
Какие страницы закрывать от индексации и как
Любая страница на сайте может быть открыта или закрыта для индексации поисковыми системами. Если страница открыта, поисковая система добавляет ее в свой индекс, если закрыта, то робот не заходит на нее и не учитывает в поисковой выдаче.
При создании сайта важно на программном уровне закрыть от индексации все страницы, которые по каким-либо причинам не должны видеть пользователи и поисковики.
К таким страницам можно отнести административную часть сайта (админку), страницы с различной служебной информацией (например, с личными данными зарегистрированных пользователей), страницы с многоуровневыми формами (например, сложные формы регистрации), формы обратной связи и т.д.
Пример:
Профиль пользователя на форуме о поисковых системах Searchengines.
Обязательным также является закрытие от индексации страниц, содержимое которых уже используется на других страницах.Такие страницы называются дублирующими.
Пример:
Типичный блог на CMSWordPress, который содержит дубли.http://reaktivist.ru/ — главная страница.
http://reaktivist.ru/category/liniya-zhizni — страница категории.
Как видим, контент на обеих страницах частично совпадает. Поэтому страницы категорий на WordPress-сайтах закрывают от индексации, либо выводят на них только название записей.
То же самое касается и страниц тэгов– такие страницы часто присутствуют в структуре блогов на WordPress. Облако тэгов облегчает навигацию по сайту и позволяет пользователям быстро находить интересующую информацию. Однако они являются частичными дублями других страниц, а значит – подлежат закрытию от индексации.
Еще один пример – магазин на CMS OpenCart.
Страница категории товаров http://www.masternet-instrument.ru/Lampy-energosberegajuschie-c-906_910_947.
html.Страница товаров, на которые распространяется скидка http://www.masternet-instrument.ru/specials.php.
Данные страницы имеют схожее содержание, так как на них размещено много одинаковых товаров.

Особенно критично к дублированию контента на различных страницах сайта относится Google. За большое количество дублей в Google можно заработать определенные санкции вплоть до временного исключения сайта из поисковой выдачи.
Мы рекомендуем закрывать страницу от индексации, если она содержит более 40 % контента с другой страницы. В идеале структуру сайта нужно создавать таким образом, чтобы дублирования контента не было вовсе.
Примечание:
Для авторитетных сайтов с большим количеством страниц и хорошей посещаемостью (от 3000 человек в сутки) дублирование не столь существенно, как для новых сайтов.
Еще один случай, когда содержимое страниц не стоит «показывать» поисковику – страницы с неуникальным контентом. Типичный пример — инструкции к медицинским препаратам в интернет-аптеке.
Сделать его уникальным практически невозможно, поскольку переписывание столь специфических текстов – дело неблагодарное и запрещенное. Наилучшим решением в этом случае будет закрытие страницы от индексации, либо написание письма в поисковые системы с просьбой лояльно отнестись к неуникальности контента, который сделать уникальным невозможно по тем или иным причинам.
Классическим инструментом для закрытия страниц от индексации является файл robots.txt. Он находится в корневом каталоге вашего сайта и создается специально для того, чтобы показать поисковым роботам, какие страницы им посещать нельзя. Это обычный текстовый файл, который вы в любой момент можете отредактировать. Если файла robots.txt у вас нет или если он пуст, поисковики по умолчанию будут индексировать все страницы, которые найдут.
Структура файла robots.txt довольно проста. Он может состоять из одного или нескольких блоков (инструкций). Каждая инструкция, в свою очередь, состоит из двух строк. Первая строка называется User-agent и определяет, какой поисковик должен следовать этой инструкции. Если вы хотите запретить индексацию для всех поисковиков, первая строка должна выглядеть так:
Он может состоять из одного или нескольких блоков (инструкций). Каждая инструкция, в свою очередь, состоит из двух строк. Первая строка называется User-agent и определяет, какой поисковик должен следовать этой инструкции. Если вы хотите запретить индексацию для всех поисковиков, первая строка должна выглядеть так:
User-agent: *
Если вы хотите запретить индексацию страницы только для одной ПС, например, для Яндекса, первая строка выглядит так:
User-agent: Yandex
Вторая строчка инструкции называется Disallow (запретить). Для запрета всех страниц сайта напишите в этой строке следующее:
Disallow: /
Чтобы разрешить индексацию всех страниц вторая строка должна иметь вид:
Disallow:
В строке Disallow вы можете указывать конкретные папки и файлы, которые нужно закрыть от индексации.
