
Как составить семантическое ядро правильно, если вы не SEO-шник
Статья написана в рамках статейного конкурса Serpstat и SEOnews.
Условия конкурса
На тот случай, если вы вдруг не знали, семантическое ядро – это список слов, по которым вы планируете продвигать сайт в поисковых системах. Если ваш сайт оптимизирован под все самые нужные и важные запросы, то потенциальный покупатель обязательно о вас узнает. Потому что ваш сайт будет находиться на первой странице в поисковой выдаче.Все ключевые слова можно разделить на 3 типа:
- ВЧ – Высокочастотные
- СЧ – Среднечастотные
- НЧ – Низкочастотные
Частотность в этом случае – это популярность запроса в поисковых системах. Какие слова мы можем считать высокочастотными?
Не существует универсальной цифры, ориентируясь на которую мы могли бы сказать, что да, этот запрос высокочастотный.
Если тематика достаточно популярная и распространенная, то статистика будет уже другой.
Но, условно говоря, если не вдаваться в детали и попытаться найти все-таки какое-то среднее значение, то высокочастотными можно считать запросы от 1000 показов в месяц.
Также по классификации запросы можно разделить на коммерческие и информационные.
Но иногда сложно сразу понять, точно ли тот или иной запрос является коммерческим/информационным. Вот, например, кажется, что по запросу «роллы с угрем» мы увидим сайты кафе и ресторанов, куда можно прийти поесть роллы или заказать на дом. А в итоге получаем совсем другое – сайты и видео с рецептами их приготовления:
Вот вам и пример явно информационного запроса. Если у вас ресторан, а не кулинарный блог, то, скорее всего, такой запрос не будет для вас целевым. Это значит, что когда голодные любители суши ищут любимое лакомство в интернете, то формируют запрос несколько иным образом. Давайте посмотрим, какую подборку сайтов мы увидим, если изменим запрос на «доставка суши».
Если у вас ресторан, а не кулинарный блог, то, скорее всего, такой запрос не будет для вас целевым. Это значит, что когда голодные любители суши ищут любимое лакомство в интернете, то формируют запрос несколько иным образом. Давайте посмотрим, какую подборку сайтов мы увидим, если изменим запрос на «доставка суши».
А вот теперь мы видим адреса ресторанов на карте, контекстную рекламу и можем с полной уверенностью сказать, что такой запрос является коммерческим.
При определении направления запроса, можно ориентироваться на следующие факторы:
- Наличие контекстной рекламы.
- Наличие хотя бы 3 сайтов коммерческой направленности в ТОП 10 поисковой выдачи.
Ладно, от теории вернемся к практике. Так как же в итоге происходит этот почти магический ритуал по сбору ключевых слов? Откроем вам секрет – нет никакой магии. Процесс этот сугубо механический, не существует такой волшебной программы, которая соберет для вас семантическое ядро, очистит его от мусора, пока вы лениво просматриваете ленту в Facebook.![]()
Вместо этого вам придется:
- выделить основные категории товаров/услуг, которые нужно продвигать
Процесс чем-то напоминает всем известную матрешку. Возвращаясь к теме спортивного питания, которую мы уже упоминали в самом начале статьи. Это общий запрос, который характеризует наше направление деятельности в целом, но существует множество разновидностей такого питания: гейнеры, протеины, жиросжигатели. Те, в свою очередь, тоже можно разделить на различные подкатегории, например, протеин сывороточный, фитнес, яичный.
Именно эти базовые понятия и станут основой, каркасом, на который вы с ловкостью фокусника будете нанизывать ваши ключевые слова. Ориентируясь на вашу базу, необходимо собрать все возможные варианты ключевых фраз, слова-синонимы, например: купить гейнер, купить протеин, жиросжигатели в Алматы.
- сбор ключевых слов для всех выбранных вами категорий
Итак, как же нам узнать, какие еще слова будут актуальны для нашей тематики? Можно, конечно, напрячь фантазию и попытаться все их как-то придумать, но зачем так делать, если есть другие, более удобные варианты?
Первый и бесплатный – это обратиться к Яндекс Вордстат или Google AdWords.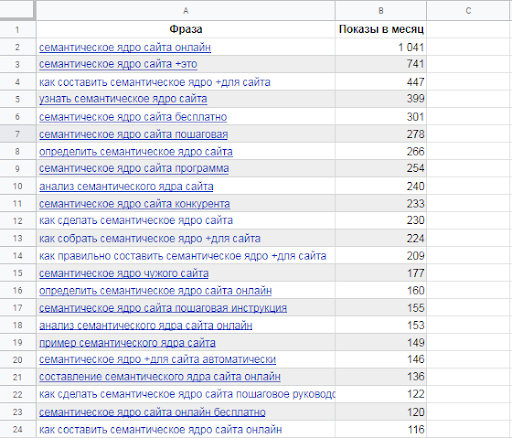
Вбиваем в строку интересующий вас запрос, выбираем нужный регион и нажимаем «Подобрать». В результате получаем не только статистику по нашему запросу, но и список сопутствующих.
Здорово облегчить работу поможет полезное расширение «Yandex Wordstat Assistant». Оно позволяет добавлять все понравившиеся вам слова в список, что намного удобней, чем вручную копировать и сохранять каждый запрос.
Сначала можно не разделять все запросы по смыслу, потому что вы еще успеете сделать это позже, когда будете кластеризовать семантическое ядро. Так что сейчас главное получить список ключевых фраз с частотностью.
Google AdWordsДа, AdWords предназначен для создания контекстной рекламы в поисковой сети Google. Ничего страшного, если вы не занимаетесь контекстной рекламой и не планируете в будущем – Планировщик ключевых слов Google подходит не только при подборе ключевых слов для рекламы. С его помощью можно прекрасно собирать семантическое ядро, главное – зарегистрироваться на сайте https:\/\/adwords\.
После того как вы авторизовались на сайте, необходимо найти вкладку «Инструменты» и выбрать раздел «Планировщик ключевых слов». Среди возможных действий выбирайте «Поиск новых ключевых слов по фразе, сайту или категории». Заполните поля, которые помогут собрать для вас максимально точные варианты ключевых слов:
- товар или услугу, по которой вы будете собирать семантику;
- целевую страницу, которую вы планируете использовать для этой категории товара/услуги;
- категорию товара/услуги из предложенного списка;
- данные для таргетинга и другие параметры.
Также можно сразу прописать возможные минус-слова – это те слова, присутствие которых в запросах для нас нежелательно, например, бесплатно, фото, скачать. После того как вы все заполнили, нажимайте «Получить варианты» и ждите. Здесь, по большому счету, ничего особо сложного, вы получите список из запросов, который нужно будет внимательно просмотреть и оставить только то, что вам подходит.
Существуют также и платные программы, которые помогут вам в сборе семантического ядра. Мы в нашей компании используем KeyCollector. По сути, программа делает все то же самое, что вы могли бы сделать вручную, но быстрее. И, что очень удобно, не нужно отдельно собирать запросы по Яндексу и по Google, можно объединить все эти процессы, а также добавить к ним запросы из поисковых подсказок. Они позволят вам еще больше расширить семантику разнообразными запросами.
Единственное, что не все сразу понятно, тем более для новичка, но существует огромное количество инструкций и обучающих видео, так что разобраться с тем, как работает программа, вполне реально.
- отфильтровать получившийся список, безжалостно удаляя из него слова, которые вам не подходят
И остается заключительный штрих – это почистить наши запросы от мусора.
