет необходимости обновлять их каждый раз. Наличие этой опции помогает сделать пользование сайтом для пользователя максимально комфортным.
История создания
Многие технологии, которые нашли свое применение в AJAX, появились больше 20 лет назад. Термин AJAX в первый раз прозвучал в 2005 году в статье Джесси Джеймса Гаррета, который является одним из создателей и главой Adaptive Path. В материале он впервые описал принцип создания приложений, который в тот период использовали в Google для своих сервисов карты и почты. Гаррет назвал эту технологию «прорывной» с точки зрения возможностей интернет-приложений. Он пояснил, что представляет собой AJAX, назвал эту технологию и указал на новую тенденцию. В конечном итоге это помогло поднять разработку сайтов и web-приложений на более высокий уровень. Именно благодаря этой технологии пользователи мобильных устройств могут видеть у себя на дисплее результаты «фонового» обмена данными между браузером и сервером.
Достаточно посмотреть на механизм работы веб-страницы, чтобы понять – перед вами AJAX сайт. До появления этой технологии юзеру приходилось выполнять много действий, постоянно перемещаться по ссылкам. Сейчас страница самостоятельно реагирует на внесение сведений. Период времени, который уходит на взаимодействие с сайтом, существенно уменьшается. По сути юзер находится в контакте с оперативно реагирующей интернет–страницей, для работы которой нужен только браузер, поддерживающий язык JavaScript, и соединение с интернетом.
Если приложение сконфигурировано грамотно, во время использования AJAX оно будет работать как любая компьютерная программа.
Как функционирует система
Технология работы AJAX включает следующие этапы:
- 1 Юзер обращается к AJAX, чаще всего это происходит нажатием кнопки, предлагающей узнать более подробную информацию.
- 2 Сервис пересылает запрос на сервер вместе с сопутствующими данными. К примеру, может понадобиться загрузка какого-то файла или определенных сведений из базы.
- 3 Получив ответ из базы данных, сервер направляет его в браузер.
- 4 JavaScript получает ответ, расшифровывает и показывает пользователю.
Для обмена данных создается объект XMLHttpRequest, он выполняет посредническую функцию между сервером и браузером. Есть два типа запросов – GET и POST. GET обращается к документу на сервере, в качестве аргумента ему предоставляется URL веб–ресурса. Для обеспечения непрерывной работы запросов можно воспользоваться функцией JavaScript Escape обеспечить непрерывность запроса. Для больших объемов информации применяется POST.
Услуги, связанные с термином:
Как сделать приложения AJAX доступными для сканирования
Если вы хотите сканировать веб-сайт с помощью приложения AJAX, вам нужно будет использовать функцию сканирования AJAX, чтобы DeepCrawl мог получить доступ к ссылкам и контенту на сайте.
Примечание: Google прекратил использование схемы сканирования AJAX в конце 2 квартала 2018 г. . Если вы полагаетесь на схему сканирования AJAX для Google для сканирования и индексации динамического контента, то это больше не поддерживается. Для получения дополнительной информации о сканировании и индексировании веб-сайтов на JavaScript, пожалуйста, прочтите новую документацию Google Developers .
В этом руководстве мы сосредоточимся на:
- Что такое AJAX?
- Как работает схема сканирования AJAX?
- Как настроить DeepCrawl для сканирования веб-сайтов AJAX?
Что такое AJAX?
Термин AJAX означает асинхронный JavaScript и XML. Это метод, используемый разработчиками для создания интерактивных веб-сайтов с использованием: XML, HTML, CSS и JavaScript.
AJAX позволяет разработчикам обновлять контент при запуске события, не заставляя пользователя перезагружать страницу.Хотя веб-сайт AJAX может создать отличные условия для пользователей, он может вызвать проблемы с сервером для поисковых систем.
Основные проблемы с сайтами AJAX заключаются в следующем:
- Они не создают уникальных URL-адресов для страницы, вместо этого они создают # для страницы.