Например, для запрета индексации папки images и всего ее содержимого пишем:
User-agent: *
Disallow: /images/
Чтобы «спрятать» от поисковиков конкретные файлы, перечисляем их:
User-agent: *
Disallow: /myfile1.htm
Disallow: /myfile2.htm
Disallow: /myfile3.htm
 htm
htmЭто – основные принципы структуры файла robots.txt. Они помогут вам закрыть от индексации отдельные страницы и папки на вашем сайте.
Еще один, менее распространенный способ запрета индексации – мета-тэг Robots. Если вы хотите закрыть от индексации страницу или запретить поисковикам индексировать ссылки, размещенные на ней, в ее HTML-коде необходимо прописать этот тэг. Его надо размещать в области HEAD, перед тэгом <title>.
Мета-тег Robots состоит из двух параметров. INDEX – параметр, отвечающий за индексацию самой страницы, а FOLLOW – параметр, разрешающий или запрещающий индексацию ссылок, расположенных на этой странице.
Для запрета индексации вместо INDEX и FOLLOW следует писать NOINDEX и NOFOLLOW соответственно.
Таким образом, если вы хотите закрыть страницу от индексации и запретить поисковикам учитывать ссылки на ней, вам надо добавить в код такую строку:
<meta name=“robots” content=“noindex,nofollow”>
Если вы не хотите скрывать страницу от индексации, но вам необходимо «спрятать» ссылки на ней, мета-тег Robots будет выглядеть так:
<metaname=“robots” content=“index,nofollow”>
Если же вам наоборот, надо скрыть страницу от ПС, но при этом учитывать ссылки, данный тэг будет иметь такой вид:
<meta name=“robots” content=“noindex,follow”>
Большинство современных CMS дают возможность закрывать некоторые страницы от индексации прямо из админ. панели сайта. Это позволяет избежать необходимости разбираться в коде и настраивать данные параметры вручную. Однако перечисленные выше способы были и остаются универсальными и самыми надежными инструментами для запрета индексации.
панели сайта. Это позволяет избежать необходимости разбираться в коде и настраивать данные параметры вручную. Однако перечисленные выше способы были и остаются универсальными и самыми надежными инструментами для запрета индексации.
Как закрыть сайт от индексации в Robots.txt
В процессе разработки или редизайна проекта бывают такие ситуации, когда лучше не допускать поисковых роботов на сайт. В таком случае необходимо закрыть сайт от индексации поисковых систем. Сделать это можно следующим образом:
Закрыть сайт от индексации очень просто, достаточно создать в корне сайта текстовый файл robots.txt и прописать в нём строки, которые закроют сайт от поискового робота Яндекса.
User-agent: Yandex
Disallow: /
А таким образом можно закрыть сайт от всех поисковых систем (Яндекса, Google и других).
User-agent: *
Disallow: /
КАК ЗАКРЫТЬ ОТ ИНДЕКСАЦИИ ОТДЕЛЬНУЮ ПАПКУ?
Отдельную папку можно закрыть от поисковых систем в том же файле robots. txt с её явным указанием (будут скрыты все файлы внутри этой папки).
txt с её явным указанием (будут скрыты все файлы внутри этой папки).
User-agent: *
Disallow: /folder/
Если какой-то отдельный файл в закрытой папке хочется отдельно разрешить к индексации, то используйте два правила Allow и Disallow совместно:
User-agent: *
Аllow: /folder/file.php
Disallow: /folder/
Всё по аналогии.
User-agent: Yandex
Disallow: /folder/file.php
КАК СКРЫТЬ ОТ ИНДЕКСАЦИИ КАРТИНКИ?
