
Как составить семантическое ядро для сайта читать онлайн бесплатно на Lifeinbooks.ru
Как составить семантическое ядро для сайта
Сервис 1ps.ru
Из нашей книги вы узнаете: • какие факторы нужно учитывать при составлении СЯ; • как максимально грамотно и эффективно cформировать семантическое ядро для вашего сайта и какие инструменты при этом использовать; • как избежать ошибок при составлении СЯ; • где применить СЯ. Данное пособие будет полезно начинающим оптимизаторам, а также владельцам бизнеса и всем желающим получить максимальную отдачу от продвижения своего сайта.
Как составить семантическое ядро для сайта
Сервис 1ps.ru
© Сервис 1ps.ru, 2016
© Арина Андреевна Блохина, дизайн обложки, 2016
Создано в интеллектуальной издательской системе Ridero
Введение
Пробиться в поисковой выдаче наверх и удержаться там – во все времена было целью владельцев сайтов, которые не собирались ограничиваться минимальным заработком и плохими результатами в ТОП-е.
Для того чтобы занять «место под солнцем», а именно улучшить позиции вашего интернет-ресурса, необходимо провести целый комплекс мер по его оптимизации и продвижению.
Если СЯ составлено некорректно, сколько бы средств вы ни тратили, желаемого успеха вряд ли добьетесь.
1. Составление семантического ядра
Семантическое ядро (СЯ) – это база поисковых слов, словосочетаний и морфологических форм, наиболее точно характеризующих вид деятельности, товары и услуги, которые предлагает сайт.
Как уже было сказано ранее, СЯ – это основа работы каждого seo-специалиста, фундамент в успешном поисковом продвижении сайта. Без подбора ключевых слов цели не будут достигнуты, будь то продажа товаров или услуг, предложение и реализация инфопродуктов или просто монетизация для получения прибыли за счёт рекламы.
Если семантическое ядро сайта составлено неправильно, посетителей из поисковых систем ждать не стоит. Они просто не найдут ваш интернет-ресурс, так как его не будет в приоритетной зоне выдачи по актуальным тематике сайта запросам.
Следовательно, отнестись к процессу составления СЯ следует очень серьёзно, ведь от этого зависит судьба вашего проекта!
1.1. Факторы, учитываемые при составлении СЯ
Подробнее о том, как правильно подбирать ключевые слова с учетом данных факторов мы поговорим в главе «1.2. Стратегия составления СЯ», поэтому если вы знакомы с основной терминологией (или просто станет скучно читать) – переходите к следующей главе.)
Перечислим основные факторы, которые вам нужно будет учитывать при подборе ключевых слов для продвижения сайта:
Количество показов или частотность.
По частоте и количеству показов все запросы можно поделить на высокочастотные, низкочастотные и среднечастотные.
Высокочастотные (ВЧ) – наиболее популярные поисковые фразы, которые часто ищут пользователи в сети Интернет. Частота такого запроса более 10 000 показов в месяц. Например, «ремонт квартир» – 484 110 показов в месяц по данным Yandex. Wordstat.
Ввиду большой востребованности продвижение по ВЧ считается наиболее финансово затратным, сложным и трудоёмким, при этом не всегда оправданным.
Среднечастотные (СЧ) – запросы, имеющие относительную популярность. Их нельзя отнести ни к ВЧ, ни к НЧ. Частота показов колеблется от 1000 до 10 000 в месяц. Например, «ремонт квартир в Иркутске» – 1342 показа в месяц по данным Yandex. Wordstat. Использование таких слов является самым популярным и оптимальным методом SEO продвижения.
Низкочастотные (НЧ) – тип ключевых слов, который запрашивается реже всего. Частота менее 1000. Например, «быстрый ремонт квартир» – 432 показа в месяц по данным Yandex. Wordstat. Несмотря на минимальную востребованность запроса, продвижение по НЧ достаточно эффективно.
Правильным шагом в начале раскрутки молодого сайта является наполнение интернет-ресурса контентом с низкочастотниками. Так, вы сможете заслужить доверие поисковиков (получить траст), что поможет в дальнейшем продвижении.
Чистый спрос – количество показов запроса без словосочетаний, в которые он входит.
Например, в количество показов запроса «обогреватели» входят все прочие запросы с этим словом: «инфракрасные обогреватели», «газовые обогреватели» и т.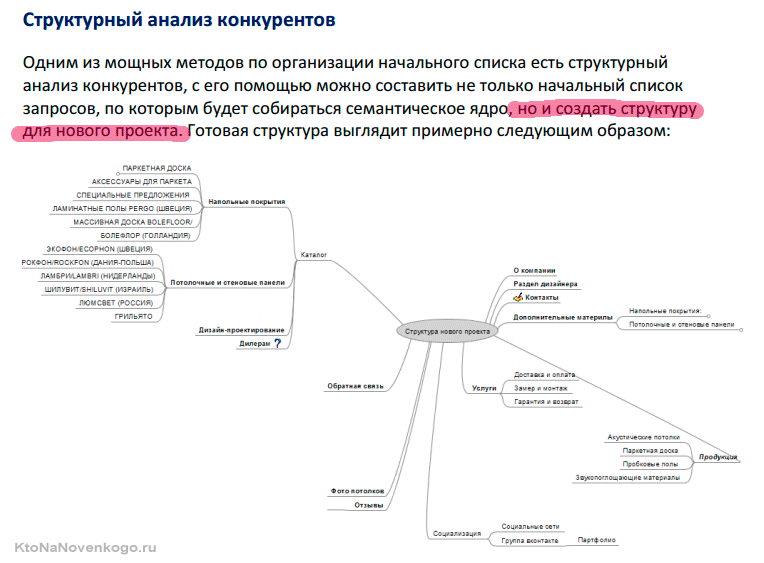 п. Важно учесть частоту именно основного запроса без учета других запросов, т. е. чистый спрос без шлейфа. Подробнее о том, как это сделать, разберем в следующей главе.
п. Важно учесть частоту именно основного запроса без учета других запросов, т. е. чистый спрос без шлейфа. Подробнее о том, как это сделать, разберем в следующей главе.
Количество показов без использования морфологических форм[1 — В морфологическом вхождении одно или даже несколько слов пользовательского запроса изменены по форме путем спряжения или склонения.].
Следует учитывать морфологию запроса (склонение, спряжение и прочее) – т. е. сколько людей ищет именно словосочетание «ремонт квартиры», а не «услуги по ремонту квартиры».
Наличие релевантных[2 — Релевантная страница – это страница сайта, которая содержательно отвечает поисковому запросу пользователя.] поисковым запросам страницы.
Нужно не просто подбирать запросы, а подбирать так, чтобы ваш сайт был лучшим ответом на этот запрос. Т. е. если в интернет-магазине музыкальных инструментов фото гитар есть только в разделе каталог товаров, то не стоит использовать запрос «фото электрогитары».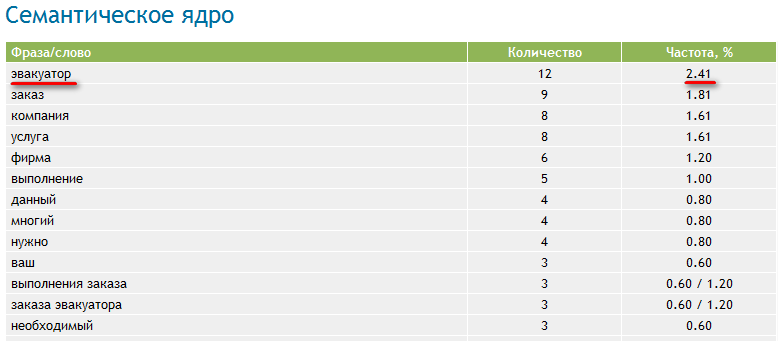
Конкурентность запроса.
Чтобы определить, сколько денег потребуется для продвижения, необходимо оценивать конкуренцию по запросу, особенно, если ваш бюджет ограничен. По конкуренции запросы можно поделить на высококонкурентные, среднеконкурентные и низкоконкурентные.
