Как запретить индексацию страниц/сайта — все доступные методы
Анализ индексируемости страниц в Linkbox.Pro
Информация обновлена 14 феврая 2023 года
Запрет индексации в Гугл и других поисковых системах прописывают в том случае, если определенная страница или сайт не должны попасть в индекс поисковой системы. Это может понадобиться по нескольким причинам:
- Страница создавалась как техническая, не имеет ценности для поисковой системы и не должна ранжироваться.
- Страница/сайт временно не готовы и пока не должны попадать в индекс.
- Страница является копией, низкокачественной, с плохим контентом.
- Страница предназначена для зарегистрированных и авторизованных пользователей, индексирование и сканирование ее ботом не должно осуществляться.
Ниже я представлю несколько способов запрета индексации страницы и опишу методы их реализации. Также в статье вы узнаете о том, как проверить запрет индексации страницы на своем сайте или запрет индексации на внешних сайтах, например проверка возможности индексации бэклинков.
Способы запрета индексации
#1 — noindex
Директива noindex — это специальное правило, запрещающее Google и других поисковым системам индексировать страницу. Данное правило не запрещает при этом страницу сканировать (читайте подробнее про разницу между индексированием и сканированием в словаре).
Реализация правила noindex возможна двумя способами — с помощью специального тега noindex (#1.1), который нужно поместить в <head>, или же с помощью http-ответа (#1.2).
#1.1 Использование тега является более простым вариантом. Код выглядит следующим образом
a) запрет индексирования для всех ботов поисковых систем
<meta name="robots" content="noindex" />
б) запрет индексирования для Гуглбота:
<meta name="googlebot" content="noindex" />
Можно запретить индексирование любому боту, для этого нужно просто узнать название бота в справке поисковой системы или краулера.
Включить вывод тега noindex в определенных CMS обычно можно благодаря специальным настройкам в интерфейсе системы или же благодаря плагинам. Например, в WordPress с подключенным Yoast нужно перейти на админ-страницу записи, проскроллить к блоку Yoast Seo Premium, открыть блок дополнительно и выбрать вариант «Нет» в вопросе «Разрешить поисковым системам показывать Страница в результатах поиска?».
Например, в WordPress с подключенным Yoast нужно перейти на админ-страницу записи, проскроллить к блоку Yoast Seo Premium, открыть блок дополнительно и выбрать вариант «Нет» в вопросе «Разрешить поисковым системам показывать Страница в результатах поиска?».
#1.2. Заголовок HTTP-ответа
Noindex как правило запрета индексирования страницы можно также прописать в HTTP-ответе. Выглядит это следующим образом:
HTTP/1.1 200 OK
(...)
X-Robots-Tag: noindex
(...)Данный метод подойдет для тех, кто умеет работать с конфигурациями на сервере, поскольку ответ сервера можно редактировать именно там.
Метод с ноиндексом идеально подходит в тех случаях, когда вам надо навсегда запретить индексирование технической страницы, или не индексировать страницы, предназначенных только для зарегистрированных и авторизованных пользователей. Читайте подробнее в справке.
#2 Запрет доступа ботам (403 ответ сервера)
С помощью специальных правил на сервере или на CDN, можно запретить Гуглботу или любому другому боту сканировать и индексировать сайт/страницу. Если правильно прописать правило, боты будут получать 403 ответ сервера (запрет доступа).
Если правильно прописать правило, боты будут получать 403 ответ сервера (запрет доступа).
Вот так например выглядит запрет сканирования (и как результат — страница не попадет в индекс) на cloudflare в разделе Firewall для Гуглбота. Подобное правило можно создать в конфигурациях на сервере.
При проверке url, для которого стоит такой запрет, вы увидите 403 ответ сервера (то есть отсутствие доступа на просмотр страницы).
