
53 сервиса и программы для сбора семантического ядра и ключевых слов, Семён Ядрён
На этой странице представлены сервисы и программное обеспечение для работы с ключевыми словами.
Сервисы от поисковых систем
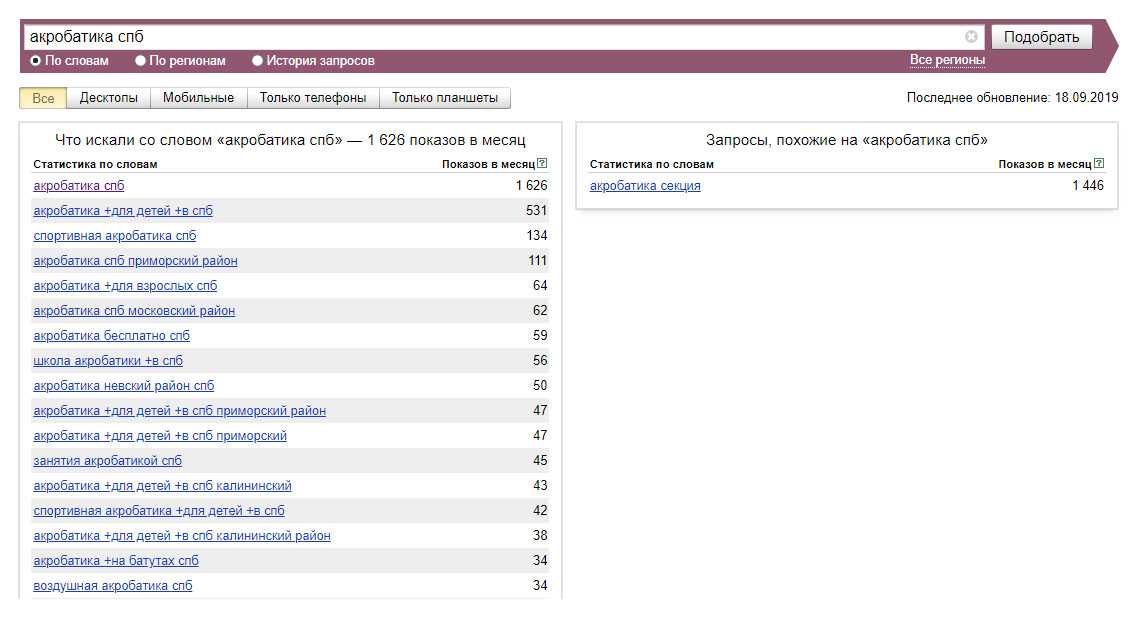
Яндекс Вордстат, wordstat.yandex.ru — главный бесплатный сервис поисковой системы Яндекс для оценки пользовательского интереса к конкретным тематикам и для сбора ключевых слов рекламодателями. Сервис содержит подробную статистику запросов на протяжении месяца.
Google KeywordPlanner, ads.google.com — бесплатный инструмент AdWords по подбору различных вариантов поисковых запросов, комбинированию имеющихся списков ключевых слов, подбору оптимальных ставок и бюджетов контекстных кампаний. Сервис полезен как опытным, так и начинающим рекламодателям.
Google Trends, trends.google.ru/trends/ — публичный сервис, основанный на поиске Google, который показывает на картах и в таблицах, как часто определенный термин ищут по отношению к общему объему поисковых запросов в различных регионах мира и на различных языках.
Mail.Ru Вордстат, webmaster.mail.ru/querystat — статистика по запросам поисковой системы Mail.Ru.
Сервисы для группировки ключевых слов
СЕМЁН ЯДРЁН, semen-yadren.com — агентство семантики. В личном кабинете присутствуют бесплатные инструменты для быстрого внедрения семантического ядра на сайт. Отличные цены на сбор семантики для сайтов и интернет магазинов. Самый большой на рынке объем выгружаемой информации после группировки(12 отчетов), включая ТЗ копирайтеру.
Just Magic, just-magic.org — система автоматизации SEO в части семантики и текстов.
Engine, engine.seointellect.ru — помощник оптимизатора, автоматическая кластеризация ключевых слов.
Coolakov, coolakov.ru/tools/razbivka — бесплатный сервис для автоматической группировки запросов. Разбивка запросов на группы производится на основе схожести топ10 Яндекса.
SEMparser, semparser.ru — платный сервис по структуризации семантики для SEO и контекста.
STOOLZ, stoolz.ru — платный сервис кластеризации запросов предназначен для быстрой автоматизированной группировки больших списков запросов на основе выдачи поисковой системы Яндекс.
Rush Analytics, rush-analytics.ru — сбор Яндекс.Вордстат, подсказок и автоматическая кластеризация запросов.
Десктопные программы для работы с ключевыми словами
Key Collector, key-collector.ru — лучшая программа по сбору и чистке ключевых фраз из разных источников, позволяет значительно облегчить процесс подготовки семантического ядра. Платная.
СловоЁБ, seom.info — младший брат Key Collector. Одна из лучших бесплатных программ для составления семантического ядра.
Allsubmitter, webloganalyzer.biz — многофункциональная программа, при помощи которой можно подбирать ключевые слова из 14 источников, используется модуль «подбор ключевых слов». Платная.
Магадан, magadanparser. ru — программа для удобного автоматического сбора, анализа и обработки ключевых слов Яндекс.Директа. Широкий спектр функциональных возможностей и удобный интерфейс.«LITE» — бесплатная ознакомительная редакция с символическими ограничениями функциональных возможностей.«PRO» — платная редакция, не содержащая искусственных ограничений по функционалу.
ru — программа для удобного автоматического сбора, анализа и обработки ключевых слов Яндекс.Директа. Широкий спектр функциональных возможностей и удобный интерфейс.«LITE» — бесплатная ознакомительная редакция с символическими ограничениями функциональных возможностей.«PRO» — платная редакция, не содержащая искусственных ограничений по функционалу.
Букварикс, bukvarix.com — бесплатная программа для ОЧЕНЬ быстрого подбора ключевых слов по собственной базе в 460 млн. слов и словосочетаний. Выбранные словосочетания сопровождаются такой полезной информацией, как количество показов в Яндексе, конкуренция в Google и Яндекс.Директ, а также годовой тренд поиска в Яндексе с выделением наиболее активного месяца.
Keyassort, keyassort.com (UPD — 17.09.2020)- это десктопная программа под windows, профессиональный софт для кластеризации и структуризации семантического ядра. Преимущества программы:
1. Возможность построения правильной структуры сайта после группировки запросов.
2. функционал 3 в 1: группировка ключей, формирование структуры сайта, поиск главных конкурентов.
3. При объединении запросов в кластеры учитываются синонимы, транслит и похожие написания.
Программа тестировалась на ядре в 150 тысяч поисковых запросов.
Плагины, расширения для браузера
Yandex Wordstat Helper — Расширение для Mozilla Firefox и Google Chrome, позволяющее значительно ускорить сбор слов с помощью сервиса wordstat.yandex.ru.
Yandex Wordstat Assistant — Расширение для браузеров Google Chrome, Яндекс.Браузер и Opera, которое позволяет значительно ускорить ручной сбор слов с помощью сервиса подбора слов Яндекс (wordstat).
Сервисы для подбора ключевых слов
Кейсо — keys.so — сервис является первым сервисом анализа ключей, специализирующимся на работе с информационными сайтами, что это означает на практике:
1. Максимальный охват ключевых фраз
2. Особое внимание на частотность и валидность слово-форм
3. Минимальное количество неточных дублей ключевых фраз
Минимальное количество неточных дублей ключевых фраз
4. Информация о сайтах и группах сайтов для упрощения анализа.
SEMrush (СЕМраш), semrush.com — сервис для исследования конкурентов, позволяет узнать кейворды (запросы), по которым любой домен или сайт попадает в SERP или Ads, обзор сервиса.
Ahrefs — Универсальный набор инструментов для SEO, главные: подбор и анализ ключевых слов (сложность ранжирования и потенциальный трафик), анализ конкурентов через всесторонний анализ ссылочного профиля и поискового трафика. (UPD — 16.10.2020)
SpyWords (СпайВордс), spywords.ru — уникальный сервис, позволяющий узнать все секреты твоих конкурентов: их запросы в контексте и поиске, тексты объявлений и позиции, бюджеты и многое другое, обзор сервиса.
Serpstat (Серпстат), serpstat.com — сервис для анализа конкурентов в поиске и подбора ключевых фраз. Сервис поможет узнать поисковые запросы конкурентов, их суммарный трафик, страницы с наибольшей видимостью.
Мутаген, mutagen.ru — платно / бесплатный сервис подбора для своего или чужого сайта ключевых слов, по которым показов много, а конкуренции почти нет.
МегаИндекс, keywords.megaindex.ru — бесплатный инструмент по определению видимости сайта и подбору ключевых фраз
Топвизор, topvisor.ru — сервис по подбору ключевых слов для составления семантического ядра сайта из всех доступных источников: Яндекс.Директ, Google Adwords, Webmaster Bing, Webmaster Mail.
SimilarWeb, similarweb.com — условно бесплатный сервис отображает разные параметры сайта, в том числе, по каким запросам он получает трафик из органического поиска или контекста.
Готовые базы ключевых слов
MOAB, moab.pro — база ключевых слов, 3.2 млрд запросов из Яндекс.Метрики Ваших конкурентов, 1.4 млрд. запросов из Яндекс.Подсказок с обновлениями 2 раза в месяц.
База Пастухова, pastukhov.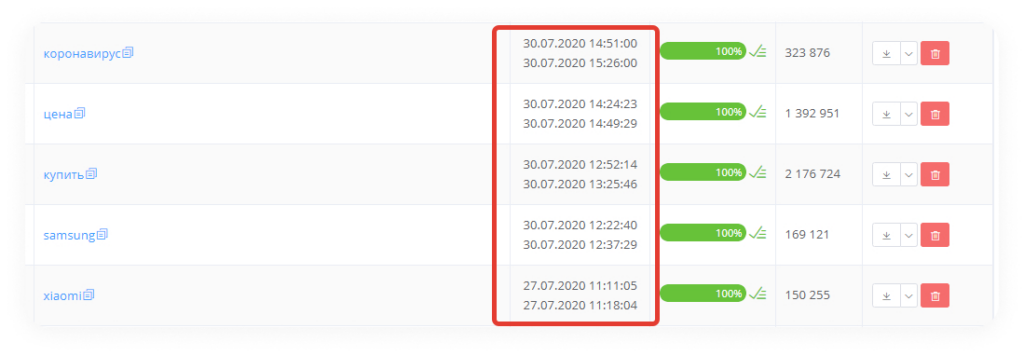 com — база ключевых слов Яндекс и Google (русских ключей в базе: 1 млрд, английских ключей в базе: 1 млрд.).
com — база ключевых слов Яндекс и Google (русских ключей в базе: 1 млрд, английских ключей в базе: 1 млрд.).
KeyBooster, keybooster.ru — онлайн-база ключевых слов, ключевых слов в базе: 55 млн. Помимо значений месячной статистики показов каждого ключевого слова, база содержит информацию о связях между ключевыми словами, сезонных трендах и другую полезную информацию.
FastKeywords.biz — онлайн-база русских ключевых слов (ключей в полной базе: 780 млн.).
Roostat.ru — база ключевых слов от сервиса Rookee (поисковых запросов в базе: 230 млн.).
Собственные системы аналитики
Собственные счетчики и системы аналитики позволяют собирать списки ключевых слов, по которым люди уже заходили на сайт.
Google Analytics, marketingplatform.google.com — Сервис веб-аналитики для сайта от Google. Ресурс не покажет зашифрованные запросы Яндекса, а также скроет многие ключи, по которым люди переходили из Google, но какой-то полезный список ключевых слов все же можно получить. При связи с панелью для вебмастеров (search.google.com) можно получить больше информации по запросам. Google Analytics позволяет оценивать рентабельность инвестиций, отслеживать Flash- и видеорекламу, а также распространение контента в приложениях и социальных сетях.
При связи с панелью для вебмастеров (search.google.com) можно получить больше информации по запросам. Google Analytics позволяет оценивать рентабельность инвестиций, отслеживать Flash- и видеорекламу, а также распространение контента в приложениях и социальных сетях.
Яндекс Метрика, metrika.yandex.ru — бесплатный сервис статистики переходов и ключевых слов на сайт из Яндекса, других поисковиков, Яндекс Картинок и других источников. Инструмент для оценки посещаемости сайта, анализа поведения посетителей и эффективности рекламы. Мониторинг доступности сайта.
LiveInternet, liveinternet.ru, Полезно использовать вместе с другими системами аналитики, чтобы собирать как можно больше данных. Сервис статистики для сайтов, предоставляющий наиболее качественные инструменты сбора, обработки и последующего анализа данных посещаемости Интернет-ресурсов. Присутствуют инструменты обработки данных, графическое отображение результатов и удобный интерфейс.
Для англоязычных проектов
Spy Fu, spyfu. com — платный сервис по подбору англоязычных запросов для зарубежных проектов. Итоговая статистика имеет параметр сложности продвижения запросов.
com — платный сервис по подбору англоязычных запросов для зарубежных проектов. Итоговая статистика имеет параметр сложности продвижения запросов.
Keyword Eye, keywordeye.com — платный ресурс для выгрузки по заданной фразе базы ключей и просмотра конкурентности заданных англоязычных ключевых слов в виде облака.
Keyword Tool, keywordtool.io — удобная и бесплатная альтернатива AdWords Planner. Больше 750 предложений для каждого ключевого слова, основанные на подсказках Google для разных языков (83 доступных языка) и регионов (192 домена Google). Присутствует возможность подбора семантики из YouTube, AppStore и Bing.
Wordtracker, wordtracker.com — популярный платный зарубежный инструмент анализа ключевых слов.
Neilpatel, neilpatel.com — бесплатный парсер поисковых подсказок Google. Можно задать язык и вертикаль поиска – например, спарсить семантику из поиска, изображениям, новостям, видео и т.д.
Keywordshitter — keywordshitter. com — бесплатный и простой сервис по подбору англоязычных подсказок поисковых запросов.
com — бесплатный и простой сервис по подбору англоязычных подсказок поисковых запросов.
Searchmetrics.com — Searchmetrics is the pioneer and leading global provider of search analytics, digital marketing software and SEO services.
Сбор семантического ядра для сайта
Семантическое ядро — это таблица ключевых запросов, которые описывают структуру Вашего бизнеса — вашего каталога товаров, и поисковые запросы пользователей, по которым они могут искать страницы вашего сайта
Семантическое ядро — это списки поисковых запросов, которые задают пользователи в поисковой системе, когда ищут информацию. Они могут искать статьи, товары, услуги, контент.
В семантике все запросы сгруппированы по кластерам и распределены по потенциальным страницам.
Как использовать семантическое ядро?
Семантическое ядро сайта необходимо для вашего сайта При помощи правильно собранной семантики вы сможете:
Создать контент
Подготовить информацию для написания текстов копирайтером. Прописать правильные Title и Description для ваших страниц сайта
Прописать правильные Title и Description для ваших страниц сайта
Оптимизировать сайт
Равномерно распределить вес страниц согласно запросам. Выявить проблемы переспама и каннибализации (повтора ключевых слов)
Настроить контекст
Равномерно распределить вес страниц согласно запросам. Выявить проблемы переспама и каннибализации (повтора ключевых слов)
При сборке семантического ядра мы используем следующие сервисы:
Примеры сайтов для сбора семантического ядра
Количество страниц
от 1 до 15
- Сбор ключевых запросов
- Выбор приоритетных по трафику
- Подбор заголовков и метаданных
- ТЗ копирайтеру для страниц сайта
Количество страниц
от 20 до 50
- Сбор ключевых запросов
- Кластеризация инфозапросов
- Структура сайта
- Выбор приоритетных по трафику
- Подбор заголовков и метаданных
- ТЗ копирайтеру для раздела услуг
- ТЗ копирайтеру для блога
Количество страниц
от 100 до 1000+
- Сбор ключевых запросов
- Подбор запросов для посадочных страниц
- Подбор тегов для фильтров по трафику
- Структура каталога для сайта
- Выбор приоритетных по трафику
- Подбор заголовков и метаданных
- ТЗ копирайтеру для блога
- ТЗ программисту для каталога сайта
Семантическое ядро должно быть удобным — для SEO и контекстной рекламы.

Вы получите готовую семантику в легкочитаемом для Вас формате:
Таблица с ключевыми словами
Каждой странице соответствует группа ключевых слов
Ключевые слова содержат необходимые метрики
Подобраны рекомендации для Title и Description
Представлена структура ключевых слов в Mind карте
Документ с семантическим ядром Онлайн
Как правильно собирать семантическое ядро?
Условно существует три этапа по созданию семантики:
Анализируем конкурентов
Первоначально мы проводим выборку Ваших конкурентов в поиске.
Внимательно изучаем нишу вашего бизнеса.
Затем собираем все ключевые слова и трафик по ним и сравниваем позиции, уровень конкуренции.
Собираем поисковые запросы
На основе собранных ключевых слов конкурентов изучается структура, ассортимент товаров и услуг вашего сайта.
Группируем запросы по страницам
На основе собранных ключевых слов конкурентов изучается структура, ассортимент товаров и услуг вашего сайта.

Кластеризируем семантику по страницам, формируем ключи для блога

Часто задаваемые вопросы по составлению семантического ядра
Зачем нужно собирать семантическое ядро
Сколько будет ключевых слов?
Мы не можем это спрогнозировать. Точное количество ключевых слов может быть вычислено только после сбора семантики до конца: некоторые страницы могут априори не иметь большого количества поисковых фраз, тогда как некоторые страницы лучше разбивать на несколько из-за разноплановой семантики
Что нужно учитывать при сборе семантического ядра?
Семантическое ядро содержит все релевантные запросы для конкретных страниц.
Ключевым показателем является отсутствие дублей, кластеризация, разделение ключевых слов по трафику – Высокочастотные, среднечастотные и низкочастотные запросы.Могу ли я купить уже готовое семантическое ядро дешево?
Да, вы можете заказать семантику дешевле, но не факт, что она будет отражать реальную картину ключевых слов для вашего сайта. Для глубокой проработки нужно опираться на все страницы на вашем сайте – учитывать реальный трафик в вебмастерах и обновлять актуальные данные согласно свежей статистики.
У меня на сайте мало страниц. Нужно ли мне создавать новые?
