
rym package — RDocumentation
===
Официальную русскоязычную документацию можно найти по этой ссылке
Краткое описание
================
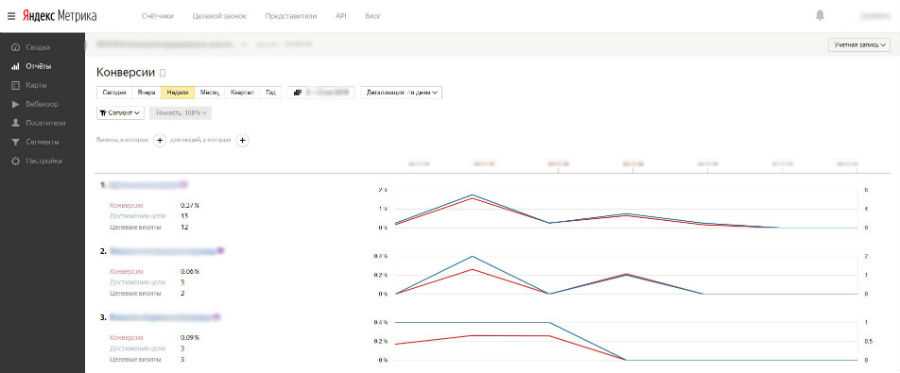
rym является R интерфейсом для работы с API Яндекс Метрики, его функции позволяют вам взаимодействовать со следующими API:
- API Управления — позволяет получить таблицы с такими объектами как достуные счётчики Яндекс.Метрики, список настроенных целей, фильтров и сегментов, а так же список пользователей у которых есть доступ к счётчику.
- API Отчётов — позволяет получать информацию о статистике посещений сайта и другие данные, не используя интерфейс Яндекс.Метрики.
- API совместимый с Core API Google Analytics (v3) — позволяет запрашивать статистические данные используя при этом название полей такие же как и при работе с Core Reporting API v3.
- Logs API — позволяет получить сырые, несгруппированные данные о посещении вашего сайта из Яндекс.Метрики.
Установка
Установить rym можно как с CRAN так и с GitHub
CRAN: install. packages('rym')
packages('rym')
GitHub: devtools::install_github("selesnow/rym")
Виньетки
========
Помимо официальной документации у пакета есть 5 виньеток, вводная, и отдельно виньетка под каждый API, открыть их можно с помощью следующих команд:
- Введение в пакет
rym:vignette('intro-to-rym', package = 'rym') - API Управления:
vignette('rym-management-api', package = 'rym') - API Отчётов:
vignette('rym-reporting-api', package = 'rym') - API совместимый с Core API Google Analytics v3:
vignette('rym-ga-api', package = 'rym') - Logs API:
vignette('rym-logs-api', package = 'rym')
Пример кода
# auth
rym_auth(login = "vipman.netpeak", token.path = "metrica_token")
rym_auth(login = "selesnow", token.path = "metrica_token")
# ManagementAPI
# get counters list
selesnow.counters <- rym_get_counters(login = "selesnow",
token. path = "metrica_token")
vipman.counters <- rym_get_counters(login = "vipman.netpeak",
token.path = "metrica_token")
# get goals list
my_goals <- rym_get_goals(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# пget filter list
my_filter <- rym_get_filters(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# get segment list
my_segments <- rym_get_segments(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# get counter list
users <- rym_users_grants(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# Reporting API
reporting.api.stat <- rym_get_data(counters = "23660530,10595804",
date.
path = "metrica_token")
vipman.counters <- rym_get_counters(login = "vipman.netpeak",
token.path = "metrica_token")
# get goals list
my_goals <- rym_get_goals(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# пget filter list
my_filter <- rym_get_filters(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# get segment list
my_segments <- rym_get_segments(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# get counter list
users <- rym_users_grants(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# Reporting API
reporting.api.stat <- rym_get_data(counters = "23660530,10595804",
date. from = "2018-08-01",
date.to = "yesterday",
dimensions = "ym:s:date,ym:s:lastTrafficSource",
metrics = "ym:s:visits,ym:s:pageviews,ym:s:users",
sort = "-ym:s:date",
login = "vipman.netpeak",
token.path = "metrica_token",
lang = "en")
# Logs API
logs.api.stat <- rym_get_logs(counter = 23660530,
date.from = "2018-08-01",
date.to = "2018-08-05",
fields = "ym:s:date,
ym:s:lastTrafficSource,
ym:s:referer",
source = "visits",
login = "vipman. netpeak",
token.path = "metrica_token")
# API compatible with Core API Google Analytics v3
ga.api.stat <- rym_get_ga(counter = "ga:22584910",
dimensions = "ga:date,ga:source",
metrics = "ga:sessions,ga:users",
start.date = "2018-08-01",
end.date = "2018-08-05",
sort = "-ga:date",
login = "selesnow",
token.path = "metrica_token") path = "metrica_token")
vipman.counters <- rym_get_counters(login = "vipman.netpeak",
token.path = "metrica_token")
# get goals list
my_goals <- rym_get_goals(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# пget filter list
my_filter <- rym_get_filters(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# get segment list
my_segments <- rym_get_segments(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# get counter list
users <- rym_users_grants(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# Reporting API
reporting.api.stat <- rym_get_data(counters = "23660530,10595804",
date.
path = "metrica_token")
vipman.counters <- rym_get_counters(login = "vipman.netpeak",
token.path = "metrica_token")
# get goals list
my_goals <- rym_get_goals(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# пget filter list
my_filter <- rym_get_filters(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# get segment list
my_segments <- rym_get_segments(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# get counter list
users <- rym_users_grants(counter = 10595804,
login = "vipman.netpeak",
token.path = "metrica_token")
# Reporting API
reporting.api.stat <- rym_get_data(counters = "23660530,10595804",
date.
 netpeak",
token.path = "metrica_token")
# API compatible with Core API Google Analytics v3
ga.api.stat <- rym_get_ga(counter = "ga:22584910",
dimensions = "ga:date,ga:source",
metrics = "ga:sessions,ga:users",
start.date = "2018-08-01",
end.date = "2018-08-05",
sort = "-ga:date",
login = "selesnow",
token.path = "metrica_token")
netpeak",
token.path = "metrica_token")
# API compatible with Core API Google Analytics v3
ga.api.stat <- rym_get_ga(counter = "ga:22584910",
dimensions = "ga:date,ga:source",
metrics = "ga:sessions,ga:users",
start.date = "2018-08-01",
end.date = "2018-08-05",
sort = "-ga:date",
login = "selesnow",
token.path = "metrica_token")Статьи:
- Как работать с API Яндекс.Метрики с помощью языка R, Алексей Селезнёв
- Как использовать Rscript в качестве источника данных в Microsoft Power BI на примере Яндекс.Метрики, Павел Мрыкин
- Построение поведенческих воронок на языке R, на основе данных полученных из Logs API Яндекс.Метрики, Алексей Селезнёв
- Обзор R пакетов для интернет маркетинга, часть 1, Алексей Селезнёв
- Насколько безопасно использовать R пакеты для работы с API рекламных систем, Алексей Селезнёв
- Как массово удалить в интернет-магазине страницы товаров, которые не приносят трафик, Богдан Неряхин
- Как загружать данные о расходах, офлайн-конверсиях и звонках в Яндекс Метрику, Алексей Селезнёв
Видео уроки:
- Как автоматизировать работу с данными Яндекс. Метрики. С помощью языка R
 Метрики. С помощью языка R
Метрики. С помощью языка RАвтор: Алексей Селезнёв (Head of Analytics Dept. at Netpeak)
Copy Link
Link to current version
Version
Version
1.0.51.0.31.0.00.5.40.5.20.5.10.4.0
Down ChevronInstall
install.packages('rym')Monthly Downloads
Version
1.0.5
License
GPL-2
Maintainer
Alexey Seleznev
Last Published
September 3rd, 2021
Проекты. Уроки настоящего
- Главная
- Сведения об ОО
- Основные сведения
- Основные направления деятельности
- Структура и органы управления образовательной организацией
- Документы
- Образование
- Образовательные стандарты и требования
- Руководство. Педагогический (научно-педагогический) состав
- Руководитель
- Заместители руководителя
- Педагогический (научно-педагогический) персонал
- Материально-техническое обеспечение и оснащенность образовательного процесса
- Платные образовательные услуги
- Финансово-хозяйственная деятельность
- Стипендии и меры поддержки обучающихся
- Вакантные места для приема (перевода) обучающихся
- Доступная среда
- Международное сотрудничество
- Организация питания в ОО
- Основные сведения
- Проекты
- СИРИУС. ЛЕТО
- Старт третьего сезона (2022)
- Старт второго сезона (2021)
- Старт первого сезона (2020)
- Сириус.Лето регистрация продлена до 1 октября
- Сириус.Лето примеры задач. Фитомониторинг
- УРОКИ НАСТОЯЩЕГО
- Уроки настоящего — 5-ый сезон (2021-2022 учебный год)
- Проект «Уроки настоящего» -5ый сезон
- Уроки настоящего
- Уроки настоящего: знакомим с участниками проекта из Кузбасса
- Уроки настоящего на Кузбасском образовательном форуме
- Итоги пятого цикла
- Уроки настоящего
- Проекты. Уроки настоящего
- Уроки настоящих нейротехнологий
- «Уроки настоящего»: старт седьмого цикла проекта
- Завершающий цикл проекта «Уроки настоящего»
- БОЛЬШИЕ ВЫЗОВЫ
- Большие вызовы — 2022
- Большие вызовы — 2021
- БОЛЬШИЕ ВЫЗОВЫ — 2021: ВЫХОДИМ НА ФИНИШ
- БОЛЬШИЕ ВЫЗОВЫ: ПРОДЛЕНИЕ СРОКОВ РЕГИСТРАЦИИ
- БОЛЬШИЕ ВЫЗОВЫ: ФИНАЛЬНАЯ ОЧНАЯ ЗАЩИТА ПРОЕКТОВ
- БОЛЬШИЕ ВЫЗОВЫ: ОПУБЛИКОВАН СПИСОК ЗАКЛЮЧИТЕЛЬНОГО ЭТАПА
- ИТОГИ КОНКУРСА «БОЛЬШИЕ ВЫЗОВЫ»
- Большие вызовы в лицах
- МАТЕМАТИЧЕСКИЙ ПРАЗДНИК
- О математическом празднике
- Итоги-2022
- Математический праздник
- Перенос даты проведения: Математический праздник
- XXXI Математический праздник: результаты
- О математическом празднике
- СИРИУС.
- Детям
- Образовательные программы
- Конференции
- НПК ДИАЛОГ-2022
- «Диалог — 2022»: прием заявок на НПК
- НПК «Диалог — 2022»: перенос сроков защиты
- НПК «Диалог»: итоги заочного этапа и расписание очной защиты
- Региональная НИК обучающихся «Кузбасская школьная академия наук-2022»
- ГАЛАКТИКА НАУКИ
- НПК ДИАЛОГ-2022
- Дистанционное обучение
- Тематические клубы РЦ «Сириус. Кузбасс»
- Педагогам
- НПК 2022
- Межрегиональная НПК
- Повышение квалификации
- Олимпиады
- ВсОШ
- Школьный этап
- Муниципальный этап
- Региональный этап
- Заключительный этап
- Олимпиада НТИ
- Всесибирская олимпиада
- Олимпиада по ИИ
- ВсОШ
- Контакты
- Партнеры
- Детям
- ОЦ Сириус
- Волгоградская обл.
- Кемеровская область — Кузбасс
- Курск
- Москва
- Нижний Новгород
- Новосибирск
- Санкт-Петербург
- Татарстан
- Томск
- Галерея
- Отчёты
- Региональная сеть
- КАРТА САЙТА
- Обратная связь
 Педагогический (научно-педагогический) состав
Педагогический (научно-педагогический) состав ЛЕТО
ЛЕТО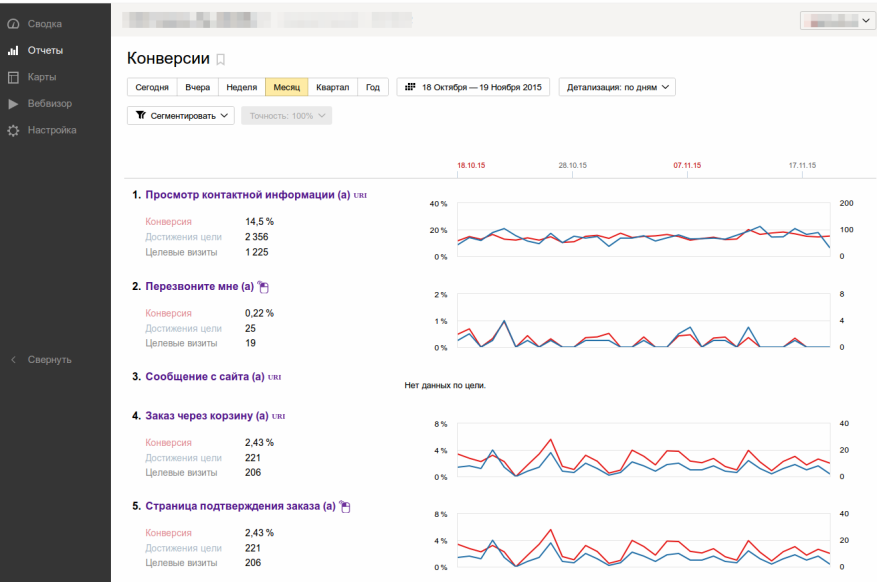 Уроки настоящего
Уроки настоящего Кузбасс»
Кузбасс»
ТОП-15 по Google и Яндекс маркетологу
Сегодня веб-аналитика — неотъемлемый инструмент для любого бизнеса, продвигающего услуги через интернет-каналы. Это может быть небольшой корпоративный сайт, лендинг, страничка в соцсети — не говоря уже о крупных предприятиях, которые запускают рекламные кампании по всем фронтам.
Это может быть небольшой корпоративный сайт, лендинг, страничка в соцсети — не говоря уже о крупных предприятиях, которые запускают рекламные кампании по всем фронтам.
Спрос на на веб-аналитиков будет только расти. От них зависят главные маркетинговые процессы: позиционирование, брендирование, таргетирование и т.д.. И я собрала самые популярные курсы, в которых Вы изучите основные инструменты, а также продвинутые техники в этой специальности.
Курсы для новичков
Эти программы акцентируют внимание на теории и основных приемах работы с метрикой. Курсы платные, но, по сравнению с самообразованием, здесь есть ряд преимуществ. Учебный формат включает выполнение домашних заданий, их проверку с куратором, а также защиту дипломного проекта. Авторы и преподаватели — практикующие эксперты, которые делятся своим опытом со студентами.
| Курс | Цена | Формат | Длительность | Школа |
| Веб-аналитики с нуля до Junior | От 3 442 ₽/мес. |
Онлайн-уроки | 5 месяцев | Skillbox |
| Веб-аналитика в Яндекс.Метрике | 4 000 ₽ | Онлайн-лекции | 6 лекций по 1,5 часа | TexTerra |
| Web-аналитик | От 4 334 ₽/мес. | Практические занятия | 13 занятий | Convert Monster |
| Веб-аналитика | $395 | Вебинары, практические занятия | 4 месяца | Web Promo Experts |
| Web-аналитик 2.0 | От 2 750 ₽/мес. | Практические занятия | 13 недель | Convert Monster |
| Маркетинговый аналитик | От 3 618 ₽/мес. | Вебинары, видеолекции | 8 месяцев | Нетология |
1. Веб-аналитик с нуля до Junior
Программа от Skillbox обучит сбору и анализу метрик сайта, начальному и продвинутому уровню работы с Google Analytics, Google Tag Manager, Яндекс. Метрикой. Кроме этого, Вам расскажут, как анализировать базы данных и составлять отчеты, проводить А/В-тесты, как работать в команде и развиваться в профессиональной сфере. После защиты диплома помогут составить резюме и подготовиться к собеседованию.
Метрикой. Кроме этого, Вам расскажут, как анализировать базы данных и составлять отчеты, проводить А/В-тесты, как работать в команде и развиваться в профессиональной сфере. После защиты диплома помогут составить резюме и подготовиться к собеседованию.
2. Веб-аналитика в Яндекс.Метрике
Краткая программа от TexTerra, которая расскажет в 6 уроках что такое Яндекс.Метрика, как в ней работать и управлять трафиком исходя из полученной статистики. Также научитесь интегрировать в Яндекс.Метрику другие сервисы и модули, чтобы составлять полноценные аналитические отчеты. Подойдет как начинающим маркетологам, так и владельцам бизнеса, которые хотят самостоятельно во всем разобраться и не нанимать отдельного человека.
3. Web-аналитик
Практический курс, для которого Вам понадобится веб-сайт. Будете обучаться по записям уроков (всего их 13), выполнять домашние задания, которые проверяют кураторы. Вас не ограничивают по времени прохождения программы, но поддержка личного куратора действует только 2 месяца, учитывайте этот момент.
Сами темы раскрывают суть веб-аналитики с нуля до уровня уверенного специалиста: метрика, UTM-метки, KPI, SEO, интерфейсы Яндекс.Директ и Google Ads, прочие аналитические инструменты. Узнаете, как построить сквозную аналитику с помощью OWOX, визуализировать данные в Power BI.
4. Веб-аналитика
Программа обучения в разнообразном формате: лекции в записи, презентации, вебинары в реальном времени от практикующих специалистов. По ходу обучения будете выполнять практические задания и готовиться к итоговому проекту так, как если бы вы презентовали его для своего работодателя.
В итоге будете свободно ориентироваться в Google Analytics, Google Tag Manager, Facebook Analytics, Google Data Studio. Научитесь оценивать эффективность сайта, проводить А/В-тесты, ставить задачи программистам, работать в команде аналитиков.
5. WEB-аналитик 2.0
Расширенная программа не только для новичков в веб-аналитике, но и для маркетологов, специалистов по контекстной рекламе, директоров предприятий. Курс состоит из 19 практических занятий, для выполнения которых Вам понадобится веб-сайт. Все занятия поделены на четыре блока, по окончании каждого проводится зачет.
Курс состоит из 19 практических занятий, для выполнения которых Вам понадобится веб-сайт. Все занятия поделены на четыре блока, по окончании каждого проводится зачет.
Вас введут в веб-аналитику, познакомят с Google Analytics, Google Tag Manager и Яндекс.Метрикой, научат рассчитывать юнит-экономику, настраивать счетчики веб-аналитики, вести e-commerce проекты, работать в поисковым движком, соцсетями. На протяжении всего периода обучения Вам будет помогать куратор.
6. Маркетинговый аналитик
Вас научат обрабатывать данные в Яндекс.Метрике и Google Analytics, а также расскажут, чем Вам помогут Google Tag Manager, Data Studio и Google Optimize. В качестве практики Вы будете составлять аналитические отчеты, визуализировать их в Power BI или Tableau на выбор. Полученные знания ориентируют на принятие верных маркетинговых решений и поиск точек роста для бизнеса.
По теме:
Курсы по веб разработке: подборка ТОП-30 + подробный разборКурсы веб дизайна: обучение UX и UI бесплатно и платноКурсы для продвинутых
Курсы подойдут для тех, кто уже работает в сфере веб-аналитики и хочет расширить компетенции, повысить свою квалификацию. Неплохой вариант, если хотите сэкономить время и напрямую перенять опыт специалистов топовых российских компаний. Также рекомендую обратить внимание на смежные специальности и пройти, например, курс интернет-маркетинга.
Неплохой вариант, если хотите сэкономить время и напрямую перенять опыт специалистов топовых российских компаний. Также рекомендую обратить внимание на смежные специальности и пройти, например, курс интернет-маркетинга.
| Курс | Цена | Формат | Длительность | Школа |
| Сквозная аналитика | От 3 442 ₽/мес. | Онлайн-лекции, практические занятия | 4 месяца | Skillbox |
| Факультет продуктовой аналитики | От 3 738 ₽/мес. | Онлайн-лекции, вебинары | 1 год | GeekBrains |
| Веб-аналитика | От 3 242 ₽/мес. | Онлайн-уроки | 3 месяца | IMBA |
| Профессия Маркетолог-аналитик | От 4 255 ₽/мес. | Онлайн-уроки | 1 год | Skillbox |
| Веб-аналитика для маркетолога | От 4 053 ₽/мес. |
Видеоуроки, вебинары, практические занятия | 7 месяцев | Нетология |
1. Сквозная аналитика
Программа подробно раскрывает коммерческий аспект сквозной аналитики. Узнаете, как оптимизировать рекламный бюджет, искать слабые места в воронке продаж, научитесь делать анализ post-view и работать с биржами данных. Кроме аналитических отчетов, которые, вероятно, Вам уже знакомы, станете готовить и финансовые: оценивать периоды, расходы и прибыли, прогнозировать графики.
Важно. С самыми популярными и надежными сервисами сквозной аналитики Вы познакомитесь на курсах, но на будущее, ловите мой личный ТОП: Roistat (Промокод «INSCALE1120» + 7500 руб на баланс), Callibri.
2. Факультет продуктовой аналитики
Специализированный курс для тех, кому нужен уклон в продакт-менеджмент. Подойдет для маркетологов, UX-дизайнеров, стартаперов и владельцев бизнеса. Сначала Вы изучите общие инструменты сквозной аналитики и ее визуализации, а дальше углубитесь в SQL и Data Science. По окончании курса у Вас уже будет 4 проекта для портфолио. А также Вам гарантируют трудоустройство. Если не найдете работу по специальности, Вам вернут деньги.
По окончании курса у Вас уже будет 4 проекта для портфолио. А также Вам гарантируют трудоустройство. Если не найдете работу по специальности, Вам вернут деньги.
По теме:
Курсы продуктовой аналитики: с нуля до профи + как выбрать3. Веб-аналитика
За 3 месяца квалифицируетесь в востребованного веб-аналитика, способного выполнять разноплановые задачи: анализировать юзабилити сайта, конкурентов, SEO, ретаргетинг, замерять и прогнозировать результаты. Приобретете профессиональные коммуникативные навыки для работы в команде. Научат не только создавать и оформлять проекты продвинутого уровня, но и правильно подавать их руководителю, аргументировать свои выводы.
4. Профессия маркетолог–аналитик
Программа ориентирует на коммерческую аналитику. Спикеры подробно ответят, как настроить Google Tag Manager, Яндекс.Метрику, коллтрекинг, рекламные кабинеты в соцсетях. Обучитесь работать в специальных сервисах сквозной аналитики: Roistat и CoMagic. На защите диплома Вам предстоит подготовить полноценный аналитический проект от лица его руководителя. То есть составите техзадание, определите, какие данные выгружать и анализировать, распределите нагрузку на команду.
На защите диплома Вам предстоит подготовить полноценный аналитический проект от лица его руководителя. То есть составите техзадание, определите, какие данные выгружать и анализировать, распределите нагрузку на команду.
5. Веб-аналитика для маркетолога
Курс повышения квалификации, состоящий из двух ступеней. Первый этап длится четыре месяца, включает 60 часов теории и 40 практики. Будете осваивать расширенный инструментарий аналитических сервисов от Google и Яндекс, анализировать системы веб-аналитики, обогащать и визуализировать данные.
Второй уровень длится 3 месяца. Тут все серьезнее: профессиональное владение Google Таблицами, интерпретация данных для любого типа предприятия и маркетинговой политики, SQL и базы данных в Google BigQuery. Интеграция в CRM-системах и построение сквозной аналитики с нуля в популярных сервисах Roistat, Calltouch и Google Analytics.
Коротко о главном
Напоследок дам несколько советов, на что обязательно нужно обратить внимание при выборе курса веб-аналитики:
- Презентация. Посмотрите промо-видео, чтобы оценить манеру и грамотность речи спикера. Также полистайте соцсети, почитайте отзывы, как реализовали себя выпускники онлайн-школ;
- Обратная связь. Отдавайте предпочтение тем курсам, где Вы сможете разбирать свои ошибки с преподавателем, получать конкретные рекомендации;
- Содержательность. Внимательно изучите программу, какие темы и дополнительные опции Вам предлагают. Обратите внимание на срок доступа к материалам;
- Формат обучения. Посмотрите, какой срок отведен на сдачу домашних заданий, есть ли фиксированная дата проведения итогового экзамена. Если есть расписание прямых трансляций, убедитесь, что Вам удобно быть онлайн в это время;
- Правовая основа. Онлайн-университеты должны иметь государственный аттестат, позволяющий оказывать образовательные услуги. В нашей подборке все ресурсы работают официально. Но, быть может, Вы ищете их где-то еще — тогда не забудьте посмотреть документацию.
 Посмотрите промо-видео, чтобы оценить манеру и грамотность речи спикера. Также полистайте соцсети, почитайте отзывы, как реализовали себя выпускники онлайн-школ;
Посмотрите промо-видео, чтобы оценить манеру и грамотность речи спикера. Также полистайте соцсети, почитайте отзывы, как реализовали себя выпускники онлайн-школ;
Конечно, можно обучиться самостоятельно, но курсы значительно облегчат старт. Вас сориентируют, на что обратить внимание в первую очередь, какие сервисы самые актуальные, расскажут об актуальных и неочевидных приемах в работе. Большинство школ помогут с трудоустройством: дадут Вам список вакансий, подготовят к собеседованию, подскажут как составить резюме и оформить портфолио.
По теме:
Веб-аналитика: 3 сервиса + инструкция(FAQ) Сквозная аналитика: руководство + ТОП-3 системы
Настройка Яндекс.Метрики: счётчик, дашборд и базовые функции
После установки счётчика Яндекс.Метрики на сайт, его нужно правильно настроить, чтобы собирать максимально возможный перечень данных. Записи сессий посещения сайта, цели и конверсии, контентная аналитика и прочее.
Разбираемся, как выполнить все настройки Яндекс.Метрики и что в них доступно, а также покажем, как настроить виджеты на главной странице Метрики.
Начните размещать официальную рекламу в Telegram Ads. Опередите конкурентов!
Зарегистрируйтесь и продавайте товары или услуги в Telegram Ads с помощью готового решения от Click.ru.
- Бюджет от 3000 евро – это гораздо дешевле, чем работать напрямую.
- Для юрлиц и физлиц – юрлица могут получить закрывающие документы, возместить НДС. Физлица могут запустить рекламу без общения с менеджерами.
- 3 способа оплаты – оплачивайте рекламу картой физического лица, с расчетного счета организации, электронными деньгами.
Подробнее >> Реклама
Читайте также: Как правильно настроить Google Analytics
Настройка Яндекс.Метрики: подробная инструкция
Открываем свой счётчик Яндекс.Метрики и кликаем пункт «Настройка» (самый последний в меню слева).