Данный способ запрета индексации подойдет для новых сайтов, которые только разрабатываются, и пока не должны сканироваться или индексироваться. Обратите внимание! Запрет доступа ботам не дает странице не только не попасть в индекс, но также и просканироваться. Подобным образом действует и запрет на сканирование в файле robots.txt но с той разницей, что урлы в robots.txt все равно могут попасть в выдачу, если, например, на них стоит много ссылок с других источников. С новыми сайтами, полностью закрытыми от ботов на сервере или CDN, обычно такого не происходит.
#3 Запрет на сканирование в Robots.txt (не рекомендуемый способ!)
Между процессами сканирования и индексирования есть разница, однако первый процесс всегда является предшественником второго. Поэтому теоретически запрет сканирования исключает возможность попадания в выдачу, ведь бот не может просканировать страницу и понять, о чем она.
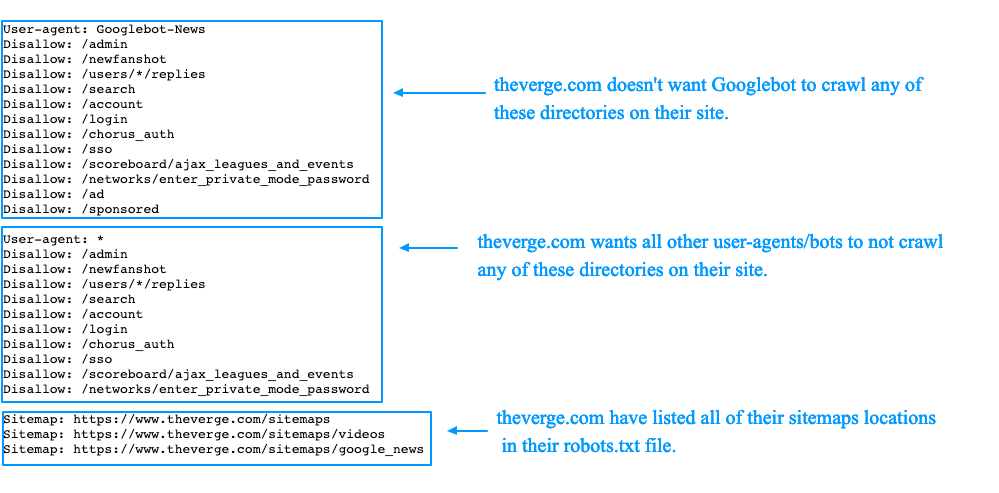
Запрет на сканирование в Robots.txt осуществляется путем прописывания в файле Robots.txt запрета на сканирование страницы/сайта/подпапки(директории)/типов файлов следующим способом:
User-agent: *
Disallow: /user/*
Disallow: /news/*Данное правило запрещает сканирование всем ботам каталогов (подпапок) /user/ и /news/ и любых файлов в этих каталогах.
На самом деле данный метод не рабочий в плане запрета индексации. «Файл robots.txt не предназначен для того, чтобы запрещать показ ваших материалов в результатах поиска Google.» — прямая цитата из справки Гугл. Другими словами, если страница, закрытая от сканирования, будет обнаружена другими методами, например на нее ведут внешние ссылки, она все равно может попасть в индекс (и в моей практике такое не раз случалось).
Еще одна цитата для подтверждения:
Если доступ к странице запрещен в файле robots.txt, она все равно может быть проиндексирована по ссылкам с других сайтов. Google не будет напрямую сканировать и индексировать контент, который заблокирован в файле robots.txt. Однако если на такой URL ссылаются другие сайты, то он все равно может быть найден и добавлен в индекс. После этого страница может появиться в результатах поиска (во многих случаях вместе с текстом ссылки, которая на нее ведет). Если вас это не устраивает, рекомендуем защитить файлы на сервере паролем или использовать директиву noindex в теге meta или HTTP-заголовке ответа. Альтернативное решение – полностью удалить страницу.
Короче, этот способ я могу порекомендовать использовать в последнюю очередь только в том случае, если вы не можете отредактировать тег роботс в head, прописать ответ сервера или настроить файерволл.
#4 Защита файлов паролем
Способ подобный к способу #2 — он будет возвращать ботам 403 ответ сервера (запрет доступа).