Чаще всего оказывается, что большая часть контента лежит в поле информационных ключей.
Но им не место на основной странице – так как они могут собрать больше трафика. Тогда такие ключи обычно используются для раздела блогов и вопросов и ответов.
У меня есть KeyCollector. Вы сможете предоставить мне семантику в виде файла?
Вы можете предоставить пример семантического ядра перед заказом?
Мы можем предоставить временные ключевые слова на основе ваших конкурентов и дать представления о популярных ключевых словах у них.
Готовое семантическое ядро уже будет сформировано согласно тех страниц, которые вы определите как приоритетные для продвиженияЧем отличается семантика для интернет-магазина?
Семантика для интернет магазина содержит огромное количество низкочастотных комбинаций ключевых слов, связанных с категориями продаваемых товаров, брендами производителей, характеристиками и материалами. Каждый раздел нужно проверить на популярность запросов и расположить в правильной очередности для создания правильного технического задания для метаданных страниц данных фильтров.

 Готовое семантическое ядро уже будет сформировано согласно тех страниц, которые вы определите как приоритетные для продвижения
Готовое семантическое ядро уже будет сформировано согласно тех страниц, которые вы определите как приоритетные для продвиженияПродвижение видео на YouTube в поиске (Секрет по оптимизации)
Продвижение видео на YouTube в поиске (Секрет по оптимизации)
Реклама в YouTube: Настройка серий видеообъявлений в AdWords
Реклама в YouTube: Настройка серий видеообъявлений в AdWords
наверх
Лучшие способы определить семантическое ядро конкурентов.
Высокая конверсия вашего сайта невозможна без грамотного SEO-продвижения, последнее же невозможно без правильно подобранного семантического ядра. Чтобы последнее было полноценным, полезно знать и использовать ключи, по которым ранжируются сайты конкурирующих компаний… А чтобы собрать семантическое ядро конкурента, сначала следует определить тех, кто главенствует в вашей сфере деятельности. Именно на их сайтах и представлены наиболее качественные ключевые запросы. Для решения этой непростой задачи можно использовать целый ряд специализированных инструментов, которые существенно её облегчат.
Чтобы последнее было полноценным, полезно знать и использовать ключи, по которым ранжируются сайты конкурирующих компаний… А чтобы собрать семантическое ядро конкурента, сначала следует определить тех, кто главенствует в вашей сфере деятельности. Именно на их сайтах и представлены наиболее качественные ключевые запросы. Для решения этой непростой задачи можно использовать целый ряд специализированных инструментов, которые существенно её облегчат.
Многофункциональная SEO-платформа “Serpstat”
Она позиционирует себя как профессиональная – и действительно, на ней представлен целый ряд полезнейших для SEO-оптимизаторов инструментов, начиная с аналитики текстового контента и заканчивая изучением семантики.
Позаботились разработчики и том, чтобы помочь своим клиентам узнать семантическое ядро конкурентов.
Определение доменных имён web-сайтов-конкурентов
Для этого нужно:
- Перейти в раздел «Анализ сайта» и выбрать поисковую систему и регион РФ для “Yandex” или страну для “Google”;
- Указать доменное имя своего сайта в поисковой строке;
- Получить полный отчёт по нему, выделив три раздела, которые касаются конкурентов:
- Позиция в поисковой выдаче;
- График;
- Контекстная реклама.

Самый полезный из них на данном этапе – график конкурентов, на котором представлены серьёзные соперники в поисковой выдаче. После их определения следует провести анализ ключевых фраз. Для этого нужно ввести ту, которая интересует в соответствующем разделе, и получить по ней отчёт. Определить семантическое ядро сайта конкурента можно выбрав необходимое доменное имя из первого отчёта.
Разрабатываем и продвигаем сайты
Построенные на современных технологиях и фреймворках
Определение сайтов конкурентов по ключевой фразе
Для этого нужно:
- Перейти в раздел «Анализ ключевых фраз»;
- Ввести интересующую фразу;
- Получить отчёт;
- Проанализировать полученные результаты.
В последних будет представлено общее число её применений, стоимость клика, стоимость фразы и конкурентов в поисковой выдаче. На что следует обратить внимание? Прежде всего – на частотность и сложность фразы. Если с первой всё понятно, то вторая является уникальным показателем того, насколько сложно придётся при выводе сайта на первые позиции именно по этой фразе. Не стоит забывать и о процентном показателе, изучив который можно понять, насколько высока конкуренция по нему среди рекламодателей.
Не стоит забывать и о процентном показателе, изучив который можно понять, насколько высока конкуренция по нему среди рекламодателей.
При проведении анализа семантического ядра конкурентов не забудьте ознакомиться с их объявлениями в поисковой выдаче. Разработчики “Serpstat” позаботились и о такой возможности для своих клиентов.
Определение web-страниц сайтов конкурентов, которые дают максимум трафика
Для этого нужно запросить отчёт «Страницы-лидеры», в котором будет представлено всё необходимое. Функционал платформы позволяет провести сортировку результатов по потенциальному трафику и числу ключевых фраз в поиске. В нём же есть данные о количестве репостов в SMM.
Стоимость
Разумеется, всё эти «вкусности» не могут быть доступны бесплатно… Разработчики предлагают пакеты услуг.
Онлайн-сервис “SpyWords”
Создатели позиционируют его как созданный специально для отслеживания семантики у конкурентов. Прямо на первой странице вам предложат узнать все их ключевые фразы в поиске и контекстной рекламе.
Функционал сервиса порадует своей простотой. Ответ на вопрос «Как узнать семантической ядро сайта конкурента?» звучит так: ввести его домен в соответствующее поле и запустить анализ, предварительно выбрав гео. Здесь же доступен анализ по определённой ключевой фразе. В отчёте будет представлена информация, которая нужна для отслеживания семантики сайта конкурента, в частности:
- Число показов в месяц;
- Позиция в поисковой выдаче;
- Snippet с ссылкой.
“SpyWords” доступен бесплатно, но с целым рядом ограничений, которые исчезают если купить пакет:
Онлайн-сервис «Букварикс»
Данный проект С. Романчи представляет целый ряд инструментов, разработанных для поискового маркетинга и рекламы, и позволяет осуществлять сбор семантики сайтов конкурентов. Чтобы приступить к решению этой задачи, достаточно ввести доменное имя в соответствующей строке.
Желающим опробовать функционал сервиса доступна демонстрационная версия, которая позволит поработать не более чем с одной тысячей ключевых фраз. Что касается платной, то она предложит целый ряд полезных функций.
Что касается платной, то она предложит целый ряд полезных функций.
Итак, что же вы получаете за свои кровные?
- Нормализатор, который удаляет пустые строки и пробелы в автоматическом режиме;
- Компаратор, который проводит сравнение ключевых фраз в списке в автоматическом режиме;
- Анализатор, который просчитает сумму уникальных слов в перечне;
- Дедупликатор, который удаляет повторяющие ключевые фразы;
- Возможность подбора ключевых фраз сразу по нескольким доменным именам.
Онлайн-сервис “PR-CY”
Он предлагает широчайший спектр инструментов для анализа и продвижения сайта. Достаточно ввести интересующее доменное имя и получить отчёт, в котором затем – изучить раздел «Поисковые фразы».
В нём будут представлены ключевые фразы не только для “Yandex”, но и для “Google” (что, надо сказать, очень удобно). Сервис является платным, тарифы представлены на изображении ниже:
Подытожим?
Вышеописанные сервисы позволяют отслеживать и собирать семантику конкурентов, правильно использовав которую вы сможете более эффективно продвигать свой сайт. Оптимально использовать “Serpstat”, располагающий целым рядом инструментов, необходимых оптимизатору. Если же задача состоит в парсинге, достаточно будет «Букварикса» или “SpyWords”. Ну а кроме того, вы можете обратиться к нам!
Оптимально использовать “Serpstat”, располагающий целым рядом инструментов, необходимых оптимизатору. Если же задача состоит в парсинге, достаточно будет «Букварикса» или “SpyWords”. Ну а кроме того, вы можете обратиться к нам!
как собрать самостоятельно семантическое ядро
13 фев., 2019
Семантическое ядро сайта — это кластеры ключевых слов, сформированные на основании семантически релевантных групп. Другими словами, это ядро сайта (или группа ключей), которые после сбора и кластеризации распределяется по тематическим страницам сайта.
Как собрать семантическое ядро сайта? Можно ли сделать это в автоматическом режиме, или же сбор СЯ выполняется только в ручном режиме? Читайте далее нашу статью и используйте наиболее удобные для вас варианты.
Основы кластеризации и семантики сайта
Зачем нужно делать семантическое ядро сайта?
Представьте ситуацию: вы создаете онлайн-магазин по продаже электронных товаров. У вас не менее 50 категорий (ноутбуки, компьютеры, комплектующие, смартфоны, смарт-часы, периферийные устройства и т.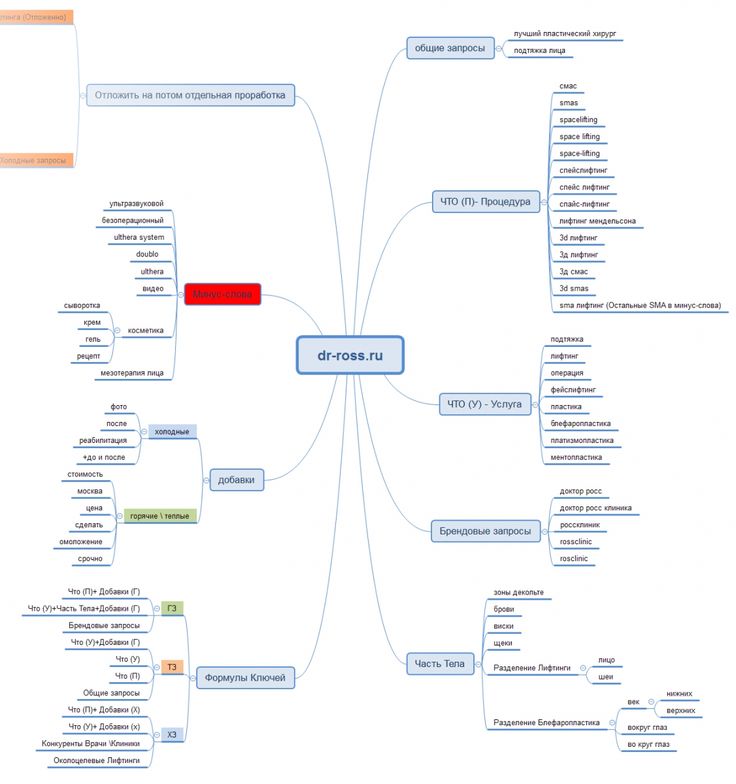 д.).
д.).
В каждой категории — не менее нескольких сотен позиций товара. Например: смартфоны → Apple → iPhone → iPhone 8 → iPhone 8 256gb. Аналогично — со всеми другими товарами.
Мы видим древовидную структуру, когда от категории товаров навигация переводит на конкретную модель или позицию товара.
Для каждого товара, категории или группы необходимо подобрать ключевые слова, по которым вы хотите, чтобы та или иная страница ранжировалась. И в данном случае сбор всех подходящих ключевых слов и их дальнейшая кластеризация и составляют семантическое ядро сайта.
Другими словами, семантическое ядро — это группа морфологически схожих словоформ и словосочетаний, которые наилучшим образом характеризуют страницу веб-сайта.
Как собрать семантическое ядро вручную?
Для ручного сбора семантического ядра необходимо выполнить следующие действия:
1. Определить центральное ключевое слово (слова)
Центральное ключевое слово — это основа вашего будущего СЯ. Центральное КС должно отвечать следующим требованиям:
Центральное КС должно отвечать следующим требованиям:
- Максимально точно характеризовать сайт в целом;
- Иметь высокую частотность;
- Быть коммерческим/информационным, в зависимости от типа сайта.
Приведем пример: ваш сайт — интернет-магазин техники. Вашими главными ключами будут: купить телефон, интернет магазин, купить ноутбук, купить смартфон и т.д.
Ключевое слово может быть не одним — их может быть несколько, в зависимости от размера сайта.
2. Определить основные группы ключевых слов
Основные группы ключевых слов — это следующий уровень после центральных ключевых слов в структуре семантического ядра.
Главные группы ключевых слов используются для категорий, разделов и прочих крупных семантических кластеров.
3. Определить ключевые слова для подгрупп и страниц
Следующим шагом необходимо собрать ключи для подгрупп и страниц, которые должны группироваться по тому же принципу, который описан выше.
Остался последний вопрос: как это всё выглядит на практике? Как собрать семантическое ядро сайта и какие инструменты нужно использовать для этого? Выглядит это всё следующим образом.
Сбор СЯ с помощью Планировщика ключевых слов Google
Перейдите в Google Keyword Planner (планировщик ключевых слов) и перейдите по внутренней ссылке.
Выберите меню с поиском ключевых слов:
Выберите категории и основные ключевые слова, которые наилучшим образом характеризуют ваш сайт.
Выберите локацию и нажмите кнопку “Получить варианты”.
Перейдите во вкладку “Варианты КС”…
…и выгрузите ключевые слова в документ:
Далее вы можете отсортировать ключевые слова по конкурентности, частотности и другим параметрам.
Аналогичным образом семантическое ядро собирается для каждой группы семантически релевантных запросов.
Что делать, если все ключевые слова относятся к разным категориям?
В таком случае возможны два варианта:
1. Ручная группировка запросов. Хороший метод, когда у вас не более 100 ключевых слов. Если же у вас тысячи ключей, группировка запросов может занять недели.
2. Автоматическая группировка (кластеризация).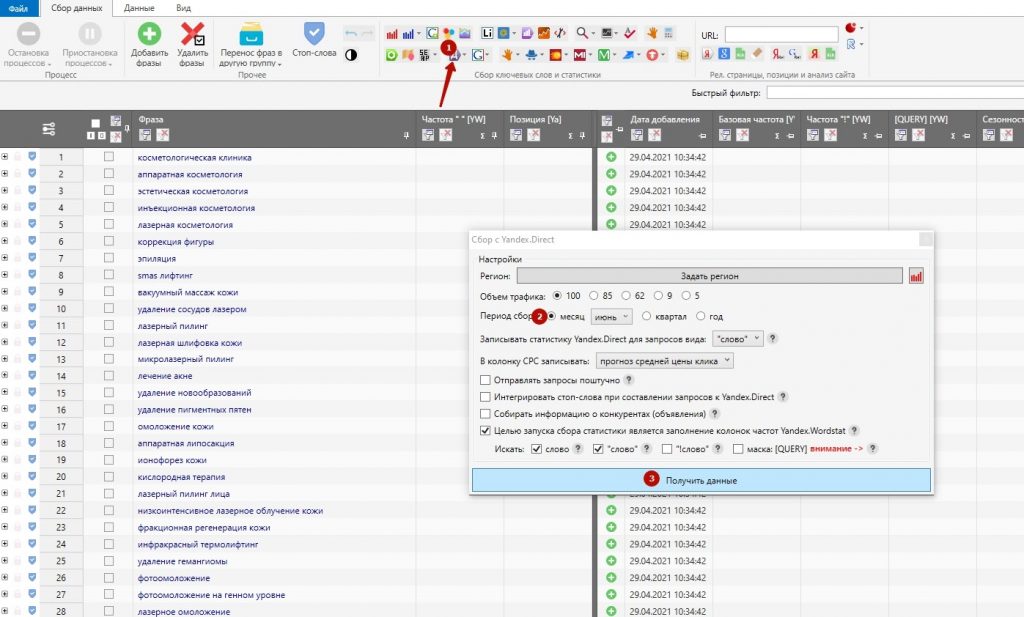 Выполняется с помощью SpySERP. Для этого необходимо зарегистрироваться на сайте, выбрать раздел “Кластеризация”, после чего все ваши ключевые слова автоматически сгруппируются по семантически релевантным кластерам.
Выполняется с помощью SpySERP. Для этого необходимо зарегистрироваться на сайте, выбрать раздел “Кластеризация”, после чего все ваши ключевые слова автоматически сгруппируются по семантически релевантным кластерам.
Семантическое ядро сайта онлайн: сервисы для автоматического сбора
Итак, вы не хотите использовать планировщик ключевых слов по каким-либо причинам. Как собрать семантическое ядро другими способами?
Вы можете собрать семантическое ядро сайта онлайн — специально для этого существует ряд сервисов, которые помогут справиться с задачей не хуже, чем ПКС от Google или Яндекс Вордстат.
Key Collector
Программа для комплексной работы с семантическим ядром сайта. Позволяет выполнять все возможные операции, начиная от сбора ключей и заканчивая чисткой полученного списка.
Сервис платный — лицензия на использование стоит $50.
Ahrefs Keyword Explorer
Если вам нужно быстро и просто собрать ключевые слова, вы можете воспользоваться функционалом Ahrefs.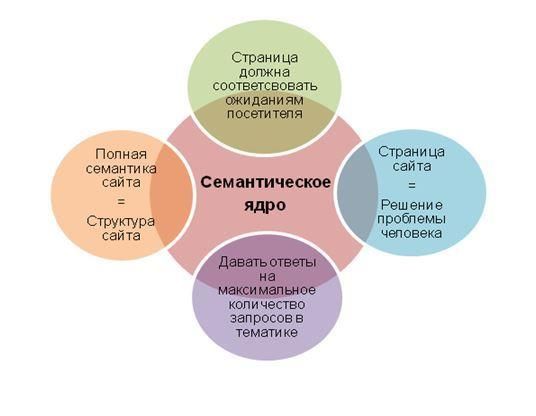 Месячная подписка стоит $99, однако если и триал-версия на неделю стоимостью $7 — такого триала вам должно более чем хватить для решения задач небольшого объема.
Месячная подписка стоит $99, однако если и триал-версия на неделю стоимостью $7 — такого триала вам должно более чем хватить для решения задач небольшого объема.
Semrush
Наконец, для сбора семантического ядра вы можете воспользоваться Semrush — ещё одним онлайн-сервисом, который работает по принципу, описанному выше. В бесплатной версии вы можете собрать до 10 фраз в широком и фразовом соответствии, с учетом региона запросов.
Выводы
Семантическое ядро — это “скелет” сайта и его основа, которая в дальнейшем послужит вам базисом для развития стратегии продвижения. Именно поэтому процессу сбора ядра необходимо уделять особое внимание и мы надеемся, что информация, описанная в статье, поможет вам сделать это максимально быстро и качественно.
