
Задачи машинного обучения — ML.NET
- Статья
- Чтение занимает 8 мин
Задача машинного обучения — это тип прогноза или вывода, основанный на возникшей проблеме или на вопросе, а также доступных данных. Например, задача классификации назначает данные категориям, а задача кластеризации группирует данные в соответствии со сходством.
Задачи машинного обучения полагаются на шаблоны в данных, а не на явное программирование.
В этой статье описываются разные задачи машинного обучения, которые вы можете выбрать в ML.NET, и распространенные варианты их использования.
Определив задачу для своего сценария, выберите наилучший алгоритм для обучения модели.
Двоичная классификация
Задача контролируемого машинного обучения, которая прогнозирует распределение элементов данных по двум классам (категориям). На вход алгоритма классификации подается набор примеров с метками, каждая из которых представляет собой целое число 0 или 1. Результатом работы алгоритма двоичной классификации является классификатор, который умеет прогнозировать класс для новых экземпляров без метки. Вот несколько примеров для сценария двоичной классификации:
- Распределение комментариев Twitter по тональности — позитивные или негативные.
- Диагностика пациента на наличие определенной болезни.
- Принятие решений о присвоении отметки «спам» сообщению электронной почты.
- Определение того, содержит ли фотография определенный элемент, например изображение собаки или фрукта.
Дополнительные сведения см. в статье о двоичной классификации в Википедии.
Алгоритмы обучения двоичной классификации
Вы можете обучить модель двоичной классификации, используя следующие алгоритмы:
- AveragedPerceptronTrainer
- SdcaLogisticRegressionBinaryTrainer
- SdcaNonCalibratedBinaryTrainer
- SymbolicSgdLogisticRegressionBinaryTrainer
- LbfgsLogisticRegressionBinaryTrainer
- LightGbmBinaryTrainer
- FastTreeBinaryTrainer
- FastForestBinaryTrainer
- GamBinaryTrainer
- FieldAwareFactorizationMachineTrainer
- PriorTrainer
- LinearSvmTrainer
Входные и выходные данные двоичной классификации
Для получения наилучших результатов обучения двоичной классификации обучающие данные должны быть сбалансированы (т. е. число положительных и отрицательных обучающих данных должно быть одинаковым). Отсутствующие значения необходимо обработать до обучения.
е. число положительных и отрицательных обучающих данных должно быть одинаковым). Отсутствующие значения необходимо обработать до обучения.
Входные данные столбца меток должны иметь тип Boolean. Входные данные столбца функций должны быть вектором Single фиксированного размера.
С помощью этих алгоритмов обучения выводятся следующие столбцы:
| Имя выходного столбца | Тип столбца | Описание |
|---|---|---|
Score | Single | Необработанная оценка, рассчитанная моделью. |
PredictedLabel | Boolean | Прогнозируемая метка, зависящая от знака оценки. Отрицательная оценка соответствует значению false, а положительная — значению true. |
Многоклассовая классификация
Задача контролируемого машинного обучения, которая прогнозирует распределение экземпляров данных по нескольким классам (категориям). На вход алгоритма классификации подается набор примеров с метками. Каждая метка обычно запускается как текст. Затем она запускается через TermTransform, который преобразует ее в тип ключа (числовой). Результатом работы алгоритма классификации является классификатор, который умеет прогнозировать класс для новых экземпляров без метки. Вот несколько примеров для сценария многоклассовой классификации:
Каждая метка обычно запускается как текст. Затем она запускается через TermTransform, который преобразует ее в тип ключа (числовой). Результатом работы алгоритма классификации является классификатор, который умеет прогнозировать класс для новых экземпляров без метки. Вот несколько примеров для сценария многоклассовой классификации:
- определение категорий рейсов например «ранние», «вовремя» или «с опозданием»;
- распределение отзывов о фильме по категориям «позитивный», «нейтральный» или «негативный»;
- выбор категорий для отзывов о гостиницах, например «местоположение», «цена», «чистота» и т. д.
Дополнительные сведения см. в статье о многоклассовой классификации в Википедии.
Примечание
В рамках стратегии one-vs.-rest обновляется любой алгоритм обучения двоичной классификации для работы с многоклассовыми наборами данных. Подробнее см. в Википедии.
Алгоритмы обучения многоклассовой классификации
Вы можете обучить модель многоклассовой классификации, используя следующие алгоритмы:
- LightGbmMulticlassTrainer
- SdcaMaximumEntropyMulticlassTrainer
- SdcaNonCalibratedMulticlassTrainer
- LbfgsMaximumEntropyMulticlassTrainer
- NaiveBayesMulticlassTrainer
- OneVersusAllTrainer
- PairwiseCouplingTrainer
Входные и выходные данные многоклассовой классификации
Входные данные столбца меток должны иметь тип key. Столбец функций должен быть вектором Single фиксированного размера.
Столбец функций должен быть вектором Single фиксированного размера.
Этот алгоритм обучения выводит приведенные ниже данные.
| Имя выходных данных | Type | Описание |
|---|---|---|
Score | Вектор Single | Оценки всех классов. Более высокое значение означает большую вероятность попадания в связанный класс. Если i-й элемент имеет самое большое значение, индекс прогнозируемой метки будет равен i. Обратите внимание, что индекс i отсчитывается от нуля. |
PredictedLabel | Тип key | Индекс прогнозируемой метки. Если его значение равно i, фактическая метка будет i-й категорией во входном типе метки с ключевым значением. |
Регрессия
Задача контролируемого машинного обучения, которая прогнозирует значение метки по набору связанных компонентов. Метка здесь может принимать любое значение, а не просто выбирается из конечного набора значений, как в задачах классификации.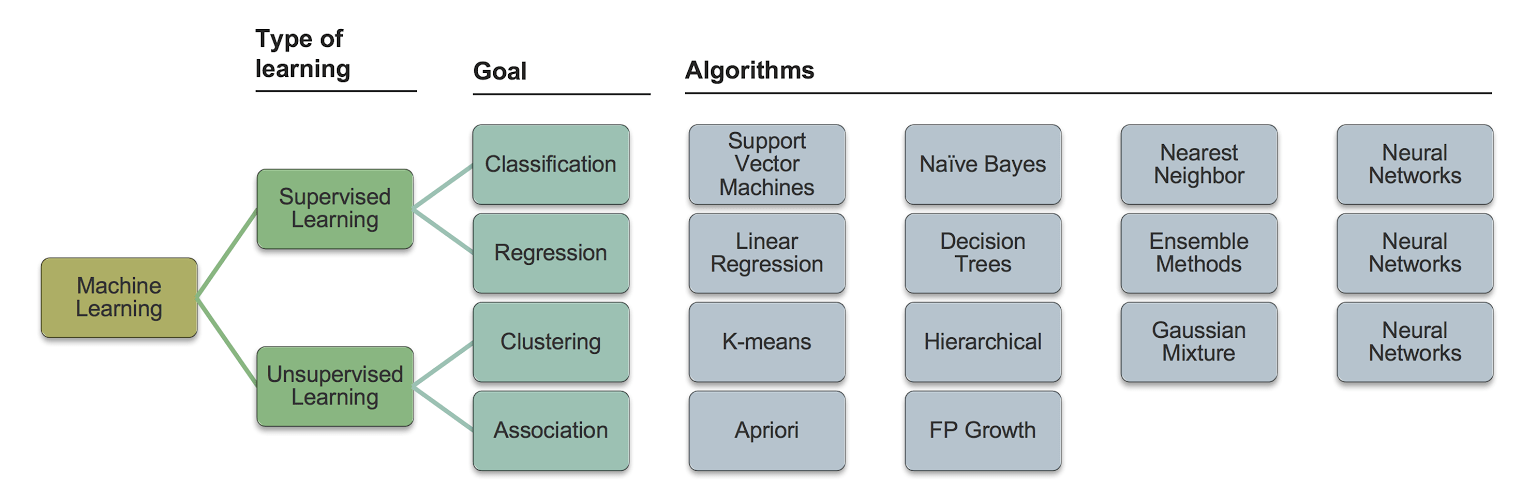 Алгоритмы регрессии моделируют зависимость меток от связанных компонентов, чтобы определить закономерности изменения меток при разных значениях компонентов. На вход алгоритма регрессии подается набор примеров с метками известных значений. Результатом работы алгоритма регрессии является функция, которая умеет прогнозировать значения метки для любого нового набора входных компонентов. Вот несколько примеров для сценария регрессии:
Алгоритмы регрессии моделируют зависимость меток от связанных компонентов, чтобы определить закономерности изменения меток при разных значениях компонентов. На вход алгоритма регрессии подается набор примеров с метками известных значений. Результатом работы алгоритма регрессии является функция, которая умеет прогнозировать значения метки для любого нового набора входных компонентов. Вот несколько примеров для сценария регрессии:
- прогнозирование цен на дома по таким атрибутам, как количество комнат, расположение и размер;
- прогнозирование будущей цены акций на основе исторических данных и текущих тенденций рынка;
- прогнозирование продаж товара в зависимости от рекламного бюджета.
Алгоритмы обучения регрессии
Вы можете обучить модель регрессии, используя следующие алгоритмы:
- LbfgsPoissonRegressionTrainer
- LightGbmRegressionTrainer
- SdcaRegressionTrainer
- OlsTrainer
- OnlineGradientDescentTrainer
- FastTreeRegressionTrainer
- FastTreeTweedieTrainer
- FastForestRegressionTrainer
- GamRegressionTrainer
Входные и выходные данные регрессии
Входные данные столбца меток должны иметь тип Single.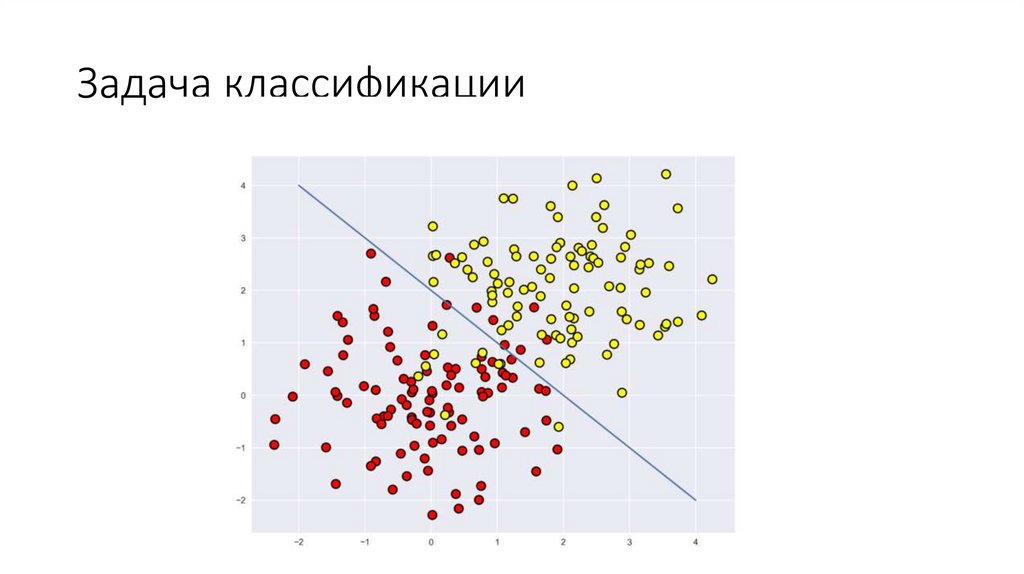
Алгоритмы обучения для этой задачи выводят приведенные ниже данные.
| Имя выходных данных | Type | Описание |
|---|---|---|
Score | Single | Необработанное оценка, спрогнозированная моделью. |
Кластеризация
Задача неконтролируемого машинного обучения, которая группирует отдельные экземпляры данных в кластеры со сходными характеристиками. Кластеризацию можно также использовать для определения в наборе данных связей, которые невозможно логически отследить просмотром или наблюдением данных. Входные и выходные данные для алгоритма кластеризации зависят от выбранного метода. Вы можете выбрать подход на основе распространения, центроида, возможности подключения или плотности. ML.NET в настоящее время поддерживает только кластеризацию методом К-средних на основе центроида. Примеры сценариев для использования кластеризации:
- распределение посетителей гостиниц на сегменты, исходя из привычек и характеристик выбора гостиниц;
- определение сегментов и демографических характеристик для клиентов, чтобы создавать целевые рекламные кампании;

Алгоритм обучения кластеризации
Вы можете обучить модель кластеризации, используя следующие алгоритмы:
- KMeansTrainer
Входные и выходные данные кластеризации
Входные данные функций должны иметь тип Single. Метки не требуются.
