
что это и как составлять (+ видеоинструкция)
Навигация:
- Что такое семантическое ядро для сайта
- Как собрать семантическое ядро (текстовая инструкция)
- Как собрать семантическое ядро (видеоинструкция)
Что такое семантическое ядро
Семантическое ядро – это упорядоченный список слов, который выглядит как запросы пользователей в поисковых системах (Яндекс, Google, Bing, Поиск Mail.ru).
У профессиональных SEO-специалистов семантическое ядро содержит более 1000 слов. Все слова – это ключевые запросы, которые пользователи вбивают в поисковые системы, ожидая увидеть какой-то интересующих их ответ.
SEO-специалист не придумывает все ключевые слова, все они доступны в сервисе Яндекс Вордстат. Специалист лишь берет их оттуда. Чуть ниже, в практической части, мы познакомимся с этим сервисом.
Еще важное понятие – кластеризация. Это процесс группировки ключевых слов в семантическом ядре по какому-либо принципу. Например, постранично (скриншот ниже).
Например, постранично (скриншот ниже).
Каждый такой сгруппированный мини-список называют кластером. В идеальном случае семантическое ядро состоит из десятков кластеров, которые бережно собраны SEO-специалистом.
Как собрать семантическое ядро (текстовая инструкция)
Все довольно просто, но не без подводных камней. Поэтому давайте по-порядку.
Теория
Перед сбором семантического ядра для сайта важно понимать, что ВСЕ ключевые слова имеют частотность употребления. Поэтому ключевые слова делятся SEO-специалистами на 3 группы.
Высокочастотные – слова, которые ежедневно запрашивают пользователи тысячи раз в день. Например, “купить телевизор”.
Среднечастотные – слова, которые ежедневно запрашивают пользователи сотни раз в день. Например, “купить телевизор LG в Екатеринбурге”
Низкочастотные – слова, которые ежедневно запрашивают пользователи десятки раз в день.
Что делать с этой информацией?
Для начала запомнить.
Во-первых, SEO-специалисты иногда кластеризируют свое семантическое ядро для сайта по этому признаку.
Во-вторых, чем запрос высокочастотней, тем его сложнее продвигать из-за конкуренции. Низкочастотные запросы могут “продвинуться сами”, им лишь нужна хорошая техническая оптимизация сайта.
В-третьих, из-за таких особенностей низкочастотные запросы добавляют в товары сайта (максимально конкретная модель телевизора), среднечастотные располагают в родительских категориях (страница с телевизорами LG), а самые высокочастотные – на главной (страница с общим списком телевизоров всех марок).
Поэтому перед сбором семантического ядра определитесь, куда будете “сажать” свои ключевые запросы.
Практика (пример на любимых телевизорах)
В примере ниже, при сборе своего семантического ядра для сайта, мы будем отталкиваться от всех вышеописанных критериев.
1.Заходим в Яндекс Wordstat. Надеемся, Вы уже определились, на какую страницу будете собирать семантическое ядро. Мы же будем показывать все на уже типичных для нас “телевизорах”. Представим, нам нужно собрать семантику для страницы, где располагаются все телевизоры бренда LG.
2. Вбиваем запросы “купить телевизор LG”. И начинаем выбирать запросы. “Плюсик” добавляет запросы к Вам в список, который одним кликом можно скопировать в буфер обмена и перенести в удобное место.
Как видите, мы выбрали 8 запросов. Первый – это наш основной, поэтому по остальным 7 давайте мы обоснуем наш выбор.
“купить телевизор lg в Москве” – допустим, наш интернет-магазин имеет магазин/склад в этом городе.
“телевизор lg смарт тв купить” – допустим, в нашем интернет-магазине, именно на этой странице, есть смарт телевизоры LG.
“купить lg телевизор цены” – потому что на данной странице сайта есть цены.
“купить телевизор lg 55 дюймов” – допустим, в нашем интернет-магазине, именно на этой странице, есть телевизоры LG 55 дюймов.
“купить телевизор lg 4k ultra hd” – допустим, в нашем интернет-магазине, именно на этой странице, есть 4K телевизоры LG.
“купить хороший телевизор lg” – просто потому, что наши телевизоры LG хорошие.
“купить 3d телевизор lg” – допустим, в нашем интернет-магазине, именно на этой странице, есть 3D телевизоры LG.
Далее жмем на “два листочка бумаги” (где панель плагина слева, рядом с большим плюсом), копируем все, что у нас получилось и сохраняем в документе. На этом все, Вы собрали первый кластер. Продолжайте в том же духе, через пару часов семантическое ядро будет куда больших размеров, чем сейчас. Если есть еще вопросы, посмотрите видео инструкцию.
Как собрать семантическое ядро (видеоинструкция)
Для тех, кому проще один раз увидеть чем сто раз услышать (или прочитать).
что это? Составление семантического ядра
При создании сайта важна его видимость для посетителей поисковой системы. Необходимо определить интересы аудитории, каким образом происходит выбор ею информации, а также понять, что такое семантическое ядро и как его составлять. Составление семантического ядра сайта — наиболее эффективное решение поставленных задач.
Для определения значения неизвестного понятия необходимо разобрать его по составу. Семантика и ядро – это две части незнакомого слова. Первая – это целый раздел языковедения. Он изучает смысловую нагрузку частей науки. Вторая рассматривается как центр, суть любой единицы. Отсюда вывод, что «смысловое ядро» и «семантическое ядро» сайта — равнозначные понятия. Успех в работе устроителей сайта во многом зависит от грамотного составления структуры условного здания с разветвлением из многообразного текста.
Строительство структуры сайта
Главная задача поисковой системы состоит в том, чтобы клиент нашел информацию в соответствии со своим запросом. Пользователи сети ориентированы на отдельные фразы на страницах интернет-ресурса. Они ожидают точных ответов на поставленные вопросы. Но маркетологи и бизнесмены способны шире взглянуть на знакомые понятия, с учетом собственного опыта и накопленных знаний.