Составление семантического ядра в контекстной рекламе
Семантическое ядро — это набор ключевых слов, которые рекламодатель использует для показа объявлений в поисковой системе. Эти слова должны максимально соответствовать тематике рекламодателя, но в некоторых случаях слова могут быть отдалены от темы в рамках стратегии получения околоцелевого трафика.
Наличие качественного семантического ядра у рекламодателя является важным фактором, который позволит достичь поставленных целей. В то же время некачественное семантическое ядро может значительно снизить эффективность работы рекламы, в некоторых случаях и вовсе привести к убыткам.
Путь и психология покупателя
Чтобы лучше понимать, как должно работать СЯ, давайте сначала разберем путь и психологию покупателя.
Этапы пути покупателя
- Осознание (околоцелевой трафик).
- Интерес (околоцелевой трафик).
- Магазин (коммерческий трафик).
- Покупка (коммерческий трафик).
| Тип запроса | Психология покупателя | Пример запроса (тематика: покупка стула) | Этапы пути покупателя |
| Ответ на вопрос | Базируется на основе проблемы | офисный стул с поясничной поддержкой | осознание |
| Прямой вопрос | Явный вопрос | как я могу лечить свою спину, если сижу целый день | интерес |
| Описание проблемы | Базируется на симптомах | моя спина болит на работе | интерес |
| Описание ситуации | Базируется на симптомах | целый день сижу на работе и из-за этого у меня болит спина | интерес |
| Название бренда и модели | Прямой запрос уже изученный | купить стул X модель | покупка |
| Информационный запрос | Осознание проблемы не изученный вопрос | магазины стульев | магазин |
Существует три этапа сбора семантического ядра:
- Поиск ключевых слов.
- Определение стратегии.
- Организация ключевых слов.

Чтобы лучше разбираться в семантическом ядре и в его свойствах, нужно понимать, какие существуют характеристики ключевых слов.
По частотности (количество запросов в месяц по заданной территории):
- ВЧ-запросы: частотность в разных нишах имеет разные значения — обычно от 200 до 10 000 и больше;
- СЧ-запросы: от 20 до 200;
- НЧ-запросы: от 1 до 20 в месяц.
По вероятности покупки:
- горячие: степень вероятности покупки максимальная, обычно запросы со словом «купить», «заказать» и так далее;
- теплые: степень вероятности покупки высокая, обычно запрос со словом «магазин», «товар +город»;
- холодные: степень вероятности покупки минимальна или не определена, например название товара «iphone».
По близости к товару/услуге, то есть соответствие поискового запроса — товару, который продает рекламодатель. К примеру, мы продаем телефон «iphone 7 16gb»:
- далеко от товара — «телефон»;
- чуть ближе — «телефон apple»;
- близко — «iphone»;
- очень близко — «iphone 7»;
- точное совпадение — «iphone 7 16gb».

Существуют две основные стратегии развития семантического ядра для поисковой рекламы.
1. Стратегия развития от качества к масштабу. Основной смысл — в добавлении в рекламную кампанию слов, которые могут принести заявки в максимально короткий период времени и потратить минимум ресурсов с последующим постепенным увеличением семантического ядра.
Очередь добавления ключевых слов в рекламную кампанию | |||
1-я | 2-я | 3-я | 4-я |
|
|
|
|
«купить iphone 7 16gb» | «iphone 7 Киев» | «iphone Киев» | «iphone» |
2. Стратегия получения околоцелевого трафика из поиска. Чтобы реализовать эту стратегию, нужен большой бюджет и «большой» сайт, который сможет конвертировать данный трафик.
Стратегия получения околоцелевого трафика из поиска. Чтобы реализовать эту стратегию, нужен большой бюджет и «большой» сайт, который сможет конвертировать данный трафик.
Также стоит отметить, от старта до получения первых результатов может пройти от 6-15 месяцев. Эта стратегия скорее направлена на развитие узнаваемости бренда и повышения уровня «экспертности» компании в глазах целевой аудитории. В этом случае необходимо добавлять максимум слов из 4 очереди.
Сбор ключевых слов для контекстной рекламыЕсть три основных подхода к сбору ключевых слов. У каждого способа есть свои преимущества и недостатки, подробно разберем каждый из них.
Ручной способПреимущества:
- наиболее качественный сбор, так как каждое ключевое слово проходит адекватную человеческую фильтрацию.
Недостатки:
- очень трудоемкий процесс, который отнимает много рабочего времени РРС-специалиста или рекламодателя;
- есть вероятность пропустить нужные ключевые слова.

Сервисы для ручного сбора ключевых слов:
- wordstat.yandex.ua — сервис, который показывает частотность в Яндексе по разным ключевым словам и подсказывает варианты новых. Из полезных свойств: показывает историю запроса в разрезе года, благодаря этому можно определить сезонность ниши, также есть удобное сравнение по регионам. Просмотр вариантов ключевых слов необходимо делать с прописанием кавычек в них (это позволит оценить точную частотность и получить более релевантные примеры;
- Google keyword planner (Планировщик ключевых слов) — сервис показывает варианты ключевых слов и конкуренцию по ним. Для его использования необходим аккаунт Google Ads. Есть удобные фильтры, которые позволяют искать слова с низкой конкуренцией.
Преимущества:
- ключевое слово проходит адекватную человеческую фильтрацию;
- процесс сбора занимает не очень много времени.
Недостатки:
- есть опасность пропустить некачественные слова.

Отличный сервис для полуавтоматического сбора ключевых слов — Серпстат. Он позволяет проанализировать конкурентов, найти их фразы и добавить их в свою рекламную кампанию.
АвтоматическийПреимущества:
- быстро собирает семантическое ядро для рекламы.
Недостатки:
- очень низкое качество ключевых слов, которое может принести плохой результат.
Для автоматического поиска ключевых слов мы советуем сервис key-collector.ru.
С чего начать сбор семантики?Кстати, использование типов соответствия ключевых слов в объявлениях позволяет контролировать соответствие поисковых запросов.
Для начала стоит пустить в ход «мозговой штурм». Нужно представить, каким образом пользователь может искать то, что собираетесь рекламировать. И проверить частотность по всем этим запросам.
Очень хороший метод — идти от общих ВЧ запросов к НЧ. Например, пользуясь любым из сервисов, можно взять самый высокочастотный запрос и посмотреть, что и как ищут в этой нише.
Таким способом нужно определить несколько основных релевантных запросов. Далее идем по пути расширения ядра. Используем подсказки как в левой, так и в правой колонке Wordstat.
Где еще искать?Вот еще несколько идей, где брать ключевые слова.
Самое простое — посмотреть в Search Console те фразы, по которым сайт уже показывается.
Второй шаг — посмотреть, по каким словам показываются конкуренты. Ведь они уже собрали семантику и показываются по ней. Остается провести анализ и использовать! Найти конкурентов можно в поисковой выдаче. Сервис Ahrefs дает возможность увидеть ключевые слова конкурента.
Откройте сервис и перейдите на вкладку Сайт Эксплорер, введите нужный домен.
Теперь вы можете посмотреть все ключи конкурента в платной выдаче. Выгрузите себе этот список.
Дальше можно посмотреть список конкурентов. Используем отчет «Домены-конкуренты».
И возвращаемся к предыдущему шагу — смотрим ключи по каждому конкуренту и анализируем их.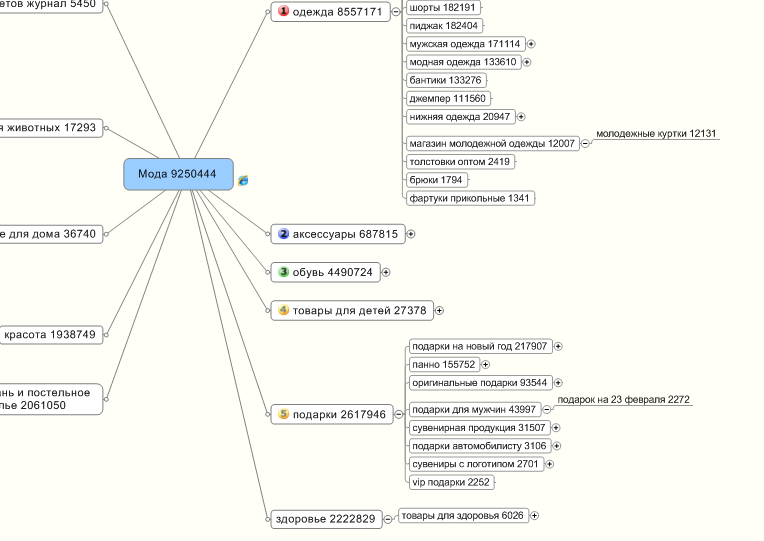
Получается некий цикл действий, который можно повторять и собирать всё больше и больше ключей. Смысл в том, чтобы найти как можно больше идей по семантике и затем отсеять лишние.
Организация ключевых слов для контекстной рекламы
Для того чтобы комфортно и удобно управлять своим семантическим ядром, мы рекомендуем сделать вспомогательный файл такого типа:
Кликните на картинку или перейдите на qps.ru/1ErLi, чтобы посмотреть весь файлНа первой вкладке у нас ключевые слова. Мы делим их на 3 группы: горячие, теплые и холодные. На второй вкладке — маркетинговый и конкурентный анализ, где мы определяем преимущества и недостатки продукта.
По возможности нужно исправить недостатки и составить ядро таким способом, чтобы оно оптимально отображало суть рекламируемого товара / услуги.
Мы советуем всегда использовать такие файлы: в них удобно хранить примечания, записывать историю тестирования (какие тесты были, как изменились метрики) и другие данные, чтобы принимать правильные решения по оптимизации рекламной кампании.
Существует множество пошаговых руководств по сбору семантики, однако каждый проект в чем-то уникален: цели, сроки, бюджеты, конкурентное окружение… Используйте основные методики и корректируйте их применительно к конкретному проекту — и успех не заставит себя ждать!
Статья была полезна? Ставьте ♥, а также читайте, как создавать эффективные кампании в нашем гайде по Google Ads!
Понравилась статья? Оцените ее:
Loading…
Как составить семантическое ядро сайта в Key Collector
Для эффективного продвижения сайтов необходимо проделать колоссальную работу по выводу его в ТОП поисковых систем в выдаче.
Для упрощения работы специалистов по продвижению написано много программ, которые помогают справляться с их задачами, а также автоматизировать некоторые рутинные процессы.
Для больших проектов попросту невозможно вести проект в ручном режиме. Большинство таких инструментов платные и стоят довольно недешево. Но при этом в сети всегда можно найти аналоги, хотя и с меньшим функционалом.
Большинство таких инструментов платные и стоят довольно недешево. Но при этом в сети всегда можно найти аналоги, хотя и с меньшим функционалом.
SEO-специалист начинает работу над любым проектом с понимания аудитории и того, какова численность потенциальных посетителей сайта. Для этого ему требуется оценить возможные ключевые слова, по которым пользователи будут попадать на сайт. Эти слова станут основой для наполнения сайта полезным контентом. Весь процесс по подбору ключевых слов называется сбором семантического ядра для сайта. Для больших проектов количество ключевых фраз в семантическом ядре может достигать нескольких тысяч.
Для упрощения работы над подбором семантики специалисты по продвижению используют ряд инструментов.
Одним из них является «База Пастухова» и программа Key Collector. Этой программе есть бесплатная альтернатива – программа Магадан, но она работает только с одним каналом поиска ключевых слов и в десятки раз уступает функционалу Кей Коллектора.
Программа Key Collector стоит 50 долларов США. Имеет обширный функционал, которому стоит обучаться не только по приложенной инструкции, но и по обрывкам информации в сети, а также на практике. Не рекомендуется приобретать программу для одного проекта. Для сохранения денег, и что немаловажно, времени, за подбором семантического ядра проще обратится к специалистам в этой области.
Программа Key Collector постоянно обновляет свои алгоритмы и функционал, так как поведение поисковых систем также довольно часто меняется.
В этой статье будут наглядно описаны все этапы подбора слов под определенный проект.
В качестве примера, будет подобрана семантика для информационного портала, который привлекает инвесторов в ПАММ системы нескольких форекс брокеров. Этот пример был выбран из-за обширности и разносторонности ключевых фраз, которые могут использоваться для привлечения посетителей.
До начала работы программа должна быть настроена для работы.
Для полноценной работы необходимо ввести данные по аккаунту в Яндекс, Гугл, настроить регион, с которым вебмастер желает работать, включить, при необходимости, Антикапчу.
В некоторых случаях есть необходимость купить списки прокси серверов, которые не находятся в бане поисковых систем.
Процесс полной настройки программы может занять несколько часов, так как для статистики необходимо вводить данные еще по ПС Маил.Ру, Рамблер, по сервисам Сеопульт, Соломоно, ЛивИнтернет, а также по ряду социальных сетей. Профессионалы готовят еще и формулы KEI.
Для демонстрации работы и сбора семантического ядра в нашем примере не стоит вдаваться в подробности настроек.
Для начала необходимо подготовить базу слов, применяя внутренний сервиса Яндекса Wordstat. У программы есть такая функция.
Нажимаем на соответствующую кнопку на панели задач. В открывшемся окне вводим несколько слов, которые соответствуют тематике сайта.
Вводить стоит высокочастотные запросы, все остальные программа вытянет со статистики сама.
Получаем список ключевых фраз, которые содержат введенные ключи, а также количество вводов этой фразы в Яндексе в прошлом месяце по региону (частотность).
Для удобства работы следует рассортировать полученные данные по группам. По необходимости стоит удалить фразы, которые не подходят под наш проект.
Можно указать ненужные слова в инструменте «Стоп-слова» перед началом сбора данных. Однако сразу можно всех слов и не учесть.
Делаем фильтр по таблице результатов и удаляем соответствующей кнопкой ненужные словосочетания.
Например, блог, на который подбираются слова не будет работать с брокером Альпари. Вводим в фильтр слова «альпари», «alpari», отмечаем полученные строки галочками и удаляем.
Дальше, с помощью такой же фильтрации, отбираем словосочетания с участием слова «отзывы» и переносим их в отдельную группу.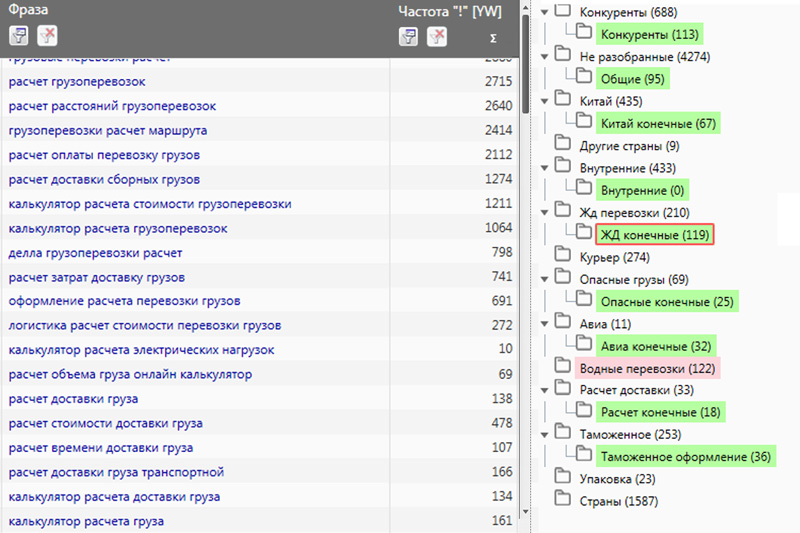
Создаем группу с необходимым названием, отмечаем отобранные слова, переходим в меню «Данные» в панели инструментов и нажимаем «Копировать выделенное в группу».
Рассортировывать ключевые слова по группам желательно потому что они будут использоваться в разных разделах сайта. Это можно сделать до начала сбора, но это возможно, если специалист точно знает какие слова будут встречаться и в какую группу их определять.
Для понимание ключевых фраз и аудитории, которая по ним придет, стоит просмотреть полученный список вручную, а уже позже сортировать фразы по группам.
Если сайт уже имеет определенный контент, то есть не создается с нуля, то программа Key Collector позволяет проанализировать уже готовый сайт, определить соответствие его содержания тем ключевым словам, которые вебмастер хочет продвигать.
Поле ввода адреса сайта находится справа на панели инструментов.
После ввода необходимо нажать кнопку Google или Yandex в соответствующей группе кнопок.
Также инструментарий работы с готовым сайтом сможет определить наиболее релевантные запросам страницы, проведет анализ тех страниц, которые уже находятся в выдаче и какие позиции они занимают.
Этот анализ покажет в каком состоянии в данный момент находится сайт по отношению к поисковым системам. В дальнейшем же все эти данные можно применить для работы на биржах покупки ссылок и прочего.
Если Вы работали с сервисом Yandex.Wordstat, то должны понимать, что означает «левая колонка» и «правая колонка» этого сервиса.
После сбора всех ключевых фраз из левой колонки стоит произвести сбор данных и из правой.
Нажимаем на соответствующий значок и выбираем выбор фраз для слов из уже найденной таблицы.
Для полного списка ключевых фраз стоит также воспользоваться инструментом «Сбор поисковых подсказок» в той же части панели программы.
При каждом новом сборе программа будет игнорировать уже добавленные фразы, так что это исключит дубли в таблице, но может существенно расширить ряд ключевиков для семантического ядра посредством сбора информации с разных источников.
После полного сбора данных по словам необходимо получить по каждому слову данные частотности и сезонности. Эти показатели будут влиять на применяемость ключевой фразы в семантическом ядре продвигаемого сайта.
В ячейке «Сбор ключевых слов и статистики» необходимо выбрать значок лупы и выбрать типы частотностей, с которыми хотите работать. Специалист по продвижению различает тип запроса ключа в кавычках “” и с применением знака восклицания «!».
Если у вас не настроены прокси-сервера и их численность невелика, то пользоваться опцией «Сбор всех видов частотностей» применять не рекомендуется.
Также, как альтернативу, можно произвести сбор частотностей через Yandex.Direct.
В той же группе инструментов выбираем соответствующую иконку с буквой «Д».
В новом окне указываем, что запускаем эту функцию только для сбора данных о частоте фраз.
