
как нейронные сети помогают поиску Яндекса
Алгоритм «Палех»: как нейронные сети помогают поиску Яндекса
Мы запустили новый поисковый алгоритм — «Палех». Он позволяет поиску Яндекса точнее понимать, о чём его спрашивают люди. Благодаря «Палеху» поиск лучше находит веб-страницы, которые соответствуют запросам не только по ключевым словам, но и по смыслу. За сопоставление смысла запросов и документов отвечает поисковая модель на основе нейронных сетей.
«Длинный хвост»
Каждый день поиск Яндекса отвечает примерно на 280 миллионов запросов. Какие-то из них, например [вконтакте], люди вводят в поисковую строку практически каждую секунду. Какие-то запросы уникальны — их задают один раз, и они, возможно, больше никогда не повторятся. Уникальных и просто редких запросов очень много — около ста миллионов в день.
График частотного распределения запросов в Яндексе часто представляют в виде птицы, у которой есть клюв, туловище и длинный хвост. Список самых распространённых запросов не особо велик, но их задают очень-очень часто — это «клюв» птички. Запросы средней частотности образуют «туловище». Низкочастотные запросы по отдельности встречаются чрезвычайно редко, но вместе составляют существенную часть поискового потока и поэтому складываются в «длинный хвост».
Новый алгоритм позволяет поиску Яндекса лучше отвечать на сложные запросы из «длинного хвоста». Такой хвост есть у сказочной Жар-птицы, которая часто появляется на палехской миниатюре. Поэтому мы дали алгоритму название «Палех».
Запросы из «длинного хвоста» очень разнообразны, но среди них можно выделить несколько групп. Например, одна из них — запросы от детей, которые пока не освоили язык общения с поиском и часто обращаются к нему как к живому собеседнику: [дорогой яндекс посоветуй пожалуйста новые интересные игры про фей для плантика]. Ещё одна группа — запросы от людей, которые хотят узнать название фильма или книги по запомнившемуся эпизоду: [фильм про человека который выращивал картошку на другой планете] («Марсианин») или [фильм где физики рассказывали даме про дейтерий] («Девять дней одного года»).
Особенность запросов из «длинного хвоста» в том, что обычно они более сложны для поисковой системы. Запросы из «клюва» задают многократно, и для них есть масса разнообразной пользовательской статистики. Чем больше знаний о запросах, страницах и действиях пользователей накопил поиск, тем лучше он находит релевантные результаты. В случае с редкими запросами поведенческой статистики может не быть — а значит, Яндексу гораздо труднее понять, какие сайты хорошо подходят для ответа, а какие не очень. Задача осложняется тем, что далеко не всегда на релевантной страничке встречаются слова из запроса — ведь один и тот же смысл в запросе и на странице может быть выражен совершенно по-разному.
Несмотря на то, что каждый из запросов «длинного хвоста» по отдельности встречается крайне редко, мы всё равно хотим находить по ним хорошие результаты. К решению этой задачи мы привлекли нейронные сети.
Семантический вектор
Искусственные нейронные сети — один из методов машинного обучения, который стал особенно популярен в последние годы. Нейросети показывают отличные результаты в анализе естественной информации: картинок, звука, текста. Например, нейронную сеть можно обучить распознавать на изображениях те или иные объекты — скажем, деревья или собак. В ходе обучения ей показывают огромное количество картинок, где есть нужные объекты (положительные примеры) и где их нет (отрицательные примеры). В результате нейросеть получает способность верно определять нужные объекты на любых изображениях.
В нашем случае мы имеем дело не с картинками, а с текстами — это тексты поисковых запросов и заголовков веб-страниц, — но обучение проходит по той же схеме: на положительных и отрицательных примерах. Каждый пример — это пара «запрос — заголовок». Подобрать примеры можно с помощью накопленной поиском статистики. Обучаясь на поведении пользователей, нейросеть начинает «понимать» смысловое соответствие между запросом и заголовками страниц.
Компьютеру проще работать с числами, чем с буквами, поэтому поиск соответствий между запросами и веб-страницами сводится к сравнению чисел. Мы научили нейронную сеть переводить миллиарды известных Яндексу заголовков веб-страниц в числа — а точнее, в группы из трёхсот чисел каждая. В результате все документы из базы данных Яндекса получили координаты в трёхсотмерном пространстве.
Вообразить такую систему координат человеку довольно трудно. Давайте упростим задачу и представим, что каждой веб-странице соответствует группа не из трёхсот, а из двух чисел — и мы имеем дело не с трёхсотмерным, а всего лишь с двумерным пространством. Тогда получится, что каждое число — это определённая координата по одной из двух осей, а каждая веб-страница просто соответствует точке на двумерной координатной плоскости.
Точно так же в набор чисел можно перевести и текст поискового запроса. Другими словами, мы можем разместить запрос в том же пространстве координат, что и веб-страницу. Замечательное свойство такого представления состоит в том, что чем ближе они будут расположены друг к другу, тем лучше страница отвечает на запрос.
Такой способ обработки запроса и его сопоставления с вероятными ответами мы назвали семантическим вектором. Этот подход хорошо работает в тех случаях, когда запрос относится к области «длинного хвоста». Семантические векторы позволяют нам лучше находить ответы на сложные низкочастотные запросы, по которым имеется слишком мало пользовательской статистики. Более того, представляя запрос и веб-страницу в виде вектора в трёхсотмерном пространстве, мы можем понять, что они хорошо соответствуют друг другу, даже если у них нет ни одного общего слова.
Мы начали использовать семантический вектор несколько месяцев назад, постепенно развивая и улучшая лежащие в его основе нейронные модели. О том, как мы обучали нейронную сеть преобразовывать запросы и документы в семантические векторы, читайте в блоге Яндекса на «Хабрахабре».
Дальше — больше
Семантический вектор применяется не только в поиске Яндекса, но и в других сервисах — например, в Картинках. Там он помогает находить в интернете изображения, которые наиболее точно соответствуют текстовому запросу.
Технология семантических векторов обладает огромным потенциалом. Например, переводить в такие векторы можно не только заголовки, но и полные тексты документов — это позволит ещё точнее сопоставлять запросы и веб-страницы. В виде семантического вектора можно представить и профиль пользователя в интернете — то есть его интересы, предыдущие поисковые запросы, переходы по ссылкам. Далёкая, но чрезвычайно интересная цель состоит в том, чтобы получить на основе нейронных сетей модели, способные «понимать» семантическое соответствие запросов и документов на уровне, сравнимом с уровнем человека.
Источник
Палех алгоритм Яндекса | Принцип работы и цель его создания
Привет, Друзья! Тема сегодняшней статьи, алгоритм Яндекса «Палех». Зачем его внедрил Yandex, какой принцип работы алгоритма, давайте разбираться!
Алгоритм Яндекса Палех