Специалисты могут не только обозначить проблему, но и найти расширенные варианты ответа. Сбор семантического ядра для сайта что это? Точное накопление и дословное воспроизведение запросов аудитории или же анализ предполагаемой информации? Смысл предварительно планируется по структуре. Создается своеобразный каркас здания из отдельных кирпичиков. А в случае запроса поиск распределяется по запланированной схеме.
Интернет-ресурс планируется заранее, выстраивается своеобразная схема, а затем уже определяются запросы клиентов. Такой подход в построении семантического ядра позволяет реагировать активно на среду, без ущерба для ресурса. Если ориентироваться на отдельные фразы поисковика, то отойти от общей структуры сайта, нарушить целостность своего детища и, в итоге, не суметь помочь людям в их стремлении найти и расширить круг обозначенной проблемы. Дилетанты в сети и не предполагают широкий спектр возможных вариантов ответа. Устроители способны оценить масштаб поставленных задач, исходя из собственного опыта в бизнесе и отрасли. Агентство интернет-маркетинга, после тщательного изучения и сбора информации подбирает центральное звено для общей структуры здания, заполняя его отдельными элементами по запланированной схеме.
Такой подход в построении семантического ядра позволяет реагировать активно на среду, без ущерба для ресурса. Если ориентироваться на отдельные фразы поисковика, то отойти от общей структуры сайта, нарушить целостность своего детища и, в итоге, не суметь помочь людям в их стремлении найти и расширить круг обозначенной проблемы. Дилетанты в сети и не предполагают широкий спектр возможных вариантов ответа. Устроители способны оценить масштаб поставленных задач, исходя из собственного опыта в бизнесе и отрасли. Агентство интернет-маркетинга, после тщательного изучения и сбора информации подбирает центральное звено для общей структуры здания, заполняя его отдельными элементами по запланированной схеме.
Сформировать семантику помогает определение круга вопросов пользователей для поиска информации. Отдельные фразы в интернете позволяют выделить страницы, наиболее отвечающие поставленным задачам. Точный анализ запросов пользователей – это готовый каркас и архитектура интернет-ресурса.
Но существует и иной подход, чтобы сформировать смысловой центр. До знакомства с запрашиваемой людьми информацией предварительно спланировать структуру семантического поля. Затем развивать ее и дополнять новыми фразами. Используют два подхода в работе над поставленными задачами. Выбирая первый, вы активно реагируете на среду. Во втором случае проактивность помогает маркетологам и бизнесменам выбрать информацию, которой поделиться с пользователями. Влияние на клиента усиливается, вы являетесь субъектом, реагирующим на среду, находясь на более высоком уровне знаний и обладая большим объемом информации.
Иерархическая схема страниц – это структура ресурса. При подборе информации вы решаете несколько задач:
-
определение логики подачи информации;
-
обеспечение изобилия смыслового текста;
-
соответствие требованиям поиска.


Следующий этап – выбор инструмента для создания структуры сайта. Это может быть простой лист бумаги или текстовый редактор, то, что поможет изобразить схематично ответы на важные вопросы:
-
Что важно сообщить пользователям, какую информацию?
-
Как расположить блок необходимого текста, фраз?
Если изобразить информацию в виде таблицы, названия страниц, их подчиненность визуально будут отражать всю картину предстоящей работы. В схематичное изображение внести колонки для указания URL страниц, ключевых слов, отобразив частоту их использования.
Ключевые слова
Ключи – это текстовые фразы, которые используются в запросах на страницах браузера. Их можно квалифицировать в зависимости от популярности:
-
Низкочастотные, встречаются с частотой от 100 в месяц.
-
Среднечастотные используются не реже 1000 раз.
-
Высокочастотные имеют большое количество показов, от 5000 и более.

Тематика влияет на популярность информации. Низкочастотные запросы становятся основным источником для устроителей ресурса. Они позволяют выявить пользователя с определенными задачами, приближенными к вашей, привлечь потенциального клиента. Ведь определить целевого покупателя значимо для развития.
Ключевые слова для семантического ядра можно подобрать, основываясь на иной классификации. Выделяют:
-
Информационные. В соответствии с названием они несут смысловую нагрузку, сведения.
-
Транзакционные. Характеризуют потенциальное действие.
-
Другие запросы. В соответствии с ними сложно определить цель клиента, исходя из слишком большого диапазона запрашиваемой структуры.
-
Навигационные.
Существуют запросы на конкретный ресурс, например «танки онлайн» и т.п.
 Существуют запросы на конкретный ресурс, например «танки онлайн» и т.п.
Существуют запросы на конкретный ресурс, например «танки онлайн» и т.п.
Когда готовятся информационные блоки, то разделение ключевых слов на группы позволяет распределить их на странице оптимально, учитывая разделы. Например, при выборе грузоперевозок, можно отфильтровать слова по массе груза, с использованием доставки и региона распространения.
Применять низкочастотные ключи при сборе смыслового ядра необходимо, чтобы выдержать конкуренцию на интернет-рынке. Базовые термины составляют основу бизнеса, хотя могут уменьшить целевую аудиторию.
Как группировать ключевые слова и строить карту релевантности
Основой сайта является семантическое ядро. После его составления важно разбить все словосочетания на группы и распределить их по разделам, разместить на страницах. Существуют правила расположения ключей. На первом плане должны быть высокочастотники, благодаря которым появится возможность привлечь большее количество людей. Для внутренних страниц желательно привлечь целевую аудиторию с узкими запросами. Все данные собираются в один документ- карту релевантности.
Для внутренних страниц желательно привлечь целевую аудиторию с узкими запросами. Все данные собираются в один документ- карту релевантности.
Карта вхождения ключевых запросов представляет собой файл с внутренними ссылками на страницу-акцептор. Это определенный план для оптимизации проекта. Он составляется исходя из запросов из смыслового ядра и схемы ресурса. Учитываются не только существующие слова, но и те, которые появятся в будущем в ходе дальнейшей работы над сайтом.
