
Составление семантического ядра. Примеры семантического ядра и принципы его создания.
24 Апреля 2006 года, 12:00
Шрифт:
Оглавление
- 1. Введение
- 2. Понятие термина “семантическое ядро”
- 3. Методика составления семантического ядра
- 3.1 Используемые сервисы
- 5. Заключение
Подпишитесь на нас в Telegram
1. Введение
Составление семантического ядра – это один из самых важных моментов оптимизации сайта. Собственно говоря, именно с этого этапа начинается продвижение сайта. Исходя из составленного семантического ядра, делаются технические доработки по сайту, выбираются страницы для продвижения, делаются доработки контента и т.д. Именно поэтому так важно составить правильную семантику для продвижения. Хорошо составленное семантическое ядро обеспечит эффективное продвижение сайта и привлечение целевых посетителей.
Чтобы создать семантическое ядро, необходимо определить наиболее популярные запросы посетителей, используемые ими для поиска информации о товарах/услугах, предлагаемых Вами на рынке.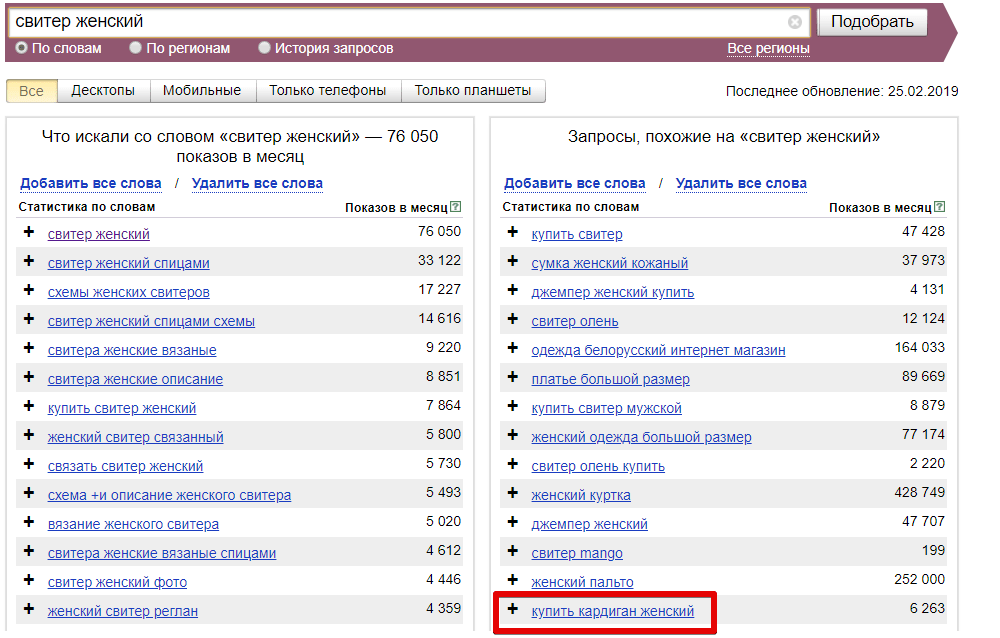
Одновременно семантическое ядро позволит эффективно оптимизировать сайт и грамотно управлять приоритетностью разделов и страниц, которые наиболее точно отражают деятельность компании на рынке товаров/услуг.
Предлагаем Вашему вниманию мастер-класс, который поможет правильно составить семантическое ядро, а также избежать возможных проблем и ошибок.
2. Понятие термина “семантическое ядро”
Семантическое ядро — это список целевых запросов для данного сайта. Технически, это список запросов (профильных запросов), по которым отслеживается продвижение сайта. Составление ядра требует совместной работы специалиста по продвижению сайта, который находит всевозможные формулировки целевых запросов поисковым системам, и специалиста в предметной области (собственно заказчика продвижения), который отфильтровывает некоторые запросы.
3. Методика составления семантического ядра
При составлении семантического ядра, в первую очередь, учитываются «коммерческие» запросы, которые задаются потенциальным покупателем (например, «продажа автомобилей»). Затем информационные запросы общего характера («автомобили в Москве»), малоцелевые «нечеткие» запросы («автомобили ремонт недорого») и запросы с ошибкой («продажа афтомобилей»).
Затем информационные запросы общего характера («автомобили в Москве»), малоцелевые «нечеткие» запросы («автомобили ремонт недорого») и запросы с ошибкой («продажа афтомобилей»).
Нижний порог популярности (спрос) для запросов из семантического ядра определяется для каждого сайта индивидуально.
3.1 Используемые сервисы
Для составления семантического ядра используют специальные сервисы, которые позволяют оценить популярность того или иного запроса среди пользователей. В основном, для этой цели в российском Интернете используются следующие:
- http:\/\/direct\.yandex\.ru\/
- http://adstat.rambler.ru/cgi-bin/wrds_stat.pl
- http:\/\/stat\.go\.mail\.ru\/cgi-bin\/stat\.cgi
- https:\/\/adwords\.google\.com\/select\/KeywordToolExternal,
при этом больше ориентируются на Яндекс, т.к. именно на этот поисковик обычно направлено продвижение ресурса. В методике составления семантического ядра мы коснемся именно этого сервиса. Использовать другие сервисы можно по аналогии.
Использовать другие сервисы можно по аналогии.
3.2 Отбор первичных ключевых слов
Первичные ключевые слова – это слова, которые являются наиболее общими в тематике сайта. Например, при создании семантическое ядра сайта фирмы, занимающейся продажей автомобилей, первичными ключевыми словами могут быть:
- продажа автомобилей
- автомобили
- авто
- и т.д.
Список первичных ключевых слов составляет сам веб-мастер, полагаясь на информацию, которой он обладает относительно деятельности фирмы.
3.3 Составление полного списка возможного семантического ядра
На этом этапе мы будем расширять список первичных ключевых слов с помощью одного из сервисов. В данном случае, как мы уже сказали ранее, коснемся сервиса «Яндекс-Директ».
Таким образом, мы расширяем наш список. С помощью Яндекс-Директ это сделать гораздо быстрее и легче, чем пытаться «логически» вычислить синонимы, сопутствующие запросы, варианты на латинице и др.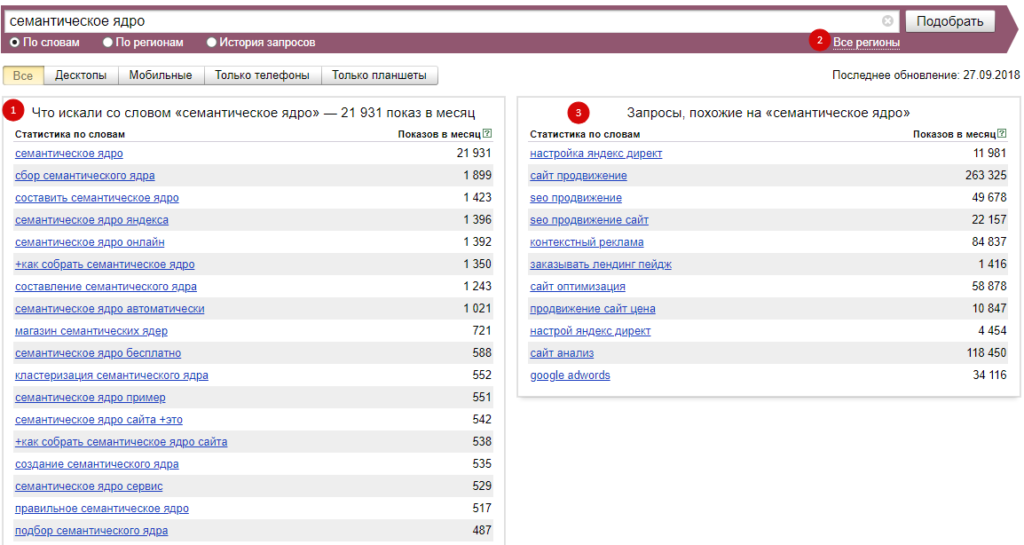
Технически это делается так:
- — нужно зайти на http:\/\/direct\.yandex\.ru\/ и кликнуть на ссылку “подбор слов”;
- — в открывшемся окне можно подробно ознакомиться с инструкцией по использованию данного сервиса.