Обрабатываемые системой поисковой выдачи запросы бывают короткие и длинные, некоторые из них могут быть слишком частыми. Есть уникальные запросы, которые не повторялись когда-либо. Идея использования алгоритма под названием «Палех» связана с возможностью анализа контента на веб-страницах по низкочастотным запросам.
Алгоритм «Палех» в понимании Яндекса
Благодаря вышедшему алгоритму Палех в ноябре 2016 года появилась возможность поиска по заголовкам, а не только по текстовому контенту на странице веб-ресурса. Вся масса обрабатываемых системой Яндекс запросов представлена разработчиками как жар-птица из палехской живописи:
клюв — символизирует поиск запросов, которые более распространены либо являются короткими;туловище — обозначает выдачу среднечастотных результатов поиска;
хвост — определяет смысловое содержание уникальных словосочетаний.
Отсюда происходит и само название алгоритма поисковой выдачи «Палех», действие которого связано с семантическим анализом контента веб-страниц. Алгоритм ранжирования страниц по низкочастотным запросам назван так в честь поселка, расположенного в Ивановской области, на гербе которого изображена жар-птица.
Цель создания алгоритма Палех
Для точного нахождения информации по запросам работа системы Яндекс основана на применении прошлого опыта пользователей с учетом следующих поведенческих факторов:
- времени, проведенного на веб-странце;
- оставленных комментариев к контенту;
- добавлении в закладки страницы;
- определении полезного контента.
Ориентация в новых запросах системой Яндекс усложнена, поскольку поисковик не имеет возможности ранжировать страницы, исходя из прошлого опыта пользователей. Разработчикам удалось решить проблему, создав алгоритм Палех, работа которого основана на машинном обучении Matrixnet, связанном с семантическим анализом.
Известно, что из общей массы ежедневных запросов 1/3 часть – это низкочастотные. Именно они позволяют сайтам выходить в ТОП 10, поэтому веб-мастера используют их чаще. Уровень конкуренции по этим словам и фразам слабый. Они сильно отличаются, но алгоритм Яндекса Палех может угадывать эти запросы, сравнивая смысл выражений и определяясь с ответом на поставленный вопрос в поисковой выдаче. «Палех» способен с первого раза определить по смысловому содержанию запроса ту информацию, которая необходима пользователю.
Использование нейронных сетей
Возможности нейронных сетей, связанные с поиском музыки либо изображений, немного изменились. Функционирование алгоритма «Палеха», обеспечивающего машинное обучение, полностью основано на переобучении искусственных нейронных сетей, получивших возможность распознавать смысл текстового контента веб-страниц. Проведение сложного семантического анализа предполагает использование накопленного опыта, связанного с простыми запросами.
Система, совмещающая вводимый пользователем запрос с заголовком текста, осуществляет перевод словосочетаний и фраз для последующего анализа, присваивая им определенный код из 300 цифр. Это позволяет сформировать семантический вектор.
Пользователи вводят в поисковик не только низкочастотные запросы, но и уникальные, которые никогда раньше не были использованы. Статистика по ним отсутствует, поэтому использование самообучаемых искусственных нейронных сетей (ИНС) и алгоритма Палех, позволяет найти правильный ответ на вопрос.
На основе разработанного алгоритма «Палех» ИНС получили возможность обрабатывать огромное количество информации. Принцип действия нейронных сетей имеет сходство с работой человеческого мозга. Открыв поисковую систему, пользователь вбивает текст, переводимый «Палехом» в 300 мерное пространство. Выстроенная алгоритмом система координат, позволяет определить наиболее подходящий по запросу документ. В результате пользователь получает релевантный ответ на заданный им вопрос.
Принцип действия системы Яндекс.Поиск предполагает понимание поисковиком степени удовлетворения потребностей пользователя, предоставляя ему возможность быстро найти ту информацию, о которой он спрашивал. Если пользователь не осуществляет повторного поиска, то Яндекс понимает, что результат выдачи был показан правильно. Выданный верный ответ по заданному вопросу будет показан и другим пользователям системы Яндекс.
Обучение SEO
Если вы хотите научиться выводить сайты в ТОП 10 поисковых систем Яндекс и Google, посетите мои онлайн-уроки по SEO-оптимизации (коротко о себе я рассказал в видео ниже). Все свои интернет-проекты я вывел на посещаемость более 1000 человек в сутки и могу научить этому Вас. В отличие от коллег я не продаю видео курсы, так как они не информативны, и просматривая их некому задавать вопросы. Я провожу обучение по скайпу индивидуально и во время урока отвечаю на все возникающие вопросы моих учеников. По времени SEO обучение длиться около 4 — 6 часов в зависимости от начальной подготовки ученика. Кому интересно обращайтесь!

На этом сегодня всё, всем удачи и до новых встреч!
Алгоритм Палех Яндекс. Зачем, о чем, как работает и кому полезен?
Палех… палех. Сейчас доберусь и до него.
Прелюдия: продвижение по низкочастотным запросам.
Но сначала давай вводную предварительно напишу. Итак, по порядку. Я довольно давно занимаюсь интернет-маркетингом, поэтому продвижение сайтов через поисковую систему Яндекс совсем родное. Это касается как СЕО, так и контекстной рекламы.
Сейчас несколько абзацев по низкочастотке, а потом перейдем к палеху.
Продвижение продвижению рознь. Попытки продвигаться по высоко частотным запросам были оставлены далеко в глубокой юности, ибо желание урвать себе кусок потолще, как правило, заканчивалось в ноль слитым бюджетом с такой же эффективностью.
И на помощь пришли низкочастотные ключевые запросы. Однако оставим в покое контекст и сосредоточимся на СЕО.