Этот метод применим, если у Вас заполнены данные в настройках Яндекс.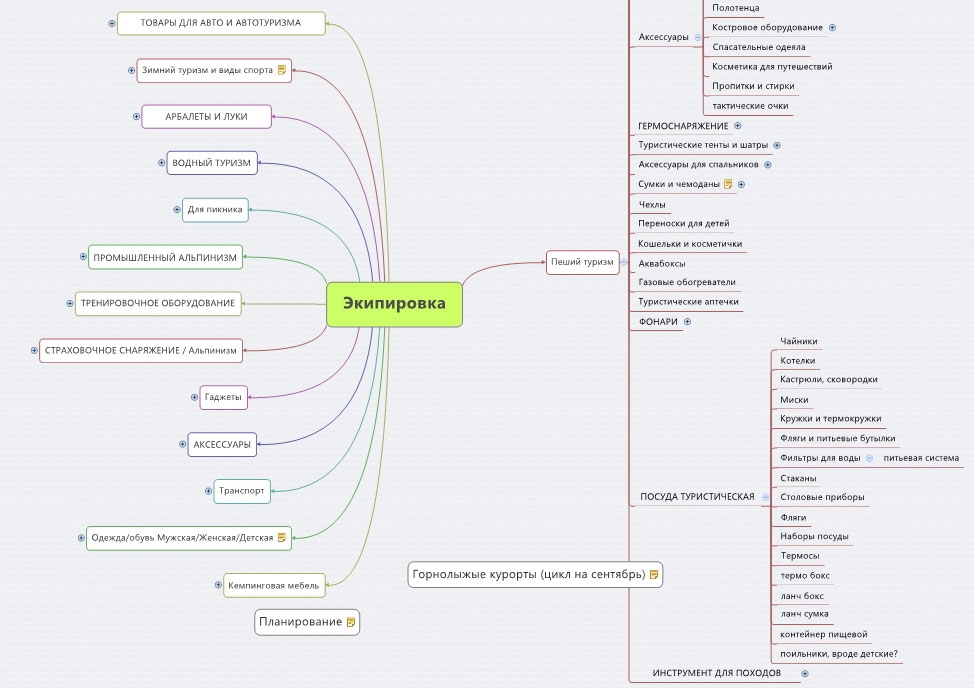 Директ. Также этим методом невозможно собрать данные для фраз, у которых больше 7 слов в ключе и в которых содержаться дополнительные символы.
Директ. Также этим методом невозможно собрать данные для фраз, у которых больше 7 слов в ключе и в которых содержаться дополнительные символы.
Исходя из полученных данных можно почистить таблицу от тех фраз, у которых точная частотность равна нулю. Если нет необходимости работать на сайте со всеми низкочастотными запросами, что не всегда оправдывает затраченное на это время, то можно удалить все фразы, частотность которых ниже 30.
После сбора частотности желательно провести сбор информации, относительно сезонности ключевых слов. Оценив сезонность ключевика, можно пересмотреть нахождение ключа в семантике.
К примеру, если частотность запроса вырастает раз в год. Яркий пример такого запроса «новогодние салаты». В нашем примере сбор данных о сезонности отпадает за ненадобностью.
Для некоторых проектов очень важна геозависимость отдельных запросов. К примеру, для России лучше оценить геозависимость ключевых фраз. Исходя из полученных данных, также можно удалить часть запросов.
Исходя из полученных данных, также можно удалить часть запросов.
Если магазин локально размещен в Москве и отправок товара в иные регионы не планируется, то регион следует указать в настройках до начала работы. А из всех полученных фраз оставить только те, для которых геозависимость соответствует региону.
Например, запрос «шиномонтаж Кунцево» является геозависимым запросом. И в зависимости от стратегии и региона продвижения вебмастер решает оставлять его или нет.
Есть возможность оценить полученные результаты по конкуренции. Но для этого необходимо на официальном сайте программы KeyCollector найти необходимые формулы, которые подставляются для сбора данных KEI.
Получив полный набор данных, всю информацию можно выгрузить в таблицы Excel и в дальнейшем работать с ним. Если фразы разбиты по группам, то их уже можно применять для планирования структуры сайта. То есть, каждая группа ключевых слов будет относится к определенной информационной группе на сайте, или же, если это интернет магазин, то разбивка на группы даст понимание того, как лучше выполнить сортировку товаров, как можно применить фильтрацию товаров для продвижения по ключевым словам.
Разберем пример.
Есть ключевые слова «телефон на андроид 4 дюйма».
Создать отдельный раздел с телефонами, которые соответствуют этим характеристикам попросту неразумно.
Специалист по SEO рекомендовал бы этот запрос к продвижению. В связке с программистом можно сделать так, чтобы под этот запрос была релевантная страница, а пользователь, который перешел на сайт по этому запросу, получил нужный результат в виде списка телефоном на системе Android, диагональ экрана которых равна 4 дюйма.
Программист может присвоить результатам поиска определенный понятный URL, в котором будут присутствовать в транскрипции необходимые ключи.
Если список с результатами отбора телефонов по параметрам сделать статическим, и разрешить его индексирование поисковыми системами, то это как раз и будет релевантная страница под запрос.
Подстраивать под каждую фразу релевантную страницу будет довольно проблематично, приведенный пример наглядно объясняет применимость данных.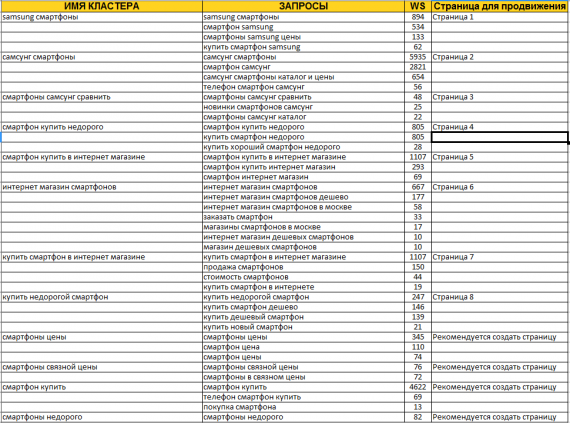
А в общем виде таблица даст понимание того, какие ключи нужно использовать на главной странице сайта, какие необходимы в описании каждой категории, а какие следует учитывать в карточках товара для максимально полного охвата аудитории и сбора трафика.
Также таблица с данными является фундаментом для формирования технических заданий копирайтерам, которые и будут наполнять ресурс.
При грамотной разбивке фраз с помощью KeyCollector, менеджеру, который работает с копирайтерами гораздо проще будет составить им задания, просто сгруппировав ключевики, применимые к отдельным статьям.
Получив качественно собранную базу ключевых слов, очень важно не перестараться с их вставкой на сайт.
Если ключей будет много на одной странице, то поисковые системы расценят данный контент как переоптимизированный, или еще хуже, сочтут ресурс переспамленным ключевыми словами.
SEO-специалист должен для каждой страницы проверять тошноту ключевых слов, их релевантность и применимость в определенных полях на странице. Не каждый ключ можно вставить в тег Title, иногда не стоит гнаться за посещаемостью, вписывая ключи так, как их нашла программа.
Не каждый ключ можно вставить в тег Title, иногда не стоит гнаться за посещаемостью, вписывая ключи так, как их нашла программа.
Текст и все сопутствующие элементы, такие как Заголовок, подзаголовки Н1, Н2 и прочие в первую очередь должны выглядеть естественно.
Процесс сбора семантического ядра имеет очень много нюансов, а в его применении их еще больше.
Это не считая того, что с самой программой также стоит разбираться не один час.
Владелец сайта должен несколько раз подумать над тем, заниматься ли этой рутинной работой самому, или же доверить такой важный фундаментальный этап в становлении сайта специалистам.
Бесплатный инструмент кластеризации семантического ядра и группировки запросов
Программа KeyClusterer предназначена для группировки семантического ядра методами Hard и Soft. Помимо кластеризации, в KeyClusterer также реализована функция ручной группировки фраз, которая стала доступна после автоматической кластеризации поисковых запросов.
Список общих сайтов в кластере
Настройки
Условия использования: Бесплатное ПО
Скачать KeyClusterer (7 Мб)
Windows 10/8/7/Vista/XP
Основные возможности
- Группировка произвольного списка ключевых слов с помощью Hard и Soft методов
- Автоматическая группировка поисковых слов с «ручным» заданием точности группировки (от 1 до 10 баллов)
- «Ручная» группировка семантического ядра, создание произвольных папок и групп
- Проверка позиций по ключевым словам поиска и определение релевантных целевых страниц
- Импорт данных SERP из Google, Bing и Яндекс для группировки фраз офлайн
- Экспорт кластеризации в Excel (CSV)
Отличия от аналогов
- Кластеризация семантических ядер практически любого размера
- Высокая скорость кластеризации, быстрое переключение между проектами
- Портативный формат
- Бесплатное ПО
Данные для группировки ключевых слов собираются из результатов поиска Google и обрабатываются с помощью SERPRiver.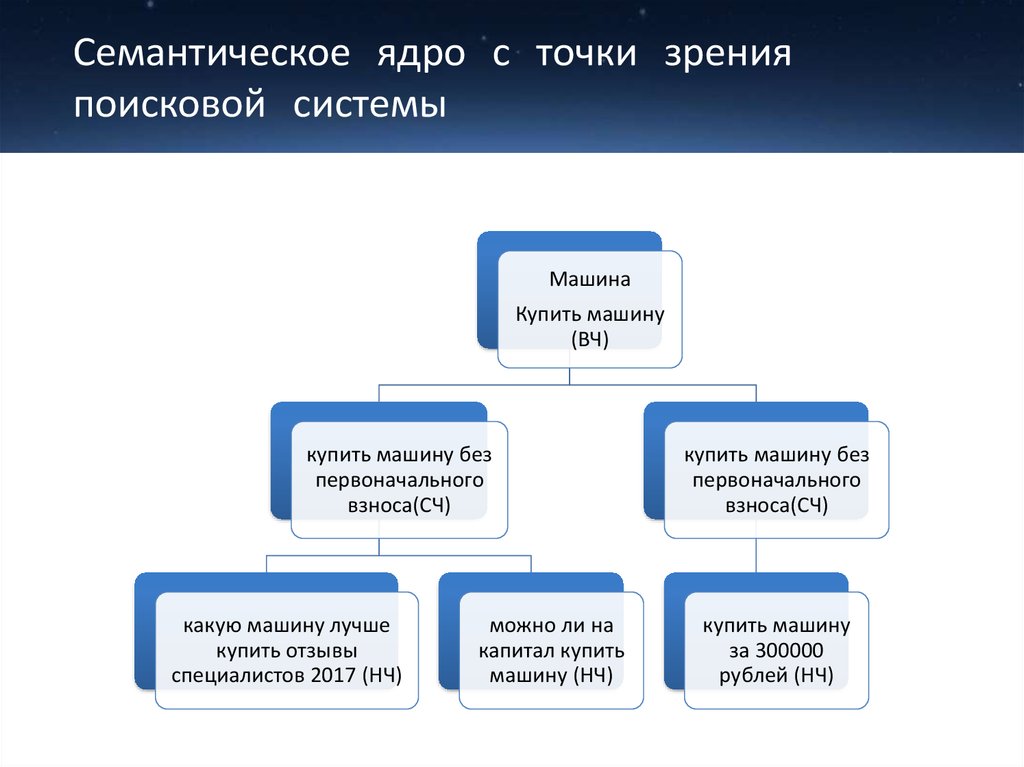 После кластеризации становится доступна ручная группировка запросов (перемещение запросов по группам, создание новых групп и удаление кластеров). Результаты запроса кластеризации экспортируются в файл CSV (Excel).
После кластеризации становится доступна ручная группировка запросов (перемещение запросов по группам, создание новых групп и удаление кластеров). Результаты запроса кластеризации экспортируются в файл CSV (Excel).
Программа умеет импортировать результаты поиска из Google и данные поисковой выдачи Bing для группировки фраз в автономном режиме (см. пример файла импорта в архиве).
Версия 2.3 (сборка 185), 11.05.2021:
- добавлен многопоточный сбор данных (до 10 потоков одновременно)
- добавлен прямой импорт данных из Key Collector 4 (файлы в формате *.kc4)
- добавлена возможность сбора данных для кластеризации в поисковике Google
- добавлено отображение ТОП сайтов по видимости (список доменов по количеству запросов в ТОП-10)
- добавлена возможность выбора параметров фильтрации в быстром фильтре
- исправлено зависание, возникающее при сборе данных результатов поиска по большому количеству запросов
- восстановлена возможность импорта списка прокси из файла и буфера обмена
Версия 2. 2 (сборка 178), 26.04.2021:
2 (сборка 178), 26.04.2021:
- оптимизирована скорость импорта и кластеризации запросов
- добавлена возможность отмены последних действий при работе с семантическим ядром
- добавлена возможность использовать список стоп-слов для управления ключевыми запросами
- добавлена возможность вырезать и вставлять группы и ключевые слова
- добавлена возможность перемещать группы и фразы в любое место списка
- добавлено выделение найденных слов и частей слова при фильтрации данных
- добавлена возможность экспорта данных с левой панели
- добавлена расширенная форма выбора региона яндекс
- добавлено диалоговое окно для импорта данных из CSV
- добавлена возможность работы со списками прокси
- добавлена возможность добавлять запросы в текущее семантическое ядро проекта
- оптимизирована работа с сайтами-исключениями в интерфейсе основных настроек программы
- при кластеризации запросы без собранных данных помещаются в папку [unallocated]
- размер шрифта теперь меняется только в панелях с запросами, а не во всем интерфейсе
- добавлено автоопределение кодировки импортируемых файлов
Версия 2. 1 (сборка 115), 08.02.2021:
1 (сборка 115), 08.02.2021:
- добавлено отображение суммы частот и среднего положения в группах
- добавлена возможность проверки релевантных страниц ключевых фраз по домену
- добавлена возможность проверки позиций запроса для Яндекс ТОП-100
- добавлена возможность автоматического повторного сканирования ключевых фраз, данные по которым были собраны с ошибками
- добавлена возможность удалять повторяющиеся поисковые фразы
- добавлена возможность очистки ранее собранных данных проекта
- добавлено автоматическое запоминание ширины столбцов панели
- добавлены сервисы аренды лимита XML: SERPRiver и XMLProxy
- оптимизирован интерфейс программы
- исправлена некорректная работа программы с кириллическими доменами
- исправлена ошибка, возникавшая при экспорте ключевых фраз в формат CSV
- исправлена ошибка при импорте ключевых фраз из буфера обмена
- исправлена ошибка, при которой пауза между запросами использовалась некорректно
Версия 2. 0 (сборка 92), 25.01.2021:
0 (сборка 92), 25.01.2021:
- полностью переработан интерфейс программы
- переход в двухпанельный режим
- значительно ускорена обработка и кластеризация ключевых фраз
Версия 1.5 (сборка 42), 22.12.2020:
- добавлена возможность хранить проекты в общей базе данных
- добавлена возможность быстрого переключения между проектами
- добавлена возможность фильтровать ключевые запросы по словам и частям слова
- добавлена возможность изменять размер шрифта в программе
- оптимизированный интерфейс и удобство использования
Версия 1.4 (сборка 33), 23.11.2017:
- добавлено отображение количества мастер-страниц для каждого запроса и для группы запросов
Версия 1.3 (сборка 31), 27.09.2017:
- добавлена возможность просмотра наиболее распространенных сайтов в конкретном кластере
- исправлена ошибка, когда в поле списка запросов не загружалось более 2000 строк
Версия 1. 2 (сборка 28), 29.08.2017:
2 (сборка 28), 29.08.2017:
- добавлена возможность указывать регион в Яндексе для сбора данных при кластеризации
- добавлена возможность «вручную» указывать порог кластеризации фразы (от 1 до 10)
- добавлена возможность импортировать данные SERP поисковых систем Google, Bing и Яндекс из файла в групповые фразы оффлайн
Версия 1.1 (сборка 22), 10.08.2017:
- добавлена возможность ручной группировки фраз
- добавлена функция экспорта кластеризованных групп в Excel (CSV)
Версия 1.0 (билд 5), 07.06.2016:
- добавлена возможность кластеризации по запросам из списка
- добавлена возможность группировать запросы с использованием Soft и Hard методов
Минимальные системные требования
– 1 ГГц (рекомендуется 3 ГГц и выше)
– 1 ГБ оперативной памяти (рекомендуется 8 ГБ и более)
– Microsoft Windows 10/8/7/Vista/XP
– Интернет
0 комментариев
Вы должны войти, чтобы оставить комментарий.
<< Назад
7 Семантических веб-инструментов для вашего сайта
Как мы уже говорили ранее, включение принципов семантической сети может иметь огромные преимущества для вашего контент-маркетинга, локального SEO и вашего онлайн-бизнеса. Но как на самом деле «сделать» семантическую паутину? Какие инструменты существуют, чтобы помочь вам использовать его?
Больше не удивляйся!
В этом посте мы собрали 7 отличных инструментов, которые вы можете использовать для создания, проверки и добавления семантических объектов на свой веб-сайт.
Создать семантическую разметку
Добавление семантической разметки для связи вашего контента с вашими сущностями является основным строительным блоком семантической сети.
А если вы не программист?
Используйте эти инструменты для создания семантической разметки для вашего сайта.
Инструмент метаданных WooRank
Метаданные схемы — отличный способ указать поисковым системам и другим роботам на другие ваши онлайн-профили:
- Твиттер
- Google+
- Фейсбук
- Четыре квадрата
- Визг
Все они могут быть источниками данных для Google Knowledge Graph, и многие расширенные фрагменты содержат ссылки на профили в социальных сетях, которые может найти Google.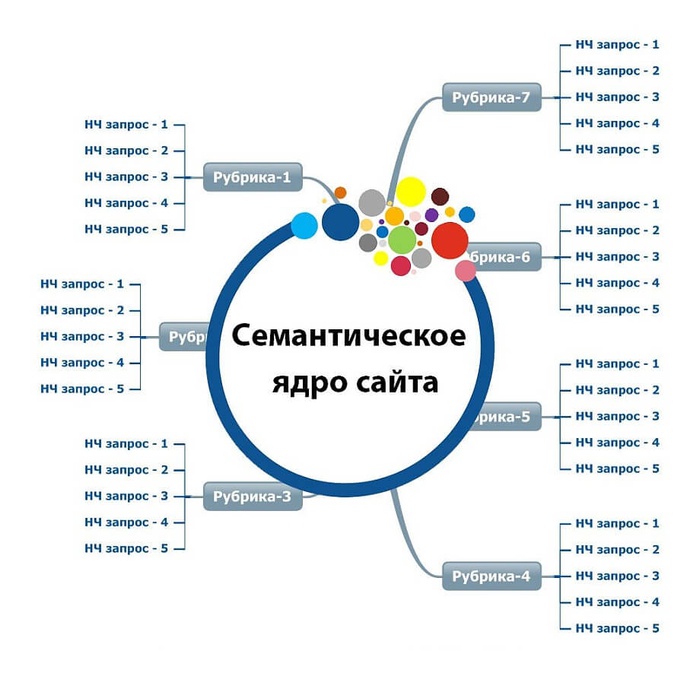
Инструмент метаданных WooRanks — отличный способ создать разметку, необходимую для того, чтобы поисковые роботы указывали на ваши страницы в социальных сетях. Просто введите свои URL-адреса в соответствующие поля, а затем скопируйте предоставленный код на свой веб-сайт.
