
Группировка запросов, разбивка ключевых слов на группы, кластеризация семантического ядра. Бесплатно онлайн.
Включите JS. Без JS ничего работать не будет.
Описание
aka кластеризатор запросов. Единственный вменяемый бесплатный кластеризатор семантического ядра.
Уникаль… Очередной сервис для автоматической группировки запросов. Разбивка запросов на группы производится на основе схожести топ10 Яндекса.
Что делает? Определяет, какие запросы из группы можно продвигать на одной странице, а какие лучше разносить на разные.
Как работать?
- В поле «Регион проверки» выберите регион.
- В поле «Запросы» введите два или более запроса, по одному на строку.
- Измените порог кластеризации при необходимости.
 i
i - Нажмите на кнопку «Сгруппировать».
Обновления
- 11.05.2018. Таки добавил Экспорт результатов в excel.
- 22.02.2018. Увеличил лимит до 1000 запросов единоразово.
- [всякая мелка фигня, удалил]
- 26.11.2015. Решил тут записывать все изменения и обновления.
Лимит на кластеризацию 500 запросов единоразово.
Количество запросов для единоразовой кластеризации пришлось таки снизить. Иначе лимитов на всех не хватает. Простите.
Группировка семантического ядра объемом более 1000 запросов производится на платной основе.
- Возможный объем: от 1000 до 100000 запросов;
- Срок исполнения: до двух рабочих дней;
- Стоимость: 20 копеек за запрос (По-моему, самая низкая цена на рынке).
Результат — файл в формате Excel, содержащий группировку и список конкурентов, наиболее успешно продвигающихся по вашему семантическому ядру.
Чтобы заказать эту услугу, присылайте ваше СЯ и регион на [email protected]
Способы оплаты: любые.
Считаете сервис полезным, желаете помочь и отблагодарить, но не знаете как? Я вас научу!
Если у вас есть XML лимиты, которыми вы не пользуетесь, я буду очень рад, если вы переведете их на мой аккаунт: coolakov-evg. Это поможет этому и другим сервисам моего сайта оставаться бесплатными.
Как передать xml-лимиты
- Добавьте (если еще не добавлены) свои сайты в webmaster.yandex.ru
- Зайдите по адресу xml.yandex.ru в раздел меню «Лимиты». Вы увидите количество доступных лимитов для каждого сайта.
- Кликните «плюсик» напротив того сайта, лимиты которого вы хотите передать на мой аккаунт.
- Впишите в появившееся поле coolakov-evg и нажмите клавишу Enter
- Спасибо! Вы великолепны!
Регион проверки
МоскваРоссияСанкт-ПетербургЕвропаСНГАзияСеверная АмерикаЮжная АмерикаАвстралия и ОкеанияАфрикаАрктика и АнтарктикаДолгопрудныйДубнаПущиноДругие города регионаЧерноголовкаМытищиЛюберцыОдинцовоПодольскЖуковскийСергиев ПосадБалашихаНогинскПушкиноРаменскоеХимкиЩелковоСерпуховКоломнаОрехово-ЗуевоКлинЧеховСтупиноКрасногорскЭлектростальКоролёвРеутовВидноеЖелезнодорожныйДомодедовоСолнечногорскДмитровПавловский ПосадДругие города регионаМосква и областьБелгородская областьБрянская областьВладимирcкая областьВоронежcкая областьИвановская областьКалужская областьКостромская областьКурская областьЛипецкая областьОрловская областьРязанская областьСмоленская областьТамбовская областьТверская областьТульская областьЯрославская областьДругие города регионаСанкт-Петербург и Ленинградская областьАрхангельская областьВологодская областьКалининградская областьМурманская областьНовгородская областьПсковская областьРеспублика КарелияРеспублика КомиНенецкий АОДругие города регионаАстраханская областьВолгоградская областьКраснодарский крайРеспублика АдыгеяРеспублика КалмыкияРостовская областьДругие города регионаКировская областьРеспублика Марий ЭлНижегородская областьОренбургская областьПензенская областьПермский крайРеспублика БашкортостанРеспублика МордовияТатарстанСамарская областьСаратовская областьУдмуртская республикаУльяновская областьЧувашская республикаДругие города регионаКурганская областьСвердловская областьТюменская областьХанты-Мансийский АОЧелябинская областьЯмало-Ненецкий АОДругие города регионаАлтайский крайИркутская областьКемеровская областьКрасноярский крайНовосибирская областьОмская областьРеспублика АлтайРеспублика БурятияРеспублика ТываРеспублика ХакасияТомская областьЗабайкальский крайДругие города регионаМагаданская областьКамчатский крайЕврейская автономная областьЧукотский автономный округХабаровский крайПриморский крайАмурская областьРеспублика Саха (Якутия)Сахалинская областьАтлантаВашингтонДетройтСан-ФранцискоСиэтлЛос-АнджелесНью-ЙоркБостонГейдельбергКельнМюнхенФранкфурт-на-МайнеШтутгартБерлинГамбургНидерландыНорвегияПольшаСловакияСловенияФинляндияФранцияЧехияШвейцарияШвецияСербияДанияИспанияИталияГерманияВеликобританияАвстрияБельгияБолгарияВенгрияГрецияСтраны БалтииКипрМальтаХорватияЧерногорияТурцияНовая ЗеландияАвстралияМинская областьГомельская областьВитебская областьБрестская областьГродненская областьМогилевская областьМинскАлматинская областьКарагандинская областьАкмолинская областьВосточно-Казахстанская областьПавлодарская областьКостанайская областьЗападно-Казахстанская областьСеверо-Казахстанская областьЮжно-Казахстанская областьАктюбинская областьАтырауская областьМангистауская областьЖамбылская областьКызылординская областьТуркменияУзбекистанУкраинаКиргизияМолдоваТаджикистанБеларусьКазахстанАзербайджанАрменияАбхазияЮжная ОсетияБеер-ШеваИерусалимТель-АвивХайфаИндияТаиландБлижний ВостокКитайКореяЯпонияГрузияКиевская областьПолтавская областьЧеркасская областьВинницкая областьКировоградская областьЖитомирская областьХарьковская областьДонецкая областьДнепропетровская областьЛуганская областьЗапорожская областьОдесская областьНиколаевская областьХерсонская областьЛьвовская областьХмельницкая областьТернопольская областьРовенская областьЧерновицкая областьВолынская областьЗакарпатская областьИвано-Франковская областьСумская областьЧерниговская областьКишиневТираспольБельцыБендерыКомратСеверо-ЗападЮгПоволжьеУралСибирьДальний ВостокОбщероссийскиеЦентрСеверный КавказКрымский федеральный округДругие города регионаСимферопольСевастопольЯлтаКерчьФеодосияЕвпаторияАлуштаЛатвияЛитваЭстонияИзраильОбъединенные Арабские ЭмиратыЕгипетМагаданПетропавловск-КамчатскийБиробиджанАнадырьХабаровскКомсомольск-на-АмуреВладивостокНаходкаУссурийскБлаговещенскБелогорскТындаЯкутскЮжно-СахалинскБарнаулБийскРубцовскАнгарскБратскИркутскУсть-ИлимскКемеровоМеждуреченскНовокузнецкПрокопьевскАчинскКрасноярскНорильскЖелезногорскКайерканБердскНовосибирскОмскГорно-АлтайскУлан-УдэКызылАбаканСаяногорскТомскСеверскКурганЕкатеринбургКаменск-УральскийНижний ТагилНовоуральскПервоуральскТюменьТобольскИшимХанты-МансийскСургутНижневартовскЧелябинскМагнитогорскМиассЗлатоустСаткаОзерскСнежинскСалехардКировКирово-ЧепецкЙошкар-ОлаАрзамасНижний НовгородСаровДзержинскСатисКстовоВыксаОренбургОрскПензаПермьСоликамскУфаНефтекамскСалаватСтерлитамакСаранскКазаньНабережные ЧелныНижнекамскЕлабугаАльметьевскБугульмаЗеленодольскЧистопольСамараТольяттиСызраньЖигулевскСаратовБалаковоЭнгельсИжевскГлазовСарапулУльяновскДимитровградЧебоксарыАстраханьВолгоградВолжскийАнапаКраснодарНовороссийскСочиТуапсеГеленджикАрмавирЕйскМайкопМахачкалаНазраньНальчикЭлистаЧеркесскВладикавказРостов-на-ДонуШахтыТаганрогНовочеркасскВолгодонскКаменск-ШахтинскийСтавропольПятигорскМинеральные ВодыЕссентукиКисловодскНевинномысскГрозныйВыборгГатчинаАрхангельскСеверодвинскВологдаЧереповецКалининградАпатитыМурманскВеликий НовгородПсковВеликие ЛукиПетрозаводскСортавалаСыктывкарУхтаБелгородСтарый ОсколБрянскВладимирАлександровГусь-ХрустальныйМуромКовровСуздальВоронежИвановоКалугаОбнинскКостромаКурскЛипецкОрелРязаньСмоленскТамбовТверьРжевТулаНовомосковскЯрославльРыбинскПереславльРостовУгличКанадаСШАМексикаАргентинаБразилияЧитаЖодиноГомельВитебскБрестГродноМогилевАлматыТалдыкорганКарагандаАстанаКокшетауСемейУсть-КаменогорскПавлодарЧимкентАктобеКиевБелая ЦерковьКременчугПолтаваЧеркассыВинницаКировоградЖитомирХарьковДонецкКраматорскМариупольМакеевкаДнепропетровскКривой РогЛуганскЗапорожьеМелитопольОдессаНиколаевХерсонЛьвовХмельницкийТернопольРовноЧерновцыЛуцкУжгородИвано-ФранковскСумыЧерниговРеспублика ДагестанРеспублика ИнгушетияРеспублика Кабардино-БалкарияРеспублика Северная Осетия-АланияСтавропольский крайКарачаево-Черкесская РеспубликаЧеченская РеспубликаКрым
Запросы
Порог кластеризации
Формат вывода 2Сбор семантического ядра: обзор программ и инструментов
Сбор семантического ядра — та еще морока! Блогеры и владельцы сайтов знают это не понаслышке.
