
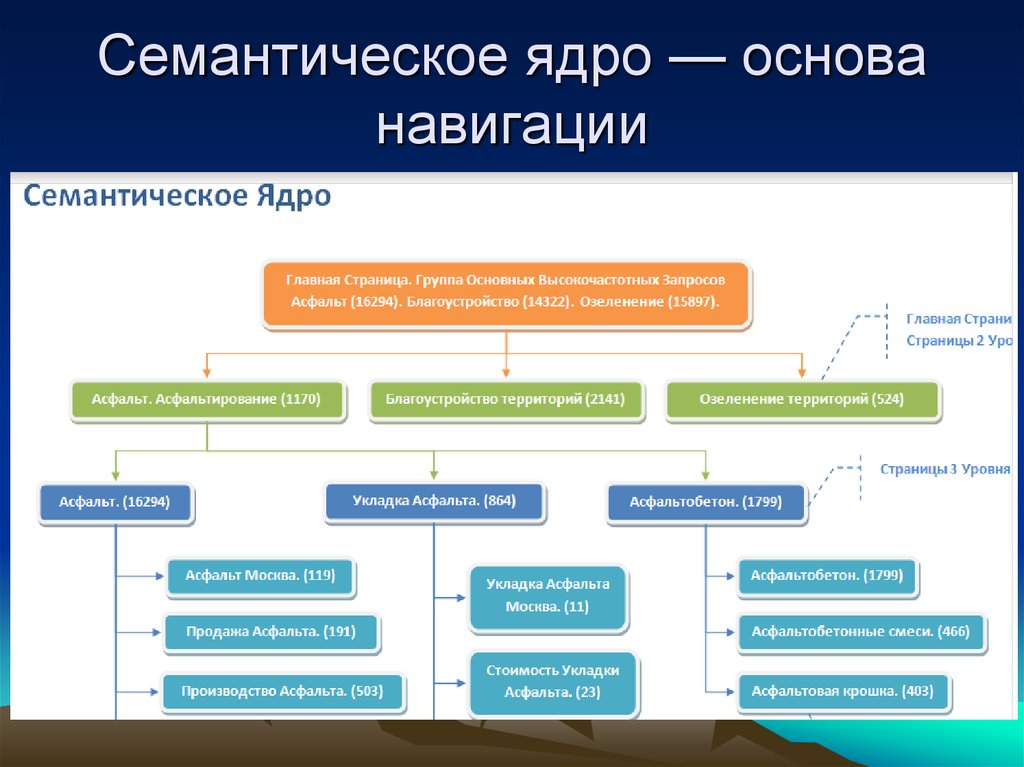
Семантическое ядро: разгруппировка и релевантные страницы
SEO
Лаппо Виталий
22 июня 2017
Просмотров: 20 683
Поговорим о распределении семантики уже собранного, правильного семантического ядра по страницам сайта.
Что это? Зачем оно нам?
Распределение семантики – это присвоение каждой странице нашего сайта, своей группы целевых запросов. Основная задача процесса распределения семантики — это сделать каждую страницу сайта наиболее релевантой запросу, т.е. все страницы должны отвечать на свой вопрос. Один вопрос — одна страница. Подбирать группы ключевых фраз нужно таким образом, чтобы они максимально точно отвечали на вопрос, которому посвящена страница. Обычно к распределению семантики на целевые страницы переходят после кластеризации коммерческих и информационных запросов.
Распределение целевых запросов по страницам
Начнем с главной страницы и основных целевых страниц.
- Выписываем все страницы по порядку, которые требуется оптимизировать
- Определяем какому запросу релевантны страницы и к каждой странице подбираем группу релевантных запросов из ядра и wordstat.
 Нужно распределить их таким образом, чтобы они не повторялись (т.е. уникальные к каждой странице). Если у страницы уже имеется позиция в выдаче, но не достаточно высокая, не стоит сразу менять ключевой запрос, оптимально будет подобрать ряд схожих дополнительных ключей, которые улучшат релевантность страницы текущему запросу и соответственно улучшат его рейтинг.
Нужно распределить их таким образом, чтобы они не повторялись (т.е. уникальные к каждой странице). Если у страницы уже имеется позиция в выдаче, но не достаточно высокая, не стоит сразу менять ключевой запрос, оптимально будет подобрать ряд схожих дополнительных ключей, которые улучшат релевантность страницы текущему запросу и соответственно улучшат его рейтинг.- К главной странице мы рекомендуем добавлять брендовые запросы и группу ВЧ запросов, которые определяют нишу сайта. Например: компания «Кавенаги» занимается транспортной логистикой и предоставляет услуги 3pl оператора. Значит группа запросов для главной страницы данного сайта будет содержать следующий список запросов:
- «Кавенаги» — название бренда;
- «Транспортная компания» — частотность в месяц: 834 437;
- «3pl оператор» — частотность в месяц: 2794.
- Страницы категорий и подкатегорий (второй и третьей степени вложенности) должны содержать запросы соответствующие конкретным услугам или группам товаров этой категории. Например: категория транспортных услуг будет группу запросов:
- «Грузоперевозки» — частотность в месяц: 596 106;
- «Транспортные услуги» — частотность в месяц: 52 644;
- «Международные перевозки» — частотность в месяц: 27 447.
- Карточки товаров (страницы третьей и ниже степени вложенности) должны соответствовать каждой конкретной услуге или товару. Например: услуга перевозок автотранспортом будет иметь группу запросов:
- «Автомобильные перевозки» — частотность в месяц: 47 520;
- «Автоперевозки по России» — частотность в месяц: 1388;
- «Международные автоперевозки» — частотность в месяц: 617.
- К главной странице мы рекомендуем добавлять брендовые запросы и группу ВЧ запросов, которые определяют нишу сайта. Например: компания «Кавенаги» занимается транспортной логистикой и предоставляет услуги 3pl оператора. Значит группа запросов для главной страницы данного сайта будет содержать следующий список запросов:
- Отмечаем в семантическом ядре запросы, которые мы уже использовали и на какой странице, чтобы видеть какие фразы остались незадействованными.
- Учитывая нововведение яндекса — алгоритм «баден-баден» будет полезным к каждому ключевому запросу добавить 2-3 синонима из правой колонки wordstat и сервисов подбора синонимов онлайн.
 Например: категория транспортных услуг будет группу запросов:
Например: категория транспортных услуг будет группу запросов:
Важно! нужно четко разделять коммерческие и информационные запросы. Коммерческий кластер запросов используется для оптимизации целевых — продающих страниц сайта, а информационные послужат фундаментом для контентной (блоговой) составляющей.
Лайфхак! Если сервисы подбора синонимов не помогают, используем справочно-информационные ресурсы, например википедию. И вытаскиваем синонимичные фразы из определения слова.
Примерно так будут выглядеть синонимичные фразы к слову «Консалтинг»:
Управленческое консультирование:
Оптимизация страниц сайта
После того как все коммерческие страницы сайта получили свои релевантные группы запросов, а так же синонимичные ключи к ним, можно перейти к оптимизации страниц:
- Проработать теги title. Title формируется из самого ВЧ запроса группы ключевых слов, с добавлением дополнительных ВЧ и СЧ запросов по смыслу.
- Заголовок h2 на страницах более художественный вариант заголовка title, также должен содержать ключевой ВЧ запрос, но не в ущерб смыслу и восприятию заголовка (данный заголовок создается для людей).
- Прописать вкусные description используя ключевые слова из утвержденных запросов к странице. При формировании важно учитывать, что description влияет на ctr, поэтому его нужно составить таким образом, чтобы у пользователя появилось желание перейти по ссылке. Один из самых хороших способов привлечь пользователя — это избегать вводных и размытых оборотов формата: «Широкий/полный спектр, низкая цена, быстрый, дешевый, самый лучший и т.д.» и всегда заменять конкретикой, формата: «Цены от…, доставка от … дней, услуги/товары перечнем самых популярных позиций и т.д».
- Обновить тексты путем добавления ключевых слов и синонимичных фраз (В приоритете использовать ключевые фразы в заголовках h2-h6)
 Title формируется из самого ВЧ запроса группы ключевых слов, с добавлением дополнительных ВЧ и СЧ запросов по смыслу.
Title формируется из самого ВЧ запроса группы ключевых слов, с добавлением дополнительных ВЧ и СЧ запросов по смыслу.Закончив с оптимизацией страниц, можно переходить к контентному продвижению.
Подводя итог
- Такая стратегия распределения запросов поможет сделать страницу максимально релевантной запросу для поисковой системы, а синонимы позволят не попасть под фильтр переспама.
- Не переусердствуйте с ключевыми словами, они должны быть адекватными!
- Отметки в семантическом ядре об уже использованных запросах, наглядно укажут как широко вы охватили тематику ниши и на чем сосредоточиться при дальнейшем контентном продвижении, а также запланировать создание контента сроком от недели до нескольких лет!
Пишите в комментариях свое мнение и делитесь постом с друзьями.
Больше вашей активности — больше интересных статей.
Заказать seo продвижение от монстров!
Теги статьи:
seo
Получайте бесплатные уроки и фишки по интернет-маркетингу
Похожие статьи:
Сделайте репост:
Группировка семантического ядра сайта онлайн вручную 2018
Семантическое ядро – одна из самых важных составляющих на этапе планирования SEO продвижения. Для успешного продвижения необходимо составить первоначальную семантику. В своем посте я написал, как составить семантическое ядро сайта, поэтому у Вас не должно возникнуть с этим проблем. После получения списка ключевых слов необходимо приступить к работе по группировке. Группировка семантического ядра позволит получить окончательный список ключевых слов (семантическое ядро) и завершить первый этап запуска сайта.
Для успешного продвижения необходимо составить первоначальную семантику. В своем посте я написал, как составить семантическое ядро сайта, поэтому у Вас не должно возникнуть с этим проблем. После получения списка ключевых слов необходимо приступить к работе по группировке. Группировка семантического ядра позволит получить окончательный список ключевых слов (семантическое ядро) и завершить первый этап запуска сайта.
Группировка ключевых запросов состоит из нескольких этапов. Первый этап – это определение параметров, по которым будет группировать семантическое ядро. Для этого мы рекомендуем в каждом запросе выделять ключевые свойство. Второй этап – это группировка ключевых слов на основе признака каждого запроса. За признак мы рекомендуем брать слово, которое формирует смысл всей фразы. От смысла фразы зависит актуальность фразы. Третий этап группировки семантического ядра – это работа по соотношению запросов с группой и окончательное формирование списка ключевых слов.
При составлении данного материала испытывались только бесплатные программы группировки. Благодаря этому достигается возможность объективно взглянуть на работу простых вебмастеров, которым нет необходимости покупать профессиональные программы и приложения для кластеризации ключевых слов. В своем обзоре я старался свести до минимума сложность работы, чтобы разгруппировать запросы мог даже человек, далекий от SEO продвижения и сбора семантического ядра.
1 этап группировки семантического ядра – определение параметров группировки
Группировка семантического ядра начинается с определения параметров, по которым Вы будете разбивать список ключевых слов. Определение параметров позволит Вам достичь конечных целей SEO продвижения. Самые распространенные параметры группировки семантического ядра:
- Группа запросов
- Ключевая фраза
- Частотность
- Целевая страница
- Уровень конкуренции
Помимо представленных параметров, Вы можете добавить свои, имеющие актуальность для конкретного интернет-проекта. Как правило, данные параметры задаются в виде верхней строчки таблицы excel (формат XLS). В программах, которые автоматически группируют семантическое ядро, параметры задаются автоматически – однако Вы можете удалить лишние столбцы.
Как правило, данные параметры задаются в виде верхней строчки таблицы excel (формат XLS). В программах, которые автоматически группируют семантическое ядро, параметры задаются автоматически – однако Вы можете удалить лишние столбцы.
Группировка семантического ядра сайта может происходить в ручном и автоматическом режиме. На следующем этапе мы рассмотрим возможность группировки в обоих режимах. Каждый способ группировки имеет свои плюсы и минусы и окончательный выбор зависит от общего количества ключевых запросов (а их может быть десятки тысяч), опыта в кластеризации запросов и необходимости в тщательном анализе списка слов.
2 группировки семантического ядра – разбивка запросов по признакам
Основной этап по группировке списка ключевых слов – это их разбивка по признакам. Признак ключевого слова подразумевает наличия у группы ключевых фраз единого признака. Например, если Вы группируете список слов на тему «Семантическое ядро», то единым признаком для группы «Как составить семантическое ядро» будет следующий список ключевых запросов:
— как составить семантическое ядро
-как составить семантическое ядро сайта
— как составить семантическое ядро для сайта
— как составить семантическое ядро своими руками
— как составить семантическое ядро самому
В данном списке запросов главным признаком группировки является «как составить семантическое ядро» которое задает значение всех фраз.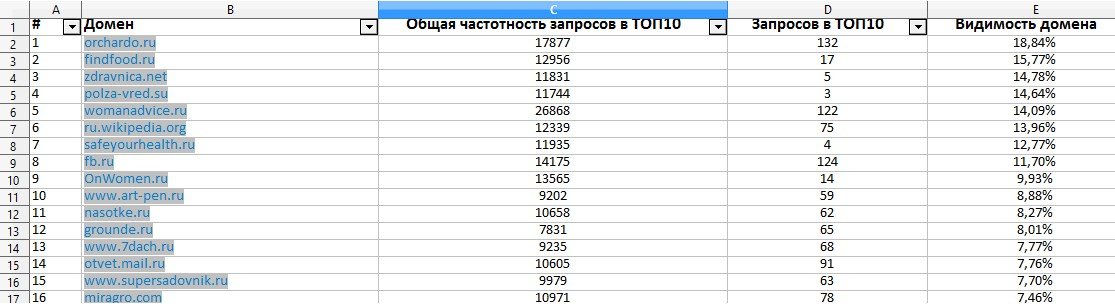 Добавление дополнительных слов «сайта, самому, своими руками» не меняет общий смысл, а только конкретизирует фразу. Все фразы, сгруппированные по данному признаку и конкретизированные дополнительными словами, имеют одинаковый смысл, и должны быть сгруппированы в единую группу. В этом и заключается весь смысл группировки семантического ядра.
Добавление дополнительных слов «сайта, самому, своими руками» не меняет общий смысл, а только конкретизирует фразу. Все фразы, сгруппированные по данному признаку и конкретизированные дополнительными словами, имеют одинаковый смысл, и должны быть сгруппированы в единую группу. В этом и заключается весь смысл группировки семантического ядра.
Ручная группировка семантического ядра
Ручная группировка семантического ядра более трудоемка, чем группировка с помощью программ. Однако можно назвать два несомненных преимущества: это более детальный анализ каждого отдельного запроса и самостоятельное формирование группы запросов. Благодаря этим преимуществам получается семантическое ядро высокого качества, которое можно использовать для продвижения сайта. Как же группировать семантическое ядро вручную? Благодаря простому алгоритму поиска в таблице excel данный процесс не вызовет больших затруднений.
Ручная группировка семантического ядраНа первом этапе Вам необходимо разгруппировать запросы по общим признакам.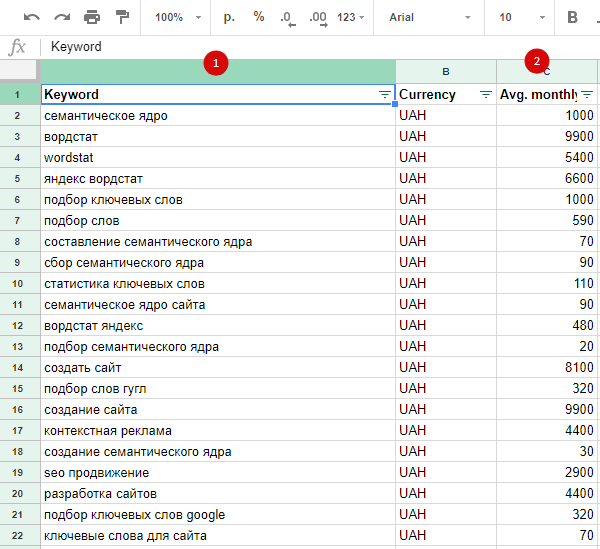 Например, выделить все запросы «как составить семантическое ядро» желтым цветом. Так у нас появляется большое количество фраз, которые мы должны свести в отдельные группы. Далее, мы должны найти отдельные слова, которые формируют конкретные группы. Данный процесс лучше всего делать через меню поиска в таблицах Excel, чтобы не тратить много время на поиск фраз с единым смыслом. Найденные таким способом слова разбиваются на отдельные группы и составляют основу для отдельной страницы.
Например, выделить все запросы «как составить семантическое ядро» желтым цветом. Так у нас появляется большое количество фраз, которые мы должны свести в отдельные группы. Далее, мы должны найти отдельные слова, которые формируют конкретные группы. Данный процесс лучше всего делать через меню поиска в таблицах Excel, чтобы не тратить много время на поиск фраз с единым смыслом. Найденные таким способом слова разбиваются на отдельные группы и составляют основу для отдельной страницы.
Как правило, целесообразно включить в одну группу ключевых слов 3 — 5 запросов. Если запросы высокочастотные, то правильным будет использовать 1 запрос на 1 страницу. Как это часто бывает, данный способ группировки семантического ядра имеет недостатки. Главный из них – сложность в работе с большим объемом. Обычно формируется тысячи ключевых фраз, которые сложно формировать вручную. Поэтому на помощь вебмастеру приходят специальные программы и приложения, которые значительно облегчают группировку.
Автоматическая группировка семантического ядра
Автоматическая группировка семантического ядра позволяет составить список ключевых слов с помощью программы. Алгоритм работы программы достаточно прост. Вы загружаете полученный список ключевых слов в программу, после чего задаете другие параметры обработки: минус-слова (слова, которые не должны включаться в семантическое ядро), обязательные слова и т.д. После этого можно запускать процесс обработки. Как правило, он занимает 1-2 минуты. На выходе у Вас будет готовое семантическое ядро сайта.
Из бесплатных сервисов для автоматической группировки я бы отметил несколько сайтов. Больше всего мне понравился инструмент от компании SEOQUICK, который в автоматическом режиме обрабатывает до 10000 запросов. Сервис группировки доступен по этому адресу https://seoquick.com.ua/keyword-grouping/ До августа работает в бесплатном режиме. Из несомненных плюсов мне понравилась возможность выбора частотности запросов и возможность задать расширенную кластеризацию семантики. Достаточно простой функционал сервиса не вызовет больших трудностей, поэтому данную программу можно смело использовать для группировки запросов.
Достаточно простой функционал сервиса не вызовет больших трудностей, поэтому данную программу можно смело использовать для группировки запросов.