Картинки форматов jpg, png и gif могут быть запрещены к индексации следующими строчками в robots.txt:
User-Agent: *
Disallow: *.jpg
Disallow: *.png
Disallow: *.gif
КАК ЗАКРЫТЬ ПОДДОМЕН?
У каждого поддомена на сайте, в общем случае, имеется свой файл robots.txt. Обычно он располагается в папке, которая является корневой для поддомена. Требуется скорректировать содержимое файла с указанием закрываемых разделов с использованием директории Disallow.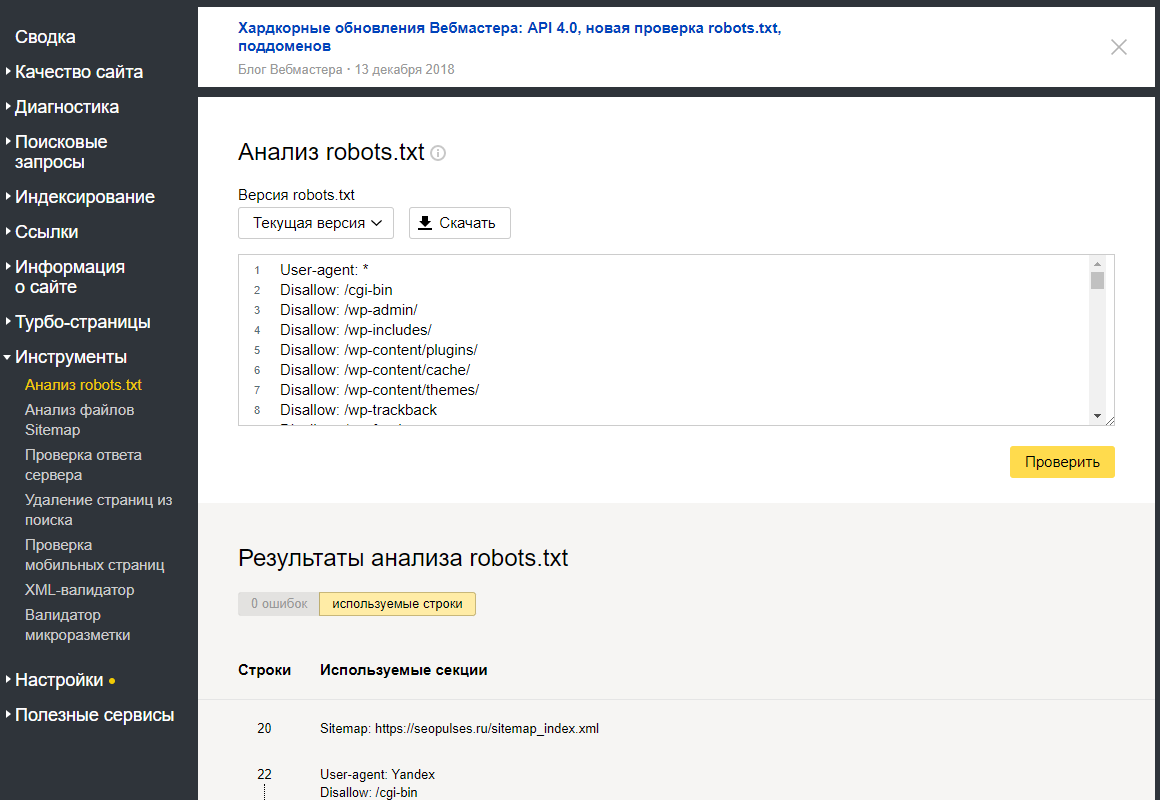 Если файл отсутствует — его требуется создать.
Если файл отсутствует — его требуется создать.
