
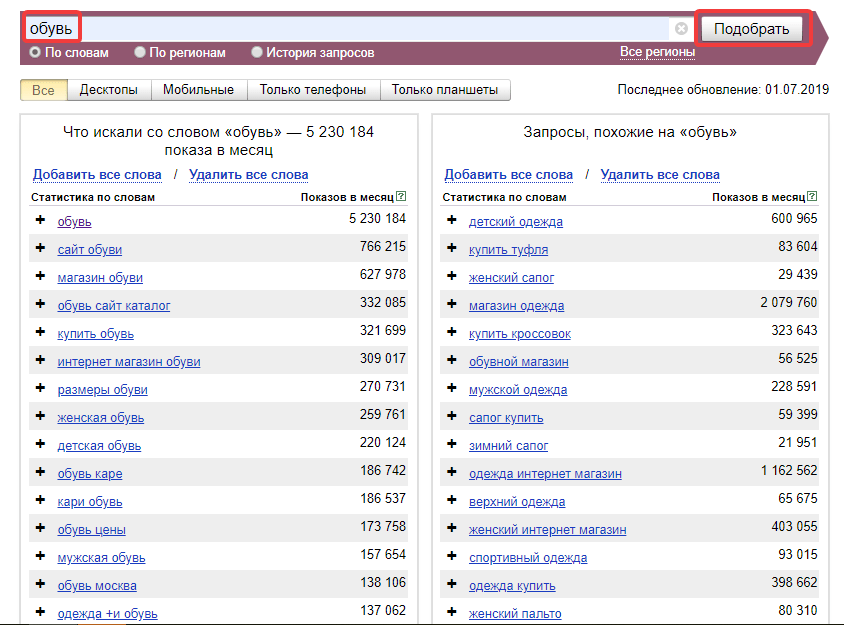
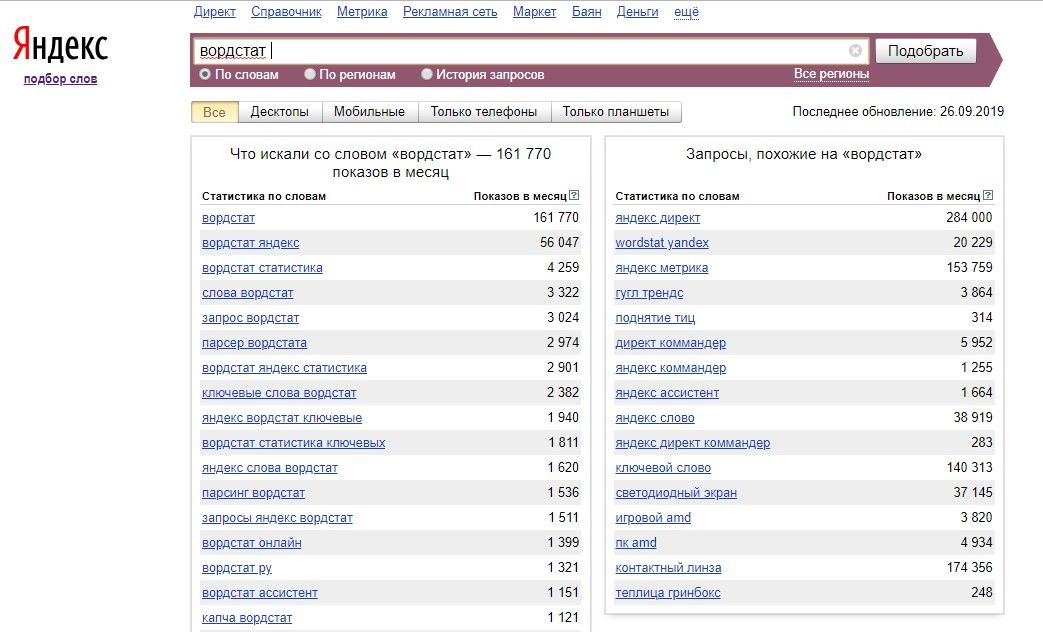
Как быстро собрать ключевые слова в Яндекс Вордстат
iMacros — расширение для браузера, которое умеет выполнять однотипные действия в браузере. Все просто: жмете кнопку Play, открываете сайт, кликайте по нужным кнопкам, вводите текст в любые поля, нажимаете Stop и сохраняете записанный макрос. Спустя время можете запустить сохраненный скрипт для выполнения тех же действий. Это очень хорошо работает с WS.
Макрос можно создать и без записи действий. Откройте новый проект и пропишите нужный код. В нашем случае мы так и поступим, так как код уже написали.
Шаг 1
Установите WS Assistant в Chrome или Яндекс.Браузере.
Шаг 2
Установите iMacros в тот же браузер.
Шаг 3
Создайте новый макрос.
Зайдите на панель Record и кликните по кнопке Record Macro.
Потом нажмите на кнопку Stop.
У вас откроется окно с кодом. Неважно, что там написано, удалите все. После вставьте код, приведенный ниже:
VERSION BUILD=844 RECORDER=CR TAG POS=1 TYPE=B ATTR=TXT:Добавить<SP>все WAIT SECONDS=3 TAG POS=2 TYPE=SPAN ATTR=TXT:Добавить WAIT SECONDS=2 TAG POS=1 TYPE=A ATTR=TXT:далее WAIT SECONDS=2
Сохраните макрос.
Шаг 4
Проверяем работу макроса. Теперь в списке доступных макросов есть новый элемент.
Названия папок могут отличаться.