- Содержимое страницы динамически создается после загрузки страницы.
Обе проблемы не позволяют поисковым системам сканировать и индексировать динамический контент на веб-сайте. Чтобы справиться с этими проблемами, Google разработал схему сканирования AJAX, которая позволяет поисковым системам сканировать и индексировать эти типы веб-сайтов.
Как работает схема сканирования AJAX?
Веб-сайт, реализующий схему сканирования AJAX, предоставляет сканерам поисковых систем снимок динамической страницы в формате HTML. Поисковой системе предоставляется «уродливый URL-адрес», в то время как пользователю предоставляется динамический «чистый URL-адрес» веб-страницы.
Например:
- Чистый URL в браузере: https://www.ajaxexample.com/#!hello
- Уродливый URL для сканера: https: //www.ajaxexample.com /? _ escaped_fragment_ = привет
Для обзора того, как создавать снимки HTML и схемы сканирования AJAX, прочтите следующее официальное руководство от Google.
Как настроить сканирование AJAX в DeepCrawl
При настройке DeepCrawl важно убедиться, что:
- Веб-сайт AJAX поддерживает схему сканирования AJAX .
- Обновлены расширенные настройки в проекте DeepCrawl.
Поддержка схемы сканирования AJAX
Наша команда рекомендует следовать инструкциям схемы сканирования AJAX, чтобы реализовать ее на веб-сайте AJAX.Важно отметить, что существует два способа указать схему: веб-сайт AJAX , на котором есть хэшбэнг (#!) В URL-адресе , и веб-сайты AJAX, на которых не содержит хэш-банга (#!) В URL-адресе .
Наша команда предоставила более подробную информацию ниже для каждой настройки и того, как она влияет на DeepCrawl.
AJAX-сайты, использующие хэшбэнг-адреса (#!)
Для DeepCrawl для сканирования веб-сайта AJAX , который имеет хэшбанг в URL-адресе , необходимы следующие требования:
- Схема сканирования AJAX указывается на чистых URL-адресах с помощью hasbang (#!).
- Сервер сайта должен быть настроен для обработки запросов на некрасивые URL.
- Уродливый URL-адрес должен содержать снимок страницы в формате HTML.
Если эти требования не соблюдены, DeepCrawl не сможет сканировать веб-сайт AJAX.
AJAX-сайты без хэшбэнг-URL (#!)
Для DeepCrawl для сканирования веб-сайта AJAX без хэш-бэнга в URL-адресе необходимы следующие требования:
- Схема сканирования AJAX указывается на чистых URL-адресах с помощью мета-тега фрагмента.
- Параметр _escape_fragment_ добавляется в конец чистых URL-адресов.
- Уродливый URL-адрес должен содержать снимок страницы в формате HTML.
Тег мета-фрагмента и параметр _escape_fragment_ необходимо включать только на страницы, использующие AJAX. Их не нужно добавлять на каждую страницу веб-сайта, если только все страницы не используют AJAX для загрузки содержимого.
Обновление настроек DeepCrawl для сканирования веб-сайтов AJAX
После обновления веб-сайта, чтобы правильно указать схему сканирования AJAX для поисковых систем, вам необходимо будет обновить расширенные настройки в DeepCrawl.
1. Во-первых, снимите флажок «Убрать # фрагментов из всех URL-адресов». Это заставит DeepCrawl сканировать хешированные URL-адреса.
2. Затем создайте следующие три правила в настройках перезаписи URL.
| Соответствие от | Соответствует | Варианты корпуса |
|---|---|---|
| #! | ? _Escaped_fragment_ = | Без изменений |
| ^ (?!.(?!. *? _ escaped_fragment _ =) (. *) | $ 1? _Escaped_fragment_ = | Без изменений |
3. Нажмите «Сохранить» в нижней части расширенных настроек проекта, чтобы сохранить настройки перезаписи.