ПРИ ИСПОЛЬЗОВАНИИ CDN-ВЕРСИИ
Дубль на поддомене может стать проблемой для SEO при использовании CDN. В данном случае рекомендуется, либо предварительно настроить работу атрибута rel=»canonical» тега <link> на основном домене, либо создать на поддомене с CDN (скажем, nnmmkk.r.cdn.skyparkcdn.ru) свой запрещающий файл robots.txt. Вариант с настройкой rel=»canonical» — предпочтительный, так как позволит сохранить/склеить всю информацию о поведенческих факторах по обоим адресам.
КАК ОБРАЩАТЬСЯ К ДРУГИМ ПОИСКОВЫМ РОБОТАМ (СПИСОК)У каждой поисковой системы есть свой список поисковых роботов (их несколько), к которым можно обращаться по имени в файле robots.txt. Приведем список основных из них (полные списки ищите в помощи Вебмастерам):
- Yandex — основной робот-индексатор Яндекса.
- Googlebot — основной робот-индексатор от Google.
- Slurp — поисковый робот от Yahoo!.
- MSNBot — поисковый робот от MSN (поисковая система Bing от Майкрософт).
- SputnikBot — имя робота российского поисковика Спутник от Ростелекома.

ПРОЧИЕ ДИРЕКТИВЫ В ROBOTS.TXT
Поисковая система Яндекс также поддерживает следующие дополнительные директивы в файле:
- «Crawl-delay:» — задает минимальный период времени в секундах для последовательного скачивания двух файлов с сервера. Также поддерживается и большинством других поисковых систем. Пример записи: Crawl-delay: 0.5
- «Clean-param:» — указывает GET-параметры, которые не влияют на отображение контента сайта (скажем UTM-метки или ref-ссылки). Пример записи: Clean-param: utm /catalog/books.php
- «Sitemap:» — указывает путь к XML-карте сайта, при этом, карт может быть несколько. Также директива поддерживается большинством поисковых систем (в том числе Google). Пример записи: Sitemap: https://coderoll.net/sitemap.xml
ЗАКРЫТЬ СТРАНИЦУ И САЙТ С ПОМОЩЬЮ META-ТЕГА NAME=»ROBOTS»
Также, можно закрыть сайт или заданную страницу от индексации с помощь мета-тега robots. Данный способ является даже предпочтительным и с большим приоритетом выполняется пауками поисковых систем. Для скрытия от индексации внутри зоны <head> </head> документа устанавливается следующий код:
Данный способ является даже предпочтительным и с большим приоритетом выполняется пауками поисковых систем. Для скрытия от индексации внутри зоны <head> </head> документа устанавливается следующий код:
<meta name="robots" content="noindex, nofollow"/>
Или (полная альтернатива):
<meta name="robots" content="none"/>
С помощью meta-тега можно обращаться и к одному из роботов, используя вместо name=»robots» имя робота, а именно:
Для робота Google:
<meta name="googlebot" content="noindex, nofollow"/>
Или для Яндекса:
<meta name="yandex" content="none"/>
страниц, перечисленных в robots.txt, просканированы и проиндексированы Google — поддержка
rbrlortie (Кара Л.) 1
Страницы, которые должны быть скрыты от Google, находятся в файле robots.
Однако Google все равно пытается их просканировать.
Поскольку они доступны по ссылкам на веб-страницах, они индексируются. Затем сканер обращается к файлу robots.txt и сканирует «пусто»/«заблокировано».
Это приводит к большому количеству ошибок в нашей аналитической консоли и напрасному сканированию.
Простым решением будет использование метатега noindex. Может ли быть способ добавить это на странице за страницей?
изображение.png1843×824 96,7 КБ
3 лайков
пфаффман (Джей Пфаффман) 2
Поскольку вы работаете в подпапке, вы самостоятельно создаете соответствующий файл robots.txt, поскольку тот, который генерирует Discourse, находится в community/forum/robots.txt
 txt не имеет значения, если внешние сайты ссылаются на профиль?).
txt не имеет значения, если внешние сайты ссылаются на профиль?). Вы также можете включить параметр скрывать профили пользователей от общедоступного сайта . Это «отключит карты пользователей, профили пользователей и каталог пользователей для анонимных пользователей». что удержит Google от них.
