
«Как правильно составить семантическое ядро?» — Яндекс Кью
Популярное
Сообщества
Анонимный вопрос
·
25,3 K
На Кью задали 2 похожих вопросаОтветитьУточнитьДмитрий Данилов
Менеджмент
605
Управляющий партнер. Агентство «Webpage Profy» · 24 июн 2019 · webpage-profy.ru
Ответить односложно на вопрос «как правильно составить семантическое ядро» нельзя, по причине, что не ясно, какие цели преследует сайт, рекламу или SEO. Важно как давно сделан ресурс, какой бюджет планируется выделить на продвижение. В зависимости от ответов, семантическое ядро будет совершенно разным и в любом случае оно будет правильным, так как соответствует своей цели
Разработка и продвижение сайтов под ключ
 ru
ruКомментировать ответ…Комментировать…
Otzyvmarketing.ru
8,9 K
Сервисы для маркетологов. 2000+ инструментов, 20000+ отзывов экспертов, кейсы и рейтинги… · 22 нояб 2019 · otzyvmarketing.ru
Отвечает
Анастасия Кузнецова
Составление семантического ядра – это рутинная процедура по сбору запросов. Для начала выбирается тема сайта и по ней собираются все высокочастотные, средне- и низкочастотные запросы. Важно максимально полно охватить тематику сайта. Какими сервисами собирать ядро Для составления семантического ядра рекомендую использовать специальные сервисы, например, отсюда, https://ot… Читать далее
Отзывы о сервисах для бизнеса мы собираем тут.
Перейти на otzyvmarketing.ruMihail Kosarev
21 января 2020
Спасибо-Вам большое за подробное разъяснение. Я слышал, что нужно создавать семантику. Но, я даже не знаю-кагда… Читать дальше
Я слышал, что нужно создавать семантику. Но, я даже не знаю-кагда… Читать дальше
Комментировать ответ…Комментировать…
Первый
Санал Эрдни-Горяев
Маркетинг
30
Частный SEO специалист. Опыт работы 10 лет. Мой блог raiseskills.ru — Бесплатный — Аудит… · 8 окт 2019 · raiseskills.ru
Однозначно точно и кратко дать ответ на данный вопрос сложно, так как для более подробного ответа необходимо понимать следующее: — Для каких целей необходимо собрать семантическое ядро (для продвижения страниц или для контекстной рекламы) — Какой тематики является сайт для которого собирается ядро (блог, интернет-магазин, сайт услуг, информационный портал, или вам нужны… Читать далее
Мой SEO блог
Перейти на raiseskills.ru/seo-blogАнна Д.
7 апреля 2020
Санал, как Вы считаете, на что нужно обратить особое внимание в технологии сбора семантического ядра? А также у. .. Читать дальше
.. Читать дальше
Комментировать ответ…Комментировать…
8-Web.ru
179
8-Web.ru — Агентство Интернет-маркетинга · 10 янв 2021 · 8-web.ru
Отвечает
Михаил Ширма
СОСТАВЛЕНИЕ СЕМАНТИЧЕСКОГО ЯДРА: 5 ТИПИЧНЫХ ОШИБОК Ошибка №1. Задействован только один сервис для сбора поисковых фраз Ошибка №2. Не проводилась разбивка ключевых фраз на группы / отсутствуют кластеры Ошибка №3. Акцент сделан исключительно на высокочастотных фразах Ошибка №4. Отказ от разных типов поисковых фраз Ошибка №5. Недооцененность простых и сложных информационных… Читать далее
Комментировать ответ…Комментировать…
Михаил Савастьянов
3,9 K
IT, Web, игры и масса других интересов · 21 янв 2019
Семантическое ядро – это список ключевых слов и фраз для сайта. Затем эти фразы используются для написания статей.
Процесс сборки качественного семантического ядра — это очень кропотливый и не простой процесс. В нем можно выделить 5 основных шагов:
— Поиск базовых ключей. Это очень широкие, высокочастотные ключи. По сути, они определяют общие темы, на которые нужно… Читать далее
Затем эти фразы используются для написания статей.
Процесс сборки качественного семантического ядра — это очень кропотливый и не простой процесс. В нем можно выделить 5 основных шагов:
— Поиск базовых ключей. Это очень широкие, высокочастотные ключи. По сути, они определяют общие темы, на которые нужно… Читать далее
16,2 K
Комментировать ответ…Комментировать…
Эвертоп
237
Поисковое продвижение сайтов с помощью системного подхода и прогнозной аналитики. · 20 февр 2020 · evertop.pro
Отвечает
Константин Дмитриев
Это очень большая тема, если кратко, то сбор семантического ядра делится на 4 этапа:
1) Сбор маркерных запросов
2) Парсинг запросов из источников по маркерным запросам
3) Чистка семантического ядра
4) Кластеризация семантического ядра
В силу очень большой глубины данной темы, не получится все описать подробнее в данном ответе =(
Поэтому вы можете воспользоваться. .. Читать далее
.. Читать далее
Продвижение сайтов с помощью системного подхода и прогнозной аналитики.
Перейти на evertop.proКлариса У.
20 февраля 2020
Большое спасибо! Не думал, что все так, одновремено, и сложно и просто!
Комментировать ответ…Комментировать…
⭕льга Новикова
262
П̲Р̲О̲Ф̲Е̲С̲С̲И̲О̲Н̲А̲Л̲Ь̲Н̲Ы̲Й КОПИРАЙТЕР www.sleepyparadise.jimdo.com · 2 апр 2019
О том, что дает семантическое ядро, о принципах составления СЯ, о способах его создания и основных инструментах подбора читайте в статье «Составление семантического ядра сайта».
Клариса У.
24 февраля 2020
Так у вас в статье и нет ничего, только ссылка на книгу
Комментировать ответ…Комментировать…
SMO-i-SEO.
35
PRO инструменты интернет-маркетинга: контент, контекст, SEO, SMM, SERM и др. на сайте !> · 26 окт 2020 · smo-i-seo.ru
Отвечает
Артем от SEO до SMM
Нет универсального правильного способа составить семантическое ядро.
Семантика подбирается под конкретный проект. Если говорить о среднечастотной и низкочастотной семантике, то мы обычно работаем по описанному алгоритму.
Комментировать ответ…Комментировать…
КИР-КИР ОМ
1 апр 2021
1.определитесь информационная или коммерческая тематика
- используйте Вордстат
- При поиске фраз ставьте купить — если у вас коммерческая тематика ( пример: «купить лампочку»)
- Собрав семантику добавляю ее в сервис Labrika
Вадим П.
15
10 февр 2019
Для правильного сбора семантического ядра необходимо составить первоначальный план: 1. Определиться с тематикой своего будущего сайта. 2. Написать на листочке несколько слов или фраз, которые относятся к вашей тематике, например, если у вас сайт о Сиамских кошках, то в принципе, вам достаточно вбить в КейКоллектор или Слово только эту фразу (как это сделать расскажу… Читать далее
Комментировать ответ…Комментировать…
Вы знаете ответ на этот вопрос?
Поделитесь своим опытом и знаниями
Войти и ответить на вопрос
2 ответа скрыто(Почему?)
Ответы на похожие вопросы
Как создать семантическое ядро? — 3 ответа, заданПервый
Nina Ton
Маркетинг
1
СММ, таргет, редактура · 25 сент 2021
Определяем, на какой ступени Ханта ваш клиент. Выгоднее работать с горячей ЦА, уже определившейся в желании купить ваш товар (услугу), а не с определяющейся с выбором или решающей, нужна ли ей вообще эта покупка.
Выгоднее работать с горячей ЦА, уже определившейся в желании купить ваш товар (услугу), а не с определяющейся с выбором или решающей, нужна ли ей вообще эта покупка.
От этого зависит, какие фразы станут ключевыми, а какие пойдут в исключение.
Обычно фраза выглядит так: «Товар (услуга)»+»целевое действие».
За поиском отправляемся в Вордстат. Между прочим, с него и следует начинать при настройке любой рекламы, чтобы определить спрос.
Составляем список, как пользователи могут искать ваш товар (услугу) в поисковике, в том числе, на английском.
Далее создаем объявления с ключевыми фразами.
Комментировать ответ…Комментировать…
Как сделать семантическое ядро сайта? — 9 ответов, заданВсеволод Мехед
Маркетинг
335
Основатель mStudio — digital агентство разработки сайтов и продвижения интернет проектов · 1 дек 2020 · mehed. pro
pro
Чтобы собрать базовое семантическое ядро, вам необходимо:
- Открыть сервис wordstat.
- Ввести в нем ваш главный ключевой запрос (к примеру, ремонт квартир).
- В столбце слева вы увидите результаты по вашему запросу со всеми словоформами. Справа будут показаны запросы, которые похожи на ваш.
- Рекомендуем установить расширение Wordstat helper для удобной дальнейшей работы.
- Если вы установили расширение, то просто отщелкайте нужные запросы и они автоматически появятся у вас в списке.
- Обратите внимание, что запросы будут делиться на категории. К примеру, некоторые будут явно выражать намерение купить (ремонт квартир цена), а некоторые будут носить справочный характер (как сделать ремонт).
- Скорее всего вам захочется удалить различные справочные запросы и оставить только то, где есть слова “купить”, “цена” и “возьмите мои деньги” 🙂
Уверяем вас, что этого делать не стоит. Пока просто читайте дальше.