Еще один бесплатный сервис для группировки семантического ядра http://kg.ppc-panel.ru/#/import от агентства Seenta. Это достаточно простой сервис, в котором можно добавить список ключевых фраз и сгруппировать их в отдельные группы. Единственным параметром, который можно добавить, является список ключевых фраз. Это один из самых простых сервисов для автоматической группировки семантики. Если его функционал не подходит для решения Вашей задачи, Вы можете воспользоваться платными сервисами.
Автоматическая группировка ядра3 этап – окончательное формирование семантического ядра
После завершения группировки запросов необходимо завершить формирование семантического ядра. Лучше всего это сделать в следующем порядке:
- Прочитать полученные группы ключевых слов и удалить неактуальные группы.
- Определить частотность для каждой группы и количество ключевых фраз для отдельной страницы.
- Составить план написания статей по месяцам, чтобы понять какое время займет у Вас реализация семантического ядра.

После завершения данных шагов Вы будете иметь на руках готовое семантическое ядро с пониманием времени, которое необходимо затратить на заполнение сайта. Замечу, что ядро – лишь часть работы по продвижении сайта. Одним из самых главных условий для вхождения сайта в ТОП является актуальность представленной на сайте информации. Для этого необходимо понимать смысл, которое имеет каждое ключевое слово. Публикуя на сайте интересную информацию, Вы можете ожидать внимание со стороны интернет-пользователей и поисковиков, и как следствие – занять самые высокие места в поисковой выдаче. Желаю, чтобы группировка семантического ядра сайта помогла Вам приобрести много новых посетителей на сайт!
Смысл семантического ядраИнтересное видео про группировку семантического ядра
 youtube.com/embed/7MgZJgyQL5c» frameborder=»0″ allowfullscreen=»allowfullscreen»>
youtube.com/embed/7MgZJgyQL5c» frameborder=»0″ allowfullscreen=»allowfullscreen»> Что такое семантическое ядро сайта: сбор и кластеризация
Разберем, что такое семантическое ядро и как его правильно собрать.
Я покажу вам основные факторы качества семантики и план сбора СЯ.
Также будет много других ценных кейсов.
Содержание:
- Что такое семантика сайта
- Факторы качества СЯ:
- Количество показов
- Релевантность
- Типы страниц
- Стоимость продвижения
- Конкурентность
- Количество переходов
- Отказы
- Сезонность
- Геозависимость запроса
- Как собрать семантическое ядро
- Как чистить от запросов:
- Пустышки
- Нецелевые запросы
- Устаревшие
- Не продающие
- Дорогие
- Слова в несколько толкований
- Цель пользователя
- Группировка запросов:
- Один запрос на одну страницу
- Максимальное уточнение
- Создание новых страниц
- Объединение старых страниц
- Логический смысл группировки
- Забыть про ВЧ на главной
- Выровняем количество запросов
- Коммерческие и информационные запросы
- Кластеризация запросов
- Выводы
Что такое семантическое ядро
Семантическое ядро — это максимально полный перечень всех ключевых слов и словосочетаний, с помощью которых люди ищут информацию, которую вы им предоставляете на своем сайте. Тут могут быть различные товары, услуги или просто какая-нибудь информация.
Тут могут быть различные товары, услуги или просто какая-нибудь информация.
Также помимо перечня слов, в СЯ обязательно должна содержаться дополнительная статистика по отобранным словам. Ведь именно она помогает нам отбирать лучшие варианты.
Сюда относится частотность, конкурентность, стоимость продвижения, сезонность, перелинковка и так далее.
Для чего нужно семантическое ядро?
С помощью семантики владельцы сайтов могут сформировать структуру сайта. Например, какие ключевики будут продвигать страницы и посты, а какие рубрики и метки.
Также можно заранее продумать иерархию разделов. Например, что будет рубриками, а что подрубриками. Это особенно важно при создании и продвижении молодого сайта.
Структура сайтаЕще зная структуру сайта, можно заранее сформировать структуру веб-дизайна. То есть какие блоки должны быть на сайте и где они будут располагаться. Сюда также относим меню с необходимыми разделами.
Помимо структуры, семантическое ядро помогает составить контент-план.
С заранее отобранных ключевых слов мы уже видим темы будущих статей. А благодаря статистике по ключевикам, мы эти темы сможем сформировать в единый план.
Также СЯ очень хорошо помогает во внешней и внутренней перелинковке. Вы уже наглядно будете видеть, какие статьи по каким ключам у вас продвигаются. А также какие страницы нужно перелинковать, а какие нет.
Еще можно сразу увидеть свой ссылочный профиль. То есть какие анкоры в ссылках употребляются чаще всего, а какие нет. Благодаря этому можно равномерно распределять ссылочную массу. Это придает дополнительную естественность для поисковых систем.
Рекомендую почитать: Что такое ссылка и каково ее влияние на seo продвижение сайта в интернете.
Для тех, кто создает рекламные кампании в интернете, СЯ тоже пригодиться. Например, можно отслеживать тренд и в нужный момент запускать онлайн рекламу.
Само семантическое ядро сайта хранится в виде электронных таблиц. Рекомендую ее сохранять в программе Microsoft Excel. В ней очень удобно просматривать всю статистику в ядре, а также редактировать ее.
В ней очень удобно просматривать всю статистику в ядре, а также редактировать ее.
Факторы качества семантического ядра
Сейчас рассмотрим важные факторы качества семантического ядра. Обязательно обращайте на них внимание при создании семантики. От этого зависит эффективность seo продвижения сайта в поисковых системах.
Количество показов
В первую очередь — это количество показов (частотность). Это то количество раз, сколько в среднем в месяц пользователи запрашивают определенное ключевое слово.
Также не забываем про количество показов только поискового запроса без словосочетаний. Ведь нам нужно понимать, сколько запрашивают конкретное ключевое слово и именно в такой форме, в которой мы хотим видеть.
Релевантность поисковым запросам
Нужно понимать, есть ли у нас на сайте страницы, которые будут релевантны поисковым запросам. Если таких нет, значит их нужно создать.
Еще обязательно нужно знать, на какие страницы нужно вести эти поисковые запросы.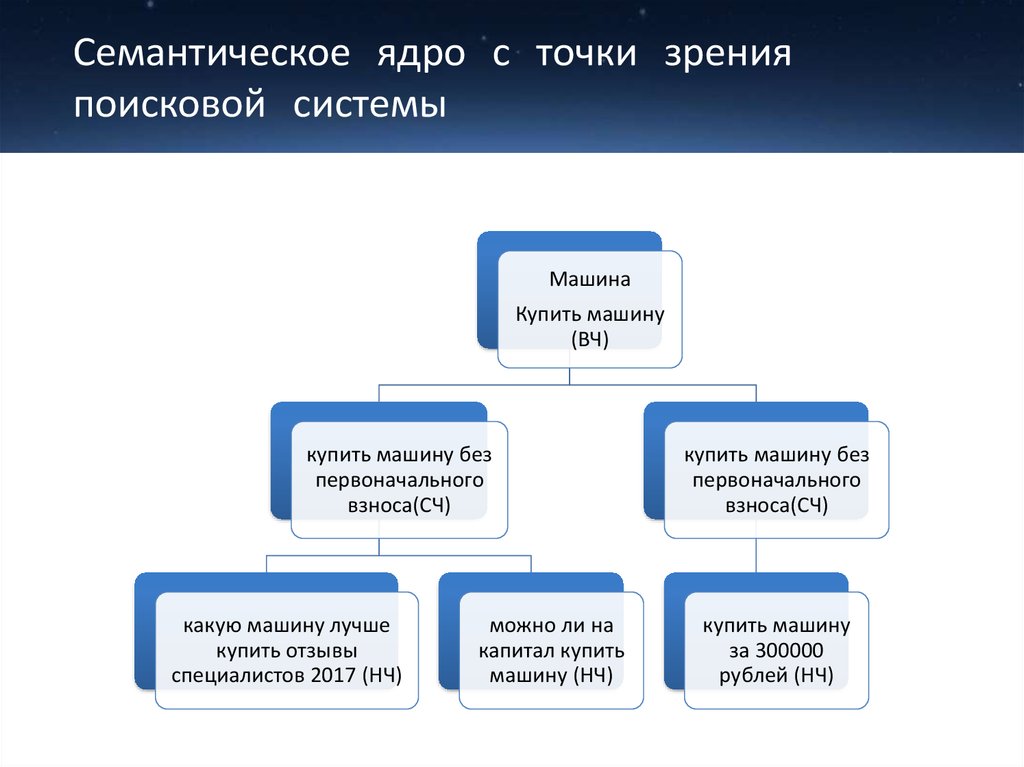
Типы страниц
В некоторых тематиках за счет высокой конкуренции, в топ можно попасть и за счет специфики запроса. Например, введя поисковый запрос «интернет-магазин» в выдаче нам выдаст только главные страницы сайтов.
Это говорит о том, что с внутренней страницей по заданному запросу будет очень проблематично пробиться в топ. Поэтому в данном случае нам нужно ориентироваться конкретно на главную страницу.
Так что небольшая аналитика топа на предмет типа страницы поможет нам заранее сэкономить силы для продвижения.
Стоимость продвижения запроса
Сейчас очень много баз с огромным количеством ключевых слов. Поэтому сегодня можно объективно оценить стоимость продвижения конкретного запроса.
Очень часто выбирая между двумя и более запросами, нужно сделать один единственный выбор. Чтобы это легко осуществить, всегда обращайте внимание на такую метрику, как примерная стоимость продвижения запроса.
Например, бывает такая ситуация, что имеется три запроса, каждый из которых приносит на сайт по 100 человек в месяц. Но в тоже время два из них очень конкурентные. Для seo продвижения по этим запросам нам понадобиться 200$.
Но в тоже время два из них очень конкурентные. Для seo продвижения по этим запросам нам понадобиться 200$.
Но есть и третий менее конкурентный запрос. Для него нам нужно потратить всего лишь 50$.
Соответственно, зная заранее стоимость продвижения, можно сразу выбрать наиболее выгодный и нужный продвигаемый запрос среди списка.
Конкурентность
Очень важно при сборе семантического ядра, оценивать насколько ваш сайт конкурентноспособен. Ну и конечно же, нужно знать, насколько высокая конкурентность ключевого слова.
Этот пункт должен обязательно присутствовать в семантическом ядре!
Ведь есть тематики, где молодым или не авторитетным проектам проблематично попасть в топ по заданному ключевому запросу.
Таким образом, мы сможем сэкономить силы и средства если заранее поймем, что по данному ключу нам пока еще рано продвигаться. Тогда можно будет сосредоточить свои силы на другие запросы.
Количество переходов (реальное и прогнозируемое)
Статистика поисковых систем дает усредненное количество переходов вне зависимости от сезона.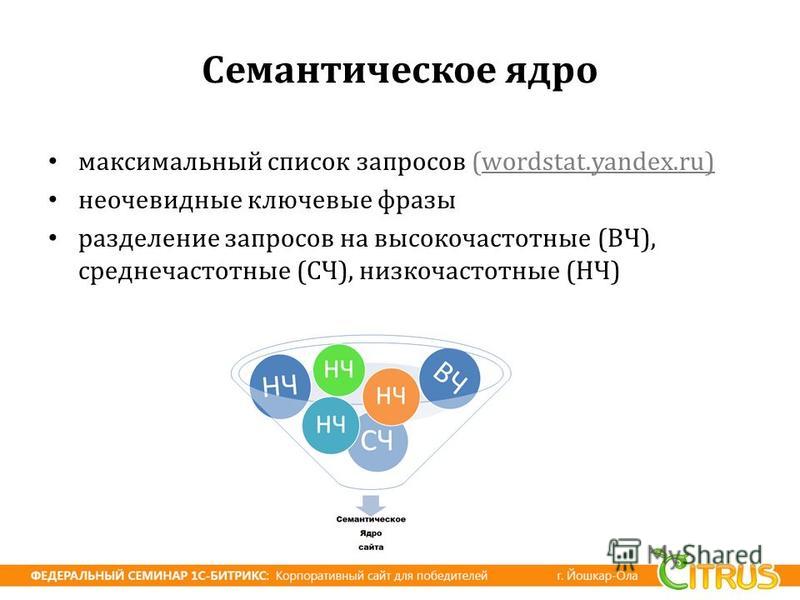 Поэтому цифры могут отличаться.
Поэтому цифры могут отличаться.
Банально может вырасти спрос на какую-то продукцию. Или наоборот, упасть. Либо по каким-то экономическим показателям в офлайне упал спрос на определенный вид продукции. В том числе может упасть спрос и в онлайн сегменте.
Поэтому мы заранее предположили, что количество переходов будет одним. Но в реальности оно оказалось совсем другим.
Показатель отказов
Показатель отказов мы можем оценить, имея трафик по какому-то ключевому слову, а также дополнительные средства веб-аналитики. Только тогда можно узнать подходит запрос под данную страницу или же нет.
Сезонность запроса
Есть тематики, в которых популярность ключевого слова либо группа ключевиков меняется в зависимости от сезонности.
Например, тематика шин имеет ярко выраженную сезонность. Как правило, сентябрь, октябрь и часть ноября. Либо же конец февраля, март и начало апреля. Июнь, июль, август имеют довольно низкий спрос на данную продукцию.
Или же, например, какое-то зимнее снаряжение или экипировка (лыжи и костюмы). Здесь ярко выраженный сезон — это декабрь, ноябрь и январь. Поэтому частотность таких запросов варьируется в зависимости от сезона. Ну и в том числе от спроса.
Здесь ярко выраженный сезон — это декабрь, ноябрь и январь. Поэтому частотность таких запросов варьируется в зависимости от сезона. Ну и в том числе от спроса.
Геозависимость запроса
В поисковой системе Google геозависимость запроса выражена на уровне стран. То есть под коммерческие поисковые запросы (например, «купить ноутбук») мы получим сугубо сайты той страны, в которой находимся.
А под запросы информационного характера мы можем видеть сайты разных стран. Тут уже не важно какой будет проект, так как мы просто хотим удовлетворить информационную потребность.
Если к примеру, мы захотим узнать, как забить гвоздь, то уже не важно, на каком сайте будет размещена информация. Поэтому такие запросы будут не геозависимыми.
А вот коммерческие, где мы конкретно хотим что-то купить (преимущественно в своем городе или стране), то это уже будут геозависимые запросы.
В поиске Яндекса геозависимость выражена более ярко!
Отличается она на уровне городов и регионов.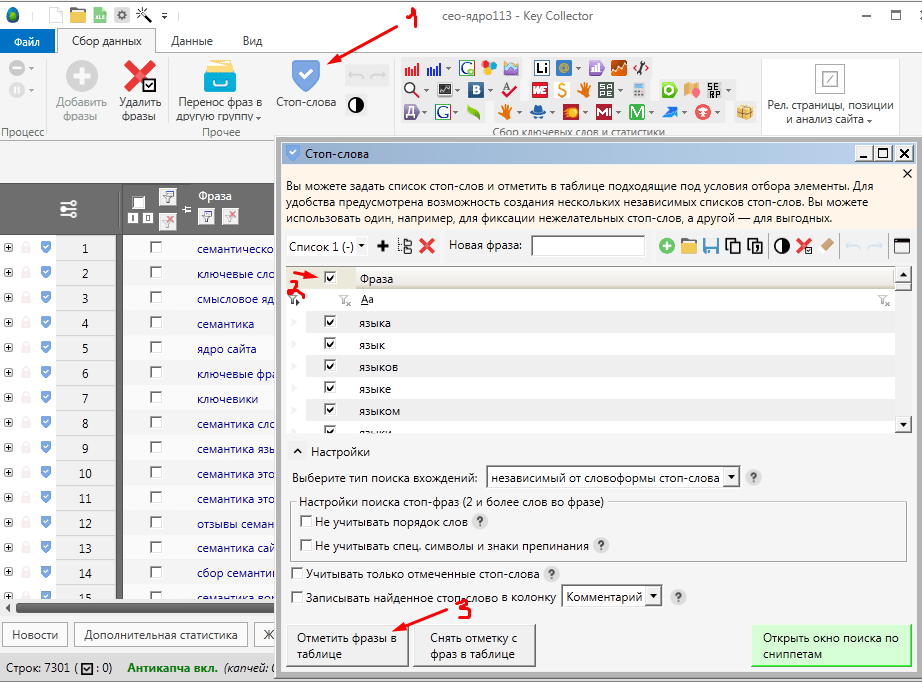 То есть пользователи из Москвы и Санкт-Петербурга будут получать разный список сайтов по одному и тому же поисковому запросу.
То есть пользователи из Москвы и Санкт-Петербурга будут получать разный список сайтов по одному и тому же поисковому запросу.
Сбор семантического ядра для сайта
Немного поговорим о том, как составить семантическое ядро. Самая большая ошибка seo специалистов в том, что они не собирают ключевые слова, а просто их придумывают.
На самом деле мы не должны тут все выдумывать. Все должно собираться на основе статистики. Поисковики предоставляют нам хорошие инструменты. С их помощью можно узнать статистику о том, что часто, а что редко ищут в интернете.
План сбора семантического ядра для сайта:
- Выписать основные направления сайта. Как правило, это категории (рубрики) проекта.
- К этим разделам выписываем подходящие ключи. Это будут первоначальные запросы, по которым в дальнейшем будет собираться семантика.
- Определяемся с регионом продвижения. Особенно это важно для коммерческих проектов (интернет-магазины и сайты услуг). Это нужно чтобы приводить свою целевую аудиторию. Также не забываем, что для разных регионов статистика по запросам будет разной.
- Сбор ключевых слов. Для этого есть как платные, так и бесплатные инструменты. Сам сбор начинаем с тех первых запросов, которые сформировали во втором пункте.
- Очистка СЯ от ненужных ключевиков. Оставляем только самые эффективные и подходящие варианты. Ниже мы об этом еще поговорим.
- Кластеризация семантического ядра. Делаем группировку запросов на отдельные кластеры. То есть для каждой продвигаемой страницы закрепляем свои ключевики. В результате этого сформируется готовая структура сайта.
- Расширение семантики. Этот пункт выполняется в том случае, если первоначальное ядро было составлено не полностью. Хоть это и трудно, но я рекомендую создавать сразу полное СЯ. Тогда можно увидеть полную картину.
 Также не забываем, что для разных регионов статистика по запросам будет разной.
Также не забываем, что для разных регионов статистика по запросам будет разной.Как чистить семантическое ядро
Давайте поговорим о том, как чистить семантическое ядро. Казалось бы, есть эффективные методы подбора.
Но даже при быстрых методах сам человек способен ошибаться. В итоге он может раздуть ядро за счет ненужных ключевых слов и инвестировать средства в них. В таком случае о дальнейших результатах говорить не приходиться.
В итоге он может раздуть ядро за счет ненужных ключевых слов и инвестировать средства в них. В таком случае о дальнейших результатах говорить не приходиться.
Поэтому перед тем, как перейти к фазе активного сео продвижения сайта, после подбора семантического ядра, нужно хорошенько его почистить.