4. Запустите тестовое сканирование, чтобы проверить, работают ли настройки нового проекта.
Как работает правило перезаписи URL?
Первое правило перезаписи заменит #! с _escaped_fragment_ = во всех URL, например:
Довольно URL: www.example.com/document#!resource_1
Переписанный URL: www.example.com/document?_escaped_fragment_=resource_1
Это позволит нашему сканеру получить доступ к снимку страницы в формате HTML.
Второе правило перезаписи добавит экранированный фрагмент в конец URL-адреса, который содержит параметры, например:
Красивый URL: www.example.com/document/?resource_1
Переписанный URL: www.example.com/document/?resource_1&_escaped_fragment_=
Третье правило перезаписи добавит экранированный фрагмент в конец URL-адреса, не содержащего параметров, например:
Довольно URL: www.example.com/document/resource_1
Переписанный URL: www.example.com/document/resource_1?_escaped_fragment_=
Эти правила также разрешают ссылки на веб-сайте, которые уже содержат «? _Escaped_fragment_», и в этом случае решение не следует добавлять.
Часто задаваемые вопросы
Почему Google больше не поддерживает схему сканирования AJAX?
Google официально прекратил сканирование #! URL-адреса летом 2018 года. Они прекратили поддержку этой схемы, поскольку теперь робот Googlebot может отображать веб-сайты AJAX с помощью службы веб-рендеринга (WRS).
Поддерживают ли другие поисковые системы схему сканирования AJAX?
На момент написания этого руководства Bing и Яндекс по-прежнему поддерживают схему сканирования AJAX. Ни одна из этих поисковых систем не объявила о планах прекратить поддержку схемы сканирования AJAX.
Как долго DeepCrawl будет поддерживать схему сканирования AJAX?
Команда DeepCrawl не планирует прекращать поддержку этой функции. Следите за обновлениями в нашем блоге.
Что мне делать, если DeepCrawl не сканирует наш сайт AJAX?
Если DeepCrawl не будет сканировать ваш веб-сайт даже при включенном сканировании AJAX, мы рекомендуем проверить следующее:
- Уродливые URL-адреса не блокируются в robots.txt
- Уродливые URL-адреса создают код состояния 200 http
- Уродливые URL-адреса содержат ссылки на другие страницы веб-сайта и доступны для навигации
Мы также рекомендуем ознакомиться с нашими руководствами по устранению заблокированных сканирований и устранению неполадок при сканировании.
AJAX обратная связь при сканировании
Если у вас есть дополнительные вопросы о сканировании AJAX, свяжитесь с нами.
Автор
Адам Гент
Специалист по поисковой оптимизации (SEO) с более чем 8-летним опытом работы в индустрии поискового маркетинга.На протяжении многих лет я работал с целым рядом клиентских кампаний, от малых и средних предприятий до всемирно известных мировых брендов FTSE 100.
Как: разрешить Google сканировать ваш контент AJAX
ОБНОВЛЕНИЕ: Теперь есть еще лучший способ решить проблему, которую я описал в этом посте. Я рекомендую вам обратить ваше внимание на мою новую публикацию по теме: Создание сканируемых и удобных для ссылок веб-сайтов AJAX с помощью pushState ().
Я оставлю этот пост для ностальгии!
Этот пост начинается с конкретной дилеммы, с которой часто сталкиваются оптимизаторы поисковых систем:
- веб-сайты, которые используют AJAX для загрузки содержимого на страницу, могут работать намного быстрее и обеспечивать лучший пользовательский интерфейс
- НО: эти веб-сайты могут быть трудными (или невозможными) для сканирования Google, а использование AJAX может повредить SEO сайта.
К счастью, Google сделал предложение о том, как веб-мастера могут получить лучшее из обоих миров. Я предоставлю ссылки на документацию Google позже в этом посте, но все сводится к некоторым относительно простым концепциям.
