
| Логины или имена пользователей | Поиск задач, у которых в поле Доступ указаны заданные пользователи. Например: |
| Названия версий | Поиск задач, у которых в поле Найдено в версиях указано заданное значение. |
| Логины или имена пользователей | Поиск задач, исполнителями которых являются заданные пользователи. Например: |
| Логины или имена пользователей | Поиск задач, авторами которых являются заданные пользователи. |
| Названия или ключи очередей | Поиск задач, у которых есть зависимые (блокируемые) задачи в заданных очередях. Например: |
| Ключи задач | Поиск задач, которые являются клонами заданных задач. Например: |
| Названия или ключи очередей | Поиск задач, которые являются клонами задач из заданных очередей. |
| Текстовая строка | Поиск задач, у которых есть комментарии с заданным текстом. Например:
|
| Логины или имена пользователей | Поиск задач, в которых оставляли комментарии заданные пользователи. |
| Логины или имена пользователей | Поиск задач, относящихся к компонентам, за которые отвечают заданные пользователи. Например: |
| Названия компонентов | Поиск задач, относящихся к заданным компонентам. |
| Дата или интервал дат | Поиск задач, созданных в заданный день или в заданном интервале дат. Например: |
| Дата или интервал дат | Поиск задач, которые имеют дедлайн в заданный день или в заданном интервале дат. |
| Названия или ключи очередей | Поиск задач, которые зависят от задач (блокируются задачами) из заданных очередей. Например: |
| Ключи задач | Поиск задач, которые зависят от заданных задач (блокируются заданными задачами). |
| Текстовая строка | Поиск задач, описание которых содержит заданный текст. Например:
|
| Названия или ключи очередей | Поиск задач, которые имеют дублирующие задачи в заданных очередях. |
| Ключи задач | Поиск задач, которые дублируют заданные задачи. Например: |
| Названия или ключи очередей | Поиск задач, которые дублируют задачи из заданных очередей. |
| Дата или интервал дат | Поиск задач, у которых значение поля Дата завершения совпадает с заданной датой или находится в заданном интервале дат. Например: |
| Ключи эпиков | Поиск задач, относящихся к заданным эпикам. |
| Названия или ключи очередей | Поиск эпиков, к которым относятся задачи из заданных очередей. Например: |
| В качестве значения параметра может использоваться только функция | Поиск ваших избранных задач. |
| Идентификаторы или имена фильтров | Поиск задач, удовлетворяющих заданным фильтрам. Например: Примечание. Если разные пользователи создали фильтры с одинаковыми именами, при выполнении одного и того же запроса с указанием имени фильтра они могут получить разные результаты, так как при поиске будет применен фильтр того пользователя, который выполняет запрос. |
| Названия версий | Поиск задач, у которых в поле Исправить в версиях указано заданное значение. |
| Логины или имена пользователей | Поиск задач, наблюдателями которых являются заданные пользователи. Например: |
| Ключи задач | Поиск задач, которые относятся к заданным эпикам. |
| Названия или ключи очередей | Поиск задач, которые имеют связи любого типа (родительские, дочерние, связанные, дубликат и так далее) с задачами из заданных очередей. Например: |
| Текстовая строка | Поиск задач, в истории изменений которых есть слова и словоформы заданной фразы. Поиск осуществляется только по значениям полей Название задачи и Описание задачи. Например: |
| Названия или ключи очередей | Поиск задач, которые относятся к эпикам заданной очереди. Например: |
| Ключи задач | Поиск задач, которые блокируют (от которых зависят) заданные задачи. |
| Ключи задач | Поиск задач, которые дублируются заданными задачами. Например: |
| Ключи задач | Поиск эпиков, к которым относятся заданные задачи. Например: |
| Ключи задач | Поиск задач, которые являются родительскими для указанных задач. |
| Ключи задач | Поиск задач, которые дочерними для указанных задач. Например: |
| Ключи задач | Поиск задач с заданными ключами. |
| Дата и время добавления последнего комментария | Поиск задач, в которых определенное время не появлялись новые комментарии. Например: |
| Ключи задач | Поиск задач, которые имеют связи любого типа (родительские, дочерние, связанные, дубликат и так далее) с заданными задачами. |
| Названия отделов или команд | Поиск задач, на которые подписаны заданные отделы или команды. Например: |
| Логины или имена пользователей | Поиск задач, последние изменения которых сделаны заданными пользователями. |
| Названия или ключи очередей | Поиск задач, перенесенных из заданных очередей. Например: |
| Ключи задач | Поиск клонов заданных задач. |
| Отрезок времени в формате | Поиск задач с заданной первоначальной оценкой. Например: |
| Названия или ключи очередей | Поиск задач, которые имеют клоны в заданных очередях. |
| Названия или ключи очередей | Поиск задач, у которых есть подзадачи в заданных очередях. Например: |
| Логины или имена пользователей | Поиск задач, в которых требуется ответ от заданного пользователя (пользователя призвали в комментарии). Например, найти задачи, в которых нужен ответ от пользователя с логином |
| Значения приоритета | Поиск задач, которые имеют заданные значения приоритета. Например: |
| Названия проектов | Поиск задач, которые относятся к заданным проектам. Например: |
| Названия или ключи очередей | Поиск задач, которые относятся к заданным очередям. Например: |
| Логины или имена пользователей | Поиск задач из очередей, владельцами которых являются заданные пользователи. Например: |
| Логины или имена пользователей | Поиск задач, авторами, исполнителями или наблюдателями которых являются заданные пользователи. Например: |
| Названия или ключи очередей | Поиск задач, которые связаны с задачами определенных очередей (связь типа «Связанные»). Например: |
| Ключи задач | Поиск задач, связанных с определенными задачами (связь типа «Связанные»). Например: |
| Дата или интервал дат | Поиск задач, которые были закрыты (была установлена резолюция) в заданный день или в заданном интервале дат. Например: |
| Логины или имена пользователей | Поиск задач, которые закрыли (установили резолюцию) заданные пользователи. Например: |
| Идентификаторы или названия спринтов | Поиск задач, относящихся к заданным спринтам. Например: |
| Идентификатор доски задач (можно узнать в URL страницы доски) | Поиск задач, относящихся к активному спринту на заданной доске задач. Например: |
| Идентификатор доски задач (можно узнать в URL страницы доски) | Поиск задач, относящихся к заданной доске задач. Например: |
| Дата или интервал дат | Поиск задач, у которых значение поля Дата начала совпадает с заданной датой или находится в заданном интервале дат. Например: |
| Названия статусов | Поиск задач, имеющих заданные статусы. Например: |
| Число очков Story Points | Поиск задач, имеющих заданную трудоемкость в очках Story Points. Например: |
| Названия или ключи очередей | Поиск задач, у которых есть родительские задачи в заданных очередях. Например: |
| Текстовая строка | Поиск задач, название которых содержит заданный текст. Например:
|
| Теги задач | Поиск задач, отмеченных заданными тегами. Например: |
| Отрезок времени в формате | Поиск задач, на решение которых потрачено заданное время. Например: |
| Тип задачи | Поиск задач с заданным типом. Например: |
| Дата или интервал дат | Поиск задач, которые были изменены в заданный день или в заданном интервале дат. Например: |
| Логины или имена пользователей | Поиск задач, за которые проголосовали заданные пользователи. Например: |
| Число голосов | Поиск задач, за которые отдали заданное число голосов. Например: |
 Например:
Например: Например:
Например: Например:
Например: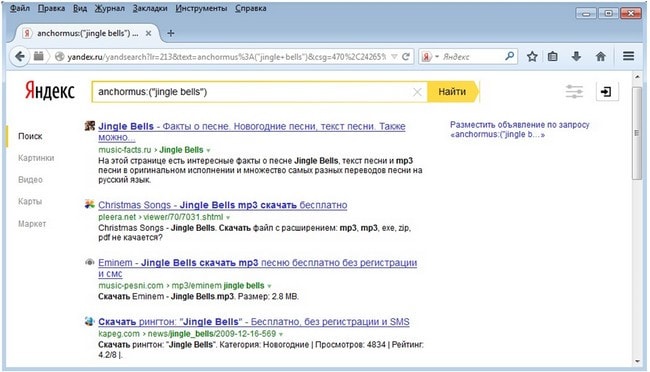 Например:
Например: Например:
Например: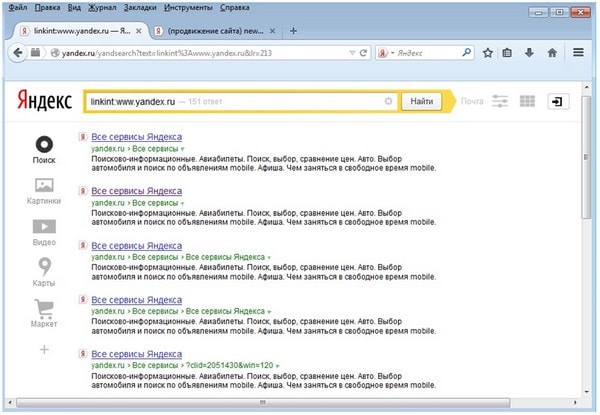 Например:
Например: Например:
Например: Например:
Например: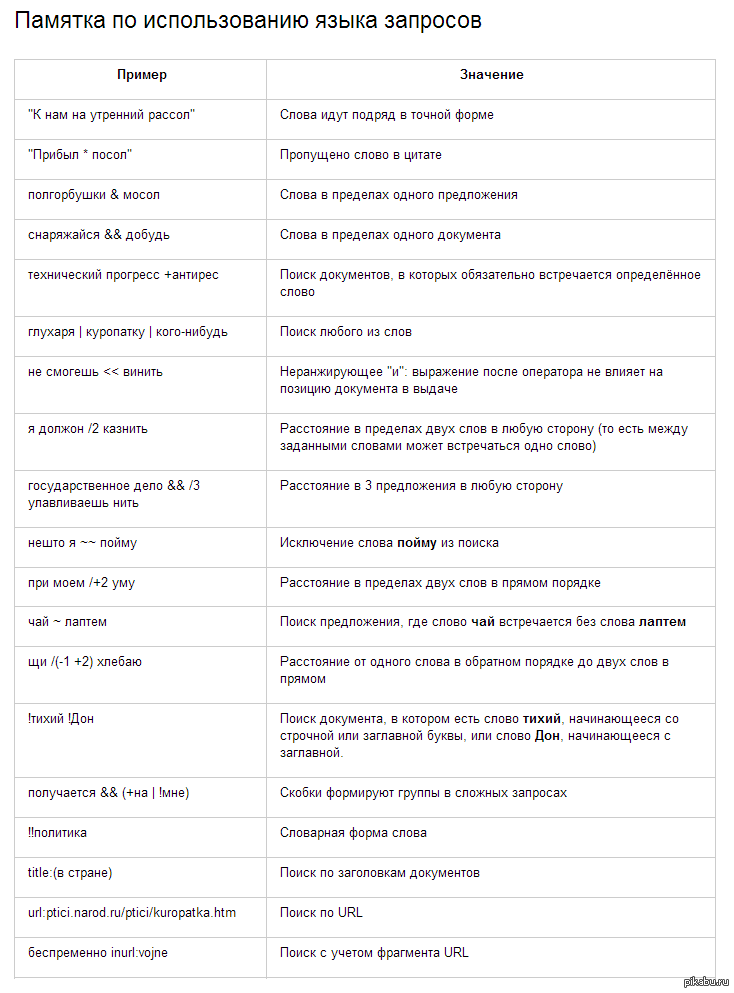 Например:
Например: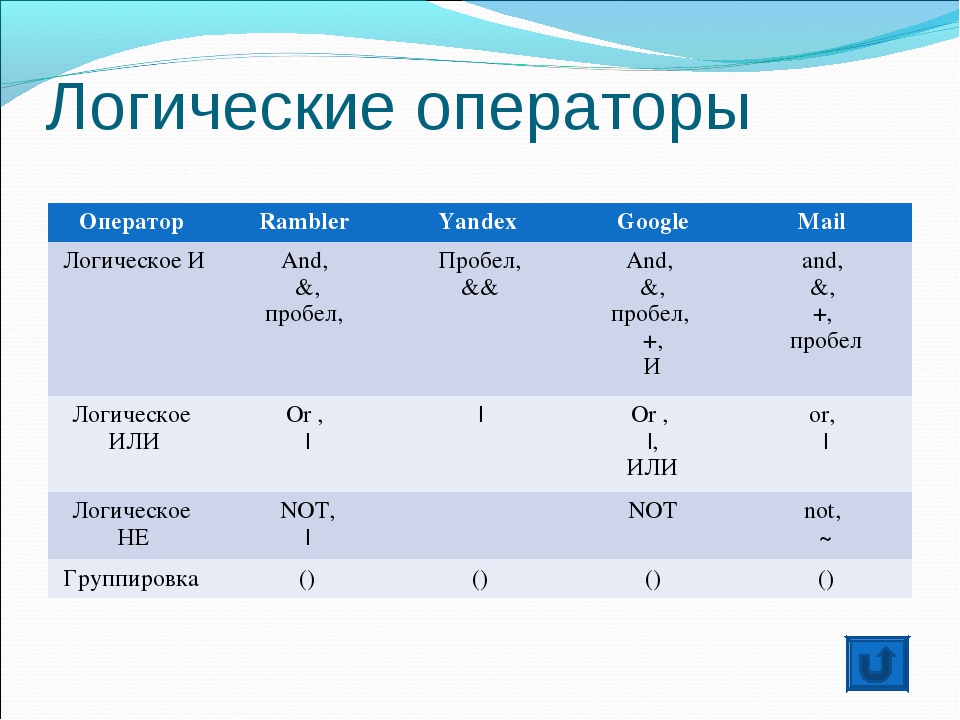 Например:
Например: Например:
Например: Например:
Например: Например:
Например:
 Например:
Например: Например:
Например: Например:
Например: Например:
Например: Например:
Например: Например:
Например: Например:
Например:
Поиск по отдельным словам и фразам
По умолчанию Яндекс ищет все формы слова (падеж, род, число, склонение и т. д.), указанного в запросе, и не учитывает однокоренные слова (другие части речи).