Для защиты страниц паролем вы можете использовать плагин ограничения контента (для WordPress это, например, Password Protected). Установите и активируйте его, затем перейдите в «Настройки» > «Защищено паролем» и включите «Статус защиты паролем». Это дает более тонкий контроль, позволяя занести в белый список определенные IP-адреса.
5 Ручное удаление из индекса
Это способ срочно (примерно в течении часа) удалить из индекса страницы. Для подтвержденного в консоли сайта инструмент удаления находится по адресу https://search.google.com/u/0/search-console/removals. Там можно запросить удаление целого сайта или каталога.
Данный способ не запрещает индексацию, а просто временно удаляет страницы из индекса.
Для удаления проиндексированного контента не своего сайта воспользуйтесь справкой https://support.google.com/websearch/answer/6349986 (там будет ссылка на инструмент).
Как проверить, разрешена ли индексация страницы
#1 Страницы своего сайта можно проверить в Search Console с помощью инструмента Test live Url. Он показывает,
#1.1 если страница закрыта от индексации с помощью тега или ответа сервера noindex:
#1.2 если у Гуглбота нет доступа к странице из-за защиты паролем или файервола (403 ответ сервера):
#1.3 если страница не может быть просканирована из-за ограничений в файле robots.txt (однако еще раз повторю: такая страница все равно может попасть в индекс):
#2 Массово проверить страницы на возможность индексации (например, проверить свои бэклинки) можно в специальных сервисах, например Linkbox.Pro, а также с помощью краулера ScreamingFrog SEO Spider (желательно с лицензией).
Быстрые ответы
Самый простой способ закрыть страницу от индексации?
Самый простой и правильный (рекомендуемый Google) способ — прописать в секции head тег Noindex.
Какой синтаксис тега Noindex?
<meta name=»robots» content=»noindex» />
Какой самый простой способ массово проверить индексируемость страниц?
Самый простой способ проверить индексирумость массово — использовать сервис ЛинкбоксПро.
Почему disallow в Robots.txt не помогает запретить индексацию?
Disallow в Robots.txt не запрещает индексацию страницы. Если Гугл находит ее в других источниках (внешних ссылках), она может все равно попасть в индекс.
Можно ли использовать noindex и disallow в robots.txt для лучшего эффекта?
Нет. В процессах оценки страницы сначала идёт сканирование, потом индексирование. Запрет сканирования в robots.txt не даст Гуглу учесть тот факт, что на странице noindex, и она может попасть в индекс все равно. Чтобы noindex работал, страница должна нормально сканироваться.
Запрет сканирования в robots.txt не даст Гуглу учесть тот факт, что на странице noindex, и она может попасть в индекс все равно. Чтобы noindex работал, страница должна нормально сканироваться.
Поддержите Украину!🇺🇦
Мы боремся за нашу независимость прямо сейчас. Поддержите нас финансово. Даже пожертвование в 1 доллар важно.
зачем и как скрывать дубликаты?
Хотите подняться выше в результатах поисковой выдачи?
Сегодня мы расскажем, как параметры страницы могут препятствовать продвижению вашего сайта. Вы узнаете что такое дубликаты страниц, разберём причины их появления, рассмотрим способы которые помогут скрыть их от индексации.
Дубликаты — страницы с полностью или частично идентичным содержанием (неполный дубль), которые имеют разные URL адреса. Динамические URL с параметрами являются самой частой причиной появления дублей.
Динамические URL с параметрами являются самой частой причиной появления дублей.
Обычно параметры применяются для:
-
поиска — внутренний поиск по сайту генерирует страницы результатов, используя параметры;
-
отслеживания источника трафика и/или поисковых запросов — обычно это utm-метки, используемые в контекстной рекламе;
-
пагинации — контент делится по отдельным страницам для удобства использования товарного каталога и увеличения скорости загрузки. При этом содержание страниц полностью или частично дублируется;
-
разделения разных версий сайта — мобильная, языковая;
-
фильтрации и сортировки товаров в каталоге.