[Зачем палить из пушки по воробьям, когда можно взять снайперскую винтовку?]
И, о Боги. Семантика сайта, сформированная на большом количестве низкочастотных запросов, творит почти чудеса. Конкуренция низкая, трафик приходит быстро и самое главное, конверсия с такого трафика значительно выше. Понимаешь почему? Сейчас поясню.
Что такое низкочастотный запрос? Низкочастотный запрос — это, по сути, сформулированная потребность человека, которую ему необходимо решить, так? Так. Ну, например:
- Как избавиться от грыжи позвоночника без операции? Или
- Наращивание волос в Апрелевке круглосуточно
- Купить ранец для школы в Москве
Потребность есть? Есть. Осталось дело за малым. Оказаться в топе по такому низкочастотному запросу и удовлетворить желание
Новый поисковый алгоритм Яндекса.

Прошел почти месяц как Яндекс анонсировал запуск нового алгоритма «Палех». Откуда взялось это название, и причем здесь клюв, туловище… а главное хвост, об этом подробно вы можете прочесть у самого Яндекса.
Я же здесь постараюсь кратко изложить суть вещей без занудства, а главное рассказать, тоже без лишней тягомотины.)) что этот алгоритм нам принес.
Непросто так мое повествование началось с НЧ. Все дело в хвосте жар-птицы, как бы глупо это не звучало. Именно он символ сложных для понимания поиска низкочастотных запросов.
Действительно, «…запросы длинного хвоста очень разнообразны…» и для того, чтобы их удовлетворить Яндекс и создал этот новый алгоритм на основе нейронных сетей.
С вашего позволения о развитии искусственного интеллекта, способности к самообучению, анализу больших объемов данных, семантическом векторе и других технических тонкостях писать не буду, просто потому что такие технические дебри убивают весь запал в работе.
Чего нам ждать от Палеха?

Итак. По факту алгоритм уже работает три месяца, до объявления о запуске он уже работал два месяца, это не секрет.
Суть сего алгоритма в том, что теперь ранжирование сайтов идет не только по точным ключевым запросам, но и по фразам, которые схожи с ними по смыслу.
Т. е. сам запрос может быть очень сложным и единственным в мире по своей уникальности, а т.к. у Яндекса по таким запросам не было статистики, поэтому ему сложно найти релевантные страницы. И тут на помощь приходит «Палех» с его нейронными сетями.
Один из примеров Яндекса, когда человек хочет найти фильм, но не знает его названия. Запрос может звучать как: «фильм про человека, который сажал картошку на другой планете» … «Марсианин».
Кого коснется новый алгоритм? Прежде всего, конечно, сайты, содержащие большое количество качественного текстового контента. Почему? Да потому что теперь такие сайты будут ранжироваться по ключам, по которым раньше не ранжировались. Понимаешь?