Тут уже начинается настоящая рутина, от которой не спрятаться, не скрыться – остается только терпеливо перебирать ваш список, подобно Золушке, которая вынуждена была перебрать 7 мешков с фасолью, отделяя черные фасоли от белых.
Например, сюда можно отнести:
- дублирующиеся запросы, которые выглядят как разные, но на самом деле одинаковые: купить спортивное питание, спортивное питание купить;
- запросы с ошибками;
- запросы с нулевой или очень низкой частотностью.
Не делайте ставку только на ВЧ запросы. Да, возникают логичные ассоциации, что если ключевое слово пользуется популярностью, значит принесет прибыль. Но это не означает, что на практике все именно так и работает.
Но по статистике и опыту, именно среднечастотные и низкочастотные запросы приводят к конверсии. Потому что это такие запросы являются более конкретными, и обычно их используют люди, которые уже определились в своих хотелках и готовы заказать у вас букет из 50 белых роз или приобрести телефон определенной модели. Да, их может быть меньше, чем тех неопределенных и витающих в облаках, но именно они вам и нужны. Не смотрите только на цифры, потому что важно не только количество, но и качество.
Не смотрите только на цифры, потому что важно не только количество, но и качество.
Представьте себя на месте пользователя. В процессе работы мы часто сталкивались с клиентами, которые очень хотели помочь/поучаствовать в процессе, поэтому предлагали свои варианты ключевых слов. Большая часть из них была составлена на каком-то особом языке, на котором обычные люди их не ищут.
Вы, возможно, очень удивитесь, но зачастую пользователи находят вас совсем не так, как вам кажется. Поэтому, прежде чем включать в список тот или иной запрос, спросите себя, стали бы вы сами таким образом искать продукцию или услугу. Ведь семантическое ядро мы составляем для того, чтобы помочь потенциальному клиенту найти вас. А это значит, что нужно говорить с ним на одном языке.Конкретизируйте. То есть не используйте только общие запросы, потому что есть шанс привести на сайт не совсем целевую аудиторию. Однажды мы долго и упорно пытались объяснить клиенту, почему запрос «розы» – это не совсем то, что подходит для его магазина.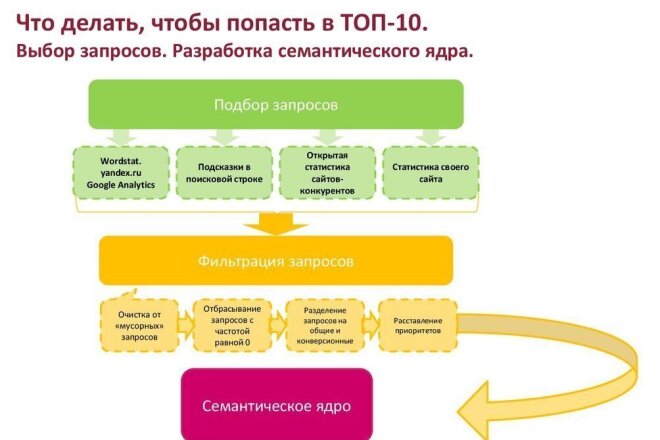 Чтобы и вам было понятно, о чем идет речь, введите в поисковую систему два варианта запроса: розы и доставка роз.
Чтобы и вам было понятно, о чем идет речь, введите в поисковую систему два варианта запроса: розы и доставка роз.
Выдача Google по этим ключевым словам разная. В первом случае мы видим сайты, которые нам расскажут о том, что такое роза, какие у нее бывают виды и много другой полезной информации. Это замечательно, при условии, что ваша аудитория – это школьники, которым нужно срочно написать доклад, студенты или просто любопытные люди, горящие желанием узнать побольше о любимых цветах.
Но если вас интересуют люди, которые будут покупать цветы, то вам больше подходит второй вариант. По такому запросу Google показывает коммерческие сайты, которые занимаются доставкой цветов. А это с гораздо большей вероятностью означает, что пользователи ищут сайты магазинов, в которых можно заказать цветы с доставкой.
И еще немного о пользе конкретизации, но уже в другом ключе. Если у вас на сайте предоставлены товары только определенного бренда, то продвинуть его по общим запросам будет проблематично, особенно если сейчас в ТОПе находятся сайты, предлагающие широкий ассортимент продукции различных брендов.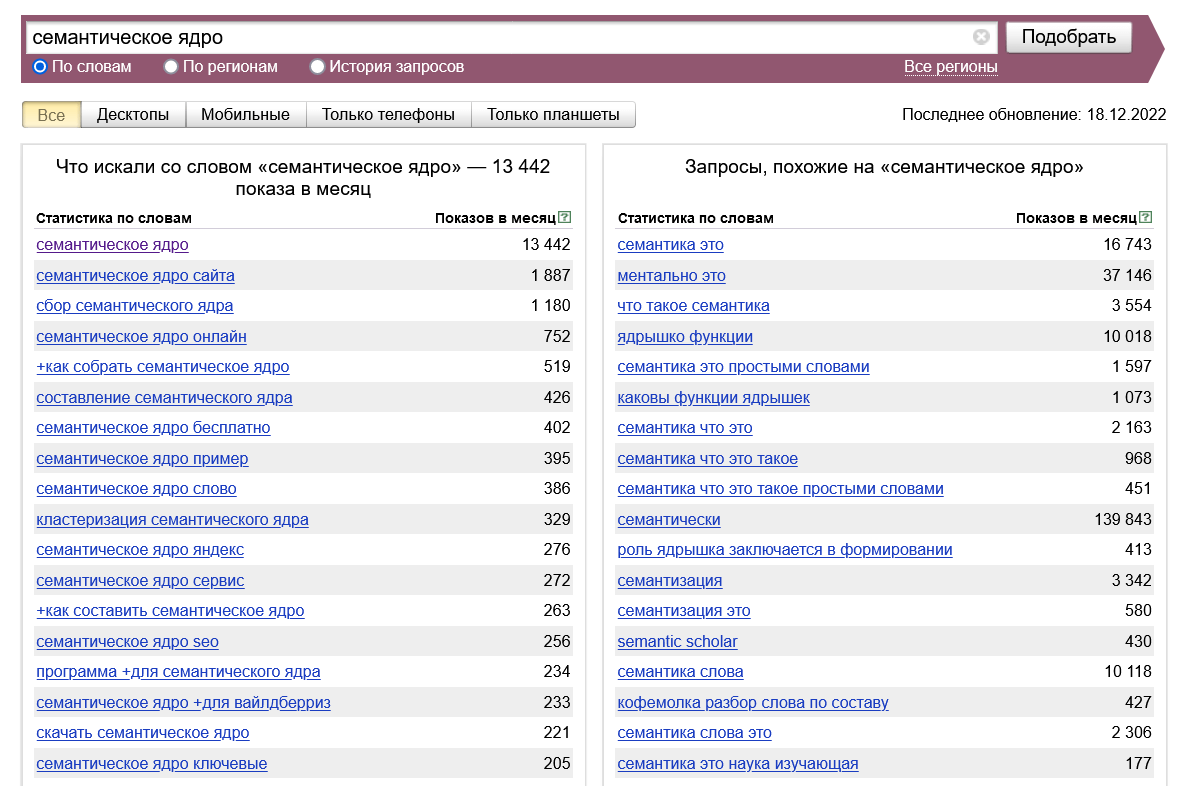
Расставляйте приоритеты. Возможно, что у вас есть основные виды продукции или услуг, реализацией которой вы занимаетесь, но также имеются еще и побочные. И вы размышляете, стоит ли вкладывать силы в их продвижение?
