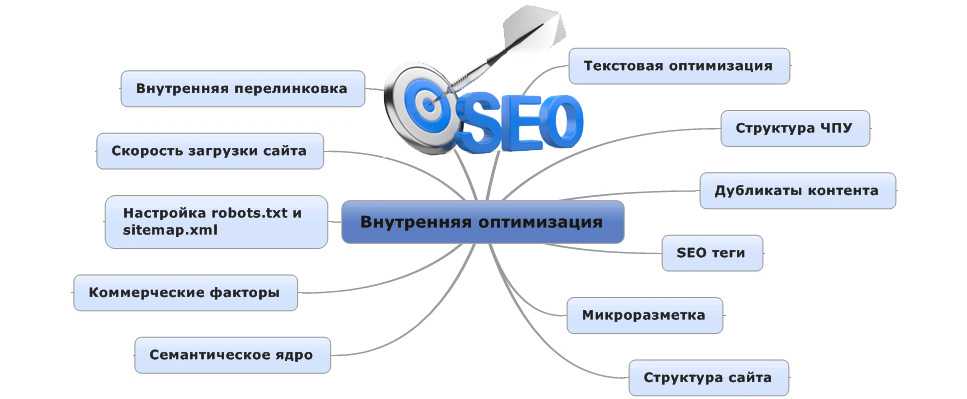
Как рассчитать слова для seo оптимизации — SEO на vc.ru
Расчет документа по BM 25
2328 просмотров
BM25 – данная функция анализирует слова запроса в каждом документе, в беспорядочном количестве терминов и количестве документов не учитывая связь между ними. Это род функций с разными параметрами и компонентами. Okapi BM25 которую разработали в университете Лондона в 1980-х и 1990-х годах и опирается на допустимости модели разработанной Стивеном Робертсоном, Карен Спарк Джоунсом в 1970-х и в 1980-х годах.
Версия BM25 – BM25F является более современные TF-IDF — определяет важность слова применяемое в тексте. Чем длиннее текст, тем больше может быть вхождений в него термина. Однако это не значит, что текст отвечает желаниям посетителей. Для этого используется формула, которая рассчитывает количество применений одного слова к общей сумме слов в документе.TF- частотность вхождений термина к общему числу слов в тексте. IDF – обратная частота документа анализирующие то как регулярно слово встречается в коллекции документов.
Так же надо вспомнить о BM25F – учет релевантности по фактору частотности, где учитывается различность важности зон документа. К примеру предложение в середине текста имеет меньшее значение, чем заголовок.
Особенности ранжирования НЧ запросов
· ВМ25 без учета расстояний между словами. Это значит, что все слова из запроса должны быть в тексте, не важно на каком расстоянии они идут.
· Минимум 1 вхождение в title, текст ссылки
· В рамках шингла (6 слов) должно быть вхождение.
Шингл- это текст, разбитый на определенные отрезки.
Можно использовать блок 2-3 предложения через весь сайт для привлечения шлейфа НЧ.
Текстовое ранжирование
· TF*idf
· Bm25
Текст нужно считать и рассчитывать.
Score = Wsin gle + Wpair + k1 *WAllWords +
k2 *WPhrase + k3 *WHalfPhrase + WPRF
Вхождение 1 слова, вхождение пар слов, есть ли все слова в тексте (фразовое соответствия, пол фразы, часть фразы), где они встречаются и т.
Пример формулы текстового ранжирования
Hdr-сумма весов слова за форматирование. CF-число вхождений леммы в коллекцию. D-число документов в коллекции.
Учет пар слов
Слова запроса встречаются в тексте-1, через слово или в обратном порядке 0.5 Слова из трехсловных запросов через слово идут подряд-0.1.
Учет фраз
Помимо перечисленного является присутствие всех слов запроса, за каждое отсутствующие слово умножается на коэффициент 0.03. Полная формула:
Nmiss-кол-во отсутствующих слов в документе.
Бонус за наличие всех слов в документе.
Концентрация всех слов в тексте (в той зоне), где надо рассматривать если отсутствуют какие-то слова будет штраф, потому что это указанно в формуле.
ВМ25 – модификация ВМ25F в которой документ представляется как совместимость нескольких полей таких как, например, заголовки, основной текст, ссылочный текст, протяженность которых самостоятельно упорядочивается и каждой из которой может быть назначен свой уровень ценности и итоговой функции ранжирования.