[Контент — двигатель торговли]
Смотри, у тебя есть хороший сайт, с нормальным трастом, есть семантика, есть полезный контент. И есть Палех. Он то и будет приводить тебе органический трафик, искавший похожее по смыслу, анализируя весь этот семантический вектор. Такой вот бонус от Яндекса по «хвостатым» низкочастотным запросом.
Сейчас люди все большего хотят от поисковика, и уже около 40% всех запросов уникальны… т. е. таких больше нет. Это и есть тот самый длинный хвост низкочастотных запросов, который раздает приятные бонусы качественным проектам.
А вот некачественные проекты, рано или поздно, останутся у разбитого корыта. И это объясняется просто. Если сейчас алгоритм распознает заголовки и на их анализе выдает страницы, то недалек тот час, когда тот же самый алгоритм научится распознавать текста… и вот тогда, все сео тексты, а может даже и рерайты, к чертям.
И на этой позитивной ноте, откланяюсь.
P.S. Напишите в комментариях, что вы думаете о новом алгоритме Яндекса и как он отразился на вашем сайте? Ну и все в том же духе.
АВТОР:
Субботин Иван
Иван Субботин владелец агентства интернет маркетинга SaturDay и ведущий бизнес консультант с уникальным опором на социальные медиа. Он пришел на этот рынок с одной целью, поднять с колен Российский бизнес. Использует в своем арсенале 10 летний опыт работы с digital, интернет маркетингом и продвижения в социальных медиа. Оставайтесь на связи со мной вступайте в мою социал-медиа страницу в Facebook (Иван Субботин).
Палех Яндекс: особенности нового алгоритма
Друзья, я рада приветствовать вас на Blog-Bridge.ru. Вы, наверное, уже слышали новость о новом алгоритме Палех? Яндекс как поисковая система постоянно совершенствует свои алгоритмы обработки информации.
Вот и в этом году он анонсировал запуск нового алгоритма с креативным названием «Палех».
Я буквально недавно узнала эту новость и сразу обратила на это внимание. Думаю, что многие блогеры и веб-мастера тоже заинтересовались данной информацией.
Кроме того, мы ведь не так давно запустили новый эксперимент и я теперь полностью погружена в его реализацию.
Эксперимент «Комплексное продвижение блога». В ходе данного эксперимента вы узнаете: какими методами мы будем продвигать блог, какие из них окажутся эффективными и какие результаты они принесут; какой прирост посещаемости будет у нас ежемесячно; какими способами мы будем набирать подписную базу; как будут задействованы социальный сети; какими сервисами мы будем пользоваться для выполнения поставленных задач; и многое другое.
Ведь что мы сейчас наблюдаем в Сети? Сайтов, блогов и веб-порталов становится всё больше и больше, и вот чтобы давать максимально точные ответы на запросы пользователей, Яндекс начал использовать нестандартные подходы в обучении своих поисковых роботов.
Цель создания нового поискового алгоритма – улучшить качество предоставляемых ответов в выдаче для пользователей. Предыдущие поисковые модели подбирали информацию по соответствию ключевым словам. Новая модель на основе нейронных сетей умеет подбирать информацию по смыслу. Представляете? И это не фантастика!
Ещё одна интересная разработка нового метода поиска «Палех» — распознавание изображений. Поисковые роботы смогут различать образы на картинках – например, деревья или дома. И это тоже не фантастика 🙂
Итак, друзья, если вам хочется узнать побольше про этот подход и познакомиться с Жар-птицей Яндекса поближе, то приглашаю к прочтению
Содержание статьи:
Как соотносятся запросы с образом Жар-Птицы
Наверняка, первый вопрос, который возникает, после прочтения названия алгоритма: «А почему собственно Палех?» Кстати, я подумала об этом в первую очередь. Есть еще среди моих читателей такие индивиды?
Название алгоритма у Яндекса «Палех» напрямую связано с палехской живописью. Ведь если вспомнить, то именно на росписях знаменитых художников часто использовался образ Жар-птицы. Я даже помню на уроках ИЗО пыталась нарисовать что-то из этого художественного жанра.
Но вернемся к теме нашей статьи.
Яндекс разделяет все поисковые запросы на три большие группы, которые соответствуют клюву, туловищу и длинному хвосту Жар-птицы.
- Первая группа – это высокочастотные запросы. Люди запрашивают ответы на них ежесекундно. О чем это могут быть запросы? Это новости, погода, такие распространённые вопросы «Как сбить температуру?» и тому подобные. Сам список высокочастотных запросов не велик – поэтому они составляют клюв Жар-птицы.
- Вторая группа — среднечастотные запросы. Их список значительно шире, поэтому они составляют туловище птицы.
- Третья группа – низкочастотные запросы. Это очень редкие и своеобразные запросы, многие из которых задаются единожды в истории поиска. Если все эти уникальные запросы сложить вместе, получится гигантская цифра: 100 млн. запросов ежедневно. Вы только вдумайтесь в эту цифру! Именно поэтому низкочастотные запросы составляют пышный и длинный хвост Жар-птицы.
Алгоритм «Палех» призван находить релевантные ответы на запросы из «длинного хвоста», чтобы не оставлять миллионы пользователей без ответа.
Статья в тему:
Как проверить релевантность страницы онлайн: самый крутой сервис
Что такое поисковая выдача Яндекса и Гугл или зачем нужен ТОП
Чем отличаются редкие запросы от обычных?
Редкие запросы не рассчитаны на прежние алгоритмы поисковых роботов. Например, люди пытаются, так сказать, по-человечески спросить у Яндекса ту или иную информацию.
Приведу конкретный пример из моего недавнего опыта. Решила дать послушать дочке песенку, которая нравилась мне в детстве, но я не помню ни её названия, ни кто поёт. И в поисковую строку Яндекса мне пришлось вбивать единственную строчку, которая всплыла в моей памяти «растет на болоте зеленая трава». Яндекс, конечно же, нашел мне эту песню, и мы и наслушались, и натанцевались под нее. Вот мой запрос — это редкий, поскольку не все ведь будут искать эту песню именно по этой строчке 🙂
Сюда же можно отнести и запросы от детей и подростков: «какой мне посмотреть интересный мультик, только не про пони».
Согласитесь, что высокочастотные запросы обрабатываются тысячи раз, поэтому Яндексу известна статистика поведения пользователей на каждый запрос из выдачи. А редкие запросы требуют индивидуального подхода, потому что по ним нет статистики – какие ответы подходят, а какие нет.
Вот чтобы различать и понимать смысл уникальных вопросов и были придуманы нейронные сети.
Как используются нейронные сети в алгоритме «Палех» Яндекс
Давайте теперь поговорим немного о нейронной сети.
В последние несколько лет они положительно зарекомендовали себя в обработке естественной информации: текстовой, звуковой и графической.
Что же из себя представляют эти сети?
Нейронные сети — это «искусственный интеллект», который после машинного обучения успешно распознает информацию.
Например, во время обучения им показывают картинки слона в ряду с другими картинками, обозначая изображения со слонами за положительные примеры, а все остальные – за отрицательные. Или сообщают нейронной сети набор характерных черт слона: длинный хобот, большие уши и так далее.
Изображения без слонов и не характерные черты выдают за отрицательные примеры. Это позволяет находить верные изображения на запрос: «картинка со слоном» из миллиона других.
Принцип обучения нейронных сетей в алгоритме «Палех» тот же, только он помогает роботам соотносить поисковые запросы с текстами и заголовками на сайтах. Нейронной сети показывают ряд примеров: положительных и отрицательных.
Таким образом, нейросеть учится распознавать, насколько заголовок и текст отражают информацию, которую ищут люди.
Как информация обрабатывается в трёхсотмерном пространстве
Думаю, сложно поспорить с тем фактом, что особенность любого компьютера в том, что ему легче работать с числами. Поэтому Яндекс и придумал, чтобы нейронные сети переводили заголовки страниц на ресурсах в числа.
В Сети размещаются миллиарды различных заголовков. Они разбиваются нейронными сетями на группы, каждая из которых состоит из трёхсот чисел. Таким образом, все документы, занесённые после обработки информации в базу Яндекса, измеряются координатами в трёхсотмерном пространстве. Да, друзья, вы не ослышались, именно трёхсотмерное!
В этом же ключе планируется работать с текстами веб-порталов.
Разобраться в такой системе для робота так же просто, как человеку представить систему координат с двумя осями х и y. Только для человека понятно двухмерное пространство, а для робота – трёхсотмерное. После того как заголовки или текст переводятся в числа и попадают в трёхсотмерное пространство, они представляют собой точку с координатами на оси (почти как в учебнике по алгебре).
Переведённые в числовой эквивалент заголовок и текст запроса располагают в одной системе координат. Таким образом, они представляют собой две точки в трёхсотмерном пространстве. В принципе все логично и достаточно просто.
Благодаря нахождению запроса и ответа в одном измерении, нейронной сети легко понять, насколько они друг другу соответствуют. Близкое расположение говорит о том, что текст точно отвечает на вопрос. И тогда именно его робот и даст в выдаче.
Технология перевода информации в числа и их последующего измерения в системе координат получила название семантического вектора.
Перспективы развития семантического вектора
Изначально технология семантического вектора была задумана для улучшения качества выдачи на редкие запросы из «хвоста Жар-птицы». Но после короткого промежутка времени она дала положительные результаты, и стала использоваться в других сервисах.
Сейчас технология семантического вектора помогает выдавать максимально точные изображения на запросы пользователя. А в обозримом будущем предполагается исследовать в трёхсотмерном пространстве целые полотна текстов с ресурсов. Вообщем то ли еще будет 🙂
Нейронные сети всё время совершенствуются и выводят на новый уровень взаимодействие человека и компьютера. Благодаря нестандартному подходу подбора информации по смыслу – поисковая система в перспективе сможет отвечать на вопросы не хуже, чем человек. К этому в принципе все и движется.
***
Друзья, на этом буду заканчивать свой пост. Интересна ли вам была данная информация? Как планируете ею воспользоваться? Делитесь в комментариях ))
С вами была Екатерина Калмыкова,
пока-пока!
Алгоритмы Яндекса и Google: RankBrain VS Палех
Сегодня речь пойдет о двух поисковых алгоритмах разных поисковых систем, но направленных на одну цель (главную цель всех поисковых систем) – понять, что именно ищет человек, задав тот или иной поисковый запрос, и предоставить релевантный исчерпывающий ответ, который удовлетворит потребности ищущего.
Представьте ситуацию – вы что-то ищете, но не знаете как точно это называется и вбиваете в поисковую строку всё, что хоть как-то может описать объект поиска.