Карта релевантности редактируется несколькими специалистами, так как в ней представлено множество данных, требующих обработки. Общая структура сайта должна отображать наглядно разделы и подразделы, информацию о семантике. Таблица, демонстрирующая как выглядит семантическое ядро, позволит определить расположение страниц, частотность, метатеги, это удобно видеть одномоментно. Многоуровневая карта нужна в том случае, если действует группировка- разгруппировка поступающих сведений, например по принципам: «одна строка-один запрос» или «одна строка- одна страница».
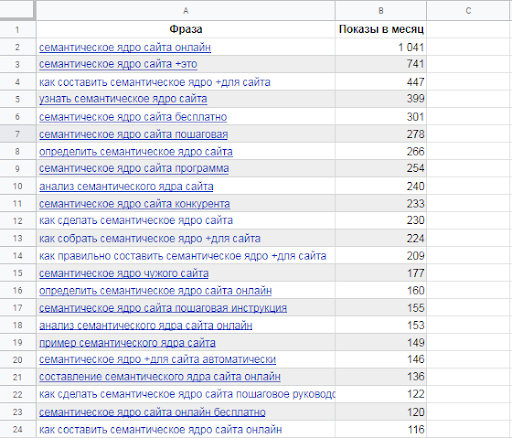
Сервисы для составления семантического ядра (краткое описание)
Сбор семантического ядра требует много времени и специфических знаний, основанных на опыте. Облегчить работу позволяют специализированные сервисы. Среди них популярны такие как Яндекс.Вордстат и Google KeywordPlanner, Key Collector, Slovoeb, Megaindex.com, SEMRush, Just Magic, Топвизор и другие. Большинство из них платные, но они значительно облегчают работу.
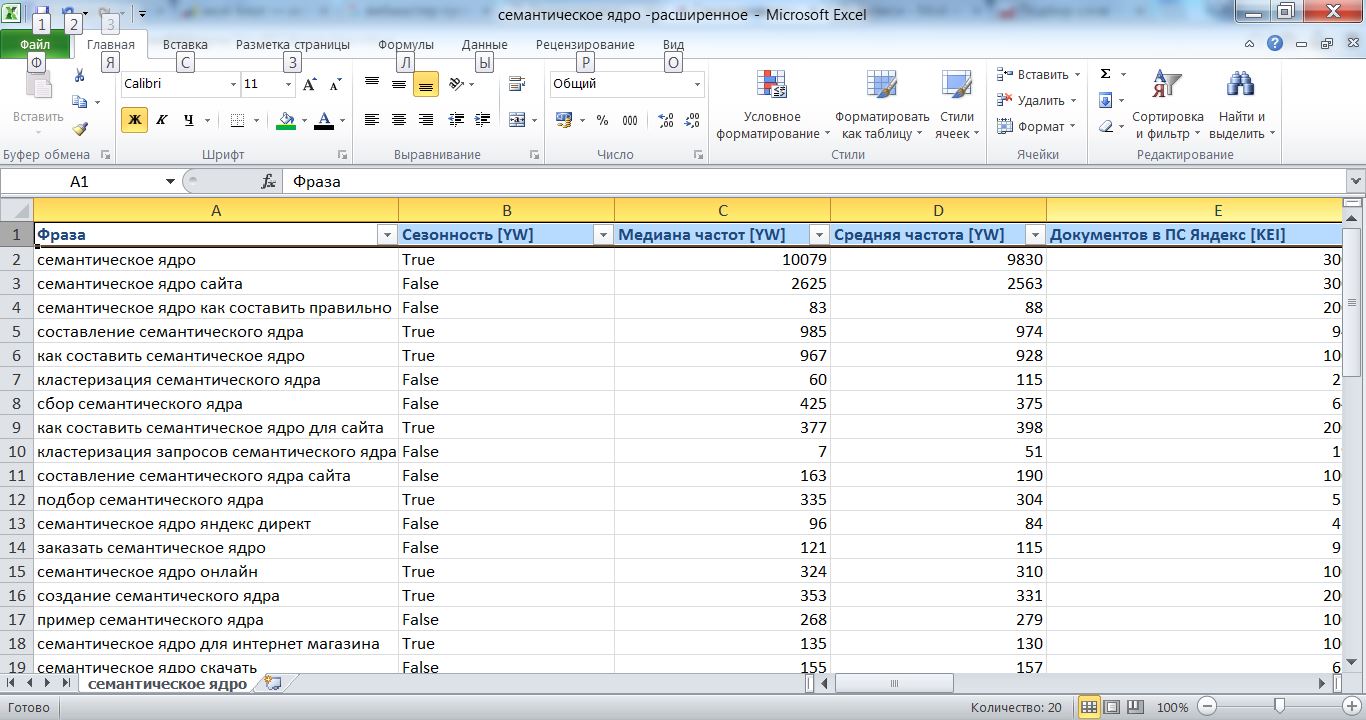
Яндекс. Вордстат
Существует и бесплатное предоставление такой услуги. Например, Вордстат, помогает при сборе необходимых запросов. Если вы поставите в начале каждого слова вопросительный знак, то сервис будет фиксировать окончание слова. Кавычки позволят заметить разные окончания порядка слов.