Кластеризация ключевых слов
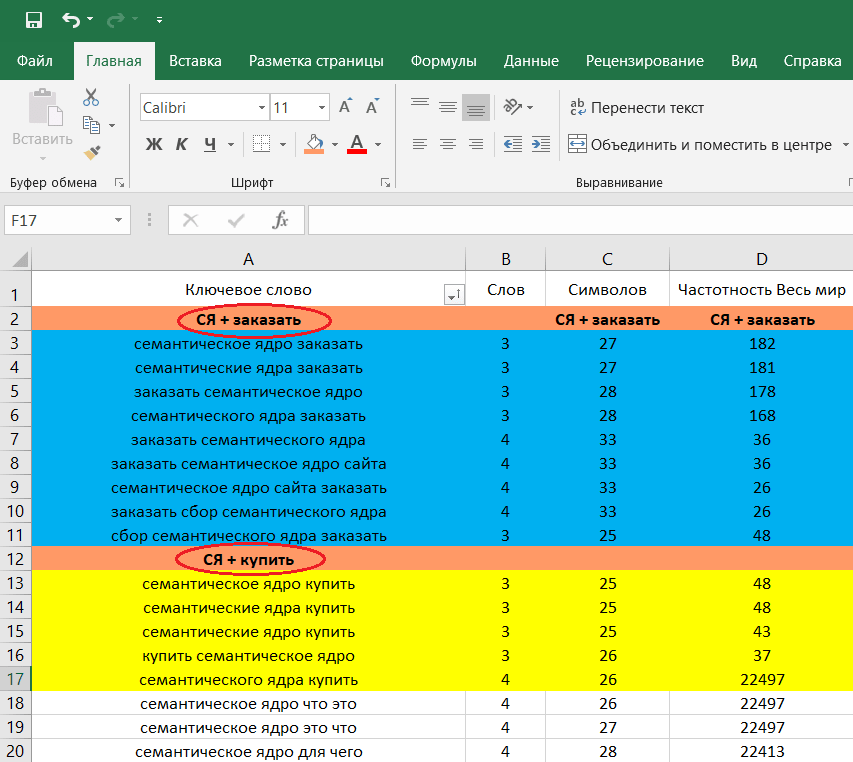
После того, как вы получили список своих ключей, их необходимо рассортировать. Этот процесс называется кластеризацией.
Этот процесс называется кластеризацией.
Перед этим не лишним будет проверить список ключевых слов на предмет “мусорных” запросов. К примеру, вы делаете дорогие дизайнерские ремонты, то тогда исключайте слова “дешево”, “бюджетно” и т.д. То же самое проводите с теми ключами, которые не соответствуют вашей деятельности.
Теперь можно приступать к кластеризации. Ее суть в том, чтобы похожие ключи объединить в группы. К примеру, у вас получатся группы ключей, которые содержать запросы о:
- Ремонте квартир-студий;
- Дизайнерском ремонте домов;
- Отделке офисов.
Поздравляем, у вас на сайте в обязательном порядке должны присутствовать эти страницы. Фактически, правильно отфильтрованное и кластеризованное ядро представляет собой структуру вашего сайта.
Про основные этапы SEO-продвижения читайте здесь:
https://mehed.pro/osnovnye-etapy-seo-prodvizheniya/
mStudio — разработка сайтов и продвижение интернет проектов
Перейти на mehed. pro
proКомментировать ответ…Комментировать…
Как сделать семантическое ядро сайта? — 9 ответов, задан8-Web.ru
179
8-Web.ru — Агентство Интернет-маркетинга · 7 февр 2021 · 8-web.ru
Отвечает
Михаил Ширма
Составление семантического ядра (СЯ) — это сбор ключевых слов, их чистка и кластеризация. На основе семантического ядра строится правильная с точки зрения SEO структура сайта — устанавливается количество и вложенность разделов и страниц, разрабатывается меню. СЯ и структура сайта являются фундаментом продвижения.
Заказать сбор семантического ядра
Комментировать ответ…Комментировать…
Как сделать семантическое ядро сайта? — 9 ответов, задан 318Z»>4 февраля 2019
318Z»>4 февраля 2019Digitalriff.ru
592
Digitalriff.ru — агентство поискового продвижения сайтов и контекстной рекламы · 12 июн 2020 · digitalriff.ru
Отвечает
Александр Савенков
Семантическое ядро для начала собирается Кей Коллектором и Яндекс Вордстатом. Сразу оговорюсь, что собирается весь спрос вместе с мусором, все, что относится к вашей тематике.
Второй этап — чистка, лучше делать это руками. Затем семантику надо разбить на логические группы. Вычищенные и сгруппированные слова называются кластерами, которые лягут в основе новых посадочных страниц.
Делаем SEO много — делаем хорошо=)
Перейти на digitalriff.ruКомментировать ответ…Комментировать…
Как сделать семантическое ядро сайта? — 9 ответов, заданДмитрий Горошко
5
Web-аналитик, SEOшник и немного блогер https://softink. ru · 10 февр 2019
ru · 10 февр 2019
Анализируете и прорабатываете нишу, поиск маркерных запросов (1-2 слова характеризующих продукт или услугу: «купить ноутбук», «игровой ноутбук» и т.д.).
Далее идете в Yandex Wordstat и собираете все запросы которые подходят для вашего сайта. В этой статье я описал, как работать с Wordstatом.
Потом подключаем следующие пункты для сбора и расширения:
Анализ конкурентов;
Мозговой штурм
Базы ключевых слов
Собираем подсказки поисковых систем.
Потом используем инструменте для парсинга KeyCollector и для кластеризации.
Это если в двух словах.
Комментировать ответ…Комментировать…
Как сделать семантическое ядро сайта? — 9 ответов, заданИван Воробьёв
16,4 K
Имею естественно научное образование, в юношестве прикипел к литературе, сейчас активно. .. · 4 февр 2019
.. · 4 февр 2019
Составить набор слов и словосочетаний, которые отражали бы тематику и общее содержание вашего сайта, нужно составить перечень информации, которая есть на сайте и предположить, на какие запросы она могла бы отвечать, те была бы релевантна, далее распространить основные поисковые запросы и ключевые слова по страницам ресурса, чтобы пользователь, в поиска какой-либо информации или продукта мог видеть в выдаче ваш сайт, раскидайте информацию по блокам, которые могли бы отвечать на схожие запросы, пример структуры ядра выглядит так
Комментировать ответ…Комментировать…
Как сделать семантическое ядро сайта? — 9 ответов, заданЭвертоп
237
Поисковое продвижение сайтов с помощью системного подхода и прогнозной аналитики. · 20 февр 2020 · evertop.pro
Отвечает
Константин Дмитриев
Это очень большая тема, если кратко, то сбор семантического ядра делится на 4 этапа:
- Сбор маркерных запросов
- Парсинг запросов из источников по маркерным запросам
- Чистка семантического ядра
- Кластеризация семантического ядра
В силу очень большой глубины данной темы, не получится все описать подробнее в данном ответе =(
Поэтому вы можете воспользоваться полной пошаговой инструкцией по сбору и кластеризации семантического ядра для сайта, чтобы узнать: что такое ключевики и семантика, виды семантических ядер, сбор маркерных запросов и различные источники ключевых фраз, сервисы и программы, полный пошаговый сбор, очистка и кластеризация семантики.
Продвижение сайтов с помощью системного подхода и прогнозной аналитики.
Перейти на evertop.proКомментировать ответ…Комментировать…
Как сделать семантическое ядро сайта? — 9 ответов, заданАлександр Олейников
203
Пью коктейли и не волнуюсь. · 4 июн 2019
Не так уж трудно его сделать, если руководствоваться толковыми инструкциями. Могу посоветовать почитать эту статью https://vysokoff.ru/seo/kak-sozdat-sait/kak-sostavit-semanticheskoe-yadro-saita.html В ней как раз все подробно описано, есть конкретные примеры и рекомендации.
Комментировать ответ…Комментировать…
Как создать семантическое ядро? — 3 ответа, заданЯрослава
2
SEO специалист с 2006 года.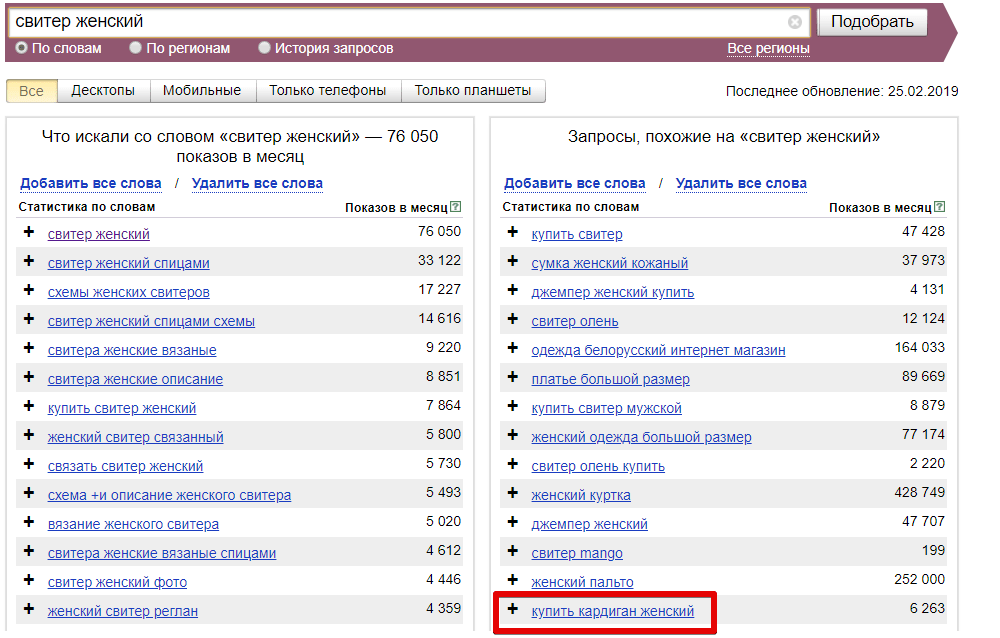 С 2010 года преподаватель курсов по интернет маркетингу… · 27 сент 2021
С 2010 года преподаватель курсов по интернет маркетингу… · 27 сент 2021
Во многих статьях вижу, что сначала собирается семантика, а после формируется структура сайта. Согласиться не могу, поскольку работаю иначе. Сначала формирую структуру сайта, будущие разделы, а после собираю семантику.