Когда я только начинала свое знакомство с блогингом, существовала лишь одна рекомендация — собирать семантическое ядро с помощью небезызвестного сервиса Яндекс.Вордстат. Единственное условие на тот момент было — это ориентация на низкочастотные запросы для новичков. Сейчас такой метод сбора семантического ядра уже не прокатывает)). Приходится пользоваться дополнительными инструментами и ресурсами. Потому как и здесь “госпожа” конкуренция диктует свои правила!
Каюсь, но я уделяю сбору семантического ядра не так много времени, потому что чаще пишу на темы, которые мне интересны здесь и сейчас. Постоянно сверяться с планом, а что там у меня по семантическому ядру, меня дико раздражает! Я признаю, что это мой недостаток).
Тем не менее я смотрю на реакцию своих читателей. И по Яндекс.Метрике чаще вижу, что пользователи идут на мой блог не по запросам, а просто в поисковике вводят “блог Ольги Абрамовой”.
И моей аудитории абсолютно все равно, что на сайте установлен бесплатный шаблон, который встречается на каждом третьем ресурсе в интернете. Их совершенно не интересует, что Яндекс.Вебмастер ставит моему блогу по скорости загрузки 1 балл из 5. А поисковики не воспринимают мой сайт всерьез, потому что я не занимаюсь покупкой внешних ссылок.
Их совершенно не интересует, что Яндекс.Вебмастер ставит моему блогу по скорости загрузки 1 балл из 5. А поисковики не воспринимают мой сайт всерьез, потому что я не занимаюсь покупкой внешних ссылок.
Смею предположить, читатели ищут мою площадку в интернете не просто так! Секрет здесь в том, что им наверняка интересно и полезно то, о чем я пишу. А пишу я всегда с душой!)
Маленьким авторским блогам, в принципе, простительно не привязываться к семантическому ядру. А вот информационным сайтам без качественной семантики никогда не заработать! Этому моменту уделяется огромное внимание при разработке стратегии продвижении сайтов.
В данной статье я хочу сделать небольшой обзор площадок для сбора семантического ядра. Как бы я не открещивалась от этой стороны в блогинге, периодически мне все равно приходится семантику собирать.
Содержание:
Яндекс.Вордстат
Вордстат позволяет собирать ключевые запросы по поисковому слову или словосочетанию. Сервис собирает не только ключи, но и отображает прогнозируемое количество показов по каждой позиции в месяц. Если вы сталкивались с такими понятиями, как высокочастотные, среднечастотные и низкочастотные запросы, то их источник как раз находится в wordstat. Для более точного прогноза по запросам рекомендуется использовать специальные операторы.
Если вы сталкивались с такими понятиями, как высокочастотные, среднечастотные и низкочастотные запросы, то их источник как раз находится в wordstat. Для более точного прогноза по запросам рекомендуется использовать специальные операторы.
Как я уже писала выше, сегодня Яндекс.Вордстат — это лишь вспомогательный сервис для создания семантического ядра. Недостаточно лишь ориентироваться на прогнозируемые цифры показов по ключам. Как минимум, важно также оценить и конкурентность каждого запроса.
Тем не менее, когда мне интересен какой-то ключ, по которому я хочу написать статью, я открываю именно wordstat. В этом случае я даже не смотрю на цифры. Сервис позволяет мне понять, какие вопросы волнуют пользователей, которые ищут информацию по данному ключу. Благодаря Яндекс.Вордстат я делаю первые наброски плана будущей статьи.
Поисковые подсказки
Поисковые подсказки — это простой инструмент поисковых систем. Возможно, вы замечали, что при вводе любого запроса в поисковую строку, появляются подсказки по интересующей вас тематике.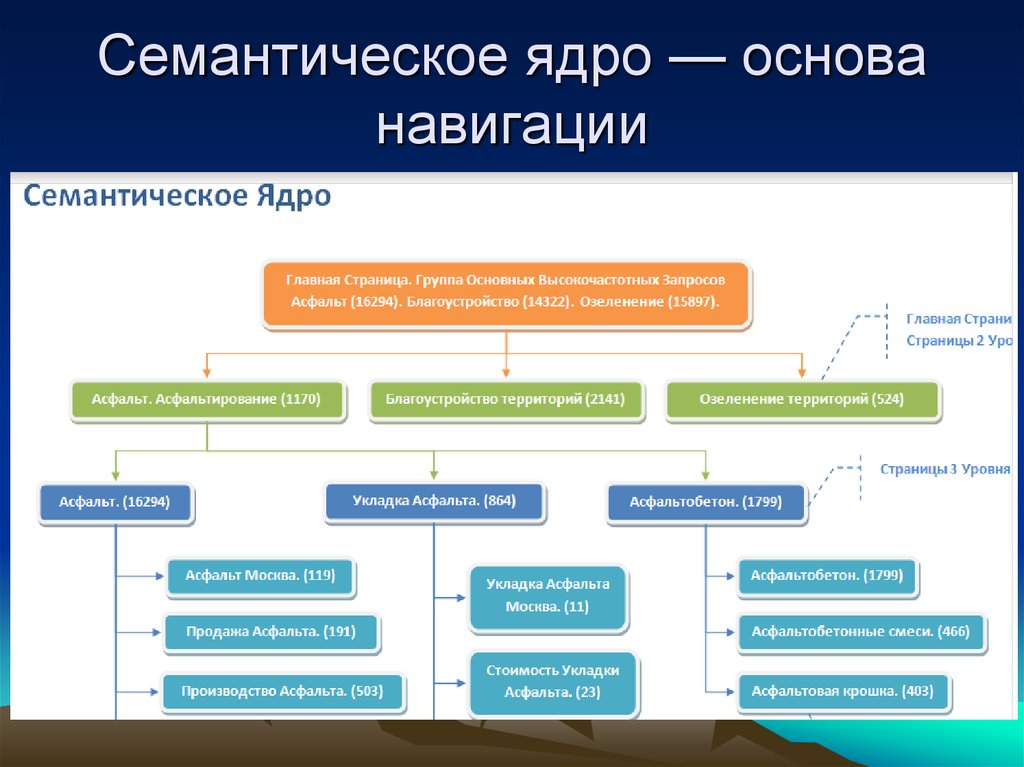 Для полноты семантического ядра их тоже нужно учитывать и включать в план статьи.
Для полноты семантического ядра их тоже нужно учитывать и включать в план статьи.
Обратите внимание, что после ввода интересующего вас запроса в поиск внизу страницы формируется блок под названием Люди ищут (для Яндекса). Здесь также дополнительно можно почерпнуть идеи для будущей статьи. Скриншоты сделаны из поисковой системы Яндекс. Но не забывайте, что этот принцип работает и в Google.