Найти дублирующиеся страницы можно с помощью онлайн-инструментов: Siteliner, Copyscape, Screamingfrog или десктопных программ-краулеров: Xenu, ScreamingFrog, ComparseR и других. Почти всегда дублирующиеся страницы имеют одинаковые title и description.
Почти всегда дублирующиеся страницы имеют одинаковые title и description.
Множество комбинаций URL адресов с повторяющимся контентом — это проблема для SEO оптимизации. Особенно характерно URL-дублирование страниц для сайтов электронной коммерции. Этому способствуют функции поиска, сортировки и фильтрации на сайте.
Например:
поиска: https://www.test.com/search?q=ноутбуки;
сортировки: https://www.test.com/pylesosy/?s=price;
фильтрации:https://www.test.com/c/355/clothes-zhenskaya-odezhda/?brands=23673
Также для сектора Ecommerce характерно частичное дублирование страниц. Это происходит из-за того, что описания товаров и в каталоге, и в карточках товаров совпадают. Поэтому не стоит выводить полную информацию о товарах на страницах каталога.
Чем страшны дубли страниц?Приоритетными в ранжировании являются сайты с высокой степенью уникальности. Повторяющийся контент и мета-теги её не добавят. Если контент повторяется, это плохо отразится на индексации сайта, а как следствие и на его поисковой оптимизации. Поисковая система не может определить, где дубликат, а где основная страница — из-за этого из выдачи могут пропасть нужные страницы, а вместо них там окажутся дубликаты.
Если контент повторяется, это плохо отразится на индексации сайта, а как следствие и на его поисковой оптимизации. Поисковая система не может определить, где дубликат, а где основная страница — из-за этого из выдачи могут пропасть нужные страницы, а вместо них там окажутся дубликаты.
-
Если релевантные страницы, которые соответствуют запросу, будут постоянно меняться — вы будете себе же мешать, и сайт может опуститься в поисковой выдаче. Это называется каннибализация.
-
При большом количестве дубликатов страниц сайт может дольше индексироваться, что тоже не выгодно и уменьшит трафик с поиска. Часто из двух страниц с похожим содержанием индексируется лишь одна и не факт, что корректная.
-
Количество страниц, которые запланировал обойти поисковый робот на вашем сайте, ограничено. А вы будете тратить краулинговый бюджет не на страницы, которые вы действительно хотите отобразить в результатах поисковой системы, а на дублирующие страницы.

Конечно же, мы не будем просто удалять все страницы с параметрами, так как они улучшают пользовательский опыт и помогают сделать сайт лучше. К примеру, строка поиска — увеличивает конверсию, а отслеживание поиска даёт владельцу сайта ценную информацию о пользователях и том, как они взаимодействуют с контентом. Опция фильтрации или сортировки является привычной и очень удобной для покупателей интернет-магазинов, потому что помогает сузить поиск и сделать его быстрее. Было бы глупо отказаться от таких функций.
Что же делать с дубликатами страниц?1. Используем тег canonicalРассмотрим способы, которые помогут нам снизить негативное влияние дубликатов страниц на продвижение сайта.
В случае, если страницы с похожим контентом индексируются как отдельные страницы, важно использовать канонические теги.
Тег canonical — это элемент, который добавляется в код страницы в раздел <head> и говорит поисковым машинам, что это неглавная версия другой страницы и указывает на её расположение.
В Ecommerce бывает, что один и тот же товар находится в разных категориях и URL формируется от категории. Как следствие, появляется несколько адресов страниц для одного и того же товара и нужно выбрать основной или канонический адрес. Результат от установки канонического тега похож на 301-редирект, но без перенаправления. То есть весь авторитет (вес) и накопленные характеристики страницы будут передаваться канонической странице от неканонической. Вам нужно будет добавить в <head> вашей дополнительной страницы специальный код.
Например:
на странице сортировки товаров по цене https://www.test.com/noutbuki/?s=price
прописан тег <link rel=»canonical» href=»https://www.test.com/noutbuki/»>,
который указывает на основную страницу (без параметра ?s=price).