7 отметок «Нравится»
(Джефф Этвуд) 3
Мой плохой @rbrlortie Я не знал, что это подпапка, так что это другое животное, заслуживающее отдельной темы.
Мой ответ в значительной степени совпадает с тем, что сказал @pfaffman выше ↑
Поскольку Discourse не контролирует верхний уровень веб-сайта, Discourse не имеет контроля над
robots.txt в этом сценарии. Вам нужно будет сгенерировать его самостоятельно.7 отметок «Нравится»
(Кара Л. ) 4
) 4
Привет вам двоим,
Спасибо за помощь. Однако проблема не в файле robots.txt.
Он присутствует в моем корне, а также содержит страницы, которые сканирует Google.
https://www.robotshop.com/robots.txt
#дискурс Запретить: /сообщество/форум/авторизация/ Запретить: /community/forum/assets/browser-update*.js Запретить: /сообщество/форум/пользователи/ Запретить: /сообщество/форум/u/ Запретить: /сообщество/форум/мой/ Запретить: /сообщество/форум/значки/ Запретить: /сообщество/форум/поиск Запретить: /сообщество/форум/поиск/ Запретить: /сообщество/форум/теги Запретить: /сообщество/форум/теги/ Запретить: /сообщество/форум/электронная почта/ Запретить: /сообщество/форум/сессия Запретить: /сообщество/форум/сессия/ ...
Проблема в том, что поисковые роботы не соблюдают их. Единственный способ убедиться, что Google не индексирует контент, — добавить метатег «noindex».
Единственный способ убедиться, что Google не индексирует контент, — добавить метатег «noindex».
См. официальный ответ Google на их официальном канале YouTube: YouTube
«Здесь следует иметь в виду одну вещь: если эти страницы заблокированы robots.txt, то теоретически может случиться так, что кто-то случайно ссылается на одну из этих страниц. И если они это сделают, может случиться так, что мы проиндексируем этот URL без какого-либо контента, потому что он заблокирован robots.txt. Таким образом, мы не знали бы, что вы не хотите, чтобы эти страницы действительно индексировались.
Принимая во внимание, что если они не заблокированы robots.txt, вы можете поместить на эти страницы метатег noindex. И если кто-то ссылается на них, и мы сканируем эту ссылку и думаем «может быть, здесь есть что-то полезное», тогда мы будем знать, что эти страницы не нужно индексировать, и мы можем просто полностью исключить их из индексации.
Итак, в этом отношении, если у вас есть что-то на этих страницах, что вы не хотите индексировать, не запрещайте их, вместо этого используйте noindex».

Поскольку Discourse по умолчанию пытается скрыть эти страницы от поисковых роботов, на мой взгляд, эта функция не работает.
На страницах в Discourse по умолчанию robots.txt должен присутствовать .
кодированиеужас (Джефф Этвуд) 5
rbrlortie:в моих глазах фича сломана.
В наших глазах это не так. Не стесняйтесь отправлять запрос на включение изменения поведения, если вы хотите, чтобы оно изменилось.
рбрлорти (Кара Л.) 6
Извините, если моя формулировка была воспринята резче, чем предполагалось.
Я имею в виду, что страницы в robots.txt сканируются и отображаются публично в Google
image.png819×307 13,8 КБ
Это вызывает примерно одну ошибку в Google Analytics для каждого члена каждый раз, когда Google сканирует наш домен.
рбрлорти (Кара Л.) 7
@pfaffman скрыть профили пользователей от общедоступных — это действительно то, что мы используем прямо сейчас, чтобы предотвратить попадание ошибок в нашу аналитику.
кодированиеужас (Джефф Этвуд) 8
Это неверный поиск, в основном это ввод URL без знаков препинания.
Моя рабочая предпосылка состоит в том, что любые настоящие условия поиска никогда не приведут вас к этому результату. Отсюда бессмысленность «ошибки».
Отсюда бессмысленность «ошибки».