Хотя Google сделал это предложение год назад, я не думаю, что оно привлекло много внимания — хотя оно должно быть особенно полезно для оптимизаторов поисковых систем. Этот пост предназначен для людей, которые еще не знакомы с предложением Google по сканированию AJAX — я постараюсь сделать его кратким и не слишком техническим!
Я объясню концепции и покажу вам известный сайт, где они уже действуют.Я также установил свою собственную демонстрацию, которая включает код, который вы можете скачать и посмотреть.
Основы
По сути, сайты, следующие этому предложению, должны предоставить две версии своего контента:
- Контент для пользователей с поддержкой JS по URL-адресу в стиле AJAX
- Контент для поисковых систем со статическим «традиционным» URL-адресом — Google называет это «снимком HTML»
Исторически разработчики использовали часть URL-адресов « named anchor » на веб-сайтах на базе AJAX (это символ «решетка», # и текст, следующий за ним).Например, взгляните на эту демонстрацию — щелчок по пунктам меню меняет имя якоря и загружает контент на страницу на лету. Это здорово для пользователей, но пауки поисковых систем не могут с этим справиться.
Вместо использования хеша # новое предложение требует использования хеша и восклицательного знака: #!
#! Комбинация иногда называлась «хэшбэнгом» людьми, более увлеченными, чем я; Мне нравится звучание этого термина, поэтому я буду придерживаться его.
Hashbang Wallop: протокол сканирования AJAX
Как только вы используете хэшбэнг в URL-адресе, Google обнаружит, что вы следуете их протоколу, и интерпретирует ваши URL-адреса особым образом — они возьмут все, что находится после хэш-бэнга, и передадут его на сайт в качестве параметра URL-адреса. вместо. Имя, которое они используют для параметра: _escaped_fragment_
Затем Google перепишет URL-адрес и запросит контент с этой статической страницы. Вот несколько примеров, чтобы показать, как выглядят перезаписанные URL-адреса:
- www.demo.com/#!seattle/hotels становится www.demo.com/?_escaped_fragment=seattle/hotels
- www.demo.com/users#!name=rob становится www.demo.com/users ? _escaped_fragment_ = name = rob
Пока вы можете заставить статическую страницу (URL-адрес справа в этих примерах) отображать тот же контент, который будет видеть пользователь (по левому URL-адресу), тогда она будет работать так, как планировалось.
Два предложения по статическим URL-адресам
На данный момент кажется, что Google возвращает статические URL-адреса в своем индексе — это имеет смысл, поскольку они не хотят навредить опыту пользователей, не использующих JS, отправив их на страницу, требующую Javascript.По этой причине сайты могут захотеть добавить некоторый Javascript, который будет обнаруживать пользователей с поддержкой JS и переходить к «расширенной» версии AJAX страницы, на которую они попали.
Кроме того, вы, вероятно, не хотите, чтобы ваши проиндексированные URL-адреса отображались в поисковой выдаче с параметром _escaped_fragment_ в них. Этого можно легко избежать, разместив страницы «статической версии» с более привлекательными URL-адресами и используя переадресацию 301, чтобы направлять пауков от версии _escaped_parameter_ к более привлекательному примеру.
E.G .: В моем первом примере выше сайт может выбрать реализацию 301 редиректа с
www.demo.com?_escaped_fragment=seattle/hotels на www.demo.com/directory/seattle/hotels
Живой пример
К счастью для нас, на довольно большом веб-сайте уже есть отличная демонстрация этого предложения: новая версия Twitter.
Если вы являетесь пользователем Twitter, вошли в систему и используете Javascript, вы сможете увидеть мой профиль здесь:
Однако робот Googlebot распознает это как URL-адрес в новом формате и вместо этого запросит этот URL-адрес:
Разумно, Twitter хочет поддерживать обратную совместимость (и чтобы их индексированные URL-адреса не выглядели как мусор), поэтому они 301 перенаправляют этот URL-адрес на:
(И если вы вошли в систему Twitter, последний URL-адрес фактически перенаправит вас обратно на первый.)