Обратите внимание, что указание канонической ссылки без протокола http:// или https:// является ошибкой. Ссылка обязательно должна быть абсолютной, то есть включать в себя протокол, домен и сам адрес.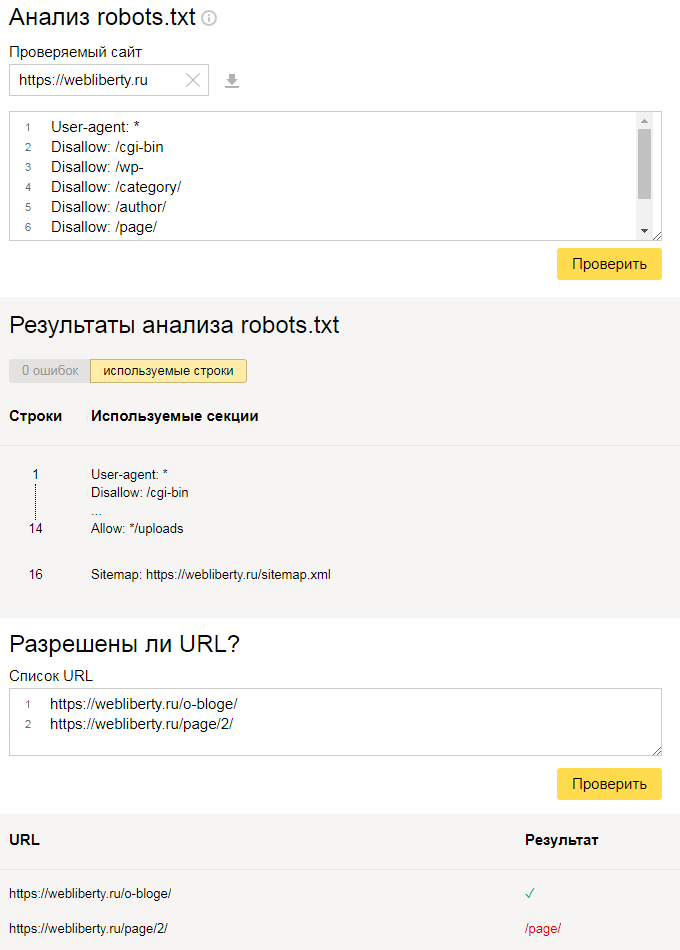
Канонический тег сообщает поисковым системам предпочтительную страницу, которая должна отображаться на страницах результата поиска. Канонический тег не сработает, если контент страниц существенно отличается — тег может быть проигнорирован, так как он носит рекомендательный характер, а не обязательный.
На сайтах, которые используют в своей практике canonical, часто встречается канонический тег. Он ссылается на ту же страницу, где он и расположен. Это не является ошибкой.
Например:
на странице https://www.test.com/pr89849/ может быть указан тег
<link rel=»canonical» href=»https://www.test.com/pr89849/» />
Страницы также можно скрыть от поисковых роботов с помощью директивы Disallow: в файле robots.txt. Этот метод подойдёт, если количество дубликатов небольшое или дубликаты генерируются однотипными параметрами — иначе этот процесс может затянуться надолго. Нам нужно будет внести изменения в файл robots. txt, который управляет поведением поисковых роботов. Вы его найдёте по адресу: www.yoursite.com/robots.txt. Если вдруг файла там нет, воспользуйтесь генератором robots.txt или просто создайте новый .txt и пропишите в него директивы. Сохраняем файл как robots.txt и помещаем в корневой каталог домена (рядом с главным index.php).
txt, который управляет поведением поисковых роботов. Вы его найдёте по адресу: www.yoursite.com/robots.txt. Если вдруг файла там нет, воспользуйтесь генератором robots.txt или просто создайте новый .txt и пропишите в него директивы. Сохраняем файл как robots.txt и помещаем в корневой каталог домена (рядом с главным index.php).