Mutagen
Мутаген изначально был интересен тем, что показывал не только количество прогнозируемых просмотров по ключам за месяц (как Яндекс.Вордстат), но и отображал конкурентность запросов.
Конкурентность запросов — на самом деле показатель немаловажный. На сервисе Мутаген уровень кокуренции оценивается в баллах. Чтобы статья гарантированно попала в ТОП выдачи и собирала трафик, необходимо найти высокочастотные запросы с низкой конкурентностью (для молодых сайтов — до 5). Mutagen такую возможность предоставляет.
Также преимуществом этого сервиса была возможность собирать хвосты запросов.
Сейчас эта возможность никуда не исчезла. Просто Мутаген расширил свой функционал за счет новых инструментов.
Дополнительно здесь можно собрать ключи любого интересующего вас сайта, расширить семантическое ядро, сделать кластеризацию ключевых слов и т.д.
Букварикс
Букварикс собирает ключевые слова из большой базы поисковых запросов. При этом автоматически подсчитывается частотность слов по точному вхождению.
Как самостоятельный инструмент я Букварикс не использую. Все ядро, которое собирается через этот сервис, выгружается в программу Key Collector для дальнейшей работы с ним. При этом ключи с частотностью по точному вхождению до 10 отсекаются на этапе выборки с помощью фильтров и в Key Collector не попадают.
Кроме подбора слов Букварикс предлагает следующие возможности:
- поиск ключевых слов по одному домену,
- сравнение ключевых слов двух доменов,
- поиск ключевых слов нескольких доменов.
Сервисы Serpstat и Keys.
 so
soSerpstat — это полноценный онлайн сервис для сбора семантического ядра. Преимущество его в том, что он не требует установки на компьютер и процесс работы с ключевыми запросами происходит в онлайн режиме. Сервис обладает широким набором различных инструментов: от сбора поисковых подсказок до полноценного аудита сайта. И я знаю, что многие специалисты работают только с этой площадкой, не используя дополнительные продукты. Обзор возможностей сервиса Serpstat есть на моем блоге. При этом информация актуальна, т.к. по просьбе представителя сервиса я обновляла статью буквально в этом году.
Из недостатков — это цена. Дорого не для тех, у кого деятельность связана со сбором семантических ядер, а для тех, кто делает это точечно и редко.
К этому же сегменту я отношу сервис Keys.so. Кроме того, что одна из его главных функций — это также сбор семантического ядра, сервис отлично анализирует и собирает информацию по вашим конкурентам! Благодаря Keys.so буквально за несколько минут вы можете собрать список запросов, по которым продвигаются ваши конкуренты, тем самым расширить семантическое ядро своего сайта.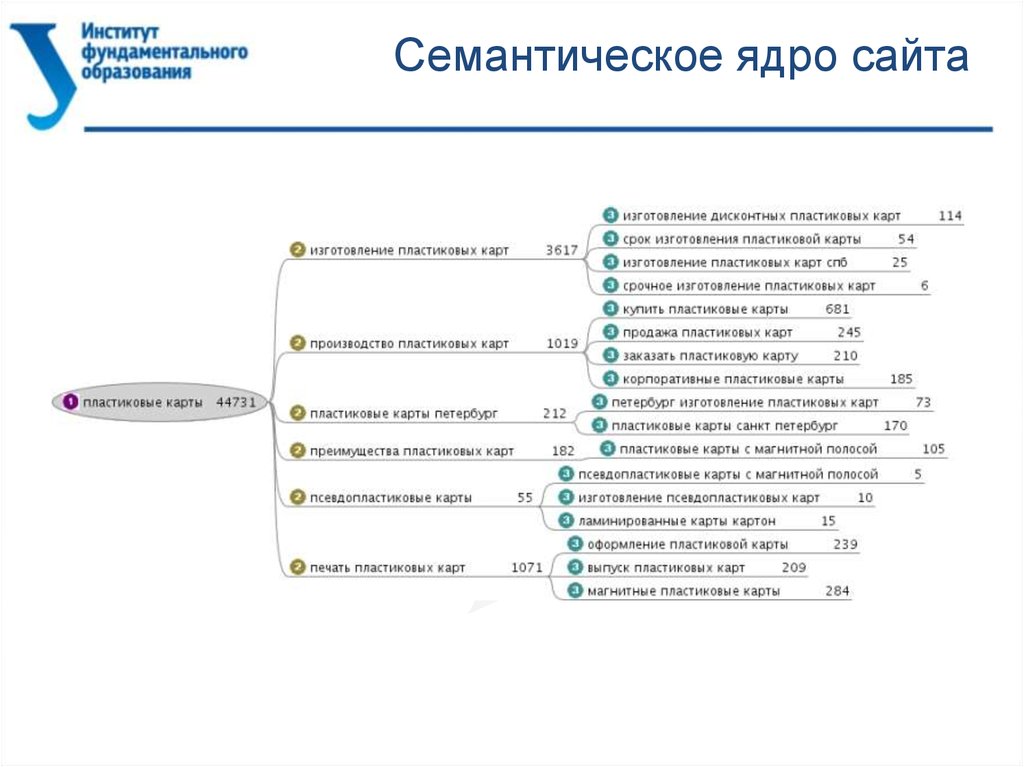
Key Collector
Key Collector — это платная программа, предназначенная для сбора семантического ядра. Требует установки на компьютер. Скорей всего я не ошибусь, если скажу, что данная программа есть у 95% владельцев сайтов и блогов.Т.к. она закрывает все задачи по сбору СЯ.
Наверняка в своей работе я использую всего 10% всех возможностей Key Collector. Но и этого мне хватает “за глаза”, чтобы собрать полноценное семантическое ядро по ключу.
Правда, открываю я эту программу, может быть, раз в полгода. И всегда в моих глазах читается немой вопрос, “а куда тыкнуть — чтобы заработало?”). Забываю! На этот случай на моем ноутбуке в отдельной папочке припасен видеоурок и необходимые инструкции.
Но если без шуток — программа действительно крутая и необходима каждому владельцу сайта или блога.
А если делегировать?
Если сбор семантического ядра навевает на вас тоску и хочется повыть на луну особенно под вечер, я рекомендую этот процесс делегировать). Работа над сайтом занимает большое количество времени — это ведь не только сбор семантики. Даже размещение одной готовой статьи “крадет” у вас часть дня. А если вы еще и пишите статьи самостоятельно?! Плюс оптимизация площадки, закупка внешних ссылок, работа с комментариями и т.д. и т.п. А когда же жить?)
Работа над сайтом занимает большое количество времени — это ведь не только сбор семантики. Даже размещение одной готовой статьи “крадет” у вас часть дня. А если вы еще и пишите статьи самостоятельно?! Плюс оптимизация площадки, закупка внешних ссылок, работа с комментариями и т.д. и т.п. А когда же жить?)
Чтобы не потерять интерес к блогингу, делегируйте часть скучных процессов. Не многих радует перспектива сбора семантического ядра! Особенно тех, кто с этим когда-либо сталкивался. Есть специалисты, предоставляющие услуги по сбору семантики. Как вариант, таких исполнителей можно найти на бирже фриланса или в небезызвестном магазине фриланс-услуг Kwork.
Также в Интернете можно найти компании, предоставляющие подобные услуги. Например, я могу порекомендовать сайт semkeys.ru. На нем работает целая команда профессионалов по составлению семантики для ваших ресурсов. В их услуги входит:
- сбор семантического ядра для информационных сайтов,
- семантическое ядро для интернет-магазинов,
- СЯ для классического бизнеса,
- сбор ключей с конкурентов,
- автоматическая кластеризация,
- семантика для контекстной рекламы.

Узнать подробности или отправить заявку можно прямо на сайте компании.
Автор статьи Ольга Абрамова, блог Денежные ручейки
Как провести кластеризацию запросов семантического ядра: используем онлайн-сервис
Разбираем, какие есть методы кластеризации семантики, и как пользоваться LINE — инструментом для группировки запросов онлайн.
Кластеризация — второй шаг в создании сайта. Первый — сбор семантики. Обе этих задачи нужно сделать еще до заказа сайта у веб-мастера, иначе будет на чем строить его структуру.
Когда у веб-мастера есть семантическое ядро, разбитое на группы-кластеры, он может проектировать структуру сайта и страницы: определять, какие разделы будут на сайте, как их перелинковать, из чего собрать каталог и какое направление выбрать для блога.
О сборе семантического ядра у нас есть отдельные материалы:
Семантическое ядро: как составить и зачем это нужно?