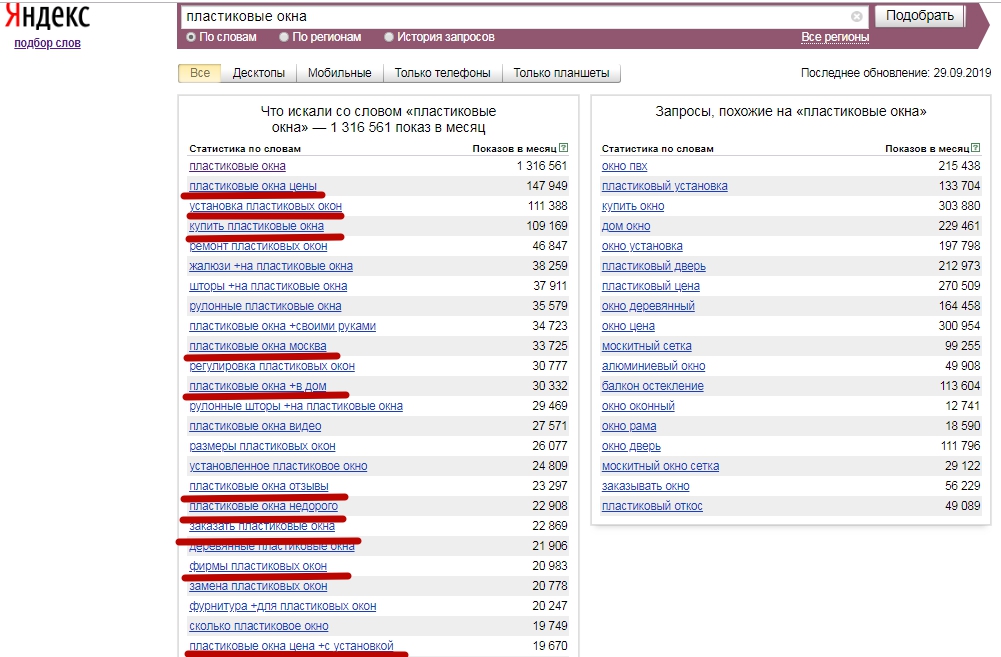
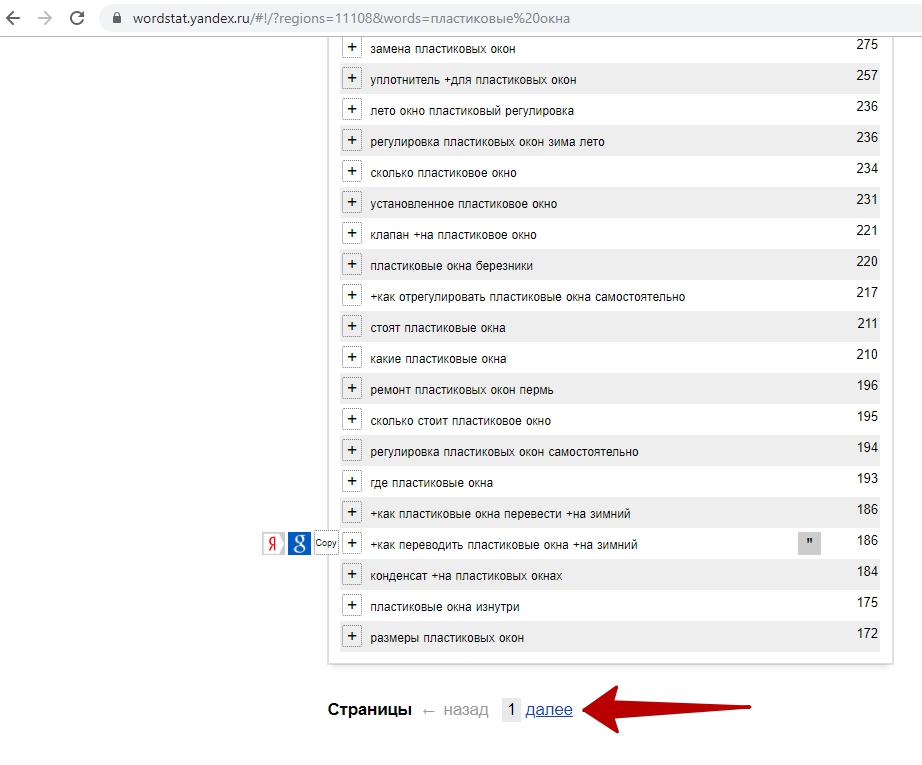
Заходим на страницу Вордстата и выполняем любой запрос.
Открываем iMacros, выбираем наш файл, устанавливаем число проходов и запускаем с повторами.
При этом в основном окне браузера вы должны оставаться на странице Вордстата, никуда не уходите. Во время работы макроса не пользуйтесь браузером.
После выполнения вы увидите, что собрано 150 запросов, соответствующих 3 страницам фраз. Если у вас всё так же, значит эта штуковина работает.
Разберем нюансы
- Пока работает макрос, пользоваться браузером нельзя, иначе ход выполнения действий собьется. Специально для сбора семантики таким способом рекомендуется установить отдельный браузер (Chrome или Яндекс) и ставить выполнение макроса в нем. При этом вы сможете спокойно работать в основном браузере.
- Для работы с WS залогиньтесь в новом аккаунте Яндекс.

- IMacros можно использовать и для любых других нужд, документация по ссылкам http://wiki.imacros.net/Main_Page, https://ru.wikipedia.org/wiki/IMacros.
- Вы можете использовать любые конструкции Вордстата при выполнении запросов.
- В любое время можно отредактировать созданный макрос. Если окно редактирования не запускается, то попробуйте запустить скрипт и тут же его остановить, затем еще раз попробовать отредактировать его.
- В коде есть 3 фрагмента типа WAIT SECONDS=3 – это периоды ожидания макроса после выполнения действий на странице Вордстата. Если у вас в запросе очень много минус-слов или объемная конструкция, то лучше увеличить эти периоды ожидания. Если же число символов в запросе невелико, то можете поставить небольшие значения. Во время своей работы макрос не ждет Вордстат, пока тот закончит выполнение запроса. Возможна ситуация, когда ВС еще грузит страницу, а макрос уже пытается добавить фразы в ассистента, естественно, у него это не получится и дальше продолжит свое выполнение, а 50 запросов со страницы не добавятся. Чтобы этого не случилось, надо выставлять достаточные таймауты в WAIT SECONDS, например 7,7,5 для очень объемных запросов. Вы всегда можете проверить все ли страницы собраны, разделив число собранной семантики на 50 и сравнив с числом проходов.
- Для парсинга всех страниц WS установите в настройках Play Loop значение 42.
- iMacros имеет платную версию, но и бесплатной вполне хватает.
- Пока скрипт собирает семантику, вы занимаетесь другими делами и больше никогда не пролистываете страницы выдачи.

 Возможна ситуация, когда ВС еще грузит страницу, а макрос уже пытается добавить фразы в ассистента, естественно, у него это не получится и дальше продолжит свое выполнение, а 50 запросов со страницы не добавятся. Чтобы этого не случилось, надо выставлять достаточные таймауты в WAIT SECONDS, например 7,7,5 для очень объемных запросов. Вы всегда можете проверить все ли страницы собраны, разделив число собранной семантики на 50 и сравнив с числом проходов.
Возможна ситуация, когда ВС еще грузит страницу, а макрос уже пытается добавить фразы в ассистента, естественно, у него это не получится и дальше продолжит свое выполнение, а 50 запросов со страницы не добавятся. Чтобы этого не случилось, надо выставлять достаточные таймауты в WAIT SECONDS, например 7,7,5 для очень объемных запросов. Вы всегда можете проверить все ли страницы собраны, разделив число собранной семантики на 50 и сравнив с числом проходов.Будем рады вашим комментариям 💬
Парсер Wordstat (вордстат) онлайн, парсинг ключевых слов Яндекс
Парсер Wordstat (вордстат) онлайн, парсинг ключевых слов Яндекс | XMLRiver
Парсер может быть использован для:
- сбора левой колонки Wordstat;
- сбора правой колонки;
- проверки всех видов частотностей по любым регионам;
- проверки сезонности ключевых слов (история запросов).