Высококонкурентные запросы (ВК) – запросы, по которым в поисковой выдаче находится много оптимизированных под них сайтов. Например: «купить мультиварку».
Среднеконкурентные (СК) – запросы, характеризующиеся неплохим количеством трафика и средней конкуренцией. Продвижение такого запроса потребует меньших финансовых вложений, чем при раскрутке ВК, Например: «купить мультиварку в Минске».
Низкоконкурентные (НК) – ключевые запросы, не обладающие популярностью. Используя такой запрос попасть в ТОП можно только за счёт внутренних факторов оптимизации. Например: «купить мультиварку редмонд в Минске».
Конец ознакомительного фрагмента.
Текст предоставлен ООО «ЛитРес».
Прочитайте эту книгу целиком, купив полную легальную версию (http://www.litres.ru/servis-1ps-ru-8341896/kak-sostavit-semanticheskoe-yadro-dlya-sayta/?lfrom=931425718) на ЛитРес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.
notes
Примечания
1
В морфологическом вхождении одно или даже несколько слов пользовательского запроса изменены по форме путем спряжения или склонения.
2
Релевантная страница – это страница сайта, которая содержательно отвечает поисковому запросу пользователя.
Конец ознакомительного фрагмента.
Текст предоставлен ООО «ЛитРес».
Прочитайте эту книгу целиком, купив полную легальную версию на ЛитРес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.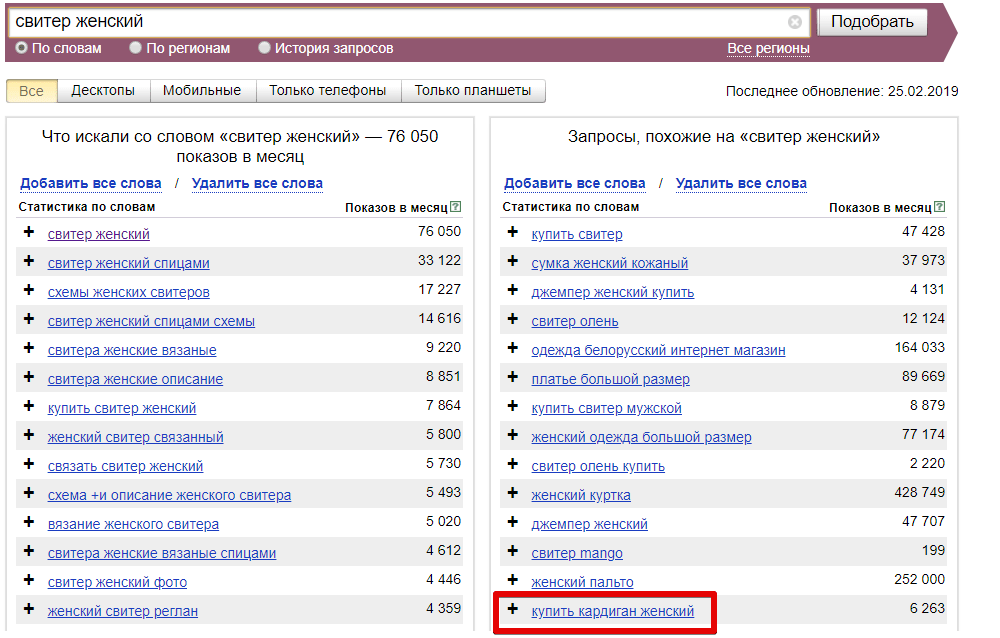 Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.
Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.
Здесь представлен ознакомительный фрагмент книги.
Для бесплатного чтения открыта только часть текста (ограничение правообладателя). Если книга вам понравилась, полный текст можно получить на сайте нашего партнера.
Купить и скачать книгу в rtf, mobi, fb2, epub, txt всего 14 форматов
Как составить семантическое ядро для сайта (книга бесплатно)
Данное пособие будет полезно начинающим оптимизаторам, а также владельцам бизнеса и всем желающим получить максимальную отдачу от своего сайта.
Из книги вы узнаете:
- Какие факторы нужно учитывать при составлении СЯ.
- Как максимально грамотно и эффективно cформировать семантическое ядро для вашего сайта и какие инструменты при этом использовать.
- Как избежать ошибок при составлении СЯ.
- Где применить СЯ.
Содержание книги «Как составить семантическое ядро для сайта»
Первый и самый важный шаг – это составление семантического ядра (СЯ).
Именно от него зависит стратегия (выбор целевых страниц под запросы, определение контента и др.) и даже приблизительная стоимость процесса продвижения. Если СЯ составлено некорректно, сколько бы средств вы ни тратили, желаемого успеха вряд ли добьетесь. © Сервис 1PS.RU
 Именно от него зависит стратегия (выбор целевых страниц под запросы, определение контента и др.) и даже приблизительная стоимость процесса продвижения. Если СЯ составлено некорректно, сколько бы средств вы ни тратили, желаемого успеха вряд ли добьетесь. © Сервис 1PS.RU
Именно от него зависит стратегия (выбор целевых страниц под запросы, определение контента и др.) и даже приблизительная стоимость процесса продвижения. Если СЯ составлено некорректно, сколько бы средств вы ни тратили, желаемого успеха вряд ли добьетесь. © Сервис 1PS.RU- Введение.
- 1. Составление семантического ядра.
- 1.1. Факторы, учитываемые при составлении СЯ.
- 1.2. Стратегия составления СЯ.
- 1.3. Пример разработки семантического ядра.
- 2. Распространённые ошибки при составлении СЯ.
- 3. Сфера применения семантического ядра.
- Заключение.
В этой книге собрана основная информация о формировании семантического ядра сайта. Опираясь на приведённые в книге рекомендации, Вы самостоятельно сможете составить семантическое ядро, чтобы вывести сайт в ТОП по запросам поисковиков и получить хороший приток целевых посетителей на сайт.
Чтобы улучшить позиции вашего интернет-ресурса, необходимо провести целый комплекс мер по его оптимизации и продвижению.
© Сервис 1PS.RU
 Первый и самый важный шаг – это составление семантического ядра (СЯ). Мы постарались максимально подробно описать процесс создания корректного семантического ядра и надеемся, что книга позволит избежать многих ошибок, которые часто совершают веб-мастера. Полезного и приятного чтения!
Первый и самый важный шаг – это составление семантического ядра (СЯ). Мы постарались максимально подробно описать процесс создания корректного семантического ядра и надеемся, что книга позволит избежать многих ошибок, которые часто совершают веб-мастера. Полезного и приятного чтения![sociallocker id=»4165″]
Ваши ссылки: скачать книгу
[/sociallocker]
Дополнительная информация
Источник: составление семантического ядра.
Автор: Сервис 1PS.RU.
Дополнительно: бесплатно.
Формат: PDF.
Страниц: 24.
Размер: 524 КБ.
*СЯ = семантическое ядро.
Автор: Сервис 1PS
Постоянная ссылка на страницу:
Вам также может понравиться
2022-02-18
2020-12-09
2020-08-25
2020-07-15
2020-04-15
О нашем сайте
Бизнес клуб
VIP club (Бизнес Клуб) — это сборник информации для создания и продвижения вашего бизнеса: скрипты и программы, семинары и тренинги, книги и специальные доклады, товары с правами перепродажи и правами личной марки, уроки и инструкции, а также скидки на товары и услуги. ..
..
Частично информацию можно скачать бесплатно и полностью в приватной зоне сайта Бизнес Клуб — выбирайте доступ:
Standart | Premium | Unlimited | Бесплатно
Внимание! Все товары и услуги добавляются в приватную зону сайта только с разрешения авторов и правообладателей.
Посмотреть все сообщения
Книги — Semantic Web и связанные данные
Похоже, вы используете Internet Explorer 11 или более раннюю версию. Этот веб-сайт лучше всего работает с современными браузерами, такими как последние версии Chrome, Firefox, Safari и Edge. Если вы продолжите работу в этом браузере, вы можете увидеть неожиданные результаты.
