
полный гайд — агентство Valverde
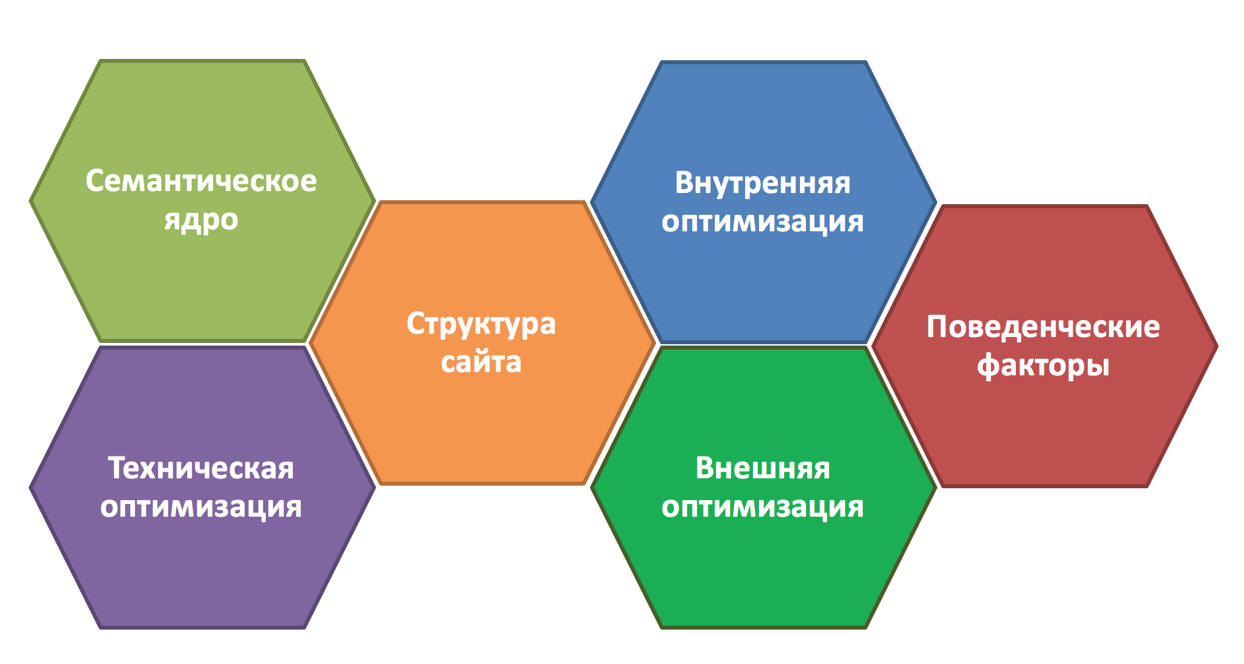
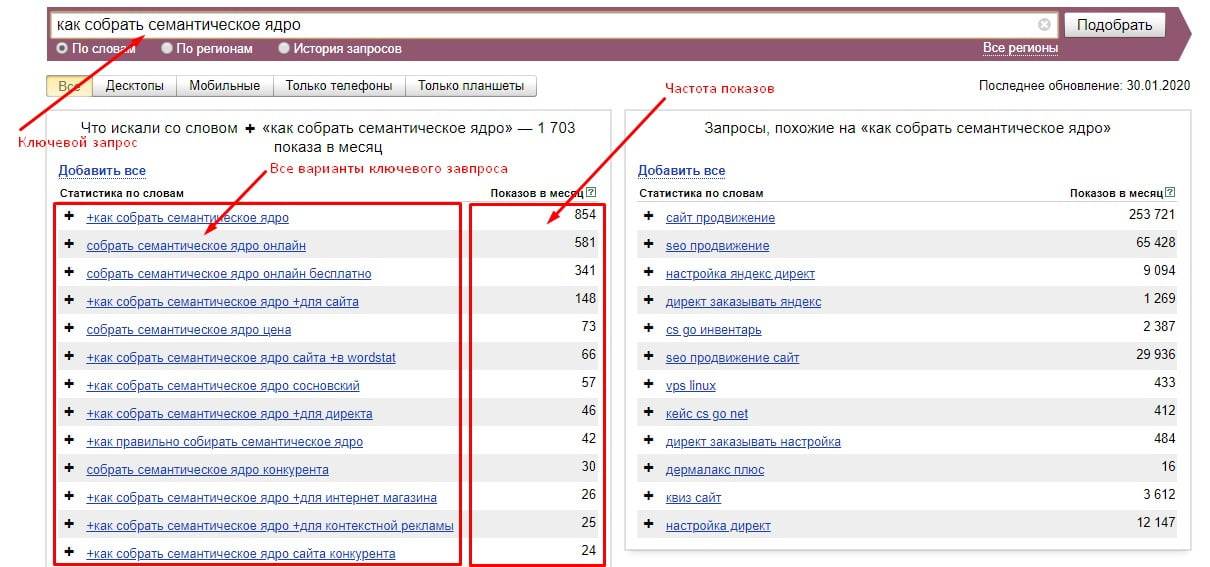
Основа успешного SEO — создание правильного семантического ядра. Главный атрибут семантического ядра состоит из релевантной семантики (ключевых запросов), которая имеет высокую частоту запросов в поисковой системе и отвечает на вопросы целевой аудитории сайта (ЦА).
Семантическое ядро (СЯ или «семантика») — это набор ключевых запросов, которые описывают сайт и содержимое его страниц. Семантическое ядро есть у каждой страницы на сайте, ведь без ключевых слов его попросту будет невозможно найти в интернете.Так как поисковые системы все чаще ориентированы на контент, и не просто индексируют содержимое страниц, а считывают реальный смысл слов.
Поэтому семантическое ядро играет важнейшую роль для SEO, оно позволяет. Важно правильно собрать его, иначе не получится продвигаться в топы поисковых систем, вести рекламную компанию и приводить заинтересованных клиентов на сайт. Анализ и сбор семантического ядра — основа для работы, как в контекстной рекламе, так и SEO-продвижении.
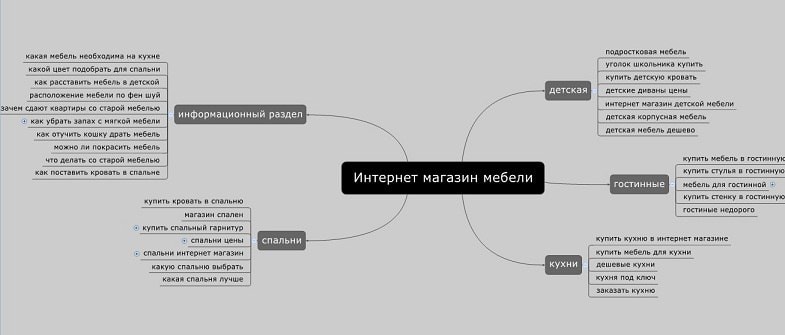
Сбор семантического ядра для сайта
Перед тем как собрать ключевые слова нам необходимо разбить процесс построения семантического ядра на несколько пунктов:
Подбор маркерных запросов
Маркерные запросы — это самые популярные ключевые слова, которые полностью описывают ваш сайт, страницу или услугу. Своего рода это будущий “скелет” семантического ядра, по которому будут подбираться более конкретные запросы. Поэтому сбор маркеров нужно проводить тщательно, продумывая наперед, насколько точным и полным будет ваше СЯ.
Существует четыре популярных способа подбора маркерных запросов:
- Ассоциативный метод — нужно собрать все ассоциации связанные с тематикой вашего сайта или бизнеса. Подумать какие вопросы интересны вашей целевой аудитории, и как можно на них ответить.
- Анализ конкурентов — нужно вбить в поисковую строку главную тематику сайта и просмотреть конкурентов которые показываются в Топ-10. Большинство этих сайтов наверняка работали над своей семантикой.
 Важно собрать ключевые слова именно заголовков h2 и мета-тегов Title и Description в сниппетах сайтов-конкурентов. Зачастую в них содержатся самые популярные поисковые запросы, которые можно использовать в качестве маркеров.
Важно собрать ключевые слова именно заголовков h2 и мета-тегов Title и Description в сниппетах сайтов-конкурентов. Зачастую в них содержатся самые популярные поисковые запросы, которые можно использовать в качестве маркеров. - Использование каталога вашей продукции или услуг — если у вас уже существует сайт, перечень основных услуг, категорий или каталог в 1С, то их можно использовать в качестве маркерных запросов.
- Анализ Яндекс Метрики/Google Search Console — этот метод подходит только тем, у кого уже есть сайт с подключенными сервисами аналитики. Спустя время после подключения – необходимо проанализировать запросы по которым к вам на сайт переходили из поисковых систем. В качестве маркерных запросов можно взять самые популярные.
 Важно собрать ключевые слова именно заголовков h2 и мета-тегов Title и Description в сниппетах сайтов-конкурентов. Зачастую в них содержатся самые популярные поисковые запросы, которые можно использовать в качестве маркеров.
Важно собрать ключевые слова именно заголовков h2 и мета-тегов Title и Description в сниппетах сайтов-конкурентов. Зачастую в них содержатся самые популярные поисковые запросы, которые можно использовать в качестве маркеров.Парсинг ключевых слов
Парсинг — это сбор ключевых слов, которые относятся к одной тематике сайта и бизнеса. Для каждой страницы сайта выбираем пул похожих по своей сути запросов. Следует собирать все ключевые слова, фразы и словосочетания, чтобы полностью охватить выбранную тематику.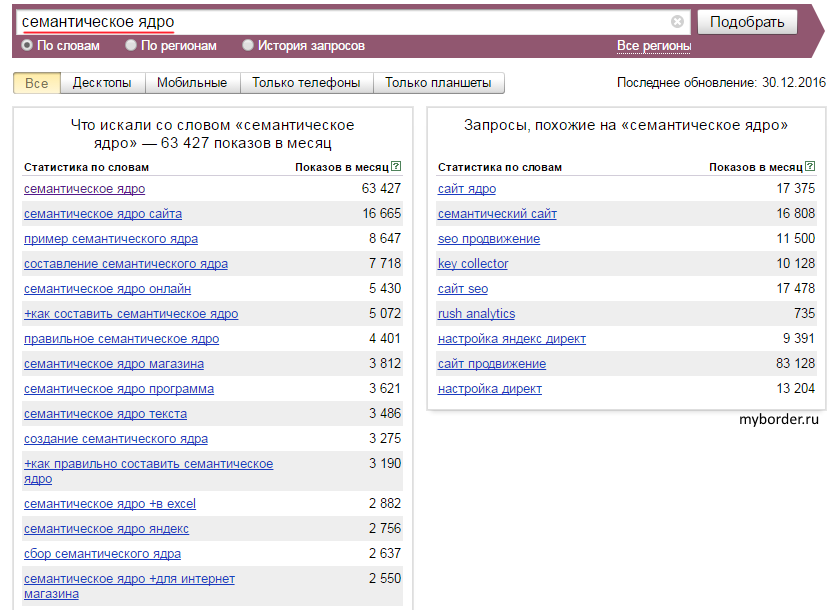
Инструменты для парсинга ключевых слов
- Яндекс Wordstat — один из лучших источников семантики в СНГ. Советуем установить любое удобное вам расширение Wordstat для браузера, чтобы собирать запросы и их частотность быстрее.