Этот алгоритм обучения выводит приведенные ниже данные.
| Имя выходных данных | Type | Описание |
|---|---|---|
Score | Вектор Single | Расстояния от заданной точки данных до всех кластеров средневзвешенных |
PredictedLabel | Тип key | Индекс ближайшего кластера, спрогнозированный моделью. |
Обнаружение аномалий
Эта задача создает модель обнаружения аномалий с помощью анализа главных компонентов (PCA). Обнаружение аномалий на основе PCA позволяет создавать модели в сценариях, где легко получить данные для обучения из одного класса, такого как допустимые транзакции, однако получить достаточную выборку аномальных значений затруднительно.
Общепринятый метод в машинном обучении, PCA, часто используется в разведочном анализе данных, так как он раскрывает внутреннюю структуру данных и объясняет их вариативность. PCA выполняется путем анализа данных с несколькими переменными. Он выполняет поиск корреляции между переменными и определяет сочетание значений, которые лучше всего фиксируют различия результатов. Эти объединенные значения компонентов используются для создания более компактных компонентов, называемых главными компонентами.
Обнаружение аномалий включает в себя ряд важных задач машинного обучения:
- Выявление потенциально мошеннических транзакций.
- Изучение шаблонов, которые указывают, что произошли сетевые атаки.
- Поиск аномальных кластеров пациентов.
- Проверка значений, введенных в систему.
Так как аномалии по определению довольно-таки редкие события, со сборкой репрезентативной выборки данных, используемых для моделирования, могут быть трудности. Алгоритмы, включенные в эту категорию, специально разработаны для решения основных проблем разработки и обучения моделей с использованием несбалансированных наборов данных.
Алгоритм обучения обнаружению аномалий
Вы можете обучить модель обнаружения аномалий, используя следующие алгоритмы:
- RandomizedPcaTrainer
Входные и выходные данные обнаружения аномалий
Входные данные функций должны быть вектором Single фиксированного размера.
Этот алгоритм обучения выводит приведенные ниже данные.
| Имя выходных данных | Type | Описание |
|---|---|---|
Score | Single | Неотрицательная неограниченная оценка, вычисленная моделью обнаружения аномалий |
PredictedLabel | Boolean | Значение true/false, указывающее, являются ли входные данные аномалией (PredictedLabel=true) или нет (PredictedLabel=false) |
Ранжирование
Задача ранжирования создает средство ранжирования на основе набора примеров с метками. Этот набор примеров состоит из групп экземпляров, которые могут быть оценены с заданными критериями.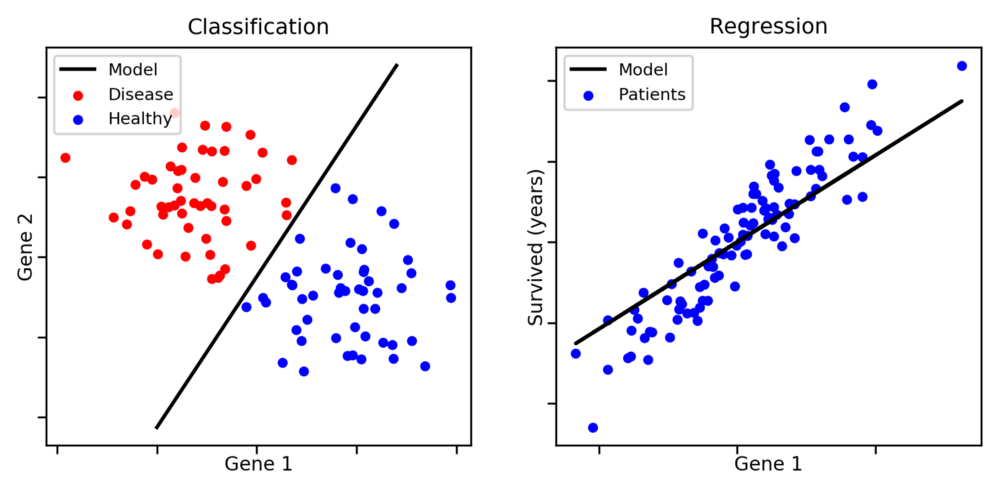 Метки ранжирования для каждого экземпляра — { 0, 1, 2, 3, 4 }. Средство ранжирования обучается ранжировать новые группы экземпляров с неизвестными оценками для каждого экземпляра. Алгоритмы обучения ранжированию ML.NET основаны на ранжировании машинного обучения.
Метки ранжирования для каждого экземпляра — { 0, 1, 2, 3, 4 }. Средство ранжирования обучается ранжировать новые группы экземпляров с неизвестными оценками для каждого экземпляра. Алгоритмы обучения ранжированию ML.NET основаны на ранжировании машинного обучения.
Алгоритмы обучения ранжированию
Вы можете обучить модель ранжирования, используя следующие алгоритмы:
- LightGbmRankingTrainer
- FastTreeRankingTrainer
Входные и выходные данные ранжирования
Входные данные метки должны иметь тип key или Single. Значение метки определяет релевантность, где более высокие значения означают более высокую степень релевантности. Если метка имеет тип key, индексом ключа будет значение релевантности, где наименьший индекс является минимально релевантным. Если метка имеет тип Single, более высокие значения означают более высокую степень релевантности.
Данные должны быть вектором Single фиксированного размера, а входной столбец группы строк должен иметь тип key.
Этот алгоритм обучения выводит приведенные ниже данные.
| Имя выходных данных | Type | Описание |
|---|---|---|
Score | Single | Неограниченная оценка, вычисленная моделью для определения прогноза |
Задача рекомендации позволяет создать список рекомендуемых продуктов или служб. ML.NET использует факторизацию матрицы (MF), алгоритм совместной фильтрации для рекомендаций при наличии исторических данных о рейтинге продуктов в вашем каталоге. Например, вы получили исторические данные о рейтинге фильмов для пользователей и хотели бы рекомендовать другие фильмы, которые, скорее всего, будут отслеживаться далее.
Алгоритмы обучения рекомендациям
Вы можете обучить модель рекомендаций, используя следующий алгоритм:
- MatrixFactorizationTrainer
Прогнозирование
Задача прогнозирования использует предыдущие данные временных рядов, чтобы делать прогнозы о будущем поведении.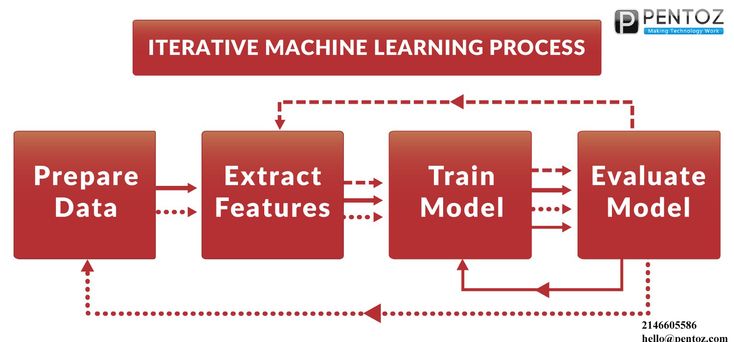 Сценарии, применимые к прогнозированию, включают прогнозирование погоды, сезонные прогнозы продаж и диагностическое обслуживание.
Сценарии, применимые к прогнозированию, включают прогнозирование погоды, сезонные прогнозы продаж и диагностическое обслуживание.
Алгоритмы обучения для прогнозирования
Вы можете обучить модель прогнозирования, используя следующий алгоритм.
ForecastBySsa
Классификация изображений
Задача контролируемого машинного обучения, которая прогнозирует распределение изображений по нескольким классам (категориям). Входные данные — это набор помеченных примеров. Каждая метка обычно запускается как текст. Затем она запускается через TermTransform, который преобразует ее в тип ключа (числовой). Результатом работы алгоритма классификации изображений является классификатор, который можно использовать для прогнозирования класса новых изображений. Задача классификации изображений — это тип классификации по нескольким классам. Вот несколько примеров для сценария классификации изображений:
- определение породы собаки, например «сибирский хаски», «золотистый ретривер», «пудель» и т. д;
- определение, является ли производственный продукт поврежденным или нет;
- определение типов цветов, например «роза», «подсолнух» и т. д.
 д;
д;Алгоритмы обучения классификации изображений
Вы можете обучить модель классификации изображений, используя следующие алгоритмы обучения:
- ImageClassificationTrainer
Входные и выходные данные классификации изображений
Входные данные столбца меток должны иметь тип key. Столбец функции должен быть вектором с переменным размером Byte.
Этот алгоритм обучения выводит следующие столбцы:
| Имя выходных данных | Type | Описание |
|---|---|---|
Score | Single | Оценки всех классов. Более высокое значение означает большую вероятность попадания в связанный класс. Если i-й элемент имеет самое большое значение, индекс прогнозируемой метки будет равен i. Обратите внимание, что индекс i отсчитывается от нуля. |
PredictedLabel | Тип key | Индекс прогнозируемой метки.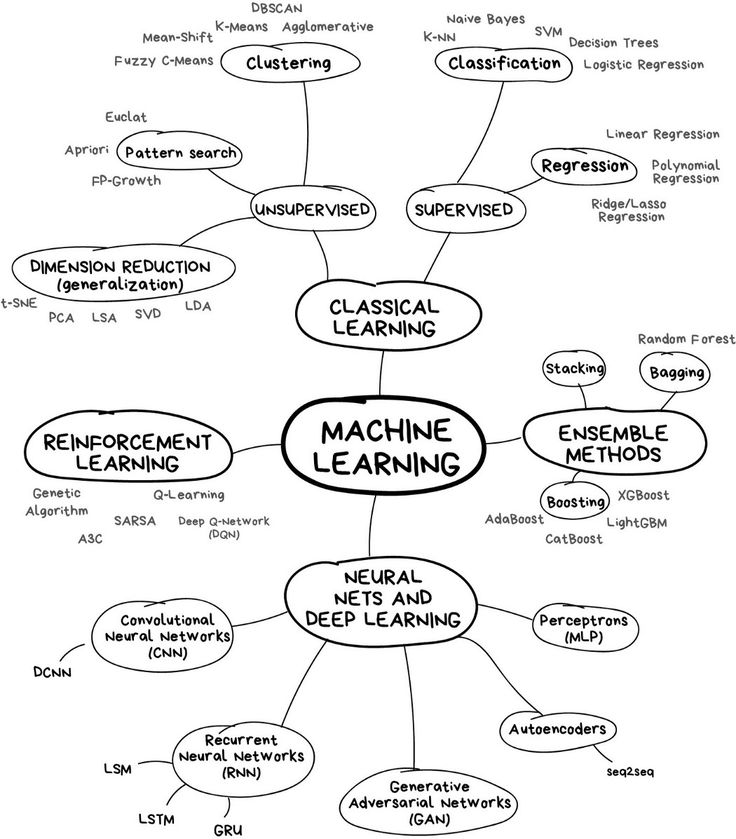 Если его значение равно i, фактическая метка будет i-й категорией во входном типе метки с ключевым значением. Если его значение равно i, фактическая метка будет i-й категорией во входном типе метки с ключевым значением. |
Обнаружение объектов
Задача контролируемого машинного обучения, которая используется для прогнозирования класса (категории) изображения, а также предоставляет ограничивающий прямоугольник для категории внутри изображения. Вместо классификации одного объекта в изображении, обнаружение объектов может определить несколько объектов в изображении. Примеры обнаружения объектов:
- обнаружение автомобилей, дорожных знаков или людей на изображениях дорог;
- обнаружение дефектов на изображениях продуктов;
- обнаружение проблемных участков на изображениях рентгеновских снимков.
Обучение модели обнаружения объектов в настоящее время доступно только в Model Builder с помощью Машинного обучения Azure.
Какие задачи позволяет решать машинное обучение?
01.06.2022
© pexels. com
com
Машинное обучение (machine learning, ML) является самым перспективным направлением искусственного интеллекта. По данным аналитического альманаха МФТИ, одно из главных событий в области искусственного интеллекта в мире в 2021 году – заявление учёных из Стэнфорда о становлении новой парадигмы в области ML: крупные корпорации будут создавать гигантские модели, которые другие компании будут дообучать и использовать для решения своих задач.
Что такое машинное обучение?
Machine learning – это область прикладной математики, которая позволяет обучать компьютерные модели для выявления общих закономерностей в данных. Модели машинного обучения на основе большого количества примеров самостоятельно учатся различать полученную информацию и использовать её для решения задач. Machine learning качественным образом отличается от детерминированных алгоритмов, которые включают в себя фиксированный набор предопределённых шагов. Машинное обучение сейчас представляет собой быстро развивающуюся отрасль. Это связано с увеличением вычислительных мощностей и накоплением знаний, появлением совокупности научно обоснованных и эффективных подходов.