Прописывая директиву Disallow, вы будете запрещать индексирование определенных страниц. В случае указанном ниже запрещается индексация всех URL с вопросительным знаком, а значит тех, которые содержат параметры:
Disallow: /*?
Пример файла www.test.com/robots.txt
User-Agent: YadirectBot
Disallow:
User-Agent: YandexDirect
Disallow:
User-agent: *
Disallow: /account
Disallow: /admin
Disallow: /cabinet
Disallow: /company-contacts
Disallow: /context/
Disallow: /error/
Disallow: /feedback/
Disallow: /map/frame_map
Disallow: /opensearch. xml
xml
Disallow: /opinions/create
Disallow: /order_mobile
Disallow: /order_mobile_confirm
Disallow: /order_v2
Disallow: /preview
Disallow: /product_opinion/create
Disallow: /product_view/ajax_
Disallow: /product_view/get_products_for_overlay
Disallow: /company/mark_invalid_phone
Disallow: /redirect
Disallow: /remote
Disallow: /search
Disallow: /shopping_cart
Disallow: /shop_settings/
Disallow: /social_auth/
Disallow: /tracker/
Disallow: /*/shopping_cart
Disallow: /*/partner_links
Disallow: /m*/offers*.html
Disallow: /for-you
Allow: /*?_escaped_fragment_=
Disallow: /*?
Allow: /.well-known/assetlinks.json
У каждой поисковой системы есть свои юзер-агенты. В robots.txt мы можем указывать отдельно каждому агенту, как себя вести на сайте. Можем также указать директиву сразу всем поисковым агентам — User-agent:*.
Использование “Disallow: /” или “Disallow:” запрещают индексацию всех страниц сайта. Так что будьте внимательны, работая с robots.txt
Есть еще два метода, которые определяют правила поведения поисковых роботов на странице:
X-Robots-Tag является частью HTTP заголовка и применяется, в основном, чтобы ограничить индексирование не HTML файлов. Это могут быть, например: PDF-документы, картинки, видео и т.д. — то есть элементы, “внутри” которых нельзя прописать мета-тег. Но так как процедура установки x-robots-tag довольно сложна, то используется она крайне редко.
Прописать же мета-тег robots в HTML-код страницы намного легче. Их используют, чтобы скрыть проиндексированные страницы. Для этого необходимо в <head> прописать <meta name=»robots» content=»noindex» />. Таким образом можно убрать страницу из индекса и не допустить попадания в него.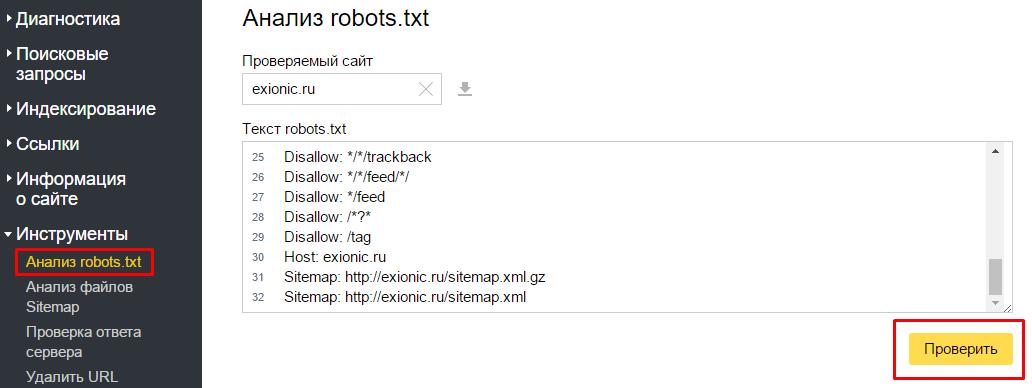
Значение параметров, которые может принимать meta robots:
-
noindex: не индексировать,
-
index: индексировать (можно не указывать, так как если не стоит noindex, страница индексируется по умолчанию,
-
follow: (следовать по ссылкам на странице, можно не указывать, аналогично index),
-
nofollow: запрет на переход по ссылкам на странице,
-
и некоторые другие, менее распространенные параметры, о которых рекомендуем прочитать в Центре Поиска Google.