Нам открывается страница с настройками счётчика. На странице есть перечень вкладок, пройдёмся по каждой из них.
Счётчик
Здесь вы можете посмотреть номер счётчика, связать счётчик с аккаунтом в Вебмастере, поменять имя счётчика и адрес сайта, с которого он собирает информацию. Также можно указать часовой пояс, указать дополнительные URL-адреса или удалить счётчик.
Самое важно здесь — номер счётчика. Он нужен, чтобы указывать Метрику при настройке рекламы в Директе. Также, можно установить Метрику на сайт, указав номер счётчика в настройках — такая опция доступна в Тильде и многих других конструкторах сайтов. Эта же возможность есть в Битриксе, WordPress (при установке плагинов), на других CMS, а также в Яндекс.Дзен.
Если пролистать этот раздел ниже, то вы найдёте блок, где можно включить следующие опции:
- Вебвизор, карта скроллинга, аналитика форм — если включить, то будет вестись запись действий посетителей на сайте: движения курсором мыши, прокручивание страницы и клики.
- Электронная коммерция — если включить, то будут отслеживаться взаимодействие посетителей с товарами сайта. Чтобы статистика начала собираться, на сайте потребуется настроить передачу данных.
- Контентная аналитика — если включить, то будут доступны отчеты по текстовым материалам сайта. Чтобы статистика начала собираться, на сайте должна быть специальная разметка: Shema.org или Open Graph.

Для всех сайтов обязательно используйте вебвизор, для интернет-магазинов — электронную коммерцию, для информационных сайтов — контентную аналитику.
Ещё ниже есть дополнительные настройки и сам код счётчика. Чтобы открыть дополнительные настройки, кликаем на них.
Смотрим, что можно настроить:
- Валюта — в выбранной валюте будет задаваться ценность цели. Из основных валют доступны: рубль, доллар и евро.
- Тайм-аут визита в минутах — это время бездействия посетителя на сайте, после которого визит считается завершенным. Проще говоря, при тайм-ауте в 30 минут, если человек открыл страницу вашего сайта, ушёл попить кофе и вернулся через 35 минут, то его посещение будет засчитано, как новый визит.
- Код счётчика — позволяет настроить код счётчика, получить информер для установки на сайт и прочее.
 Проще говоря, при тайм-ауте в 30 минут, если человек открыл страницу вашего сайта, ушёл попить кофе и вернулся через 35 минут, то его посещение будет засчитано, как новый визит.
Проще говоря, при тайм-ауте в 30 минут, если человек открыл страницу вашего сайта, ушёл попить кофе и вернулся через 35 минут, то его посещение будет засчитано, как новый визит.Важно: Если вы внесли изменения в настройки счётчика и Метрика установлена вручную, обязательно обновите код счётчика на сайте.
Вебвизор
На этой вкладке, вы можете включить или выключить Вебвизор 2.0, а также выбрать нужно ли записывать данные из всех полей.
Новый Вебвизор работает без каких-либо дополнительных настроек — его можно либо включить, либо отключить.
Подробнее по теме: Как включить и настроить Вебвизор
Цели
На этой вкладке можно добавить цели, которые позволят отслеживать конверсии на сайте. Есть два типа целей: конверсионные и ретаргетинговые, каждая из которых может подразумевать посещение определённого URL на сайте, JavaScript-событие, цепочку действий, количество просмотров.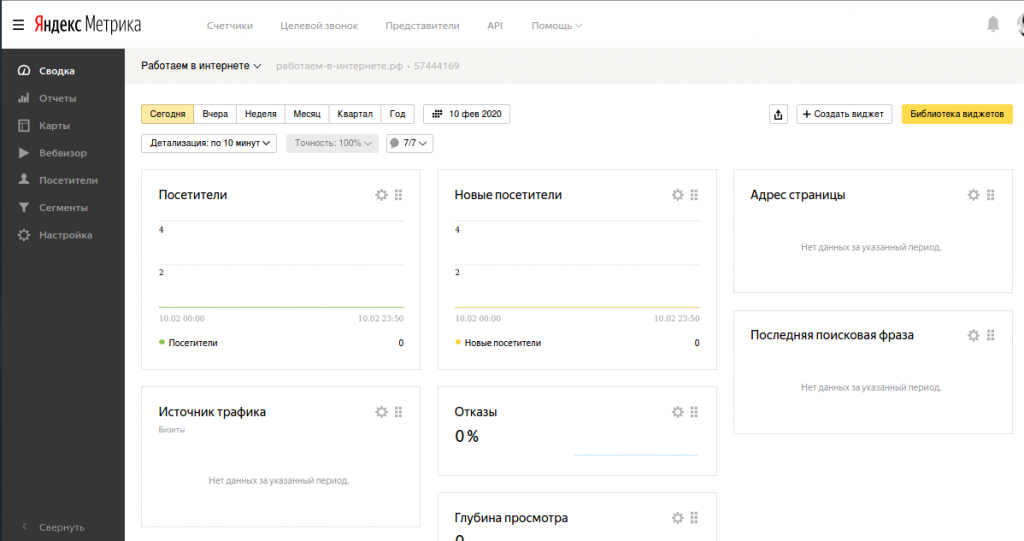 Для одного счётчика можно создать 200 целей.
Для одного счётчика можно создать 200 целей.
Для настройки цели кликаем «Добавить цель». В появившемся окне пишем название, выбираем тип условия и задаём само условие. Если вы хотите использовать данные для дальнейшей настройки ретаргитинга, отметьте соответствующий пункт.
Подробнее: Как правильно настроить цели в Яндекс.Метрике
Фильтры
В этом разделе можно настроить фильтрацию входящего трафика, а также выполнять операции над уже собранными данными. Для одного счетчика вы можете задать 30 фильтров и 30 операций.
Изменения, вызванные фильтрами, необратимы. При отсутствии фильтров в отчеты будут попадать все записи. Фильтры могут применяться к следующим типам данных: IP-адрес посетителя, URL-страницы, заголовок страницы.
Чтобы Яндекс.Метрика не учитывала ваши посещения, включите опцию «Не учитывать мои визиты». Если хотите, не учитывать посещения своих сотрудников, можете добавить фильтр по IP-адресам.
Операции. Операции производятся над исходными данными, которые уже есть в отчётах. Они модифицируют адреса страниц отчетного или ссылающегося сайта, которые отображаются в отчетах.
Операции производятся над исходными данными, которые уже есть в отчётах. Они модифицируют адреса страниц отчетного или ссылающегося сайта, которые отображаются в отчетах.
Фильтрация роботов позволяет фильтровать информацию о посещениях роботов в отчетах сервиса. Независимо от того, включена ли фильтрация, информация о роботах, которые посетили сайт, будет отражена в отчете Роботы.
Если вы хотите обнаружить большинство роботов, используйте «Фильтровать роботов по строгим правилам и по поведению». Если хотите, чтобы визиты роботов учитывались в Метрике, выберите «Учитывать визиты всех роботов».
Уведомления
Здесь вы можете подписаться на уведомления, о доступности сайта по электронной почте и SMS. Чтобы подписаться на уведомления, активируйте соответствующую опцию в настройках.
Для SMS-уведомлений можно также задать дни и время, когда эти уведомления могут приходить. Обратите внимание, что время отправки московское.
Загрузка данных
Эта вкладка отвечает за выгрузку и загрузку данных. Здесь мы можем скачать данные по посетителям, включить отслеживание оффлайн-конверсий, а также дополнить наши данные расходами на рекламу.
Здесь мы можем скачать данные по посетителям, включить отслеживание оффлайн-конверсий, а также дополнить наши данные расходами на рекламу.
Отслеживание оффлайн конверсий позволяет отслеживать заключение договора, факт оплаты, звонок и прочее. Данные об этих действиях можно передавать в Метрику и связывать поведение ваших клиентов на сайте с их действиями в офлайне. Добавить данные можно вручную с помощью CSV-файла, API Метрики или настроить передачу данных из системы коллтрекинга.
Расходы на рекламу — помогут отслеживать эффективность рекламной кампании, созданной в любой рекламной системе. Для передачи данных о расходах на рекламу используйте сервис автоматизации (Медианация, Albato) или CSV-файл.
Обратите внимание, что данные из Яндекс.Директ загружать не нужно — они передаются в Метрику автоматически.
Доступ
Здесь вы можете включить или отключить публичный доступ к статистике сайта, а также добавить пользователей, которые получат доступ к счётчику.
Чтобы добавить человека, которые сможет посмотреть отчёты Метрики по сайту, нажмите «Добавить пользователя», укажите его логин в Яндексе и установите уровень доступа в пункте «Права».
Отчёты
В этой вкладе доступны отчёты, которые вы можете настроить в Яндекс.Метрике.
Если отчёт уже включен, то в правом углу плашки с ним отображается статус «Подключено». У не подключённых отчётов есть кнопка со ссылкой на инструкцию по подключению.
Всего доступно 7 отчётов: Яндекс.Директ, Турбо-страницы, звонки, Вебвизор, контентная аналитика, электронная коммерция и кросс-девайс.
Всё вышеперечисленное и есть базовые настройки Яндекс.Метрики. Постарайтесь максимально задействовать каждую из них, чтобы собирать и анализировать наиболее полную информацию по сайту.
Как настроить дашборд в Яндекс.Метрике
Теперь разберёмся, как настроить дашборд и виджеты, чтобы заходя в Метрику вы могли видеть визуализацию самых важных показателей. Для примера, выведем показатели по SEO-трафику и переходам с рекламы, а также данные по конверсиям.
Удаление стандартных виджетов
Для начала нужно удалить все виджеты. Нажимаем, на шестерёнку в правом верхнем углу виджета.
Открывается окно настроек, в левом нижнем углу которого нужно нажать на корзину для удаления.
Полностью очистив страницу вы увидите следующий экран.
Создание и настройка новых виджетов
SEO-трафик. Для того, чтобы создать первый виджет жмём «Создать виджет — Круговая диаграмма», открывается окно с настройками виджета. В названии пишем «SEO-трафик», в пункте Метрика выбираем «Посетители», в пункте Группировка — «Источники — Последний значимый источник — Поиск — Последняя значимая поисковая система».
Рекламный трафик. Создаём виджет «Круговая диаграмма». В названии пишем «Рекламный трафик», в пункте Метрика выбираем «Посетители», в пункте Группировка — «Рекламная система».
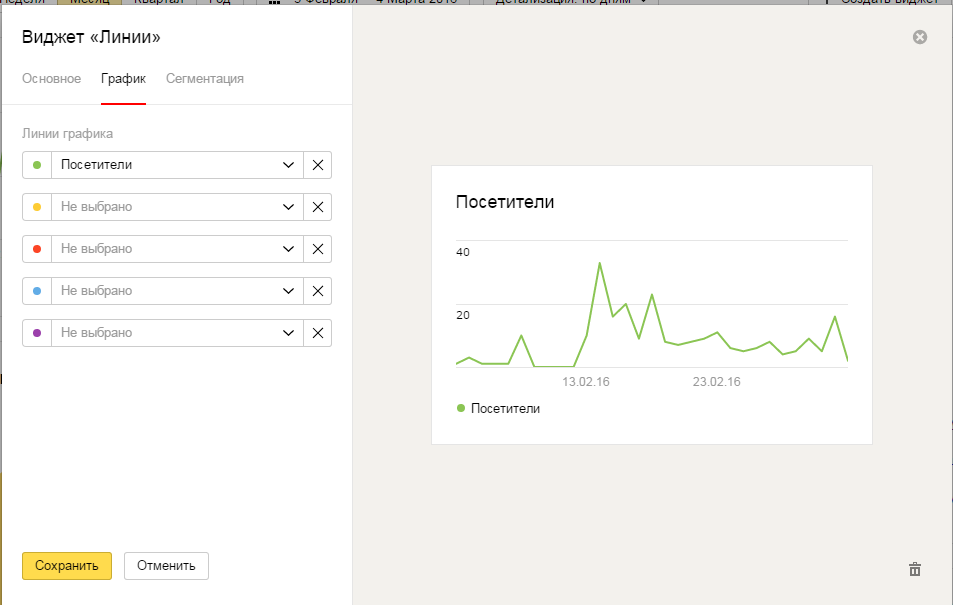
Конверсии с SEO. Чтобы видеть, как конвертируется наш SEO трафик создаём новый виджет «Линии».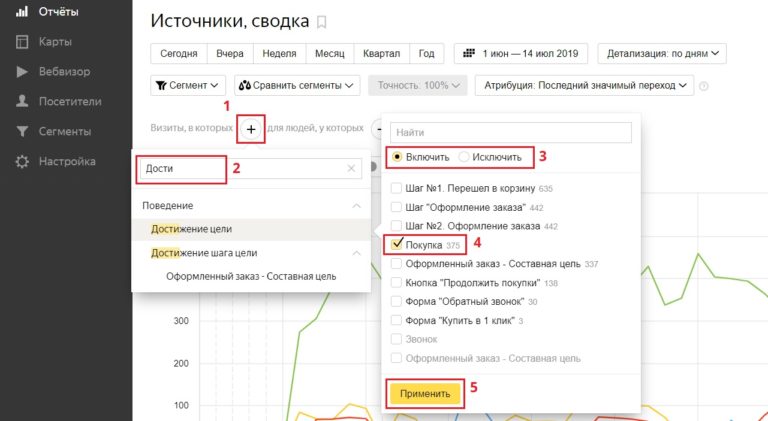 В названии пишем «Конверсии с SEO», указываем цель из Метрики, которая будет считаться конверсией. В пункте Метрика выбираем «Целевые визиты», в пункте Группировка — «Источники трафика (детально)».
В названии пишем «Конверсии с SEO», указываем цель из Метрики, которая будет считаться конверсией. В пункте Метрика выбираем «Целевые визиты», в пункте Группировка — «Источники трафика (детально)».
Переходим на вкладку «График» и здесь выбираем цвет линий для разных поисковых систем.
Конверсии с рекламы. Создаём виджет «Линии». В названии пишем «Конверсии с рекламы», выбираем цель, в пункте Метрика выбираем «Целевые визиты», в пункте Группировка — «Источники трафика (детально)».
Переходим на вкладку «График» и здесь выбираем цвет линий для разных рекламных систем.
В зависимости от ваших задач, вы можете сами создавать нужные виджеты. Также, можете воспользоваться библиотекой виджетов и добавить на дашборд Метрики нужные показатели.
ЗаключениеИспользуя базовые возможности Яндекс.Метрики, можно проанализировать различные источники трафика и оценить их рентабельность,. По этому же принципу можно создавать другие виджеты, сегментируя посетителей по географии, выделяя мобильный трафик, интересы и прочее. Это поможет быстро анализировать эффективность различных рекламных каналов и вносить необходимые корректировки в свои действия.
Это поможет быстро анализировать эффективность различных рекламных каналов и вносить необходимые корректировки в свои действия.
Полезные ссылки:
- Как правильно настроить рекламу в Яндекс.Директ
- Отслеживание конверсий в Google Ads
- Что такое ROI и как его посчитать
- Как сделать турбо-сайт в Яндекс.Директ
Яндекс.Метрика для бизнеса — полный курс по анализу данных
Что можно сделать с помощью «Яндекс.Метрики»?
- Отфильтровать нецелевой трафик и повысить конверсию с запущенной рекламной кампании.
- Сегментировать аудиторию по полу, возрасту, количеству просмотренных страниц, географии, чтобы настроить эффективный ретаргетинг и направить рекламу на лояльных клиентов.
- Проанализировать аудиторию по разным рубрикам и собрать подробную статистику по каждой единице контента.
- Отследить самые кликабельные и конверсионные элементы (кнопки, формы, конкретные страницы) и оптимизировать юзабилити сайта.
Что вы получите?
- 6 лекций по 1,5 часа от специалистов топового интернет-агентства рунета.
- Систематизированные знания по сквозной аналитике, электронной коммерции и настройке отчетов в «Яндекс.Метрике».
- Диплом, который можно будет предъявить вашему работодателю.
- Доступ ко всем лекциям и дополнительным материалам в течение года.
Расписание занятий
Мы даем информацию строго по делу: никакой воды и отвлеченных рассуждений. Несколько подробных и интенсивных лекций, практические задания – и вы уже готовы налаживать виджеты, следить в вебвизоре за пользователями и собирать подробную аналитику.
Главное о «Яндекс.Метрике». Для чего она нужна бизнесу и какие задачи решает. Обзор интерфейса и основных функций. Регистрация и настройка «Яндекс.Метрики». Создание аккаунта и его настройка. Проверка работы счётчика.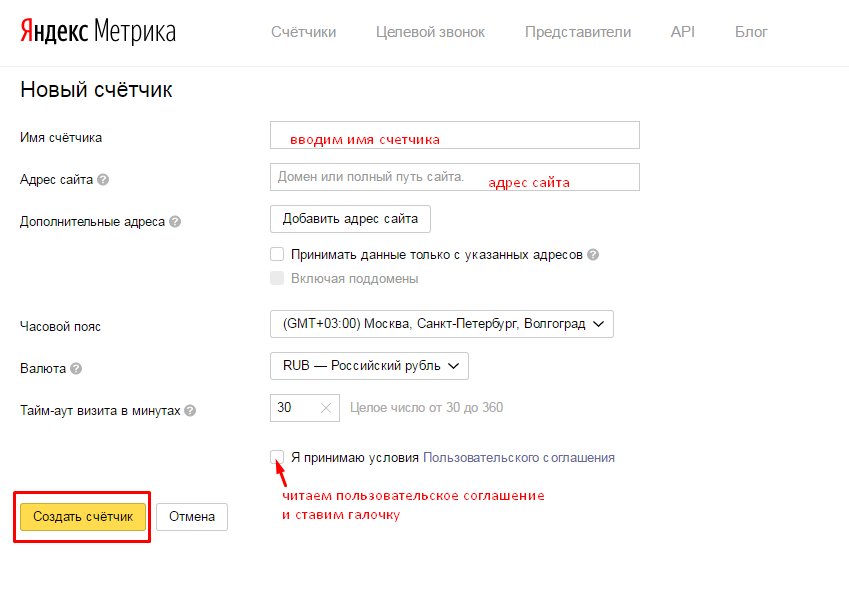
Анализ базовых данных. Пример маркетингового отчёта. Общий трафик. Источники трафика. Поисковый трафик. Брендированные запросы. Поисковые запросы. Страницы входа.
Анализ эффективности конверсий на сайте. Что такое электронная коммерция и как её подключить. Что такое код отслеживания событий и как его подключить. Как отслеживать конверсию: основные способы. Как анализировать транзакцию на сайте. Как проверить эффективность рекламы и переходов.
Аудит поведенческих метрик. Как подключить вебвизор. Анализируем поведение людей на сайте, улучшаем поведенческие метрики. Карта скроллинга. Карта кликов. Анализ контента на сайте.
Сквозная аналитика. «Яндекс.Звонки» и коллтрекинг, синхронизация их с «Яндекс.Метрикой».
Практикум. Совместное решение задач «Яндекс.Метрики». Ответы на вопросы.
Подарите именной сертификат на обучение
1. Оплатите курс в нужном тарифе
2. Напишите на info@teachline. ru ФИО и почту получателя подарка
ru ФИО и почту получателя подарка
3. Получите сертификат в электронном виде на вашу почту
Кому подойдет этот курс?
Начинающим интернет-маркетологам
Без «Яндекс.Метрики» вы как без рук. Самое время освоить сквозную аналитику, научиться эффективно тратить бюджет на рекламу и разобраться, как оптимизировать любой сайт.
Диджитал-специалистам
Неважно, настраиваете вы рекламу или занимаетесь SEO-оптимизацией: «Яндекс.Метрика» поможет вам углубить профессиональные знания, повысить квалификацию и начать больше зарабатывать.
Владельцам бизнеса
Если вы самостоятельно продвигаете свой сайт, но не понимаете, за что хвататься и как проконтролировать подрядчиков, навыки обращения с «Яндекс.Метрикой» решат ваши проблемы.
Наглядно о том, почему «Яндекс.Метрика» полезна
Prev slide
Next slide
К нам пришел клиент. Смотрим статистику – показатель отказов 80 %. Начали думать, с чем это связано. Оказалось, на сайте установлен счетчик «Метрики» с неправильными параметрами, из-за чего он выдавал неверные показатели. Поправили счетчик – показатель отказов упал до нормальных 18 %.
Оказалось, на сайте установлен счетчик «Метрики» с неправильными параметрами, из-за чего он выдавал неверные показатели. Поправили счетчик – показатель отказов упал до нормальных 18 %.
Одноклассники не велись, просто дублировали контент для поддержания жизни в сообществе. Готовили отчет, зашли на метрику и увидели, что кол-во переходов выше или почти наравне, касаемо других соцсетей. К тому же там самая большая глубина просмотра. Так и поняли, что нужно развивать эту соцсеть. Разработали концепцию «Сделай сам» и стали публиковать уникальный контент.
На сайте резко упал поисковый трафик. Начали выяснять причину. Залезли в robots.txt, а там… барабанная дробь… сайт закрыт от индексации – забыли открыть, когда завершили работу по переносу сайта на другой движок. Поменяли одну строчку кода, и трафик вернулся на свои показатели.
Наши преподаватели
Prev slide
Next slide
Иван Смирнов
Project-менеджер
Проектный менеджер TexTerra. Опыт работы в интернет-маркетинге — более четырёх лет. Личный рекорд по увеличению поискового трафика — 149 млн до 182 млн за один год.
Опыт работы в интернет-маркетинге — более четырёх лет. Личный рекорд по увеличению поискового трафика — 149 млн до 182 млн за один год.
Павел Антипов
Project-менеджер
Эксперт по SEO-оптимизации сайтов и контекстной рекламе. Знает всё о «Яндекс.Метрике». Вырастил месячный поисковый трафик «Ароматного Мира» более чем в 4 раза. Ведущий специалист на курсе «Контекстная реклама в «Яндекс.Директ»».
Светлана Шульман
Маркетолог TeachLine
Ведущий специалист по ведению соцсетей и таргетированной рекламы. Знает всё о платных методах продвижения и обучает, как продвигаться в разных социальных сетях. А также организовывает и ведет корпоративные обучения в TeachLine.
Стоимость
Prev slide
Next slide
очень быстро и очень удобно / Хабр
Виктор Тарнавский показывает, что оно работает. Перед вами расшифровка доклада Highload++ 2016.
Здравствуйте. Меня зовут Виктор Тарнавский. Я работаю в «Яндексе». Расскажу про очень быструю, очень отказоустойчивую и супермасштабируемую базу данных ClickHouse для аналитических задач, которую мы разработали.
Я работаю в «Яндексе». Расскажу про очень быструю, очень отказоустойчивую и супермасштабируемую базу данных ClickHouse для аналитических задач, которую мы разработали.
Пару слов обо мне. Я Виктор, работаю в «Яндексе» и руковожу отделом, который занимается разработкой аналитических продуктов, таких как «Яндекс.Метрика» и «Яндекс.AppMetrica». Я думаю, многие из вас пользовались этими продуктами и знают их. Ну, и в прошлом, и по-прежнему пишу много кода, а раньше еще занимался разработкой железа.
Что сегодня вообще будет
Я расскажу немного истории: почему мы решили создать свою систему, как дошли до жизни такой, что в современном мире, в котором, казалось бы, существует решение для любой задачи, нам все равно понадобилось создать свою базу данных. Потом расскажу о том, какие фичи сейчас есть в ClickHouse, из чего он состоит, и какие в нём есть возможности, которые можно использовать. Потом хочется погрузиться немного вглубь и рассказать вам, какие решения мы принимали внутри ClickHouse, и из чего он состоит, и почему ClickHouse работает наcтолько быстро.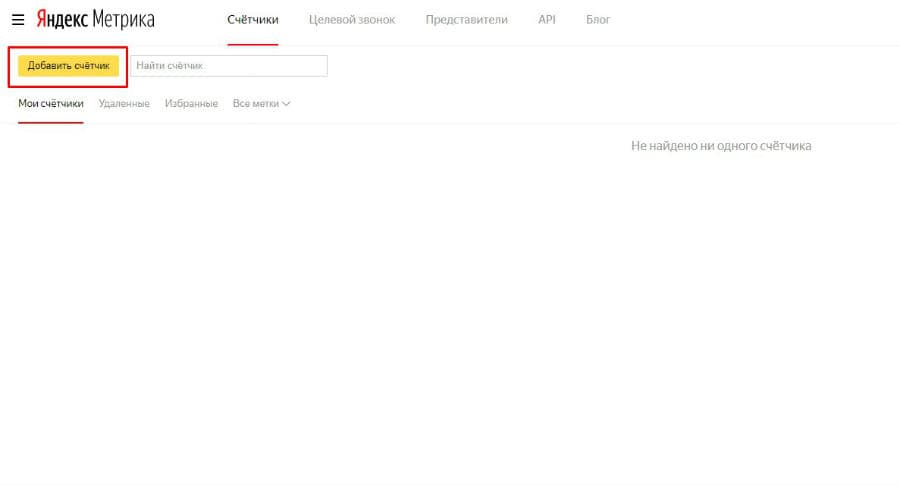 И в конце хочу показать, как ClickHouse может помочь именно вам лично или компании, в которой вы работаете, для каких задач стоит его применять, какие кейсы можно построить вокруг ClickHouse.
И в конце хочу показать, как ClickHouse может помочь именно вам лично или компании, в которой вы работаете, для каких задач стоит его применять, какие кейсы можно построить вокруг ClickHouse.
Немного истории
Все начиналось в 2009 году. Тогда мы делали «Яндекс.Метрику» — веб-аналитический инструмент. То есть такой инструмент, который владельцы или разработчики сайтов ставят себе на сайт. Это кусочек JavaScript, он отсылает данные в «Яндекс.Метрику». Потом в «Метрике» можно видеть статистику: сколько на сайте было людей, что они делали, купили ли они холодильник и всякое такое.