Чаще всего в этом случае вводятся longtale-запросы (или «длиннохвостые», низкочастотные запросы, состоящие из более 3-4 слов):

Раньше поисковики выводили в результатах ответы, в которых было больше всего вхождений из запроса пользователя.
Но часто случалось, что такие результаты совсем не отвечали на запрос пользователя:

Поисковикам нужно было как-то научиться понимать, что конкретно ищет человек, вбивая ту или иную фразу в поиск, самую суть запроса. Помочь в этом поисковым системам может искусственный интеллект, или как его еще называют – машинный интеллект.
Google RankBrain
Для начала оглянемся назад в 2013 год и обратим своё внимание на блог компании Google, а именно, на новость от 14 августа: https://opensource.googleblog.com/2013/08/learning-meaning-behind-words.html
Новость с загадочным заголовком Learning the meaning behind words – «Понять смысл слов».
В двух словах: данная статья рассказывает о прогрессе в области машинного обучения и технологиях распознавания речи.
Приводится интересный эксперимент recognize cats (and many other objects) по распознаванию кошек и других объектов. Эксперимент закончился успехом – просмотрев более миллиона случайных скриншотов из YouTube алгоритм с использованием нейронных сетей смог распознать и построить лица людей и морды кошки. При том, что первоначальных параметров о том, как выглядят объекты, алгоритм не имел:

Но нас больше интересует вторая часть данной статьи, в которой рассказывается про технологию машинного обучения и обработку текстовой информации Word2Vec.
Данная технология занимается поиском связей между словами. Word2vec разбирает текст таким образом, чтобы найти сходства между понятиями.
Например, он понимает, что Париж и Франция связаны так же, как Берлин и Германия (столица и страна). На диаграмме ниже показано, насколько хорошо данная технология может разобрать города по странам, просто прочитав множество новостных статей – без участия человека.

У многих сейчас возникает вопрос, каким образом это все относится к RankBrain?
Дело в том, что RankBrain – это название системы искусственного интеллекта, созданной на базе алгоритмов машинного обучения. Своим действием RankBrain очень похож на Word2Vec.
RankBrain помогает обрабатывать результаты поиска. Смысл работы алгоритма следующий: так же, как Word2Vec, RankBrain ищет связи понятий, которые поисковый робот может распознать. Когда алгоритм встречает незнакомые для себя слова или фразы, он начинает искать и разбирать подсказки.
Таким образом, он пытается осознать, какие синонимы имеются по данному запросу. Найденные аналогии и ложатся в основу при фильтрации результатов.
Затем алгоритм сопоставляет поведенческие факторы пользователей по предложенным им результатам. И сортирует результаты, убирая неподходящие.
Возможно, это покажется непонятным и замысловатым, но чуть ниже покажем на конкретных примерах, и все встанет на свои места. А пока пару слов скажем о Яндексе.
Яндекс «Палех»
2 ноября 2016 компания Яндекс анонсировала свой новый алгоритм «Палех»:

Более подробно об Алгоритме «Палех» можете прочитать в нашей статье или в блоге Яндекса. Суть работы нового алгоритма очень схожа с RankBrain.
Чтобы не уходить в дебри теории, рассмотрим на примерах работу данных алгоритмов и оценим, кто из поисковых систем ответит лучше на наши запросы. Итак, раунд первый. Вбиваем запрос: «Кто является самым высоким млекопитающим». Видим следующие результаты выдачи:
- Google

В выдаче видим общую информацию о крупных млекопитающих, в первом источнике видно, что это Жираф.
- Яндекс
Яндекс только на 4-м месте предоставляет верный интересующий нас ответ и то только по прямому вхождению.


Безусловно, в самом источнике, который Яндекс показывает на первом месте в результате выдачи, говорится о том, что это Жираф, но в сниппете информация об этом не отражена. Плюсуем Гуглу.
Раунд второй. Запрос: «Вид спорта при котором штанга поднимается с груди спортсмена».
- Google
На первом месте четкий ответ – тяжелая атлетика. Браво! Смотрим, что в Яндексе:
- Яндекс
Выдача очень похожа. Ставим «плюс» как Яндексу, так и Google. Ответ на запрос есть на 1-м месте результатов выдачи.