Вернемся к нашему примеру. Введем в строке “ключевые слова и словосочетания” запрос “автомобили”. В результатах подбора будут приведены запросы пользователей, включающие заданное нами слово “автомобили” (слева), и другие запросы, которые делали искавшие его люди (справа). На основе этих списков мы расширяем семантическое ядро, добавляя в него слова и словосочетания, которые можно применить к нашей фирме.
- автомобили
- продажа автомобилей
- подержанные автомобили
- …
- продажа авто
- авто
- …
- и т.д.
В результате мы получим большой список слов и словосочетаний, по которым мог бы продвигаться сайт фирмы.
3.4 Семантическое ядро как результат работы
Продвигаться по всем возможным словосочетаниям, которые были составлены, практически невозможно. Поэтому из этого большого списка необходимо отобрать запросы, которые нам наиболее важны, а вернее которые более важны нашей фирме.
Поэтому из этого большого списка необходимо отобрать запросы, которые нам наиболее важны, а вернее которые более важны нашей фирме.
Для отбора необходимых запросов используют показатели популярности каждого из этих запросов в Интернете. При подборе ключевых слов через Яндекс-Директ эта цифра отображается рядом с каждым словосочетанием.
Выбрав из полного списка основные и наиболее целевые запросы, мы получаем полный список словосочетаний, которые составляют семантическое ядро.
4. Возможные проблемы и ошибки, возникающие при составлении семантического ядра.
При составлении семантического ядра могут возникнуть следующие проблемы:
- Семантическое ядро составлено по общим фразам и не дает притока целевых посетителей. Например, если пользователь хочет купить автомобиль «Ваз», то скорее он наберет в строке поиска «автомобиль Ваз», нежели просто «автомобиль»;
- Семантическое ядро не учитывает ошибки, которые может сделать пользователь. Например, по невнимательности или неграмотности, написав «котедж» вместо «коттедж».


Если все из вышеперечисленного Вами учтено, то семантическое ядро составлено правильно, продвижение по выбранным запросам будет давать хороший приток целевых посетителей, и о ресурсе узнает множество потенциальных потребителей!
5. Заключение
Итак, составление семантического ядра – это этап, который ни в коем случае нельзя упускать. Весь процесс поискового продвижения основывается на составленном семантическом ядре. Неправильное составление семантики может привести к неграмотной оптимизации, неточному определению запросов посетителей и, как следствие, к неэффективному продвижению.
Теги: Семантическое ядроSEOВебмастерамНовичкам
(Голосов: 5, Рейтинг: 5) | ||||
Читайте нас в Telegram — digital_bar
Есть о чем рассказать? Тогда присылайте свои материалы Марине Ибушевой
Как собрать максимально полное семантическое ядро + документ с готовой семантикой
31734 1370 4
| SEO | – Читать 17 минут |
Прочитать позже
Александр Ожгибесов рассказывает о своем методе сбора семантического ядра и делится готовой семантикой в нише «Туристические товары»
Анастасия Сотула
Редактор блога Serpstat
Вы часто сталкиваетесь со статьями о том, как собрать семантическое ядро? Скорее всего, ответ утвердительный.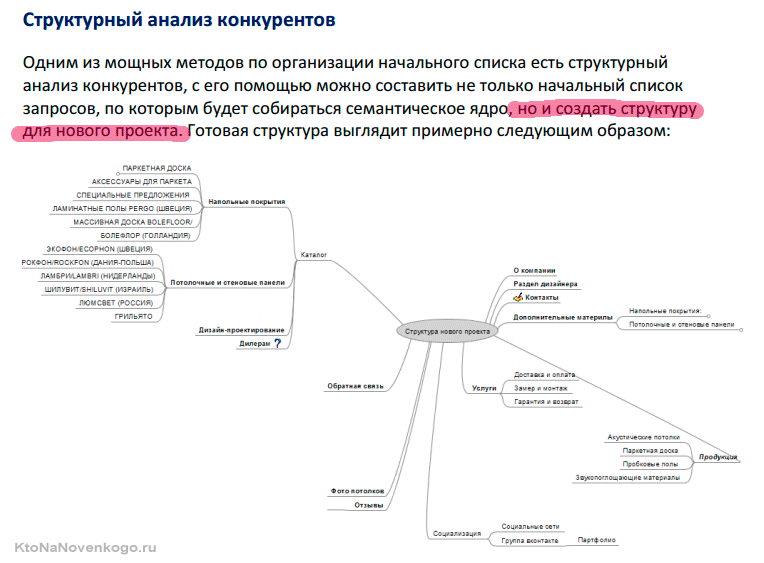 Но чаще всего пишут о самом процессе и забывают о конечном результате. Мы попросили SEO-экспертов поделиться своими секретиками и разложить все по полочкам, а также показать готовую семантику.
Но чаще всего пишут о самом процессе и забывают о конечном результате. Мы попросили SEO-экспертов поделиться своими секретиками и разложить все по полочкам, а также показать готовую семантику.
В сегодняшней статье Александр Ожгибесов поделится своим методом. Саша — специалист с многолетним опытом, эксперт по разработке семантических ядер, руководитель агентства «Семантические ядра», автор образовательных видео по SEO на YouTube-канале «Александр Ожгибесов», докладчик профильных конференций: Cyber Marketing, Sempro, Baltic Digital Days. И еще кое-что: в качестве приятного бонуса к материалу вы найдете пример майнд-карты сайта и документ с готовой семантикой.
Содержание
1. Общая механика работы
2. Сбор семантики: пошаговая инструкция
Этап #1. Анализ маркерных запросов
Этап #2. Расширение семантики
Этап #3. Парсинг поисковых подсказок
Этап #4. Чистка и кластеризация фраз
Этап #5. Создание структуры сайта
3. Аналитика после сбора семантики
4. Бонус
Бонус
— Что делать, когда сайт стоит на 8-м месте, а нужно попасть в топ-3
— Методики работы со сложной тематикой
Выводы
Александр Ожгибесов
Руководитель агентства «Семантические ядра OZHGIBESOV.NET»
Общая механика работы
Сбор семантики — это трудоемкий, а порой и вовсе бесконечный процесс, есть множество методик и подходов, которые позволяют собрать семантическое ядро. Однако зачастую в опубликованных инструкциях мы видим только общую схему работы, которая не учитывает множество нюансов, и не можем наблюдать конечный результат.
В данном материале я хочу рассказать о процессе сбора семантики и аналитики после, а также о принимаемых на основе семантики решениях.
В работе с клиентами мы придерживаемся такой схемы:
Анализируем нишу и согласовываем с клиентом все детали.
Собираем ключевые запросы.
Разрабатываем структуру сайта на основе семантики.
Составляем ТЗ на написание текстов.
В статье мы подробно остановимся именно на этапе сбора семантики. Для этого возьмем реальный проект клиента — интернет-магазин туристических товаров.
Наша задача — провести анализ конкурентов и выяснить ситуацию на рынке: товары, их типы, бренды и тд. Зачем? Потому что за счет полноты достаточно быстро семантики можно стать лидером узконишевых тем, а в некоторых нишах даже конкурировать с не очень сложными агрегаторами.
Как собрать семантическое ядро, чтобы полностью охватить тематику
| Читать |
Сбор семантики: пошаговая инструкция
Начну с того, что для нас в работе с семантикой важна именно «полнота семантики», поэтому наш подход очень скрупулезен. Что я под этим подразумеваю?
