
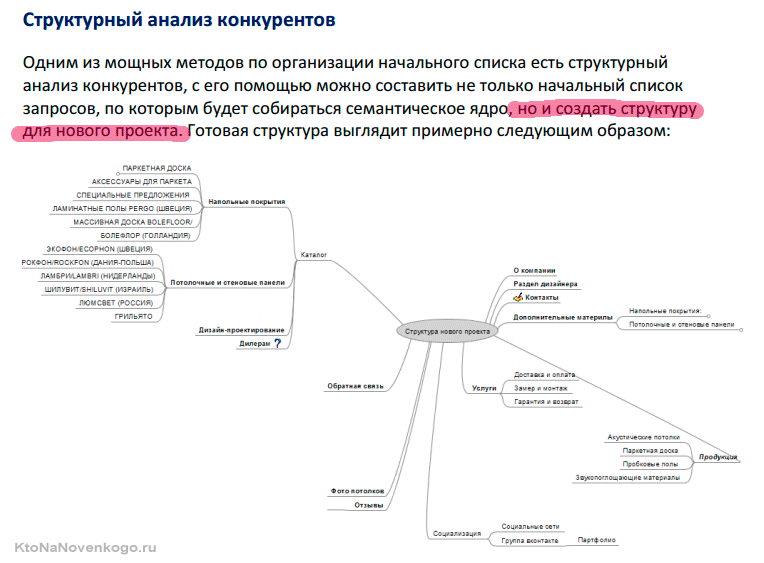
Что такое семантическое ядро, как собрать для SEO сайта в 2022 году
О том, как правильно собрать семантическое ядро, написано много профессиональной литературы. Наша задача – рассказать, как и зачем происходит сбор семантического ядра для сайта, людям, не погруженным в тему. Вы найдете пошаговую инструкцию, как составить семантическое ядро сайта, с примерами, перечислением программ/сервисов, которые в этом помогут.
Содержание
- Что такое семантическое ядро сайта и для чего нужно
- Что важно знать при сборе семантического ядра
- Как правильно подобрать ключевые слова
- Дилетантский (классический) способ
- Профессиональный (маркетинговый) способ
- Инструкция сбора семантического ядра в 5 этапов
- Пример качественного семантического ядра (образец)
- Анализ семантического ядра или как определить качество
- Резюме – что делать с этим семантическим ядром
Что такое семантическое ядро сайта и для чего нужно
Поисковые системы Яндекс и Google – рабочая среда для SEO-специалиста. Задача этих обширных корпораций дать пользователю релевантный ответ на его запрос, простыми словами чтобы человек быстро нашел то, что ему нужно, и остался доволен, а компании, жаждущие продвижения в ПС, улучшали свои ресурсы, тем самым делая саму поисковую систему более популярной.
Задача этих обширных корпораций дать пользователю релевантный ответ на его запрос, простыми словами чтобы человек быстро нашел то, что ему нужно, и остался доволен, а компании, жаждущие продвижения в ПС, улучшали свои ресурсы, тем самым делая саму поисковую систему более популярной.
СЕО-специалист должен максимально изучить алгоритмы и правила поисковых систем, чтобы, получить хорошие позиции по продвигаемым запросам. На продвижение веб-ресурса влияет множество факторов. Но если сбор семантики для сайта проведен неверно, каркас и архитектура ресурса будут собраны некорректно, из-за чего дальнейшее продвижение будет неэффективным.
Создание семантического ядра – это фундамент, на котором строится всё остальное SEO-продвижение сайта
Семантическое ядро (СЯ) – это группированные запросы, которые характеризуют вид деятельности, специфику и всё что касается вашего сайта. Простыми словами, это выборка запросов которые пользователи пишут в поисковую строку ПС с целью получить ответ на их запрос.
В ходе сбора фраз, специалист сразу может узнать:
- Что именно ищут люди
- Каким образом запрашивают информацию
- Зачем она им нужна – купить, узнать, заказать, прицениться
Где можно использовать СЯ
Сем. ядро используется в SEO-продвижении сайтов, настройке контекстной рекламы, составлении контент-плана. При грамотном использовании семантики можно добиваться поставленных маркетинговых целей. Но нужно отталкиваться от того, как человек запрашивает информацию и отвечает ли ваш сайт (текущий, будущий) данному запросу.
Допустим, у вас фирма по ремонту офисов, соответственно вы не заинтересованы в оказании услуги по ремонту мобильных телефонов. Также и со сбором запросов, ваш целевой запрос будет “ремонт офисов”, а не “ремонт смартфона”.
Кроме органического поиска, семантика сайта решает еще 2 задачи:
- Грамотный сбор семантики поможет спрогнозировать, когда и сколько трафика из поисковой системы вы получите. Это поможет подсчитать потенциальные доходы бизнеса
- Вторая задача не про технологии, но про маркетинг.
 До запуска сайта предпринимателю и нанятому специалисту необходимо решить – какую информацию транслируем. Хороший сео-специалист досконально изучает целевую аудиторию (ЦА) либо работает в связке с бизнесменом. Для составления семантического ядра сайта нужно знать – какого пола, возраста люди к вам придут, как они мыслят и их ценовой сегмент.
До запуска сайта предпринимателю и нанятому специалисту необходимо решить – какую информацию транслируем. Хороший сео-специалист досконально изучает целевую аудиторию (ЦА) либо работает в связке с бизнесменом. Для составления семантического ядра сайта нужно знать – какого пола, возраста люди к вам придут, как они мыслят и их ценовой сегмент.
 До запуска сайта предпринимателю и нанятому специалисту необходимо решить – какую информацию транслируем. Хороший сео-специалист досконально изучает целевую аудиторию (ЦА) либо работает в связке с бизнесменом. Для составления семантического ядра сайта нужно знать – какого пола, возраста люди к вам придут, как они мыслят и их ценовой сегмент.
До запуска сайта предпринимателю и нанятому специалисту необходимо решить – какую информацию транслируем. Хороший сео-специалист досконально изучает целевую аудиторию (ЦА) либо работает в связке с бизнесменом. Для составления семантического ядра сайта нужно знать – какого пола, возраста люди к вам придут, как они мыслят и их ценовой сегмент.Бизнес должен решать, что говорить клиентам, самостоятельно формируя тренд, а не просто создавать страницы, чтобы организовать оптимизацию сайта. Тактических вариантов для решения поставленных двух задач может быть множество. Но стратегий всего 2. Прочее – производное от них.
Продвигать сайт без семантического ядра – это тоже самое что ловить рыбу голыми руками
Что важно знать при сборе семантического ядра
Чем лучше вы знаете проект, бизнес и целевую аудиторию, тем грамотнее можно собрать СЯ.
Ядро должно быть ориентировано на ключи – слова или фразы, которые используют ваши потенциальные клиенты. SEO-специалисты делят ключевые фразы по различным параметрам, но базовые показатели на которые должен обращать внимание даже начинающий специалист.
SEO-специалисты делят ключевые фразы по различным параметрам, но базовые показатели на которые должен обращать внимание даже начинающий специалист.
Классификации:
- Частотность запроса
- Тип запроса
- Привязка запроса к местоположению
Ниже мы расскажем о каждом виде запросов подробнее.
При сборе ключевых запросов нужно обязательно учитывать основные классификации
Как правильно подобрать ключевые слова
Есть 2 случая сбора семантики: сбор семантики для текущего сайта и сбор семантики для будущего (нового) сайта. В первом случае анализируем, что есть, добавляем недостающее, расширяем семантику. Во втором случае всю работу производим с самого начала, собираем максимально объемное ядро.
Но и в том, и в другом случае ключи в ходе анализа и чистки распределяют по группам (кластеризация). Группы (кластеры) запросов указывают на количество нужных страниц на сайте т.к. каждая группа должна быть “привязана” к определённой странице.
Запросы которые могут относится к вашей тематике и отвечать ряду факторов которые вам выгодны, не все могут быть полезны.
Пример: У вас бизнес по ремонту офисных помещений в Москве. При сборе запросов вам обязательно попадутся запросы “ремонт офисов в Москве”, “ремонт офисов в МО”, “ремонт офисов СПБ”, если первый запрос будет полностью соответствовать вашему бизнесу и сайту, то два других нет т.к. вы не оказываете услуги в этих городах.
В зависимости от того разработан ваш сайт или только будет разрабатываться после сбора СЯ, будет завесить метод сбора ключей и количество необходимых инструментов
Дилетантский (классический) способ
Самый простой метод формирования ядра – надергать из WordStat высокочастотные и отвечающие общим критериям бизнеса запросы. Допустим, у вас бизнес по ремонту офисных помещений в Москве. В сервисе WordStat запрос “ремонт офисов” будет иметь хорошую частоту и любой специалист его точно добавит, но также там будут и менее частотные запросы производные от основного запроса: “косметический ремонт офисов”, “ремонт офисов под ключ” или “срочный ремонт офиса”.
Если собирать только жирные ключи надеясь что основной запрос наберёт больше трафика, это приведёт к тому что вы недополучите клиентов которые запрашивают услугу с уточнением или пишут более сложные запросы.
В случае с дилетантским способом используется и такой метод, когда человек берет ключевые фразы “из головы”, придумываем их сам на основании того, как ему кажется, запрашивают другие люди. Проще говоря, вообще не пользуется инструментами, пишет ключи, основываясь на своём представление поисковых запросов.
Понятно, что, не имея подходящих программ и сервисов, запросы впоследствии не кластеризуются, не проводится анализ. А если программы и используются, например, тот же WordStat, то итоговая семантика обычно ограничивается сбором ключевых запросов по самому популярному запросу и только по нему.
В большинстве случаев при таком сборе запросы несовместимых типов будут содержаться в одном кластере, а это большая ошибка.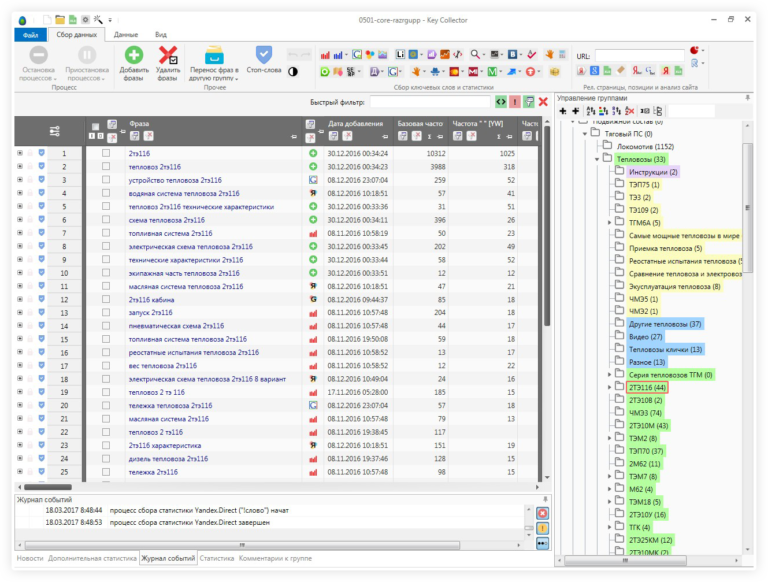
Профессиональный (маркетинговый) способВышеописанное – не лучший вариант формирования семантического ядра, как составить правильно?