При одновременном использовании кавычек и восклицательного знака вы увидите окончание. Изменится лишь порядок слов. Для отбора можно выбрать регион, узнать количество обращения к интернет – ресурсу в определенном городе.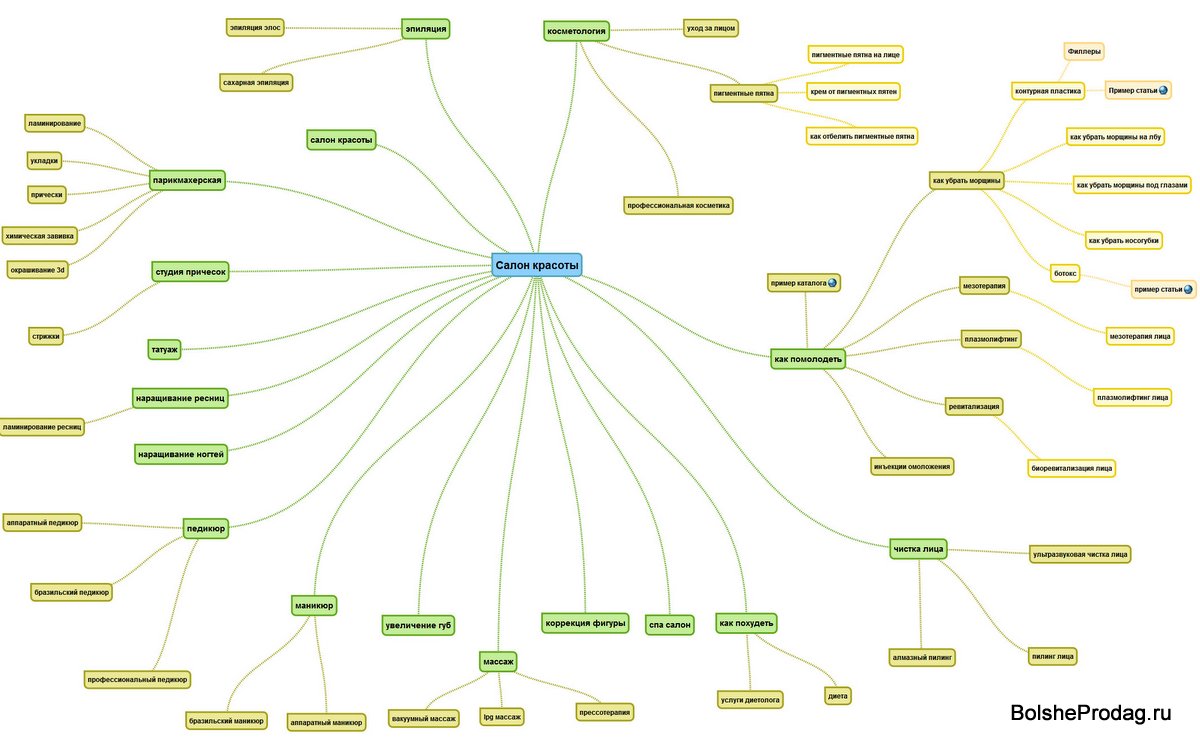 Полученная сематика значительно облегчает работу.
Полученная сематика значительно облегчает работу.
Promotools
Для анкоров пользователи могут выбрать сервис Promotools, вводить продвигаемые фразы и коммерческие предложения и получать в результате перемноженные фразы.
Кей Коллектор
Для составления семантического ядра можно обратиться к Кей Коллектор. Многофункциональность программы оправдывает невысокую цену за обслуживание.
Можно удалить скрытые дубли, ненужную информацию. Немного работы, и основа смыслового центра готова к дальнейшей работе.
Screaming Frog SEO Spider
С помощью Screaming Frog SEO Spider подготовливают аудит сайта, чистят семантику.
KeyAssort
Понятие кластеризация означает предоставление услуги по распределению сходных запросов в группировки. С такой задачей отлично справляется сервер KeyAssort. Достаточно разместить «грязное» ядро и нажать «собрать данные». Затем анализируется каждый материал, клавиша «Кластеризовать» позволит получить необходимые кластеры.
Затем анализируется каждый материал, клавиша «Кластеризовать» позволит получить необходимые кластеры.
Приоритизация-сложный процесс, который поможет составить план отличного SEO. Он основан на нескольких моментах:
На сервисах в едином окне можно собирать карты, перемножать слова, парсить, группировать, минусовать и выгружать готовые тексты.
Работает все очень просто. Все ключевые слова собираются в одно ядро с помощью парсера. Списки можно группировать, выделяя «списки минус» и располагая отдельно. Собирать запросы можно из ключевых слов без подсказок. При этом важно понимать, что существует два варианта развития анализа: вглубь и вширь. После фильтрации по частоте использования, получается запустить и получить готовый результат. Подобный анализ значительно облегчает работу составителю сайта.
Как подобрать семантическое ядробез лишних усилий и экономя время помогут специалисты в режиме онлайн. Сделать заказ на оказание услуги и ожидать результат тоже возможно. Выглядеть созданный проект будет не хуже других, но главное, чтобы работал эффективно и был полезен интернет-пользователям. С помощью профессиональной поддержки легко продвинуть свой ресурс на первые позиции в выдаче поисковиков. Это обеспечит широкий охват аудитории и рост клиентов, позволит получать выгоду и решать проблему клиентоориентированности.
Сделать заказ на оказание услуги и ожидать результат тоже возможно. Выглядеть созданный проект будет не хуже других, но главное, чтобы работал эффективно и был полезен интернет-пользователям. С помощью профессиональной поддержки легко продвинуть свой ресурс на первые позиции в выдаче поисковиков. Это обеспечит широкий охват аудитории и рост клиентов, позволит получать выгоду и решать проблему клиентоориентированности.
Существуют сервисы, прослеживающие динамику роста проекта. В случае временного ухудшения позиций помогает своевременное и быстрое реагирование, обновление ключей.
Использование современных сервисов позволяет разработать семантическое ядро. Это основа любого интернет ресурса, которая необходима для его активного продвижения. Для правильной работы с ядром необходима подробная аналитика каждого сайта, его оптимизация и клиентоориентированность.
Понимание компонентов семантического уровня dbt
TLDR: семантический уровень состоит из комбинации предложений с открытым исходным кодом и SaaS и изменит то, как ваша команда определяет и использует метрики.

На прошлогоднем Coalesce Дрю показал нам будущее 1 — видение того, как могут выглядеть метрики в dbt. С тех пор мы создаем инфраструктуру, чтобы воплотить это видение в реальность. Мы хотели поделиться с вами тем, где мы находимся сегодня и как это вписывается в более широкую картину того, куда мы идем.
Для тех, кто не следил за этой сагой с таким вниманием, как кто-то, наблюдающий за своими инвестициями на рынке криптовалют, мы запускаем этот новый ресурс, чтобы помочь вам лучше понять семантический слой dbt и дать разъяснения по следующим вещам:
- Что такое семантический слой dbt?