Полнота семантики — это подход к сбору семантического ядра, при котором учитываются все НЧ и супер-НЧ запросы. Если мы говорим о простых тематиках, то у них все лежит на поверхности — там все решают синонимы.
Если мы говорим о простых тематиках, то у них все лежит на поверхности — там все решают синонимы.
Но к нам обращаются разные компании. К примеру, сайт по металлопрокату, у которого есть позиция «трос канат стальной размер ГОСТ». Есть запрос «трос стальной», при этом трос называется канатом и дальше уже идет перебор: «канат стальной размер», «канат стальной ГОСТ» и т. д.
Если ты мало информирован в конкретной тематике, то можешь не учесть такие моменты. Значит, ты не сможешь получать трафик там, где мог бы его получать. Поэтому ниже я расскажу, как мы подходим к этому вопросу.
Этап #1
Анализ маркерных запросов
Маркерные запросы или маркеры — это ключевые фразы, которые определяют тематику ниши. Они должны четко отвечать тематике страницы (1 маркер — 1 страница). Зачастую маркерными запросами являются категории, разделы и рубрики на сайте. Отталкиваясь от маркерных запросов можно расширять семантику.
По каждой категории изучали конкурентов и составляли первый вариант структуры для сайта клиента.
Как это делается:
Анализируем поисковую выдачу по коммерческим маркерным запросам (туристические товары), которые характеризуют тематику.
Собираем список сайтов-конкурентов, которые занимаются этим направлением.
Просматриваем все сайты и набрасываем структуру сайта.
Переносим категории каждого из сайтов на майнд-карту и анализируем структуру каждой категории.
Обращаем внимание на фильтры, сортировки, тегирование и используем всю полезную информацию от конкурентов.
Совет от Serpstat #1
Чтобы найти и проанализировать конкурентов, можно воспользоваться Serpstat. Сервис покажет всем релевантных конкурентов сайта на основе пересечения семантического ядра.
Для этого нужно всего лишь ввести адрес своего домена в поисковую строку сервиса и нажать «Поиск», а потом перейти в отчет «Анализ сайта→ Анализ домена→ SEO-анализ→ Конкуренты».
Также с помощью Serpstat можно найти конкурентов по конкретной ключевой фразе. Для этого вводим ключевик в поисковую строку и переходим в «Анализ ключевых фраз→ SEO-анализ→ Конкуренты». Более подробно об анализе конкурентов читайте в статье.
В результате получаем структуру сайта с набором категорий, типов товаров, странам-производителям и брендам. На этом этапе подключается заказчик, поскольку у каждого магазина свой ассортимент и он должен принимать окончательное решение о товарах, которые представлены на сайте.
Начинаем с простейшей майнд-карты: в название категорий выводим маркерные запросы и уже от них двигаемся. Постепенно усложняем и дополняем, чтобы охватить максимум тематики.
Фрагмент майнд-карты для сайта в тематике «Туристические товары»
В зависимости от наличия товаров и приоритетов клиента, вносим коррективы в майнд-карту, которая станет основой для сбора семантики. Такие корректировки неизбежны, так как полный ассортимент возможен только у сайтов-агрегаторов, а у клиента могут быть свои приоритеты.
Такие корректировки неизбежны, так как полный ассортимент возможен только у сайтов-агрегаторов, а у клиента могут быть свои приоритеты.
Смотреть!
Этап #2
Расширение семантики
После того как карта готова, наращиванием запросы по каждому элементу структуры. Для этого используем SEO-инструменты и собираем семантику конкурентов, используя синонимы.
Наша задача на этом этапе — выбрать ключевые фразы, которые использует конечный потребитель и найти все возможные синонимы.
Совет от Serpstat #2
В процессе сбора семантики поможет Serpstat. Благодаря отчетам сервиса можно собрать:
Все поисковые запросы, включающие искомую фразу. Их вы найдете в отчете «Анализ ключевых фраз→ SEO-анализ→ Подбор фраз»:
Ключевые фразы, семантически связанные с анализируемой: синонимы, альтернативное написание, сленг. Для этого нужно перейти в отчет «Анализ ключевых фраз→ SEO-анализ→ Похожие фразы»:
Хотите узнать, как наиболее эффективно использовать Serpstat для задач своего бизнеса? Обращайтесь к нам! Мы все расскажем, чтобы вы могли сэкономить свое время.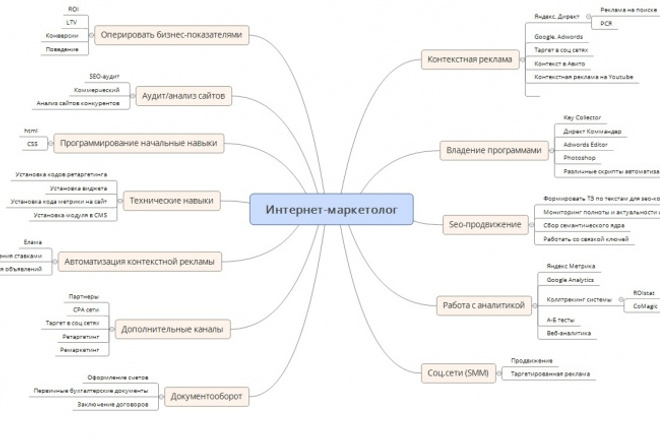
Как собрать семантическое ядро самостоятельно с помощью Serpstat
| Читать |
Этап #3
Парсинг поисковых подсказок
Поисковые подсказки — это ключевые фразы, которые поисковая система предлагает, когда пользователь начинает вводить анализируемый запрос в строку поиска.
Парсинг поисковых подсказок и похожих результатов помогает сделать семантическое ядро сайта максимально полным. Кроме того, по этим фразам часто конкуренция ниже. Таким образом прорабатывается вся карта, согласованная с заказчиком, до необходимого уровня детализации.
При этом важно оценивать пересечения семантики у конкурентов. Чем больше конкурентов используют ключевую фразу у себя, тем выше вероятность того, что фраза необходима и на вашем сайте.
Совет от Serpstat #3
Поисковые подсказки и поисковые вопросы. Поисковые подсказки наиболее оперативно реагируют на изменение пользовательского интереса. Фразы для этого отчета собираются в реальном времени, а это значит, что вы можете всегда отслеживать наиболее горячие темы и давать аудитории ответы на интересующие ее вопросы.
Фразы для этого отчета собираются в реальном времени, а это значит, что вы можете всегда отслеживать наиболее горячие темы и давать аудитории ответы на интересующие ее вопросы.
Все, что нужно сделать — это перейти в отчет «Анализ ключевых фраз→ SEO-анализ→ Поисковые подсказки», а чтобы перейти к поисковым вопросам — кликнуть «Только вопросы».
Также о том, как искать подсказки автоматически с помощью скрипта на базе API Serpstat, читайте в статье.
Этап #4
Чистка и кластеризация фраз
В результате сбора запросов мы получили список ключей. Изначально собранная семантика сортируется по убывающей частоте запросов. Поэтому следующий шаг в сборе семантики — почистить и сгруппировать фразы по конкретным страницам.