От каких запросов его нужно чистить:
- пустые запросы
- не целевые
- устаревшие
- не продающие
- дорогие
- имеющие несколько толкований
Ниже более подробно рассмотрим каждый из них.
Пустые запросы
Что такое пустые запросы? Это запросы, которые могут иметь очень низкую частотность. Они не являются популярными, но по какой-то причине мы их просто выбрали.
Соответственно, даже занятие высоких позиций по данному ключу не принесет никакого результата. Ведь пользователи данный запрос не будут вводит в поиске. В итоге они никак не попадут на сайт.
Также к пустышкам относятся запросы, которые имеют низкое соотношение общей частотности к точным показам. То есть по широкому соответствию запрос имеет большое количество показов в месяц. Но в точной форме, он имеет очень низкое число показов.
То есть по широкому соответствию запрос имеет большое количество показов в месяц. Но в точной форме, он имеет очень низкое число показов.
Значит, те слова, которые употребляются в широком соответствии данного ключа, являются наиболее эффективными. Потому что они имеют выше частотность, чем первоначальная форма этого ключа. Так что лучше сосредоточится именно на них.
Нецелевые запросы
Что такое не целевые запросы? Это запросы, которые приводят нецелевых посетителей. От таких людей толку мало, так как они не совершают целевые действия на сайте.
Пользуясь уже ранее представленным инструментом Spywords, я вбил один из коммерческих сайтов по бытовой технике.
В списке ключевых слов, по которым он ранжируется обнаружились совсем не те ключи, которые подходили для данного проекта. Такая ситуация тоже не редко встречается.
Нецелевые запросы сайтаГде еще мы можем увидеть не целевые запросы?
Например, пользуясь методом подбора ключевиков через поисковые подсказки, мы можем ввести начальную фразу и одну букву.
Вот мы видим список ключевых слов, которые предлагает нам поисковая система.
Некоторые из них целевые. Но есть запросы, которые не совсем смогут подойти сайту. Например, если вы продаете новые товары, то запросы с бу вам точно не подойдут.
Устаревшие запросы
Что такое устаревшие запросы? Это запросы, которые потеряли свою актуальность по прошествии времени. Например, «лучший мобильный телефон 2012» или «туры в Египет 2013».
Такие запросы становятся не актуальными. Поэтому нужно постоянно чистить свое семантическое ядро сайта от такого мусора.
Не продающие запросы
Вот не продающие запросы — это уже более сложнее чем с предыдущим вариантом. Тут нужен опыт и плотная работа с системами веб-аналитики.
Понять продающий этот запрос или нет можно только увидев какие-то результаты. То есть было ли произведено нужное конверсионное действие от пользователя, который нашел вас по заданному ключу.
К примеру, ключевой запрос «почему не включается ноутбук» на первый взгляд может показаться не продающим.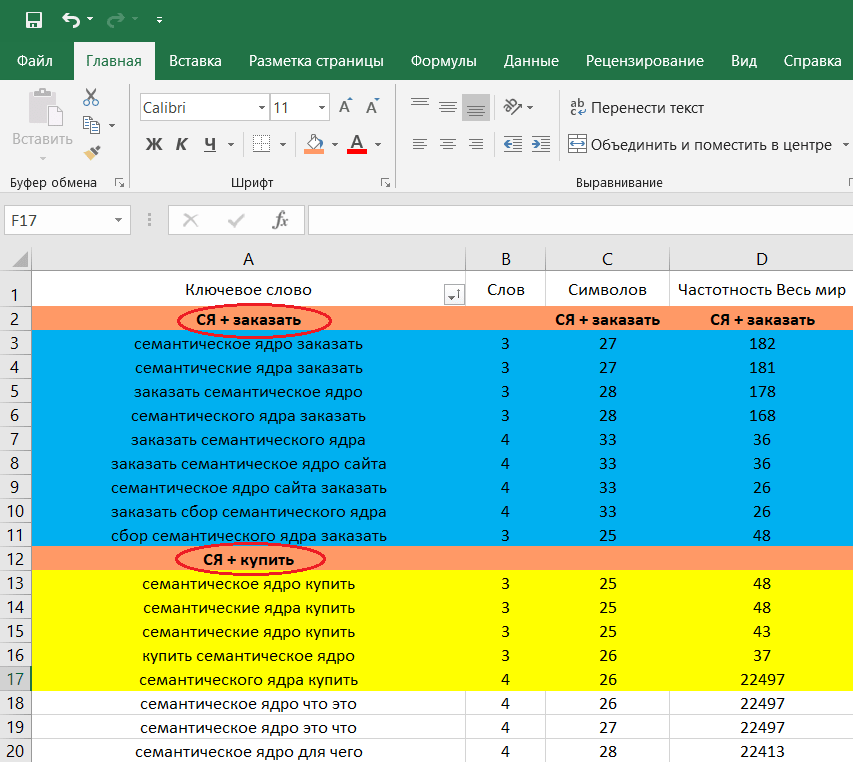
Но в то же время до конца не все понятно. Ведь пользователь, который пришел на информационную статью по этому ключу, может сразу не купить у нас ноутбук.
Однако через определенное время он может снова к нам вернуться и на этот раз купить товар. Поэтому полностью до конца узнать продающий был запрос или нет можно только средствами веб-аналитики.
Дорогие запросы
Дорогие запросы — это те запросы, где количество вложенных в них инвестиций даже не окупает выход в топ. Это также оценивается средствами веб-аналитики.
Зная примерно выделенный бюджет на ту же ссылочную массу под ключевое слово, можно оценить, привел ли выход в топ к нужному результату или нет.
Поэтому лучше инвестируемые средства с возвратами инвестиций оценивать сразу при составлении семантического ядра.
Запросы в несколько толкований
Ну и последнее — это запросы, имеющие несколько толкований. Например, запрос «банки» может подразумевать как специальные учреждения, так и стеклянные банки.
Поэтому такие неоднозначные запросы могут лишь мешать нам в СЯ. Лучше добавлять туда какой-то наиболее уточняющий вариант.
Определение цели пользователя
Очень важно понять, что хочет получить от нас целевой пользователь. Ведь не каждый посетитель сайта, придя по каким-то ключевым словам, будет являться целевым.
Где-то актуальными для нас будут те пользователи, которые спрашивают цену.
Но в тоже время у нас на сайте цена может являться не конкурентным преимуществом, а скорее наоборот (очень дорого). Тогда пользователи, которые будут приходить по ключевым запросам (название товара + цена или недорого), будут уходить с сайта. В итоге такие люди для нас будут не целевыми.
В таком случае, нам нужно будет отказаться от активного продвижения по таким ключевым словам либо пересмотреть ценовую политику.
То есть сбор семантического ядра не должен быть глупым. Не нужно ориентироваться только на одну частотность. Ориентируйтесь также и на то, сможет ли сайт ответить на запрос пользователя.
Группировка семантического ядра
Рассмотрим такой этап в seo продвижении, как группировка семантического ядра. Само по себе ядро без сгруппированных запросов, распределенных на посадочные страницы не имеет никакого значения.
То есть каждый ключевой запрос должен быть определен на какую-то конкретную продвигаемую страницу. Но перед этим все слова должны быть сгруппированы в логические группы.
Есть основные правила группировки. Вот их сейчас мы и рассмотрим.
Один запрос на одну страницу
Нельзя пытаться двигать две страницы по одному и тому же ключевому слову. Тогда будет конфликт релевантности. Это в свою очередь очень негативно сказывается на сео оптимизации сайта.
Максимально уточняющие страницы
Запросы должны идти на максимально уточняющие страницы.
К примеру, запрос «ноутбук samsung» должен вести конкретно на страницу данного бренда. То есть нельзя вести его на общую страницу с ноутбуками.
И чем более уточняющий запрос, тем более уточняющая страница должна быть для этого запроса.
Создавайте новые страницы
Не нужно бояться создавать новые страницы по итогам сбора семантического ядра.
Конечно же, процесс создания новых страниц — это дополнительные вложения. Но я не рекомендую пытаться продвинуть ключевые слова только на уже существующие страницы лишь бы не прилагать лишних усилий.
Это наоборот позволит потратить в разы больше усилий, чем сразу создать необходимые страницы и продолжить самостоятельное продвижение сайта.
Объединяйте старые страницы
Нельзя бояться объединять старые страницы по итогам сбора СЯ. Многие сео оптимизаторы грешат тем, что предыдущее правило понимают в рамках «лучшее враг хорошего». То есть они создают отдельные посадочные страницы под созвучные ключевые слова.
Однажды на seo аудит попал один сайт.
В нем отдельно были созданы страницы под запросы «букет для девушки», «букет для девочки», «букет для женщины» и так далее. То есть слова, которые по сути своей являются созвучными и должны объединяться в одну группу, были разбиты на разные страницы
Поэтому нельзя пытаться до тошноты разбить под каждый ключ отдельную страницу. Все должно делаться с умом и разумно.
Все должно делаться с умом и разумно.
Если запрос объединяется в одну группу, то под эту группу создаем отдельную посадочную страницу. Если запросы разбиваются на две и более групп, значит создаем две и более страниц.
Должен быть логический смысл
У дифференциации страниц должен быть логичный смысл. Это как раз то, о чем я говорил, когда разбивают фактически под каждый запрос отдельную страницу.
Приведу еще один пример, когда попался сайт с плохими результатами продвижения. Выполняя seo аудит, я заметил, что также было создано множество посадочных страниц на созвучные запросы.
Например, «подарки на день Валентина», «подарки на день влюбленных» и «подарки на 14 февраля». Все эти три запроса — это все одна группа. Однако под каждую из них была создана отдельная посадочная страница.
Забыть про ВЧ на главной
Нужно забыть про принцип «высокочастотные запросы на главную, а остальное на внутренние страницы».
Это старое правило, когда seo продвижение было хаотичным. Тогда для наибольшей легкости ВЧ запросы кидали на главную, а все остальное на внутренние страницы.
Тогда для наибольшей легкости ВЧ запросы кидали на главную, а все остальное на внутренние страницы.
Но это правило уже давно не работает!
Выровнять количество запросов
Не забываем выровнять количество запросов по страницам.
Чем чреват большой разброс? Например, на одну посадочную страницу 20 ключевых запросов, на другую 2, на третью 100, а на четвертую 5.
А чревато это тем, что когда начнется закупаться ссылочная масса на данные страницы, то получится большой дисбаланс между внутренними страницами. Это в свою очередь будет выглядеть не естественно для поисковых систем.
Отделяем коммерческие и информационные запросы
Коммерческие и информационные запросы нельзя группировать вместе. Коммерческие должны вести на коммерческие страницы, а информационные на инфо-страницы.
Это разные потребности пользователей и совсем разные цели. Соответственно, тут их нужно разумно разделять.
Запросы с приставками «купить», «заказать» и так далее должны вести на коммерческие страницы. Запросы с приставками «что», «как», «почему» и так далее должны вести на информационные страницы со статьями.
Запросы с приставками «что», «как», «почему» и так далее должны вести на информационные страницы со статьями.
На коммерческих страницах все должно быть создано весьма просто чтобы пользователь непринужденно выполнил целевое действие. Для информационных же страниц должны быть статьи с подробным раскрытием проблемы пользователя.
Кластеризация семантического ядра
Давайте немного поговорим про кластеризацию семантического ядра. При больших объемах ключевых слов она помогает нам достаточно быстро и эффективно их разгруппировать.
Кластеризация семантического ядраНа рисунке приведен пример алгоритма программы, которая автоматическим способом кластеризирует заданный список ключевых слов.
Подается запрос в поисковую систему. Далее выбирается топ 10 по каждому из ключу. Затем сравнивается выдача по первому и второму.
Если есть совпадения с определенным индикатором (например, 3 — 4 совпадения), то они попадают в одну группу. Если нет совпадений, то они идут в разные группы.
Потом сравниваются полученные результаты первого и третьего, первого и четвертого, второго и четвертого, второго и третьего. Операция продолжается пока каждые из запросов не будут сравнены и не сформированы окончательно списки кластеров.
Существует много программ и сервисов по кластеризации запросов семантического ядра. Он них мы как-нибудь поговорим в отдельной статье.
Но есть бесплатный способ проверить через поисковик.
Просто введите отдельно поисковые запросы и посмотрите на выдачу. Если в выдаче присутствуют практически одни и те же сайты, то запросы будут относится к одной общей группе. Если сайты разные, то скорее всего, это слова с разных групп.
В общем, автоматизировав этот процесс и опираясь на поисковую выдачу, можно определять кластеры ключевых слов без долгого и ручного их группирования.
Выводы
Теперь вы знаете, что такое семантическое ядро и как собрать его правильно. Также разобрали основные факторы качества семантики.
Скажу, что грамотно почищенное СЯ существенно экономит деньги и силы.
Сами запросы можно продвигать посезонно. То есть нет смысла вести постоянную активность по сугубо сезонным запросам, когда ваши конкуренты глубоко спят. Можно это сделать наиболее чаще, чем конкуренты, но выбрав при этом золотую середину.
На группировке запросов нельзя халтурить. Ведь если мы распределим запросы на неправильные группы и посадочные страницы, то дальнейшее seo продвижение будет неэффективным.
Поисковики стали умнее группировать запросы. Они лучше понимают информационные или коммерческие запросы и в какие группы они объединяются.
К примеру, есть неявные запросы, которые должны идти в одну группу. Кластеризация помогает выявить неявные для человека группы слов и сэкономить ему силы на их распределение.
Группировка по поисковой выдаче – Key Collector
Алгоритм объединяет в группы фразы с похожей поисковой выдачей. Чем больше совпадений между результатами поисковой выдачи по запросам — тем с большей вероятностью они окажутся в одной группе.
Данный режим группировки удобен для автоматической кластеризации семантического ядра.
Группировка по поисковой выдаче v.3 использует другой алгоритм объединения фраз по объединению и пересечению признаков (также известный как SOFT и HARD). Она способна быстро и качественно разгруппировать большие объемы фраз.
Данные поисковой выдачи должны быть получены перед началом анализа.
- Работа с результатами
- Редактирование группировки
- Создание структуры
- Настройки
После завершения анализа в главную рабочую область добавляется вкладка с результатами группировки (1). Вы можете переименовать эту вкладку позже при сохранении изменений.
Вкладка содержит таблицу результатов группировки (2). Здесь фразы сгруппированы согласно выставленным настройкам. Каждая группа имеет дополнительные поля с размерностью группы (кол-во фраз), колонку статуса пометки, колонку произвольного комментария и колонку переопределенного заголовка группы. Также имеется колонка с функциональными кнопками.
Каждая группа имеет дополнительные поля с размерностью группы (кол-во фраз), колонку статуса пометки, колонку произвольного комментария и колонку переопределенного заголовка группы. Также имеется колонка с функциональными кнопками.
В панели состояния добавляется блок счетчиков (3) фраз и групп в результатах группировки: общее кол-во фраз и групп, кол-во отмеченных фраз и групп, кол-во выделенных фраз и групп.
Для работы с результатами группировки в ленту инструментов добавляется группа контекстных вкладок «Анализ групп» (4).
Инструменты вне контекстной вкладки «Анализ групп» выполняют действия над фразами на основной вкладке «Ключевые запросы». Вкладки не переключаются автоматически!
Работа с результатами
Внутри каждой группы отображаются фразы вместе со статистикой из основной таблицы данных. Поддерживается сортировка и фильтрация данных.
Колонка «Коэфф.» (коэффициент) отражает степень связи между фразами в группе: чем больше значение коэффициента — тем более похожи фразы внутри группы.
Редактирование группировки
Группировка по составу фраз может скорректирована вручную: группы могут быть созданы или удалены, фразы могут быть перемещены между группами.
Создание структуры
Вы можете скопировать структуру, полученную в результатах группировки, в основные группы проекта.
Узнать больше о создании структуры
Настройки
Рассматривать только отфильтрованные фразы
При использовании этой опции только фразы, удовлетворяющие текущим условиям фильтрации в группе, будут рассматриваться алгоритмом.
Опция может потребоваться при необходимости выполнить группировку некоторого подмножества фраз в большой группе.
Следить за статусом отметки в группах
Группа фраз в результатах группировки имеет статус отметки, вычисляемый на основе статусов отметки фраз внутри этой группы.
Вычисление состояния этого элемента интерфейса занимает время, и это может ощущаться при работе с огромными проектами.
Если опция выключена, программа не пытается автоматически обновлять это состояние.
Если вы ощущаете замедление работы интерфейса программы, можно попробовать отключить эту опцию.
Колонка суммы
Таблица результатов содержит столбец «Сумма»для каждой группы.
В нем отображается сумма значений выбранного в параметре «Колонка суммы» параметра для всех фраз внутри группы.
Если вы используете этот столбец для сортировки или фильтрации групп в результатах, укажите столбец суммы. В остальных случаях можно этого не делать, чтобы не выполнять лишние вычисления.
Колонка средних
Таблица результатов содержит столбец «Ср.
зн.» (среднее значение) для каждой группы.В нем отображается среднее арифметическое значений выбранного в параметре «Колонка средних» параметра для всех фраз внутри группы.
Если вы используете этот столбец для сортировки или фильтрации групп в результатах, укажите столбец средних. В остальных случаях можно этого не делать, чтобы не выполнять лишние вычисления.
Сила группировки
Сила группировки определяет минимальный порог совпадений между любыми двумя фразами, чтобы алгоритм начал рассматривать их как похожие фразы для включения в одну группу.
Если требуется получить более широкие группы, то уменьшите силу группировки, а если нужны группы сильно похожих друг на друга запросов — увеличьте силу.
Мин.
размер группыПараметр минимального размера группы определяет, сколько фраз должно минимально содержаться в группе для ее создания.
Если алгоритм не смог найти заданное кол-во подходящих для включения в единую групп фраз, то он попытается распределить эти фразы по другим ранее сформированным группам допустимого размера.
Если указать слишком большой минимальный размер группы, то много запросов могут не найти себе подходящей группы и останутся не сгруппированы. В этом случае можно попробовать уменьшить мин. размер группы.
Учитывать сперва сильные связи
В процессе группировки алгоритм сравнивает похожие друг на друга фразы и подсчитывает кол-во совпадений. Найденные похожие фразы могут иметь различное кол-во совпадений с рассматриваемой фразой.
Если опция включена, то на одном шаге алгоритм сгруппирует только наиболее тесно связанные фразы, а другие менее похожие отложит на потом для следующей итерации.
Использование данное опции может немного увеличить время анализа, а также может привести к формированию более точно подобранных и тесных групп.
Усиливать связи в группах
В процессе группировки алгоритм сравнивает похожие друг на друга фразы, подсчитывает кол-во совпадений и группирует фразы.
Если опция включена, то после завершения группировки алгоритм проверяет наличие более тесных связей для сгруппированных ранее фраз и перемещает их между группами при наличии возможности.