Начать работу
Экономия времени
Не нужно возиться с прокси и аккаунтами, решением капчей и с другими сопутствующими проблемами. Это мы берём на себя.
Удобный формат
Выдаём данные в том формате, который вы используете для сбора вордстата напрямую в JSON.
Экономия денег
Платите только за то, что использовали. Не нужно арендовать прокси на месяц или оплачивать месячные тарифные планы. Стоимость 1000 запросов от 10р.
В режиме реального времени
Всё происходит в режиме реального времени, вы сразу видите результаты живой выдачи, не используем баз. Парсим Wordstat, а не Яндекс.Директ.
Проверка частотностей запросов в вордстат
Собирайте любые виды частот — 1) базовую; 2) фразовую “”; 3) точную “!”; 4) уточненную [].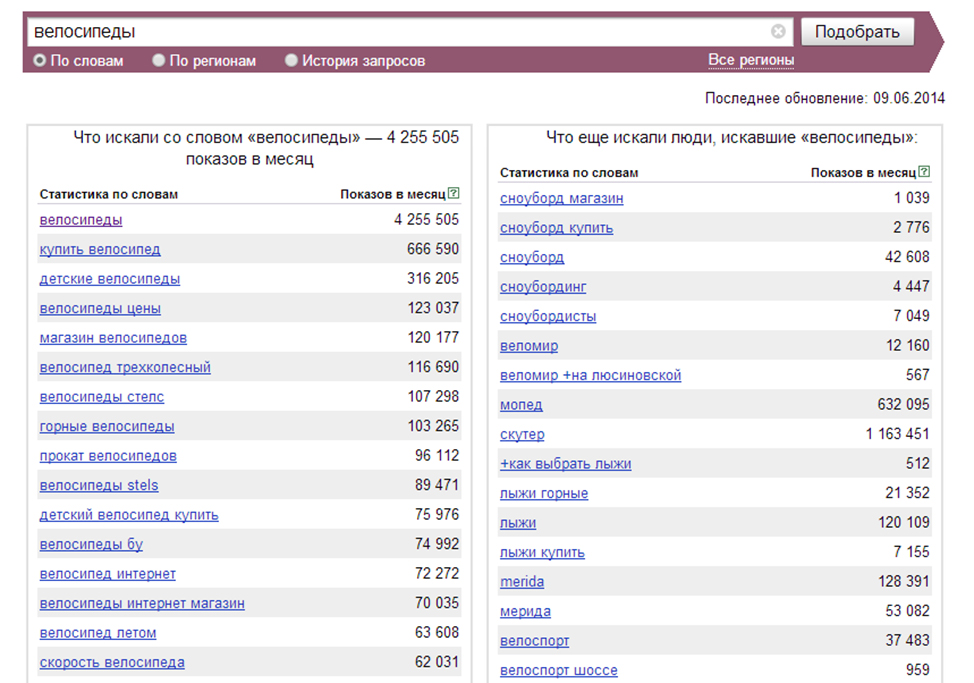 Поддерживаем настройки сбора: выбор региона или нескольких регионов и устройства).
Поддерживаем настройки сбора: выбор региона или нескольких регионов и устройства).
Сбор ключевых слов с wordstat
Сбор ключевых фраз из левой и правой колонки на любую глубину. Сервис позволяет собирать от 1 до 40 страницы.
История запросов
Поддерживаем выбор регионов и устройств (десктопные, мобильные, планшеты или все). Функционал позволяет отследить, как менялась популярность ключевых фраз. С помощью этих данных Вы можете определить сезонность ключа и общий тренд.
Бесплатная десктопная программа для сбора данных
Предоставляем программу XMLRiver.Parser для сбора фраз, частот всех видов и истории запросов. Выгрузка осуществляется в csv формат.
Павел Горбунов,
SEO-оптимизатор, pavel-gorbunov.ru
Мне понравился сервис. Я парсил выдачу Гугл с его помощью, скорость была хорошая, 1000 запросов сервис собрал очень быстро. В сравнении с другими сервисами получилось чуть быстрее.
 Открытость к диалогу — это главный плюс сервиса для меня. При возникновении нетиповой задачи всегда можно обратиться с запросом на доработку, и будет найдено решение (которого, возможно, еще и нет на рынке). Поэтому рекомендую сервис для типовых и нетиповых задач.
Открытость к диалогу — это главный плюс сервиса для меня. При возникновении нетиповой задачи всегда можно обратиться с запросом на доработку, и будет найдено решение (которого, возможно, еще и нет на рынке). Поэтому рекомендую сервис для типовых и нетиповых задач.Александр Ожгибесов,
SEO-оптимизатор, ozhgibesov.net
XMLRiver — это единственный работоспособный вариант в больших объемах за адекватный чек парсить Google. Я, как специалист по семантике, использую сервис для парсинга выдачи для SEO. Относительно недавно добавили множество вариаций для дополнительного парсинга, который очень полезен для серьёзной аналитики выдачи (0 позиция, доп ссылки и т.д.). Всячески хвалю и рекомендую XMLRiver для работы!
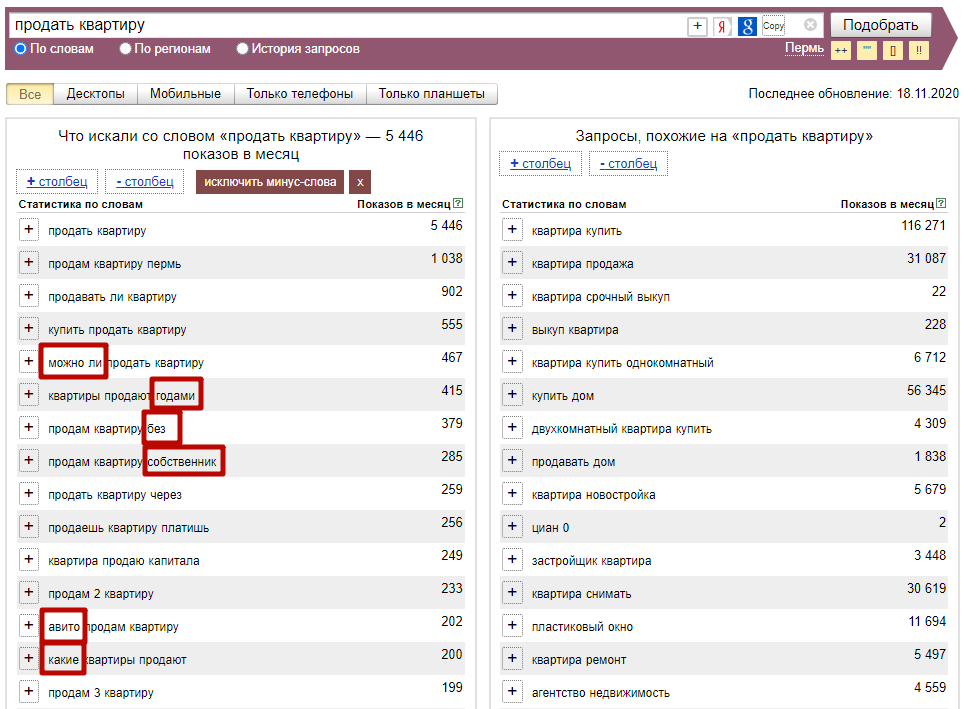
Тарифы
Basic
- Срок действия: ∞
Предоплата: нет - Цена за 1 тыс. запросов
Google: ₽20
Яндекс: ₽20
Wordstat: ₽20
Pro
- Срок действия: 30 дней
Предоплата: ₽3000 - Цена за 1 тыс. запросов
Google: ₽15
Яндекс: ₽15
Wordstat: ₽15
 запросов
запросовMega
- Срок действия: 30 дней
Предоплата: ₽10000 - Цена за 1 тыс. запросов
Google: ₽10
Яндекс: ₽10
Wordstat: ₽10
Если для Вас важны скорость сбора, точность и полнота выдачи, удобный формат, то Вам к нам!