Этот метод учитывает анатомию поисковых запросов. Каждый, как правило, состоит из:
- Тела (в примере “ремонт офиса”)
- Спецификатора (определяет намерение пользователя – “заказать”)
- Хвоста (детализирует и поясняет интерес пользователя – “под ключ”)
Анализ ”хвостатых” фраз – фирменная фишка хорошего сео-специалиста, позволяющая уменьшить конкурентность ядра и увеличить охват
По сути, типы запросов семантического ядра – это фильтр, через который мы пропускаем имеющиеся ключи.
Классификации ключевых слов
Разновидностей ключевых фраз делятся на 3 основных вида, ниже рассмотрим каждый из них.
Основные типы ключевых фраз семантического ядра
- Общие. К ним относятся запросы, по которым невозможно определить, каково намерение пользователя. “Ремонт” – как проводить, какие этапы, что понадобится, сколько стоит?
- Транзакционные. Коммерческое направление, их можно безошибочно определить по словам, “заказать”, “найти фирму в Москве”, “оставить заявку”
- Информационные. Пользователь ищет необходимые сведения: “из каких этапов состоит ремонт в офисе”
- Витальные. Привязаны к конкретной сети, бренду или магазину: “материалы для ремонта офиса СтройДвор”. Если нам не принадлежит сеть “СтройДвор”, такие запросы для нас бесполезны, мы их не учитываем в семантическом ядре для SEO
- Навигационные. Запросы связанные с поиском адреса, маршрута, точки продажи
- Мультимедийные. Кроме текста, присутствует дополнительный контент – видеоряд, музыка. Это может быть информационным запросом или коммерческим
 “Ремонт” – как проводить, какие этапы, что понадобится, сколько стоит?
“Ремонт” – как проводить, какие этапы, что понадобится, сколько стоит?Ключевые фразы по частотностям (поисковые запросы в месяц)
- К высокочастотным запросам отходят фразы, имеющие от 1 000 запросов в месяц
- Среднечастотные фразы – это от 100 до 1 000 запросов в месяц
- Низкочастотные содержат до 100 запросов в месяц
Разновидности в зависимости от местоположения пользователя
- Геозависимые. По таким запросам выдача поисковых система зависит от местоположения пользователя в момент поиска. Допустим если человек делает запрос ”заказать пиццу” находясь в Новосибирске, то в выдаче будут преобладать сайты пиццерий которые находятся именно в Новосибирске
- Геонезависимые. Выдача поисковых систем по таким запросам в разных городах чаще всего не особо отличается. Пример такого запроса ”как приготовить пиццу пепперони”
 По таким запросам выдача поисковых система зависит от местоположения пользователя в момент поиска. Допустим если человек делает запрос ”заказать пиццу” находясь в Новосибирске, то в выдаче будут преобладать сайты пиццерий которые находятся именно в Новосибирске
По таким запросам выдача поисковых система зависит от местоположения пользователя в момент поиска. Допустим если человек делает запрос ”заказать пиццу” находясь в Новосибирске, то в выдаче будут преобладать сайты пиццерий которые находятся именно в НовосибирскеЗадача SEO-специалиста – поработать с общими и мультимедийными, чтобы просеять ненужное и отобрать необходимое. С транзакционными, информационными и навигационными разбираемся по частотности и профилю сайта.
Инструкция сбора семантического ядра в 5 этапов
Для создание грамотного семантического ядра не достаточно просто собрать много запросов, нужно выполнить ряд работ.
Этап 1 – Анализ конкурентов
Анализ топа конкурентов поможет увидеть объём желаемой для достижения подобного результата семантики. Также можно понять как примерно будет выглядеть структура сайта.
Вспомогательные сервисы для анализа конкурентов SpyWords и Serpstat.
Этап 2 – Сбор маркеров или базовых ключевых слов
Мы не можем забивать в инструменты для парсинга все, что приходит в голову. Нужно сначала заняться разработкой семантической картой. У нас сайт крупной строительно-ремонтной бригады. Вероятно, услуги разделим на две больших группы: строительство и ремонт. В “ремонте” поделим услуги на ремонт квартир, загородных домов, гаражей, производственных и торговых площадей, офисов.
Возьмем офисную “ветвь”. Это косметический ремонт, капитальный, дизайнерский. Соответственно, в капитальном это услуги: ремонт офисов под ключ, разработка проекта для офисного ремонта, закупка материалов для ремонта в офисе. Это база, с которой будем работать. “Накидать” первичные слова и фразы надо будет по всем “ветвям”.
Список фраз, которые должны быть в семантической карте:
- Общие: “ремонт в офисе”, “офисный ремонт”
- Транзакционные (коммерческие): “заказать ремонт офиса под ключ”
- Информационные: “сколько стоит ремонт офиса”, “как проходит офисный ремонт”
- Навигационные (географические): “ремонт офиса в Москве”, “офисный ремонт в Балашихе”
- Мультимедийные: “фото до и после ремонта в офисе”
Для комбинирования (пересечения фраз) можно воспользоваться сервисом peresekator. ru.
ru.
Этап 3 – Парсинг и расширение ключевых запросов
При создании семантического ядра стоит учитывать перспективные ключи. Вы на данный момент продаете пиццу, но не продаете суши и роллы. А люди часто ищут их совместно. На будущее, когда бизнес будет расширяться, это пригодится. Для расширения полученного пула берем инструменты для подбора ключевых слов и фраз. Выставляем настройки, анализируем. Что явно не подходит – сразу отсеиваем. Можно использовать такие инструменты:
- Yandex.Wordstat: основной упор на правую колонку, но и левую не игнорируем
- Планировщик Google Ads
- Поисковые подсказки Яндекс, Google и YouTube – вы их увидите в соответствующих полях при вводе как продолжение вашей фразы
- Сбор ассоциаций (вместе с запросом ищут) под результатами поиска Яндекс и Google
Помимо инструментов от поисковых систем, также используем программы:
- Bukvarix – подбор ключевых слов
- Pastukhov – база ключевых слов
Если есть статистика по сайту, нам пригодится:
- Яндекс. Метрика – ”Источники” – ”Статистика по запросам”
- Яндекс.Вебмастер – ”Поисковые запросы” – ”Получить рек. запросы”
- Google Search Console – ”Отчёт” – ”Эффективность” – ”Запросы”
 Метрика – ”Источники” – ”Статистика по запросам”
Метрика – ”Источники” – ”Статистика по запросам”Дополнительных сервисов для парсинга запросов огромное множество, вот дюжина из них:
- Moab
- keys.so
- Megaindex
- Moab.tools
- Key collector
- A-parser
- Rush analytics
- Топвизор
- SE Ranking
- Promopult.ru
Большинство ключей будут повторяться, но появятся и те, которых не было ранее. Всё собранное потребует объединения и дальнейшей очистки.
Этап 4 – Чистка и нормализация фраз
Оценив, что люди ищут, и собрав сотни или даже тысячи ключей, начинаем чистку. Если понимаем, что ищут они не то, что нам нужно, от таких запросов нужно избавляться. Длительно, муторно, но делать это нужно вручную. Автоматике здесь веры нет.
Чистка запросов- Чистка ненужных запросов. В корзину попадут запросы с упоминанием непосредственных конкурентов, с теми регионами и городами, где мы не работаем
- Удаление дубликатов. В корзине окажутся запросы-синонимы. Если есть запрос “заказать ремонт”, то “ремонт заказать” нам уже не нужен. Не требуется нам и те запросы, которые являются уточнением основного ключа.
- Проверка орфография (без опечаток). Запросы, которые набраны по какой-то причине с ошибками, сносим. Удаляем запросы, смысла которых мы не понимаем
- Удаление лишних символов и запросов с частотностью 0. Убираем смело и микрозапросы с частотностью ниже 10
 В корзине окажутся запросы-синонимы. Если есть запрос “заказать ремонт”, то “ремонт заказать” нам уже не нужен. Не требуется нам и те запросы, которые являются уточнением основного ключа.
В корзине окажутся запросы-синонимы. Если есть запрос “заказать ремонт”, то “ремонт заказать” нам уже не нужен. Не требуется нам и те запросы, которые являются уточнением основного ключа.Для определения точной частоты запросов можно воспользоваться одной из программ:
- Key collector
- A-parser
- Spyserp
- Rush analytics
- Топвизор
Все это выгружаем в файл и сохраняем.
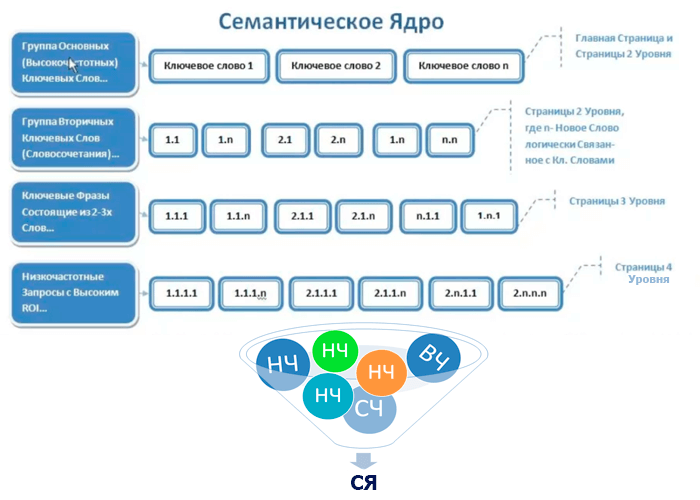
Этап 5 – Кластеризация семантического ядра
Итогом работы должно стать грамотное распределение ключевых запросов по типу и группам.
Определяем тип запроса и соответствия страницы
Например, коммерческий, информационный и типы страниц: главная и внутренняя – информационные отправляем в раздел «Статьи» или «Блог», а коммерческие запросы оставляем на страницах «Услуг» или «Товаров».