Например, если выясняется, что ранее сгруппированная фраза 1, допустим, по 5 совпадениям имеет похожую и тоже сгруппированную фразу 2 по 7 совпадениям (ее группа создавалась позже), то фраза 1 может быть перемещена в эту более подходящую и тесную группу.
Использование данное опции может увеличить время анализа, а также может привести к формированию более точно подобранных и тесных групп.
Вычислять лучшие фразы в группе
Если опция включена, то после завершения группировки алгоритм находит лучшие фразы в группе — фразы, которые больше всех похожи на все остальные фразы группы.
Лучшей фразой считается такая фраза, которая имеет наибольшее кол-во совпадений по критерию выбранного алгоритма группировки с остальными фразами рассматриваемой группы.
Просмотр списка лучших фраз возможен в таблице результатов группировки.
Записывать лучшую фразу в свой заголовок
Если опция включена, то после завершения группировки алгоритм находит лучшие фразы в группе, а затем записывает одну из них в поле «Свой заголовок» для каждой из найденных групп.
Лучшей фразой считается такая фраза, которая имеет наибольшее кол-во совпадений по критерию выбранного алгоритма группировки с остальными фразами рассматриваемой группы.
В дальнейшем вы можете лучше понимать суть найденных групп по найденным маркерным запросам. Также поле «Свой заголовок» может использоваться при создании структуры групп в качестве заголовка групп.
Просмотр списка лучших фраз возможен в таблице результатов группировки.
Показывать статистику групп
Если опция включена, то после завершения группировки под таблицей результатов появится панель статистики выделенной группы.
В настоящий момент там отображается метрика тренда по выбранной колонке.
Выберите колонку для исследования и выделите любую группу в таблице результатов. Программа подсчитает долю и кол-во каждого из уникальных значений в выбранной колонке для фраз группы.
Например, можно выяснить, какие страницы находятся в ТОП по снятым позициям. Или же распределение пользовательских комментариев.
Несгруппированные фразы
Некоторые фразы могут остаться несгруппированными либо из-за их непохожести на остальные запросы, либо из-за высоких значений силы группировки, либо если алгоритм не нашел для них подходящей группы.
Эта опция определяет, что произойдет с такими фразами: они могут быть скрыты из результатов группировки, либо объединены в отдельную группу несгруппированных запросов.
Ограничение TOP
В зависимости от выбранного значения алгоритм будет искать совпадения между результатами в поисковой выдаче только в пределах первых N адресов (ограничение по TOP).
Источник
Алгоритм будет исследовать результаты поисковой выдачи только для выбранных поисковых систем.
Разбивать группы по силе
По умолчанию если некоторая фраза 1 имеет N совпадений с другой фразой 2, имеющей более сильную связь из M совпадений с какой-то другой фразой 3 (N < M), то фраза 1 может быть присоединена к группе, где находится фраза 3. Другими словами, сильная связь может притягивать к себе слабые, если для них нет более подходящих кандидатов.
Если опция включена, то фраза 1 из рассмотренного выше примера не будет притягиваться к сильной связи степени M, а образует новую группу.
Список исключений
При группировке по поисковой выдаче вы можете захотеть на учитывать совпадения между фразами по некоторым популярным сайтам. Например, можно не учитывать аукционы, сервисы ПС и пр.
Здесь вы можете ввести домены в формате site.ru или *.site.ru (* — любой поддомен).
Обратите внимание, что вписав site.ru, вы не исключаете shop.site.ru (поддомены этого сайта), а вписав *.site.ru вы не исключаете site.ru (основной сайт без поддомена).

 зн.» (среднее значение) для каждой группы.
зн.» (среднее значение) для каждой группы.3 способа собрать семантическое ядро для контекстной рекламы
Сбор семантического ядра — один из самых важных этапов в создании контекстной рекламной кампании, проектировании сайта, SEO и создании контент-плана для блога. Принцип сбора у всех этих задач похож, но в статье я расскажу про то, как эффективно собрать семантическое ядро именно для контекста. И рассмотрю для этого три способа (чтобы перейти к одному из способов, воспользуйтесь меню справа):
И рассмотрю для этого три способа (чтобы перейти к одному из способов, воспользуйтесь меню справа):
- Key Collector и таблицы — платный инструмент для сбора семантики на 1000 ключей и более.
- «Вордстат» и таблицы — бесплатный способ для ядра размером меньше 1000 ключей.
- Интерфейс «Яндекс.Директ» — бесплатный способ, но сложно обрабатывать больше 10 ключей.
Но прежде чем мы начнем, давайте разберемся с терминами, которые будут встречаться в статье.
Семантическое ядро = семантика — это слова или словосочетания, по которым пользователь увидит вашу рекламу.
Ключевые фразы = ключевые слова = ключи — это слова или словосочетания, по которым пользователи ищут материал в интернете. Из ключевых слов состоит семантическое ядро.
Низкочастотные запросы = НЧ запросы = низкочастотные ключи = НЧ Ключи — запросы, которые ищут менее 100 раз в месяц.
Высокочастотные запросы = ВЧ запросы = высокочастотные ключи = ВЧ ключи — запросы, которые ищут более 1000 раз в месяц
Маска — это самый ВЧ ключ, обычно состоит из 1-3 слов.
Хвосты — это слова, которые добавляются к маске, уменьшая частотность запроса.
Минус-фразы = минус-слова — это слова, по которым ваши объявления не должны показываться.
Но собранное семантическое ядро — это не готовый продукт. Готовый продукт — это семантика разбитая на группы, потому что для групп вы можете писать объявления, сделать посадочную страницу, оптимизировать текст.
Поэтому мы с вами поэтапно разберем процесс сбора, очистки и группировки семантического ядра.
Способ 1. Key Collector и таблицы
Преимущества способа: быстро, можно без проблем обработать более 1000 ключей.
Недостатки способа: платный Key Collector.
Этап 1. Сбор основных масок
Перед тем, как начать собирать семантику, нужно составить таблицу, в которую вы будете заносить ключевые запросы, по которым клиенты могут искать ваш продукт. Пример таблицы приведен ниже.
Первый столбец определяет товар или услугу (ответ на вопрос «Что вы предлагаете?»). Для примера возьмем токарные станки. Как люди могут искать токарные станки? Они могут вбивать запрос «токарные станки», могут искать на сленге — «токарка».
Второй столбец определяет характеристику вашего продукта. Какие токарные станки вы предлагаете? По дереву? По металлу?
Третий столбец содержит название марки.
Четвертый столбец определяет действие, которое с вашим товаром или услугой можно совершить. Для чего нужен токарный станок? Для точения конусов? Для нарезки пазов? все возможные синонимы заносите в таблицу.
Пятый столбец содержит дополнительные преимущества вашего продукта.
Шестой столбец содержит слова, которые показывают заинтересованность пользователя в покупке. Как пользователь может выражать желание купить ваш продукт? К примеру, пытается узнать стоимость.
Седьмой столбец также несет дополнительную информацию о продукте. Факты, которые для некоторых пользователей будут решающими. Какие это могут быть факты? Доставка? От производителя?
Столбцы, в зависимости от продукта, могут совпадать, а могут и различаться. Главное — понимать: чтобы собрать максимально широкое семантическое ядро, нужно продумать все возможные варианты того, как ваш продукт могут искать разные люди.
Откуда брать все эти варианты запросов? Во-первых, из головы. Устройте мозговой штурм, придумайте различные варианты, по которым пользователи могут вас искать. Когда идеи закончатся, вам может помочь «Яндекс.Метрика» со своим отчетом «Поисковые фразы».
.
Этап 2. Составляем список ключевых запросов
Из получившейся таблицы мы будем составлять семантическое ядро. Нам нужно по очереди скомпоновать между собой ключевики из разных столбцов, «перемножить» их друг с другом, чтобы получить все возможные комбинации. Через таблицы выполнять эту работу слишком долго, поэтому мы пользуемся сервисами — компоновщиками ключевых фраз. Существует их большое количество, вы обязательно найдете удобный для вас. Мы чаще всего используем генератор от Key.so.
Пользоваться генераторами просто: вы поочередно заносите ключевики в соответствующие ячейки и система автоматически выдает вам все возможные комбинации.
Скопируйте их на отдельный лист таблицы. После того как вы прогоните через программу все столбцы из таблички, у вас должен получиться большой список, состоящий из нескольких тысяч ключевых запросов. Безусловно, некоторая часть этих запросов будет «мусорной». От них мы и будем избавляться на следующем этапе.
Этап 3. Удаляем мусорные запросы
Чтобы избавиться от нерелевантных запросов и собрать частоты по целевым, воспользуйтесь программой Key Collector. Сервис платный, но у него огромный функционал. Если вы собираетесь заниматься рекламой или SEO на профессиональном уровне, не пожалейте денег. Лицензия отработает себя в первый же месяц.
Настройка Key Collector
Прежде всего нужно купить лицензию на официальном сайте. Далее по инструкции установить программу.
Установили — переходим в настройки и в разделе «Парсинг → Общие ». Выставляем сбор слов с частотностью более 10. Так как по словам с частотностью менее 10 объявления не будут показываться.
После этого переходим в подраздел «Парсинг → Антикапча» и настраиваем антикапчу. Мы используем этот сервис антикапчи, самый дешевый тариф.
После этого переходим в раздел «Yandex → Аккаунты» и вводим почту от «Яндекса» и пароль. Рекомендуем для Key Collector завести отдельный аккаунт — основной могут заблокировать, так как вы используете автоматическую систему сбора.
Но это еще не все. Нужен прокси-сервер. Его можно купить тут.
Сбор частотности
После этого переходим к сбору частотности семантики. Создайте новый проект, перейдите на вкладку «Парсинг» и выберите иконку Wordstat.
Выберите регион, вставьте список масок, которые вам выдал генератор, и нажмите «Начать сбор».
Можно идти пить чай. Инструмент соберет частотности запросов самостоятельно.
Когда KeyCollector закончит собирать ключи, перейдите на вкладку «Данные», нажмите кнопку «Анализ групп».
В настройках выберите тип группировки «по отдельным словам». Этот тип нам нужен, чтобы сформировать список минус-фраз.
Программа создаст группы слов, из которых состоит ваше семантическое ядро.
Пометьте флажками слова, по которым Яндекс не должен показывать рекламу.
Google тоже не будет показывать по ним объявления, но рекламы в Google в России больше нет 🙁
После того как выберете всё, кликните правой кнопкой мыши по отмеченному слову и нажмите «Отправить все слова из заголовков помеченных групп в минус-слова»
Добавьте выделенные слова в список минус-слов.
Переходим на основную вкладку с данными.
Переходим во вкладку «Главная → Минус-слова».
Выделите минус-слова, которые добавили, и отметьте фразы из семантического ядра, которые содержат эти слова.
И удалите отмеченные фразы.
Этап 4. Группировка ключевых запросов.
Чтобы сгруппировать ключевые запросы, в строку поиска вводите слово, которое характеризовало бы группу. Это могут быть коммерческие слова «купить/ цена» или слова, которые характеризуют группу качественно — «красный/ стационарный».
Главное правило: объединяйте ключевые фразы так, чтобы вы могли написать под них объявление, которое подходило бы для каждой фразы в группе.
После того, как отметили фразы, выбираем на вкладке «Главная → Коп./перенести фразы»
И создаём новую группу либо подгруппу.
В настройках группы выбираем «Перенос», задаём название и кликаем «Выполнить перенос».
Если в группе слишком много ключей, можно её открыть и разбить на подгруппы.
Способ 2. «Вордстат» и таблицы
Преимущества способа: Быстро, бесплатно.
Недостатки способа: Сложно обрабатывать более 1000 ключей, риск собрать не все.
Этап 1.
Сбор основных масокОн заключается в том, что мы выбираем самую ВЧ маску и собираем все ключи по ней.
В нашем случае мы возьмем маски «Токарный станок» и «Токарка».
Обратите внимание на то, что мы не берем маску «Станок», потому что это очень широкая маска и нам придется очень много чистить мусора. А если возьмем маску «Токарно-винторезный станок», то пропустим много целевых запросов. Поэтому используйте самую широкую подходящую маску.
Этап 2.Сбор основных масок
Чтобы собрать семантику этим способом, нужно установить расширение Yandex Wordstat Assistant. Это расширение поможет скопировать фразы и их частотность из списка. Копировать можно как по одной фразе, так и по 50 фраз со страницы.
Не забудьте указать регион, по которому вы хотите собрать семантику. Это важно! Если вы соберете семантику по всей России, а показывать рекламу будете для жителей небольшого городка, то можете получить статус «мало показов» и пользователи вашу рекламу не увидят. Да и много лишнего придется минусовать. Поэтому собирайте семантику в том регионе, где хотите показывать рекламу.
Теперь, когда все настроено, вы можете собрать семантические ядро.
Если вы собираете по нескольким широким маскам, то просто вводите запрос и добавляете все запросы из левого столбца. Вносите со всех страниц, пока частотность не будет меньше 10 запросов.
Но если ключей много, вы можете недолистать до запросов с частотностью менее 10, потому что статистика показов ограничена 41 страницей.
Чтобы собрать всевозможные хвосты, на первых 10-20 страницах кликайте на запрос, чтобы Wordstat показал его хвосты.
И обращайте внимание на запросы из правой колонки. В этой колонке содержатся запросы, которые ищут вместе с тем, который вы ввели. Поэтому там могут быть широкие маски, которые мы могли не учесть.
После того как закончили сбор семантического ядра, скопируйте в буфер обмена запросы с их частотностью и вставьте на лист таблицы.
Этап 3. Удаляем мусорные запросы.
Теперь вам нужно, прочитывая каждую фразу, искать нерелевантные слова и выписывать их в соседний столбец.
По окончании выделите все столбцы и отсортируйте по столбцу с минус-словами.
После скопируйте очищенную семантику на отдельный лист, а в столбце с минус-словами удалите дубли. В итоге у вас должен остаться лист с минус-словами и лист с чистой семантикой.
Этап 4. Группировка ключевых запросов.
Чтобы разгруппировать вручную, вам придется просматривать все очищенные запросы в таблице и окрашивать их в цвет группы. Чтобы ускорить этот процесс, я через фильтр по условию «Текст содержит» ввожу слова, которые бы характеризовали всю группу, и окрашиваю их в цвет группы.
После сортирую по цветам, а оставшиеся незакрашенные группы сортирую вручную.
Способ 3. Интерфейс «Яндекс.Директ»
Преимущества способа: Интуитивно понятно
Недостатки способа: Сложно обрабатывать больше 10 ключей
Этап 4.
Группировка ключевых запросов.Это не ошибка. Этот способ начинается с группировки.
Если вы решили воспользоваться инструментом сбора семантики через интерфейс директа, то вы уже должны создать кампанию и внутри кампании группу. И семантику собирать под созданную группу.
Этап 1. Сбор основных масок
Полностью повторяет Этап 1. Сбор основных масок
Этап 2. Составляем список ключевых запросов
Если вы собираете ключи через встроенный функционал «Яндекс.Директ», то вам не нужны сторонние генераторы фраз. На этом хорошие новости для этого способа заканчиваются.
При добавлении новой группы, в условиях показа выберите «Подобрать фразы».
Здесь, как в комбинаторе, добавьте фразы в столбцы и создайте комбинации. Но помните, что вы генерируете фразы, которые должны попасть в одну группу. Поэтому для примера мы взяли один тип станка и коммерческие фразы.
Чтобы избавиться от лишней работы включите функцию «Исключить фразы с нулевыми показами» и создайте комбинации.
Здесь вы можете посмотреть частотность, глубину запроса, добавить фразу в список ключевых или минус-слово.
Окошко для работы очень маленькое, поэтому мне пользоваться сервисом неудобно.
Также вы можете создать комбинации фраз в стороннем сервисе и загрузить их в тот же раздел «Условия показа», но выбрать там «Прогноз и уточнение». И помните, что фразы должны быть уже сгруппированы.
Этап 3. Удаляем мусорные запросы.
После того, как добавили ключи, в разделе «Прогноз и уточнение» вы можете посмотреть частотность, хвосты и добавить минус-фразы. Но мне этот функционал не нравится, он требует много лишних кликов, которые отнимают время.
Этап 4. Группировка ключевых запросов.
Если вы решили воспользоваться инструментом сбора семантики через интерфейс директа, то вы уже должны создать кампанию и внутри кампании группу. И семантику собирать под созданную группу.
Вывод
Мы предложили вам три способа сбора семантического ядра. Выбирайте любой в зависимости от задачи.
Если задача большая, то используйте Key Collector.
Если нужно настроить рекламу по новому продукту, то используйте Wordstat и таблицы.
Если нужно точечно добавить ключи в группы, то используйте интерфейс «Директа».
Но также вы можете и комбинировать различные способы в зависимости от этапа. Лично я люблю собрать семантику по ВЧ маскам и почистить её в Key Collector, а группирую уже в Google таблицах.
цена, отзывы, акции в студии «Филигрань»
Владельцам коммерческих интернет-проектов важно, чтобы их ресурсы приносили доход, для этого нужно проводить их грамотную раскрутку и продвижение. Студия «Филигрань» занимается составлением семантического ядра (СЯ) на заказ, а также последующими внутренней и внешней СЕО-оптимизацией сайтов на его основе.
Зачем нужно создание семантического ядра?
СЯ — это упорядоченный набор слов, словосочетаний (ключей), которые точно отражают тематику проекта, предлагаемые услуги и товары. Это база, фундамент построения дальнейшего seo продвижения, а также основа для кампаний контекстной рекламы.
Чтобы посетители и клиенты перешли на страницы вебсайта через поисковые системы (Яндекс, Гугл и др.), он должен соответствовать их требованиям и рекомендациям. При профессиональном подборе семантического ядра определяются актуальные запросы потенциальных клиентов, чтобы создать под них новые страницы или оптимизировать уже существующие.
Также формирование семантического ядра сайта необходимо для правильного структурирования web-сайта, выделения разделов, подразделов, разработки основного и дополнительного меню. Построенная на основе ядра структура сайта помогает создать проект с простой навигацией, удобный для пользователей и понятный для поисковых систем.
Наши преимущества разработки семантического ядра на заказ
Семантика является одним из главных составляющих успешного продвижения. Наша студия профессионально подходит к работе с поиском ключевых фраз и обладает рядом преимуществ перед конкурентами:
- Индивидуальный подход. Мы учитываем специфику продвигаемых интернет-проектов и делаем сбор ядра под каждый индивидуально.
- Нацеленность на результат. Наша компания ориентирована на продвижение бизнеса клиента, а не на предоставление абстрактных цифр. Собранные ядра дают трафик и позволяют ранжироваться сайту по релевантным запросам.
- Исследование ниши. Перед построением эффективного СЯ и продвижением проекта необходимо произвести углубленный анализ информации по тематике сайта. Это позволит правильно задать направление работы и оценить объемы.