Стивен (Стивен) 9
Я думаю, что проблема в том, что, поскольку Google дает каждому сайту ограниченное время сканирования, люди хотят noindex, чтобы ни один из этих ресурсов не тратился впустую на сканирование и ошибки на страницах, которые они не хотели индексировать в первую очередь.
Только с этой точки зрения все становится понятным. Я видел, сколько времени Google может сканировать и обнаруживать весь контент на крупных только что проиндексированных сайтах. Для Google может потребоваться несколько дней, чтобы просканировать все это, и гораздо больше, прежде чем он поймет, где он должен проверять чаще.
2 лайков
(Джефф Этвуд) 10
Логика не имеет смысла; robots.txt предназначен специально для исключения контента из веб-сканеров. В этом вся цель его существования.
После перехода на веб-сайт, но до его сканирования поисковый робот будет искать файл robots.txt. Если он найдет его, сканер сначала прочитает этот файл, прежде чем продолжить просмотр страницы. Поскольку файл robots.txt содержит информацию о как поисковая система должна сканировать, найденная там информация будет указывать дальнейшие действия сканера на этом конкретном сайте. Если файл robots.txt , а не содержит какие-либо директивы, запрещающие деятельность пользовательского агента (или если на сайте нет файла robots.txt), он продолжит сканирование другой информации на сайте.
Что Google делает, так это уважает это (вроде как), но все равно сканирует его «на всякий случай». Так что я ожидаю, что это сканирование «на всякий случай» уже имеет более низкий приоритет, чем сканирование, ну знаете, что не является явным образом исключенным из веб-сканеров…
codinghorror (Джефф Этвуд) 11
Ха, похоже noindex уже может поддерживаться в robots.txt ?
Обновление Noindex для Robots.txt: все, что нужно знать SEO-специалистам — DeepCrawl
После недавнего обновления протокола robots.txt узнайте все, что вам нужно знать об использовании директивы noindex в файле robots.txt.
И вроде работает
В конечном счете, директива NoIndex в Robots.txt довольно эффективна. Это сработало в 11 из 12 протестированных нами случаев. Это может сработать для вашего сайта, и из-за того, как он реализован, он дает вам возможность предотвратить сканирование страницы, а также удалить ее из индекса.
cc @sam это будет самый простой способ.
6 отметок «Нравится»
(Кара Л.) 13
Кажется, что Robots.txt Noindex: был частью головоломки, которую мы все упустили.
Если мы воспользуемся им, я вернусь сюда с обновлением. До сих пор мы «решали» проблему, делая профили пользователей скрытыми для незарегистрированных пользователей.
Спасибо за поддержку!
3 отметок «Нравится»
(Джефф Этвуд) 14
Не стесняйтесь переназначать это, если это необходимо @sam, чтобы это было сделано.
Сэм (Сэм Саффрон) 15
Завершено для:
https://github.com/discourse/discourse/commit/d84256a876a9fa4fc7bcb4b8ac8c5865f8c10701
5 лайков
рбрлорти
(Кара Л. ) 16
) 16
Отлично! Google продолжал ворчать на всех по этому поводу. Теперь это, наконец, позади.
2 нравится
система (система) Закрыто 17
Эта тема была автоматически закрыта через 30 дней после последнего ответа. Новые ответы больше не допускаются.
кодированиеужас (Джефф Этвуд) 18
код ужас:Ха, похоже
noindexуже может поддерживаться вrobots.?Robots.txt Noindex Update: все, что нужно знать специалистам по поисковой оптимизации — DeepCrawl
И вроде работает
В конечном счете, директива NoIndex в Robots.txt довольно эффективна. Это сработало в 11 из 12 протестированных нами случаев. Это может сработать для вашего сайта, и из-за того, как он реализован, он дает вам возможность предотвратить сканирование страницы, а также удалить ее из индекса.
 txt
txt И снова халтурные SEO-эксперты наткнулись на косяк.
Google подтвердил, что это никогда не поддерживалось и никогда не работало. Нам нужно вернуть эту работу @sam. Я удалю все другие дурацкие темы на эту тему.