Например, при запросе [рассказал] поиск будет производиться по глагольным формам: «рассказать», «расскажу», «рассказывать» и т. д., но не по однокоренным словам типа «рассказ», «рассказчик». Исключение составляют случаи, когда используются операторы ! и «.
Вы можете уточнить запрос с помощью операторов.
- Искать слова в заданной форме
- Искать документы с определенным словом
- Искать по цитате
- Искать по цитате с пропущенным словом
- Искать документы с любым словом из запроса
- Искать документы, в которых нет определенного слова
Можно использовать несколько операторов ! в одном запросе.
Можно использовать несколько операторов + в одном запросе.
Поиск документов, содержащих слова запроса в заданной последовательности и форме.
Один оператор * соответствует одному пропущенному слову.
".Можно использовать несколько операторов | в одном запросе.
Исключается только слово, перед которым стоит оператор. При этом исключаемое слово должно размещаться в конце поискового запроса.
Можно использовать несколько операторов - в одном запросе.
Если вы попробуете поставить оператор - перед цифрой, это будет считаться запросом на поиск отрицательного числа. Чтобы оператор сработал, возьмите слово, начинающееся с цифры, в кавычки.
1.3.3. Язык запросов. Яндекс для всех
1.3.3. Язык запросов
Для того чтобы Яндекс корректно понимал запросы, состоящие из нескольких слов, был разработан специальный язык запросов. Отдельные его элементы мы уже рассмотрели — это и специальные символы, используемые в обычном поиске, и дополнительные параметры, которые применяются при расширенном поиске. Но язык запросов содержит и иные команды, используемые для еще более точного формирования поискового выражения.
Взаиморасположение слов в документе
Когда в запросе указывается несколько слов, Яндекс самостоятельно определяет, на каком максимальном расстоянии должны находиться эти слова, чтобы искомая страница лучше отвечала на запрос. Но у вас есть возможность самим указать требования к расстоянию. Об этом мы уже говорили ранее, а теперь добавим к сказанному информацию по другим операторам.
Когда слова идут подряд
Самый простой способ — поместить эти слова в кавычки, например: «кому на Руси жить хорошо». В результате будут приведены ссылки на страницы, на которых встречается это выражение с указанным порядком слов.
Когда слова должны находиться в одном предложении
Наложить это ограничение на результаты поиска можно с помощью оператора &, поставив его между словами поиска. Например, если в запросе задать слова политика & России, среди результатов окажутся страницы, на которых эти слова могут содержаться в выражениях: «политика современной России», «политика России в XIX веке» и др.
Когда слова должны быть в одном документе
Вы не всегда знаете, могут ли находиться в одном предложении выбранные слова. Но желательно, чтобы они были хотя бы в одном документе. Добиться этого можно с помощью оператора &&. Поставьте его между необходимыми словами, и Яндекс найдет документы, где слова расположены в одном документе, неважно на каком расстоянии друг от друга.
Пример
Если в запросе ввести слова доставка & пицца && Казань, то будут найдены страницы, на которых слова «доставка» и «пицца» будут расположены в одном предложении, а где-то на странице будет слово «Казань».
Определяем порядок слов
Как было показано ранее, определив расстояние между словами, мы не можем сказать, в какой последовательности они должны появляться на странице или в документе. Исправить этот недостаток можно с помощью других операторов.
Слова следуют в определенном порядке на нужном расстоянии
Если требуется найти слова, расположенные строго на определенном расстоянии друг от друга (расстояние определяется количеством иных слов, расположенных между искомыми), применяется оператор /. Сразу после него записывается знак + для прямого порядка, и знак — для обратного следования слов, а после знака — число, показывающее, на каком месте после первого слова должно располагаться второе.
Пример
Если вы хотите вспомнить, как звали отца Татьяны Лариной, задайте вопрос Татьяна /+2 Ларина. В результатах поиска будут приведены страницы, на которых между словами «Татьяна» и «Ларина» находится еще одно слово. Имейте в виду, что знаки, которые могут находиться между словами, в расчет не берутся. Например, среди результатов была ссылка на страницу, содержащую текст: «Отец Татьяны — Дмитрий Ларин».
Слова расположены в заданной окрестности
Не всегда ясно, на каком расстоянии по отношению к первому, должно находиться второе слово. И где — до первого слова или после него. В этом случае можно применить другой оператор. В нем указывается минимальное и максимальное количество слов между первым и вторым словами запроса. Выглядит оператор так: /(n m). Используя знаки + и — вы укажете помимо расстояния, еще и расположение слов друг относительно друга.
Пример
Запрос крокодилы /(-2 +2) Амазонки найдет как страницы с текстом «Амазонка кишит крокодилами», так и «крокодилы в Амазонке».
Поиск любого из предложенных слов
В ряде случае необходимо найти страницы, содержащие один из возможных вариантов названия какого-либо предмета или явления. Причем вы точно не знаете, какой из вариантов использовался в интересующей вас статье. В этом случае вы можете перечислить все возможные синонимы, поставив между ними символ |. Результат поиска выдаст страницы, содержащие хотя бы одно из заданных слов.
Пример
Запрос печь | камин | обогреватель | чувал найдет страницы, где встречается хотя бы одно из этих слов.
Исключение слов из поиска
В ряде случаев вам заранее известно, что ответ на ваш запрос сформирует список ссылок, многие из которых вам не нужны. Но вы можете предположить, что ненужные ссылки будут содержать, помимо основного слова вашего запроса, дополнительные слова. Используя оператор —, можно заранее исключить ненужные страницы. Для этого слева от оператора запишите требуемое слово, а справа — слово, при наличии которого страницы будут исключены из результата поиска.
Пример
Вы хотите узнать, с чем, помимо автомобиля, связано слово «Таврия». В этом вам поможет запрос таврия ~~ (компания | машина | запчасти), максимально исключивший из результатов все, что связано с автомобилями.
В ряде случаев требуется исключить из поиска устоявшиеся выражения, в которых определенные и нужные вам слова находятся в одном предложении. Вам же требуется, чтобы были все указанные вами слова, но они были бы в разных предложениях. Ничего сложного, просто используйте оператор ~.
Пример
Если вы ищете информацию о г-же Кузькиной, то более информативные результаты даст запрос Кузькина ~ мать, который ищет страницы со словом «Кузькина», исключая страницы, где в одном предложении с ним есть слово «мать».
Усложняем запросы
А теперь хотелось бы напомнить вам об основах даже не математики, а арифметики. Что применяется для определения последовательности выполнения арифметических действий? Совершенно верно — круглые скобки. Так и в поисковой системе Яндекс вы можете применять круглые скобки для создания каких угодно сложных поисковых выражений.
Учет морфологии
Вспомним то, о чем мы уже говорили. Яндекс ищет все слова, включенные в запрос, с учетом морфологии. Если вы хотите отключить ее, перед нужным словом поставьте оператор!. Помните, что между оператором и словом пробела быть не должно.
Пример
Если вы ищете документы, в которых должно быть слово «громоотводящий», наберите его в строке поиска и поставьте перед ним восклицательный знак —! громоотводящий. Если восклицательный знак не поставить, то в результаты попадут документы, в которых искомое слово выглядит совершенно иначе: «Вот пускай и громоотводит».
Если одна или несколько форм слова совпадают с другими словами, поиск может находить лишние страницы. Указав нормальную форму слова с помощью оператора!! вы уберете многие из ненужных страниц.
Вне зависимости от формы слов, Яндекс воспринимает слова, набранные с большой и маленькой буквы, по-разному.
Дополнительные операторы
Кроме операторов, о которых уже было сказано, есть и другие, применяемые для выполнения запроса в определенных элементах страницы, либо в связанной со страницей информации. Среди них хотелось бы обратить внимание на следующие.
? Оператор: site: — осуществляет поиск в пределах домена и всех его поддоменов.
Пример
Вывести все документы с домена domain.com, а также его поддоменов: site: domain.com.
? Оператор: hostname: — выполняет поиск в указанном домене или субдомене.
Пример
Вывести все документы с поддомена news.domain.com: hostname: news.domain.com.
? Оператор: intitle: — выполняет поиск по заголовкам документов.