ВходитURL, выходит семантическая разметка. Это просто и бесплатно.
Генератор схем JSON-LD
Генератор схем от Hall Analysis — еще один бесплатный инструмент для создания семантической разметки, которую вы можете добавить на свой сайт. Генератор схем создаст код для контекста вашего сайта для
.- Местные предприятия
- Люди
- Продукты
- События
- Организация
- веб-сайтов
Как и в случае с инструментом метаданных WooRank, генератор схемы берет предоставленную вами информацию и преобразует ее в данные, структурированные для машинного чтения.
Проверка семантической разметки
После того, как вы пометили свои метаданные своей разметкой, вам необходимо проверить код.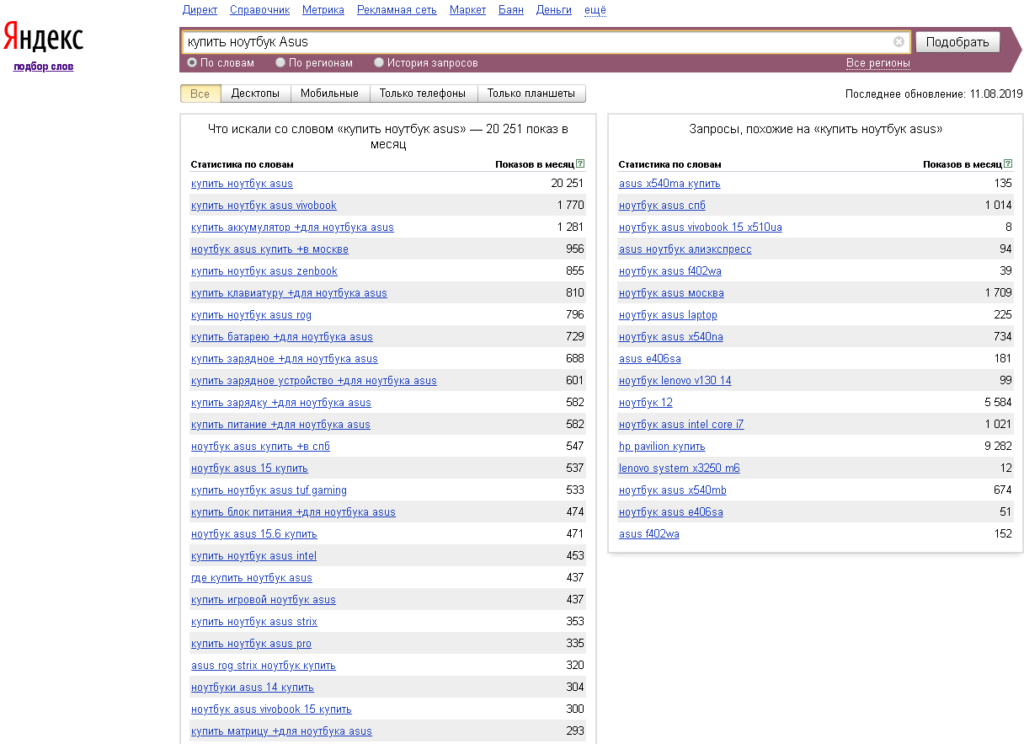 Проверка является важным шагом — добавление неработающего и неправильного кода на ваш сайт не принесет вам никакой пользы и, скорее всего, приведет к неприятным последствиям.
Проверка является важным шагом — добавление неработающего и неправильного кода на ваш сайт не принесет вам никакой пользы и, скорее всего, приведет к неприятным последствиям.
Если, конечно, вы не использовали инструмент метаданных WooRank, чтобы связать свой бренд с профилями в социальных сетях. Тогда вы можете быть уверены, что это идеальный код.
Инструмент тестирования структурированных данных Google
Если вы добавляете семантическую разметку, чтобы улучшить SEO, нет никаких причин не использовать сам Google для проверки вашего кода. Инструмент тестирования структурированных данных Google работает двумя способами:
- Скопируйте и вставьте код, который вы хотите проверить, в инструмент
- Введите URL-адрес страницы, которую вы хотите протестировать
В любом случае инструменты вернутся с объектами, которые они обнаружат на странице, и данными, с которыми они связаны.
Таким образом, по коду, созданному инструментом метаданных WooRank, Google может найти сущности для организации (в данном случае Acme. org) и ее блога. Инструмент также обнаруживает ссылки на профили в социальных сетях.
org) и ее блога. Инструмент также обнаруживает ссылки на профили в социальных сетях.
Валидатор семантической разметки Яндекса
Этот бесплатный инструмент, как и инструмент Google, проверяет URL-адрес вашей страницы или фрагмент кода и возвращает ссылки JSON-LD, которые он может прочитать.
Вот пример того, что происходит, когда вы пытаетесь использовать поле, не связанное со схемой:
Линтер структурированных данных
Структурированный линтер данных имеет несколько отличий от других инструментов семантической разметки. Во-первых, вы можете загрузить локальные файлы в валидатор, а также вставить код или отправить URL-адрес.
Во-вторых, Линтер может создавать расширенные фрагменты из метаданных, которые он находит на вашей странице, так что вы можете увидеть свою разметку в действии.
Наконец, у вас также есть программный доступ к Линтеру, поэтому вам фактически не нужно вручную проверять страницы или блоки кода. Линтер вернет запрос со следующей информацией о метаданных страницы:
Линтер вернет запрос со следующей информацией о метаданных страницы:
- Фрагмент: Макет Linter’а расширенного фрагмента страницы
- Извлечено данных: Таблица семантических данных, которые ЛИНТЕР может обнаружить в файле
- Статистика: Информация об использовании шаблонов сниппетов и анализируемых троек
- Отладка: «Расширенная информация» по отладке проблем, обнаруженных Линтером при проверке разметки
Создание, хранение и управление вашей семантической паутиной
После того, как вы создали и проверили свою семантическую разметку, вам просто нужно добавить ее на свой веб-сайт и подождать, пока Google найдет и просканирует ее.
Однако семантическая разметка не является фактором ранжирования, и просто наличие кода на ваших страницах не позволяет в полной мере использовать возможности семантической сети. Для этого вам нужно создайте свои собственные объекты и используйте их для создания семантической сети для вашего веб-сайта .
WordLift
Wordlift.io — это плагин WordPress для создателей контента, которые хотят использовать преимущества семантической сети для своего контент-маркетинга. Wordlift использует технологию обработки естественного языка (NLP), которая анализирует текст и обогащает его настраиваемой семантической разметкой.
По сути, если вы вернетесь к примеру, который мы использовали в первой части нашей семантической веб-серии, WordLift увидит это предложение:
Грег родился в Мичигане, а я живу в Брюсселе.
И обнаруживает объекты для «Грег», «Мичиган» и «Брюссель». Затем он использует открытые источники данных для разметки страницы, чтобы добавить контекст для этих сущностей.
WordLift также позволяет создавать собственные объекты для вашего веб-сайта и автоматически определять ваш словарный запас, чтобы обогатить ваш контент. Итак, это предложение:
Добавьте расположение карты сайта xml в файл robots.
 txt.
txt.Обогащается за счет ссылки на данные для «xml sitemap» и «файла robots.txt».
TextRazor — это инфраструктура для анализа и обогащения текста, которая добавляет к вашему контенту семантическую паутину. Он читает ваш текст, анализирует его, а затем добавляет к нему контекст, ссылаясь на соответствующие источники в Интернете. Вы можете увидеть простую демонстрацию его анализа в действии на их веб-сайте.
TextRazor также извлекает актуальность сущностей на странице для широких тем. В случае их демонстрации статьи BBC вы можете увидеть объекты и темы, для которых статья семантически релевантна.
С точки зрения SEO, это темы запросов, для которых Google считает релевантной эту страницу. Эта информация очень важна при оптимизации контента на странице и должна информировать вас о том, как вы формируете словарный запас своего веб-сайта. Если у вас есть страница о яблоках (фруктах), вы не хотите как-то писать свой контент, чтобы он выглядел так, как будто он о компьютерах.
Заключение
Семантическая паутина может стать мощной силой для SEO вашего веб-сайта и пользовательского опыта. Однако, чтобы по-настоящему использовать его потенциал, вам нужны правильные семантические веб-инструменты. Используя инструменты, перечисленные выше, или даже некоторые, которые мы могли пропустить, вы сможете создавать разметку, проверять ее и добавлять на свой сайт быстро и легко.
К Грег Сноу-Вассерман
Последние сообщения
Как использовать тематические кластеры для повышения авторитетности темы
Готов ли ваш сайт к Черной пятнице и Киберпонедельнику?
Оптимизация контента: люди против роботов
Семантическая сеть в Интернете
Семантическая сеть во всемирной сети — это все о данных. В Сети все остальные части стека технологий семантической паутины — онтологии, запросы, рассуждения — отходят на второй план по сравнению с публикацией и потреблением структурированных данных. В этом уроке рассматриваются некоторые из наиболее ярких примеров публикации и использования структурированных данных людьми и организациями в Интернете.
В Сети все остальные части стека технологий семантической паутины — онтологии, запросы, рассуждения — отходят на второй план по сравнению с публикацией и потреблением структурированных данных. В этом уроке рассматриваются некоторые из наиболее ярких примеров публикации и использования структурированных данных людьми и организациями в Интернете.
Задачи
После прохождения этого урока вы будете знать:
- Не менее пяти доменов, в которых данные Semantic Web в настоящее время публикуются во Всемирной паутине.
- Как данные Semantic Web используются в Интернете в различных областях, таких как наука, электронная коммерция и правительство.
- Как Semantic Web сегодня улучшает результаты поиска в Интернете.
Сегодняшний урок
В известной статье 2001 года в журнале Scientific American, которая познакомила большую часть мира с семантикой паутиной, Тим Бернерс-Ли, Джим Хендлер и ОраЛасилла изложили свое видение взаимосвязанных данных в сети, которые открыть мир персонализированных автоматизированных агентов, которые могли бы выписывать для нас рецепты, бронировать столики для нас на ужин, организовывать доставку из школы и многое другое, используя семантические данные, доступные в Интернете.
В последующие годы после выхода этого новаторского трактата тысячи людей из промышленности, академических кругов, правительства и W3C объединились, чтобы опубликовать стандарты, разработать передовой опыт и создать инструменты, работающие для воплощения этого видения в жизнь.
Давайте рассмотрим некоторые наиболее яркие примеры людей и организаций, публикующих и потребляющих структурированные данные в Интернете.
Публикация данных в Интернете
В 2007 году группа W3C Semantic Web Education and Outreach запустила проект Linking Open Data для продвижения публикации данных в Интернете. Проект начался с предложения Тима Бернерса-Ли о принципах связанных данных, и усилия быстро набрали обороты в качестве информационно-пропагандистской и образовательной деятельности, направленной на поощрение веб-издателей к тому, чтобы их контент был доступен в виде данных RDF.
В выступлении на TED в 2009 году Тим Бернерс-Ли страстно призвал людей публиковать структурированные данные в Интернете.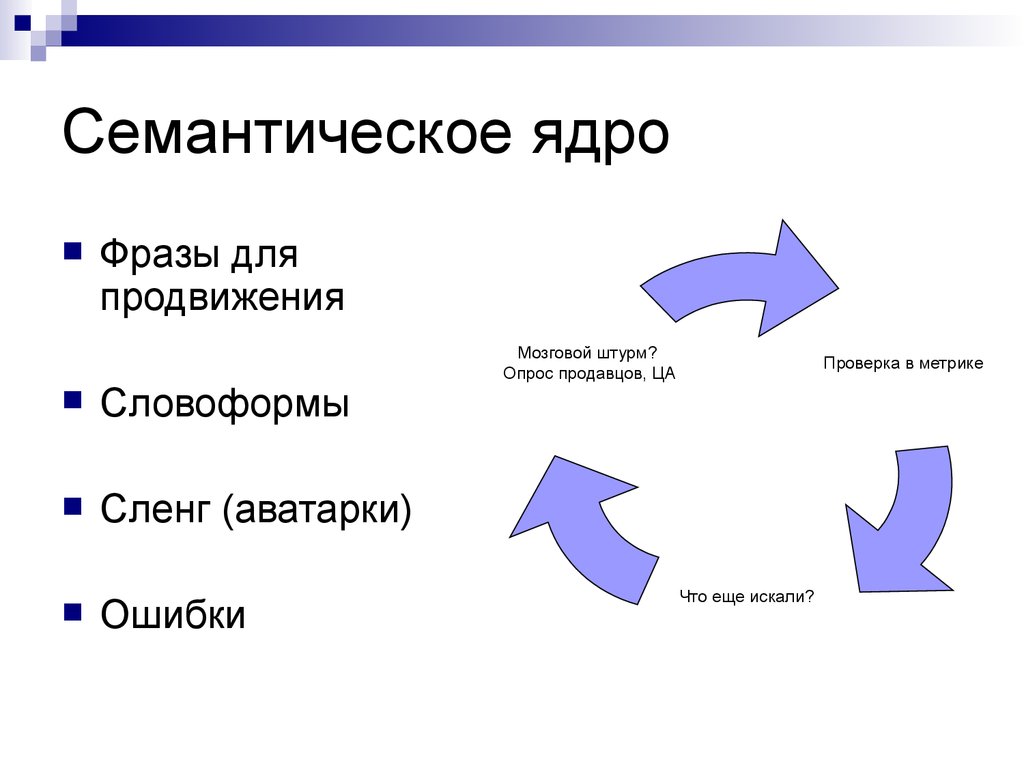
Видео на сайте TED.
Сегодня данные семантической паутины в паутине охватывают большое и постоянно растущее число дисциплин.
Социальные данные. Проект «Друг друга» (FOAF) позволяет людям публиковать простые биографические данные о себе и своих друзьях на личных веб-сайтах. Эти данные в прошлом собирались сайтами социальных сетей, такими как LiveJournal и hi5. Drupal, популярный пакет управления веб-контентом, который используется более чем на 1% веб-сайтов в мире, автоматически публикует данные Semantic Web, относящиеся ко всем, кто его использует. С 2011 года Facebook использует свой протокол Open Graph, чтобы побудить людей публиковать данные Semantic Web в качестве основного способа интеграции любого стороннего веб-сайта с Facebook.
Научные данные. Научные данные, особенно в области наук о жизни, составляют значительную часть данных Семантической сети в Интернете. Данные о белках и генах, путях и последовательностях, химии и генетике и многом другом уже существуют и активно используются.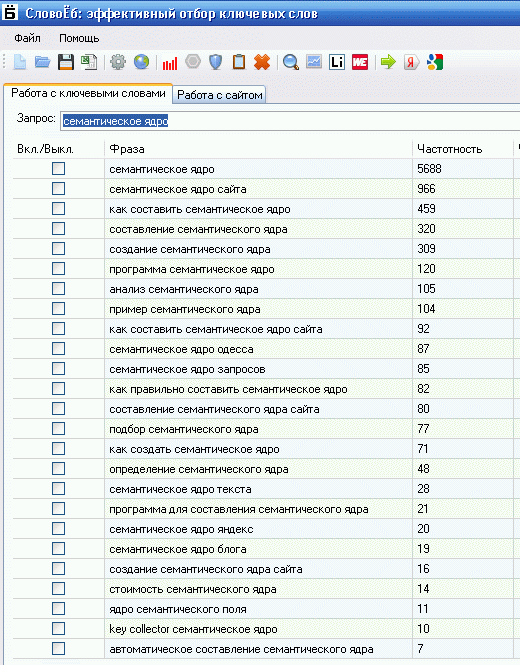 Две основные инициативы в настоящее время способствуют доступности научных данных в семантической сети:
Две основные инициативы в настоящее время способствуют доступности научных данных в семантической сети:
Bio2RDF: проект Bio2RDF начался в 2005 году и сегодня является одним из крупнейших поставщиков взаимосвязанных биологических данных семантической сети. Проект включает в себя более пятидесяти наборов данных по наукам о жизни, включая информацию о химических веществах, экспрессии генов, взаимодействии белков, пути, лекарствах, заболеваниях, геноме, последовательности и профессиональной литературе.
W3C Semantic Web in Healthcare and Life Sciences Interest Group (HCLS IG): через две рабочие группы BioRDF и Linking Open Drug Data (LODD), обе из которых приветствуют участников как из отрасли, так и из академических кругов, эта группа W3C уже опубликовала значительное количество данных о жизни. научные данные в Semantic Web. Группа TheLODD каталогизирует результаты своих усилий по публикации данных о заболеваниях, лекарствах и клинических испытаниях на вики-странице. Группа BioRDF создала базу знаний Semantic Web по наукам о жизни, которая содержит биомедицинские данные, собранные в рамках проекта NeuroCommons, и включает данные из MeSH, Medine и NCBI.
Данные электронной коммерции. Интернет-магазины охотно берутся за структурированные данные в Сети, чтобы сделать информацию о товарных запасах более доступной для поисковых систем. Чаще всего это делается с помощью словаря GoodRelations для добавления данных Semantic Web на существующие веб-страницы продуктов. Розничные продавцы, публикующие данные семантической сети электронной коммерции, включают Best Buy, Sears, Kmart, O’Reilly Publishing и Overstock.com.