Как пользоваться Яндекс Вордстат: операторы, расширения и секреты
В этой статье разберем, почему бы не использовать семантику без кластеров, какие методы группировки есть и как кластеризовать запросы в онлайне, не скачивая дополнительный софт.
Семантическая кластеризация: что это и каким сайтам нужна
Кластеризация — это объединение ключевых фраз в группы (кластеры), по контексту и признакам объектов, к которым они относятся.
Как сортируют ключи
По группам ключи разделяют на основе анализа выдачи поисковиков. Например, проверяем топовую выдачу по запросам «купить гироскутер» и «купить сегвей». Если она разная, значит поисковик считает эти запросы отличающимися, стоит распределить ключи по разным группам. Ключи с коммерческими и информационными интентами также лучше разделить — «купить блютуз наушники» и «как выбрать блютуз наушники» будут в разных группах.
Правда, такое разделение служит скорее рекомендацией. Иногда ключи попадают в разные группы, потому что при разбивке специалист ориентировался на релевантные результаты топа, а сайты в выдаче недостаточно полно раскрыли фразы на странице или топ поменялся.
Группировку запросов семантического ядра используют
- Оптимизаторы:
они разделяют ключевые слова, чтобы определить целевые страницы, понимать, как делить и продвигать категории товаров, какие статьи писать для продвижения услуг. - Специалисты по контекстной рекламе:
например, чтобы тестировать разные объявления в рамках одной группы слов или настраивать объявления с разными посылами.
После сортировки запросов по группам каждому кластеру обычно назначают страницу сайта, на которой нужно реализовать эти ключи. Создают рекламные объявления в рамках группы, если кластеризацию проводили для контекстной рекламы.
К примеру, если в результате образовались кластеры с запросами про ботулотоксин для губ и в отдельной группе про ботокс для моделирования лица, или про эстетическую ринопластику и отдельно лечебную, этим услугам создают разные посадочные.
В чем поможет кластеризация:
- улучшить оптимизацию ресурса;
- составить структуру сайта;
- выделить целевые страницы для продвижения;
- оценить популярность продуктов и услуг у пользователей;
- разделить ключи по страницам для составления ТЗ копирайтерам.
Каким сайтам она нужна
Группировку ключей лучше проводить даже для небольшого количества, а для семантики от 3000 запросов рекомендуем ее обязательно. Трудность может возникнуть с распределением запросов в нише с низкой конкуренцией, где мало релевантных ответов и не на что опираться при анализе выдачи.
Самостоятельная кластеризация запросов
Разберем, как провести ее самостоятельно без установки отдельного софта.
По каким параметрам делить ключи
Некоторые веб-мастеры объединяют ключи в группы по признаку семантического построения фраз. Тогда в одной группе сосредотачиваются ключи типа «снять ресторан на праздник», «снять ресторан», «снять ресторан на юбилей», потому что они похожи.
Но у ключей есть и другие признаки, кроме формы образования. В эту же группу подойдут ключи по типу «аренда ресторана» — интент тот же, а семантической схожести нет.
Параметры кластеризации:
- Смысловая близость — похожее построение фраз, синонимы;
«монтаж двери», «установка двери». - Морфологическая близость — однокоренные слова;
«заказ ресторана», «заказать ресторан». - Намерение пользователя (интент) — ключи, с которыми пользователи могут искать одно и то же;
«страхование авто», «ОСАГО», «автострахование цена», «калькулятор страховки», «застраховать машину». - Этап воронки продаж — обычно используют для настройки контекстной рекламы, группируют ключи по этапам, на которых находятся пользователи.
Решение проблемы — «боли в спине», группа товаров «ортопедические матрасы», конкретный товар — «матрасы Аскона Ковров».
На скриншоте фрагмент сбора семантического ядра для сайта туристической компании, которая продает путевки в детские лагеря по всей России. Для ключей определили намерение пользователя и подходящую страницу, на которую должен вести запрос, в соответствие с этим можно составлять группы запросов.
Фрагмент семантического ядра туристического сайтаВ зависимости от тематики сайта, его структуры и целей можно комбинировать несколько параметров. К примеру, сначала строят группы по интенту, а потом по этапам воронки продаж. Можно добавить принцип важности услуги или товара для компании — объединить сопутствующие позиции, выделить товары-локомотивы.
Способы кластеризации
Некоторые веб-мастеры ориентируются на выдачу поисковиков. Как проходит группировка по выдаче:
- Веб-мастер обращается в выдачу поисковика по нужным запросам: смотрит релевантные страницы в выдаче и сравнивает результаты по разным ключам. Нужно проанализировать, какие ключи успешные конкуренты сочетают на страницах.
- Для каждого ключевого слова он находит в выдаче определенное количество страниц, где оно употребляется. Устанавливает минимальное количество совпадений — например, четыре — и объединяет ключи в пары, если по этим запросам находится четыре общие страницы.
Минус системы в том, что результаты поисковиков меняются, готовая кластеризованная семантика через неделю может отличаться из-за смены сайтов в выдаче.
Простую кластеризацию для маленького семантического ядра можно сделать вручную, используя таблицу Excel. Но ручная кластеризация — это кропотливые манипуляции с данными, где нужна постоянная внимательность. С большим количеством данных лучше не работать руками, а использовать сервисы автоматической кластеризации.
Как провести кластеризацию онлайн
Есть разные сервисы для группировки запросов онлайн, мы рассмотрим автоматическую кластеризацию на примере сервиса LINE. В нем можно следить за позициями сайта по ключевым фразам и разбить семантику на группы.
1. Начало работы
Перейдите в раздел «Кластеризация» и нажмите «Новая задача»:
Интерфейс сервисаНастройте кластеризацию для вашей семантики: выберите регион, поисковик, укажите, нужна ли частотность, и выберите метод кластеризации и порог.
2. Выбор типа кластеризации: «мягкий» и «жесткий» методы
Объединять запросы в группы можно двумя методами:
- «Soft» — мягкий метод объединения ключей
Метод подходит для статей, информационных, трафиковых проектов, поскольку так получается больше ключей.За основу берут один из запросов с сравнивают с ним остальные ключи: смотрят, сколько у этого ключа общих URL у с основным запросом. Ключ попадает в группу, если набирает больше установленного числа общих URL. Получается, все запросы должны иметь совпадения URL с главным ключевым словом, а между собой не обязательно.
- «Hard» — жесткий метод
Получается меньше ключей, метод подходит для конкурентных тематик, коммерческих проектов.В этом методе сравнивают общие URL у всех ключей. Запросы помещают в одну группу, только если набирается определенное количество общих URL для всех запросов группы. То есть в мягком методе ключи имеют общие URL с контрольным запросом, а в жестком все ключи в группе должны иметь общие URL.
3. Установка порога кластеризации
Порог определяет, сколько нужно общих URL — чем он выше, тем больше нужно общих URL чтобы объединить ключи в группу. При низком пороге в группе будет слишком много лишних запросов, при слишком высоком группы могут не сформироваться.
Обычно устанавливают порог в четыре URL для мягкой кластеризации и три для жесткой, но можно настроить другие показатели.
4. Запуск группировки и обработка
Запустите систему и через несколько минут сервис выдаст готовый отчет с группами ключевых слов. Его можно смотреть на экране или скачать в файле Excel.
Если вы нашли запросы, которые не входят в кластеры, не торопитесь их удалять. Проверьте, если они подходят теме вашего сайта, их все равно можно использовать: внедрите ключи на другие страницы — в статью блога или отзывы, добавьте в один из кластеров, куда они подходят по смыслу.
Попробовать кластеризацию в Line
Что делать потом
Используйте полученные кластеры в работе:
- настраивайте рекламные кампании на разные группы;
- отслеживайте эффект РК по тематическим группам запросов;
- пишите контент, используя ключи из кластеров;
- заполняйте Title, Description, h2 и другие мета-теги страницы согласно запросам из одной группы;
- создавайте структуру сайта согласно разделению ключей.
Кластеризация делает работу с ключами точнее и проще — позволяет рассортировать массив ключей по группам, страницам и объявлениям. Используйте для этого сервисы, чтобы экономить свое время.