Это связано с увеличением вычислительных мощностей и накоплением знаний, появлением совокупности научно обоснованных и эффективных подходов.
Как связаны между собой машинное обучение, нейросети и искусственный интеллект?
Машинное обучение – это область, в которой исследуются и применяются модели, обучающиеся на входных данных. Оно является одним из направлений искусственного интеллекта.
Нейронные сети – одно из семейств моделей машинного обучения.
Искусственный интеллект – группа методов с использованием различных алгоритмов, в том числе на основе машинного обучения, направленных на создание интеллектуальных машин. Сильный искусственный интеллект способен решать повседневные задачи человека, а слабый – выполнять лишь узконаправленные задачи, например, различать разнообразные объекты, объединять в группы похожие изображения. При работе с такими моделями человек передаёт им часть знаний и тем самым ускоряет собственную работу.
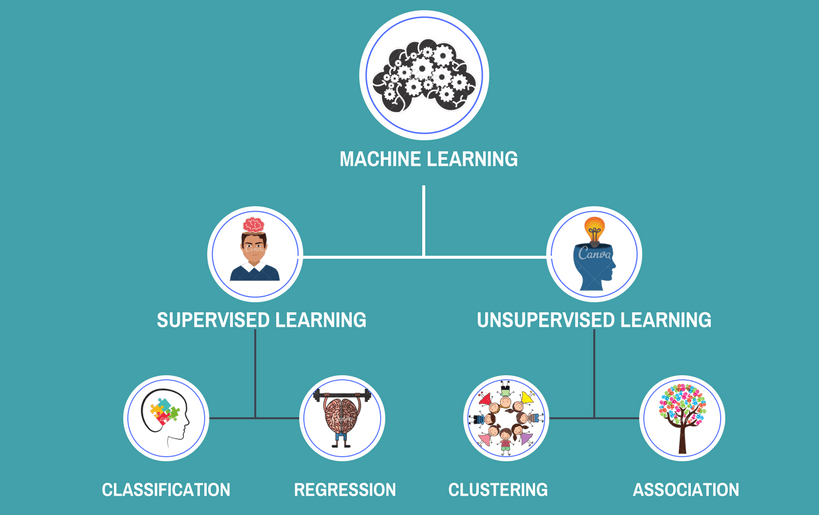
Основные направления в machine learning
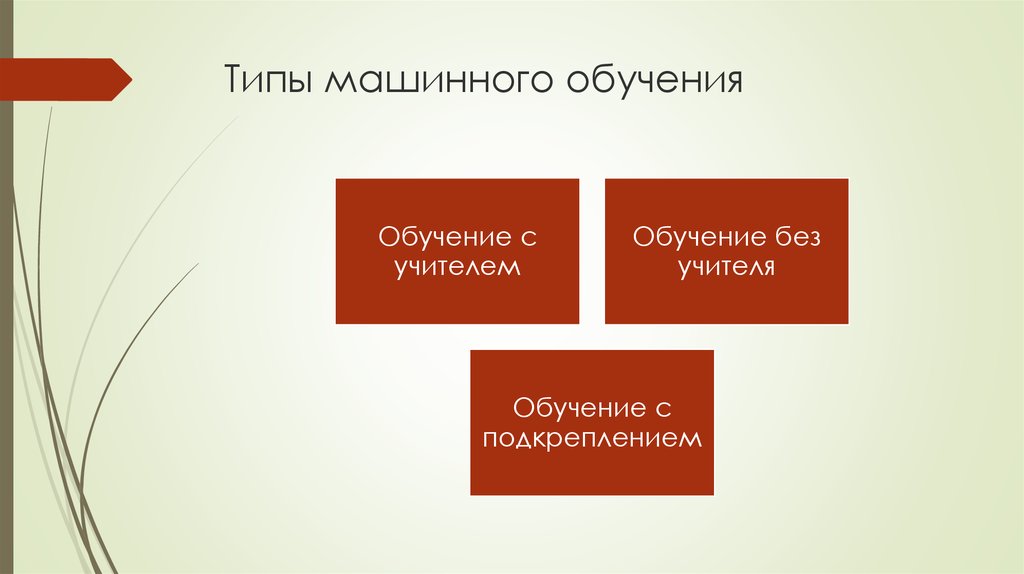
- Обучение с учителем (supervised learning)
Для анализа используются размеченные данные, все объекты заранее промаркированы. Например, для обучения модели представлены фотографии с кошками и собаками с соответствующими метками. Задача – научиться различать этих животных.
- Обучение без учителя (unsupervised learning)
При обработке массивов информации нет описания или меток объектов, алгоритм должен самостоятельно выявлять закономерности, взаимосвязи и зависимости в данных. Обучение без учителя применяется для поиска похожих текстов, изображений и документов, визуализации и выявления аномалий.
- Обучение с подкреплением (reinforcement learning)
Машина ищет оптимальные действия для выполнения поставленной задачи в различных условиях. Например, модель космического корабля совершает посадку. На основании информации о меняющемся окружении необходимо адаптировать способ действия. Оптимизированные шаги и есть результат обучения.
На основании информации о меняющемся окружении необходимо адаптировать способ действия. Оптимизированные шаги и есть результат обучения.
Какие задачи решает машинное обучение?
Машинное обучение помогает в решении экономических и социально значимых проблем. Основные классы задач, решаемых с помощью machine learning:
- Регрессия – это прогнозирование числового значения на основе выборки объектов с различными признаками. Например, оценка платёжеспособности заёмщика, ожидаемого дохода компании или цены квартиры на рынке недвижимости.
- Классификация – отнесение объектов на основе имеющихся параметров к одному из предопределённых классов. В рамках работы Центра изучения и сетевого мониторинга молодёжи именно качественная классификация помогает выявить деструктивный контент среди текстовых или визуальных объектов. Ежедневно благодаря машинному обучению анализируется более миллиона изображений и текстов.
- Кластеризация – объединение похожих данных в группы (кластеры). Например, поиск сообществ, похожих по контенту, или объединение схожих по смыслу постов в социальной сети.
 Например, поиск сообществ, похожих по контенту, или объединение схожих по смыслу постов в социальной сети.
Например, поиск сообществ, похожих по контенту, или объединение схожих по смыслу постов в социальной сети.- Прогнозирование временного ряда – работа с данными, полученными в определённый период времени, и предсказание на их основе значений в задаваемый исследуемый период. Решение этой задачи позволяет спрогнозировать сейсмическую активность или изменение стоимости ценных бумаг.
Также существуют вспомогательные задачи, которые можно решить с помощью machine learning – распознавание текста на изображениях, детекция символов, идентификация речи и так далее.
Машинное обучение и анализ данных
По мнению доктора физико-математических наук, профессора МФТИ, специалиста в области машинного обучения Константина Воронцова, интеллектуальный анализ данных в целом основывается на подходах и методах машинного обучения. ML занимается построением математических моделей для обобщения информации, а анализ данных как прикладная дисциплина позволяет решать конкретные практические задачи. Модели помогают исследовать и обрабатывать гигантские потоки информации, выявлять закономерности.
Модели помогают исследовать и обрабатывать гигантские потоки информации, выявлять закономерности.
В каких сферах применяют machine learning?
Машинное обучение активно используется во многих отраслях экономики. Например, в бизнесе широко применяются модели для предсказания поведения клиентов, создания рекомендательных систем, кластеризации аудитории для настройки показов рекламы (объединение людей в группы по схожим интересам, возрасту или социальному положению). Например, такой метод, как анализ временных рядов, необходим для глубокого понимания происходящих бизнес-процессов, в частности, динамики закупок и продаж товаров, посещаемости сайта и охвата пользователей.
В медицине machine learning помогает анализировать данные различных исследований состояния здоровья пациента. Умные системы на базе ML могут по рентгеновскому снимку выявлять патологии или предсказывать вероятность наличия какого-либо заболевания по совокупности результатов анализов.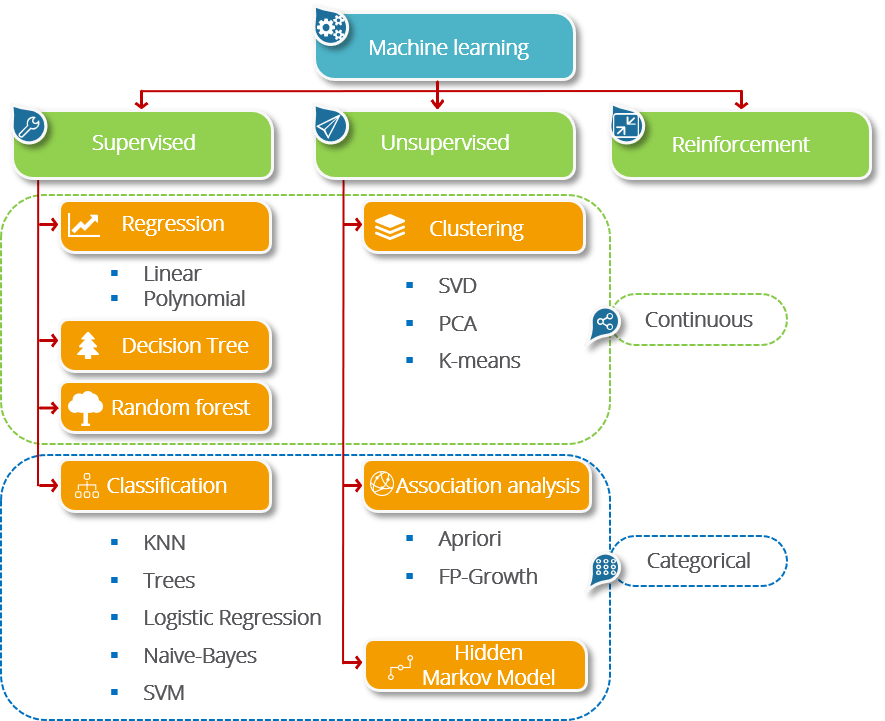
В промышленности с помощью моделей машинного обучения внедряется автоматизация технологических процессов. Это позволяет снижать затраты на выпуск продукции и увеличивать производительность.
В сельском хозяйстве с использованием подходов машинного обучения были запущены первые беспилотные комбайны. Автопилот помогает управлять транспортом в то время, когда комбайнёр следит за процессом жатвы.
ML также позволяет обеспечивать безопасность в реальном мире и цифровом пространстве. Например, машинное обучение помогает автоматически вычислять мошеннические транзакции среди многочисленных банковских операций, контролировать заданный периметр и использовать системы биометрического распознавания.
Машинное обучение широко применяется в рамках работы Центра изучения и сетевого мониторинга молодёжи. Цифровое пространство – непрерывно обновляемая среда, которая ежесекундно пополняется полезным, нейтральным и деструктивным контентом.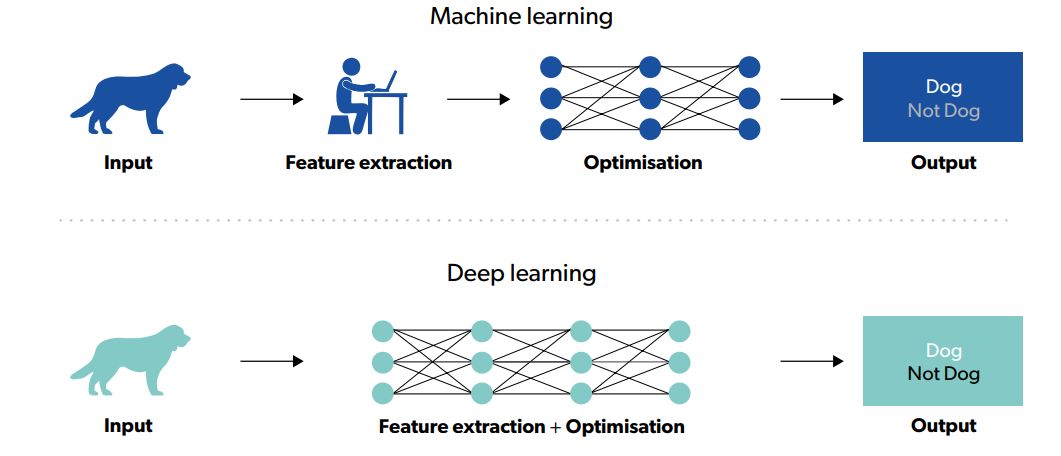 В целях мониторинга и анализа негативных явлений в Интернете специалисты Центра разрабатывают или адаптируют существующие модели машинного обучения. ML значительно упрощает поиск потенциально опасной для пользователей информации среди большого объёма сетевых данных.