Обеспечим бесперебойность работы, доброжелательный саппорт и высочайшее качество сервиса.
Зарегистрируйтесь   –или–   Войдите
последние новые функции интеллектуального анализа текста
Что нового в версии 8.0?
WordStat 8 имеет новые функции и опции, повышающие гибкость и позволяющие использовать программное обеспечение как менее опытным, так и опытным пользователям.
Мы знаем, что вы получаете все больше и больше текстовых данных и ищете способы их анализа и классификации. Вам нужны инструменты, которые помогут вам быстро находить темы, контекст, важные понятия и смысл в больших объемах текстовых данных. Мы знаем, что это вызов для опытных специалистов по данным и менее опытных исследователей и аналитиков. Поиск способа поддержки этих групп был идеей WordStat 8. Мы хотели улучшить удобство использования и гибкость, одновременно повышая производительность и точность.
Вам нужны инструменты, которые помогут вам быстро находить темы, контекст, важные понятия и смысл в больших объемах текстовых данных. Мы знаем, что это вызов для опытных специалистов по данным и менее опытных исследователей и аналитиков. Поиск способа поддержки этих групп был идеей WordStat 8. Мы хотели улучшить удобство использования и гибкость, одновременно повышая производительность и точность.
Мы считаем, что новый подход WordStat 8 достигает этих целей. Вы можете обрабатывать огромные объемы неструктурированных данных за считанные секунды с минимальным опытом или легко создавать свои собственные обширные словари категорий для точного измерения понятий.
1. Автономная платформа для анализа текста
Изучение нового программного обеспечения может оказаться непростой задачей. Особенно программное обеспечение со многими функциями, такими как WordStat. Раньше WordStat был дополнительным модулем QDA Miner. Это требовало от пользователей не только изучения WordStat, но и элементов QDA Miner для настройки своего проекта. WordStat 8 теперь является самостоятельным продуктом. Это снижает сложность и время обучения, поскольку теперь пользователи могут создавать свои проекты непосредственно в WordStat. Однако его по-прежнему можно запускать как надстройку для анализа контента QDA Miner, STATA или SimStat.
WordStat 8 теперь является самостоятельным продуктом. Это снижает сложность и время обучения, поскольку теперь пользователи могут создавать свои проекты непосредственно в WordStat. Однако его по-прежнему можно запускать как надстройку для анализа контента QDA Miner, STATA или SimStat.
Теперь вы можете создать проект в самом WordStat из разных источников:
- Документы: MS Word, RTF, PDF, HTML и т.д.
- Файлы данных: Excel, CSV, Stata и т. д.
- Платформы веб-опросов: SurveyMonkey, Qualtrics, SurveyGizmo и т. д.
- Инструменты управления ссылками: Endnote, Zotero, Mendeley
- Социальные сети: Twitter, Facebook, Reddit, RSS-каналы, Youtube
- Платформы электронной почты: Outlook, Gmail, Hotmail, Mbox и формат EML
- Многие другие источники…
2. Новый режим проводника
Новый режим проводника позволяет пользователям с небольшим опытом анализа текста быстро и легко извлекать смысл из больших объемов текстовых данных. Вы можете определить наиболее часто встречающиеся слова и фразы и выделить наиболее важные темы в своих документах с помощью улучшенного инструмента моделирования тем WordStat 8. В любой момент вы можете переключиться в экспертный режим, который дает вам доступ ко всем функциям WordStat, включая анализ контента. словари, кросс-таблицы и функции анализа совпадений.
Вы можете определить наиболее часто встречающиеся слова и фразы и выделить наиболее важные темы в своих документах с помощью улучшенного инструмента моделирования тем WordStat 8. В любой момент вы можете переключиться в экспертный режим, который дает вам доступ ко всем функциям WordStat, включая анализ контента. словари, кросс-таблицы и функции анализа совпадений.
3. Улучшенное тематическое моделирование
Существующая процедура тематического моделирования выигрывает от многочисленных улучшений, таких как дополнительный алгоритм извлечения (NNMF) для более быстрого извлечения тем, а также инновационный процесс обогащения тем. Этот метод позволяет выйти за рамки решения «мешка слов», типичного для традиционного тематического моделирования, путем автоматического выбора связанных фраз и предоставления предложений для дополнительных выражений, возможных исключений, а также исправлений правописания. Все эти инновации должны привести к более точному и всестороннему измерению основных тем в вашей текстовой коллекции.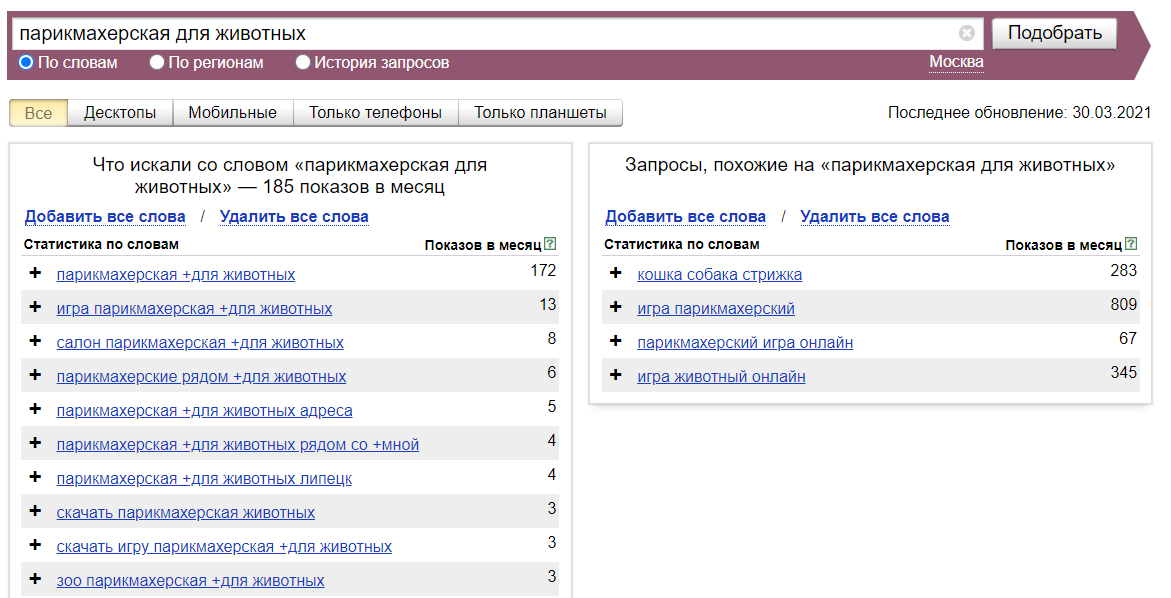
4. Новые и улучшенные графические дисплеи
WordStat 8 имеет несколько новых графических дисплеев, которые помогут вам лучше понять результаты анализа данных. Мы улучшили интерактивные облака слов, кольцевые и радиолокационные диаграммы.