Правительственные данные. В 2010 году национальное правительство Соединенного Королевства Великобритании и Северной Ирландии стало первым в своем роде, опубликовавшим значительные объемы общедоступной информации в Интернете в виде данных семантической сети. С января 2010 года Великобритания опубликовала 2500 больших наборов данных Semantic Web. Кроме того, правительство Соединенных Штатов публикует свои собственные структурированные общедоступные данные на сайте data.gov и недавно начало включать в эту коллекцию значительное количество наборов данных Semantic Web.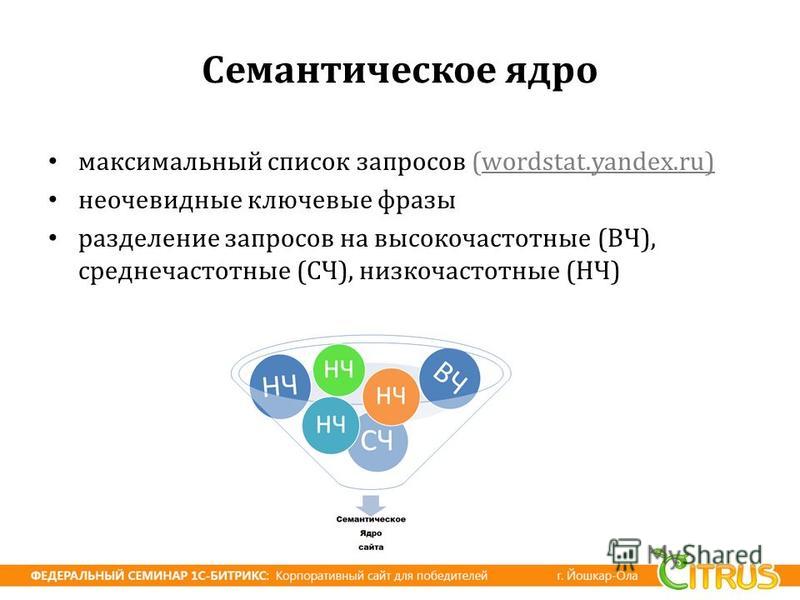
DBPedia. Как один из основных центров структурированных данных в Интернете, DBPedia заслуживает отдельной записи в этом списке. DBPedia — это хранилище данных Semantic Web, извлеченных из Википедии. Он включает информацию из информационных блоков Википедии (т. е. полей со сводной информацией по теме, которые появляются в правом верхнем углу статьи Википедии), а также заголовки статей, аннотации и данные классификации на основе множества категорий Википедии. Точно так же, как Википедия стала популярным центральным ресурсом во Всемирной паутине для поиска общей информации по известным темам, DBPedia является основным ресурсом в семантической сети для определения и предоставления структурированной информации по любой теме, уже затронутой в Википедии. Многие другие наборы данных Semantic Web ссылаются на данные из DBPedia, что делает их ключевым звеном в соединении ранее не связанной информации в Интернете.
Использование данных в Интернете
Вообще говоря, сегодня люди используют это богатство структурированных данных в Интернете двумя способами. Во-первых, они создают специальные приложения, которые используют и комбинируют данные Semantic Web в Интернете для определенных целей. Во-вторых, основные поисковые системы собирают данные Semantic Web из Интернета, чтобы дополнить и обогатить результаты поиска.
Во-первых, они создают специальные приложения, которые используют и комбинируют данные Semantic Web в Интернете для определенных целей. Во-вторых, основные поисковые системы собирают данные Semantic Web из Интернета, чтобы дополнить и обогатить результаты поиска.
Количество данных Semantic Web в Интернете представляет собой значительный объем обнаруживаемых взаимосвязанных данных, которые включаются в точечные решения и приложения как в Интернете, так и внутри предприятий. В 2010 году Тим Бернерс-Ли вернулся на TED, чтобы обсудить некоторые из этих способов использования структурированных веб-данных.
Видео на сайте TED.
Возможно, наиболее заметное использование данных семантической паутины в Сети наблюдается в трех популярных поисковых системах: Google, Yahoo! и Bing. Эти сайты считывают данные Semantic Web, встроенные в Web-страницы, и используют эти данные для предоставления более подробных результатов поиска для своих пользователей. В Google, например, это означает, что если веб-страница продукта размечена с помощью данных Semantic Web, то его список результатов поиска вполне может включать информацию об обзорах, рейтингах, ценах и запасах.![]()
Проект schema.org — совместная работа Google, Yahoo! и Microsoft — документирует концепции и атрибуты, которые эти три поисковые системы будут искать, когда веб-издатели включают данные Semantic Web на свои сайты.
Хотя включение такого рода расширенных данных не влияет на общий рейтинг веб-страницы в результатах поиска, оно может оказать существенное влияние на общий трафик с точки зрения того, сколько людей нажимают на определенный элемент в результатах поиска. Через несколько месяцев после публикации данных Semantic Web для своего ассортимента продуктов Best Buy отметила 30-процентное увеличение общих результатов обычного поиска и 15-процентное увеличение количества людей, нажимающих страницы своих продуктов в результатах поиска.
Заключение
Сегодня технологии семантического веба используются для широкого круга приложений как в Интернете, так и внутри различных организаций. В то время как использование Semantic Web в Интернете в основном связано с публикацией и потреблением данных, технологии Semantic Web также применяются на предприятиях для гораздо более широкого набора приложений.
Семантический поиск | Advanced Web Ranking
Семантический поиск был популярной темой для разговоров в течение многих лет — и не без оснований, поскольку он привел к значительным изменениям в том, как современные оптимизаторы оценивают и планируют контент.
В этом руководстве я шаг за шагом расскажу, как можно интегрировать семантический поиск в свою SEO-стратегию для достижения еще лучших результатов.
Что такое семантический поиск?
Хотя это звучит сложно, термин «семантический» означает просто отношения между словами и их значением при их сочетании.
Google использует семантику, чтобы понять цель запроса искателя и получить лучшие результаты. Семантика перевела Google из механизма сопоставления ключевых слов в механизм сопоставления намерений.
Когда вы включаете семантический поиск в свою стратегию, вы используете связанные темы и слова, чтобы добавить смысла и глубины вашему контенту.
Вы больше не ориентируетесь на ключевые слова; вы ориентируетесь на темы.
Например, Google использует семантику, чтобы понять, когда кто-то ищет «как сделать торт» или «приготовить торт», он ищет «рецепты торта».
Поскольку поисковые системы лучше понимают семантику, вы можете даже не упоминать прямо на своей странице фразы, по которым ранжируются.
Почему семантика важна для поиска?
Почти в любом языке есть слова с несколькими значениями. Поисковые системы полагаются на контекст, предоставленный предыдущими поисковыми запросами, и другие термины в текущем запросе, чтобы понять, какое значение хочет пользователь.
Поисковые системы делают то же самое при анализе ваших страниц; если вы упомянули «яблоко», вы имеете в виду бренд или фрукт? Если в одной и той же статье вы сказали «Тим Кук», «Стив Джобс» или «Купертино», уверенность в том, что вы говорите о бренде, возрастает.
Эволюция семантики в поиске
Когда-то было достаточно заспамить страницу ключевым словом, по которому вы искали ранжирование.
За последние десять лет Google предпринял гигантские шаги, чтобы улучшить понимание семантики; вот некоторые основные моменты.
График знаний
График знаний был первым шагом Google к более глубокому пониманию значения слов.
Одним из способов использования Google Knowledge Graph является отображение панелей знаний в результатах поиска.
Граф знаний — это карта сущностей и их связей с другими связанными сущностями. Entities are «things,» so that could be:
- Landmarks
- Celebrities
- Cities
- Sports teams
- Buildings
- Movies
- Celestial objects
- Works of art
- And more
Google states that информация для графа знаний поступает из различных источников, включая государственные органы, лицензионные данные и фактическую информацию непосредственно в контенте или структурированных данных.
График знаний помогает добавлять информацию в поисковую выдачу, но он также потенциально полезен для владельцев сайтов, предоставляя своим пользователям краткую информацию, такую как:
- Описание бизнеса
- Контактные телефоны, адреса, учредители, и текущий генеральный директор
- Обзоры и рейтинги со всего Интернета
- Ссылки на его социальные профили
Колибри часто называют обновлением алгоритма, но это было гораздо больше.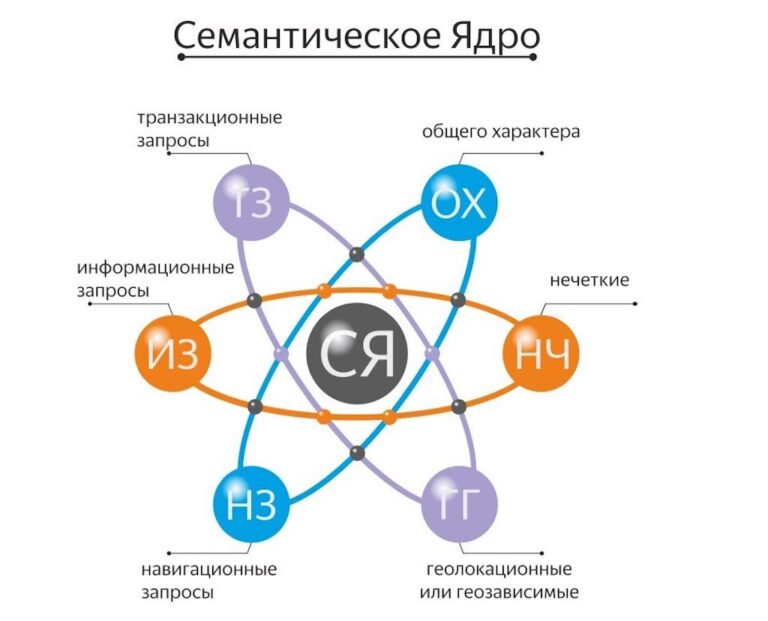
Думайте о других алгоритмах, таких как Panda и Penguin, как о маленьких деталях автомобильного двигателя, таких как воздушный фильтр или поршни. Колибри сродни главному блоку двигателя. Когда это изменится, его нельзя будет считать тем же двигателем, что и раньше.
Основной целью обновления Hummingbird было сделать семантический поиск приоритетным элементом всех поисковых запросов. Он делает это, применяя понимание сущностей из графа знаний к результатам поиска.
В этом обновлении Google перешел к пониманию намерения и значения слов, а не просто к сопоставлению текста в содержании с поисковым запросом.
RankBrain
RankBrain — это система машинного обучения, которая является частью основного алгоритма Google.
RankBrain связывает слова с темами, вероятно, с помощью программного обеспечения, похожего на word2vec, как упоминалось в этом сообщении в блоге Google.
Сопоставляя слова с более широкими темами, RankBrain может связать никогда не встречавшиеся ранее запросы с историческими данными поиска для похожих запросов.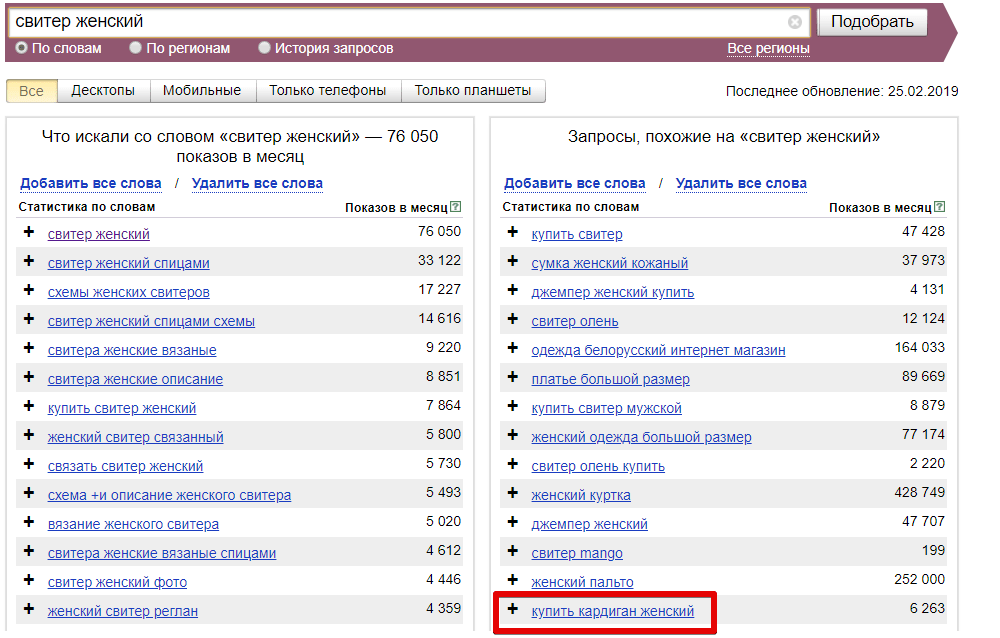
Информация о поведении пользователей из этих исторических данных затем используется для прогнозирования наилучшего результата для нового запроса, и поисковая выдача реорганизуется соответствующим образом.
Например, RankBrain может связать поиск «большая кошка-хищник» с поиском «большие кошки».
В этом обновлении ничего не изменилось в том, как работает SEO, потому что вы не можете оптимизировать для RankBrain. Оптимизация для RankBrain — это то же самое, что и создание целевого полезного контента для пользователей, что не было чем-то новым для индустрии.
вы оптимизируете свой контент для пользователей и, таким образом, для rankbrain. это не изменилось
— Гэри 鯨理/경리 Illyes (@methode) 26 сентября 2019 г.
BERT
Представления двунаправленного кодировщика от Transformers, более известные как «BERT», помогают Google понимать более длинные поисковые запросы.
Поисковый запрос часто представляет собой строку слов, обычно содержащую одно или несколько ключевых слов, вместо предложения.
Как правило, ключевые слова в запросе сопоставляются со страницами в Интернете.
При использовании BERT вместо того, чтобы рассматривать слово в запросе и сопоставлять каждое слово отдельно с содержимым, BERT делает вывод о намерении, просматривая, как слова запроса могут изменить ваше значение при совместном использовании.
В объявлении Google о BERT есть несколько замечательных примеров использования BERT на практике.
Оптимизация для семантического поиска
Теперь вы понимаете важность семантического поиска, давайте рассмотрим некоторые шаги, которые вы можете сделать, чтобы включить его в свою стратегию!
Улучшите свой исследовательский процесс
Во-первых, термин «семантический» означает, что все дело в содержании. Чтобы включить правильные семантически связанные темы, вам нужно улучшить способ исследования.
Как всегда, начните с улучшения исследования ключевых слов. Вот как я начинаю свой анализ.
Разработайте ключевые темы, которые вы хотите осветить, выделив широкие ключевые слова с большим объемом, по которым вы хотели бы ранжироваться.
В этом примере я исследую тему «чанка пьедра», тропического растения с лечебными свойствами.
Используйте инструмент исследования ключевых слов Advanced Web Ranking, чтобы получить список связанных поисковых запросов по вашей обширной теме.
Выберите ключевые слова, которые, по вашему мнению, относятся к вашей основной теме, и распределите их по группам для лучшего управления.
После того, как они будут добавлены в ваш проект, вы также сможете оценить сложность ключевых слов и решить, на какие ключевые слова лучше ориентироваться.
В дополнение к этому вы также можете использовать Проводник ключевых слов Ahrefs.
Поместите тему, о которой вы пишете, в Проводник ключевых слов, перейдите в раздел «Фразовое соответствие» на левой боковой панели и выберите список ключевых слов с разными намерениями.
Затем перейдите к отчету «Также рейтинг для» и выберите потенциально связанные темы. Этот отчет отлично подходит для обнаружения связанных сущностей, по которым ранжируется страница.
Хотя мы не можем получить хороший рейтинг по всем этим ключевым словам в одной статье, они, скорее всего, релевантны по теме. Это помогает ссылаться на эти ключевые слова в вашем контенте и планировать связанные статьи, которые вы можете создать специально по этим темам.
Затем найдите ключевое слово, по которому вы хотите ранжироваться, и возьмите URL страницы с самым высоким рейтингом.
Используйте отчеты Top Sites и Top Sites in Time в Advanced Web Ranking для углубленного анализа поисковой выдачи.
Чтобы узнать, можете ли вы найти больше вариантов ключевых слов, перейдите в Ahrefs Site Explorer, введите URL-адрес в инструмент, а затем перейдите к отчету «Обычные ключевые слова» на левой боковой панели.
Вы можете увидеть различные связанные ключевые слова, по которым ранжируется страница; используйте его для дальнейшего создания списка ключевых слов.
Затем вернитесь к поисковой выдаче, на которой вы только что были.
Используйте функцию «Люди также спрашивают» (PAA), чтобы найти другие идеи контента.
Если вы выберете вопрос, PAA развернется и покажет вопросы, связанные с тем, на который вы щелкнули. Используйте это в своих интересах, чтобы найти связанные вопросы, которые могут улучшить ваш контент.
Вы также можете использовать соответствующий блок поиска в нижней части страницы для получения дополнительных идей.
Я часто обнаруживаю, что большинство из них я обнаруживаю с помощью исследования ключевых слов, но всегда удобно проверить.
Информационное или коммерческое
Правильная формулировка намерения имеет решающее значение. Если поисковик находится на стадии исследования, создание коммерческого контента не сработает. Вместо этого, если это уместно, хорошо осветите тему и создайте страницы как для информационного, так и для коммерческого контента.
Вы можете получить представление о типе контента, который нужно создать, выполнив поиск по ключевому слову/термину и сравнив намерение контента в первой поисковой выдаче.
Усовершенствуйте процесс брифинга
Подробные описания содержания помогают:
- Уменьшение каннибализации ключевых слов
- Повышение семантической релевантности страницы
- Ответьте на все соответствующие вопросы
Вот несколько советов по брифингу, когда вы передаете писателю.
Структура заголовков
Сначала создайте структуру заголовков, на которую повлияли как ваша PAA, так и исследование ключевых слов. Вот пример:
- Чанка Пьедра
- Что это?
- Дозировки
- Преимущества
- Stone Breaker
- Камни в желчном пузыре
- Камни в почках
- Печень
- Отложения кальция
- Stone Breaker
- Побочные эффекты
- Безопасно ли это?
- Сколько времени нужно, чтобы это сработало?
- Как взять?
- Капсулы
- Порошок
- В чае
- Где взять?
- Лучшие бренды
После обновления Hummingbird Google понимает, как связаны все вопросы и поисковые запросы, которые вы обнаружили ранее, поэтому не бойтесь создавать всеобъемлющую страницу вместо страницы для каждого целевого ключевого слова.
Связанные объекты
Во время брифинга предоставьте своему автору соответствующие термины, которые можно включить или изучить. Мы обнаружили некоторые из них, когда использовали отчет «также ранжировать для» в Ahrefs.