В целях мониторинга и анализа негативных явлений в Интернете специалисты Центра разрабатывают или адаптируют существующие модели машинного обучения. ML значительно упрощает поиск потенциально опасной для пользователей информации среди большого объёма сетевых данных.
Перспективы развития машинного обучения: будет ли искусственный интеллект умнее человека?
Machine learning в перспективе освободит человека от выполнения рутинных операций и сделает его труд более эффективным. Благодаря этому жизнь станет легче, а компьютеры – ещё умнее. Несмотря на большие успехи в области искусственного интеллекта, современное машинное обучение и другие подходы пока не могут заменить человеческий интеллект. Модели занимаются статистическим обобщением свойств объектов, но помимо общих характеристик также существуют особенности, которые можно определить только методом «ручного» анализа. На данный момент это единственная возможность выявлять единичные (уникальные) признаки, распознавать сложные объекты и новые явления во всей их полноте.
У машинного обучения огромные перспективы, капиталовложения в ML постоянно растут. Это те технологии, которые поменяют мир точно так же, как когда-то его изменило изобретение полупроводников или лазера. Сегодня исследовательское сообщество и инженеры стремятся облегчить повседневную жизнь с помощью machine learning и расширить горизонты человеческого знания.
Дополнительные материалы:
Нейросети и дети: как технологии защищают от цифровых угроз?
Теги:
технологии
#2. Постановка задачи машинного обучения
Смотреть материал на видео
Здравствуйте, дорогие друзья! Мы продолжаем курс по машинному обучению. На предыдущем занятии мы ввели понятие обучающей выборки и признакового пространства в виде матрицы . Будем полагать, что набор этих признаков и подается на вход алгоритмов. Причем, в частном случае, когда
имеем неизменные
исходные данные измерений .
Получается, что идеальный алгоритм должен уметь отображать входы в соответствующие выходы . На уровне математики это можно записать через функциональную зависимость между входами и выходами:
Причем, функциональная в широком смысле слова – это может быть любой алгоритм, связывающий вход с выходом. Но мы эту взаимосвязь не знаем. Целью обучения, как раз и является найти такую модель, решающую функцию (decision function), которая бы приближала ответы
к требуемым на всем множестве возможных входных данных X (не только для обучающей выборки, но для всех возможных наблюдений той же природы). Это и есть общая постановка задачи машинного обучения.
Конечно, в таком
виде совершенно непонятно, как ее решать, как искать правило преобразования ? Необходима
конкретизация. По сути, весь курс машинного обучения – это и есть различные
вариации решения поставленной задачи.
Как можно ее решить? Наверное, одним из самых простых подходов (и наиболее часто используемых), представить функционал в виде некоторой выбранной нами параметрической функции:
с настраиваемым набором параметров . То есть, мы сводим задачу обучения к поиску неизвестных параметров и делаем это (в самом простом, но распространенном случае) по обучающей выборке. Причем вид самой функции может быть сколь угодно сложным (в математическом смысле) и в общем случае состоять из композиции других, более простых функций. То есть, вид функции должен отражать характер (природу, модель) изменения данных между входом и выходом, а параметры подгоняют ее под конкретный набор данных.
Чтобы все это было понятнее, давайте рассмотрим классический пример такой задачи – линейную регрессию, когда входы и выходы имеют ярко выраженную функциональную зависимость вида:
(здесь -
гауссовский (нормальный) шум с нулевым средним и некоторой небольшой дисперсией). Так как мы не можем прогнозировать случайные отклонения, то самое разумное
описать модель данных в виде линейной функции с двумя неизвестными параметрами :
Так как мы не можем прогнозировать случайные отклонения, то самое разумное
описать модель данных в виде линейной функции с двумя неизвестными параметрами :
В результате, мы имеем вектор параметров , которые определяют конкретный наклон и сдвиг линейной функции. То есть, исходная функция описывает весь класс прямых, а при конкретных получаем определенную прямую для данных обучающей выборки.
Вот принцип параметрической оптимизации, который расширяется на произвольные функциональные зависимости выходов от входов.
Хорошо, решающая функция в виде параметрической функции, определена. Как теперь нам найти значения параметров на множестве входов и выходов обучающей выборки? Очевидно, они должны быть подобраны так, чтобы уменьшить ошибки между заданными выходами и теми, которые получаются в нашей модели :
Но сама по себе
ошибка в качестве оптимизируемой величины не очень удобна, т. к. в точке
минимума (нуля) она не образует точки экстремума. Математически было бы лучше использовать
функцию, которая бы возрастала с увеличением ошибки и убывала бы с ее
уменьшением. Например, можно выбрать, следующие:
к. в точке
минимума (нуля) она не образует точки экстремума. Математически было бы лучше использовать
функцию, которая бы возрастала с увеличением ошибки и убывала бы с ее
уменьшением. Например, можно выбрать, следующие:
- — абсолютная ошибка;
- — квадратичная ошибка.
Подобные функции получили название функций потерь (loss function), которые, фактически, вычисляет меру потерь (несоответствия) между нашей моделью и обучающей выборкой. Конечно, таких функций огромное количество и с некоторыми из них мы будем знакомиться по мере прохождения этого курса.
Однако, сама по
себе функция потерь – это случайная величина, которая зависит от алгоритма и
текущего входного вектора .
Поэтому оптимизировать одно какое-то конкретное значение функции потерь –
неправильно. Нужно сделать так, чтобы на всем обучающем множестве, в среднем, ошибка
была бы минимальна.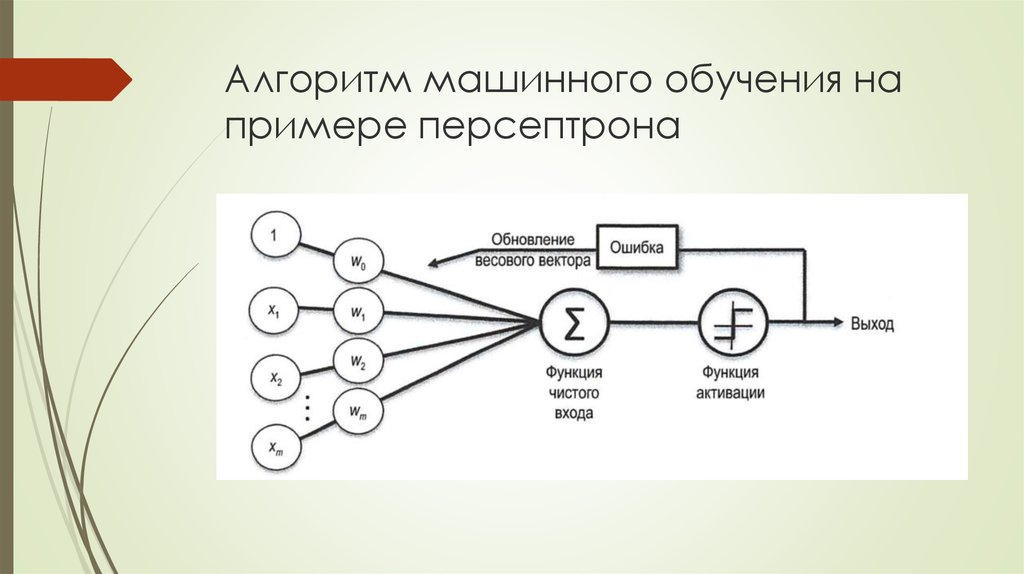 В результате мы приходим к понятию среднего
эмпирического риска:
В результате мы приходим к понятию среднего
эмпирического риска:
(Здесь — обучающее множество). Фактически, это и есть показатель качества, который нужно минимизировать, подбирая значения вектора параметров .
Например, если вернуться к нашей задаче линейной регрессии и в качестве функции потерь выбрать квадрат ошибки, то получим функционал качества в виде:
В данном случае параметры легко вычисляются из решения следующей системы линейных уравнений:
Это известная задача под названием метод наименьших квадратов (МНК) и я ее подробно рассматривал в одном из видео:
https://youtu.be/8sVfWyQrMiM
Если вы с ним не знакомы, то советую посмотреть этот материал.
Итак, резюмируя материал этого занятия, можно отметить следующие четыре пункта:
- Общая задача
машинного обучения ставится как поиск модели ,
которая наилучшим образом описывает природу зависимости входных данных и
целевых выходных значений .
- Задачу поиска наилучшей модели часто сводят к задаче параметрической оптимизации функции вида .
- Для нахождения подходящих параметров вводится функция потерь и определяется средний эмпирический риск . Минимизируя этот показатель качества, получаем набор параметров по обучающей выборке.
- На основе найденной зависимости в дальнейшем вычисляются выходные значения при предъявлении нового входного вектора той же природы, что и при обучении.
Эти четыре этапа представляют собой общий принцип, лежащий в основе всех алгоритмов машинного обучения.
Видео по теме
Машинное обучение. Начало
#1. Что такое машинное обучение? Обучающая выборка и признаковое пространство
#2. Постановка задачи машинного обучения
#3. Линейная модель. Понятие переобучения
#4.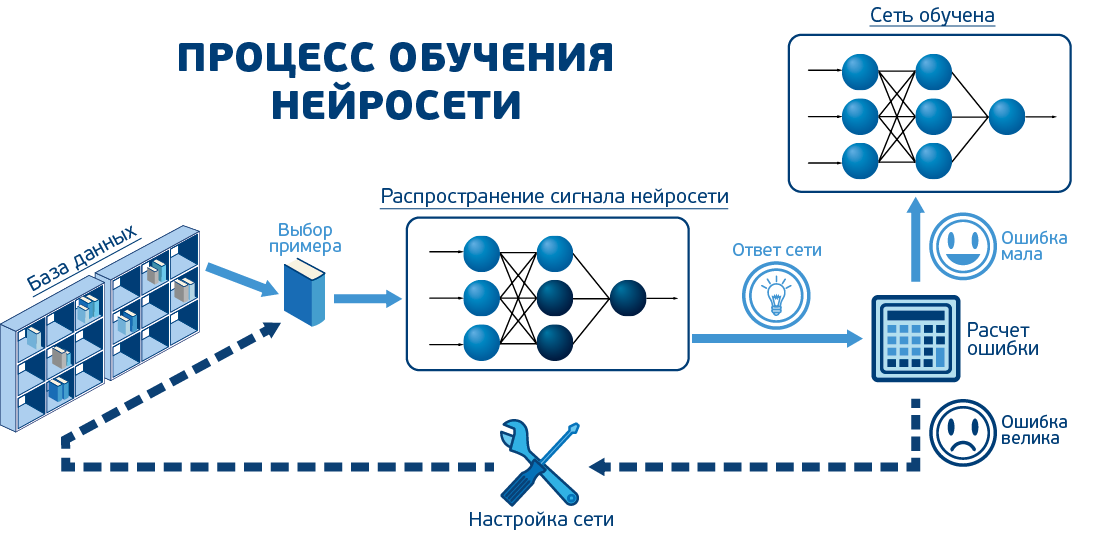 Способы оценивания степени переобучения моделей
Способы оценивания степени переобучения моделей
#5. Уравнение гиперплоскости в задачах бинарной классификации
#6. Решение простой задачи бинарной классификации
#7. Функции потерь в задачах линейной бинарной классификации
#8. Стохастический градиентный спуск SGD и алгоритм SAG
#9. Пример использования SGD при бинарной классификации образов
#10. Оптимизаторы градиентных алгоритмов: RMSProp, AdaDelta, Adam, Nadam
#11. L2-регуляризатор. Математическое обоснование и пример работы
#12. L1-регуляризатор. Отличия между L1- и L2-регуляризаторами
#13. Логистическая регрессия. Вероятностный взгляд на машинное обучение
#14. Вероятностный взгляд на L1 и L2-регуляризаторы
#15. Формула Байеса при решении конкретных задач
#16. Байесовский вывод. Наивная байесовская классификация
Байесовский вывод. Наивная байесовская классификация
#17. Гауссовский байесовский классификатор
#18. Линейный дискриминант Фишера
#19. Введение в метод опорных векторов (SVM)
#20. Реализация метода опорных векторов (SVM)
#21. Метод опорных векторов (SVM) с нелинейными ядрами
#22. Вероятностная оценка качества моделей
#23. Показатели precision и recall. F-мера
#24. Метрики качества ранжирования. ROC-кривая
#25. Метод главных компонент (Principal Component Analysis)
#26. Сокращение размерности признакового пространства с помощью PCA
#27. Сингулярное разложение и его связь с PCA
#28. Многоклассовая классификация. Методы one-vs-all и all-vs-all
#29. Метрические методы классификации. Метод k ближайших соседей
Метрические методы классификации. Метод k ближайших соседей
#30. Методы парзеновского окна и потенциальных функций
#31. Метрические регрессионные методы. Формула Надарая-Ватсона
#32. Задачи кластеризации. Постановка задачи
#33. Алгоритм кластеризации Ллойда (K-средних, K-means)
#34. Алгоритм кластеризации DBSCAN