Кластеризация — это разделение списка ключевых запросов на группы (кластеры). Ее проводят для того, чтобы в дальнейшем упростить создание полезного контента.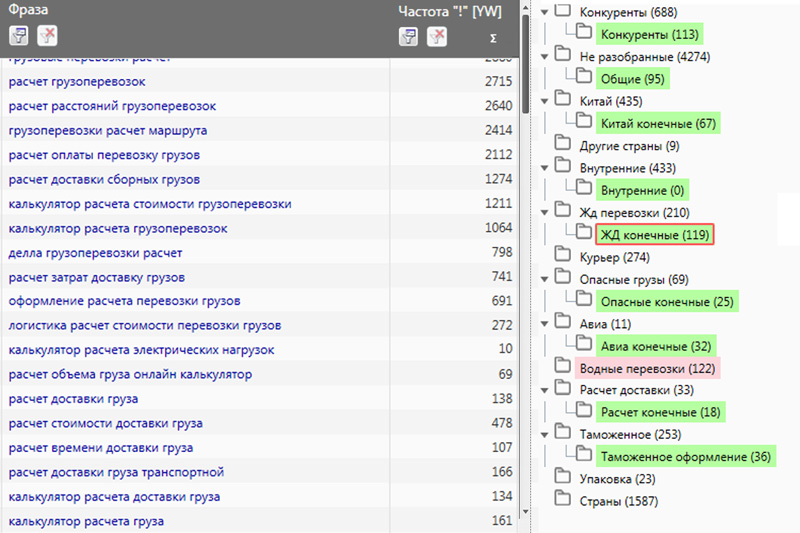 Таким образом, сортировка запросов является завершающим и важнейшим этапом работы с семантическим ядром.
Таким образом, сортировка запросов является завершающим и важнейшим этапом работы с семантическим ядром.
В конечном итоге мы получаем кластеры, сформированные по логике карты, созданной на первом этапе.
Фрагмент кластеризованной семантики
Совет от Serpstat #4
Serpstat позволяет кластеризовать ключевые запросы автоматически. Вы просто загружаете фразы, и сервис сам выстраивает их в иерархическую структуру: фразы объединяются в группы — кластеры, кластеры формируют группы более высокого уровня — суперкластеры, а суперкластеры объединяются в протокластеры. Полученную структуру можно соотнести с иерархией страниц сайта.
Этап #5
Создание структуры сайта
Структура сайта — это логически выстроенная разметка информации на сайте. Она необходима для создания дружественного интерфейса, который будет четко соответствовать требованиям пользователей. Структура, которая ориентирована на пользователя, значительно увеличивает шансы на то, что посетители быстро найдут на сайте нужную информацию или товар.
Семантическое ядро — отличная база для составления структуры сайта. Именно благодаря семантическому ядру можно создать сайт, который максимально удовлетворит требования и пользователей и поисковиков.
Структура сайта готовится в таком виде: категории, подкатегории, страницы товаров, фильтрации (параметры товаров), прописываем URL:
существующие страницы;
запланированные страницы;
страницы, требующие доработки.
Для каждой страницы составляется ТЗ с данными для клиента: запросы, частотность, конкуренция, ссылочные параметры. Если у него нет команды SEO-специалистов, которые могут внедрить эти ТЗ, мы продолжаем работу на следующем этапе: создание страниц под структуру сайта на основе семантики.
Фрагмент постраничной структуры сайта (для проекта по пищевому оборудованию)
URL без цветной заливки — готовые страницы, страницы с желтой заливкой требуют доработок, розовые — нужно создавать.
Как создать структуру сайта на основе семантики
| Читать |
Аналитика после сбора семантики
Дальше на сайте начинается самое интересное. У нас есть пункт «аналитика семантики». На основе собранной семантики проводится глубинная текстовая аналитика, чтобы понять, какие ключевики и где будут наиболее эффективны: мы выгружаем всю семантику, когда у нас сайт уже в топе, снимаем позиции и смотрим, в каком месте и по каким запросам идет просадка.
К примеру, мы видим, что сайт находится на седьмой позиции по какому-то запросу и практически не получает конверсию. Исходя из этого планируем дальнейшие действия.
Когда есть полный список запросов с данными о конкуренции и агрегаторах в топе, выполняем скоринг семантики и отфильтровываем ключи, по которым сложно продвигаться. В приоритет же лучше поставить запросы, по которым нет агрегаторов и сложных коммерческих проектов.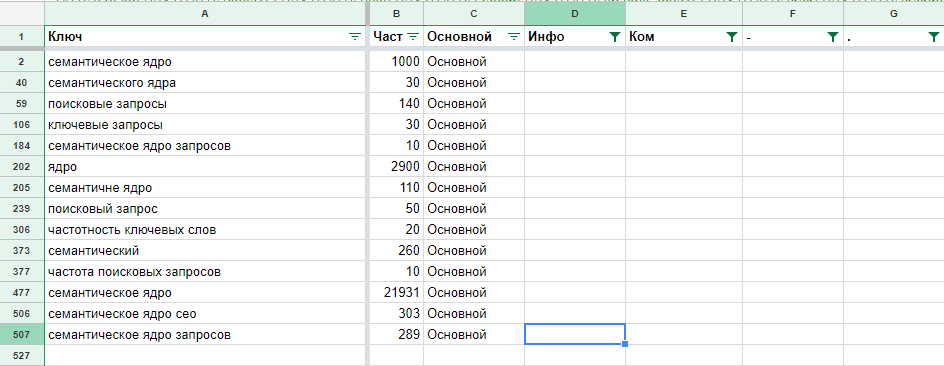 Пример работы вы найдете в документе ниже.
Пример работы вы найдете в документе ниже.
На изображении ниже показана текстовая аналитика с момента создания страницы до PRO-уровня. Изначально мы работаем над внешним видом страницы, делаем текстовый анализ для работы с контентом, пишем тексты.
Если в результате этих действий больше 50% запросов поднялись выше 40 страницы, мы переходим к текстовой аналитике. После того как желаемый результат достигнут, мы переходим к PRO-уровню.
Ниже — пример ТЗ на внешний вид страницы на основе анализов сайтов конкурентов + ТЗ, которое мы получили из текстовых анализаторов для написания контента.
Очень важный момент: текстовые анализаторы иногда несут чушь. Поэтому перепроверяйте на разных тематиках разные инструменты и сравнивайте вручную с выдачей.
Второй важный момент: если у вас молодой сайт, убирайте трастовых конкурентов при анализе.
Вы не знаете, находятся ли они в топе благодаря текстовым факторам или ссылочным.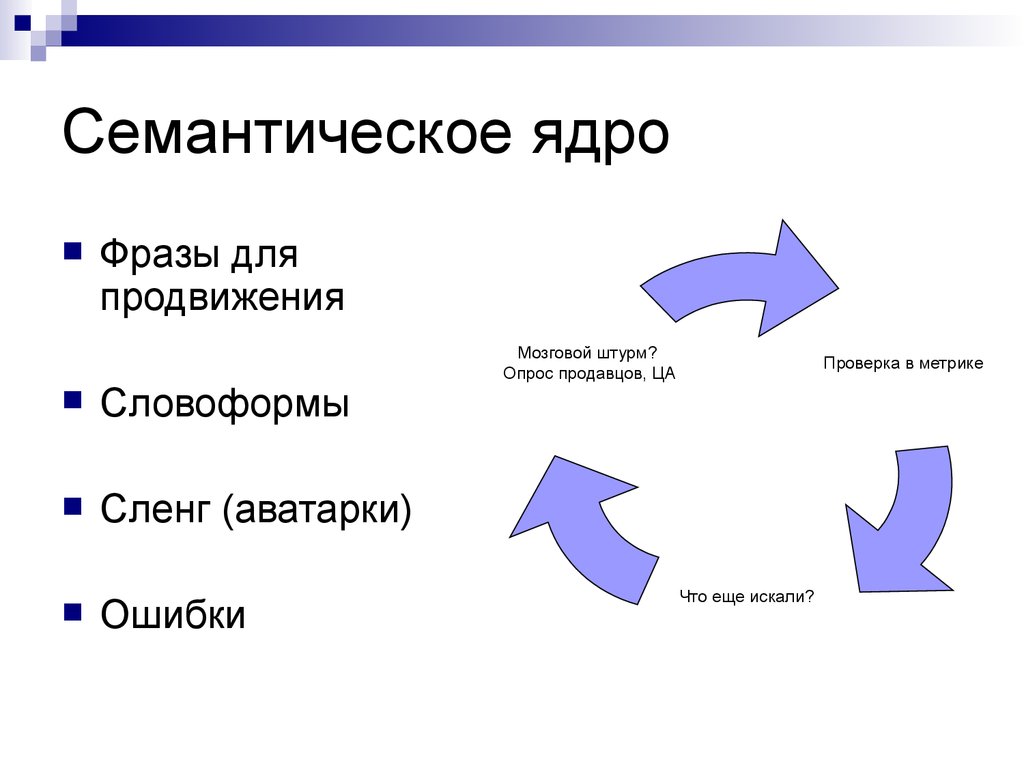 Поэтому, если есть возможность отказаться от анализа трастовых сайтов (относительно молодых сайтов в топе), то убирайте их.