Домашний
Добро пожаловать!
Семантическая сеть включает в себя технологию, которая соединяет данные из разных источников в Интернете, как это было задумано Тимом Бернерсом-Ли и возглавляется Консорциумом World Wide Web (W3C). Эта сеть данных позволяет связывать наборы данных между хранилищами данных в Интернете, обеспечивая связь между машинами с помощью связанных данных. В этом руководстве содержатся описания и ссылки на ресурсы, используемые для реализации этой технологии.
Эта сеть данных позволяет связывать наборы данных между хранилищами данных в Интернете, обеспечивая связь между машинами с помощью связанных данных. В этом руководстве содержатся описания и ссылки на ресурсы, используемые для реализации этой технологии.
Дом
ПРИМЕЧАНИЕ:
The UCLA Semantic Web LibGuide был скомпилирован и написан Рондой Супер. Это началось как страница данных на домашней странице личного ресурса г-жи Супер. За более чем двадцатилетний период ресурсы Semantic Web, перечисленные на странице ресурсов Rhonda, превратились в отдельный LibGuide, который служил всеобъемлющим ресурсом для сообщества Semantic Web и Linked Data, предоставляя ссылки на инструменты, лучшие стандарты, учебные материалы, варианты использования, словари. , и более.
Руководство постоянно обновлялось до августа 2022 года с использованием платформы SpringShare LibGuide, настроенной библиотекой Калифорнийского университета в Лос-Анджелесе.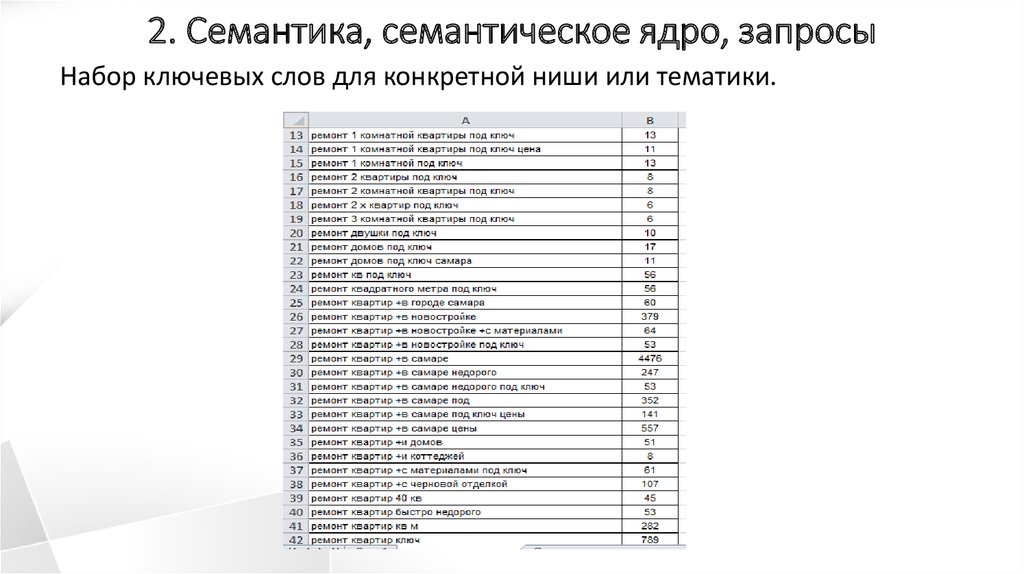 Многие из его ресурсов предоставляют исторический взгляд на развитие связанных данных.
Многие из его ресурсов предоставляют исторический взгляд на развитие связанных данных.
Г-жа Супер имеет степень бакалавра английского языка и государственного управления и степень магистра коммуникаций Университета Огайо. Она получила степень MLIS в Государственном университете Сан-Хосе, специализируясь на архивах, редких книгах и академических библиотеках. Она получила сертификат по системам XML и RDF в Library Juice Academy. Г-жа Супер получила стипендию для посещения Калифорнийской школы редких книг, где она изучала редкие книги для ученых и архивистов, описательную библиографию и историю книги: девятнадцатый и двадцатый века. Г-жа Супер работала в библиотеке Калифорнийского университета в Лос-Анджелесе с 2007 г. до выхода на пенсию в 2022 г.
Окончательная версия Руководства размещена в репозитории открытого доступа Калифорнийского университета по электронной стипендии, чтобы сообщество связанных данных могло продолжать использовать его в качестве ресурса.
Если вы цитируете ресурсы из этого Руководства, пожалуйста, проверьте исходный ресурс на соответствие требованиям к авторскому праву и цитированию.
Содержание
Прокрутите страницу вниз, чтобы получить доступ к темам, перечисленным ниже.
- Дом
- Передовой опыт, стандарты и профили приложений метаданных (MAPS)
- Блоги, серверы рассылки и вики
- Книги
- Наборы данных
- Учебные ресурсы
- Журналы, статьи и статьи
- Семантические веб-службы
- Семантические веб-инструменты
- СПАРКЛ
- Словари, онтологии и фреймворки
- Онтологии и фреймворки
- Реестры, порталы и органы
- Схемы
- Словари
- Викибаза и Викиданные
- ВикиПроекты
- Свойства Викиданных
- Инструменты Викиданных
- Мастерские и проекты
- Варианты использования
О семантической сети
Semantic Web предоставляет возможность семантически связывать отношения между веб-ресурсами, ресурсами реального мира и концепциями посредством использования связанных данных, поддерживаемых платформой описания ресурсов (RDF).
СВЯЗАННЫЕ ОТКРЫТЫЕ ДАННЫЕ (LOD) ОБЛАКО
Об облаке LOD
Диаграмма на этой странице представляет собой визуализацию связанных открытых наборов данных, опубликованных в формате связанных данных по состоянию на апрель 2014 г. Большой круг в центре — это Dbpedia, версия Википедии со связанными данными. Нажмите на диаграмму, чтобы узнать больше о диаграмме, лицензированных и открытых связанных данных, статистике о наборах данных на диаграмме и последней версии LOD Cloud. По состоянию на июнь 2018 года вы можете просматривать Sub-Clouds по предметным областям.
Диаграмма Linking Open Data cloud 2014, Макс Шмахтенберг, Кристиан Бизер, Аня Дженцш и Ричард Цыганиак.
Содержание
Передовой опыт, стандарты и профили приложений метаданных (MAP)
5-звездочные правила открытых данных
5 звезд Открытые данные
Нажмите на изображение кружки и откройте ссылку, чтобы получить дополнительную информацию.
Документация по словарям Getty
Словари Getty см. на странице «Реестры, порталы и органы» в разделе «Словари, онтологии и структуры».