Пример
Вывести все документы, в заголовке которых содержатся слова «каталог ссылок». Решение — intitle: каталог ссылок.
? Оператор: link: URL — выводит документы, ссылающиеся на указанный URL.
Пример
link: http://www.domain.com/news.html.
В табл. 1.4 приведены эти и другие операторы языка запросов. Источник: http://help.yandex.ru/search/?id=481939.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРесОсновы Интернет — 7.4. Синтаксис языка запросов
Урок 7.
-
Проблема поиска и поисковые системы
- Поиск по ключевым словам
- Советы при поиске в системе Яндекс
- Синтаксис языка запросов
- Поиск по каталогам
7.4. Синтаксис языка запросов
В системе Яндекс существует специальный язык запросов, использовать который более сложно, чем форму расширенного поиска но при его использовании можно получить наилучший результат.
Поисковый запрос вводится в поисковое поле, он может содержать ключевые слова и специальные символы, позволяющие установить взаимосвязи между этими словами и ввести дополнительные параметры. Большинство этих символов представлено в следующей таблице.
Синтаксис языка запросов системы Яндекс.
| Символ | Назначение | Пример |
|---|---|---|
| » « | поиск фразы |
«красная
шапочка» (эквивалентно красная /+1 шапочка) |
| + | обязательное наличие слова в найденном документе | +быть или +не быть |
| ~~ или — | не должно быть слова в пределах документа (И НЕ) | путеводитель по парижу ~~ (агентство | тур) |
| ~ | не должно быть слова в пределах предложения (И НЕ) | банки ~ закон |
| ! | искать только указанную форму слова | !Путин |
| пробел или & | логическое И (в пределах предложения) | фабрика звезд |
| логическое И (в пределах документа) | музыка && (фабрика звезд) | |
| | | логическое ИЛИ | рисунок | картинка | фото | коллаж |
| /(n m) | расстояние между словами (-назад +вперед) |
поставщики /2
кофе музыкальное /(-2 4) образование вакансии ~ /+1 студентов |
| &&/(n m) | расстояние в предложениях (-назад +вперед) | банк && /1 налоги |
| ( ) | группировка слов | (технология | изготовление) (сыра | творога) |
Основные положения языка запросов:
- Если ключевые слова являются устойчивым словосочетанием или единой фразой, то заключите их в кавычки.
- Если слова не объединены кавычками, то каждое слово будет само по себе и перед каждым их них можно поставить знак плюс «+», если слово обязательно должно быть в найденных документах, минус «-», если слово не должно быть в найденных документах (пробел ставится перед знаком, но не после). Если перед словом поставить знак ~ (тильда), то этого слова не должно быть в пределах предложения в совокупности с рядом стоящим в запросе словом. Примечание: по умолчанию будут найдены и те документы, которые удовлетворяют хотя бы одному из ключевых слов. Такие ссылки будут иметь низкую ревалентность и будут находиться в конце результатов запроса.
- Независимо от того, в какой форме вы употребили слово в запросе, Яндекс учитывает все формы этого слова по правилам русского языка. Чтобы этого не происходило, поставьте знак восклицания перед неизменяемым словом.
- Все слова, написанные через пробел или знак & (логическое И) должны одновременно находиться в найденных документах в пределах предложения. Все слова, написанные через && должны одновременно находиться в найденных документах, но расстояние между ними не оговаривается.
- Слова, написанные через символ | (логическое ИЛИ) являются заменяющими друг друга (синонимами), и будут найдены документы, удовлетворяющие хотя бы одному из этих слов.
- Можно указать расстояние между словами. Если пронумеровать слова в предложении, то расстояние между словами – это разность номеров слов. Например, если между двумя словами может находиться только одно слово, то расстояние между ними равно 2 (3 минус 1). Число указывается после знака /, например региональный /2 центр. В этом случае будут найдены документы, в которых эти слова находятся либо вместе, либо между ними есть еще одно слово. Запись /2 эквивалентна записи /(-2 +2), в такой форме можно указать максимальное и минимальное количество слов, например, от 3 до 5 записывается /(3 5). Минус и плюс указывают на порядок слов: минус – обратный порядок. Если перед символом / указать &&, то расстояние будет вычисляться в предложениях.
- Для группировки отдельных частей запроса используйте круглые скобки.
Поиск в зонах и элементах web-страницы.
Web-страница состоит из определенных зон и элементов. Соответственно можно осуществлять поиск в зонах и в элементах. Например, для поиска в заголовке страницы (заголовок отображается в заголовке окна обозревателя) указывают: $title (выражение), поиск в тексте ссылок аналогичен (см. следующую таблицу), а общий синтаксис таков:
$имя_зоны (выражение)
Примечание: выражение может быть представлено как одним ключевым словом, так и несколькими словами, объединенными указанными выше знаками логических операций.
Для поиска в элементах используется синтаксис:
#имя_элемента=(выражение)
Элементы отличаются от зон тем, что в большинстве своем не видны пользователю, просматривающему страницу. Так, например, ключевые слова указываются в невидимом заголовке Web-страницы и не выводятся в обозревателе. Их можно увидеть только выполнив Вид ® В виде HTML. Большинство документов имеют описание (abstract), которое также не выводится на страницу. Подписи рисунков видны только в том случае, если загрузка рисунков отключена, либо если навести мышь на рисунок, то подпись появится в виде подсказки.
Синтаксис поиска в элементах и зонах.
| Синтаксис | Назначение | Пример |
|---|---|---|
| $title (выражение) | поиск в заголовке | $title (Яндекс) |
| $anchor (выражение) | поиск в тексте ссылок | $anchor (Яндекс | Апорт) |
| #keywords=(выражение) | поиск в ключевых словах | #keywords=(поисковая система) |
| #abstract=(выражение) | поиск в описании | #abstract=(искалка | поиск) |
| #image=»значение» | поиск файла изображения | #image=»tort*» |
| #hint=(выражение) | поиск в подписях к изображениям | #hint=(lenin | ленин) |
| #url=»значение» | поиск на заданном сайте (странице) | #url=»www.comptek.ru*» |
| #link=»значение» | поиск ссылок на заданный URL | #link=»www.yandex.ru*» |
| #mime=»значение» | поиск в документах данного (pdf или rtf) типа | #mime=»pdf» |
Сортировка результатов запроса.
После того, как поисковая система выберет страницы, удовлетворяющие запросу, она сортирует ссылки на эти страницы в порядке убывания их ревалентности.
Ревалентность – это степень соответствия содержания документа поисковому запросу. Релевантность документа зависит от ряда факторов, в том числе от частотных характеристик искомых слов, веса слова или выражения, близости искомых слов в тексте документа друг к другу и т.д.
Пользователь может повлиять на порядок сортировки, используя операторы веса и уточнения запроса.
Вес указывается для того, чтобы увеличить ревалентность документов, содержащих слово или выражение, вес которого указан.
Синтаксис: слово:число или (поисковое_выражение):число
Чем больший вес указан у слова (или выражения), тем выше ревалентность документов его содержащих.
Например, по запросу родина Путина:5 в результатах поиска наверху списка окажутся документы, где чаще встречается именно слово Путин.
Уточняющее слово или выражение применяется для того, чтобы увеличить релеватность документов, их cодержащих.
Синтаксис: <- слово или <- (уточняющее_выражение)
Например, по запросу телефон <- автоответчик будут найдены все документы, содержащие слово телефон, но первыми будут выданы страницы, содержащие слово автоответчик.
Примечание: кроме сортировки по ревалентности Вы можете выбрать сортировку по дате документов, щелкнув по соответствующей ссылке.
Язык поисковых запросов. Новости от Яндекса
Зачастую в поиске пользователи ограничиваются типом информации, выбирая раздел «Картинки», «Видео», «Новости», «Музыка» и т.д. Использование языка запросов позволяет уточнить предлагаемую информацию с учетом префиксов обязательности, морфологии языка, регистра слов, расстояний между словами.
По статистике менее 5% пользователей используют расширенные возможности поиска
Для более узконаправленного профиля не только по типам документов, но и по их местонахождению, дате создания, аналогам и другим параметрам продвинутые пользователи интернета используют специальные операторы.
Язык поисковых запросов Google
Конечно, разные поисковые системы употребляют разный синтаксис и операторов запроса. Например, Google, позволяет добавлять к вводимым словам дополнительные уточнения на английском. Примеры полезных операторов:
- site: Ограничиваем поиск границами только определенного сайта (используют для сайтов, у которых плохо развит или отсутствует внутренний поиск).
- related: Находим похожие ресурсы (может быть полезно для определения сайтов-конкурентов).
- link: Находим ссылающиеся страницы (нужно применять для проверки популярности).
- cache: Для поиска в кэше (полезно в ситуациях, когда искомый ресурс не доступен).
- allintitle: Для показа искомых слов только в заголовках страниц.
- allinurl: Ищем и анализируем только адреса страниц. Можно применять для поиска шаблонов, каких-то технических страниц сайта или страницы регистрации.
- intext: Используем для поиска ключевых слов в тексте.
Новое в языке поисковых запросов Яндекса
Расширенный поиск от Яндекс с готовыми наиболее популярными фильтрами значительно облегчил жизнь рядовых пользователей. Поэтому отказ от некоторых трудных для запоминания операторов поиска стал вполне естественным. Поисковая система Яндекс прекращает использование некоторых операторов запроса, которые редко используются. Это связано с изменением формата поискового индекса и механизма разбора поисковых запросов. В течение февраля Яндекс отказывается от следующих символов:
- & — поиск только таких документов, в которых слова запроса (между которыми ставится оператор) встречаются в одном предложении.
- && и « — поиск набранных слов в пределах одного документа.
- ~— поиск документов, в которых слова с данным оператором, не стоят в одном предложении.
- ()— задается группировка слов в сложных запросах.
- !! — поиск слова а начальной форме, указанной в запросе.
Общие операторы поиска Google и Яндекса
Рейтинг самых популярных совместных поисковых операторов выглядит так:
- + Для поиска таких документов, которые обязательно содержат указанные слова.
- — Для информации, исключающей содержание написанных слов. Кстати, в одном поисковом запросе возможно сочетание плюса и минуса в качестве операторов.
- «» Для точного поиска фразы. Допускает многократное использование в запросе.
- | Поиск ресурсов, содержащих любое из слов/фраз, разделенных вертикальной чертой.
Кто ищет, тот всегда найдет: используйте правильные операторы и следите за нововведениями вместе с нами.
Язык запросов: язык поисковых запросов Яндекса, синтаксис языка поисковых запросов, информационно поисковый язык
В результате лингвистической обработки тот запрос, который вводит пользователь, и тот, который обрабатывается поисковой системой, сильно отличаются друг от друга
Язык, на котором сформулированы запросы к поисковым машинам, называется информационно-поисковым, или языком поисковых запросов.» означает расширение запроса дополнительными словами, цифры – расстояние между словами (в предложениях). «&&/» означает, что поиск осуществляется в пределах соседних слов.
Информационно-поисковый язык состоит из логических операторов, морфологии языка, регистра слов, префиксов обязательности, возможности учета расстояния между словами и расширенного поиска. Подобное представление запроса помогает быстрее ориентироваться в индексных базах.
