
Как скрыть от поисковых систем часть контента на странице (текст, часть страницы, ссылки)? И зачем? || Блог Megaindex.com
На некоторых сайтах имеет смысл скрыть часть контента от поисковых систем.
Как скрыть часть контента на страницах сайта от роботов поисковых систем?
Для каких целей следует скрывать содержание?
Разберемся с вопросами далее.
Зачем скрывать контент сайта от индексации?
Контент на сайте скрывается от поисковых систем для достижения различных целей.
Если скрыть часть контента от поискового краулера, то алгоритмы ранжирования обработают не всю страницу, а лишь ее часть. В результате поисковый оптимизатор может извлечь выгоду.
Если от поисковых систем часть сайта скрывается, то для пользователей весь контент остается полностью видимым.
Итак, какой контент имеет смысл скрывать и зачем? Например:
- Ссылки для улучшения внутренней перелинковки на сайте.
 Улучшение достигается за счет оптимизации распределения статического ссылочного веса на сайте;
Улучшение достигается за счет оптимизации распределения статического ссылочного веса на сайте; - Часть текста для повышения релевантности страницы;
- Часть страницы для улучшения ранжирования. Например, скрытие рекламных блоков со страницы, которые находятся в верхней части страницы. Если такие рекламные блоки не скрывать, то поисковая система после рендеринга на так называемом первом экране распознает нерелевантный контент, что не позволит сайту ранжироваться лучше;
- Часть страницы для защиты от санкций поисковых систем. Например, часто требуется скрывать исходящие ссылки на различные сайты.
 Улучшение достигается за счет оптимизации распределения статического ссылочного веса на сайте;
Улучшение достигается за счет оптимизации распределения статического ссылочного веса на сайте;Есть еще множество различных ситуаций при которых требуется скрывать от поисковых систем часть страницы.
Например, поисковые системы пессимизируют сайты с реферальными ссылками. Такие сайты зарабатывают на партнерских отчислениях. С точки поисковых систем таких как Google подобные сайты не несут никакой дополнительной ценности для пользователя, а значит и не должны находиться среди лидеров поиска.
Если реферальные ссылки скрыть, проблем не будет.
Как скрыть от поисковых систем часть страницы?
На практике скрыть контент сайта от индексации можно используя разные способы.
Наиболее распространенным способом по скрытию текста от поисковых систем является использование подгрузки текста по параметру в хеш-ссылке. Исходя из заявлений Google, протокол HTTP/HTTPS не был разработан для такого использования, поэтому при использовании данного метода индексация не происходит.
Наиболее распространенным способом по скрытию ссылки от поисковых систем является использование контейнера div при создании ссылки.
Но что делать, если речь идет о создании системы для скрытия контента?
Какую технологию использовать? Основные требования следующие:
- У пользователя на экране должен отображаться весь контент страницы сайта;
- Для поисковой системы должен отдаваться не весь контент страницы сайта;
- Способ должен быть условно белым, чтобы сложнее было найти повод для санкций.

В результате оптимальной технологией является та технология, которая официально:
- Не поддерживается движком поисковой системы;
- Поддерживается популярными браузерами.
Ситуация ухудшается тем, что Google обновил поисковый краулер. Теперь Google выполняет скрипты, написанные на современном JavaScript.
Рекомендованный материал в блоге MegaIndex по теме обновления краулера по ссылке далее — Google обновил поисковый краулер. Что изменилось? Как это повлияет на ранжирование?
Все приведенные способы основаны на принципах работы поискового краулера.
Но лазейка все еще есть. В результате обновления стала известна информация о принципах работы поискового краулера, используя которую можно сделать выводы о том, какие именно технологии поисковый робот не поддерживает, а значит не передает в систему ранжирования.
До начала этапа ранжирования происходит ряд процессов.
Весь процесс обработки информации до этапа ранжирования выглядит так:
После рендеринга происходит передача данных в систему ранжирования.
Если после рендеринга часть документа отсутствует, значит данная часть документа не будет участвовать и в ранжировании.
Теперь требуется разобраться с тем, какую технологию пока еще не поддерживает движок рендеринга
Итак, скрыть любую часть страницы от поисковой системы можно используя так называемые service workers.
Что такое сервис-воркеры? Сервис-воркеры — это событийный управляемый веб-воркер, регистрируемый на уровне источника и пути. Сервис-воркер может контролировать сайт, с которым ассоциируется, перехватывать и модифицировать запросы навигации и ресурсов.
Да, я вижу ваши лица. Подождите пугаться.
Если упростить, то сервис-воркером является программируемый сетевой проксификатор.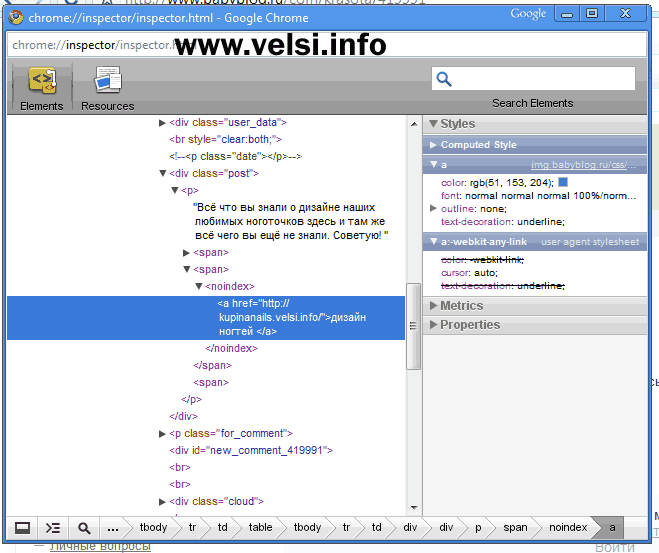
Иными словами, применяя сервис-воркер можно контролировать контент, который передаются пользователю.
В результате применения сервис-воркеров контент может изменяться. Поисковая система же обрабатывает такие корректировки, так как не поддерживает выполнения таких скриптов.
Почему метод эффективен в применении на практике? Сервис-воркеры поддерживаются всеми популярными браузерами и не поддерживаются движком рендеринга поисковой системы Google, через который данные передаются в систему ранжирования.
Следующие браузеры поддерживают сервис-воркеры:
- Chrome;
- Android Chrome;
- Opera;
- Safari;
- iOS Safari;
- Edge;
- Firefox.
Задача поискового оптимизатора заключается в следующем:
- Найти элементы, которые требуется скрыть от поисковой системы;
- Если такие элементы есть, то передать задачу в отдел разработки и оповестить про способы реализации на практике;
- Протестировать работу на примере одного документа путем использования программного решения Chrome Dev Tools или путем анализа кеша страницы в Google после индексации.

Вопросы и ответы
Есть ли официальные заявления о том, что Google действительно не поддерживает сервис-воркеры
Да, такие заявление являются публичными и есть на видео.
Зачем нужны сервис-воркеры?
На сайтах серивс-воркеры используют для разных целей. Например, для адаптации сайта под ситуацию с прерванным доступом к интернету.
Если интернет пропал, то при использовании сервис-воркеров сайты могут вести себя как приложения на мобильных устройствах, то есть отдавать уже скачанный контент и сигнализировать о необходимости подключения.
На практике сервис-воркеры используются еще и для кеширования изображений.
Еще используя сервис-воркеры можно сохранять данные заполненных форм и отправлять их в интернет при появлении подключения. Для реализации используется Background Sync API. Цепь следующая:
Цепь следующая:
Сайт - Index DB - Service Worker - Интернет
Еще сервис-воркеры вместе с Content-Length и Range можно использовать для загрузки больших файлов частями. Например, так можно защищать видео от копирования.
Еще сервис-воркеры используются для отправки push уведомлений.
Кстати, сервис-воркеры продолжают работать даже когда окно браузера закрыто.
Кто использует сервис-воркеры?
Например сервис-воркеры используются на таких сайтах как:
- Google;
- YouTube;
- Twitter;
- Booking;
- Facebook;
- Washington Post;
Как скрыть весь сайт от поисковых систем?
В редких случаях сайты полностью могут быть закрыты от поисковых роботов. Например так защищают площадки от  Если стоит задача скрыть всю страницу или весь сайт от конкретных роботов, то наиболее эффективный способ заключается в запрете индексации на уровне сервера. Рекомендованный материал в блоге MegaIndex по теме защиты сайта от парсинга различными роботами по ссылке далее — Эффективные способы защиты от парсинга сайта.
Если стоит задача скрыть всю страницу или весь сайт от конкретных роботов, то наиболее эффективный способ заключается в запрете индексации на уровне сервера. Рекомендованный материал в блоге MegaIndex по теме защиты сайта от парсинга различными роботами по ссылке далее — Эффективные способы защиты от парсинга сайта.
Кстати, краулер MegaIndex индексирует больше ссылок за счет того, что для робота MegaIndex доступ к сайтам не закрыт.
Почему так происходит? Поисковые оптимизаторы используют различные плагины для того, чтобы закрыть ссылки от таких сервисов как SEMrush, Majestic, Ahrefs. В таких плагинах используются черные списки. Если вести речь про глобальный рынок, то MegaIndex является менее расхожим сервисом, и поэтому часто краулер MegaIndex не входит в черный список. Как результат, применяя сервис MegaIndex у поисковых оптимизаторов есть возможность найти те ссылки, которые не находят другие сервисы.
Ссылка на сервис — Внешние ссылки.
Еще выгрузку ссылок можно провести посредством API. Полный список методов доступен по ссылке — MegaIndex API. Метод для выгрузки внешних ссылок называется backlinks. Ссылка на описание метода — метод backlinks.
Пример запроса для сайта indexoid.com:
http://api.megaindex.com/backlinks?key={ключ}&domain=indexoid.com&link_per_domain=1&offset=0Пример запроса для сайта smmnews.com:
http://api.megaindex.com/backlinks?key={ключ}&domain=smmnews.com&link_per_domain=1&offset=0Выводы
С обновлением Googlebot скрыть ссылки, текст и другие части страниц сайта от поисковой системы стало сложнее, но лазейки есть. Поисковый движок рендеринга по прежнему не поддерживает
Используя service workers с запросами можно проводить следующие манипуляции:
- Отправлять;
- Принимать.
- Модифицировать.
Применяя сервис-воркеры можно скрыть от поисковых систем ссылки, текст, и даже блок страницы.
Итак, в результате при необходимости поисковый оптимизатор может:
- Закрыть от индексации внешние ссылки с целью улучшения распределения статического ссылочного веса;
- Закрыть от индексации страницы тегов с низкой частотностью;
- Закрыть от индексации страницы пагинации;
- Скрытый текст или часть текста от индексации;
- Закрыть от индексации файлы;
- Закрыть от индексации блок и часть страницы;
- Скрыть от индексации реферальные ссылки.
Сервис-воркеры можно использовать и в целях улучшения производительности сайта. Например, намедни Google стал использовать сервис-воркеры в поисковой выдаче.
Схема одного из интересных трюков выглядит так:
- Вы искали ресторан, например утром;
- Спустя время, вы снова искали ресторан, например по той причине, что забыли о том, где находится заведение. На данном шаге Google выдаст результаты из кеша, который управляется сервис-воркером. Как результат, данные выдаются без отправки запроса в интернет.
 На данном шаге Google выдаст результаты из кеша, который управляется сервис-воркером. Как результат, данные выдаются без отправки запроса в интернет.
На данном шаге Google выдаст результаты из кеша, который управляется сервис-воркером. Как результат, данные выдаются без отправки запроса в интернет.Преимущества следующие:
- Снижается нагрузка на сервер Google, что приводит к снижению затрат;
- Увеличивается скорость загрузки страницы с ответом. Повышается лояльность пользователя;
- Страницы откроется даже без интернета. Повышается лояльность пользователя.
Остались ли у вас вопросы, замечания или комментарии по теме скрытия части содержания страниц от поисковых систем?
Закрыть текст статьи от индексации
У любого блогера возникает потребность закрыть текст статьи от индексации. Зачем? Одна из самых распространённых причин — это скопированные выдержки с другого сайта. Если данный текст уже давно существует на другом сайте, и поисковые системы его давно проиндексировали, они определяют тот сайт как хозяина контента. Да, существует ещё помощник от Яши, который как бы сохраняет за вами авторские права на текст, который вы туда внесёте. Но в паутине есть разные мнения на этот счёт: и положительные, и отрицательные. Я считаю, добавлять туда написанные вами статьи надо обязательно, а вот скрывать от индексации чужие тексты или выдержки не помешает.
Да, существует ещё помощник от Яши, который как бы сохраняет за вами авторские права на текст, который вы туда внесёте. Но в паутине есть разные мнения на этот счёт: и положительные, и отрицательные. Я считаю, добавлять туда написанные вами статьи надо обязательно, а вот скрывать от индексации чужие тексты или выдержки не помешает.
Итак, закрыть можно как текст, так и ссылку. И как я говорил ранее, внешняя ссылка на сторонний ресурс — это вселенское зло вашего блога, будем практиковаться )
Мы определились с нашими флагманами в статье Настройка Title и Description для блога — это Яша и Гена.
1. Закрыть ссылки от индексации.
Чтобы наша ссылка на сторонний сайт была закрыта от индексации, так как индексируемая ссылка передаёт как ТИЦ сайта, так и траст, что немаловажно, передавать их всем подряд чревато потерей доверия, что повлечёт потерю и ТИЦа, и траста вашего сайта. Используем тэг «nofollow». Оба поисковика с 2010 года, если почитать описание изменений ядер поисковых систем, понимают этот тэг одинаково и рекомендуют к использованию при закрытии ссылок от индексации. Нам остаётся только добавлять тэг при создании ссылок. Вот пример ссылки в моей статье на скачивание дистрибутива самого WordPress:
Нам остаётся только добавлять тэг при создании ссылок. Вот пример ссылки в моей статье на скачивание дистрибутива самого WordPress:
Достаточно <a target=»_blank» href=»https://ru.wordpress.org/releases/» rel=»nofollow»> скачать дистрибутив </a> самого WordPress
Текст до и текст после. Анкор ссылки. Тэг закрывающий от индексации. Сама ссылка
<a target=»_blank» rel=»nofollow»> href=»https://ru.wordpress.org/releases/» скачать дистрибутив </a>
Тем самым мы ставим ссылку для удобства пользования, но закрываем её от передачи веса ТИЦ и траста. Да и просто закрываем ссылки на буржуйские сайты.
2. Закрыть текст статьи от индексации.
В данном случае у поисковиков есть различия понимания данного действия.
У Яши, проще простого, необходимо поместить текст в тэг noindex.
Вот текст, который я скопировал с support Яши и поместил его в noindex.
Тег noindex не чувствителен к вложенности (может находиться в любом месте html-кода страницы).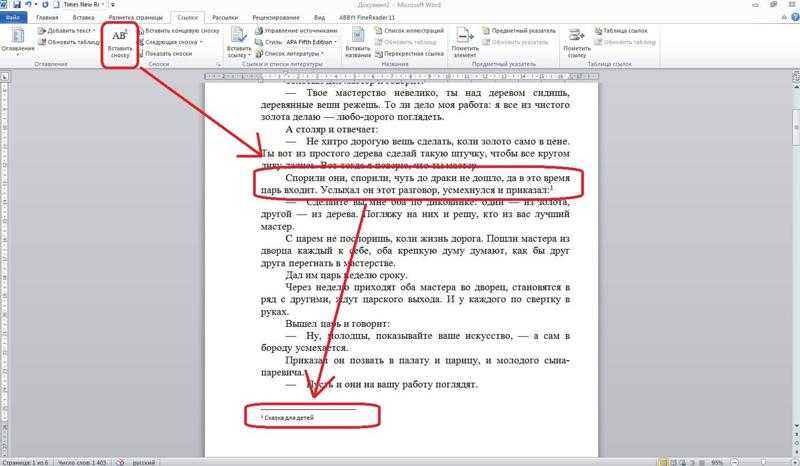 При необходимости сделать код сайта валидным возможно использование тега в следующем формате:
При необходимости сделать код сайта валидным возможно использование тега в следующем формате:
<span><code><span><!—noindex—></span>текст, индексирование которого нужно запретить<span><!—/noindex—></span></code></span>
<span><code><span><!—noindex—></span>текст, индексирование которого нужно запретить<span><!—/noindex—></span></code></span> |
И сам код до скрываемого текста и после скрываемого текста.
<!—noindex—>
Тег <span class=»tag codeph»>noindex</span> не чувствителен к вложенности (может находиться в любом месте html-кода страницы). При необходимости сделать код сайта валидным возможно использование тега в следующем формате:
<div class=»codeblock»>
<pre><code class=»xml»><span class=»comment»><!—noindex—></span>текст, индексирование которого нужно запретить<span class=»comment»><!—/noindex—></span></code></pre>
</div><!—/noindex—>
Как быть с Геной? У него есть свой тэг и работает он аналогично тэгу от Яши. Отсюда вывод: если мы хотим закрыть от Яши и Гены одновременно, надо ставить два тэга.
Отсюда вывод: если мы хотим закрыть от Яши и Гены одновременно, надо ставить два тэга.
Сам тэг Гены несёт аналогичную функцию, но выглядит по-другому.
<!—googleoff: index—> закрываемый текст <!—googleon: index—>
Текст, закрытый от индексации Яши и Гены, будет выглядеть вот так:
<!—noindex—><!—googleoff: index—> закрываемый текст <!—googleon: index—><!—/ noindex—>
Одно очень важное добавление: Гена закрывает тэгом даже ссылки. Для Яши все ссылки внутри тега <!—noindex—> необходимо закрывать обязательно ещё и «nofollow».
Удачи в передаче и приобретении ТИЦ и траста.
Надеюсь, что после данной статьи вопроса, как закрыть текст статьи от индексации, у вас больше не возникнет.
консоль поиска Google — Как мне «не индексировать» текстовый файл (.txt)?
спросил
Изменено 2 года, 1 месяц назад
Просмотрено 401 раз
У меня есть каталог, полный файлов .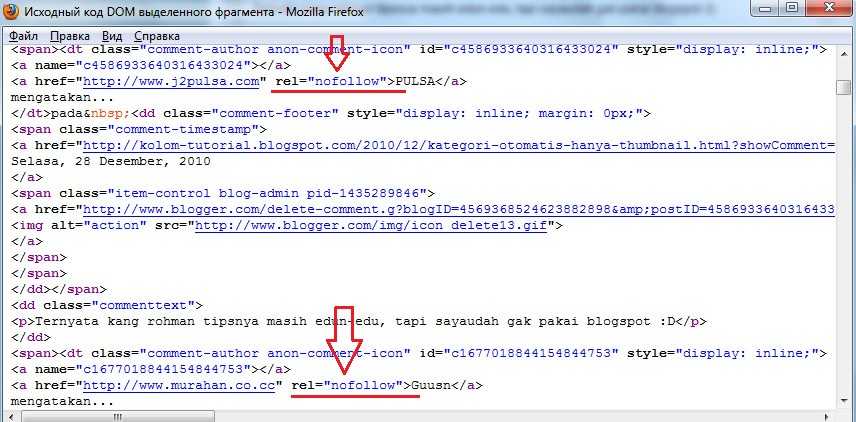 txt, которые используются как часть более крупного приложения javascript. Текстовые файлы не предназначены для прямого доступа и используются как включения на отдельных страницах как часть функциональных возможностей приложения).
txt, которые используются как часть более крупного приложения javascript. Текстовые файлы не предназначены для прямого доступа и используются как включения на отдельных страницах как часть функциональных возможностей приложения).
Итак… Я добавил каталог в файл robots.txt, потому что не хочу, чтобы файлы отображались независимо в результатах поиска.
Однако robots.txt просто делает файлы .txt недоступными для роботов. На самом деле это не делает файлы .txt неиндексируемыми.
Что я действительно хочу сделать, так это «не индексировать» файлы .txt. Но файлы .txt не похожи на файлы .html. В тексте будет виден метатег noindex.
Итак, как сделать «неиндексировать» файл с необработанным текстом, не повреждая текст тегом?
Есть ли другой способ запретить индексацию текстового файла извне? Или не индексировать общий каталог?
- google-search-console
- google-search
- web-crawlers
- robots.txt
- noindex
Решение такое же, как для файлов PDF и файлов X-Robots noindex.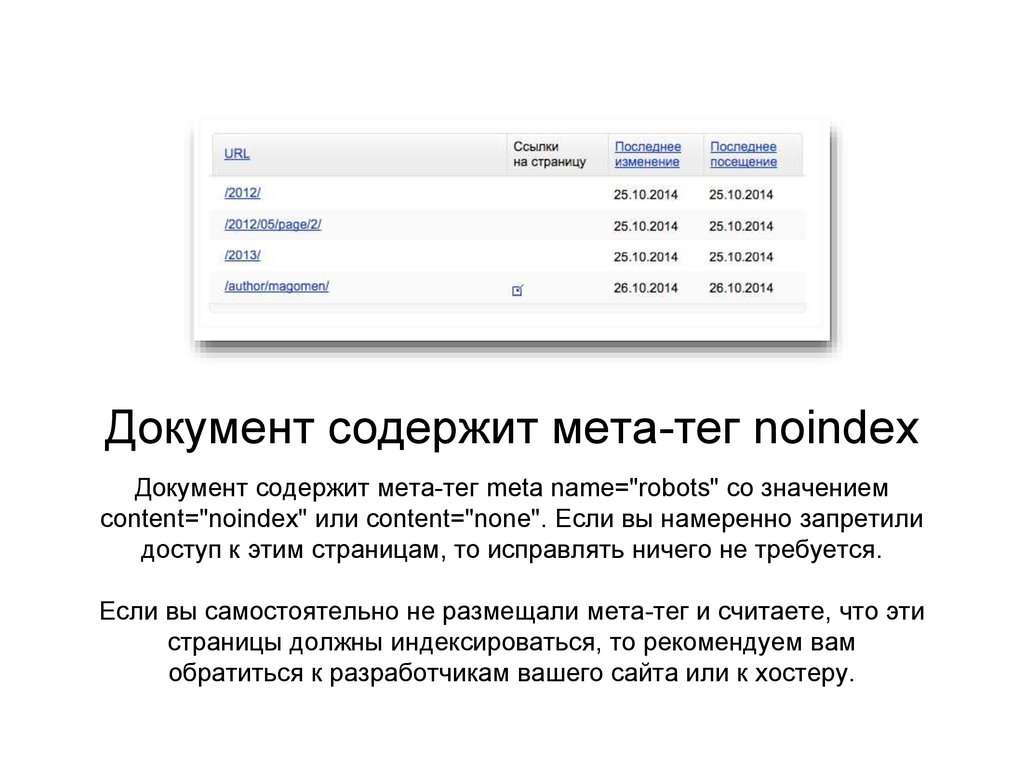 в результатах поиска Google. Вы используете HTTP-заголовок
в результатах поиска Google. Вы используете HTTP-заголовок X-Robots-Tag , а не метатег. Заголовок HTTP, обслуживаемый файлом txt, должен выглядеть так:
X-Robots-Tag: noindex
После реализации HTTP-заголовка удалите запрет из файла robots.txt . Чтобы поисковые роботы могли видеть и учитывать заголовок, вам нужно сделать файлы txt доступными для сканирования.
На веб-серверах Apache (большинство общих хостингов) поместите следующий код в файл .htaccess в каталоге, содержащем файлы .txt:
Набор заголовков X-Robots-Tag "noindex" 9/txtfiledir/.*\.txt$" />
4
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания, политикой конфиденциальности и политикой использования файлов cookie
Любопытный случай, когда страница не индексируется
Это интересная история, с которой я впервые столкнулся более 2 лет назад.
Однажды я написал статью о SEO для Magento 2. Это было одно из первых руководств для платформы Magento 2.0, и оно стало очень популярным среди продавцов, маркетологов и оптимизаторов.
Даже сейчас пост находится в избранном сниппете над официальным сайтом Magento:
Однажды мне нужно было отправить ссылку на этот пост моему клиенту. Я погуглил… и пост не появился на 1-й странице. Или на любой другой странице. Он даже не появился для моего имени + темы.
Это было странно, поэтому я начал копаться в этом.
Все это привело к этой истории и эксперименту, который я провел тогда и еще раз пересмотрел, прежде чем писать этот пост.
Начнем?
Содержание
Почему страницы нет в индексе Google?
Существует множество возможных причин, по которым страница может не индексироваться Google, в том числе:
- Страница не индексируется
- Страница не проиндексирована из-за недостаточного или дублированного контента
- Весь веб-сайт удален из индекса из-за технических проблем или проблем с качеством
В моем случае веб-сайт был в порядке, все остальные страницы ранжировались как обычно.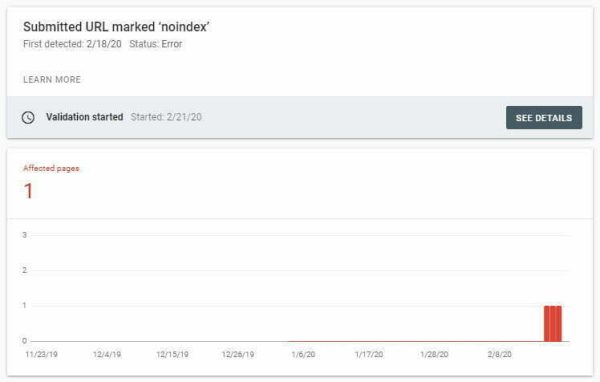
Страница, которую я искал, была очень высокого качества и раньше входила в тройку лучших.
Значит, единственной возможной причиной было… страница не проиндексирована?
Но почему? Зачем кому-то не индексировать только одну запись в блоге, которая действительно хорошо работает?
Вот что я начал изучать.
Страница проиндексирована… Верно? Правильно?!
Как оказалось, ответ был «да» и «нет» (может быть, это просто страница Шредингера!).
Мета-тег robots в разделе
страницы был установлен на «index,follow».Но кое-что бросилось в глаза: на странице была такая фаза:
Вместо канонизации страницы с отсортированными или отфильтрованными результатами можно не индексировать либо путем настройки исключений в Google Console, либо путем добавления мета-роботов к таким URL-адресам.
Когда я проверил эту часть в исходном коде страницы, она читалась так:
Вместо канонизации страницы с отсортированными или отфильтрованными результатами могут быть не проиндексированы либо путем настройки исключений в Google Console, либо путем добавления мета-роботов META NAME=» ROBOTS” CONTENT=»NOINDEX, FOLLOW» на такие URL.
Таким образом, META NAME=»ROBOTS» CONTENT=»NOINDEX, FOLLOW» отсутствует в копии, видимой визуально на странице, но имеется в исходном коде страницы .
Это может означать только одно:
Google использует метатег robots, добавленный в
страницы вместо раздела этой страницы.Так странно и интересно!
Раньше форматирование было правильным. Но кажется, что после некоторых изменений в дизайне текст был переформатирован, и вместо визуального отображения META NAME=»ROBOTS» CONTENT=»NOINDEX, FOLLOW» эта часть стала частью исходного кода этой страницы.
Я связался с командой блога, и они быстро все исправили. После этого страница была повторно проиндексирована Google и вернулась на верхние позиции.
Эксперимент с Noindex на странице
Я не был бы специалистом по SEO, если бы не попытался воспроизвести этот вывод в своем эксперименте.
Я сделал это некоторое время назад. Это сработало.
Это сработало.
И я сделал это еще раз, прежде чем написать этот пост. Это снова сработало.
Вот что я сделал и какие результаты получил.
Станьте продвинутым техническим специалистом по поисковой оптимизации
(даже если у вас нет навыков программирования или опыта разработки). Присоединяйтесь к Tech SEO Pro сегодня>>
Перед проведением эксперимента я также задал людям в своих социальных сетях один вопрос:
Большинство людей ответили, что мета-тег noindex для роботов на странице
не будет работать. Давайте проверим!Этап 1: индексация
Я создал страницу на своем веб-сайте под названием «Страница для тестирования без индексации» (креативно, правда?).
Страница проиндексирована:
Этап 2: Добавление noindex в
Затем я добавил мета-тег noindex robots в
страницы в одном из абзацев с помощью HTML-редактора:Если вы посмотрите на исходный код страницы (и отрендеренный HTML), вы увидите, что метатег robots в разделе
позволяет индексировать эту страницу: Но тогда тег в теле выглядит так .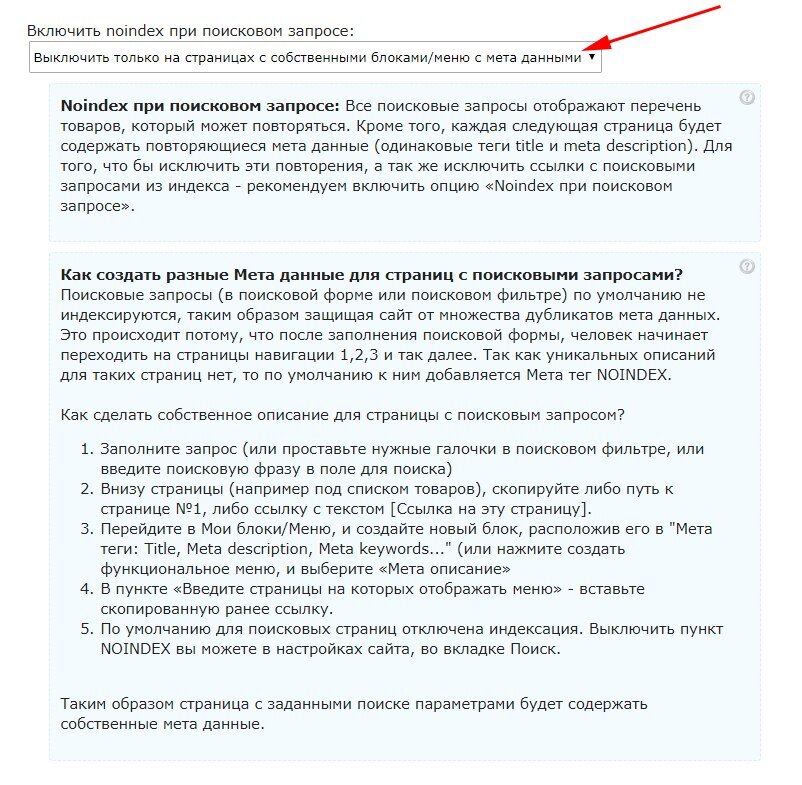
Но что показали инструменты?
Инструмент проверки URL-адресов Google Search Console обнаруживает noindex в
:Инструмент тестирования для мобильных устройств также обнаруживает тег noindex:
Тег noindex также виден в отображаемом HTML:
Screaming Frog заметил и noindex:
Этап 4: Переиндексация страницы
Для завершения эксперимента я решил сделать последний шаг: удалить тег noindex из тела и посмотреть, будет ли страница добавлена в индекс Google.
Для этого я заменил отредактированную в HTML копию визуально отредактированной копией. Чтобы на фронтенде это выглядело так:
А на бекенде это выглядело так:
Результат? Убедитесь сами:
Мои выводы после эксперимента с Noindex
Судя по доказательствам, робот Googlebot читает и учитывает метатег robots, найденный на странице
. Это противоречит официальному руководству Google, которое гласит:. Что это значит для оптимизаторов:
9. 0022
0022Когда вы видите, что страница не проиндексирована, но не можете найти тег в разделе заголовка, просмотрите остальную часть страницы.
Не думаю, что это частый сценарий. Но хорошо быть хорошо экипированным, если вы столкнетесь с чем-то подобным в будущем.
- Потенциально вы можете добавить тег noindex в тело страницы, чтобы быстро не индексировать страницу
Я не рекомендую использовать тег метатега robots noindex в теле страницы регулярно или в качестве замены рекомендуемого размещения тега на странице
.Но если возникает редкая ситуация, когда вам нужно, чтобы страница не индексировалась как можно скорее, и вы полагаетесь на кого-то другого, чтобы реализовать это, и вам нужно подождать, вы можете использовать этот метод, добавив тег
к странице в HTML.
После правильной реализации тега — в разделе
— удалите свой из.Опять же, я не рекомендую это в целом, поэтому руководствуйтесь здравым смыслом (или вы можете просто использовать инструмент «Удалить URL» в GSC).
Станьте продвинутым техническим специалистом по поисковой оптимизации
(даже если у вас нет навыков программирования или опыта разработки). Присоединяйтесь к Tech SEO Pro сегодня >>
Вернемся к вам
Техническое SEO — это увлекательно. И, как видите, это может быть важно знать, даже если вы хотите быть хорошо разбирающимся в SEO профессионалом.
P.S. Эта страница разрешена для индексации 🙂
Подождите! Вот еще:
JavaScript SEO Best Practices and Debugging Tools
Google Search Central Live: пример ленивой загрузки изображений
Кристина Азаренко
После 10 с лишним лет в SEO я основал MarketingSyrup Academy, где преподаю умные SEO.