И с точки зрения разработки веб-аналитической системы — это некоторый challenge. Когда вы разрабатываете один сервис или какой-то продукт, вы проектируете нагрузку так, чтобы выдерживать какие-то RPS и прочие параметры этого одного сервиса или продукта. А когда вы разрабатываете веб-аналитический инструмент, вам нужно выдерживать нагрузку всех сайтов, на которых стоит ваш веб-аналитический инструмент.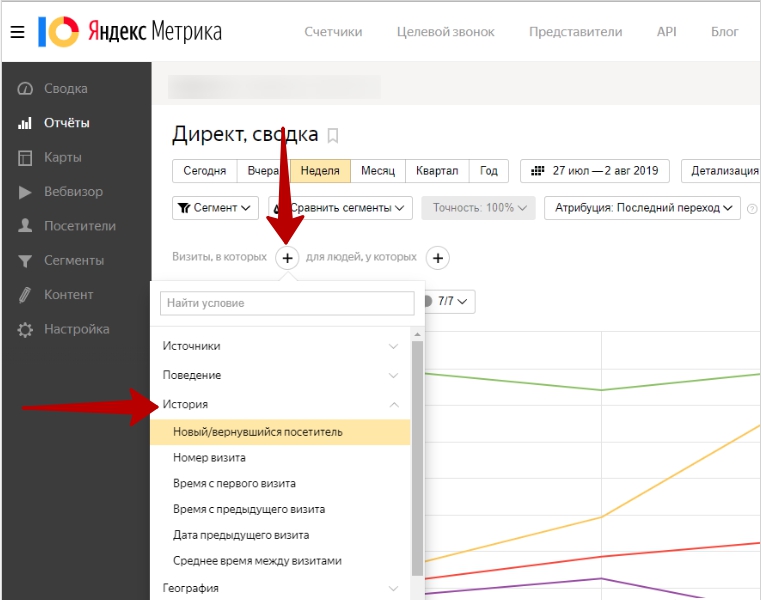 И в случае «Метрики» — это очень большие масштабы: десятки миллиардов событий, которые мы принимаем каждый день.
И в случае «Метрики» — это очень большие масштабы: десятки миллиардов событий, которые мы принимаем каждый день.
«Метрика» стоит на миллионах веб-сайтов. Сотни тысяч аналитиков каждый день сидят и смотрят в интерфейс «Метрики», запрашивают какие-то отчёты, выбирают фильтры и пытаются понять, что происходит у них на сайте, купил ли этот человек этот холодильник, или что происходит. По внешним данным «Метрика» — это система, которая входит в тройку самых крупных игроков на этом рынке. То есть количество сайтов, которые у нас, и количество людей, которых видит «Метрика», — это продукт из топа, продуктов большего масштаба практически нет.
В 2009 году «Метрика» выглядела не так:
Это текущее её состояние. Видно, что в «Метрике» есть много чего. Есть Dashboards, на которых можно строить свои отчёты. Есть графики, которые позволяют что-то построить в режиме реального времени. Есть сложная система фильтров, с помощью которой можно посмотреть данные в любом срезе. Например, посмотреть данные только для девочек или только для людей, которые пришли с Зимбабве, — что-то такое.
Возникает вопрос — как нужно хранить данные, чтобы реализовать все эти возможности?
И в 2009 году мы жили, как мы это называем, в мире «классического» подхода агрегированных данных. Как это выглядит?
Допустим, вы хотите построить отчёт по полу. Как известно, полов в мире три: мужской, женский и «не определено», когда нам не удалось понять какой пол у человека. Вы берёте вашу любимую базу данных, делаете в ней колоночку с полом, делаете её enumerate какой-нибудь из трёх значений, делаете колоночку с датой, потому что нужно построить график, и делаете столбцы с метриками, которые вы считаете: количество людей, количество событий, например, заходов на сайт, количество купленных холодильников и так далее. Такую табличку, например, по Cron раз в день пересчитываете и записываете в MySQL новые строчки, и всё успешно работает.
В 2009 году мы жили в такой парадигме. Поэтому для каждого отчёта, который мы делали, мы создавали, по сути, новую такую таблицу. А в случае «Метрики» было больше 50 подобных разных таблиц с разным предагрегированным ключом. Наша система была существенно сложнее. Мы умели делать это в режиме реального времени. Мы умели выдерживать любые нагрузки, но тем не менее смысл оставался таким же.
Наша система была существенно сложнее. Мы умели делать это в режиме реального времени. Мы умели выдерживать любые нагрузки, но тем не менее смысл оставался таким же.
Проблема этого подхода — в том, что вот такой интерфейс реализовать поверх этой структуры данных невозможно. Потому что если вы записали в вашу табличку, что мужской пол, дата такая-то, было куплено 4 холодильника, то вы не сможете уже эти данные отфильтровать, потому что там написана цифра 4 и неизвестно сколько из этих людей какого возраста, например. Поэтому со временем мы пришли к понятию неагрегированного подхода.
Это выглядит следующим образом. Мы сохраняем небольшое количество очень широких таблиц исходных событий. Например, в случае «Метрики» — это просмотры страниц. Одна строчка означает один просмотр страницы, у одного просмотра страницы очень много разных атрибутов: пол человека, возраст, куплен холодильник или нет, и еще какие-то колонки. В нашем случае в просмотрах мы записываем более 500 разных атрибутов для каждого просмотра.
Что такой подход позволяет делать? Он позволяет строить любые отчёты поверх такой модели данных. Данные можно как угодно фильтровать и группировать, потому что все параметры у вас есть, можно посчитать, что угодно. Получается небольшое количество таблиц, в случае «Метрики» их можно пересчитать на пальцах одной руки, но в них очень большое количество столбцов.
Проблема такого подхода
Нужна база данных, которая позволяет по такой широкой и длинной таблице — потому что очевидно, что она будет длиннее, чем агрегированные данные — быстро считать любые запросы.
Выбор СУБД
Это был основной вопрос, который у нас стоял в 2009 году. Тогда у нас уже были свои эксперименты. У нас была такая система, мы ее называли All Up. В неё уже были неагрегированные данные, и, если кто-то помнит старую «Метрику», в ней был конструктор отчетов, в котором можно было выбрать какие-то фильтры, измерения и построить произвольный отчёт. Он как раз был поверх этой системы All Up. Она была достаточно простой, у неё было много недостатков, она была недостаточно гибкой, недостаточно быстрой. Но она дала нам понимание того, что этот подход в принципе применим.
Он как раз был поверх этой системы All Up. Она была достаточно простой, у неё было много недостатков, она была недостаточно гибкой, недостаточно быстрой. Но она дала нам понимание того, что этот подход в принципе применим.
Мы начали выбирать базы, сформировали для себя какие-то требования. Мы поняли, что у нас примерно такой список требований.
Конечно, нам нужно максимально быстро выполнять запросы. Потому что наше основное продуктовое преимущество — максимально быстро выполнять запросы на больших объемах данных. Чем больше сайт, для которого мы можем быстро считать данные, тем лучше. Чтобы вы понимали паттерн: человек смотрит в интерфейс в «Метрике», меняет какие-то параметры, добавляет фильтры. Он хочет быстро получить результат, он не желает ждать до завтра или полчаса, пока ему это придёт. Нужно делать эти запросы за секунды.
Нужна обработка данных в реальном времени. Как на уровне вот этого запроса, когда человек сидит и хочет быстро увидеть результат, так и на уровне времени, которое проходит между покупкой холодильника на сайте и моментом, когда владелец сайта увидит, что человек купил этот холодильник. Это тоже очень важное преимущество, например, для новостных сайтов, которые выпускают какую-то новость и хотят быстро смотреть, насколько быстро она растёт. Нам нужна система, которая позволяет вставлять эти данные в реальном времени в базу и параллельно с этим забирать оттуда свежие результаты и агрегированные данные.
Это тоже очень важное преимущество, например, для новостных сайтов, которые выпускают какую-то новость и хотят быстро смотреть, насколько быстро она растёт. Нам нужна система, которая позволяет вставлять эти данные в реальном времени в базу и параллельно с этим забирать оттуда свежие результаты и агрегированные данные.
Нужна возможность хранить петабайты данных, потому что они у нас есть. «Метрика» очень большая — объём измеряется петабайтами. Далеко не каждая база может так масштабироваться. Для нас это очень важный параметр.
Отказоустойчивость в терминах датацентров. Ну что это означает?
Мы живем в России и много чего видели. Периодически приезжает трактор и выкапывает кабель, который ведёт к твоему датацентру, а потом совершенно неожиданно в тот же день приезжает экскаватор и выкапывает резервный кабель в твой другой датацентр, который находится через 100 километров. И ладно, если б я так шутил. Но оно и правда так было. Если, иногда, какая-нибудь кошка заползает в трансформатор, он взрывается. Иногда метеорит падает, рушит датацентр. В общем всякое происходит — датацентры выключаются.
Иногда метеорит падает, рушит датацентр. В общем всякое происходит — датацентры выключаются.
В «Яндексе» мы проектируем все наши сервисы таким образом, чтобы они жили — не деградировали в своих продуктовых характеристиках, когда отключаются датацентры. Любой из датацентров может отключиться и сервисы должны выживать. На уровне базы данных для «Метрики» нам нужна такая база, которая может выживать при падании датацентра, что особенно это сложно с учетом предыдущих пунктов, про хранение петабайт данных и обработку в реальном времени.
Так же нужен гибкий язык запросов, потому что «Метрика» — сложный продукт и у нас много разных комбинаций, отчетов, фильтров и всего на свете. Если язык будет похож на какой-нибудь aggregation API MongoDB — если кто-то пытался пользоваться им, то вот такой нам не подходит. Нужен какой-то язык, которым удобно пользоваться, поэтому это было одним из ключевых критериев для нас.
Тогда было примерно как? На рынке не было ничего. Нам удалось найти базы, которые реализовывали, максимум, три из этих пяти параметров и то с какими-то там натяжками, а про пять даже речи не шло. У нас шло создание All Up системы и мы поняли, что мы, кажется, можем построить такую систему сами. Мы начали прототипировать. Начали создавать систему с нуля.
У нас шло создание All Up системы и мы поняли, что мы, кажется, можем построить такую систему сами. Мы начали прототипировать. Начали создавать систему с нуля.
Основные идеи, которые мы преследовали, когда создавали новую систему и это изначально было понятно — что это должен быть SQL. Потому что его гибкости хватает для наших задач.
Понятно, что SQL это расширяемый язык, потому что в него можно свои какие-то функции добавлять, даже какие-то сверхнавороты делать. Это язык с низким порогом входа. Все аналитики и большая часть разработчиков с этим языком знакомы.
Линейная масштабируемость. Что означает «линейная»? Линейная означает, что если у вас есть какой-то кластер и вы в него добавляете сервера, то производительность должна расти, потому что количество серверов увеличилось. Но если взять какую-то более типичную систему, которая недостаточно хорошо масштабируется, то легко может выясниться, что вы добавляете сервера, а потом делаете запрос сразу на весь кластер и производительность не будет расти.
Вам повезёт, если она будет такой же, но в большинстве случаев она еще и падать будет со временем. Нам такое не подходит.
Изначально мы проектировали систему с фокусом на быстрое исполнение запросов, потому что, как я уже говорил, это наша основная фича. С точки зрения дизайна системы, с самого начала было понятно, что это должно быть Column-oriented — колоночное решение. Только поколоночное решение способно реализовать все, что нам нужно, закрывать все наши потребности.
И мы начали создавать, начали прототипировать. В 2009 году у нас был прототип, который делал какие-то простейшие вещи.
В 2012 году мы начали переводить части нашего продакшена на ClickHouse. Появились элементы продакшена, которые начали работать поверх ClickHouse.
В 2014 году мы поняли, что ClickHouse дорос до состояния, когда можно создавать продукт нового поколения. Metrica 2.0 поверх ClickHouse, а мы начали копировать данные.
Это очень нетривиальный процесс, если кто-то пытался скопировать два петабайта с одного места в другое, это не очень просто — на флешке это нельзя сделать.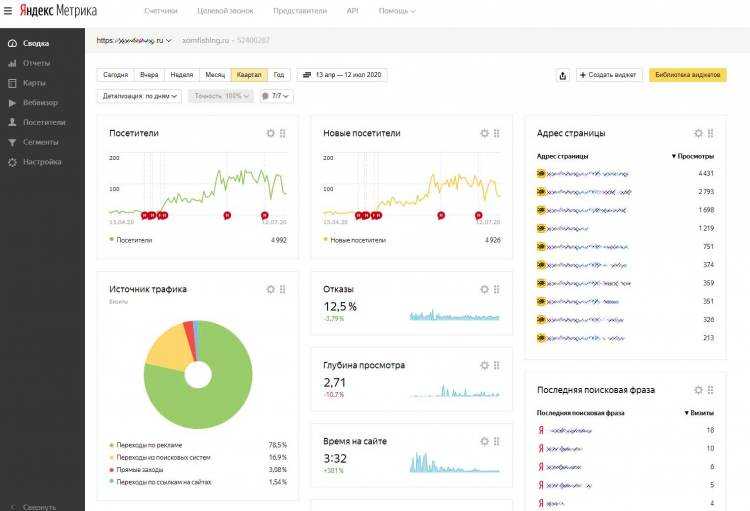
В декабре 2014 года мы запустили новую «Метрику» поверх ClickHouse — это был прям прорыв, сегментация, куча фич, и все это работало поверх этой базы.
Несколько месяцев назад, в июне, мы выложили ClickHouse в Open Source. Мы поняли, что есть ниша и на рынке всё по-прежнему. У меня был сайт про «на рынке ничего», сейчас мы всё ещё близки к этой ситуации, мало что изменилось. На рынке не так много хороших решений для этой задачи. Мы поняли, что мы вовремя — мы можем сейчас выложить в Open Source и принести много пользы людям. Многие задачи сейчас очень плохо решаются, но их очень хорошо решает ClickHouse.
Оно как-то взрывом произошло. Конечно мы ожидали какой-то большой эффект от того, что мы выложили Open Source. Но то, что произошло превзошло все наши ожидания. У нас до этого было много проектов «Яндексе», которые реализованы были в ClickHouse, но прямо сейчас, когда мы выложили, о нас начали писать везде.
Где о нас только не писали: на HackerNews, на всех профильных изданиях. Нас стали спрашивать куча крупных компаний, куча компаний помельче, про новые решения. Кто-то уже пытался делать, а прямо сейчас статус такой, что ClickHouse использует, я могу сказать — более сотни разных компаний за пределами «Яндекса». Либо на стадии уже готовых каких-то прототипов, либо уже в продакшене. Есть компании, которые используют ClickHouse прямо в продакшене и строят куски своих сервисов поверх ClickHouse.
Нас стали спрашивать куча крупных компаний, куча компаний помельче, про новые решения. Кто-то уже пытался делать, а прямо сейчас статус такой, что ClickHouse использует, я могу сказать — более сотни разных компаний за пределами «Яндекса». Либо на стадии уже готовых каких-то прототипов, либо уже в продакшене. Есть компании, которые используют ClickHouse прямо в продакшене и строят куски своих сервисов поверх ClickHouse.
Мы получили 1500 звёздочек на GitHub — но это устаревший слайд, сейчас их там 1800. Метрика так себе, но на всякий случай могу сказать для сравнения, что у Hadoop 2500 звёздочек. Понимаете, уровень. Мы скоро Hadoop обгоним, я думаю и тогда будет, о чем говорить.
Действительно сейчас очень много каких активностей происходит. Мы начинаем устраивать всякие митапы и будем их устраивать, так что приходите и спрашивайте.
Какие есть возможности
О чем я вообще говорю?
Линейная масштабируемость – это очень важное преимущество ClickHouse по сравнению с аналогичными решениями. Из коробки ClickHouse способен линейно масштабироваться и можно построить кластера очень большого размера и все будет хорошо работать. Например, потому что у нас оно очень хорошо работает. Петабайты данных — построить петабайтный кластер на ClickHouse не проблема. Из коробки работает cross-datacenter, для этого ничего не надо делать и он изначально задумывался как cross-datacenter решение. У нас в «Яндексе» в основном используются такие кластера.
Из коробки ClickHouse способен линейно масштабироваться и можно построить кластера очень большого размера и все будет хорошо работать. Например, потому что у нас оно очень хорошо работает. Петабайты данных — построить петабайтный кластер на ClickHouse не проблема. Из коробки работает cross-datacenter, для этого ничего не надо делать и он изначально задумывался как cross-datacenter решение. У нас в «Яндексе» в основном используются такие кластера.
High availability означает, что ваши данные и вообще кластер, и на чтение, и на запись всегда будет доступен. В этом смысле ClickHouse такой конструктор — можно построить кластер с любыми гарантиями, которые вам нужны. Если вы хотите выдерживать падение датацентра — вы ставите, в типичном случае, в трёх датацентрах кластер с фактором репликации х2. Если вы хотите построить решение — кластер, который выдерживает падение датацентра и одной ноды, обычно это означает, что нужно взять фактор репликации х3 и построить на базе как минимум трёх датацентров.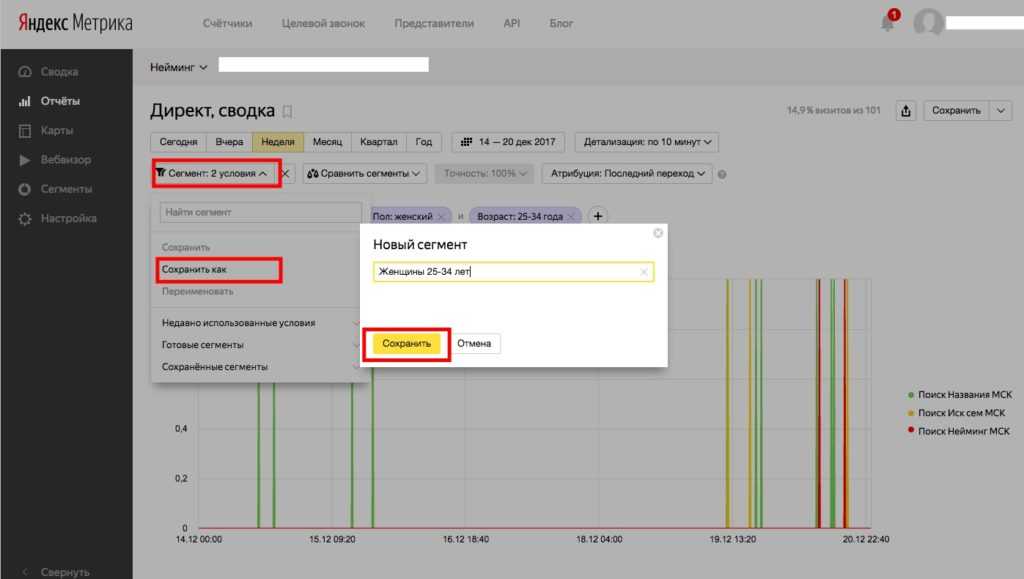 Это достаточно гибкая система, можно любой гарантии построить, если знать как.
Это достаточно гибкая система, можно любой гарантии построить, если знать как.
Сжатие данных. ClickHouse это поколоночная система, что само по себе означает, что сжатие данных работает очень хорошо. Потому что смысл поколоночного решения: данные из одной колонки хранятся, по сути, в одном файле на жестком диске и, если там примерно одинаковое написано, то сжимается это очень эффективно — а если хранить это по строчкам, то там идёт все подряд и сжимается достаточно плохо.
В ClickHouse применено достаточно большое количество оптимизаций на эту тему, а потому сжимаются данные очень хорошо. Если сравнивать это с обычной базой данных, или с Hadoop, или еще с чем-то — разница от десятка до сотен раз, легко. Обычно у нас с этим проблема бывает: люди пробуют ClickHouse, загружают туда данные, смотрят сколько там места занимается и такие «кажется я не все загрузил», еще посмотрели — вроде все загрузилось. На самом деле очень эффективное сжатие — люди такого не ожидают.
На примере кластера «Яндекс. Метрики»:
Метрики»:
У нас есть несколько кластеров — это самый большой из них. У нас лежит 3 петабайта прямо сейчас, 3,4 что ли — слайд устаревший, на нем 412, а сейчас уже 420 серверов. Мы их увеличиваем потихоньку. Кластер размазан по шести датацентрам в разных странах. Несмотря на сложную конфигурацию, кластер имеет какие-то единицы часов даунтайма за все время существования. Это очень мало и невероятное количество девяток. Это все несмотря на то, что мы выкладываем каждый раз самую свежую версию ClickHouse, с самым большим количеством багов, видимо, однако это нам не помешало обеспечивать требуемые гарантии.
Это показывает, что данное решение способно работать 24/7 без всяких проблем. Да, «Метрика» работает 24/7, у нас нет никаких maintenance-периодов.
Запросы
Да, поддерживается SQL. SQL — это, по-сути, единственный способ спросить ClickHouse что-нибудь. Строго говоря, это диалект SQL, потому что есть некоторые отличия от стандарта, но в большинстве случаев, если вы делаете какой-то запрос на SQL, он скорей всего сработает нормально. Есть разнообразные дополнительные функции для приблизительных вычислений, когда можно пожертвовать точностью — зато запрос будет работать быстрее, или в память влезет. Есть множество разнообразных функций для различных типов данных, например, для URL — в «Яндекс.Метрике» очевидно много URL и там есть целый большой набор функций для работы с URL: можно вытащить домен, какие-то пути разложить, параметры. Для каждого типа данных есть большой набор функций. В «Метрике», наверное, есть самые разнообразные данные и скорее всего, примерно для всех типов данных, уже есть все возможности.
Есть разнообразные дополнительные функции для приблизительных вычислений, когда можно пожертвовать точностью — зато запрос будет работать быстрее, или в память влезет. Есть множество разнообразных функций для различных типов данных, например, для URL — в «Яндекс.Метрике» очевидно много URL и там есть целый большой набор функций для работы с URL: можно вытащить домен, какие-то пути разложить, параметры. Для каждого типа данных есть большой набор функций. В «Метрике», наверное, есть самые разнообразные данные и скорее всего, примерно для всех типов данных, уже есть все возможности.
Из коробки поддерживаются массивы и кортежи. Это означает, что можно создать табличку, в которой в одной из колонок будет не колонка, а массив. Это может быть просто массив, например, много чисел, а может быть кортеж — массив со сложной структурой из нескольких полей. Поддержка массивов работает на уровне запросов — на уровне схемы базы, сверху донизу и есть много функций для работы с массивами, которые позволяют эффективно с ними работать. Можно, например, размножить остальные данные по этому массиву, а можно из массива извлечь любую информацию. Есть даже специальный лямбда-синтаксис, которым можно сделать map на массив или фильтр на массив, такие вещи.
Можно, например, размножить остальные данные по этому массиву, а можно из массива извлечь любую информацию. Есть даже специальный лямбда-синтаксис, которым можно сделать map на массив или фильтр на массив, такие вещи.
Из коробки все запросы работают распределённо, не нужно ничего менять, нужно табличку другую указать, в которую будет распределено — будет работать на уровне всего кластера.
Так же есть такая фича, как внешние словари. Такая возможность, о которой хотелось бы немножко отдельно сказать. Когда мы её разработали, в «Метрике» это решило проблему ну, наверное, 80% join. Они просто перестали существовать. В чем смысл? Допустим, у вас есть основная табличка с данными, а в ней есть какие-то идентификаторы — предположим это идентификатор какого-то клиента. Есть отдельно справочник, который переводит этот идентификатор в имя клиента. Достаточно классическая ситуация. Как это выглядит на обычной SQL?
Вы делаете join — правильно, делаете join одного на другого и переводите ID в имя, если вы хотите в результате имя получить. В ClickHouse можно эту таблицу подключить, как внешний словарь, с помощью очень простого синтаксиса в конфиге — после этого на уровне запроса можно указать просто функцию, которая переведёт этот идентификатор в значение, ну или какие-то другие поля, которые у вас есть в этой удалённой таблице.
В ClickHouse можно эту таблицу подключить, как внешний словарь, с помощью очень простого синтаксиса в конфиге — после этого на уровне запроса можно указать просто функцию, которая переведёт этот идентификатор в значение, ну или какие-то другие поля, которые у вас есть в этой удалённой таблице.
Что это означает? Это означает, что если вы делаете select из основной таблицы, например, множества идентификаторов, штук 5 — перевести эти идентификаторы в какую-то расшифровку вопрос одной функции. Если бы вы это делали через join, то у вас было бы 5-6 join, что выглядит ужасно. Кроме того, внешние словари можно подключить из любой базы, можно из MySQL, можно из файлика — из любой базы, которая поддерживает ODBC, например, из PostgreSQL. Это позволяет этим именам как-то обновляться, что сразу подхватится на уровне запроса. Невероятно удобная фича.
Пара примеров запросов:
Это запрос, который забирает трафик и размер аудитории, то есть количество пользователей из кластера «Метрики» за неделю. Видно, что этот запрос достаточно простой, обычный SQL. Ничего особенного тут нет, вот только count написан без звездочки, со звездочкой если что тоже можно, но мы привыкли так писать.
Видно, что этот запрос достаточно простой, обычный SQL. Ничего особенного тут нет, вот только count написан без звездочки, со звездочкой если что тоже можно, но мы привыкли так писать.
Это пример использования внешних словарей. Если посмотреть, где строчка regionToName в этой строчке — мы переводим RegionID — идентификатор региона, где был человек. Сначала в идентификатор страны, где он был. У нас есть справочник с региона на страну, и потом в название страны на английском языке. Как можно увидеть это вызов двух функций, очень понятно и очень просто выглядит. На классическом SQL это было бы два JOIN и запрос не влез бы в этот слайд, и пришлось бы его разбить слайда на три. Очень упрощает работу.
Скорость
Самая главная фича ClickHouse — это скорость. Скорость невероятная. Я думаю, что у всех есть какие-то ожидания по тому, как ClickHouse может работать. К нам приходят со своими ожиданиями — вот у вас есть какие-то ожидания. Скорее всего ClickHouse превосходит ваши ожидания — так это происходит со всеми людьми, которые к нам приходят.
Скорее всего ClickHouse превосходит ваши ожидания — так это происходит со всеми людьми, которые к нам приходят.
Обычно типичные запросы работают быстрее, чем за секунду даже в масштабах кластера «Метрики», то есть петабайты меньше чем за секунду — несмотря на то, что данные у нас хранятся на обычных (не твердотельных) жёстких дисках.
Если сравнивать с обычными базами данных, то выигрыш в сотни тысяч раз по сравнению с Hadoop, MySQL, PostgreSQL. Оно будет давать результаты в сотни тысяч раз выше. Это реальность — у нас есть бенчмарки, я потом покажу.
Какие-то классные цифры, вплоть до 1 миллиарда строк в секунду — ClickHouse умеет обрабатывать на одной ноде, что достаточно много. В масштабах кластера «Метрики» 1 запрос может обрабатывать до 2 терабайт в секунду. Можете себе представить, что такое 2 терабайта — это такие жесткие диски, сейчас в него только 2 терабайта и влазит, бывают на 4 Тб, но пореже. И вот в секунду этот объём информации обрабатывается кластером «Метрики».
И в чем тут смысл? Почему эта скорость так важна
Она важна, примерно, вот поэтому:
Это меняет подход к работе полностью. Особенно для аналитиков и людей, которые копаются в data science. Вот это модно сейчас.