Semantic Web — Том 12, выпуск 2 — Журналы
Авторы: Бикакис, Антонис | Хювенен, Ээро | Жан, Стефан | Маркхофф, Беатрис | Моска, Алессандро
Тип статьи: Редакция
Абстрактный:
Культурное наследие и цифровые гуманитарные науки стали основными областями применения технологий связанных данных и семантической сети. Эта редакционная статья представляет специальный выпуск журнала Semantic Web (SWJ), посвященный Semantic Web для культурного наследия. Всего на конкурс поступило 30 материалов, из которых 11 были отобраны для публикации. Документы охватывают широкий спектр смоделированных тем, связанных с языком, чтением и письмом, повествованиями, историческими событиями и культурными артефактами, а также описывают многоразовые методологии и инструменты для управления культурными данными.
Ключевые слова: семантика, онтологии и информационное моделирование, доступ к данным и исследование, графы знаний и связанные данные, культурное наследие, цифровые гуманитарные науки
DOI: 10.3233/SW-210425
Образец цитирования: Semantic Web, об. 12, нет. 2, стр. 163-167, 2021 г.
Получить PDF
Авторы: Felicetti, Achille | Мурано, Франческа
Тип изделия: научная статья
Абстрактный:
В данной статье представлены новые разработки CRMtex, онтологической модели, основанной на CIDOC CRM, созданной для описания древних текстов и других семиотических признаков, встречающихся на надписях, папирусах, рукописях и других подобных носителях. Модель также предназначена для формального описания явлений, связанных с производством, использованием, сохранением, изучением и интерпретацией текстовых объектов. Первоначально CRMtex предназначался для обнаружения тесной связи, связывающей древние тексты с физическими объектами, на которых они поддерживаются, инструментами и системами письма, используемыми для их создания, а также различными научными исследованиями и чтениями, проведенными с текстом.
…современными учеными. В конечном итоге он развился, чтобы предоставить исследователям фундаментальные концепции для правильного и полного отображения текстовых объектов, событий, представляющих их историю, а также культурную и социальную среду, в которой и для которой они были созданы. Полная совместимость CRMtex с онтологией CIDOC CRM и ее расширениями обеспечивает постоянную интероперабельность данных, закодированных с помощью его сущностей, с другой семантической информацией, полученной в культурном наследии и цифровых гуманитарных науках. Новые объекты, представленные в этой статье, более тесно связаны с текстовыми и интертекстуальными структурами и пытаются углубить тесные отношения, существующие между фрагментами текста или последовательностями знаков и лежащим в их основе значением, которое они изначально предназначались для передачи.
Показать больше
Ключевые слова: Древние тексты, онтологии, лингвистика, CIDOC CRM, CRMtex
DOI: 10.3233/SW-200418
Образец цитирования: Semantic Web, об. 12, нет. 2, стр. 169-180, 2021 г.
Цена: 27,50 евро
Авторы: Лиуццо, Пьетро Мария | Evangelisti, Silvia
Тип статьи: научная статья
Абстрактный:
В статье обсуждается небольшая онтология для описания особенностей техники выполнения надписей, основанная на недавнем вкладе, посвященном методологиям классификации. Моделирование осуществляется на основе существующих недавних попыток моделирования эпиграфических документов, а не на общей оценке существующих онтологий. Описанная онтология используется параллельно для обогащения и дальнейшего структурирования словарей EAGLE для техники выполнения, в которой используется SKOS, что, возможно, оказывает непосредственное влияние на многие проекты, использующие содержащиеся в нем концепции.
Ключевые слова: Техника исполнения, CIDOC-CRM, EAGLE, IDEA
DOI: 10.3233/SW-200395
Образец цитирования: Semantic Web, об. 12, нет. 2, стр. 181-190, 2021 г.
Цена: 27,50 евро
Авторы: Антонини, Алессио | Суарес-Фигероа, Мари Кармен | Адаму, Алессандро | Бенатти, Франческа | Виньяле, Франсуа | Гравье, Гийом | Лупи, Лючия
Тип изделия: научная статья
Абстрактный:
Крупномасштабные наборы данных о культурном наследии и вычислительные методы для рамок гуманитарных исследований являются двумя столпами цифровых гуманитарных наук (DH), исследовательской области, направленной на расширение гуманитарных исследований за пределы конкретных источников и периодов для решения макромасштабных вопросов исследования широких человеческих явлений. В связи с этим разработка машиночитаемых семантически обогащенных моделей данных на основе междисциплинарного «языка» явлений имеет решающее значение для достижения интероперабельности исследовательских данных. В этом документе сообщается, документируется и обсуждается разработка модели изучения опыта чтения в рамках проекта EU JPI-CH Reading Europe Advanced Data Investigation.
…Инструмент (ПРОЧИТАЙТЕ). Посредством обсуждения онтологии опыта чтения READ-IT в этом вкладе будут освещены и рассмотрены три проблемы, возникающие в результате разработки концептуальной модели поддержки исследований культурного наследия. Во-первых, этот вклад касается моделирования для междисциплинарных исследований. Во-вторых, эта работа описывает развитие онтологии читательского опыта в свете опыта предыдущих проектов, а также текущих и будущих исследовательских разработок. Наконец, этот вклад касается проверки концептуальной модели в контексте текущих исследований, отсутствия консолидированного набора теорий и консенсуса экспертов в предметной области. Показать больше
Ключевые слова: Опыт чтения, концептуальное моделирование, онтология опыта, цифровые гуманитарные науки, методы моделирования
DOI: 10.3233/SW-200396
Образец цитирования: Semantic Web, об. 12, нет. 2, стр. 191-217, 2021 г.
Цена: 27,50 евро
Авторы: Паннах, Франциска | Спорледер, Кэролайн | Май, Вольфганг | Кришнан, Аравинд | Севчурран, Анушарани
Тип изделия: научная статья
Абстрактный:
Теория Владимира Проппа «Морфология сказки» выделяет 31 инвариантную функцию, подфункции и семь классов сказочных персонажей для описания повествовательной структуры русской волшебной сказки. С тех пор как он был впервые опубликован в 1928 году, подход Проппа использовался в различных народных сказках разного культурного происхождения. ProppOntology моделирует теорию Проппа, описывая нарративные функции, используя комбинацию иерархии функциональных классов и характерных отношений между Dramatis Personae для каждой функции. Особое внимание уделяется ограничениям, определенным Проппом в отношении того, какие Dramatis Personae выполняют определенную функцию. В этой статье исследуется, как онтология может
…помочь традиционным гуманитарным исследованиям в изучении того, насколько хорошо теория Проппа подходит для сказок за пределами русско-европейской сказочной культуры. Для этого реализована облегченная система запросов. Чтобы определить, насколько хорошо работают как схема аннотации, так и система запросов, были аннотированы двадцать африканских сказок и пятнадцать сказок из региона Керала в Индии. Система оценивается путем изучения двух тематических исследований, касающихся представления персонажей и использования пропповских функций в африканских и индийских сказках. Результаты согласуются с традиционными аналогичными гуманитарными исследованиями. Этот проект показывает, как тщательно смоделированные онтологии можно использовать в качестве базы знаний для сравнительного исследования фольклора.
Показать больше
Ключевые слова: Компьютерная фольклористика, онтологии, сказки, нарративная структура, Владимир Пропп
DOI: 10.3233/SW-200417
Образец цитирования: Semantic Web, об. 12, нет. 2, стр. 219-239, 2021 г.
Цена: 27,50 евро
Авторы: Мегини, Карло | Барталеси, Валентина | Метилли, Даниэле
Тип статьи: научная статья
Абстрактный:
Электронные библиотеки (DL), особенно в области культурного наследия, богаты нарративами. Каждый цифровой объект в DL рассказывает какую-то историю, независимо от носителя, жанра или типа объекта. Однако DL не предлагают услуги по нарративам, например, невозможно найти нарратив, создать его или сравнить два нарратива. Конечно, DL предлагают функциональные возможности обнаружения своего содержимого, но эти службы просто обращаются к объектам, которые несут нарративы (например, книги, изображения, аудиовизуальные объекты), без учета самих нарративов. Настоящая работа направлена на то, чтобы представить нарративы как
… первоклассные граждане в DL, предоставляя формальное выражение того, что такое нарратив. В частности, в этой статье представлена концептуализация области нарративов и ее спецификация через нарративную онтологию (сокращенно NOnt), выраженную в логике первого порядка. NOnt был реализован как расширение трех стандартных словарей, то есть CIDOC CRM, FRBRoo и OWL Time, и использует язык правил SWRL для выражения аксиом. На основе NOnt мы разработали инструмент построения и визуализации повествования (NBVT) и применили его в четырех тематических исследованиях для проверки онтологии. NOnt также проверяется в контексте европейского проекта Mingei, в котором он применяется для представления знаний о ремесленном наследии.