Интересный эксперимент описан у блогера Игоря Бакалова — он проверял на самом ли деле поисковые системы учитывают meta-robots. Результаты оказались неожиданными, так что рекомендуем ознакомиться.
Справедливо будет добавить, что обычно вручную редактируется только robots. txt файл, а остальные методы управления индексацией страниц или всего сайта в целом осуществляются из CMS и специальных знаний для этого не требуется.
txt файл, а остальные методы управления индексацией страниц или всего сайта в целом осуществляются из CMS и специальных знаний для этого не требуется.
«Лично я предпочитаю использовать meta robots везде, где это возможно»
Александр Алаев
руководитель веб-студии “АлаичЪ и Ко” и автор “блог Алаича”
“Так как методов больше одного, появляется логичный вопрос — каким же лучше воспользоваться? Из собственной практики могу выделить самый надежный способ — мета-тег robots. Его можно применять не только для избавления от дублей, но и в любом другом случае, когда необходимо скрыть от поисковиков какую-то страницу. Ограничением для использования тега canonical является требование “одинаковости” страниц, а x-robots-tag — вообще вгоняет в ступор большинство специалистов.
Поэтому фактически мы выбираем сейчас между robots.txt и meta robots. Использовать robots.txt очень просто и быстро, любой справится, но у него есть изъян — закрытые страницы все равно могут отображаться в поисковой выдаче (с припиской о том, что контент страницы запрещен для индексации при помощи robots. txt вместо сниппета), если на них стоят внешние ссылки. А meta robots не имеет такой проблемы. Хотя если говорить конкретно про seo и влияние на него, эта “проблема” — не проблема, на самом деле.
txt вместо сниппета), если на них стоят внешние ссылки. А meta robots не имеет такой проблемы. Хотя если говорить конкретно про seo и влияние на него, эта “проблема” — не проблема, на самом деле.
Лично я предпочитаю использовать meta robots везде, где это возможно. Но вы можете выбрать более простой и быстрый способ (robots.txt). Повторюсь, для seo это не имеет никакой разницы”.
ИтогиИзбежать дубликатов страниц, связанных с параметрами страницы, полностью не получится. Но их нужно исключать из индексации, чтобы не терять позиции в поисковой выдаче. Методы описанные выше помогут вам это сделать.
Также полезной будет функция прямые переходы от Multisearch. Суть функции такая: при введении точного запроса пользователь сразу переходит на страницу категории/бренда/фильтра/товара, минуя при этом страницу поисковых результатов. Таким образом увеличивается количество просмотров страниц в каталоге, а не внутри неиндексируемых страниц внутреннего поиска.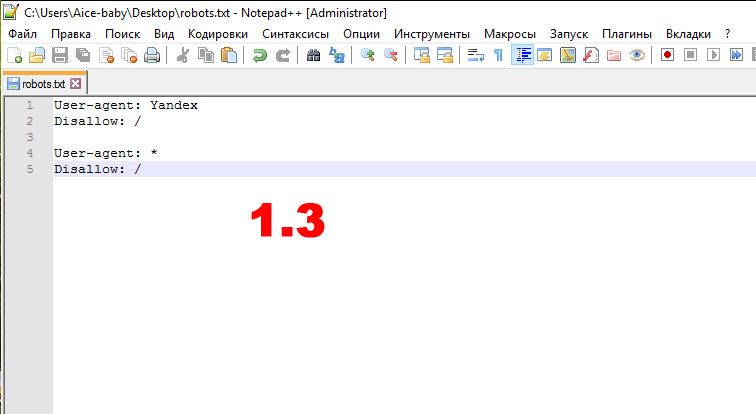 Это положительно скажется на ранжировании сайта, так как количество пользователей и качество сеанса на целевых страницах учитывается в алгоритмах Google и Yandex.