- Сбор AdWords — сбор ключевых слов из базы Google AdWords по маркерным запросам;
- Сбор подсказок в поисковой выдаче — они появляются после ввода марека в поисковую строку и подсказывают как можно его дополнить. Для SEO, сбор подсказок Яндекса и Google очень важен, так как они расширяют семантику, разбавляют их, снижая спамность, повышают релевантность текста, позволяют занять позиции в ТОПе.
Перед парсингом, используйте СТОП-СЛОВА — они позволяют экономят время и предотвращают попадание в семантику «мусорных», плохих поисковых запросов. Во многих сервисах предусмотрен специальный функционал, который позволяет добавить списки стоп-слов. Если нет понимания какие именно слова нужны в стоп-листе – можно взять примеры с сайтов с готовыми списками.
Также используйте фильтрацию по городам или регионам — это важно если вы планируете показываться в конкретном месте. Важно отметить, что ключевые слова с упоминанием в других городах и регионах будут автоматически удалены и вы их не увидите.
После того, как ключевые слова собраны из всех источников — следует объединить их в один список в таблице.
Частотность ключевых слов
Список ключевых слов получается внушительным по размерам, но в нем не хватает частотности. Используйте расширение для сбора семантики, чтобы получить статистику для своих ключевых слов — количество запросов за месяц в поисковой системе.
На выходе получается полная таблица с данными – окончательный список ваших ключевых слов. Теперь нужно сделать кластеризацию, получить структуру из данного списка запросов.
Кластеризация семантического ядра
Кластеризация (кластерный анализ) — это процедура, которая выполняет обработку запросов, анализирует их и упорядочивает в группы. В один кластер попадают только совместимые и похожие по смыслу ключевые слова.
В один кластер попадают только совместимые и похожие по смыслу ключевые слова.
Кластеризация работает по такому принципу — анализируется Топ-10 выдача по каждому ключевому слову, затем проверяется наличие общих страниц (URL) в выдаче. Если у запросов имеются общие URL в ТОП10 — они попадают в группу, и значит их можно продвигать вместе на одной странице. То есть происходит деление ключевых запросов из семантики на кластеры, где каждый кластер — своя тема.
С кластеризацией проще структурировать сайт. Так получается древовидная структура — как у интернет-магазинов. Каждый тематический кластер ведёт на свою страницу. В основе кластеризации лежит интент — от английского intent, «намерение». Это желание пользователя что-то найти в Интернете. Его поиск можно разделить на основе логики, семантического сходства и пиков распределения. Для этого метода можно зайти в Яндекс и собрать семантику с сайтов из Топ-10 выдачи.
Самый надежный метод семантической кластеризации – это справочник. Вы открываете таблицу и вручную разделяете ключевые слова на наборы. Однако этот метод является самым дорогим и даже больше подходит для небольших участков. Для них не так много важных запросов – обычно в пределах 500.
Вы открываете таблицу и вручную разделяете ключевые слова на наборы. Однако этот метод является самым дорогим и даже больше подходит для небольших участков. Для них не так много важных запросов – обычно в пределах 500.
Если у вас большой сайт или у вас мало времени на кластеризацию, вы можете обратится к сервисам-помощникам, а вручную уже проверять или дополнять.
Key Collector
Key Collector — популярная программа для профессионалов в области контекстной рекламы и SEO. Он помогает собрать семантическое ядро для сайта и подготавливает отчеты о запросах.
Это платная программа, которая может разделить поисковые фразы с помощью шлейфа по запросу, группируя кластеры. Есть встроенные фильтры для выбора наилучших запросов. Вы можете сразу создать структуру, вы можете сложить “дерево сайта”. Кроме того, Key Collector может легко искать дубликаты ключевых запросов.
«Словоёб»
«Словоёб» — это бесплатный аналог Key Collector. В этом приложении меньше функций, чем в предыдущем, но оно подойдет для работы с семантикой на небольших сайтах. Вы также можете научиться извлекать из него семантическое ядро.
Вы также можете научиться извлекать из него семантическое ядро.
«Разбивка по Кулакову»
Один из инструментов кластеризации, с помощью которого можно группировать запросы. “Разбивка по Кулакову,” не собирает семантическое ядро. Сервис лучше использовать с уже готовым списком запросов. Инструмент разобьет их на основе поисковых систем для этих запросов, и проанализирует семантическое ядро сайта. Главное преимущество этого сервиса в том, что он доступен онлайн.
У кластеризации существует два основных метода
- SOFT — этот метод ставит перед собой задачу сгруппировать как можно больше ключевых слов в один кластер. В результате получается небольшое количество групп на выходе, но большого размера. Алгоритм идеально подходит для кластеризации интернет-магазинов. Например, у вас есть информационный портал или форум, вы готовите статью, и вам нужно собрать как можно больше запросов, чтобы получить трафик. У данного метода слабая точность, поэтому в одну группу могут попасть и слабо совместимые ключевые слова.
- HARD — данный метод ставит перед собой задачу сгруппировать только самые подходящие друг для друга запросы. На выходе получается больше групп, но меньшего размера. Этот метод подходит для большинства сайтов, так как он гарантирует высокую точность группировки, и подходит для дальнейшего текстового анализа.

В итоге получается полноценный файл со сгруппированной и отсортированной по частотности статистикой.
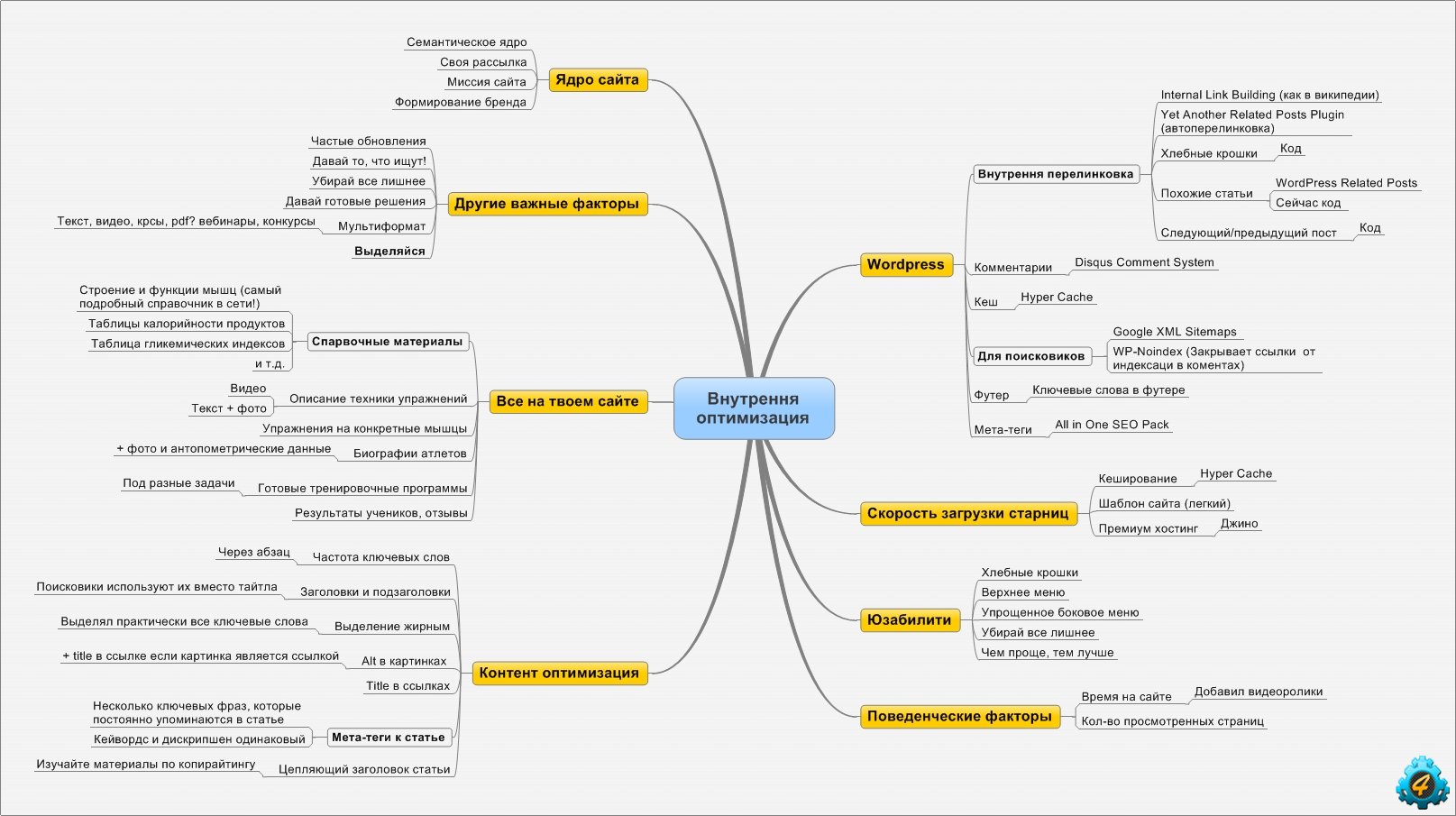
Формирование и классификация семантического ядра
При сборе семантического ядра, важно учитывать какой тип семантики подходит к вашему сайту. Всю собранную семантику можно поделить на:
- коммерческая / информационная;
Коммерческая семантика — называется семантикой “продажи” с целью превращения посетителя сайта в потенциального покупателя / клиента. В большинстве случаев в нее входят такие слова как: купить, цена, заказать, продать, опт, и так далее. Они также называются транзакционными запросами.