Здесь стоит отталкиваться от таких факторов как:
- конкурентность этих запросов. Если в ТОП 10 находятся сайты, которые посвящены исключительно этой продукции и предлагают ее в огромном ассортименте, в то время как у вас в лучшем случае всего парочка товаров, то, скорее всего, бой будет неравным, и вы проиграете. Потому что ваш сайт в таком случае будет уступать более сильным соперникам. Ведь позиция поисковых систем (что Яндекса, что Google) – быть пользователям максимально полезными, показывая сайты, которые наиболее точно и полно отвечают на их запросы.
- наличие на вашем сайте подходящих разделов. Или, если их нет, готовы ли вы такие разделы создать? Потому что недостаточно будет просто вскользь упомянуть где-то в тексте о том, что у вас есть такой товар или услуга.
 Иначе страница на сайте не будет релевантна запросу пользователя, а значит
Иначе страница на сайте не будет релевантна запросу пользователя, а значит
 Иначе страница на сайте не будет релевантна запросу пользователя, а значит
Иначе страница на сайте не будет релевантна запросу пользователя, а значитВ свое время мы занимались кропотливым сбором семантического ядра вручную, используя данные из Вордстат, фильтровали километровые списки слов из AdWords. Потом оценили преимущества платных сервисов и ответили взаимностью сервису KeyCollector, в итоге не прогадали, потому что и по сей день живем мы с ним долго и счастливо. Преимущества использования платных сервисов, например, KeyCollector в том, что они значительно упрощают работу.
Мы ни в коем случае не призываем к чему-то и не подталкиваем к обязательной трате денег на какой-то платный сервис. Все зависит от масштаба планируемых работ. Если у вас бизнес, который включает в себя небольшой ассортимент товаров или услуг, то можно смело выделить некоторое время на ручной сбор ключевых слов. Но вот обладателям, например, интернет-магазина с огромным количеством товаров, придется изрядно попотеть, собирая семантику.
ИтогПодведем итоги нашей статьи. Чтобы составить нормальное семантическое ядро, по которому вы будете оптимизировать ваш сайт в поисковых системах, нужно:
Чтобы составить нормальное семантическое ядро, по которому вы будете оптимизировать ваш сайт в поисковых системах, нужно:
1. Составить базу – список из товаров или услуг, которые вы собираетесь продвигать.
2. Подобрать слова-синонимы, ориентируясь на ту базу, которую вы уже собрали. Используя для этого платные или бесплатные сервисы по сбору семантического ядра.
3. Провести чистку запросов:
- Удалить все нерелевантные запросы;
- Удалить запросы с нулевой частотностью.
Зачем сайту нужно семантическое ядро и что оно собой представляет
Многие при фразе “нужно собрать семантическое ядро” нервно вздрагивают, покрываются мурашками ужаса и стараются поскорее забыть его, как страшный сон. А забывать не стоит. Грамотно составленное семантическое ядро – едва ли не половина успеха в поисковом продвижении.
Что такое семантическое ядро
Семантическое ядро — это наиболее полный перечень ключевых запросов, по которым пользователи ищут информацию в вашей тематике. Но не просто список, а грамотно сгруппированный и распределенный по посадочным страницам вашего сайта. Правильный подбор ключевых запросов обеспечивает сайт органическим трафиком, является основой стратегии поискового продвижения. Тут-то вам и необходимо семантическое ядро.
Но не просто список, а грамотно сгруппированный и распределенный по посадочным страницам вашего сайта. Правильный подбор ключевых запросов обеспечивает сайт органическим трафиком, является основой стратегии поискового продвижения. Тут-то вам и необходимо семантическое ядро.
Органический трафик из поиска все еще считается лучшим. И это не пустой звук. Многие компании существуют за счет того, что клиенты к ним приходят только из поиска: они не тратят десятки тысяч долларов на контекстную рекламу, но стабильно получают клиентов и заказы.
Что такое ключевые слова
Ключевые слова (ключи, поисковые запросы) — те слова и словосочетания, с помощью которых люди ищут информацию в поиске.
Да, это именно та фраза, которую вы вводите в адресной строке Google или Яндекс. Например, релевантными ключевыми словами для российского интернет-магазина рыболовных товаров будут «купить силиконовые приманки в России».
Обычно все ключевые слова разделяют по частоте запросов:
- Низкочастотные — ключевые слова с частотой показов примерно до 200 раз в месяц.
- Среднечастотные — запросы с частотой до 1000-2000 показов в месяц.
- Высокочастотные — ключи с числом показов от 2000 до 5000 или даже 10 000 раз в месяц.
Пример: если вы продаете мобильные телефоны, то ключ «купить iphone» с более чем 300 тысячами показов будет считаться высокочастотным. А фраза «iphone 7 купить спб» с 4000 показов следует отнести к среднечастотным запросам. Поэтому при сборе SEO-ядра стоит обязательно учитывать общую картину по вашей тематике.
Эти цифры относительные, и для каждой ниши низкочастотными будут запросы с абсолютно разным числом показов. Например, в менее популярной нише запрос с количеством в 1000 показов может оказаться высокочастотным, т.к. сама ниша не имеет высокого спроса, а ключ с таким низким числом показов окажется высокочастотным и конкурентным.
Например, ниша – “Выставочный бизнес” сама по себе обладает невысоким спросом, и в ней точно не будет идти расчет на многотысячную поисковую аудиторию.
Зачем же нужно такое разделение?
Любой SEO-специалист скажет вам: продвинуться по высокочастотным ключам довольно трудно. Конкуренция по ним очень высока, а ТОП выдачи годами занимают настоящие гиганты — крупные интернет-магазины, известные бренды и сайты-агрегаторы. Молодому сайту трудно тягаться с этими ребятами. Имеет смысл начинать продвижение со средне- и низкочастотных запросов. Хорошо проработав их, вы сможете постепенно подтянуть и более конкурентные ключи.
Проверить, насколько сложно продвинуться по тому или иному запросу, можно в сервисе Мутаген. Сервис платный, но очень полезный.
Поисковые запросы и их намерения
Важно уловить поисковую цель пользователя и сгенерировать под нее отдельную посадочную страницу с релевантным контентом (да, контент по-прежнему решает). Перед поисковой системой стоит задача выяснить, какое из этих намерений сейчас актуально для пользователя. Ваша задача — найти ключевые слова, соответствующие каждой поисковой цели, и создать соответствующий тип страницы, чтобы удовлетворить спрос.
Ключевые слова принято делить по намерению пользователей. Чаще всего выделяют:
- Информационные. Когда пользователь ищет ответ на вопрос, хочет получить информацию. Например, такие ключи: «как приготовить салат оливье», «кто изобрел колесо» и т.д.
- Коммерческие (запросы действия). Вводя такие запросы люди планируют совершить какое-то действие — что-то купить, продать, заказать услугу и так далее. На эти ключи делает упор любой коммерческий сайт. Пример: «заказать продвижение сайта», «купить iphone 10» и т.д
- Общие. Когда неясно, какую цель преследует человек, запрос относят к общим.
Чтобы отследить намерение запроса (коммерческое или информационное), вбейте ключевое слово или фразу в поисковую систему и посмотрите на результаты выдачи:
Например, по ключевому запросу “пицца” в ТОПе рецепты (информационная цель) и заказ пиццы (коммерческая цель). Это значит, что этот поисковый запрос общий и пользователи в равной степени нацелены как на простой поиск информации, так и на заказ услуги. Такой способ порой помогает определиться, нужно ли вам продвигаться по тем или иным ключевым словам в конкретном случае.