Как это обычно работает
Они делают запрос в классическую систему, в Hadoop, например, или в MapReduce какой-то. Делают запрос, нажимают ОК, берут кружку и идут на кухню. И на кухне они там с кем-то флиртуют, с кем-то общаются, возвращаются назад через полчаса, а запрос еще выполняется или уже выполнился, но только если повезло.
В случае с ClickHouse, они начинают переходить на ClickHouse и это выглядит следующим образом: печатают запрос, нажимают Enter, берут кружку, идут и замечают, что запрос уже выполнился — и они такие «ладно, погоди», ставят кружку и еще раз делают запрос другой какой-то, потому что уже увидели, что что-то там не так, и он тоже выполняется и они делают запрос ещё и ещё, входят в цикл.
Это полностью меняет подход к работе с данными, вы получаете результат мгновенно — ну, буквально за секунды. Это позволяет проверить огромное количество гипотез очень быстро и посмотреть на свои данные и так, и сяк, под одним углом, под другим углом. Проводить исследовательскую работу невероятно быстро или расследовать какие-то инциденты, которые у вас произошли, очень быстро.
У нас внутри компании даже есть проблема, связанная с этим. Аналитики, они пробуют ClickHouse, например, кластер «Метрики» или какие-то другие кластера. Потом они заражаются какой-то заразой, идут в Hadoop или какой-то MapReduce и уже не могут им пользоваться, потому что он работает слишком медленно для них. Они уже думают по-другому. Они ходят и всем говорят: «Мы хотим данные в ClickHouse. Мы всё хотим в ClickHouse».
На самом деле ClickHouse, строго говоря, не решает всех тех задач, которые решает MapReduce. MapReduce это система немножко другая, но для типичных задач ClickHouse работает намного-намного быстрее, что это реально меняет работу с данными.
Немного бенчмарков, чтобы не быть голословным. Эти бенчмарки мы гоняли год назад на миллиарде строк, наших собственных, из «Яндекс.Метрики». Запросы, которые в этом бенчмарке были — разные. В основном это запросы, которые мы сами используем в «Метрике», нормальные аналитические запросы: select group by, достаточно сложные или достаточно простые, set из примерно сотни запросов.
На наших собственных данных результаты примерно такие, если сравнивать с Hive или MySQL — с какими-то классическими решениями, то разница в сотни раз, как я уже говорил, что не совсем честно, потому что они не поколоночные и не заточены под это.
Ниже есть более реальные конкуренты — базы, которые решают такие же задачи и видно, что сама крутая из них, которую мы пробовали, это Vertica. Vertica действительно очень хорошая база данных, хорошо спроектирована, хорошо написана и очень-очень дорогая.
ClickHouse по нашим измерениям в два раза быстрее был по этим бенчмаркам, 2 года назад. С тех пор мы очень много чего заоптимизировали.
Больше информации по ссылке: https://clickhouse.yandex/benchmark.html
Эта ссылка не ошибка — действительно ClickHouse.yandex. Дальше ничего нет — в «Яндексе» купили домен .yandex — очень круто выглядит, стоит кучу денег, но стоит видимо того. В общем, не ошибётесь.
Интерфейсы
Можно по-разному работать с ClickHouse. Есть отличный консольный клиент — очень удобный для быстрой работы и удобный для быстрой автоматизации, потому что он может работать в неинтерактивном режиме. Для скриптов это достаточно удобно. Дефолтный протокол — это HTTP, через который можно делать все: запрашивать данные, загружать данные. Всё что угодно.
Поверх HTTP у нас есть JDBC драйвер, он тоже в Open Source. Можете его использовать в Java, Scala — в каком угодно environment. Так же люди уже понаписали разных коннекторов под разные языки, можете тоже пользоваться. Если под ваш любимый язык коннектора нет, то конечно же — пишите его и люди снова порадуются.
Немного внутрь
Прежде всего хочется ответить на самый главный вопрос: «Почему ClickHouse такой быстрый? В чем магия? Почему это так?» Тут есть несколько ответов. Во-первых, с точки зрения кода, как я уже говорил — мы изначально проектировали решение чтобы оно максимально было заточено под производительность. Поэтому весь код там максимально оптимизируется.
Когда пишется какая-то фича, всегда прогоняются performance тесты и проверяется, можно ли эту фичу еще дооптимизировать. Поэтому в ClickHouse сейчас нет медленно работающих функций — все работают настолько быстро, насколько это возможно, в пределах разумного. Также используется векторная обработка данных — это означает что данные никогда не обрабатываются по строчкам, обрабатываются только колоночками. Если у вас есть колоночка чисел — вы пишете в сумму какое-то число, берётся большой массив чисел, применяется какая-нибудь классная SSE-что-нибудь-инструкция и очень быстро все это складывается. Это позволяет действительно сильно ускорить обработку.
Это позволяет действительно сильно ускорить обработку.
С точки зрения данных — колоночное решение, понятно, очень эффективно работает, потому что вы запрашиваете только те данные, которые вам нужны, а не все колонки. И Merge Tree используется, кто не знаком — почитайте на Википедии, прекрасная структура для хранения данных, используется в ClickHouse. Это значит, что ваши данные будут лежать в каком-то небольшом количестве файлов, гарантировано — в ограниченном количестве файлов. Поэтому с точки зрения seek-ов на жестком диске — их количество будет минимальным. Вообще ClickHouse оптимизирован под работу на жестких дисках, потому что в «Метрике» мы используем жесткие диски, данных очень много на SSD не влезет.
Обработка данных происходит максимально близко к этим данным. Если у вас есть удаленный запрос, то ClickHouse старается максимальное количество работы сделать ближе к данным, чтобы по сети передать какие-то агрегаты и небольшое количество информации. Это, в частности одна из причин, по которой ClickHouse работает в cross-datacenter environment хорошо — потому что по сети передаётся не так много данных.
Также есть некоторые возможности, которые в ClickHouse из коробки работают для ускорения запросов, если это необходимо.
Есть семплирование.
Работает примерно так: если запрос работает недостаточно быстро, вы можете посчитать за ваш запрос не все данным, а скажем по 10 % или 1 %. Это нужно для исследовательской работы — если вы хотите поисследовать ваши данные, то делать это можно по 1% нормально и будет работать, примерно, в 100 раз быстрее. Очень удобно.
Есть функции с вероятностными алгоритмами — можно выбирать какой-то компромисс между скорость и точностью. Есть на уровне запроса возможность редактировать параметры, например — выбирать количество потоков, которые обработают именно этот запрос, что добавляет гибкости.
Масштабируемость и отказоустойчивость
Тут нужно сказать, что ClickHouse это такая полностью децентрализованная система и нет единой точки, которая принимает эти запросы, и единой точки, которая как-то регулирует, что происходит.
Асинхронная репликация применяется по умолчанию. Это означает, что вы данные записываете в какую-то любую реплику, а они будут гарантированно скопированы на другую реплику когда-нибудь. Ну как работает асинхронная репликация — в терминах ClickHouse это секунды, но на самом деле есть режим, который позволяет все сделать синхронно, если вам это необходимо. Обычно это не нужно.
ZooKeeper очень активно используется для синхронизации действий, для leader election и других операций. Не используется во время запросов, потому что ZooKeeper не способен выдержать RPS. Вообще он способен, но это внесёт дополнительные задержки, однако внутри он используется очень активно.
На примере кластера «Яндекс.Метрики»:
Тут изображено 6 датацентров. Синеньким изображен один шард, это две копии, х2 фактор репликации. Данные одинаково располагаются в двух датацентрах — все достаточно просто. Если фактор репликации будет х3, то синих и красных квадратиков будет 3 штуки.
Самое интересное.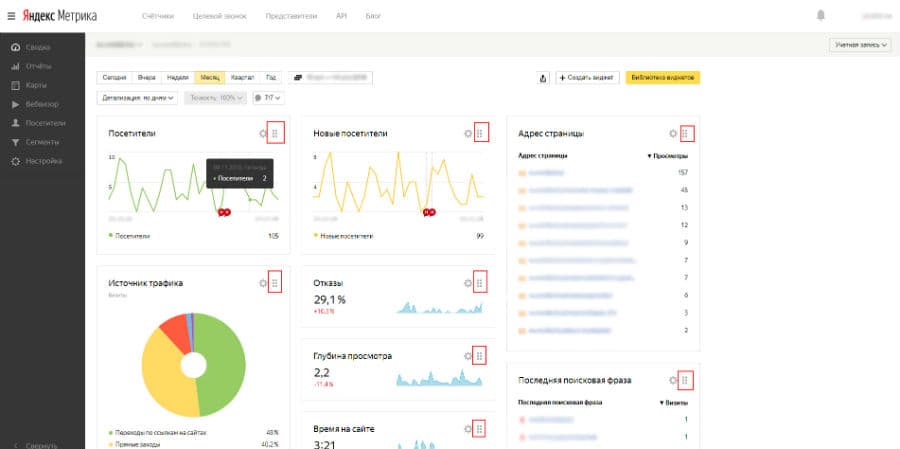 Как вы можете использовать ClickHouse?
Как вы можете использовать ClickHouse?
Начать хотелось бы с того, как ClickHouse не нужно использовать. Не стоит микроскопом гвозди забивать. ClickHouse это не OLTP решение, что означает следующее — если вы хотите какой-то транзакционности, если вы хотите какую-то бизнес логику поверх базы делать, не используйте для этого ClickHouse. Используйте классические решения: PostgreSQL, MySQL, что вам нравится. ClickHouse это база данных для аналитики, для исследовательской работы и для каких-то real-time отчетов. ClickHouse это не key-value решение. Не надо его использовать, как storage файлов или еще что-то такое. Не складывайте туда свои любимые фильмы, сложите их куда-нибудь в другое место.
ClickHouse — не document-oriented система, это означает, что в ClickHouse жесткая схема. Её нужно задать на уровне create table и описать структуру. Чем эффективнее вы опишите эту структуру, чем правильнее вы это сделаете — тем больше профита вы получите от ClickHouse с точки зрения производительности и удобства работы.
В ClickHouse нельзя модифицировать данные. Это для многих может быть сюрпризом, но на самом деле вам не нужно модифицировать данные — это иллюзия. Ну, то есть на самом деле в ClickHouse можно модифицировать данные — есть поддержка, можно удалять целиком куски большие. Есть возможность работать с данными — такая концепция SRDT, когда вы меняете данные не меняя их, то есть вставляете новые записи. И в ClickHouse можно работать таким образом, но основная идея тут в том, что если вам нужно часто менять данные, то, скорее всего, вам не нужно использовать ClickHouse — он вряд ли подходит для ваших задач.
Когда нужно использовать ClickHouse?
Нужно использовать ClickHouse, когда у вас есть широкие таблички с большим количеством колонок. Это отлично работает в ClickHouse, в отличие от большого количества других баз, потому что это поколоночное решение. Если вы считаете аналитику — замечательное решение будет.
Если у вас паттерн такой, что запросов не очень много, но в каждом запросе используется очень много данных — то ClickHouse отлично работает в таком паттерне. «Немного» в данном случае это: единицы, десятки, сотни RPS.
«Немного» в данном случае это: единицы, десятки, сотни RPS.
Если у вас большой поток входящих данных, прям постоянно течёт в базу. В случае «Метрики» это какие-то 20 миллиардов событий день и они в реальном времени пишутся. Очень немного баз способны работать в таких условиях, когда у них постоянно всё пишет, при этом постоянно запрашивает. ClickHouse может, он под это заточен.
Если у вас в принципе есть петабайты данных и вам нужно считать аналитику по ним, то вообще говоря не так много решений способны это сделать. Прям их можно на пальцах одной руки пересчитать, ну может двух. И ClickHouse отлично с этим справляется (не пальцы считать).
У меня есть пара небольших кейсов. С чего обычно начинают — это пытаются анализировать, что у них происходит в их текущем продакшене.
Как это обычно выглядит
Люди берут свои access-логи или логи просто daemons, буквально простым скриптом раскладывают их на колонки, которые интересны и записывают в ClickHouse. Всё. Это делается очень просто, реально за часы написать этот скрипт на Python или Bash, на чем вам больше нравится.
Всё. Это делается очень просто, реально за часы написать этот скрипт на Python или Bash, на чем вам больше нравится.
А что получается на выходе? Можно в любой момент очень просто анализировать любые странные ситуации. Какой-то клиент сделал что-то странное — нужно посмотреть, нужно посмотреть DDoS-ит ли меня этот клиент или нет. Можно все это select и мгновенно получить результат. Можно построить любые мониторинги сверху и посчитать любые метрики, это работает тоже мгновенно. С этого кейса начинали, из «Метрики» ClickHouse расползался именно используя этот кейс. И другие отделы начали загружать свои логи и строить incident reporting какой-то.
Второй, более большой и общий кейс — это база для аналитики внутри компании Data Warehouse.
Что там
В компании есть какая-то база, которая используется для продакшн процесса: Oracle, PostgreSQL, что-то такое. Она заточена совсем не под аналитику, это понятно — она заточена на то, чтобы бизнес логику реализовывать.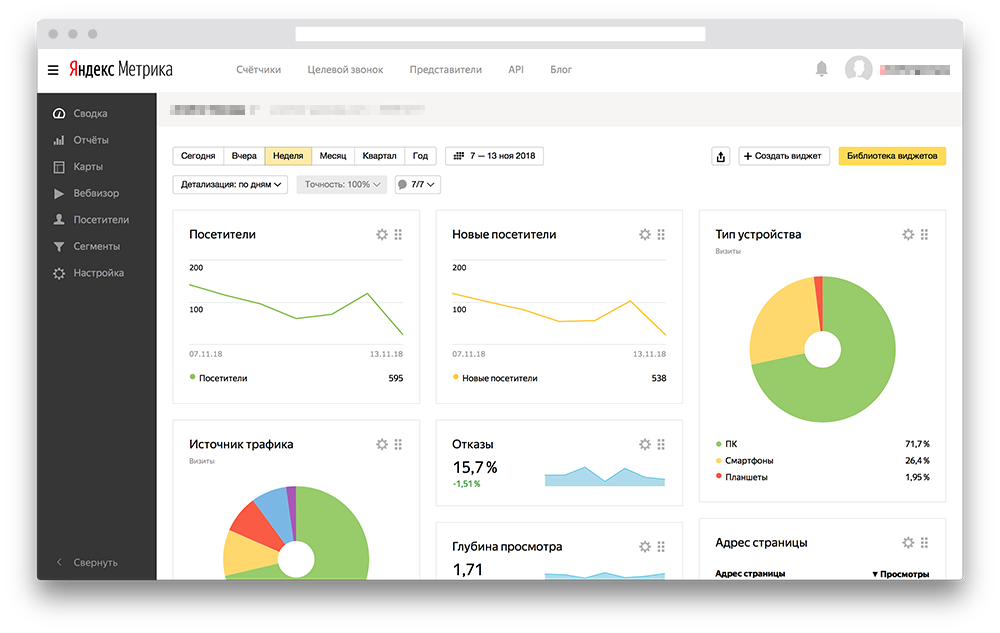 И аналитику по ней считать очень неудобно. Или есть ситуация, когда есть Hadoop, в который все тоже заливается и там тоже сидят аналитики, пытаются что-то в этом Hadoop понять, что работает очень медленно.
И аналитику по ней считать очень неудобно. Или есть ситуация, когда есть Hadoop, в который все тоже заливается и там тоже сидят аналитики, пытаются что-то в этом Hadoop понять, что работает очень медленно.
Что можно сделать?
Можно поднять кластер ClickHouse, небольшой, буквально один сервер — или нужно посчитать сколько, при этом помня, что данные в ClickHouse займут намного меньше места, чем данные в вашей текущей базе. Можно просто скопировать туда данные. Копировать их, например, периодически — раз в сутки. На выходе вы получите невероятную скорость по работе с вашими данными, которые касаются бизнеса или касаются разработки. У ваших аналитиков сразу волосы станут шелковистыми. Они могут быстро расследовать инциденты, очень быстро строить бизнес показатели, очень быстро строить даже какие-то dashboards поверх ClickHouse. Разница в скорости, вы сами видели, в сотню раз. Настроить всё это очень просто и поднять это просто. Вообще порог входа в ClickHouse намного ниже, чем в типичной системе, например, в Hadoop.
С чего начать?
У нас есть прекрасный tutorial — с ним можно зайти, поиграться, поставить ClickHouse, весь tutorial проходится за какие-то часы. Там уже есть сет данных, его можно скачать, закачать, посмотреть насколько просто все это ставится. Реально очень просто. Я ClickHouse настраивал позавчера на совершенно новом сервере и у меня это заняло буквально 2 минуты.
Пишите вопросы на рассылку, мы всегда отвечаем.
Зайдите на GitHub — посмотрите код. Это самый супероптимальный способ и все такое, код открыт весь.
И заходите на Google group и остальные источники. Больше информации по ссылке ClickHouse.yandex, там есть все, что вам может понадобиться — в том числе отличная документация.
Итог
Open Source база данных открытая для всех по лицензии apache2. Отличная лицензия.
Можете использовать для задач, в которых нужна линейная масштабируемость и для которых нужна невероятная скорость запросов. Вообще, если у вас есть проблема со скоростью аналитических запросов — попробуйте ClickHouse.
Поддерживается SQL c кучей всякий наворотов.
Спасибо всем.
Доклад: ClickHouse: очень быстро и очень удобно.
[PDF] Оценка фрагмента поиска в Яндексе: извлеченные уроки и будущие направления title={Оценка фрагмента поиска в Яндексе: извлеченные уроки и направления развития}, author={Денис Савенков, Павел Браславский и Михаил Лебедев}, название книги={CLEF}, год = {2011} }
- Денис Савенков, Павел Браславский, Михаил Лебедев
- Опубликовано в CLEF 19Сентябрь 2011 г.
- Бизнес
В статье рассматриваются различные подходы к оценке результатов веб-поиска и описываются эксперименты, проведенные в Яндекс. Мы предполагаем, что сложная задача оценки фрагмента лучше всего решается с помощью ряда различных методов. Перспективным направлением является автоматизация оценки на основе доступных ручных оценок и анализа переходов.
Просмотр через Publisher
mathcs.emory.eduИсследование длины фрагмента и информативности
- Дэвид Максвелл, Л. Аззопарди, Яшар Мошфеги
Психология
- 2018
 Аззопарди, Яшар Мошфеги
Аззопарди, Яшар МошфегиДизайн и представление страницы результатов поисковой системы (SERP) были предметом многочисленных исследований. Поскольку многие современные аспекты поисковой выдачи в настоящее время находятся под пристальным вниманием, все еще остается работа по расследованию…
Что случилось в CLEF. . . Какое-то время?
- Н. Ферро
Образование
- 2019
2019отмечает 20-летие CLEF, оценочной кампании, в рамках которой парадигма оценки Крэнфилда применялась для тестирования многоязычных и мультимодальных систем доступа к информации в…
Пользовательское исследование генерации фрагментов: повторное использование текста и перефразирование
- Wei-Fan Chen, Matthias Hagen, Benno Stein, Martin Potthast
Информатика
SIGIR
- 2018
Краудсорсинговый эксперимент вместе со статистическим анализом показывает, что тестируемые пользователи не отдают значительного предпочтения ни одному из фрагментов, которые открываются. дверь в новую парадигму синтеза фрагментов.
дверь в новую парадигму синтеза фрагментов.
Исследование длины и информативности фрагмента: поведение, производительность и пользовательский опыт
- David Maxwell, L. Azzopardi, Yashar Moshfeghi
Психология
SIGIR
- 2017
находки показывают, что народные находки. резюме, поскольку они воспринимались как более информативные, и выявили положительную связь между длиной и информативностью резюме и их привлекательностью (т. е. рейтингом кликов).
Помимо выделения, ориентированного на запрос: исследование влияния выделения текста фрагмента на поведение пользователей при поиске
В этом документе делается попытка выяснить, является ли стандартная стратегия выделения условий запроса, используемая большинством коммерческих поисковых систем, наилучшей для пользователей поиска, и предлагается автоматический метод, который использует CRF, чтобы научиться выделять термины на основе встраивания слов, информации из Википедии и информации о содержании фрагментов.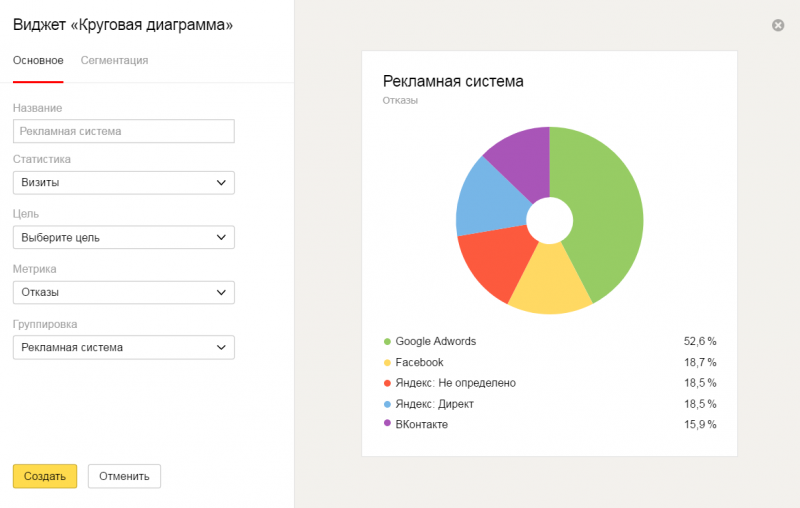
Меньше значит меньше: когда сниппетов недостаточно для оценки релевантности человека и машины?
- G. Kazai, Bhaskar Mitra, Anlei Dong, Nick Craswell, Linjun Yang
Информатика
ECIR
- 2022
Изучение релевантности на основе оценок нейронных сетей и запросов2, основанных на оценках человеческих ресурсов и выборочных документов2 Журналы поиска Bing показывают, что полный текст полезен для людей, а модель BERT для аналогичных запросов и типов документов, например хвостовых, длинных запросов.
Что произошло в CLEF \ldots в последнее время?
- N. Ferro
Образование
CLEF
- 2019
Представлено краткое изложение мотивов, которые привели к созданию CLEF, и описание того, как он развивался на протяжении многих лет, основные достижения и описаны следующие задачи.
Отчет о семинаре SIGIR 2013 по моделированию поведения пользователей для оценки информационного поиска (MUBE 2013)
- C. Clarke, L. Freund, M. Smucker, Emine Yilmaz
Информатика
Форум SIGIR
- 2013
 Clarke, L. Freund, M. Smucker, Emine Yilmaz
Clarke, L. Freund, M. Smucker, Emine YilmazСеминар SIGIR 2013 по моделированию поведения пользователей при оценке информационного поиска собрал вместе исследователей, заинтересованных в улучшении оценки информационного поиска по методу Крэнфилда посредством моделирования поведения пользователей. набор направлений исследований по совершенствованию оценки извлеченной информации.
План дополнительных авторских прав: оригинальные фрагменты
- Martin Potthast, Wei-Fan Chen, Matthias Hagen, Benno Stein
Computer Science
NewsIR@ECIR
- 2018
повторное использование, чтобы свести к минимуму влияние требований издателей новостей о денежной компенсации при повторном использовании их текста.
Понимание и моделирование пользователей современных поисковых систем
- Чуклин А.
Информатика
- 2017

Чем сложнее становятся поисковые системы, тем сложнее становится понять пользователей и их взаимодействие со страницами результатов, а также измерить качество взаимодействия с пользователем.
ПОКАЗАНЫ 1–10 ИЗ 25 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантности Наиболее влиятельные документыНедавность
Об оценке выбора фрагментов для WebCLEF
- Арнольд Овервейк, Донг Нгуен, Д.0004
Информатика
CLEF
- 2008
Показано, что метод оценки и набор тестов, использованный для WebCLEF 2007, нельзя использовать для оценки новых систем, и даны рекомендации по улучшению оценки.
Повышение качества результатов поиска путем настройки длины сводки
- Майкл Кайзер, Марти А. Херст, Джон Б. Лоу
Информатика
ACL
- 2008
Оценка DUC 2005 с использованием базовых элементов
- E. Hovy, Chin-Yew Lin, Liang Zhou
Информатика
- 2005
Показано, что этот метод лучше коррелирует с человеческими методами оценки, чем любые другие автоматизированные методы. на сегодняшний день, и преодолевает проблемы субъективности/изменчивости ручных методов, которые требуют, чтобы люди предварительно обрабатывали сводки для оценки.
Обзор WebClef 2008
- V. Jijkoun, M. de Rijke
Компьютерная наука
Clef
- 2008
Эта работа описывает задачу WebClef 2008, которая вносит многослого многослойного «ИЗОБРАЖЕНИЯ», «ИСПОЛЬЗОВАНИЕ», «ИСПЫТАТЕЛЬНА», «ИСПЫТАТЕЛЬНА», «ИСПЫТАТЕЛЬНА». где для заданной темы участвующие системы должны извлекать важные фрагменты из веб-страниц.
Эффективность временных фрагментов
- Омар Алонсо, Р. Баеза-Йейтс, Майкл Герц
Информатика
- 2009
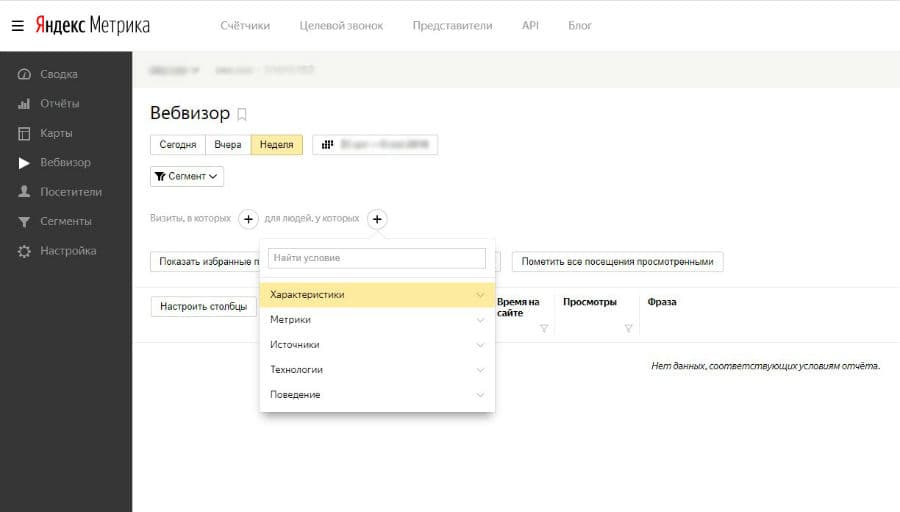 Баеза-Йейтс, Майкл Герц
Баеза-Йейтс, Майкл ГерцМы вводим понятие фрагментов, ориентированных на время, называемых TSnippet, в качестве заменителей документов для поиска и исследования документов. Мы предлагаем альтернативный фрагмент документа, основанный на временном…
Влияние элементов подписи на характер кликов в веб-поиске
- C. Clarke, Eugene Agichtein, S. Dumais, Ryen W. White
Информатика
SIGIR
- 2007
Результаты этого исследования показывают, что относительно простые функции подписи, такие как наличие всех условий запроса, удобочитаемость фрагмента и длина URL-адреса, отображаемого в подписи, могут значительно повлиять на поведение пользователей при поиске в Интернете.