Мы обнаружили некоторые из них, когда использовали отчет «также ранжировать для» в Ahrefs.
Например, ранее мы обнаружили фразу «Phyllanthus niruri», которая является научным названием Chanca Piedra.
Мнения экспертов
Хотя мы можем рассматривать приведенную выше информацию как основу того, что нам нужно включить, вам также следует пригласить эксперта по данной теме для написания статьи или проверки ее фактов.
Эксперт может гарантировать, что ваш контент является фактически правильным и обеспечивает ценность, превышающую ту, которую может предоставить копирайтер.
Они также, естественно, включают семантически связанные темы просто потому, что это их область знаний.
При найме эксперта поощряйте его высказывать собственное мнение; вы, вероятно, также получите уникальный ракурс, который может отличаться от конкурирующих статей.
В некоторых случаях специалисты не потребуются, так как тема не настолько сложна, чтобы требовать специалиста.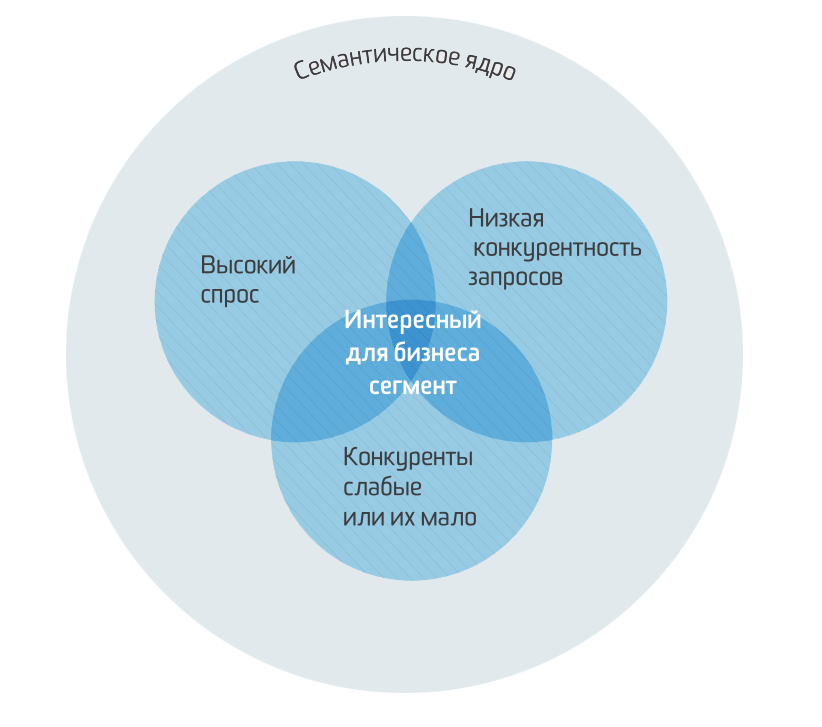 В этих случаях продолжайте тщательное исследование, инструктаж и проверку фактов самостоятельно.
В этих случаях продолжайте тщательное исследование, инструктаж и проверку фактов самостоятельно.
Если бюджет не позволяет нанять эксперта, попробуйте включить цитаты экспертов по теме, о которой вы пишете. Опять же, это дает ценную информацию и позволяет нескольким экспертам обсуждать связанные темы, которые вы, возможно, пропустили в своем исследовании.
Используйте инструменты анализа текста
Чтобы убедиться, что вы включили в свой контент семантически релевантные фразы, используйте инструмент анализа текста, чтобы найти пропущенные термины в том, что вы написали.
Инструмент Ryte Content Success выполняет анализ TF-IDF на небольшом наборе данных (ранжирование страниц в поисковой выдаче).
Инструмент выбирает слова, которые используются в конкурирующих статьях, и предлагает вам включить их в свой контент.
Он также имеет редактор контента, в котором всплывают предложения ключевых слов, когда вы пишете.
Frase.io — еще один отличный инструмент для исследования и анализа контента.
Он также очищает и анализирует рейтинг контента для заданной темы и предоставляет информацию, включенную другими URL-адресами, например:0030
Имейте в виду, что ваша основная цель исследования связанных объектов — создание лучшего контента для пользователей . Мы не добавляем связанные объекты для поисковых систем.
Как я уже упоминал, связанные термины должны быть в содержании естественным образом, если оно было хорошо изучено и проинформировано, но подобные инструменты, безусловно, могут помочь.
Разметка семантического поиска
Мы сосредоточились на том, что читает аудитория, но теперь пришло время выйти за рамки видимого контента.
Некоторая семантическая разметка HTML может помочь поисковым системам понять структуру вашей страницы.
HTML5 — это последняя версия спецификации HTML, предоставляющая семантическую разметку, которую можно использовать вместо стандартного элемента
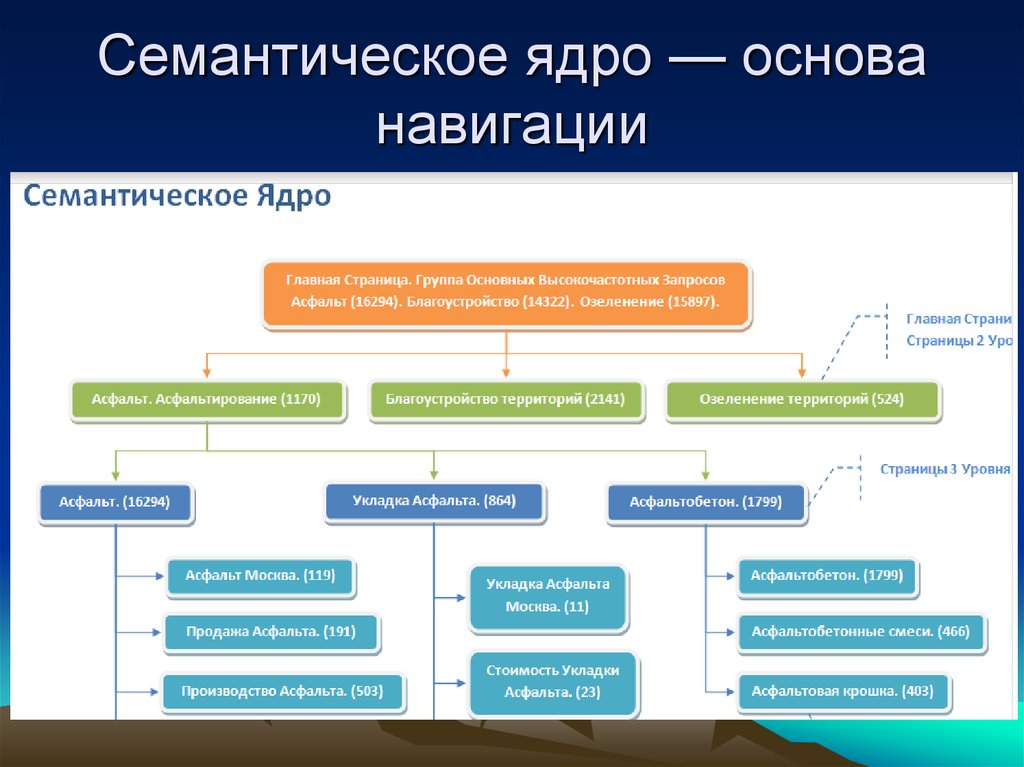
Пример тегов Semantic HTML5:
<заголовок> <нижний колонтитул>
Эти теги могут помочь поисковым роботам точно понять, какова роль контента, поэтому их стоит включить.
Добавить структурированные данные
Структурированные данные обеспечивают контекст вашего контента.
Например, вместо того, чтобы Google пытался выяснить, является ли страница статьей или продуктом, структурированные данные прямо сообщат «это статья».
Джон Мюллер ранее объяснял роль структурированных данных в ранжировании и ясно давал понять их важность для понимания страницы Google.
«… мы используем структурированные данные, чтобы лучше понять объекты на странице и выяснить, где эта страница более актуальна».
Добавление структурированных данных напрямую не влияет на ранжирование; тем не менее, Google может помочь лучше понять содержание страницы.
Добавляя эту разметку, вы также можете получать расширенные сниппеты, которые могут повысить ваш органический рейтинг кликов.
Заключительные слова
Семантика играет важную роль в органическом поиске. В то время как Google улучшает свою способность понимать семантику, фундаментальные принципы SEO остаются прежними. Продолжайте совершенствовать процесс создания контента, от исследования и брифинга до доставки.
Надеюсь, это руководство помогло вам лучше понять семантику и то, как она влияет на современный процесс SEO.
Соединение значений слов посредством семантического отображения
Введение
Семантические карты (или графические организаторы) — это карты или сети слов. Цель создания карты — визуально отобразить основанные на значении связи между словом или фразой и набором связанных слов или понятий. Семантические карты помогают учащимся, особенно учащимся, испытывающим затруднения, и людям с ограниченными возможностями, определять, понимать и вспоминать значение слов, которые они читают в тексте.
Обучение созданию этих карт соответствует трем основным стандартам ELA Common Core State:
- CCSS. ELA-Literacy.CCRA.L.3 Применяйте знание языка, чтобы понять, как язык функционирует в различных контекстах, чтобы сделать эффективный выбор для смысл или стиль, а также для более полного понимания при чтении или прослушивании.
- CCSS.ELA-Literacy.CCRA.L.4 Определение или уточнение значения неизвестных и многозначных слов и фраз с помощью контекстных подсказок, анализа значимых частей слов и обращения к общим и специализированным справочным материалам, по мере необходимости.
- CCSS.ELA-Literacy.CCRA.L.5 Продемонстрировать понимание образного языка, отношений слов и нюансов в значениях слов.
 ELA-Literacy.CCRA.L.3 Применяйте знание языка, чтобы понять, как язык функционирует в различных контекстах, чтобы сделать эффективный выбор для смысл или стиль, а также для более полного понимания при чтении или прослушивании.
ELA-Literacy.CCRA.L.3 Применяйте знание языка, чтобы понять, как язык функционирует в различных контекстах, чтобы сделать эффективный выбор для смысл или стиль, а также для более полного понимания при чтении или прослушивании.Обучение учащихся использованию семантических карт
Вы можете предоставить своим ученикам прямые инструкции по использованию семантических карт. Ниже приведен пример пошагового набора указаний, который может быть особенно полезен для отстающих учащихся.
- Выберите незнакомое вам слово из текста, который вы читаете, и отметьте его. Если вы используете цифровой текст, вы можете выделить слово, выделить его жирным шрифтом или подчеркнуть.
- Используйте пустую карту или начните рисовать карту или сеть (либо на бумаге, либо с помощью онлайн-инструмента).
- Поместите неизвестное вам слово в центр карты.
- Произнесите слово. При необходимости используйте онлайн-словарь со звуком, чтобы помочь вам.
- Прочитайте текст вокруг слова, чтобы увидеть, есть ли связанные слова, которые вы можете добавить на свою карту. Если вы используете цифровой текст, вы можете заставить компьютер читать вам текст, используя функцию преобразования текста в речь (при необходимости).
- Используйте онлайн-словарь или онлайн-тезаурус, чтобы найти слово и определение.
- Найдите слова и фразы, соответствующие смыслу. Выберите картинки/изображения (онлайн или из доступных ресурсов) или нарисуйте картинки, соответствующие смыслу.
- Добавьте эти слова, фразы или изображения на свою семантическую карту.
- Если вы работаете онлайн, распечатайте карту.
- Прочитайте текст еще раз, применяя значение слова к тексту.
- Поделись и сравни свою карту с одноклассниками.


При прямом обучении и повторной практике учащиеся, испытывающие затруднения, обнаружат, что использование семантических карт — очень хороший способ расширить свой словарный запас.
Интеграция технологий
Существует множество технологических инструментов, которые могут помочь учащимся создавать семантические карты (включая карты мышления, интеллект-карты, пузырьковые карты и концептуальные карты). Возможно, вы захотите проверить Webspiration, Bubblus, Gliffy, Thinklinkr, Glinkr, Creately, Diagrammr и Mindomo.
Кроме того, многие веб-сайты (в том числе перечисленные ниже) предоставляют информацию о различных типах графических органайзеров, которые можно использовать в качестве отправной точки при настройке обучения в соответствии с потребностями учащихся.
- Графические органайзеры Education Place
- Интерактивные графические органайзеры Holt
- Органайзеры для обучающей графики Enchanted
- Графические органайзеры Thinkport
Урок семантического картирования
Пятый класс мистера Грина изучает американских президентов. Он хочет, чтобы его 25 студентов поняли, как личность каждого президента могла повлиять на его политическую карьеру. Хотя некоторые учащиеся не испытывают трудностей с декодированием, некоторые учащиеся с трудом узнают или запоминают значения слов. Г-н Грин снова вводит использование семантических карт для поддержки развития словарного запаса.
Он хочет, чтобы его 25 студентов поняли, как личность каждого президента могла повлиять на его политическую карьеру. Хотя некоторые учащиеся не испытывают трудностей с декодированием, некоторые учащиеся с трудом узнают или запоминают значения слов. Г-н Грин снова вводит использование семантических карт для поддержки развития словарного запаса.
Конкретная цель урока состоит в том, чтобы учащиеся расширили свой словарный запас, создав семантические карты для представления различных характеристик личности. Г-н Грин планирует сначала смоделировать эту стратегию, а затем учащиеся получат возможность попрактиковаться в ней самостоятельно. Кульминацией модуля станет создание мультимодальных карточек президента, одним из компонентов которых будет семантическая карта, которые будут размещены на веб-сайте класса.
В рамках своей постоянной практики г-н Грин будет использовать свою интерактивную доску для демонстрации и привлечения учащихся к созданию карт. Чтобы собрать информацию для развития словарного запаса, он зайдет на веб-сайт под названием «Личность Авраама Линкольна».
Ниже приведен план урока мистера Грина. Он состоит из трех разделов, чтобы показать шаги, которые он предпримет перед чтением, во время чтения и после чтения.
План урока
Перед чтением
- Расскажите о целях модуля, которые состоят в том, чтобы узнать о президентах и создать мультимодальные карточки президентов с новой лексикой.
- Просмотрите и обсудите три различных типа семантических карт.
- Показать и обсудить веб-сайт, посвященный личности Авраама Линкольна.
- Предложите учащимся заполнить семантическую карту словами, определениями и изображениями.
- Сохраните карту на сайте класса.
Во время чтения
- Продолжайте практиковаться в использовании семантических карт.
- Попросите группы создать новые мультимедийные карты.
- Предложите учащимся поделиться и обсудить новую лексику на картах.
После прочтения
- Предложите учащимся приступить к изготовлению мультимодальных карточек президента.
- Установите критерии для этих карточек: имя президента, словарные слова, определения, изображения и предложения.

Дополнительные ресурсы для учителей по семантическому отображению
Эта статья основана на веб-сайте PowerUp WHAT WORKS, в частности, на Руководстве по стратегии обучения семантическому отображению. PowerUp — это бесплатный, удобный для учителей веб-сайт, не требующий входа в систему или регистрации. Учебное руководство по стратегии включает краткий обзор, определяющий семантическое отображение, и сопроводительное слайд-шоу; список соответствующих стандартов ELA Common Core State; стратегии обучения, основанные на фактических данных, для дифференцированного обучения с использованием технологий; история случая; короткие видеоролики; и ссылки на ресурсы, которые помогут вам использовать технологии для обучения семантической картографии. Если вы отвечаете за профессиональное развитие, вспомогательные материалы PD содержат полезные идеи и материалы для использования ресурсов по семантическому картированию.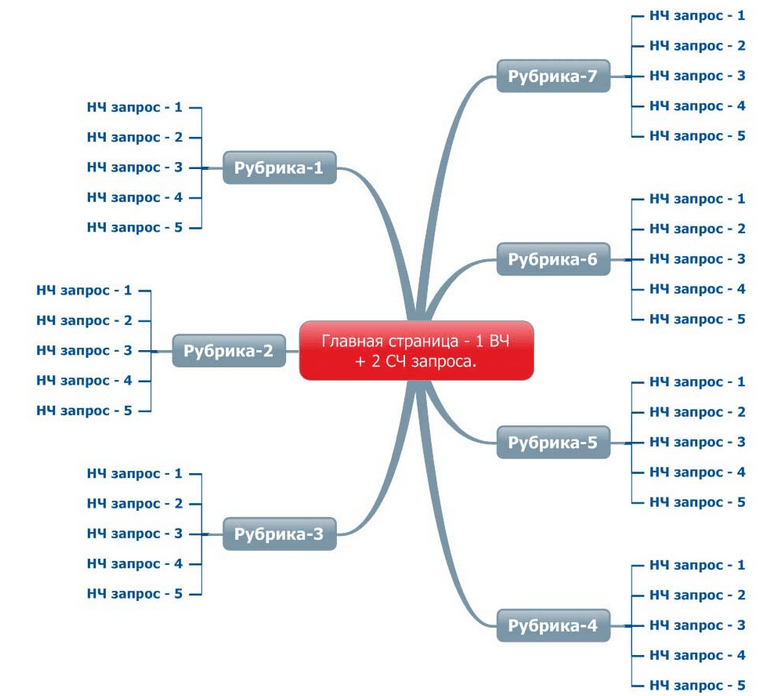 Хотите больше информации? См. PowerUp ЧТО РАБОТАЕТ.
Хотите больше информации? См. PowerUp ЧТО РАБОТАЕТ.
Достаточно ли семантического поиска для электронной торговли?
Что такое семантический поиск ? Семантический поиск относится к семейству методов поиска информации, которые сосредоточены на контексте запроса и взаимосвязях между словами, чтобы вывести поиск за рамки простого сопоставления ключевых слов.
Google проделывает потрясающую работу по пониманию того, что если вы смотрите на цифровую коммерцию, вы также можете иметь в виду электронную торговлю или электронную торговлю или любую другую последнюю тенденцию.
Но, несмотря на то, что семантический поиск превосходен, когда вы просматриваете темы или категории, в электронной коммерции он иногда терпит неудачу. Почему? В электронной коммерции поисковый запрос обычно короткий, широкий, двусмысленный и недостаточно конкретизированный, а это означает, что не хватает лингвистических элементов для получения результатов, полностью соответствующих намерениям покупателей.
Покупатели, ищущие идеальный продукт, не просто хотят, чтобы поисковая система соответствовала их ключевому слову, они хотят, чтобы поисковое решение понимало их покупательское намерение – , даже если они вводят в поле поиска всего три слова.