Синтаксис языка поисковых запросов может изменяться в зависимости от особенностей конкретной поисковой машины. Но есть определенные правила, которые используют все. Рассмотрим наиболее распространенные из них:
- команды логического объединения и исключения.
Символы «+» и «-» в запросе позволяют добавлять или исключать какие-либо слова из текста. Слово, помеченное «+», будет обязательно присутствовать в документах, которые найдет поисковая система по запросу. Слово, помеченное «-», будет отсутствовать в выдаче.
Команды «+» и «-» должны быть написаны слитно со словом, к которому они относятся. В противном случае поисковая машина начнет рассматривать их как элементы запроса, а не как команды. - «логическое И» (обозначается как амперсанд (&)).
Позволяет перечислить слова, которые обязательно должны встречаться в пределах одного предложения в искомом документе. - «логическое ИЛИ» (обозначается символом «|»).
Дает возможность осуществлять поиск по документам, в тексте которых присутствует только одно из перечисленных слов.
Если правило необходимо распространить не только на одно предложение, но и на весь документ, используется удвоение команды. Чтобы применить несколько команд в одном запросе, следует использовать символы открывающей и закрывающей скобки. Допускается комбинирование логических операторов и без использования скобок.
Также поисковые системы могут производить поиск по точному вхождению. Для этого используются кавычки.
Как правило, поисковые системы учитывают все словоформы исходного запроса согласно правилам русского языка. Поэтому в выдаче можно увидеть документы, в которых встречаются не только точные вхождения запроса, но и различные его формы. Для того чтобы осуществить поиск точной словоформы по правилам языка запросов Яндекса, перед запросом необходимо поставить восклицательный знак. Если запрос состоит из 2 и более слов, можно использовать уже знакомые нам кавычки или поставить «!» перед скобками, в которых заключена фраза.
Скопируйте какую-либо фразу с вашего сайта, введите ее в поисковую строку Яндекса или Google в кавычках и проверьте, дублирует ли кто-то вашу информацию.
Меняя местами слова в тексте запроса, можно заметить следующее: если слова располагаются в разных предложениях, в одном случае поисковая система не считает страницу со всеми словами в тексте релевантной запросу, а в другом случае считает. Расположение ключевых слов в тексте можно оценить, посмотрев сохраненную копию страницы из поисковой выдачи Яндекса. В ней подсвечиваются все учитывающиеся ключевики. Также Яндекс подсвечивает ключевые слова в сниппетах и заголовках страниц.
Поисковые системы постоянно развиваются и, конечно, не ограничиваются поиском только по словам из запроса. Чтобы учесть все возможные варианты ответа на запрос пользователя, Яндекс расширяет исходный текст, введенный в строку поиска. Он добавляет другие формулировки с тем же значением и ведет поиск уже по новому запросу.
Используя язык запросов поисковой системы, можно находить необходимую информацию за максимально короткое время. Знание языка поисковых запросов также дает возможность анализировать выдачу с различных сторон. Это помогает написать текст, который будет влиять на позиции и станет интересен пользователям.
Вернуться назад: Представление сайтов внутри поисковых системЧитать далее: Поиск релевантной информации
Сеанс поисковой магии. Недокументированные операторы языка запросов Яндекса
Автор: Сергей Людкевич, “Яндекс”
За время своего существования язык запросов Яндекса претерпел существенные изменения. Причем изменения эти были далеко не в лучшую сторону для пользователя. Постепенно исчезло много операторов, применение которых пытливому исследователю позволяло творить чудеса. Так, в 2006-м году исключительно применением стандартного функционала языка запросов можно было полностью восстановить формулу текстового ранжирования Яндекса в аналитическом виде. И частично – формулу ссылочного ранжирования. Например, можно было установить, что вхождение термина в тег title ровно в два раза весомее вхождения в body. И многие другие интересные факты. С той поры исчезли замечательные операторы, такие как link (поиск по ссылающимся документам), anchor (поиск по текстам ссылок), : и :: (разные варианты присвоения веса термину из запроса), softness (настройка мягкости для фильтрации по кворуму) и другие. Текущий список документированных операторов можно найти в помощи Яндекса.
Однако, до сих пор в поиске продолжают использоваться операторы, которые исчезли из документации. Например, оператор << (неранжирующее логическое «И») бывает очень полезен при построении достаточно сложных конструкций в запросе. Более того, до сих пор используются операторы, которые никогда не были задокументированы. По крайней мере для большого поиска.
В свое время в разделе помощи Яндекса, посвященной Яндекс.Серверу (приложению для поиска в корпоративных сетях и поиска по сайту), содержался многостраничный документ «Яндекс.Сервер. Руководство по установке и эксплуатации» (до сих пор отдельные версии этого документа для различных сборок, закачанные на сторонние сайты, можно найти в глубинах сети). Там довольно подробно описывался язык запроса, который был несколько шире задокументированного языка запросов для большого поиска по вебу. Но что самое интересное, многие операторы из руководства Яндекс.Сервера работали (и до сих пор работают) в большом поиске. Рассмотрим самые, на мой взгляд, интересные из них.
Оператор intext.
Пожалуй, наиболее интересный оператор. Выдача с его использованием не пустая и отличается от выдачи без его использования:
Заявлено, что этот оператор используется для поиска только в текстах документов. И это действительно похоже на правду. Например, документы, найденные по ссылке, этим оператором, не ищутся:
То есть, при ранжировании по сути игнорируется анкор-файл. Этот оператор может быть весьма полезен при исследовании текстовой релевантности документов.
Оператор inlink.
Заявлено, что оператор используется для поиска в ссылках на документы. Однако, к большому сожалению, если этот оператор применять целиком ко всей поисковой фразе, выдача пуста:
Выдача становится непустой, если хотя бы одно слово запроса вынести из-под данного оператора:
Однако трудности с интерпретацией полученных результатов сводят к минимуму полезность этого оператора.
Оператор inpos.
Выдержка из руководства: «Специальное имя атрибута для указания точного диапазона позиций, в которых должен находиться предыдущий лист или скобка. Имеет синтаксис inpos:N1..N2, где N1 и N2 — целые положительные числа». Применение различных интервалов к запросу дает любопытные эффекты. Например, при достаточно малом диапазоне выдача сужается до документов, содержащих ключевые слова только в адресе документа:
Оператор linkint.
Сильно ужатая версия былого оператора link, осуществляющая поиск внутренних ссылок на определенный документ. Однако может быть полезен при решении определенных задач.
Оператор anchorint.
Аналогичным образом ужатая на внутренние ссылки версия отмененного оператора anchor. Осуществляет поиск по документам, содержащих ключевую фразу в текстах своих ссылок, ведущих на внутренние страницы того же сайта. Любопытна конструкция, объединяющая операторы linkint и anchorint (аналогичным образом в свое время можно было объединить в одном запросе операторы link и anchor), и позволяющая найти все внутренние страницы сайта, ссылающиеся на данную страницу заданной ключевой фразой:
Менее любопытны, но на мой взгляд, заслуживают упоминания операторы, позволяющие искать по определенным фрагментам текста документов:
- address – поиск внутри текстов, заключенных в теге
- quote – поиск внутри текстов, заключенных в теге
Источник >>
| ~ | Содержит | = «Display region» ~ austr | Выбирает группы объявлений с полем Display region, содержащим Australia или Austria (и, возможно, некоторые другие регионы) |
| = «Изображение «~ [черный белый] | Выбирает объявления с полем» Изображение «, содержащим черный или белый в качестве подстроки | ||
| =» Область отображения «~ [Рекламные сети] | Выбирает кампании, в которых есть Рекламные сети значение в поле Область отображения | ||
| ! ~ | Не содержит | = «Область отображения»! ~ austr | Выбирает группы объявлений с полем Область отображения, не содержащими Австралия и Австрия |
| = Keyword! ~ [Ticket hotel] | Выбирает ключевые слова с полем Keyword, не содержащим подстрок ticket и hotel | ||
| = Модерация! ~ [Ожидание] | Выбирает объявления, в которых столбец Модерации содержит любое значение, кроме Ожидание . | ||
| = | Равно / соответствует | = «Область отображения» = Австралия | Выбирает только группы, для которых установлено значение области отображения Австралия |
| = Число = [111111 222222] | Выбирает объявления с номера 111111 и 222222. | ||
| ! = | Не равно / не совпадает | = «Область отображения»! = Австралия | Выбирает группы, в которых область отображения отличается от Австралия |
| = Число! = [111111 222222] | Выбирает все числа, кроме 111111 и 222222. | ||
| > | Больше | = ctr> 0,5 | Выбирает ключевые слова с CTR выше 0,5 |
| < | Меньше | = ctr <0,5 | Выбирает ключевые слова с CTR16 меньше 0,5 |
| > = | Больше или равно | = Ставка> = 1 | Выбирает ключевые слова, для которых ставка на поиске больше или равна 1 |
| <= | Меньше или равна | = Ставка <= 1 | Выбирает ключевые слова, для которых ставка при поиске меньше или равна 1 |
| & | Логическое «И» в сложных условиях поиска | = Текст ~ полет и изображение = пробел | Выбирает объявления с текстом, содержащим подстроку flight , и именем изображения, содержащим пробел подстроку |
| | | Логическое «ИЛИ» в сложных поисковых запросах | = Текст ~ пробел | Текст ~ рейс | Выбирает объявления, текст которых содержит пробел подстроку ИЛИ рейс подстроку |
| Логины и имена пользователей | Поиск проблем, в которых указаны конкретные пользователи в поле «Доступ». Пример: | ||
| Имена версий | Поиск проблем, в которых указано конкретное значение поле версии.Пример: | ||
| Логины и имена пользователей | Поиск проблем, в которых указаны конкретные пользователи как ответственные. Пример: | ||
| Логины и имена пользователей | Поиск проблем, в которых указаны конкретные пользователи в качестве ответственных.Пример: | ||
| Имена очередей или ключи | Поиск проблем, у которых есть зависимые (заблокированные) проблемы в указанные очереди. Пример: | ||
| Ключи выдачи | Поиск проблем, клонированных из определенных проблем. Пример: | ||
| Имена очереди или ключи | Поиск проблем, клонированных из проблем в определенных очередях.Пример: | ||
| Текстовая строка | Поиск проблем, содержащих комментарий с определенным текстом. Пример:
| ||
| Логины и имена пользователей | Поиск вопросов, содержащих комментарии, оставленные конкретными пользователями.Пример: | ||
| Логины и имена пользователей | Поиск конкретных проблем, которые включают компоненты, управляемые компонентами пользователей. Пример: | ||
| Имена компонентов | Поиск проблем, связанных с конкретными компонентами.Пример: | ||
| Дата или диапазон дат | Поиск проблем, созданных в определенную дату или в течение определенного диапазон дат. Пример: | ||