#35. Агломеративная иерархическая кластеризация. Дендограмма
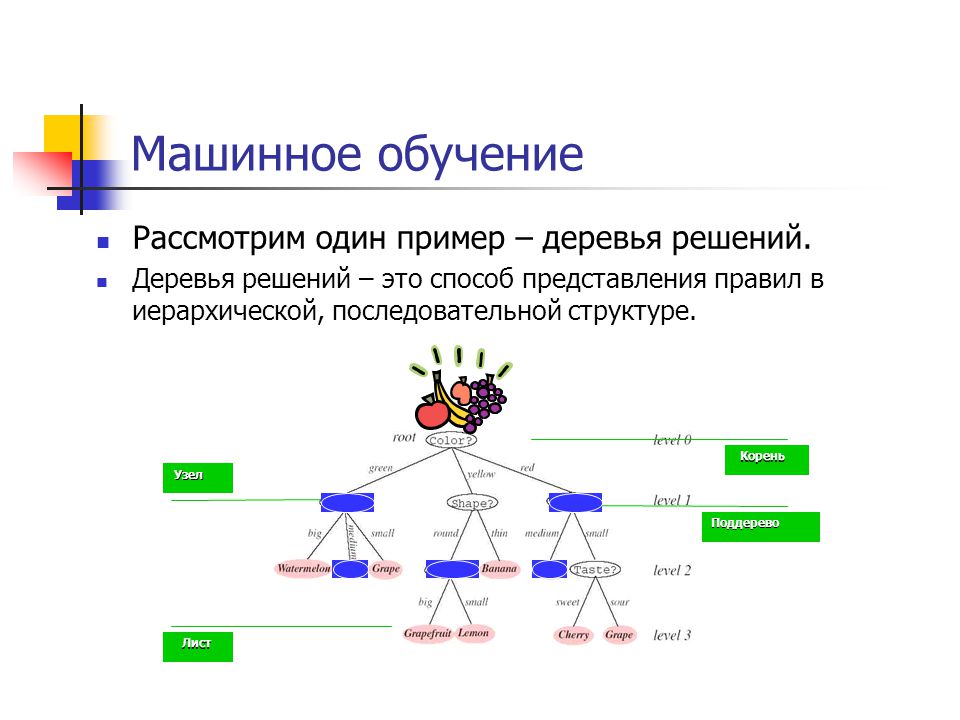
#36. Логические методы классификации
#37. Критерии качества для построения решающих деревьев
#38. Построение решающих деревьев жадным алгоритмом ID3
#39. Усечение (prunning) дерева, обработка пропусков и категориальных признаков
#40. Решающие деревья в задачах регрессии. Алгоритм CART
#41. Случайные деревья и случайный лес. Бутстрэп и бэггинг
Бутстрэп и бэггинг
#42. Введение в бустинг (boosting). Алгоритм AdaBoost при классификации
#43. Алгоритм AdaBoost в задачах регрессии
#44. Градиентный бустинг и стохастический градиентный бустинг
#45. Нейронные сети. Краткое введение в теорию
#46. Обучение нейронной сети. Алгоритм back propagation
задач машинного обучения — ML.NET
- Статья
- 9 минут на чтение
Задача машинного обучения — это тип прогноза или вывода, основанный на заданной проблеме или вопросе и доступных данных. Например, задача классификации распределяет данные по категориям, а задача кластеризации группирует данные по сходству.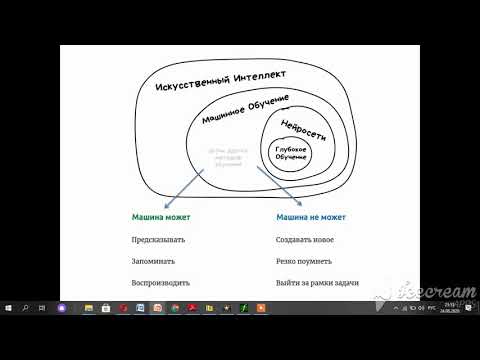
Задачи машинного обучения основаны на шаблонах данных, а не явно запрограммированы.
В этой статье описываются различные задачи машинного обучения, которые можно выбрать в ML.NET, и некоторые распространенные варианты использования.
После того, как вы решили, какая задача подходит для вашего сценария, вам нужно выбрать лучший алгоритм для обучения вашей модели. Доступные алгоритмы перечислены в разделе для каждой задачи.
Двоичная классификация
Задача машинного обучения под наблюдением, которая используется для прогнозирования того, к какому из двух классов (категорий) принадлежит экземпляр данных. Входными данными алгоритма классификации является набор помеченных примеров, где каждая метка представляет собой целое число, равное 0 или 1. Выходными данными алгоритма бинарной классификации является классификатор, который можно использовать для прогнозирования класса новых непомеченных экземпляров. Примеры сценариев бинарной классификации включают:
- Толкование комментариев в Твиттере как «положительное» или «отрицательное».
- Диагностика наличия у пациента того или иного заболевания.
- Принятие решения помечать письмо как спам или нет.
- Определение того, содержит ли фотография определенный предмет или нет, например, собаку или фрукт.
Для получения дополнительной информации см. статью о двоичной классификации в Википедии.
Тренажеры бинарной классификации
Вы можете обучить модель бинарной классификации, используя следующие алгоритмы:
- Тренажер среднего персептрона
- SdcaLogisticRegressionBinaryTrainer
- SdcaNonCalibratedBinaryTrainer
- SymbolicSgdLogisticRegressionBinaryTrainer
- LbfgsLogisticRegressionBinaryTrainer
- LightGbmBinaryTrainer
- FastTreeBinaryTrainer
- FastForestBinaryTrainer
- GamBinaryTrainer
- FieldAwareFactorizationMachineTrainer
- ПриорТрейнер
- LinearSvmTrainer
Входы и выходы двоичной классификации
Для достижения наилучших результатов с двоичной классификацией обучающие данные должны быть сбалансированы (т. е. равное количество положительных и отрицательных обучающих данных). Пропущенные значения должны быть обработаны до обучения.
е. равное количество положительных и отрицательных обучающих данных). Пропущенные значения должны быть обработаны до обучения.
Данные столбца меток ввода должны быть логическими. Данные столбца входных объектов должны быть вектором фиксированного размера Single.
Эти тренажеры выводят следующие столбцы:
| Имя выходного столбца | Тип колонны | Описание |
|---|---|---|
Оценка | Одноместный | Необработанная оценка, рассчитанная моделью |
PredictedLabel | Булево значение | Прогнозируемая метка на основе знака оценки. Отрицательная оценка соответствует false , а положительная оценка соответствует true . |
Многоклассовая классификация
Задача контролируемого машинного обучения, которая используется для прогнозирования класса (категории) экземпляра данных. Входными данными алгоритма классификации является набор помеченных примеров. Каждая метка обычно начинается с текста. Затем он проходит через TermTransform, который преобразует его в тип Key (числовой). Результатом алгоритма классификации является классификатор, который можно использовать для прогнозирования класса новых непомеченных экземпляров. Примеры сценариев многоклассовой классификации включают:
Входными данными алгоритма классификации является набор помеченных примеров. Каждая метка обычно начинается с текста. Затем он проходит через TermTransform, который преобразует его в тип Key (числовой). Результатом алгоритма классификации является классификатор, который можно использовать для прогнозирования класса новых непомеченных экземпляров. Примеры сценариев многоклассовой классификации включают:
- Классификация рейсов как «ранние», «своевременные» или «поздние».
- Понимание обзоров фильмов как «положительных», «нейтральных» или «отрицательных».
- Классификация отзывов об отелях по категориям «расположение», «цена», «чистота» и т. д.
Для получения дополнительной информации см. статью о классификации мультиклассов в Википедии.
Примечание
Один против всех обновляет любой модуль обучения бинарной классификации для работы с мультиклассовыми наборами данных. Больше информации в Википедии.
Тренажеры многоклассовой классификации
Вы можете обучить модель многоклассовой классификации, используя следующие алгоритмы обучения:
- LightGbm MulticlassTrainer
- SdcaMaximumEntropyMulticlassTrainer
- SdcaNonCalibratedMulticlassTrainer
- LbfgsMaximumEntropyMulticlassTrainer
- NaiveBayesMulticlassTrainer
- OneVersusAllTrainer
- Тренажер для парных соединений
Многоклассовая классификация входов и выходов
Данные столбца метки ввода должны быть ключевого типа. Столбец объектов должен быть вектором фиксированного размера Single.
Столбец объектов должен быть вектором фиксированного размера Single.
Этот тренажер выводит следующее:
| Имя выхода | Тип | Описание |
|---|---|---|
Оценка | Вектор одиночного | Баллы всех классов. Более высокое значение означает более высокую вероятность попадания в соответствующий класс. Если i-й элемент имеет наибольшее значение, прогнозируемый индекс метки будет равен i. Обратите внимание, что i — это индекс, начинающийся с нуля. |
PredictedLabel | тип ключа | Прогнозируемый индекс метки. Если его значение равно i, фактическая метка будет i-й категорией в типе входной метки с ключом. |
Регрессия
Задача контролируемого машинного обучения, которая используется для прогнозирования значения метки на основе набора связанных функций. Метка может иметь любое реальное значение, а не из конечного набора значений, как в задачах классификации. Алгоритмы регрессии моделируют зависимость метки от связанных с ней функций, чтобы определить, как будет меняться метка при изменении значений функций. Входные данные алгоритма регрессии представляют собой набор примеров с метками известных значений. Результатом алгоритма регрессии является функция, которую можно использовать для прогнозирования значения метки для любого нового набора входных функций. Примеры сценариев регрессии включают:
Алгоритмы регрессии моделируют зависимость метки от связанных с ней функций, чтобы определить, как будет меняться метка при изменении значений функций. Входные данные алгоритма регрессии представляют собой набор примеров с метками известных значений. Результатом алгоритма регрессии является функция, которую можно использовать для прогнозирования значения метки для любого нового набора входных функций. Примеры сценариев регрессии включают:
- Прогнозирование цен на жилье на основе атрибутов дома, таких как количество спален, расположение или размер.
- Прогнозирование будущих цен на акции на основе исторических данных и текущих рыночных тенденций.
- Прогнозирование продаж продукта на основе рекламных бюджетов.
Тренажеры регрессии
Вы можете обучать модель регрессии, используя следующие алгоритмы:
- LbfgsPoissonRegressionTrainer
- LightGbmRegressionTrainer
- SdcaRegressionTrainer
- OlsTrainer
- OnlineGradientDescentTrainer
- FastTreeRegressionTrainer
- FastTreeTweedieTrainer
- FastForestRegressionTrainer
- GamRegressionTrainer
Входные и выходные данные регрессии
Данные столбца метки ввода должны быть Single.
Тренеры для этой задачи выводят следующее:
| Выходное имя | Тип | Описание |
|---|---|---|
Оценка | Одноместный | Необработанная оценка, предсказанная моделью |
Кластеризация
Неконтролируемая задача машинного обучения, используемая для группировки экземпляров данных в кластеры со схожими характеристиками. Кластеризацию также можно использовать для выявления взаимосвязей в наборе данных, которые вы не можете логически вывести путем просмотра или простого наблюдения. Входные и выходные данные алгоритма кластеризации зависят от выбранной методологии. Вы можете использовать подход, основанный на распределении, центроиде, связности или плотности. ML.NET в настоящее время поддерживает подход на основе центроидов с использованием кластеризации K-средних. Примеры сценариев кластеризации включают:
- Понимание сегментов гостей отеля на основе привычек и особенностей выбора отеля.
- Определение сегментов и демографических характеристик клиентов для создания целевых рекламных кампаний.
- Классификация запасов на основе производственных показателей.

Тренажер кластеризации
Обучить модель кластеризации можно по следующему алгоритму:
- KMeansTrainer
Кластеризация входных и выходных данных
Входные данные объектов должны быть Single. Никакие ярлыки не нужны.