Поэтому, если есть возможность отказаться от анализа трастовых сайтов (относительно молодых сайтов в топе), то убирайте их.
Как повысить текстовую релевантность страниц сайта: инструмент Serpstat «Текстовая Аналитика»
| Читать |
Что делать, когда сайт стоит на 8-м месте, а нужно попасть в топ-3
Так как страница сайта уже находится в топе, значит, с точки зрения коммерческой составляющей с ней все хорошо. Это значит, что страница отдает интент и релевантна запросу.
Если у нас есть текстовая составляющая, есть фрагменты страницы, то дальше мы начинаем постепенно вставлять ключевые слова в страницу, и после каждой правки отслеживать изменения. За некоторое количество таких итераций мы дойдем до той черты, где начинается переспам и откатываться назад в позициях. С помощью таких итераций мы получим необходимый результат.
Методики работы со сложной тематикой
Яндекс и Google имеет огромное количество факторов ранжирования. Их можно поделить на блоки: текстовые, поведенческие, коммерческие, документные, ссылочные и т. д. Не получится использовать только один фактор — к примеру, покупать ссылки и верить, что вы продвинетесь по позициям или накручивать поведенческие факторы.
Их можно поделить на блоки: текстовые, поведенческие, коммерческие, документные, ссылочные и т. д. Не получится использовать только один фактор — к примеру, покупать ссылки и верить, что вы продвинетесь по позициям или накручивать поведенческие факторы.
Работать нужно в комплексе и по всем фронтам. В моей компании процесс устроен так: сбор полного семантического ядра → построение структуры → аудиты для исправления ошибок сайта (SEO и технический аудит, обязательно юзабилити-аудит через AskUsers для понимания общей картины с точки зрения максимально приближенной к боевой ЦА) → анализ конкурентов и их точек давления на поиск.
После этого мы пишем собственную стратегию продвижения на основе оценки общего состояния сайта и стратегии конкурентов. Если сайт трастовый, то можно не ограничиваться и использовать все запросы.
Если у нас молодой сайт, то необходимо выполнить скоринг семантики, найти максимально простые запросы для продвижения, чтобы привести трафик и показать результат по продажам в первый этап работы.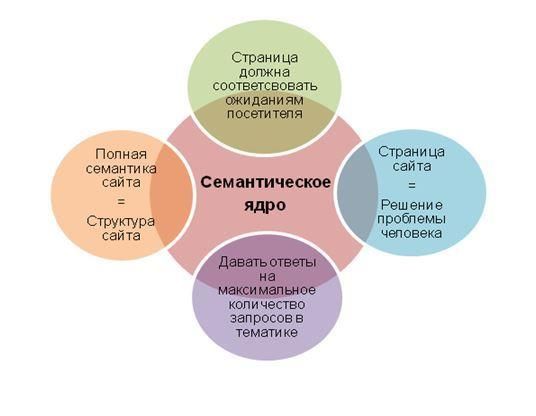 После этого уже концентрироваться на сложных ключах. Ну а дальше всем известная рутина.
После этого уже концентрироваться на сложных ключах. Ну а дальше всем известная рутина.
Главное — не накосячить с семантикой, чтобы не тратить деньги по ключам, в которых в ближайший год нам даже топ-10 не светит, и при этом вести работы по всем фронтам, а не только переписывать портянки и Title.
Как продвинуть молодой сайт и не слить бюджет впустую
| Читать |
Выводы
Теперь еще раз пройдемся по всем пунктам, описанных выше. Для сбора качественного семантического ядра мы делаем такие шаги:
Анализ ниши и согласование с клиентом всех деталей.
Сбор маркерных запросов.
Составление майнд-карты на основе маркеров.
Расширение семантики на основе майнд-карты.
Сбор поисковых подсказок.
Кластеризация собранных фраз, чистка от мусора.
Формирование структуры сайта на основе семантики.
Внесение корректировок, последующее дополнение.
Аналитика семантики.
Поздравляю, вы дочитали статью до конца! А это значит, что самое время перейти к тому, что обещали в начале статьи — полной версии семантики!
Бегу смотреть результаты!
Чтобы быть в курсе всех новостей блога Serpstat, подписывайтесь рассылку. А также вступайте в чат любителей Серпстатить и подписывайтесь на наш канал в Telegram.
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
Получить бесплатный доступ на 7 дней
Оцените статью по 5-бальной шкале
4.53 из 5 на основе 55 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
SEO +1
Яна Дручинина
Как мы вышли в топ-10 увеличили органический трафик почти в 7 раз после вылета из топ-100 — Кейс BondSoft
SEO
Михаил Ахромушкин
5 главных ошибок при работе с семантическим ядром.
SEO
Юлия Гончаренко
Какие страницы сайта нужно оптимизировать в первую очередь?
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.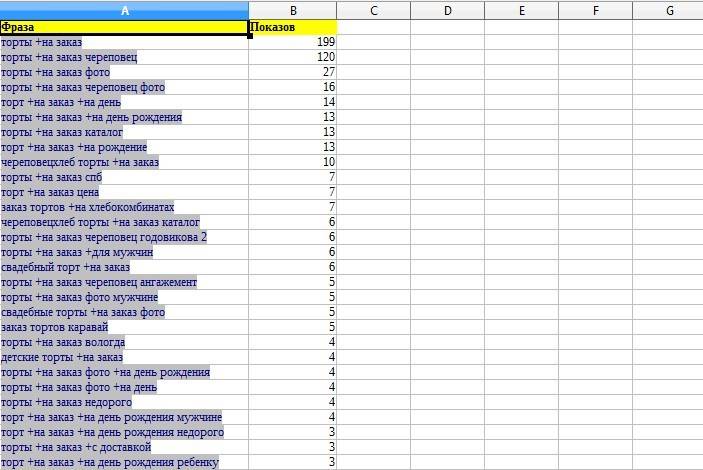
Сообщить об ошибке
Отменить
семантических градиентов | Классные стратегии
Семантические градиенты — это способ расширить и углубить понимание учащимися родственных слов. Студенты рассматривают континуум слов по порядку степени. Семантические градиенты часто начинаются с антонимов или противоположностей на каждом конце континуума. Эта стратегия помогает учащимся различать оттенки значения. Увеличивая свой словарный запас, студенты могут быть более точными и творческими в своем письме.
| Как использовать: | Индивидуально | С небольшими группами | Установка для всего класса |
Дополнительные словарные стратегии
Зачем использовать семантические градиенты?
- Помогает расширить и углубить понимание учащимися родственных слов
- Помогает учащимся различать оттенки значения
- Повышает словарный запас учащихся, что может помочь им быть более точными и творческими при письме
Как использовать семантические градиенты
- Выберите пару полярно противоположных слов.
- Сгенерируйте не менее пяти синонимов для каждого из противоположных слов.
- Расположите слова таким образом, чтобы получился мостик от одного противоположного слова к другому. Континуумы можно делать горизонтальными или вертикальными в виде лестницы.
- Предложите учащимся обсудить причины размещения определенных слов в определенных местах. Поощряйте разговор о тонких различиях между словами.
ИЛИ
- Выберите определенное словарное слово, например, большой.
- Используя прочитанную книгу, учебный предмет или различные образцы письменности, создайте список семантически похожих слов. Преподаватель может разработать список или совместно с учениками создать список. Лучше всего думать о целевом слове как о центре континуума.