Определяем совместимость продвижения запросов на одной странице
“Сколько стоит ремонт”, “Стоимость ремонтных услуг” отлично пойдут вместе на страницу с прайсом. А вот “демонтажные работы” и “монтаж кровли” никак не “лягут” на страницу, посвященную услуге ремонта офисов.
Сервисы кластеризации семантического ядра:
- Spyserp — сервис, платный
- Rush analytics — сервис, платный
- Топвизор — сервис, платный
- coolakov.ru/tools/razbivka/ — сервис, бесплатный
- Keyassort — программа, платная
- Key collector 4
В итоге вы получите разветвленное “дерево” со всеми собранными, очищенными ключами, распределенными по всей карте сайта. Для постобработки кластеризованной семантики можно воспользоваться бесплатной надстройкой для Excel. Это будет удобно, наглядно и понятно.
Пример качественного семантического ядра (образец)
Пример как выглядит СЯВажно понимать, собираем мы семантику для уже существующего сайта или намереваемся запускать проект с нуля.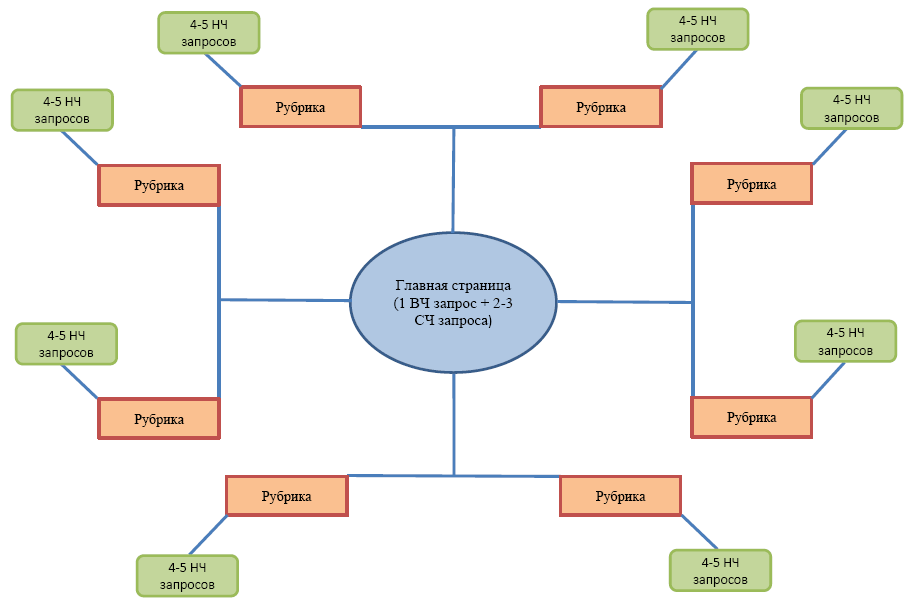 Представленная ниже таблица позволит проверить вашего СЕО-специалиста, но не сделать за него работу (не стоит заниматься самолечением). Так это выглядит на практике:
Представленная ниже таблица позволит проверить вашего СЕО-специалиста, но не сделать за него работу (не стоит заниматься самолечением). Так это выглядит на практике:
Пример семантического ядраСкачать
Анализ семантического ядра или как определить качество
Хороший вариант заказать экспресс-аудит семантики от KeyClient. Вы узнали как сделать правильный сбор семантического ядра, собрали его, но не уверены в его качестве? Получите аудит семантики от KeyClient.
Заказать экспресс-аудит семантического ядра
Резюме – что делать с этим семантическим ядром
Что делать с семантическим ядром? Семантика – фундамент, на нем возводится “дом” сайта. Имея ядро, составляем контент-план. После анализа уже есть понимание того, сколько фраз, сколько страниц и каких нужно сделать на сайте. Основные потребности ЦА определены. Решаем, какая фраза берется в качестве центральной. Это далеко не в 100% случаев наиболее популярный ключ. Главное – чтобы он в полной мере отражал потребность аудитории ресурса. Прочие ключи распределяем:
Прочие ключи распределяем:
- Информационный материал, страница, где дается описание продукта
- Вопрос-ответ
- Специальный блог, где рассматриваются нюансы использования продукции
- Страницы товаров или услуг
- Страница заказа
Не упирайтесь в информационные потребности. Ключи важны. Вписаны в текст? Замечательно. Но вы пишете не для поисковика, а для людей. Информация, которая дана, должна быть полезна и удобна для восприятия. Если это не сделано, успеха и ТОПа не будет никогда. Что не надо делать с семантическим ядром:
- Не обращать внимания на “супер конкурентные” ключи. Чтобы обрастать трафиком и реализовывать продукт, не обязательно быть в ТОПе. Пусть запрос будет
- Обратная ситуация – отказ от низкочастотных фраз – тоже нежелательна. Рекомендуем оставлять по возможности больше ультранизкочастотников – впоследствии их можно развернуть до контент-идеи
- Ориентироваться при составлении семантики сайта только на формулы и коэффициенты. Лечат не анализы, лечат пациентов. KEI важен, но у нас не школа математики, не надо на него молиться
- Не формируйте страницы исключительно ради запросов. Не надо делать две страницы “купить осетинские пироги” и “заказать осетинские пироги”. Здесь это одно и то же. Страничка будет одна
- Не пытайтесь переложить все на автоматику. Программы, сервисы неплохи, это хорошее рабочее средство. Но сами по себе без ручного анализа они не стоят ничего. Алгоритм умеет систематизировать, но не умеет думать – для этого нужен человек
 Лечат не анализы, лечат пациентов. KEI важен, но у нас не школа математики, не надо на него молиться
Лечат не анализы, лечат пациентов. KEI важен, но у нас не школа математики, не надо на него молитьсяАкцентироваться на сборе ключевых фраз. Не превращайтесь в агента 007, который бесконечно следит за конкурентами, денно и нощно собирает ключи. Это избыточно. На старте достаточно статистики Яндекса. Расширять количество источников стоит, если ядро требует расширения, или у команды возник дефицит идей.
Не стоит строить семантическое ядро ради того, чтобы строить семантическое ядро. Процедура проводится ради цели. Какая она у вас?
Не потеряйте нас, подпишитесь на дайджест
и сразу получите: «10 лайфхаков по привлечению клиентов»
руководство для инди-студий — Gamedev на DTF
В статье описаны этапы сбора семантического ядра, составления фундамента всей текстовой ASO оптимизации и продвижения в поиске.
1172 просмотров
На данный момент в Google Play более 11,4 млн., а в App Store более 4.4 млн. приложений.
Создавая и публикуя собственное приложение или игру в Google Play или App Store, вы задаетесь вопросом — как и по каким запросам пользователи найдут ваш проект? Как строить свое семантическое ядро для текстового ASO, чтобы приложение было заметно на фоне конкурентов и получало качественный органический трафик?
Чтобы ответить на эти вопросы, разберемся в терминах “ключевое слово” и “семантическое ядро”.
ASO терминология
Ключевые слова (поисковые запросы, ключи, ключевики, keywords) — это слова или фразы, которые включают интент (намерение,потребность) пользователя найти то или иное приложение или игру. Ключевые слова могут состоять из наименований жанров игры, категорий приложений, отдельных их функций или прямого описания. Например ключ “idle tycoon game” описывает инкрементальную игру в жанре tycoon.
Юзеры набирают ключи в строке поиска, ожидая найти наиболее подходящее их запросу приложение. Соответственно, разработчикам и ASO специалистам необходимо внедрять такие запросы в метаданные на страницах приложений, чтобы повысить поисковую видимость и конверсию.
Соответственно, разработчикам и ASO специалистам необходимо внедрять такие запросы в метаданные на страницах приложений, чтобы повысить поисковую видимость и конверсию.
Семантическое ядро (СЯ) — это все релевантные ключевые слова и фразы, описывающие ваше приложение. СЯ- это фундамент всей текстовой оптимизации и продвижения в поиске. От того насколько релевантны и ценны найденные вами ключевые слова и фразы зависит ваше ранжирование в поиске, а также появление в категориях и похожих (similar apps) в Google Play.
Важно не забывать, что семантическое ядро для Google Play и App Store отличается, так как это два разных не связанных между собой магазина приложений со своими уникальными алгоритмами.
При составлении СЯ необходимо собрать как можно больше ключевых слов, которые потенциально принесут установки вашему проекту. В этой статье мы подробно расскажем, как это сделать.
Этап 1: Исследование
Как правило разработчики инди-студий и ASO специалисты могут быстро описать своё приложение на 15 — 20 слов без труда. А для расширения списка ключей понадобится помощь команды разработки. Вы можете устроить мозговой штурм или пустить в коллективе Google Форму, где каждый причастный к проекту поделится своими ассоциациями.
А для расширения списка ключей понадобится помощь команды разработки. Вы можете устроить мозговой штурм или пустить в коллективе Google Форму, где каждый причастный к проекту поделится своими ассоциациями.
Обычно полученный список содержит большинство высокочастотных (ВЧ) и среднечастотных (СЧ) запросов, описывающих основные функции, жанр и задачи, которые решает ваше приложение.
Например, если это игра в жанре idle simulator, первыми запросами в списке скорее всего будут: idle simulator, idle simulation, simulator offline, idle simulation game. А если у вас брендовое приложение, список будет состоять из брендовых ключевых слов с общими запросами.
Добавьте их в свое стартовое семантическое ядро и переходите к следующему этапу.
Этап 2: Автоматические подсказки (Keyword Auto-Suggestions)
Воспользуйтесь инструментами ASO-сервисов и ASA для App Store и изучите, что ищут пользователи и что они находят по поисковым запросам. Потому что часто юзеры не вводят запрос целиком, а нажимают на поисковую подсказку, которую предлагает маркет.
На этом этапе введите в поисковую строку релевантные запросы из своего стартового списка и вы получите ключи, которые ранее уже вводили юзеры. Они могут быть похожи на ваши, но с дополнительными словами, если они релевантны вашему приложению — добавьте их в свое семантическое ядро.
Для Google Play обращайте внимание на длинные запросы (long-tail keywords), они низкочастотные (НЧ) и конкуренция по ним низкая, более 60% поискового трафика приходится на long-tail запросы. И на старте вашего приложения long-tail ключи принесут вам первый целевой органический трафик.
При сборе семантики для App Store учитывайте показатель популярности запроса Search Ads Popularity (SAP). Apple маркирует им запросы при настройке рекламных кампаний в Apple Search Ads. И для App Store лучше не использовать и не вносить в ядро низкочастотные запросы, SAP которых меньше 5.
Автоматические сервисы помогут вам увеличить количество ключей в разы. Популярные ASO-сервисы с функцией автоматических подсказок по бесплатной пробной версии: AppFollow, ASO Desk, Checkaso, ASO Mobile.