5. Таблица отклонений
Это совершенно новая функция, включенная в WordStat 8. Она была добавлена после выпуска, и вам необходимо загрузить WordStat 8.0.7 или более позднюю версию, чтобы иметь к ней доступ. Таблица отклонений позволяет увидеть, какие слова/фразы используются в большей или меньшей степени по сравнению с другими переменными. Сначала вам нужно активировать кнопку кросс-таблицы, чтобы увидеть значок. Вы можете щелкнуть правой кнопкой мыши, чтобы найти KWIC, удалить и сохранить в формате Tab Delimited, HTML или Bitmap. Чтобы узнать больше об этой специфической функции WordStat 8, щелкните следующую ссылку: таблица отклонений/
6. Экспорт результатов в Tableau Software
Одним щелчком мыши вы также можете экспортировать свои результаты в Tableau Software, чтобы использовать его расширенные интерактивные инструменты визуализации данных.
7. Улучшенное построение словаря для контент-анализа
Несколько новых функций и улучшений были внесены в раздел словарей категоризации, чтобы помочь вам быть более точным при текстовом поиске и получать более точные результаты.
Записи с учетом регистра: словари категорий и список исключений теперь поддерживают записи с учетом регистра для устранения неоднозначности таких слов, как «Bill» и «bill», «Buck» и «buck» или «us» и «US».
Регулярные выражения (регулярные выражения) Поиски: мы создали редактор регулярных выражений, в котором вы можете создавать свои собственные формулы регулярных выражений, чтобы быстро извлекать определенную информацию из ваших текстовых данных, таких как адреса электронной почты или почтовые индексы.
Новый процесс замены: w e мы улучшили процесс замены, разделив его на две части. Отделив его от нашего процесса лемматизации, вы можете легко отслеживать замены и не допускать ошибок в словаре вашего контента.
Списки исключений и замен вместе со словарем категоризации теперь можно сохранять в файл модели категоризации. Этот файл можно использовать в других проектах WordStat, а также в QDA Miner, WordStat Document Explorer или в нашем SDK.
8. Улучшенный интерфейс
Улучшенный интерфейс позволяет быстро получать доступ к результатам и сравнивать их, благодаря чему вы можете извлечь ценную информацию за несколько секунд.
WordStat 7
WordStat 8
9. Преобразование текста с помощью скриптов Python
WordStat 8 открывает специалистам по обработке и анализу данных возможность использовать скрипт Python и полный спектр его библиотек с открытым исходным кодом для предварительной обработки или преобразования текстовых документов для анализа в WordStat. Эта новая функция повышает гибкость WordStat и позволяет пользователям использовать свои навыки программирования на Python.
10. Числовое преобразование
Новое диалоговое окно числового преобразования позволяет вычислять числовые переменные из других переменных с использованием до 50 функций преобразования, включая тригонометрические, статистические функции и функции случайных чисел. Условное преобразование также может быть выполнено с использованием логической структуры IF-THEN-ELSE.
11. Объединение в группы
Функцию объединения теперь можно использовать для преобразования непрерывных значений в меньшее количество отдельных категорий. Его можно использовать для уменьшения влияния числовых выбросов, аномальных распределений или преобразования непрерывной числовой переменной в порядковую. Это особенно полезно для создания графических отображений сравнений, когда количество различных значений в числовой переменной слишком велико. используется для представления объекта, выражения идеи или чувства или добавления нюанса к письменному сообщению. Они часто являются неотъемлемой частью сообщения и вряд ли могут быть проигнорированы. WordStat 8.0 может преобразовывать эмодзи в их текстовое представление, что позволяет анализировать их либо отдельно, либо как часть всего сообщения.
WordStat 8.0 может преобразовывать эмодзи в их текстовое представление, что позволяет анализировать их либо отдельно, либо как часть всего сообщения.
13. Исследуйте свои документы из проводника Windows
Новый инструмент проводника документов позволяет пользователям быстро просматривать содержимое своих документов из проводника Windows без необходимости импортировать документы или создавать проект. Вам просто нужно выбрать документы, которые вы хотите изучить, или папку, содержащую их, щелкнуть правой кнопкой мыши и выбрать «Исследовать», чтобы быстро определить наиболее часто встречающиеся слова и фразы и их местонахождение в ваших документах. С помощью простого щелчка правой кнопкой мыши вы также можете выполнить семантический поиск в ваших документах, используя существующий словарь категоризации, или классифицировать документы, используя модель прогнозирования в WordStat. Посмотрите видеодемонстрацию обозревателя документов WordStat
Новые возможности WordStat 7 можно посмотреть здесь
Примеры исследований с использованием WordStat
Контент-анализ и анализ текста |
Полный список из более чем 350 исследований, в которых использовались Wordstat и/или QDA Miner, можно найти здесь.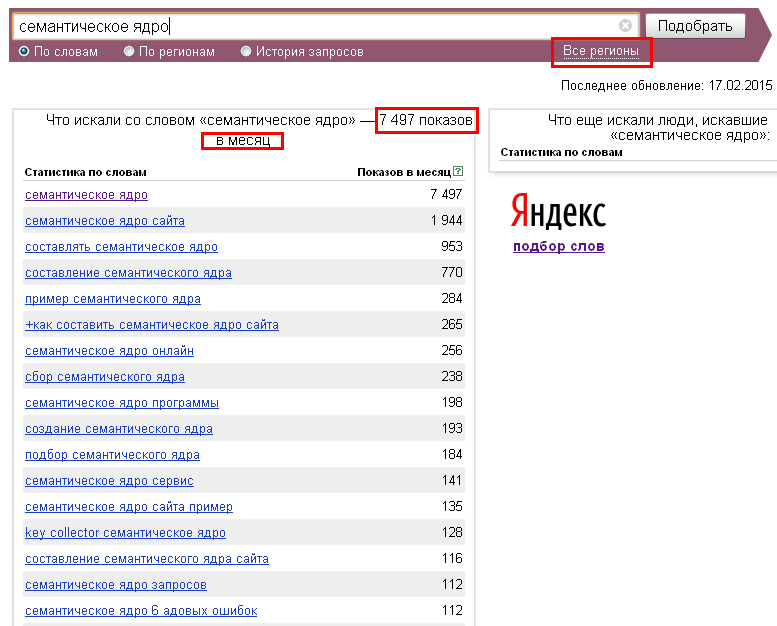
Применение анализа текста к данным о безопасности полетов
Авторы:
Normand Péladeau (Provalis Research) и Крейг Стовалл (авиакомпания JetBlue). Описание: Эта демонстрация технологии прикладной текст процедуры майнинга от Provalis Research Corporation до текстоемких отчеты о безопасности в JetBlue Airways.