Такой способ порой помогает определиться, нужно ли вам продвигаться по тем или иным ключевым словам в конкретном случае.
Некоторые специалисты считают, что бизнесу не стоит вообще учитывать информационные намерения. Это большое упущение! Правильно подобранная семантика и качественные статьи создадут вокруг вас репутацию эксперта. Люди будут доверять вам, как профессионалу, а значит, когда им потребуются товары или услуги, обратятся к вам.
Яркий пример — Тинькофф Журнал. Издание публикует злободневные статьи на тему денег и всего, что с ними связано. Все материалы тщательно отбираются. Вместо обычного блога Тинькофф развили свое собственное медиа. ТЖ у всех на слуху, он формирует лояльность к самому банку.
Кажется, что люди, которые так грамотно пишут про деньги, не могут оказывать плохие услуги.
Читайте также:
Кейс: эффективный блог для интернет-магазина и сайта услугРазумеется, далеко не все информационные запросы стоят внимания. Для того, чтобы спрогнозировать, какие ключи будут работать, а какие нет, нужен SEO-специалист. Информационные запросы могут постепенно добавляться ядро в процессе поискового продвижения сайта.
Для того, чтобы спрогнозировать, какие ключи будут работать, а какие нет, нужен SEO-специалист. Информационные запросы могут постепенно добавляться ядро в процессе поискового продвижения сайта.
Не стоит размещать информационные запросы на страницах услуг. Лучше создайте блог или раздел «Полезная информация». Сваливая все в кучу, вы не достигните высоких позиций, только оттолкнете посетителей.
Что нужно знать о смысловом аспекте
Поисковые системы стремятся сделать выдачу максимально релевантной (соответствующей смыслу запроса), поэтому ориентируются не только на ключевые слова, но и определяют поисковой смысл. Боты анализируют связь слов и сущностей, наличие синонимов и другие подобные факторы.
К примеру, раздел “аккумуляторы Samsung” может также выдаваться, когда пользователь ищет по фразам “батарея Samsung”, “АКБ для Samsung”. Намерение у ищущих одно и то же – присмотреть для себя аккумуляторную батарею для телефона Samsung. Поэтому нет необходимости готовить для каждого ключевого слова отдельную страницу или раздел – все смысловые синонимы и подсказки должны относиться к одной странице, одному кластеру.
Как собрать семантическое ядро
Необходимо собрать все ключи, описывающие содержимое сайта с учетом его тематики и цели. Для этого нужно понимание вашей аудитории, а именно знание того, какими словами она выражает свое поисковое намерение. Помните, что аудитория вашего ресурса может быть весьма широкой: люди разных возрастов и интересов по-разному формулируют запрос. В профессиональном сборе семантического ядра помогут специальные сервисы.
Сервисы для составления семантического ядра
Существует огромное количество сервисов этой тематики. Они подскажут на какие ключевые слова обратить внимание, проанализируют сайты конкурентов, предоставят статистику поисковых фраз (в том числе по регионам) и историю запросов в разрезе года или другого периода. Большинство из них платные, но есть и не требующие дополнительных вложений. Расскажем о некоторых.
1. Яндекс Wordstat
Бесплатный инструмент от Яндекса, который показывает частотность запросов, а также альтернативные ключи. Введите один поисковый запрос, и сервис покажет вам другие варианты, которые используют люди в поиске.
Введите один поисковый запрос, и сервис покажет вам другие варианты, которые используют люди в поиске.Обязательно собирайте поисковые похожие слова:
Wordstat вполне хватит для самостоятельного сбора ядра, продвижения небольшого сайта. Минус в том, что он показывает статистику только поисковой системы Яндекс. Для продвижения Google придется подключить другие сервисы.
Какие? Ну, например…
2. Планировщик слов для Google Рекламы
В первую очередь предназначен для настройки рекламных компаний. Но что мешает использовать его в SEO? Инструмент бесплатный – вам потребуется только зарегистрировать свой аккаунт в Google.
Подбирать ключи можно с помощью анализа сайта, запросов или определенной темы.
3. Google Trends
Взлет запроса “День Святого Валентина” обозначен конкретной датой
Показывает, насколько популярна та или иная фраза в поиске. Помогает отследить сезонность запросов, популярность по регионам и другим странам.
Можно добавить одновременно два запроса и сравнить их динамику.
4. Поисковые подсказки Яндекс и Google
Слова и фразы, которые появляются в строке поиска, когда вы только начинаете вводить запрос. Также поисковые подсказки можно найти в самом низу страницы под выдачей, когда поиск уже выполнен. Не игнорируйте эти словосочетания.
5. KeyCollector
Это инструмент профессиональных интернет-маркетологов и сеошников. Подписка платная, но затраты на него окупятся в полной мере, если вы продвигаете большой сайт или ведете несколько проектов одновременно.
Главный плюс KeyCollector в том, что он сочетает в себе возможности нескольких бесплатных сервисов. Здесь и парсинг ключей из Яндекс Wordstat, подбор слов для объявлений в Директе, сбор из Google Analytics, ВК и других источников. Слова можно удобно сгруппировать, отсортировать с помощью стоп-слов и подобрать к ним подходящую страницу на вашем сайте.
6. Serpstat
Чрезвычайно полезный платный сервис с комплектом инструментов для комплексного продвижения сайта.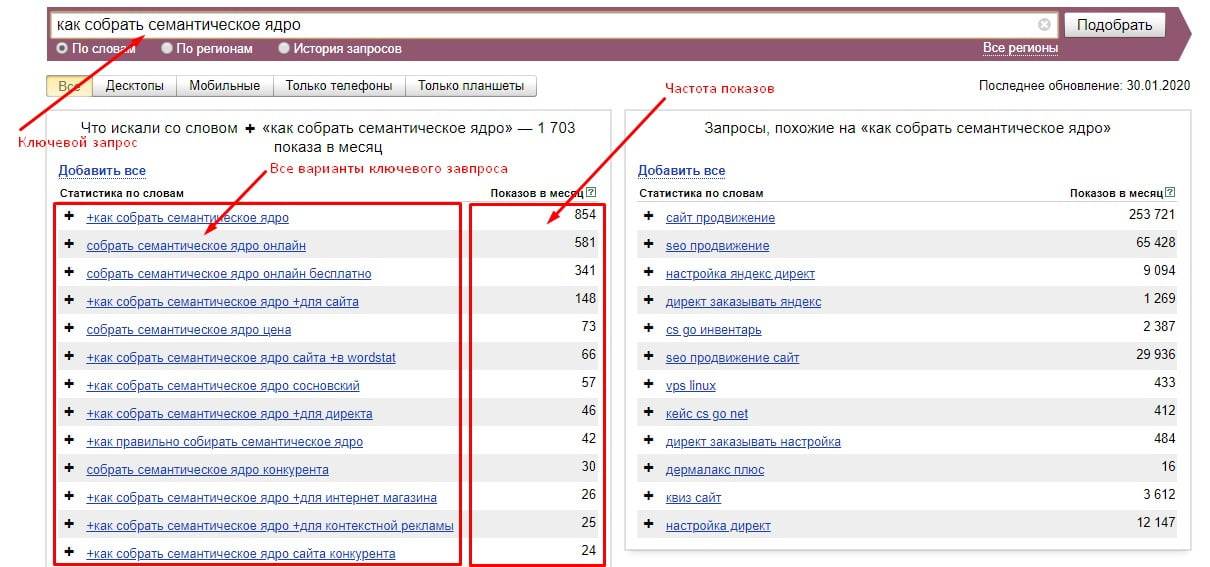 Платформа позволяет подбирать ключи, проверять частотность и показатели конкуренции, уточнять стоимость слов для контекстной рекламы. С помощью Serpstat вы можете узнать, по каким запросам продвигаются ваши конкуренты.