Этот тренажер выводит следующее:
| Имя вывода | Тип | Описание |
|---|---|---|
Оценка | вектор одиночного | Расстояния данной точки данных до центроидов всех кластеров |
PredictedLabel | тип ключа | Индекс ближайшего кластера, предсказанный моделью. |
Обнаружение аномалий
Эта задача создает модель обнаружения аномалий с помощью анализа главных компонентов (PCA).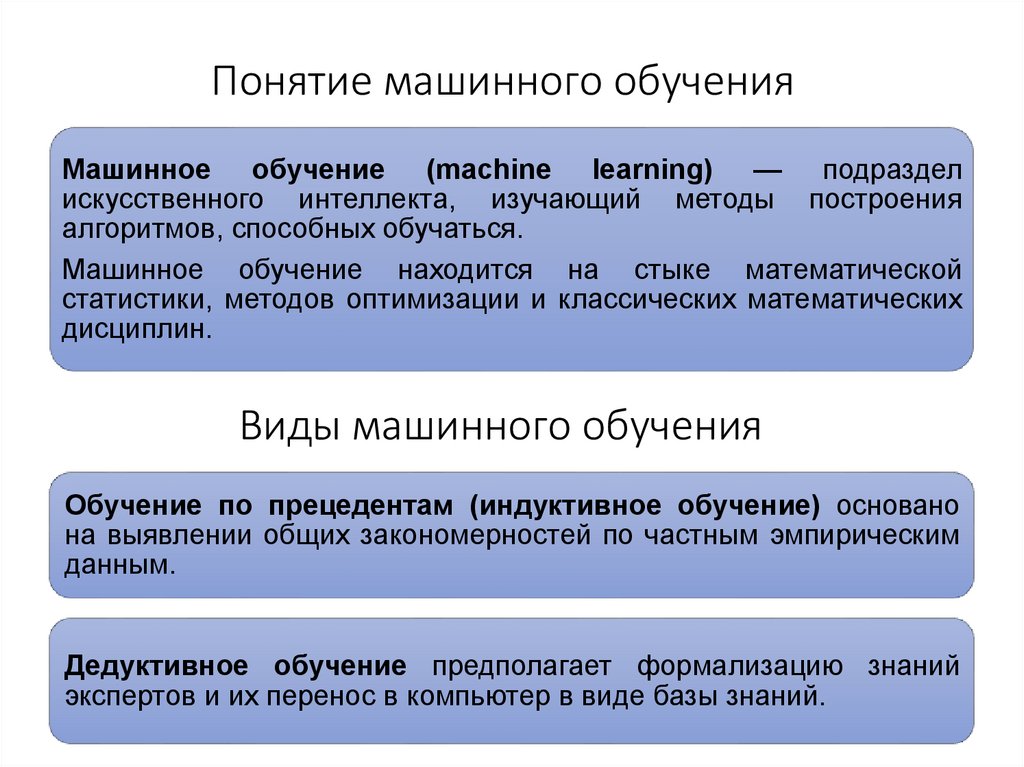 Обнаружение аномалий на основе PCA помогает построить модель в сценариях, где легко получить обучающие данные из одного класса, например действительные транзакции, но сложно получить достаточное количество выборок целевых аномалий.
Обнаружение аномалий на основе PCA помогает построить модель в сценариях, где легко получить обучающие данные из одного класса, например действительные транзакции, но сложно получить достаточное количество выборок целевых аномалий.
Устоявшийся метод машинного обучения, PCA часто используется в исследовательском анализе данных, поскольку он раскрывает внутреннюю структуру данных и объясняет дисперсию данных. PCA работает путем анализа данных, содержащих несколько переменных. Он ищет корреляции между переменными и определяет комбинацию значений, которая лучше всего отражает различия в результатах. Эти комбинированные значения функций используются для создания более компактного пространства функций, называемого главными компонентами.
Обнаружение аномалий включает в себя множество важных задач машинного обучения:
- Выявление потенциально мошеннических транзакций.
- Шаблоны обучения, указывающие на то, что произошло вторжение в сеть.
- Обнаружение аномальных скоплений пациентов.
- Проверка введенных в систему значений.
Поскольку аномалии по определению являются редкими событиями, может быть сложно собрать репрезентативную выборку данных для использования в моделировании. Алгоритмы, включенные в эту категорию, были специально разработаны для решения основных задач построения и обучения моделей с использованием несбалансированных наборов данных.
Тренажер обнаружения аномалий
Вы можете обучить модель обнаружения аномалий, используя следующий алгоритм:
- RandomizedPcaTrainer
Входы и выходы обнаружения аномалий
Входные объекты должны быть вектором фиксированного размера Single.
Этот тренажер выводит следующее:
| Имя вывода | Тип | Описание |
|---|---|---|
Оценка | Одноместный | Неотрицательная неограниченная оценка, рассчитанная с помощью модели обнаружения аномалий |
PredictedLabel | Булево значение | Значение true/false, указывающее, является ли ввод аномалией (PredictedLabel=true) или нет (PredictedLabel=false) |
Ранжирование
Задача ранжирования создает ранжировщик из набора помеченных примеров. Этот набор примеров состоит из групп экземпляров, которые можно оценить по заданным критериям. Метки ранжирования {0, 1, 2, 3, 4} для каждого экземпляра. Ранкер обучен ранжировать новые группы экземпляров с неизвестными оценками для каждого экземпляра. Обучающиеся ранжирования ML.NET основаны на машинном обучении ранжирования.
Этот набор примеров состоит из групп экземпляров, которые можно оценить по заданным критериям. Метки ранжирования {0, 1, 2, 3, 4} для каждого экземпляра. Ранкер обучен ранжировать новые группы экземпляров с неизвестными оценками для каждого экземпляра. Обучающиеся ранжирования ML.NET основаны на машинном обучении ранжирования.
Алгоритмы обучения ранжированию
Вы можете обучать модель ранжирования со следующими алгоритмами:
- LightGbmRankingTrainer
- FastTreeRankingTrainer
Ранжирование ввода и вывода
Тип данных метки ввода должен быть ключевым тип или одиночный. Значение метки определяет релевантность, где более высокие значения указывают на более высокую релевантность. Если этикетка представляет собой тип ключа, то индекс ключа — это значение релевантности, где наименьший индекс является наименее релевантным. Если этикетка представляет собой Одиночные большие значения указывают на более высокую релевантность.
Данные объекта должны быть вектором фиксированного размера Single и входной группой строк
столбец должен быть ключевым типом.
Этот тренажер выводит следующее:
| Имя вывода | Тип | Описание |
|---|---|---|
Оценка | Одноместный | Неограниченная оценка, рассчитанная моделью для определения прогноза |
Задача рекомендации позволяет создать список рекомендуемых продуктов или услуг. ML.NET использует матричную факторизацию (MF), алгоритм совместной фильтрации для рекомендаций, когда в вашем каталоге есть исторические данные о рейтингах продуктов. Например, у вас есть исторические данные о рейтингах фильмов для ваших пользователей, и вы хотите порекомендовать другие фильмы, которые они, вероятно, посмотрят в следующий раз.
Алгоритмы обучения рекомендаций
Вы можете обучить модель рекомендаций с помощью следующего алгоритма:
- MatrixFactorizationTrainer
Прогнозирование
Задача прогнозирования использует прошлые данные временных рядов для прогнозирования поведения в будущем. Сценарии, применимые к прогнозированию, включают прогнозирование погоды, прогнозирование сезонных продаж и профилактическое обслуживание.
Сценарии, применимые к прогнозированию, включают прогнозирование погоды, прогнозирование сезонных продаж и профилактическое обслуживание.
Тренеры прогнозирования
Вы можете обучить модель прогнозирования по следующему алгоритму:
ForecastBySsa
Классификация изображений
Задача контролируемого машинного обучения, которая используется для прогнозирования класса (категории) изображения. Вход представляет собой набор помеченных примеров. Каждая метка обычно начинается с текста. Затем он проходит через TermTransform, который преобразует его в тип Key (числовой). Результатом алгоритма классификации изображений является классификатор, который можно использовать для прогнозирования класса новых изображений. Задача классификации изображений является разновидностью мультиклассовой классификации. Примеры сценариев классификации изображений включают:
- Определение породы собаки «сибирский хаски», «золотистый ретривер», «пудель» и др.
- Определение того, является ли производственный продукт бракованным или нет.
- Определение видов цветов как «Роза», «Подсолнух» и т.д.

Тренажеры классификации изображений
Вы можете обучить модель классификации изображений, используя следующие алгоритмы обучения:
- ImageClassificationTrainer
Входы и выходы классификации изображений
Данные столбца метки ввода должны быть ключевого типа. Столбец функций должен быть вектором переменного размера в байтах.
Этот тренажер выводит следующие столбцы:
| Имя вывода | Тип | Описание |
|---|---|---|
Оценка | Одноместный | Баллы всех классов. Чем выше значение, тем выше вероятность попасть в соответствующий класс. Если i-й элемент имеет наибольшее значение, прогнозируемый индекс метки будет i. Обратите внимание, что индекс i отсчитывается от нуля. |
PredictedLabel | Тип ключа | Прогнозируемый индекс метки. Если его значение равно i, фактическая метка будет i-й категорией в типе входной метки с ключом. Если его значение равно i, фактическая метка будет i-й категорией в типе входной метки с ключом. |
Обнаружение объектов
Задача контролируемого машинного обучения, которая используется для прогнозирования класса (категории) изображения, но также дает ограничивающую рамку, где эта категория находится на изображении. Вместо того, чтобы классифицировать один объект на изображении, обнаружение объектов может обнаруживать несколько объектов на изображении. Примеры обнаружения объектов включают:
- Обнаружение автомобилей, знаков или людей на изображениях дороги.
- Выявление дефектов на изображениях товаров.
- Обнаружение проблемных областей на рентгеновских изображениях.
Обучение модели обнаружения объектов в настоящее время доступно только в построителе моделей с использованием машинного обучения Azure.
наиболее распространенных задач машинного обучения
14 мая 2022 г., Ajitesh Kumar · 1 комментарий
0532, с которым можно столкнуться, пытаясь решить проблемы с машинным обучением . Также указан набор из методов машинного обучения , которые можно использовать для решения этих задач. Пожалуйста, не стесняйтесь комментировать/предлагать, если я пропустил упоминание одного или нескольких важных моментов. Также извините за опечатки.
Также указан набор из методов машинного обучения , которые можно использовать для решения этих задач. Пожалуйста, не стесняйтесь комментировать/предлагать, если я пропустил упоминание одного или нескольких важных моментов. Также извините за опечатки.
Возможно, вы захотите прочитать пост о том, что такое машинное обучение? Различные аспекты концепций машинного обучения были объяснены с помощью примеров. Вот выдержка со страницы:
Машинное обучение — это аппроксимация математических функций (уравнений), представляющих сценарии реального мира. Эти математические функции также называют «математическими моделями» или просто моделями.
Ниже приведены основные задачи машинного обучения, описанные далее в этой статье:
- Регрессия
- Классификация
- Кластеризация
- Транскрипция
- Машинный перевод
- Обнаружение аномалии
- Синтез и отбор проб
- Оценка плотности вероятности и функции массы вероятности
Ниже приведены основные этапы разработки, которые используются для решения различных задач, перечисленных выше. Они составляют ключевые этапы жизненного цикла моделей машинного обучения (MLM).
Они составляют ключевые этапы жизненного цикла моделей машинного обучения (MLM).