Другой пример, с бесплатно загружаемым кодом
Я установил демонстрацию этих практик в действии по адресу: www.gingerhost.com/ajax-demo
Не стесняйтесь поиграть и посмотреть, как ведет себя эта страница. Если вы хотите увидеть, как это реализовано с точки зрения «серверной части», нажмите ссылку для загрузки на этой странице, чтобы получить код PHP, который я использовал. (Примечание: я не разработчик; если кто-то обнаружит какие-либо явные ошибки, дайте мне знать, и я смогу их исправить!)
Дополнительные примеры, дополнительная информация
Витрина Google Web Toolkit придерживается этого предложения; экспериментирование с удалением hasbang оставлено в качестве упражнения для читателя.
Лучшее место для дальнейшего чтения по этой теме — определенно собственные справочные страницы Google. Они предоставляют информацию о том, как сайты должны работать, чтобы соответствовать этому предложению, и некоторые интересные советы по реализации, такие как использование серверных манипуляций с DOM для создания моментального снимка (хотя я думаю, что их внимание к этому «безголовому браузеру» вполне могло заставить людей от реализации этого раньше.)
В блоге Google Webmaster Central есть официальное объявление об этом, и Джон Мюллер предложил обсудить это на форумах WMC.
Между блогом Google, форумом и страницами справки вы должны найти все, что вам нужно, чтобы превратить ваши модные сайты AJAX во что-то, что может понравиться Google, а также вашим пользователям. Повеселись!
SEO для AJAX
AJAX и SEO — сложная тема. В конце концов, веб-сайт на основе AJAX более или менее похож на веб-сайт FLASH: он может выглядеть модно, но по нему невозможно ориентироваться.
AJAX получил плохую репутацию в области SEO по ряду причин, в том числе:
— проблемы со сканированием (вы рискуете не просканировать весь свой контент)
— проблемы с индексацией (вы рискуете не проиндексировать весь свой контент)
— неработающая навигация по сайту и бесполезная адресная строка (потому что все страницы загружаются под одним и тем же URL)
— бесполезные кнопки возврата / следующей / перезагрузки
— потенциальные проблемы маскировки — которые могут быть непреднамеренными — когда пользователь видит другой контент, чем поисковый робот
Объявление
Продолжить чтение ниже
Вот разница в том, что сканер может видеть без AJAX и не может видеть с помощью AJAX *:
* Отправьте запрос в Google за изображением: http: // docs.google.com/present/view?id=dc75gmks_120cjkt2chf
Реклама
Продолжить чтение Ниже
Тем не менее, AJAX может и должен быть дружественным к поисковым системам, и следование этим простым передовым методам приведет вас туда (или, по крайней мере, намного ближе к тому месту, где вы должны be):
1) Решите, где заканчивается ваш веб-сайт и начинается приложение: не имеет смысла заставлять пауков сканировать ваши черновики, вместо этого документы VMWare Octopus опубликованы и заархивированы
2) Убедитесь, что у вас есть URL-адрес для каждая «страница», которую вы хотите просканировать и проиндексировать
3) Загрузить основной контент, содержащий ключевые слова в начале, нединамически
4) Кэшировать динамические страницы и использовать их как статические, вы даже можете делать снимки «страниц», содержимое которых постоянно меняется, и публикуют снимки
5) Пункты меню, ссылки и другие важные структурные аспекты сайта должны работать без AJAX и / или JavaScript
6) Не используйте A JAX для эффектов, но для дополнительных функций, которые действительно улучшают взаимодействие с пользователем
Некоторые дополнительные советы:
AJAX следует использовать для того, для чего он предназначен — динамическое взаимодействие текущей страницы с сервером (например, если вам нужно отправить формы, загрузить изображение без перезагрузки страницы или обновления виджета (т.е. календарь)).