| Дата или диапазон дат | Поиск проблем с крайний срок установлен для определенной даты или диапазона дат.Пример: | ||
| Имена очереди или ключи | Поиск проблем, зависящих от (заблокированных) проблем из определенных очереди. Пример: | ||
| Ключи выдачи | Поиск проблем, зависящих от (заблокированных) конкретных проблем.Пример: | ||
| Текстовая строка | Поиск проблем с определенным текстом в описании. Пример:
| ||
| Имена или ключи очередей | Поиск проблем, дублирующихся в определенных очередях.Пример: | ||
| Ключи выдачи | Поиск проблем, дублирующих определенные проблемы. Пример: | ||
| Имена очереди или ключи | Поиск дубликатов проблем вопросов в указанных очередях.Пример: | ||
| Дата или диапазон дат | Поиск задач, значение конечной даты которых соответствует определенной дате или ее диапазон дат. Пример: | ||
| Эпические ключи | Поиск проблем из определенных эпиков.Пример: | ||
| Имена очереди или ключи | Поиск эпиков, содержащих проблемы из определенных очереди. Пример: | ||
| В качестве значения параметра можно использовать только функцию | Поиск избранного. Пример: | ||
| Имена или идентификаторы фильтров | Поиск проблем, соответствующих указанным фильтрам. Пример: | ||
| Имена версий | Поиск проблем, для которых указано конкретное значение в поле «Чтобы исправить» в поле версии.Пример: | ||
| Логины и имена пользователей | Поиск проблем, в которых указаны конкретные пользователи в качестве подписчиков. Пример: | ||
| Ключи выдачи | Поиск проблем из определенных эпиков.Пример: | ||
| Имена или ключи очередей | Поиск проблем, которые каким-то образом связаны с проблемами из указанных очередей (родительские, связанные, дублирующие, вторичные, и так далее). Пример: | ||
| Текстовая строка | Поиск проблем с историей, включающей слова или формы слов из указанная фраза. Поиск выполняется только по значениям полей «Имя проблемы» и «Описание проблемы». Пример: | ||
| Имена или ключи очередей | Поиск проблем, связанных с эпиками, из определенных очередей . Пример: | ||
| Ключи выдачи | Поиск проблем, которые блокируют определенные проблемы.Пример: | ||
| Ключи выдачи | Поиск дублирующихся проблем по конкретным вопросам. Пример: | ||
| Ключи выдачи | Поиск эпиков, вопросы.Пример: | ||
| Ключи выдачи | Поиск родительского вопросы по указанным подвопросам. Пример: | ||
| Ключи выдачи | Поиск для подзадачи -выпуски по указанным родительским проблемам.Пример: | ||
| Ключи выдачи | Поиск проблем с конкретными ключами . Пример: | ||
| Дата и время публикации последнего комментария | Поиск проблем, по которым не было новых комментариев в течение определенного периода времени.Пример: | ||
| Ключи выдачи | Поиск проблем, связанных с указанными проблемами ( родительский, связанный, дублирующий, вторичный и т. д.). Пример: | ||
| Названия отделов или команд | Поиск проблем за ними следуют определенные отделы или команды.Пример: | ||
| Логины и имена пользователей | Поиск проблем, недавно обновленных конкретными пользователями. Пример: | ||
| Имена очереди или ключи | Поиск проблем, перемещенных из указанных очередей.Пример: | ||
| Ключи выдачи | Поиск клонов указанных проблем. Пример: | ||
| Временной диапазон в формате | Поиск проблем с определенной начальной оценкой.Пример: | ||
| Имена или ключи очередей | Поиск проблем, у которых есть клоны в определенных очередях. Пример: | ||
| Имена или ключи очередей | Поиск проблем, имеющих под-проблемы в указанных очередях.Пример: | ||
| Логины и имена пользователей | Поиск проблем с ожидающим ответом от указанного пользователя пользователю было предложено оставить комментарий). Допустим, вам нужно найти проблемы, ожидающие ответа от пользователя с именем пользователя | ||
| Значение приоритета | Поиск проблем с указанными значениями приоритета.Пример: | ||
| Названия проектов | Поиск проблем по конкретным проектам. Пример: | ||
| Имена или ключи очередей | Поиск проблем из определенных очередей.Пример: | ||
| Логины и имена пользователей | Поиск проблем, в которых указаны конкретные пользователи в качестве владельцев очереди. Пример: | ||
| Логины и имена пользователей | 90ee183 Поиск проблем, в которых указаны конкретные пользователи , репортеры или последователи.Пример: | ||
| Имена или ключи очередей | Поиск проблем, связанных с проблемами из определенных очереди (ссылка типа «Связанные»). Пример: | ||
| Ключи выдачи | Поиск проблем, связанных с конкретными проблемами (ссылка типа «Связанные»).Пример: | ||
| Дата или диапазон дат | Поиск проблем, которые были закрыто (решено) в определенную дату или в течение определенного диапазона дат. Пример: | ||
| Логины и имена пользователей | Поиск проблем, которые были закрыто (разрешено) указанными пользователями.Пример: | ||
| Имена или идентификаторы спринтов | Поиск проблем из определенных спринтов. Пример: | ||
| ID Board ID (можно найти в URL страницы Board) | Поиск проблем, связанных с активная весна на указанном табло выпуска.Пример: | ||
| Идентификатор доски выдачи (можно найти в URL страницы доски) | Поиск по вопросам из конкретных досок. Пример: | ||
| Дата или диапазон дат | Поиск задач, значение даты начала которых совпадает с определенной датой или падает в пределах диапазона дат.Пример: | ||
| Имена состояний | Поиск проблем с определенными именами состояний. Пример: | ||
| Очки истории | Поиск проблем с определенным количеством очков истории.Пример: | ||
| Имена или ключи очередей | Поиск проблем, у которых есть родительские проблемы, в указанных очередях. Пример: | ||
| Текстовая строка | Поиск проблем с определенным заголовком.Пример:
| ||
| Выдать теги | Поиск проблем с указанными тегами.Пример: | ||
| Диапазон времени в формате | Поиск проблем, на выполнение которых потребовалось указанное время. Пример: | ||
| Дата или диапазон дат | Поиск проблем с измененным сроком дату или в течение определенного диапазона дат.Пример: | ||
| Логины и имена пользователей | Поиск проблем, за которые проголосовали определенные пользователи. Пример: | ||
| Количество голосов | Поиск задач с определенным количеством голосов.Пример: |
Синтаксис | Документация ClickHouse
- Справочник по SQL
В системе есть два типа синтаксических анализаторов: полный синтаксический анализатор SQL (рекурсивный спусковой синтаксический анализатор) и синтаксический анализатор формата данных (быстрый синтаксический анализатор потока).
Во всех случаях, кроме запроса INSERT , используется только полный синтаксический анализатор SQL.
Запрос INSERT использует оба парсера:
INSERT INTO t VALUES (1, 'Hello, world'), (2, 'abc'), (3, 'def')
Фрагмент INSERT INTO t VALUES анализируется полным анализатором, а данные (1, 'Hello, world'), (2, 'abc'), (3, 'def') анализируются парсером быстрого потока.Вы также можете включить полный анализатор данных с помощью параметра input_format_values_interpret_expressions. Когда input_format_values_interpret_expressions = 1 , ClickHouse сначала пытается проанализировать значения с помощью парсера быстрого потока. Если это не удается, ClickHouse пытается использовать полный анализатор данных, рассматривая его как выражение SQL.
Данные могут иметь любой формат. Когда запрос получен, сервер вычисляет не более max_query_size байтов запроса в ОЗУ (по умолчанию 1 МБ), а остальная часть анализируется потоком.
Это позволяет избежать проблем с большими запросами INSERT .
При использовании формата Values в запросе INSERT может показаться, что данные анализируются так же, как выражения в запросе SELECT , но это неверно. Формат Values гораздо более ограничен.
Остальная часть статьи посвящена синтаксическому анализатору полностью. Дополнительные сведения о синтаксических анализаторах формата см. В разделе «Форматы».
Пробелы
Между синтаксическими конструкциями (включая начало и конец запроса) может быть любое количество пробелов.К символам пробела относятся пробел, табуляция, перевод строки, CR и перевод страницы.
ClickHouse поддерживает комментарии в стиле SQL и C:
- Комментарии в стиле SQL начинаются с
–и продолжаются до конца строки, пробел после–можно опустить. - C-стиль от
/ *до* /и может быть многострочным, пробелы также не требуются.
Ключевые слова
Ключевые слова нечувствительны к регистру, если они соответствуют:
- стандарту SQL.Например,
SELECT,selectиSeLeCtвсе допустимы. - Реализация в некоторых популярных СУБД (MySQL или Postgres). Например,
DateTimeсовпадает сdatetime.
Вы можете проверить, учитывается ли регистр имени типа данных в таблице system.data_type_families.
В отличие от стандартного SQL, все остальные ключевые слова (включая имена функций) чувствительны к регистру .
Ключевые слова не зарезервированы; они рассматриваются как таковые только в соответствующем контексте.Если вы используете идентификаторы с тем же именем, что и ключевые слова, заключите их в двойные кавычки или обратные кавычки. Например, запрос SELECT «FROM» FROM имя_таблицы действителен, если таблица имя_таблицы имеет столбец с именем «FROM» .
Идентификаторы
Идентификаторы:
- Имена кластера, базы данных, таблицы, раздела и столбца.
- Функции.
- Типы данных.
- Псевдонимы выражений.
Идентификаторы могут заключаться в кавычки или не заключаться в кавычки.[a-zA-Z _] [0-9a-zA-Z _] * $ и не может совпадать с ключевыми словами. Примеры: x , _1 , X_y__Z123_ .
Если вы хотите использовать идентификаторы, такие же, как ключевые слова, или вы хотите использовать другие символы в идентификаторах, заключите его в двойные кавычки или обратные кавычки, например, «id» , `id` .
Литералы
Существуют числовые, строковые, составные и NULL литералы.
Числовой
Числовой литерал пытается проанализировать:
- Сначала как 64-битное число со знаком, используя функцию strtoull.
- В случае неудачи, как 64-битное беззнаковое число, с использованием функции strtoll.
- В случае неудачи в виде числа с плавающей запятой с помощью функции strtod.
- В противном случае возвращается ошибка.
Литеральное значение имеет наименьший тип, которому подходит значение.
Например, 1 анализируется как UInt8 , а 256 анализируется как UInt16 . Для получения дополнительной информации см. Типы данных.
Примеры: 1 , 18446744073709551615 , 0xDEADBEEF , 01 , 0.1 , 1e100 , -1e-100 , inf , nan .
Строка
Поддерживаются только строковые литералы в одинарных кавычках. Заключенные символы могут быть экранированы обратной косой чертой. Следующие escape-последовательности имеют соответствующее специальное значение: \ b , \ f , \ r , \ n , \ t , \ 0 , \ a , \ v , \ xHH . Во всех остальных случаях управляющие последовательности в формате \ c , где c - любой символ, преобразуются в c .Это означает, что вы можете использовать последовательности \ ' и \\ . Значение будет иметь тип String.
В строковых литералах нужно экранировать как минимум ' и \ . Одиночные кавычки могут быть экранированы одинарными кавычками, литералы 'It''s' и 'It''s' равны.
Соединение
Массивы состоят из квадратных скобок [1, 2, 3] . Кортежи состоят из круглых скобок (1, 'Hello, world!', 2) .
Технически это не литералы, а выражения с оператором создания массива и оператором создания кортежа соответственно.
Массив должен состоять как минимум из одного элемента, а кортеж должен иметь как минимум два элемента.