- Сбор данных
- Предварительная обработка данных
- Исследовательский анализ данных (EDA)
- Разработка признаков, включая создание/извлечение признаков, выбор признаков, уменьшение размерности
- Обучение моделей машинного обучения
- Выбор модели/алгоритма
- Тестирование и согласование
- Мониторинг модели
- Переподготовка моделей
Содержание
Задачи машинного обучения
Ниже приведены некоторые из ключевых задач, которые могут быть выполнены с использованием моделей машинного обучения: ). Некоторые из примеров включают оценку цены на жилье, цены продукта, цены акций и т. д. Некоторые из следующих методов машинного обучения можно использовать для решения задач регрессии:
- Регрессия ядра (более высокая точность)
- Регрессия гауссовского процесса (более высокая точность)
- Деревья регрессии
- Линейная регрессия
- Регрессия опорного вектора
- ЛАССО / Ридж
- Глубокое обучение
- Случайные леса
 Одним из наиболее распространенных примеров является прогнозирование того, является ли электронное письмо спамом или ветчиной. Некоторые из распространенных вариантов использования можно найти в области здравоохранения, например, страдает ли человек определенным заболеванием или нет. Он также применяется в финансовых случаях, таких как определение того, является ли транзакция мошенничеством или нет. Возможно, вы захотите проверить эту страницу на реальных примерах моделей классификации, реальных примерах моделей классификации машинного обучения. Для решения задач классификации можно применять следующие методы машинного обучения:
Одним из наиболее распространенных примеров является прогнозирование того, является ли электронное письмо спамом или ветчиной. Некоторые из распространенных вариантов использования можно найти в области здравоохранения, например, страдает ли человек определенным заболеванием или нет. Он также применяется в финансовых случаях, таких как определение того, является ли транзакция мошенничеством или нет. Возможно, вы захотите проверить эту страницу на реальных примерах моделей классификации, реальных примерах моделей классификации машинного обучения. Для решения задач классификации можно применять следующие методы машинного обучения:- Ядерный дискриминантный анализ (повышенная точность)
- K-ближайших соседей (более высокая точность)
- Искусственные нейронные сети (ИНС) (более высокая точность)
- Метод опорных векторов (SVM) (более высокая точность)
- Случайные леса (более высокая точность)
- Деревья принятия решений
- Увеличенные деревья
- Логистическая регрессия
- наивный Байес
- Глубокое обучение
 Некоторые из распространенных примеров включают сегментацию клиентов и определение характеристик продукта для дорожной карты продукта. Некоторые из следующих методов являются распространенными методами машинного обучения:
Некоторые из распространенных примеров включают сегментацию клиентов и определение характеристик продукта для дорожной карты продукта. Некоторые из следующих методов являются распространенными методами машинного обучения:- Среднее смещение (Более высокая точность)
- Иерархическая кластеризация
- К-значит
- Тематические модели
- Ближайшие соседи
- Поиск диапазона
- Самые дальние соседи
 Некоторые из следующих методов машинного обучения могут быть использованы для решения задач оценки плотности:
Некоторые из следующих методов машинного обучения могут быть использованы для решения задач оценки плотности:- Оценка плотности ядра (более высокая точность)
- Смесь гауссианов
- Дерево оценки плотности

 Они используются для создания новых данных из существующих данных или для выбора репрезентативного подмножества данных для дальнейшего анализа. Синтез и выборка часто используются вместе, чтобы создать более разнообразный и репрезентативный набор данных. Синтез можно использовать для создания новых точек данных путем экстраполяции существующих точек данных. Например, если у нас есть набор изображений животных, мы можем использовать синтез для создания новых изображений животных, похожих на изображения в наборе данных. Выборку можно использовать для выбора подмножества данных, которое является репрезентативным для всего набора данных. Например, если у нас есть набор данных изображений животных, мы можем использовать выборку, чтобы выбрать подмножество изображений, которое представляет все различные типы животных в наборе данных.
Они используются для создания новых данных из существующих данных или для выбора репрезентативного подмножества данных для дальнейшего анализа. Синтез и выборка часто используются вместе, чтобы создать более разнообразный и репрезентативный набор данных. Синтез можно использовать для создания новых точек данных путем экстраполяции существующих точек данных. Например, если у нас есть набор изображений животных, мы можем использовать синтез для создания новых изображений животных, похожих на изображения в наборе данных. Выборку можно использовать для выбора подмножества данных, которое является репрезентативным для всего набора данных. Например, если у нас есть набор данных изображений животных, мы можем использовать выборку, чтобы выбрать подмножество изображений, которое представляет все различные типы животных в наборе данных.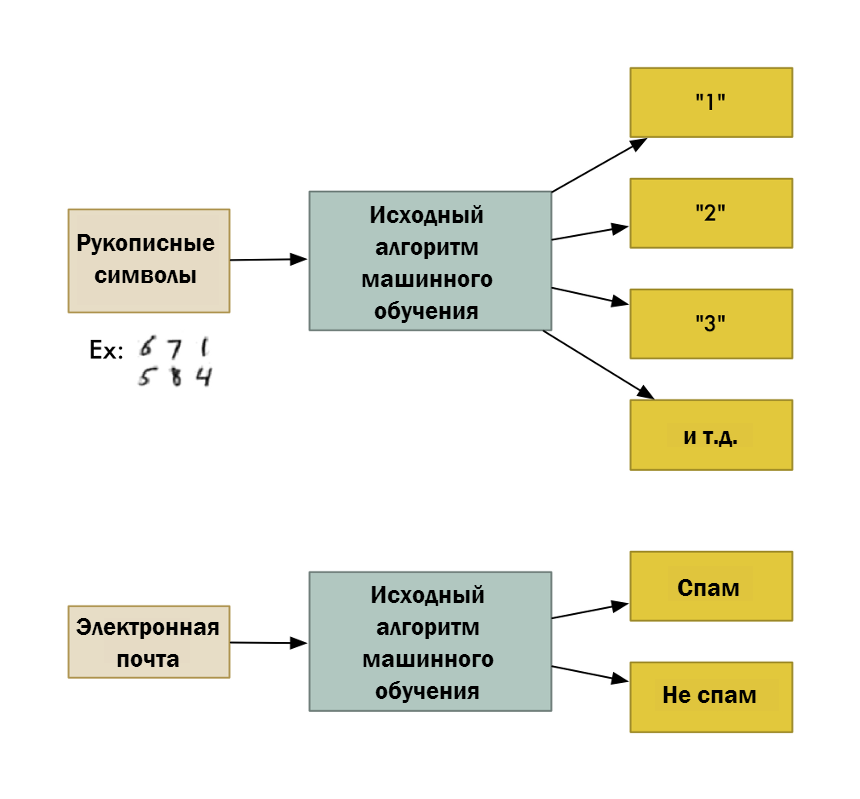 В последние годы задачи транскрипции были до некоторой степени автоматизированы с использованием алгоритмов машинного обучения. Модели глубокого обучения можно научить расшифровывать аудиозаписи с высокой степенью точности. Однако для обучения этим моделям требуется большой объем данных, и они часто борются с фоновым шумом и акцентами. В результате транскрипция по-прежнему в основном выполняется вручную. Профессиональные транскрибаторы используют свое знание языка и внимание к деталям для предоставления точных услуг транскрипции.
В последние годы задачи транскрипции были до некоторой степени автоматизированы с использованием алгоритмов машинного обучения. Модели глубокого обучения можно научить расшифровывать аудиозаписи с высокой степенью точности. Однако для обучения этим моделям требуется большой объем данных, и они часто борются с фоновым шумом и акцентами. В результате транскрипция по-прежнему в основном выполняется вручную. Профессиональные транскрибаторы используют свое знание языка и внимание к деталям для предоставления точных услуг транскрипции.Этапы разработки жизненного цикла разработки MLM
Ниже приведены наиболее распространенные этапы разработки моделей машинного обучения, с которыми чаще всего можно столкнуться при решении различных задач машинного обучения:
- Сбор данных : Любая задача машинного обучения требует много данных для обучения/тестирования. Ключевым моментом является определение правильных источников данных и сбор данных из этих источников данных. Данные можно найти в базах данных, внешних агентствах, Интернете и т. д.
- Предварительная обработка данных : Перед началом обучения моделей чрезвычайно важно правильно подготовить данные. В рамках предварительной обработки данных выполняются некоторые из следующих действий:
- Очистка данных : Очистка данных требует определения атрибутов с недостаточным количеством данных или атрибутов, не имеющих дисперсии. Эти данные (строки и столбцы) необходимо удалить из набора обучающих данных.
- Импутация отсутствующих данных : Обработка отсутствующих данных с использованием методов импутации данных, таких как замена отсутствующих данных средним значением, медианой или модой. Вот мой пост на эту тему: Замените пропущенные значения средним, медианным или режимом 9.0004
- Исследовательский анализ данных (EDA) : После предварительной обработки данных следующим шагом является выполнение исследовательского анализа данных для понимания распределения данных и взаимосвязей между данными или внутри них. Некоторые из следующих действий выполняются в рамках EDA:
- Корреляционный анализ
- Анализ мультиколлинеарности
- Анализ распределения данных
- Разработка функций : Разработка функций — одна из важнейших задач, которые будут использоваться при построении моделей машинного обучения. Разработка признаков важна, потому что выбор правильных признаков не только поможет построить модели с более высокой точностью, но также поможет достичь целей, связанных с построением более простых моделей, уменьшением переобучения и т. д. Разработка признаков включает в себя такие задачи, как получение признаков из необработанных признаков, определение важных признаков, извлечение признаков и выбор признаков. Ниже приведены некоторые из методов, которые можно использовать для выбора признаков:
- Методы фильтрации помогают выбирать функции на основе результатов статистических тестов. Ниже приведены некоторые из используемых статистических тестов:
- Корреляция Пирсона
- Линейный дискриминантный анализ (LDA)
- Дисперсионный анализ (ANOVA)
- Критерии хи-квадрат
Методы оболочки - помогают в выборе признаков, используя подмножество признаков и определяя точность модели. Ниже приведены некоторые из используемых алгоритмов:
- Выбор вперед
- Обратная элиминация
- Удаление рекурсивных признаков
- Методы регуляризации наказывают одну или несколько функций соответствующим образом, чтобы получить наиболее важные функции. Ниже приведены некоторые из используемых алгоритмов:
- ЛАССО (L1) регуляризация
- Ридж (L2) регуляризация
- Эластичная сетка регуляризация
- Регуляризация с помощью алгоритмов классификации, таких как логистическая регрессия, SVM и т. д.
- Методы фильтрации помогают выбирать функции на основе результатов статистических тестов. Ниже приведены некоторые из используемых статистических тестов:
- Учебные модели: После того, как некоторые функции определены, появляются обучающие модели с данными, связанными с этими функциями. Ниже приведен список различных типов задач машинного обучения и связанных с ними алгоритмов, которые можно использовать для решения этих задач:
- Уменьшение размерности (извлечение признаков) : Согласно странице Википедии, посвященной уменьшению размерности, уменьшение размерности — это процесс уменьшения количества рассматриваемых случайных переменных, который можно разделить на выбор признаков и извлечение признаков. Ниже приведены некоторые методы машинного обучения, которые можно использовать для уменьшения размера:
- Обучение по коллектору/KPCA (повышенная точность)
- Анализ главных компонентов
- Анализ независимых компонентов
- Графические модели Гаусса
- Неотрицательная матричная факторизация
- Сжатое измерение
- Выбор модели/выбор алгоритма : Часто существует несколько моделей, которые обучаются с использованием разных алгоритмов. Одной из важных задач является выбор наиболее оптимальных моделей для развертывания их в продакшене. Настройка гиперпараметров — наиболее распространенная задача, выполняемая в рамках выбора модели. Кроме того, если есть две модели, обученные с использованием разных алгоритмов, которые имеют одинаковую производительность, то также необходимо выполнить выбор алгоритма.
- Тестирование и сопоставление : Задачи тестирования и сопоставления относятся к сравнению наборов данных. Ниже приведены некоторые из методов, которые можно использовать для таких проблем:
- Минимальное остовное дерево
- Двудольное перекрестное сопоставление
- N-точечная корреляция
- Мониторинг моделей : После обучения и развертывания моделей их необходимо регулярно контролировать. Модели мониторинга требуют обработки фактических и прогнозируемых значений, а также измерения производительности модели на основе соответствующих показателей.
- Повторное обучение модели : В случае ухудшения производительности модели требуется повторное обучение моделей. В рамках переобучения модели делается следующее:
- Определены новые функции
- Можно использовать новые алгоритмы
- Гиперпараметры можно настраивать
- Ансамбли моделей могут быть развернуты
 Данные можно найти в базах данных, внешних агентствах, Интернете и т. д.