- Современные технологии. Чтобы собрать семантику наши специалисты используют современные инструменты. В комплексе с ручной обработкой данных нам удается составить ядро, отвечающее всем требованиям эффективного продвижения.
- Узкая направленность. Наша студия специализируется исключительно на интернет-продвижении проектов. Это позволяет нам сосредоточиться на конкретной задаче, не распыляясь на разработку, администрирование, настройку вебсайтов и прочее.
- Виртуальный офис. Нам не нужно включать в стоимость услуг по сбору СЯ и продвижению веб-проектов расходы на аренду помещения, его содержание и пр. Все вложенные средства идут на развитие вашего интернет-бизнеса.
Портфолио
Создание семантического ядро для Яндекс Директа и для Adwords
Контекстная реклама это мощный инструмент продвижения услуг в интернете. Она позволяет в сжатые сроки получать целевой трафик. Но для эффективного расхода средств необходимо правильно подобрать ключи, составить кампанию и выбрать стратегию. Поэтому для контекстной рекламы необходимо собрать семантическое ядро.
Человек без должного опыта самостоятельно не сможет качественно сделать такую работу — в этом случае расходы на рекламу могут превысить прибыль организации. Чтобы избежать таких ситуаций стоит обратиться к специалистам нашей студии. Мы быстро составим семантику, а также окажем услуги по составлению объявлений и ведению рекламной кампании. Студия интернет маркетинга Филигрань предоставляет услуги настройки и ведения кампании для Яндекс Директ и Гугл Адвордс.
Хотите получить правильное семантическое ядро?
Правильное составление ядра зависит от многих факторов. Наши специалисты для большей эффективности используют сразу несколько различных инструментов. Перед сборкой проводится детальное изучение услуг заказчика и формируется начальный список возможных поисковых фраз и их синонимов.
На следующем этапе производится расширение запросов с помощью анализа конкурентов и сбора данных из поисковых систем. В результате получается большой список, впоследствии он подвергается чистке от нерелевантных запросов (которые не подходят по тематике) и пустышек (накрученных в статистике запросов, которые не дадут реального трафика).
Затем осуществляется кластеризация семантического ядра — разгруппировка для составления структуры по разделам, страницам и пр. Далее определяются существующие посадочные страницы под конкретные запросы. На основе собранного семантического ядра производится оптимизация контента и составляется техническое задание для написания текстов копирайтеру.
Цены на составление семантического ядра сайта
Вы всегда можете узнать цену за составление семантического ядра по телефону или на странице цен. Мы готовы ответить на все возникнувшие вопросы и оценить ориентировочный объем работ.
Услуги по составлению семантического ядра оказываются на основе аналитических данных, полученных из поисковых систем, поэтому мы гарантируем актуальность подборки поисковых фраз. Стоит учитывать, что цена сбора семантического ядра большого объема будет выше, так же на итоговую стоимость влияет срочность исполнения заказа.
Для постоянных клиентов в нашей студии предусмотрены скидки. Дополнительную информацию по акциям вы можете посмотреть здесь.
Семантическое ядро на русском
от 5 000 р
Заказать
Семантическое ядро на английском
от 150$
Заказать
Как заказать семантическое ядро для сайта у студии Филигрань?
Кластеризация ключевых слов: как группировать ключевые слова
Подпишитесь на наши информационные бюллетени и дайджесты, чтобы получать новости, статьи экспертов и советы по SEO
Введите правильный адрес электронной почты
Спасибо за подписку! 15 мин чтения работы, направленной на их анализ перед применением. Кластеризация или группировка — это процесс, который помогает вам сортировать собранные вами ключевые слова, расставлять приоритеты и отфильтровывать нерелевантные. Это максимизирует ваши шансы на высокий рейтинг, и мы объясним, почему.
Что такое кластеризация ключевых слов?
Кластеризация ключевых слов — это объединение похожих релевантных запросов в группы и использование целых групп вместо отдельных ключевых слов для оптимизации сайта. Помогает очистить семантическое ядро, разделив его на управляемые группы.
Семантика кластеризации всегда была важным шагом в создании веб-сайта. Это стало особенно очевидно с переходом на тематическое SEO в 2013 году, когда Google выпустил обновление Hummingbird, и алгоритм начал фокусироваться на фразах, а не на отдельных ключевых словах. Сдвиг был дополнительно поддержан обновлением RankBrain 2015 года: алгоритм стал умнее и мог определять темы поисковых запросов и находить несколько похожих фраз.
Существует два основных типа кластеризации ключевых слов:
- на основе леммы, которая находит сходство в значении фраз и их морфологических совпадениях,
- и на основе поисковой выдачи, которая ищет совпадения среди результатов поиска.
Преимущества семантической группировки ключевых слов
Преимущество кластеризации ключевых слов заключается в том, что она дает более четкое представление о том, какой контент создавать и как организовать его на страницах, по каким фразам ранжироваться и как продвигать различные сегменты вашего сайта. сайт.
Группируя ключевые слова, вы можете:
- Лучше понять намерения пользователя . SEO, ориентированное на тему, предлагает более тщательный ответ пользователям: когда вы объединяете похожие фразы, вы ориентируетесь на намерение пользователя, а не на одно ключевое слово, и поэтому вы с большей вероятностью охватите это намерение.
- Максимальное количество ключевых слов для ранжирования . С помощью кластеров вы можете ранжироваться по ряду связанных ключевых слов вместо того, чтобы нацеливаться на отдельные запросы по отдельности.
- Удалить ненужные ключевые слова . Кластеризация делает огромный список ключевых слов более управляемым и полным — вы сможете легко обнаружить нерелевантные запросы. Программное обеспечение для группировки ключевых слов SE Ranking предоставит вам несгруппированные ключевые слова, которые не соответствуют ни одной теме, которую различает инструмент, и позволит вам перепроверить, нужны ли они вам в вашей стратегии.
- Понимание потенциала сегментов . Кластеры, которые вы получите в результате, помогут вам понять, как разные части контента связаны или должны быть связаны. Этот процесс позволит вам увидеть свой сайт с точки зрения поисковой системы и оценить различные категории, которые у вас есть или должны быть лучше.
- Создать эффективную структуру сайта или проанализировать существующую . Кластеризация помогает анализировать семантические отношения между страницами и улучшать архитектуру сайта.
- Повысьте узнаваемость и авторитет вашего сайта . Благодаря группировке ключевых слов вы сможете лучше понять семантику и сделать свой контент более мощным, что, в свою очередь, сделает ваш сайт более авторитетным в глазах поисковых систем.
- Экономия времени и устранение ошибок . Если делать это автоматически, кластеризация ключевых слов дает вам все вышеупомянутые преимущества быстро и эффективно.
Ручная или автоматическая группировка
Существует множество инструментов для автоматизации процесса группировки, хотя некоторые предпочитают делать это вручную с помощью Excel или других программ. Одно дело, когда у вас есть сотня слов, но когда исследование для проекта оставляет вас с тысячами ключевых слов, представьте, сколько времени потребуется, чтобы управлять всеми ими вручную. Ручная кластеризация потребует от вас разбить каждое ключевое слово на термины, определить их назначение и составить списки фраз на основе необходимых вам параметров.
Автоматизированный инструмент кластеризации ключевых слов в SE Ranking сэкономит ваше время и усилия и сделает всю работу за вас. Вы получите представление о том, из чего состоят ваши ключевые слова, и о том, как разделить их на полезные группы, не утруждая себя просмотром каждого собранного вами запроса.
Как сгруппировать ключевые слова с помощью SE Ranking
Теперь, когда мы знаем, насколько мощной может быть кластеризация ключевых слов, давайте углубимся в механизм ее выполнения с помощью инструментов SE Ranking.
Первоначальное исследование ключевых слов
Чтобы отсортировать ключевые слова по тематическим группам, необходимо сначала собрать полный список ключевых слов. Собрать как можно больше запросов — ваша первая фундаментальная задача в процессе создания и продвижения вашего сайта. Первоначальный процесс исследования поможет вам понять, что пользователи ищут в вашей нише и как ваши конкуренты обрабатывают ключевые слова.
Существует множество бесплатных и платных инструментов, которые помогут вам найти ключевые слова для вашего веб-сайта. Используйте Google Trends и Google Analytics, чтобы отслеживать популярные поисковые запросы и текущие тенденции в результатах поиска. Проводя исследование, обратите внимание, что существуют разные типы поисковых запросов: их можно различать по длине и специфичности (одно-, двух-, трех- и четырехсловные фразы, а также ключевые слова с длинным хвостом) и по пользовательским запросам. намерение (навигационное, информационное, транзакционное). Эти различия дадут вам представление о том, насколько жесткая конкуренция за определенные ключевые слова и каковы шансы на конверсию.
Определение и анализ ваших конкурентов — еще один важный шаг в исследовании ключевых слов. Узнайте, кто лидирует в обычных результатах поиска и каковы их самые прибыльные ключевые слова, и найдите самые эффективные рекламные объявления с оплатой за клик в вашей нише. Сравнение семантики, доступное в SE Ranking, может показать вам совпадения ключевых слов между разными доменами: фразы, общие для ваших основных конкурентов, будут в вашем списке целей.
Инструмент SE Ranking Keyword Research включает Предложения по ключевым словам , где вы можете найти похожие и связанные ключевые слова. Изучите список фраз с низким объемом поиска, чтобы полностью охватить свою нишу и увеличить количество ключевых слов для ранжирования. Вы можете экспортировать результаты из SE Ranking, а затем отсортировать ключевые слова в формате xls. или CSV. файл.
Создание кластеров
Теперь, когда у вас есть полный список ключевых слов, существующих в вашей нише, пришло время создать управляемые группы и исключить ненужные запросы. Инструмент группировки ключевых слов SE Ranking фильтрует запросы на основе их сходства с поисковой выдачей. Он ищет совпадения в результатах поиска для заданных ключевых слов и группирует фразы, ранжирующиеся для идентичных страниц.
Давайте сравним, как работает группировка, если она выполняется вручную и автоматически, а затем рассмотрим все шаги, которые необходимо предпринять для кластеризации запросов в SE Ranking.
Кластеризация ключевых слов вручную
Чтобы создать кластеры ключевых слов вручную, вы можете отфильтровать список по их семантике или типу намерения. Например, у вас есть огромный список запросов о «программном обеспечении для редактирования фотографий». «создатель коллажей» и т. д.) и сгруппируйте ключевые слова, содержащие идентичные термины.
д.). .). Затем вам нужно будет сопоставить теги и создать кластеры.Автоматическая группировка ключевых слов в SE Ranking
Чтобы начать кластеризацию ключевых слов в SE Ranking, вам необходимо выбрать свой регион и язык интерфейса. Сосредоточьтесь на регионах, в которых вы хотите продвигать свой сайт, и выполняйте группировку отдельно для каждого языка, если вы ориентируетесь на несколько из них. Затем вам нужно выбрать уровень точности группировки и метод группировки — это факторы, которые будут влиять на ваши результаты.
Наконец, вам нужно вставить ключевые слова — вы можете добавить их вручную или импортировать из файла. Выберите, хотите ли вы проверить объем поиска поверх группировки (его также можно загрузить отдельно), и запустите инструмент. Теперь вам нужно немного подождать, пока наш робот ищет совпадающие результаты и группирует ваши ключевые слова на основе заданного количества идентичных страниц в топ-10 результатов.
Выбор метода кластеризации и точности
Теперь давайте рассмотрим, как работают различные настройки. Необходимо выбрать два основных параметра: точность группировки и метод.
Как работает точность группировки ключевых слов
Точность группировки ключевых слов (в диапазоне от 1 до 9) указывает минимальное количество совпадающих URL-адресов для запросов. Например, если вы установите значение 3, фразы будут сгруппированы вместе только в том случае, если они имеют 3 одинаковых URL-адреса в результатах поиска. Чем выше точность, тем меньше будет совпадений и тем меньше ключевых слов будет включено в каждый кластер.
Подобные запросы, естественно, имеют сходство с поисковой выдачей:
Давайте пропустим один и тот же набор ключевых слов через разные настройки точности и сравним результаты. Мы взяли 212 запросов на тему программного обеспечения для редактирования фотографий и сгруппировали их по мягкому методу с максимальным (9) и минимальным (1) уровнем точности.
Высокоточная кластеризация дает нам более конкретные категории для работы, а также оставляет множество фраз не сгруппированными:
С такими настройками мы получаем представление о потребностях разных искателей: мы видим, что люди ищут фоторедакторы для разных операционные системы, для онлайн- и офлайн-режима работы и так далее.
Однако многие кластеры, разделенные инструментом, можно логически сгруппировать вместе: «лучшая программа для редактирования фотографий» семантически ничем не отличается от «лучшая программа для редактирования фотографий». негруппированные.
Напротив, низкоточная группировка ключевых слов оставляет нас с более широкими кластерами, которые не сильно помогают в категоризации различных намерений:
При таких настройках вам, вероятно, придется вручную перегруппировать большинство ключевых слов, сопоставляя их значения. Как правило, рекомендуется применять как автоматизированные, так и ручные методы кластеризации.
Как работают различные методы группировки ключевых слов
Метод (жесткий и программный) определяет, как сравниваются поисковые запросы: мягкая кластеризация сравнивает все запросы с одним с наибольшим объемом поиска, а жесткая кластеризация сравнивает запросы друг с другом.
Мягкая кластеризация дает более общее представление о нише и различных ключевых словах, на которые ориентируются ваши конкуренты. При таком подходе вы также получите меньше разгруппированных запросов (показанных внизу страницы результатов в кластере «Разгруппированные») — тех, которые вам придется сортировать вручную и решать, хотите ли вы использовать их в своей поисковой оптимизации.
Жесткая кластеризация может помочь устранить нерелевантные поисковые запросы и различать намерения многих пользователей. Сравнение запросов друг с другом дает более широкий выбор конкретных намерений и создает больше групп даже при самом низком уровне точности:
Однако кластеризация с низкой точностью — даже при использовании жесткого метода — игнорирует многие важные различия внутри каждой группы. Например, список, сгруппированный под «бесплатное программное обеспечение для редактирования фотографий», включает ключевые слова, которые не связаны напрямую друг с другом: «программное обеспечение для редактирования фотографий Windows», «программа для простого редактирования фотографий», «программа для редактирования фотографий, загружаемая для загрузки» представляют разные цели поиска.
Высокоточная жесткая кластеризация, в свою очередь, может игнорировать сходство между несколькими группами. Например, мы получили «лучшее программное обеспечение для редактирования фотографий» и «лучшее программное обеспечение для редактирования фотографий» в виде отдельных кластеров, что семантически не имеет особого смысла.
Подытожим характеристики каждого подхода к кластеризации ключевых слов, доступного в SE Ranking:
| Количество кластеров | Разгруппированные ключевые слова | Дифференциация намерения | Лучший для | |||
|---|---|---|---|---|---|---|
| Soft Method / Low Abugary | Многие крупные группы | среднее значение | Многие крупные группы | Средний № | . некоторые похожие ключевые слова помещены в разные группы | Определение вашей ниши в целом |
| Мягкий метод / Высокая точность | Среднее количество небольших групп | Большинство ключевых слов | Некоторые поисковые намерения пропущены | Сегментирование вашей ниши | ||
| Жесткий метод / Низкая точность | Среднее количество малых групп | Среднее количество ключевых слов | Обнаружено много намерений; низкая релевантность внутри групп | Изучение потребностей различных искателей | ||
| Жесткий метод/высокая точность | Несколько очень маленьких групп | Большинство ключевых слов | Некоторые намерения поиска пропущены; высокая релевантность в группах | Полное сегментирование ключевых слов |
Управление результатами группирования
Независимо от выбранных настроек, каждая группа называется по ключевому слову с наибольшим объемом поиска. На странице результатов вы можете получить доступ к информации о количестве совпадающих URL-адресов, топ-10 результатов с ключевыми словами, включенными в группы, и фрагментам, содержащим эти ключевые слова. Если вы решите выполнить проверку объема поиска, результаты кластеризации также будут отображать этот показатель.
Как только вы узнаете, какие группы вам подходят, отметьте их флажком и экспортируйте в свой проект. В настройках проекта вы можете создавать и называть свои группы, а также добавлять комментарии к любому ключевому слову. Автоматизации распределения групп по страницам сайта нет: можно создать несколько страниц для охвата большого кластера ключевых слов, а также объединить несколько кластеров.
Разумно сочетать ручной и автоматический подходы : пропустив ключевые слова через автоматизированный инструмент, вы сможете проанализировать, как поисковые системы видят эти фразы, а последующая перегруппировка кластеров позволит учитывать ваши цели. и структура конкретного веб-сайта.
Создание контента и рекламы на основе кластеров ключевых слов
Кластеризация ключевых слов помогает разобраться в семантике и создать эффективную структуру веб-сайта. На основе групп, которые вы получаете в результате, вы можете разработать иерархию страниц вашего сайта, категории и подкатегории, фильтры и т. д. Хотя кластеризация является важным шагом в создании структуры, она также может облегчить создание вашего контента и рекламы.
Имея на руках отдельные группы ключевых слов, вы можете максимизировать количество фраз, по которым ранжируется ваш контент. Когда вы решите, какая группа соответствует какой странице и разделу вашего веб-сайта, вы можете разблокировать дополнительные термины для включения в свой контент: изучение полного списка ключевых слов в группе позволит вам найти некоторые новые концепции и намерения для охвата . Таким образом, вы сделаете свой контент более заслуживающим доверия и соответствующим ожиданиям пользователя.
То же самое относится и к вашим платным кампаниям. Google Ads позволяет создавать группы объявлений так же, как вы создаете кластеры ключевых слов. Для каждого показываемого объявления Google выбирает его из групп объявлений на основе релевантности для определенного поиска.
Продвижение предложений вашего сайта с помощью кластеров ключевых слов более эффективно. Например, если вы настраиваете таргетинг на различные «здоровые закуски» и не сужаете свою кампанию до нескольких конкретных групп объявлений, таких как «перекусы для похудения», «веганские закуски», «органические закуски», «здоровые закуски для дети» и т. д., ваше объявление может оказаться совершенно нерелевантным поисковой цели. И если ваши объявления окажутся бесполезными для поисковиков, вы получите низкий показатель качества и рейтинг объявления. Но инструменты организатора ключевых слов могут различать разные намерения и группировать похожие вместе, что делает ваш контент и рекламу более полезными.
Final words
Семантическая кластеризация ключевых слов — это мощный SEO-инструмент, который поможет вам упорядочить контент, разнообразить язык и ранжировать по большему количеству терминов. Когда вы расширяете свой список ключевых слов, разбейте его на отдельные тесно связанные группы и используйте их для охвата различных намерений пользователей.