Подсказки и запросы мы ищем в мобильном поиске (магазины приложений), а не в web поиске, так как это две абсолютно разных платформы размещения.
Этап 3: Анализ конкурентов
На этом этапе вам необходимо отобрать конкурентов, которые имеют сильные позиции на интересующих вас рынках. Воспользуйтесь вышеуказанными ASO-сервисами, добавьте конкурентов и оцените запросы, которые они используют, проверьте их на релевантность и добавьте в свое семантическое ядро.
Сбор семантического ядра при помощи конкурентов на примере Jumper Cat: Bouncing Kitten
Если же вы не знаете, кто ваш конкурент, введите запрос в строку и посмотрите, кто ранжируется по нему. Если приложения похожи на ваше, используйте этот запрос.
Также обращайте внимание на то, сколько приложений использует выбранный вами ключ. В случае, если ваше приложение пока не популярно, выйти в топ по ВЧ и СЧ запросам будет сложно и поэтому нужно ранжироваться по запросам с низкой конкуренцией.
Этап 4: Чистка семантического ядра
На этом этапе вам необходимо очистить семантическое ядро от нерелевантных и низкочастотных запросов. Количество символов в метаданных ограничено, а значит включить в них все найденные запросы не получится. Нужно оставить именно те ключи, которые могут дать установки.
Следует оставлять только релевантные запросы, чтобы приложение находили только те юзеры, которым оно нужно. Иначе будут расти удаления, retention будет падать.
Для Google Play удаляйте запросы с ошибкой, по ним вы можете проиндексироваться, но использовать в метаданных их не следует.
Для App Store вы можете оставить запросы с ошибкой, их можно добавить поле ключевых слов и проиндексироваться по ним. Однако такие ключи следует проверять вручную, так как автокоррекция в IOS устройствах автоматически исправляет опечатки и такие ключи могут не дать трафика.
Если в вашем ASO-сервисе в списке с ключевыми фразами есть показатель Popularity и Difficulty, удаляйте слова с низким Popularity и высоким Difficulty.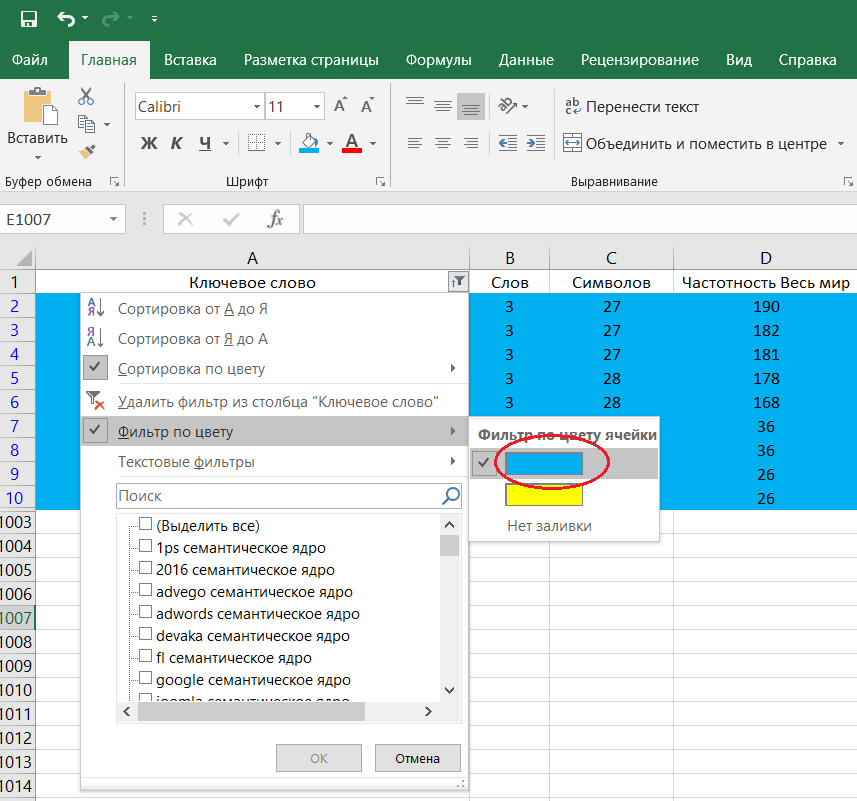 Вырасти в топе по таким ключам новому приложению будет невозможно.
Вырасти в топе по таким ключам новому приложению будет невозможно.
Если вам необходимо собрать запросы для иностранных локализаций, переведите и проработайте СЯ на English. Такой способ даст понимание поведения пользователей и облегчит локализацию поисковых фраз.
Этап 5: Кластеризация семантического ядра
Кластеризация как этап работы с семантикой в ASO оптимизации пришла к нам из SEO, где кластеризация запросов по Топу или семантическим когортам определяет пул запросов на посадочную страницу.
Кластеризация запросов по семантическим группам в ASO позволяет охватить большее количество запросов производных из одного ключа и проиндексировать их.
Выглядит кластеризация следующим образом, вы оцениваете свое семантическое ядро и выделяете отдельные кластеры по термам (подсловам), разбивая поисковые фразы и автоподсказки.
Кластеризация запросов в семантическом ядре на примере Samedi Manor: Idle Simulator
Метод поможет вам быстро отслеживать покрытие метаданных ключевыми фразами и выстроить поэтапно итеративную работу с текстовым ASO:
- сужать семантику и увеличивать ранжирование по выгодным кластерам из ТОП 5 — ТОП 20;
- увеличивать охват в рамках узкой семантической когорты;
- максимизировать установки, двигая ключевые слова из ТОП 50 в ТОП20; из ТОП 20 в ТОП 5 в рамках выбранного кластера.

Выводы
Чтобы собрать семантическое ядро, вам необходимо провести 5 этапов:
- Добавить все поисковые слова, которые ассоциируются с приложением у вас и вашей команды.
- Расширить семантическое ядро за счета автоматических подсказок ASO-сервисов и инструментов ASA.
- Проанализировать конкурентов и найти релевантные вам запросы, по которым они ранжируются.
- Очистить семантическое ядро от низкоконкурентных и нерелевантных запросов.
- Провести кластеризацию запросов для дальнейшей итеративной работы.
Учитывайте правила App Store и Google Play, подготовьте текстовые метаданные на основе вашей семантики.
Бонус! Вы можете скопировать Шаблон семантического ядра и распределения ключевых слов под метаданные для App Store и Google Play. В нем уже есть скрипт “Распред”, фильтрующий ключевые слова по кластерам для быстрой итеративной работы.
Работа с ключевыми словами — фундамент текстовой ASO оптимизации приложений. Собирая поэтапно семантическое ядро, вы найдете релевантные и ценные запросы, по которым пользователи найдут ваше приложение. Так вы сделаете ваше приложение более заметным на фоне конкурентов и получите качественный органический трафик.
Козловская Людмила
ASO Specialist /// Black Caviar Games
Подписывайтесь на официальный аккаунт Black Caviar Games на DTF, чтобы не пропустить новые интересные статьи! 😉
Мы также есть в YouTube, VK, Telegram, Яндекс.Дзен и TikTok.
Что такое основная семантическая модель и как она строится?
Чтобы прочитать предыдущую запись в этой серии от команды [A] Semantics для получения дополнительной информации, щелкните здесь.
Что такое основная семантическая модель?
[A] определяет Базовую семантическую модель как комплексную модель, которая определяет термины и терминологию организации, а также их отношения, чтобы обеспечить идентификацию этих терминов в предметной области и в разных системах.
Это определение состоит из четырех ключевых компонентов:
- Семантические определения — Основная семантическая модель включает канонические определения всех ключевых терминов для управления использованием этих терминов в организации. Эти определения могут исходить из таксономий предприятия и определений глоссария.
- Отношения между терминами — Основная семантическая модель использует принятые стандарты, такие как Простая система организации знаний (SKOS), для моделирования семантических отношений между терминами в машиночитаемом виде. Эти отношения можно использовать, например, для расширения возможностей контента для многоканальной доставки.
- Облегчает идентификацию терминов в предметной области и в разных системах. — Семантический уровень, представленный базовой семантической моделью, позволяет системе определять, какие термины означают одно и то же, и доставлять правильный термин по нужному каналу.
- Интеграция с CMR в CCM — CSM выполняет важную функцию в сочетании с CCM. CCM обеспечивает структуру контента, а CSM обеспечивает значение и интерпретацию этого контента. Говоря более формально, CSM интегрируется с CCM, связывая содержащиеся в нем семантические определения и отношения в виде метаданных, определенных в компоненте CMR CCM.
Компоненты базовой семантической модели
Из чего состоит основная семантическая модель? Создание интерпретируемой компьютером карты значения, безусловно, нуждается в логической основе для ее построения. Вот компоненты, которые [A] включает в CSM: Таксономии и SKOS.
Таксономии и СКОС
CSM начинается с существующих таксономий организации. Скорее всего, они уже разработаны, чтобы облегчить маркировку и навигацию по контенту организации или улучшить использование поисковых систем в организации.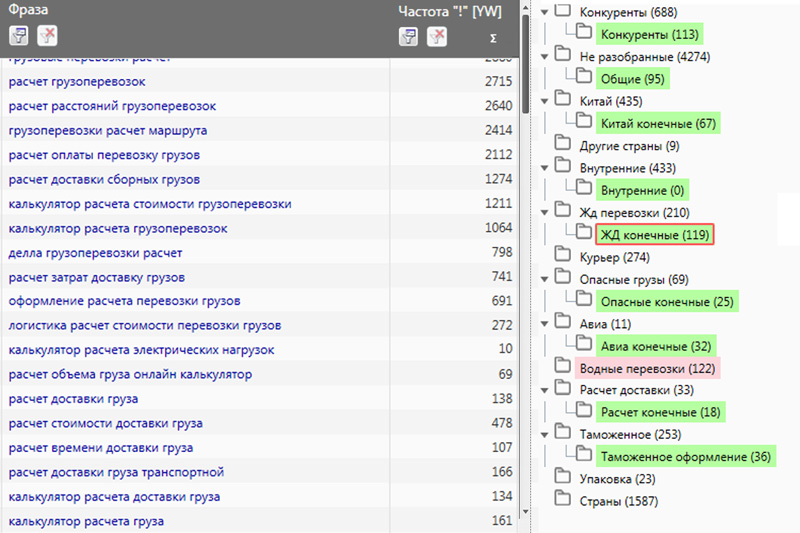 После завершения аудита таксономий организации при необходимости строятся дополнительные таксономии, чтобы охватить все активы контента, которые выиграют от семантического слоя.