Полная ссылка: Пеладо, Н., и Совалл, К. (2005). Заявление Статистического анализа содержания Text Mining компании Provalis Research Corp. к отчетам о безопасности авиакомпаний. Глобальная сеть авиационной информации.
Контент-анализ удовлетворенности клиентов отеля
Авторы: Мадлен Пуллман, Келли Макгуайр, Чарльз Кливленд (Школа гостиничного администрирования Корнельского университета; Quester Linguistics)
Описание: Опросы клиентов и карточки с комментариями — это хорошо, но лучший способ получить полное представление об отношении клиентов к отелю — это проанализировать контекст комментариев клиентов.
Прежде трудоемкий процесс, качественный анализ данных быстро становится доступным для владельцев отелей с использованием программных приложений, поддерживающих анализ контента и связывание данных, а также тех, которые предлагают расширенный лингвистический анализ. Приложения для контент-анализа позволяют аналитику оценить, сколько раз клиент использует конкретное слово или фразу в письменных материалах или расшифрованных замечаниях. Подсчитывая частоту слов и отмечая ассоциации определенных слов, можно классифицировать темы и понятия. Таким образом, «количественно определяя» качественную коммуникацию, аналитик может связать полученную информацию с демографическими или другими количественными данными. Более сложный анализ возможен при лингвистическом анализе, который исследует семантику, синтаксис и контекст вербальной коммуникации клиентов.Полная ссылка: Pullman, M. McGuire, K, Cleveland, C. (2005). Позвольте мне считать слова: количественная оценка открытых взаимодействий с гостями .
 Ежеквартальный отчет администрации отелей и ресторанов Корнелла. Том. 46 (3), 323-343.
Ежеквартальный отчет администрации отелей и ресторанов Корнелла. Том. 46 (3), 323-343.Контент-анализ объявлений о вакансиях, посвященных исследованию операций.
Авторы: МанМохан С. Содхи и Бьюнг-Гак Сон (Cass Business School, City University London)
Описание: Предварительные результаты анализа объявлений о вакансиях дают представление о рынке труда для студентов, преподавателей, руководителей университетских программ и работодателей
Полная ссылка: Sodhi, M.S. & Son, B.-G. (2005). Что промышленность хочет от O.R. Грады . OR/MS Today, выпуск за август 2005 г.
Mining Microarray Expression Data by Literature Profiling.
Авторы: Дэмиен Шоссабель и Алан Шер (Лаборатория паразитарных болезней, Национальная Институт аллергии и инфекционных заболеваний, Национальные институты здоровья)
Описание: авторы разработали методику добычи на основе анализа литературы профили, созданные путем извлечения частот определенных терминов из тысяч рефератов, хранящихся в базе данных литературы Medline.
Полная ссылка: Chaussabel, D.
 Затем термины фильтруются на основе повторяющихся
и совместное появление среди нескольких записей генов. Наконец, кластеризация
анализ выполняется по сохраненным значениям частоты, формируя
целостную картину функциональной взаимосвязи между крупными и
неоднородные списки генов. Такая обработка данных также обеспечивает
информацию о характере и актуальности ассоциаций, которые
были сформированы. Анализ закономерностей появления терминов в рефератах
представляет собой средство изучения биологического значения
большие и разнородные списки генов. Такой подход должен способствовать
оптимизации использования технологий микрочипов путем предоставления
исследователи с интерфейсом между данными сложных выражений
и большие литературные ресурсы.
Затем термины фильтруются на основе повторяющихся
и совместное появление среди нескольких записей генов. Наконец, кластеризация
анализ выполняется по сохраненным значениям частоты, формируя
целостную картину функциональной взаимосвязи между крупными и
неоднородные списки генов. Такая обработка данных также обеспечивает
информацию о характере и актуальности ассоциаций, которые
были сформированы. Анализ закономерностей появления терминов в рефератах
представляет собой средство изучения биологического значения
большие и разнородные списки генов. Такой подход должен способствовать
оптимизации использования технологий микрочипов путем предоставления
исследователи с интерфейсом между данными сложных выражений
и большие литературные ресурсы. , & Sher, A. (2001). Микрочип для майнинга
данные экспрессии по литературному профилированию. Биология генома, 3 , 1-55.
, & Sher, A. (2001). Микрочип для майнинга
данные экспрессии по литературному профилированию. Биология генома, 3 , 1-55.Оценка раскрытия информации о нематериальных ресурсах в корпоративных годовых отчетах.
Авторы: Дина Грей и Йоран Роос (Центр эффективности бизнеса, Школа менеджмента Кэнфилда).
Описание: В сфере бухгалтерского учета наблюдается движение, направленное на то, чтобы побудить компании раскрывать стоимость своих нематериальных активов, и исследователи утверждают, что спрос на внешнюю коммуникацию нематериальных активов и факторов стоимости растет на рынках капитала. В этой статье обсуждается эмпирическое исследование, которое было проведено в 95 компаниях в Великобритании и 16 компаниях в Финляндии, чтобы определить, какие нематериальные ресурсы компании считают важными для создания стоимости, какие нематериальные ресурсы они фактически измеряют, и какие из этих показателей они используют.
Полная ссылка: Gray, D. & Roos, G. (2004). Какие нематериальные ресурсы компании оценивают, измеряют и сообщают? Синтез исследований Великобритании и Финляндии . Международный журнал обучения и интеллектуального капитала, том. 1(3), 242-261.