Информационная семантика — это семантика, которая не имеет коммерческой цели, а ее основная цель – говорить о чем-то / ком-то, рассказать о продукте или человек. Это может быть статья, справочная информация, просто текст, но он должен быть информативным.
- геозависимая / геонезависимая;
Географически зависимая семантика — это семантика, которая имеет четкую связь с определенным населением. Например, “Ремонт автомобилей в Москве”. И это в основном коммерческая семантика. Такая семантика нацелена на поисковую выдачу по конкретному городу, а это означает, что при сборе семантического ядра вы должны максимально учитывать ключевые слова в этом регионе – все остальные населенные пункты игнорируются.
Географически независимая семантика — это в основном информативная тема, без привязки к конкретному месту размещения. Например, новостные сайты, информационные порталы, сборники статей, аналитические ресурсы и т.д. То есть это тип семантики, который не зависит от региона и будет полезен везде.
- сезонная / несезонная;
Сезонная семантика — популярна в определенное время года, в основном в коммерческих целях. Например, интернет-магазин, торгующий меховыми изделиями, или наоборот – летней обувью, босоножками и т.д. Зимой количество клиентов резко увеличивается, а летом падает. Это называется сезонностью.
Несезонная семантика — это семантика, которая востребована независимо от времени года. Большинство из них являются информационными темами.
- высококонкурентная / среднеконкурентная / низкоконкурентная;
Высококонкурентная семантика — очень популярна у широкой аудитории, а также с уважаемыми конкурентами в поисковой выдаче. Если у вас высококонкурентная тема, очень важно собрать семантику конкурирующих сайтов отдельно. Сразу выйти на первое место в таком вопросе практически невозможно. Семантический сбор требует значительных затрат времени, поскольку он может содержать от 20 до 100 тысяч ключевых слов с частотой от 800 показов в месяц.
Семантика средней конкуренции — популярная семантика у небольших сайтов, но в меньших масштабах. Семантическое ядро может содержать от 5 до 20 тысяч ключевых слов с частотой от ~ 300 показов в месяц. Сайту немного легче подняться на вершину поисковой выдачи, но все равно нужно подробно поработать с семантикой.
Семантика с низкой конкуренцией — это узкие темы с низким спросом, подходящие маленьким или совсем молодым сайтам. Например, сайты, посвященные каким-то индивидуальным интересам. По вопросам с низкой конкуренцией легко выйти на первое место, поскольку в поисковой выдаче мало конкурирующих сайтов. Часто это проблемы с низкой конкуренцией, которые специалисты по SEO используют при разработке нового сайта, а затем постепенно доводят его до желаемого количества показов с помощью контекстной рекламы, социальных сетей, ссылок и других методов.
Чтобы точно определить какой вид семантики отвечает вашему сайту, нужно проанализировать все запросы и по ним структурировать все столбцы.
Не рекомендуется создавать семантическое ядро смешанной тематики — запросы могут не правильно сгруппироваться и вы получите, некорректную структуру. Если же у вас сайт, на котором планируется несколько типов семантики — лучше разместить их на разных разделах и собрать отдельное семантическое ядро под каждый.
Создание семантического ядра — один из важнейших этапов разработки и оптимизации веб-сайта. Именно по этим запросам пользователи будут находить сайт в интернете.
Сайт без семантического ядра обречен на провал в работе с контекстной рекламой и для SEO-продвижения сайта. Так как не учитывает реальные запросы пользователей в поисковой выдаче и игнорирует алгоритмы ранжирования поисковиков.
В процессе составления семантического ядра очень важно:
- подобрать правильно маркерные запросы;
- парсить семантику с применением стоп-слов;
- грамотно распределить ключевые слова по страницам сайта
Вся работа по SEO-оптимизации страницы начинается со сбора семантического ядра.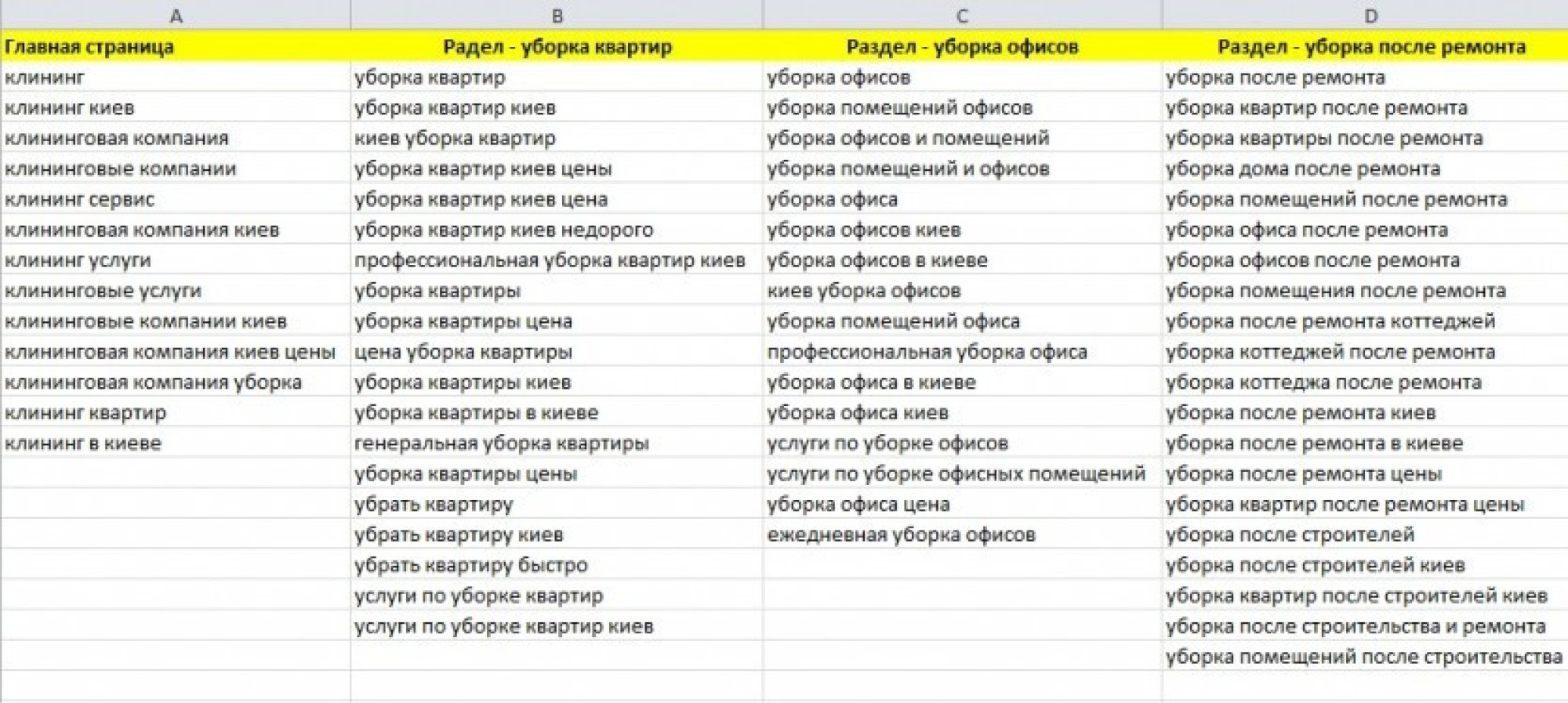 Данная статья не только поможет создать семантическое ядро для сайта, но и подскажет, что с ним делать. Конечно, это не все работы, которые нужно проводить для успешного продвижения сайта в интернете. Остается еще написать метатеги, сделать перелинковку, корректировать тексты и многое другое. Все эти услуги вы можете заказать, обратившись в маркетинговое агентство Valverde. Подробности по вашему проекту обсудим на консультации.
Данная статья не только поможет создать семантическое ядро для сайта, но и подскажет, что с ним делать. Конечно, это не все работы, которые нужно проводить для успешного продвижения сайта в интернете. Остается еще написать метатеги, сделать перелинковку, корректировать тексты и многое другое. Все эти услуги вы можете заказать, обратившись в маркетинговое агентство Valverde. Подробности по вашему проекту обсудим на консультации.
▷ З семантики в структуру — як скласти структуру сайту виходячи з семантичного ядра
Просування сайту починається зі збору семантичного ядра на всі сторінки сайту і складання структури, тільки після цього потрібно переходити до наступних етапів роботи. Сьогодні ми з вами на прикладі розберемо як потрібно складати структуру сайту виходячи з семантичного ядра.
1. Почнемо зі збору семантики:
Як приклад візьмемо категорію товарів «мікрохвильові печі» і на її прикладі складемо структуру сайту.
Ми не будемо зупинятися на зборі семантики, не бачу сенсу писати полотно тексту про те як це робити. В інтернеті на кожному блозі / форумі присвяченому seo є безліч методів збору семантичного ядра.
В інтернеті на кожному блозі / форумі присвяченому seo є безліч методів збору семантичного ядра.
Я наведу лише невеликий шматочок семантики, який необхідний для ілюстрації принципу побудови структури, це не вся семантика на дану категорію.
Семантичне ядро:
- купити мікрохвильову піч
- мікрохвильовка ціна
- купити свч
- мікрохвильовки Київ
- мікрохвильовка Samsung
- купити свч самсунг
- мікрохвильова піч Gorenje
- мікрохвильовка Gorenje
- мікрохвильова піч Panasonic
- мікрохвильовка Panasonic
- мікрохвильовка з грилем
- мікрохвильовка без гриля
- мікрохвильовка з конвекцією
- мікрохвильовка без конвекції
- мікрохвильові печі з грилем
Семантика заснована на асортименті сайту.