2 лайка
сэм (Сэм Саффрон) 19
Отменено по:
https://github. com/discourse/discourse/commit/5feb342914d30de72d19d97900fb58e5447d712a
com/discourse/discourse/commit/5feb342914d30de72d19d97900fb58e5447d712a
2 лайков
(Джефф Этвуд) 20
Нам, вероятно, следует сделать резервную копию и этого.
2 лайка
сэм (Сэм Саффрон) 21
Конечно… готово, теперь это портировано
4 Likes
Как исправить заблокировано robots.txt Ошибки
Поисковые системы находят информацию путем сканирования (что означает, что они запрашивают / извлекают URL-адрес), чтобы затем проанализировать то, что они находят по URL-адресу.
Правила robots.txt следует использовать только для управления процессом сканирования поисковыми системами, но не процессом индексации. Это означает, что большинство ошибок Search Console, заблокированных robots.txt, возникают из-за неправильных правил, используемых владельцем веб-сайта, а не из-за неправильной настройки веб-сайта.
Это означает, что большинство ошибок Search Console, заблокированных robots.txt, возникают из-за неправильных правил, используемых владельцем веб-сайта, а не из-за неправильной настройки веб-сайта.
Что делать, если файл robots.txt создается автоматически?
Некоторые системы управления контентом, такие как Blogger, Google Sites, WordPress Hosted Sites, WiX или другие платформы, могут автоматически генерировать файл robots.txt. В таких случаях вы не можете обновить фактический файл robots.txt, если он создается автоматически. В таких случаях единственное, что вы можете сделать для устранения проблем с индексацией Страницы, — это убедиться, что XML-карта сайта, которую вы отправили в поисковую консоль Google, содержит только те URL-адреса, которые Google должен сканировать и индексировать .
Видеоурок по исправлению ошибок, заблокированных robots.txt
Как исправить URL-адрес, заблокированный robots.txt — отчеты об индексации страниц
Когда отправленные страницы заблокированы файлом robots. txt. Вы можете протестировать и проверить, какие правила в файле robots.txt запрещают поисковым роботам Google, используя инструмент тестирования robots.txt в Search Console.
txt. Вы можете протестировать и проверить, какие правила в файле robots.txt запрещают поисковым роботам Google, используя инструмент тестирования robots.txt в Search Console.
После того, как вы подтвердите, какие правила блокируют доступ Google, вам останется только удалить эту строку (или строки) правил в фактическом файле robots.txt на веб-сервере.
О файле /robots.txt
Первые поисковые системы, такие как Google или Bing, или другие законопослушные поисковые роботы ищут файл robots.txt. Веб-мастера используют файл robots.txt, чтобы предоставить агентам пользователя (веб-сканерам, ботам) инструкции относительно того, какую (если есть) часть веб-сайта им разрешено сканировать и получать к ней доступ. Это делается с помощью директив протокола исключения роботов, размещенных в файле robots.txt.