Существует отдельный случай, когда кортежи появляются в предложении IN запроса SELECT . Результаты запроса могут включать кортежи, но кортежи не могут быть сохранены в базе данных (за исключением таблиц с механизмом памяти).
NULL
Указывает, что значение отсутствует.
Чтобы сохранить NULL в поле таблицы, оно должно иметь тип Nullable.
В зависимости от формата данных (входных или выходных) NULL может иметь другое представление. Для получения дополнительной информации см. Документацию по форматам данных.
Есть много нюансов обработки NULL . Например, если хотя бы один из аргументов операции сравнения равен NULL , результатом этой операции также будет NULL .То же самое верно для умножения, сложения и других операций. Для получения дополнительной информации прочтите документацию по каждой операции.
В запросах вы можете проверить NULL с помощью операторов IS NULL и IS NOT NULL и связанных функций isNull и isNotNull .
Функции
Вызов функций записывается как идентификатор со списком аргументов (возможно, пустым) в круглых скобках. В отличие от стандартного SQL, скобки необходимы даже для пустого списка аргументов.Пример: сейчас () .
Существуют обычные и агрегатные функции (см. Раздел «Агрегатные функции»). Некоторые агрегатные функции могут содержать два списка аргументов в скобках. Пример: квантиль (0,9) (x) . Эти агрегатные функции называются «параметрическими» функциями, а аргументы в первом списке называются «параметрами». Синтаксис агрегатных функций без параметров такой же, как и у обычных функций.
Операторы
Операторы преобразуются в соответствующие им функции во время синтаксического анализа запроса с учетом их приоритета и ассоциативности.
Например, выражение 1 + 2 * 3 + 4 преобразуется в plus (plus (1, multiply (2, 3)), 4) .
Типы данных и механизмы таблиц базы данных
Типы данных и механизмы таблиц в запросе CREATE записываются так же, как идентификаторы или функции. Другими словами, они могут содержать или не содержать список аргументов в скобках. Для получения дополнительной информации см. Разделы «Типы данных», «Механизмы таблиц» и «СОЗДАТЬ».
Псевдонимы выражений
Псевдоним - это определяемое пользователем имя для выражения в запросе.
AS- ключевое слово для определения псевдонимов. Вы можете определить псевдоним для имени таблицы или имени столбца в предложенииSELECTбез использования ключевого словаAS.Например, `SELECT имя_таблицы_алиас.имя_столбца ИЗ имя_таблицы псевдоним_таблицы`. В функции [CAST] (sql_reference / functions / type_conversion_functions.md # type_conversion_function-cast) ключевое слово `AS` имеет другое значение. См. Описание функции.expr- любое выражение, поддерживаемое ClickHouse.Например, `SELECT column_name * 2 AS double FROM some_table`.псевдоним- имя дляexpr. Псевдонимы должны соответствовать синтаксису идентификаторов.Например, `SELECT" table t ".column_name FROM table_name AS" table t "`.
Примечания по использованию
Псевдонимы являются глобальными для запроса или подзапроса, и вы можете определить псевдоним в любой части запроса для любого выражения.Например, SELECT (1 AS n) + 2, n .
Псевдонимы не отображаются в подзапросах и между подзапросами. Например, при выполнении запроса SELECT (SELECT sum (b.a) + num FROM b) - a.a AS num FROM ClickHouse генерирует исключение Неизвестный идентификатор: num .
Если псевдоним определен для столбцов результатов в предложении SELECT подзапроса, эти столбцы видны во внешнем запросе. Например, ВЫБРАТЬ n + m ИЗ (ВЫБРАТЬ 1 КАК n, 2 КАК m) .
Будьте осторожны с псевдонимами, которые совпадают с именами столбцов или таблиц. Рассмотрим следующий пример:
СОЗДАТЬ ТАБЛИЦУ t
(
a Int,
b Int
)
ДВИГАТЕЛЬ = TinyLog ()
ВЫБРАТЬ
argMax (а, б),
сумма (b) AS b
ОТ Т
Получено исключение от сервера (версия 18.14.17):
Код: 184. DB :: Exception: получено от localhost: 9000, 127.0.0.1. DB :: Exception: сумма агрегатной функции (b) находится внутри другой агрегатной функции в запросе. В этом примере мы объявили таблицу t со столбцом b . Затем при выборе данных мы определили псевдоним sum (b) AS b . Поскольку псевдонимы являются глобальными, ClickHouse заменил литерал b в выражении argMax (a, b) выражением sum (b) . Эта замена вызвала исключение. Вы можете изменить это поведение по умолчанию, установив для параметра имя_столбца_то_алиас значение 1 .
Asterisk
В запросе SELECT звездочка может заменить выражение.Для получения дополнительной информации см. Раздел «ВЫБРАТЬ».
Выражения
Выражение - это функция, идентификатор, литерал, применение оператора, выражение в скобках, подзапрос или звездочка. Он также может содержать псевдоним.
Список выражений - это одно или несколько выражений, разделенных запятыми.
Функции и операторы, в свою очередь, могут иметь выражения в качестве аргументов.
Оригинал статьи
Язык поисковых запросов "Яндекс": описание, особенности и отзывы
Интернет сегодня - это кладезь информации.планетарного масштаба, где каждый житель Земли может найти практически все, что ему нужно. Обладая немыслимыми объемами данных и информации, человечество также имеет все необходимые инструменты для максимально быстрого и комфортного поиска того, что нужно каждому в определенный момент времени. Эти инструменты представляют собой поисковые системы, которые каждый из нас использует ежедневно: Google, Яндекс, Рамблер, Yahoo и многие другие технологии со своими уникальными возможностями для различных предпочтений.
И объединяет их всего одно простое свойство - ни одна из систем не является своего рода супертехнологическим центром, хранящим в своих ресурсах невообразимое количество информации на все случаи жизни.Все они по сути являются гидами для пользователей на просторах Интернета и работают над определенными программными алгоритмами.
Язык запросов поисковой системы «Яндекс»: основы
Функционал «Яндекса» позволяет достаточно гибко отсортировать все полученные результаты с учетом конкретных доменов, регионов, языков и многих других параметров. Формат входных данных и полученные результаты могут быть настроены и отфильтрованы пользователями с помощью простых комбинаций символов.Это значительно увеличивает эффективность и удобство поиска.
Каждый запрос от пользователя сначала отправляется на самый свободный сервер (сразу после автоматического анализа загрузки системы), после чего его обрабатывает программа Meta Search. Программное обеспечение в режиме реального времени анализирует информацию, введенную в строку поиска по лингвистике, географическому положению пользователя, запросу, относящемуся к «самым популярным» / «недавно определенным» категориям и т. Д. Результаты поиска для этих случаев сохраняются в течение некоторого времени в папке « Мета-поиск »кеш.», Благодаря которому выдача необходимой информации происходит быстрее.
В случае поиска более редкой информации, которая отсутствует в кэше, обработка запроса перенаправляется на другой программный механизм - «Базовый поиск». Он анализирует всю базу данных, разделенную на различные дублирующие серверы, чтобы ускорить процесс поиска, и возвращает найденную информацию обратно в «Метапоиск».
Все полученные данные в конечном итоге упорядочиваются и представляются пользователю в готовой, удобной для восприятия форме.Весь процесс занимает в среднем 1-2 секунды максимум.
Правильный поиск в Яндексе: язык поисковых запросов и особенности синтаксиса
Наличие определенных слов в полученных результатах, а также их взаимное расположение можно легко настроить с помощью специальных операторов, формирующих язык поисковых запросов Яндекса .
| Оператор | Функция | Пример использования |
| + | Отображает результаты ресурсов, в которых обязательно есть слово, назначенное оператором.Язык запросов поисковой системы Яндекс допускает повторное использование, если в запросе два и более слов. | world + web + internet «Яндекс» выдаст те результаты, которые точно содержат слова «сеть», «Интернет» и, возможно, «весь мир». |
| " | Поиск определенной формы или последовательности символов. | " уходит далеко в малиновый закат " Результаты поиска обязательно будут содержать эту фразу без изменений. |
| * | Используется только с предыдущим утверждением. Этот символ позволяет организовать поиск цитат с пропущенными словами. | * переходит в пурпурный закат Поисковая система отобразит результаты с этой цитатой и пропущенным словом. ** закатные листья Поисковая система отобразит результаты с этой цитатой и пропущенными словами. |
| & | Поиск результатов с предложениями, которые содержат слова, объединенные заданным оператором. | красивый и интерьер и дом Пользователю будут представлены результаты, в которых хотя бы одно предложение содержит заданный набор слов (они могут быть установлены оператором из двух или более). |
| && | Найдите ресурсы, которые просто содержат этот набор слов. | Референдум && Великобритания && Европа и кризис Будут отображаться все результаты, содержащие эти слова, независимо от расстояния и местоположения друг от друга. |
На основании официальной информации
Существуют операторы поискового запроса «Яндекс» для уточнения информации по таким параметрам, как: заголовки, типы файлов, хост, домены, дата последнего изменения страниц результатов и их язык.
| Оператор | Функция | Пример использования |
| title: | Поиск документов, содержащих слова из запроса в заголовках. | название: инженерное дело Документы будут найдены со словом «инженерия» и его словоформы в названии. title: (German Engineering) Будут найдены документы с заголовками, содержащими слова «Engineering» и «Germany» (для запросов, в которых вам нужно объединить два или более слов для поиска, вы должны заключить скобки) . |
| mime: | Поиск в документах определенного формата. | шаблон резюме mime: docx Результатами поиска будут все документы в формате .docx, содержащие слова «шаблон» и «сводка». |
| хост: | Поиск страниц, размещенных на определенном хосте. | хост-счет: www.yandex.ru На хосте www.yandex.ru поиск будет проводиться по всем документам, содержащим слово «счет». |
| домен: | Поиск по всем страницам домена. | Хилари Клинтон хост: www.whitehouse.gov В домене www.whitehouse.gov будет производиться поиск всех документов, содержащих слова «Хилари» и «Клинтон». |
| дата: | Поиск страниц с учетом даты их последнего изменения (использование языка запросов Яндекса также подразумевает отсутствие значений дня и месяца в случае их замены на символ *) . | событие дня дата: 20160624 Все документы, содержащие слова «событие» и «дня», а также их словоформы, дата последнего изменения которой соответствует 24.06.2016 Дата саммита: 20150819..date20150909 Искать результаты, дата последних изменений которых находится в диапазоне с 19.08.2015 по 09.09.2015 дата круиза:> 20160611 Отображаются все результаты, дата последние изменения, которые произошли позже 11.06.2016
|
| lang: | Искать страницы на определенном языке:
| green card lang: en Найдите англоязычные документы по этому запросу. |
Практически любой зарубежный аналог имеет аналогичный язык запросов. Язык поисковых запросов «Яндекса», в свою очередь, отличается от конкурентов в целом чуть более продвинутыми функциями и возможностями.