Бажано, при підборі семантики, аналізувати конкурентів, можна це робити за допомогою сервісу Serpstat.com. При аналізі конкурентів, я виявив на популярному магазині фільтр «мікрохвильові печі з грилем» подивившись частотність я переконався в тому що користувачі цікавляться такими моделями свч і додав запит в СЯ.
Кластеризація запитів:
Тепер виходячи з отриманої семантики необхідно розбити її по сторінках, для великих семантичних ядер використовують різні кластерізатори, але оскільки у нас семантики не багато, зробимо це руками.
Я розподілив ось так:
Мікрохвильові печі:
- купити мікрохвильову піч
- мікрохвильовка ціна
- купити свч
- мікрохвильовки Київ
Samsung:
- мікрохвильовка Samsung
- купити свч самсунг
Gorenje:
- мікрохвильова піч Gorenje
- мікрохвильовка Gorenje
З грилем:
- мікрохвильовка з грилем
Без гриля:
- мікрохвильовка без гриля
З конвекцією:
- мікрохвильовка з конвекцією
З грилем та конвекцією:
- мікрохвильові печі з грилем та конвекцією
На сайті у категорії «мікрохвильові печі» обов’язково повинні бути наступні підкатегорії (фільтри, теги):
- Samsung;
- Gorenje;
- З грилем;
- Без гриля;
- З конвекцією;
- З грилем і конвекцією.
Логіка наступна: якщо створивши окрему сторінку під групу запитів ми допоможемо користувачеві швидше знайти те, що він шукає, і якщо це обумовлено попитом – треба робити.
Якщо ж створення додаткової сторінки тягне за собою якісь спамні мети – не варто цим займатися.
Користувач вводить запит «мікрохвильові печі з грилем» він вже визначився зі своєю потребою і точно знає що він хоче. Ми, в свою чергу, показуємо йому сторінку каталогу на якій знаходяться тільки мікрохвильові печі з грилем, такий документ є більш релевантним.
Таким чином всі у виграші:
- користувач швидко знайшов потрібну сторінку з товарами;
- пошукова система дала користувачеві релевантну відповідь;
- магазин отримав цільовий трафік.
1. Як визначити чи потрібно створювати сторінку під групу запитів?
Це дуже складне питання, для того, щоб на нього відповісти потрібно вирішити чи потрібна ця сторінка користувачеві, чи дійсно вона буде корисна. Тут існує дуже тонка грань між спамом і поліпшенням структури сайту. Завжди потрібно дивитися в видачу пошукових систем і аналізувати що хоче бачити пошукова система за запитом.
Тут існує дуже тонка грань між спамом і поліпшенням структури сайту. Завжди потрібно дивитися в видачу пошукових систем і аналізувати що хоче бачити пошукова система за запитом.
Для того, щоб краще з цим розібратися приведу кілька прикладів:
1.Створення сторінок під бренди.
- Мікрохвильові печі Samsung
- Мікрохвильові печі Gorenje
Під бренди завжди варто створювати окремі сторінки.
2.Створення сторінок під характеристики товарів.
- Мікрохвильові печі з грилем
- Мікрохвильові печі з конвекцією
Такі сторінки генерують найбільше трафіку бо прекрасно відповідають на запит користувача. Користувач хоче купити свч з грилем, навіщо йому показувати весь каталог товарів? Щоб він там ще в фільтрах копався і шукав де вибрати «з грилем»?
Ми це робимо за нього.
3.Створення сторінок під кольори
- Ціна на білу мікрохвильовку
- купити синю мікрохвильовку
Тільки якщо обумовлено попитом.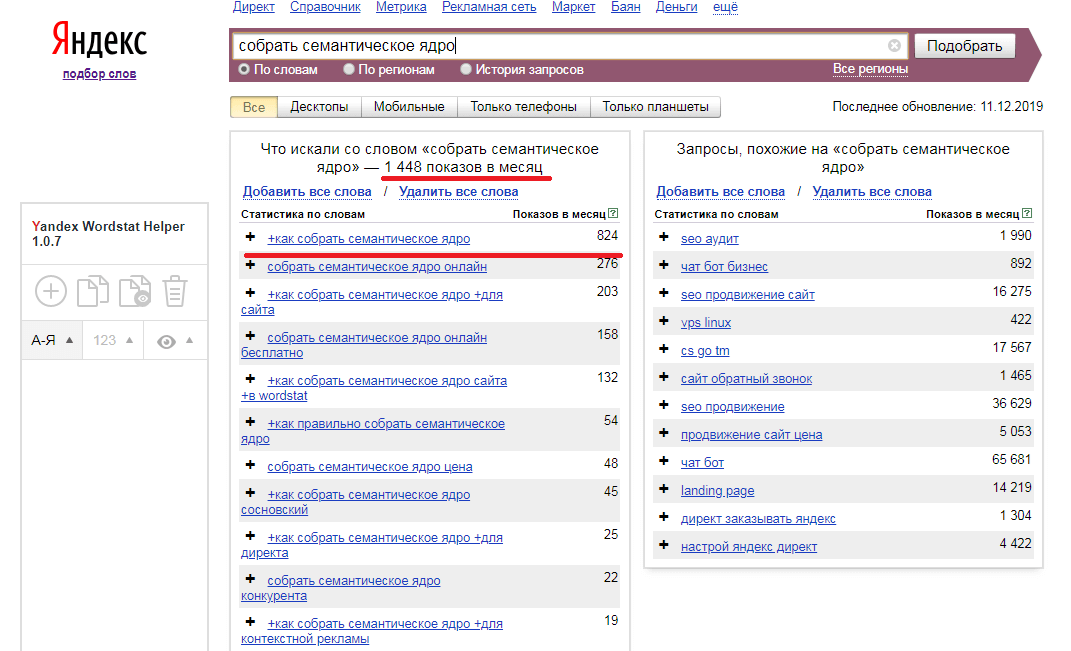 Не варто плодити мільйон сторінок з різними кольорами.
Не варто плодити мільйон сторінок з різними кольорами.
4.Створення сторінок під певну ціну
- vікрохвильовка 150 грн
- мікрохвильові печі 1500 грн
Це в 99.9% не обумовлено попитом, отже цього робити не варто.
5.Створення сторінок під цінові діапазони
- мікрохвильові печі недорого
- дорогі мікрохвильові печі
Я переконаний що для таких груп запитів окремі сторінки не потрібні, через те, що дешевизна або ж дорожнеча поняття суб’єктивні. Такі запити та без окремої сторінки завжди добре ранжуються на основній сторінці категорії.
6.Створення сторінок за регіоном / вулицею
- Купити мікрохвильову піч в Києві
- Купити мікрохвильову піч в Дніпропетровську
- Ціни на мікрохвильові печі в Харкові
- Мікрохвильові печі на вул. Соборна купити
Якщо ви зможете пояснити чим відрізнятимуться дані сторінки – можете створювати.
Для інтернет-магазинів цього робити не потрібно, а ось для сайтів, що займаються нерухомістю – дуже навіть хороше рішення.
Варто створювати окремі сторінки якщо:
- Створення доп. сторінки обумовлено попитом;
- Список товарів в каталозі буде відповідати запиту і буде відрізнятися від вихідного;
- У пошуковій видачі у більшості конкурентів окрема сторінка під цю групу запитів.
3. Оптимізація сторінок підкатегорій
Після створення нової структури сайту дуже важливо оптимізувати нові сторінки, інакше результату ніякого ми не доб’ємося, це дійсно важливо.
Що потрібно зробити:
- Прописати релевантні теги Title, Description і заголовок h2 виходячи з семантичного ядра.
- Необхідно написати релевантний контент на сторінку для поліпшення текстової релевантності.
- Подбати про внутрішню перелінковку, щоб створені сторінки отримували достатньої ваги.
Очікуваний результат
У разі якщо все буде реалізовано вірно, всі запити з семантики будуть вести на релевантні сторінки, то, з часом, створені сторінки сайту будуть приносити трафік. Навіть в конкурентній тематиці такі сторінки в рази простіше просувати, бо конкуренція там значно нижче.
Навіть в конкурентній тематиці такі сторінки в рази простіше просувати, бо конкуренція там значно нижче.
Як мінімум тому що у тисяч сайтів є категорія «мікрохвильові печі», а ось оптимізована сторінка під групу запитів «мікрохвильові печі з грилем» є у десятків.
Отже, просунути ці запити набагато простіше, а трафік з них більш цільовий, оскільки користувач вже визначився з тим, що йому потрібно.
Висновок
Дуже важливо перед початком просування, а ще краще перед створенням ресурсу, зібрати максимально повне семантичне ядро. Це дозволить сформувати коректну структуру сайту, зрозуміти попит і прогнозувати результат просування.
За допомогою побудови структури на основі попиту сайт зможе охопити всю релевантну семантику і не упустити потенційного покупця.
Семантика в Compose | Jetpack Compose
Композиция описывает пользовательский интерфейс вашего приложения и
создается путем запуска составных объектов. Композиция представляет собой древовидную структуру,
состоит из составных частей, описывающих ваш пользовательский интерфейс.
Рядом с композицией существует параллельное дерево, называемое семантикой . дерево . Это дерево описывает ваш пользовательский интерфейс альтернативным способом, т.е. понятно для служб специальных возможностей и для платформы тестирования. Услуги доступности используйте дерево, чтобы описать приложение пользователям с особыми потребностями. Тестирование Framework использует его для взаимодействия с вашим приложением и создания утверждений о нем. Дерево семантики не содержит информации о том, как нарисуй твой компонуемые, но содержит информацию о семантике , означающей ваши составные части.
Рис. 1. Типичная иерархия пользовательского интерфейса и ее семантическое дерево.
Если ваше приложение состоит из компонуемых компонентов и модификаторов из основы Compose
и библиотеки материалов, автоматически заполняется и генерируется дерево семантики
для тебя. Однако , когда вы добавляете пользовательские низкоуровневые компонуемые элементы, вы
необходимо вручную указать его семантику . Также могут быть ситуации, когда
ваше дерево неправильно или не полностью представляет значение элементов на
экран, в случае чего можно адаптировать дерево.
Также могут быть ситуации, когда
ваше дерево неправильно или не полностью представляет значение элементов на
экран, в случае чего можно адаптировать дерево.