После завершения аудита таксономий организации при необходимости строятся дополнительные таксономии, чтобы охватить все активы контента, которые выиграют от семантического слоя.
Таксономия включает иерархические отношения между ее терминами. Он указывает, какие термины шире или уже, чем другие термины. Например, у организации может быть категория товаров кухонные столовые приборы. Эта категория может быть классифицирована как более узкая, чем категория кухонных инструментов, а также более широкая, чем категория кухонных ножей. Но чтобы быть полностью функциональной и полезной во всех наборах, Базовая семантическая модель должна пойти дальше и включить моделирующие отношения из широко применяемого стандарта для простой системы организации знаний (SKOS).
В частности, модели потребуется способность определять, когда разные термины означают одно и то же, определять, какие термины семантически связаны друг с другом, и идентифицировать существенные наборы терминов. Продолжая наш пример с кухонными столовыми приборами, расширив нашу модель, включив в нее отношения SKOS, мы можем включить дополнительную ключевую информацию.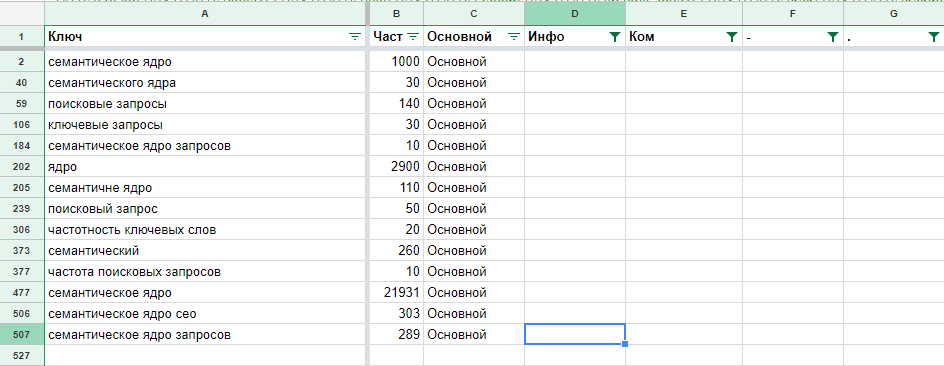 Мы можем смоделировать тот факт, что термин «столовое серебро» является распространенным альтернативным термином для «кухонных столовых приборов». Поскольку клиенты, покупающие кухонные ножи, скорее всего, будут заинтересованы в покупке разделочной доски, мы также можем отметить, что кухонные ножи связаны с разделочными досками. Наконец, мы могли бы отметить, что кухонные ножи требуют предосторожности при использовании, и сделать это, собирая кухонные ножи с другими продуктами, требующими предосторожности.
Мы можем смоделировать тот факт, что термин «столовое серебро» является распространенным альтернативным термином для «кухонных столовых приборов». Поскольку клиенты, покупающие кухонные ножи, скорее всего, будут заинтересованы в покупке разделочной доски, мы также можем отметить, что кухонные ножи связаны с разделочными досками. Наконец, мы могли бы отметить, что кухонные ножи требуют предосторожности при использовании, и сделать это, собирая кухонные ножи с другими продуктами, требующими предосторожности.
Определения семантической модели
Следующим компонентом CSM является канонический контролируемый список определений для всех семантически релевантных терминов. Это связано с базовой моделью контента, предоставляя разработчикам контента возможность понять интегрированную взаимосвязь между двумя моделями.
Отношения между терминами
Для большей функциональности CSM со временем будет расширяться для моделирования более сложных семантических отношений. Выйдя за пределы отношений, представленных в таксономии или модели SKOS, CSM в конечном итоге разовьется в полную онтологию, то есть машиночитаемую формальную модель домена терминов с более широким набором отношений, чем в модели таксономии или SKOS. . С помощью онтологии у нас есть машиночитаемый способ выражения почти любого отношения между терминами, которое мы пожелаем. Возвращаясь к нашему примеру с кухонными ножами, в нашей семантической модели SKOS мы могли бы смоделировать, что кухонные ножи связаны с разделочными досками. Но если мы расширим используемые нами отношения, мы сможем быть более конкретными. Мы могли бы использовать более конкретное отношение, например, используемые вместе: кухонные ножи и разделочные доски используются вместе. Используя эту более конкретную взаимосвязь между кухонными ножами и разделочными досками, можно затем увеличить продажи кухонных ножей, ориентируясь на клиентов, которые покупают разделочные доски.
Выйдя за пределы отношений, представленных в таксономии или модели SKOS, CSM в конечном итоге разовьется в полную онтологию, то есть машиночитаемую формальную модель домена терминов с более широким набором отношений, чем в модели таксономии или SKOS. . С помощью онтологии у нас есть машиночитаемый способ выражения почти любого отношения между терминами, которое мы пожелаем. Возвращаясь к нашему примеру с кухонными ножами, в нашей семантической модели SKOS мы могли бы смоделировать, что кухонные ножи связаны с разделочными досками. Но если мы расширим используемые нами отношения, мы сможем быть более конкретными. Мы могли бы использовать более конкретное отношение, например, используемые вместе: кухонные ножи и разделочные доски используются вместе. Используя эту более конкретную взаимосвязь между кухонными ножами и разделочными досками, можно затем увеличить продажи кухонных ножей, ориентируясь на клиентов, которые покупают разделочные доски.
Как строится основная семантическая модель?
Оценка существующих таксономий и источников семантической достоверности
Во многих организациях уже есть таксономии, наборы тегов, словари терминов, руководства по поисковой оптимизации, системы управления терминологией, метаданные с информацией о продуктах и множество других источников семантической достоверности, которые могут быть получены из существующих ресурсов контента.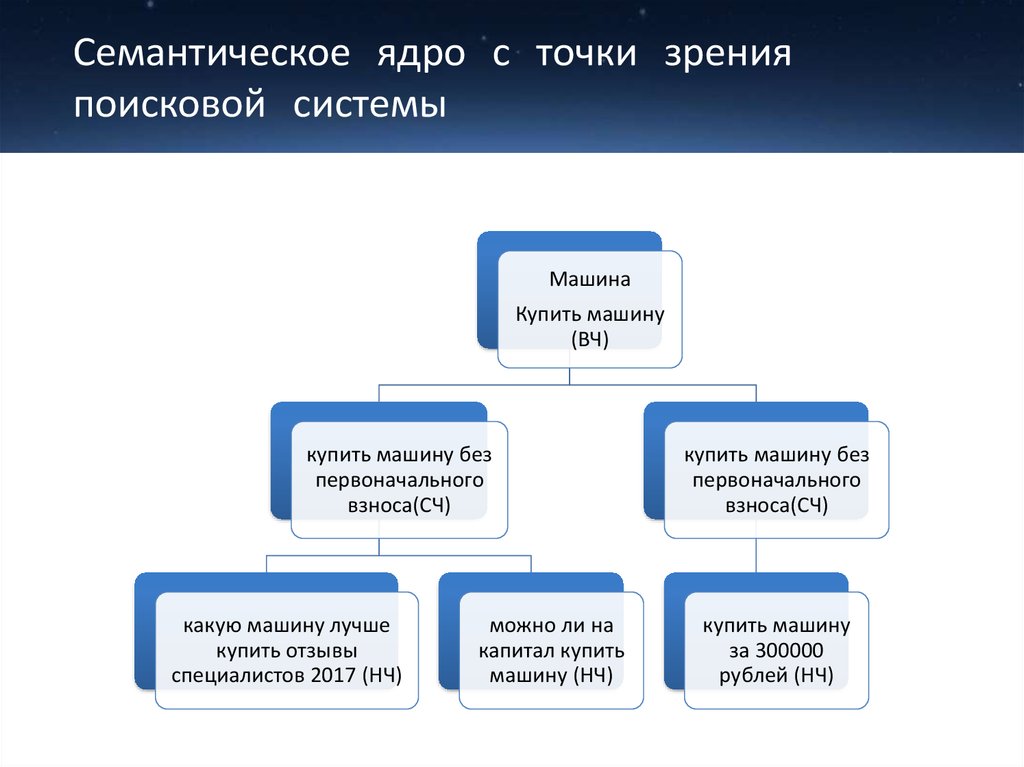 Таким образом, первый шаг к построению CSM включает в себя аудит этих существующих таксономий и других семантических источников. Эти аудиты предоставляют начальный набор терминов, используемых для начала моделирования их отношений с полями метаданных в базовой модели содержимого. Эти таксономии составят начальную основу нашего CSM.
Таким образом, первый шаг к построению CSM включает в себя аудит этих существующих таксономий и других семантических источников. Эти аудиты предоставляют начальный набор терминов, используемых для начала моделирования их отношений с полями метаданных в базовой модели содержимого. Эти таксономии составят начальную основу нашего CSM.
Интеграция с моделью основного содержимого
После того, как был проведен аудит существующих таксономий организации, мы можем обратиться к CCM ресурсов контента организации в качестве руководства по построению CSM. Это обеспечит правильную интеграцию CSM с CCM, что является ключом к обеспечению интеллектуального взаимодействия с клиентами. Интеграцию CSM с CCM можно выполнить, выполнив следующие действия:
- Инвентаризация активов контента: мы отвечаем на следующие вопросы:
- Какие активы моделируются в CCM?
- Какие активы имеют наибольшее семантическое значение?
- Как они используются?
- Как они доставляются?
- Где они созданы?
- Семантический анализ
После проведения инвентаризации ресурсов контента мы можем приступить к семантическому анализу.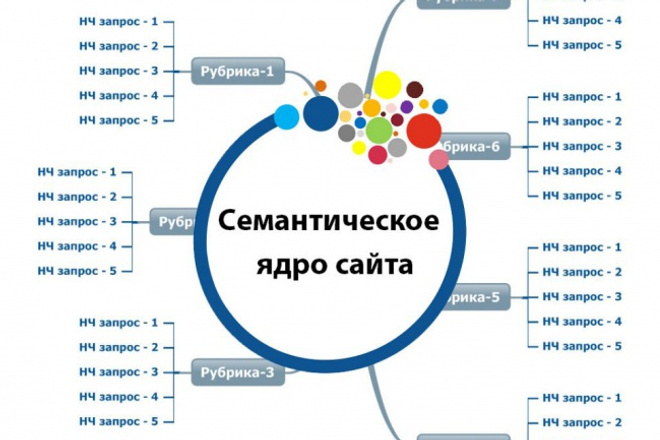 Именно здесь мы определяем важную семантическую информацию, которую мы в конечном итоге хотим смоделировать в нашем CSM, отвечая на следующие вопросы:
Именно здесь мы определяем важную семантическую информацию, которую мы в конечном итоге хотим смоделировать в нашем CSM, отвечая на следующие вопросы:
- Какие термины вместе образуют естественную категорию?