Показать больше
Ключевые слова: Нарратив, электронные библиотеки, Semantic Web, онтология, культурное наследие, ремесленное наследие
DOI: 10.3233/SW-200421
Образец цитирования: Semantic Web, об. 12, нет. 2, стр. 241-264, 2021 г.
Цена: 27,50 евро
Авторы: Кохо, Микко | Иккала, Эско | Лескинен, Петри | Тампер, Минна | Туоминен, Йоуни | Хювенен, Ээро
Тип изделия: научная статья
Абстрактный:
Вторая мировая война (WW2), возможно, самая разрушительная катастрофа в истории человечества, тема, представляющая большой интерес не только для исследователей, но и для широкой общественности. Однако данные о Второй мировой войне разнородны и разбросаны по разным организациям и странам, что затрудняет их использование. Чтобы создать агрегированные глобальные представления о войне, необходима общая онтология и инфраструктура данных для согласования информации в различных хранилищах данных. Это позволяет обмениваться данными между издателями и разработчиками приложений, поддерживать анализ данных в исследованиях цифровых гуманитарных наук и разрабатывать интеллектуальные приложения на основе данных. В качестве
…в качестве первого шага к этим целям в этой статье представлены граф знаний WarSampo (KG), общая семантическая инфраструктура и служба связанных открытых данных (LOD) для публикации данных о Второй мировой войне с акцентом на военной истории Финляндии. Общая семантическая инфраструктура основана на идее представления войны как пространственно-временной последовательности событий, в которых участвуют солдаты, воинские части и другие акторы. Используемая схема метаданных является расширением CIDOC CRM, дополненным различными онтологиями предметной области военной истории. . В инфраструктуре, содержащей общие онтологии, поддержка взаимосвязанных данных создает новые проблемы, поскольку одно изменение в онтологии может распространяться на несколько наборов данных, которые его используют. Для поддержки устойчивости был создан повторяемый конвейер автоматического преобразования и связывания данных для восстановления всего WarSampo KG из отдельных исходных наборов данных. WarSampo KG размещается в службе данных, основанной на стандартах и передовых методах W3C Semantic Web, включая согласование контента, SPARQL API, загрузку, автоматическую документацию и другие службы, поддерживающие повторное использование данных. WarSampo KG, часть международного LOD Cloud, всего ок. 14 миллионов троек используется в девяти представлениях приложений для конечных пользователей портала WarSampo, который имеет более 690 000 конечных пользователей с момента открытия в 2015 году. Показать больше
Ключевые слова: связанные открытые данные, семантическая сеть, военная история, Вторая мировая война, Финляндия, культурное наследие, цифровые гуманитарные науки
DOI: 10.3233/SW-200392
Образец цитирования: Semantic Web, об. 12, нет. 2, стр. 265-278, 2021 г.
Цена: 27,50 евро
Авторы: Беретта, Франческо
Тип статьи: научная статья
Абстрактный:
В этом документе рассматривается вопрос функциональной совместимости данных, созданных историческими исследовательскими учреждениями и учреждениями наследия, чтобы сделать их пригодными для повторного использования в новых исследовательских программах в соответствии с принципами FAIR. После представления онтологии проекта symogih.org предлагается описание существенных аспектов процесса производства исторических знаний. Затем проводится эпистемологический и семантический анализ концептуального моделирования данных применительно к фактической исторической информации на основе основополагающих онтологий «Конструктивные описания и ситуации» и «DOLCE», а также обсуждаются причины принятия CIDOC CRM в качестве базовой онтологии для области
…историческое исследование, но дополненное некоторыми важными отсутствующими классами высокого уровня. Наконец, он показывает, как совместное моделирование данных, осуществляемое в среде управления онтологией OntoME, позволяет разработать общую детальную и адаптивную онтологию предметной области при условии, что в этом процессе участвует активное исследовательское сообщество. Имея это в виду, в 2017 году был основан консорциум «Данные для истории», который способствует принятию общей концептуализации в области исторических исследований. Показать больше
Ключевые слова: принципы FAIR, интероперабельность данных исторических исследований, культурное наследие, модель фактоидных данных, конструктивные описания и ситуации, DOLCE, CIDOC CRM, OntoME, dataforhistory.org
DOI: 10.3233/SW-200416
Образец цитирования: Semantic Web, об. 12, нет. 2, стр. 279-294, 2021 г.
Авторы: Алмейда, Бруно | Коста, Руте
Тип статьи: научная статья
Абстрактный:
OntoAndalus стремится создать общую концептуализацию предметной области в рамках будущего многоязычного терминологического ресурса, предназначенного для экспертов и студентов, изучающих исламскую археологию. Текущая версия OntoAndalus согласована с DOLCE+DnS Ultralite (DUL), признанной онтологией верхнего уровня для Semantic Web. В этой статье описываются допущения моделирования, лежащие в основе OntoAndalus, а также наиболее важные шаблоны проектирования (например, типы артефактов, события и отдельные лица). Последние иллюстрируются соответствующими исследованиями в этой области, а именно артефактами освещения, жизненным циклом керамики и несколькими описаниями Васо де Тавира.
Ключевые слова: онтология, терминология, артефакты, исламская археология
DOI: 10.3233/SW-200387
Образец цитирования: Semantic Web, об. 12, нет. 2, стр. 295-311, 2021 г.
Цена: 27,50 евро
Авторы: Carriero, Валентина Анита | Гангеми, Альдо | Манчинелли, Мария Летиция | Нуццолезе, Андреа Джованни | Пресутти, Валентина | Венината, Кьяра
Тип изделия: научная статья
Абстрактный:
Шаблоны проектирования онтологий (ODP) стали устоявшейся и признанной практикой, гарантирующей высокое качество разработки онтологий. Существует несколько репозиториев ODP, где ODP являются общими, а также методологии проектирования онтологий, рекомендующие их повторное использование. Также рекомендуется проводить тщательное тестирование для поддержки обслуживания онтологий и проверки результирующего ресурса на соответствие его мотивирующим требованиям. Тем не менее, не так просто найти руководство по применению таких методологий для разработки графов знаний в предметной области. ArCo — это граф знаний об итальянском культурном наследии, который был разработан с использованием eXtreme Design (XD), методологии ODP и тестирования. Во время своего
… развитие, XD был адаптирован к потребностям домена CH, например. собирая требования от открытого, разнообразного сообщества потребителей, был определен новый ODP, и многие из них были специализированы для удовлетворения конкретных требований CH. В этом документе представлен ArCo и описано, как применять XD для разработки и проверки графа знаний CH, а также подробно описан (интеллектуальный) процесс, реализованный для сопоставления возникающих проблем моделирования с ODP. Соответствующие вклады также включают новый веб-инструмент для поддержки модульного тестирования графов знаний, тщательную оценку ArCo и обсуждение методологических уроков, извлеченных в ходе разработки ArCo.
Показать больше
Ключевые слова: граф знаний о культурном наследии, шаблоны проектирования онтологий, тестирование онтологий, оценка онтологий
DOI: 10.3233/SW-200422
Образец цитирования: Semantic Web, об. 12, нет. 2, стр. 313-357, 2021 г.
Цена: 27,50 евро
Судьба семантической паутины
Обзор
Сэр Тим Бернерс-Ли, изобретатель Всемирной паутины, работал вместе со многими другими в интернет-сообществе более десяти лет, чтобы осуществить свою следующую большую мечту: семантическая сеть. Его видение — это сеть, которая позволяет программным агентам выполнять сложные задачи для пользователей, создавая осмысленные связи между битами информации, чтобы «компьютеры могли выполнять больше утомительной работы, связанной с поиском, объединением и обработкой информации в сети». 1
Около 895 экспертов ответили на приглашение Исследовательского центра Pew Internet & American Life Project и Imagining the Internet Center Университета Элона предсказать вероятный прогресс в достижении целей семантической паутины к 2020 году. Что касается вероятности того, что Бернерс-Ли и его союзники реализуют свое видение, часто называемое Web 3.0, эти эксперты по технологиям и заинтересованные стороны разделились и часто спорили.
Некоторые 47% согласился с утверждением:
- «К 2020 году семантическая сеть, задуманная Тимом Бернерсом-Ли, не будет настолько эффективной, как надеялись ее создатели, и обычные пользователи не заметят большой разницы».