Прогнозирование читаемости коротких веб -резюме
- T. Kanungo, David Orr
Компьютерная наука
WSDM ’09
- 2009
Подход к машинному обучению к проблеме читаемости веб -итогов. совокупность случайных запросов и соответствующие им сводки результатов поиска для оценки модели, которая предсказывает человеческие суждения с учетом особенностей и демонстрирует значительно лучшую корреляцию с редакционными суждениями, что измеряется коэффициентом корреляции Пирсона.
совокупность случайных запросов и соответствующие им сводки результатов поиска для оценки модели, которая предсказывает человеческие суждения с учетом особенностей и демонстрирует значительно лучшую корреляцию с редакционными суждениями, что измеряется коэффициентом корреляции Пирсона.
Конструирование запросов, представленных в сфере запросов: сравнение сгенерированных человеческих и системных фрагментов
- L. L. Bando, F. Scholer, A. Turpin
Компьютерная наука
IIIX
- 2010
. создание сниппетов: участники сначала генерируют свой сниппет на естественном языке, а затем отдельно извлекают сниппет, выбирая фрагменты текста, по четырем запросам, относящимся к двум документам.
Включение сводок в оценку системы
- A. Turpin, F. Scholer, K. Järvelin, Mingfang Wu, J. Culpepper
Computer Science
SIGIR
- 2009
этап чтения итогов процесса поиска, а также изучается влияние на ранжирование системы с использованием данных TREC.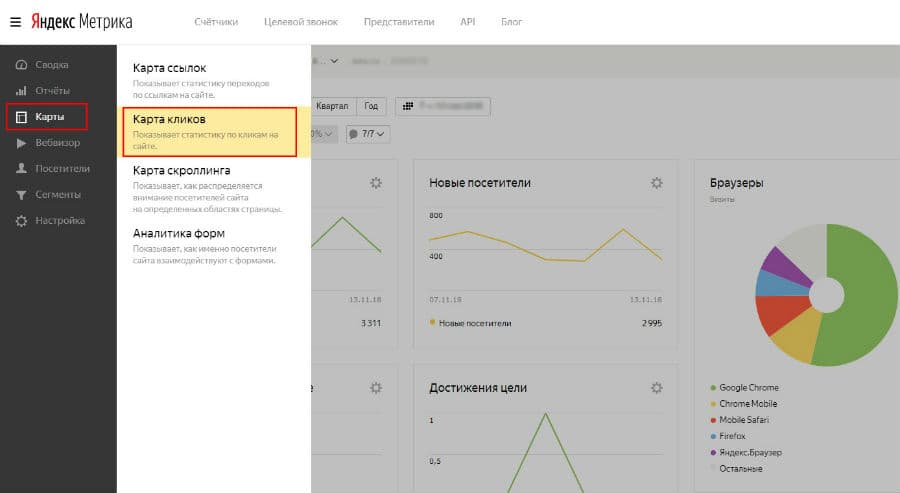
Поиск и оценка отрывков
- К. Уэйд, Джеймс Аллан
Информатика
- 2005
Сравниваются пять мер и задач оценки прохождения на уровне персонажа и несколько моделей извлечения отрывка, включая новую генеративную смешанную модель, которая превосходит сильные базовые показатели по многим показателям оценки, обсуждаемым в первой части.
Не копирую, а ищу подбрюшье Google
Илья Сегалович, главный технический мозг Яндекса, очень хороший парень. Я говорю это не только потому, что он позволил мне прервать его плотный график, но и потому, что вы не можете разговаривать с ним, не думая, что вы и делитесь, и учитесь одновременно — он внимательно слушает то, что вы должен сказать, расширяет его и развивает его и дает вам больше каждый раз.
Слоном в комнате во время нашего разговора был Google. Нельзя говорить о Яндексе, не сравнивая с Гуглом — как с мерилом.
Но это не значит, что Яндекс копирует Google, на что очень хочет обратить внимание Илья. Первые слайды, которые он подготовил, чтобы показать мне, изначально были составлены как возражение Роберту Скоблу, который назвал Яндекс клоном Google в ответ на вопрос на Quora.
Первые слайды, которые он подготовил, чтобы показать мне, изначально были составлены как возражение Роберту Скоблу, который назвал Яндекс клоном Google в ответ на вопрос на Quora.
В вышках Яндекса на ул. Льва Толстого, где все развито, это не пройдет» Чтобы ответить на все вопросы пользователя », и определенно не потому, что калифорнийский конкурент, который также активно действует на территории России, приходит к похожим, но не идентичным выводам.
Хронология Яндекса – Google
На самом деле, на слайдах перечисляется ряд вещей, которые Яндекс запустил первым, указывая, во-первых, на то, что они фактически были запущены как поисковая система в 1997 году, на год раньше, чем Google. Яндекс также первым запустил карты в 2004 году, Google годом позже, в 2005 году. Яндекс первым запустил поиск по новостям в 2000 году, Google в 2002 году. Поиск по блогам появился в России в 2004 году, а в Калифорнии только в 2006 году. запустил агрегатор RSS в 2005 г., Google последовал за ним в 2006 г.
Для скептиков, вот еще одно доказательство, которое вы можете проверить сами. Согласно данным Whois, google.com был зарегистрирован 15 сентября 1997 года, а yandex.ru всего восемь дней спустя, 23 сентября 1997 года. предшественница, тогда как Google потребовалось еще шесть с половиной лет, чтобы 4 марта 2004 года претендовать на google.ru . Так что , если Яндекс скопировал Google через восемь дней, ну, по крайней мере, вы должны отдать должное их удивительной предусмотрительности!
Рождение Яндекса
Илья также показывает мне эту захватывающую фотографию, сделанную в 1981 году, когда молодые люди Аркадий Волож (крайний слева) и Илья (в центре) только поступали в университет и уже знали друг друга другой колодец. Спустя еще 16 лет, в 1997 году, yandex.ru наконец-то был запущен, а между тем было много приключений.
- Источник: Илья Сегалович
Отец Ильи был известным русским геологом, которому приписывают выявление тектонических аномалий на Урале, приведших к открытию огромных запасов хромита.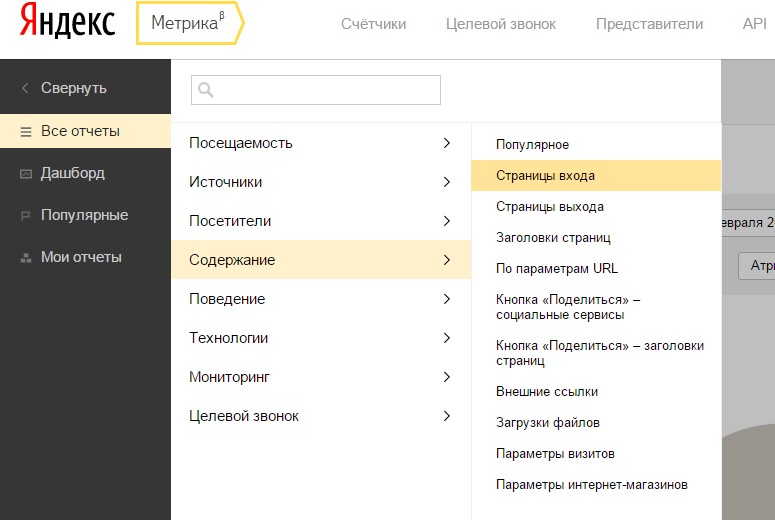 Ему была присуждена Государственная премия в те дни, когда Советский Союз занимался подобными вещами.
Ему была присуждена Государственная премия в те дни, когда Советский Союз занимался подобными вещами.
Аркадий Волож также является сыном геологов, и они впервые встретились в Алмате в Казахстане в школьные годы. (Любопытно, что Аркадий Волож мне тоже отдельно упомянул, что семьи Сергея Брина и Аркадия тоже знают друг друга).
Илья ушел из университета, увлекаясь разработкой программного обеспечения, но в 1989 году он подумал, что «Поиск был очень глупой идеей» — если честно, тогда не было ни Интернета, ни Сети.
Компьютеры едва ли были компьютерами (я могу поручиться за это — я помню паровые машины той эпохи), и для загрузки раннего программного обеспечения для поиска данных и текста Comptek, например, означало загрузку 9дискеты с установочным кодом. У Ильи были свои планы по программному обеспечению и команда.
Наконец, в 1990 году Аркадий добился своего и сумел завербовать Илью в команду Аркадия. В конечном итоге это привело к тому, что у Ильи появился шанс оставить свой след в истории, поскольку несколько лет спустя российские венчурные капиталисты стремились инвестировать во все, что связано с Интернетом.
Это привлекло внимание к конкретному проекту Arcadia, которому в результате потребовалось название. В 1993 году Аркадий Волож и Илья Сегалович разработали поисковую систему «неструктурированной информации с русской морфологией».
Илья предложил название «Яндекс», производное от идеи «Yet Another inDEX», хотя в русском языке есть лишняя игра слов, так как первая буква «я» (произносится как «я») также означает «я». Он прижился, и в 1997 году родился yandex.ru, поисковая система была запущена в 1998 году, а в 2000 году Яндекс стал компанией.
Еще в 1994 году тип поиска, над которым работал Илья, иллюстрируется изображением ниже, которое иллюстрирует ключевую функцию, которая сделала Яндекс великим и которую Google не воспроизвел до 2006 года, примерно 12 лет спустя, — это текстовый поиск по русской морфологии. .
Критерий поиска в окне поиска представляет собой поисковый запрос из двух слов в одной конкретной грамматической форме – выделенные красным цветом «находит» в тексте показывают термины, которые, хотя и соответствуют поисковому запросу, были изменены в правописании в соответствии с правилами Русский.
Рисунок также довольно четко иллюстрирует работу, над которой работала команда Arcadia/Comptek и которая позже превратилась в веб-поиск.
- Предтеча Яндекса в 1994 году – Источник: Илья Сегалович
На самом деле, параллельные пути развития слона Google и Яндекса увлекательны и доминируют в нашем разговоре. Илья ссылается на опубликованное в Google заявление, объясняющее методы поиска в 2000 году, в котором говорилось, что «Google не использует «выборку корней» и не поддерживает поиск по подстановочным знакам. Другими словами, Google ищет именно те слова, которые вы вводите в поле поиска».
Формулировка подразумевает, что это приведет к более релевантным результатам. Учитывая, что рождение Яндекса в 1997 непосредственно последовало решение провести «неточный» поиск с использованием стемминга, который был единственным способом достижения релевантности в русском языке, вы можете понять, что на улице Льва Толстого должно быть несколько кривых улыбок.
Я спрашиваю Илью, когда он впервые узнал о Google? «Дэнни Салливан обратил мое внимание на это в статье». Я полагаю, что он имеет в виду статью под названием «Подсчет кликов и просмотр ссылок» от августа 1998 года, в которой объявляется о новом экспериментальном Google, все еще размещенном на URL-адресе Стэнфордского университета.
Илья продолжает описывать историю развертывания Google в России: «В 2000 году Google сосредоточился на дистрибьюторских сделках, 2001 был годом интернационализации, когда они сосредоточились на полноте индекса и имели русский контент, но только в 2006 году мы считали Google угрозой. Это был год, когда Google начал поддерживать русскую морфологию».
Он отмечает: «Нам не хватало ресурсов и нужных людей на нужных должностях. Пришлось вносить изменения и реорганизовываться. К счастью, мы нашли отличных парней, которые нас спасли».
Любопытно, что Илья связывает показатели Яндекса и Google в 2008–2009 годах, когда Яндекс потерял долю рынка, благодаря эффективности поиска в 2006–2007 годах.
«Кажется, пройдет два года, прежде чем пользователи действительно заметят разницу после внесения улучшений», — говорит он. «Мы внедрили машинное обучение MatrixNet в начале 2009 года и только в 2010 году заметили существенную разницу в долях поисковых запросов”. Он добавляет: «Сложнее разработать поисковую систему, чем космическую программу, пять стран имеют свои собственные поисковые системы, а 20 — космические программы». В этот момент к нам присоединился начальник отдела поиска Анатолий Орлов и добавил: «Поиск — это ракетостроение!»
Чем Яндекс отличается от других поисковых систем
Поисковая страница Яндекса сильно отличается от страницы Google. В то время как у Яндекса есть страница только с окном поиска для тех, кто спешит по короткому URL-адресу Ya.ru, главная страница выглядит скорее в стиле портала. Яндекс тестировал страницу только с окном поиска в течение нескольких недель, но обнаружил, что большинство российских пользователей предпочитают обычную более загруженную страницу.
Илья отмечает, что люди могут изменить страницу поиска по умолчанию. «Мы даже позволяем пользователям отключать некоторые объявления», — говорит он. Одно совершенно ясно, Яндекс был и всегда был одержим поиском и удовлетворением потребностей пользователя.
В розыске нет ни развлечений, ни свиданий, и Илья признается: «Я не смотрю телевизор, но я понимаю, что люди его смотрят». Видимо, дома много детей, так что, возможно, это понятно. Обычная страница поиска может выглядеть как портал, но это еще не все.
Яндекс рассматривает его (объяснено ниже) как ответ на вопрос «Что нового? Что нового вокруг меня?» Вот почему есть новости, погода, информация о дорожном движении (важно для москвичей), новости рынка, трендовые деньги и автомобили — главный вертикальный рынок Яндекса. Так как это Россия, цена на нефть включена в список курсов валют!
- Объяснение главной поисковой страницы Яндекса Источник: Илья Сегалович
Как и все поисковые системы, Яндекс очень внимательно следит за качеством своего поиска. Илья показывает мне серию графиков от AnalyzeThis.ru — российской независимой SEO-фирмы, которая отслеживает качество работы поисковых систем в России. Илья очень хотел подчеркнуть, что это всего лишь один из источников, который предоставляет такие данные, но я нашел результат интересным и достойным публикации.
На первом графике ниже показан процент отсутствующих результатов навигации в Яндексе, Google и Bing в России, где чем ниже показатель, тем лучше результат.
Несмотря на краткий всплеск Яндекса (причины которого неясны), в целом Google и Яндекс очень близко отслеживают друг друга по этому показателю, что дает очень похожее качество результата для пользователя — но результаты Bing не так хороши, хотя они показали некоторое улучшение с октября прошлого года.
- % отсутствующих результатов навигации, где чем ниже балл, тем лучше – Источник: AnalyzeThis.ru 2007-2010
Следующий показатель качества относится к измерению того, имеет ли исходный текст более высокий или более низкий рейтинг, чем копии контента, при этом более высокий балл дает лучший результат. Это серьезная проблема для многих из нас, кто хочет разрешить синдикацию нашего контента, но не хочет, чтобы синдикаторы добивались лучших результатов, чем мы.
В России Google является самым слабым исполнителем по этому показателю, опережая даже Bing. Оценка Яндекса намного лучше, чем у Google или Bing: на 50% больше, чем у Google на 20%, и снижается производительность. Конечно, обновление Farmer не будет учитываться в этих цифрах, но если бы вы были Google, глядя на эти цифры, вы бы тоже хотели ориентироваться на контент-фермы!
- Исходный текст имеет более высокий рейтинг, чем копии контента %, где чем выше балл, тем лучше — Источник: AnalyzeThis.ru 2009-2011
Теперь перейдем к излюбленной всеми теме — спам-результатам. Естественно, лучшие результаты для пользователей получают те, у кого процент спама ниже.
Угадай, кто победит? В индексе AnalyzeThis.ru с 2009 года и по сегодняшний день Яндекс ни разу не уступал ни Google, ни Bing. Они действительно заслужили репутацию очень жестких борцов со спамом, и эти цифры подтверждают это.
- Явно спамные результаты – чем меньше, тем лучше — Источник: AnalyzeThis.Ru 2009 -2011
Предоставляет ли поисковая система чисто коммерческие ответы на коммерческие вопросы? Здесь показатель на нашей диаграмме ниже тем лучше, чем меньше процент, и снова Яндекс побеждает в России, обыгрывая Bing и обыгрывая Google.
Что наиболее важно, Яндекс показывает непрерывный нисходящий тренд, Bing аналогично и в некоторых точках лидирует. Google не показал хороших результатов по этому показателю. Возможно, Google не нацелен на эту меру?
- Чисто коммерческие ответы на коммерческие запросы – Источник:AnalyzeThis.ru 2009-2011
Может показаться, что Яндекс обслуживает только одну страну, но это не совсем так. Есть 15 стран, которые используют кириллицу, и 77 регионов в самой России — и Яндекс стремится везде быть локальным. Культура, уровень жизни и средний доход сильно различаются в разных регионах, которые обслуживает Яндекс, поэтому результаты поиска тоже должны сильно различаться, включая автозаполнение.
Наша окончательная диаграмма показывает процент местных результатов с более высоким баллом победителя. Здесь Яндекс серьезно отстает от Google, и, что касается Bing, их локальные результаты выглядят так, как будто они могут быть случайностью.
- Локальные результаты по локальным запросам % Чем выше балл, тем лучше результат – Источник: AnalyzeThis.ru 2009-2011
Yandex.com, версия Яндекса с латинским алфавитом и английским языком, описывается как «экспериментальная» и, несмотря на то, что вызвала ажиотаж среди западных блоггеров, поясняется, что Яндекс некоторое время работал над индексацией сайтов на других рынках. и намерение состояло не в том, чтобы выйти на международный уровень, а в том, чтобы российские пользователи могли выполнять поиск в латинском тексте, не выходя из Яндекса.
Примерно 7% россиян знают английский язык, но только 1% знает английский язык достаточно хорошо, чтобы свободно ориентироваться на английском языке и на англоязычных сайтах. Тем не менее российская пресса была очень взволнована выходом Яндекса на международные рынки.
Поэтому я спрашиваю Илью напрямую, есть ли планы по расширению Яндекса на международном уровне. Ответ подтверждает, что планы есть, но, конечно, ничем конкретным они со мной поделиться не могут.
Затем мы перейдем к тому, что вам нужно, чтобы добиться успеха с поисковой системой на местных рынках. Язык и правильное обращение с языком являются важным фактором, но «наличие локальной базы данных влияет примерно на 18% поисковых запросов». Есть также специфические для рынка вещи, которые вам нужно сделать. Илья говорит: «Мы довольно ясно понимаем, как это сделать!»
ВКонтакте складывается ощущение, что мало делает их аналог в мире социальной сети – иными словами, локальный игрок и социальная сеть номер один. Однако оказывается, что «вКонтакте» — это поисковый запрос номер один в Яндексе, отражающий позицию Facebook в логах Google.
Делаю вывод, что Яндекс очень внимательно следит за Google и ищет его слабое изнаночное место, прежде чем начать тщательно продуманную атаку. Похоже, что это будет на рынках, где Google является номером один, но только потому, что там нет конкуренции, и на самом деле у Google нет надежной инфраструктуры и локализованного подхода на этом рынке, несмотря на его положение, и нет локальной базы данных.
В следующий раз мы будем иметь дело с подходом машинного обучения Яндекса к его алгоритмам и последствиями для российского SEO и SEO в целом.
Мнения, высказанные в этой статье, принадлежат приглашенному автору и не обязательно принадлежат Search Engine Land. Штатные авторы перечислены здесь.
Новое на сайте Search Engine Land
Об авторе
| Редакционная информация, предоставленная DB-инженерами | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Имя | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Описание | Широколонное хранилище на основе идей BigTable и DynamoDB, оптимизированное для write | на основе идей BigTable и Dynamodb, оптимизированного для Write | . отказоустойчивая служба базы данных с высокой доступностью, масштабируемостью, мгновенной согласованностью и транзакциями ACID, а также API, совместимый с Amazon DynamoDB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Primary database model | Wide column store | Relational DBMS | Document store Relational DBMS | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Secondary database models | Time Series DBMS | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Website | cassandra.apache .org | clickhouse.tech | cloud.yandex.com/en/services/ydb github.com/ydb-platform/ydb ydb.tech | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Техническая документация | cassandra.apache.org/doc/latest | clickhouse.tech/docs | cloud.yandex.com/en/docs/managed-ydb ydb.tech/en/docs | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Программное обеспечение Apache | Foundation Apache top level project, originally developped by Facebook | Clickhouse Inc. | Yandex | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Initial release | 2008 | 2016 | 2019 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Current release | 4.0.6, August 2022 | v22.8.5.29-lts, сентябрь 2022 г. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Лицензия Коммерческая или с открытым исходным кодом | Apache с открытым исходным кодом, версия 2 | Apache с открытым исходным кодом 2.0 | Apache с открытым исходным кодом 2.0; доступна коммерческая лицензия | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Только облачная служба Доступна только в виде облачной службы быть перечислены. |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Implementation language | Java | C++ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Server operating systems | BSD Linux OS X Windows | FreeBSD Linux MacOS | Linux | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Схема данных | Без схемы | Да | ГИБКАЯ СКАКА (Определенная схема, чартная схема, не имеет Schema Free). | да | да | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Поддержка XML Некоторая форма обработки данных в формате XML, напр. поддержка структур данных XML и/или поддержка XPath, XQuery или XSLT. | нет | NO | NO | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Вторичные индексы | Ограниченные только запросы на равенство | Да, при использовании Mergetree Engine | YES | Близко к ANSI SQL | SQL-подобный язык запросов (YQL) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| API и другие методы доступа | Собственный протокол CQL (Cassandra Query Language, язык, подобный SQL) Thrift | HTTP REST JDBC ODBC Proprietary protocol | RESTful HTTP API (DynamoDB compatible) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Supported programming languages | C# C++ Clojure Erlang Go Haskell Java JavaScript Node. js Perl PHP Python Ruby Scala | C# сторонняя библиотека C++ Elixir сторонняя библиотека Go сторонняя библиотека Java сторонняя библиотека JavaScript (Node.js) сторонняя библиотека Сторонняя библиотека Kotlin Сторонняя библиотека Nim Сторонняя библиотека Perl Сторонняя библиотека PHP Сторонняя библиотека Python Сторонняя библиотека R Сторонняя библиотека Ruby Сторонняя библиотека Scala | Go Java 9051 (Node.1.1) js) PHP Python | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Server-side scripts Stored procedures | no | no | no | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Triggers | yes | no | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Методы секционирования Методы хранения различных данных на разных узлах | Шардинг без «единой точки отказа» | Шардинг | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Методы репликации Методы избыточного хранения данных на нескольких узлах географического распределения с возможностью выбора фактора репликации | серверов | Активно-пассивная репликация сегментов | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MapReduce Предлагает API для пользовательских методов Map/Reduce | Да | NO | NO | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Консистенционные концепции. Внешние ключи Ссылочная целостность | нет | нет | нет | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Концепции транзакций Поддержка обеспечения целостности данных после неатомарных манипуляций с данными | no Atomicity and isolation are supported for single operations | no | ACID | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Concurrency Support for concurrent manipulation of data | yes | yes | yes | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Durability Support for making data persistent | yes | да | да | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Возможности в памяти Есть ли возможность определить некоторые или все структуры, которые будут храниться только в памяти. | нет | да | нет | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Концепции пользователей Контроль доступа | Права доступа для пользователей могут быть определены для каждого объекта | Права доступа для пользователей и ролей | Права доступа определены для пользователей Yandex Cloud | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Особые характеристики | Apache Cassandra — это ведущая система управления распределенными базами данных NoSQL, ну. .. » подробнее | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Конкурентные преимущества | Отсутствие единой точки отказа обеспечивает 100% доступность. Простота эксплуатации для… » подробнее | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Типичные сценарии применения | Интернет вещей (IOT), приложения для обнаружения мошенничества, системы рекомендаций, продукты… » подробнее | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 8 Key | Apple, Netflix, Uber, ING, Intuit, Fidelity, NY Times, Outbrain, BazaarVoice, Best… »Подробнее | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Рыночные метрики | Кассандра используется 40% от Fortune 100. ». More | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Новости | Блокчейн (данные) без боли Взламываем свои эмоции и общаемся во времена высоких ставок с Дженнифер Эдвардс Создание непобедимых приложений с помощью Temporal и Astra DB Опыт документирования нового продукта Знание того, когда рисковать, а когда отказаться, с Kelly Battles 7 сентября 9002 7 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Мы приглашаем представителей поставщиков систем связаться с нами для обновления и расширения системной информации, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Связанные продукты и услуги | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Третьи стороны | CData: подключение к большим данным и NoSQL через стандартные драйверы. » подробнее Instaclustr: размещение и управление Apache Cassandra как услуга DataStax Cassandra: операции, настройка и управление без участия оператора с настоящим автоматическим масштабированием Aiven для Apache Cassandra: по-настоящему распределенная база данных, которая может обрабатывать большие объемы данных. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Мы приглашаем представителей поставщиков сопутствующих товаров связаться с нами для предоставления информации о своих предложениях здесь. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Подробнее ресурсы | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| DB-инженеры. 5 января 2016 г., Пол Андлингер, Матиас Гельбманн Winners, losers and an attractive newcomer in Novembers DB-Engines ranking show all | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Conferences and events more DBMS events | Cassandra Day London | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Последние цитаты в новостях | Почему стоит выбрать базу данных NoSQL? Есть много веских причин Что такое CRUD? Создание, чтение, обновление и удаление 4 часто задаваемых вопроса об Apache Cassandra Связь с NoSQL в масштабе предприятия: уроки Amazon Основные угрозы безопасности баз данных и способы их предотвращения предоставлено Google News | Aiven улучшает доступ к технологиям данных с открытым исходным кодом с помощью нового предложения ClickHouse Новости управления данными за неделю от 16 сентября; Обновления от Kensu, Oracle, Syniti и др. В системе баз данных OLAP ClickHouse для больших данных обнаружено множество недостатков Данные о сообществе Kubernetes объявляют о расписании DoK Day North America 2022 @ KubeCon Стартап по аналитике данных StarTree получает деньги для расширения своей платформы на базе Apache Pinot предоставлено Новостями Google | Узнать, что думают россияне, не спрашивая их Утечка из службы доставки еды Яндекса раскрыла личную информацию секретной полиции России 52 202 390 Tech Times предоставлено Google News | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Вакансии | ИНЖЕНЕР ПО ДАННЫМ (M/F/X) Java-разработчик (редактор данных) Java Backend Developer (m/f/d) Инженер Databricks со Scala и Spark Ориентированный на клиента инженер — PostgreSQL/MySQL (EMEA-remote) | Консультант по PostgreSQL (удаленный) Консультант по PostgreSQL (удаленный) Старший инженер-программист по интеграции (удаленный) Администратор базы данных — администратор базы данных / Берлин, Виннипег или удаленный доступ в Европе Инженер DevOps (м/ф/х) вакансий по | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3
3 Сравнение Cassandra и Базы данных Яндекса (YDB)
Наши посетители часто сравнивают Cassandra и Базу данных Яндекса (YDB) с ClickHouse, PostgreSQL и Tarantool.