Семантическое ядро должно содержать максимальное количество запросов, которые можно использовать в продвижении. Не стоит ограничиваться 100-1000 ключевых слов, запросов, которые могут принести трафик на сайт гораздо больше (полноценное ядро может содержать сотни тысяч запросов).
Например, у вас есть интернет магазин одежды для женщин. Подумайте, как ваш потенциальный клиент будет искать тот или иной товар. Чаще всего поисковый запрос, который содержит детальную информацию о товаре продает лучше, чем общий запрос.
Для примера возьмем два запроса:
Общий запрос: купить женскую одежду
Детальный запрос: купить черную юбку 50 размера в Москве
В первом варианте человек еще не определился, чего хочет.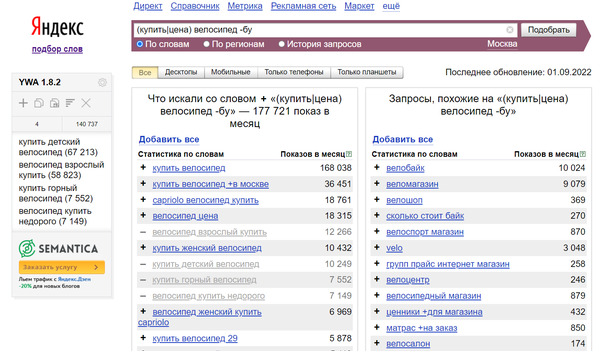 Во втором варианте потенциальный покупатель знает точно, что хочет купить и в каком регионе.
Во втором варианте потенциальный покупатель знает точно, что хочет купить и в каком регионе.
Подобрать поисковые запросы вам поможет сервис wordstat.yandex.ru здесь же, вы можете посмотреть историю запросов и определить сезонность того или иного товара или услуги.
Комментировать ответ…Комментировать…
Как создать семантическое ядро? — 3 ответа, заданЕвгений Вагнер Доктор SEO
Группа специалистов по продвижению сайтов · 20 сент 2021
С помощью:
- Янлекс Вордстата;
- просмотра конкурентов
- смежные запросы «Люди ищут» в поисковиках.
Не забудьте кластеризировать ключи по страницам сайта.
Комментировать ответ…Комментировать…
«Как создать семантическое ядро?» — Яндекс Кью
Популярное
Сообщества
МаркетингБизнес
Илья Перевалов
 291Z»>12 сентября 2021 ·
291Z»>12 сентября 2021 ·
117
На Кью задали 2 похожих вопросаОтветитьУточнитьПервый
Nina Ton
Маркетинг
1
СММ, таргет, редактура · 25 сент 2021
Определяем, на какой ступени Ханта ваш клиент. Выгоднее работать с горячей ЦА, уже определившейся в желании купить ваш товар (услугу), а не с определяющейся с выбором или решающей, нужна ли ей вообще эта покупка.
От этого зависит, какие фразы станут ключевыми, а какие пойдут в исключение.
Обычно фраза выглядит так: «Товар (услуга)»+»целевое действие».
За поиском отправляемся в Вордстат. Между прочим, с него и следует начинать при настройке любой рекламы, чтобы определить спрос.
Составляем список, как пользователи могут искать ваш товар (услугу) в поисковике, в том числе, на английском.
Обращаемся к сервису мультипликации ключевых фраз, затем просеиваем через сервис минус-слов.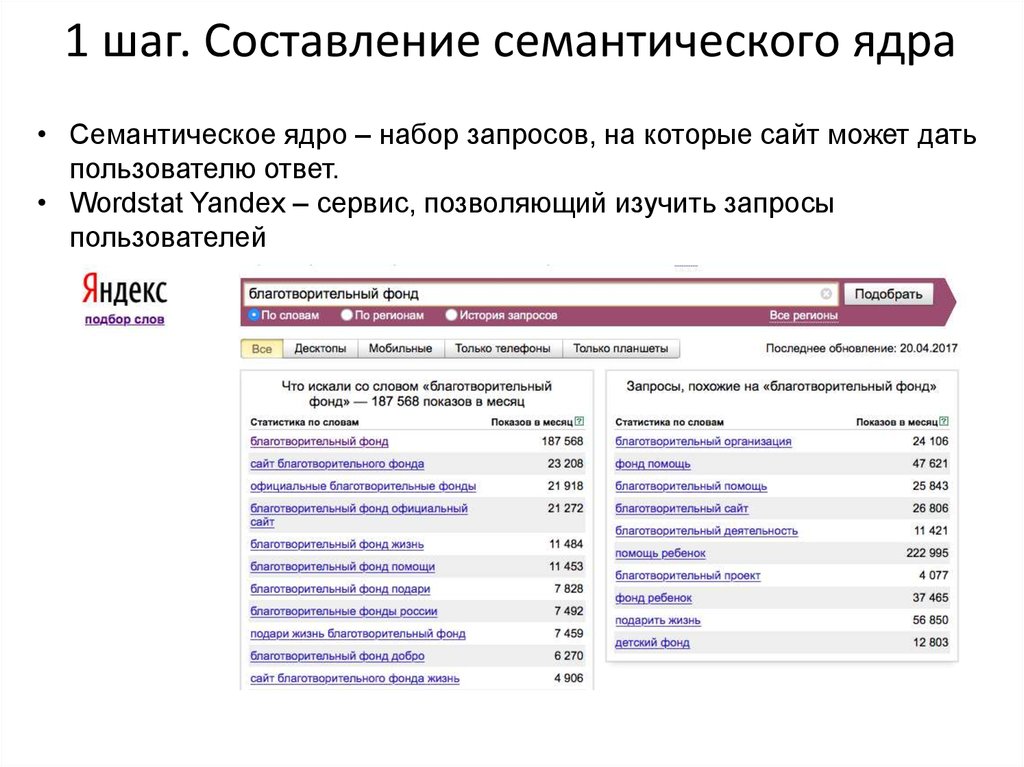 Исключаем нецелевые запросы.
Исключаем нецелевые запросы.
Далее создаем объявления с ключевыми фразами.
Комментировать ответ…Комментировать…
Ярослава
2
SEO специалист с 2006 года. С 2010 года преподаватель курсов по интернет маркетингу… · 27 сент 2021
Во многих статьях вижу, что сначала собирается семантика, а после формируется структура сайта. Согласиться не могу, поскольку работаю иначе. Сначала формирую структуру сайта, будущие разделы, а после собираю семантику. Семантическое ядро должно содержать максимальное количество запросов, которые можно использовать в продвижении. Не стоит ограничиваться 100-1000… Читать далее
Комментарий был удалён за нарушение правил
Комментировать ответ…Комментировать…
Евгений Вагнер Доктор SEO
Группа специалистов по продвижению сайтов · 20 сент 2021
С помощью:
- Янлекс Вордстата;
- просмотра конкурентов
- смежные запросы «Люди ищут» в поисковиках.


Не забудьте кластеризировать ключи по страницам сайта.
Комментировать ответ…Комментировать…
Вы знаете ответ на этот вопрос?
Поделитесь своим опытом и знаниями
Войти и ответить на вопрос
Ответы на похожие вопросы
Как правильно составить семантическое ядро? — 12 ответов, заданДмитрий Данилов
Менеджмент
605
Управляющий партнер. Агентство «Webpage Profy» · 24 июн 2019 · webpage-profy.ru
Ответить односложно на вопрос «как правильно составить семантическое ядро» нельзя, по причине, что не ясно, какие цели преследует сайт, рекламу или SEO. Важно как давно сделан ресурс, какой бюджет планируется выделить на продвижение. В зависимости от ответов, семантическое ядро будет совершенно разным и в любом случае оно будет правильным, так как соответствует своей цели
Разработка и продвижение сайтов под ключ
Перейти на webpage-profy. ru
ruКомментировать ответ…Комментировать…
Как правильно составить семантическое ядро? — 12 ответов, заданOtzyvmarketing.ru
8,9 K
Сервисы для маркетологов. 2000+ инструментов, 20000+ отзывов экспертов, кейсы и рейтинги… · 22 нояб 2019 · otzyvmarketing.ru
Отвечает
Анастасия Кузнецова
Составление семантического ядра – это рутинная процедура по сбору запросов. Для начала выбирается тема сайта и по ней собираются все высокочастотные, средне- и низкочастотные запросы. Важно максимально полно охватить тематику сайта.
Какими сервисами собирать ядро
Для составления семантического ядра рекомендую использовать специальные сервисы, например, отсюда, https://otzyvmarketing.ru/best/servisy-dlya-semanticheskogo-yadra/. Здесь целая куча полезных сервисов, с помощью которых можно достаточно быстро создать семантическое ядро для любого сайта.
Здесь целая куча полезных сервисов, с помощью которых можно достаточно быстро создать семантическое ядро для любого сайта.
Почему нельзя заполнять сайт постепенно
Ведь можно равномерно изо дня в день находить все новые запросы.
- Лучше всего сразу заполнить сайт. Ведь поисковые системы любят, когда сайт раскрывает тематику полностью, то есть дает ответ на все более-менее популярные запросы по выбранной теме.
- Запросы необходимо группировать. Поскольку часто одна статья может ответить сразу на несколько запросов. Например, на запросы «купить козу» и «купить козу в Москве» можно ответить на одной странице. Сначала рассказать, как вообще покупать козу в России, а потом раскрыть специфику козьего рынка Москвы.