- Расположите слова так, чтобы проиллюстрировать понимание значения каждого слова. Континуумы могут быть горизонтальными или вертикальными, в виде лестницы.
- Предложите учащимся обсудить причины размещения определенных слов в определенных местах. Поощряйте разговор о тонких различиях между словами.
 Поощряйте разговор о тонких различиях между словами.
Поощряйте разговор о тонких различиях между словами.
Смотреть: Семантические градиенты
Зайдите в класс второго класса Кэти Дойл в Эванстоне, штат Иллинойс, чтобы посмотреть, как ее ученики используют эту стратегию, чтобы говорить о тонких различиях в значении родственных слов. Недавнее чтение вслух, Семя сонное , является трамплином для оживленной дискуссии о словах, которые описывают относительный размер вещей (например, массивный или гигантский, крошечный или микроскопический). Джоанна Мейер, наш директор по исследованиям, представляет стратегию и описывает, как семантические градиенты помогают детям лучше читать и писать описания.
Сбор ресурсов
Словесность
Загрузите этот раздаточный материал по семантическим градиентам с информацией о семантических градиентах, демонстрацией шагов, связанных с созданием континуума слов, и примерами тем или тем и слов, которые относятся к этой теме .
Урок «Разгадывание значений слов: вовлекающие стратегии развития словарного запаса» предоставляет учащимся 6-го, 7-го и 8-го классов возможность попрактиковаться в использовании контекстных подсказок, которыми целенаправленно манипулируют. Затем контекстные подсказки объединяются с семантическими градиентами, требуя от учащихся как выбирать, так и генерировать связанные слова вдоль континуумов.
Естествознание и обществознание
Учителя классов K-3 могут просмотреть свою учебную программу, чтобы увидеть, есть ли слова, противоположные словам, которые можно было бы использовать для слова с семантическим градиентом. Например, плотность различных горных пород может работать на жестком/мягком континууме. Возможно, другой контент поддается рассмотрению гигантского/крошечного или горячего/холодного масштаба.
Дифференцированное обучение
для изучающих второй язык, учащихся с разными навыками чтения и для учащихся младшего возраста
- В зависимости от уровня навыков учащихся, пусть они работают в небольших группах или парах.
- Учителя могут указать ключевые слова для концов континуума. Другой вариант — позволить якорным словам развиться из студенческой беседы.
- Учителя могут попросить учащихся составить собственный список слов на основе того, что они недавно прочитали или над чем работали.
- Учащиеся могут нарисовать иллюстрацию для каждого слова континуума или написать предложение, в котором каждое слово используется правильно.

См. исследование, подтверждающее эту стратегию
Greenwood, S.C., & Flanigan, K. (2007, ноябрь). Перекрывающийся словарный запас и понимание: контекстные подсказки дополняют семантические градиенты. Учитель чтения, 61 (3), 249-254.
Stahl, S.A., & Nagy, W.E. (2006). Обучение значениям слов . Махва, Нью-Джерси: Эрлбаум.
Детские книги для использования с этой стратегией
Точно наоборот
Автор: Тана Хобан
Жанр: Художественная литература
Возрастной уровень: 6–9 лет понятия, определенные в названиях. Еще одна замечательная книжка с картинками Таны Хобан — Is It Rough? Это гладко? Это блестящее?. Оба они обязательно создадут богатый язык, поскольку каждое изображение рассматривается и описывается несколько раз. [Может также использоваться для развития навыков наблюдения в науке.]
Еще одна замечательная книжка с картинками Таны Хобан — Is It Rough? Это гладко? Это блестящее?. Оба они обязательно создадут богатый язык, поскольку каждое изображение рассматривается и описывается несколько раз. [Может также использоваться для развития навыков наблюдения в науке.]
Fancy Любимые словечки Нэнси: От аксессуаров до Zany
Автор: Джейн О’Коннор
Жанр: Художественная литература
Возрастной уровень: 6-9
Уровень чтения: Независимый читатель
Стильный ребенок, чья любовь к словам легла в основу серии книг, поделилась своей любовью к словам в этом алфавитном словаре книг с картинками. Юмористические иллюстрации обязательно произведут дополнительные слова, чтобы описать причудливый, шикарный, привлекательный мир Нэнси.
Лимоны не красные
Автор: Лаура Ваккаро Сигер
Уровень возраста: 6–9 лет
Уровень чтения: независимый читатель
В этой, казалось бы, простой цветной концептуальной книге представлен ряд утверждений, за которыми следуют прямые ответы.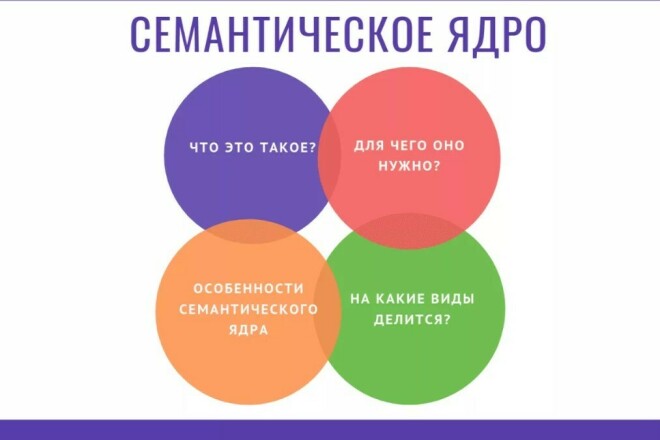
Что делать с таким хвостом?
Автор: Стив Дженкинс
Жанр: документальная литература
Возрастной уровень: 6-9 лет
Уровень чтения: начинающий читатель
Четкие, рельефные иллюстрации животных и их особых частей (например, хвоста, носа) акцентируют внимание читателей на особой функции каждого из них. Он может дать описание не только придатка, но и его функции (что он делает), а также животного и его окружения. Другие книги Стива Дженкинса, такие как «Самый большой, самый сильный, самый быстрый», также могут генерировать богатый описательный язык.
Bring on the Birds
Автор: Susan Stockdale
Жанр: документальная литература
Возрастной уровень: 3-6
Уровень чтения: начинающий читатель разнообразные птицы. Краткая информация о показанных птицах побуждает юных читателей хотеть узнать больше об этих красавцах.
Как дела? Еда с настроением
Автор: Сакстон Фрейманн
Жанр: Художественная литература
Возрастной уровень: 6-9 лет
Уровень чтения: Начинающий
Кто бы мог подумать, что фрукты и овощи могут выражать рог изобилия эмоций? Выразительные продукты помечены рубками, которые они демонстрируют. Читатели всех возрастов могут идентифицировать себя с этой умной книгой и найдут слова, которые можно использовать в стрессовых ситуациях.
Комментарии
Автодополнение кодаML повышает продуктивность разработчиков — блог Google AI
Авторы: Максим Табачник, штатный инженер-программист, и Стоян Николов, старший инженер-менеджер, Google Research
Обновление — 06.09.2022: Этот пост был обновлен, чтобы удалить утверждение о наблюдаемом снижении числа переключений контекста, которое не может быть подтверждено статистически значимо.
Возрастающая сложность кода создает ключевую проблему для производительности в разработке программного обеспечения. Завершение кода было важным инструментом, который помог уменьшить эту сложность в интегрированных средах разработки (IDE). Традиционно предложения по завершению кода реализуются с помощью семантических механизмов (SE), основанных на правилах, которые обычно имеют доступ к полному репозиторию и понимают его семантическую структуру. Недавние исследования показали, что большие языковые модели (например, Codex и PaLM) позволяют предлагать более длинные и сложные варианты кода, и в результате появились полезные продукты (например, Copilot). Однако вопрос о том, как завершение кода на основе машинного обучения (ML) влияет на производительность разработчиков, помимо предполагаемой производительности и принятых предложений, остается открытым.