Морфологические пояснения
По умолчанию поисковая система предлагает пользователю широкий спектр результатов, которые будут выданы по введенному запросу, в основе которых лежит не только само введенное слово / фраза, но и различные его формы (падеж, пол , склонение, число и т. д.). Также учитываются вариации части речи (будь то существительное, глагол, прилагательное и т. Д.) И первой буквы. Например, когда вы вводите в поле поиска слово «атаковано», пользователь получит информацию о других формах глагола: «атака», «атака», «атакованный» (но такие однокоренные слова, как «атака», «атакованный» не засчитываются). В этом случае результаты будут отображаться как с первой заглавной буквой в запрошенном слове, так и с маленькой.
Практически все возможности языка запросов различных поисковых систем основаны на схожих принципах работы.В Яндексе ограничение по морфологическим признакам может быть полезно для более точной работы поисковой системы:
| Оператор | Функция | Пример использования |
| ! | Искать слова исключительно в заданной форме. Язык поисковых запросов «Яндекс» допускает многократное использование оператора при наличии двух и более слов в запросе. | ! Интернет «Яндекс» выдаст все результаты в заданной форме запроса с заглавной и строчной первой буквой. ! Интернет «Яндекс» выдает результаты по заданной форме запроса, начиная только с заглавной буквы. |
| !! | Немного расширенный поиск слова и производных от него. | !! пень Будут выданы результаты любой из форм этого слова («пень», «пень», «конопля» и т. Д., Но результат будет с аналогичной словоформой глагола «Удар» будет исключен. |
Специальные методы подбора ключевых слов для контекстной рекламы
Также распространены языки поисковых запросов.далеко за пределами пользовательского сегмента, вознаграждение простыми рабочими инструментами и рекламодателями. В частности, для этих целей «Яндекс» вооружен рядом алгоритмов и операторов, позволяющих эффективно продвигать свои сайты и сервисы в поисковой системе.
Логика отображения контекстной рекламы запросов пользователя основана на выборе слов, тематически связанных с тематикой этого объявления, а также других их словоформ. Например, такие методы позволяют показывать рекламу юридических услуг не только в ответ на «юридические услуги в городе N», но и тем пользователям, которые сделали аналогичные запросы (будь то «юристы города N цен» , «Юридические фирмы», «дешево юрист город N» и др.). В результате реклама будет отображаться более широкой аудитории пользователей, а это, соответственно, потенциально привлечет к ней больше внимания.
Однако рекламу должны показывать только пользователи, которые делают тематически связанные запросы в поисковой системе. Например, реклама юридических курсов не будет эффективной, если она будет показана пользователям, которым в данный момент требуются услуги юриста. Регулирование таких моментов осуществляется с помощью целого списка операторов в поисковой системе Яндекс.Описание языка запросов для рекламных задач в целом будет выглядеть так, как показано ниже.
| Оператор | Функция | Пример использования |
| - | Исключение для слов в запросах, когда не будет показываться реклама. Допускается повторное использование оператора при необходимости установки двух и более исключений | курсы юриста дешевы Объявление будет показано по всем запросам со словами «юрист» и «дешево», за исключением тех, которые содержат слово «курсы». юрист-курсы-практика В этом случае реклама будет видна пользователям по запросам, содержащим слово «юрист», но не будет отображаться для запросов со словами «курсы» и «практика». |
| + | Показывать объявления для тех запросов, которые содержат определенное слово / слова. | + аренда + квартиры + дешево Сочи Объявление отображается в запросах, содержащих слова «аренда», «апартаменты», «Сочи», и может отображаться, если в запросе есть слово «недорого». |
| ! | Оператор служит определением определенной формы слова в запросах, в соответствии с которой будет отображаться сообщение (или наоборот). | ! клуб! Lepasso Объявления показываются только для тех запросов, в которых содержится хотя бы одно из этих двух слов в определенной форме. В этом случае «Лепассо» в запросе обязательно должно начинаться с заглавной буквы для показа объявления. ! клуб! Лепас-! пейнтбол |
() | Группировка слов для сложных запросов, состоящих из нескольких слов (язык поисковых запросов Яндекса позволяет использовать эту функцию для двух и более слов). | car- (аренда) По запросу будет показано объявление, содержащее слово «автомобиль», но без слов «аренда» и «аренда». + (покупка машины Владивосток) дешево Реклама отображается по запросам, которые обязательно содержат слова «машина», «купить», «Владивосток» и могут содержать слово «дешево»." |
| " " | Показывать объявления по запросам, содержащим только слова в кавычках или словоформы. | " программист " Рекламы показываются по запросам этого слова и его словоформ, таких как" программист ", «программист». При этом реклама не будет показываться по таким запросам пользователей, как «дешевый программист по ремонту компьютеров», «программист взлома сайтов». |
Уроки комфорта и простоты из подсказок по поиску » Яндекс »
Упростите процесс ввода поисковой информации, когда подсказка подсказок уже воспринимается без особой спешки.Такая технология сегодня есть в каждой популярной поисковой системе, она основана на предварительном выдаче популярных запросов, похожих на буквы, вводимые пользователем в поле поиска.
Яндекс реализует эту систему через некоторые особенности бренда. Все наборы подсказок обрабатываются и группируются из числа наиболее популярных запросов пользователей. Также используются научные термины из энциклопедических статей, названий фильмов, музыкальных произведений и другого тематического содержания. В результате пользователь с момента ввода самой первой буквы в строке поиска попадает под нее целым списком вариантов наиболее популярных запросов, начинающихся с одних и тех же символов.
Кроме того, в подсказках можно сразу указать ссылки на нужные сайты или ответ на вопрос. Например, достаточно ввести половину запроса «длина круга», так как в соответствующем поле под поисковой строкой пользователю будет представлена готовая формула расчета. Спрашивая «столица Австралии», вы не успеете закончить фразу до конца, так как «Яндекс» сразу выдаст эту информацию в списке подсказок.
Если ссылка на какой-либо сайт является релевантным ответом на запрос, то этот адрес будет доступен сразу в том же поле.Такой подход позволит быстро перейти к нужному ресурсу, минуя список всех найденных результатов.
Фильтрация непристойного контента
Функционал «Яндекса» также предусматривает исключение ресурсов «18+» из результатов поиска независимо от используемых инструментов языка запросов. Эта функция будет полезна в первую очередь для защиты молодых пользователей от «материалов для взрослых» в Интернете. И даже если ребенок не стесняется использовать в действии все средства, с помощью которых богат язык поисковых запросов «Яндекса», он все равно никак не помогает ему преодолеть барьер от таких сайтов.
В поиске «Яндекс» для пользователей есть 3 режима фильтрации контента:
- «Без защиты» - какие-либо ограничения на результаты полностью отсутствуют.
- «Умеренный» - если запрос пользователя явно не направлен на поиск сайтов «18+», они удаляются из результатов поиска.
- «Семья» - нецензурная лексика полностью отсутствует в результатах поиска.
Все эти варианты защиты от недетского контента отслеживаются в соответствующем меню настроек Яндекса.
Дополнительные функции поисковой системы
Помимо широкого набора операторов различных языков запросов, Яндекс также предлагает несколько способов поиска информации:
- «Расширенный» - более приятный сервис с интуитивно понятной структурой для тех, кому нужно использовать инструменты языка запросов. Просто введите необходимые параметры в соответствующие поля (поиск по конкретному ресурсу, региону, точность совпадения со словами поискового запроса, поиск по заголовкам, языку, формату документа, дате последнего обновления и т. Д.)), не прибегая к менее удобному ручному вводу операторов. «Расширенный поиск» и язык запросов «Яндекса» - это один и тот же функционал, но с той разницей, что первый предлагает использовать одни и те же операторы в более удобной форме.
- Zen Search. На основе истории поиска пользователя Яндекс предлагает новейший сервис публикации медиа. Доступен только для мобильных устройств и представляет собой набор предварительных просмотров новостей, выбранных в соответствии с историей просмотра.Пользователь может выбрать любую понравившуюся публикацию, прочитать несколько первых абзацев и, если он ему интересен, перейти на сайт издателя за этим материалом. В противном случае достаточно выбрать «Не нравится», чтобы не отображать конкретную новость или пометить таким образом весь ресурс, исключив его из своей ленты новостей.
Механизмы защиты от нежелательной и вредоносной информации
Главное свойство любой поисковой системы - это не только различные операторы поисковых запросов.Яндекс также обеспечивает высокий уровень безопасности для всех найденных результатов. Базовые поисковые страницы и предупреждения о вредоносных сайтах в этой поисковой системе появились в 2009 году. Обнаружение угроз осуществляется двумя технологиями:
- Антивирусная защита, полученная от компании Sophhos, и сигнатурный подход: доступ к антивирусной системе при посещении пользователем веб-страницу в базу данных, содержащую информацию об известных вредоносных программах. Несмотря на высокую скорость, эта технология практически полностью бесполезна при столкновении с новыми вирусными угрозами.Поэтому Яндекс дополнительно использует вторую технологию.
- Корпоративный антивирусный комплекс, в основе которого лежит поведенческий фактор. Во-первых, защита при доступе к сайту анализирует, делает ли он запрос из браузера на дополнительные файлы, перенаправляет ли он на внешний ресурс и т. Д. Если посторонние действия ресурса обнаруживаются без ведома пользователя (запуск модулей JavaScript, полные программы, каскадный стиль листов), затем добавляется в черный список опасных сайтов и базу данных сигнатур вирусов.Об этих угрозах будет уведомлен и сам владелец сайта, и все последующие проверки будут периодически проводиться до полного устранения всех проблем с безопасностью на нем.
Аналогичный подход к анализу страниц предоставлен. С результатами поиска в сочетании с проприетарными технологиями «Яндекса» удалось свести процент зараженных сайтов в этой поисковой системе к единице. Ежедневные проверки Яндекса охватывают в общей сложности до 23 миллионов ресурсов, а через месяц это число достигает около 1 миллиарда.
IMSMWU / RClickhouse: интерфейс DBI для базы данных Yandex Clickhouse, обеспечивающий базовую поддержку dplyr
Обзор
Yandex Clickhouse - это высокопроизводительная реляционная база данных с хранилищем столбцов, позволяющая анализировать большие данные и масштабировать «аналитику» до петабайт данных. Предусмотрены методы, позволяющие работать с базами данных «Яндекс Кликхаус» методами «DBI» и с использованием идиом «dplyr» / «dbplyr».
Этот пакет R представляет собой интерфейс DBI для базы данных Yandex Clickhouse.Он обеспечивает базовую поддержку dplyr путем автоматической генерации SQL-команд с помощью dbplyr и основан на официальном клиенте C ++ Clickhouse.
Чтобы процитировать эту библиотеку, используйте запись BibTeX, предоставленную в inst / CITATION .