Некоторые 41% согласились с противоположным утверждением, которое гласило:
- «К 2020 году семантическая сеть, задуманная Тимом Бернерсом-Ли и его союзниками, будет в значительной степени реализована и явно изменит ситуацию. для обычных интернет-пользователей».
Эксперты в целом согласились с тем, что прогресс будет продолжаться в том, чтобы сделать Интернет более полезным, а поиск и оценку информации более значимым. Они признали тот факт, что уже существуют элементы и программы семантической сети, которые помогают людям легче ориентироваться в своей жизни. Хотя многие участники опроса отметили, что современные и появляющиеся технологии используются для положительного развития сети в отношении связывания данных, не было единого мнения о технических механизмах и действиях человека, которые могут привести к следующей волне улучшений, а также о том, насколько масштабными могут быть эти изменения. быть.
Многие считают, что видение Бернерса-Ли будет реализовано намного дольше, чем сроки, указанные в вопросе, до 2020 года. Критики отмечали, что использование языка людьми часто бывает нелогичным, игриво вводящим в заблуждение, ложным или гнусным, поэтому человеческая семантика никогда не может быть понята машинами. Около 12% из тех, кто ответил на опрос, не осмелились высказать предположение о будущем семантической паутины, что само по себе является признаком того, что по этой теме все еще существует значительная доля неопределенности и путаницы даже среди тех, кто имеет непосредственное отношение к этой теме. мир технологий.
Также в этом отчете:
» Метод опроса
» Перспективы семантической сети: основные выводы 70
1 Обзор результатов опросов
» Дополнительные интервью и доклады экспертов FutureWeb 2010
» Об отчете
«Напряженные пары» были разработаны, чтобы спровоцировать детальные разработки
Этот материал был собран в ходе четвертого исследования «Будущее Интернета», проведенного проектом «Интернет и американская жизнь» Исследовательского центра Пью и Центром воображения Интернета Университета Элона. Опросы проводятся с помощью онлайн-анкет, на которые приглашаются избранная группа экспертов и активная интернет-публика. Опросы представляют сценарии потенциального будущего, на которые респонденты реагируют своими ожиданиями, основанными на текущих знаниях и отношении. Подробные результаты опросов 2004, 2006, 2008 и 2010 годов можно просмотреть здесь: https://www.pewresearch.org/internet/topics/Future-of-the-internet.aspx и http://www.elon.edu. /e-web/predictions/expertsurveys/default.xhtml. Расширенные результаты опубликованы в серии «Будущее Интернета», опубликованной Cambria Press.
Респондентам опроса «Будущее Интернета IV», проводившегося со 2 декабря 2009 г. по 11 января 2010 г., было предложено подумать о будущем мира, подключенного к Интернету, в период до 2020 г., а также о вероятных инновациях, которые появятся. Их попросили оценить 10 различных «пар напряженности» — каждая пара предлагает два разных сценария 2020 года с одной и той же общей темой и противоположными результатами — и их попросили выбрать один наиболее вероятный вариант из двух утверждений. Пары напряженности и их альтернативные результаты были построены, чтобы отразить предыдущие заявления о вероятном развитии Интернета. Они были рассмотрены и отредактированы Консультативным советом Pew Internet. Результаты публикуются на четырех площадках в течение 2010 г.
Представленные здесь результаты являются ответами на пару вопросов, связанных с будущим влиянием Интернета на учреждения и организации. Результаты по пяти другим парам напряженности — в отношении Интернета и эволюции интеллекта; чтение и передача знаний; идентификация и аутентификация; гаджеты и приложения; и основные ценности Интернета – были обнародованы ранее в 2010 году на собрании Американской ассоциации содействия развитию науки. Их можно прочитать по адресу: https://www.pewresearch.org/internet/Reports/2010/Future-of-the-Internet-IV.aspx. Дополнительные результаты пары противоречий, связанных с влиянием Интернета на институты, обсуждались в Capital Cabal в Вашингтоне, округ Колумбия, 31 марта 2010 г., и их можно прочитать по адресу: https://www. pewresearch.org/internet/Reports/ 2010/Impact-of-the-Internet-on-Institutions-in-the-Future.aspx.
Другие результаты будут обнародованы на конференции World Future Society 2010 (http://www.wfs.org/meetings.htm).
Обратите внимание, что этот опрос в первую очередь направлен на получение целенаправленных наблюдений о вероятном воздействии и влиянии Интернета, а не на выбор респондентов из пар прогностических утверждений. Много раз, когда респонденты «голосовали» за один сценарий, а не за другой, они в своем уточнении отвечали, что оба исхода в определенной степени вероятны или что исход, который не был предложен, был бы их истинным выбором. Участники опроса были проинформированы о том, что «вероятно, вы будете испытывать затруднения с большинством или всеми вариантами выбора, а с некоторыми из них будет невозможно определиться; мы надеемся, что это вдохновит вас на написание ответов, которые объяснят ваш ответ и осветят важные вопросы».
Эксперты находились двумя способами. Во-первых, в результате тщательного изучения научных, государственных и деловых документов за период 1990-1995 гг. было выявлено несколько тысяч человек, чтобы выяснить, кто осмелился предсказать будущее влияние Интернета. Несколько сотен из них участвовали в первых трех опросах, проведенных Pew Internet и Elon University, и с ними повторно связались для этого опроса. Во-вторых, участники-эксперты были отобраны вручную из-за их позиции в качестве заинтересованных сторон в развитии Интернета.
Вот некоторые из респондентов: Клэй Ширки, Эстер Дайсон, Док Серлс, Николас Карр, Сьюзен Кроуфорд, Дэвид Кларк, Джамейс Кассио, Питер Норвиг, Крейг Ньюмарк, Хэл Вариан, Ховард Рейнгольд, Андреас Клут, Джефф Джарвис, Энди Орам. , Кевин Вербах, Дэвид Сифри, Дэн Гиллмор, Марк Ротенберг, Стоу Бойд, Эндрю Начисон, Энтони Таунсенд, Итан Цукерман, Том Вользин, Стивен Даунс, Ребекка Маккиннон, Джим Уоррен, Сандра Брахман, Барри Веллман, Сет Финкельштейн, Джерри Берман, Тиффани Шлейн и Стюарт Бейкер.
Замечания респондентов отражают их личную позицию по вопросам и не являются позицией их работодателей, однако их руководящие роли в ключевых организациях помогают идентифицировать их как экспертов. Ниже приводится репрезентативный список некоторых учреждений, в которых респонденты работают или имеют филиалы: Google, Microsoft. Cisco Systems, Yahoo!, Intel, IBM, Hewlett-Packard, Ericsson Research, Nokia, New York Times, O’Reilly Media, Thomson Reuters, журнал Wired, журнал The Economist, NBC, RAND Corporation, Verizon Communications, Linden Lab, Institute для будущего, British Telecom, Qwest Communications, Raytheon, Adobe, Meetup, Craigslist, Ask.com, Intuit, MITRE Corporation
Министерство обороны, Государственный департамент, Федеральная комиссия по связи, Министерство здравоохранения и социальных служб, Центры по контролю и профилактике заболеваний, Управление социального обеспечения, Управление общих служб, British OfCom, Консорциум World Wide Web, Национальное географическое общество, Фонд Бентона , Фонд Linux, Ассоциация исследователей Интернета, Internet2, Общество Интернета, Институт будущего, Институт Санта-Фе, Yankee Group
Гарвардский университет, Массачусетский технологический институт, Йельский университет, Джорджтаунский университет, Оксфордский институт Интернета, Принстонский университет, Университет Карнеги-Меллона, Пенсильванский университет, Калифорнийский университет в Беркли, Колумбийский университет, Университет Южной Калифорнии, Корнельский университет, Университет Северной Каролины, Университет Пердью, Университет Дьюка, Сиракузский университет, Нью-Йоркский университет, Северо-Западный университет, Университет Огайо, Технологический институт Джорджии, Государственный университет Флориды, Кентукский университет y, Техасский университет, Университет Мэриленда, Университет Канзаса, Университет Иллинойса, Бостонский колледж, Университет Талсы, Университет Миннесоты, штат Аризона, Университет штата Мичиган, Калифорнийский университет в Ирвине, Университет Джорджа Мейсона, Университет Юты, Государственный университет Болла, Университет Бейлора, Университет Массачусетса в Амхерсте, Университет Джорджии, Колледж Уильямс и Университет Флориды.