Раунд третий. Усложним игру. Возьмем запрос «Жена Трампа»:
- Google
- Яндекс


Что Яндекс, что Google дали нам ответ. В выдаче Яндекса у нас отработал колдунщик, а в Гугле – быстрые ответы. Но в выдаче Гугла видим, что в сниппете на первом месте у нас выделено именно то, что мы ищем.
Теперь немного изменим запрос – следом поищем: «жена Дональда Трампа».
- Google
Ответ был расширен, теперь мы знаем что у Американского президента было 3 жены. Чем парирует Яндекс?
- Яндекс
А в Яндексе все без особых изменений. В третьем раунде получаем вновь превосходство Гугла.


Поможем Яндексу, проведем 4-й раунд, возьмем запрос, который сам Яндекс анонсировал при запуске Палеха: «Фильм про человека который выращивал картошку на другой планете». Что на этот запрос ответит Гугл?
- Google
Ответ четкий и однозначный – Марсианин. Что насчет Яндекса?
- Яндекс
Как мы видим, выдача Яндекса в данном случае «забита» новостями об алгоритме, хотя информация о фильме и представлена в блоке справа.


Раунд 5. Последний запрос возьмем коммерческий. Прикинемся блондинкой, вобьем запрос: «купить инструмент для проделывания дырок в бетоне небольшого размера»:) Итак, что скажет Гугл?
- Google
Google на первом месте показывает статью о видах инструментов для сверления отверстий в бетоне, в общем-то – неплохо. Хотя ответ не совсем релевантен: мы всё-таки хотели купить, а не почитать о нём.
- Яндекс
А в Яндексе почему-то релевантнее оказалась статья про дыроколы для кожи… Полный разгром и победа за google.