- Какие виды отношений существуют между терминами?
- Какие термины взаимозаменяемо используются организацией?
- Дизайн семантической модели
После завершения анализа мы можем приступить к построению самой семантической модели. Сюда входит построение таксономии всех семантически релевантных терминов с указанием иерархических отношений между терминами. Это также включает в себя моделирование того, какие термины уже или шире, чем другие термины.
Это также включает другие семантически релевантные отношения между терминами, такие как отношения SKOS, рассмотренные выше, или более конкретные отношения, составляющие онтологию. Как упоминалось ранее, крайне важно, чтобы модель CSM соответствовала установленным отраслевым стандартам. SKOS является одним из таких стандартов. По мере того, как модель превращается в онтологию, разработчики моделей должны быть внимательны к другим соответствующим стандартам, таким как RDF или OWL.
SKOS является одним из таких стандартов. По мере того, как модель превращается в онтологию, разработчики моделей должны быть внимательны к другим соответствующим стандартам, таким как RDF или OWL.
Наконец, модель также включает контролируемый список канонических семантических определений всех терминов.
Часто эта работа включает сотрудничество с различными заинтересованными сторонами для достижения общих семантических конструкций. Не каждая группа должна соглашаться. Тезаурусы могут отображать вместе то, что нужно каждой группе, чтобы называть вещи для своих целей. Но сущность смыслов нуждается в общей основе в согласованной истине; и эта общая истина — это то, что мы кодифицируем в семантической модели.
Демонстрация семантической модели
Ценность CSM должна быть осязаема посредством демонстрации. Таким образом, следующим шагом является создание парадигмы использования семантической модели. Например, окончательная таксономия может использоваться для облегчения доступа к активам контента или навигации по ним, или может использоваться модель альтернативных меток для терминов, чтобы обеспечить согласованность маркировки контента.
Демонстрация выполняет две важные функции. Во-первых, это дает возможность заинтересованным сторонам в CSM увидеть конкретную ценность, обеспечиваемую моделью. Во-вторых, это дает решающую возможность проверить качество CSM. Часто бывает трудно получить представление о том, насколько хорошо будет работать семантическая модель, не протестировав ее «в реальных условиях».
Демонстрационная реализация затем может быть использована для вдохновения инициатив по развитию дополнительных возможностей, обеспечивающих успех и пример ранней демонстрации. Затем семантические интеграции начинают, в конечном счете, жить своей собственной жизнью, разделяя одно и то же понимание смысла, обеспечиваемое CSM.
Узнайте больше об услугах семантического моделирования [A] или позвоните по телефону
, чтобы получить бесплатную консультацию.
Готов к разговору
Сущности Google, ключ к созданию семантической сети
Время чтения: 11 минут
Вещи, а не струны. Это было в 2012 году, когда тогдашний старший вице-президент Google Амит Сингхал использовал это выражение, чтобы представить Граф знаний и его инновационный подход, который вскоре будет применяться 9.0014 для поиска и SEO в целом . Немногим более чем за десятилетие ландшафт изменился, и сегодня семантическая сеть, графики и особенно сущности являются важными компонентами поиска и современного SEO, , обрабатывающего множество факторов, чтобы дать полезные ответы, такие как контекст, намерение пользователя и отношений между словами. В основе этого лежит именно концепция сущностей , которая, возможно, наиболее сложна для понимания и является ядром семантической сети и ключом, с помощью которого алгоритмы поиска могут идентифицируют темы и связывают их друг с другом. Сущности для Google — это именно те узлы, которые позволяют нам понять связи между различными терминами, потребности, выраженные пользователями, и контекст, в котором эти сущности существуют и переплетаются .
Это было в 2012 году, когда тогдашний старший вице-президент Google Амит Сингхал использовал это выражение, чтобы представить Граф знаний и его инновационный подход, который вскоре будет применяться 9.0014 для поиска и SEO в целом . Немногим более чем за десятилетие ландшафт изменился, и сегодня семантическая сеть, графики и особенно сущности являются важными компонентами поиска и современного SEO, , обрабатывающего множество факторов, чтобы дать полезные ответы, такие как контекст, намерение пользователя и отношений между словами. В основе этого лежит именно концепция сущностей , которая, возможно, наиболее сложна для понимания и является ядром семантической сети и ключом, с помощью которого алгоритмы поиска могут идентифицируют темы и связывают их друг с другом. Сущности для Google — это именно те узлы, которые позволяют нам понять связи между различными терминами, потребности, выраженные пользователями, и контекст, в котором эти сущности существуют и переплетаются .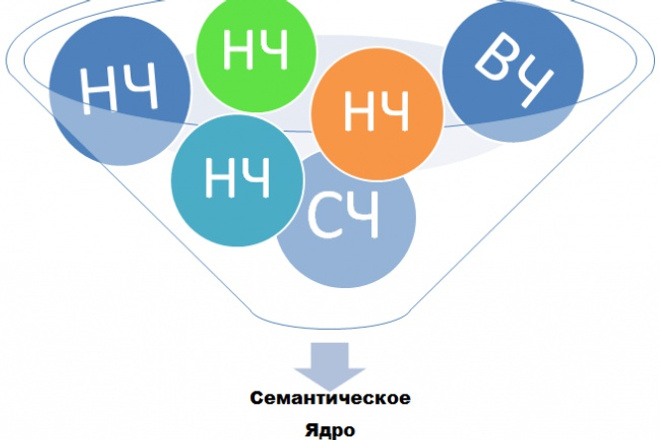 По этой причине работа над оптимизацией сущностей в нашем контенте является одним из направлений, в котором следует направлять деятельность SEO, выходя за рамки старых концепций ключевых слов.
По этой причине работа над оптимизацией сущностей в нашем контенте является одним из направлений, в котором следует направлять деятельность SEO, выходя за рамки старых концепций ключевых слов.
Что такое объект согласно Google
Определение объекта происходит непосредственно из патента Google, уже зарегистрированного в 2012 году и постоянно обновляемого на протяжении многих лет, чтобы адаптировать его к новым технологиям и эволюции алгоритма, который сразу же используется для построения Графика знаний, но затем также распространяется на Исследования в целом . В документе говорится, что в интересующем нас значении сущность — это
« вещь или понятие, которое является своеобразным, уникальным, четко определенным и различимым «.
Более конкретно, объект может быть человеком, местом, объектом, идеей, абстрактным понятием, практическим элементом или любой их комбинацией, объясняет команда Google, и, вообще говоря, объекты включают вещей или понятий с лингвистической точки зрения. представлено существительными.
представлено существительными.
Понимание сущностей: примеры и пояснения
Таким образом, сущности — это не просто имена или физические объекты, учитывая тот факт, что Google преуспел в следующем шаге: сущность может быть идея или теория (например, теорема Пифагора), прилагательное (например, цвет), абстрактное понятие (единорог), глобально интересная тема (глобальное потепление), актуальная дата и так далее, чтобы все можно было собрать уникальным образом без какой-либо путаницы.
Кроме того, еще одно отличие от классических ключевых слов, которые привязаны к языковым -специфическим терминам, сущность несет в себе значение и составляет независимый от языка и подобных ключевых слов, которые его обозначают, и его можно найти с помощью ряда различных условий поиска. Это также снижает двусмысленность в переводе слов, которые иногда имеют несколько значений в зависимости от контекста и нюансов, которые могут быть трудны для понимания теми, кто не владеет этим языком, а также для машин поисковых систем.
Эти вещи, по словам Сингала, сопровождали эволюцию поисковой системы и ее алгоритмов, сначала с введением Hummingbird , а затем с RankBrain, с помощью которого Google изменил подход к пониманию смысла и предмета, охватываемого веб-страницей, полагаясь больше не исключительно и просто на ключевые слова, а на анализ понятий, содержащихся в тексте.
Это стало еще более очевидным в последние годы с появлением Google BERT, а затем Google MUM, двух технологий, основанных на искусственном интеллекте и машинном обучении, применяемых к поисковой выдаче, которые способны лучше понимать языка пользователей и глубоко анализировать их запросы и потребности, выходя за пределы буквального значения запроса (понимаемого как строка символов или слов) для определения намерения.
И затем мы не должны забывать о постоянном увеличении структурированных данных и разметки schema.org, части информации, которую мы предоставляем через наши страницы, чтобы поисковые роботы могли лучше понять содержание и, действительно, присутствующие объекты и отношения.
Все эти данные помогают поисковым системам предоставлять пользователям больше результатов по теме , сфокусированных на реальных намерениях, с возможными выводами (см. также экспоненциальный рост полей, которые люди также запрашивают в поисковой выдаче), но, что наиболее важно, уменьшить недопонимание и свести к минимуму не в фокусе Результаты.
Какие сущности полезны для
Таким образом, на общем уровне сущностью может быть человек, место, понятие, конкретная вещь , то есть все, что мы можем представить лингвистически; для Google это то, как он пытается обучает свои алгоритмы естественно понимать язык, как мы это делаем автоматически (простите за каламбур).