Редакционная информация предоставлена DB-Engines Название Описание Хранилище с широкими столбцами, основанное на идеях BigTable и DynamoDB Оптимизировано для доступа на запись Распределенная отказоустойчивая служба базы данных с высокой доступностью, масштабируемостью, немедленной согласованностью и транзакциями ACID и предоставлением Amazon API, совместимый с DynamoDB Модель первичной базы данных Хранилище широких столбцов Хранилище документов
Реляционная СУБД Website cassandra.apache.org cloud.yandex.com/en/services/ydb
github.com/ydb-platform/ydb
ydb.tech Technical documentation cassandra. apache.org/doc/latest cloud.yandex.com/en/docs/managed-ydb
ydb.tech/en/docs Developer Apache Software Foundation Проект верхнего уровня Apache, первоначально разработанный Facebook Яндекс Initial release 2008 2019 Current release 4. 0.6, August 2022 License Commercial or Open Source Open Source Apache version 2 Open Source Apache 2.0; доступна коммерческая лицензия Только облачная версия Доступна только как облачная служба нет нет Предложения DBaaS (рекламные ссылки) База данных как услуга Поставщики предложений DBaaS, пожалуйста, свяжитесь с нами, чтобы получить список.
- Aiven для Apache Cassandra: полностью управляемая база данных NoSQL с открытым исходным кодом, специально разработанная для обеспечения высокой доступности, производительности и масштабируемости.
- Astra DB: Мультиоблачная DBaaS, построенная на Apache Cassandra.
Язык реализации Java Серверные операционные системы BSD
Linux
OS X
Windows Linux Схема данных Без схемы ГИБКА Поддержка XML Некоторые формы обработки данных в формате XML, например. поддержка структур данных XML и/или поддержка XPath, XQuery или XSLT. нет нет Дополнительные индексы ограничены только запросы на равенство, не всегда лучшее решение да SQL Поддержка SQL SQL-подобные операторы SELECT, DML и DDL (CQL) SQL-подобный язык запросов (YQL) API и другие методы доступа Собственный протокол CQL (язык запросов Cassandra, язык, подобный SQL)
Thrift RESTful HTTP API (совместимый с DynamoDB) Поддерживаемые языки программирования C#
C++
Clojure
Erlang
Go
Haskell
Java
JavaScript Node.js
Perl
PHP
Python
Ruby
Scala Go
Java
JavaScript (Node.js)
PHP
Python Скрипты на стороне сервера Хранимые процедуры нет нет Триггеры да Методы разделения Способы хранения разных данных на разных узлах Шардинг без «единой точки отказа» Шардинг Методы репликации Методы избыточного хранения данных на нескольких узлах выбираемый коэффициент репликации Возможно представление географического распределения серверов Активно-пассивная репликация 519 MapReduce Предлагает API для определяемых пользователем методов Map/Reduce да нет Концепции согласованности Методы обеспечения согласованности в распределенной системе Непротиворечивость в конечном итоге
Немедленная непротиворечивость может быть определена индивидуально для каждой операции записи Немедленная непротиворечивость Внешние ключи Ссылочная целостность нет нет 6 Поддержка концепций неатомарных манипуляций с данными 6 данные нет Атомарность и изоляция поддерживаются для одиночных операций ACID Параллелизм Поддержка параллельного манипулирования данными да да Долговечность Поддержка сохранения данных да да Возможности в памяти Есть ли возможность определить некоторые или все структуры, которые будут храниться только в памяти. нет нет Концепции пользователей Контроль доступа Права доступа для пользователей могут быть определены для каждого объекта Права доступа определены для пользователей Yandex Cloud Дополнительная информация предоставлена производителем системы0518 Особенности Apache Cassandra — ведущая система управления распределенными базами данных NoSQL, ну…
» подробнее Конкурентные преимущества 100521 Отсутствие единой точки отказа 100521 гарантирует отсутствие единой точки отказа. Простота эксплуатации для…
» подробнее Типичные сценарии применения Интернет вещей (IOT), приложения для обнаружения мошенничества, системы рекомендаций, продукты…
» подробнее Ключевые клиенты Apple, Netflix, Uber, ING, Intuit,Fidelity, NY Times, Outbrain, BazaarVoice, Best. .. используется 40% компаний из списка Fortune 100.
» подробнее Модели лицензирования и ценообразования Лицензия Apache Цены на коммерческие дистрибутивы, предоставленные DataStax и доступные…
» подробнее Новости Блокчейн (данные) без боли
26 сентября 2022
Взлом ваших эмоций и общение во времена высоких ставок с Дженнифер Эдвардс
22 сентября 2022
Создание непобедимых приложений с помощью Temporal и Astra 2 2 сентября 290 Astra 2 290 Astra DB
Опыт документирования нового продукта
14 сентября 2022 г.
Узнайте, когда стоит рискнуть, а когда отказаться с помощью Kelly Battles
7 сентября 2022 г.
Мы приглашаем представителей поставщиков систем связаться с нами для обновления и расширения информации о системе,
и для отображения предоставленной поставщиком информации, такой как ключевые клиенты, конкурентные преимущества и рыночные показатели.
Связанные продукты и услуги Третьи стороны Instaclustr: Размещение и управление Apache Cassandra как услуга
» Подробнее Aiven для Apache Cassandra: действительно распределенная база данных, которая может обрабатывать большие объемы данных.
» подробнее
CData: подключение к большим данным и NoSQL через стандартные драйверы.
» подробнее
DataStax Cassandra: операции, настройка и управление без участия пользователя с настоящим автомасштабированием
» подробнее
Мы приглашаем представителей поставщиков сопутствующих товаров связаться с нами для предоставления информации о своих предложениях здесь.
Дополнительные ресурсы Сообщения в блоге DB-Engine Cassandra продолжает подниматься в рейтинге DB-Engines Ranking
3 мая 2016 г., Matthias Gelbmann
Oracle — СУБД года
5 января 2016 г. , Paul Andlinger, Matthias Gelbmann
Победители, проигравшие и привлекательный новичок в Ноябрь Рейтинг DB-Engines
2 Ноябрь 2015, Пол Андлингер
показать все
Конференции и мероприятия другие мероприятия DBMS
Cassandra Day London
Лондон, Великобритания, 11 октября 2022 г.
Последние цитаты в новостях Почему стоит выбрать базу данных NoSQL? Есть много веских причин
23 сентября 2022 г., thenewstack.io
Что такое CRUD? Создание, чтение, обновление и удаление
21 сентября 2022 г., CrowdStrike
4 часто задаваемых вопроса об Apache Cassandra
14 сентября 2022 г., thenewstack.io
Связь с NoSQL в масштабе предприятия: уроки Amazon
9Сентябрь 2022 г., thenewstack.io
Основные угрозы безопасности баз данных и способы их предотвращения
26 сентября 2022 г., tripwire.com
предоставлено новостями Google
Узнать, что думают русские, не спрашивая их
22, 21 сентября 2020 г. Lawfare
Утечка из службы доставки еды Яндекса раскрыла личную информацию секретной полиции России
3 апреля 2022 г., Tech Times
предоставлено Google News
Вакансии ИНЖЕНЕР ПО ДАННЫМ (M/F/X)
DHL, Бонн
Java-разработчик (редактор данных)
JetBrains, München
Java Backend-разработчик (м/ж/д)
sMeet Communications GmbH, Берлин
Databricks Engineer со Scala и Spark
версии 1, домашний офис
Ориентированный на клиента инженер — PostgreSQL/MySQL (EMEA-remote)
Айвен, Берлин
вакансий от
Мониторинг моделей в производстве с Emeli Le 9 Dral — Джеймс Ле 9 Драл0001
Джеймс Ле
Датакаст
Джеймс Ле
Датакаст
66-й выпуск Datacast — это мой разговор с Эмели Драл — соучредителем и техническим директором стартапа Evidently AI, разрабатывающего инструменты для анализа и мониторинга производительности моделей машинного обучения.
Наш обширный разговор касается ее образования в области прикладной математики и информатики; работа над рекомендательными системами и прикладным машинным обучением в Яндексе; ее популярные учебные материалы онлайн и лично; ее стартап по промышленному ИИ; ее нынешнее путешествие с Очевидно, чтобы заняться модельным мониторингом, и многое другое.
Пожалуйста, наслаждайтесь моим разговором с Эмели!
Слушайте шоу на (1) Spotify, (2) Apple Podcasts, (3) Google Podcasts, (4) TuneIn, (5) RadioPublic, (6) Stitcher и (7) iHeart Radio.
Вот основные моменты моего разговора с Эмели:
Об изучении прикладной математики в колледже
При выборе университета у меня было почти два варианта. Первый вариант — поступить в один из ведущих технических вузов России, например, в Санкт-Петербургский государственный или Московский государственный университет. Вторым вариантом было поступление в университет с большими международными связями и большим количеством студентов из разных стран. Я из мультикультурной семьи (мой отец африканец, а мама русская). Мне было очень интересно встречаться с людьми из разных культур, поэтому я выбрал второй вариант. Это лучшее решение в моей жизни .
Источник: https://www.rudn.ru/
Российский университет дружбы народов не технический вуз, но в нем много хороших математических курсов. В результате у меня была хорошая математическая подготовка, но не хватало современных курсов по информатике. Я компенсировал это тем, что поступил в Школу анализа данных Яндекса.
Все мои любимые уроки математики связаны со статистикой, потому что мне нравится идея принимать решения на основе данных. Известные курсы включали теорию вероятностей, вводную статистику и финансовую математику.
Приступая к компьютерным наукам
На третьем курсе бакалавриата я начал думать о своей будущей работе. Я искал разные варианты от разных компаний. В конце концов я решил, что мне нужно идти в Яндекс, потому что это одна из лучших ИТ-компаний в России. Я решил, что мне не хватает опыта в компьютерных науках и программировании, потому что я не участвовал ни в каких соревнованиях по программированию и не работал над какими-либо программными проектами. Поэтому я начал думать о том, чтобы получить больше опыта и стать лучшим инженером, чтобы хотя бы иметь шанс в Яндексе.
Источник: https://yandexdataschool.com/education
Я узнал, что у них есть какие-то магистерские программы, поэтому я очень, очень усердно готовился к этому . Я провел три месяца, изучая все, что мне было нужно, чтобы ходить в школу. Это конкурсная программа, и я думал, что у меня есть крошечный шанс, потому что я не из лучшего технического университета. Но я все же решил попробовать. Это сработало для меня. Я был очень счастлив. Это мое второе лучшее решение в жизни.
В 2010 году в Яндексе было всего две программы: одна по науке о данных/анализу и одна по информатике. Я подумал, что мне нужно сосредоточиться на инженерных курсах, поэтому я выбрал программу информатики.
О работе разработчиком ПО
Первая работа в Рамблере была для меня очень стрессовой. Я не был уверен, что смогу начать карьеру инженера-программиста . Моя предыдущая стажировка была связана с анализом данных, и я беспокоился о своих инженерных навыках. Моей первой большой задачей была работа с распределенными системами. Мне пришлось научиться писать задания MapReduce, писать запросы Hive, использовать распределенные файловые системы и тому подобное. Я так боялся, что сломаю что-нибудь.
В конце концов я понял, что учиться на лету во время работы — это нормально. Если я хочу остаться в этой профессии надолго, мне нужно, чтобы мне было комфортно в этом процессе обучения.
Я до сих пор помню все, что узнал о распределенных вычислениях. Вначале я очень боялся запускать распределенные задания MapReduce. Если что-то пойдет не так, весь кластер сломается, и все узнают, что это моя вина. Но позже этот процесс стал более экспериментальным, и мне это нравилось.
О создании систем рекомендаций для электронной коммерции в Яндексе
Источник: https://yandex.com/company/
После окончания Школы анализа данных Яндекса я знал, что Яндекс будет моей домашней компанией. Я люблю культуру Яндекса; даже работая в Рамблере, я все равно общался с людьми из Яндекса. Поэтому, когда они прошли испытания и формулировки проблем в рекомендательных системах, я был так рад присоединиться.
От системы Яндекса возлагались большие надежды: время отклика должно быть коротким, а решение должно быть достаточно стабильным, чтобы его могла принять команда инженеров. Это было, когда я научился писать код производственного уровня и хорошие тесты, создавать стабильную систему с множеством откатов и проектировать красивую схему базы данных .
Я также узнал о прямой связи между качеством моделей машинного обучения и ключевыми показателями эффективности бизнеса. Очень важно знать, как решение влияет на реальных пользователей и согласуется с правильными показателями.
Я очень горд, что меня пригласили присоединиться к Yandex Data Factory. Это был новый отдел, ориентированный на прикладное машинное обучение для разных бизнесов. Они пригласили много опытных специалистов по данным из Яндекса. Я не был уверен, что я был достаточно хорош, чтобы присоединиться к команде, поэтому я так хотел доказать, что я способен.
Источник: https://cloud.yandex.com/ru/
В моем первом проекте мы работали с одной из крупнейших коммуникационных компаний России.
Они пытались решить проблем прогнозирования/предотвращения оттока . Они разработали модель машинного обучения, чтобы предсказать, какие клиенты покинут сервис, чтобы сохранить их. Они хотели сравнить качество нашей модели со своими внутренними.
В то время я чувствовал, что должен участвовать в этом конкурсе, чтобы представлять Яндекс. Так что я потратил слишком много времени на этот проект. В итоге мы выиграли конкурс.
Второй проект был интереснее с точки зрения бизнеса.
Я работал с инженерной компанией, которая пыталась решить проблему человеческих ресурсов. У них было много стажеров-инженеров, которые уходили менее чем через год. Но, конечно, компания потеряла довольно много денег на обучении этих стажеров, поэтому они определенно хотели бы сохранить их как можно дольше.
Они предоставили нам свои внутренние данные и попросили построить модели машинного обучения для прогнозирования увольнений. Вначале многие думали, что невозможно предсказать, кто покинет компанию, потому что может быть много разных мотивов. Поэтому я потратил много времени на изучение предметной области, просмотр различных версий наборов данных, изучение отдельных функций и т. д.
В самом конце, после 5-6 итераций, наша окончательная модель успешно предсказала 26 человек из 50 случаев в невидимом наборе данных. Это был огромный успех, и наш клиент был удивлен, что машинное обучение действительно работает.
Промышленный ИИ существенно отличается от онлайн-сервисов. Работая в любой онлайн-компании, вы имеете доступ к пользовательским данным. События связаны с пользователями и могут быть агрегированы по идентификаторам пользователей, что упрощает создание функций, создание наборов обучающих данных и продолжение жизненного цикла машинного обучения.
Источник: http://mechanica.ai/blog/ai-at-industrial-scale-how-industrial-data-science-is- Different
Когда дело доходит до производства, у вас нет данных, связанных непосредственно с объектами.
Допустим, вы пытаетесь предсказать дефект стали на площади поверхности. В значительной степени данные, которые вы получили от некоторых датчиков в другом месте. Прямой связи между данными датчика и объектами нет. Вам нужно сделать много агрегаций (в большинстве случаев по времени), чтобы сделать эти ассоциации. Если вы потерпите неудачу на этом этапе, будет невозможно продолжить проект.
Таким образом, я считаю, что для промышленного ИИ; очень важно выучить данные наизусть — понять, как они были сгенерированы, как атрибуты связаны друг с другом, есть ли временные промежутки и т. д.
область. Без понимания того, как работает производство стали (например), невозможно сформулировать постановку задачи и начать проект.
О создании курсов Coursera
Это произошло, когда Coursera взялась за российский рынок. На работу по специализации Coursera «Машинное обучение и анализ данных» меня пригласил Константин Воронцов, преподаватель машинного обучения Школы анализа данных Яндекса и преподаватель МФТИ. Я готовил семинары с практическим программированием на Python и прикладными проектами.
Источник: https://www. coursera.org/lecture/big-data-essentials/meet-emeli-BxFP6
Вначале никто не знал, сколько времени мы в конечном итоге потратим на этот проект. На создание этой специализации у нас ушло больше года. Для нас это стало второй работой. Нам нужно было действительно спланировать, как структурировать материалы и синхронизировать контент между модулями. Я научился очень эффективно работать в команде.
Это тоже не то, что можно сделать на 100% безупречным. Всегда было что-то, что можно было бы сделать лучше. Поэтому важно выяснить, когда он «достаточно хорош», и тогда запустить продукт.
Очень важно иметь толстую кожу. Когда вы публикуете что-то в Интернете, вы должны быть готовы получить обратную связь.
Источник: https://evidentlyai.com/
В Mechanica AI наша производственная система машинного обучения должна работать правильно. Если что-то пойдет не так в производстве, деньги будут потеряны. Поэтому мы настраиваем схему мониторинга с нуля для каждого проекта, потому что есть разные части решения, на которые нужно обращать внимание.
В некоторых случаях нам нужно было контролировать наши источники данных, так как они были нестабильны из-за сломанных датчиков.
В других случаях нам нужно было контролировать наш конвейер, поскольку внутри конвейера данных были разные этапы разработки функций.
Я разобрался, что общего решения для системы мониторинга ML нет. Итак, я подумал, почему бы не попытаться создать продукт, который может работать с моделями машинного обучения в производстве. Так, очевидно, родился ИИ.
Большинство компаний начинают отслеживать свои модели машинного обучения только после первого крупного перерыва. Я думаю, что это ошибка, потому что к такому сценарию нужно готовиться и следить за моделями с самого начала. Также важно понимать, что сервис на основе машинного обучения отличается от других сервисов. Таким образом, крайне важно отслеживать работоспособность службы, время отклика, использование памяти/графического процессора и т. д. не так с вашими моделями . Поэтому еще более важно контролировать входные данные. Важно проанализировать ваш конкретный случай, чтобы определить, где ваши модели могут сломаться, и использовать соответствующую стратегию мониторинга.
Когда речь идет о качестве и целостности данных, с вашими моделями может случиться многое.
Например, вы можете потерять доступ к данным (ваши источники данных могут быть повреждены), а ваши модели могут потерять очень важные сигналы.
Или, например, ваши модели машинного обучения могут использовать данные из системы CRM. Если пользователь CRM обновит данные, ваши модели сломаются, потому что они используют новую схему данных в качестве входных данных. Такие вещи часто случаются, особенно со сторонними источниками, поэтому для них вам нужен мониторинг целостности данных.
Такие проблемы, как смещение данных и концепции, возникают при изменении конкретных функций и целей. Если ваши модели не готовы к этому, они деградируют или ломаются.
О дорожной карте с открытым исходным кодом
Источник: https://github.com/evidentlyai/evidently
Мой соучредитель, Елена, и я много обсуждали открытый исходный код. Трудно быть перфекционистом, потому что мы строим публично. Если что-то не работает, то все это увидят. Так что это было трудное решение для нас.
Но когда вы строите что-то публично, вы очень рано получаете обратную связь и можете быстро проверять гипотезы.
Когда вы строите систему мониторинга для оценки других систем, лучше понять, как она на самом деле работает, какие проблемы она объясняет и каковы слабые стороны. Реальные системы машинного обучения напрямую влияют на жизнь людей (здравоохранение, финансы, социальные услуги). На самом деле ни у кого нет полной картины всех возможных проблем, которые могут возникнуть. Когда мы создаем общедоступный инструмент мониторинга, мы можем объединить опыт множества разных инженеров и бизнес-специалистов. Для нас это была главная причина, по которой мы создали Очевидно ИИ публично.
Я сталкивался с мониторингом моделей ML в производстве в Mechanica и Yandex Data Factory, поэтому мы расставляем приоритеты по этим вопросам и основываем нашу дорожную карту на этом приоритете. Я также провел много времени, общаясь с потенциальными пользователями из различных компаний. В результате мы поняли, что дрейф данных и дрейф концепций являются для них более важными проблемами. Поэтому, , мы уделяем нашей дорожной карте еще больше внимания, помимо отзывов пользователей .
О сообществе данных в Москве
Сообщество данных в России большое и молодое. У нас много молодых дата-сайентистов, которые только заканчивают школу. Они очень активны и полны энтузиазма.
Еще один забавный факт о российских специалистах по данным: мы действительно хорошо реализуем вещи, даже если мы переделываем велосипеды. Нам нравится переделывать вещи самостоятельно, и иногда это не очень эффективно .
Новый модуль🎙️#Datacast E66 включает @EmeliDral. Обсуждаем:
— Прикладное машинное обучение @YandexAI
— Преподавание @coursera
— Проблемы промышленного ИИ
— Мониторинг моделей с помощью @EvidentlyAI
Emeli создает инструменты с открытым исходным кодом, чтобы сделать мониторинг машинного обучения менее скучным. Наслаждаться! 👇https://t.co/5dTqVhQwFg
— Джеймс (@le_james94) 9 июня 2021 г.
(02:07) Эмели поделилась своим образованием, получив степень в области прикладной математики и информатики в Российском университете дружбы народов в начале 2010-х.
(04:24) Эмели рассказала о своем опыте получения степени магистра в Школе анализа данных Яндекса.
(07:06) Эмели размышляет об уроках, извлеченных из ее первой работы после окончания университета, когда она работала разработчиком программного обеспечения в Рамблере, одном из крупнейших российских веб-порталов.
(09:33) Эмели провела свой первый год работы Data Scientist, разрабатывая рекомендательные системы электронной коммерции в Яндексе.
(13:38) Эмели рассказал об основных проектах, реализованных в качестве главного специалиста по анализу данных в Yandex Data Factory, комплексной платформе данных Яндекса.
(17:52) Эмели поделилась своими знаниями о переходе от IC к роли менеджера.
(19:21) Эмели упомянула ключевые составляющие успеха промышленного ИИ, учитывая, что она была соучредителем и главным специалистом по данным в Mechanica AI.
(22:40) Эмели рассказала о своих специализациях на Coursera — «Машинное обучение и анализ данных» и «Основы больших данных».
(26:14) Эмели рассказала о своей преподавательской деятельности в МФТИ, Школе анализа данных Яндекса, Harbour. Space и Высшей школе менеджмента — СПбГУ.
(30:12) Эмели поделился историей основания компании Evidently AI, которая создает человеческий интерфейс для машинного обучения, чтобы компании могли доверять своим решениям в области ИИ, отслеживать их и повышать их эффективность.
(32:32) Эмели объяснил концепцию модельного мониторинга и выявил пробелы в мониторинге на предприятии (читайте часть 1 и часть 2 серии «Мониторинг»).
(34:13) Emeli рассмотрел возможные проблемы с качеством и целостностью данных, предложив способы их отслеживания (см. части 3, части 4 и части 5 серии «Мониторинг»).
(36:47) Эмели рассказал о плюсах и минусах создания продукта с открытым исходным кодом.
(39:13) Эмели рассказал о том, как расставить приоритеты в планах развития продуктов для Evidently AI.
(41:24) Емели описал информационное сообщество в Москве.
(42:03) Заключительный сегмент.
Контактная информация Эмели
LinkedIn
Twitter
Coursera
GitHub
Medium
Evidently AI’s Resources
Website
Twitter
LinkedIn
GitHub
Documentation
Blog Posts
Мониторинг машинного обучения, часть 1: что это такое и чем оно отличается? (август 2020 г.)
Мониторинг отмывания денег, часть 2: кого это должно волновать и что нам не хватает? (август 2020 г.)
Мониторинг машинного обучения, часть 3: что может пойти не так с вашими данными? (сентябрь 2020 г.)
Мониторинг машинного обучения, часть 4: как отслеживать качество и целостность данных? (октябрь 2020 г.)
Мониторинг машинного обучения, часть 5: почему вас должны волновать отклонения данных и концепций? (ноябрь 2020 г. )
Мониторинг машинного обучения, часть 6: можно ли создать модель машинного обучения для мониторинга другой модели? (апрель 2021 г.)
Курсы
«Машинное обучение и анализ данных»
«Основы больших данных»
People
Yann Lecun (профессор NYU, главный AI Scientist at Facebook)
Томас Микол (Создатель Facebook, Ex-Scistist stcistist stcistist x-stcistist xcient x-stcistist x xpcient xpecist x xpcient xpecient z-stcist x xpcient xpecient z-stcist x xpecist x x x xpcient x x x x xтечный )
Эндрю Нг (профессор Стэнфордского университета, соучредитель Google Brain, Coursera и Landing AI, бывший главный научный сотрудник Baidu)
Книга
С момента записи подкаста в Очевидно! Вы можете использовать этот инструмент с открытым исходным кодом (https://github.com/evidentlyai/evidently), чтобы создавать различные интерактивные отчеты о производительности модели ML и интегрировать их в свои конвейеры с помощью профилей JSON.
Это руководство по мониторингу — отличная демонстрация того, что может пойти не так с вашими моделями в процессе производства, и как за ними следить: https://evidentlyai.com/blog/tutorial-1-model-analytics-in-production.
Datacast представляет собой подробные беседы с практиками и исследователями в сообществе данных, чтобы пройти их профессиональный путь и извлечь уроки, извлеченные на этом пути. Я приглашаю гостей с самым разным карьерным ростом — от ученых и аналитиков до основателей и инвесторов — проанализировать аргументы в пользу использования данных в реальном мире и извлечь свои ментальные модели («ПОЧЕМУ»), лежащие в основе их занятий. Надеемся, что эти беседы могут послужить ценным инструментом начинающим специалистам по данным, когда они будут ориентироваться в своей карьере в захватывающей вселенной данных.
Datacast подготовлен и отредактирован Джеймсом Ле. Свяжитесь с отзывами или предложениями гостей по электронной почте khanhle.1013@gmail. com .
Подпишитесь, выполнив поиск DATACAST , где бы вы ни получили подкасты, или нажмите одну из ссылок ниже:
Слушайте на Spotify
Прослушивание Apple Podcasts
Listen On Google Podcast
- 118. вы новичок, посетите домашнюю страницу подкаста, чтобы послушать самые последние выпуски, или просмотрите полный список гостей.