Существуют разные подходы к кластеризации — вы можете сортировать выбранные запросы по их значению или по количеству общих URL-адресов. Выберите метод — «жесткий» или «мягкий» — и уровень точности в зависимости от ваших целей SEO, будь то получение общих сведений о отрасли, тщательный отбор наиболее релевантных фраз или что-то еще.
С помощью группировщика ключевых слов в SE Ranking вы позволяете алгоритму фильтровать запросы за вас, указывая предпочтения вашей поисковой системы и параметры кластеризации. Хотя кластеризация дает вам лучшее представление о вашей нише и потребностях искателей, если она выполняется автоматически, она освобождает вас от дополнительных усилий и представляет все, что вам нужно, в одном месте.
Контент-маркетинг
Исследование ключевых слов
Ключевые слова
7723 представления
Определение запроса рабочего элемента с помощью редактора запросов в Azure Boards — Azure Boards
- Статья
- 14 минут на чтение
Службы Azure DevOps | Azure DevOps Server 2022 — Azure DevOps Server 2019 | TFS 2018
Visual Studio 2022 | Visual Studio 2019 | Visual Studio 2017 | Visual Studio 2015 | Visual Studio 2013
Запросы рабочих элементов создают списки рабочих элементов на основе заданных вами критериев фильтрации. Затем вы можете сохранить и поделиться этими управляемыми запросами с другими. Напротив, при семантическом поиске перечисляются рабочие элементы, но их нельзя сохранить или предоставить к ним общий доступ.
Создавайте запросы с веб-портала или из поддерживаемого клиента, например Visual Studio Team Explorer и Team Explorer Everywhere. Вы также можете определить и импортировать запрос рабочего элемента, используя синтаксис WIQL и файл .wiq. Для поддержки массовых обновлений или дополнений импортируйте или экспортируйте запросы с помощью файлов Excel или .csv.
Создавайте запросы с веб-портала или из поддерживаемого клиента, например Visual Studio Team Explorer и Team Explorer Everywhere. Вы также можете определить и импортировать запрос рабочего элемента, используя синтаксис WIQL и файл .wiq. Для поддержки массовых обновлений или дополнений импортируйте или экспортируйте запросы с помощью Excel.
- Браузер
- Визуальная студия
Если вы обнаружите, что ваши запросы слишком долго возвращают результаты, просмотрите руководство по созданию высокопроизводительных запросов.
В этой статье вы узнаете:
- Как добавить или создать запрос
- Как делать запросы между проектами
- Как сгруппировать и разгруппировать предложения запроса
- Как создать дерево рабочих элементов или запрос прямых ссылок
Для быстрого доступа ко всем задачам запросов поддерживаются операторы, такие как Содержит , В , В группе и <> (не оператор) — в зависимости от типа данных поля и примеры запросов см. Запросите краткую справку.
Выберите фильтр запроса
В редакторе запросов выполните следующие функции фильтра. Выберите фильтр, чтобы перейти к статье с примерами запросов. Наряду с фильтрами запроса вы можете интерактивно применять фильтры к результатам запроса.
Примечание
Управляемые запросы не поддерживают поиск по близости, в отличие от семантического поиска. Кроме того, семантический поиск поддерживает как * , так и ? в качестве подстановочных знаков, и вы можете использовать более одного подстановочного знака для соответствия более чем одному символу. Дополнительные сведения см. в разделе Поиск функциональных рабочих элементов.
Характеристики фильтра
Макросы
- Сравнение полей
- Ключевые слова
- Связанные рабочие элементы
- Логические группы
- Макросы запросов
- Теги
- Всегда был
- Был когда-либо (колонка на доске)
- Подстановочный знак
- Сравнение полей
- Ключевые слова
- Связанные рабочие элементы
- Логические группы
- Макросы запросов
- Теги
- Всегда был
- Подстановочный знак
- Пустые или пустые поля
- Булев поиск
- Поиск личности
- История и обсуждение
- Поля доски Канбан
- В и не в групповом поиске
- Поиск по проектам
- Логический поиск
- История и обсуждение
- В и не в групповом поиске
- Поиск по проектам
- [Любой]
- @Я
- @Сегодня
- @CurrentIteration, @CurrentIteration +/-n
- @Следует за
- @MyRecentActivity, @RecentMentions, @RecentProjectActivity
- @StartOfDay, @StartOfMonth, @StartOfWeek, @StartOfYear
- @TeamAreas
- [Любой]
- @Я
- @Сегодня
- @CurrentIteration
- @Следует за
- @MyRecentActivity, @RecentMentions, @RecentProjectActivity
Наряду с фильтрами, которые вы используете в редакторе запросов, вы можете интерактивно фильтровать результат запроса, используя функцию Фильтр . Чтобы узнать, как это сделать, см. раздел Интерактивная фильтрация невыполненных работ, досок, запросов и планов.
Предварительные требования
- По умолчанию все участники проекта и пользователи с доступом Заинтересованное лицо могут просматривать и выполнять все общие запросы. Вы можете изменить набор разрешений для общей папки запроса или общего запроса. Дополнительные сведения см. в разделе Установка разрешений для запросов.
- Чтобы добавить и сохранить запрос в разделе Общие запросы , вам необходимо предоставить доступ Basic или выше. Кроме того, у вас должно быть установлено разрешение Contribute на Разрешить для папки, в которую вы хотите добавить запрос. По умолчанию группа Contributors не имеет этого разрешения.
Примечание
Пользователи с доступом Stakeholder для общедоступного проекта имеют полный доступ к функциям запроса, как и пользователи с Базовый доступ . Дополнительные сведения см. в разделе Краткий справочник по доступу для заинтересованных сторон.
- По умолчанию все участники проекта и пользователи с доступом Stakeholder могут просматривать и выполнять все общие запросы. Вы можете изменить набор разрешений для общей папки запроса или общего запроса. Дополнительные сведения см. в разделе Установка разрешений для запросов.
- Чтобы добавить и сохранить запрос в разделе Общие запросы , вам необходимо предоставить доступ Basic или выше. Кроме того, у вас должен быть свой Contribute 9Разрешение 0024 установлено на Разрешить для папки, в которую вы хотите добавить запрос. По умолчанию группа Contributors не имеет этого разрешения.
Открытые запросы
- Браузер
- Визуальная студия
В веб-браузере (1) убедитесь, что вы выбрали правильный проект, (2) выберите Доски>Запросы , а затем (3) выберите Все .
Если вы открываете в первый раз Запросы , открывается страница Избранное . На этой странице перечислены те запросы, которые вы указали как избранные. В противном случае вы можете выбрать Все , чтобы просмотреть все запросы, которые вы определили, и общие запросы, определенные для проекта.
Подсказка
Запросы, выбранные вами или вашей командой в качестве избранных, отображаются на странице Избранное . Избранные запросы вместе с другими объектами также отображаются на вашей странице Project . Дополнительные сведения см. в разделе Установка личного или группового избранного.
В веб-браузере откройте Boards>Queries .
Определение запроса плоского списка
Вы можете запустить новый новый запрос на вкладке Запросы на веб-портале или на вкладке Рабочие элементы в Team Explorer.
- Браузер
- Визуальная студия
Редактор запросов отображается со следующими настройками по умолчанию: Плоский список рабочих элементов , Тип рабочего элемента = [Любой] и State=[Any] .
Вы можете изменить Значения и добавить или удалить пункты. Или измените Тип запроса на Рабочие элементы и прямые ссылки или на Дерево рабочих элементов.
Редактор запросов отображается со следующими настройками по умолчанию: Плоский список рабочих элементов , Team Project=@Project (текущий проект), Work Item Type=[Any] , и State=[Any ] .
Вы можете изменить значения и добавить или удалить пункты. Или измените Тип запроса на Рабочие элементы и прямые ссылки или на Дерево рабочих элементов.
Запрос между проектами или внутри них
Новая область запросов к текущему проекту по умолчанию. Однако вы можете создавать запросы для поиска рабочих элементов, определенных в организации или наборе проектов. Однако все запросы, которые вы сохраняете, сохраняются в конкретном проекте.
- Браузер
- Визуальная студия
Чтобы перечислить рабочие элементы, определенные в двух или более проектах, установите флажок Запрос между проектами . Например, следующий запрос находит все функции, созданные во всех проектах за последние 30 дней.
Если установлен флажок Запрос по проектам , вы можете добавить поле Командный проект для фильтрации по выбранному количеству проектов.
Примечание
Разделяйте несколько имен проектов разделителем списка, который соответствует региональным параметрам, определенным для вашего клиентского компьютера, например, запятой (,).
Поле Team Project доступно только после того, как вы отметите Запрос между проектами . Кроме того, когда флажок Запрос по проектам снят, в раскрывающемся меню Поле отображаются только те поля из тех типов рабочих элементов, которые определены в текущем проекте. Когда установлен флажок Запрос между проектами , все поля из всех типов рабочих элементов, определенных во всех проектах в коллекции, отображаются в раскрывающемся меню Поле .
Определите предложение
Вы создаете запрос, определяя одно или несколько предложений. Каждое предложение определяет критерии фильтрации для одного поля.
Пример запроса
| И/или | Поле | Оператор | Значение |
|---|---|---|---|
| И | Назначено | = | @Me |
Список доступных операторов в зависимости от типа данных поля см. в разделе Краткий справочник по индексу запросов.
Все добавляемые вами предложения добавляются как операторы и . Выберите или , чтобы изменить группировку. Вы группируете предложения, чтобы убедиться, что операторы предложения выполняются в требуемой последовательности.
- Браузер
- Визуальная студия
Выберите Добавить новое предложение , чтобы добавить другое предложение в конце запроса, а затем выберите Поле , Оператор и Значение для этого предложения.
Например, найдите все рабочие элементы, назначенные вам, указав поле Assigned To , оператор равенства ( = ) и макрос @Me , который представляет вашу личность пользователя.
Совет
Чтобы просмотреть синтаксис WIQL для запроса и то, как скобки используются для группировки предложений, установите Marketplace Wiql Editor. Это расширение поддерживает просмотр синтаксиса WIQL и его экспорт в файл WIQL для использования в вызовах REST API. Дополнительные сведения см. в разделе Синтаксис языка запросов рабочих элементов (WIQL).
Контрольный список для определения предложения запроса
В первой пустой строке под заголовком столбца Поле щелкните стрелку вниз, чтобы отобразить список доступных полей, и выберите элемент в списке.
Дополнительные сведения см. в разделе Поля и значения запроса.
В той же строке под заголовком столбца Оператор щелкните стрелку вниз, чтобы отобразить список доступных операторов, и выберите элемент в списке.
Дополнительные сведения см. в разделе Операторы.
В той же строке под заголовком столбца Значение введите значение или нажмите стрелку вниз и выберите элемент в списке.
Дополнительные сведения о том, как использовать макрос или переменную для указания текущего проекта, пользователя, даты или другого выбора, см.
в разделе Переменные.Чтобы добавить пункт, выберите Добавить новый пункт .
Вы можете добавить предложение в конец запроса или выполнить следующие задачи с соответствующими значками:
- Вставить новую линию фильтра
- Снимите эту линию фильтра
- Группа избранных статей
- Разгруппировать статьи
Используйте дерево рабочих элементов для просмотра иерархий
Используйте запрос Дерево рабочих элементов для просмотра многоуровневого вложенного списка рабочих элементов. Например, вы можете просмотреть все элементы невыполненной работы и связанные с ними задачи. Чтобы сосредоточиться на разных частях дерева, выберите Развернуть все или Свернуть все .
Примечание
Вы не можете создать запрос, который показывает иерархическое представление планов тестирования, наборов тестов и тестовых наборов. Эти элементы не связаны друг с другом с помощью типов ссылок родитель-потомок. Однако вы можете создать запрос прямых ссылок, в котором перечислены рабочие элементы, связанные с тестами. Кроме того, вы можете просмотреть иерархию на странице «Планы тестирования».
- Браузер
- Визуальная студия
Определите критерии фильтрации для родительских и дочерних рабочих элементов. Чтобы найти связанные дочерние элементы, выберите Сначала найти рабочие элементы верхнего уровня . Чтобы найти связанные родительские элементы, выберите Сначала сопоставить связанные рабочие элементы .
Используйте запрос Рабочие элементы и Прямые ссылки для отслеживания рабочих элементов, которые зависят от других отслеживаемых рабочих процессов, таких как задачи, ошибки, проблемы или функции. Например, вы можете просмотреть элементы незавершенной работы, которые зависят от реализации других элементов или исправления ошибки.
Используйте запрос прямых ссылок для отслеживания зависимостей между командами. Запрос также помогает вам управлять обязательствами, которые берет на себя ваша команда. Выберите критерии фильтрации для основных и связанных рабочих элементов. И выберите типы ссылок для фильтрации зависимостей.
- Браузер
- Визуальная студия
Отфильтруйте список рабочих элементов первого уровня, выбрав один из следующих вариантов:
Возвращать только те элементы, которые имеют совпадающие ссылки : Рабочие элементы первого уровня возвращаются, но только если они имеют ссылки на рабочие элементы, указанные в критериях фильтрации связанных рабочих элементов.
Возврат всех элементов верхнего уровня : Возврат всех рабочих элементов первого уровня, несмотря на критерии фильтрации связанных рабочих элементов. Рабочие элементы второго уровня, связанные с первым уровнем, возвращаются, если они соответствуют критериям фильтрации связанных рабочих элементов.
Возвращаются только элементы, не имеющие соответствующих ссылок : Рабочие элементы первого уровня возвращаются, но только если они не имеют ссылок на рабочие элементы, указанные в критериях фильтрации связанных рабочих элементов.
Дополнительные сведения о каждом типе ссылок см. в разделе Связывание, отслеживаемость и управление зависимостями.
И/или логическое выражение
Вы указываете И или Или для создания логических выражений ваших предложений запроса. Укажите и , чтобы найти рабочие элементы, соответствующие критериям как в текущем, так и в предыдущем предложении. Укажите или , чтобы найти рабочие элементы, соответствующие критерию либо в текущем предложении, либо в предыдущем предложении.
Добавьте одно новое предложение для каждого поля рабочего элемента, чтобы уточнить критерии поиска. Добавьте предложения, чтобы возвращать только нужный набор рабочих элементов. Если вы не получили ожидаемых результатов от своего запроса, уточните его. Вы можете добавлять, удалять, группировать или разгруппировать предложения запроса, чтобы улучшить результаты запроса.
Сгруппируйте предложения запроса, чтобы они работали как единое целое, отдельное от остальной части запроса. Группировка предложений аналогична заключению выражения в круглые скобки в математическом уравнении или логическом выражении. Когда вы группируете предложения, И или ИЛИ для первого пункта в группе применяются ко всей группе.
Групповые предложения
Групповые предложения работают как единое целое, отдельное от остальной части запроса. Группировка предложений аналогична заключению в скобки математического уравнения или логического выражения. Оператор И или Или для первого предложения в группе применяется ко всей группе.
Как показывают следующие примеры, сгруппированные предложения преобразуются в соответствующее логическое выражение.
Совет
Чтобы просмотреть синтаксис WIQL для запроса, установите расширение редактора запросов WIQL, которое позволит вам увидеть версию WIQL любой записи пользовательского интерфейса запроса. Это расширение позволяет вам увидеть, как обрабатываются сгруппированные предложения AND/OR.
| Запрос | Сгруппированные статьи | Логическое выражение |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 |
Эти запросы возвращают рабочие элементы типа «Ошибка» и соответствуют следующим логическим выражениям:
- Запрос 1 :
И Состояние=Активно ИЛИ Назначено @Me - Запрос 2 :
И (Состояние = Активен ИЛИ Назначен @Me) - Запрос 3 :
ИЛИ (Состояние = Активно И Назначено @Me)
Чтобы сгруппировать одно или несколько предложений, выберите их, а затем выберите
значок групповых предложений.
Вы также можете сгруппировать несколько сгруппированных предложений. Установите флажки для каждого предложения, которое уже было сгруппировано. Затем выберите значок групповых предложений.
Если результаты вашего запроса не возвращают ожидаемые результаты, выполните следующие действия:
- Убедитесь, что каждое предложение определено так, как вы предполагали.
- Проверка И/Или присвоения каждому пункту. Если ваши результаты содержат больше рабочих элементов, чем ожидалось, часто вместо предложения And присутствует предложение Or.
- Определите, нужно ли вам сгруппировать или изменить группировку предложений запроса и назначения И/Или каждого сгруппированного предложения.
- Добавьте больше предложений запроса, чтобы уточнить критерии фильтра запроса.
- Просмотрите доступные параметры для указания полей, операторов и значений.
Разгруппировать статью
- Браузер
- Визуальная студия
Чтобы разгруппировать предложение, выберите
значок разгруппировки предложений для сгруппированного предложения.
Это основы определения запросов. Указатель примеров запросов см. в разделе Краткий справочник по запросам.
- Часто задаваемые вопросы
- Диаграмма запроса плоского списка
- Изменить параметры столбца
- Индекс поля рабочего элемента
- Сочетания клавиш
[PDF] Сравнение непараметрических методов разгруппировки грубо агрегированных данных
- title={Сравнение непараметрических методов разгруппировки грубо агрегированных данных},
автор = {Сильвия Рицци, Микаэль Тинггаард, Герда Энгхольм, Нильс Кристенсен, Том Берге Йоханнесен, Джеймс В. Вопель и Руне Линдал-Якобсен},
Journal={Методология медицинских исследований BMC},
год = {2016},
громкость={16}
}
- S. Rizzi, M. Thinggaard, R. Lindahl-Jacobsen
- Опубликовано 23 мая 2016 г.
- Медицина
- BMC Medical Research Methodology
Базовые гистограммы являются распространенным инструментом для непараметрической оценки.
Они широко используются в медицинских науках для обобщения данных в компактном формате. Примерами являются возрастные распределения смертности или начала заболевания, сгруппированные в 5-летние возрастные классы с открытой возрастной группой в самом старшем возрасте. Когда интервалы гистограмм слишком грубые, информация теряется, и сравнение между гистограммами с разными границами затруднено. В этих случаях полезно оценить… View on Springer
bmcmedresmethodol.biomedcentral.comКак оценить тенденции смертности на основе групповой статистики естественного движения населения
- S. Rizzi, U. Halekoh, R. Lindahl-Jacobsen
- 2018
Модель составных связей со штрафом (PCLM) для разгруппирования для моделирования поверхностей смертности от рака создает подробные гладкие поверхности смертности на основе подсчетов смертей, наблюдаемых в грубых возрастных группах с умеренными предположениями, то есть подсчеты с распределением Пуассона и гладкость расчетного распределения.
ungroup: пакет R для эффективной оценки гладких распределений на основе данных с грубым бинированием.
ungroup — это программная библиотека с открытым исходным кодом, написанная на языке программирования R (R Core Team, 2018 г.), которая представляет универсальный метод разгруппирования гистограмм (количество бинов). данные) при условии, что…
Оценка распределения ядра для сгруппированных данных
- Мигель Рейес, М. Ф. Фернандес, Р. Као, Даниэль Баррейро Урес
Математика
- 2019
Данные, сгруппированные по интервалам, появляются, когда наблюдения получены не в непрерывном времени, а отслеживаются в периодические моменты времени. В этой структуре непараметрическая оценка распределения ядра…
Практическое сглаживание
- П. Эйлерс, Б. Маркс
Информатика
- 2021
Это простое, практическое руководство по P-сплайнам гибкий и мощный инструмент для сглаживания, который может обрабатывать периодические и циклические данные, а также ограничения формы и демонстрирует оптимальное сглаживание с использованием технологии смешанной модели и байесовского оценивания.