Рассмотрим, например, этот составной пользовательский календарь:
Рисунок 2. Составляемый пользовательский календарь с выбираемыми элементами дня.
В этом примере весь календарь реализован как единый низкоуровневый
компонуемый, используя макет компонуемый и рисующий непосредственно на Холст .
Если вы ничего не сделаете, службы доступности не получат достаточно
информация о содержимом компонуемого и выборе пользователя в пределах
календарь. Например, если пользователь нажимает на день, содержащий 17,
инфраструктура доступности получает только информацию описания для всего
календарный контроль. В этом случае служба специальных возможностей TalkBack просто
объявить «Календарь» или, чуть лучше, «Апрельский календарь» и пользователь
останется только гадать, какой день был выбран.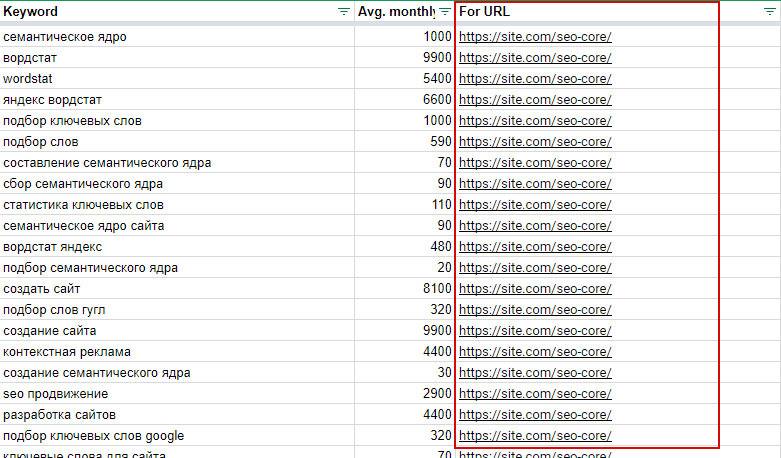 Чтобы сделать это более компонуемым
доступны, вам нужно будет добавить семантическую информацию вручную.
Чтобы сделать это более компонуемым
доступны, вам нужно будет добавить семантическую информацию вручную.
Свойства семантики
Все узлы в дереве пользовательского интерфейса с некоторым семантическим значением имеют параллельный узел в
Семантическое дерево. Узел в дереве семантики содержит те свойства, которые
передать смысл соответствующего составного слова. Например, Текст composable содержит семантическое свойство text , потому что это означает из
что составной. Значок Icon содержит свойство contentDescription (если установлено
разработчик), который передает в тексте значение Значок есть.
Составные элементы и модификаторы, созданные поверх Compose.
базовая библиотека уже установлена
соответствующие свойства для вас. При желании вы можете установить или переопределить
свойства себя с семантикой и ясноандсетсемантика модификаторы. Например, вы можете добавить к узлу настраиваемые действия специальных возможностей, предоставить
описание альтернативного состояния для
переключаемый элемент или указать, что определенный компонуемый текст должен быть
рассматривается как заголовок.
Например, вы можете добавить к узлу настраиваемые действия специальных возможностей, предоставить
описание альтернативного состояния для
переключаемый элемент или указать, что определенный компонуемый текст должен быть
рассматривается как заголовок.
Чтобы визуализировать дерево семантики, мы можем использовать инструмент Layout Inspector или использовать printToLog() внутри наших тестов. Это напечатает текущее дерево семантики внутри
Логкат.
класс MyComposeTest {
@получить:Правило
val composeTestRule = createComposeRule()
@Тест
весело MyTest () {
// Запускаем приложение
composeTestRule.setContent {
Моя Тема {
Текст("Привет, мир!")
}
}
// Зарегистрировать полное семантическое дерево
composeTestRule. onRoot().printToLog("МОЙ ТЕГ")
}
} SemanticsSnippets.kt
 onRoot().printToLog("МОЙ ТЕГ")
}
}
onRoot().printToLog("МОЙ ТЕГ")
}
} Результат этого теста будет следующим:
Печать с useUnmergedTree = 'false'
Узел № 1 в (l = 0,0, t = 63,0, r = 221,0, b = 120,0) пикселей
|-Узел № 2 в (l = 0,0, t = 63,0, r = 221,0, b = 120,0) пикселей
Текст = '[Привет, мир!]'
Действия = [GetTextLayoutResult]
Давайте рассмотрим пример, чтобы увидеть, как семантические свойства используются для передачи значения составного объекта. Давайте подумаем о коммутаторе . Вот как это выглядит для пользователя:
Рис. 3. A Выключатель в состояниях «включено» и «выключено».
Чтобы описать , означающее этого элемента, можно сказать следующее: «Этот
— это Switch, который является переключаемым элементом, который в настоящее время находится в состоянии «Включено». Ты
можете щелкнуть по нему, чтобы взаимодействовать с ним».
Это именно то, для чего используются семантические свойства. Семантический узел этого элемента Switch содержит следующие свойства, как показано с помощью Инспектор макетов:
Рисунок 4. Инспектор макетов , показывающий семантические свойства коммутатора компонуемый.
Роль указывает, какой тип элемента мы рассматриваем. StateDescription описывает, как следует ссылаться на состояние «Включено». К
по умолчанию это просто локализованная версия слова «Вкл.», но это может быть
делается более конкретным (например, «Включено») в зависимости от контекста. ToggleableState — текущее состояние коммутатора. Свойство OnClick ссылается на метод, используемый для взаимодействия с этим элементом. Полный список
semantics, проверьте объект SemanticsProperties . Полный список возможных действий специальных возможностей см.
Полный список возможных действий специальных возможностей см. Объект SemanticsActions .
Отслеживание семантических свойств каждого компонуемого в вашем приложении разблокирует много мощных возможностей. Некоторые примеры:
- Talkback использует свойства для чтения вслух того, что показано на экране. и позволяет пользователю плавно взаимодействовать с ним. Для нашего коммутатора это может сказать: «На; Выключатель; дважды нажмите для переключения». Пользователь может дважды коснуться своего экран, чтобы переключить Выключить.
- Среда тестирования использует свойства для поиска узлов, взаимодействия с
их и делать утверждения. Пример теста для нашего коммутатора может быть таким:
 kt" data-region-tag="android_compose_semantics_test_switch" dir="ltr"> val mySwitch = SemanticsMatcher.expectValue(
SemanticsProperties.Role, Role.Switch
)
composeTestRule.onNode(mySwitch)
.performClick()
.assertIsOff()
kt" data-region-tag="android_compose_semantics_test_switch" dir="ltr"> val mySwitch = SemanticsMatcher.expectValue(
SemanticsProperties.Role, Role.Switch
)
composeTestRule.onNode(mySwitch)
.performClick()
.assertIsOff() SemanticsSnippets.kt
Объединенное и неслитное дерево семантики
Как упоминалось ранее, каждый компонуемый элемент в дереве пользовательского интерфейса может иметь ноль или более
набор свойств семантики. Если составной объект не имеет заданных семантических свойств, он
не входит в состав дерева семантики.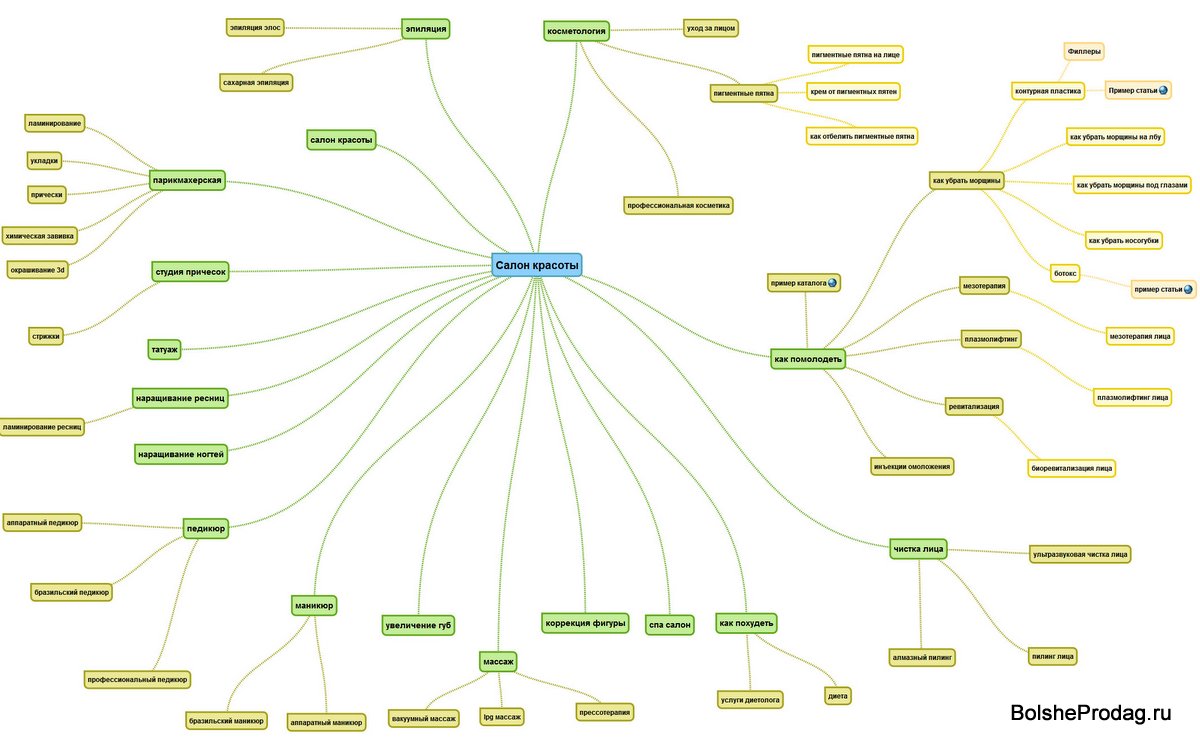 Таким образом, семантическое дерево
содержит только те узлы, которые действительно содержат семантическое значение. Однако,
иногда для передачи правильного смысла того, что показано на экране,
также полезно объединять определенные поддеревья узлов и рассматривать их как единое целое. Сюда
мы можем рассуждать о множестве узлов в целом, вместо того, чтобы иметь дело с каждым
узел-потомок индивидуально. Как правило, каждый узел в этом дереве
представляет фокусируемый элемент при использовании служб специальных возможностей.
Таким образом, семантическое дерево
содержит только те узлы, которые действительно содержат семантическое значение. Однако,
иногда для передачи правильного смысла того, что показано на экране,
также полезно объединять определенные поддеревья узлов и рассматривать их как единое целое. Сюда
мы можем рассуждать о множестве узлов в целом, вместо того, чтобы иметь дело с каждым
узел-потомок индивидуально. Как правило, каждый узел в этом дереве
представляет фокусируемый элемент при использовании служб специальных возможностей.
Примером такого составного объекта является Button. Мы хотели бы порассуждать о кнопке как единый элемент, даже если он может содержать несколько дочерних узлов:
Button(onClick = { /*TODO*/ }) {
Икона(
imageVector = Icons. Filled.Favorite,
описание содержимого = ноль
)
Spacer(Modifier.size(ButtonDefaults.IconSpacing))
Текст("Мне нравится")
} SemanticsSnippets.kt
 Filled.Favorite,
описание содержимого = ноль
)
Spacer(Modifier.size(ButtonDefaults.IconSpacing))
Текст("Мне нравится")
}
Filled.Favorite,
описание содержимого = ноль
)
Spacer(Modifier.size(ButtonDefaults.IconSpacing))
Текст("Мне нравится")
} В нашем семантическом дереве свойства потомков Button объединены, а кнопка представлена в виде одного конечного узла в дереве:
Составные элементы и модификаторы могут указать, что они хотят объединить свои
свойства семантики потомков, вызывая Modifier.semantics
(mergeDescendants = true) {} . Установка для этого свойства значения true указывает, что
семантические свойства должны быть объединены. В нашем примере Button кнопка Button composable использует внутренний модификатор clickable , который включает это модификатор семантики . Следовательно, узлы-потомки кнопки будут
объединены. Прочтите документацию по специальным возможностям, чтобы узнать больше о том, когда вы
должен изменить поведение слияния в вашем составном.
Прочтите документацию по специальным возможностям, чтобы узнать больше о том, когда вы
должен изменить поведение слияния в вашем составном.
Несколько модификаторов и компоновок в Foundation и Material Compose
библиотеки имеют этот набор свойств. Например, кликабельный и переключаемый модификаторы автоматически объединят своих потомков. Кроме того, ListItem composable объединит своих потомков.
Проверка деревьев
Говоря о дереве семантики, мы фактически говорим о двух
разные деревья. Существует объединенных семантических деревьев, которые объединяют потомков
узлов, когда mergeDescendants имеет значение true . Также есть неслитный Дерево семантики, которое не применяет слияние, но сохраняет каждый узел нетронутым. Службы специальных возможностей используют неслитное дерево и применяют собственное слияние.
алгоритмы с учетом свойства
Службы специальных возможностей используют неслитное дерево и применяют собственное слияние.
алгоритмы с учетом свойства mergeDescendants .
Среда тестирования по умолчанию использует объединенное дерево.
Оба дерева можно проверить с помощью метода printToLog() . По умолчанию и как в
в более ранних примерах объединенное дерево будет зарегистрировано. Для печати неслитых
дерево вместо этого установите параметр useUnmergedTree функции сопоставления onRoot() для true :
composeTestRule.onRoot(useUnmergedTree = true).SemanticsSnippets.kt
 printToLog("MY TAG")
printToLog("MY TAG") Инспектор макетов позволяет отображать как объединенные, так и не объединенные Дерево семантики, выбрав нужный в фильтре просмотра:
объединенное и неслитное семантическое дерево.
Для каждого узла в вашем дереве Инспектор макетов показывает объединенную семантику и набор семантики для этого узла на панели свойств:
По умолчанию сопоставители в Testing Framework используют объединенное дерево семантики. Вот почему вы можете взаимодействовать с кнопкой, сопоставляя текст, показанный внутри it:
composeTestRule.onNodeWithText("Like").performClick() SemanticsSnippets.kt
Вы можете переопределить это поведение, установив useUnmergedTree параметр
сопоставляется с true , как мы делали раньше с сопоставителем onRoot .
Поведение при слиянии
Когда компонуемый объект указывает, что его потомки должны быть объединены, как это происходит? слияние произошло точно?
Каждое свойство семантики имеет определенную стратегию слияния. Например, Свойство ContentDescription добавляет все значения потомка ContentDescription в
список. Вы можете проверить стратегию слияния свойства семантики, проверив
это Реализация mergePolicy в SemanticsProperties.kt .
Свойства могут всегда выбирать родительское или дочернее значение, объединять
значения в список или строку, вообще не разрешать слияние и выдавать исключение
вместо этого или любую другую пользовательскую стратегию слияния.
Важно отметить, что потомки, которые сами установили слияние потомков = истина не входят в слияние. Рассмотрим пример:
Рисунок 6.![]() Элемент списка с изображением, текстом и значком закладки.
Элемент списка с изображением, текстом и значком закладки.
Здесь у нас есть кликабельный элемент списка. Когда пользователь нажимает строку, приложение переходит на страницу сведений о статье, где пользователь может прочитать статью. Внутри элемента списка есть кнопка, чтобы добавить эту статью в закладки. В этом случае у нас есть вложенный кликабельный элемент, поэтому кнопка будет отображаться отдельно в объединенное дерево. Остальное содержимое в строке объединяется:
Рисунок 7. Объединенное дерево содержит несколько текстов в списке внутри узла Row. Необъединенное дерево содержит отдельные узлы для каждого компонента Text.
Адаптация дерева семантики
Как упоминалось ранее, вы можете переопределить или очистить определенные свойства семантики или
изменить поведение слияния дерева. Это особенно актуально, когда
вы создаете свои собственные пользовательские компоненты. Без установки правильного
свойства и поведение слияния, ваше приложение может быть недоступно, а тесты
может вести себя не так, как вы ожидаете. Чтобы узнать больше о некоторых распространенных случаях использования
случаях, когда вам следует адаптировать дерево семантики, прочтите
документация по доступности. Если вы хотите
узнать больше о тестировании можно в Руководстве по тестированию.
Чтобы узнать больше о некоторых распространенных случаях использования
случаях, когда вам следует адаптировать дерево семантики, прочтите
документация по доступности. Если вы хотите
узнать больше о тестировании можно в Руководстве по тестированию.
Специальные возможности в Compose | Jetpack Compose
Приложения, написанные на Compose, должны поддерживать специальные возможности для пользователей с разными
потребности. Службы специальных возможностей используются для преобразования того, что отображается на экране, в
более подходящий формат для пользователя с особыми потребностями. Для поддержки доступности
службы, приложения используют API в среде Android для предоставления семантической информации
об их элементах пользовательского интерфейса. Платформа Android затем сообщит о доступности
службы об этой семантической информации. Каждая служба доступности может выбрать
как лучше всего описать приложение пользователю. Android предоставляет несколько специальных возможностей
услуги, в том числе
Двусторонняя связь и
Выключатель
Доступ.
Семантика
Compose использует свойства семантики для передачи информации в специальные возможности
услуги. Свойства семантики предоставляют информацию об элементах пользовательского интерфейса, которые
отображается пользователю. Большинство встроенных композиций, таких как Текст и Кнопка заполнить эти семантические свойства информацией, полученной из составного
и его дети. Некоторые модификаторы, такие как переключаемый и кликабельно также установит определенные семантические свойства. Однако иногда рамки
требуется больше информации, чтобы понять, как описать элемент пользовательского интерфейса пользователю.

В этом документе описываются различные ситуации, в которых необходимо явно добавить дополнительную информацию к составному объекту, чтобы его можно было правильно описать Фреймворк андроид. Также объясняется, как заменить информацию о семантике полностью для данного компонуемого. Он предполагает базовое понимание доступность в Android.
Примечание: Чтобы узнать больше о семантике Compose, см. Семантику в Составьте руководство.Распространенные варианты использования
Чтобы помочь людям с ограниченными возможностями успешно использовать ваше приложение, ваше приложение должны следовать рекомендациям, описанным на этой странице.
Учитывайте минимальные размеры цели касания
Примечание. Поведение цели касания изменено в Compose 1.1.0. Более ранние версии библиотека может вести себя по-разному. Любой элемент на экране, который можно щелкнуть, коснуться или с которым можно взаимодействовать, должен быть
достаточно большой для надежного взаимодействия.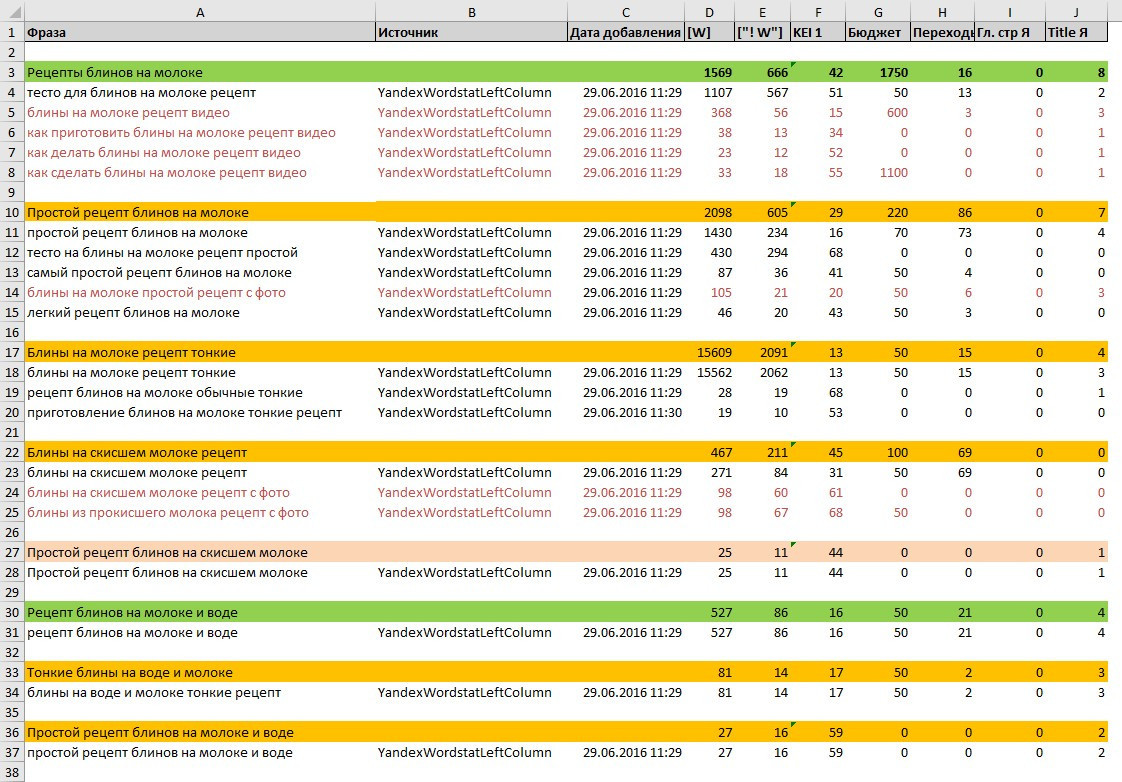 При выборе размеров этих элементов убедитесь, что
установите минимальный размер 48dp, чтобы правильно следовать дизайну материалов
Руководство по доступности.
При выборе размеров этих элементов убедитесь, что
установите минимальный размер 48dp, чтобы правильно следовать дизайну материалов
Руководство по доступности.
Материальные компоненты, подобные Флажок , Радиокнопка , Переключатель , Ползунок и Поверхность —набор
этот минимальный размер внутренне, но только тогда, когда компонент может принимать пользовательские
действия. Например, когда для флажка установлен параметр onCheckedChange .
к ненулевому значению, оно будет включать отступы, чтобы иметь ширину и высоту в
не менее 48dp.
 kt" data-region-tag="android_compose_accessibility_checkbox_expanded_touch_target" dir="ltr"> @Составной
частное развлечение CheckableCheckbox() {
Флажок (отмечен = истина, onCheckedChange = {})
}
kt" data-region-tag="android_compose_accessibility_checkbox_expanded_touch_target" dir="ltr"> @Составной
частное развлечение CheckableCheckbox() {
Флажок (отмечен = истина, onCheckedChange = {})
} AccessibilitySnippets.kt
Когда для параметра onCheckedChange установлено значение null, заполнение не включается, поскольку с компонентом нельзя взаимодействовать напрямую.
@Составной
частное развлечение NonClickableCheckbox() {
Флажок (проверено = true, onCheckedChange = null)
} AccessibilitySnippets.kt
При реализации элементов управления выбором, таких как Switch , RadioButton или Флажок , вы обычно переносите кликабельное поведение в родительский контейнер,
установите обратный вызов щелчка на составном элементе null и добавьте переключаемый или выбираемый модификатор для родительского компонуемого.
@Составной
частное развлечение CheckableRow() {
МатериалТема {
var проверяется по памяти { mutableStateOf(false) }
Ряд(
Модификатор
.переключаемый(
значение = проверено,
роль = Роль. Флажок,
onValueChange = { проверено = ! проверено }
)
.padding(16.dp)
.fillMaxWidth ()
) {
Текст("Опция", Modifier.weight(1f))
Флажок (отмечено = проверено, onCheckedChange = ноль)
}
}
} AccessibilitySnippets.kt
Когда размер интерактивного составного элемента меньше минимальной цели касания
размер, Compose по-прежнему увеличивает размер сенсорной цели. Это достигается за счет расширения
размер сенсорной цели за пределами компонуемого.
Это достигается за счет расширения
размер сенсорной цели за пределами компонуемого.
В следующем примере мы создаем очень маленький кликабельный Box . Прикосновение
целевая область автоматически расширяется за пределы поля Box , поэтому
нажав рядом с Box по-прежнему вызывает событие click.
@Составной
частное развлечение SmallBox() {
var щелкнул помните { mutableStateOf (false) }
Коробка(
Модификатор
.размер(100.dp)
.background(если (нажато) Color.DarkGray иначе Color.LightGray)
) {
Коробка(
Модификатор
. align(Выравнивание.Центр)
.clickable {щелкнул = !щелкнул}
.background(Цвет.Черный)
.размер(1.дп)
)
}
} AccessibilitySnippets.kt
 align(Выравнивание.Центр)
.clickable {щелкнул = !щелкнул}
.background(Цвет.Черный)
.размер(1.дп)
)
}
}
align(Выравнивание.Центр)
.clickable {щелкнул = !щелкнул}
.background(Цвет.Черный)
.размер(1.дп)
)
}
} всегда следует стремиться использовать достаточно большой минимальный размер для компонуемого. В нашем
например, это означало бы использование модификатора sizeIn для установки минимального размера для
внутренняя коробка:
@Composable
частное развлечение LargeBox() {
var щелкнул помните { mutableStateOf (false) }
Коробка(
Модификатор
.размер(100.dp)
.background(если (нажато) Color.DarkGray иначе Color.LightGray)
) {
Коробка(
Модификатор
. align(Выравнивание.Центр)
.clickable {щелкнул = !щелкнул}
.background(Цвет.Черный)
.sizeIn(minWidth = 48.dp, minHeight = 48.dp)
)
}
} AccessibilitySnippets.kt
 align(Выравнивание.Центр)
.clickable {щелкнул = !щелкнул}
.background(Цвет.Черный)
.sizeIn(minWidth = 48.dp, minHeight = 48.dp)
)
}
}
align(Выравнивание.Центр)
.clickable {щелкнул = !щелкнул}
.background(Цвет.Черный)
.sizeIn(minWidth = 48.dp, minHeight = 48.dp)
)
}
} Добавить метки кликов
Вы можете использовать метку клика, чтобы добавить семантическое значение к поведению щелчка компонуемый. Метки кликов описывают, что происходит, когда пользователь взаимодействует с компонуемым. Службы специальных возможностей используют метки кликов, чтобы помочь описать приложение пользователям с особыми потребностями.
Установите метку клика, передав параметр в кликабельно модификатор:
@Composable
частная забава ArticleListItem(openArticle: () -> Unit) {
Ряд(
Модификатор. кликабельно(
// R.string.action_read_article = "прочитать статью"
onClickLabel = stringResource(R.string.action_read_article),
onClick = открыть статью
)
) {
// ..
}
} AccessibilitySnippets.kt
 кликабельно(
// R.string.action_read_article = "прочитать статью"
onClickLabel = stringResource(R.string.action_read_article),
onClick = открыть статью
)
) {
// ..
}
}
кликабельно(
// R.string.action_read_article = "прочитать статью"
onClickLabel = stringResource(R.string.action_read_article),
onClick = открыть статью
)
) {
// ..
}
} В качестве альтернативы, если у вас нет доступа к кликабельному модификатору, вы можете установите метку клика в семантика модификатор:
@Composable
частное развлечение LowLevelClickLabel(openArticle: () -> Boolean) {
// R.string.action_read_article = "прочитать статью"
val readArticleLabel = stringResource (R.string.action_read_article)
Холст(
Модификатор.semantics {
onClick(метка = readArticleLabel, действие = openArticle)
}
) {
// . .
}
} AccessibilitySnippets.kt
 .
}
}
.
}
} Описать визуальные элементы
При определении Изображение или Значок компонуемый, платформа Android не может автоматически понять
что отображается. Вам необходимо передать текстовое описание визуального
элемент.
Представьте себе экран, на котором пользователь может поделиться текущей страницей с друзьями. Этот экран содержит интерактивный значок общего доступа:
Основываясь только на значке, платформа Android не может понять, как описать пользователю с ослабленным зрением. Фреймворк Android нуждается в дополнительном текстовое описание иконки.
Параметр contentDescription используется для описания визуального элемента. Ты
следует использовать локализованную строку, так как она будет сообщена пользователю.
 kt" data-region-tag="android_compose_accessibility_content_descr" dir="ltr"> @Составной
частная забава ShareButton (onClick: () -> Unit) {
IconButton(onClick = onClick) {
Икона(
imageVector = Icons.Filled.Share,
contentDescription = stringResource (R.string.label_share)
)
}
}
kt" data-region-tag="android_compose_accessibility_content_descr" dir="ltr"> @Составной
частная забава ShareButton (onClick: () -> Unit) {
IconButton(onClick = onClick) {
Икона(
imageVector = Icons.Filled.Share,
contentDescription = stringResource (R.string.label_share)
)
}
} AccessibilitySnippets.kt
Некоторые визуальные элементы носят исключительно декоративный характер, и вы можете не захотеть их сообщать
их пользователю. Когда вы устанавливаете contentDescription параметр для null ,
вы указываете платформе Android, что этот элемент не связан
действия или состояния.
@Составной
приватная забава PostImage(post: Post, modifier: Modifier = Modifier) {
val image = post. imageThumb ?: painterResource (R.drawable.placeholder_1_1)
Изображение(
художник = изображение,
// Указываем, что это изображение не имеет смыслового значения
описание содержимого = ноль,
модификатор = модификатор
.размер(40.дп, 40.дп)
.clip(MaterialTheme.shapes.small)
)
} AccessibilitySnippets.kt
 imageThumb ?: painterResource (R.drawable.placeholder_1_1)
Изображение(
художник = изображение,
// Указываем, что это изображение не имеет смыслового значения
описание содержимого = ноль,
модификатор = модификатор
.размер(40.дп, 40.дп)
.clip(MaterialTheme.shapes.small)
)
}
imageThumb ?: painterResource (R.drawable.placeholder_1_1)
Изображение(
художник = изображение,
// Указываем, что это изображение не имеет смыслового значения
описание содержимого = ноль,
модификатор = модификатор
.размер(40.дп, 40.дп)
.clip(MaterialTheme.shapes.small)
)
} Вам решать, нужен ли данный визуальный элемент содержаниеОписание . Спросите себя, передает ли элемент информацию, которую
пользователю нужно будет выполнить свою задачу. Если нет, то лучше оставить
описание вышло.