Источник: https://datacast.simplecast.com/episodes/emeli-dral
Tagged: Наука о данных, Мониторинг, Старт, Open Source, Россия, Рекомендательные системы, Преподавание, Информатика, Математика
Yandex N.V. (YNDX) Отчет о доходах за 1 квартал 2020 г.
Источник изображения: The Motley Fool.
Yandex N.V. (YNDX -6,79%)
Отчет о доходах за первый квартал 2020 г.
28 апреля 2020 г., , 8:00 по восточноевропейскому времени,
Содержание:
- Подготовленные замечания
- Вопросы и ответы
- Участники вызова
Подготовленные комментарии:
Оператор
Дамы и господа, спасибо за внимание и добро пожаловать в финансовые результаты за первый квартал 2020 года. [Инструкция оператору] Должен также сообщить вам, что звонок записывается сегодня, во вторник, 28 апреля 2020 года. Пожалуйста продолжай.
Юлия Герасимова — Начальник отдела по связям с инвесторами
Всем привет и добро пожаловать на звонок о доходах Яндекса за первый квартал 2020 года. Сегодня мы распространили отчет о доходах. Вы можете найти копию на нашем сайте IR, а также в службах Newswire.
Сегодня на связи Тигран Худавердян, наш заместитель генерального директора; Даниил Шулейко, наш генеральный директор Яндекс.Такси; и Грег Абовски, наш главный операционный и финансовый директор. Аркадий Волож, наш основатель и генеральный директор; Вадим Марчук, наш вице-президент по корпоративному развитию; и Евгений Сендеров, финансовый директор Яндекс.Такси, примут участие в сессии вопросов и ответов. Звонок будет записан, и через несколько часов запись будет доступна на сайте IR. Как обычно, мы подготовили несколько дополнительных слайдов, которые сейчас доступны на сайте.
Теперь я быстро проведу вас через заявление о безопасной гавани. Различные замечания, которые мы делаем во время этой телеконференции о наших будущих ожиданиях, планах и перспективах, представляют собой прогнозные заявления. Наши фактические результаты могут существенно отличаться от указанных или предполагаемых в этих прогнозных заявлениях в результате различных важных факторов, включая влияние продолжающейся пандемии COVID-19, а также те, которые обсуждаются в разделе «Факторы риска» нашего годового отчета. в форме 20-F от 2 апреля 2020 г., которая хранится в SEC и доступна в Интернете. Кроме того, любые прогнозные заявления представляют наши взгляды только на сегодняшний день, и на них не следует полагаться как на представление наших взглядов на любую последующую дату. Хотя мы можем решить обновить эти прогнозные заявления в какой-то момент в будущем, мы специально отказываемся от каких-либо обязательств делать это, даже если наши взгляды изменятся. Таким образом, вы не должны полагаться на эти прогнозные заявления как на представление наших взглядов на любую дату после сегодняшнего дня.
Во время разговора мы будем ссылаться на определенные финансовые показатели, не относящиеся к GAAP. Эти финансовые показатели non-GAAP не подготовлены в соответствии с US GAAP. Сверка финансовых показателей, не относящихся к GAAP, с наиболее сопоставимыми показателями GAAP представлена в опубликованном нами сегодня отчете о прибылях и убытках.
А сейчас я перевожу звонок на Тиграна.
Тигран Худавердян — Заместитель генерального директора
Спасибо, Юла, и спасибо, что присоединились к нашему сегодняшнему разговору. Первая четверть началась для нас хорошо. Все наши предприятия демонстрировали стабильную производительность до середины марта, когда мы начали замечать неблагоприятное воздействие вспышки COVID. С тех пор нашим главным приоритетом было благополучие наших сотрудников, наших партнеров и наших пользователей. В то время как некоторые из наших предприятий, такие как реклама и такси, значительно пострадали от более строгих мер социального дистанцирования, введенных властями, спрос на технологии питания, электронную коммерцию, образование и медиа-услуги существенно увеличился.
Итак, позвольте мне перейти к краткому обзору тенденций первого квартала, прежде чем мы обсудим наши инициативы, связанные с COVID. Сегмент «Поиск и порталы» рос хорошо и превзошел наши внутренние ожидания в январе и феврале. Важно отметить, что мы получили очень сильный прирост доли поиска как на мобильных устройствах, так и на настольных компьютерах. В марте мы достигли рекордных 55,9% доли Android, увеличившись на 130 базисных пунктов с декабря и на 430 базисных пунктов с марта 2019 года. Наша общая доля продолжала активно расти и приблизилась к 60% в апреле.
Рост ядра поиска существенно ускорился в апреле до 40%, 45% в годовом исчислении с однозначных цифр в конце февраля. Важно отметить, что ключевым драйвером для этого стал рост молодой аудитории до 24 лет. Его доля в поисковом трафике увеличилась на 28% по сравнению с февралем, а доля школьников увеличилась на 56%. Трафик самой школьной аудитории за тот же период увеличился почти вдвое. В первом квартале наш мобильный поисковый трафик составил 59% от общего поискового трафика. Доходы от мобильной связи составили 50,4% наших доходов от услуг. Это был первый квартал, когда доходы от мобильного поиска превысили доходы от настольных компьютеров.
Обращение к дзен. Мы по-прежнему наблюдаем значительный рост числа пользователей: в марте число активных пользователей в день составило 14,6 миллиона человек, а в апреле количество активных пользователей Zen в день увеличилось до более чем 16 миллионов пользователей. Что касается вовлеченности, общее время, проведенное в марте, выросло на 56% по сравнению с аналогичным периодом прошлого года, а в апреле рост ускорился почти до 90%.
В сфере медиа-услуг общее число подписчиков достигло 4,3 миллиона в марте и продолжало расти в апреле. Количество ежемесячно просматривающих подписчиков на платформе «КиноПоиск АГ» превысило 1,5 миллиона человек.
А теперь позвольте мне рассказать вам о наших ключевых действиях в ответ на вспышку COVID. Во-первых, Яндекс — важный источник точной и достоверной информации для наших пользователей, включая все актуальные данные о COVID. Среди многочисленных инициатив публичного информирования мы представили индекс самоизоляции в режиме реального времени, доступный на главной странице Яндекса. Этот индекс показывает степень социального дистанцирования в разных городах путем сравнения анонимных данных о городской активности с нормализованной датой до пандемии. В настоящее время индекс доступен в 570 городах России, а также в восьми других странах.
Во-вторых, наши платформы, такие как Яндекс.Такси, Яндекс.Еда или Яндекс.Лавка, дают заработок сотням тысяч водителей и курьеров. Например, мы вложили значительные средства в расширение службы доставки, а также наших платформ доставки еды.
В-третьих, дистанционное обучение. Мы запустили Яндекс Школу как платформу, объединяющую все наши новые и существующие образовательные проекты, в том числе полноценную онлайн-школу для 5–11 классов по 15 предметам. В апреле ежедневное количество активных пользователей Яндекс.Учебника увеличилось в восемь раз по сравнению с серединой марта и превысило 1 млн пользователей.
И, наконец, наша социальная инициатива «Рука помощи». В рамках этого проекта мы перевозим врачей и доставляем лекарства, предоставляем наборы для тестирования на коронавирус и распределяем товары первой необходимости. Мы вложили в этот проект 250 миллионов рублей. В целом мы выделили около 1,5 млрд рублей на различные инициативы, включая фонд поддержки водителей такси и курьеров, рекламные кредиты для малого и среднего бизнеса и нашу образовательную деятельность. Полный список мер и инициатив намного длиннее. Наши собственные команды очень усердно работают над внедрением новых функций и услуг. Честно говоря, я думаю, что мы никогда не видели, чтобы инициативы и улучшения внедрялись такими быстрыми темпами.
Помимо пандемии, наш главный приоритет — обеспечить устойчивый долгосрочный рост. И я верю, что мы выйдем из этого кризиса сильнее, чем когда-либо. Нынешний спад в сочетании с изменением поведения потребителей предоставляет нам ряд привлекательных долгосрочных возможностей по многим вертикалям. В нашем основном рекламном бизнесе мы ожидаем получить выгоду от ускорения перехода от традиционной рекламы к онлайн-рекламе, увеличения потребления потокового видео в медиасервисах и цифрового контента в Zen.
Как корпорация мы считаем, что операционные модели, включающие больше сценариев удаленной работы, выиграют от более быстрого внедрения облачных сервисов. Есть также много привлекательных возможностей в области райдшеринговых и фуд-тек.
И с этим я передаю микрофон Даниилу.
Даниил Шулейко — Генеральный директор Яндекс.Такси
Спасибо, Тигран, и всем привет. Мы начали год в службе такси с хорошими показателями по всем нашим показателям. Поездки выросли на 40% по сравнению с аналогичным периодом прошлого года в первом квартале, а январь и февраль превзошли наши внутренние прогнозы. Мы начали наблюдать замедление во второй половине марта из-за распространения COVID-19.. В то время как в начале марта мы совершали почти 5 миллионов поездок в день. К концу марта это число значительно уменьшилось, что отрицательно сказалось на темпах роста в первом квартале.
Официальный карантин в Москве начался 30 марта, поэтому во втором квартале мы увидим гораздо большее влияние на наш бизнес. В Москве райдшеринг сильно пострадал. GMV Москвы снизилась примерно на 60% по сравнению с апрелем прошлого года и примерно на 70% по сравнению с началом марта. Наш общий показатель GMV по вызову пассажиров снизился меньше, чем в Москве, поскольку регионы, как правило, отстают от Москвы на несколько недель с точки зрения COVID-19.влияние. Мы вложили значительные средства в защиту водителей и курьеров. Мы предоставили сотни тысяч масок, огромный запас дезинфицирующих средств и усиленную дезинфекцию автомобилей [фонетическая].
Мы создали фонд в размере 500 миллионов рублей для поддержки пострадавших водителей и курьеров. Команда усердно работает над тем, чтобы предоставить водителям новые возможности получения дохода, включая доставку. Мы предоставляем транспортные услуги врачам и доставляем тесты на COVID и наборы питания в поликлиники и пенсионерам. Мы заключили партнерские отношения с крупными розничными компаниями, включая Леруа Мерлен, [Неразборчиво], Теле2, Азбука Вкуса и ВкусВилл, чтобы помочь им своевременно доставлять товары своим пользователям.
Что касается пищевых технологий, мы наблюдаем значительный рост спроса. Приток новых ресторанов через нашу платформу значительно увеличился, и мы упростили процесс регистрации новых ресторанов. На сегодняшний день к нашей платформе подключено более 20 000 ресторанов. Чтобы поддержать местные рестораны и действительно подключиться к нашей платформе, мы убрали для них условия.
В наши дни доставка продуктов питания стала неотъемлемой частью жизни людей, и мы явно выиграли от нашей модели доставки через гиперлокальный круглосуточный магазин Lavka. На сегодняшний день у нас более 100 аптек в Москве и Санкт-Петербурге, из которых наши курьеры доставляют в течение 10-15 минут, несмотря на значительный рост спроса. Недавно мы расширили зону обслуживания подключенными таксистами до Лавки. Сейчас он доступен примерно двум третям населения Москвы и более половины жителей Санкт-Петербурга. На данный момент количество пользователей нашей службы пищевых технологий выросло на 73% по сравнению с началом марта, и это на 130% больше, чем в прошлом году. Этому росту способствовало недавно запущенное приложение Supera [Phonetic]. В последние дни Lavka превысила треть своих заказов от Supera.
В целом, мы видим множество возможностей в будущем, кризисы ясно демонстрируют, что мы являемся одной из самых уникальных компаний в мире с невероятным сочетанием логистики, технологий и снабжения водителей и курьеров, чтобы мгновенно стать неотъемлемая часть жизни людей.
На этом я передаю микрофон Грегу, который расскажет вам о финансах.
Грег Абовски — Главный операционный и финансовый директор
Спасибо, Даниил, и спасибо всем за то, что присоединились к нашей сегодняшней телеконференции о доходах за первый квартал. Вы видели пресс-релиз со всеми нашими ключевыми финансовыми показателями, поэтому я не буду их повторять, а вместо этого позвольте мне сосредоточиться на производительности и текущих тенденциях в наших бизнес-подразделениях.
Поиск и портал. Search и Portal показали хорошие результаты, несмотря на жесткие ограничения и влияние COVID-19, начиная с середины марта. Выручка без учета TAC увеличилась на 14%, а рентабельность по скорректированному показателю EBITDA составила 48,7%, что на 130 базисных пунктов больше по сравнению с прошлым годом. Учитывая строго соблюдаемую политику изоляции по всей стране и ее влияние на деловую активность, снижение выручки от поиска и портала TAC в апреле находится на территории старшего подросткового возраста с начала месяца. Это было вызвано сочетанием таких факторов, как сокращение рекламных бюджетов, давление на динамику цены за клик и снижение доли коммерческих поисковых запросов. Важно отметить, что наши поисковые запросы в апреле растут самыми быстрыми темпами за последние пять лет, и рост числа кликов ускоряется. Динамика доходов от поисковой выдачи ex-TAC за последние несколько дней восстановилась до значительного снижения. По секторам ИТ и телекоммуникации, доставка еды и продуктов, здравоохранение, дом и сад показали относительно лучшие результаты, в то время как путешествия, одежда, недвижимость и автомобили находятся под большим давлением.
Тем не менее, я хотел подчеркнуть несколько моментов. Прежде всего, снижение явно вызвано внешними факторами, которые в значительной степени находятся вне нашего контроля. До COVID рост нашей выручки за январь и февраль по сравнению с TAC был на территории старшего подросткового возраста. Во-вторых, наша главная цель сейчас — увеличить нашу долю рынка и базу пользователей, чтобы, когда экономика восстановится, мы могли преобразовать это в рост доходов, и наш прогресс здесь впечатляет, особенно с более молодой аудиторией. В целом динамика выручки за весь год будет зависеть от продолжительности и строгости карантинных мер и экономического воздействия, а также от скорости восстановления, которые на данном этапе трудно предсказать.
Несколько слов о структуре затрат нашего бизнеса Search and Portal. Постоянные затраты составляют около половины общих денежных затрат в сегменте «Поиск и портал», где персонал является самым большим компонентом. Переменная часть включает TAC и себестоимость продаж.
Переход на такси. Доходы от такси выросли на 50% по сравнению с прошлым годом, в первую очередь за счет роста количества поездок на 40%, продолжающейся оптимизации стимулов в сфере такси, а также быстрого развития сервисов общественного питания. Нам удалось увеличить скорректированную маржу EBITDA без учета беспилотных автомобилей до 7,6% благодаря повышению прибыльности в сфере такси, компенсируемому нашими инвестициями в Lavka, а также общей слабости, которую мы наблюдали в конце марта. В райдшеринге переменные расходы составляют примерно две трети наших общих расходов, включая стимулы, а оставшаяся часть является фиксированной и состоит из расходов на персонал, аренды, определенной рекламы и маркетинга, а также других операционных расходов. Мы видим возможности для оптимизации затрат, в том числе на рекламу и маркетинг, затраты на приобретение товаров и некоторые накладные расходы.
В Яндекс.Еде мы увидели дальнейшее улучшение юнит-экономики, прежде всего в результате увеличения плотности заказов. Мы продолжаем инвестировать в Lavka, помня о влиянии этого бизнеса на общий показатель EBITDA такси.
Обращение к другим предприятиям. Медиа-сервисы продемонстрировали очень сильный рост выручки на 95% в годовом исчислении с улучшенной скорректированной маржой EBITDA как в годовом, так и в квартальном исчислении. В первом квартале доходы Media Services от подписки выросли на 152% по сравнению с аналогичным периодом прошлого года, и мы видим, что в апреле сохраняются сильные тенденции. Мы продолжаем инвестировать в бизнес, как и планировали, и сосредоточены на удержании новых пользователей.
Доходы от наших объявлений увеличились на 35% в первом квартале, рост за первые два месяца был очень сильным. Тем не менее, мы увидели, что в конце марта поток материалов замедлился после того, как автодилерам было приказано закрыться, что, очевидно, оказало очень существенное влияние на это бизнес-подразделение. Несмотря на то, что в апреле давление на доходы от объявлений продолжалось, трафик на нашей платформе остается устойчивым. Мы видим формирование отложенного спроса, который планируем монетизировать, как только деловая активность начнет восстанавливаться.
Наконец, о других ставках и экспериментах. Наша выручка почти удвоилась по сравнению с прошлым годом благодаря росту Яндекс.Драйва, Geo и Zen. Яндекс.Драйв, Cloud и Geo также стали ключевыми факторами нашего скорректированного убытка EBITDA в размере 1,9 млрд руб. Как упомянул Тигран, в апреле Zen продолжает показывать хорошие результаты, в то время как наш каршеринговый бизнес сильно пострадал, особенно после того, как 13 апреля сервисы каршеринга были приостановлены в Москве и Санкт-Петербурге. об оптимизации наших договоров аренды и размера автопарка с целью снижения скорости выгорания.
Руководство. Учитывая сложность прогнозирования того, как долго продлится пандемия, и неопределенность в отношении ее воздействия на экономику и наш бизнес, в настоящее время мы не можем надежно оценить влияние вспышки COVID-19 на наши будущие финансовые результаты. Таким образом, мы отзываем наши рекомендации на 2020 год, которые мы предоставили 14 февраля 2020 года.
Что мы делаем, чтобы смягчить влияние COVID-19 на нашу деятельность? Мы разработали различные стресс-тесты, которые помогли нам определить приоритеты, и эти приоритеты включают в себя инвестиции в бизнесы с повышенной активностью и более высокой социальной значимостью в текущих условиях, а также стратегические проекты для укрепления позиций Компании в долгосрочной перспективе. После адаптации около 1300 новых сотрудников в 2019 г., и еще 333 человека в 1 квартале 2020 года, мы решили замедлить темпы найма, учитывая текущие обстоятельства. Отчасти это связано с трудностями интеграции и обучения новых людей, пока мы все работаем удаленно. Но мы также хотим убедиться, что к 2021 году у нас будет соответствующий размер. стратегические приоритеты. Мы также приняли решение отказаться от денежных премий для высшего руководства в 2020 году. Кроме того, высшее руководство согласилось на добровольное сокращение заработной платы. Мы сокращаем несущественные расходы на маркетинг и строго контролируем наши накладные расходы. Мы считаем, что эти инициативы помогут нам уменьшить негативное влияние пандемии и макроэкономических факторов на нашу EBITDA в 2020 году.
В заключение хочу напомнить, что наш баланс крепкий. В настоящее время у нас есть 2,5 миллиарда долларов наличными, в том числе 390 миллионов долларов на балансе Taxi. Более двух третей этой наличности в долларах США.
Весь наш долг является долгосрочным и подлежит погашению в 2025 году. Мы уверены, что наша сильная позиция ликвидности поможет нам противостоять вызовам текущей ситуации, а также предоставит нам гибкость для продолжения инвестирования в долгосрочные стратегические проекты. .
На этом я переключаю микрофон на оператора для сеанса вопросов и ответов.
Вопросы и ответы:
Оператор
Большое спасибо. [Инструкции для оператора] Первый вопрос, который у нас есть сегодня, исходит от линии Cesar Tiron из Bank of America. Пожалуйста продолжай.
Сезар Тайрон — Bank of America Merrill Lynch — Аналитик
Да. Всем привет. Спасибо за звонок и спасибо за возможность задать вопросы. Так что у меня есть два, я буду только первый. Просто хотел проверить, можете ли вы объяснить значительный рост доли рынка за последние пару недель. Я думаю, что доля рынка смешанной продукции, о которой сообщалось в последний раз, составляет около 59.%. Что является ключевым фактором и видите ли вы увеличение доли рынка даже без помощи регулирования? Большое спасибо.
Грег Абовски — Главный операционный и финансовый директор
Привет, Цезарь. Это Грег. Вы меня слышите?
Сезар Тайрон — Bank of America Merrill Lynch — Аналитик
Да.
Грег Абовски — Главный операционный и финансовый директор
Идеально. Так что, я думаю, основные драйверы роста доли рынка как раз в том, что мы стали стандартом де-факто для получения большого количества знаний и информации о коронавирусе, а также предоставления множества различных вариантов развлечений и тому подобного. Мы запустили ряд инициатив, которые дают людям гораздо больше информации об этом. И я думаю, что по сравнению с нашими конкурентами широта информации намного богаче и гораздо больше адаптирована к местному содержанию — контексту. Вещи, которые мы запустили в сфере образования и тому подобное, также важны с точки зрения привлечения более молодой аудитории, о чем мы говорили в подготовленных комментариях. Итак, более молодая аудитория, которая исторически, вероятно, отклонялась от нас в сторону конкурентов, теперь переключилась на Яндекс, и это здорово.
И помните, предварительная установка никак не повлияла на увеличение доли рынка. Все эти увеличения доли рынка являются естественными и обусловлены качеством нашего поискового продукта и нашей платформы в целом. Предварительная установка теперь перенесена на январь 2021 года. Надеюсь, мы повлияем на результаты 2021 года. Но, очевидно, мы очень рады очень сильному увеличению доли рынка на Android и на настольных компьютерах. Фактически, в апреле наша доля рынка настольных компьютеров превысила 70%. А наша доля рынка на андроиде в апреле составляет 56%. Все это — я думаю, весьма впечатляющие показатели. Спасибо.
Сезар Тайрон — Bank of America Merrill Lynch — Аналитик
Грег, можно еще один вопрос? Просто хотел проверить, как повлияет отключение Диска, которое, как я понимаю, связано с нормативными требованиями. Что касается экспериментов с EBITDA за 2 квартал, можно ли предположить, что выручки нет, но вам все равно придется платить за лизинг автомобилей? Или как это будет работать? Спасибо.
Грег Абовски — Главный операционный и финансовый директор
Отличный вопрос. Таким образом, мы смогли пересмотреть наш лизинговый договор, чтобы существенно компенсировать последствия закрытия Яндекс.Драйва и других каршеринговых компаний в Москве. В результате вы абсолютно правы в том, что у нас не будет дохода, но и наша база затрат будет значительно снижена. Итак, я думаю, что еще слишком рано точно оценивать влияние, но мы чувствуем себя относительно комфортно, потому что это не просто черная дыра, в которую исчезнут деньги.
Вдобавок ко всему, я думаю, мы говорили об этом в последнем ежеквартальном звонке, мы уже предприняли шаги по оптимизации размера флота, чтобы лучше соответствовать спросу на услугу. И я думаю, что в целом мы все равно потеряем деньги в сегменте Яндекс.Драйва во втором квартале. Не то чтобы мы смогли полностью отсрочить все наши арендные платежи, но это не будет той черной дырой, о которой я говорил.
Сезар Тайрон — Bank of America Merrill Lynch — Аналитик
Большое спасибо. Очень полезно. Спасибо.
Оператор
Большое спасибо. Следующий вопрос сегодня с линии Ульяны Ленвальской из UBS. Пожалуйста продолжай.
Ульяна Ленвальская — UBS — Аналитик
Всем привет. Большое спасибо за презентацию. Мой первый вопрос будет по основному бизнесу. Не могли бы вы более подробно рассказать о категориях и эффективности рекламы, особенно о том, какие секторы способствуют восстановлению, о котором вы упоминали за последние пару дней? А можно ли раскрыть, каков вклад малого и среднего бизнеса в выручку на данный момент?
Грег Абовский — Главный операционный и финансовый директор
Конечно, Ульяна. Это Грег. Попробую ответить на них. Итак, дальше — сначала я отвечу на ваш второй вопрос, просто потому, что он простой. Наши малые и средние предприятия приносят примерно половину наших доходов от рекламы. И что интересно, за последние несколько недель мы фактически не видим существенной разницы в производительности сегмента малого и среднего бизнеса по сравнению с сегментом крупных предприятий в рамках рекламного бизнеса.
Важно помнить, что для малого и среднего бизнеса Яндекс, Яндекс.Поиск, Яндекс.Рекламная сеть часто представляют собой единственный канал продаж, который есть у этих предприятий. И, как мы видели в ходе предыдущих экономических спадов, это последнее, что люди отключают. Надеюсь, это ответ на вторую часть вопроса.
Что касается первой части вопроса, по категориям, то, что я сказал в подготовленных комментариях, очевидно, что мы видим силу в таких секторах, как ИТ и телекоммуникации, электронная коммерция, дом и сад. Что находится под давлением, так это то, что вы ожидаете, такие вещи, как путешествия, такие вещи, как автомобили. Помните, автосалонам приказали закрыться, по-моему, почти месяц назад. Так что, как и следовало ожидать, реклама там резко сократилась. Одежда была еще одной категорией — опять же, это не стало большим сюрпризом, — еще одной категорией, которая находилась под давлением.
С точки зрения того, что мы видим с точки зрения тенденций и того, что заставляет нас фактически видеть — потенциально видеть зеленые ростки, как я сказал, производительность в течение апреля отслеживалась вверх и вправо от первоначального шок. Мы видим лучшие результаты в области финансов и страхования. Мы видим лучшую производительность дома и в саду. Мы видим лучшую производительность в B2B. То, что в основном осталось без изменений — почти исчезло, — это такая категория, как путешествия. Еда вне дома как категория в основном плоская, ситуация не ухудшается, но и не улучшается. Улучшаются такие вещи, как здравоохранение, улучшаются информационные технологии и телекоммуникации, немного улучшаются услуги по строительству и ремонту. Надеюсь, этого цвета достаточно.
Ульяна Ленвальская — УБС — Аналитик
Ага. Большой. Спасибо. И второй вопрос будет о Такси. Предоставленные вами тренды GMV весьма полезны. Но не могли бы вы сначала прокомментировать ставки, особенно поощрения? Как это меняется в Москве и в бизнесе?
Грег Абовски — Главный операционный и финансовый директор
Да. Я позволю Даниилу взять его.
Даниил Шулейко — Генеральный директор Яндекс.Такси
Еще раз здравствуйте. Это Даниил. Вы меня слышите?
Ульяна Ленвальская — УБС — Аналитик
Да, да. Вперед, продолжать.