- Как его использовать?
- Что сейчас общедоступно?
- Что еще находится в разработке?
Итак, приступим!
Некоторые из вас, возможно, были рядом, когда это первоначально называлось уровнем показателей. Когда мы оценили долгосрочные планы того, чем должна была стать эта часть dbt, мы поняли, что название «Семантический слой» лучше отражает его возможности и то, где мы планируем его использовать.
Семантический уровень dbt — это новая часть dbt, помогающая повысить точность и согласованность при одновременном расширении гибкости и возможностей современного стека данных. Наш маэстро метрик, Дрю Банин, опубликовал запись в блоге, в которой подробно изложил свое видение того, куда мы идем. Первый вариант использования, который мы рассматриваем, — это тот, который большинство практиков 9Заинтересованные стороны 0029 и знакомы с метриками. Далее в этом посте мы рассмотрим, как это выглядит на практике.
Под капотом семантический уровень dbt представляет собой набор нескольких компонентов — некоторые из них являются частью dbt Core, некоторые частью dbt Cloud, а некоторые представляют собой новые функциональные возможности. Все они объединяются вместе, как Voltron, чтобы создать единый интерфейс, с помощью которого бизнес-пользователи могут запрашивать данные в контексте наиболее знакомой им метрики. И самое приятное то, что они могут делать это в системах, которые им уже удобно использовать.
Как это будет выглядеть для моих потребителей данных и заинтересованных сторон?
В конечном итоге это выглядит так, что люди могут взаимодействовать с надежными наборами данных в удобных для них инструментах (и, в конечном итоге, в новых инструментах, разработанных специально для метрик).
Примером, который мы нашли полезным, является ARR. Критическая для бизнеса метрика для SaaS-компаний, ARR может быть сложным расчетом, чтобы обеспечить согласованность для всех инструментов, используемых в бизнесе. С семантическим уровнем dbt это определение будет жить в dbt, и логика создания набора данных для этой метрики будет единой для всех различных способов потребления. Лучше всего то, что изменения определения будут отражаться в нижестоящих инструментах, поэтому вам больше не нужно вручную искать и обновлять каждую нижестоящую зависимость. Каллум трехлетней давности прыгает от радости.
Это хорошо и все такое, но как это выглядит для практикующих?
Семантический уровень dbt состоит из следующих компонентов 2 :
Доступен сегодня
-
метрикаузел в dbt Core : Подобно моделямmanifest.jsonточно так же, какмоделируети упоминается в DAG. -
Пакет dbt_metrics: Этот пакет содержит макросы, которые объединяют определение метрики с контролем версии и параметры времени запроса (такие как измерения, временной интервал и вторичные вычисления) для создания SQL-запроса, который вычисляет значение метрики. - API облачных метаданных dbt: API GraphQL, который поддерживает произвольные запросы к метаданным, созданным облачными заданиями dbt. Содержит метаданные, связанные с точностью, актуальностью, конфигурацией и структурой представлений и таблиц в хранилище, а также многое другое.
 Это определение агрегации временных рядов по таблице, которая поддерживает ноль или более измерений. Полученный узел сохраняется в
Это определение агрегации временных рядов по таблице, которая поддерживает ноль или более измерений. Полученный узел сохраняется в Новый
- Сервер dbt: этот компонент упаковывает ядро dbt в постоянный сервер, который отвечает за обработку запросов RESTful API для операций dbt. Это тонкий интерфейс, который в первую очередь отвечает за производительность и надежность в производственных средах.
- Прокси-сервер dbt Cloud: этот компонент позволяет dbt Cloud динамически переписывать запросы к хранилищу данных и компилировать dbt-SQL в необработанный SQL, понятный базе данных. Затем он возвращает набор данных, созданный необработанным SQL, на платформу, которая его отправила.
 Это тонкий интерфейс, который в первую очередь отвечает за производительность и надежность в производственных средах.
Это тонкий интерфейс, который в первую очередь отвечает за производительность и надежность в производственных средах.Понимание того, как и когда использовать метрики?
Давайте рассмотрим пример того, как вы можете использовать вышеперечисленные компоненты, чтобы начать работу с нашим старым другом — магазином Jaffle Shop. Мы рассмотрим, как вы можете начать определять и тестировать метрики сегодня, а также как вы будете взаимодействовать с ними после выпуска новых компонентов.
Когда использовать метрики
Первый вопрос, который вам нужно задать: Должны ли мы использовать метрики?
Мы считаем, что метрики не являются универсальным решением. Они предназначены для основных бизнес-показателей, где согласованность и точность имеют ключевое значение, а не для исследовательских вариантов использования или специального анализа. Наш сокращенный способ определить, должна ли метрика быть определена в dbt, был — , это то, о чем должны сообщать наши команды?
Они предназначены для основных бизнес-показателей, где согласованность и точность имеют ключевое значение, а не для исследовательских вариантов использования или специального анализа. Наш сокращенный способ определить, должна ли метрика быть определена в dbt, был — , это то, о чем должны сообщать наши команды?
Итак, предположим, финансовый директор нашего Jaffle приходит к нам в понедельник утром и приказывает группе данных пересмотреть то, как мы отчитываемся о доходах. Наш региональный менеджер Джим и директор по продажам Пэм 3 давали ему разные отчеты! Прямо сейчас это беспорядок инструментов и несоответствий — числа Джима определены в Таблице и говорят одно, Пэм в Хексе и говорят другое! Финансовый директор недоволен этим и хочет, чтобы во всей компании была слаженная работа, где у всех были бы одинаковые цифры дохода. Он проходит тест отчета, это важная бизнес-метрика; понеслось!