Передовая практика и стандарты
Доверие является основным компонентом Semantic Web. Это требует предоставления точной информации при публикации экземпляра связанных данных. Консорциум World Wide Web (W3C), состоящий из представителей международного сообщества, разрабатывает веб-стандарты и передовой опыт. Кроме того, авторитеты в предметных дисциплинах устанавливают, администрируют и поддерживают стандарты в своих дисциплинах, которые соответствуют лучшим практикам W3C.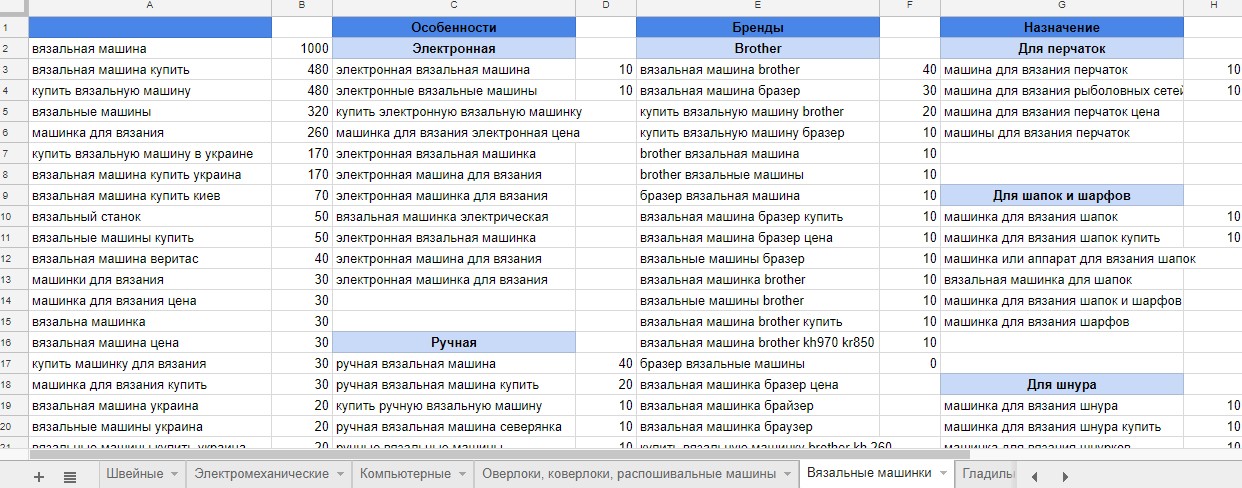
Эта страница предоставляет доступ к информации о передовом опыте и стандартах, относящихся к технологии Semantic Web, разработанной W3C и другими авторитетными организациями. Контролируемые словари, онтологии и т. д. см. на странице Словари, онтологии и Fameworks.
Дополнительные ресурсы о стандартах
Профили приложений метаданных (MAP)
Профиль приложения метаданных (MAP) — это набор записанных решений об общем приложении или службе метаданных, будь то хранилище данных, репозиторий, система управления, уровень индексации обнаружения или другое, для данного сообщества. MAP определяют, какие типы сущностей будут описаны и как они соотносятся друг с другом (модель), какие контролируемые словари используются, какие поля являются обязательными и какие поля имеют ограничение на количество раз, которое они могут использовать, типы данных для строковые значения, а также направляющие примечания к тексту/областям для последовательного использования полей/свойств.
MAP может быть многочастной спецификацией с удобочитаемым и машиночитаемым аспектами, иногда в одном файле, иногда в нескольких файлах (например, удобочитаемый файл, который может включать правила ввода, машиночитаемый словарь, и схему проверки).
Функция MAP состоит в том, чтобы прояснить ожидания от метаданных, принимаемых, обрабатываемых, управляемых и предоставляемых приложением или службой, и документировать общие модели и стандарты сообщества, а также отмечать, где реализации могут отличаться от стандартов сообщества.
Библиотека Корнельского университета. (2018, 23 октября). Профили приложений метаданных CUL. Загружено в январе 2020 г. из
Библиотеки Конгресса. (2019, 30 апреля). Целевая группа PCC по профилям приложений метаданных. Загружено 19 июля 2022 г. с https://confluence.cornell.edu/display/mwgweb/CUL+Metadata+Application+Profiles
Блоги, серверы рассылок и вики
Блоги, серверы списков и вики
Книги
Книги
Ниже приведен список книг, дающих хорошее введение в семантическую паутину. Элементы, заголовки которых выделены синим цветом, ссылаются либо на запись библиотеки Калифорнийского университета в Лос-Анджелесе для этого заголовка, если плитка хранится в библиотеке, либо на онлайн-копию, если она доступна. Используйте ссылку Safari Books Online для поиска дополнительных ресурсов.
Элементы, заголовки которых выделены синим цветом, ссылаются либо на запись библиотеки Калифорнийского университета в Лос-Анджелесе для этого заголовка, если плитка хранится в библиотеке, либо на онлайн-копию, если она доступна. Используйте ссылку Safari Books Online для поиска дополнительных ресурсов.
Наборы данных
Наборы данных
На этой странице представлен краткий список наборов данных и порталов данных. Чтобы изучить глобальную сеть наборов данных, подключенных к Интернету, щелкните Linked Open Data Cloud на главной странице.
Учебные ресурсы
Учебные ресурсы
Существует множество ресурсов, которые помогут вам узнать о Semantic Web и связанных данных. Эта страница предоставляет доступ к нескольким учебным ресурсам по темам, связанным со связанными данными, в различных форматах. См. страницу SPARQL для учебных ресурсов, связанных с SPARQL.
Журналы, статьи и документы
Журналы, статьи и документы
Статьи и документы
Семантические веб-службы
Семантические веб-службы
На этой странице перечислены сервисы Semantic Web, представляющие интерес для специалистов по информации, библиотек, музеев и культурных организаций.
Инструменты семантической сети
Инструменты семантической сети
Технология Semantic Web использует множество инструментов. На этой странице перечислены инструменты преобразования, инструменты управления данными, глоссарии, платформы для построения онтологий и словарей, семантические веб-браузеры, валидаторы, редакторы XML и инструменты XPath.
Инструменты оценки
Инструменты авторизации
Инструменты BIBFRAME
Инструменты преобразования
Средства управления данными
Интерфейсы обнаружения
Редакторы
Генераторы
Глоссарии
Платформы и инструменты для создания онтологий/словарей
Инструменты запросов, поисковые системы и надстройки для браузера
серверов
Инструменты для тройного магазина
Валидаторы
Средства визуализации
Инструменты XPath
Разное
Учебные ресурсы для семантических инструментов
СПАРКЛ
СПАРКЛ
SPARQL служит поисковой системой для RDF. Это набор спецификаций, рекомендованных Рекомендацией W3C, которые предоставляют языки и протоколы для запроса и управления содержимым графа RDF в Интернете или в тройном хранилище RDF.
Это набор спецификаций, рекомендованных Рекомендацией W3C, которые предоставляют языки и протоколы для запроса и управления содержимым графа RDF в Интернете или в тройном хранилище RDF.
Документация SPARQL
GeoSpatial SPARQL
В дополнение к документам W3c SPARQL существует документация для языка запросов Geospatial SPARQL.
Конечные точки SPARQL
В этом поле содержатся ссылки на некоторые конечные точки SPARQL, полезные для исследователей и являющиеся хорошими примерами наборов данных для практики использования запросов SPARQL. Набор данных Europeana используется в учебнике SPARQL для гуманитариев слева.
Инструменты SPARQL
Этот ящик содержит инструменты SPARQL.
Учебные ресурсы SPARQL
Словари, онтологии и рамки
Словари, онтологии и основы
Контролируемые словари, онтологии, схемы, тезаурусы и синтаксисы — это стандартные блоки, используемые платформой описания ресурсов (RDF) для семантической структуризации данных, идентификации ресурсов и отображения взаимосвязей между ресурсами в связанных данных. Библиотеки и учреждения культуры принадлежат к одной из многих областей организации знаний, использующих контролируемые органы. На этих страницах особое внимание уделяется словарям и компьютерным языкам, которые используются в информационном ландшафте библиотек и учреждений культурного наследия.
Библиотеки и учреждения культуры принадлежат к одной из многих областей организации знаний, использующих контролируемые органы. На этих страницах особое внимание уделяется словарям и компьютерным языкам, которые используются в информационном ландшафте библиотек и учреждений культурного наследия.
Стандарты видения: визуализация вселенной метаданных
О стандартах зрения
Беккер, Девин и Дженн Л. Райли. (2010). Видение стандартов: визуализация вселенной метаданных . Нажмите на диаграмму, чтобы открыть PDF-версию и Глоссарий стандартов метаданных.
О словарях
Онтологии и фреймворки
Онтологии и фреймворки
International Image Interoperability Framework (IIIF)
IIIF — это платформа для доставки изображений, разработанная сообществом ведущих исследовательских библиотек и репозиториев изображений. Цели состоят в том, чтобы обеспечить доступ к беспрецедентному уровню единообразного и богатого доступа к ресурсам на основе изображений, размещенным по всему миру, определить набор общих интерфейсов прикладного программирования, поддерживающих взаимодействие между репозиториями изображений, разрабатывать, развивать и документировать общие технологии, такие как изображения серверы и веб-клиенты для обеспечения просмотра, сравнения, обработки и аннотирования изображений.