ВМ25 – это формула текстового ранжирования которая используется в ПС, для того что бы понять какой текст релевантный по определенному слову, фразе. Соответственно используется в ПС модификация F (что значит field- поле). Считается ВМ25 не для всего документа, а по каждому отдельному полю. Поле может быть, как title, так h2, текст, большой сео текст, так и фрагменты теста, входящих внешних ссылок, внутренних анкоров, исходящих ссылок из документа, то есть посчитать можно по абсолютно разные поля в документе.
Связанные с ВМ25
· Предложения, в которых есть вхождения
· Заголовки
· Различные теги выделений (<b> strong и др.)
· Учет позиции в док-те
· С учётом синонимов в документе
· Различные участки текста
Не относящиеся к ВМ25
· Наличие всех слов в документе
· Точное вхождение
· Позиция в документе
· Вхождение фраз в анкоры исходящих ссылок
· Вхождение лемм
· Релевантные пассажи
· Все выше перечисленное с учетом синонимов.
Тематическая близость-ISI
Ни где не отмечено в факторах ПС слова, которые чаще всего используют сайты из ТОПа.
Тематическая близость, не каким индексом в тематике, условно, что в Топе есть сайты по запросам, которых есть схожий набор слов в тематике который может оказывать влияние на ранжирование. Учитывая, что нельзя найти нормальные синонимы. Очень часто могут оказываться синонимы, слова имеющие отношения к тематике и из-за этого можно понять контент. Можно использовать слова, которые используют конкуренты.
Расчет ВМ25 для 2-х зон документа. Title
Bady (без разбиения на фрагменты). Bady- весь основной контент.
Есть зависимость от контента, но это не значит, что чем больше текста, тем лучше, но вероятность есть.
Важен расчет, может быть дан в видеTF (частота использования слова или фразы), или в виде рекомендаций по количеству вхождений и объему зоны документа. ВМ25 сильно зависит как раз от объема самого документа и от количества вхождений в него.
Выводы
1. Существует зависимость между позицией документа и формулой текстовой релевантности ВМ25.
2. По зоне документа (bady) большой ВМ25 не значит лучше
3. Нужно рассчитывать по разным полям документа
4. ВАЖНО. Расчет возможен по TF
5. Для ВЧ запросов данные отличаются (потому что факторы текстового влияния меньше больше учитывается коммерческие и поведенческие факторы)
Если не известно какое слово использовать по составной фразе, нужно отдать предпочтение более редко встречающемуся слову.
Особенности ранжирования СЧ запросов
СЧ
Title аналогично с НЧ
Необходимость текста
Статистический вес. Перелить вес с не нужных страниц
Работа с сниппетами
Слова имеют разные веса IDF
Анкор лист считается по ВМ25
Вхождение дополнительных слов улучшают релевантность
Все тоже самое, что НЧ
Сам текст, нужно определить нужна ли большая текстовая область, для продвижения СЧ. Определить можно по поисковые выдачи у какого количества конкурентов есть текст, сколько текста, если у 3 конкурентов текст есть значит писать. Так же принимается решение писать текст не большой на страницу СЧ запросов, если туда ведет несколько ключевых фраз, если дополнительных слов нет нужно проверять по конкурентам.
Определить можно по поисковые выдачи у какого количества конкурентов есть текст, сколько текста, если у 3 конкурентов текст есть значит писать. Так же принимается решение писать текст не большой на страницу СЧ запросов, если туда ведет несколько ключевых фраз, если дополнительных слов нет нужно проверять по конкурентам.
Особенности ранжирования ВЧ запросов
Первое место ПФ занимает кликстрим
Важна связка вопрос + документ
Работа со сниппетами
Корректная работа со всеми остальными факторами
Корректно нужно проработать все факторы для НЧ и СЧ + очень важно соблюдать связку запрос + документ по типу сайта, по типу страницы, с которой идти в ТОП. Количество запросов, которые надо двигать на одной странице. И очень важно поведенческий фактор. Проработать сниппеты. Для более успешного продвижения сайтов seo необходимо учитывать все факторы.
Построение вектора релевантности согласно формуле BM25
Оксана Мамчуева
1016
Автор: команда агентства интеллектуального web-маркетинга Darwin Global
На сегодняшний день в интернете существует множество материалов, касающихся эффективного продвижения, информации о факторах ранжирования от представителей поисковых систем. Несмотря на все эти полезные материалы, не стоит забывать о старенькой формуле BM25. Большинство специалистов области SEO проводили исследования и семинары касательно данной темы. Впервые об этом методе расчета Яндекс заявил девять лет назад. После этого доклада последовала массовая активность в познании расчетов формулы BM25.
Несмотря на все эти полезные материалы, не стоит забывать о старенькой формуле BM25. Большинство специалистов области SEO проводили исследования и семинары касательно данной темы. Впервые об этом методе расчета Яндекс заявил девять лет назад. После этого доклада последовала массовая активность в познании расчетов формулы BM25.
Углубляться в историю и дублировать популярные источники типа Wikipedia не будем. Важно, что поисковик, к сожалению или счастью, очень ограничен в возможностях. Он может учитывать только то, что будет объективно, универсально и применимо для математического анализа.
И фактически мы получаем «таблицу или список в базе данных», где на основании каждой заполненной ячейки-признака строится вектор релевантности для каждой страницы.
Напомним, что в докладах специалистов все просчеты формулы BM25 на примерах отображали в таблицах Excel.
Наверное, данный материал полезен к прочтению. Но вот как он может помочь на практике? Особенно seo-компаниям, у которых сотни клиентов. Анализ релевантности, согласно существующей формуле, на выходе становится дорогостоящим и трудозатратным.
Анализ релевантности, согласно существующей формуле, на выходе становится дорогостоящим и трудозатратным.
В рамках выхода функционала сравнения страницы с конкурентами, специалисты Seo Shield внедрили автоматический просчет релевантности по формуле BM25 и вот, что получилось:
1. Отображение информации о ТОП-10 конкурентов из выдачи Яндекс, Google нужной продвигаемой страницы
2. Отображение сравнительной таблицы со страницей конкурента (все контентные составляющие, основанные на формуле BМ25)
3. Расчет оптимального рекомендуемого кол-ва вхождений слов из запросов на странице (в разных зонах)
Помните, конкурируют не сайты, конкурируют страницы! Обращайте внимание на конкурентов и выполняйте только полезные действия, которые отразятся на результатах ваших интернет проектов.
- Статьи
- SEO
Рандомная выдача Яндекса — как с этим жить дальше
Ваш сайт внезапно и беспричинно теряет позиции в выдаче Яндекса? Что делать, и кто виноват? Вероятнее всего, дело в рандомизации поисковой выдачи
Как разбить SEO-задачи по приоритетности и добиться максимальной эффективности в работе
Автор: Рэнд Фишкин (Rand Fishkin) – генеральный директор Moz.
SEO 2016: Ловкость рук и никакого рандома
Анализируя ситуацию, сложившуюся сегодня на рынке продвижения, хочется начать с фильтров, которыми в прошлом году нас осчастливил Яндекс — АГС— и Минусинск
Максим Матиков: SEO 2.0 – оптимизацию можно и нужно делать эффективной
Разговоры о SEO 2.0 в сети ведутся достаточно давно, первые упоминания в рунете появились еще в 2008 году
Алексей Штарев: Хороним SEO?
Последние три года наблюдается не самая позитивная тенденция встречать новогодние праздники с достаточно грустным, отчасти пессимистичным настроением
Дмитрий Шахов: Хоронить SEO рано, но с трона его уже подвинули
2015 год прошел под знаком борьбы со спамным ссылочным
Молниеносная семантическая поисковая система с использованием BM25 и Neural Re-Ranking
- Автор сообщения: mehul
- Сообщение опубликовано: 18 июля 2020 г.

- Категория сообщения: Без категории

Недавно у нас появилась возможность поработать над проектом НЛП. Нам нужно было создать поисковую систему, которая могла бы получать первые n результатов на основе семантического сходства между набором текстов и неизвестным текстом. Мы пробовали различные методы, такие как TF-IDF/BM25, косинусное/евклидово расстояние между различными вложениями, такими как BERT, RoBERTA, XLNET и т. д.
Цель состояла в том, чтобы, имея неизвестный текст, сравнить его с каждым текстом из набора из 10 миллионов текстов, рассчитать показатель сходства для каждого сравнения и получить 500 лучших результатов на основе самых высоких показателей сходства.
Это был кропотливый процесс, но, к счастью, мы наткнулись на содержательное обсуждение на GitHub. Ниже мы подытожили уроки, извлеченные из этого испытания, и надеемся, что кому-то еще, занимающемуся подобным проектом, это будет полезно.
Шаги по созданию двигателя:
Создание текстовой поисковой системы включало множество шагов. Однако, если бы нам нужно было обобщить это, нужно было бы помнить только о двух основных этапах:
- Разработка надежного и точного алгоритма подобия.
- Чтобы найти способ быстро получить наилучшие результаты из области поиска.
Мы достигли вышеуказанного с помощью комбинации Elasticsearch (BM25)*, преобразователей предложений (встраивание среднего слова) и FAISS от Facebook.
- Elasticsearch (BM25)*:
- Высокий уровень ложноотрицательных результатов и низкий уровень ложноположительных результатов.
- Очень хорошо работает с длинными текстами, состоящими из нескольких предложений.
- Преобразователь предложения (встраивание среднего слова):
- Высокий уровень ложноположительных результатов и низкий уровень ложноотрицательных результатов.
- Очень хорошо работает с короткими предложениями.
Если приведенные выше термины смущают вас, ложноотрицательный результат означает, что даже когда тексты очень похожи, алгоритм считает их непохожими, а случай ложноположительного результата возникает, когда разные тексты признаются похожими.
Проще говоря, если Elasticsearch (BM25)* помечает пару текстов как похожие, то мы можем с высокой уверенностью сказать, что они похожи, но он может пропустить некоторые похожие тексты. С другой стороны, если два предложения на самом деле похожи, модель преобразователя предложений не пропустит их, однако может расценить некоторые непохожие тексты как похожие.
Чтобы найти баланс между уникальными характеристиками двух подходов, мы использовали оба в тандеме. Во-первых, мы использовали Elasticsearch (BM25)*, чтобы найти с высокой достоверностью первые n похожих текстов, а затем применили встраивание преобразователя предложений для повторной оценки ранга в первых n похожих текстах, чтобы получить более точные результаты по сравнению с каждым алгоритмом, работающим по отдельности.
Получение похожих результатов из области поиска
Поскольку мы работали с областью поиска объемом 10 М, следующей задачей была оптимизация поиска.
Чтобы решить эту проблему, мы создали оптимизированный индекс базы данных для всех 10 миллионов внедрений с помощью FAISS, что значительно сократило время поиска до менее 1 секунды.
Давайте поможем вам понять, как это делает FAISS. Прежде всего, FAISS предназначен для работы с вложениями. Во-вторых, FAISS дает приблизительную оценку, которая может иметь небольшое, хотя и очень незначительное, отклонение от исходного расстояния. Но, поскольку нас интересует только их относительное сравнение, это работает как шарм.
Диаграмма процесса
Мы следовали рабочему процессу, чтобы создать сверхбыструю поисковую систему, основанную на семантическом сходстве. Это помогло нашим клиентам создать собственные поисковые системы для внутренних данных и сэкономить значительное количество времени.
Примечание. Мы использовали Elasticsearch BM25 в нашем рабочем процессе, однако TF-IDF также может использоваться как не менее жизнеспособная альтернатива с аналогичными характеристиками.
Мы использовали Elasticsearch BM25 в нашем рабочем процессе, однако TF-IDF также может использоваться как не менее жизнеспособная альтернатива с аналогичными характеристиками.
Пожалуйста, не стесняйтесь обращаться к нам по адресу www.aidetic.in или по адресу [email protected] для получения дополнительной информации. Наконец, спасибо Нильсу Реймерсу за содержательное обсуждение на GitHub.
Ссылки
https://github.com/huggingface/transformers/issues/876
https://github.com/facebookresearch/faiss
https://www.elastic.co/blog/practical-bm25 -part-2-the-bm25-algorithm-and-its-variables
https://github.com/UKPLab/sentence-transformers
Теги: aidetic, bert, bm25, глубокое обучение, faiss, нейронное ранжирование, nlp, поисковая система, семантическое сходство, преобразователь предложений, сходство текста, tf-idf
bm25 · Темы GitHub · GitHub
Вот 128 публичных репозиториев соответствует этой теме.
 ..
..мантикорапрограммное обеспечение / поиск мантикоры
Звезда 2,3кподмигивающий / подмигивание-нлп
Звезда 825ДорианБраун / rank_bm25
Звезда 500cjymz886 / сходство предложений
Звезда 263Рафаэльсти / cherche
Звезда 224Нхиракава / БМ25
Звезда 204шибинг624 / сходство
Звезда 147iresearch-инструментарий / исследование
Звезда 145Сартакджайн1206 / Intelligent_Document_Finder
Звезда 55подмигивающий / подмигнуть-bm25-текстовый поиск
Звезда 43Кван2049 / easy-elasticsearch
Звезда 25жуссон / фастбм25
Звезда 18свджек / Sbert-ChineseПример
Звезда 17zjohn77 / восстановление
Звезда 21фанта-мникс / питон-bm25
Звезда 16searchivarius / ТочныйLuceneBM25
Звезда 15АминьРа / вернуть
Звезда 13шубхам16394 / Текстовое сходство
Звезда 12джбесоми / Короно
Звезда 12Абиная-Кришнан / Bm25Plus_Model — реализация Python
Звезда 11Улучшить эту страницу
Добавьте описание, изображение и ссылки на
бм25
страницу темы, чтобы разработчикам было легче узнать о ней.