Вот поэтому приходится перед созданием сайта составлять его семантическое ядро. Ведь ясно, что ядро будет определять структуру самого сайта. От ядра будет зависеть, сколько у сайта будет категорий, сколько у него будет страниц.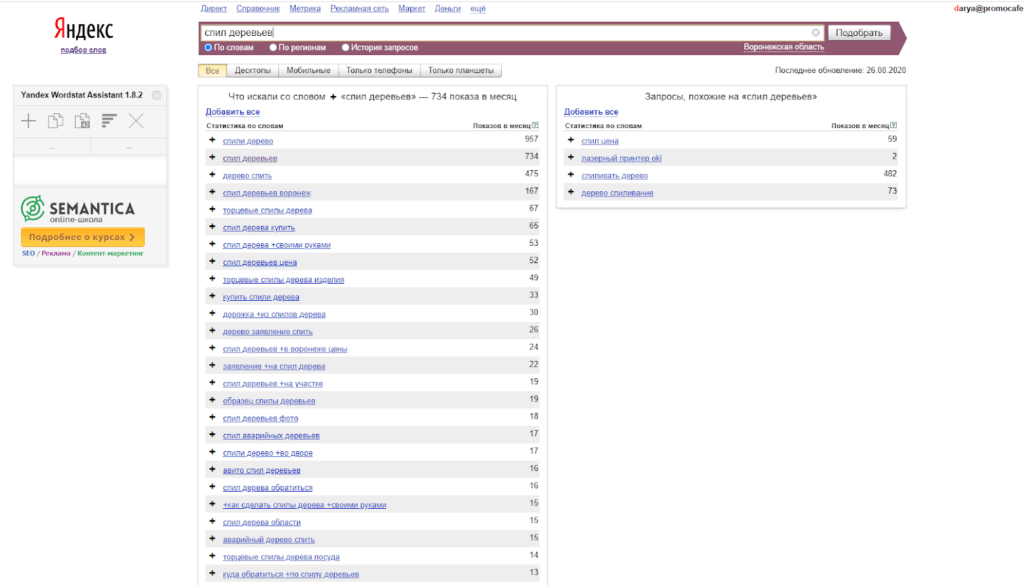 Разумеется, бюджет будет вносить в структуру свои корректировки.
Разумеется, бюджет будет вносить в структуру свои корректировки.
Отметим, что семантическое ядро может быть большим (10 тыс. запросов) или маленьким (100 запросов). Все будет зависеть от выбора тематики.
Шаги по созданию ядра
- Первый шаг – сбор базовых запросов. Это основные ключевые слова, самые высокочастотные и простые. Для их сбора вам нужна только смекался. Вы должны разбираться в выбранной теме. Конечно, можно использовать «вордстат».
- Нужно будет расширять ваши запросы. Для этого можно использовать Serpstat или сервисы из списка выше.
- Нужно избавиться от лишних запросов. Суть в том, что некоторые запросы могут привести нецелевую аудиторию. Самый простой пример: если у вас коммерческий сайт, то вам нужно убрать все информационные запросы.
- Группировка запросов. Каждая группа запросов будет соответствовать отдельной странице.
Надеюсь, мой ответ смог вам помочь. Я постаралась изложить в ответе суть. Если вы хотите у меня что-то спросить или, наоборот, высказать свою точку зрения, оставляйте свои комментарии под моим ответом!
Отзывы о сервисах для бизнеса мы собираем тут.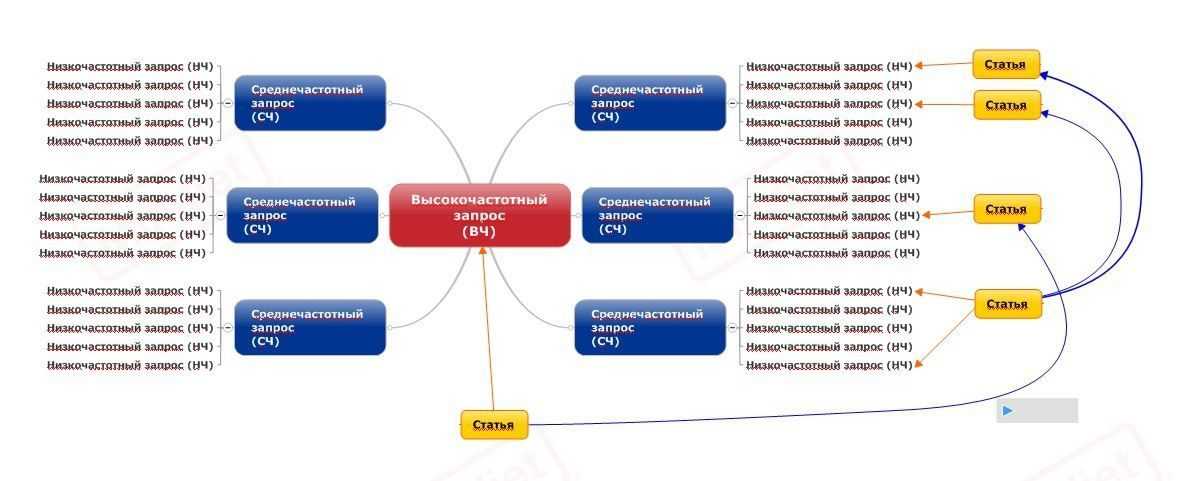
Комментировать ответ…Комментировать…
Как правильно составить семантическое ядро? — 12 ответов, заданПервый
Санал Эрдни-Горяев
Маркетинг
30
Частный SEO специалист. Опыт работы 10 лет. Мой блог raiseskills.ru — Бесплатный — Аудит… · 8 окт 2019 · raiseskills.ru
Однозначно точно и кратко дать ответ на данный вопрос сложно, так как для более подробного ответа необходимо понимать следующее:
- Для каких целей необходимо собрать семантическое ядро (для продвижения страниц или для контекстной рекламы)
- Какой тематики является сайт для которого собирается ядро (блог, интернет-магазин, сайт услуг, информационный портал, или вам нужны запросы для отдельной страницы)
Для общего понимания семантическое ядро — это список ключевых слов (словосочетаний) которые характеризуют содержание сайта (страницы) или вида вашей деятельности.
При сборе семантического ядра важно не забывать про такую важную вещь как интент запроса (интент запроса это то что хочет пользователь, то что он подразумевает под запросом)
Опишу технологию сбора семантического ядра
- Мозговой штурм (выписать все слова как на ваш взгляд могут искать вашу услуг или товар в интернете)
- Из выписанных слов выписать слова маркеры (одно слово или словосочетание характеризующие вашу деятельность)
- Распределить каждую группу запросов в отдельную категорию (собрать все запросы из Wordstat)
- Отчистить запросы от мусора и выделить дополнительные подкатегории и категории (в основном по интенту)
- Проанализировать запросы конкурентов и дополнить Вашу уже собранную семантику.
Для того чтобы более точно все понимать рекомендую ознакомится с 2-3 статьями на эту тему.
- Хорошая статья про семантику с описанием основных сервисов.
- Подробно расписанные этапы и инсрументы для сбора семантического ядра.

Спасибо надеюсь ответ будет вам полезным!
Мой SEO блог
Перейти на raiseskills.ru/seo-blogКомментировать ответ…Комментировать…
Как правильно составить семантическое ядро? — 12 ответов, задан8-Web.ru
179
8-Web.ru — Агентство Интернет-маркетинга · 10 янв 2021 · 8-web.ru
Отвечает
Михаил Ширма
СОСТАВЛЕНИЕ СЕМАНТИЧЕСКОГО ЯДРА: 5 ТИПИЧНЫХ ОШИБОК
Ошибка №1. Задействован только один сервис для сбора поисковых фраз
Ошибка №2. Не проводилась разбивка ключевых фраз на группы / отсутствуют кластеры
Ошибка №3. Акцент сделан исключительно на высокочастотных фразах
Ошибка №4. Отказ от разных типов поисковых фраз
Ошибка №5. Недооцененность простых и сложных информационных фраз
Источник: https://8-web.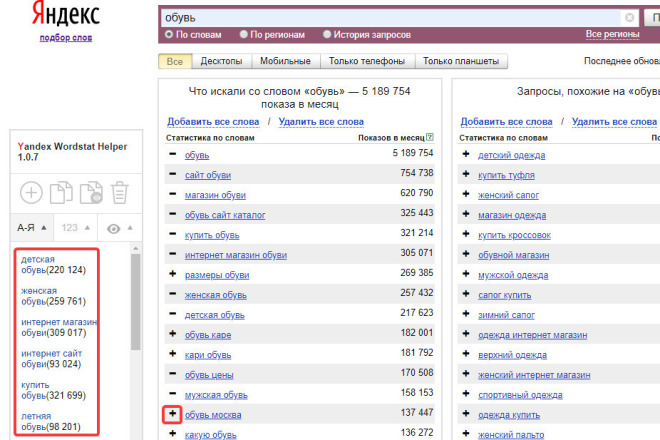 ru/blog/sostavlenie-semanticheskogo-yadra-5-tipichnyh-oshibok/
ru/blog/sostavlenie-semanticheskogo-yadra-5-tipichnyh-oshibok/
#8web
Комментировать ответ…Комментировать…
Как сделать семантическое ядро сайта? — 9 ответов, заданВсеволод Мехед
Маркетинг
335
Основатель mStudio — digital агентство разработки сайтов и продвижения интернет проектов · 1 дек 2020 · mehed.pro
Чтобы собрать базовое семантическое ядро, вам необходимо:
- Открыть сервис wordstat.
- Ввести в нем ваш главный ключевой запрос (к примеру, ремонт квартир).
- В столбце слева вы увидите результаты по вашему запросу со всеми словоформами. Справа будут показаны запросы, которые похожи на ваш.
- Рекомендуем установить расширение Wordstat helper для удобной дальнейшей работы.
- Если вы установили расширение, то просто отщелкайте нужные запросы и они автоматически появятся у вас в списке.