В свете этого лидеры цифровых технологий изучают сложные способы использования комбинации исторических и сессионных переменных для создания семантической сети или графа знаний слов. Но лучший ли это подход?
Чтобы помочь разобраться во всем этом и выяснить, что лучше для вас, я разбил это на три области.
- Проблемы соответствия ключевых слов в электронной торговле
- Недостатки семантического поиска в электронной торговле
- Новое поколение инноваций для поиска в электронной торговле
Проблемы сопоставления ключевых слов в электронной торговле объяснить, что такое соответствие ключевых слов.
Краткое руководство по подбору ключевых слов
Многие популярные поисковые системы для электронной коммерции полагаются на алгоритмы поиска по ключевым словам общего назначения.
Хорошо известная библиотека Apache Lucene, на которой работают системы Solr и Elasticsearch, является хорошим примером ведущей поисковой системы, основанной на сопоставлении ключевых слов. Применительно к электронной коммерции эти поисковые системы рассматривают всю информацию о продукте (такую как название, атрибуты и описание) как части одного большого текстового документа.
Когда покупатель вводит поисковый запрос, эти запросы разбиваются на отдельные слова. Каждый термин ищется в тексте описания продукта с использованием логической логики. Затем все совпадения ранжируются в соответствии со статистикой слов, которая основана на подсчете того, как часто определенные слова из запроса упоминаются в данных о продукте и насколько часто это слово встречается во всех продуктах в каталоге.
Формулы ранжирования могут быть довольно сложными и учитывать различные статистические факторы и дополнительные данные, такие как новизна продукта. Тем не менее, по сути, это примерно слов, считая .
Многие проблемы релевантности при сопоставлении ключевых слов
Есть несколько приемов, которые поисковые системы на основе сопоставления ключевых слов используют для обеспечения лучшего отзыва результатов. Например, они могут нормализовать слова, сводя их к основам, так что «чистый» будет соответствовать «чище».
Но из-за механики подходов к поиску информации они все равно могут не дать релевантного результата.
Проблема релевантности № 1: Пробелы в словарном запасе
Покупатели сигнализируют о намерении совершить покупку несколькими способами, иногда используя словарь, отличный от словарного запаса в каталоге товаров. Например, люди, которые ищут «мускусную дыню», «арбузную дыню» или «сладкую дыню», имеют одно и то же намерение. Как показано ниже, поиск Safeway показывает интересный пример проблемы. Никаких фруктов для покупателей, использующих что-либо, кроме мускусной дыни!
Хотя поисковые системы, основанные на сопоставлении ключевых слов, могут использовать тезаурусы с многочисленными синонимами, так что «платье» будет соответствовать «платью», это плохо подходит для поиска в электронной торговле.
Многие каталоги электронной коммерции основаны на техническом и часто идиосинкразическом языке, с которым, скорее всего, не справятся доступные общие тезаурусы. Подумайте: «пергола из цельного дерева с монтажным комплектом» в обустройстве дома или «фигуристские платья» в моде. Из-за этого компании, полагающиеся на поисковые системы, основанные на сопоставлении ключевых слов, в конечном итоге будут управлять синонимами вручную, что не только утомительно, но и не масштабируемо, дорого и подвержено ошибкам.
Например, жесткое определение синонимов может скрыть контекстно-зависимый характер слов. Следует ли рассматривать «черный» и «темный» как синонимы? Конечно, в некоторых контекстах: «черная ночь» может означать «темная ночь». Но всегда ли «черное платье» означает «темное платье»? Нет, если вы хотите избежать модной faux pas .
Проблема релевантности № 2: сопутствующие товары
Если в вашем интернет-магазине нет определенного бренда, недостаточно просто не указывать это название.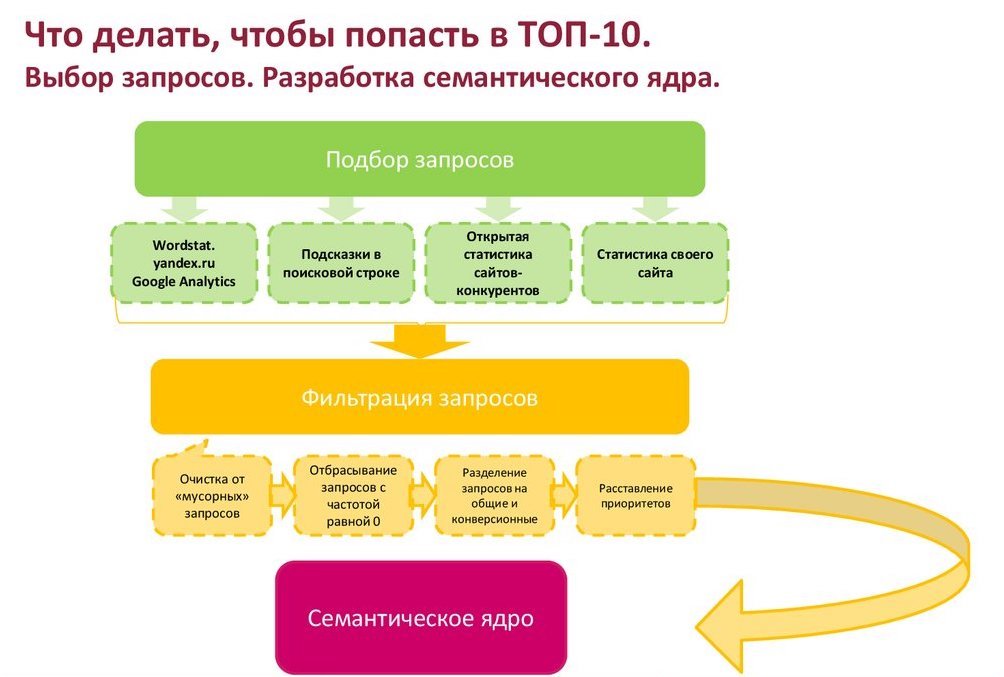 Покупатели, у которых показаны нулевые результаты, убегут, чтобы найти то, что ищут. Вместо этого ваш поиск по сайту снова должен понимать цель запроса и предлагать интеллектуальные рекомендации по продукту.
Покупатели, у которых показаны нулевые результаты, убегут, чтобы найти то, что ищут. Вместо этого ваш поиск по сайту снова должен понимать цель запроса и предлагать интеллектуальные рекомендации по продукту.
Допустим, у вас есть покупатель, который ищет кроссовки марки Mizuno, но у вас их нет. Не бросайте в них все других туфель , которые у вас есть! Вместо этого ваш поиск на сайте электронной коммерции должен распознавать, что ваш клиент ищет спортивную обувь, и предлагать аналогичные продукты, например кроссовки Nike или Asics.
Сопоставление намерения покупателя с тем, что есть , доступным в вашем инвентаре, не совсем осуществимо, если вы полагаетесь на строки текста, а не на концепции и отношения между ними.
Как оказалось, веб-сайты электронной коммерции часто с трудом справляются с такими сценариями. Например, в приведенном ниже примере я посещаю веб-сайт Ulta Beauty в поисках шампуня от Sachajuan, следуя отличным отзывам и отзывам друзей. К сожалению, я не только получил нулевой результат (предполагая, что Ulta не имеет этой марки среди сотен доступных шампуней), но также мне показали кучу рекомендаций, которые явно не имеют отношения к моему поиску. намерение.
К сожалению, я не только получил нулевой результат (предполагая, что Ulta не имеет этой марки среди сотен доступных шампуней), но также мне показали кучу рекомендаций, которые явно не имеют отношения к моему поиску. намерение.
Проблема релевантности № 3: Неоднозначные и общие запросы
Знаете ли вы, что двусмысленности бывают разных видов?
Один структурный; способ упорядочения поискового запроса может сильно изменить намерение. Например, рассмотрим «классическая рубашка» и «платье-рубашка»: одно — это рубашка для деловых или торжественных случаев , а другое — платье , выполненное в стиле рубашки . Одни и те же слова, совершенно разные значения — просто изменив порядок слов!
Люди могут быстро ориентироваться в этой сложности, полагаясь на контекст взаимодействия и собственные обширные знания о мире. Но любой, кто ожидает, что поисковая система, основанная на сопоставлении ключевых слов, будет такой умной, будет разочарован. Сопоставление ключевых слов плохо приспособлено для обработки таких запросов. На самом деле, даже такой популярный веб-сайт, как ASOS (Alexa 235), выдает одинаковые результаты по двум запросам.
Сопоставление ключевых слов плохо приспособлено для обработки таких запросов. На самом деле, даже такой популярный веб-сайт, как ASOS (Alexa 235), выдает одинаковые результаты по двум запросам.
Другим типом неоднозначности является семантика, которая напрямую связана со значением запроса. Если я ищу «джинсы», я могу иметь в виду тип ткани или искать новую пару джинсов. Поисковые системы с сопоставлением ключевых слов сопоставляют строки текста, а не понятия, что затрудняет обработку не только синтаксической, но и семантической неоднозначности.
Проблема релевантности № 4: точность результатов поиска
Недостаточно просто показать своим клиентам что-то . В то время как показ нулевых результатов может привести к отказу клиента, показ несвязанных результатов также может отправить покупателей в другое место. Поиск, основанный на совпадении ключевых слов, с трудом справляется с точностью результатов.
Например, вы ищете «мужской черный кожаный кошелек». В каталоге товаров нет артикулов, точно соответствующих этому запросу. Неискушенные поисковые системы прибегнут к частичному совпадению и могут выдать «мужские коричневые кожаные кошельки» (что актуально!) вместе с «мужские черные кожаные ремни» (неактуально!).
В каталоге товаров нет артикулов, точно соответствующих этому запросу. Неискушенные поисковые системы прибегнут к частичному совпадению и могут выдать «мужские коричневые кожаные кошельки» (что актуально!) вместе с «мужские черные кожаные ремни» (неактуально!).
Хотя вы можете вывести наиболее релевантные товары на первое место, следует помнить, что большинство сайтов электронной коммерции позволяют клиентам пересортировать товары по цене, новизне, количеству продаж или рейтингу. Потерянный.
Является ли семантический поиск ответом?
Очевидно, что интернет-торговцам нужна альтернативная — и превосходящая — технология поиска для решения вышеупомянутых проблем. Семантический поиск предлагает альтернативный подход, но и у этого метода есть определенные недостатки.
Хотя термин семантический поиск был придуман в 2003 году, он не получил широкого распространения до развертывания Google Hummingbird в 2013 году. Годом ранее Google объявил, что пользователи его поисковой системы смогут искать «вещи, а не строки» (текста), и это довольно эффективно отражает основную идею семантического поиска.
Вообще говоря, семантический поиск направлен на сопоставление документов, которые соответствуют смыслу и намерениям пользователя, а не только его словам, как раньше подход полнотекстового поиска.
Семантический поиск не говорит одним голосом
Существует не только один способ выполнения семантического поиска. На самом деле существует несколько доступных подходов, начиная от графов знаний и заканчивая семантическими векторными пространствами.
Графы знаний
Распространенным подходом к семантическому поиску является граф знаний. Хотя этот термин был популяризирован Google Knowledge Graph в 2012 году, графы знаний намного старше. Проще говоря, они организуют данные из нескольких источников, собирают информацию об объектах, представляющих интерес в данной области или задаче, и устанавливают связи между ними.
Они представляют знания тройками субъект-предикат-объект, где предикат указывает на отношение между парой сущностей (субъект и объект).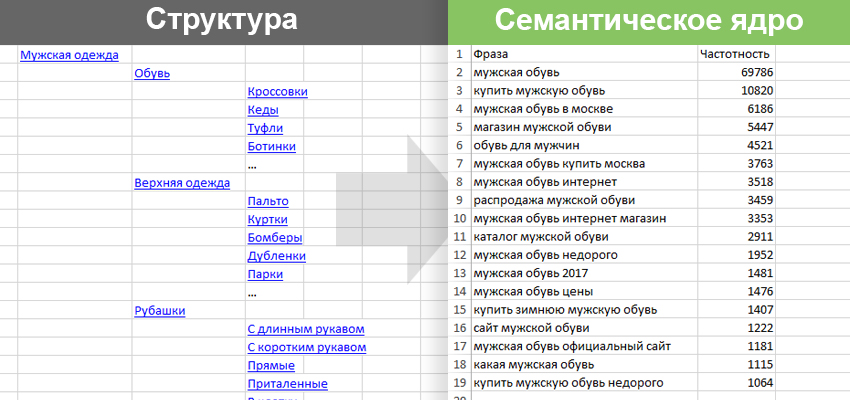 Сущности связаны друг с другом предикатами/отношениями.
Сущности связаны друг с другом предикатами/отношениями.
Семантическая природа графов знаний исходит из того факта, что значение данных закодировано в онтологии. Это описывает типы сущностей на графике и их характеристики. Таким образом, граф — это не только место для организации и хранения данных, но также (что очень важно) для получения информации и обеспечения расширенной обработки запросов. Когда клиент ищет «фиолетовый пиджак», диаграмма знаний понимает взаимосвязь между разными словами и помогает получить релевантные результаты.
Семантический векторный поиск
Еще один подход, привлекший большое внимание в последние годы, — семантический векторный поиск. К настоящему времени этот подход стал настолько устоявшимся, что существуют проекты с открытым исходным кодом (например, Facebook FAISS), которые используются цифровыми игроками и поставщиками.
Основная идея этого семантического векторного поиска заключается в том, что нам необходимо глубже проникнуть в значение как данных, так и запросов таким образом, чтобы он был непосредственно доступен и понятен компьютерам.
Компьютеры могут работать только с числами, поэтому нам нужен способ представления наших данных в числовом виде. Очевидно, что одно число не может представить всю сложность запроса или продукта, поэтому нам нужно их много. Упорядоченный список чисел, например [24, -5,14, 0, -14], называется вектором, а длина этого списка называется размерностью вектора.
Представьте себе, что все запросы и продукты представлены в виде двумерных векторов — создается векторное пространство. С семантическими векторами продукты и запросы, похожие по смыслу, представлены векторами, близкими по расстоянию. Например, у нас может быть четкий кластер запросов и продуктов, представляющих концепции платьев.
Векторное пространство визуализирует расстояние между различными продуктами и их взаимосвязь. Расстояния между точками представляют уровни сходства между соответствующими понятиями. Таким образом, мы можем построить семантическое векторное пространство для наших данных. С семантическим векторным пространством сложная и неопределенная проблема поиска релевантных продуктов с помощью текстовых запросов может быть преобразована в хорошо сформулированную проблему поиска ближайших векторов в векторном пространстве, в чем компьютеры очень хороши.
Преимущества и ценность семантического поиска
За счет применения этих более сложных подходов и выхода за рамки базового сопоставления ключевых слов семантический поиск обещает решить некоторые критические проблемы, от которых страдает поиск по ключевым словам.
Например, используя возможности семантического поиска, Google может справиться с пробелами в словарном запасе. Он понимает, что и «кредиты на ремонт дома», и «кредиты на ремонт дома» означают одно и то же, и намерения пользователей, стоящие за обоими поисковыми запросами, практически одинаковы.
Точно так же, если, поскольку я читал звездные обзоры, я поищу на Netflix фильм ужасов Бабадук — я обнаружу, что он недоступен. Это может быть плохой новостью, но Netflix все же удается вернуться с рядом результатов, которые весьма актуальны, потому что он понял мое намерение.
Более того, сопоставление ключевых слов затруднено, когда запросы похожи по словам и структуре, но на самом деле относятся к очень разным продуктам. Семантический поиск справляется с этим эффективно. Например, Google выдает разные результаты по запросам «камера с объективом» и «объектив для камеры», потому что понимает значение слов «для» и «с».
Итак, является ли использование семантического поиска лучшим вариантом для поиска в электронной торговле? А может и нет…
Лучшая альтернатива семантическому поиску
В веб-поиске запросы, как правило, относительно длинные. Но в электронной коммерции это не так. Например, исследование Nielsen Norman Group показывает, что среднее количество символов для поиска в Интернете составляет 20,5. Между тем, около 30-40% клиентов электронной коммерции начинают сеанс покупок с общих запросов, таких как «мужские топы», «nike» или «сумки».
Подобные короткие запросы дают очень ограниченную информацию о том, что они действительно хотят купить. Некоторые из этих запросов, например «мужские топы», соответствуют значительной части каталога, и ничто в самом поисковом запросе не может помочь определить соответствующий продукт.
Языковой контент, связанный с запросами онлайн-покупателей, обычно не обеспечивает достаточного семантического контекста для определения предпочтений и потребностей покупателя (то, что мы называем намерением покупателя или пользователя).
Покупатель, набрав «обувь», хочет кроссовки, и как определить это по одному слову? Поиск «куртки» означает зимнюю или летнюю куртку, которые являются совершенно разными, но оба релевантными наборами продуктов?
Если чисто семантические подходы не гарантируют улавливание покупательского намерения для огромной и важной части сеансов клиентов, то что же тогда?
От векторов Word к векторам продуктов
Ведущие отраслевые аналитики ввели новые категории, чтобы отметить необходимость превращения семантического поиска в более зрелый, полный и интеллектуальный подход к поиску информации. Например, компания Forrester Research ввела категорию когнитивного поиска для обозначения более полного и сложного подхода, который использует несколько типов релевантных данных и искусственный интеллект для предоставления наиболее релевантных результатов поиска.
В недавнем отчете аналитик Forrester Скотт Комптон отметил, что «Когнитивный поиск может показывать результаты на основе комбинации исторических и сеансовых переменных, что делает его более актуальным для потребителя даже во время его первого посещения».
Именно в этом духе Coveo недавно представила подход, получивший название «Персонализация по ходу». каталог заказчика. Отображая продукты, которые более похожи друг на друга, используя такие атрибуты, как бренд, размер, цена, цвет. Думайте об этом как о карте магазина с похожими товарами, расположенными рядом друг с другом.
Идея состоит в том, чтобы объединить эту векторную карту с переменными в сеансе и поведением клиентов на месте, чтобы зафиксировать намерения искателя. Применяйте машинное обучение в режиме реального времени, чтобы адаптировать предложения запросов, автозаполнение, динамические аспекты или рекомендации для покупателя.
Например, в запросе «перчатки» нет ничего, что указывало бы на то, что пользователя интересуют перчатки для гольфа, а не, скажем, зимние перчатки.