Платформа позволяет подбирать ключи, проверять частотность и показатели конкуренции, уточнять стоимость слов для контекстной рекламы. С помощью Serpstat вы можете узнать, по каким запросам продвигаются ваши конкуренты.
Будет полезна как оптимизаторам, так и владельцам нескольких сайтов. Некоторые возможности дает демо-версия, но для полноценного использования нужно оформить платную подписку.
Как расширить существующее семантическое ядро
Семантику уже существующего сайта следует расширять и обновлять. Из-за высокой конкуренции необходимо постоянно анализировать конкурентов и синонимы в поисковой выдаче, чтобы всегда отслеживать отсутствующий семантический кластер и поспевать за спросом пользователей.
Позвольте конкурентам сделать часть вашей работы: изучите их сайты, проанализируйте, по каким запросам они получают посетителей из поиска или контекстной рекламы. Ищите синонимы. Их можно легко подобрать, изучив результаты поисковой выдачи, адаптировав высокочастотные запросы ваших конкурентов или более предметно изучив жаргон вашей области бизнеса. Эти действия помогут вам увеличить количество средне- и низкочастотных запросов.
Эти действия помогут вам увеличить количество средне- и низкочастотных запросов.
Что делать с семантическим ядром
Готовое семантическое ядро предоставляет множество возможностей: это инструмент для внедрения семантики на сайт, источник идей для контент-плана, инструкция по расширению ассортимента и страниц сайта, помощь в построении соответствующей структуры. Но прежде всего необходима кластеризация ключевых слов — разделение их по группам для продвижения на отдельных страницах.
Кластеризация и построение структуры
Кластеризация необходима для группировки фраз семантического ядра по смыслу. Она помогает избежать ошибок, связанных с некорректным объединением запросов разного типа (информационных и коммерческих) в одну группу, из-за чего целевая страница может не попасть в топ. Распределение можно проводить вручную или с помощью сервисов, например, вышеуказанного SerpStat. Однако в большинстве случаев затем потребуется ручная корректировка, с учетом поисковых намерений пользователей.
Составляем структуру сайта
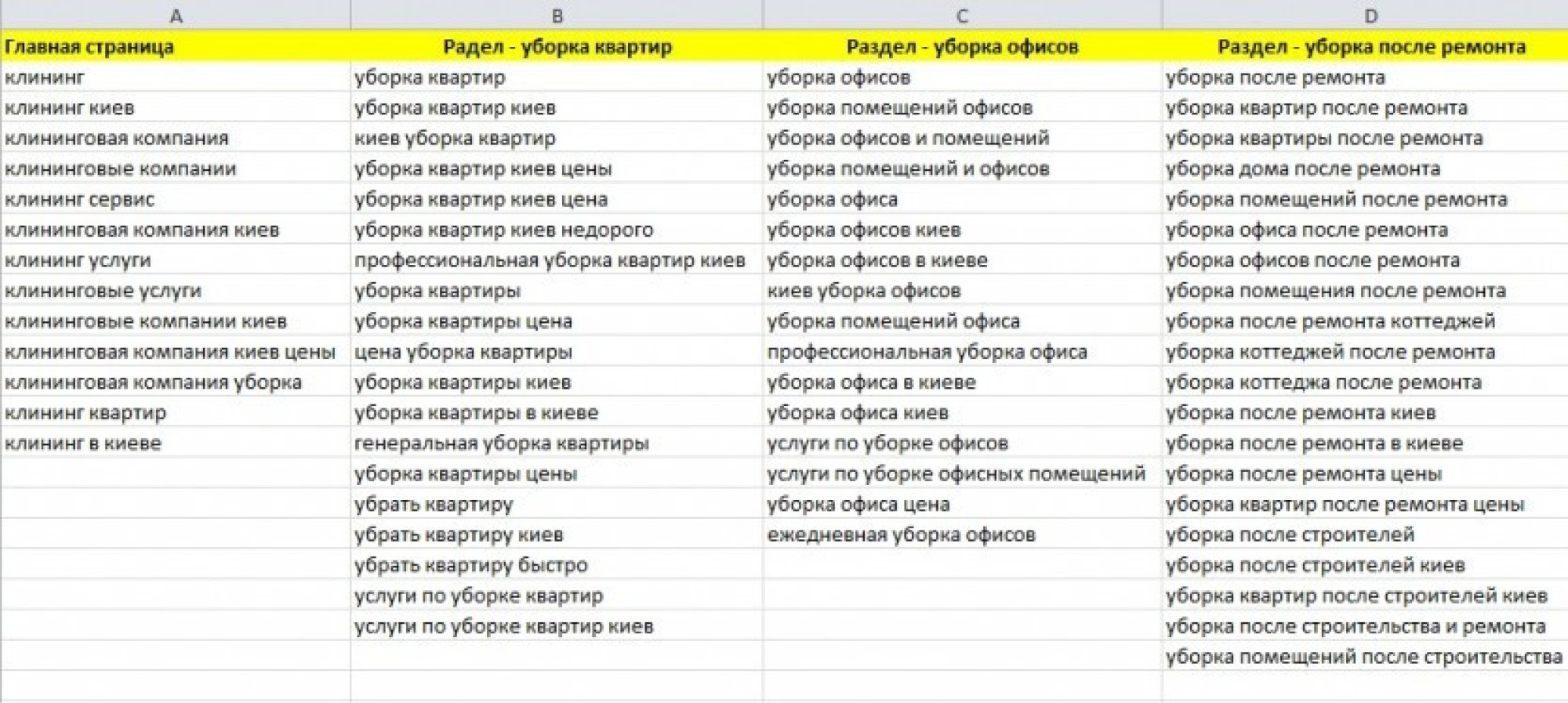
Многие сайты организованы очень удобно для их создателей, но не для их посетителей. Клиент не всегда разбирается в специфике товара, поэтому использование профессиональных терминов и многоуровневая структура могут, наоборот, сбить с толку. Нужно уметь смотреть на сайт глазами клиента, понимать, как он представляет ваши услуги и что именно может иметь в виду.После сбора ядра перед вами будет лежать набор данных, который покажет, какими категориями мыслит ваш клиент. Можно приступать к его кластеризации под поисковые намерения (!). Один кластер может насчитывать десятки целевых запросов – нет необходимости под каждый из них готовить отдельные посадочные страницы. Особое внимание нужно уделять низко- и микрочастотным запросам, которые следует обязательно раскрывать в контенте.
Распишите в Excel-таблице текущую структуру вашего сайта, распределив группы запросов по категориям. Если останется кластер популярных ключевых слов, который не относится ни к одной категории — это повод расширить структуру, добавив новые страницы.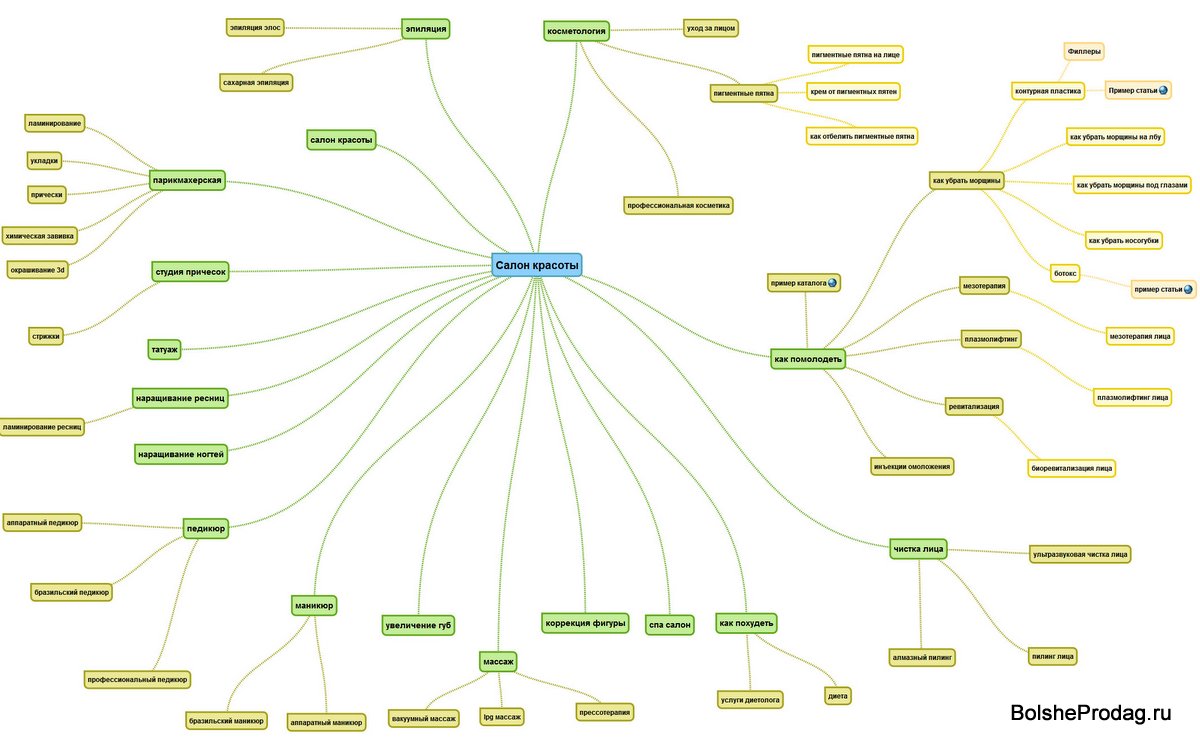 Помимо списка разделов, семантическое ядро поможет и в составлении списка фильтров под каждую категорию.
Помимо списка разделов, семантическое ядро поможет и в составлении списка фильтров под каждую категорию.
Читайте также:
SILO или как построить идеальную SEO-структуру сайтаКак составить контент-план на основе семантики
Распределенные по группам поисковые запросы могут быть отличным источником идей для контент-плана. Вопрос «о чём писать» отпадает, так как у вас на руках уже есть список потребностей аудитории. Остаётся только уточнить название публикации и поставить ее в план. Если ваш контент не просто содержит популярные ключи, но и является полезным для посетителей — успех гарантирован.Пару слов о семантическом проектировании
Семантическое проектирование — это проектирование сайта до запуска, учитывая семантику и сформированный спрос на услуги. Включает в себя создание структуры проекта, построение логической иерархии страниц и написание текстов по заданной тематике. Проводится на основе анализа сайтов-конкурентов, на полноценное проектирование уходит до месяца времени (в зависимости от масштабности онлайн-проекта).
Проводится на основе анализа сайтов-конкурентов, на полноценное проектирование уходит до месяца времени (в зависимости от масштабности онлайн-проекта).
Собирать семантику рекомендуют еще на этапе разработки сайта. Структура ресурса, навигационное меню, контентная часть, созданная с опорой на семантическое ядро — всё вместе обеспечивает хорошую индексацию. Такой сайт будет легче развивать и продвигать в дальнейшем.
По сути, это объединение двух предыдущих пунктов, с той лишь разницей, что в этом случае сайт создаётся с нуля. В этом случае ресурс не будет отягощен предыдущими наработками, содержа лишь релевантный контент.
Вам не обойтись без семантического ядра если вы хотите, чтобы:- вы смогли закрыть спрос аудитории соответствующим предложением (читай – поисковой страницей)/li>
- ваш сайт имел максимально расширенную структуру и был максимально видимым в нише;
- ресурс легко попадал на первые страницы поисковых систем по кластерам, имеющим низкую конкуренцию
- предлагаемый вами продукт активно покупали, а услуги заказывали.

Towards a Pattern Science for the Semantic Web
Название статьи:
Towards a Pattern Science for the Semantic Web
Авторы:
Aldo Gangemi and Valentina Presutti
Abstract:
900 02 В сети данных семантическая сеть может быть эмпирической наукой. Необходимо решить две проблемы. Проблема супа знаний связана с семантической неоднородностью и может считаться сложной технической проблемой, требующей соответствующей трансформации и логических конвейеров, которые могут помочь разобраться в различных контекстах знаний. Проблема границы знаний лежит в основе эмпирического исследования семантической сети: какие значимые единицы составляют объекты исследования семантической сети? Этот вопрос затрагивает многие аспекты семантических веб-исследований: данные, схемы, представление и рассуждение, взаимодействие, лингвистическое обоснование и т. д.Полная версия PDF:
Тип представления:
Ответственный редактор:
Кшиштоф Янович
Решение/Статус:
Принят
Отзывы :
Обзор 1 Паскаля Хитцлера:
Авторы подчеркивают необходимость контекстно-ориентированного управления знаниями для Semantic Web. Начиная с точки зрения связанных открытых данных, они определяют две концептуальные трудности в существующих подходах, называемые «супом знаний» и проблемой «границы знаний». Они обсуждаются в историческом контексте, и затем авторы решительно утверждают, что они имеют центральное значение для семантического веб-видения и что для решения этих проблем следует изучать «образцы знаний» в качестве основных объектов исследования.
Начиная с точки зрения связанных открытых данных, они определяют две концептуальные трудности в существующих подходах, называемые «супом знаний» и проблемой «границы знаний». Они обсуждаются в историческом контексте, и затем авторы решительно утверждают, что они имеют центральное значение для семантического веб-видения и что для решения этих проблем следует изучать «образцы знаний» в качестве основных объектов исследования.
Я нахожу статью очень вдохновляющей. Она прекрасно сочетается с другими статьями в этом специальном выпуске (Раубаль, Кун, Хитцлер и др., Поллерес и др.).
Можете ли вы прокомментировать проблемы масштабируемости в контексте предлагаемого вами подхода?
Возможно, вы могли бы также добавить предложение о том, как фреймы соединяются с зеркальными нейронами (страница 4, слева, внизу).