- Обратите внимание, что запросы будут делиться на категории. К примеру, некоторые будут явно выражать намерение купить (ремонт квартир цена), а некоторые будут носить справочный характер (как сделать ремонт).
- Скорее всего вам захочется удалить различные справочные запросы и оставить только то, где есть слова “купить”, “цена” и “возьмите мои деньги” 🙂

Уверяем вас, что этого делать не стоит. Пока просто читайте дальше.
Кластеризация ключевых слов
После того, как вы получили список своих ключей, их необходимо рассортировать. Этот процесс называется кластеризацией.
Перед этим не лишним будет проверить список ключевых слов на предмет “мусорных” запросов. К примеру, вы делаете дорогие дизайнерские ремонты, то тогда исключайте слова “дешево”, “бюджетно” и т.д. То же самое проводите с теми ключами, которые не соответствуют вашей деятельности.
Теперь можно приступать к кластеризации. Ее суть в том, чтобы похожие ключи объединить в группы.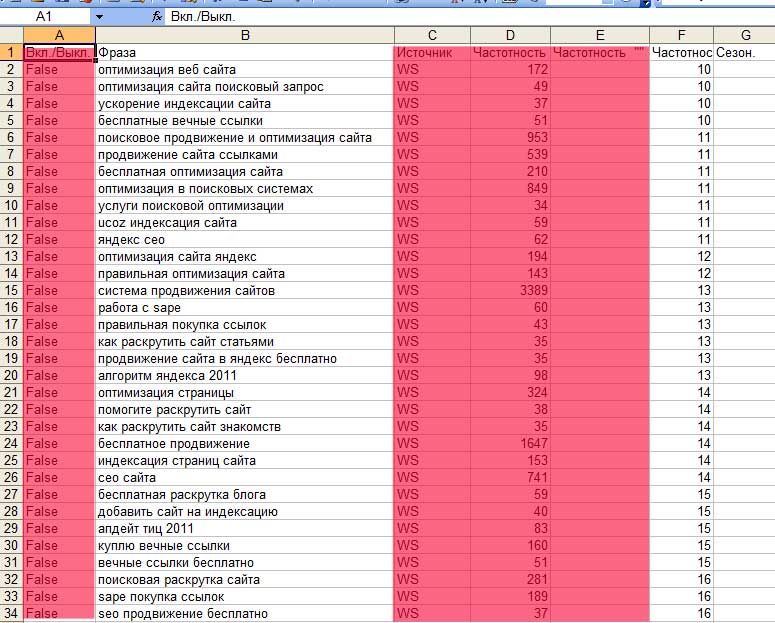 К примеру, у вас получатся группы ключей, которые содержать запросы о:
К примеру, у вас получатся группы ключей, которые содержать запросы о:
- Ремонте квартир-студий;
- Дизайнерском ремонте домов;
- Отделке офисов.
Поздравляем, у вас на сайте в обязательном порядке должны присутствовать эти страницы. Фактически, правильно отфильтрованное и кластеризованное ядро представляет собой структуру вашего сайта.
Про основные этапы SEO-продвижения читайте здесь:
https://mehed.pro/osnovnye-etapy-seo-prodvizheniya/
mStudio — разработка сайтов и продвижение интернет проектов
Перейти на mehed.proКомментировать ответ…Комментировать…
Как сделать семантическое ядро сайта? — 9 ответов, задан8-Web.ru
179
8-Web.ru — Агентство Интернет-маркетинга · 7 февр 2021 · 8-web.ru
Отвечает
Михаил Ширма
Составление семантического ядра (СЯ) — это сбор ключевых слов, их чистка и кластеризация. На основе семантического ядра строится правильная с точки зрения SEO структура сайта — устанавливается количество и вложенность разделов и страниц, разрабатывается меню. СЯ и структура сайта являются фундаментом продвижения.
На основе семантического ядра строится правильная с точки зрения SEO структура сайта — устанавливается количество и вложенность разделов и страниц, разрабатывается меню. СЯ и структура сайта являются фундаментом продвижения.
Заказать сбор семантического ядра
Комментировать ответ…Комментировать…
Как сделать семантическое ядро сайта? — 9 ответов, заданDigitalriff.ru
592
Digitalriff.ru — агентство поискового продвижения сайтов и контекстной рекламы · 12 июн 2020 · digitalriff.ru
Отвечает
Александр Савенков
Семантическое ядро для начала собирается Кей Коллектором и Яндекс Вордстатом. Сразу оговорюсь, что собирается весь спрос вместе с мусором, все, что относится к вашей тематике.
Второй этап — чистка, лучше делать это руками. Затем семантику надо разбить на логические группы. Вычищенные и сгруппированные слова называются кластерами, которые лягут в основе новых посадочных страниц.
Затем семантику надо разбить на логические группы. Вычищенные и сгруппированные слова называются кластерами, которые лягут в основе новых посадочных страниц.
Делаем SEO много — делаем хорошо=)
Перейти на digitalriff.ruКомментировать ответ…Комментировать…
Как правильно составить семантическое ядро? — 12 ответов, заданМихаил Савастьянов
3,9 K
IT, Web, игры и масса других интересов · 21 янв 2019
Семантическое ядро – это список ключевых слов и фраз для сайта. Затем эти фразы используются для написания статей.
Процесс сборки качественного семантического ядра — это очень кропотливый и не простой процесс. В нем можно выделить 5 основных шагов:
- Поиск базовых ключей. Это очень широкие, высокочастотные ключи. По сути, они определяют общие темы, на которые нужно будет писать статьи.
- Расширение семантического ядра. На этом этапе делается анализ различных поисковых запросов, которые подходят обозначенным ранее темам. Сделать это можно с помощью сервиса Wordstat. В результате для каждого базового ключа получается масштабный список запросов.
- Чистка. Теперь нужно проанализировать все запросы и убрать неподходящие по смыслу ключи.
- Группировка ключей. Все запросы разбиваются на кластеры (группы) по смыслу.
- В итоге получится большая страница, в которой будут содержаться группы запросов для каждой страницы/статьи сайта. Далее остается писать качественные тексты и грамотно вставлять в них ключевые фразы.

16,2 K
Комментировать ответ…Комментировать…
Как сделать семантическое ядро сайта? — 9 ответов, заданДмитрий Горошко
5
Web-аналитик, SEOшник и немного блогер https://softink. ru · 10 февр 2019
ru · 10 февр 2019
Анализируете и прорабатываете нишу, поиск маркерных запросов (1-2 слова характеризующих продукт или услугу: «купить ноутбук», «игровой ноутбук» и т.д.).
Далее идете в Yandex Wordstat и собираете все запросы которые подходят для вашего сайта. В этой статье я описал, как работать с Wordstatом.
Потом подключаем следующие пункты для сбора и расширения:
Анализ конкурентов;
Мозговой штурм
Базы ключевых слов
Собираем подсказки поисковых систем.
Потом используем инструменте для парсинга KeyCollector и для кластеризации.
Это если в двух словах.
Комментировать ответ…Комментировать…
Как сделать семантическое ядро сайта? — 9 ответов, заданИван Воробьёв
16,4 K
Имею естественно научное образование, в юношестве прикипел к литературе, сейчас активно.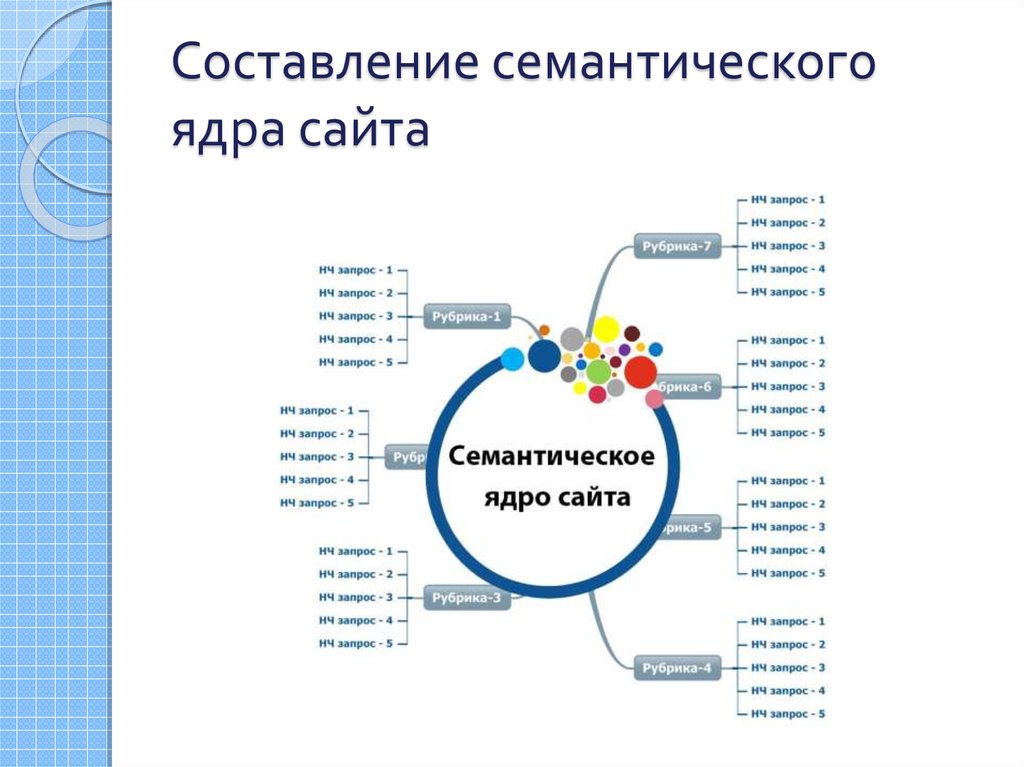 .. · 4 февр 2019
.. · 4 февр 2019
Составить набор слов и словосочетаний, которые отражали бы тематику и общее содержание вашего сайта, нужно составить перечень информации, которая есть на сайте и предположить, на какие запросы она могла бы отвечать, те была бы релевантна, далее распространить основные поисковые запросы и ключевые слова по страницам ресурса, чтобы пользователь, в поиска какой-либо информации или продукта мог видеть в выдаче ваш сайт, раскидайте информацию по блокам, которые могли бы отвечать на схожие запросы, пример структуры ядра выглядит так
Комментировать ответ…Комментировать…
Как оптимизировать сайт под Яндекс и Гугл одновременно
# КПП 8 октября 2021 г. Оценить статью
★★★★★
Релевантность семантического ядра
Первым делом нужно проверить позиции по всем запросам семантического ядра в поисковых системах.