Разгруппирование распределения доходов — итальянское исследование Doxa за 1948 год
- Маттео Санти
Экономика
- 2020
В этой статье исследуются альтернативные статистические подходы к разгруппированию данных в табличной форме. После теоретического обсуждения проблемы интерполяции и особенностей методов разгруппировки…
Ряды данных о краткосрочных колебаниях смертности, отслеживание шоков смертности во времени и пространстве 9
Научные данные единообразные и полностью задокументированные данные о еженедельной смертности от всех причин.
О связи ожидаемой продолжительности жизни с равенством продолжительности жизни
- Дж. Абурто
Экономика
- 2020
1 По мере того, как люди живут дольше, возраст смерти становится все более схожим. Этот двойной прогресс за последние два столетия, центральная цель политики общественного здравоохранения, является крупным достижением современной…
- Дж. Абурто, М. Венсинк, Элисон А. ван Раалте, Р. Линдал-Якобсен
Медицина
BMC Public Health
- 2018
Дания Повышение ожидаемой продолжительности жизни и равенство продолжительности жизни были остановлены связанной с курением смертностью среди тех, кто родился в 1919–1939 гг. Дания может сократить неравенство в продолжительности жизни и увеличить ожидаемую продолжительность жизни за счет последовательной цели политики: сокращения рака и младенческой смертности.
Вклад внутрибольничных инфекций в COVID-19эпидемия в Англии в первой половине 2020 г.
Передача SARS-CoV-2 госпитализированным пациентам, вероятно, стала причиной примерно пятой части выявленных случаев госпитализации COVID-19 в «первой волне» в Англии, но менее 1% всех инфекций в Англии.
ПОКАЗАНЫ 1–10 ИЗ 38 ССЫЛОК
СОРТИРОВАТЬ ПО Релевантности Наиболее влиятельные документы Недавность
Эффективная оценка гладких распределений по грубо сгруппированным данным
В этой работе предлагается универсальный метод разгруппировки гистограмм, который предполагает, что только основное распределение может быть гладким распространяется на оценку ставок, когда сгруппированы как количество событий, так и подверженность риску.
Анализ грубо сгруппированных данных из логнормального распределения
Резюме Метод отсутствующей информации применяется к данным о свинцах крови, которые сгруппированы и, как предполагается, распределены логнормально. Эти методы максимального правдоподобия расширены от простых…
Дегруппирование данных о смертности пожилых людей
- А. Костаки, Дж. Ланке
Экономика
- 2000
В этой статье грубо сгруппированные эмпирические данные о смертности, повозрастные показатели смертности пожилого населения. Этот вопрос прежде всего интересует…
Методы градации для получения возрастных коэффициентов рождаемости по сокращенным данным: сравнение 10 методов с использованием данных HFD
- Е Лю, П. Герланд, Т. Шпооренберг, Канторова Владимира, К. Андреев
Экономика
- 2011
Резюме: В этом документе основное внимание уделяется преобразованию повозрастных коэффициентов рождаемости из пятилетних возрастных групп в одновозрастные.
Мы анализируем и применяем различные статистические подходы и математические…Локальная оценка плотности правдоподобия для интервальных цензурированных данных
- Джон Браун, Т. Дюшен, Дж. Стаффорд
Математика
- 2005
Авторы предлагают класс процедур для локальной интервальной оценки правдоподобия по данным, которые являются — цензурированные или собранные в корзины. Одна из таких процедур основана на алгоритме…
Протокол методов для базы данных о смертности людей
- Андреев К., Жданов Д., Вашон П.
Экономика
- 2002
Эта версия Протокола методов базы данных о смертности среди людей (версия 6) вводит два изменения в способ построения таблиц коэффициентов смертности и смертности. Во-первых, реализован новый метод для…
DBKGrad: пакет R для градации коэффициентов смертности с помощью методов дискретного бета-ядра
- A. Mazza, A. Punzo
Информатика
- 2024 9003 Пакет Представлен DBKGrad, предназначенный для облегчения использования сглаживания ядра при градуировке коэффициентов смертности и реализующий одномерные и двумерные адаптивные дискретные бета-ядерные оценки.
Нелинейная ядерная оценка плотности для группированных данных: сходимость по энтропии
- Г. Блоуэр, Дж. Келсолл
Информатика, математика
- 2002
- 2002
выборка группированных данных, которая представляет собой стационарное распределение марковского процесса, напоминающего процесс Орнштейна-Уленбека.
Неправильно поставленные задачи с подсчетами, моделью составных связей и штрафной вероятностью
- P. Eilers
Информатика
- 2007
Определенные наборы данных с распределениями или подсчетами могут быть интерпретированы как косвенные наблюдения скрытых распределений или (временных) рядов подсчетов, а оптимальный параметр сглаживания находится эффективно с помощью минимизация информационного критерия Акаике.
Оценка плотности данных с ошибками округления
Компьютерный метод расчета Тау Кендалла с негруппированными данными
- DOI: 10. 1080/01621459.1966.10480879
- Идентификатор корпуса: 121570240
@article{Knight1966ACM, title={Компьютерный метод расчета Тау Кендалла с негруппированными данными}, автор={Уильям Найт}, journal={Журнал Американской статистической ассоциации}, год = {1966}, объем = {61}, страницы={436-439} }- W. Knight
- Опубликовано 1 июня 1966 г.
- Информатика
- Журнал Американской статистической ассоциации
Резюме Адаптация обычных ручных методов вычисления тау Кендалла к автоматическим вычислениям приводит к времени выполнения порядка N 2. Метод описан со временем выполнения порядка N log N.
Просмотр через Publisher
Эффективный вывод для тау Кендалла
- Сэмюэл Перро
Информатика, математика
- 2022
В этой работе представлен эффективный метод вычисления эмпирической оценки тау Кендалла и стандартной оценки его дисперсии методом складного ножа путем модификации алгоритм вычисления эмпирического тау Кендалла для получения оценок слагаемых, составляющих его проекцию Хайека.
Применение частичного тау Кендалла к проблеме анализа аварий.
Использование корреляции в больших образцах
- P. Moran
Математика
- 1979
. Асимптотическая относительная эффективность к Кендаллу и коэффициенту коэффициента Спирмана. Спустями. Используется, а для коэффициента является коэффициент, а не в коэффициенте — это, а не в коэффициенте — это, и коэффициенты, а не в стиле. И, и, и, по сравнению с коэффициентом, и коэффициенты. сделано на…
Эффективный расчет доверительных интервалов складного ножа для ранговой статистики
- Р. Ньюсон
Математика
- 2005
Представлен алгоритм вычисления сумм совпадений-несогласий за время порядка N log N , где N число наблюдений, с использованием сбалансированного бинарного дерева поиска . Эти суммы могут быть…
Алгоритм и программа расчета коэффициента ранговой корреляции Кендалла
- А. Брофи
Математика
- 1986
Хотя коэффициент ранговой корреляции (тау) Кендалла (1938, 1975) используется менее широко, чем ро Спирмена, он обладает преимуществами, которые могут сделать его предпочтительным статистическим показателем:
- С. Рей
Информатика
Вычисл. Стат.
- 2014
Также обнаружено, что древовидная реализация пространственного согласования доминирует над реализацией сортировки слиянием, и выявлен значительный прирост эффективности при отказе от алгоритмов грубой силы.
Parallelized Kendall’s Tau Coefficient Computation via SIMD Vectorized Sorting On Many-Integrated-Core Processors
- Yongchao Liu, Tony Pan, Oded Green, S. Aluru
Computer Science
ArXiv
- 2017
This paper исследовал параллельный алгоритм, ускоряющий вычисление тау-коэффициента Кендалла для всех пар с помощью векторизованной сортировки одной инструкции с несколькими данными (SIMD) на Intel Xeon Phis с использованием преимуществ множества процессорных ядер и 512-битных векторных инструкций SIMD.
Вывод регрессии Пассинга–Баблока из тау Кендалла
Вывод оценок регрессии из коэффициента корреляции Кендалла позволяет дать аналитические оценки дисперсий наклона, точки пересечения и систематической ошибки в точке принятия медицинского решения, которые не было доступно на сегодняшний день.
Ассортативность Кендалла
- П. Болди, С. Винья
Информатика
КОМПЛЕКСНЫЕ СЕТИ
- 2019
Аналитически утверждается, что версия \(\tau \) с учетом связей решает проблемы, наблюдаемые в [6], и показано, что на ассортативность Ньюмана сильно влияют сплоченные сообщества.
Взвешенный индекс корреляции для рейтинга с связями
- S. Vigna
Компьютерная наука
WWW
- 2015
Предложение о том, чтобы расширить определение Кендалла по натуральному. наличие связей и доказывает полезность взвешенной меры корреляции с использованием экспериментальных данных в социальных сетях и веб-графиков.
с показателем 1-8 из 8 ссылок
Ортанские меры ассоциации
- W. Kruskal
Математика
- 1958
Аннотация упор на вероятностную и операционную интерпретацию их совокупности…
Методы ранговой корреляции
- М. Кендалл
Математика
9I FloresИнформатика
JACM
- 1961
Методы, доступные для сортировки информации в компьютере с использованием его внутренней памяти, описаны и обсуждены с помощью логических блок-схем, которые разбивают шаги, необходимые для сортировки, на ряд основных типов.
Меры ассоциации для перекрестных классификаций III: приблизительная теория выборки , иметь образцы-аналоги, приблизительно нормально распределенные для больших…
Связь между доверительными интервалами и критериями значимости: Учебное пособие
- M. Natrella
Математика
- 1960
Нерафические вычисления Cendall’s Tau
- S. Lieberson
Mathematics 9003
- 1.1
- 1.1
- 1. 2100311.1
- 92929292 3
- 900 3
- .
- 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003 9003
- .
.0095 тропические сезоны . Как видно, пользовательскому разделу не обязательно заполнять весь год. Вы можете определить любой желаемый раздел, если включенные сезоны охватывают разные временные диапазоны. — еще один распространенный коэффициент корреляции рангового порядка, ро Спирмена. Кроме того, эта относительная сложность быстро возрастает при больших…Высокоскоростная обработка данных
- C. Gotlieb, J. Hume
Computer Science
- 1958
Sorting on Electronic Computer Systems
- E. Friend
Computer Science
JACM
- 1956
SEO Services
SEO имеет разовые или постоянные преимущества улучшения веб-сайта, которые улучшают SEO-службу вашей веб-страницы Birmingham , чтобы расширить ее естественное восприятие и трафик. Специалисты, консультанты и организации предлагают SEO-администрирование.
SEO (Search Engine Optimization, поисковая оптимизация) — комплексная разработка сайта клиента для выхода на верхние позиции в выдаче поисковых систем Яндекс и Google по выбранным запросам для увеличения посещаемости и получения оплаты.
Высокоуровневое SEO
Расскажем, как начать SEO продвижение сайта, чтобы уже через пару месяцев быть в ТОПе запросов. Для этого не нужно быть SEO-специалистом высокого уровня. В проекте Pixel Tools администрация доски, которой мы пользуемся сами, поможет компьютеризировать взаимодействие и не допустить лажи.
Начните ПРОЕКТ В PIXEL TOOLSПредприятие в помощь для простого запуска SEO. Модуль подходит для новых локалей и тех, которые сейчас получают трафик.
Работу с сайтом можно разделить на несколько этапов:
- Сбор семантического центра.
- Настройка админки сайта Яндекс и Гугл.
- Специализированный обзор и исправление ошибок.
- Улучшение интерьера.
Семантика — это предпосылка продвижения, структура, на которой строится SEO. Без тотального семантического центра (SN) сложно построить правильную структуру сайта, составить мощный SEO-текст и заполнить мета-метки, которые будут продвигать страницу.
Долго и упорно Собирать правоцентр. Многочисленные владельцы сайтов и SEO-специалисты стараются работать над взаимодействием. Наша администрация соберет для вас фундаментальный пул квестовых запросов.
Семантическое ядро
SEO услуги, прописано собрать и разгруппировать полный центр. Сегменты и страницы будут сделаны из вашего SA. Одно собрание продвигает одну страницу.
Собирая семантику, очень хочется использовать разные источники ключей: Вордстат, Яндекс и Гугл подсказки, вопросы от топ-претендентов, Букварикс.
Необходимо очистить центр мусора от требований – неактуальных, неадекватных, с туманными ожиданиями.
При группировании семантического центра вы зависите от обоснования, а также от проиндексированных списков и главных претендентов.
Распространенные ошибки при сборке удила:Собирать фрагментарно, мелкими кусочками. Такой подход приводит к копированию страниц и неполноценных групп.
«Полный обратный путь» — создайте страницу на определенную тему и поищите под ней лозунги.
Такой подход является ошибкой фреймворка. Построение сайта и его страниц производится по центральным связкам, а не наоборот.Точка разрыва одинокого источника ключей. Например, анализировать только вопросы претендентов, игнорируя статистику Word и варианты поиска.
Полностью разделить разгруппировку бита с запрограммированными кластерами. Автоматы умнеют, их использует большинство семантик. При физической проверке групп выявляются многочисленные ошибки и тонкости, которые «не улавливаются» запрограммированными программами.
ДОБАВИТЬ САЙТ В ЯНДЕКС И GOOGLE ВЕБМАСТЕРЫВ начале продвижения сайта добавляются в админку сайта.
Поручаем вам начать услуги SEO Бирмингем для продвижения сайта со специализированного обзора.
Эти администрации являются источником важных данных, но в то же время средством продвижения. Они позволяют отслеживать ошибки, влияющие на позиции и порядок, «видеть» поисковые запросы (настоящие и предполагаемые), контролировать зеркала, внешние соединения, легитимность микроданных, запись robots.
txt и многое другое.В Яндекс Вебмастере можно настроить региональность, отправить страницы на перепрошивку, настроить суперстраницы.
Подключите свою задачу к Webmaster. Это должно быть возможно в области настроек.
ПРОВЕДЕНИЕ ТЕХНИЧЕСКОГО АУДИТА И ИСПРАВЛЕНИЕ ОШИБОКВот повестка дня, чтобы действительно взглянуть на специализированное состояние сайта. Такой обзор должен быть завершен до отправки предприятия и последовательно переформулирован.
Fix the Bugs
- Наличие зеркал (дубликатов сайта, доступных по разным адресам).
- Точность файла robots.txt. Эта запись является руководством для поисковых роботов, которые улучшают или нарушают порядок страниц.
- Безупречность HTML-кода.
- Правая микромаркировка.
- Правильность отсутствия индекса и отсутствия последующих меток.
- Коды реакции сервера. Сосредоточьтесь на кодах 200 OK.
- Секретный текст. Устаревший метод SEO с темной шапкой может повредить вашему рейтингу.
- Правильный набор страниц пагинации.
- Скорость сайта, смотри пояснения к низкому стеку.
- Копировать страницы (негативный компонент).
Важные элементы внутренней оптимизации сайта:
Структура проекта: области, подразделы, страницы. Дизайн формируется на основе смыслового центра. Администрация Pixel Tools поможет вам точно распределить требования по страницам.
Улучшены тексты с записанными ключами. Крайне важно придерживаться идеального количества событий для предмета. Under spam и over-spam не позволят странице занять высокие места в поисковой выдаче.
Оптимизация страницы
Первоклассные изображения с заполненными альтернативными метками.
Метаметки Title и Description. Название SEO зависит от набора крылатых фраз. Самая успешная просьба подходит к началу.
Понятный URL-адрес страницы.
Внутренние соединения (соединительные).
ВЫПОЛНИТЬ ВНЕШНЮЮ ОПТИМИЗАЦИЯВнешнее продвижение — работа с внешними переменными, влияющими на продвижение сайта в поисковых роботах.
Добавьте свою организацию и сайт в справочники и указатели.
Организация соединений из внешних ресурсов. Создание внешней ссылки необходимо для хорошего позиционирования в поисковых системах и для подключения кликов. Эталонная масса, независимо от того, была ли она получена ошибочно, должна имитировать норму:
- Соединения должны существенно отличаться от ожидаемых (якорные, неякорные, роевые, по картинкам).
- Огромный уровень якорных соединений может подсказывать каналы.
- Элементы проявки должны быть гладкими.
Продвигая пункты назначения, чтобы начать, многие движимы волнением. Тем не менее, когда SEO-сервис Birmingham превращается в задачу, специальные упражнения выполняются спорадически, «вторжения» или просто вылетело из головы.
Такая бурная методология недееспособна.Для развития сайта каждый уровень пирамиды и каждая часть SEO требуют постоянного наблюдения и активности: семантика, контент, оптимизация на странице, установление внешних ссылок и т. д. С этим можно ознакомиться здесь и здесь.
Модуль проекта Pixel Tools упорядочивает вашу работу. Вы поймете, на каком этапе находится задача, каковы ее цели, места развития и элементы развития.
Рекомендуемая статья: Советы по поисковой оптимизации, которые помогут вам увеличить трафик
5 Строительные блоки | Руководство Sen2Cube.at
Модели строятся путем соединения нескольких строительных блоков , где каждый блок представляет отдельную, четко определенную задачу или значение. Существуют различные классы блоков, которые подробно описаны ниже.
5.1 Определения
Блоки определения хранят выходные данные набора других блоков, так что они могут быть доступны в любом другом месте модели.
Существует несколько типов определений.Все определения должны быть названы. Имейте в виду, что эти имена должны быть уникальными!
5.1.1 Сущности и свойства
5.1.1.1 Сущности
Сущность представляет собой идентифицируемый представляющий интерес феномен в реальном мире, который далее не подразделяется на явления того же вида. Например, озеро или поле . Система Sen2Cube.at позволяет обращаться к сущностям на разных семантических уровнях, включая воду или растительность . Возможность окончательного выбора объектов на более высоком или более низком семантическом уровне зависит от возможностей датчика наблюдения Земли, шума при наблюдении и построения модели. Определения объекта описывают для каждого наблюдения, идентифицировано ли оно как часть этого типа объекта или не входит в пространственно-временной охват семантического запроса. Например, когда мы определяем сущность вода , определение объекта будет хранить набор логических наблюдений со значением
Истинно, когда он был идентифицирован как вода , иЛожьв противном случае. Эти наблюдения выровнены по двум пространственным измерениям. Измерениями являются координаты X и Y географического местоположения наблюдений и одно временное измерение. Измерение времени идентифицируется с помощью временных меток, в которые были сделаны наблюдения. Поэтому мы называем эту структуру данных куб . См. рисунок ниже, где синие блоки представляют наблюдения, идентифицированные как вода, а серые блоки представляют наблюдения, которые не были идентифицированы как вода.Наблюдения будут связаны с типом объекта, а не с отдельным объектом. Это означает, что наблюдения могут быть связаны с типом сущности вода , но не с группами наблюдений, которые могут составлять разные водоемы.