Определение метрики с помощью Metric Node
В этом примере мы скажем, что и Джим, и Пэм извлекают данные из таблицы, созданной dbt, с именем orders . В настоящее время он содержит поля для
В настоящее время он содержит поля для суммы и всех различных методов payment_amounts, таких как кредитные карты или подарочные карты. Джим вычислял доход, суммируя поля Credit_card_amount и gift_card_amount , так как он забыл обновить свое определение, когда компания добавила купоны и платежи банковским переводом. Между тем, Пэм правильно суммирует сумма поле, но не учитываются заказы на возврат, которые не должны учитываться!
Первым шагом является создание единого определения дохода. Для этого мы создадим следующее определение yml в нашем репозитории dbt:
версия: 2метрики:
- имя: доход
метка: доход
модель: ref('orders')
описание: "Общий доход нашего бизнеса по продаже джемов"тип: сумма
sql: суммаметка времени: order_date
time_grains: [день, неделя, месяц, год]размеры:
- customer_status
- has_coupon_payment
- has_bank_transfer_payment
- has_credit_card_payment
- has_gift_card_paymentфильтры:
- поле: статус
оператор: '='
значение: "завершено"
Эта метрика теперь определена в метаданных dbt и ее можно увидеть в DAG!
Запуск пакета метрик Расчет метрики
Чтобы убедиться, что и Джим, и Пэм получают одни и те же числа для своей метрики, нам нужно, чтобы они оба выполнили запрос метрики для вычисления . В этом примере нас не интересуют конкретные типы платежей, а мы хотим увидеть доход, разделенный на
В этом примере нас не интересуют конкретные типы платежей, а мы хотим увидеть доход, разделенный на неделю и customer_status .
выберите *
из {{ metrics.calculate(
метрика('доход'),
зернистость='неделя',
размеры=['customer_status']
) }}
Это вернет набор данных, который выглядит следующим образом:
| date_week | customer_status | доход |
|---|---|---|
| 2018-0 1-01 | Риск оттока | 43 |
| 2018-01-01 | Отток | 0 |
| 01.01.2018 | Здоровый | 26 |
| 08.01.2018 | Риск оттока | 27 |
Тогда Джим и Пэм смогут ссылаться на столбец дохода во вновь созданном наборе данных, и вам никогда больше не придется беспокоиться о расчете дохода 4 ! Мир совершенен, и баланс восстановлен.
В ближайшем будущем с dbt Server
Когда dbt Server будет выпущен позднее в этом году, порядок использования метрик значительно изменится. Вашей организации больше не нужно материализовывать каждую метрику в модели, чтобы воспользоваться преимуществом определения метрики. Вместо этого вы сможете напрямую запросить сервер dbt с предоставленным кодом метрики и получить правильный набор данных, возвращенный выбранному вами инструменту BI.
Кроме того, партнеры по интеграции наработают опыт работы с метриками с помощью API метаданных, чтобы создать уникальные и творческие способы для потребителей получать данные метрик, абстрагируясь от сложности. Например, поле, которое позволяет пользователю выбирать из списка показатели, интервалы времени, измерения и вторичные вычисления, а затем получать правильную информацию независимо от выбора!
Итак, что сейчас общедоступно?
На данный момент два основных общедоступных компонента с открытым исходным0061 metric узел в dbt Core и пакет dbt_metrics . Вместе эти два компонента могут работать на вводном семантическом уровне, позволяя инженерам-аналитикам определять метрики, а затем запрашивать эти метрики через пакет метрик.
Вместе эти два компонента могут работать на вводном семантическом уровне, позволяя инженерам-аналитикам определять метрики, а затем запрашивать эти метрики через пакет метрик.
Эти два компонента представляют собой статический интерфейс, который необходимо определить в проекте dbt (поскольку выбранные измерения определяются при создании модели), но они полезны для тех, кто хочет обеспечить согласованность показателей во всех инструментах бизнес-аналитики. Если вы идентифицируете себя с любым из следующих условий, вы можете хорошо подойти для реализации этого в том виде, в каком он существует сегодня:
- Вы хотите подготовить свою организацию к полному запуску семантического уровня.
- В вашей организации есть по крайней мере несколько ключевых показателей
- В вашей организации используется один или несколько инструментов бизнес-аналитики
- В вашей организации иногда возникают проблемы, связанные с расчетом различных показателей отличные причины, чтобы начать изучение внедрения метрик в ваш проект dbt! Если вам интересно, как может выглядеть реализация этого, мы рекомендуем обратиться к репозиторию jaffle_shop_metrics!
Что еще находится в разработке?
И облачный прокси-сервер dbt, и сервер dbt в настоящее время находятся в разработке, релиз запланирован на конец этого года.
Если вам интересно протестировать их после их выпуска, мы рекомендуем следить за объявлениями о наших продуктах, а затем обращаться к ним, как только они станут общедоступными!Что делать, если у меня есть вопросы?
Если у вас есть какие-либо вопросы об этих компонентах или метриках в целом, пожалуйста, не стесняйтесь размещать сообщения в канале #dbt-metrics-and-server на dbt Slack! Я слоняюсь там и всегда готов пообщаться с метриками!