Если вдруг по каким-то причинам ваш сайт не в ТОПе, вам необходимо дополнить ключевые слова в этом направлении. В результате вы получите более полное и актуальное ядро с запросами.
Актуальность текстов
- Необходимо своевременно обновлять контент на сайте, чтобы помогать посетителям решать их проблемы, а не вводить в заблуждение (тексты должны быть в первую очередь для пользователей, а не для поисковых систем)
- Доработка контент-плана для новых запросов, добавленных в семантическое ядро
Проверить элементы оптимизации
Нужно проверить, есть ли важные запросы, по которым больше всего трафика в следующих элементах:
- Название, описания
- Заголовки h2-H6
- В текстах
Очевидно, что все это было проработано на начальном этапе SEO-оптимизации, но все же стоит перепроверить.
Работа со ссылочным профилем
Для привлечения большего целевого трафика с внешних ресурсов необходима работа со ссылочным профилем на постоянной основе (подбор новых доменов-доноров, проверка «живых» ссылок на существующие не реже одного раза в месяц ).
Вы также можете поделиться в социальных сетях. сети материалами с сайта для привлечения целевого трафика.
Анализ сайтов конкурентов из ТОП выдачи
Если агрегаторы и сервисы (Яндекс и Гугл) находятся в ТОПе выдачи поисковых систем по вашим приоритетным запросам, их не следует брать для анализа. Вам необходимо проанализировать те сайты, которые подходят по возрасту вашему сайту, а для повышения юзабилити и коммерческих факторов (об этом мы напишем ниже) можно взять некоторые ТОПовые сайты.
Вам необходимо проанализировать и сравнить коммерческие факторы конкурентов и вашего сайта. К ним относятся:
- Основная информация о компании (наличие лицензий, информация о доставке и оплате и т.д.)
- Наличие контактной информации, с которой можно связаться через мессенджеры, почту, телефон. Также должен быть онлайн-консультант.
- Активные социальные сети (если актуально в вашей тематике). Наличие в них подписчиков, постоянное ведение канала/профиля/группы).

На основе анализа этих данных уже будет понятно, что нужно внедрить на ваш сайт.
Анализ и оценка поведенческих факторов
Не секрет, что поведенческие факторы очень сильно влияют на должности и само продвижение по службе. Поэтому необходимо как можно чаще анализировать ПФ.
Для анализа можно использовать Вебвизор, карту кликов, карту прокрутки, формировать аналитику (если вам нужно раскрутить и оптимизировать сайт под Яндекс и Гугл, рекомендую для анализа использовать как Метрику, так и Аналитику. Коды счетчиков можно добавить в Гугл Диспетчер тегов, чтобы он не сильно влиял на скорость загрузки сайта).
При анализе необходимо учитывать удобство пользователей на сайте (использование Вебвизора). Посмотрите, куда переходят пользователи, удобно ли им делать заказ и т. д.
Все вышеперечисленные действия помогут вам точнее проработать сайт для обеих поисковых систем.
Александр Шмидко SEO-специалист
Узнайте, как мы можем помочь развитию вашего бизнеса
Свяжитесь с нами!
похожие статьи
подписываться:
# КПП 6 октября 2021
# КПП 13 октября 2021
# КПП 25 октября 2021
Комментарии
Улучшение SEO с помощью семантического поиска по ключевым словам в KNIME
Методы семантического поиска с неструктурированными данными становятся все более распространенными в большинстве поисковых систем. В этой статье мы покажем вам, как создать рабочий процесс KNIME для семантического поиска по ключевым словам. Результаты рабочего процесса позволят вам создавать тексты веб-страниц для повышения рейтинга поиска по заданному поисковому запросу. Вы можете загрузить рабочий процесс, который извлекает эту информацию из KNIME Hub: Поисковая оптимизация (SEO) с проверенными компонентами.
В этой статье мы покажем вам, как создать рабочий процесс KNIME для семантического поиска по ключевым словам. Результаты рабочего процесса позволят вам создавать тексты веб-страниц для повышения рейтинга поиска по заданному поисковому запросу. Вы можете загрузить рабочий процесс, который извлекает эту информацию из KNIME Hub: Поисковая оптимизация (SEO) с проверенными компонентами.
Но сначала: что такое семантический поиск по ключевым словам?
В контексте поисковой оптимизации (SEO) семантический поиск по ключевым словам направлен на поиск наиболее релевантных ключевых слов для заданного поискового запроса. Ключевые слова могут быть часто встречающимися отдельными словами, а также словами, рассматриваемыми в контексте, например, совместно встречающимися словами или синонимами текущих ключевых слов. Современные поисковые системы, такие как Google и Bing, могут выполнять семантический поиск, включая некоторое понимание естественного языка и того, как ключевые слова соотносятся друг с другом для улучшения результатов поиска.
Как объясняет Пол Шапиро в книге «Исследование семантических ключевых слов с помощью KNIME и интеллектуальный анализ данных в социальных сетях», семантический поиск можно выполнять двумя способами: со структурированными или неструктурированными данными.
Структурированный семантический поиск использует разметку схемы — семантический словарь, предоставленный пользователем и включенный в виде метаданных в HTML веб-сайта. Такие метаданные будут отображаться на странице результатов поисковой системы (SERP). На рисунке 2 вы можете увидеть пример фрагмента поисковой выдачи, возвращенной Google. Обратите внимание, как он показывает поддержку операционной системы, последнюю стабильную версию, ссылку на репозиторий Github и другие метаданные с найденной веб-страницы. Создание метаданных в синтаксисе HTML может быть выполнено с помощью schema.org, совместной работы Google, Bing, Yahoo и Yandex, используемой для создания подходящей семантической разметки для веб-сайтов. Соответствующие метаданные помогают улучшить рейтинг веб-страницы в поисковых системах.
Соответствующие метаданные помогают улучшить рейтинг веб-страницы в поисковых системах.
Между тем, неструктурированных семантических поисков используют машинное обучение и обработку естественного языка для анализа текста на веб-страницах для лучшего ранжирования в поисковой выдаче. Чем релевантнее текст для поиска, тем выше веб-позиция в списке поисковой выдачи.
Рисунок 2: Фрагмент поисковой выдачи после поиска «KNIME» в Google.Хотя структурированный поиск по метаданным присутствует во всех поисковых системах, методы с неструктурированными данными также становятся все более распространенными. Есть два места, где происходит поиск: поисковые системы (конечно) и социальные сети. Мы хотим изучить результаты поисковых запросов в поисковой выдаче и социальных сетях и извлечь уроки из текста на самых эффективных страницах.
Поиск путем очистки текста со страницы результатов поисковой системы (SERP)
Вплоть до 2013 года поисковые системы, такие как Google, проверяли частоту слов на веб-страницах, чтобы определить их релевантность. Это побудило людей добавлять случайные ключевые слова либо в разметку, либо в текст веб-страницы, чтобы улучшить свои позиции в поиске Google. В 2013 году Google Search представил алгоритм Hummingbird. Этот алгоритм пытается понять намерения пользователя в режиме реального времени. Например, если пользователь пишет «пиво» в поле поиска, его намерения не столь ясны. Пользователь хочет купить пиво, ищет пивной магазин, ищет подробности приготовления пива или что-то еще? Таким образом, поисковые системы будут показывать все возможные результаты, касающиеся «пива». Однако, если человек напишет «пивной бар», движок покажет списки ближайших пабов, ресторанов, кафе и т. д. В последнем запросе Google лучше понял намерение пользователя. Следовательно, этот алгоритм также отображает результаты Google Map в поисковой выдаче.
Это побудило людей добавлять случайные ключевые слова либо в разметку, либо в текст веб-страницы, чтобы улучшить свои позиции в поиске Google. В 2013 году Google Search представил алгоритм Hummingbird. Этот алгоритм пытается понять намерения пользователя в режиме реального времени. Например, если пользователь пишет «пиво» в поле поиска, его намерения не столь ясны. Пользователь хочет купить пиво, ищет пивной магазин, ищет подробности приготовления пива или что-то еще? Таким образом, поисковые системы будут показывать все возможные результаты, касающиеся «пива». Однако, если человек напишет «пивной бар», движок покажет списки ближайших пабов, ресторанов, кафе и т. д. В последнем запросе Google лучше понял намерение пользователя. Следовательно, этот алгоритм также отображает результаты Google Map в поисковой выдаче.
Алгоритм Hummingbird позволяет с поисковым запросом связывать несколько тем и соответствующих ключевых слов. Таким образом, веб-страницы, занимающие первые места в поисковой выдаче, содержат такие ключевые слова и такие темы. Если мы хотим, чтобы наша веб-страница работала лучше с SEO, мы можем узнать на страницах с самым высоким рейтингом, как формировать наш текст, например, какие отдельные ключевые слова и какие пары слов использовать. Правильный набор ключевых слов с похожих веб-сайтов может очень помочь с ранжированием страницы в результатах поиска.
Если мы хотим, чтобы наша веб-страница работала лучше с SEO, мы можем узнать на страницах с самым высоким рейтингом, как формировать наш текст, например, какие отдельные ключевые слова и какие пары слов использовать. Правильный набор ключевых слов с похожих веб-сайтов может очень помочь с ранжированием страницы в результатах поиска.
В этой статье мы уделим особое внимание текстам на страницах с высоким рейтингом для данного поискового запроса с целью извлечения значимых ключевых слов и ключевых пар слов.
Поиск путем извлечения текста из ссылок в социальных сетях
В то время как извлечение текста из поисковой выдачи может быть одним из способов извлечения ключевых слов, извлечение текста из ссылок в социальных сетях может быть вторичным источником. Мнения и идеи, которыми делятся пользователи в этих сетях, действительно помогают расширить кругозор для сбора правильных ключевых слов. В контексте цифрового маркетинга разговоры в социальных сетях используются для взаимодействия с посетителями, чтобы заставить их остаться на веб-сайте или побудить их выполнить действие — например, побудить посетителя на веб-сайте электронной коммерции совершить покупку. Это можно оптимизировать, улучшив показатель коэффициента конверсии (в данном примере количество посетителей, деленное на количество совершенных покупок). Это называется оптимизацией коэффициента конверсии (CRO).
Это можно оптимизировать, улучшив показатель коэффициента конверсии (в данном примере количество посетителей, деленное на количество совершенных покупок). Это называется оптимизацией коэффициента конверсии (CRO).
Действия в социальных сетях часто используют ссылки на веб-страницы для призыва к действию, и они сильно оптимизированы по коэффициенту конверсии. Таким образом, анализ текста социальных сетей и текста связанных веб-страниц может помочь в процессе извлечения ключевых слов, особенно тех ключевых слов, которые наиболее «привлекательны» для посетителей.
Три метода, которые мы использовали для извлечения ключевых слов
На основе предыдущих наблюдений мы создали приложение, которое будет выполнять поисковый запрос в веб-поисковике (Google) и платформе социальных сетей (Twitter), очищать тексты от ссылок появляются в поисковой выдаче и твитах и, наконец, извлекают ключевые слова.
Мы использовали три разных метода извлечения ключевых слов:
- Совпадения терминов — извлекаются наиболее часто встречающиеся пары слов.
- Скрытое распределение Дирихле (LDA) — алгоритм, который группирует документы в корпусе по темам, где каждая тема описывается набором соответствующих связанных ключевых слов.
- Частота термина — обратная частота документа (TF-IDF) — важность отдельного ключевого слова в документе измеряется частотой термина (TF), а важность того же ключевого слова в корпусе измеряется обратным документом. частота (IDF). Произведение этих метрик (TF-IDF) дает хороший компромисс того, насколько релевантно слово для идентификации документа и только этот документ в корпусе. Затем извлекаются слова с самым высоким рейтингом TF-IDF.
Как мы внедрили наше приложение для поиска по ключевым словам для SEO
Наше «Приложение для поиска по ключевым словам» состоит из четырех этапов:
- Запуск поисковых запросов в поисковых системах и социальных сетях и извлечение ссылок на самые популярные веб-страницы.
- Соскоблить текст с идентифицированных веб-страниц с самым высоким рейтингом.
- Извлечение ключевых слов из очищенных текстов.
- Суммируйте полученные ключевые слова в приложении данных.

Шаг 1: извлечение URL-адресов
Первый шаг состоит в извлечении URL-адресов страниц с самым высоким рейтингом вокруг заданного хэштега или ключевого слова. Для этого шага мы создали два очень полезных проверенных компонента: экстрактор URL-адресов Google и экстрактор URL-адресов Twitter (рис. 3).
Рис. 3. Проверенные компоненты для извлечения URL-адресов со страницы результатов поиска Google и твитов.Шаг 2: Из поисковой выдачи Google и из твитов
Из поисковой выдачи Google
Компонент Google URLs Extractor выполняет поиск в системе пользовательского поиска Google (CSE) через веб-службу. Он отправляет ключ Google API, поисковый запрос и идентификатор движка, а в ответ получает максимальное количество SERP в формате JSON. Из этого ответа JSON компонент извлекает веб-ссылки для всех найденных страниц и возвращает их вместе с фрагментами текста, заголовком SERP и кодом состояния. Поиск Google можно улучшить за счет некоторых дополнительных настроек компонентов: определенного языка или расположения страниц результатов поиска (рис. 4).
Поиск Google можно улучшить за счет некоторых дополнительных настроек компонентов: определенного языка или расположения страниц результатов поиска (рис. 4).
Так же, как бесплатных обедов не бывает 😏, Google предлагает только закуски, но не основное блюдо. Бесплатная версия веб-службы Google Custom Search Engine (CSE) может возвращать только 10 результатов поиска при последовательных вызовах, что означает максимум 100 результатов поиска. Веб-служба CSE премиум-класса, очевидно, решает эту проблему.
Рис. 4: Окно настройки компонента Google URLs Extractor.Чтобы создать ключ Google API и идентификатор поисковой системы, см. страницу документации Google Custom Search API JSON или Google Cloud Console.
Для начала вам понадобится ключ API, который позволяет идентифицировать клиент Google. Этот ключ можно получить на этой странице. Если эта ссылка не работает, то аналогичный ключ можно создать в Google Cloud Console. Затем необходим параметр аутентификации — идентификатор поисковой системы, поисковая система, созданная пользователем с определенными настройками. На рис. 5 показано, как его можно получить.
На рис. 5 показано, как его можно получить.
Из твитов
Здесь мы использовали компонент Twitter URLs Extractor. Этот компонент извлекает твиты из Twitter по заданному поисковому запросу, а затем извлекает содержащиеся в них URL-адреса. Мы также могли бы использовать Facebook, LinkedIn или любую другую социальную сеть. Мы использовали Twitter из-за более легкого доступа к своему контенту.
Если вам интересно, почему мы выбрали URL-адреса, а не основной текст твитов, мы лично считаем, что использование текста со связанных URL-адресов должно предоставить больше информации, чем то, что содержится в простом коротком твите.
Для запуска компонента необходима учетная запись разработчика Twitter и соответствующие параметры доступа (рис. 6). Вы можете получить все это на портале разработчиков Twitter.
Дополнительные поисковые фильтры для применения в запросе, такие как фильтрация ретвитов или хэштегов, описаны на странице документации оператора поиска Twitter. Выходные данные компонента включают URL-адреса, твит, идентификатор твита, пользователя, имя пользователя и идентификатор пользователя.
Выходные данные компонента включают URL-адреса, твит, идентификатор твита, пользователя, имя пользователя и идентификатор пользователя.
Шаг 3: Извлечение текста из URL-адресов
При использовании URL-адресов как из поисковой выдачи, так и из твитов приложение должно продолжить очистку их текстов, чтобы получить корпус для извлечения ключевых слов. Для этого шага у нас есть еще один проверенный компонент — «Web Text Scraper» (рис. 7). Этот компонент подключается к внешней веб-библиотеке — «BoilerPipe» — для извлечения текста из входного URL. Затем он отфильтровывает ненужные теги HTML и шаблонный текст. (Заголовки, меню, навигационные блоки, раздельные тексты, весь ненужный контент за пределами основного текста.)
Подробная информация об алгоритмах, используемых в Boilerpipe, и его оптимизации производительности упоминается в исследовательской статье «Обнаружение шаблонов с использованием функций мелкого текста».
Этот компонент принимает столбец URL-адресов в качестве входных данных и создает столбец с текстами в формате String в качестве выходных данных. Поддерживается только действительный HTML-контент — все остальные связанные скрипты пропускаются. При сканировании длинных списков URL-адресов этот компонент может работать медленно, поскольку определение шаблонов для каждого URL-адреса занимает много времени.
Шаг 4. Обобщение результатов в приложении данных
Компонент поиска по ключевым словам
После создания корпуса документа приложение преобразует его в формат документа с помощью узла «Строки в документ». Результирующий столбец «Документ» становится входными данными для компонента «Поиск по ключевым словам». Этот компонент реализует три метода, описанные ранее (совпадение терминов, извлечение темы с использованием LDA и TF-DIF) для извлечения ключевых слов.
На рис. 8 представлен диалог настройки компонента «Поиск по ключевым словам». Это включает в себя выбор столбца «Документ», несколько параметров для алгоритма LDA (т. е. количество тем и ключевых слов, а также значения параметров «Альфа» и «Бета»), меру IDF для подхода TF-IDF и флаг для включения обработка текста по умолчанию. Для дальнейшего понимания извлечения тем с использованием LDA, пожалуйста, прочитайте «Извлечение тем: оптимизация количества тем с помощью метода локтя».
8 представлен диалог настройки компонента «Поиск по ключевым словам». Это включает в себя выбор столбца «Документ», несколько параметров для алгоритма LDA (т. е. количество тем и ключевых слов, а также значения параметров «Альфа» и «Бета»), меру IDF для подхода TF-IDF и флаг для включения обработка текста по умолчанию. Для дальнейшего понимания извлечения тем с использованием LDA, пожалуйста, прочитайте «Извлечение тем: оптимизация количества тем с помощью метода локтя».
Этот компонент имеет три выхода:
- Термины (существительные, прилагательные и глаголы) вместе с их весами, полученными с помощью алгоритма LDA.
- Термины (существительные, прилагательные и глаголы) совместно встречающихся пар вместе с количеством встречаемости.
- Топ тегированных терминов (существительные, прилагательные и глаголы) с самыми высокими значениями TF-IDF.
Каждая из этих выходных таблиц сортируется в порядке убывания в соответствии с их соответствующими весами/частотами/значениями.
Для нашего последнего шага эти выходные данные были визуализированы:
- Top 10 LDA с гистограммой.
- Совместно встречающиеся термины в сетевом графе, где каждый узел является термином, а количество документов — ребрами.
- Основные термины, идентифицированные максимальными значениями TF-IDF с облаком тегов, где размер слова определяется максимальным значением TF-IDF для каждого термина.
Полный рабочий процесс «Поисковая оптимизация (SEO) с проверенными компонентами», включающий все четыре компонента, доступен на KNIME Hub (рис. 9).).
Рис. 9. Рабочий процесс определения URL-адресов из поисковой выдачи и твитов, извлечения текстов из URL-адресов, а также извлечения и визуализации ключевых слов из очищенных текстов.Пример: запрос документов по теме «Наука о данных»
В качестве примера давайте запросим в Google и Twitter термин «Наука о данных». Ключевые слова — по отдельности или в комбинации — извлеченные со страниц с высоким рейтингом, извлеченные как из поисковой выдачи, так и из твитов, ведут к диаграммам и картам, показанным на рис. 10, 11 и 12. Давайте посмотрим, что это за ключевые слова и как они соотносятся с каждым из них. Другие.
10, 11 и 12. Давайте посмотрим, что это за ключевые слова и как они соотносятся с каждым из них. Другие.
Ключевые слова из LDA
10 основных ключевых слов, связанных с темой, отсортированных по весу LDA, представлены на рисунке 10. Слова «данные» и «наука» имеют наибольший вес, что имеет смысл, но также очевидно. Следующими важными ключевыми словами являются «машина» и «обучение», за которыми следует «курс». Ссылка на «машинное обучение» понятна, а «курс», вероятно, связан с недавним расцветом учебных материалов по этой теме. Добавление ссылки на машинное обучение и одного или двух курсов на вашу страницу по науке о данных может улучшить ее рейтинг.
Рис. 10: Топ-10 терминов, возвращенных из LDA, отсортированных в порядке убывания их веса.Сопутствующие ключевые слова
Однако на сетевом графике (рис. 11) мы наблюдаем другой набор ключевых слов. «Данные» и «наука» по-прежнему составляют ядро набора ключевых слов, так как располагаются в центре графика и имеют наивысшую степень. «Машина» и «обучение» также снова присутствуют, и на этот раз мы узнаем, что они связаны друг с другом. Точно так же «программа» связана с «курсами», поскольку эти слова часто встречаются вместе на высокорейтинговых страницах о «науке о данных».
«Машина» и «обучение» также снова присутствуют, и на этот раз мы узнаем, что они связаны друг с другом. Точно так же «программа» связана с «курсами», поскольку эти слова часто встречаются вместе на высокорейтинговых страницах о «науке о данных».
Из этого графика мы можем узнать столько же о словах, которые не встречаются вместе. Например, «программа» сосуществует только с «наукой» и «курсами», а «навыки» и «курс» сосуществуют только с «данными», а не с «наукой», «машиной», «обучением, » или «бизнес». Таким образом становится ясно, какие пары слов вы должны включить в свою страницу науки о данных.
Рис. 11: Сетевой граф совпадения терминов, в котором каждый уникальный термин является узлом, а счетчики совпадения документов являются ребрами. Однако вес на краях игнорируется, чтобы просто визуализировать связанные термины.Ключевые слова из облака слов
Наконец, если мы посмотрим на отдельные ключевые слова в облаке тегов (рис. 12), то увидим, что чаще всего встречаются термины «мастер», «понимание», «книга» и «специализация».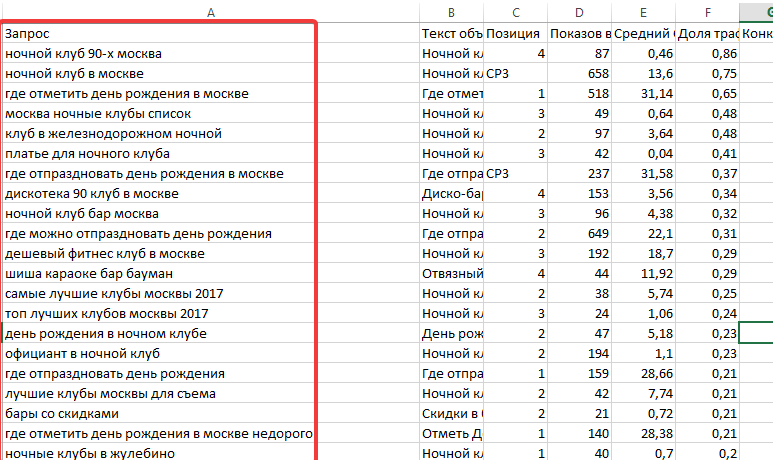 заметно. Это имеет смысл, так как в сети есть большое количество предложений курсов специализации с университетами, онлайн-платформ и книг. В словесном облаке также можно увидеть названия институтов, издательств и университетов, предлагающих такие варианты обучения. Только во втором случае вы видите слова «данные», «наука», «машина», «обучение», «философия», «модель» и так далее.
заметно. Это имеет смысл, так как в сети есть большое количество предложений курсов специализации с университетами, онлайн-платформ и книг. В словесном облаке также можно увидеть названия институтов, издательств и университетов, предлагающих такие варианты обучения. Только во втором случае вы видите слова «данные», «наука», «машина», «обучение», «философия», «модель» и так далее.
Отдельные ключевые слова, по-видимому, лучше описывают один аспект сообщества «науки о данных», то есть обучение, в то время как совместно встречающиеся ключевые слова и темы лучше всего извлекают содержание дисциплины «наука о данных».
Обратите внимание, что многогранный подход к визуализации ключевых слов, который мы использовали в этом проекте, позволяет исследовать результаты с разных точек зрения.
Рис. 12: Облако тегов для терминов с наивысшим показателем TF-IDF. Чтобы улучшить поисковую оптимизацию, изучая самые эффективные страницы для данного поискового запроса, мы создали инструмент, который может помочь вам извлечь наиболее часто используемые ключевые слова, попарно или по отдельности, или из самых популярных страниц вокруг данный поиск по любой теме, которую вы выберете.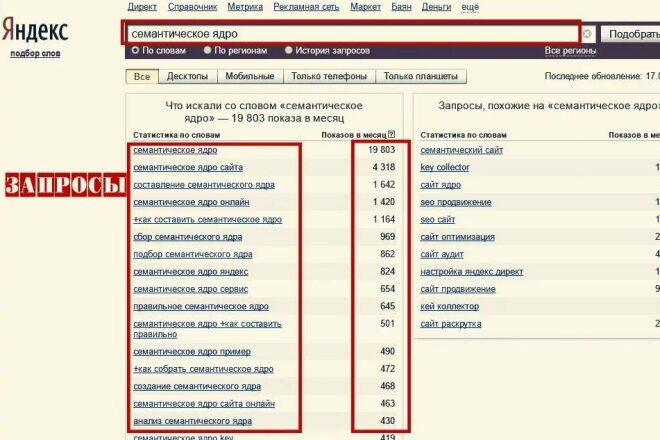
Приложение идентифицирует URL-адреса наиболее эффективных твитов и страниц в поисковой выдаче, извлекает тексты из URL-адресов и извлекает ключевые слова из очищенных текстов с помощью алгоритма LDA, метрики TF-IDF и совпадения пар слов.
Вы можете загрузить рабочий процесс из KNIME Hub: Поисковая оптимизация (SEO) с проверенными компонентами. Конечно, чтобы запустить его, вам нужно ввести свои собственные учетные данные для аутентификации для учетных записей Google и Twitter.
Раздел «Машинное обучение и маркетинг» в KNIME Hub содержит примеры рабочих процессов для решения распространенных проблем обработки данных в Marketing Analytics. Первоначальная задача была объяснена в: Ф. Вильярроэль Орденес и Р. Силипо, «Машинное обучение для маркетинга в KNIME Hub: разработка живого репозитория для маркетинговых приложений», Journal of Business Research 137 (1): 393-410, DOI: 10.1016/j.jbusres.2021.08.036. Пожалуйста, цитируйте эту статью, если вы используете какие-либо рабочие процессы в репозитории.
Автор
Али Асгар Марви
Али работает студентом в команде евангелистов в KNIME. В студенческие годы он изучал информатику и проявлял большой интерес к приложениям науки о данных. Он также имеет более чем трехлетний опыт работы на технических линиях, включая анализ данных в Пакистане. В настоящее время он получает степень магистра компьютерных наук по специальности «Наука о данных» в Констанцском университете. В KNIME Али любит изучать различные приложения KNIME и разрабатывать рабочие процессы.
Скачать Рабочий процесс
Поделиться этой статьей
Загрузите рабочий процесс, описанный в этой статье, для семантического поиска по ключевым словам и улучшите SEO
Скачать Рабочий процесс
Краткое изложение шагов
- Приложение запускается с запроса API пользовательского поиска Google, определения URL-адресов самых популярных результатов и очистки текста веб-сайта. Те же операции выполняются после запроса Twitter по той же теме.
- После извлечения текстов из веб-ссылок приложение работает с этим текстовым корпусом, чтобы извлечь лучшие ключевые слова для SEO. Компонент, используемый для этой части, идентифицирует несколько тем и соответствующие ключевые слова с помощью алгоритма LDA. Затем он извлекает количество совпадений терминов и использует меру TF-IDF для извлечения отдельных ключевых слов.
- Наконец, каждый вывод данных визуализируется с помощью диаграмм. Ключевые слова LDA визуализируются на гистограмме, совместно встречающиеся термины — на сетевом графике, а ключевые слова на основе TF-IDF — в облаке слов.
- Использование различных стратегий извлечения ключевых слов позволило нам увидеть релевантные ключевые слова с разных точек зрения. Хотя основные ключевые слова одинаковы для всех результатов — «наука о данных», «машинное обучение», «курсы», «книги» — релевантность каждого из них меняется в зависимости от того, рассматриваются ли они вместе или по отдельности.
 Те же операции выполняются после запроса Twitter по той же теме.
Те же операции выполняются после запроса Twitter по той же теме.