5.1.1.2 Свойства
Сущности всегда определяются с использованием одного или нескольких свойств . Например, свойством воды может быть ее голубоватый цвет, а для более крупных водоемов также ее приблизительная плоскостность (т.
е. уклон приблизительно 0%). Таким образом, за блоком определения сущности должен следовать один или несколько блоков определения свойств. Свойства не должны быть взаимоисключающими и не должны перекрываться, т. е. несколько свойств всегда будут связаны с И . Рассмотрим реальное озеро сущностей, где три свойства * цвет , текстура и компактность : они могут быть нечеткими или необязательными, но они не являются или-или. Например, озеро может выглядеть синим как цвет свойства И * выглядеть плоским как текстура свойства, но не быть синим ИЛИ плоским. Могут быть ситуации, когда в некоторых случаях думают о вариантах «или-или», но это указывает на то, что свойство не определено должным образом и должно решаться по-другому.Блоки определения объектов и соответствующие им блоки определения свойств используются исключительно внутри словарь семантических понятий компонент модели. В компоненте приложения сохраненные определения сущностей можно извлекать, обрабатывать и экспортировать.
5.1.2 Результаты
Результатом является результат вывода, при этом один вывод может иметь более одного результата разных типов. В зависимости от процессов, используемых в семантическом запросе, результатами могут быть отдельные значения, одномерные массивы или многомерные кубы. Блоки определения результатов используются исключительно внутри приложение компонент модели. Сохраненные определения результатов можно получить в любом месте других определений результатов в той же модели. Не необходимо экспортировать каждое определение результата. Определение результата также можно использовать в качестве предварительного вывода, который служит промежуточным шагом к окончательному выводу семантического запроса.
5.1.3 Сезоны и разделы
5.1.3.1 Сезоны
При выполнении анализа во времени разделение временного измерения является обычной задачей. Например, вместо общая водность , нас интересует средняя водность за сезон , или соотношение летней и зимней водности .
Определены сезоны, которые обычно появляются в умеренных широтах, такие как лето и зима . В Sen2Cube.at есть возможность для разных определений сезонов . Например:- Сезон сбора урожая как период времени с августа по октябрь.
- Посевная как период времени с марта по май.
- Сезон дождей как период времени с декабря по май.
- Сухой сезон как период времени с августа по ноябрь.
5.1.3.2 Разделы
Различные, но связанные сезоны могут быть затем объединены в раздел временного измерения. Подобно тому, как лето, осень, зима и весна вместе образуют метеорологических сезонов , определенные сезоны сбора урожая и посева могут образовывать сельскохозяйственных сезонов , а сезон дождей и сухой сезон
Блоки определения сезона и раздела считаются семантическими понятиями и поэтому используются исключительно внутри словаря семантических понятий компонента модели. В отличие от сущностей и результатов, определения сезонов и разделов равны , а не 9.0096 оцениваются в момент их определения. Временное измерение куба разделяется только в тот момент, когда конкретный сезон или раздел упоминается внутри прикладного компонента модели.
5.3 Команды
Основные блоки обработки называются командами . Каждая команда представляет определенное действие , которое может быть применено к кубу данных. Поэтому блоки глаголов помечены одним словом действия (например, глаголом ), которое описывает, что делает процесс.
Такое действие всегда применяется к конкретному кубу, например, к сохраненному объекту, определению результата или некоторым извлеченным исходным данным. С точки зрения блоков это моделируется структурой with-do , где ссылка на куб находится в части with , а действие, которое должно быть применено к нему, — в части do .
Например, единичное сокращение с течением времени, примененное к нашему определенному кубу сущностей воды , будет выглядеть так:Часто требуется применить более одного действия к одному и тому же кубу. Это возможно, если предоставить цепочка глаголов , где выходные данные первого процесса формируют входные данные для второго процесса и так далее. Например, начните с куба объекта воды, инвертируйте значения
TrueиFalse, затем оставьте только значенияTrue, а затем со временем уменьшите этот отфильтрованный куб. Следовательно, цепочка обработки выстроена в логическом порядке того, как вы думаете о задаче.Каждый блок verb более подробно описан ниже.
5.3.1 Оценить
Глагол оценить оценивает выражение для каждого наблюдения во входном кубе. Выражение имеет следующую структуру:
\[ Выражение = (Значение, Математический оператор, Значение) \]
В нашем случае левое значение — это наблюдение из входного куба, к которому применяется глагол.
Правое значение может быть соответствующим наблюдением из другого куба, списком чисел или даже одним числом. Поскольку выражение оценивается для каждого наблюдения во входном кубе, выход блока оценки представляет собой новый куб с те же размеры , что и входной куб.Это показано на рисунке ниже. Синий куб слева образует левую часть выражения, красный куб в середине образует правую часть выражения. Куб справа со смешанными цветами — это результат оценки. В этом случае синий и красный куб имеют абсолютно одинаковые размеры, а это означает, что каждому наблюдению в синем кубе соответствует наблюдение в красном кубе. Предположим, мы используем математический оператор
+в качестве нашего оператора. Затем значение наблюдения № 1 — скажем, того, что находится на нижнем левом краю — в выходном кубе равно значению наблюдения № 1 в синем кубе , добавленному к значению наблюдения № 1 в красном куб. То же самое получается и для всех других наблюдений.Однако куб в правой части выражения может иметь другие размеры, чем в левой части.
Например, представьте, что наш куб с правой стороны имеет только пространственных измерений. В таком случае значения в правой части дублируются для каждой метки времени в кубе с левой стороны. Это работает и наоборот. На жаргоне это называется вещанием массива.Тот же принцип применяется, когда правая часть представляет собой только одно значение. Затем это значение равно , дублированному для каждого наблюдения в левом кубе.
Sen2Cube.at имеет несколько встроенных операторов, которые можно использовать для построения выражений.
- Операторы сравнения : операторы, которые сравнивают значения и возвращают либо
True, либоFalse. Это=,в,>,<,≥и≤. - Логические операторы : операторы, объединяющие логические значения (например,
TrueиFalse). Это ииили. - Алгебраические операторы : операторы, объединяющие числовые значения. это
+,-,*и\.
Функциональность каждого поддерживаемого оператора проиллюстрирована с помощью игрушечных примеров ниже.
Оператор в является особенным в том смысле, что каждое наблюдение во входном кубе сравнивается со списком значений , а не с одним значением. Если наблюдаемое значение равно в заданном списке, результатом будет True . Если нет, результатом будет False 9009.6 . Один и тот же список значений используется для каждого наблюдения во входном кубе.
Помните, какой тип данных содержат обе части выражения. Например, логические операторы применимы только в том случае, если обе части выражения содержат логические значения (например, True или False ). Алгебраические операторы имеют смысл только для числовых значений, но не для категорий.
…5.3.2 Фильтр
Глагол filter следует применять только к кубам, которые содержат логические значения данных. Затем он сохраняет только те значения, которые равны
True, и удаляет значенияFalse. Технически это то же самое, что маскировать (см. 5.3.6) логический куб сам по себе.5.3.3 Группировать и разгруппировать
5.3.3.1 Группировать по
Команда group by разбивает входной куб на отдельные группы на основе заданной группирующей переменной. Все последующие операции будут применяться к каждой группе отдельно , пока не будет вызвана команда ungroup . В этот момент группы будут снова объединены в один куб. Этот рабочий процесс также известен как Split-Apply-Combine. Например, входной куб можно разделить на группы так, чтобы каждая группа содержала исключительно наблюдений за определенный год.
Затем эти наблюдения могут быть сведены во времени и в пространстве. Остается одно значение для каждого года. Эти значения можно комбинировать в новом временном измерении, в котором каждая временная координата относится к году.Интерфейс Sen2Cube.at предлагает несколько предопределенных группирующих переменных:
- Временные группирующие переменные : группирующие переменные, которые будут разделять временное измерение таким образом, что каждая группа содержит исключительно наблюдений, сделанных в течение определенного периода времени. Переменные на выбор:
год,сезон,месяц,неделя,день годаидень недели. - Переменные пространственной группировки : переменные группировки, которые будут разделять пространственные измерения таким образом, чтобы каждая группа содержала исключительно наблюдений, сделанных в определенной подобласти внутри определенной области интереса. В настоящее время поддерживается только одна переменная с именем
пространственная функция. Для этого требуется, чтобы интересующая область состояла из нескольких отдельных пространственных объектов (точек, линий или полигонов), которые не пересекаются друг с другом. Затем каждая из этих отдельных функций образует группу.
Также возможно группировать на основе нескольких группирующих переменных . Например, при наличии данных за два года по крайней мере с одним наблюдением каждый месяц группировка по
месяцуприведет к 12 различным группам. Наблюдения за январь первого года окажутся в той же группе, что и наблюдения за январь второго года. Однако при группировке по месяцамгодамполучится 24 разные группы. Такие множественные операции группирования активируются в интерфейсе блока с помощью группа список блок.В-третьих, вы также можете предоставить определенный пользовательский раздел (см.
?? ) измерения времени в качестве группирующей переменной.В настоящее время интерфейс Sen2Cube.at не поддерживает кубы с более чем одним временным измерением или более чем с двумя пространственными измерениями . При группировании с временной группирующей переменной каждая группа представляет определенный период времени, например год, сезон или месяц. При объединении обратно в один куб во время разгруппировки создается новое измерение времени, в котором каждая временная координата относится к одной из этих групп. Поскольку множественные измерения времени не допускаются, исходное измерение времени должно быть уменьшено на перед разгруппировкой — то же самое получается для операций пространственной группировки. Исходные пространственные измерения должны быть уменьшены перед разгруппировкой.
5.3.3.2 Разгруппировать
После группировки все последующие операции будут применяться к каждой группе отдельно , пока не будет вызвана команда ungroup .
В этот момент группы будут снова объединены в один куб.5.3.4 Инвертировать
Глагол инвертировать следует применять только к кубам, которые содержат логические значения данных. Затем он заменяет все значения
TrueзначениямиFalseи наоборот.5.3.5 Метка
Глагол label никак не влияет на значения данных. Он просто хранит метку для всего входного куба. Это полезно, например, перед объединением (см. 5.4.1) нескольких кубов в новом измерении. Метка каждого куба будет служить значением координат нового измерения.
5.3.6 Маска
Команда mask применяет маску логического значения к входному кубу. Маска логических значений — это куб с логическими значениями данных (например,
TrueиFalse). Когда наблюдение во входном кубе соответствует значениюTrueв маске, наблюдение сохраняется. Однако, когда наблюдение во входном кубе соответствует значениюFalseв маске, наблюдение удаляется.Подобно глаголу оценить , логическая маска в операции маскирования может иметь размеры, отличные от размеров входного куба. Например, если маска имеет только пространственные измерения, ее значения будут равны дубликатов для каждой метки времени во входном кубе. Когда маска имеет только временное измерение, ее значения будут дублироваться для каждого пространственного положения во входном кубе.
5.3.7 Уменьшить
Глагол уменьшить применяет функцию сокращения к определенному измерению или набору измерений. Это означает, что для каждой уникальной комбинации значений координат всех других измерений во входном кубе значения измерений, подлежащих уменьшению, суммируются в одно значение на основе некоторой функции. Например, предположим, что входной куб имеет одно временное и два пространственных измерения. По сути, это означает, что для каждого места в пространстве у нас есть несколько наблюдений, каждое из которых сделано в разный момент времени.
Когда мы уменьшаем этот куб по измерению времени, используя означает как функцию редукции, мы уменьшаем наши наблюдаемые значения только до — единственного значения для каждого пространственного местоположения, равного среднему всех наблюдаемых значений в этом местоположении. Это удаляет временное измерение, оставляя нам куб, который имеет только пространственные измерения.Точно так же мы можем уменьшить пространственные измерения, чтобы получить одно значение для каждой метки времени. Интерфейс Sen2Cube.at поддерживает только уменьшение двух пространственных измерений одновременно и , а не размера X или Y отдельно.
Sen2Cube.at имеет несколько встроенных функций сокращения, которые можно использовать.
Помните, какой тип данных и какие измерения содержит входной куб. Некоторые функции редукции полезны только при применении к логическим значениям (например, True и False ).
Другие, например, вычисление среднего или суммы, имеют смысл для числовых данных, но не для категориальных или логических данных и т. д. Кроме того, некоторые функции редукции предназначены только для применения к измерению времени, в то время как другие предназначены только для применяться к пространственным измерениям.Две специальные функции сокращения:
площадьипродолжительность. Первый предназначен для применения к 90 095 пространственным измерениям 90 096 и равен счету в пространстве, умноженному на площадь одного пикселя в квадратных метрах. Последнее предназначено для применения к временному измерению и равняется подсчету во времени после передискретизации наблюдений до дневного уровня. То есть при двух наблюдениях в один и тот же день они будут засчитаны как один .5.3.8 Заменить
Глагол replace заменяет значения действительных наблюдений входного куба (таким образом, не отсутствующие значения!) значениями соответствующих наблюдений в другом кубе.
5.3.9 Select
Команда select выбирает подмножество координат определенного измерения. Он сохраняет во входном кубе только те наблюдения, которые совпадают с этими значениями координат. В настоящее время возможно только подмножество временного измерения. Для этого вы можете использовать один или несколько блоков значений времени (см. 5.5), которые представляют либо момент времени , сбор времени или период времени . Например, операция выбора может сохранить только те наблюдения, которые были сделаны в период с марта 2020 года по июнь 2020 года.
Выбор подобен маскированию в том смысле, что они оба берут подмножество данных. Во время маскирования подмножество определяется другим кубом, содержащим логические значения. Однако во время выбора подмножество определяется прямой адресацией значений координат.
5.4 Объединители
Глаголы применяются к одному входному кубу, такому как сохраненная сущность или определение результата или некоторые извлеченные исходные данные.
Однако также можно сначала объединить несколько кубов в один, а затем применить к этому объединенному кубу глаголы. Блоки объединителя , которые облегчают это, описаны ниже.5.4.1 Объединение
Объединитель объединения объединения объединяет несколько входных кубов по существующему или новому измерению в один куб большего размера. При объединении по существующему измерению это измерение должно присутствовать во всех входных кубах, и все входные кубы должны иметь различных значений координат для этого измерения. Например, входной куб A имеет измерение времени с 01-01-2020 и 01-02-2020 в качестве значений координат. Входной куб B имеет измерение времени с 03-01-2020 в качестве значений координат. Объединение двух значений по измерению времени приводит к одному кубу с измерением времени длины 3, содержащим 01-01-20, 02-01-2020 и 03-01-2020 в качестве значений координат.
Конкатенация по новому измерению создаст выходной куб с новым измерением, для которого наблюдения поступают из входа куб A будет иметь значение координат A , наблюдения, поступающие из ввода куб B , значение координат B и т.
д. То, что мы называем A и B , на практике будет меткой (см. 5.3.5), связанный с входным кубом.Ожидается, что все кубы, предоставленные объединителю конкатенации, будут иметь совпадающих форм , за исключением объединяемого измерения.
5.4.2 Составление
Составление объединяет несколько кубов с логическими значениями данных в один куб с категориальными значениями данных . Требуется, чтобы входные кубы были различными . Это означает, что когда наблюдение во входном кубе A равно
True, соответствующие наблюдения (т. е. имеющие те же координаты) в других входных кубах могут , а не бытьTrue. Затем выходной куб присвоит значение категории 1 всем истинным наблюдениям входного куба A, значение категории 2 всем истинным наблюдениям входного куба B и так далее.5.4.3 Слияние
Объединитель слияния работает так же, как глагол оценить (см.
5.3.1), но допускает выражение с более чем двумя переменными. Например, куб A + куб B + … + куб n . Он предлагает только логические и алгебраические операторы. Выходной куб всегда будет иметь те же размеры, что и первый входной куб .5.5 Время
Блоки значений времени относятся к временному измерению запроса. Они позволяют создавать подмножества кубов по времени, определять пользовательские сезоны и так далее. Имеется три разных блока значений времени.
5.5.1 Момент времени
Момент времени — это конкретный момент времени. Его можно смоделировать тремя компонентами: год , месяц и день . То есть полностью указанный момент времени может быть 2020-07-23. Однако не все компоненты должны быть указаны. Можно также не указывать год и создать момент времени XXXX-07-23, который будет ссылаться на всех дат 23 июля в общем временном интервале запроса. Точно так же 2020-07-XX будет относиться ко всем дням в июле 2020 года, а XXXX-07-XX — ко всем дням в июле для всех лет во временном интервале.
5.5.2 Периоды времени
Период времени представляет собой последовательный период времени, определяемый моментом времени от и моментом времени от до . Интервал замкнут с обеих сторон, поэтому в период времени включаются моменты времени от и до. Также возможно использование не полностью указанных моментов времени. Например, период времени с XXXX-05-XX по XXXX-08-XX — это период времени с мая по август, независимо от года. Таким образом, при подстановке временного измерения куба с этим периодом времени все метки времени в мае, июне, июле или августе будут выбраны для каждого года в общем временном интервале.
В периоде времени момент времени с по всегда должен предшествовать моменту времени с по . В настоящее время это означает, что невозможно создать такие периоды времени, как [от XXXX-11-XX до XXXX-01-XX], то есть с ноября по январь. Вместо этого для моделирования такого периода времени можно использовать коллекцию времени.
5.5.3 Коллекция времени
Коллекция времени представляет собой список моментов времени, которые , а не должны быть последовательными. Например, коллекция времени [XXXX-05-XX, XXXX-08-XX] относится ко всем меткам времени в мае и августе.
5.6 Пробел
В настоящее время нет поддержки для пространственного подмножества кубов или определения пользовательских областей, которые делят общую область интереса. Такие функции могут быть добавлены в будущем.
5.8 Отключение блоков
Блоки могут быть (временно) отключены. После этого механизм логического вывода будет игнорировать этот блок и все блоки, напрямую зависящие от него. Отключить блок можно, щелкнув правой кнопкой мыши блок и выбрав Disable Block 9.0096 в контекстном меню.
Отключенные блоки будут отмечены желтым штрихом. Конечно, не имеет смысла отключать каждый тип блокировки. Отключение блока может даже привести к сбою в процессе вывода. Однако это имеет смысл для всего объекта или результата (если они больше не упоминаются позже) или отдельного глагола в цепочке.