Незначительные пожелания:
— проведите тщательную корректуру
— улучшите рисунки, чтобы они были более читаемыми
— что-то не так со списком авторов [IB82]
— третий автор [JHY+10] имеет фамилию Yeh, а не Yehy
Review 2 by Ban Adams:
В этой статье используется очень интересный подход к супу знаний и граничным проблемам, предлагая шаблоны знаний на основе фреймов. Насколько я понимаю, использование фреймов, как описано в статье, не обязательно должно заменить формализм логики описания для понятий, поскольку это все еще один фасад (рис. 5), а скорее действует как мета-метаданные для организации знаний в шаблоны для различных контекстов. Кроме того, я абсолютно согласен с представленным здесь представлением о том, что процесс проектирования онтологий (прискорбно) был отодвинут на второй план в семантической сети в пользу вычислительных проблем. На мой взгляд, семантическая паутина пострадала от применения теории, а не наоборот. В целом, очень наводящая на размышления статья, и следующие комментарии/вопросы идут в произвольном порядке:
Насколько я понимаю, использование фреймов, как описано в статье, не обязательно должно заменить формализм логики описания для понятий, поскольку это все еще один фасад (рис. 5), а скорее действует как мета-метаданные для организации знаний в шаблоны для различных контекстов. Кроме того, я абсолютно согласен с представленным здесь представлением о том, что процесс проектирования онтологий (прискорбно) был отодвинут на второй план в семантической сети в пользу вычислительных проблем. На мой взгляд, семантическая паутина пострадала от применения теории, а не наоборот. В целом, очень наводящая на размышления статья, и следующие комментарии/вопросы идут в произвольном порядке:
Основной аргумент в пользу фреймов как «единицы значения» для семантической паутины, по-видимому, исходит из точки зрения, что фреймы являются более естественной (то есть более простой) моделью для использования людьми, что, хотя и возможно, не подтверждается никакими доказательствами в статье и кажется субъективным. Я не уверен, что они более выразительны семантически, за исключением того, что некоторые слоты заполнены текстом на естественном языке, а другие — DL и правилами.
Я не уверен, что они более выразительны семантически, за исключением того, что некоторые слоты заполнены текстом на естественном языке, а другие — DL и правилами.
Несколько раз в статье я не был уверен, что представляет собой предполагаемый агент, который интерпретирует знание, представленное в кадре. Для меня, безусловно, имеет смысл то, что описание понятий, задействованных в разработке онтологий, не обязательно должно быть формальным, поскольку мы не просим искусственных агентов разрабатывать онтологии, а только выводим из них значение. Как уже было сказано, шаблоны знаний кажутся более полезными для разработчиков онтологий. Тем не менее, авторы говорят: «Агенты и рассуждающие должны уметь распознавать такие фреймы и рассуждать на них…», так в какой степени эти фреймы подходят для синтеза онтологий по сравнению с анализом (т.е. рассуждениями) онтологий? Единственные фасады, которые кажутся возможными для рассуждений на основе агентов, — это «формальное представление» и «выводная структура», которые уже охвачены OWL/SWRL, но как агенту рассуждать над фасадами без формального представления, такими как «вариант использования», «словарь» и т.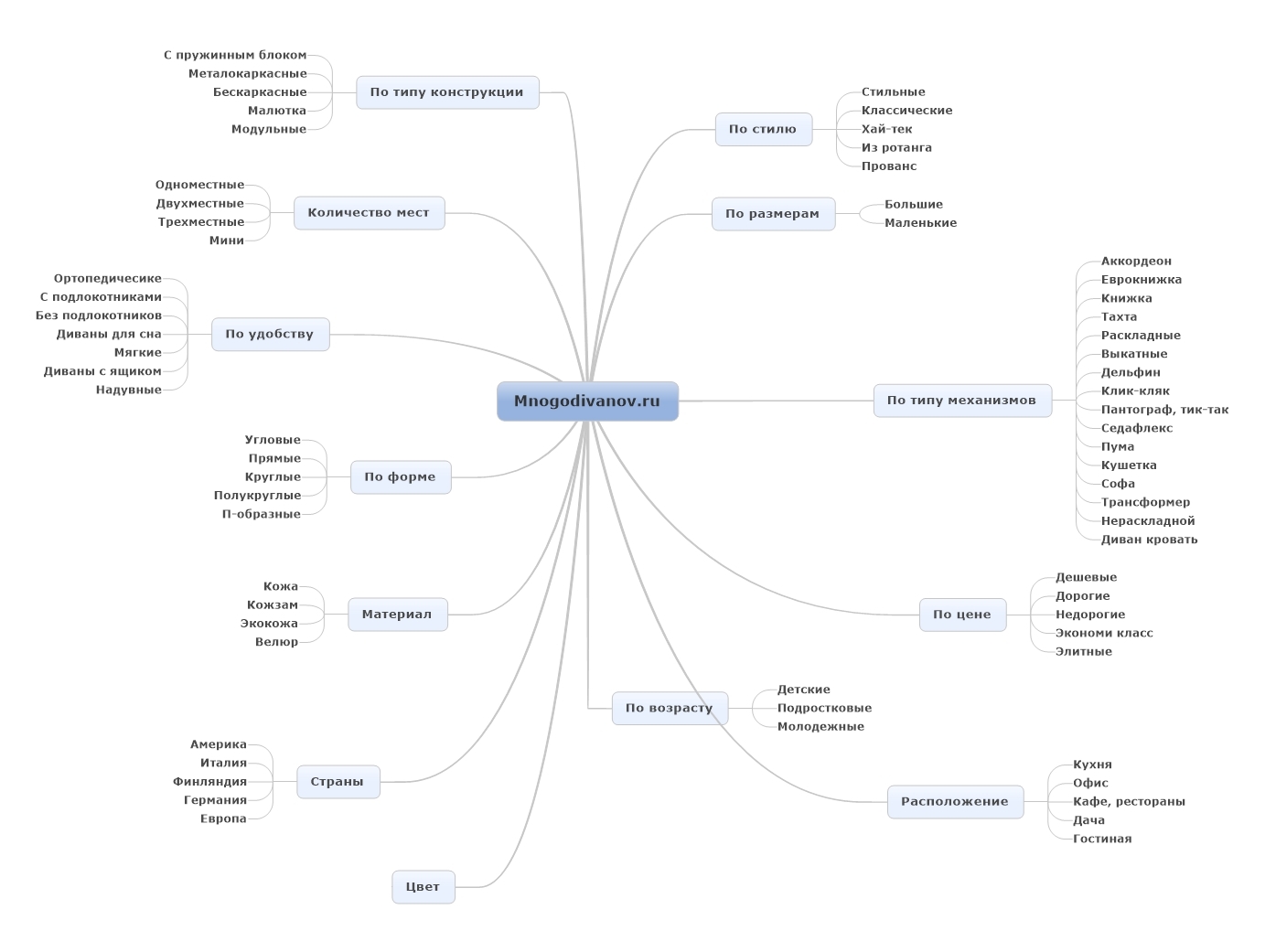 д. (без НЛП)? Также, например, на стр. 6: «Чтобы разобраться в этих данных, одной формальной семантики недостаточно». Это человек-разработчик/программист онтологий, которому нужно разобраться в данных, или искусственный агент? Если последнее, то как агент может понять «смысл» данных, которые формально не определены?
д. (без НЛП)? Также, например, на стр. 6: «Чтобы разобраться в этих данных, одной формальной семантики недостаточно». Это человек-разработчик/программист онтологий, которому нужно разобраться в данных, или искусственный агент? Если последнее, то как агент может понять «смысл» данных, которые формально не определены?
ВВЕДЕНИЕ — Я хотел бы дать четкое определение того, что понимается под «объектом исследования». Во введении есть некоторые опечатки (не знал, что паутина данных была мужской ;-). Что подразумевается под каноническими наборами данных (вы имеете в виду модели данных?) для географических и биологических данных, музыкальных и т. д.? В целом введение читается хуже, чем остальная часть статьи, и я бы посоветовал еще раз вычитать.
Поскольку выравнивание с конкретной верхней онтологией, такой как DOLCE, не кажется вполне возможным решением проблемы супа знаний, авторы предлагают понятие представления контекстов знаний в онтологии. Контекст — это, конечно, все, но формализовать его может быть сложно. Немного больше о том, каков механизм того, как перечисленные контексты (описательные, информационные, ситуационные и т. д.) практически помогают с точки зрения интерпретации значения, было бы неплохо, хотя, возможно, выходит за рамки статьи.
Несколько дополнительных вопросов/комментариев:
В каком смысле шаблоны знаний похожи на многие другие системы, основанные на фреймах, в том смысле, что они делают допущение о закрытом мире (в отличие от допущения логики описания об открытом мире)? Являются ли контексты знания способами проектирования если не закрытых миров, то «огороженных миров»? Возможно, эти предположения следует пересмотреть в семантической сети, поскольку для многих объектов исследования существует предполагаемая вселенная дискурса.
Почему структура логического вывода (которая кажется правилами) является отдельным фасадом от формального представления? Также мне непонятно определение фасада данных: «Данные, которые можно использовать для заполнения онтологии, схема которой является формальным представлением для КП». Можете ли вы уточнить формулировку: вы говорите, что схема данных определена в фасаде формального представления?
Можете ли вы уточнить формулировку: вы говорите, что схема данных определена в фасаде формального представления?
Можно установить связь с шаблонами проектирования в языках программирования, учитывая их популярность и успех [например, процитируйте Gamma, et al. 1995].
Раздел 2 можно немного сократить.
Скорее философский вопрос, но в какой момент модель знаний становится слишком ограничительной с точки зрения ограничения видов исследовательской деятельности, которые могут быть выполнены с объектом исследования?
В какой момент граница знаний определяется в базе знаний по сравнению с тем, что определяется приложением, использующим знания? Например, я не уверен, какое отношение структура взаимодействия имеет к «объекту исследования». Кажется, это отдельный вопрос для каждого приложения, использующего знания.
Возможно, вы захотите сослаться на манчестерский синтаксис для OWL 2, который разработан для работы с фреймами: http://www.w3.org/TR/owl2-manchester-syntax/ и показать, что отличается/одинаково в вашем обозначении системы на основе фреймов.
Теги:
Обзор
[PDF] Основные образцы лексического использования в сопоставимом корпусе английской повествовательной прозы
- DOI:10.7202/003425AR
- ID корпуса: 6 78873
@article{Laviosa1998CorePO,
title={Основные модели лексического использования в сопоставимом корпусе английской повествовательной прозы},
автор={Сара Лавиоса},
journal={Мета: журнал переводчиков},
год = {1998},
объем={43},
страницы = {557-570}
} - С. Лавиоса
- Опубликовано в 1998 году
- Лингвистика
- Мета: Журнал переводчиков
В этой статье исследуется лингвистическая природа текстов, переведенных на английский язык. Авторский корпус состоит из подраздела English Comparable Corpus (ECC). Он состоит из двух сборников повествовательной прозы на английском языке: один состоит из переводов с разных исходных языков, другой включает оригинальные английские тексты, созданные в течение аналогичного периода времени. Исследование выявило четыре модели использования лексики в переведенных и оригинальных текстах.
Исследование выявило четыре модели использования лексики в переведенных и оригинальных текстах.
Просмотр через Publisher
erudit.org
Что может метафора рассказать нам о языке перевода переводческая специфика перепредставленных многословных паттернов в шведских художественных текстах, переведенных с английского оценить с количественной и качественной точки зрения статус данных о переводческих словосочетаниях, полученных с помощью методов, основанных на данных, из сопоставимого и параллельно выровненного корпуса оригинальных и переведенных текстов на английском и шведском языках.
Регистр и особенности переведенного языка
- Х. Крюгер, Б. Рой
- 2012
Лингвистика
Универсалии перевода: корпусное исследование китайской переведенной художественной литературы поэтому четвертый (выравнивание) будет тщательно…
Исследование экспликации союзов в переведенном китайском языке: исследование на основе корпуса
- Уоллес Чен
- 2004
Лингвистика

Словосочетания в популярной религиозной литературе: анализ в корпусном переводоведении
- Ж. Марэ, Ж. Ноде
- 2007
Лингвистика
Целью статьи является исследование определенного регистра языка. Этот регистр, вообще говоря, язык специального назначения (LSP) и, в частности, популярная религиозная литература…
О меньшей частоте встречаемости испанских глагольных перифраз в переводных текстах как доказательство гипотезы уникальных предметов 089 В этой статье представлены результаты исследования частот встречаемости испанских глагольных перифраз в испанских оригинальных текстах и испанских переводах с английского, а также подтверждаются выводы предыдущих исследований, проведенных по этому вопросу.
Корпусное исследование синтаксических сдвигов в китайско-английском переводе конференций
- Лэй Гао
- 2020
Лингвистика
Из-за лингвистических различий между китайским и английским языками и ожидания немедленного коммуникативного эффекта синтаксические сдвиги часто происходят в Устный перевод конференций C-E. Через самодельный…
Через самодельный…
Переводы английского языка и универсалии перевода
- Дж. Яджун, Рен Зайсин
- 2008
Лингвистика
English Today
АННОТАЦИЯ В данной статье исследуется понятие «переведенный английский язык» в отличие от «непереведенного английского языка». Его центральным моментом является то, что переведенные английские тексты отличаются от сопоставимых непереведенных…
Чему SLA может научиться из сопоставительной корпусной лингвистики?: Случай пассивных конструкций в китайском языке, изучающем английский язык
- Р. Сяо
- 2007
Лингвистика
Связность в английском языке
- М.
- 1976
 Холлидей, Р. Хасан
Холлидей, Р. ХасанЛингвистика
Текстовый и корпусной анализ: компьютерные исследования языка и культуры
- М. Стаббс
- 1996
Лингвистика
Список рисунков, соответствий и таблиц. Благодарности. Соглашения о данных и терминология. Заметки о корпусных данных и программном обеспечении. Часть I: Понятия и история:. 1. Тексты и типы текстов. 2. Британский…
Другими словами: Учебник по переводу
- Мона Бейкер
- 1992
Лингвистика
Расширенный метод количественного анализа HAYASHI типа III и его применение в корпусной лингвистике
- Дж. Накамура
- 1995
- 1997
- 1990
Лингвистика местоименные формы в 728 текстовых образцах, взятых из Book Corpus, Spoken Corpus и Times Corpus, накопленных в Банке английского языка в COBUILD.
Описательные переводческие исследования и не только
- Гидеон Тури
Бизнес
Это расширенная и слегка переработанная версия одноименной книги, вызвавшей настоящий переполох, когда она была впервые опубликована (1995). Таким образом, это отражает дополнительный шаг в продолжающемся исследовании…
Насколько сопоставимыми могут быть «сравнимые корпуса»?
- С. Лавиоса
Лингвистика
Резюме: Разработка последовательной методологии корпусной работы в переводоведении имеет важное значение для эволюции этой новой области исследований в полноценную парадигму в…
Разговор о тексте
- Д. Олсон, Дж. Эстингтон
Образование
Введение в функциональную грамматику
- М. Холлидей
Лингвистика
9 0093 1985 Часть 1 Предложение: группа по отношению к предложению функциональной грамматики в качестве предложения сообщения в качестве предложения обмена в качестве представления.