Данные можно найти в базах данных, внешних агентствах, Интернете и т. д. Некоторые из следующих действий выполняются в рамках EDA:
Некоторые из следующих действий выполняются в рамках EDA: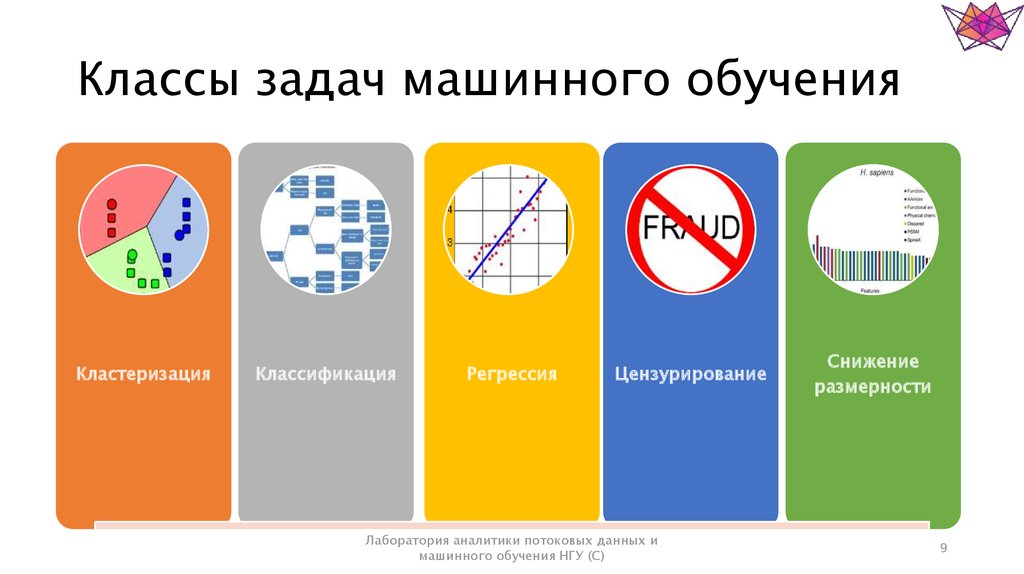 Ниже приведены некоторые из используемых алгоритмов:
Ниже приведены некоторые из используемых алгоритмов: Ниже приведены некоторые методы машинного обучения, которые можно использовать для уменьшения размера:
Ниже приведены некоторые методы машинного обучения, которые можно использовать для уменьшения размера: Ниже приведены некоторые из методов, которые можно использовать для таких проблем:
Ниже приведены некоторые из методов, которые можно использовать для таких проблем:- Автор
- Последние сообщения
Аджитеш Кумар
Недавно я работал в области анализа данных, включая науку о данных и машинное обучение / глубокое обучение. Я также увлекаюсь различными технологиями, включая языки программирования, такие как Java/JEE, Javascript, Python, R, Julia и т. д., а также такие технологии, как блокчейн, мобильные вычисления, облачные технологии, безопасность приложений, платформы облачных вычислений, большие данные, и т. д. Чтобы быть в курсе последних обновлений и блогов, следите за нами в Twitter. Я хотел бы связаться с вами на Linkedin.
Я также увлекаюсь различными технологиями, включая языки программирования, такие как Java/JEE, Javascript, Python, R, Julia и т. д., а также такие технологии, как блокчейн, мобильные вычисления, облачные технологии, безопасность приложений, платформы облачных вычислений, большие данные, и т. д. Чтобы быть в курсе последних обновлений и блогов, следите за нами в Twitter. Я хотел бы связаться с вами на Linkedin.
Ознакомьтесь с моей последней книгой, озаглавленной «Основы мышления: создание успешных продуктов с использованием первых принципов».
Недавно я работал в области аналитики данных, включая науку о данных и машинное обучение/глубокое обучение. Я также увлекаюсь различными технологиями, включая языки программирования, такие как Java/JEE, Javascript, Python, R, Julia и т. д., а также такие технологии, как блокчейн, мобильные вычисления, облачные технологии, безопасность приложений, платформы облачных вычислений, большие данные, и т. д. Чтобы быть в курсе последних обновлений и блогов, следите за нами в Twitter. Я хотел бы связаться с вами на Linkedin.
Ознакомьтесь с моей последней книгой под названием «Мышление на основе первых принципов: создание успешных продуктов с использованием мышления на основе первых принципов».0015
Я хотел бы связаться с вами на Linkedin.
Ознакомьтесь с моей последней книгой под названием «Мышление на основе первых принципов: создание успешных продуктов с использованием мышления на основе первых принципов».0015
Опубликовано в ИИ, большие данные, наука о данных, машинное обучение. Метки: наука о данных, машинное обучение.
Краткий обзор задач машинного обучения🚀
В этой статье мы рассмотрим обзор методов машинного обучения и их эффективность на основе наших задач, включая простое описание, визуализацию и примеры для каждой из них.
Вот методы, которые мы собираемся рассмотреть.
- Регрессия
- Классификация
- Кластеризация
- Уменьшение размерности
- Обучение с подкреплением (рейтинг)
Это все основы машинного обучения, где вы получите некоторые важные хорошие навыки и идеи о задачах машинного обучения, которые помогут начать вашу карьеру в машинном обучении.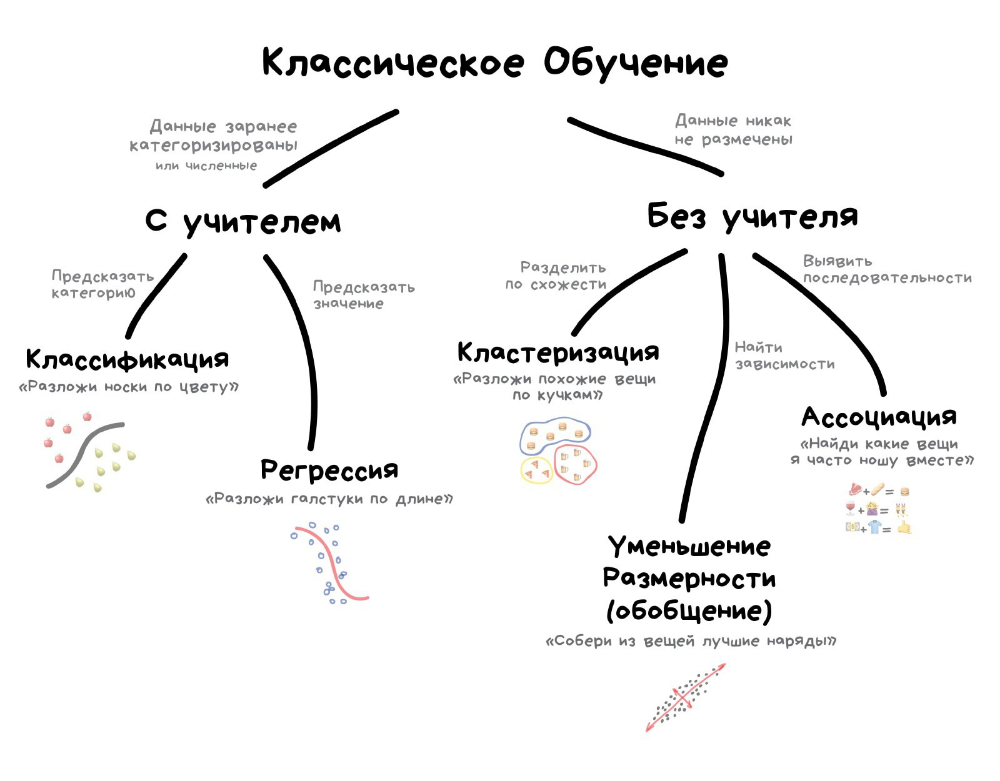
Регрессия
Задача регрессии исходит из контролируемого машинного обучения. Что может помочь нам прогнозировать (ожидать продолжения значений) и объяснять объекты на основе заданного набора числовых и категориальных данных. Например, мы можем прогнозировать цены на жилье на основе таких атрибутов дома, как несколько комнат, размер и местоположение.
С математической точки зрения метод регрессии предоставляет нам линейную линию, принадлежащую уравнению Y = aX+b для моделирования набора данных. Здесь мы берем точки данных X (зависимая переменная) и Y (независимая переменная) для обучения нашей модели линейной регрессии. Наилучшую линию наблюдения можно найти, рассчитав значения наклона (m) и точки пересечения с осью y (b).
В приведенном выше изображении представлена задача линейной регрессии, которая содержит две разные точки данных, рассматриваемые как рост и вес человека.
Если рост измеряется по оси X, а вес измеряется по оси Y.
Точки данных двух объектов отмечены синим цветом.
Используя формулу Y=aX+b, мы можем нарисовать линейную линию, представленную красным цветом, известную как предсказанная линия.
Здесь регрессионный анализ выполняется с использованием различных эффективных алгоритмов,
- Простая линейная регрессия
- Множественная линейная регрессия
- Полиномиальная линейная регрессия
- Дерево решений
- Радомский лес
- Машина опорных векторов (SVM)
Приложения
- Оценка рисков
- Прогноз счета
- Прогнозирование рынка
- Прогнозирование
- Прогноз цен на жилье и продукты
- Персональный цифровой помощник (Siri и YouTube)
- Для лучшего понимания см. изображение ниже.
Классификация
Классификация — это контролируемая задача обучения, используемая, когда нам нужен ограниченный набор результатов. Обычно он предоставляет прогнозируемые выходные значения, которые могут быть True или False. Он работает в двух типах, таких как биномиальный и многоклассовый. Например, мы можем определить, является ли полученное электронное письмо спамом или нет.
Обычно он предоставляет прогнозируемые выходные значения, которые могут быть True или False. Он работает в двух типах, таких как биномиальный и многоклассовый. Например, мы можем определить, является ли полученное электронное письмо спамом или нет.
Здесь у нас есть точки данных, принадлежащие трем разным фруктам, таким как черника, лайм и яблоко. Мы можем классифицировать их, используя методы классификации машинного обучения. Три плода представлены тремя различными родственными цветами, такими как синий, оранжевый и желтый соответственно. Затем мы проводим линейную линию между ними для четкого разделения и видим, как они представлены.
Классификация поддерживается Алгоритмы
- Логистическая регрессия
- KNN (k-ближайший сосед)
- Наивная база
- Дискриминантный анализ
- SVM (машина опорных векторов)
- Дерево решений
- Нейронная сеть
Приложения
- Классификация изображений
- Обнаружение спама по электронной почте
- Обнаружение мошенничества
Кластеризация
Техника неконтролируемого обучения работает как способ группировки связанных элементов в различные кластеры. Он не имеет никакой выходной информации для тренировочного процесса. Тем не менее алгоритм кластеризации будет определять выходные данные. Здесь лучшим алгоритмом кластеризации является K-средних, где K представляет количество кластеров.
Он не имеет никакой выходной информации для тренировочного процесса. Тем не менее алгоритм кластеризации будет определять выходные данные. Здесь лучшим алгоритмом кластеризации является K-средних, где K представляет количество кластеров.
Здесь у нас есть три разных типа точек данных, представленных тремя цветами. Кластеры могут организовать кучу данных на основе их характеристик.
Если выше упомянуто, три разные точки данных разделены на три разных кластера и названы кластером 1, кластером 2 и кластером 3
Алгоритмы
- Разложение по сингулярным числам (SVD)
- Скрытая модель Маркова
- К-значит
- Гауссова смесь
- Нейронные сети
Приложения
- Система рекомендаций
- Градостроительство
- Целевой маркетинг
- Сегментация клиентов
Уменьшение размерности
Задача обучения без учителя, используемая для уменьшения избыточной информации из больших наборов данных. Это обеспечивает меньше вычислений и сокращает время обучения.
Это обеспечивает меньше вычислений и сокращает время обучения.
Затем он может отфильтровать их низкую дисперсию и высокую корреляцию. Когда у нас большое измерение, некоторые алгоритмы работают плохо.
Здесь популярный алгоритм PCA может помочь нам уменьшить размерность будущего пространства.
Давайте рассмотрим простой пример задач уменьшения размерности.
Здесь мы рассматриваем выше многомерный куб, который сам включает в себя множество различных точек данных.
Итак, мы можем выполнять операции нарезки, чтобы разделить измерения для нашей конкретной задачи, представленной как уменьшение размерности.
В задании 1 мы отделили лицевую сторону куба, который был представлен 2. Вид измерения содержит 100 позиций.
Так же, как мы также отделяем 50 позиций только как в 1-мерном виде сверху куба.
Алгоритмы
- Анализ главных компонентов (АГК)
- Линейный дискриминантный анализ (LDA)
- Обобщенный дискриминантный анализ (GDA)
Приложения
- Интеллектуальный анализ текста
- Распознавание лиц
- Визуализация больших данных
- Обнаружение структуры
- Распознавание изображений
Обучение с подкреплением (рейтинг)
Метод обучения с подкреплением не имеет целевых переменных, вместо этого это система, основанная на вознаграждении. В отличие от контролируемого обучения, в котором есть обучающие данные, оно включает в себя ключ ответа, агент подкрепления будет определять, что делать для выполнения данной задачи.
В отличие от контролируемого обучения, в котором есть обучающие данные, оно включает в себя ключ ответа, агент подкрепления будет определять, что делать для выполнения данной задачи.
Здесь мы рассмотрим игрушечный пример: переход к точной точке в матрице 4 * 4.
Машина стартует из правого нижнего угла лабиринта. Есть четыре варианта действий (справа, слева, вверху и в городе), чтобы достичь точной точки местоположения. Матричная диаграмма включает брандмауэры и обычные стены. Если машина выберет неверное действие, то ее подстрелят, иначе она переместит следующую матрицу. Эти результаты рассчитываются как отрицательное и положительное вознаграждение соответственно.
Первое действие — перемещение верхней или левой матрицы. Если вы переместите левую сторону, вас уволят, и вы получите вознаграждение -1 к машине, в противном случае награда 0 для следующего движения. Теперь автомобиль может определить, в какую сторону ему лучше двигаться дальше. Автомобиль выполняет несколько итераций, пока не достигнет точного местоположения на основе своего опыта.