Цели состоят в том, чтобы обеспечить доступ к беспрецедентному уровню единообразного и богатого доступа к ресурсам на основе изображений, размещенным по всему миру, определить набор общих интерфейсов прикладного программирования, поддерживающих взаимодействие между репозиториями изображений, разрабатывать, развивать и документировать общие технологии, такие как изображения серверы и веб-клиенты для обеспечения просмотра, сравнения, обработки и аннотирования изображений.
Два основных API для платформы:
- IIIF Image API 3.0
IIIF Консорциум. (2021). Эпплби, Майкл, Крейн, Том, Сандерсон, Роберт, Струп, Джон и Уорнер, Симеон. В этом документе описывается спецификация API доставки изображений для веб-службы , которая возвращает изображение в ответ на стандартный запрос HTTP или HTTPS . URI может указывать регион, размер, поворот, характеристики качества и формат запрошенного изображения, а также может запрашивать базовую техническую информацию об изображении для поддержки клиентских приложений.
URI может указывать регион, размер, поворот, характеристики качества и формат запрошенного изображения, а также может запрашивать базовую техническую информацию об изображении для поддержки клиентских приложений.
- IIIF Презентация API 3.0.
IIIF Консорциум. (2021). Эпплби, Майкл, Крейн, Том, Сандерсон, Роберт, Струп, Джон и Уорнер, Симеон. IIF Presentation API предоставляет информацию, необходимую пользователям-людям, чтобы обеспечить богатую онлайн-среду просмотра сложных цифровых объектов. Он позволяет отображать оцифрованные изображения, видео, аудио и другие типы контента, связанные с конкретным физическим или изначально цифровым объектом, обеспечивает навигацию между несколькими представлениями или временными экстентами объекта, последовательно или иерархически, отображает описательную информацию об объекте. , представления или структуры навигации, а также предоставляет общую среду, в которой издатели и пользователи могут снабжать объект и его содержимое дополнительной информацией.
- Презентация поваренной книги рецептов IIIF
The Cookbook предоставляет типы ресурсов и свойства спецификации Presentation и для визуализации средствами просмотра и другими программными клиентами. Приведены примеры, чтобы побудить издателей принять общие шаблоны при моделировании классов сложных объектов, дать возможность разработчикам клиентского программного обеспечения поддерживать эти шаблоны для единообразия взаимодействия с пользователем и продемонстрировать применимость IIIF в широком диапазоне вариантов использования.
Дополнительные API для платформы:
- API аутентификации IIF 1.0
IIIF Консорциум. (2021). Эпплби, Майкл, Крейн, Том, Сандерсон, Роберт, Струп, Джон и Уорнер, Симеон. Спецификация аутентификации описывает набор рабочих процессов для проведения пользователя через существующую систему контроля доступа . Он предоставляет ссылку на пользовательский интерфейс для входа в систему и службы, которые предоставляют учетные данные, смоделированные по образцу элементов рабочего процесса OAuth3, выступающих в качестве моста к системе управления доступом, используемой на сервере, при этом клиенту не требуется знание этой системы.
- API поиска контента IIIF 1.0
IIIF Консорциум. (2021). Эпплби, Майкл, Крейн, Том, Сандерсон, Роберт, Струп, Джон и Уорнер, Симеон. Спецификация Content Search устанавливает механизм взаимодействия для выполнения поиска среди различных типов контента из разных источников. Областью применения спецификации является поиск содержимого аннотаций в одном ресурсе IIIF , таком как манифест, диапазон или коллекция.
Связанное искусство
Linked Art — это модель данных, которая обеспечивает профиль приложения, используемый для описания ресурсов культурного наследия с упором на произведения искусства и музейную деятельность. Основываясь на реальных данных и вариантах использования, он определяет общие шаблоны и термины, используемые в его концептуальной модели, онтологиях и словаре. Linked Art следует существующим стандартам и рекомендациям, включая CIDOC-CRM, словари Getty и JSON-LD 1. 1 в качестве основного формата сериализации.
1 в качестве основного формата сериализации.
OWL 2
Онтологии представляют собой формализованные словари терминов, часто охватывающие определенную область. Они определяют определения терминов, описывая их отношения с другими терминами в онтологии. OWL 2 — это язык веб-онтологий, предназначенный для облегчения разработки онтологий и обмена ими через Интернет. Он предоставляет классы, свойства, отдельных лиц и значения данных, которые хранятся в виде документов Semantic Web. В качестве словаря RDF OWL можно использовать в сочетании со схемой RDF.
VOWL : Визуальная нотация для онтологий OWL
Негру, Стефан, Ломанн, Сеффан и Хааг, Флориан. (2014, 7 апреля). Спецификация версии 2.0. VOWL определяет визуальный язык для ориентированного на пользователя представления онтологий. Язык предоставляет графические изображения для элементов OWL, которые объединены в силовой макет графа, визуализирующий онтологию. Он фокусируется на визуализации классов, свойств и типов данных, иногда называемых TBox, а также включает рекомендации о том, как изображать людей и значения данных, ABox.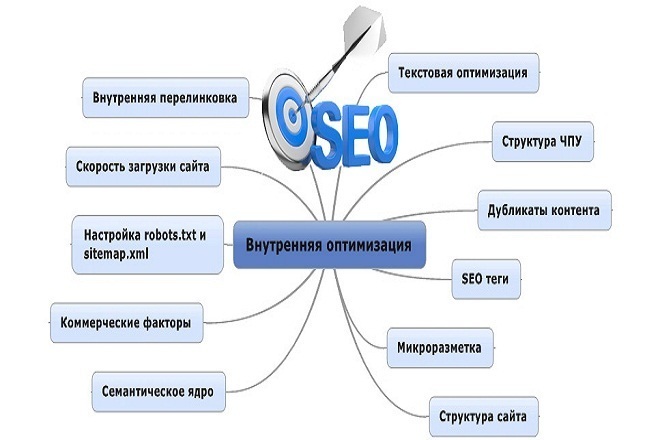 Для понимания этой спецификации требуется знакомство с OWL и другими технологиями Semantic Web.
Для понимания этой спецификации требуется знакомство с OWL и другими технологиями Semantic Web.
PRESSoo
RDF 1.1
Структура описания ресурсов (RDF) представляет собой структуру для представления информации в сети данных. Он включает набор стандартов и спецификаций, документация по которым приведена ниже.
RDF 1.1 Сериализации
Существует несколько форматов сериализации RDF для реализации RDF. Первым форматом был XML/RDF. Последующие форматы сериализации были разработаны и могут больше подходить для конкретных сред.