В то время как многие респонденты находятся на вершине лидерства в Интернете, некоторые из респондентов опроса «работают в окопах» создания сети. Большинство людей из этого последнего сегмента респондентов пришли на опрос по приглашению, потому что они включены в список адресов электронной почты Pew Internet & American Life Project или иным образом известны проекту. Они не обязательно являются лидерами общественного мнения в своих отраслях или известными футурологами, но поразительно, насколько их взгляды были распространены таким же образом, как и те, кто прославился в области технологий.
Несмотря на то, что был запрошен широкий спектр мнений экспертов, организаций и заинтересованных учреждений, этот опрос не следует воспринимать как репрезентативную агитацию интернет-экспертов. По задумке, этот опрос был попыткой самовыбора. Этот процесс не дает случайной репрезентативной выборки. Количественные результаты основаны на неслучайной онлайн-выборке 895 интернет-экспертов и других интернет-пользователей, набранных по приглашению по электронной почте, через Twitter или Facebook. Поскольку данные основаны на неслучайной выборке, погрешность не может быть рассчитана, а результаты не могут быть проецированы на какую-либо совокупность, кроме респондентов в этой выборке.
Многие из респондентов являются интернет-ветеранами: 50% используют Интернет с 1992 года или ранее, а 11% активно используют Интернет с 1982 года или ранее. На вопрос об их основной области интересов в Интернете 15% участников опроса назвали себя учеными-исследователями; 14% как бизнес-лидеры или предприниматели; 12% в качестве консультантов или футуристов, 12% в качестве авторов, редакторов или журналистов; 9% как разработчики технологий или администраторы; 7% как защитники или пользователи-активисты; 3% как пионеры или создатели; 2% в качестве законодателей, политиков или юристов; и 25% указали свою основную область интересов как «другое».
Ответы этих респондентов на вопросы приведены в двух столбцах. В первой колонке представлены ответы 371 опытного эксперта, регулярно участвовавшего в этих опросах. Во втором столбце представлены ответы всех респондентов, в том числе 524, которые были наняты другими экспертами или их ассоциацией с Интернет-проектом Пью. Интересно, что нет большой разницы между меньшими и большими группами респондентов.
[PDF] Порядок слов в русском жестовом языке: расширенный отчет
- Идентификатор корпуса: 55258451
@inproceedings{Kimmelman2012WordOI,
title={Порядок слов в русском жестовом языке: расширенный отчет},
автор={Вадим Киммельман},
год = {2012}
} - В. Киммельман
- Опубликовано в 2012 г.
- Языкознание
В статье представлены результаты исследования порядка слов в русском жестовом языке (РЖЯ). Был проанализирован небольшой корпус (16 минут) нарративов, основанных на комиксах 9 местных авторов, и был проанализирован эксперимент по описанию изображений (на основе Volterra et al. 19).84) было проведено с 6 носителями языка. Данные показывают, что наиболее частым порядком слов в RSL является SVO для простых и согласующихся глаголов и SOV для предикатов классификатора. На порядок слов могут влиять некоторые факторы, а именно вид… порядок слов в русском жестовом языке (РЖЯ). Был проанализирован небольшой корпус нарративов, основанных на комиксах девяти местных сурдопереводчиков, и…
Краткая заметка о методологических проблемах исследования основных составных частей жестового языка
- Се Йим Бинь Феликс
Лингвистика
- 2018
В данной статье обсуждаются основные методологические вопросы изучения жестовых языков. В литературе по разговорному языку есть три возможных стратегии для выявления основных…
Фиксированный и НЕсвободный : пересмотр порядка основных клаузальных составляющих в финском жестовом языке с точки зрения корпуса
- Томми Янтунен
Лингвистика
- 2017
Исследование показывает, что порядок основных составляющих в предложениях FinSL более фиксирован, чем это утверждалось в предыдущем исследовании, и их внутренняя структура явно благоприятствует порядку SV и АВП соответственно.
Кросс-лингвистическое преобладание порядков слов SOV и SVO отражает последовательное и иерархическое представление действия в области Брока
Результаты подтверждают гипотезу о том, что наиболее кросс-лингвистически распространенные паттерны порядка слов отражают наиболее естественные способы линеаризации и вложения основные концептуальные компоненты действий в зоне Брока.
Темы и известность темы на двух языках знаков
- V. Kimmelman
Linguistics
- 2015
Development Of For Computer Sign Язы
В работе рассматриваются особенности грамматики русского жестового языка, которые необходимо обязательно учитывать при разработке компьютерного сурдопереводчика, делая литеральную адаптивную…
Порядок жестов в словенском языке жестов Переходные и дитранзитивные предложения
Основной порядок жестов в словенском языке жестов (SZJ) — субъект-глагол-объект (SVO). Это показано путем анализа нетопикализованных или фокальных переходных и дитранзитивных предложений, которые были вызваны…
Морфосинтаксические аспекты дитранзитивных конструкций с глаголом DAR ‘дать’ в португальском языке жестов
- Сельда Шупина, Ана Мария Брито, Фернанда Беттанкур
Лингвистика
- 2017
В этом исследовании утверждается, что основной порядок слов в дитранзитивных конструкциях — S V DO IO, хотя другие синтаксические процессы, такие как простая и двойная тематика, могут, по-видимому, поставить под сомнение существование этой базовой модели. .
Квантификаторы в русском жестовом языке
- В. Киммельман
Лингвистика
- 2017
После представления некоторых основных генетических, исторических и типологических данных о русском жестовом языке в общих чертах излагается квантификация. Он иллюстрирует различные…
Удвоение в RSL и NGT: на пути к единому объяснению Гебарентаал).
В обоих жестовых языках разные составляющие (включая глаголы, существительные,…)ПОКАЗАНЫ 1-10 ИЗ 108 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантностьНаиболее влиятельные статьиПоследность
Порядок слов в русском языке жестов
- В. Киммельман
Лингвистика
- 2012
В статье представлены результаты исследования порядка слов в русском жестовом языке (РЖЯ). Был проанализирован небольшой корпус рассказов, основанных на комиксах девяти местных сурдопереводчиков, и… в каких языках устанавливается связь между глаголом и его аргументами. Разговорные языки мира подразделяются на три основных порядка слов: SOV, SVO и…
Word order in Croatian Sign Language
- M. Milković, Sandra Bradarić-Jončić, R. Wilbur
Linguistics
- 2006
Investigation on the interaction of word order and the grammatical usage of facial expressions and head position (неручная маркировка) указывает на то, что неручная маркировка играет прагматическую роль и может иметь синтаксические функции, которые ждут дальнейшего исследования.
Учредительный порядок во фламандском языке жестов (VGT) и южноафриканском языке жестов (SASL): кросс-лингвистическое исследование
- Myriam Vermeerbergen, M. V. Herreweghe, P. Akach, E. Matabane
Лингвистика
- 2007
Результаты показывают некоторое интересное сходство среди всех подписавших важные различия между двумя языками.
Грамматика, порядок и расположение знаков Wh в языке жестов Квебека
- Денис Бушар, Колетт Дюбюиссон
Лингвистика
- 1995
Считается, что не все языки имеют базовый порядок и что только языки, в которых порядок слов играет важную функциональную роль, будут иметь базовый порядок.
Части речи в русском жестовом языке: роль иконичности и экономии
- В. Киммельман
Языкознание
- 2009
Представлены данные, проливающие свет на части системы русского жестового языка ( RSL), в частности, различие между существительным и глаголом, и утверждается, что эти различия могут быть результатом более высокой иконичности глаголов и более высокой экономии существительных.
Аспекты синтаксиса американского языка жестов
- Дебра Ааронс
Лингвистика
- 1994
Эта диссертация предлагает анализ синтаксической структуры X-теории американского языка жестов в контексте контекста. Исследуется внутренняя структура предложения. Несмотря на разницу…
Тематическое соглашение на NGT (язык жестов Нидерландов)
- О. Красборн, Эльс ван дер Коой, Дж. Рос, Хелен де Хооп
Лингвистика
- 2009
Резюме В этой статье мы исследуем темы в NGT (язык жестов Нидерландов). NGT — тематический язык, в котором предложения начинаются с темы (тем), а остальная часть…
Референтный выбор в жестовом и разговорном языках
- А. Кибрик, Евгения В. Прозорова
Лингвистика
- 5
2 2007
Мы предлагаем явное сравнение референциальных процессов в двух наиболее контрастных типах языков – разговорном и жестовом языках.