Это положительно скажется на ранжировании сайта, так как количество пользователей и качество сеанса на целевых страницах учитывается в алгоритмах Google и Yandex.
seo — Должен ли я удалить мета-роботов (индексировать, следить), когда у меня есть файл robots.txt?
спросил
Изменено 4 года, 5 месяцев назад
Просмотрено 1к раз
Я немного не понимаю, следует ли удалять метатег robots, если я хочу, чтобы поисковые системы следовали моим правилам robots.txt.
Если на странице существует метатег robots (index, follow), будут ли поисковые системы игнорировать мой файл robots.txt и индексировать указанные запрещенные URL-адреса в моем файле robots.txt?
Причина, по которой я спрашиваю об этом, заключается в том, что поисковые системы (в основном Google) по-прежнему индексируют запрещенные страницы моего сайта.
- поисковая оптимизация
- метатеги
- robots.txt
0
Если бот поисковой системы принимает ваш файл robots.txt, а вы запрещаете сканирование /foo , то бот никогда не будет сканировать страницы, пути URL которых начинаются с /foo . Следовательно, бот никогда не узнает, что есть мета — роботов элементов.
И наоборот, если вы хотите запретить индексировать страницу (указав meta — robots с noindex ), вы не должны запрещать сканирование этой страницы в файле robots.txt. В противном случае доступ к noindex никогда не осуществляется, и бот считает, что сканирование запрещено, а не индексация .
С помощью файла robots.txt вы можете указать поисковым системам не сканировать определенные страницы, но это не помешает им индексировать страницы. Если страница, запрещенная в robots.txt, будет найдена сканером по внешней ссылке, она может быть проиндексирована. Это можно предотвратить с помощью метатега.
Таким образом, robots.txt и метатег работают по-разному.
Если страница, запрещенная в robots.txt, будет найдена сканером по внешней ссылке, она может быть проиндексирована. Это можно предотвратить с помощью метатега.
Таким образом, robots.txt и метатег работают по-разному.
https://developers.google.com/search/reference/robots_meta_tag?hl=en#combining-crawling-with-indexing—serving-directives
Метатеги Robots и заголовки HTTP X-Robots-Tag обнаруживаются при сканировании URL-адреса. Если страница запрещена для сканирования через файл robots.txt, то любая информация об индексации или обслуживании директив не будет найдена и, следовательно, будет проигнорирована. Если необходимо следовать директивам индексации или обслуживания, URL-адреса, содержащие эти директивы, не могут быть запрещены для сканирования.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
seo — Как удалить сайт из индекса Google после обновления robots.
 txt?
txt?спросил
Изменено 2 года, 6 месяцев назад
Просмотрено 206 раз
Я отправил свой сайт в Google, но изначально у меня не было файла robots.txt. Несколько дней спустя я добавил файл robots.txt, запрещающий некоторые страницы, но эти страницы все еще находятся в индексе, например. когда я делаю запрос site:domain.com , я все еще вижу эти страницы. Как я могу заставить Google удалить те страницы, которые я только что добавил в robots.txt?
- поисковая оптимизация
- консоль поиска google
1
Вы можете немедленно и временно удалить URL-адрес из индекса с помощью инструмента удаления Google.
Чтобы навсегда исключить его из индекса, добавьте html-тег noindex или заголовок http.
НЕ блокируйте страницу с robots.txt , так как это не предотвращает индексацию, а только предотвращает сканирование. Согласно гуглу:
Если ваша страница по-прежнему отображается в результатах, возможно, это связано с тем, что мы не сканировали ваш сайт с тех пор, как вы добавили тег. Вы можете запросить у Google повторное сканирование вашей страницы с помощью инструмента «Просмотреть как Google». Другая причина может заключаться в том, что ваш файл robots.txt блокирует этот URL-адрес от поисковых роботов Google, поэтому мы не можем увидеть этот тег.
https://support.google.com/webmasters/answer/93710?hl=en
Правильный и единственный способ — изначально разрешить сканирование страниц (снова удалить страницы из robots.txt ). Установите метатег name="robots" content="noindex,follow" на затронутых страницах.