 фактически раскрыть их заинтересованным сторонам. Функции контент-анализа WordStat использовались для оценки уровня раскрытия информации в корпоративных годовых отчетах этих компаний.
фактически раскрыть их заинтересованным сторонам. Функции контент-анализа WordStat использовались для оценки уровня раскрытия информации в корпоративных годовых отчетах этих компаний.Оценка ожиданий работодателей от информационных специалистов
Авторы: Линда Мэрион, Мэри Энн Кеннан, Патрициал Уиллард и Концепшн С. Уилсон (Школа информационных систем, технологий и менеджмента Университета Нового Южного Уэльса).
Описание: В этом документе представлены результаты предварительного исследования 395 объявлений о вакансиях в библиотеках Австралии и США с августа по октябрь 2004 г.
Полная ссылка: Марион, Л., Кеннан, Массачусетс, Уиллард, П. и Уилсон, К.С. (август 2005 г.). История двух рынков: ожидания работодателей от специалистов в области информации в Австралии и Соединенных Штатах Америки . Доклад, представленный на Всемирном библиотечно-информационном конгрессе: 71-я Генеральная конференция и Совет ИФЛА, Осло: Норвегия.
 анализ профессиональных объявлений о вакансиях из академических, публичных и специализированных библиотек. Навыки межличностного общения, поведенческие характеристики и способность реагировать на изменчивую среду1 были определены в качестве важнейших требований в обеих странах.
анализ профессиональных объявлений о вакансиях из академических, публичных и специализированных библиотек. Навыки межличностного общения, поведенческие характеристики и способность реагировать на изменчивую среду1 были определены в качестве важнейших требований в обеих странах.Контент-анализ журналов обучения менеджеров по маркетингу
Авторы: Фриснер, Тим и Харт, Майк (Группа управления бизнесом, Винчестерский университет).
Описание: В этом исследовательском проекте журналы обучения использовались в качестве исследовательского инструмента для сбора данных о размышлениях, опыте и обучении выборки менеджеров по маркетингу из британских театров.
Полная ссылка: Friesner, Tim and Hart, Mike (2005) Анализ журнала обучения: анализ данных, которые фиксируют размышления, опыт и обучение Университет Париж-Дофин, 21-22 апреля 2005 г.
.png) В этой статье представлен анализ журнала обучения как аналитический подход, помогающий исследователям интерпретировать результаты. Для этого исследовательского проекта Анализ журнала обучения использует контент-анализ, анализ тематических исследований, а также анализ повествования и повествования. Эта статья нацелена просто на то, чтобы представить подход. Он никоим образом не пытается быть окончательной формулой и поощряет дальнейшие исследования и диалог.
В этой статье представлен анализ журнала обучения как аналитический подход, помогающий исследователям интерпретировать результаты. Для этого исследовательского проекта Анализ журнала обучения использует контент-анализ, анализ тематических исследований, а также анализ повествования и повествования. Эта статья нацелена просто на то, чтобы представить подход. Он никоим образом не пытается быть окончательной формулой и поощряет дальнейшие исследования и диалог.Поиск правил клинического прогнозирования в MEDLINE
Авторов: Инги, Бетт Джин; и Мэри А.М., Роджерс (Медицинский университет северной части штата, Сиракузы, Нью-Йорк).
Описание: Нажмите здесь, чтобы прочитать аннотацию.
Ссылка: Инги, Би Джей и Роджерс, Массачусетс (2001). В поисках клинического прогноза правила в MEDLINE. Журнал американской медицинской информатики Ассоциация, 8 , 391-397.

Концептуальный анализ гендерных, феминистских и женских исследований в коммуникационной литературе
Автор: Тимоти Стивен (факультет коммуникаций, университет в Олбани и Президент CIOS)
Описание: В за последние десятилетия накопилась своеобразная литература, обсуждающая роль гендера, феминизма и исследований, связанных с женскими исследованиями (GFWS) в сфере связи; однако остаются вопросы о как это исследование представлено в специальной литературе.
Артикул: Стивен, Т. (2000). Концепция Анализ гендерных, феминистских и женских исследований в Коммуникативная литература. Коммуникационные монографии. 67 , 193-214.
 Этот
статья обрисовывает историю этого представления в полевых испытаниях
метода картирования понятий, который отслеживает модели публикации
и выделяет концептуальные ассоциации в названиях статей GFWS.
Выводы подтверждают идею о том, что феминистская наука представлена
уникальной конфигурацией концептуальных отношений, имеет историю
отдельно от изучения гендера или половых различий,
и что феминистские исследования вошли в литературу в двух отчетливых формах.
разные эпохи. Феминистские исследования имеют уникальную и неоднородную структуру
репрезентации в отраслевой литературе. Концептуальное отображение
Утверждается, что методология обеспечивает одно средство для компенсации фрагментации
стипендии дисциплины, которая произошла в результате
быстрое распространение новых специализированных коммуникационных журналов
происходящие в течение последних трех десятилетий.
Этот
статья обрисовывает историю этого представления в полевых испытаниях
метода картирования понятий, который отслеживает модели публикации
и выделяет концептуальные ассоциации в названиях статей GFWS.
Выводы подтверждают идею о том, что феминистская наука представлена
уникальной конфигурацией концептуальных отношений, имеет историю
отдельно от изучения гендера или половых различий,
и что феминистские исследования вошли в литературу в двух отчетливых формах.
разные эпохи. Феминистские исследования имеют уникальную и неоднородную структуру
репрезентации в отраслевой литературе. Концептуальное отображение
Утверждается, что методология обеспечивает одно средство для компенсации фрагментации
стипендии дисциплины, которая произошла в результате
быстрое распространение новых специализированных коммуникационных журналов
происходящие в течение последних трех десятилетий.
Дифференциация региональных коммуникационных журналов: компьютер Помощь в анализе концепции
Автор: Тимоти Стивен (факультет коммуникаций, университет в Олбани и Президент КИОС)
Описание: журналы четырех региональных коммуникационных ассоциаций США, все придерживаясь эквивалентной редакционной политики, опубликовали совместно более 2900 статей с 1970 года. контент-анализ был использован для изучения концептуальной структуры дисциплины, представленной в этой литературе.
Артикул: Стивен, Т. (2001). Дифференциация региональные коммуникационные журналы США: компьютеризированная концепция анализ. Представлено на заседании Международная коммуникационная ассоциация.
 Использование данных
из базы данных ComIndex слова в названиях статей были лингвистически
нормализованы и отфильтрованы для выделения значимых понятийных терминов. Кластер
Затем к преобразованным данным был применен анализ. Эта процедура
выделили 12 кластеров понятий, представляющих области значимости
научный интерес в четырех журналах. Процедуры ANOVA выявили
различия между четырьмя журналами по 5 из 12 кластеров. Полученные результаты
рассматриваются в свете различий между журналами и
последствия результатов для роли всенаправленных журналов
в эпоху растущей фрагментации научных публикаций.