Завершение кода было важным инструментом, который помог уменьшить эту сложность в интегрированных средах разработки (IDE). Традиционно предложения по завершению кода реализуются с помощью семантических механизмов (SE), основанных на правилах, которые обычно имеют доступ к полному репозиторию и понимают его семантическую структуру. Недавние исследования показали, что большие языковые модели (например, Codex и PaLM) позволяют предлагать более длинные и сложные варианты кода, и в результате появились полезные продукты (например, Copilot). Однако вопрос о том, как завершение кода на основе машинного обучения (ML) влияет на производительность разработчиков, помимо предполагаемой производительности и принятых предложений, остается открытым.
Сегодня мы расскажем, как мы объединили ML и SE для разработки нового гибридного семантического завершения кода ML на основе Transformer, который теперь доступен для внутренних разработчиков Google. Мы обсудим, как ML и SE могут быть объединены путем (1) повторного ранжирования предложений одиночных токенов SE с использованием ML, (2) применения однострочных и многострочных дополнений с использованием ML и проверки правильности с помощью SE или (3) использования одиночных и многострочное продолжение с помощью ML семантических предложений с одним токеном.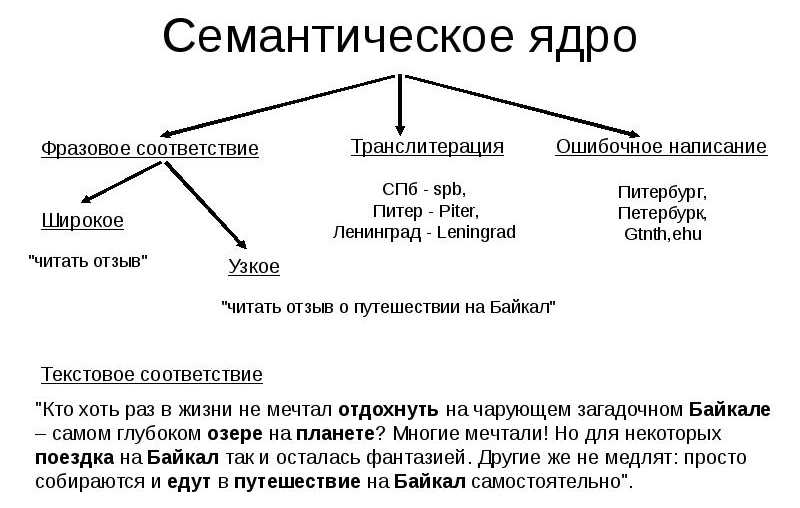 Мы сравнили завершение кода гибридного семантического машинного обучения более чем 10 000 сотрудников Google (более трех месяцев на восьми языках программирования) с контрольной группой и увидели сокращение времени итерации кода (время между сборками и тестами) на 6 % при однострочном завершении машинного обучения. Эти результаты показывают, что сочетание ML и SE может повысить производительность разработчиков. В настоящее время 3 % нового кода (измеряемого в символах) генерируется за счет принятия предложений по завершению машинного обучения.
Мы сравнили завершение кода гибридного семантического машинного обучения более чем 10 000 сотрудников Google (более трех месяцев на восьми языках программирования) с контрольной группой и увидели сокращение времени итерации кода (время между сборками и тестами) на 6 % при однострочном завершении машинного обучения. Эти результаты показывают, что сочетание ML и SE может повысить производительность разработчиков. В настоящее время 3 % нового кода (измеряемого в символах) генерируется за счет принятия предложений по завершению машинного обучения.
Трансформаторы для комплектации
Обычный подход к завершению кода заключается в обучении моделей преобразователей, которые используют механизм самоконтроля для понимания языка, чтобы обеспечить понимание кода и прогнозирование завершения. Мы рассматриваем код, аналогичный языку, представленному токенами подслов и словарем SentencePiece, и используем модели преобразования кодер-декодер, работающие на TPU, для прогнозирования завершения.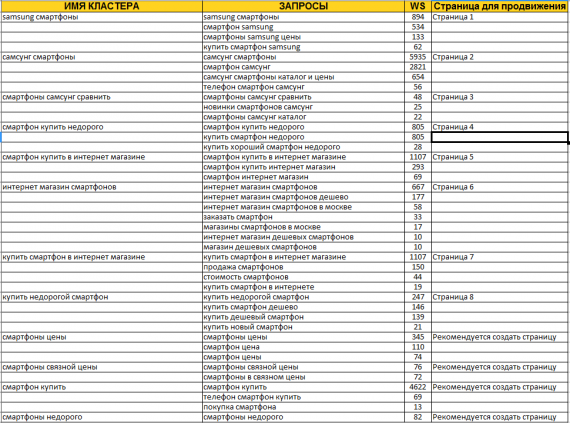 Вход — это код, окружающий курсор (~ 1000-2000 токенов), а выход — набор предложений для завершения текущей или нескольких строк. Последовательности генерируются с помощью поиска луча (или исследования дерева) в декодере.
Вход — это код, окружающий курсор (~ 1000-2000 токенов), а выход — набор предложений для завершения текущей или нескольких строк. Последовательности генерируются с помощью поиска луча (или исследования дерева) в декодере.
Во время обучения монорепозиторию Google мы маскируем оставшуюся часть строки и некоторые последующие строки, чтобы имитировать активно разрабатываемый код. Мы обучаем одну модель на восьми языках (C++, Java, Python, Go, Typescript, Proto, Kotlin и Dart) и наблюдаем улучшенную или одинаковую производительность на всех языках, устраняя необходимость в специальных моделях. Кроме того, мы обнаружили, что размер модели ~ 0,5 млрд параметров дает хороший компромисс для высокой точности прогнозирования с низкой задержкой и стоимостью ресурсов. Модель сильно выигрывает от качества монорепозитория, которое обеспечивается рекомендациями и обзорами. Для многострочных предложений мы итеративно применяем однострочную модель с изученными пороговыми значениями для принятия решения о том, начинать ли прогнозирование завершения для следующей строки.
| Модели преобразования кодер-декодер используются для прогнозирования оставшейся части строки или строк кода. |
Переоценка предложений с одним токеном с помощью ML
Пока пользователь вводит текст в IDE, автозавершение кода в интерактивном режиме одновременно запрашивается моделью ML и SE в серверной части. SE обычно предсказывает только один токен. Модели ML, которые мы используем, предсказывают несколько токенов до конца строки, но мы рассматриваем только первый токен, который соответствует предсказаниям из SE. Мы определяем три лучших предложения ML, которые также содержатся в предложениях SE, и повышаем их рейтинг до вершины. Затем результаты повторного ранжирования отображаются в качестве предложений для пользователя в среде IDE.
На практике наши SE работают в облаке, предоставляя языковые услуги (например, семантическое завершение, диагностику и т. д.), с которыми разработчики знакомы, поэтому мы расположили SE так, чтобы они работали в тех же местах, что и TPU, выполняющие вывод ML. SE основаны на внутренней библиотеке, которая предлагает функции, подобные компилятору, с низкими задержками. Из-за настройки дизайна, в которой запросы выполняются параллельно, а ML обычно быстрее обслуживается (в среднем ~ 40 мс), мы не добавляем задержки к завершениям. Мы наблюдаем значительное улучшение качества при реальном использовании. Для 28% принятых завершений ранг завершения выше за счет бустинга, а в 0,4% случаев хуже. Кроме того, мы обнаружили, что пользователи вводят >10 % меньше символов, прежде чем принять предложение о завершении.