Выводы:
Хотя в нашей битве алгоритм Палех и проигрывает RankBrain, но не стоит забывать, что эти алгоритмы являются самообучающимися, а алгоритм Яндекса по времени был запущен намного позже алгоритма Google.
Возможно, в скором времени ситуация изменится.
Что с SEO?
Также хочется отметить, что запуск данных алгоритмов открывает новые реалии в области SEO. Во-первых, RankBrain является третьим по важности сигналом ранжирования.
Во-вторых, Палех и RankBrain наконец-то дают возможность владельцам сайтов писать тексты именно для людей, а не для поисковых машин, и быть в ТОПе.
Рекомендации для вебмастеров от Gary Illyes, о том как оптимизировать свой сайт под RankBrain, можно озвучить следующим образом:
«Если вы писали тексты для людей, используя язык, который вы обычно используйте при общении, то будьте уверены – ваш ресурс уже оптимизирован под RankBrain».
О том, что надо писать для людей и создавать сайты именно для них, поисковые системы говорят уже более 15 лет. Надеемся, что скоро это станет повсеместной реальностью.
P.S. Мы уже давно в своей работе по раскрутке сайтов заменили написание оптимизированных текстов на LSI-копирайтинг.
История алгоритмов ранжирования поисковой системы Яндекс
Суть ранжирования заключается в обработке запросов пользователей поисковой системой, после чего происходит автоматическая сортировка результатов согласно искомой информации. На сегодня для выдачи упорядоченного рейтинга веб-страниц система Яндекс использует специальные формулы ранжирования, построенные с применением машинного обучения — MatrixNet.
Со времени появления поисковой системы Яндекс (дата запуска 23 сентября 1997 г.) алгоритмы ранжирования периодически модернизуются, а также уделяется внимание их устойчивости к внешним факторам, таким как искусственные методы оптимизации сайта с целью обмана поисковика и т.п.
Хронология алгоритмов ранжирования
За время работы Яндекс внедрил множество алгоритмов. Предлагаю ознакомиться с историей за прошедшие 11 лет. Приведу краткую таблицу, а дальше в статье остановлюсь подробнее на каждом из алгоритмов.
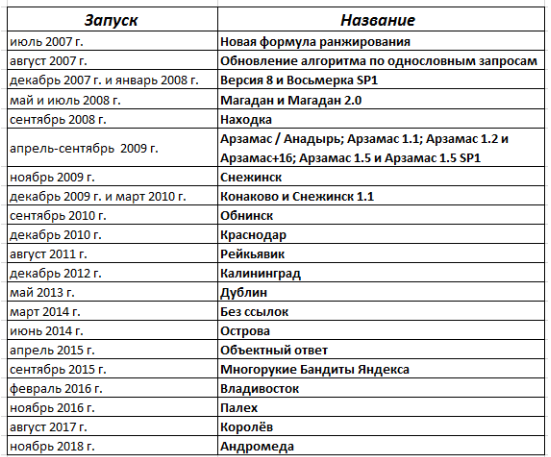
Новая формула ранжирования: 02.07.2007 г.
Об изменении в алгоритме ранжирования сообщил представитель Яндекса на Forum.Searchengines.ru. По отношению к запросам, состоящим из одного или нескольких слов, стали использоваться различные формулы.
Обновление алгоритма по однословным запросам: 07.08.2007 г.
Благодаря нововведениям изменились настройки самой формулы, выросла численность рассматриваемых по «однословным» запросам компонент релевантности. Анонс изменений появился также на Forum.Searchengines.ru.
«Версия 8» и «Восьмерка SP1»: 20.12.2007 г. и 17.01.2008 г.
На этот раз сайты с высоким уровнем авторитета стали обладать преимуществами в ранжировании, началось понижение веса ссылок с главных страниц. В результате вебмастерами начинают закупаться ссылки с внутренних страниц-доноров.
«Магадан» и «Магадан 2.0»: 16.05.2008 г. и 02.07.2008 г.
В 2008 году появляются алгоритмы ранжирования, которым разработчик присваивает имена и анонсирует их уже на официальном сайте Яндекса:
- В поисковой программе «Магадан» была в 2 раза увеличена численность факторов ранжирования, добавлены классификаторы для улучшенного понимания типа веб-страниц и ссылок, смягчена фильтрация выбора документов для ранжирования, а также модернизирована технология расшифровки аббревиатур и транслитерации.
- Алгоритм «Магадан 2.0» получил новые факторы, отслеживающие контент по уникальности, а также были внедрены классификаторы по гео и коммерческим запросам.
«Находка»: 11.09.2008 г.
Новшества коснулись учёта стоп-слов и модернизировалось машинное обучение. Произошло расширение тезауруса благодаря автоматическому исследованию подлежащей индексации «оболочки» текста. К примеру, он пополнился словосочетаниями, которые слитно и раздельно несут один смысл: по запросу [авто пром] также находятся веб-страницы с «автопром».
«Арзамас» («Анадырь»): 08.04.2009 г.
Разработчик анонсировал данный алгоритм, как «снятие омонимии». Это означает, что при ранжировании ресурсов в поисковой выдаче для запросов с неоднозначной смысловой нагрузкой применяется история запросов других пользователей (учитывается частотность слов и их словосочетаний). Анализируя такие запросы, Яндекс выбирал чаще всего встречающуюся конструкцию слов. В результате поисковая программа научилась понимать, что «день весны и труда» — это праздник, а не призыв к работе. Стали учитываться регионы пользователей, но сначала только для отдельных стран и некоторых городов. Спустя 3 месяца стало возможным привязать ресурс к региону.
- Арзамас 1.1.: 24.06.2009 г. Усовершенствована формула ранжирования для интернет-пользователей Российской Федерации помимо Москвы, Санкт-Петербурга, Екатеринбурга.
- Арзамас 1.2.: 20.09.2009 г. Появляется разделение поисковых запросов на зависимые и независимые по гео, что автоматически определяется поисковиком. В случаях, где регион не имеет особого значения, ранжирование происходит по качеству контента, авторитетности ресурса и другим признакам.
- «Арзамас+16»: 31.09.2009 г. Результаты поиска локализовались – ранжирование по гео пополнилось 16-ю регионами РФ. Обновлённая поисковая программа коснулась, как я упомянул выше, геозависимых запросов на усмотрение Яндекса.
- «Арзамас 1.5»: 23.09.2009 г. Улучшена формула ранжирования, устанавливающая рейтинг результатов выдачи независимых по гео запросов и запросов пользователей из регионов, где не применяется локализованное ранжирование.
- «Арзамас 1.5 SP1»: 28.09.2009 г. Объединение предыдущей версии ранжирования с улучшенной формулой поиска по регионам.
«Снежинск»: 10.11.2009 г.
Стал первым алгоритмом на основе самообучающейся платформы MatrixNet. Чего удалось достичь: введены новые параметры (несколько тысяч), учитываемые в процессе ранжирования одного документа, а сама формула пополнилась поведенческими факторами, 19 городов РФ получили региональную выдачу. На этом этапе важнее стало качество ресурса в целом, а не его отдельных веб-страниц. Система Яндекс научилась различать между собой коммерческие и некоммерческие ссылки.
«Конаково» и «Снежинск 1.1»: 22 декабря 2009 г. и 17.03.2010 г.
Благодаря разработке «Конаково» локальное ранжирование распространилось на 1250 городов Российской Федерации. Следующий алгоритм — «Снежинск 1.1», который претерпел обновлений в общей формуле по гео независимым запросам. Тогда свои позиции в выдаче повысили некоммерческие ресурсы с энциклопедической информацией, обзорами и т.п.
«Обнинск»: 13.09.2010 г.
Улучшилась обработка по гео независимым запросам, появилось ограничение влияния искусственных ссылок на ранжирование. Таким образом, в поисковой выдаче свои позиции улучшили ресурсы, не имеющие привязки к определённому региону. Кроме того, повысилась эффективность выявления авторских текстов.
«Краснодар»: 15.12.2010 г.
За основу данного алгоритма была взята новая поисковая технология «Спектр». На тот момент веб-ресурсы были разделены на 60 категорий по смыслу. Возможность классифицировать запросы и выявлять в них отдельные объекты (имя человека, название книги/фильма и т.д.) помогли поисковой системе более чётко распознавать различные значения слов в запросах, соответственно, генерировать выдачу согласно потребностям пользователя. Данная технология использовала статистику запросов пользователей, информацию из энциклопедий и различных справочных материалов.
«Рейкьявик»: 08.09.2011 г.
На этот раз пользователи стали получать поисковую выдачу согласно языковым предпочтениям. Так, при написании запроса латиницей пользователь при желании мог получить выдачу на русскоязычные веб-сайты. Более того, была внедрена новая формула для запросов с опечатками: для русских пользователей результаты выдачи показывались по 2 запросам – с опечаткой и в исправленном системой варианте (не во всех случаях).
У коммерческих организаций появилась возможность размещения сведений о своей компании в Яндекс.Справочнике. Ещё был внедрён инструмент для авторов оригинальных текстов: перед публикацией уникального контента в интернете нужно было сообщить об этом разработчику, отправив заявку через Яндекс.Вебмастер.
«Калининград»: 28.12.2012 г.
Результаты поисковой выдачи стали персонализированными. Система начала предлагать интернет-пользователям ответы и подсказки согласно их интересам, используя историю запросов и поведенческих факторов на странице поисковой выдачи. К примеру, на запрос [пираты карибского моря] читающим людям поисковик предложит в первую очередь книгу, киноманам – фильм, а геймерам – одноименную игру.
В браузере и на странице поиска Яндекса стали появляться предупреждения о веб-сайтах, которые предлагают загрузку и установку вредоносного программного обеспечения.
«Дублин»: 30.05.2013 г.
Совершенствование персонализации поисковой выдачи. Теперь стали учитываться предпочтения и интересы пользователей в реальном времени – результаты выдачи подстраиваются в процессе поиска.
«Без ссылок»: 12.03.2014 г.
Положено начало отмене ссылок. На этот раз обновилась формула ссылочного ранжирования для запросов по коммерции для города Москвы по нескольким категориям, а именно недвижимость, туризм, электроника и бытовая техника.
«Острова»: 05.06.2014 г.
Обновление дизайна поисковой выдачи. Пользователь мог увидеть интерактивные ответы на странице результатов поиска, не переходя на веб-сайт. Однако этот эксперимент был признан неудачным самими разработчиками, и впоследствии был отменён.
«Объектный ответ»: 01.04.2015 г.
Страница результатов поиска претерпела нововведений: в правой части экрана появилась так называемая Яндекс.Карточка (блок), содержащая сведения о предмете поискового запроса. В Яндексе внедрена классификация и база со множеством объектов поиска.
«Многорукие бандиты Яндекса»: 14.09.2015 г.
Происходит рандомизация поисковой выдачи – в ТОПе к трастовым ресурсам подмешиваются «молодые» сайты. В результате возраст ресурса перестаёт быть ключевым фактором в поисковом продвижении.
«Владивосток»: 02.02.2016 г.
Яндекс начинает учитывать адаптацию ресурса для просмотра на мобильных устройствах. В результате нововведений более высокие позиции в мобильной выдаче присваиваются сайтам, оптимизированным для пользования с мобильных девайсов.
«Палех»: 03.11.2016 г.
Система Яндекс научилась искать не по словам в запросе, а по смыслу запроса и заголовка (Title) страницы, благодаря использованию нейронных сетей. Причём поиск соответствия между ними мог осуществляться даже в тех случаях, когда в документе нет слова или фразы из вводимого пользователем запроса. Задача данного алгоритма – качественный поиск страниц по редким запросам и словам, например, заданным в формате разговорной речи.
«Королев»: 22.08.2017 г.
Алгоритм с использованием нейронной сети для сопоставления смысла запроса и страниц сайтов. По сути, он является доработанной версией алгоритма «Палех». На этот раз в обучении искусственного интеллекта задействованы статистика поиска, ассесоры и толокеры, а также оценки самих пользователей системы. В отличие от «Палех», данный алгоритм научился подвергать анализу не только заголовок, но и всё содержимое веб-страницы.
«Андромеда»: 19.11.2018 г.
В алгоритме внедрены ряд новшеств – модернизация быстрых ответов для мгновенного решения задач пользователей, помощь при отборе источников (появление непосредственно в поиске меток «Популярный сайт», «Выбор пользователей», оценок и отзывов к фильмам, заведениям), возможность сохранения найденных страниц в Яндекс.Коллекции, которые доступны пользователям на любом устройстве, где есть Яндекс.
Алгоритм «Палех»: как изменился Яндекс?