Мы можем думать об этих семантических объектах как о наборах родственных слов , которые очень часто встречаются в содержании, имеющем отношение к определенной теме или понятию, и передают значения, обычно связанные с ключевым словом: замечая эти взаимосвязи и корреляции , машины умеют усваивать и понимать смысл понятия.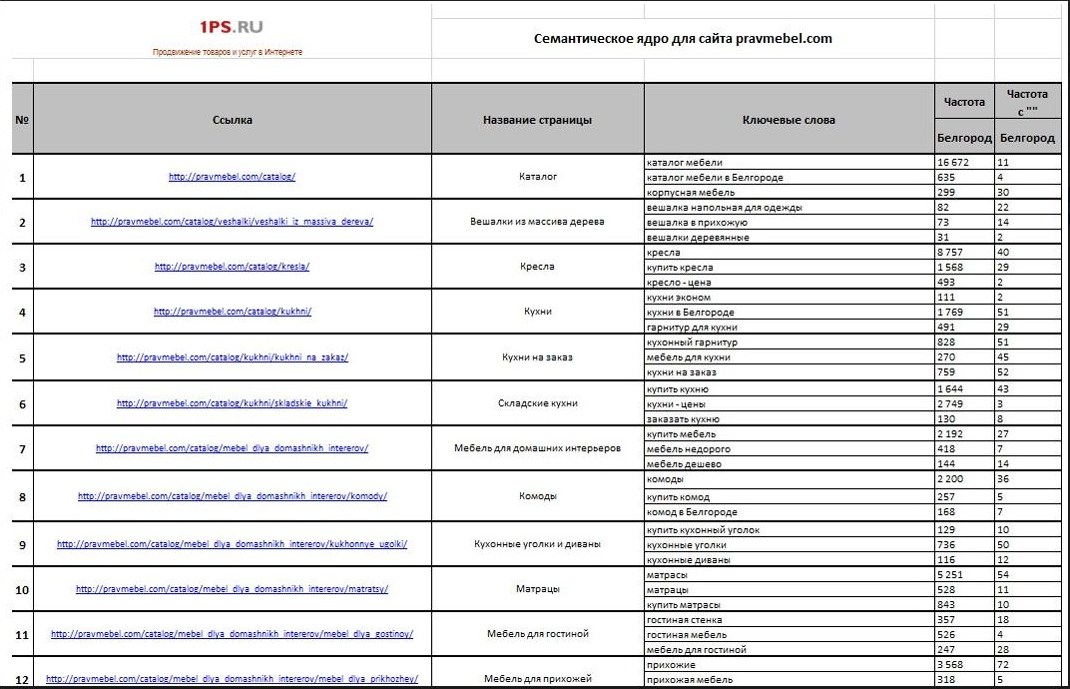
Алгоритм ищет и анализирует не простое ключевое слово, а широкий спектр взаимосвязанной информации , с помощью которой он обрабатывает подробный и подробный ответ на запрос пользователя. Эти объекты хранятся и сгруппированы в графе знаний Google, графе знаний, который точно представляет сеть информации и данных в Интернете и предоставляет поисковым системам точный контекст , в котором можно сканировать страницу и сайт.
Таким образом, именно контекст становится решающим понятием, ключевой переменной для определения степень релевантности части контента по заданному поисковому запросу и, следовательно, для понимания намерений человека и устранения двусмысленности в отношении контента, который он или она обнаруживает.
Мы говорим, опять же, о семантическом SEO, которое способно выйти за рамки простых строк символов запроса, чтобы сосредоточиться на намерении пользователя, и которое перехватывает направление, взятое поисковыми системами, которые сегодня больше не награждают контент большим количеством ключевых слов или зависит от таких параметров, как плотность ключевых слов и т. п., но страницы, которые знают, как реагировать на запросы людей нуждается в информации и развлечениях.
п., но страницы, которые знают, как реагировать на запросы людей нуждается в информации и развлечениях.
База данных сущностей Google
В свете различных соображений аналитиков, которые также основаны на изучении самых последних оригинальных патентов Маунтин-Вью, мы можем предположить, что Google создает и развивает свою базу данных сущностей (которая когда-то назад было около 5 миллиардов сущностей и более 500 миллиардов владельцев сущностей) с использованием двух разных методов: копирование существующих сущностей и обнаружение новых .
В первом случае поисковая система идентифицирует объекты, которые уже известны (благодаря надежным источникам, таким как Википедия и Imdb, например) и согласовывает их с реальным миром: недостатком является то, что сроки сообщения о новых объектах или обновление старых зависит от источников, и, таким образом, Google зависит от них для предоставления соответствующего контента.
Чтобы преодолеть это ограничение, группа запатентовала несколько методов обнаружения новых сущностей из неструктурированных данных, доступных в Интернете, с использованием двух разных стратегий. В частности, поисковая система может использовать известные объекты и проверять через синтаксис или другие сигналы (например, частое появление в документах по той же теме), относятся ли они к неизвестным объектам , которые необходимо учитывать. Другой метод измеряет значение объекта по сравнению с размером его области действия, из чего следует, что легче стать авторитетным объектом в узкой области, чем появиться в широкой нише.
Организации и Google: как работает ранжирование организаций
Как упоминалось ранее, График знаний Google играет важную роль в поисковой оптимизации сущностей, и именно анализ патента, связанного с этим инструментом, дает нам представление о том, как работает определение отношений сущностей.
Анализ был проведен Дэйвом Дэвисом в 2017 году на основе патента Google США № US 2015/0331866 A1: несмотря на то, что это «старое» исследование, предоставленная информация все еще может дать нам полезное понимание основ современной сущности отношения и то, как мы о них думаем.
По Исследование Дэвиса , классификация сущностей в Поиске рассматривает четыре фактора : родство (родство), известность, вклад и вознаграждение; Алгоритм Google исследует эти факторы и использует их для создания сети связей между различными объектами и повышения эффективности поиска для пользователя. Технически каждому объекту присваивается уникальный идентификационный номер , , который затем «преобразовывает» его в код и данные, чтобы их можно было отобразить в графе знаний.
- Корреляция позволяет нам понять связь между терминами в запросе и показать различные SERP (в Google USA), которые различают президента США и президента США:
- Заметность. Google использует формулу (подробно описанную в патенте) для определения заметности объекта. Помимо формулы, в нем отмечается, что объекты более ценны в категориях с низкой конкуренцией и более ценны, когда у них больше ссылок, обзоров, упоминаний и релевантности. По сути, это означает, что «быть большой рыбой в маленьком пруду — значит получить большую известность, чем быть такой же рыбой, плавающей в океане».
- Вклад , относящийся к тому, насколько организация вносит свой вклад в тему: он определяется внешними сигналами, такими как или обзоры, а обзор или обратная ссылка с более авторитетного веб-сайта будут иметь больший вес, чем менее уважаемый.
- Награды . Это именно то, что это означает, то есть мера соответствующих наград, полученных организацией, таких как Нобелевская премия или премия Академии. Чем престижнее награда, тем выше ценность организации.
 Google использует формулу (подробно описанную в патенте) для определения заметности объекта. Помимо формулы, в нем отмечается, что объекты более ценны в категориях с низкой конкуренцией и более ценны, когда у них больше ссылок, обзоров, упоминаний и релевантности. По сути, это означает, что «быть большой рыбой в маленьком пруду — значит получить большую известность, чем быть такой же рыбой, плавающей в океане».
Google использует формулу (подробно описанную в патенте) для определения заметности объекта. Помимо формулы, в нем отмечается, что объекты более ценны в категориях с низкой конкуренцией и более ценны, когда у них больше ссылок, обзоров, упоминаний и релевантности. По сути, это означает, что «быть большой рыбой в маленьком пруду — значит получить большую известность, чем быть такой же рыбой, плавающей в океане». Собирая всю эту информацию вместе, для каждого запроса Google определяет родство, известность, вклад и награды других сущностей и присваивает значения, своего рода окончательный балл для каждой возможной сущности.
Если мы ищем, например, «лучшие актеры», поисковая выдача возвращает список, в котором в основном фигурируют победителей Оскара за лучшую мужскую роль, потому что Google пытается дать «объективный» ответ даже на такую субъективную тему, рассматривая четыре фактора ранжирования сущностей в качестве эталона ранжирования — в этом смысле награда за лучшую мужскую роль на церемонии вручения премии Оскар, знаменитый Оскар, представляет собой показатель «качества». На практике сосредоточение внимания на анализе «наград» и «веса» этих наград позволяет Google выявлять и показывать наиболее релевантные сущности 9.0005
Другая полезная информация о том, как работает этот механизм, включает в себя наличие базы данных сущностей , которая просто хранит сущности и их соединения и служит Google, чтобы избежать необходимости обрабатывать лучшие результаты каждый раз при выполнении запроса, и рейтинг сущностей, основанных на некотором показателе качества , который может включать свежесть, предыдущие выборы пользователей, входящие ссылки и, возможно, исходящие ссылки.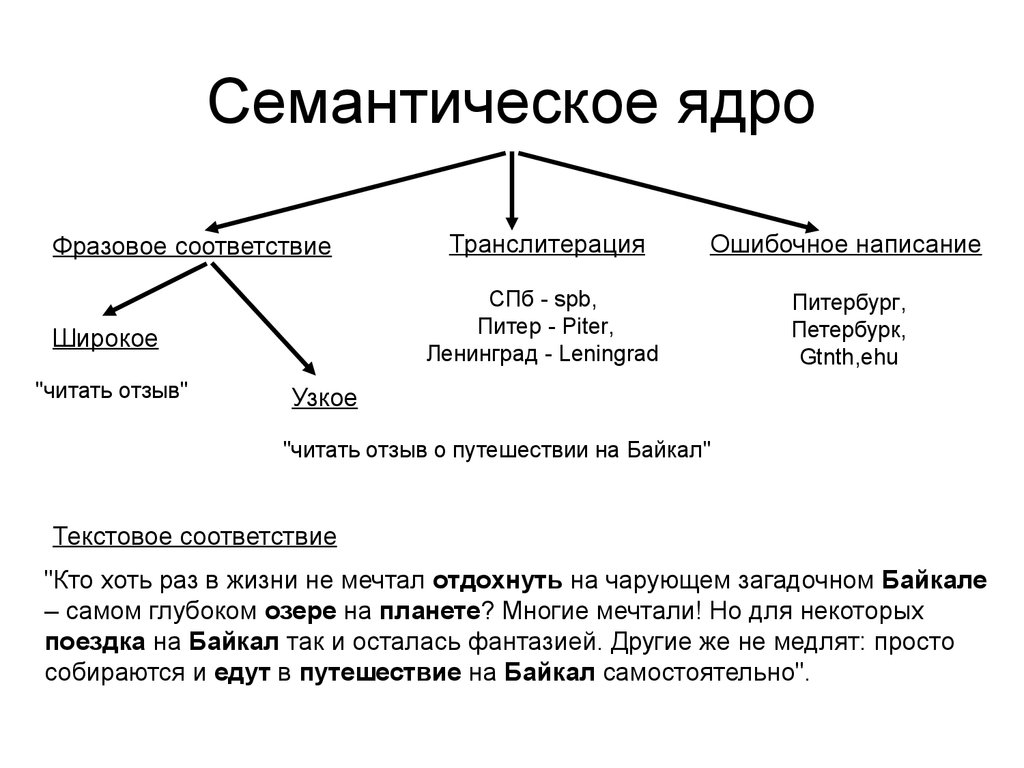
Существуют также методы, позволяющие Google вывести контекст для нескольких объектов с одним и тем же именем: например, Филадельфия может относиться к городу, сливочному сыру и фильму, но если мы включим в запрос такие слова, как «где», мы направим поиск в город США. , «актер» или «сюжет» к фильму и «сочетания» или «калории» к еде. Таким образом, Google может определять объекты и их отношения , когда данные неструктурированы (информация, которая не имеет заранее определенной модели данных или не организована заранее определенным образом), а также может изучать новые объекты.