Footnotes
- Возможно, в этом будущем не упоминались роботы, но я держусь за утреннюю машину в стиле Jetson, которая поможет мне подготовиться по утрам. ↩
- Мы специально призываем к лицензированию, потому что в сообществе существует много путаницы в отношении того, что является открытым исходным кодом, а что нет. Это становится только сложнее с введением лицензирования BSL, которое гарантирует, что пользователи могут запускать свой собственный сервер, но его нельзя продавать как облачный сервис. Для получения дополнительной информации о том, почему были выбраны эти типы лицензирования, мы рекомендуем блог Тристана о лицензировании dbt. Главный вывод о лицензировании заключается в том, что вы все равно можете запускать компоненты семантического уровня dbt, даже если вы не являетесь клиентом dbt Cloud! ↩
- Полная прозрачность, я никогда не видел Офис. Неуклюжий юмор заставляет меня чувствовать себя так неловко, что я вынужден выключить телевизор. Извините, если названия персонажей неверны.↩
- Псих! Они определенно заинтересованы в расчете ARR. На самом деле, они не очень доверяют числам , если не понимают, как они вычисляются. Именно здесь они могут использовать API метаданных, чтобы запросить всю информацию о метрике, такую как определение, время выполнения, допустимые размеры и т. д. Прямо сейчас Джиму и Пэм нужно будет напрямую запрашивать API, но в будущем мы ожидаем, что будет несколько различных способов получить эту информацию, начиная от прямой интеграции с инструментом BI и заканчивая материализацией этой информации в информационной схеме dbt! Для текущих табличных альтернатив есть несколько интересных макросов в недавно выпущенном пакете dbt-project-evaluator. Взгляните туда, если вам интересно материализовать свою метрическую информацию! ↩
Семантическая технология и интеграция 101: что это такое и почему это важно
Новые технологии, такие как ChatGPT, находятся в моде, поскольку они направлены на то, чтобы отвечать на вопросы и предоставлять информацию, облегчающую нашу жизнь. Тем не менее, достоверность полученных результатов подверглась тщательной проверке, и в результате большое внимание было уделено тому, как организации могут передавать релевантные и достоверные данные в руки пользователей. Даже при огромном объеме доступной информации достижение понимания является сложной задачей, если используемые платформы не могут понять смысл запроса, понять выводы вопроса, определить, где находится информация, и предоставить данные, необходимые для ответа на вопрос.
Структуры данных, которые Gartner определяет как новый дизайн управления данными для достижения гибких, многократно используемых и расширенных конвейеров интеграции данных, услуг и семантики, помогают обеспечить доступность данных как для бизнеса, так и для технических пользователей.
Определение семантической технологии Предприятия применяют фабрики данных для поддержки как операционных, так и аналитических вариантов использования, реализуемых на нескольких платформах и процессах развертывания и оркестровки, но для эффективности им необходимы различные технологии и концепции проектирования. Им требуется сочетание активных метаданных, графов знаний, семантики и машинного обучения, чтобы улучшить дизайн и доставку интеграции данных. Из них принятие и установление семантики и установление семантических стандартов, которые создают контекст и значение (через реализации графа знаний), являются одними из самых важных и запутанных частей головоломки и заслуживают некоторого объяснения.Семантическая технология использует формальную семантику, чтобы придать смысл разрозненным и необработанным данным, которые нас окружают. Семантическая технология вместе с технологией связанных данных, как это представлял изобретатель Всемирной паутины сэр Тим Бернерс-Ли, выстраивает связи между данными в различных форматах и источниках, от одной строки к другой, помогая создавать контекст и создавать связи из этих отношений.
При использовании с формальной семантикой, которая изучает логические аспекты значения, такие как смысл, ссылка, импликация и логическая форма, технология помогает системам ИИ понимать язык и обрабатывать информацию так, как это делают люди, что позволяет им хранить, управлять и извлекать информацию на основе значения и логических отношений.Семантическая технология определяет и связывает данные в Интернете или внутри предприятия путем разработки языков для выражения богатых взаимосвязей данных с самоописанием в форме, которую могут обрабатывать машины. В результате эти машины могут обрабатывать длинные строки символов и индексировать тонны данных, а затем хранить, управлять и извлекать информацию на основе смысла и логических связей. Что еще более важно, он помогает отображать связанные факты, а не просто сопоставлять слова, что помогает предприятиям делать выводы о взаимосвязях, находить более точные данные и извлекать знания из огромных наборов необработанных данных в различных форматах и из различных источников.
Это особенно важно, поскольку, согласно другому отчету Gartner, растущие уровни объема и распространения данных затрудняют организациям эффективное использование своих активов данных. Лидеры данных и аналитики должны рассмотреть семантический подход к своим корпоративным данным; в противном случае они столкнутся с бесконечной борьбой с хранилищами данных. Основное различие между семантической технологией и другими технологиями данных, такими как реляционная база данных, заключается в том, что она имеет дело со смыслом, а не со структурой данных. Инициатива Semantic Web Консорциума World Wide Web (W3C) заявляет, что целью этой технологии в контексте Semantic Web является создание «универсальной среды для обмена данными» путем плавного соединения глобального обмена любыми личными, коммерческими, научными и культурными данными.
W3C разработал открытые спецификации для семантической технологии для разработчиков и определил с помощью разработки с открытым исходным кодом инфраструктуру, необходимую для масштабирования в Интернете и в других местах, и включает:
- Структура описания ресурсов (RDF): Формат семантической технологии, используемый для хранения данных в семантической сети или в базе данных семантического графа.
- SPARQL (протокол SPARQL и язык запросов RDF): Язык семантических запросов, специально разработанный для запроса данных в различных системах и базах данных, а также для извлечения и обработки данных, хранящихся в формате RDF.
- Язык веб-онтологий (OWL): Дополнительно используемый язык, основанный на вычислительной логике, предназначен для отображения схемы данных и представляет обширные и сложные знания об иерархиях вещей и отношениях между ними. Он дополняет RDF и позволяет формализовать схему/онтологию данных в заданной области отдельно от данных.
Проще говоря, формализуя значение независимо от данных, семантическая технология позволяет машинам «понимать», делиться и анализировать данные, чтобы создавать больше ценности для людей. Семантическая технология помогает предприятиям обнаруживать более точные данные, делать выводы о взаимосвязях и извлекать знания из огромных наборов необработанных данных в различных форматах и из различных источников.
Базы данных семантических графов, основанные на видении Semantic Web, упрощают интеграцию, обработку и извлечение данных машинами.Это, в свою очередь, позволяет организациям получать более быстрый и экономичный доступ к значимым и точным данным, анализировать эти данные и преобразовывать их в знания, которые позволяют им получать информацию о бизнесе, применять модели прогнозирования и принимать решения на основе данных. Еще в 2007 году сэр Бернерс-Ли сказал Bloomberg: «Семантическая технология не является сложной по своей сути. Язык семантической технологии в своей основе очень и очень прост. Это просто отношения между вещами. Скорее всего, «отношения между вещами» помогут организациям более эффективно управлять данными».
Интеграция семантических данных ОпределеноИнтеграция семантических данных — это процесс объединения данных из разрозненных источников и консолидации их в значимую и ценную информацию посредством использования семантической технологии.
По мере того, как организации увеличиваются в размерах, растут и их данные. Без правильной стратегии управления данными быстро возникают разрозненные хранилища данных внутри отделов и/или приложений, что снижает производительность и сотрудничество. Интеграция семантических данных предлагает решение, выходящее за рамки стандартных решений по интеграции корпоративных приложений, за счет использования ориентированной на данные архитектуры, построенной на стандартизированной модели публикации и обмена данными, а именно RDF.В этой структуре все разнородные данные организации — будь то структурированные, полуструктурированные и/или неструктурированные — выражаются, хранятся и доступны одинаково. Поскольку структура данных выражается через ссылки внутри самих данных, она не ограничивается структурой, навязываемой базой данных, и не устаревает по мере развития данных. Когда происходят изменения в структуре данных, они отражаются в базе данных через изменения связей внутри данных. Кроме того, как основа семантической технологии, RDF позволяет делать выводы о новых фактах из существующих данных, а также обогащать имеющиеся знания за счет доступа к ресурсам связанных открытых данных (LOD).
Семантические данные в действии: достижение всестороннего обзораВ мире, где полная прозрачность, точный анализ и решение проблем сложности данных доминируют в бизнес-ландшафте, интеграция разрозненных данных в синхронизированную 360-градусную перспективу имеет первостепенное значение. Подобно ChatGPT, организации сегодня ищут решения, которые позволят им управлять всеми своими данными и сделать их пригодными для принятия решений и различных вариантов использования в бизнесе.
Независимо от того, работает ли их база данных автономно или интегрирована в более крупную корпоративную экосистему, такую как структура данных, компаниям необходим полный набор инструментов интеграции данных, которые могут выполнять сложные задачи и просты в использовании. Возможность легко импортировать и преобразовывать разнородные данные из нескольких источников, интегрировать и связывать данные в виде операторов RDF, а также объединять две или более баз данных графов — все это важные функции, поддерживающие семантические решения мирового уровня.
 Если вам интересно протестировать их после их выпуска, мы рекомендуем следить за объявлениями о наших продуктах, а затем обращаться к ним, как только они станут общедоступными!
Если вам интересно протестировать их после их выпуска, мы рекомендуем следить за объявлениями о наших продуктах, а затем обращаться к ним, как только они станут общедоступными! Для получения дополнительной информации о том, почему были выбраны эти типы лицензирования, мы рекомендуем блог Тристана о лицензировании dbt. Главный вывод о лицензировании заключается в том, что вы все равно можете запускать компоненты семантического уровня dbt, даже если вы не являетесь клиентом dbt Cloud! ↩
Для получения дополнительной информации о том, почему были выбраны эти типы лицензирования, мы рекомендуем блог Тристана о лицензировании dbt. Главный вывод о лицензировании заключается в том, что вы все равно можете запускать компоненты семантического уровня dbt, даже если вы не являетесь клиентом dbt Cloud! ↩ Взгляните туда, если вам интересно материализовать свою метрическую информацию! ↩
Взгляните туда, если вам интересно материализовать свою метрическую информацию! ↩ Предприятия применяют фабрики данных для поддержки как операционных, так и аналитических вариантов использования, реализуемых на нескольких платформах и процессах развертывания и оркестровки, но для эффективности им необходимы различные технологии и концепции проектирования. Им требуется сочетание активных метаданных, графов знаний, семантики и машинного обучения, чтобы улучшить дизайн и доставку интеграции данных. Из них принятие и установление семантики и установление семантических стандартов, которые создают контекст и значение (через реализации графа знаний), являются одними из самых важных и запутанных частей головоломки и заслуживают некоторого объяснения.
Предприятия применяют фабрики данных для поддержки как операционных, так и аналитических вариантов использования, реализуемых на нескольких платформах и процессах развертывания и оркестровки, но для эффективности им необходимы различные технологии и концепции проектирования. Им требуется сочетание активных метаданных, графов знаний, семантики и машинного обучения, чтобы улучшить дизайн и доставку интеграции данных. Из них принятие и установление семантики и установление семантических стандартов, которые создают контекст и значение (через реализации графа знаний), являются одними из самых важных и запутанных частей головоломки и заслуживают некоторого объяснения. При использовании с формальной семантикой, которая изучает логические аспекты значения, такие как смысл, ссылка, импликация и логическая форма, технология помогает системам ИИ понимать язык и обрабатывать информацию так, как это делают люди, что позволяет им хранить, управлять и извлекать информацию на основе значения и логических отношений.
При использовании с формальной семантикой, которая изучает логические аспекты значения, такие как смысл, ссылка, импликация и логическая форма, технология помогает системам ИИ понимать язык и обрабатывать информацию так, как это делают люди, что позволяет им хранить, управлять и извлекать информацию на основе значения и логических отношений.
 Базы данных семантических графов, основанные на видении Semantic Web, упрощают интеграцию, обработку и извлечение данных машинами.
Базы данных семантических графов, основанные на видении Semantic Web, упрощают интеграцию, обработку и извлечение данных машинами. По мере того, как организации увеличиваются в размерах, растут и их данные. Без правильной стратегии управления данными быстро возникают разрозненные хранилища данных внутри отделов и/или приложений, что снижает производительность и сотрудничество. Интеграция семантических данных предлагает решение, выходящее за рамки стандартных решений по интеграции корпоративных приложений, за счет использования ориентированной на данные архитектуры, построенной на стандартизированной модели публикации и обмена данными, а именно RDF.
По мере того, как организации увеличиваются в размерах, растут и их данные. Без правильной стратегии управления данными быстро возникают разрозненные хранилища данных внутри отделов и/или приложений, что снижает производительность и сотрудничество. Интеграция семантических данных предлагает решение, выходящее за рамки стандартных решений по интеграции корпоративных приложений, за счет использования ориентированной на данные архитектуры, построенной на стандартизированной модели публикации и обмена данными, а именно RDF.