д.), с которыми разработчики знакомы, поэтому мы расположили SE так, чтобы они работали в тех же местах, что и TPU, выполняющие вывод ML. SE основаны на внутренней библиотеке, которая предлагает функции, подобные компилятору, с низкими задержками. Из-за настройки дизайна, в которой запросы выполняются параллельно, а ML обычно быстрее обслуживается (в среднем ~ 40 мс), мы не добавляем задержки к завершениям. Мы наблюдаем значительное улучшение качества при реальном использовании. Для 28% принятых завершений ранг завершения выше за счет бустинга, а в 0,4% случаев хуже. Кроме того, мы обнаружили, что пользователи вводят >10 % меньше символов, прежде чем принять предложение о завершении.
Проверка однострочных/многострочных ML-завершений на семантическую правильность
Во время логического вывода модели машинного обучения обычно не знают о коде за пределами своего окна ввода, а код, наблюдаемый во время обучения, может пропустить последние дополнения, необходимые для завершения в активно меняющихся репозиториях.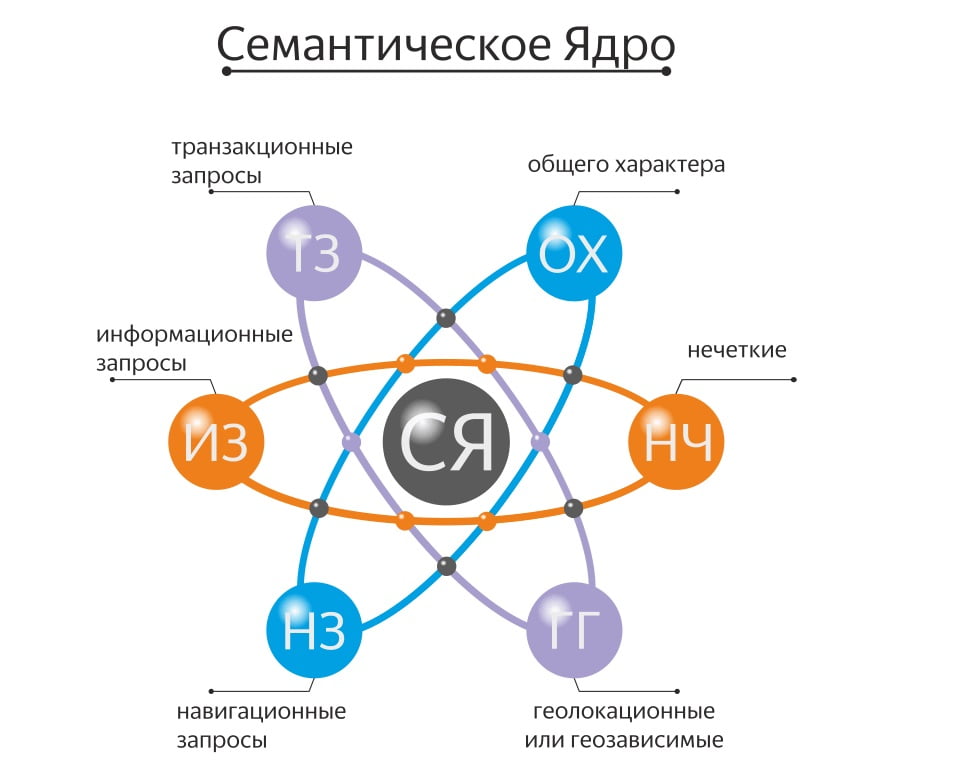 Это приводит к общему недостатку завершения кода на основе ML, когда модель может предлагать код, который выглядит правильно, но не компилируется. Основываясь на внутренних исследованиях пользовательского опыта, эта проблема может со временем привести к подрыву доверия пользователей и снижению производительности.
Это приводит к общему недостатку завершения кода на основе ML, когда модель может предлагать код, который выглядит правильно, но не компилируется. Основываясь на внутренних исследованиях пользовательского опыта, эта проблема может со временем привести к подрыву доверия пользователей и снижению производительности.
Мы используем SE для выполнения быстрых проверок семантической правильности в пределах заданного бюджета задержки (<100 мс для сквозного завершения) и используем кешированные абстрактные синтаксические деревья, чтобы обеспечить «полное» структурное понимание. Типичные семантические проверки включают разрешение ссылки (т. е. существует ли этот объект), проверки вызова метода (например, подтверждение того, что метод был вызван с правильным числом параметров) и проверки присваиваемости (подтверждение того, что тип соответствует ожидаемому).
Например, для языка программирования Go ~8% предложений содержат ошибки компиляции до семантической проверки. Однако применение семантических проверок отфильтровало 80% некомпилируемых предложений. Скорость принятия однострочных завершений улучшилась на 1,9.x в течение первых шести недель после включения этой функции, предположительно из-за возросшего доверия пользователей. Для сравнения, для языков, где мы не добавили семантическую проверку, мы увидели увеличение приемлемости только в 1,3 раза.
Скорость принятия однострочных завершений улучшилась на 1,9.x в течение первых шести недель после включения этой функции, предположительно из-за возросшего доверия пользователей. Для сравнения, для языков, где мы не добавили семантическую проверку, мы увидели увеличение приемлемости только в 1,3 раза.
| Языковые серверы с доступом к исходному коду и серверной части машинного обучения расположены в облаке. Оба они выполняют семантическую проверку предложений завершения ML. |
Результаты
С более чем 10 000 внутренних разработчиков Google, использующих настройку завершения в своей IDE, мы измерили уровень принятия пользователями 25–34%. Мы определили, что завершение кода гибридного семантического машинного обучения на основе преобразователя завершает> 3% кода, сокращая время итерации кодирования для сотрудников Google на 6% (при 90% уровень достоверности). Размер сдвига соответствует типичным эффектам, наблюдаемым для трансформационных функций (например, ключевой фреймворк), которые обычно затрагивают только часть населения, тогда как ML может обобщать большинство основных языков и инженеров.
Размер сдвига соответствует типичным эффектам, наблюдаемым для трансформационных функций (например, ключевой фреймворк), которые обычно затрагивают только часть населения, тогда как ML может обобщать большинство основных языков и инженеров.
| Доля всего кода, добавленного ML | 2,6% |
| Сокращение продолжительности итерации кодирования | 6% |
| Скорость принятия (предложения видны более 750 мс) | 25% |
| Среднее количество символов за прием | 21 |
Ключевые показатели однострочного завершения кода, измеренные в рабочей среде более чем 10 000 внутренних разработчиков Google, использующих его в своей ежедневной разработке на восьми языках. | ||||
| Доля всего кода, добавленного ML (с >1 строкой в предложении) | 0,6% |
| Среднее количество символов за прием | 73 |
| Скорость принятия (предложения видны более 750 мс) | 34% |
| Ключевые показатели многострочного завершения кода, измеренные в рабочей среде более чем 5 000 внутренних разработчиков Google, использующих его в своей ежедневной разработке на восьми языках. | ||||
Предоставление длинных дополнений при изучении API
Мы также тесно интегрировали семантическое завершение с полным завершением строки. Когда появляется раскрывающийся список с семантическими одиночными завершениями токена, мы отображаем встроенные однострочные завершения, возвращенные из модели ML. Последние представляют собой продолжение элемента, находящегося в центре раскрывающегося списка. Например, если пользователь просматривает возможные методы API, встроенные завершения полной строки показывают полный вызов метода, также содержащий все параметры вызова.
Последние представляют собой продолжение элемента, находящегося в центре раскрывающегося списка. Например, если пользователь просматривает возможные методы API, встроенные завершения полной строки показывают полный вызов метода, также содержащий все параметры вызова.
| Интегрированное завершение полной строки с помощью ML, продолжающее семантическое завершение раскрывающегося списка, которое находится в центре внимания. |
| Предложения по заполнению нескольких строк ML. |
Заключение и будущая работа
Мы демонстрируем, как сочетание семантических механизмов, основанных на правилах, и больших языковых моделей может использоваться для значительного повышения производительности разработчиков за счет лучшего завершения кода. В качестве следующего шага мы хотим дальше использовать SE, предоставляя дополнительную информацию моделям ML во время вывода.