Содержание:
Если 10 лет назад интернет использовался в основном для поиска и передачи необходимой информации, то сегодняшняя Всемирная Сеть стала больше похожа на площадку для продажи товаров и услуг. Постепенно мы отказываемся от привычных походов в магазин, понимая, что гораздо удобнее и выгоднее совершить покупку в онлайн-режиме. Такая ситуация значительно усилила нагрузку на поисковики, которым ежедневно приходится обрабатывать сотни тысяч разнообразных запросов. Работая над улучшением качества выдачи, сотрудники Яндекса создали алгоритм «Палех». Как он повлиял на работу поисковой системы? Как отразилось на целевой аудитории данное нововведение? Давайте вместе более детально изучим эти вопросы.
Для чего был нужен новый алгоритм?
Как показывает статистика, ежедневно Яндекс обрабатывает сотни тысяч запросов. Их условно делят на три категории:
- высокочастотные;
- среднечастотные;
- низкочастотные.
Последние включают в себя более подробное описание того, что пользователю необходимо найти. До появления «Палеха» по ним часто выдавалось большое количество неподходящих ресурсов? С чем это связано? Ответ совершенно прост. Ранее внедренный в систему алгоритм «Матрикснет» осуществлял подбор сайтов для выдачи по ключевым словам, из которых строилась фраза запроса. Если в поисковик вносилось достаточно большое и сложное выражение, получить по ним полезную информацию было достаточно сложно. Это привело к тому, что все чаще стала возникать проблема релевантности выдаваемых ответов. Она стала требовать оперативного решения. Появление «Палеха» в корне изменило ситуацию.
Особенности «Палеха»
Перед разработчиками нового алгоритма стояла важная и ответственная задача. Ин необходимо было научить систему не просто осуществлять выдачу сайтов, в названии которых были ключевые слова, указанные в запросе, но и научить ее «понимать» смысл заголовков. Обновленный поиск работает на основе нейронных сетей. Ранее они использовались для анализа картинок и звуков. Искусственный интеллект изучает поведение пользователей поисковых систем, проводит их анализ и определяет смысловую связь между запросом и названием сайта.
Влияние алгоритма на SEO
«Палех» – это алгоритм, который не относится к категории нововведений, накладывающих санкции и фильтры.
Его основная задача – улучшение качества поиска и точности выдачи по низкочастотным запросам. С его внедрением грамотно оптимизированный под несколько НЗ текст статьи получил все шансы обойти «конкурентов» и попасть в ТОП.
Появление «Палеха» не усложнило работу SEO-студиям, создающим качественные сайты, наполненные грамотным и уникальным контентом. Чтобы хорошо ранжироваться в условиях данного алгоритма, было достаточно соблюдать такие основные требования:
- сайт должен быть трастовым;
- необходимо наличие большого количества текстового контента;
- статьи должны быть качественными.
Что касается коммерческих Интернет-ресурсов, на которых тексты практически отсутствуют, то данное нововведение не оказало на их продвижение практически никакого влияния.
Резюме
Появление алгоритма «Палех» стало заключительным моментом периода, когда в ТОП можно было попасть, используя в текстах большое количество ключевых слов. Теперь чтобы добиться желаемой вершины вебмастерам придется усердно работать над внутренней и внешней оптимизацией.
Искусственный интеллект существенно усложнил задачи, которые ставятся сегодня перед копирайтерами.
Времена нечитабельных текстов навсегда ушли в прошлое! Востребованными остались только те специалисты, которые умеют писать качественные, понятные людям статьи. И то замечательно! Гораздо приятнее открыть текст, и прочитать, например, «покупка квартиры в жилом комплексе…», чем «покупка квартира жилой комплекс». Текстового «мусора» в интернете становится все меньше и меньше.
Разработчики Яндекса существенно улучшили качество выдачи и «понимание» системы запросов, поэтому пишите красивые и грамотные тексты, регулярно обновляйте и дорабатывайте сайты, и никакие нововведения Вам не страшны!