Связи между сущностями и важность ссылок
Пытаясь упростить довольно сложные концепции, мы могли бы сказать, что Google использует набор из систем для оценки связей между сущностями и придания важности каждой из них: например, это может установить корреляцию между двумя объектами, сравнивая количество раз, когда они цитируются как на веб-страницах.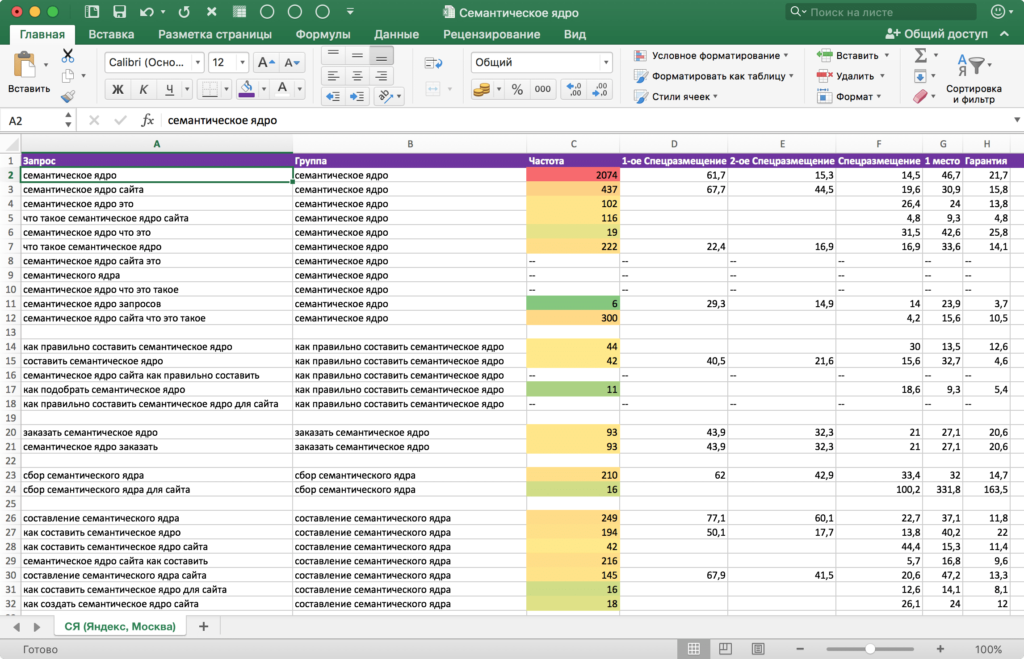
Внешним фактором понимания являются материалы, предоставленные различными источниками, такими как обзоры, опубликованные третьими лицами диаграммы и т. д.: в данном конкретном случае 9Значение 0014 также аргументировано на основании источника. Особой типологией является та, которая касается призов , используемых для определения воспринимаемой ценности объекта по сравнению с деятельностью, профессиональной областью или компетенцией.
Кроме того, ссылки и упоминания также играют важную роль, учитывая тот факт, что они используются в качестве фактора для измерения важности ( заметности ) объекта на основе того, как он относится к запросу или другому объекту: Алгоритм перекрестно проверяет глобальную популярность объекта и, следовательно, количество обратных ссылок, упоминаний в социальных сетях и т. д., и анализирует его по сравнению с значение объекта определенного типа .
Давайте вернемся к разговору о ценности ссылок, но в другом смысле (может быть, не так много, на самом деле): мы определили их как «голоса» от сайта к сайту, но ссылки также являются способом создания связи между объекты (например, ссылающийся сайт и связанный сайт), поэтому, вероятно, считаются объектами PageRank страниц, используемый якорный текст, релевантность темы и т. д.
д.
Schema.org и тип данных, структурированных для построения семантической сети.
Прежде всего, однако, те инструменты, которые у нас есть для передачи сущностей в Google (и для предложения нашего контента как такового), представляют собой структурированные данные и информацию schema.org, и они нужны нам для реализации семантической сети. . Это означает, что новый (и уже не очень) способ напрямую сообщать поисковой системе всю информацию, содержащуюся на веб-страницах и за ними (бренды, авторы…), чтобы Google мог ускорить сбор и обработку данных и ответы на них. на поисковый запрос быстрее и точнее.
Используя сущности и их данные, алгоритм может фактически вычислить вероятности перехватить реальное намерение пользователя с большей точностью и в то же время – по языку и используемому тону – понять, будет ли результат положительным или отрицательный .
По сути, как мы уже говорили в прошлых посвященных статьях (в частности, в этой статье о микроформатах), для того, чтобы определить объекты и предоставить их поисковым системам в виде данных, вы должны использовать структурированные данные, поэтому для выделения сети тема страницы и корреляция между различными объектами.
Объекты в рамках SEO
Достигая наших профессиональных тем, внутри объектов поля SEO также являются элементами, лежащими в основе исследований пользователей : продукт для покупки, бренд , новости, кулинарные рецепты все объекты в поисковую систему. Эффективно используя словарный запас схемы и структурированные данные, мы напрямую общаемся с Google — целенаправленным и безошибочным языком — о наших страницах и темах веб-сайта , давая алгоритму реальный шанс лучше понять , без какой-либо путаницы.
Зачем заниматься SEO-оптимизацией объектов?
Мы уже давно сказали это с помощью провокации «ключевого слова нет»: текущая тенденция поисковых систем состоит в том, чтобы преодолеть ограничения, налагаемые простым пониманием (и поиском) ключевых слов , а скорее определить темы и контекст активируется этими ключевыми словами. Таким образом, мы преодолеваем типичные критические проблемы с ключевыми словами, которые могут быть слишком буквальное и надуманное и вносят двусмысленность , когда, например, один и тот же термин относится к разным понятиям, и только тщательный анализ контекста может точно разрешить сомнения.
Итак, Google и другие поисковые системы все больше и больше движутся в направлении изучения комбинации ключевых слов в запросе и, благодаря сущностям, через анализа страниц, которых уже не понять, какой контент актуален опирается на упрощенное совпадение темы с ключевыми словами, поэтому уже некоторое время мы повторяем, что нам нужно работать над расширением нашего контента и расширение семантического поля ключевых слов другими связанными терминами, принадлежащими к тому же объекту и намерению, которые помогают поисковым роботам лучше определять и понимать контекст.
Методы реализации сущностей на сайте
Внедрение сущностей на контент сопряжено с собственным набором проблем , поскольку техническая инфраструктура меняется, а словарь schema.org постоянно обновляется, поэтому для этого требуется настроить постоянный мониторинг и обслуживание , чтобы убедиться, что добавленные структурированные данные эффективны и безошибочны.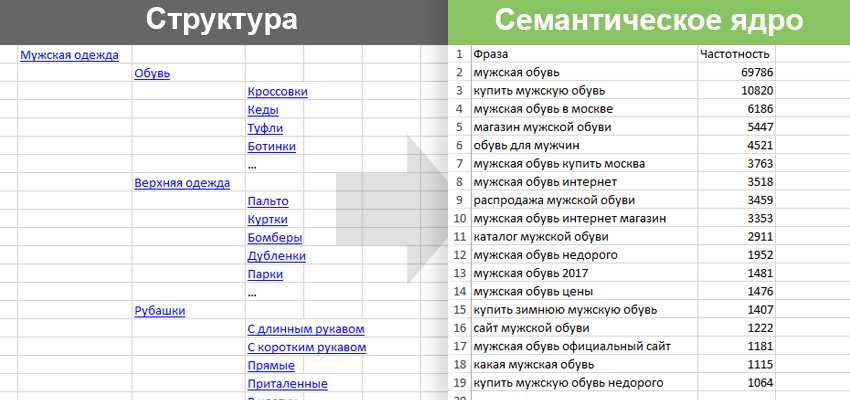
Первый шаг — создать и укрепить идентичность бренда для нашего бренда или для себя, попытавшись войти в граф знаний Google через личную панель или панель знаний о бренде; Таким образом, для бизнеса крайне важно активировать бизнес-профиль (ранее Google My Business), который, хотя и не делает бренд автоматически сущностью, все же является полезным шагом, поскольку Google будет использовать эту вкладку для узнать достоверную информацию и создать связи между сайтом и другими локальными объектами.
Критическое значение имеет использование структурированных данных , которые могут указать поисковым роботам, какие части контента являются сущностями и с какими атрибутами. Например, схема местного бизнеса может служить для связи бизнеса с другими близлежащими географическими объектами, повышая его видимость в локальном поиске; другая разметка, такая как организация, человек и автор , с другой стороны, может помочь создать соединений между объектами на одном веб-сайте, но также и в других доменах, усиливая концепцию «сети».
С практической точки зрения, мы можем проверить, чтобы включал объекты, относящиеся к нашему контенту каждый раз, когда мы публикуем статью, ища другие объекты либо через Поисковую систему (используя, например, отображаемые предложения в других результатах, чтобы выяснить, какие темы и темы Google считает связанными с основной темой нашего контента), или через Страницы Википедии или другие подобные инструменты, которые связаны с известными объектами.
Как лучше сообщать сущности на сайте и в контенте
Итак, есть некоторые шаги и меры, которые мы можем применить на практике, чтобы попытаться повысить ценность нашего сайта как объекта (который, в свою очередь, содержит бесчисленное множество других сущностей), то есть усилить его значение и отношения с другими элементами сети, с которыми мы хотим установить ассоциацию.
Некоторые операции являются более «простыми» и к настоящему моменту должны быть рутинными, например, добавление schema. org на сайт, использование безошибочных структурированных данных, создание листа бизнес-профиля, если мы являемся физическим бизнесом, и его сохранение. в актуальном состоянии, имея соответствующий профиль обратных ссылок благодаря более стратегическому построению ссылок, а также, конечно, уделяя первостепенное внимание созданию качественного контента , который затрагивает темы в широком и глубоком смысле и отвечает на поисковые намерения людей.
org на сайт, использование безошибочных структурированных данных, создание листа бизнес-профиля, если мы являемся физическим бизнесом, и его сохранение. в актуальном состоянии, имея соответствующий профиль обратных ссылок благодаря более стратегическому построению ссылок, а также, конечно, уделяя первостепенное внимание созданию качественного контента , который затрагивает темы в широком и глубоком смысле и отвечает на поисковые намерения людей.
Контент-стратегия и оптимизация сущностей
В заключение, больше нельзя игнорировать растущее значение, которое сущности имеют и будут иметь для SEO, как для поисковой системы , сканирующей , так и для нашего собственного контента.
Это также требует, чтобы мы изменили наш подход к контентной стратегии : в настоящее время для надежной стратегии нам необходимо учитывать (как минимум) общий объем выполненных поисков и намерение, которое Google выбирает для отображения с результатами запроса, используя его алгоритмы.