Использование данных
из базы данных ComIndex слова в названиях статей были лингвистически
нормализованы и отфильтрованы для выделения значимых понятийных терминов. Кластер
Затем к преобразованным данным был применен анализ. Эта процедура
выделили 12 кластеров понятий, представляющих области значимости
научный интерес в четырех журналах. Процедуры ANOVA выявили
различия между четырьмя журналами по 5 из 12 кластеров. Полученные результаты
рассматриваются в свете различий между журналами и
последствия результатов для роли всенаправленных журналов
в эпоху растущей фрагментации научных публикаций. Вашингтон, округ Колумбия, май.
Вашингтон, округ Колумбия, май.Контент-анализ рефератов журналов в коммуникации
Автор: Тимоти Стивен (факультет коммуникаций, университет в Олбани и Президент КИОС)
Описание: С помощью программного обеспечения WORDSTAT, автор проанализировал названия статей, опубликованных в Human Communication Исследовательская работа. Были выявлены совпадения слов, а затем проведен кластерный анализ. выявление пяти основных кластеров, четыре из которых также содержали не менее два подкластера. Эта процедура, как предлагает автор, показывает, как Контент-анализ можно использовать в библиометрических исследованиях.
Ссылка: Стивен, Т. (1999). Компьютерный концептуальный анализ HCR First 25 Годы.
 Исследования человеческого общения, 25 , 498-513.
Исследования человеческого общения, 25 , 498-513.Автоматический анализ содержимого банков тестовых заданий с множественным выбором
Авторы: Форд, Джон М., Томас А. Стец, Мэрилин М. Ботт и Брайан С. О’Лири (Управление по управлению персоналом США)
Описание: Тест рецензирование элементов — это специализированный тип контент-анализа, проводимый выявлять и исправлять недостатки тестовых заданий на ранних этапах разработки теста процесс. Рецензенты тестовых заданий не только изучают целевой контент теста, но и удалить нежелательный контент и сбалансировать различные Типы случайного контента. Реализация автоматизированного контент-анализа шкал вербальной неоднозначности Хиллера и общей шкалы Лаффаля. Концептуальный словарь английского языка был использован для изучения 576 множественных вариантов ответов.
Ссылка: Ford, J.M., Stetz, T.A., Bott, M.M. и Б.С. О’Лири. Автоматизированный Контент-анализ банков тестовых заданий с множественным выбором. Социальные науки & Computer Review, 18 , 258-271.
 тестовые элементы до и после проверки и проверки тестовых элементов опытным
редакторы предметов. Весы Хиллера обнаружили некоторые проблемы с товаром.
ясность. Категории Laffal обнаружили дисбаланс содержания между
тестовые формы, но не неподходящий элемент
содержание.
тестовые элементы до и после проверки и проверки тестовых элементов опытным
редакторы предметов. Весы Хиллера обнаружили некоторые проблемы с товаром.
ясность. Категории Laffal обнаружили дисбаланс содержания между
тестовые формы, но не неподходящий элемент
содержание.Контент-анализ навыков и характеристик в онлайн-рекламе для академических библиотек
Автор: Линда Марион (Университет Дрекселя)
Описание: статья исследует территорию цифрового библиотечного дела и исследует навыки, которые работодатели ищут в новых сотрудниках при технологическом заполнении ориентированные рабочие места.
Ссылка: Марион, Л. (2001). Цифровой библиотекарь, кибраарий или библиотекарь со специализированным навыки: Кто будет укомплектовывать электронные библиотеки? В Х. Томпсон (ред.), Преодолевая водораздел: материалы Десятой национальной конференции Ассоциации университетских и исследовательских библиотек, 15-18 марта, 2001, Денвер, Колорадо (стр. 143-149).), Чикаго: Американская библиотечная ассоциация. Лауреат студенческой исследовательской премии ACRL 2001 года.
 Презентация Мэрион содержит контент-анализ
объявлений о вакансиях, чтобы предоставить карту, описывающую область цифрового библиотечного дела.
Презентация Мэрион содержит контент-анализ
объявлений о вакансиях, чтобы предоставить карту, описывающую область цифрового библиотечного дела.Оценка знаний о природе науки
Авторов: Памела С. Бернли, Уильям Эванс и Ольга С. Джарретт (Грузия государственный университет)
Описание: авторы изучали изменения в научных знаниях и отношении к науки среди участников летнего исследовательского опыта для Программа бакалавриата.
Артикул: Бернли, П.К., Эванс, В., и Джарретт, О.С. (2002). Сравнение подходов и инструментов оценки геологической науки Программа исследовательского опыта. Журнал образования в области наук о Земле, 50 (1), 15-24. (Нажмите здесь сокращенная версия)
 Они разработали и протестировали новый инструмент опроса
на основе групп утверждений, представляющих различные философские
позиции. Они также изучали использование открытых вопросов, касающихся
природа науки. Статистический анализ ответов на открытые
было обнаружено, что вопросы позволяют различать студентов колледжей с
различные научные знания и обнаруживать некоторые изменения в течение курса
своей программы (полный тезис).
Они разработали и протестировали новый инструмент опроса
на основе групп утверждений, представляющих различные философские
позиции. Они также изучали использование открытых вопросов, касающихся
природа науки. Статистический анализ ответов на открытые
было обнаружено, что вопросы позволяют различать студентов колледжей с
различные научные знания и обнаруживать некоторые изменения в течение курса
своей программы (полный тезис).Вымышленное исследование рынка клиентов отелей среднего класса:
Авторы: Васамон Апичатвуллоп и Марианна Воленски (студенты Технологического института Нью-Джерси)
Описание: Вымышленное исследование рынка, проведенное двумя студентами.
Артикул: Нажмите здесь, чтобы получить PDF-версию исследования. (1.7Мб)
 в курсе по информационному поиску и интеллектуальному анализу текста (профессор
доктор Брук Ву). Целью данного исследования было определить, какие
аспекты отелей среднего класса, которые клиенты считают наиболее привлекательными и
чтобы лучше определить потребности клиентов.
в курсе по информационному поиску и интеллектуальному анализу текста (профессор
доктор Брук Ву). Целью данного исследования было определить, какие
аспекты отелей среднего класса, которые клиенты считают наиболее привлекательными и
чтобы лучше определить потребности клиентов.Контент-анализ выступлений кандидатов в президенты США
Автор: Норманд Пеладо (Provalis Research)
Описание: Это работа была представлена в рамках конкурсного конкурса компьютерных вспомогательное программное обеспечение для контент-анализа. Выступления были доступны примерно за неделю до конференции.