SKOS (Простая система организации знаний)
SKOS — это модель данных W3C, определенная как полная онтология OWL для использования с системами организации знаний, включая тезаурусы, схемы классификации, системы предметных рубрик и таксономии. Многие словари Semanatic Web включают модель SKOS. Предметные рубрики Библиотеки Конгресса и словари Гетти являются примерами словарей, опубликованных как словари SKOS.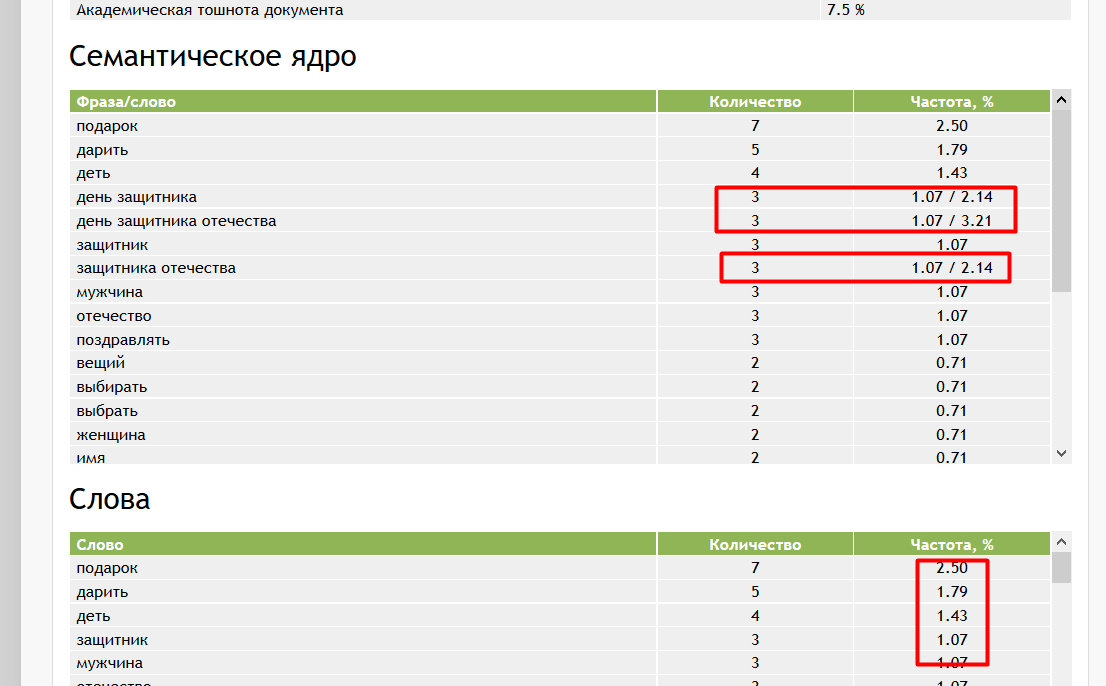
Разработка онтологии
Реестры, порталы и органы власти
Открытые связанные словари (LOV)
Нажмите на изображение LOV, чтобы получить доступ к словарям, выбранным на основе требований к качеству и лучших практик публикации.
Нажмите на словарь. Найдите обведенный эллипс в правом верхнем углу, нажмите на него и получайте удовольствие, играя с инструментами для словарей. Исследуйте немного больше и найдите полезную информацию о выбранной вами лексике.
Реестры, порталы и органы
Словари Гетти
Схемы
Схемы
Схема использует формальный язык для описания системы баз данных и относится к тому, как построена организация данных в базе данных. В этом поле перечислены несколько схем, адресованных различным доменным областям. Прокрутите вниз до поля Dublin Core, чтобы получить доступ к информации о схеме и инструментах Dublin Core.
Прокрутите вниз до поля Dublin Core, чтобы получить доступ к информации о схеме и инструментах Dublin Core.
Дублинское ядро
Юридические схемы
СВЯЗАННЫЕ РЕСУРСЫ
Словари
Словари
Словарь взаимосвязанных наборов данных (VoID)
Примечания
Словари Getty см. на странице «Реестры, порталы и органы».
Викибаза и Викиданные
Викибаза и Викиданные
Викибаза — это платформа, на которой строятся Викиданные, проект Викимедиа. Это позволяет использовать многоязычные экземпляры. Сценарии использования Wikibase см. в поле «Случаи использования Wikibase» в нижней части страницы «Случаи использования».
Движение Викимедиа
Викимедиа — это глобальное движение, которое стремится предоставить миру бесплатное образование с помощью веб-сайтов, известных как проекты Викимедиа.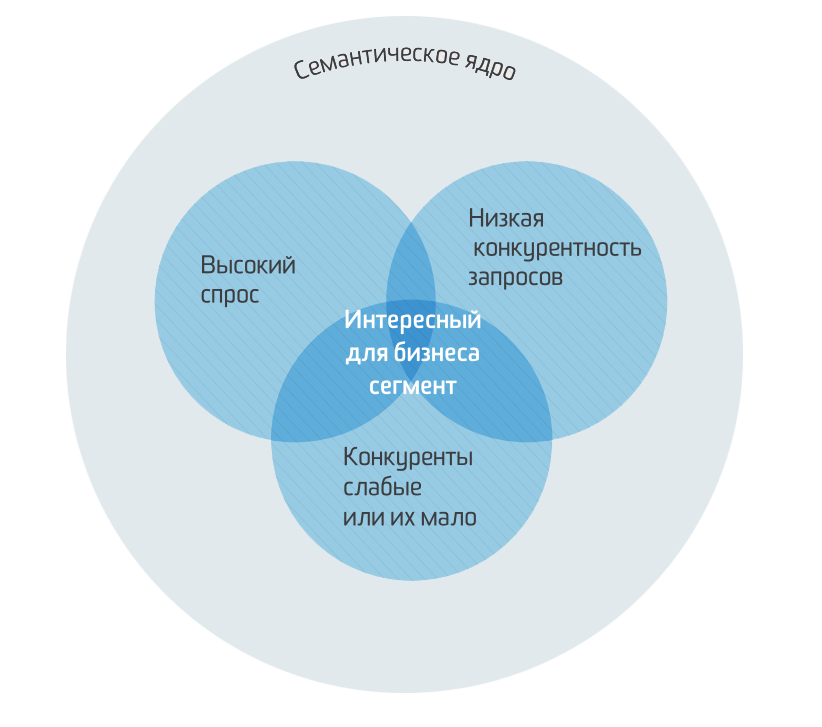 Проекты Викимедиа размещаются Фондом Викимедиа. Некоторые из этих проектов перечислены ниже. Получите доступ ко всему семейству проектов Викимедиа здесь.
Проекты Викимедиа размещаются Фондом Викимедиа. Некоторые из этих проектов перечислены ниже. Получите доступ ко всему семейству проектов Викимедиа здесь.
Викибаза
Ресурсы Викибазы
Предупреждение Викиданных
Викиданные
Викиданные — это бесплатное многоязычное программное приложение для совместной работы, созданное из компонентов Викибазы, которые могут читать и редактировать люди и машины. Он собирает структурированные данные для поддержки проектов Викимедиа, включая Википедию, Викисклад, Википутешествие, Викисловарь, Викиресурс и другие. Содержимое Викиданных доступно по бесплатной лицензии, экспортируется с использованием стандартных форматов и может быть связано с другими наборами открытых данных в сети связанных данных.
Статьи, планы развития и отчеты
Ресурсы, связанные с Викиданными
WikiProjects
Университеты WikiProject
ВикиПроекты
Свойства Викиданных
Свойства Викиданных
Викиданные/Инструменты Викимедиа
Викиданные/Инструменты Викимедиа
Для работы с Викиданными разработано множество инструментов, многие из которых перечислены на странице Инструменты Викиданных, указанной ниже. Общие инструменты, полезные для редактирования и добавления элементов в Викиданные, перечислены здесь.
Общие инструменты, полезные для редактирования и добавления элементов в Викиданные, перечислены здесь.
Мастерские и проекты
Мастерские и проекты
Эта страница предоставляет доступ к документам и отчетам, связанным с семинарами, учреждениями, организациями или другими субъектами, которые содержат ценную информацию или описывают инициативы или проекты, касающиеся Semantic Web или связанных данных.
Основные моменты
Варианты использования
Варианты использования
На этой странице приведены ссылки на примеры используемых в настоящее время связанных данных.
Примеры использования Wikibase
Эдинбургский университет Wikimedian in Residence Projects
UW Libraries Semantic Web Blog
Опубликовано Автор Кристал Э. Клементс
Последнее обновление 05.04.2022
LRM/RDA/RDF — наша предпочтительная онтология для представления наборов описаний RDA в виде связанных данных. Этот пост предназначен для быстрого ознакомления с работой, проделанной нами в этой области, со ссылками на сопроводительную документацию и презентации.
2016 Опубликовано Сопоставление RDA Core с BIBFRAME 2.0 (сопоставление)
2019–2020 Получил субгрант и участвовал в качестве когортного учреждения в LD4P2 (проект wiki). Мы начали работу над LRM/RDA/RDF в Sinopia и расширили наше раннее отображение RDA на BIBFRAME.
2020 Опубликовано расширенное преобразование RDA/RDF в BIBFRAME Mapping и соответствующий инструмент преобразования на основе RML. (сопоставление) (инструмент преобразования)
2020 Начат проект Sinopia MAPs для создания обновленных профилей приложений LRM/RDA/RDF для использования в Sinopia (проект)
2021 Представлено в работе LD4P2 в ALA BCM-IG (запись)
2021 Представлено о местных проектах LRM/RDA/RDF на SWIB21 (запись)
2021 Модерировал панель на семинаре BIBFRAME в Европе, «Какую роль могут играть RDA/RDF в переходе к связанным библиотечным данным?» (слайды с вопросами) (запись) (слайды Zapounidou) (сообщение в блоге Dunsire) (сообщение в блоге Zapounidou)
2021 Запущен проект библиографии MARC21 для LRM/RDA/RDF Mapping Project (проект)
Posted in UncategorizedTagged RDA, RDA (Описание и доступ к ресурсам, RDA-in-RDF, Sinopia
Опубликовано Автор Бенджамин Ризенберг
Это вторая из двух публикаций 1 в панельной дискуссии «Какую роль может играть RDA/RDF в переходе к данным связанных библиотек?» которое состоялось во время пятого ежегодного совещания семинара BIBFRAME в Европе, и на нем были представлены комментарии пяти выдающихся участников дискуссии. В этом посте кратко излагаются и обсуждаются комментарии доктора Софии Запуниду, библиотекаря Университета Аристотеля в Салониках и члена Постоянного комитета Секции каталогизации ИФЛА. 2 Ей было предложено ответить на следующий вопрос во время мероприятия:
RDA тщательно согласуется с LRM; BIBFRAME 3 нет. Одной из наиболее обсуждаемых проблемных областей является отсутствие объекта выражения в BIBFRAME. Может ли это или другие несовместимости между RDA и BIBFRAME иметь серьезные последствия?
Подробнее RDA, BIBFRAME и моделирование библиографических отношений
Posted in UncategorizedTagged BIBFRAME, RDA (Описание ресурсов и доступ к ним, RDA-in-RDF
Опубликовано Автор tgis
Мы начинаем согласовывать MARC с RDA/LRM. Мы начали с согласования поля MARC 490 с RDA/LRM. Как и ожидалось, возникли сложности.
Подробнее Наше первое согласование MARC с RDA/LRM: создание прецедента
Опубликовано в Без рубрикиОпубликовано Автор tgis
Это первая из двух публикаций на панельной дискуссии «Какую роль может играть RDA/RDF в переходе к данным связанных библиотек?» который состоялся во время 5-го ежегодного собрания семинара BIBFRAME в Европе [1] и содержал комментарии пяти выдающихся участников дискуссии [2]. Этот пост представляет собой расшифровку ответа Гордона Дансира (бывшего председателя руководящего комитета RDA и нынешнего члена технической рабочей группы RSC [3]) на вопрос, заданный на семинаре BIBFRAME, за которым последовала аннотированная версия (аннотированная Тео Gerontakos) с участием некоторых из обсуждаемых областей.
RDA/LRM/RDF содержит элементы, которые по существу являются материализованными цепочками свойств в RDA, известными как ярлыки, в то время как BIBFRAME содержит множество цепочек свойств, которые не являются конкретными элементами, что многие люди называют « «вложенные» данные. Каковы плюсы и минусы цепочек свойств и реификации, и вызывают ли они проблемы совместимости?
Читать далее Гордон Дансир о цепочках собственности и ярлыках в RDA/LRM
Опубликовано в Без рубрикиМоделирование данных с тегами, связанные данные, цепочки свойств, RDA (описание и доступ к ресурсам, RDA-in-RDF, ярлыки
Опубликовано Автор Мелисса Морган
Мы разрабатываем документ сопоставления для преобразования RDA-in-RDF, созданного во время тестирования редактора связанных данных Sinopia в библиотеках Вашингтонского университета, в BIBFRAME. Чтобы реализовать это отображение, мы экспериментировали с языком отображения RDF (RML), разработанным IDLab Гентского университета.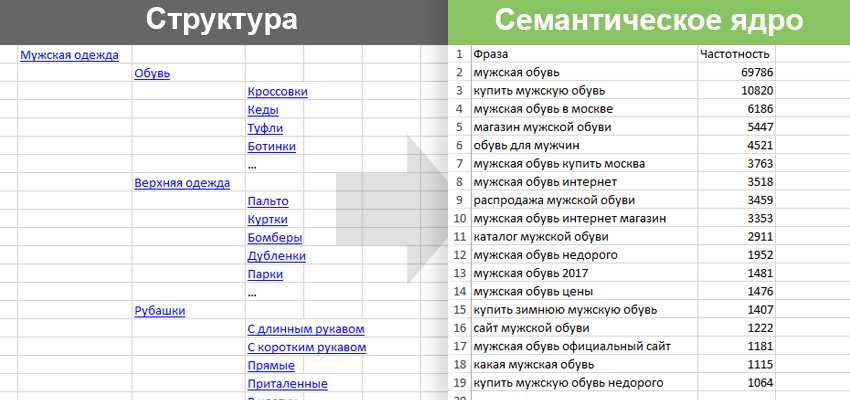 Используя RML, мы можем преобразовывать данные RDA, представленные в RDF/XML, в данные BIBFRAME либо в Turtle, либо в N-quads.
Используя RML, мы можем преобразовывать данные RDA, представленные в RDF/XML, в данные BIBFRAME либо в Turtle, либо в N-quads.
Наш прогресс можно просмотреть в нашем репозитории GitHub, включая примеры данных для преобразования, рабочие документы сопоставления и примеры результатов, которые мы получили с помощью RMLMapper. Наш самый обширный документ сопоставления (workMonographMap.xml.ttl) предназначен для преобразования данных, созданных с использованием нашего профиля приложения монографии, для объектов, классифицируемых как RDA Work.
Мы надеемся, что наши документы по сопоставлению RML могут служить примерами для тех, кто пытается использовать RML, поскольку текущие спецификации для RML являются неофициальным проектом (последнее обновление в июле 2020 г.). Примеры в спецификациях представляют относительно простые преобразования, предоставляя пользователям RML возможность создавать свои собственные решения для любых данных или преобразований, немного более сложных.
Подробнее Использование RML для преобразования RDA в BIBFRAME
Опубликовано в UncategorizedTagged BIBFRAME, Linked Data, RDA, RDA (описание и доступ к ресурсам, RDA-in-RDF, RML
Опубликовано Автор tgis
Проблема:
Используя рекомендации RDA (описание и доступ к ресурсам, 2017 г.), мы можем точно представить работу, которая является предметом другой работы; например, книга, анализирующая шекспировского «Гамлета», может быть представлена в RDA следующим образом:
Подделка: исследование # воображаемая книга о Гамлете
RDAW: 10140 # RDA Собственность «Анализ работы»
Фах: Гамлет. # местная запись о работе для Гамлета.
Или, если у нас есть литерал для представления Гамлета:
Как их можно выразить с помощью BIBFRAME?
Предлагаемое решение:
fake:studyOfHamlet a bf:Work ;
bf:subject подделка: Гамлет ;
bf:relatedTo fake:Hamlet .
Или, когда Гамлет описывается с помощью литерала:
fake:studyOfHamlet a bf:Work ;
bf:subject [ a madsrdf:Title ;
rdfs:label «Гамлет» ] ;
bf:relatedTo [ a bf:Work ;
rdfs:label «Гамлет»].
Анализ:
Чтобы выразить отношения в приведенном выше примере (и в подобных отношениях, используя обозначения отношений в Приложении M), мы решили, что BIBFRAME требует, чтобы мы выбирали свойства либо из набора свойств «отношений» в иерархии bf:relatedTo, либо из другого « subject» за пределами этой иерархии, bf:subject. В результате решающий вопрос заключался в том, являются ли обозначения отношений в Приложении М («является ли анализ работы» в приведенном выше примере) «предметами» или «отношениями»? Если указатель отношения является «отношением», мы должны использовать свойство bf:relatedTo или одно из его подсвойств; если обозначение отношения является «субъектом», мы должны использовать свойство BIBFRAME bf:subject, а затем, когда значение является литералом, использовать классы и свойства MADS/RDF для завершения описания этого «субъекта».
Решение, предложенное выше, рассматривает отношение как отношения BIBFRAME , так и отношения с субъектом BIBFRAME. Это решение исходит из реестра RDA, где «элементам» RDA присваивается семантическая веб-идентификация. Создатели RDA-RDF увеличили количество свойств и разместили каждое свойство в богатой иерархии. Обозначения отношения RDA, Приложение M, для предметных отношений помещаются в иерархию ниже следующей ветви «отношения»: «имеет связанный объект объекта RDA» → «имеет связанный объект RDA объекта RDA» → «имеет связанный объект RDA работы». В этот момент иерархия разбивается на несколько ветвей, в том числе две «тематические» ветви, «имеет субъектную сущность RDA» и «имеет субъектную». Обе эти предметные ветви ведут к обозначениям отношений Приложения M, включая тот, который используется в приведенном выше примере, «является анализом работы». Это демонстрирует, что создатели RDA-RDF учитывают эти свойства отношений и «отношения» и «субъекты», поскольку «верхняя часть» иерархии описывает отношения, а «нижняя часть» иерархии описывает субъекты.
Решение также возникло из общего принципа при отображении одной онтологии на другую: если целевая онтология имеет несколько решений для одного утверждения, созданного с использованием исходной онтологии, используйте несколько решений — по возможности все, а не только одно. В этом случае одно утверждение из RDA имеет несколько значений с одним предикатом; если BIBFRAME имеет несколько предикатов, которые приближают полную сложность исходного оператора, используйте несколько предикатов, а не только один. Конкретно мы не будем говорить, что изучение Гамлета составляет всего 9 лет.0574 связан с Гамлетом, но Гамлет также является предметом изучения Гамлета.
Дополнительные соображения по поводу предлагаемого решения в примере
- Использование всех возможных решений с использованием целевой онтологии может привести к ненужной избыточности, особенно при использовании глубоко иерархических онтологий. Нам все равно?
- BIBFRAME не имеет более конкретного свойства, чем bf:relatedTo, для выражения отношения в приведенном выше примере.
- При описании ресурса литералом:
- a madrdf:Title «Описывает ресурс, метка которого представляет заголовок» и применяется в данном случае.
- rdfs:label на самом деле является реализацией MADS/RDF, где madsrdf:authoritativeLabel было бы правильным свойством, если бы контролировалась метка «Гамлет». Это не. madsrdf:authoritativeLabel — это подсвойство rdfs:label, которое применимо в данном случае и использовалось в решении.

Tagged BIBFRAME, MADS/RDF, Ontology Matching, RDA (описание ресурсов и доступ к ним).
Опубликовано Автор tgis
Перейдите по этой ссылке: Памятка SHACL
версия 0.2 30 мая 2020 г.
Описание
Памятка для помощи в написании кода на языке ограничений фигур (https://www.w3.org/TR/shacl /). В этой памятке представлены две основные группы SHACL:
(1) «Основное ядро»
(2) «Промежуточное ядро»
Есть надежда, что «Core Core» предоставляет большую часть свойств и классов, необходимых для написания большинства форм.
Опубликовано в Без рубрики
Опубликовано Автор Бенджамин Ризенберг
- Сотрудничество между библиотеками Вашингтонского университета (UW) и UW iSchool запускает группу исследователей семантической сети (SWIG)
- SWIG инициирует проект по представлению списка жанров газет в виде словаря простой системы организации знаний (SKOS) (RDF доступен по адресу https://doi.org/10.6069)./uwlib.55.d.5)
- Библиотеки Университета Вашингтона созывают общеуниверситетское собрание с заинтересованными сторонами, связанными с данными
- Библиотекарь по каталогизации и метаданным Теодор Геронтакос является сопредседателем группы по интересам связанных библиотек данных (LITA/ALCTS)
- Сотрудники Службы каталогизации и метаданных (CAMS) библиотек UW предоставляют отзывы о BIBFRAME 1 и 2 через серверы рассылки Библиотеки Конгресса (LOC) и репозитории кода GitHub
- Сотрудники CAMS готовят учебные материалы по BIBFRAME и проводят занятия
- Более 100 записей MARC преобразуются в BIBFRAME 1 и просматриваются каталогизаторами
- Персонал CAMS создает форму ввода RDA в качестве проверки концепции, демонстрируя вывод как RDA-in-RDF, так и BIBFRAME из входных данных
- LoC выпускает BIBFRAME 2
- Тестовое преобразование записей MARC в BIBFRAME 2
- Сравнительное тестирование поиска по данным BIBFRAME, преобразованным из MARC и цифровых коллекций XML
- CAMS публикует сопоставление элементов RDA стандартной записи BIBCO с BIBFRAME 2. 0
- Первая направленная полевая работа по стандартам и данным семантической сети, проведенная студентом iSchool Университета Вашингтона
- CAMS публикует предварительные рекомендации по языковым тегам в библиографических связанных данных
 0
0- XML-сервер CAMS расширен за счет включения тройного хранилища RDF для обучения
- Исследовательская группа SPARQL собралась в библиотеках UW
- UW Libraries начинает участие в качестве субгрантополучателя проекта «Связанные данные для производства: путь к реализации» (LD4P2)
Tagged BIBFRAME, Linked Data, RDA-in-RDF
Опубликовано Автор Бенджамин Ризенберг
Идея списка первого чтения для всех, кто приступает к библиотечной работе со связанными данными, нереалистична по очевидным причинам. Мы все проявляемся с разным опытом, набором навыков и стилями обучения, а это означает, что разные ресурсы будут более или менее полезными. По этой причине я должен немного рассказать о своем опыте работы с библиотечными связанными данными.
По этой причине я должен немного рассказать о своем опыте работы с библиотечными связанными данными.
Когда я начал свою программу MLIS, у меня не было реального опыта программирования. У меня действительно был интерес к компьютерам, и, возможно, из-за этого я довольно рано сосредоточился на цифровых коллекциях и цифровом сохранении. Это поставило меня в сложное положение – я чувствовал, что должен наверстать упущенное в плане технических навыков. Я начал получать их благодаря курсовой работе и практическому обучению, но эти вещи требуют времени, и этот процесс продолжается. Мой подход к работе со связанными данными — и этот список для чтения — были сформированы тем фактом, что я относительный новичок.
Кроме того, я выбрал из уже прочитанного, чтобы составить этот (очень короткий) список, а я не все прочитал на эту тему! Я надеюсь получить ответ от читателей, желающих поделиться своим опытом с ресурсами, не включенными в этот список.
Подробнее Чтения связанных данных библиотеки: запуск
Posted in UncategorizedTagged Linked Data, Readings
Опубликовано Автор tgis
Мы пишем профиль приложения метаданных. Мы используем синтаксис профиля Библиотеки Конгресса для создания профилей BIBFRAME (http://www.loc.gov/bibframe/docs/bibframe-profiles.html). Почти все наши свойства были взяты из описания ресурсов и доступа (RDA; см. https://www.rdatoolkit.org/about и реестр RDA на https://www.rdaregistry.info). Это профили json, предназначенные для создания форм ввода данных, которые выводят связанные данные. Формы ввода данных будут отображаться в разрабатываемом связанном редакторе данных Sinopia (https://sinopia.io/), что позволит специалистам по вводу данных (например, каталогизаторам) вводить значения для свойств RDA. После ввода данные могут быть выведены как данные RDF; этот результат является предпосылкой нашей работы. На самом деле, мы часто создаем профиль в соответствии с концептуальным выводом, который мы моделируем для данного свойства. Эта запись иллюстрирует эту практику создания профиля: понимание того, какие структуры формы ввода данных требуются, путем моделирования ожидаемого вывода формы; более конкретно, эта запись фокусируется на том, как форма выводит свойства и значения для предметных заголовков (категорий, описывающих содержание ресурса).