Объединение элементов
Услуги специальных возможностей, такие как Talkback и Switch Access, позволяют пользователям перемещать фокус
через элементы на экране. Важно, чтобы элементы были сосредоточены на
правильная зернистость. Если каждый низкоуровневый компонуемый элемент на вашем экране
сосредоточены независимо друг от друга, пользователю придется много взаимодействовать, чтобы перемещаться по
экран. Если элементы объединены слишком агрессивно, пользователи могут не понять
какие элементы принадлежат друг другу.
Если элементы объединены слишком агрессивно, пользователи могут не понять
какие элементы принадлежат друг другу.
При применении кликабельно модификатор компонуемого, Compose автоматически объединит все элементы, которые он
содержит. Это справедливо и для Элемент списка ;
элементы в элементе списка будут объединены, а службы специальных возможностей будут просматривать
их как один элемент.
Можно иметь набор составных частей, образующих логическую группу, но это группа не кликабельна и не является частью элемента списка. Вам все еще нужна доступность сервисы, чтобы рассматривать их как один элемент. Например, представьте составной элемент, который показывает аватар пользователя, его имя и некоторую дополнительную информацию:
Вы можете указать Compose объединить эти элементы, используя mergeDescendants параметр в модификаторе семантики . Таким образом, службы доступности будут
выбрать только объединенный элемент и все семантические свойства потомков
объединены.
Таким образом, службы доступности будут
выбрать только объединенный элемент и все семантические свойства потомков
объединены.
@Составной
частное развлечение PostMetadata(метаданные: метаданные) {
// Объединяем элементы ниже для удобства доступа
Строка (модификатор = Modifier.semantics (mergeDescendants = true) {}) {
Изображение(
imageVector = Icons.Filled.AccountCircle,
contentDescription = null // декоративный
)
Столбец {
Текст(метаданные.автор.имя)
Text("${metadata.date} • ${metadata.readTimeMinutes} мин чтения")
}
}
} AccessibilitySnippets.kt
Службы доступности теперь будут фокусироваться сразу на всем контейнере, объединяя их содержимое:
Примечание: Потомки которые сами установили mergeDescendants to true не будет
включены в слияние.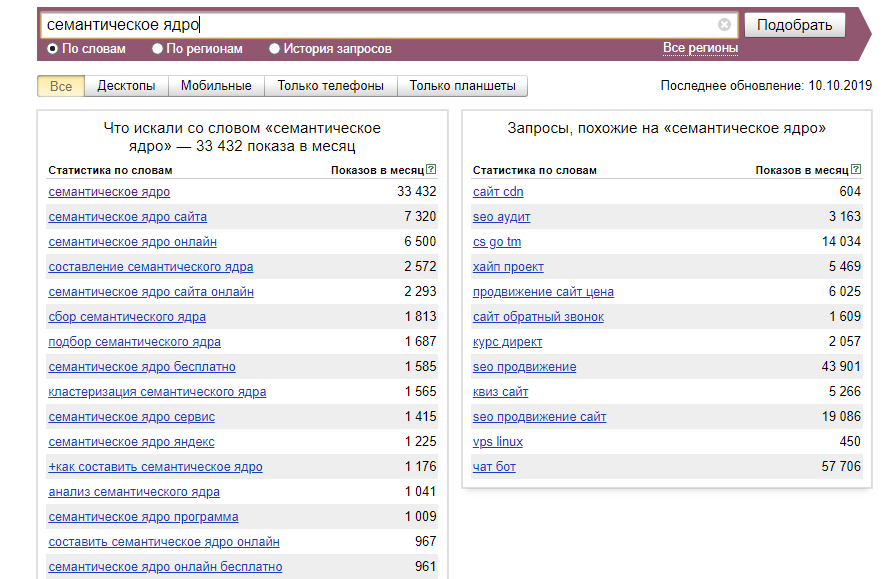 Это предотвращает слишком агрессивное слияние.
Это предотвращает слишком агрессивное слияние.Добавить дополнительные действия
Взгляните на следующий элемент списка:
Когда вы используете программу чтения с экрана, такую как Talkback, чтобы услышать, что отображается на экран, он сначала выберет весь элемент, а затем значок закладки.
В длинном списке это может стать очень повторяющимся. Лучшим подходом было бы
определить настраиваемое действие, позволяющее пользователю добавить элемент в закладки. Держите в
помните, что вам также придется явно удалить поведение закладки
самого значка, чтобы убедиться, что он не будет выбран службой специальных возможностей.
Это делается с помощью ясноандсетсемантика модификатор:
 kt" data-region-tag="android_compose_accessibility_custom_action" dir="ltr"> @Composable
частное развлечение PostCardSimple(
/* ... */
isFavorite: логическое значение,
onToggleFavorite: () -> логическое значение
) {
val actionLabel = stringResource(
if (isFavorite) R.string.unfavorite else R.string.favorite
)
Ряд(
модификатор = модификатор
.clickable(onClick = {/* ... */})
.семантика {
// Установить любые явные семантические свойства
customActions = список(
CustomAccessibilityAction (actionLabel, onToggleFavorite)
)
}
) {
/* ... */
ЗакладкаКнопка(
isBookmarked = избранное,
onClick = onToggleFavorite,
// Очистить все семантические свойства, установленные на этом узле
модификатор = Modifier.clearAndSetSemantics {}
)
}
}
kt" data-region-tag="android_compose_accessibility_custom_action" dir="ltr"> @Composable
частное развлечение PostCardSimple(
/* ... */
isFavorite: логическое значение,
onToggleFavorite: () -> логическое значение
) {
val actionLabel = stringResource(
if (isFavorite) R.string.unfavorite else R.string.favorite
)
Ряд(
модификатор = модификатор
.clickable(onClick = {/* ... */})
.семантика {
// Установить любые явные семантические свойства
customActions = список(
CustomAccessibilityAction (actionLabel, onToggleFavorite)
)
}
) {
/* ... */
ЗакладкаКнопка(
isBookmarked = избранное,
onClick = onToggleFavorite,
// Очистить все семантические свойства, установленные на этом узле
модификатор = Modifier.clearAndSetSemantics {}
)
}
} AccessibilitySnippets.kt
Описать состояние элемента
Составной элемент может определить stateDescription для семантики, которая используется платформой Android для считывания состояния, в котором находится составной элемент. Например, переключаемый составной элемент может находиться в состоянии либо в состоянии «Проверено», либо в состоянии «Не проверено». В некоторых случаях может потребоваться переопределить метки описания состояния по умолчанию, используемые Compose. Вы можете сделать это, явно указав метки описания состояния перед определением компонуемого как переключаемого:
Например, переключаемый составной элемент может находиться в состоянии либо в состоянии «Проверено», либо в состоянии «Не проверено». В некоторых случаях может потребоваться переопределить метки описания состояния по умолчанию, используемые Compose. Вы можете сделать это, явно указав метки описания состояния перед определением компонуемого как переключаемого:
@Составной
частное развлечение TopicItem (itemTitle: String, selected: Boolean, onToggle: () -> Unit) {
val stateSubscribed = stringResource (R.string.subscribed)
val stateNotSubscribed = stringResource (R.string.not_subscribed)
Ряд(
модификатор = модификатор
.семантика {
// Установить любые явные семантические свойства
stateDescription = если (выбрано) stateSubscribed иначе stateNotSubscribed
}
. переключаемый(
значение = выбрано,
onValueChange = { onToggle() }
)
) {
/* ... */
}
} AccessibilitySnippets.kt
 переключаемый(
значение = выбрано,
onValueChange = { onToggle() }
)
) {
/* ... */
}
}
переключаемый(
значение = выбрано,
onValueChange = { onToggle() }
)
) {
/* ... */
}
} Определение заголовков
Приложения иногда отображают много контента на одном экране в прокручиваемом контейнере. Например, на экране может отображаться полное содержание статьи, которую пользователь читает:
Пользователям с особыми потребностями будет трудно ориентироваться на таком экране. Чтобы упростить навигацию, вы можете указать, какие элементы являются заголовками. В примере выше, название каждого подраздела может быть определено как заголовок для доступности. Некоторые службы специальных возможностей, такие как Talkback, позволяют пользователям перемещаться напрямую. от заголовка к заголовку.
В Compose вы указываете, что компонуемый объект — это заголовок путем определения свойства семантики:
 kt" data-region-tag="android_compose_accessibility_headings" dir="ltr"> @Composable
частный забавный подраздел (текст: строка) {
Текст(
текст = текст,
стиль = MaterialTheme.typography.headlineSmall,
модификатор = Modifier.semantics { заголовок() }
)
}
kt" data-region-tag="android_compose_accessibility_headings" dir="ltr"> @Composable
частный забавный подраздел (текст: строка) {
Текст(
текст = текст,
стиль = MaterialTheme.typography.headlineSmall,
модификатор = Modifier.semantics { заголовок() }
)
} AccessibilitySnippets.kt
Автоматическое тестирование свойств специальных возможностей
При настройке семантических свойств вашего приложения, например, при следовании случаи использования, перечисленные выше, вы можете проверить правильность и предотвратить регрессии с помощью автоматизированных тестов пользовательского интерфейса.
Например, чтобы проверить правильность установки метки щелчка элемента, используйте следующий код:
 kt" data-region-tag="android_compose_accessibility_testing" dir="ltr"> @Test
забавный тест () {
составитьTestRule
.onNode(сопоставление узлов)
.утверждать(
SemanticsMatcher("onClickLabel установлен правильно") {
it.config.getOrNull(SemanticsActions.OnClick)?.label == "Мой ярлык клика"
}
)
}
kt" data-region-tag="android_compose_accessibility_testing" dir="ltr"> @Test
забавный тест () {
составитьTestRule
.onNode(сопоставление узлов)
.утверждать(
SemanticsMatcher("onClickLabel установлен правильно") {
it.config.getOrNull(SemanticsActions.OnClick)?.label == "Мой ярлык клика"
}
)
} AccessibilitySnippets.kt
Создание пользовательских низкоуровневых составных объектов
Более сложный вариант использования включает замену определенных компонентов Материала в вашем
приложение с пользовательскими версиями. В этом случае жизненно важно, чтобы вы сохраняли
соображения доступности в виду. Скажите, что вы заменяете Материал Флажок со своей реализацией. Было бы очень легко забыть добавить TriStateToggleable модификатор, который обрабатывает свойства доступности для этого компонента.