Установка
Этот пакет доступен в CRAN, поэтому его можно установить, запустив:
инсталляционных пакетов («RClickhouse»)
Вы также можете установить последнюю версию разработки прямо из github с помощью devtools:
devtools :: install_github ("IMSMWU / RClickhouse") Использование
Создание соединения DBI:
Примечание. имейте в виду, что {RClickhouse} не использует интерфейс HTTP для связи с Clickhouse.Таким образом, Вы можете использовать порт собственного интерфейса (по умолчанию 9000) вместо интерфейса HTTP (8123).
con <- DBI :: dbConnect (RClickhouse :: clickhouse (), host = "example-db.com")
Записать данные в базу:
DBI :: dbWriteTable (con, "mtcars", mtcars) dbListTables (con) dbListFields (con, "mtcars")
Запрос базы данных с помощью dplyr:
библиотека (dplyr) tbl (con, "mtcars")%>% group_by (цил)%>% суммировать (smpg = сумма (миль на галлон)) tbl (con, "mtcars")%>% фильтр (цил == 8, vs == 0)%>% group_by (am)%>% суммировать (среднее (qsec)) # Закрываем соединение dbDisconnect (con)
Запрос базы данных с помощью команд в стиле SQL с помощью
DBI :: dbGetQuery : DBI :: dbGetQuery (con, "ВЫБРАТЬ
против
, COUNT (*) КАК "количество случаев"
, AVG (qsec) AS 'среднее qsec'
ОТ МТКАС
GROUP BY vs ")
# Сохраняем результаты запроса:
res <- DBI :: dbGetQuery (con, "ВЫБРАТЬ (*)
ОТ МТКАС
ГДЕ am = 1 ")
# Или сохраните весь набор данных (полезно только для небольших наборов данных, для повышения производительности и для больших наборов данных всегда используйте удаленные серверы):
mtcars <- dbReadTable (con, mtcars)
# Закрываем соединение
dbDisconnect (con) Запрос базы данных с помощью функций ClickHouse
# Получить имена всех доступных баз данных
DBI :: dbGetQuery (con, "ПОКАЗАТЬ БАЗЫ ДАННЫХ")
# Получить информацию об именах и типах переменных
DBI :: dbGetQuery (con, «ОПИСАТЬ ТАБЛИЦУ mtcars»)
# Компактный CASE - WHEN - THEN условные выражения
DBI :: dbGetQuery (con, "SELECT multiIf (am = '1', 'automatic', 'manual') AS 'передача'
, multiIf (vs = '1', 'прямой', 'V-образный') AS 'двигатель'
ОТ МТКАС »)
# Закрываем соединение
dbDisconnect (con) Файл конфигурации
Вы можете использовать файл конфигурации, который ищется для автоматической инициализации параметров dbConnect.
Для этого создайте файл yaml (по умолчанию RClickhouse.yaml ) хотя бы в одном каталоге (пути поиска по умолчанию для параметра config_paths: ./RClickhouse.yaml, ~ / .R / RClickhouse.yaml, / etc / RClickhouse.yaml ), например ~ / .R / configs / RClickhouse.yaml и передайте вектор соответствующих путей к файлам в dbConnect как параметр config_paths .
В RClickhouse.yaml вы можете указать переменное количество параметров ( хост, порт, база данных, пользователь, пароль, сжатие ) для инициализации, используя следующий формат (пример):
хост: example-db.ком порт: 1111
Фактическая инициализация параметров dbConnect следует иерархической структуре с различными приоритетами (от 1 до 3, где 1 - наивысший):
- Указанные входные параметры при вызове
dbConnect. Если параметры не указаны, вернитесь к (2) - Параметры, указанные в
RClickhouse.yaml, где уровень приоритета зависит от позиции пути во входном векторе config_path (первая позиция, наивысший приоритет и т. Д.)). Если параметры не указаны, вернитесь к (3). - Параметры по умолчанию (
host = "localhost", port = 9000, db = "default", user = "default", password = "", compress = "lz4").
Благодарности
Большое спасибо Кириллу Мюллеру, Максвеллу Петерсону, Артемкину Павлу и Ханнесу Мюляйзен.
What’s Inside: Data Analyst Program | по Практикуму от Яндекса | Практикум Яндекс
В 2017 году журнал The Economist писал, что «самая ценная валюта мира - это уже не нефть, а данные.«Средняя компания сейчас управляет невероятными 163 терабайтами (163 000 гигабайт) информации - это столько данных, сколько вы бы потребили, просмотрев 24 000 часов видео в формате Ultra-HD.
Возможность обрабатывать, анализировать и интерпретировать данные становится очень ценным и очень прибыльным навыком. Это также хороший шаг с точки зрения безопасности карьеры. Ожидается, что количество рабочих мест в области анализа данных будет расти стремительными темпами: 14,3% в течение следующих 10 лет. Сейчас, как никогда ранее, нам нужны квалифицированные специалисты по данным, которые могут преодолеть разрыв между бизнесом и ИТ и помочь принимать более разумные решения на основе данных.
Обязанности и навыки аналитиков данных
Аналитик данных - это человек, чья работа заключается в анализе данных и выявлении скрытых связей и идей. Аналитики данных несут ответственность за преобразование информации в идеи и передачу своих выводов другим людям, что требует как технических навыков, так и навыков межличностного общения. Анализ данных необходим в бизнесе, управлении и науке.
Анализ данных состоит из сбора и структурирования данных, формирования и проверки гипотез, выявления закономерностей и вывода выводов.Как минимум, аналитики данных должны знать SQL (язык структурированных запросов), предпочтительный язык запросов для взаимодействия с реляционными базами данных (включая поиск, добавление и обновление данных). Кроме того, аналитики данных должны быть знакомы хотя бы с одним языком программирования. Два наиболее распространенных языка для аналитиков данных:
- Python, очень популярный и удобный язык программирования, который включает в себя множество библиотек и фреймворков для анализа данных.
- R, язык программирования и программная среда для статистических вычислений и анализа данных.
Кроме того, аналитики данных также должны иметь солидный опыт в математике, особенно в области теории вероятностей и статистики. Другие полезные разделы математики для аналитиков данных включают линейную алгебру, исчисление, оптимизацию и дискретную математику.
Аналитики данных используют эти технологии и концепции для преобразования необработанных данных в ценные бизнес-идеи. В обязанности аналитика данных входит:
- Сбор данных, формирование гипотез, проведение экспериментов и формирование выводов.
- Создание отчетов и информационных панелей, четко отражающих их выводы.
- Помогаем интерпретировать результаты и делиться своими выводами с коллегами.
Здесь важно различать аналитиков данных и специалистов по обработке данных.
Подробнее о профессии специалиста по данным читайте в статье «Что внутри: программа Data Scientist».
Хотя оба работают с информацией, они взаимодействуют с ней и используют ее по-разному:
- Аналитики данных используют свои таланты, чтобы принимать разумные стратегические бизнес-решения на основе данных.Хорошие аналитики данных должны обладать как техническими знаниями, так и сильными человеческими навыками, которые помогают им сообщать свои выводы своим коллегам, особенно нетехническим руководителям и ключевым заинтересованным сторонам.
- Специалисты по обработке данных гораздо больше вовлечены в техническую сторону науки о данных, включая разработку алгоритмов и моделей и создание вопросов, которые нужно задать. Они используют сложные методы для решения сложных проблем, и их работа иногда совпадает с разработкой программного обеспечения. Таким образом, работа в области анализа данных обычно требует более глубоких знаний в области программирования и математики.Коммуникация - полезный навык и для специалистов по анализу данных, но специалисты по данным больше взаимодействуют с коллегами-техническими специалистами, а не с нетехнической бизнес-стороной организации.
Диапазон заработной платы для аналитиков данных
Заработная плата аналитиков данных будет зависеть от вашей отрасли, ваших навыков и уровня вашего опыта. Однако талантливые аналитики данных должны иметь возможность получать зарплату, значительно превышающую средний доход.
Ниже приведены некоторые оценки средней заработной платы аналитиков данных в США:
Высокий спрос на аналитиков данных среди предприятий любого размера и из всех отраслей, а также высокий интерес среди работников к удовлетворению этого спроса вдохновили Practicum на создание нашей уникальной Программа Data Analyst.Никаких официальных предпосылок у нас нет - только мотивация и жажда знаний.
Многие из наших студентов уже имеют работу, поэтому им сложно посещать дневные курсы. Вот почему программа Data Analyst от Practicum является интерактивной и асинхронной: вы можете завершить программу в удобном темпе, подготовившись к карьере в области анализа данных, даже если вы работаете в другой сфере.
Однако не заблуждайтесь: вы будете усердно работать на протяжении всей программы, и на другом конце вы получите фундамент, необходимый для успешного аналитика.Программа Data Analyst от Practicum использует ориентированный на результат подход, побуждая студентов учиться, применяя свои знания в бизнес-кейсах, основанных на реальных данных.
Программа была разработана рядом опытных преподавателей и профессионалов из Школы анализа данных Яндекса при участии успешных технических специалистов. Мы основали программу на навыках, которые необходимы настоящим аналитикам данных в их повседневной работе, а также на тщательном исследовании рынка труда для анализа данных.
Мы хотим убедиться, что все наши студенты понимают, на что похожа программа, и что у них есть мотивация, необходимая для достижения успеха. Вот почему мы предлагаем бесплатный 20-часовой вводный курс, содержащий информацию об анализе данных и основах программирования на Python.
По окончании вводного курса вы пройдете через серию модулей, каждый из которых предназначен для ознакомления с определенным аспектом анализа данных. Обучение будет проходить через специально разработанную интерактивную платформу Practicum, которая позволяет вам учиться, задавать вопросы и получать помощь от нашей круглосуточной службы технической поддержки.
У вас будет неделя на завершение каждого проекта, после чего рецензент кода его рассмотрит. Если ваш проект не будет принят, у вас будет несколько дней на исправление ошибок.Каждый модуль завершается проектом, который помогает закрепить то, что вы уже узнали. После завершения каждого проекта студенты получат подробный обзор кода от наших знающих профессионалов.
По окончании программы вы получите профессиональный сертификат, подтверждающий, что вы успешно закончили программу, а также дополнительный заключительный курс для помощи с трудоустройством (см. Ниже).Даже после завершения программы у вас будет доступ к обучающей платформе, чтобы вы могли освежить в памяти материал по мере необходимости.
Серьезное содержание
Полная программа Data Analyst рассчитана на шесть месяцев. За 220 часов обучения вы превратитесь из новичка в мастера.
Распространение переформулировки запросов в журналах запросов Яндекса
Целью данного исследования является определение факторов, влияющих на создание предложений запросов. Предложение запроса стало одной из самых фундаментальных функций поисковых систем, которые помогают пользователю сформулировать запрос и удовлетворить информационные потребности путем предоставления возможных ключевых слов.В этом исследовании, чтобы определить эффективные факторов при создании предложений запроса использовался систематический обзор. С этой целью ключевые слова английского и персидского языков, относящиеся к предложениям запросов, были найдены в зарубежных научных базах данных, таких как Science Direct, Emerald, Scopus, Online Willy, IEEE, а также во внутренних базах данных Magiran, База данных научной информации Джихада и Cilivica. нашел статьи, связанные с эффективными контекстными факторами при создании предложений запроса.Для систематического обзора метод Wright et al. (2007), который включает семь шагов: определение вопроса исследования, определение протокола, поиск литературы, извлечение данных, оценка качества, анализ данных и результат. После поиска по ключевым словам на персидском и английском языках и сопоставления их с критериями входа и выхода было отобрано 36 статей для извлечения эффективных факторов. Результаты систематического обзора в области предложения запроса показывают, что пять факторов: местоположение, время, пользовательские поисковые сеансы. (включая текущий сеанс поиска пользователя и пользователя история поиска), гибридные факторы и другие контексты были эффективны при создании предложений запроса.