Даниил Шулейко — Генеральный директор Яндекс.Такси
Очень хорошо. Итак, вперед. Смотрите, сейчас наш валовой коэффициент продаж значительно ниже, чем у наших мировых аналогов. Например, наша смешанная эффективная доля дублей в первом квартале была ниже 10%. Значительную часть нашей комиссии за рост мы выплатили водителям в виде различных поощрений. Всего в 2019 г., выручка партнеров нашей райдшеринговой платформы составила 250 млрд рублей, тогда как в первом квартале она составляла примерно 75 млрд рублей. Наши главные приоритеты на сегодняшний день — сделать так, чтобы сотни тысяч водителей и курьеров, зарабатывающих на нашей платформе, чувствовали себя в безопасности, а также делаем все возможное, чтобы предоставить им дополнительные возможности заработка. Итак, мы вкладываем в это дело сотни миллионов рублей, и это лишь часть того, что мы делаем в целом для поддержки наших водителей. Наша команда также очень усердно работала над поиском новых способов предоставления водителям дополнительных поездок. Поэтому мы создаем и запускаем новые сервисы. Как я уже упоминал ранее, мы запустили другой тип партнерства с крупными игроками на этом рынке. Кроме того, всего пару часов назад мы объявили о нашем новом партнерстве с OZON для их доставки последней мили, и мы считаем, что это еще одно важное событие для нас.
Итак, прямо сейчас мы доставляем тесты, медицинские профессии и еще кучу всего. А с финансовой точки зрения, если вы посмотрите на все, что мы делаем вместе, это выходит за рамки того, что мы — влияние снижения комиссионных. Мы считаем, что создание новых возможностей для получения дохода — гораздо более эффективный и устойчивый способ поддержать наших водителей и общество, чем простое снижение комиссии.
Ленвальская Ульяна — УБС — Аналитик
Спасибо.
Оператор
Большое спасибо. Следующий вопрос сегодня с линии Вячеслава Дегтярева из Goldman Sachs. Пожалуйста продолжай.
Вячеслав Дегтярев — Goldman Sachs — Аналитик
Да. Большое спасибо за звонок. Первый вопрос касается полей поиска. Они были достаточно сильны в первом квартале.
Катя Жукова — Директор по связям с инвесторами
Вячеслав, извините. Вячеслав, извините.
Вячеслав Дегтярев — Goldman Sachs — Аналитик
Да?
Катя Жукова — Директор по связям с инвесторами
Просто — говорит Катя Жукова. Просто дайте нам секунду. У нас есть некоторые технические трудности.
Вячеслав Дегтярев — Goldman Sachs — Аналитик
Абсолютно.
Катя Жукова — Директор по связям с инвесторами
Повторное подключение. Хорошо. Пожалуйста продолжай.
Вячеслав Дегтярев — Goldman Sachs — Аналитик
Ага. Итак, мой первый вопрос был о полях поиска. Они были достаточно сильны в первом квартале. Мне интересно, насколько на это повлияли одноразовые факторы, если таковые имеются. Или есть какие-либо элементы слабой маржи в четвертом квартале, и насколько устойчивой была бы эта маржа, если бы не было последствий COVID в течение всего года?
Грег Абовский — Главный операционный и финансовый директор
Привет, Вячеслав, это Грег. Позвольте мне попробовать взять это. Итак, я… что касается разовых выплат, очевидно, решение, принятое высшим руководством отказаться от денежных премий, а также добровольно урезать свои зарплаты, окажет положительное влияние на прибыль в течение всего года, как и вы, очевидно, они начинают накапливаться с 1 января. Другое положительное влияние оказывается на спину TAC, и это конкретно некоторые TAC распределения. И если вы помните, это то, о чем мы говорили в отчете о прибылях и убытках за четвертый квартал, где мы сказали, что ожидаем увидеть преимущества от распределения TAC в 2020 году, и вы начинаете видеть, что это происходит.
Другие вещи, которые… мы будем компенсировать это будут инвестиции и такие вещи, как контент и так далее, как в сегменте поиска/портала. Помните, у нас есть контент и в Поиске/Портале, где мы показываем видео в сервисе Яндекс.Live.
Что касается маржи в целом, я думаю, что это во многом зависит от доходов, и их очень трудно предсказать на данный момент. И, очевидно, мы пытаемся сделать все возможное, чтобы изменить приоритеты проектов, чтобы сократить расходы там, где мы считаем это разумным, и перераспределить наши инвестиции в те вещи, которые, по нашему мнению, принесут наибольшую прибыль нашим акционерам.
Вячеслав Дегтярев — Goldman Sachs — Аналитик
Хорошо. Спасибо за это. И, во-вторых, можете ли вы описать конкурентные преимущества различных бизнес-подразделений? Может быть, вы заметили какие-либо возможности для доли рынка в определенных подсегментах? И вообще, предвидите ли вы кризис для создания таких возможностей? Можете ли вы уточнить это, пожалуйста?
Грег Абовски — Главный операционный и финансовый директор
Конечно, Вячеслав. Я думаю, я надеюсь, что это окажется настоящим скрытым благословением. Мы видим невероятную силу в плане завоевания доли практически в каждой вертикали, с которой мы конкурируем. Мы увеличили долю райдшеринга в первом квартале. Мы очень хорошо справились с доставкой еды. Мы добились большого успеха с нашей гиперлокальной продуктовой инициативой Яндекс.Лавка. Как я уже говорил, мы также получили значительную долю в поиске. И затем, если вы посмотрите на что-то вроде новостной ленты Яндекс.Дзен, то ясно, что она невероятно сильно растет. А на прошлой неделе мы дразнили нас 17 миллионами пользователей в день, что довольно много с декабря. И тенденции там очень сильные. Таким образом, я думаю, что хотя очевидно, что трудно предсказать, как все сложится, мы, безусловно, столкнемся с препятствиями в отношении доходов от рекламы и других вещей. Я думаю, что этот — этот кризис действительно продемонстрирует силу платформы, которую мы построили.
Вячеслав Дегтярев — Goldman Sachs — Аналитик
Хорошо. Большое спасибо, Грег.
Оператор
Большое спасибо. Кажется, мы потеряли очередь вопросов и ответов. [Инструкция оператору] Мы — я открываю линию Владимира Беспалова из ВТБ Капитал. Пожалуйста продолжай.
Владимир Беспалов — ВТБ Капитал — Аналитик
Здравствуйте. Поздравляю с числом и спасибо, что ответили на мои вопросы. Прежде всего, я хочу спросить у вас, какова тогда была доходность? В марте вы обычно приводите эти цифры. И я хотел бы также, возможно, уточнить тенденции в рекламе, поправьте меня, если я ошибаюсь. Но насколько я понял, Грег, вы упомянули, что видите некоторые улучшения в кликах. Но как насчет ценообразования и общей тенденции доходов? Если мы посмотрим на апрельскую ситуацию, как она развивается сейчас? Спасибо.
Грег Абовски — Главный операционный и финансовый директор
Здравствуйте, Владимир. На Дзене, поэтому пробег Дзена немного снизился по сравнению с декабрем. Годовая выручка в марте составила около 8 млрд рублей по сравнению с 8,8 млрд рублей в декабре. И это, очевидно, на фоне воздействия COVID-19. В то время как тенденции вовлеченности были чрезвычайно устойчивыми, общее время, проведенное в марте, выросло на 56%, а в апреле этот рост ускорился до 90%. И потом, люди проводят в апреле почти 13 миллионов часов в день с Яндекс.Дзен.
И затем в отношении кликов и цены за клик. Очевидно, что мы видим, что, несмотря на быстрый рост пиковых кликов, цены за клик снижаются. И эта тенденция, скорее всего, продолжится с ценой за клик, которая является просто результатом общей рекламы, которая в этом году стала слабее, чем в прошлом. И влияние этого на целый месяц, в отличие от двух недель, которые мы видели в первом квартале или около того. Но что важно иметь в виду, так это то, что я думаю, что сегодня поиск является амбаром на платформе с самой высокой рентабельностью инвестиций для рекламодателей. И в результате тенденции, которые мы наблюдаем в поиске, который восстанавливается быстрее, чем другие формы рекламы, я думаю, являются причиной этого. Это платформа с самой высокой окупаемостью инвестиций для рекламодателей, как для крупных корпоративных клиентов, так и для малого и среднего бизнеса, и поэтому они продолжают обращаться к ней.
Владимир Беспалов — ВТБ Капитал — Аналитик
Хорошо. Большое спасибо. Но вы не могли бы прокомментировать тенденции доходов прямо сейчас. Для рекламы непонятно.
Грег Абовски — Главный операционный и финансовый директор
Что ж, это именно то, что я сказал в подготовленных комментариях, а именно то, что в апреле общий спад рекламы достиг подросткового возраста. И затем, если вы посмотрите на последние несколько недель, спад, особенно в поиске, теперь сократился до высоких однозначных цифр. На самом деле, бывают дни, когда в апреле в поиске наблюдается прямая или слегка положительная динамика рекламы.
Владимир Беспалов — ВТБ Капитал — Аналитик
Хорошо. Спасибо. Может я пропустил это. И еще один вопрос по райдшеринговому бизнесу. Партнерские отношения, которые у вас есть в настоящее время со многими розничными торговцами, скажем, игроками электронной коммерции и тому подобными вещами. Являются ли эти партнерства и бизнес-модели, основанные на этом партнерстве, устойчивыми для развития этого бизнеса в будущем после окончания периода блокировки? Видите ли вы новые возможности в этой области? И какова рентабельность этого бизнеса, может, потенциального, если нет, то текущего? Спасибо.
Даниил Шулейко — Генеральный директор Яндекс.Такси
Здравствуйте, Владимир, это Даниил. Итак, смотрите, мы видим, что тенденции в целом в этом секторе будут меняться. А значит, люди начнут покупать онлайн намного чаще, чем это было раньше. Вот почему мы считаем, что это устойчивая бизнес-модель для нас в долгосрочной перспективе. Например, прямо сейчас мы оптимизируем нашу структуру затрат на эту доставку, чтобы в большинстве случаев в некоторых случаях выбор номер один с точки зрения затрат для компаний, с которыми мы подписали партнерские соглашения.
Владимир Беспалов — ВТБ Капитал — Аналитик
Хорошо. Большое спасибо.
Оператор
Большое спасибо. Следующий вопрос сегодня исходит от Мириам Адиса из Morgan Stanley. Пожалуйста продолжай.
Мириам Адиса — Morgan Stanley — Аналитик
Привет. Спасибо за звонок. Грег, я опираюсь на то, что вы только что сказали о том, что поиск является платформой с самой высокой окупаемостью инвестиций для рекламодателей. Просто интересно, что вы думаете о росте поиска по мере того, как вы выходите из режима самоизоляции и, возможно, впадаете в рецессию. Ходит много разговоров о том, что в этом году цифровые технологии могут впервые прийти в упадок. Согласны ли вы с такой оценкой? И что вы думаете о росте поиска в условиях рецессии, возможно, по сравнению с 2015 годом, потому что, очевидно, сейчас это самая высокая доля рынка? Так что просто интересно, как вы думаете о том, как бизнес работает в этой среде.
Грег Абовски — Главный операционный и финансовый директор
Привет, Мириам. Хотел бы я иметь хрустальный шар. Я не. Я не знаю, как будет работать цифровая реклама. Я думаю, вполне возможно, что цифровая реклама сократится в 2020 году. Но, прежде всего, цифровая реклама по-прежнему предлагает рекламодателям одну из самых высоких возможностей рентабельности инвестиций. И я думаю, что рекламодатели будут продолжать обращаться к нему раньше, чем к другим видам рекламы.
Очевидно, этот кризис отличается от кризиса 2009 года.. Это отличается от 2015 года. Цифровые технологии намного больше в процентах от общего пирога. Так что за ним стоит не вековой попутный ветер, а скорее вековой попутный ветер. Кроме того, вы получите сочетание COVID и сокращения ВВП из-за снижения цен на нефть и ослабления рубля. Таким образом, все, что мы пытаемся сделать и на чем мы сосредоточены, — это обеспечение высокой рентабельности инвестиций для наших рекламодателей, обеспечение кликов — высококачественных кликов для наших рекламодателей, разработка новых рекламных форматов для наших рекламодателей и предоставление им лучших инструментов, которые мы можем идти за своей аудиторией. Сейчас рано говорить о том, будет ли Search отключен или нет. Будет ли цифровая реклама отключена или нет, пока рано говорить, но мы, безусловно, моделируем всевозможные сценарии. И поэтому, когда мы запускаем различные симуляции и сценарии, мы думаем, что он может выйти из строя.
Мириам Адиса — Morgan Stanley — Аналитик
Хорошо. Это ясно. Спасибо. И затем мой второй вопрос только о марже Такси для основных поездок и доставки еды. Просто интересно, как мы должны думать о последовательном увеличении маржи во втором квартале, учитывая, я думаю, что вы оказываете большее влияние на Лавку.
Евгений Сендеров — Финансовый директор Яндекс.Такси
Привет, Мириам, это Евгений. Итак, давайте сначала поговорим о райдхейлинге. В первом квартале у нас был очень устойчивый рост, но в дальнейшем наш базовый сценарий предполагает пик спада и подъема во втором квартале. И, опять же, у меня тоже нет хрустального шара, как у Грега, но мы видим постепенное восстановление в третьем и четвертом квартале. Как мы упоминали ранее, переменные затраты в райдшеринге составляют две трети наших общих затрат, включая поощрения. А с точки зрения постоянных расходов, когда мы смотрим на наш бизнес в следующем квартале и до конца года, мы значительно сократили расходы, в первую очередь на рекламу и маркетинг, а также расходы на приобретение товаров и некоторые другие операционные расходы. расходы. И мы снижаем приоритеты или откладываем некоторые проекты, которые на данный момент не являются необходимыми. Очевидно, что у нас будут значительные дополнительные расходы, связанные с пандемией, в том числе наш фонд поддержки водителей в размере 500 млн рублей, а также расходы, связанные с приобретением различных масок и дезинфицирующих средств, расходы на транспорт медицинского персонала и тесты на COVID, которые мы делаем. А также поддержка новых ресторанов, где мы отказываемся от комиссий для новых ресторанов и у нас есть определенные инициативы.
Итак, на данный момент трудно делать какие-либо прогнозы, но для игры с цифрами, если у нас будет 60%-ное снижение GMV по сравнению с прошлым годом во втором квартале, у нас есть — скорее всего мы опубликуем убыток EBITDA в этом конкретном квартале. В случае, если наша консолидированная GMV по вызову такси снизится на 40% во втором квартале, я думаю, что мы будем безубыточны с текущей структурой затрат. И это структура затрат, направленная на быстрое восстановление и восстановление объемов после карантина. Итак, если мы сравним вторую половину 2020 года с первой половиной, мы ожидаем, что наш бизнес по вызову такси будет прибыльным в годовом исчислении.
И если вы посмотрите на Taxi в целом, то, конечно же, общие результаты будут зависеть от наших инвестиций в беспилотные автомобили и быстрорастущий бизнес в сфере пищевых технологий. Поэтому мы продолжим активно инвестировать в наш бизнес Eats. Мы видим некоторые улучшения в юнит-экономике, и мы уделяем особое внимание юнит-экономике бизнеса Eats. Таким образом, по итогам года мы ожидаем значительного улучшения убыточности EBITDA нашего Яндекс.Еда ближе к концу года.
И Lavka, наш гиперлокальный бизнес по доставке, находится на стадии инвестиций. Мы значительно увеличили «Лавку» с 50 магазинов в конце прошлого года до более 100 магазинов в настоящее время, как я уже упоминал, я думаю. Но наши средние ежедневные заказы выросли на 350% по сравнению с концом — по сравнению с декабрем прошлого года. А GMV вырос в этом году на 550%. А что касается Лавки, мы продолжим оценивать возможности роста, и интенсивность инвестиций будет зависеть от нашего успеха в этом формате до конца года. И мы продолжим инвестировать в SBC, потому что считаем, что это стратегически важное направление инвестиций для нас, для Компании.
И одна вещь, о которой я хотел бы упомянуть, уже упоминалась, но чтобы подчеркнуть, что у нас очень сильный баланс. У нас есть 393 миллиона долларов, большая часть которых в долларах США. Таким образом, мы думаем, что находимся в отличной форме, чтобы справиться с текущей ситуацией, и у нас есть хорошие возможности для продолжения роста, когда мы ее преодолеваем.
Мириам Адиса — Morgan Stanley — Аналитик
Отлично. Спасибо.
Оператор
Большое спасибо. Следующий вопрос сегодня исходит от линии Себастьяна Патулеа из Джеффриса. Пожалуйста продолжай.
Себастьян Патулеа — Джеффрис — Аналитик
Привет всем, и спасибо, что разрешили задавать вопросы. Поэтому я попрошу два, пожалуйста. Во-первых, кажется, что во время установки пользователи отказываются от маленьких экранов смартфонов и больше в пользу более крупных, таких как ноутбуки и настольные ПК. Вы тоже наблюдаете такое поведение в апреле? И следует ли нам ожидать в результате некоторого попутного ветра от этого эффекта?
А во-вторых, в период с марта по июнь этого года Яндекс появится в окне выбора поисковой системы по умолчанию в Эстонии, Колумбии [Фонетическая] и Латвии, опять же Польше. Не могли бы вы немного рассказать о первых результатах этой акции и некоторых тенденциях, которые вы здесь видите? Большое спасибо.
Грег Абовски — Главный операционный и финансовый директор
Привет, Себастьян. Что касается сочетания настольных компьютеров и мобильных устройств, я бы сказал, что оно не сильно изменилось. Я бы сказал, что в промежутке между днями состав немного изменился, так как, например, по выходным мы видим немного больше рабочих столов, чем обычно. Но я бы сказал, что это не очень большое изменение. Так что я бы не стал встраивать в ваши модели огромное влияние, так или иначе. И если вы посмотрите, где нас отслеживают с точки зрения процента поисковых запросов, поступающих с мобильных устройств, они все еще выше в первом квартале, верно? В четвертом квартале примерно 57,5% нашего поискового трафика приходилось на мобильные устройства. В первом квартале было 59%.
И затем в отношении экрана выбора Европейского Союза, который будет применяться к новым устройствам. Так что, если вы помните, это похоже на то, как это работало с антимонопольным элементом в России. Это влияет на новые устройства. Таким образом, требуется довольно много времени, чтобы количество устройств, содержащих экран выбора, действительно проникло в установленную базу. Таким образом, это то, что займет некоторое время, чтобы проявиться в данных.
Себастьян Патулеа — Джеффрис — Аналитик
Большое спасибо.
Грег Абовски — Главный операционный и финансовый директор
Спасибо.
Оператор
Большое спасибо. Следующий вопрос сегодня исходит от Ллойда Уолмсли из Deutsche Bank. Пожалуйста продолжай.
Ллойд Уолмсли — Дойче Банк — Аналитик
Хорошо, спасибо. Два, наверное, оба для Грега. Грег, я знаю, что вы больше не разделяете поиск и контекстно-медийную сеть, но не могли бы вы дать нам представление о том, как выглядят основные тенденции поиска по сравнению с медийной рекламой?
И тогда второй будет просто на ходу FX. Я думаю, что вы, ребята, перенесли наименьшую волатильность из отчета о прибылях и убытках в отчет о движении денежных средств. Но стоит ли ожидать каких-либо изменений в расходах на персонал из-за слабости валюты, учитывая глобальную конкуренцию за таланты? Все, что вы можете поделиться, было бы полезно.
Грег Абовски — Главный операционный и финансовый директор
Эй, Ллойд. Итак, вы правы, что мы не ломаем его. Но я мог бы просто дать вам немного цвета. Медийная реклама, безусловно, пользуется гораздо большим успехом, чем контекстная реклама и перформанс-реклама. Причина этого в том, что большинство покупателей медийной рекламы — это крупные предприятия, и именно они в большинстве — в самой жесткой форме — реагируют на внешние события быстрее всего. Таким образом, в первом квартале этот показатель снизился больше, чем в других формах рекламы, и мы ожидаем, что во втором квартале он ухудшится.
А что касается второго вопроса, напомните еще раз, что это было? Мне жаль.
Ллойд Уолмсли — Дойче Банк — Аналитик
Да. Повлиял ли обмен валюты на расходы на персонал или на другие области, за которыми мы должны следить?
Грег Абовски — Главный операционный и финансовый директор
А, да, и еще иммиграционная служба. Итак, учитывая, что большинство стран сейчас закрыты из-за COVID, пока мы не видим какого-либо значимого влияния девальвации иностранной валюты. То, как последствия повлияют на наши прибыли и убытки, сейчас не так велико, как во время последнего кризиса. Мы надеемся, что мы усвоили некоторые из наших уроков. Влияние будет отражено в отчете о движении денежных средств, где покупки серверов по-прежнему номинированы в долларах США, и нам все еще нужны эти серверы, поскольку мы продолжаем инвестировать в наши различные платформы. Итак, на данный момент мы перераспределяем приоритеты наших капиталовложений и пытаемся оптимизировать их таким образом, чтобы выраженная в рублях сумма совокупных капиталовложений в 2020 г. существенно не отличалась от нашего первоначального бюджета при предыдущем валютном режиме.
Ллойд Уолмсли — Deutsche Bank — Аналитик
Хорошо. Спасибо.
Грег Абовски — Главный операционный и финансовый директор
Спасибо.
Оператор
Большое спасибо. Следующий вопрос сегодня с линии Анны Куприяновой из Газпромбанка. Пожалуйста продолжай.
Анна Куприянова — Газпромбанк — Аналитик
Здравствуйте. Большое спасибо за презентацию и возможность задать вопрос. Мой вопрос касается вашей интернет-рекламы. Насколько я вижу, ваша доля TAC в затратах на интернет-рекламу свойств Яндекса снизилась. Сейчас это около 11%, если эта тенденция будет устойчивой. Кроме того, мой вопрос касается доли свойств Яндекса и онлайн-рекламы, могу ли я предположить, что она будет на том же уровне, что и сейчас, в первом квартале 20-го года? Спасибо.
Грег Абовски — Главный операционный и финансовый директор
Привет, Анна. Что касается TAC, мы, конечно же, ожидаем, что TAC по распределению должен быть чем-то вроде попутного ветра. Как мы уже говорили в отчете о прибылях и убытках за четвертый квартал, где мы сказали, что ожидаем, что TAC по дистрибуции будет расти существенно медленнее в 2021 г. по сравнению с — извините, в 2020 г. по сравнению с 2019 г. Таким образом, это дает ответ на вопрос о TAC по дистрибуции.
В партнерском TAC. Это все еще подлежит уточнению. Мы работаем с нашими партнерами по рекламной сети. И мы пытаемся найти, какая там оптимальная точка. Но вполне возможно, что и сократится.
И, наконец, ваш последний вопрос был о… напомните мне.
Куприянова Анна — Газпромбанк — Аналитик
Речь идет о доле свойств Яндекса и онлайна.
Грег Абовски — Главный операционный и финансовый директор
Правильно. Таким образом, мы, безусловно, надеемся, что получим больше трафика и получим больше доходов от наших объектов. Мы вкладываем в них очень много. Я думаю, что качество нашей недвижимости растет. Мы лучше интегрируем их в наши продукты. Например, то, как мы интегрировали Дзен, я думаю, намного лучше в приложение «Поиск» и на главную страницу Яндекса. Итак, мы ожидаем, что свойства Яндекса должны хорошо расти и должны продолжать расти в процентах от общего числа.
Анна Куприянова — Газпромбанк — Аналитик
Большое спасибо. И очень быстрый дополнительный вопрос относительно вашего выкупа акций. Какие-нибудь изменения в планах выкупа, пожалуйста, сообщите нам?
Грег Абовски — Главный операционный и финансовый директор
Конечно. Итак, на сегодняшний день мы выкупили 4,5 миллиона акций. И мы потратили примерно половину из 300-миллионной программы обратного выкупа. Наше решение между обратным выкупом и инвестициями в бизнес будет зависеть от того, что принесет наибольшую прибыль акционерам. Итак, прямо сейчас нет каких-то конкретных обновлений, но мы будем — я ожидаю, что мы будем время от времени выкупать акции по привлекательным ценам, как мы это делали раньше.
Анна Куприянова — Газпромбанк — Аналитик
Большое спасибо.
Грег Абовски — Главный операционный и финансовый директор
Спасибо.
Оператор
Большое спасибо. Следующий вопрос поступает с линии Марии Сухановой из БКС. Пожалуйста продолжай.
Мария Суханова — BCS Global Markets — Аналитик
Да. Добрый день. Я хотел спросить о вашей деятельности по слияниям и поглощениям. Теперь, учитывая слабость макроэкономических показателей, мне интересно, следует ли нам ожидать от вас ускорения вашей деятельности по слияниям и поглощениям, особенно с учетом вашей кучи денег на балансе. А также второй, на Лавке, с прибавкой заказов, которую вы видели в последнее время. Есть ли какие-либо места, которые уже являются прибыльными, или что-то — или в экономике нужно улучшить дальше, чтобы места стали прибыльными?
Грег Абовски — Главный операционный и финансовый директор
Конечно, Мария. Евгений ответит про Лавку, а я постараюсь ответить про M&A активность. Таким образом, очевидно, что наличие сухого пороха на сумму около 2,5 миллиардов долларов чрезвычайно полезно в этой среде, потому что это дает нам стратегическую гибкость для заключения сделок по возможности. Итак, мы смотрим на различные активы и оцениваем их. Но вопрос в том, насколько они стратегические. Цена привлекательна? И это самая высокая доходность для наших акционеров?
Евгений, может Вы ответите на какие-то вопросы по Лавке?
Евгений Сендеров — Финансовый директор Яндекс.Такси
Мария, привет. Что ж, я бы не стал называть вам точную цифру, но да, у нас есть места, вклад которых в показатель EBITDA до накладных расходов положителен. Но мы — просто чтобы отметить, что мы не только увеличиваем выручку в Lavka, но и очень сосредоточены на улучшении картины маржи, которая на самом деле улучшается из месяца в месяц и, возможно, даже из недели в неделю. . Так что да, наша цель, конечно же, иметь прибыльные по EBITDA магазины, и мы наблюдаем значительный прогресс в этом направлении.
Мария Суханова — BCS Global Markets — Аналитик
Понятно. Спасибо.
Оператор
Большое спасибо. Следующий вопрос сегодня от Анны Курбатовой из Альфа-Банка. Пожалуйста продолжай.
Курбатова Анна — Альфа-Банк — Аналитик
Добрый день. Большое спасибо за презентацию. У меня есть два вопроса. В первую очередь о беспилотных автомобилях и инвестициях в СМИ, так что и проекты, и бизнес-направления находятся в активной инвестиционной стадии. Поэтому мне интересно, склонны ли вы в нынешних условиях придерживаться первоначального темпа инвестиций в беспилотные автомобили и медиаконтент, особенно видео. Или вы также внесли или собираетесь внести какие-то корректировки в бюджет во втором квартале или в будущем?
Второй вопрос по Яндекс.Маркету, было бы здорово понять, чтобы были какие-то указания от вас, вели ли вы переговоры с вашим партнером. Также есть коррективы в бюджете Яндекс.Маркета на этот год? Итак, какие есть тренды и события на Яндекс.Маркете?
Тигран Худавердян — