
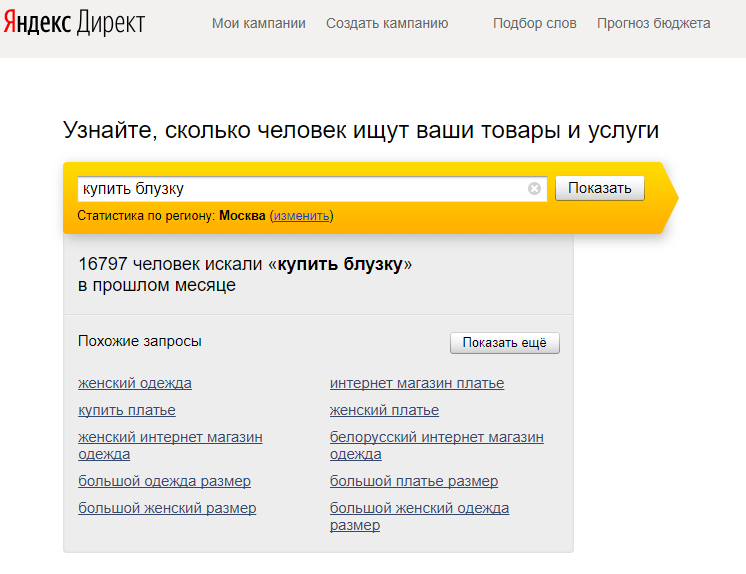
Десять по-настоящему полезных фишек поиска Яндекса
Интернет без поисковика представить невозможно — им пользуется абсолютно каждый человек, который заходит в Сеть. Но поисковые машины давно перестали быть тривиальным инструментом, лишь выдающим ссылки в ответ на те или иные запросы. У Яндекса, например, есть масса удобных и полезных фишек, которые существенно облегчают поиск контента и экономят время. О некоторых из них я расскажу в этом материале. Поехали!
Визуальный поиск на картинках
Искать изображения по ключевым словам умеют многие поисковики, а вот распознавать объекты и даже текст на картинке далеко не все. Яндекс автоматически определяет предметы на изображениях, а затем подсказывает, где найти такие же или похожие.
Ниже пример того, как поисковик распознал стул на фотографии интерьера и тут же выдал ссылки на магазины, где такой или похожий можно приобрести. Однозначно полезная штука:
Причём это работает не только с товарами, но и, например, с местностью и достопримечательностями. Понравилось фото друга из соцсетей, но не знаете, где это находится? Просто загружаете изображение в поиск по картинкам и Яндекс подсказывает:
Понравилось фото друга из соцсетей, но не знаете, где это находится? Просто загружаете изображение в поиск по картинкам и Яндекс подсказывает:
«Умная» камера в мобильном приложении
В мобильное приложение Яндекса встроена «умная» камера, которая в реальном времени распознаёт и находит объекты, попадающие в объектив смартфона.
Её ключевая фишка заключается в том, что она проводит товарный поиск с учётом того, какие товары продаются в России. Это выгодно отличает отечественный поисковик от той же Google Lens, осуществляющей поиск в основном по заграничным маркетплейсам.
Аналогично поиску по картинкам, «умная» камера с лёгкостью распознаёт и другие объекты, например, здания и достопримечательности, а также приводит подробную справку о них.
Кроме того, в «умную» камеру Яндекса встроен переводчик и сканер документов, что крайне полезно при чтении иноязычных надписей на офлайн-поверхностях и для работы с бумажными документами.
Фильмовые подсказки
Если попросить Яндекс показать «фильм о. ..», то поисковик не просто выдаст подборку кинолент, но и сделает это с учётом предпочтений пользователя, а также покажет персональный рейтинг в процентах, то есть то, насколько ему подходит то или иное кино. При желании фильмы можно отсортировать по популярности или году выхода.
..», то поисковик не просто выдаст подборку кинолент, но и сделает это с учётом предпочтений пользователя, а также покажет персональный рейтинг в процентах, то есть то, насколько ему подходит то или иное кино. При желании фильмы можно отсортировать по популярности или году выхода.
Поиск фильма по описанию
Более того, Яндекс умеет искать фильмы даже по самому странному или отрывочному описанию, а затем сразу предлагает их посмотреть прямо в выдаче. Вот пример:
Поиск нужного фрагмента видео по текстовому запросу
Одна из фишек последнего обновления поиска Яндекса Y1 — это поиск фрагмента видео.
Новшество позволяет не только найти необходимый ролик, но и начать просмотр сразу с нужного момента. Для этого Яндекс сопоставляет смысл текстовых запросов с содержанием видеороликов и ищет, по сути, внутри видео.
Стоит пользователю ввести запрос, например, «как приготовить стейк из тунца», то Яндекс не просто покажет какой-то ролик, но и предложит пользователю включить его с того места, где рассказывается суть. Причём поиск фрагмента видео работает с множеством различных инструкций, например, «как помыть собаку» или «как научиться кататься на скейте».
Причём поиск фрагмента видео работает с множеством различных инструкций, например, «как помыть собаку» или «как научиться кататься на скейте».
Виджеты крупных событий прямо в поисковой выдаче
Яндекс в курсе важных событий, происходящих в мире, поэтому при соответствующих запросах поисковик выводит информативные виджеты, благодаря которым можно получить исчерпывающие сведения о предмете поиска, не переходя по ссылкам. Яркий и актуальный пример — Евро 2020.
Поиск по номерам телефона и запросы из разряда «кто звонил»
Яндекс имеет обширную базу телефонов не только всевозможных организаций, но и спамеров с мошенниками. Именно на основе неё работает определитель номера, который при установленном приложении Яндекса можно активировать в настройках смартфона. Самый простой способ сделать это — сказать: «Алиса, включи определитель номера».
Но если такое решение по каким-то причинам вы не используете, то можете «пробить», кто вам позвонил, прямо в поисковой строке:
Быстрые ответы для пользователей iPhone и других гаджетов Apple
Если спрашивать у Яндекса что-то о продуктах Apple, то необходимые инструкции появляются сразу в поисковой выдаче.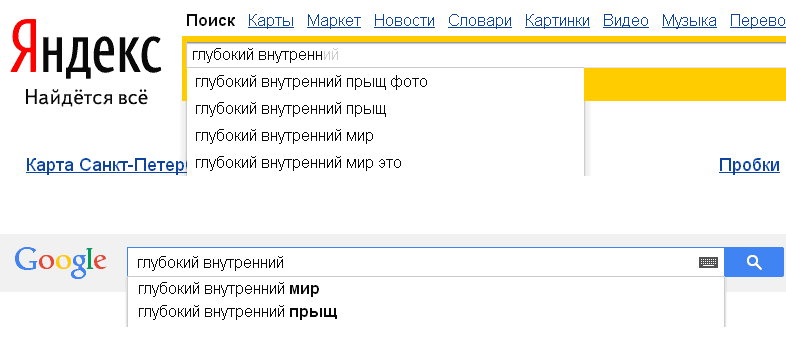 При чём здесь может выводиться не только текст, но и скриншоты, кнопки, иконки и сопутствующие ссылки, указанные на сайте поддержки Apple.
При чём здесь может выводиться не только текст, но и скриншоты, кнопки, иконки и сопутствующие ссылки, указанные на сайте поддержки Apple.
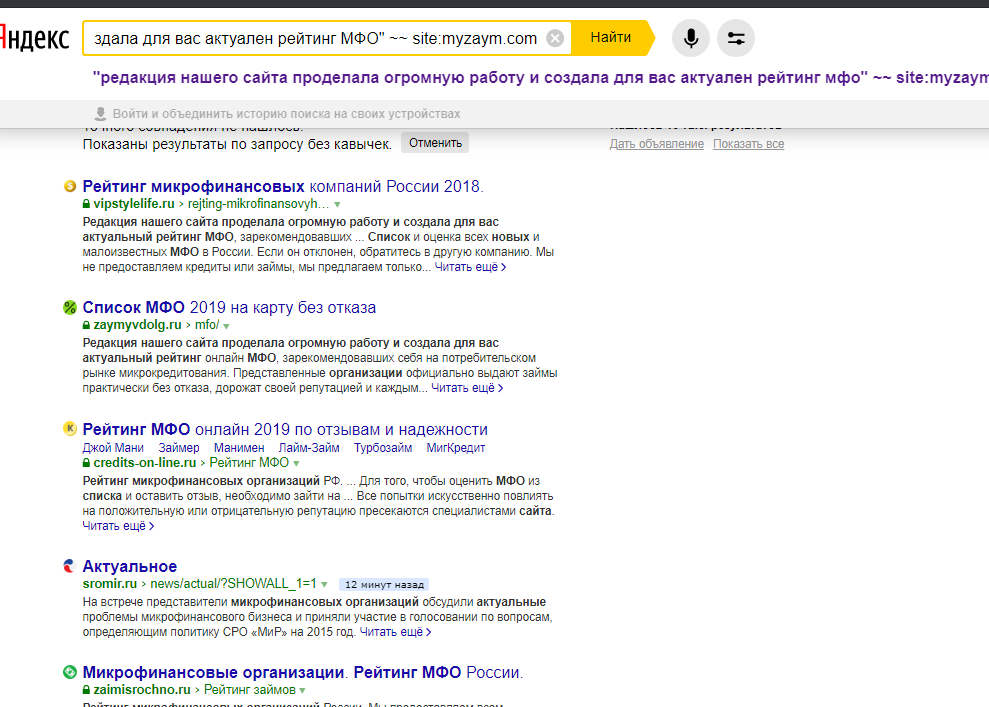
Однако это лишь малая часть — всего в базе Яндекса более 130 млн уникальных быстрых ответов, которые дают ответ пользователю сразу в поисковой выдаче, без перехода на другие сайты.
Ответ сразу в поисковой строке
А на некоторые запросы, которые подразумевают точный и короткий ответ, Яндекс отвечает и вовсе в подсказке, которая появляется, пока вы набираете запрос, что избавляет от необходимости переходить к выдаче. Вот несколько примеров:
Отзывы на кафе, рестораны и другие организации
Это ещё одно новшество, появившееся в последнем обновлении поиска. Яндекс начал анализировать отзывы пользователей о различных организациях: кафе, ресторанах, магазинах и так далее. Поиск обобщает эти данные и показывает в результатах визуальную шкалу оценок.
Например, если спросить Яндекс о каком-нибудь ресторане, то поиск покажет, как люди оценивают блюда, обслуживание и другие важные аспекты.
Вас много — «Я» один
Поисковый алгоритм скрывается за ширмой пользовательского интерфейса. Год за годом его учат все лучше понимать человеческие вопросы и отвечать на них как можно быстрее. Как алгоритм учится сам у себя и у людей, рассказывают руководитель службы качества ранжирования Екатерина Серажим и руководитель группы нейросетевых технологий Александр Готманов. Этой статьей N + 1 продолжает серию совместных материалов с Яндексом о технологиях, которые стоят за работой поиска в интернете.
Задача
Основная поисковая задача Яндекса — находить максимально релевантные запросу документы. В этом ему помогают нейронные сети. Для них запрос и документ — это объекты, между содержанием которых ищется смысловая связь. Иногда понимать смысл заголовка документа необязательно: нейронная сеть не требуется, чтобы предсказать, что Википедия будет релевантна запросу «Википедия». Но бывают и более сложные случаи.
Например, нейронная сеть должна понять, что ответом на запрос «ягоды годжи» будет «Дереза обыкновенная». Или же «догадаться», что хорошим ответом на запрос «движение кораблей онлайн в реальном времени» будет документ с тайтлом «MarineTraffic: Global Ship Tracking Intelligence». Поскольку солидная часть запросов встречается всего один раз, иногда просто невозможно воспользоваться предыдущим опытом и ответить то же самое. Многие запросы приходится обрабатывать с нуля и искать ответ среди огромного числа документов в сети.
По словам Екатерины, уровень нейронных сетей сейчас недостаточен для осознания смысла произвольного документа. Но если правильно обучить нейросеть и поставить ей нужную задачу, она будет способна самостоятельно выделять нетривиальные закономерности в тексте. Можно научить ее исправлять опечатки в словах, определять значимость отдельных слов. Она может научиться переводить их. И в некотором смысле будет делать это более эффективно, чем создатели применяемых эвристик — приемов и методов решения соответствующих задач до появления нейронных сетей.
Перед разработчиками эвристик теперь стоит другая цель. Они должны правильно поставить задачу нейросети, чтобы она могла самостоятельно найти эвристические закономерности в данных.
Помимо выбора множества релевантных документов, нейросеть должна еще и распределить их в порядке соответствия пользовательскому запросу. Задача следующего уровня для нейросети — поиск документов, которые будут соответствовать не только запросу, но и персональным предпочтениям пользователя.
Архитектура
Поиск Яндекса — это система, которая работает постоянно и под большой нагрузкой. Как рассказывает Александр, в сутки только основному веб-поиску приходится обрабатывать сотни миллионов запросов. Из них значительная часть никогда не встречалась ранее.
На ранних этапах системе необходимо рассмотреть десятки миллионов веб-страниц, чтобы выбрать несколько сотен лучших. Они и будут отсортированы в порядке уменьшения релевантности. На обработку всего запроса дается около секунды.
Для достижения этой цели Яндекс используют не одну нейросеть, а целый ансамбль низкоуровневых нейронных моделей, каждая из которых под своим углом описывает связь между запросом и документом. Затем полученные от них данные обрабатываются верхнеуровневой моделью. Она определяет, какой модели следует больше верить и с каким весом какой признак использовать. По словам Екатерины и Александра, такой эмпирический ансамбль работает лучше одной «большой» нейросети.
Нейронная сеть — это алгоритм, который работает не со словами и предложения, а с длинными векторами. Преобразованием текстов векторы занимаются особые словари. BPE — Byte Pair Encoding — один из алгоритмов, применяемых Яндексом для построения словарей. Суть алгоритма заключается в пошаговой замене самой распространенной пары последовательных байтов на незанятый байт.
Поделиться
Нейронная сеть должна превратить входные данные в один или два вектора, чтобы затем получить на выходе одно число. Здесь на помощь приходит пулинг — один из способов объединения векторов. К примеру, векторы можно сложить (не путать с конкатенацией). Можно также брать покомпонентные минимумы или максимумы. Саму конкатенацию — «приклеивание» одного вектора к другому, тоже используют в случаях, если есть два вектора из двух разных текстов.
Поделиться
К полученным векторам затем применяются несколько слоев нейронной сети. Каждый слой — это одно матричное умножение и одно нелинейное преобразование, которое может различаться в зависимости от задачи. В матричном умножении заключается основная вычислительная сложность применения нейросети. При этом матрицы могут быть разреженными, то есть содержать большое количество нулей, только на первом слое. На всех последующих слоях они плотные. Размерность этих матриц составляет несколько сотен на несколько сотен. Яндекс активно использует метод каскадной нейронной сети — векторы или их части из предыдущих слоев могут перебрасываться непосредственно на следующие слои. Такой подход часто работает лучше обычных методов. При этом Яндексу, по словам Александра, удается уместить эти вычисления в несколько миллисекунд без использования специализированных ускорителей (GPU-карт).
При этом матрицы могут быть разреженными, то есть содержать большое количество нулей, только на первом слое. На всех последующих слоях они плотные. Размерность этих матриц составляет несколько сотен на несколько сотен. Яндекс активно использует метод каскадной нейронной сети — векторы или их части из предыдущих слоев могут перебрасываться непосредственно на следующие слои. Такой подход часто работает лучше обычных методов. При этом Яндексу, по словам Александра, удается уместить эти вычисления в несколько миллисекунд без использования специализированных ускорителей (GPU-карт).
Задача практического внедрения нового алгоритма существенно отличается от абстрактной задачи его создания. Теоретические подсчеты иногда могут не прояснить всю ситуацию. Поэтому в Яндексе даже для сложных внедрений финальный тест — это их осторожное использование в системе веб-поиска.
Обучение
Один из самых простых способов оценить вероятность, что документ оказался релевантным для пользователя — использовать информацию о кликах и других действиях в системе (разумеется, обезличенно).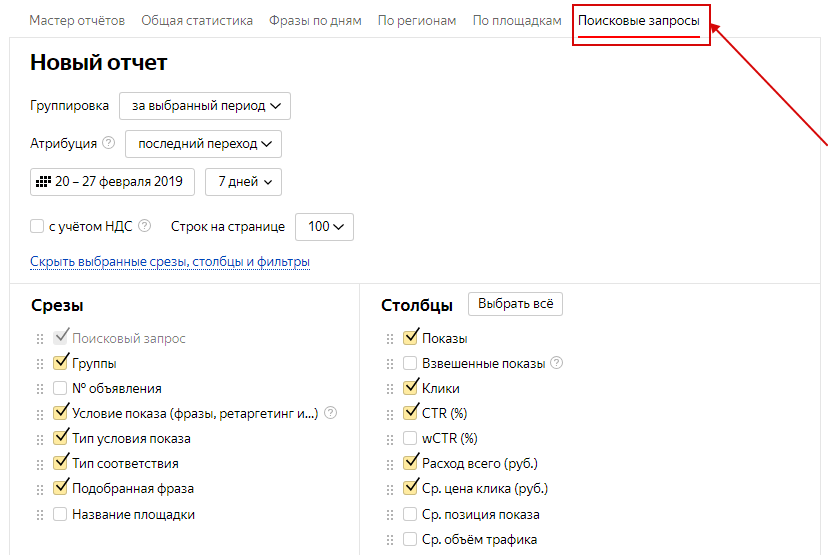 При огромном количестве пользователей нейросеть получила бы бесчисленное множество данных для самообучения. На них можно было бы обучить ее предсказывать, куда кликнет пользователь. Но, как утверждает Серажим, зачастую это имеет мало общего с тем, насколько релевантен этот документ на самом деле. С одной стороны, пользователь мог кликнуть на документ по одному ему известным причинам. С другой, то, что пользователь не кликнул на документ, не значит, что он нерелевантен. Как рассказывает Готманов, нейронная сеть, которая учится предсказывать клики, часто выучивает что-то и про релевантность. Но связь между ними непрямая и ее не всегда можно разглядеть.
При огромном количестве пользователей нейросеть получила бы бесчисленное множество данных для самообучения. На них можно было бы обучить ее предсказывать, куда кликнет пользователь. Но, как утверждает Серажим, зачастую это имеет мало общего с тем, насколько релевантен этот документ на самом деле. С одной стороны, пользователь мог кликнуть на документ по одному ему известным причинам. С другой, то, что пользователь не кликнул на документ, не значит, что он нерелевантен. Как рассказывает Готманов, нейронная сеть, которая учится предсказывать клики, часто выучивает что-то и про релевантность. Но связь между ними непрямая и ее не всегда можно разглядеть.
Чтобы качественно обучить нейросеть, Яндекс перешел к новой методике. Для обучения можно использовать случайно взятые документы. Но если брать их просто в качестве отрицательных примеров, нейросеть быстро упростит себе задачу. Страницы, в заголовках которых встречаются слова из запроса, автоматически бы считались подходящими. Все остальные — нет. Поэтому был выбран другой подход. В качестве положительных примеров нейросеть получала все те же клики. А в качестве отрицательного примера брался не просто случайный документ, а тот, который сама нейросеть считала самым релевантным из случайного набора документов. Скорее всего, такой документ будет нерелевантным, поскольку его тоже случайным образом выбрали из огромной базы. Но для нейронной сети этот пример получится гораздо более сложным и информативным.
Поэтому был выбран другой подход. В качестве положительных примеров нейросеть получала все те же клики. А в качестве отрицательного примера брался не просто случайный документ, а тот, который сама нейросеть считала самым релевантным из случайного набора документов. Скорее всего, такой документ будет нерелевантным, поскольку его тоже случайным образом выбрали из огромной базы. Но для нейронной сети этот пример получится гораздо более сложным и информативным.
Рассматривать можно не только связь документа и запроса. Вокруг документа можно построить облако запросов, по которым пользователи на него переходили. Исходная задача сводится к поиску расстояния между текущим запросом и этим облаком.
Другим способом обучения является анализ пользовательской сессии. Пользовательская сессия — это более «целостная» единица поведения, чем один запрос. В ее рамках, как правило, легче найти смысловую связь с веб-страницей. Используя несложные эвристики, можно понять, что цепочка пользовательских действий связана с одной и той же задачей. Чтобы затем в рамках этой сессии определить, на каком документе пользователь не решил свою задачу и на каком он все-таки нашел требуемый ответ. Этот документ можно назвать релевантным и назначить его положительным примером для обучения нейросети.
Чтобы затем в рамках этой сессии определить, на каком документе пользователь не решил свою задачу и на каком он все-таки нашел требуемый ответ. Этот документ можно назвать релевантным и назначить его положительным примером для обучения нейросети.
Сейчас Яндекс применяет для обучения композитные выборки. Сначала модель учится на огромном множестве простых примеров. Это позволяет ей запоминать базовые закономерности. Затем модель доучивается на небольшом множестве экспертных оценок. Их составляют компетентные в тематике конкретного запроса люди. С помощью такого подхода составляют модели, которые очень хорошо определяют семантическую связь между запросом и документом.
Тестирование
Первое, что должен сделать исследователь после обучения нейронной сети, — понять, насколько хорошо она аппроксимирует целевую функцию, которую он ей дал. Если рассматривать результат работы нейросети только в рамках успеха-неуспеха, то получим бинарную функцию. Единичкой будет положительный пример, нулем — отрицательный. Для того же, чтобы понять, насколько хорошо нейронная сеть приближает целевую функцию, вводится функция ошибки. Разработчик следит за тем, как сильно она убывает в процессе обучения нейросети.
Для того же, чтобы понять, насколько хорошо нейронная сеть приближает целевую функцию, вводится функция ошибки. Разработчик следит за тем, как сильно она убывает в процессе обучения нейросети.
В случае бинарной классификации часто используется функция logloss.
где ŷi — ответ алгоритма на i-ом объекте, yi — истинная метка класса на i-ом объекте, n — размер выборки.
Поделиться
Для других задач, например регрессии, применяют функцию MSE (среднеквадратичная ошибка).
где ŷi — ответ алгоритма на i-ом объекте, yi— истинная метка класса на i-ом объекте, n — размер выборки.
Поделиться
Но даже если функция ошибки минимизируется успешно, это не значит, что нейросеть улучшит качество поиска. В случае, если модель предполагается внедрить в ансамбль нейросетей, измеряются результаты ансамбля с ней и без нее. На этом этапе в качестве выборки служит множество пар «запрос-документ», размеченных экспертами. В качестве метода проверки на этой стадии хорошо работает кросс-валидация. Но это не дает модели безусловный «зеленый свет». Задача улучшения веб-поиска решается в условиях ограниченных ресурсов. Поэтому нейросеть должна вписываться в заданные технические рамки.
На этом этапе в качестве выборки служит множество пар «запрос-документ», размеченных экспертами. В качестве метода проверки на этой стадии хорошо работает кросс-валидация. Но это не дает модели безусловный «зеленый свет». Задача улучшения веб-поиска решается в условиях ограниченных ресурсов. Поэтому нейросеть должна вписываться в заданные технические рамки.
Если модель успешно справляется и с этой задачей, ей предстоят испытания трафиком. К примеру, бета-тестирование. Для пользователей новый алгоритм остается пока недоступным. На модель имитируется поток запросов, так называемый синтетический трафик. В ходе ее работы оценивается, насколько она справилась с ними лучше, чем действующая модель. Этот метод обычно применяется для оценки работы некоторого набора улучшений сразу.
Если этот этап успешно пройден моделью, следующим шагом для нее является А/В-тестирование — испытание настоящими пользователями. Весь трафик делится на контрольную и экспериментальную группу. Специалисты следят за изменениями в экспериментальной группе и смотрят, будут ли пользователи чаще и успешнее находить ответы на свои вопросы.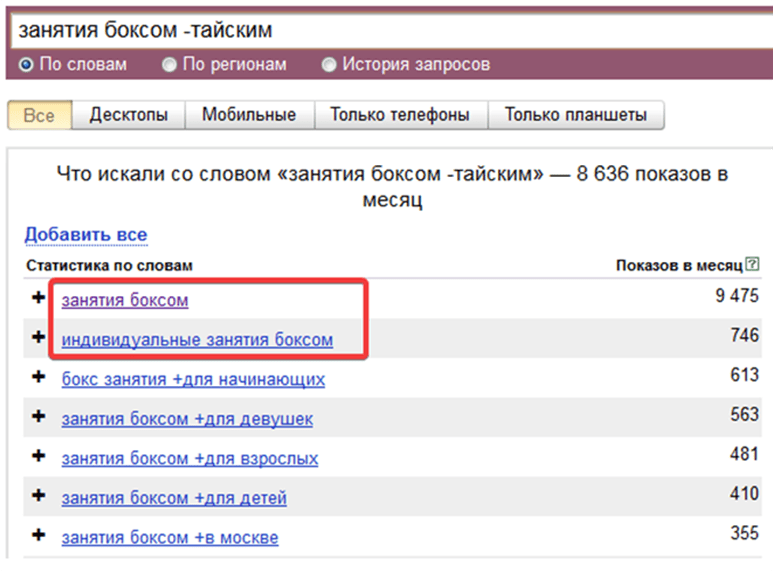
Богдан Сиротич
Составление списка поисковых запросов при помощи Яндекс Метрики и Google для оптимизации страниц сайта
Привет, друзья. Сегодня утром я вдруг соскучился и полез в наш корпоративный аккаунт Яндекс Метрики – этакий способ прокрастинации – смотреть статистику счетчиков клиентских сайтов.
Выводы? Какие выводы, я просто сидел и смотрел графики трафика с поисковых систем сайтов наших клиентов. Учитывая, сколько там сайтов, залипнуть можно надолго с умным видом – ну я же по работе…
Среди сайтов попался мой блог и его, конечно, я тоже посмотрел. Я знал, что последние годы там идет стагнация.
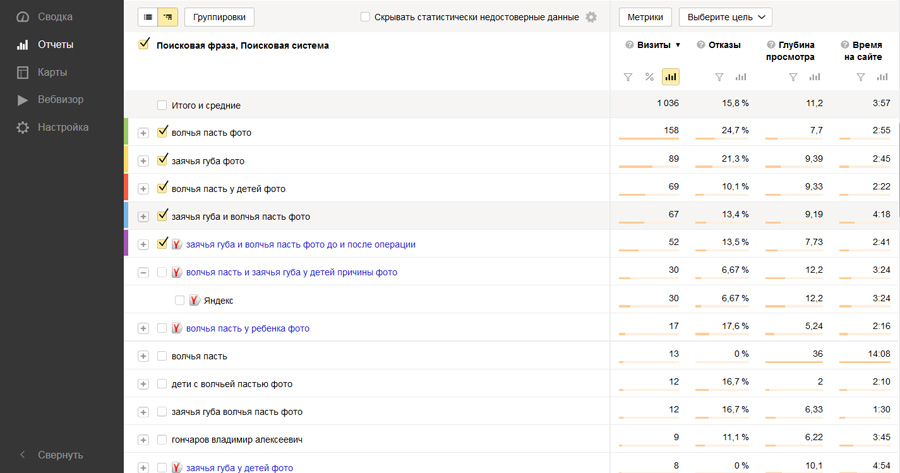
Вот статистика из Метрики за 8+ лет. Когда-то количество посетителей доходило до 80к посетителей в месяц (из них 43к переходов с ПС):
Если посмотреть на график в разрезе именно органического трафика с поисковых систем, получается так:
С июня 2018 по январь 2019 года трафик с поиска стабильно держится на уровне 9-10к переходов (скорее всего, потому, что стал на блог писать).
Год назад я решил посмотреть открытую статистику самых популярных seo-блогов и заметил эту неприятную и удручающую тенденцию. Я выкладывал скрины графиков на fb — абсолютные показатели у всех разные, но наглядно видно, как все одинаково падает. Так что не только у меня, но у всех seo-блогов турдные времена (а может быть, и не только у seo-блогов, но и в других тематиках, но я их не изучал).
Кроме общей тенденции (интерес к формату блогов угасает, появляются новые каналы – чаты/группы в ТГ, нет больше романтики в seo, трафик забирают себе говно-инфо-сайты даже в этой тематике), очевидно, есть и другие причины: новые посты появляются редко, все фундаментальное уже давно размусолено и описано, а что-то новое перестало появляться (такое, чтобы можно было сорвать кучу трафика).
И вот я подумал, а почему бы не проработать существующие страницы, подтянуть их повыше и объять больше запросов? Может быть перелинковку сделать внутреннюю получше…
И раз уж заняться нечем, то взять и описать весь этот процесс в реальном времени. Буду делать оптимизацию для своего блога и документировать это для вас.
Буду делать оптимизацию для своего блога и документировать это для вас.
А спустя какое-то время добавить отдельным постом информацию о том, как трафик на проработанные страницы изменился.
7 лет назад я публиковал пост про трафиковое продвижение сайта на основе анализа данных Google Analytics – тогда я активно работал с Аналитиксом, потому что Метрика была слаба и не давала полезную статистику кроме общих графиков. В те времена еще работали ссылки, и любой даже информационный запрос можно был хорошенько пнуть вверх парочкой вечных ссылок. Другими словами – с тех пор изменились и инструменты, и методы. Об этих изменениях и о том, как работать теперь, я и расскажу.
Итак, допустим, вы решили поработать с существующим контентом на сайте, чтобы увеличить трафик, не добавляя новые страницы. Обратите внимание, речь сейчас про информационный сайт (блог, статейник, в том числе раздел статей в интернет-магазине и т. д.), а не коммерческий проект.
Как я уже говорил, изменились инструменты, например, я предпочитаю теперь пользоваться Яндекс Метрикой вместо Google Analytics: первая обзавелась расширенным функционалам и удобным интерфейсом, а второй так и остался запутанным и неочевидным инструментом для простого пользователя.
Поэтому открываем Метрику, выбираем там свой сайт из списка и переходим к статистике:
Переходим в отчет «Источники трафика». Я предпочитаю вид графиков «Линии», а не круговую диаграмму. Период выбираем год или больше:
Чем больше вы выберите промежуток времени, тем больше данных получите (поисковые фразы), но не стоит забывать и про актуальность данных – нет смысла прорабатывать страницы, актуальность информации на которых прошла.
У меня на блоге, в основном, самые трафиковые страницы про вечное: title, кластеризация запросов, перелинковка, ссылки и т. д. – все то, что не перестанут спрашивать те, кто интересуется seo. Но есть и неактуальные статьи, например, про обзоры фототехники (раньше увлекался) или про переустановку винды (однажды я насобирал все неприятности, какие только могли возникнуть в процессе, аж пост захотелось написать).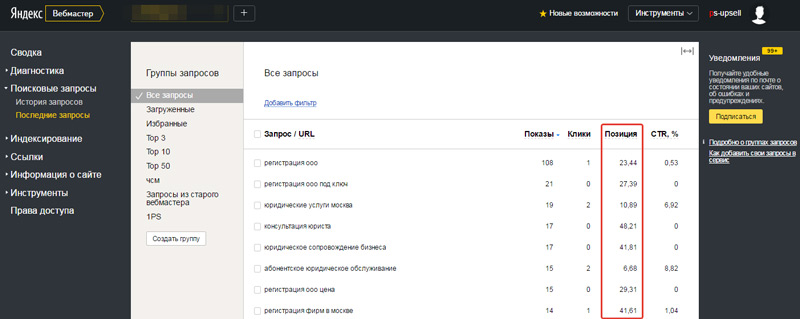
Далее на открытой странице источников трафика прокрутим немного вниз, где увидим в таблице «Переходы из поисковых систем», жмем, чтобы увидеть график переходов в разрезе разных поисковых систем. Как правило, кроме Яндекс и Гугла там нечего смотреть, но стоит знать, как распределяется трафик, потому что, если есть перекос в сторону одной из ПС, это свидетельствует о проблемах (но в рамках этого поста мы не будем разбирать возможные причины).
Открывайте меню: Отчеты – Стандартные отчеты – Содержание – Страницы входа:
На открывшейся странице надо построить статистику с учетом трафика только с ПС. Для этого нажимаем на выпадающий список «Сегмент» – Готовые сегменты – Поисковый трафик:
Результат будет такой:
Далее я изменю у себя период на максимально возможный. Так как блог у меня существует с начала 2010 года, то я решил указать эту дату, но Яндекс показал мне сообщение «Отчет может содержать неполные данные», где было среди прочего два важных предупреждения:
Группировка «Страница входа» начала действовать с 01.
09.2013
Группировка «Поисковая фраза» начала действовать с 26.10.2014
 09.2013
09.2013Поэтому стоит выбирать период, начинающийся не раньше, чем с 26 октября 2014. В общем я выбрал себе период 01.11.2014 – 28.02.2019. Детализация: по месяцам.
Прокрутим страницу ниже до таблицы, где увидим элементы, отмеченные на скриншоте:
- Нажимаем на иконку «Древовидный список» (если выбран не он),
- Нажимаем на «Группировки», и в открывшемся окне удаляем группы «Страницы входа, ур. 1, 2, 3». Оставляем только группы «Страницы входа» и «Поисковая фраза»:
- После применения мы получим таблицу со списком самых популярных страниц по переходам из поиска:
Прямо из отчета можно переходить по ссылкам, чтобы посмотреть, актуальна ли страница и надо ли ее прорабатывать. Например, у меня самая популярная страница про прошивку телефона Nexus 4. Когда-то эта страница была очень популярной (4к переходов с ПС в месяц), сейчас ее мало кто посещает (275 переходов с ПС), это я и имел в виду, когда говорил про актуальность.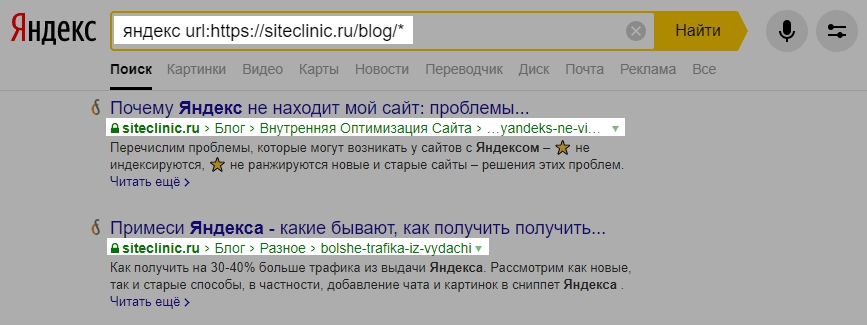 Конечно, эту страницу я проигнорирую и не стану заниматься ее улучшением.
Конечно, эту страницу я проигнорирую и не стану заниматься ее улучшением.
Чем еще может быть интересен данный отчет?
При наведении на строку, можно заметить 2 иконки: воронка и треугольник play. Play – открывает страницу с записями визитов посетителей в Вебвизоре, практическая польза данного отчета для инфосайта сомнительна, но если у вас настроены какие-то конверсионные цели (у меня, например, это отправка сообщения через форму обратной связи или посещение страниц услуг), то польза уже приобретает очертания!
А теперь к чему мы шли с самого начала – узнать ключевые слова, поисковые фразы по которым на наши страницы приходили посетители. Напротив каждого url в списке популярных страниц есть иконка с плюсиком, нажав на которую вы получите список поисковых фраз, по которым заходили на конкретную страницу. Все это будет отсортировано в порядке убывания популярности, так что вы сразу будете видеть топовые фразы:
Теперь вы можете на графике отразить не только популярность конкретной страницы, но и любой ключевой фразы. С данным отчетом можно долго играться, если вам нравится.
С данным отчетом можно долго играться, если вам нравится.
Почему в списке фразы только с иконкой Яндекса и где же переходы с Гугла, ведь с него тоже идет трафик?
А дело в том, что Google шифрует все данные о переходах посетителей с поисковой выдачи, потому метрика знает только то, что человек перешел на какую-то страницу сайта с выдачи Гугла и все, без подробностей. Так что в данном отчете мы опираемся только на посетителей, пользующихся Яндексом.
Очень удобным в данном отчете для нас будет и то, что можно открывать выдачу по каждому представленному запросу, что поможет при анализе конкурентов в будущем.
У меня самая популярная публикация на блоге про 301-редирект. Я хочу изучить, насколько она себя хорошо чувствует, собирает ли она максимум возможного трафика или это лишь отблески былого успеха?
Похоже, что именно второй вариант – как я и опасался – страница держится в топе популярных страницы входа благодаря былым успехам. Когда-то она собирала 2500 трафика за период, а теперь за тот же период – всего 500. Это колоссальный проёб!
Это колоссальный проёб!
Догадываюсь, что меня попросту выдавили из топа по самым популярным частотным запросам, потому что трафик еще есть, но сильно уменьшился. Если бы случилось что-то иное (фильтр там какой-нибудь наложили бы, например), то трафик бы обнулился или был близок к нулю.
Я отметил на графике пять самых популярных запросов для этой страницы. Видно, что только они приносили немало переходов, но потом что-то случилось и трафик по ним прекратился (я вылетел из топ-10?):
Но это не правда. Я проверил выдачу по этим запросам и везде нашел свой блог в топ-10, а последний запрос так и вообще на первом месте… Сложно назвать причину такого поведения?
Вы могли обратить внимание на желтую плашку вверху страницы «Из отчёта могли быть удалены некоторые данные», а внутри написано:
Для поддержки алгоритмов контроля безопасности сервисов Яндекса и обеспечения конфиденциальности социально-демографических данных в отчётах отключена детализация до уровня отдельных визитов и посетителей.
 Показываются только строки с информацией не менее чем по 10 посетителям.
Показываются только строки с информацией не менее чем по 10 посетителям.Вполне вероятно, что причина именно в этом. Значит на график полагаться точно не стоит.
И вот еще что очень важно знать, в связи с этим ограничением.
Я выяснил это буквально недавно. Яндекс скрывает все поисковые фразы, по которым за выбранный период было менее 10 переходов. И это убивает не только НЧ запросы, но и многие СЧ (частотность в зависимости от тематики вещь очень относительная), что мешает анализу и последующей проработке целевых страниц по определенным запросам.
Так что отчет по поисковым фразам в разрезе точек входа внезапно может сказать, что для страницы с 4854 переходами с поиска имеет всего 10 поисковых фраз, которые можно показать или даже так: страница с 5266 переходами с поиска не имеет данных – то есть все эти запросы супер НЧ, и даже за несколько лет ни один из них не набрал суммарно 10 переходов:
Кроме ругательных слов тут добавить нечего, разве что ссылку на мое обсуждение сложившейся ситуации в fb.
Экспорт поисковых запросов из Метрики и их обработка
Как бы то ни было, давайте пока работать с тем, что есть, а в конце поста я вам подскажу альтернативу, как и откуда можно брать запросы с разбивкой по страницам.
(Данный пост я начал писать еще в январе, а продолжил спустя месяц-полтора потому данные на скриншотах ниже могут незначительно отличаться от скриншотов выше.)
Сейчас я выберу для себя 10 самых интересных страниц, с которыми буду работать, для каждой страницы возьму максимум доступных (но не более 30) поисковых запросов и закину в Топвизор (можете использовать любой удобный для вас сервис для съема позиций).
Как быстро дернуть статистику из нашего отчета по поисковым фразам?
Есть, конечно, самый примитивный вариант – выделить нужные строки на странице отчета и нажать ctrl+c:
А потом открыть excel и использовать вставку с очисткой форматирования:
И повторить эту процедуру для нужного количества страницы вашего сайта.
Если вам нужны данные по небольшому количеству страниц, то данный вариант нормальный.
Но люди, более или менее шарящие скажут «ты шо, дэбил?», и будут правы. Потому давайте использовать прогрессивные методы взаимодействия с данными.
Прокручиваем страницу с отчетом Метрики вверх, видим иконку экспорта, выбираем XLSX в блоке «Данные таблицы»:
Загрузится файл export.xlsx. Открываем его в Экселе (или что там у вас?)
Вы удивитесь, что это совсем не то, что вы ожидали увидеть – какой-то уродский список без группировок и с кучей «Не определено» в начале:
Но мы его сейчас причешем, удалим лишние данные и сделаем очень удобным.
- Удаляем первые 6 строк, оставляя вверху только заголовки столбцов,
- Удаляем строку с «Итого и среднее»,
- Выделяем строку с заголовками и делаем ее фильтром:
- Выбираем фильтр в заголовке «Последняя поисковая фраза» и там отщёлкиваем все галки, находим «Не определено», выделяем и жмем ОК:
- Таблица отфильтруется, а мы увидим только строки с «Не определено» (кстати, это и есть все те запросы, по которым переходили с Гугла, их определить нельзя, потому они объединяются в одну группу, которая, как правило, является самой крупной для каждой страницы). Теперь выделяем через shift все строки от начала и до конца и удаляем их.
Потом сбрасываем фильтрацию. Теперь мы видим только определенные запросы: - Подготовка завершена. Теперь выбираем фильтр по первой колонке и ищем нужную нам страницу. Мой пост про 301 редирект имеет url https://alaev.info/blog/post/4393, поэтому я ищу его через внутренний поиск и выделяю:
- Теперь я вижу данные только для нужной мне страницы с запросами, отсортированными в порядке убывания популярности:
Все в точности совпадает с тем, что я вижу в отчете в интерфейсе Яндекс.Метрики:
 Теперь выделяем через shift все строки от начала и до конца и удаляем их.
Теперь выделяем через shift все строки от начала и до конца и удаляем их.С чего все началось-то вообще?
С того, что я хотел выбрать 10 страниц, над которыми я буду работать, выбрать для каждой из них по 30 запросов и добавить для отслеживания позиций.
Я просто открываю в отчете метрики все подряд страницы моего блога и оставляю открытыми только те, что мне интересны для прокачки. Вот что я выбрал:
- Упомянутый выше пост про 301-редирект — https://alaev. info/blog/post/4393 — это актуальная информация во веки веков. Трафик на данный пост будет идти всегда, надо его собирать.
- Пост про оптимизацию title — https://alaev.info/blog/post/5036 – я уверен, что мой пост является лучшим в сети мануалом по работе с title, надо убедиться, что его находят все, кто интересуется темой.
- Пост про покупку ссылок — https://alaev.info/blog/post/5745 – полная аналогия с предыдущим пунктом. Мой пост лучший, надо чтобы в выдаче тоже был в топе.
- О том, как выводить деньги с WebMoney — https://alaev.info/blog/post/4783 — когда-то это было очень актуально для меня. Но я знаю, что с тех пор описанный алгоритм изменился и мой способ не работает. Но на мой пост стоит много ссылок, получается, что люди не находят у меня решения проблемы, это не хорошо, надо обновить пост и заодно оптимизировать.
- 10 правил эффективного использования ключевых слов для SEO — https://alaev. info/blog/post/752 — какой-то древний пост, являющийся переводом с какого-то буржуйского блога. Надо понять, почему он попал в топ популярных, по каким запросам собирает трафик и отвечает ли на них. Надо просто актуализировать его.
- Как закрыть ссылку от индексации — https://alaev.info/blog/post/4042 — тоже пост, который цитируется всеми в интернете. Решил посмотреть, так ли это, и оказалось, что это самая цитируемая страница на моем блоге после главной страницы. Надо поддерживать пост в актуальном состоянии, чтобы все посетители остались довольными.
- Как сделать кнопку «Вверх» — https://alaev.info/blog/post/4381 — тоже интересный пост, я знаю, многие мою кнопку используют. Но в посте описана только одна реализация, а я на своем блоге использую две различных кнопки вверх, добавлю в пост второй способ.
- Аналитический шпионаж или как узнать ключевые слова конкурентов — https://alaev.info/blog/post/4358 — один из постов, которым я горжусь. Его процитировали (скопировали) многие крупные издания, но самый прикол в том, что это я спалил, что можно без авторизации смотреть чужие метрики, после чего все стали массово этим пользоваться. После моего поста довольно быстро закрыли дырку в метрике, эх… Но вообще в этом посте почти все способы уже умерли, мне интересно, по каким запросам люди туда приходят, что ищут. Возможно, надо просто написать новый аналогичный пост, где рассказать про актуальные инструменты.
- Пост про canonical — https://alaev.info/blog/post/4775 — каноничный пост, надо просто убедиться, что он занимает первые места или приложить все усилия, чтобы добиться этого.
- О том, как составить крутое резюме — https://alaev.info/blog/post/4829 — мне просто очень нравится этот пост, хочу узнать, как его находят, возможно что-то добавить от себя, что могло измениться за пошедшие 6 лет с момента публикации.
 info/blog/post/4393 — это актуальная информация во веки веков. Трафик на данный пост будет идти всегда, надо его собирать.
info/blog/post/4393 — это актуальная информация во веки веков. Трафик на данный пост будет идти всегда, надо его собирать.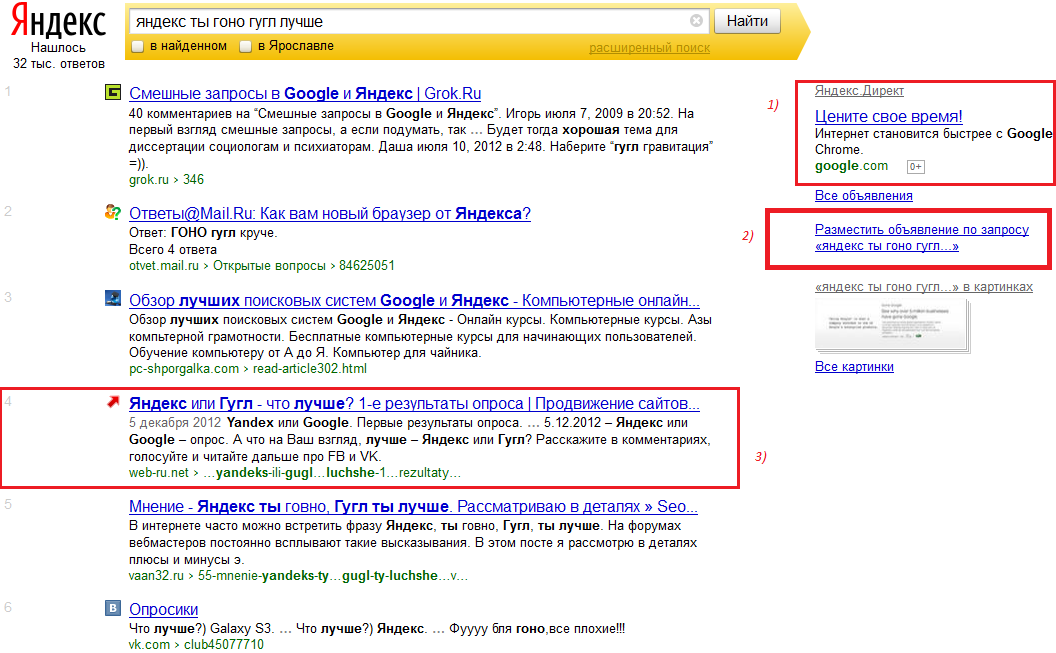 info/blog/post/752 — какой-то древний пост, являющийся переводом с какого-то буржуйского блога. Надо понять, почему он попал в топ популярных, по каким запросам собирает трафик и отвечает ли на них. Надо просто актуализировать его.
info/blog/post/752 — какой-то древний пост, являющийся переводом с какого-то буржуйского блога. Надо понять, почему он попал в топ популярных, по каким запросам собирает трафик и отвечает ли на них. Надо просто актуализировать его.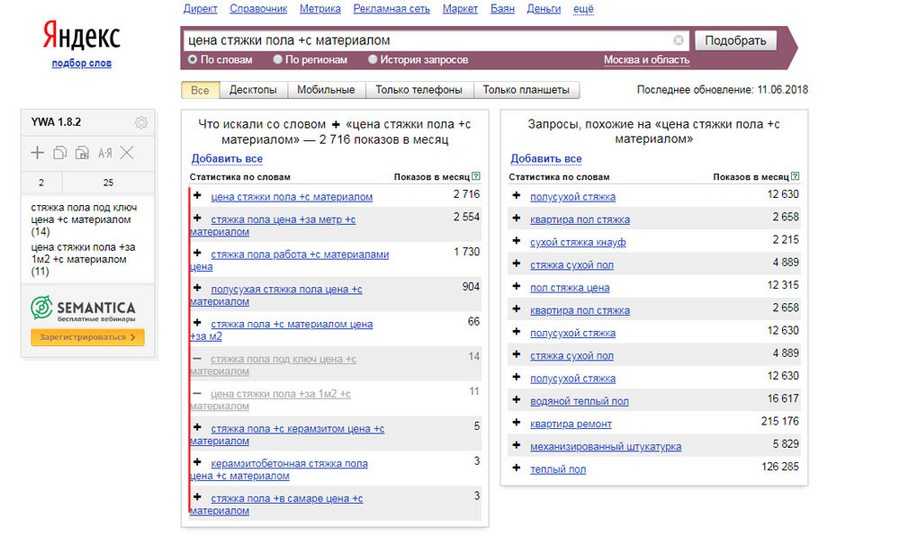 Его процитировали (скопировали) многие крупные издания, но самый прикол в том, что это я спалил, что можно без авторизации смотреть чужие метрики, после чего все стали массово этим пользоваться. После моего поста довольно быстро закрыли дырку в метрике, эх… Но вообще в этом посте почти все способы уже умерли, мне интересно, по каким запросам люди туда приходят, что ищут. Возможно, надо просто написать новый аналогичный пост, где рассказать про актуальные инструменты.
Его процитировали (скопировали) многие крупные издания, но самый прикол в том, что это я спалил, что можно без авторизации смотреть чужие метрики, после чего все стали массово этим пользоваться. После моего поста довольно быстро закрыли дырку в метрике, эх… Но вообще в этом посте почти все способы уже умерли, мне интересно, по каким запросам люди туда приходят, что ищут. Возможно, надо просто написать новый аналогичный пост, где рассказать про актуальные инструменты.Проработка каждой страницы займет, вероятно, не менее одного дня.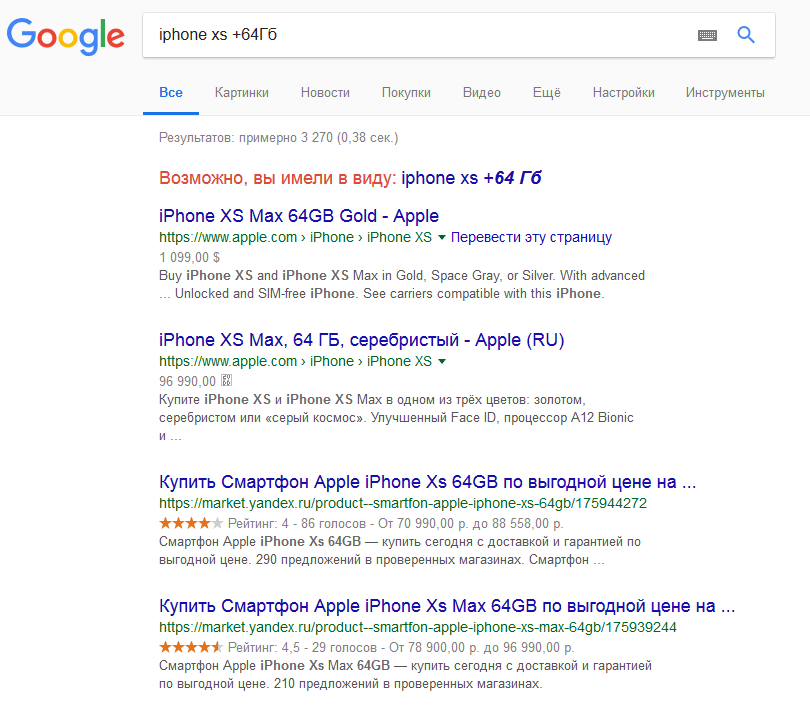 Придется забросить работу и заняться блогом 🙂
Придется забросить работу и заняться блогом 🙂
Теперь мне надо из нашего файлы export.xlsx для этих страниц собрать топ запросы для отслеживания позиций. Так как в Топвизоре формат импорта запросов «запрос;группа;url», я соберу себе нужные данные в соседнем листе экселя.
Я определил для каждой страницы по 30 запросов (кое-где меньше) и загнал их в Топвизор.
Я снял позиции по всем запросам и получил видимость по Яндексу и Google ровно 60% (Не знаю, баг это или нет, что везде ровно 60%, со временем видно будет).
Успехом всего мероприятия в целом будет улучшение видимости на 20%. Надеюсь, мне удастся этого добиться.
Но надо смотреть отдельно каждую группу запросов, чтобы понять, что именно предстоит делать.
Например, я горжусь своей статьей про покупку ссылок, и Гугл со мной согласен (видимость 100%), а Яндекс удивил (видимость 43%):
Так надо просмотреть каждую группу запросов в разрезе поисковых систем Яндекс и Гугл.
Далее будем изучать конкурентов в выдаче по запросам, где наши страницы не в топе, чтобы понять, чего нам не хватает. Обычно так делается коммерческий аудит для коммерческих сайтов (у меня есть большой пост про коммерческие факторы ранжирования). А мы с вами будем делать контентный аудит для информационного сайта.
Изначально я планировал описать быстрый способ проработки трафиковых страниц, когда одна страница может занять не больше 1 часа. Грубо говоря за 20% времени и усилий, мы могли бы добиться 80% эффективности. Это разумно. Но потом я подумал, что в моем случае вот так с полпинка я не добьюсь ничего, потому что уже ни раз ранее дорабатывал свои посты. И надо делать глубокий аудит.
Но для тех, кто желает для начала испробовать быстрый способ, я опишу алгоритм:
- На основании выбранных поисковых запросов дорабатываем title. Как это делать во всех подробностях написано здесь.
- Дорабатываем h2 заголовок. Также вписываем ключевые слова туда.
- Прорабатываем подзаголовки h3, h4 в самом посте: добавляем, если их нет, оптимизируем, если есть.
 Также вписываем ключевые слова туда.
Также вписываем ключевые слова туда.Как правило, только этих 3 шага дают хороший результат, если вы никогда этого не делали. Если же вы оптимизировали и тайтлы и подзаголовки, большого смысла их переделывать не имеется, да и заметного результат это не даст. 7 лет назад в этом списке был и четвертый пункт – покупка ссылок – но сейчас, а особенно в информационке, это не даст никакого эффекта. Поэтому быстрых решений больше нет.
Когда я только начинал писать данный пост, я хотел объять в нем необъятное, то есть написать еще и о том, как буду прорабатывать целевые страницы, анализировать конкурентов и вносить необходимые правки, но оказалось, что это настолько огромная работа, что делать все в рамках одного поста просто издевательство над читателем. Поэтому я решил разделить историю на несколько частей, сейчас вы читаете первую.
И раз анализ конкурентов и доработка страницы будет отдельно, закончить первую часть я хочу небольшой инструкцией, как добывать ключевые слова для Гугла, статистику которого не получает Метрика.
На помощь нам приходит Google Search Console с ее обновленным интерфейсом.
Авторизуемся и заходим в свой аккаунт, выбираем интересующий нас сайт – у меня это alaev.info.
В разделе «Эффективность» сразу видим график кликов и показов и ниже список ключевых слов, по которым на сайт переходили из Google.
Я выбрал период 16 месяцев для более полной картины.
Экспортировать полный список запросов с привязкой в конкретному url не получится, как в Метирке (может я тупой, тогда кто знает, подскажите, как это сделать?), потому во вкладке «Страницы» по очереди находит интересующие нас страницы, я возьму одну – самую популярную https://alaev.info/blog/post/5745 — про покупку ссылок. Нажимаем на строку с этой ссылкой, а потом переходим на вкладку «Запросы».
Перед нами список из 1000 самых популярных запросов, в том числе тех, по которым был всего 1 переход или даже 0, но были показы (а это вообще отдельная тема для разговора – почему было много показов страницы, но мало переходов, но она тоже за рамками данного поста).
Можно также скопировать запросы просто из списка, а можно экспортировать.
Я предлагаю вам второй вариант, экспортировать в Google Таблицы (если будете экспортировать в CSV то могут возникнуть проблемы с кодировкой, а оно вам надо?).
Получим красивую табличку с запросами, кликами, показами, CTR и даже средней позицией.
Этот отчет можно совместить с отчетом из Метрики, который мы сделали выше. Но я уже настолько устал колдовать, что делать этого не буду, а вы можете. Также этот отчет будет бесценен для тех, у кого основной трафик идет с Гугла или в Метрике запросы имеют частотность меньше 10.
Вот, пожалуй, стоит завершить первую часть на том, что мы с вами узнали, как получить список эффективных ключевых слов из Яндекс Метрики и Google Search Console, поняли, как быстро оптимизировать страницы (title, h2 и подзаголовки) и уже начать получать больше трафика.
В следующей части я буду рассказывать, как детально проработать наши целевые страницы, провести анализ конкурентов и понять, что именно стоит менять и добавлять и т. д.
д.
Спасибо за внимание.
До связи в следующей части!
API поиска Яндекса — доступ к результатам поисковой выдачи Яндекса в режиме реального времени
Доступ к результатам поиска Яндекса с помощью нашего сверхнадежного, быстрого и доступного API поисковой выдачи Яндекса.
К сожалению, эта конечная точка больше не поддерживается. Наш API возвращает самые свежие свежие данные со 100% точностью.
Формат JSON или Raw HTML
Используйте нашу обычную конечную точку для получения результатов поиска Google в формате JSON или используйте нашу расширенную конечную точку, если вам нужны необработанные данные HTML.
Результаты для конкретного местоположения
Доступ к результатам из любой точки мира. Установите требования к местоположению по стране, городу или даже координатам GPS.
Что говорят клиенты
Мы использовали множество различных поставщиков API, и SerpsBot является лучшим с точки зрения времени отклика, цены и надежности. Поддержка тоже отличная. Очень приятно работать с командой SerpsBot.
Jens Brandt
Founder, Docoloc
PricingFeatures | Yandex Endpoint |
|---|---|
Real-time results | Yes |
Время отклика | Менее 3 секунд |
Количество результатов на запрос | 100 |
Multiple page requests | Yes |
Result formats | JSON or Raw HTML |
Concurrency (default) * | 500 requests per second |
Стоимость ** | 0,002 доллара за запрос 2 доллара за 1000 запросов |
| 9 116 0064 К сожалению, эта конечная точка больше не поддерживается. |
* Уровень параллелизма можно настроить, если требуется большее количество запросов в секунду.
** Собираетесь ли вы делать большие объемы вызовов API (более 250 000 в месяц)? Мы можем предложить вам индивидуальную цену, свяжитесь с нами.
Что включено
Быстрая интеграция
Наш API прост в дизайне и совместим с большинством основных языков программирования.
Простая документация
Начните использовать наш API за считанные минуты с нашей простой документацией.
Служба технической поддержки
Наша служба технической поддержки работает каждый день, чтобы помочь ответить на любые вопросы или решить проблемы.
JSON или Raw HTML
Запросы отправляются с использованием HTTP GET, ответы доставляются в облегченном формате JSON или Raw HTML.
Любое местоположение/устройство
Собирайте данные из любого города, региона или страны по всему миру, используя любое устройство (настольный компьютер, мобильный телефон, планшет).
Все функции поиска
Получите все функции поисковой выдачи одним нажатием, люди также спрашивают, избранные фрагменты и многое другое.
faqВ каких форматах вы предоставляете результаты Яндекса?
Наш расширенный эндпоинт Яндекса возвращает данные в формате JSON или необработанный HTML.
Налагаете ли вы какие-либо ограничения на скорость параллелизма? Наш API использует параметр параллелизма по умолчанию, равный 500 запросам в секунду. Если вам нужно делать больше запросов в секунду, мы можем настроить вашу настройку.
Если вам нужно делать больше запросов в секунду, мы можем настроить вашу настройку.
Да. Наш поисковый API Яндекса предоставляет данные в режиме реального времени. Данные зависят от устройства определения местоположения и языка, который вы укажете.
Какую поддержку клиентов вы предоставляете?Мы доступны с понедельника по пятницу с 08:00 до 19:00 по Гринвичу. Наша служба технической поддержки также доступна в выходные дни; однако ответы могут быть медленнее.
Существует ли верхний предел для вызовов API? Нет, верхнего предела нет. Мы можем и поддерживаем корпоративное использование (несколько миллионов звонков в месяц). Наш API поиска Яндекса работает на инфраструктуре автоматического масштабирования. Если вам нужно совершать большие объемы звонков, пожалуйста, свяжитесь с нами для получения индивидуальных ценовых вариантов.
Если вам нужно совершать большие объемы звонков, пожалуйста, свяжитесь с нами для получения индивидуальных ценовых вариантов.
Мы предлагаем простую оплату по мере использования как для наших обычных, так и для расширенных конечных точек API. Ознакомьтесь с нашими тарифными планами, чтобы получить представление о том, сколько будет стоить наша услуга для вашего объема использования. Если вы планируете делать большие объемы запросов (например, более 250 000 звонков в месяц), мы можем предложить индивидуальные цены.
Вы предлагаете бесплатную пробную версию? Да. Зарегистрируйтесь и добавьте карту в свой аккаунт. Затем наша система применит тестовые кредиты, чтобы вы могли опробовать наш поисковый API Яндекса, прежде чем брать на себя какие-либо обязательства.
Если наш Yandex SERP API не подходит для вашего случая использования, сообщите нам об этом, и мы вернем вам деньги за любой неиспользованный остаток.
Как работает выставление счетов?Баланс расходуется только в том случае, если вызов API возвращает результаты. Вызовы API для получения сведений об учетной записи и вызовы API с пустыми результатами не расходуют баланс.
Какие другие поисковые системы вы поддерживаете?Как использовать OxyLabs Real-Time Crawler [Часть 2]: Real-Time Crawler для Яндекса
Знаете ли вы, как использовать OxyLabs Real-Time Crawler для Яндекса? Это наиболее полное введение от официального лица OxyLabs.

Быстрый старт
Искатель в реальном времени создан для ресурсоемких операций по поиску данных. Вы можете использовать Real-Time Crawler для доступа к различным страницам Яндекса. Это позволяет легко извлекать веб-данные из поисковых систем без каких-либо задержек или ошибок.
Сканер реального времени для Яндекса использует базовую HTTP-аутентификацию, требующую отправки имени пользователя и пароля.
Это самый быстрый способ начать использовать Real-Time Crawler для Яндекса. Вы отправите запрос adidas на yandex_search , используя метод интеграции в реальном времени. Не забудьте заменить USERNAME
PASSWORD учетными данными пользователя прокси. curl --user "ИМЯ ПОЛЬЗОВАТЕЛЯ:ПАРОЛЬ" 'https://realtime.oxylabs.io/v1/queries' -H "Тип контента: application/json" -d '{"source": "yandex_search", " домен": "com", "запрос": "adidas"}'
Если у вас есть какие-либо вопросы, не охваченные этой документацией, обратитесь к менеджеру своего аккаунта или в нашу службу поддержки по адресу [email protected].
Методы интеграции
Сканер реального времени для Яндекса поддерживает три метода интеграции, которые имеют свои уникальные преимущества:
- Push-Pull. Используя этот метод, теперь требуется поддерживать активное соединение с нашей конечной точкой для получения данных. После выполнения запроса наша система может автоматически пинговать сервер пользователей, когда работа выполнена (см. Обратный вызов). Этот метод экономит вычислительные ресурсы и легко масштабируется.
- В реальном времени. Этот метод требует, чтобы пользователь поддерживал активное соединение с нашей конечной точкой, чтобы успешно получить результаты после завершения задания. Этот метод может быть реализован в одной службе, в то время как метод Push-Pull представляет собой двухэтапный процесс.
- СуперАПИ. Этот метод очень похож на Realtime, но вместо отправки данных на нашу конечную точку пользователь может использовать HTML Cralwer в качестве прокси. Чтобы получить данные, пользователь должен настроить конечную точку прокси и сделать запрос GET на нужный URL-адрес. Дополнительные параметры необходимо добавлять с помощью заголовков.
 Дополнительные параметры необходимо добавлять с помощью заголовков.
Дополнительные параметры необходимо добавлять с помощью заголовков.Рекомендуемый нами метод извлечения данных — Push-Pull.
Push-Pull
Это самый простой, но самый надежный и рекомендуемый способ доставки данных. В сценарии Push-Pull вы отправляете нам запрос, мы возвращаем вам задание с идентификатором , и после завершения задания вы можете использовать этот идентификатор для извлечения контента из конечной точки /results . Вы можете самостоятельно проверять статус завершения задания или настроить простой слушатель, способный принимать POST-запросы.
Таким образом, мы отправим вам сообщение обратного вызова, как только задание будет готово к получению. В этом конкретном примере результаты будут автоматически загружены в корзину S3 с именем YOUR_BUCKET_NAME .
Одиночный запрос
Следующая конечная точка будет обрабатывать одиночные запросы для одного ключевого слова или URL-адреса.
. Вы можете проверить статус завершения задания, используя это id , или вы можете попросить нас пропинговать вашу конечную точку обратного вызова после завершения задачи парсинга, добавив callback_url в запрос.ОТПРАВКА https://data.oxylabs.io/v1/queries
Вам необходимо опубликовать параметры запроса в виде данных в теле JSON.
curl --user user:pass1 'https://data.oxylabs.io/v1/queries' -H "Тип содержимого: приложение/json"
-d '{"source": "yandex_search", "domain": "com", "query": "adidas", "callback_url": "https://ваш.callback.url", "storage_type": "s3 ", "storage_url": "YOUR_BUCKET_NAME"}'
API ответит информацией о запросе в формате JSON, распечатав ее в тексте ответа, примерно так:
{
"callback_url": "https://ваш.callback.url",
"идентификатор_клиента": 5,
"created_at": "2019-10-01 00:00:01",
"домен": "com",
"гео_локация": ноль,
"id": "123456787654321",
"лимит": 10,
"локаль": ноль,
"страниц": 1,
"разбор": ложь,
«рендеринг»: ноль,
"запрос": "адидас",
"источник": "yandex_search",
"стартовая_страница": 1,
"Статус: ожидание",
"тип_хранилища": "s3",
"storage_url": "ВАШЕ_ВЕДРО_ИМЯ/12345678
7654321. json",
"субдомен": "www",
"updated_at": "2019-10-01 00:00:01",
"user_agent_type": "рабочий стол",
"_ссылки": [
{
"отн": "я",
"href": "http://data.oxylabs.io/v1/queries/12345678
7654321",
"метод": "ПОЛУЧИТЬ"
},
{
"отн": "результаты",
"href": "http://data.oxylabs.io/v1/queries/12345678
7654321/results",
"метод": "ПОЛУЧИТЬ"
}
]
}
 json",
"субдомен": "www",
"updated_at": "2019-10-01 00:00:01",
"user_agent_type": "рабочий стол",
"_ссылки": [
{
"отн": "я",
"href": "http://data.oxylabs.io/v1/queries/12345678
json",
"субдомен": "www",
"updated_at": "2019-10-01 00:00:01",
"user_agent_type": "рабочий стол",
"_ссылки": [
{
"отн": "я",
"href": "http://data.oxylabs.io/v1/queries/12345678Проверить статус задания
Если ваш запрос содержит callback_url , мы отправим вам сообщение, содержащее ссылку на контент, как только задача очистки будет выполнена. Однако, если в запросе не было callback_url , вам нужно будет проверить статус задания самостоятельно. Для этого вам нужно использовать URL-адрес в href под rel : self в ответном сообщении, которое вы получили после отправки запроса в наш API. Он должен выглядеть примерно так: http://data. . oxylabs.io/v1/queries/123456789.00987654321
oxylabs.io/v1/queries/123456789.00987654321
ПОЛУЧИТЬ https://data.oxylabs.io/v1/queries/{id}
При запросе по этой ссылке будет возвращена информация о задании, включая его статус . Возможны 3 статуса значения:
в ожидании | Задание все еще находится в очереди и не завершено. |
готово | Задание выполнено, вы можете получить результат, запросив URL-адрес в href 9.0276 под |
неисправный | Возникла проблема с заданием, и мы не смогли его выполнить, скорее всего, из-за ошибки сервера на стороне целевого сайта. |
curl --user user:pass1 'http://data.oxylabs.io/v1/queries/123456787654321'
API ответит информацией о запросе в формате JSON, распечатав ее в тексте ответа. 7654321/results  Обратите внимание, что задание
Обратите внимание, что задание статус изменен на выполнено . Теперь вы можете получить контент, отправив запрос http://data.oxylabs.io/v1/queries/12345678 .
Вы также можете видеть, что задача была updated_at 2019-10-01 00:00:15 – выполнение запроса заняло 14 секунд.
{
"идентификатор_клиента": 5,
"created_at": "2019-10-01 00:00:01",
"домен": "com",
"гео_локация": ноль,
"id": "123456787654321",
"лимит": 10,
"локаль": ноль,
"страниц": 1,
"разбор": ложь,
«рендеринг»: ноль,
"запрос": "адидас",
"источник": "yandex_search",
"стартовая_страница": 1,
"статус": "сделано",
"субдомен": "www",
"update_at": "2019-10-01 00:00:15",
"user_agent_type": "рабочий стол",
"_ссылки": [
{
"отн": "я",
"href": "http://data.oxylabs.io/v1/queries/12345678
7654321",
"метод": "ПОЛУЧИТЬ"
},
{
"отн": "результаты",
"href": "http://data. oxylabs.io/v1/queries/12345678
7654321/results",
"метод": "ПОЛУЧИТЬ"
}
]
}
 oxylabs.io/v1/queries/12345678
oxylabs.io/v1/queries/12345678Получить содержание задания
Как только вы узнаете, что задание готово к получению, либо проверив его статус, либо получив обратный звонок от нас, вы можете ПОЛУЧИТЬ его, используя URL-адрес в 7654321/results href под rel : приводит к либо в нашем первоначальном ответе, либо в сообщении обратного вызова. Он должен выглядеть примерно так: http://data.oxylabs.io/v1/queries/12345678 .
ПОЛУЧИТЬ https://data.oxylabs.io/v1/queries/{id}/results
Результаты могут быть получены автоматически без периодической проверки статуса задания путем настройки службы обратного звонка. Пользователю необходимо указать IP или домен сервера, на котором работает служба обратного вызова. Когда наша система завершит задание, она отправит сообщение на указанный IP-адрес или домен, а служба обратного вызова загрузит результаты, как описано в примере реализации обратного вызова.
curl --user user:pass1 'http://data.oxylabs.io/v1/queries/123456787654321/results'
API вернет содержимое задания:
{
"полученные результаты": [
{
"content": "
СОДЕРЖАНИЕ
",
"created_at": "2019-10-01 00:00:01",
"updated_at": "2019-10-01 00:00:15",
"Страница 1,
"url": "https://www.yandex.com/search?q=adidas&hl=en&gl=US",
"job_id": "123456787654321",
"код_статуса": 200
}
]
}
Обратный вызов
Обратный вызов — это запрос POST , который мы отправляем на ваш компьютер, информируя о том, что задача извлечения данных завершена, и предоставляя URL-адрес для загрузки очищенного контента. Это означает, что вам больше не нужно проверять статус задания вручную. Как только данные будут здесь, мы сообщим вам, и все, что вам нужно сделать сейчас, это получить их.
# См. примеры кода на Python и PHP.
Пример вывода обратного вызова
{
"created_at":"2019-10-01 00:00:01",
"updated_at":"2019-10-01 00:00:15",
"локаль": ноль,
«идентификатор_клиента»: 163,
"user_agent_type":"рабочий стол",
"источник":"yandex_search",
"страницы":1,
"субдомен":"www",
"статус": "сделано",
"стартовая_страница":1,
"разобрать":0,
«рендеринг»: ноль,
"приоритет":0,
"ттл":0,
"происхождение":"апи",
«настойчиво»: правда,
"id":"123456787654321",
"callback_url":"http://your.callback.url/",
«запрос»: «адидас»,
"домен":"com",
"лимит":10,
"гео_локация": ноль,
{...}
"_ссылки":[
{
"href":"https://data.oxylabs.io/v1/queries/12345678
7654321",
"метод": "ПОЛУЧИТЬ",
"отн":"я"
},
{
"href":"https://data.oxylabs.io/v1/queries/12345678
7654321/results",
"метод": "ПОЛУЧИТЬ",
"отн":"результаты"
}
],
}
Пакетный запрос
Искатель в реальном времени также поддерживает выполнение нескольких ключевых слов, до 1000 ключевых слов в каждом пакете.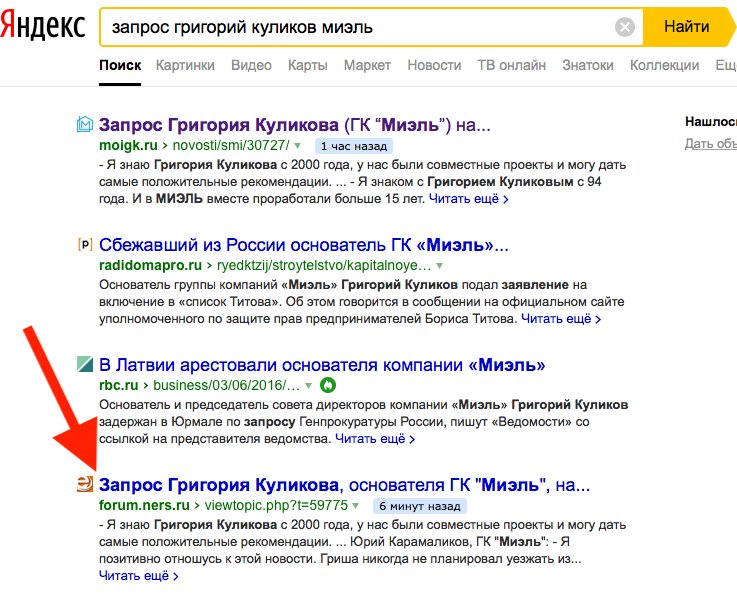 Следующая конечная точка отправит несколько ключевых слов в очередь извлечения.
Следующая конечная точка отправит несколько ключевых слов в очередь извлечения.
ОТПРАВКА https://data.oxylabs.io/v1/queries/batch
Вам необходимо опубликовать параметры запроса в виде данных в теле JSON.
Система будет обрабатывать каждое ключевое слово как отдельный запрос. Если вы указали URL-адрес обратного вызова, вы получите отдельный вызов для каждого ключевого слова. В противном случае наш первоначальный ответ будет содержать задание 9.0275 id для всех ключевых слов. Например, если вы отправили 50 ключевых слов, мы вернем 50 уникальных заданий id s.
Важно! запрос — единственный параметр, который может иметь несколько значений. Все остальные параметры одинаковы для этого пакетного запроса.
curl --user user:pass1 'https://data.oxylabs.io/v1/queries/batch' -H 'Content-Type: application/json' -d '@keywords.json'
keywords.json content:
{
"запрос":[
"адидас",
"найк",
"рибок"
],
"источник": "yandex_search",
"домен": "com",
"callback_url": "https://ваш. callback.url"
}
 callback.url"
}
callback.url"
}
API ответит информацией о запросе в формате JSON, распечатав ее в тексте ответа, примерно так:
{
"запросы": [
{
"callback_url": "https://ваш.callback.url",
{...}
"created_at": "2019-10-01 00:00:01",
"домен": "com",
"id": "123456787654321",
{...}
"запрос": "адидас",
"источник": "yandex_search",
{...}
"отн": "результаты",
"href": "http://data.oxylabs.io/v1/queries/12345678
7654321/результаты",
"метод": "ПОЛУЧИТЬ"
}
]
},
{
"callback_url": "https://ваш.callback.url",
{...}
"created_at": "2019-10-01 00:00:01",
"домен": "com",
"id": "12345678
4567890",
{...}
"запрос": "найк",
"источник": "yandex_search",
{...}
"отн": "результаты",
"href": "http://data. oxylabs.io/v1/queries/12345678 4567890/результаты",
"метод": "ПОЛУЧИТЬ"
}
]
},
{
"callback_url": "https://ваш.callback.url",
{...}
"created_at": "2019-10-01 00:00:01",
"домен": "com",
"id": "01234567899876543210",
{...}
"запрос": "reebok",
"источник": "yandex_search",
{...}
"отн": "результаты",
"href": "http://data.oxylabs.io/v1/queries/01234567899876543210/results",
"метод": "ПОЛУЧИТЬ"
}
]
}
]
}
Получить список IP-адресов уведомителя Вы можете внести в белый список IP-адреса, отправляющие вам сообщения обратного вызова, или получить список этих IP-адресов для других целей. Это можно сделать, отправив GET на эту конечную точку: https://data.oxylabs.io/v1/info/callbacker_ips .
curl --user user:pass1 'https://data. oxylabs.io/v1/info/callbacker_ips'
API вернет список IP-адресов, отправляющих запросы обратного вызова в вашу систему:
{
"айпс": [
"х.х.х.х",
"ГГГГ"
]
}
Загрузить в хранилище По умолчанию результаты заданий RTC хранятся в наших базах данных. Это означает, что вам нужно будет запросить нашу конечную точку результатов и получить контент самостоятельно. Функция пользовательского хранилища позволяет хранить результаты в собственном облачном хранилище. Преимущество этой функции в том, что вам не нужно делать дополнительные запросы для получения результатов — все идет прямо в вашу корзину хранилища.
Мы поддерживаем Amazon S3 и Google Cloud Storage. Если вы хотите использовать другой тип хранилища, свяжитесь с вашим менеджером по работе с клиентами, чтобы обсудить график предоставления функции.
Amazon S3
Чтобы результаты вашей работы загружались в корзину Amazon S3, настройте права доступа для нашего сервиса. Для этого перейдите на https://s3.console.aws.amazon.com/ > S3 > Хранилище > Имя сегмента (если его нет, создайте новый) > Разрешения > Политика сегмента
Вы политику сегментов можно найти в этом JSON или в области примеров кода справа. Не забудьте изменить имя корзины под YOUR_BUCKET_NAME 9.0276 . Эта политика позволяет нам писать в вашу корзину, предоставлять вам доступ к загруженным файлам и знать местоположение корзины.
Google Cloud Storage
Чтобы результаты вашей работы загружались в корзину Google Cloud Storage, настройте специальные разрешения для нашего сервиса. Для этого создайте пользовательскую роль с разрешением storage.objects.create и назначьте ее адресу электронной почты сервисной учетной записи Oxylabs [email protected] .
Использование
Чтобы использовать эту функцию, укажите два дополнительных параметра в своих запросах. Подробнее здесь.
Путь загрузки выглядит следующим образом: YOUR_BUCKET_NAME/job_ID.json . Вы найдете идентификатор задания в теле ответа, которое вы получите от нас после отправки запроса. В этом примере идентификатор задания – 123456787654321
.
{
«Версия»: «2012-10-17»,
"Идентификатор": "Политика1577442634787",
"Заявление": [
{
"Сид": "Stmt1577442633719",
«Эффект»: «Разрешить»,
"Главный": {
"AWS": "arn:aws:iam::3243118:user/oxylabs.s3.uploader"
},
«Действие»: «s3: GetBucketLocation»,
"Ресурс": "arn:aws:s3:::YOUR_BUCKET_NAME"
},
{
"Сид": "Stmt1577442633719",
«Эффект»: «Разрешить»,
"Главный": {
"AWS": "arn:aws:iam::3243118:user/oxylabs.s3.uploader"
},
"Действие": [
"s3:ПоместитьОбъект",
"s3:путобжектакл"
],
"Ресурс": "arn:aws:s3:::YOUR_BUCKET_NAME/*"
}
]
}
В реальном времени
Отправка данных такая же, как и в методе Push-Pull, но в случае реального времени мы вернем контент при открытом соединении. Вы отправляете нам запрос, соединение остается открытым, мы извлекаем контент и доставляем его вам. Конечная точка, которая обрабатывает это:
POST https://realtime.oxylabs.io/v1/queries
Время ожидания для открытых подключений составляет 150 секунд, поэтому в редких случаях большой нагрузки мы не сможем гарантировать, что данные дойдут до вас.
Вам необходимо опубликовать параметры запроса в виде данных в теле JSON. Пожалуйста, смотрите пример для более подробной информации.
curl --user user:pass1 'https://realtime.oxylabs.io/v1/queries' -H "Тип контента: приложение/json"
-d '{"source": "yandex_search", "domain": "com", "query": "adidas"}'
Пример тела ответа, которое будет возвращено при открытом соединении:
{
"полученные результаты": [
{
"содержание": "
СОДЕРЖАНИЕ
"
"created_at": "2019-10-01 00:00:01",
"updated_at": "2019-10-01 00:00:15",
"идентификатор": ноль,
"Страница 1,
"url": "https://www. yandex.com/search?q=adidas&hl=en&gl=US",
"job_id": "123456787654321",
"код_статуса": 200
}
]
}
SuperAPI
Если вы когда-либо использовали обычные прокси для очистки данных, интеграция метода доставки SuperAPI будет легкой задачей. Все, что нужно сделать, это использовать наш входной узел в качестве прокси, авторизоваться с помощью учетных данных Real-Time Crawler и игнорировать сертификаты. В cURL это -k или --insecure . Ваши данные будут доставлены вам по открытому соединению.
ПОЛУЧИТЬ realtime.oxylabs.io:60000
SuperAPI поддерживает только несколько параметров, поскольку работает только с прямым источником данных , где указан полный URL-адрес. Эти параметры должны быть отправлены в виде заголовков. Это список допустимых параметров:
X-OxySERPs-User-Agent-Type Невозможно указать конкретный User-Agent, но вы можете сообщить нам, какой браузер и платформу использовать. Список поддерживаемых пользовательских агентов можно найти здесь. X-OxySERPs-Геолокация Географическое положение в Яндексе рстр формат
Если вам нужна помощь в настройке SuperAPI, напишите по адресу [email protected].
curl -k -x realtime.oxylabs.io:60000 -U пользователь:pass1 -H "X-OxySERPs-User-Agent-Type: desktop_chrome"
-H "X-OxySERPs-Гео-Расположение: 15550" "https://yandex.com/search/?text=nike"
Тип содержимого
Искатель в реальном времени возвращает необработанный HTML .
Источники данных
Существует два подхода к извлечению данных из Яндекса с помощью Real-Time Crawler. Вы можете дать нам полный URL через Директ или указать параметры через специально созданный источник данных — Поиск.
Технически это не тип контента, но Real-Time Crawler может отображать JavaScript при очистке. Это может понадобиться на некоторых страницах Яндекса. Флажок под Render JS указывает, можно ли выполнить парсинг определенного источника данных с включенным JavaScript.
Если вы не уверены, какой способ выбрать, напишите нам по адресу [email protected] или обратитесь к менеджеру своего аккаунта.
Директ
yandex Источник предназначен для извлечения содержимого прямых URL различных страниц Яндекса. Это означает, что вместо отправки нескольких параметров вы можете предоставить нам прямой URL на нужную страницу Яндекса. Мы не удаляем какие-либо параметры и не изменяем ваши URL-адреса каким-либо другим образом.
Параметры запроса
Параметр Описание Значение по умолчанию источник Источник данных яндекс адрес Прямой URL (ссылка) на страницу Яндекса – user_agent_type Тип устройства и браузер. Полный список можно найти здесь. настольный визуализация Включить рендеринг JavaScript. Используйте, когда целевому объекту требуется JavaScript для загрузки контента. Работает только методом Push-Pull (он же Callback). Для этого параметра доступны два значения: html (получить необработанный вывод) и png (получить снимок экрана в кодировке Base64). callback_url URL-адрес конечной точки обратного вызова – тип_хранилища Поставщик услуг хранения. Мы поддерживаем Amazon S3 и Google Cloud Storage. Значения параметра storage_type для этих провайдеров хранилища — соответственно s3 и gcs. Полную реализацию можно найти на странице Загрузить в хранилище . Эта функция работает только методом Push-Pull (обратный вызов). – storage_url Имя сегмента хранилища. Работает только методом Push-Pull (Callback). – – обязательный параметр
В этом примере API будет получать результаты поиска Яндекса по ключевому слову nike методом Push-Pull:
curl --user user:pass1 'https://data. oxylabs.io/v1/queries' - H "Тип контента: приложение/json"
-d '{"source": "yandex", "url": "https://yandex.com/search/?text=nike&"}'
Вот тот же пример в реальном времени:
curl --user user:pass1 'https://realtime.oxylabs.io/v1/queries' -H "Content-Type: application/json"
-d '{"source": "yandex", "url": "https://yandex.com/search/?text=nike&"}'
И через SuperAPI:
curl -k -x realtime.oxylabs.io:60000 -U user:pass1 "https://yandex.com/search/?text=nike&"
Поиск
yandex_search Источник предназначен для получения результатов поиска Яндекса (SERP).
Параметры запроса
Параметр Описание Значение по умолчанию источник Источник данных yandex_search домен Локализация домена. Доступные домены: com, ru, ua, by, kz, tr ком запрос Ключевое слово в кодировке UTF – стартовая_страница Номер стартовой страницы 1 стр. Количество страниц для извлечения 1 предел Количество результатов для извлечения на каждой странице 10 местный Язык. Доступные языки: en, ru, by, fr, de, id, kk, tt, tr, uk. – геолокация Географическое положение в формате Яндекс rstr – user_agent_type Тип устройства и браузер. Полный список можно найти здесь. настольный callback_url URL-адрес конечной точки обратного вызова – тип_хранилища Поставщик услуг хранения. Мы поддерживаем Amazon S3 и Google Cloud Storage. Значения параметра storage_type для этих провайдеров хранилища — соответственно s3 и gcs. Полную реализацию можно найти на странице Загрузить в хранилище . Эта функция работает только методом Push-Pull (обратный вызов). – storage_url Имя сегмента хранилища. Работает только методом Push-Pull (Callback). – – обязательный параметр
API отправляет запрос на yandex.com для получения страниц результатов поиска с 11 по 20 по ключевому слову adidas . API отправит запрос JSON на адрес your.callback.url , содержащий URL-адрес для загрузки необработанного вывода HTML после успешного завершения задачи извлечения данных. Это двухтактный:
curl --user user:pass1 'https://data.oxylabs.io/v1/queries' -H "Тип содержимого: приложение/json"
-d '{"source": "yandex_search", "domain": "com", "query": "adidas", "start_page": 11, "pages": 10, "callback_url": "https://ваш .callback.url"}'
А вот тот же пример в реальном времени:
curl --user user:pass1 'https://realtime.oxylabs.io/v1/queries' -H "Content-Type: application/json"
-d '{"source": "yandex_search", "domain": "com", "query": "adidas", "start_page": 11, "pages": 10, "callback_url": "https://ваш . callback.url"}'
Значения параметров
User-Agent
Загрузите полный список значений user_agent_type в формате JSON здесь.
[
{
"user_agent_type": "рабочий стол",
"description": "Пользовательский агент случайного настольного браузера"
},
{
"user_agent_type": "рабочий стол_firefox",
"description": "Случайный пользовательский агент одной из последних версий настольного Firefox"
},
{
"user_agent_type": "desktop_chrome",
"description": "Случайный пользовательский агент одной из последних версий настольного Chrome"
},
{
"user_agent_type": "desktop_opera",
"description": "Случайный пользовательский агент одной из последних версий десктопной Opera"
},
{
"user_agent_type": "desktop_edge",
"description": "Случайный пользовательский агент одной из последних версий настольного Edge"
},
{
"user_agent_type": "настольное_сафари",
"description": "Случайный пользовательский агент одной из последних версий настольного Safari"
},
{
"user_agent_type": "мобильный",
"description": "Случайный пользовательский агент мобильного браузера"
},
{
"user_agent_type": "мобильный_андроид",
"description": "Случайный пользовательский агент одной из последних версий браузера Android"
},
{
"user_agent_type": "мобильный_ios",
"description": "Случайный пользовательский агент одной из последних версий браузера iPhone"
},
{
"user_agent_type": "планшет",
"description": "Пользовательский агент браузера случайного планшета"
},
{
"user_agent_type": "планшет_андроид",
"description": "Случайный пользовательский агент одной из последних версий Android-планшета"
},
{
"user_agent_type": "планшет_ios",
"description": "Случайный пользовательский агент одной из последних версий планшета iPad"
}
]
Статистика использования
Вы можете найти статистику использования, запросив следующую конечную точку:
GET https://data. oxylabs.io/v1/stats
По умолчанию API возвращает статистику использования за все время. Добавление ?group_by=month вернет ежемесячную статистику, а ?group_by=day возвратит ежедневные числа.
Этот запрос возвращает статистику за все время. Вы можете узнать свое ежедневное и ежемесячное использование, добавив либо ?group_by=day или ?group_by=month
curl --user user:pass1 'https://data.oxylabs.io/v1/stats'
Пример вывода:
{
"данные": {
"источники": [
{
"realtime_results_count": "90",
"результаты_счетчик": "10",
"название": "яндекс"
},
{
"realtime_results_count": "19",
"результаты_счетчик": "87",
"название": "yandex_search"
}
]
},
"мета": {
"группа_по": ноль
}
}
Ограничения
Следующая конечная точка предоставит информацию о ваших ежемесячных обязательствах, а также о том, сколько уже было использовано:
GET https://data. oxylabs.io/v1/stats/limits
curl --user user:pass1 'https://data.oxylabs.io/v1/stats/limits'
Пример вывода:
{
"monthly_requests_commitment": 4500000,
"используемые_запросы": 985000
}
Коды ответов
Код Статус Описание 204 Нет содержимого Вы пытаетесь получить задание, которое еще не завершено. 400 Несколько сообщений об ошибках Неверная структура запроса, может быть параметр с ошибкой или недопустимое значение. Тело ответа будет содержать более конкретное сообщение об ошибке. 401 «Заголовок авторизации не предоставлен» / «Неверный заголовок авторизации» / «Клиент не найден» Отсутствует заголовок авторизации или неверные учетные данные для входа. 403 Запрещено У вашей учетной записи нет доступа к этому ресурсу. 404 Не найдено Идентификатор вакансии, который вы ищете, больше недоступен. 429 Слишком много запросов Превышен предел скорости. Пожалуйста, свяжитесь с менеджером вашего аккаунта, чтобы увеличить лимиты. 500 Неизвестная ошибка Служба недоступна. 524 Тайм-аут Служба недоступна. 612 Неопределенная внутренняя ошибка Что-то пошло не так, и мы не смогли выполнить отправленное вами задание. Вы можете попробовать еще раз без дополнительной оплаты, так как мы не взимаем плату за ошибочно выполненных заданий. Если это не сработает, дайте нам крик. 613 Ошибка после слишком большого количества попыток Мы попытались очистить задание, которое вы отправили, но отказались от него после достижения лимита повторных попыток. Вы можете попробовать еще раз без дополнительной оплаты, так как мы не взимаем плату за ошибочно выполненных заданий. Если это не сработает, дайте нам крик.
Коды ответа на загрузку облачного хранилища:
Код Статус Описание 10001 Неожиданное исключение Произошло что-то ужасное. Вероятно, мы уже знаем об этом и исправляем. Дайте нам знать в любом случае. 13000 Загрузка успешна Все хорошо! 13001 Загрузка не удалась Нам не удалось загрузить результаты задания в вашу корзину. 13102 Нет такого пути Не удалось найти ведро с таким именем. Пожалуйста, проверьте дважды. 13103 Доступ запрещен Bucket не имеет необходимых разрешений. Чтобы узнать, как предоставить нам требуемый доступ, см. здесь.
Ссылки
- https://docs.oxylabs.io/rtc/source/yandex/index.html
- https://docs.oxylabs.io/rtc/index.html
Отказ от ответственности: Эта часть контента в основном от торговца. Если продавец не хочет, чтобы он отображался на моем веб-сайте, свяжитесь с нами, чтобы удалить ваш контент.
Последнее обновление 16 мая 2022 г.
Вы рекомендуете прокси-сервис?
Нажмите на трофей, чтобы наградить его!
Средняя оценка 5 / 5. Количество голосов: 1
Голосов пока нет! Будьте первым, кто оценит этот пост.
Блог — Ботнет Mēris, восхождение на рекорд
Введение
За последние пять лет практически не было глобальных атак на прикладном уровне.
За этот период отрасль научилась справляться с атаками на сетевом уровне с высокой пропускной способностью, включая атаки на основе усиления. Это не означает, что ботнеты теперь безвредны.
В конце июня 2021 года компания Qrator Labs начала замечать в Интернете признаки новой атакующей силы — ботнета нового типа. Это совместное исследование, которое мы провели вместе с Яндексом, чтобы уточнить особенности средства реализации DDoS-атак, возникающих практически в режиме реального времени.
Discovery
Здесь мы видим довольно значительную атакующую силу — десятки тысяч хост-устройств, которые растут. Отдельно Qrator Labs увидел 30 000 хост-устройств в реальных цифрах через несколько атак, а Яндекс собрал данные о 56 000 атакующих хостов.
Однако, мы полагаем, что цифра выше – вероятно, более 200 000 устройств, из-за ротации и отсутствия желания сразу показать атакующую «полную силу». Более того, все это высокопроизводительные устройства, а не ваш типичный IoT-мигалка, подключенный к WiFi, — здесь мы говорим о ботнете, состоящем, с наибольшей вероятностью, из устройств, подключенных через Ethernet-соединение, в первую очередь сетевых устройств.
Некоторые люди и организации уже назвали ботнет « возвращением Mirai », что мы не считаем правильным. Mirai обладала большим количеством скомпрометированных устройств, объединенных под C2C, и атаковала в основном объемным трафиком.
Мы не видели вредоносного кода и пока не готовы сказать, имеет он какое-то отношение к семейству Mirai или нет. Мы склонны думать, что это не так, поскольку устройства, которые он объединяет под одной крышей, похоже, относятся только к одному производителю — Mikrotik.
Еще одна причина, по которой мы хотели назвать этот конкретный ботнет, работающий под неуловимым C2C, другим именем – Mēris , что в переводе с латышского означает «Чума». Это кажется уместным и относительно близким к Mirai с точки зрения произношения.
Особенности ботнета Mēris:
Прокси-сервер Socks4 на уязвимом устройстве (неподтверждено, хотя устройства Mikrotik используют socks4 )
Использование технологии конвейерной обработки HTTP (http/1. 1) для DDoS-атак (подтверждено)
Создание самих DDoS-атак на основе RPS (подтверждено)
Открытый порт 5678 (подтверждено)
Мы точно не знаем, какие именно уязвимости приводят к ситуации, когда устройства Mikrotik подвергаются такому крупномасштабному взлому. Несколько записей на форуме Mikrotik указывают на то, что его клиенты сталкивались с попытками взлома более старых версий RouterOS, в частности 6.40.1 от 2017 года. Если это верно, и мы видим, что старая уязвимость все еще активна на тысячах устройств, которые не были исправлены и не обновлены, это ужасная новость. Однако наши с Яндексом данные показывают, что это не так, потому что спектр версий RouterOS, которые мы видим в этом ботнете, варьируется от года до недавнего. Наибольшая доля принадлежит версии прошивки, предшествующей текущей Stable.
Версия RouterOS, задействованная в DDoS-атаках. 6.48.4 — это текущая «стабильная» версия. Также ясно, что этот конкретный ботнет все еще растет. Есть предположение, что сила ботнета может увеличиться за счет перебора паролей, хотя мы склонны пренебрегать этим как незначительной возможностью. Похоже на какую-то уязвимость, которую либо держали в секрете до начала масштабной кампании, либо продали на черном рынке.
Расследовать происхождение не входит в наши обязанности, поэтому мы должны продолжить наши наблюдения.
За последние пару недель мы стали свидетелями разрушительных атак на Новую Зеландию, США и Россию, которые мы все приписываем этому виду ботнетов. Теперь он может перегрузить практически любую инфраструктуру, включая некоторые высоконадежные сети. Все это из-за огромной мощности RPS, которую он приносит.
Недавно в новостях рассказывали о «крупнейшей DDoS-атаке на рунет и Яндекс», но мы в Яндексе увидели гораздо большую картину. Cloudflare зафиксировала первые атаки такого типа. Сообщение в их блоге от 19 августа., 2021, упоминается, что атака достигает 17 млн запросов в секунду. Мы наблюдали аналогичную продолжительность и распределение по странам и сообщили эту информацию в Cloudflare.
RPS-график DDoS-атаки на Яндекс, 5 сентября 2021 г. Вот история атак этого же ботнета, которую мы зафиксировали на Яндексе:
07.08.2021 - 5,2 млн об/с
09.08.2021 - 6,5 млн об/с
2021-08-29- 9,6 млн об/с
31.08.2021 - 10,9 млн об/с
05.09.2021 - 21,8 млн об/с
Сотрудникам службы безопасности Яндекса удалось установить четкое представление о внутренней структуре ботнета. Туннели L2TP используются для межсетевого взаимодействия. Количество зараженных устройств, судя по внутренностям ботнета, которые мы видели, достигает 250 000.
Как именно Яндекс выдержал такое огромное количество запросов в секунду?
В Яндексе входящий пользовательский трафик проходит через несколько компонентов инфраструктуры, работающих на разных уровнях ISO/OSI. Первый компонент защищает Яндекс от SYN-флуда. Следующие уровни анализируют входящий трафик в режиме реального времени. Основываясь на технической и сетевой статистике, система оценивает каждый запрос на уровень подозрительности. Благодаря надежной и хорошо поддерживаемой инфраструктуре мы быстро масштабировали наши компоненты по горизонтали после первой атаки. Мы смогли справиться с самой масштабной RPS-атакой в истории Интернета, не переходя в режим бана по IP.
Атакующие источники (IP-адреса), которые не подделываются, по-видимому, преимущественно имеют один и тот же признак — открыты порты 2000 и 5678 . Конечно, многие поставщики размещают свои услуги на этих конкретных портах. Однако специфическое сочетание порта 2000 «Сервер проверки пропускной способности» и порта 5678 «Протокол обнаружения соседей Mikrotik» делает практически невозможным его игнорирование. Хотя Mikrotik использует UDP для своей стандартной службы на порту 5678, открытый TCP-порт обнаруживается на скомпрометированных устройствах. Подобная маскировка может быть одной из причин, по которой устройства взламывались незаметно для их владельцев.
Основываясь на этой информации, мы решили прощупать TCP-порт 5678 с помощью Qrator.Radar. Полученные нами результаты были неожиданными и пугающими одновременно.
Распределение открытых портов 5678. Чем темнее цвет - тем больше устройств Получается, что в Интернете 328 723 активных хоста, отвечающих на пробу TCP на порту 5678. Конечно, не обязательно каждый из них уязвимый Mikrotik — там есть свидетельство , что устройства Linksys также используют службу TCP на порту 5678. Их может быть больше, но в то же время мы должны предположить, что это число может представлять собой всю активную ботнет.
Страна
Хосты
% от общего числа
Соединенные Штаты Америки
139930
42,6%
Китай
61994
18,9%
Бразилия
9244
2,8%
Индонезия
7359
2,2%
Индия
6767
2,1%
Гонконг
5225
1,6%
Япония
4928
1,5%
Швеция
4750
1,4%
Южная Африка
4729
1,4%
Важно, что открытый порт 2000 отвечает на входящее соединение сигнатурой \x01\x00\x00\x00, которая принадлежит протоколу RouterOS. Так что это не какой-то случайный тестовый сервер пропускной способности, а идентифицируемый.
Со ссылкой https://github.com/samm-git/btest-opensource :
«Официального описания протокола нет, поэтому все было получено с помощью инструмента WireShark и RouterOS 6, работающего в виртуальном боксе, который подключался к настоящее устройство.
Сервер всегда запускается с командой «hello» (01:00:00:00) после установления TCP-соединения с портом 2000. Если в клиенте указан протокол UDP, TCP-соединение все еще установлено.»
По нашим наблюдениям, у 60% злоумышленников открытый socks4 на порту 5678, а у 90-95% — Bandwidth Test на порту 2000. в HTTP 1.1, в HTTP 2.0 это «мультиплексирование»), делает смягчение таких атак задачей, о которой давно забыли. Потому что, во-первых, сетевые устройства обычно обозначают легитимных пользователей — нельзя быть уверенным, что конечная точка полностью скомпрометирована в «бот-зомби», или часть пропускной способности используется в трафике атаки, а остальная законный пользовательский трафик. Пользователи, которые могут быть зарегистрированы на ресурсе, к которому они пытаются обратиться.
Конвейерная обработка HTTP, Википедия Это означает, что оптимизация внешнего интерфейса может нанести еще больший ущерб, отвечая на каждый конкретный сетевой запрос, поскольку конвейерная обработка в основном заключается в пакетной отправке запросов на целевой сервер, заставляя его отвечать на эти мусорные пакеты запросов. Кроме того, мы говорим о HTTP-запросах, которые уже составляют наибольшую вычислительную мощность сервера, тем более, если мы говорим о защищенном соединении, несущем криптографическую нагрузку поверх обычных запросов.
Конвейеризация запросов (в HTTP 1.1) является основным источником проблем для всех, кто сталкивается с этим конкретным ботнетом. Хотя браузеры обычно не используют конвейерную обработку (за исключением веб-браузера Pale Moon, , который делает это ), боты делают это. Кроме того, его легко распознать и смягчить, поскольку общепринятой последовательностью TCP является запрос-ответ, а не запрос-запрос-запрос-ответ.
Здесь мы видим сценарий «качество против количества». Из-за техники конвейерной обработки запросов злоумышленники могут получить гораздо больше запросов в секунду, чем обычно делают ботнеты. Это произошло потому, что традиционные меры по смягчению последствий, конечно же, заблокировали исходный IP-адрес. Однако некоторые запросы (около 10-20), оставшиеся в буферах, обрабатываются даже после блокировки IP.
Что делать в такой ситуации?
Черные списки по-прежнему актуальны. Поскольку эти атаки не подделываются, каждая жертва видит источник атаки таким, какой он есть. Блокировки на некоторое время должно быть достаточно, чтобы предотвратить атаку и не беспокоить возможного конечного пользователя.
Хотя, конечно, неясно, как будут действовать владельцы C2C ботнета Mēris в будущем — они могли воспользоваться скомпрометированными устройствами, отдав 100% его мощности (как пропускной способности, так и процессора) в свои руки. .
В этом случае нет другого выхода, кроме как блокировать каждый последующий запрос после первого, не позволяя отвечать на конвейерные запросы.
 oxylabs.io/v1/queries/12345678
oxylabs.io/v1/queries/12345678 oxylabs.io/v1/info/callbacker_ips'
oxylabs.io/v1/info/callbacker_ips'
 Для этого перейдите на
Для этого перейдите на  Подробнее здесь.
Подробнее здесь.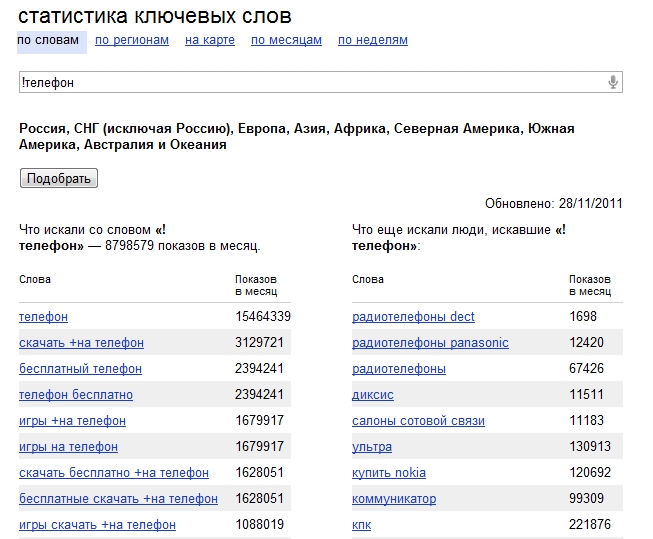 Вы отправляете нам запрос, соединение остается открытым, мы извлекаем контент и доставляем его вам. Конечная точка, которая обрабатывает это:
Вы отправляете нам запрос, соединение остается открытым, мы извлекаем контент и доставляем его вам. Конечная точка, которая обрабатывает это: yandex.com/search?q=adidas&hl=en&gl=US",
"job_id": "12345678
yandex.com/search?q=adidas&hl=en&gl=US",
"job_id": "12345678 Список поддерживаемых пользовательских агентов можно найти здесь.
Список поддерживаемых пользовательских агентов можно найти здесь. Флажок под
Флажок под 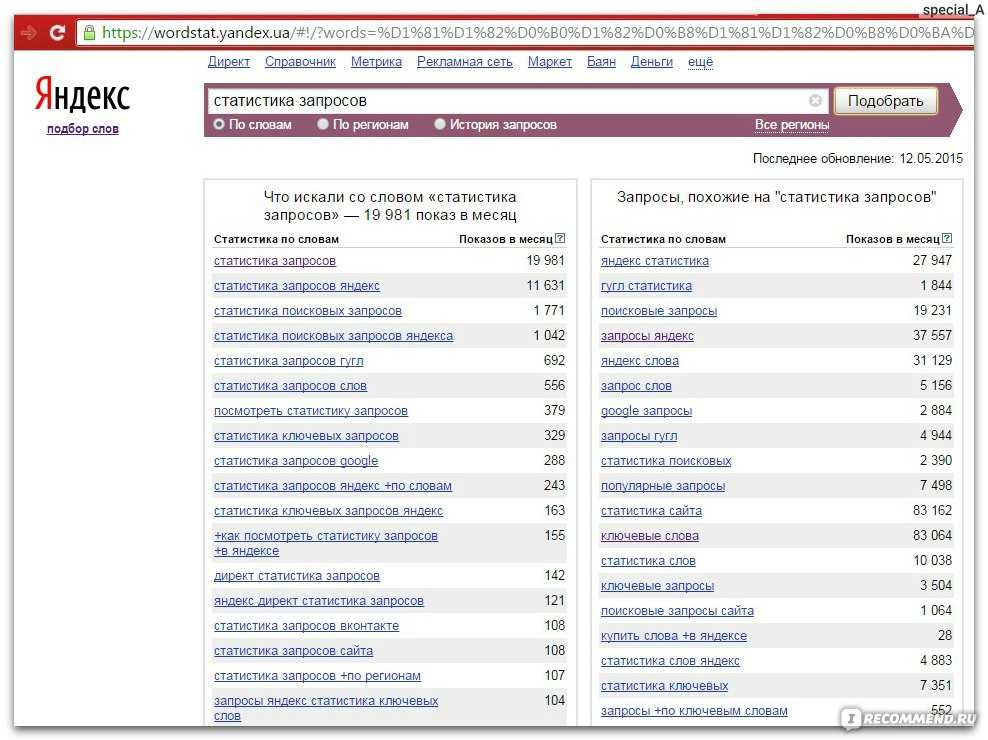 Полный список можно найти здесь.
Полный список можно найти здесь. oxylabs.io/v1/queries' - H "Тип контента: приложение/json"
-d '{"source": "yandex", "url": "https://yandex.com/search/?text=nike&"}'
oxylabs.io/v1/queries' - H "Тип контента: приложение/json"
-d '{"source": "yandex", "url": "https://yandex.com/search/?text=nike&"}'
 Работает только методом Push-Pull (Callback).
Работает только методом Push-Pull (Callback). callback.url"}'
callback.url"}'
 oxylabs.io/v1/stats
oxylabs.io/v1/stats
 oxylabs.io/v1/stats/limits
oxylabs.io/v1/stats/limits
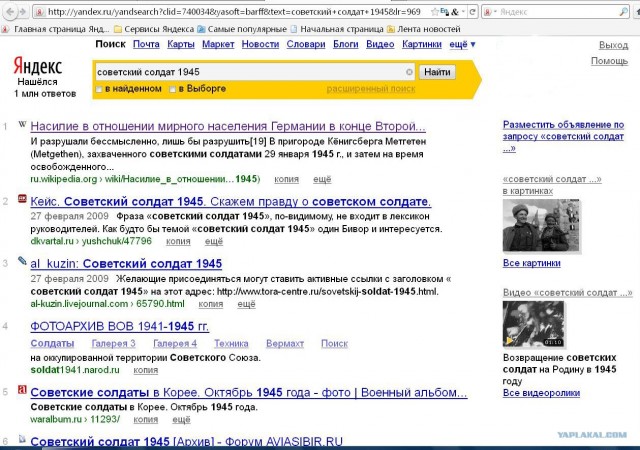
 Вы можете попробовать еще раз без дополнительной оплаты, так как мы не взимаем плату за
Вы можете попробовать еще раз без дополнительной оплаты, так как мы не взимаем плату за 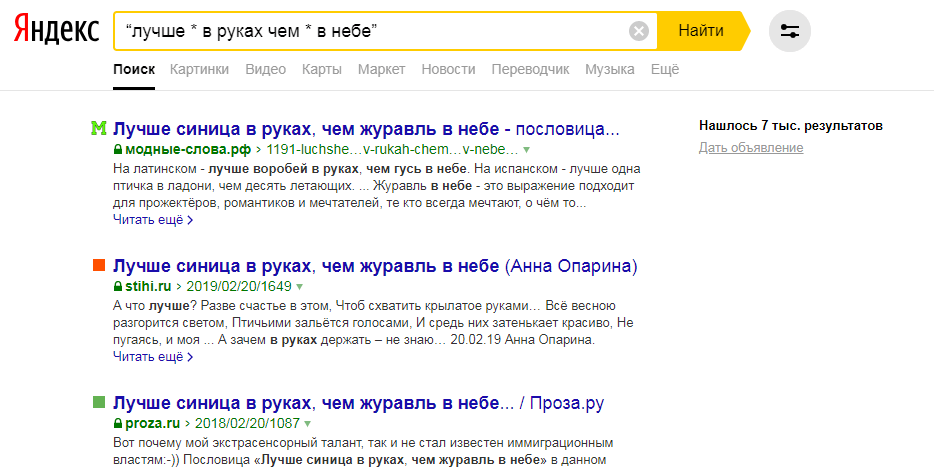 Чтобы узнать, как предоставить нам требуемый доступ, см. здесь.
Чтобы узнать, как предоставить нам требуемый доступ, см. здесь.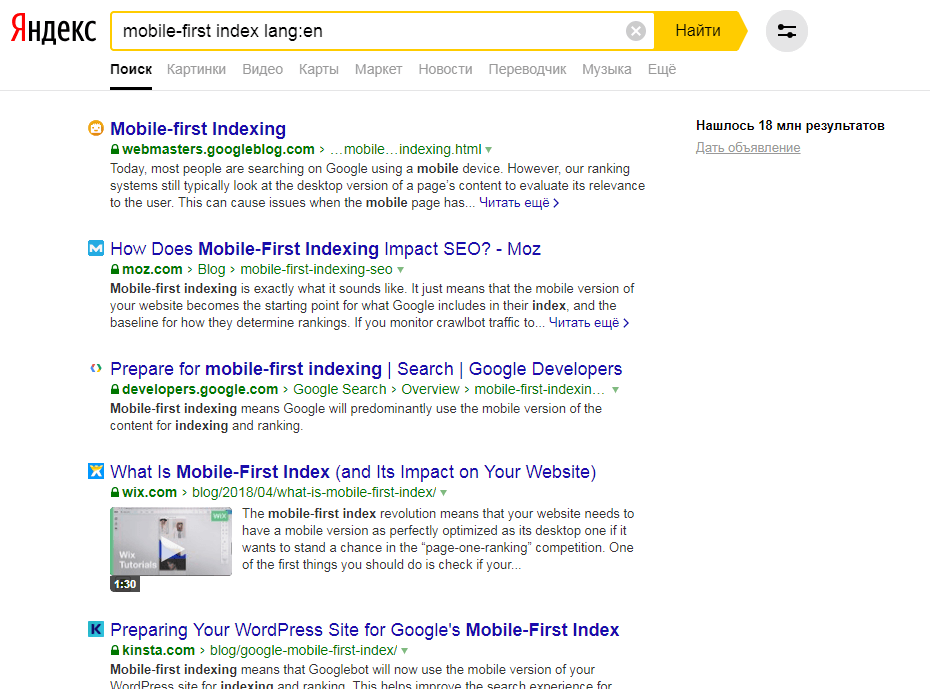 Это не означает, что ботнеты теперь безвредны.
Это не означает, что ботнеты теперь безвредны.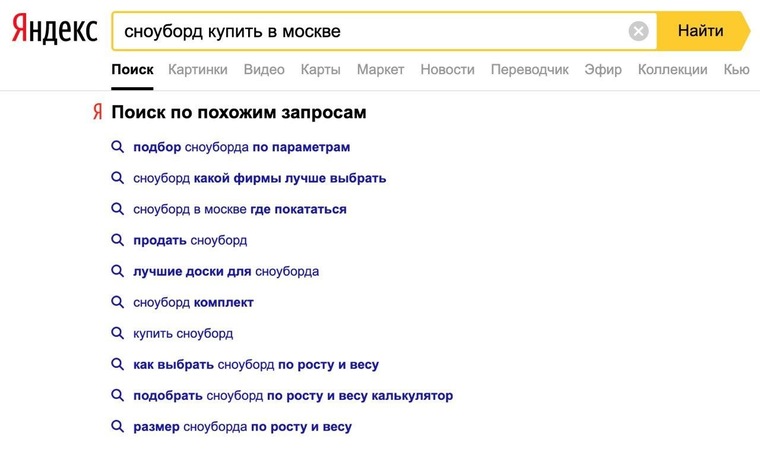
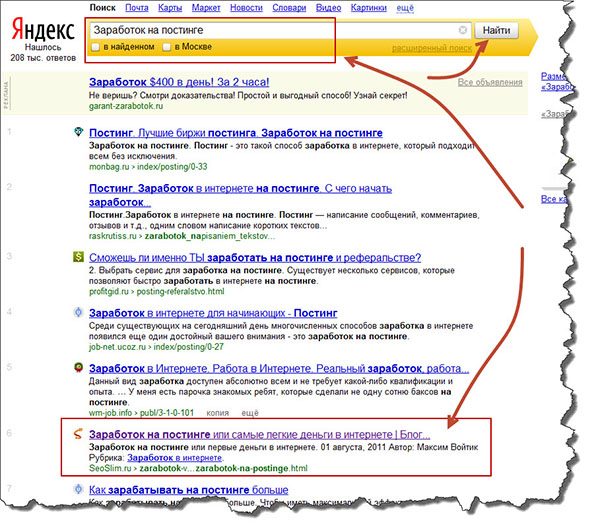 1) для DDoS-атак (подтверждено)
1) для DDoS-атак (подтверждено) Есть предположение, что сила ботнета может увеличиться за счет перебора паролей, хотя мы склонны пренебрегать этим как незначительной возможностью. Похоже на какую-то уязвимость, которую либо держали в секрете до начала масштабной кампании, либо продали на черном рынке.
Есть предположение, что сила ботнета может увеличиться за счет перебора паролей, хотя мы склонны пренебрегать этим как незначительной возможностью. Похоже на какую-то уязвимость, которую либо держали в секрете до начала масштабной кампании, либо продали на черном рынке.
 Основываясь на технической и сетевой статистике, система оценивает каждый запрос на уровень подозрительности. Благодаря надежной и хорошо поддерживаемой инфраструктуре мы быстро масштабировали наши компоненты по горизонтали после первой атаки. Мы смогли справиться с самой масштабной RPS-атакой в истории Интернета, не переходя в режим бана по IP.
Основываясь на технической и сетевой статистике, система оценивает каждый запрос на уровень подозрительности. Благодаря надежной и хорошо поддерживаемой инфраструктуре мы быстро масштабировали наши компоненты по горизонтали после первой атаки. Мы смогли справиться с самой масштабной RPS-атакой в истории Интернета, не переходя в режим бана по IP.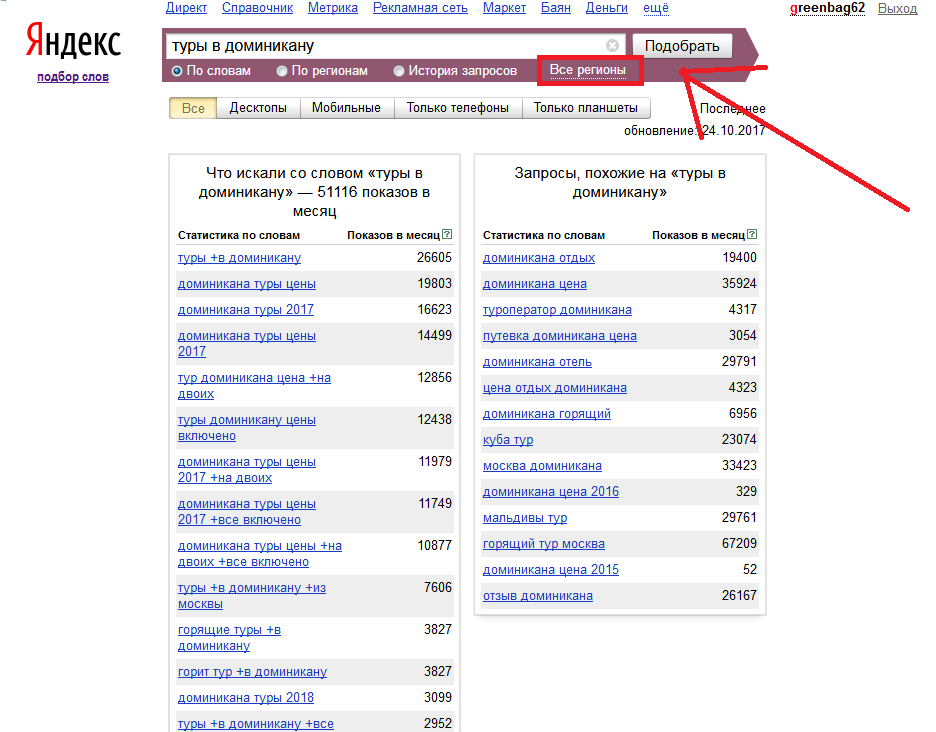
 Так что это не какой-то случайный тестовый сервер пропускной способности, а идентифицируемый.
Так что это не какой-то случайный тестовый сервер пропускной способности, а идентифицируемый. Пользователи, которые могут быть зарегистрированы на ресурсе, к которому они пытаются обратиться.
Пользователи, которые могут быть зарегистрированы на ресурсе, к которому они пытаются обратиться.