Это гарантирует, что владельцы веб-сайтов, которые не хотят, чтобы поисковые системы получали доступ к их веб-сайту, могут запретить ВСЕМ (*) ботам НЕ сканировать их веб-сайт, просто поместив это в файл robots.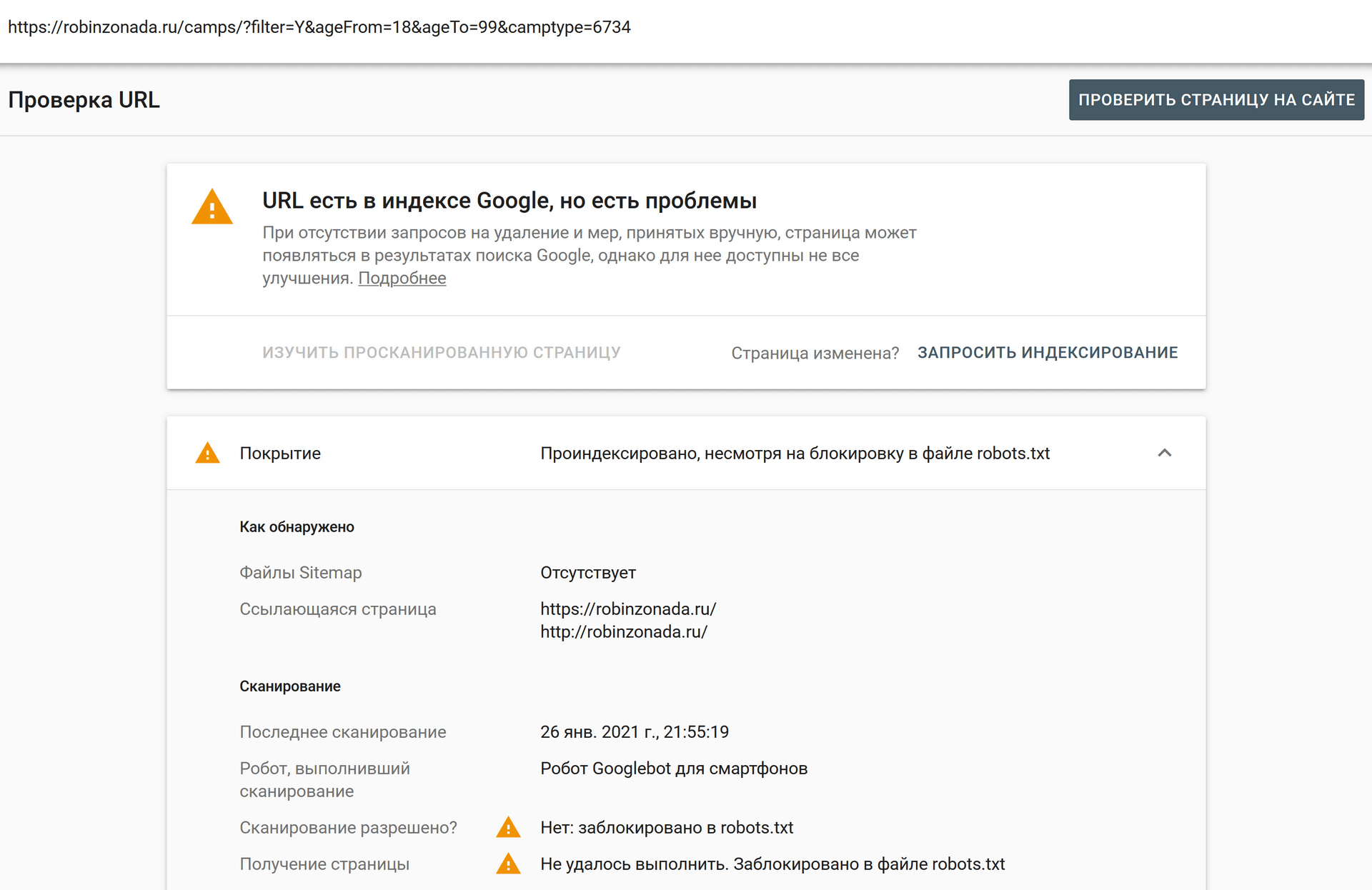 txt.
txt. Агент пользователя: *
Запретить&двоеточие; / Поскольку большинство владельцев веб-сайтов хотят разрешить Google сканировать их веб-сайт, использование приведенного выше правила запрета не является идеальным и НЕ должно использоваться, если вы не разрабатываете веб-сайт, который не готов к работе.
Но что, если есть часть веб-сайта, которую вы НЕ хотите сканировать роботом Googlebot? Тогда вы бы сделали что-то вроде этого: Агент пользователя: *
Запретить&двоеточие; /privatepage
Причина, по которой владельцы веб-сайтов перепутали правила robots.txt
Наиболее распространенная причина возникновения проблем с отчетами Google Search Console об индексации страниц, заблокированных robots.txt, заключается в том, что владелец веб-сайта считает, что с помощью robots.txt они могут контролировать, какие URL-адреса видны / индексируются для поисковых систем.
Если вы хотите, чтобы веб-страницы не индексировались Google, удалите файл robots.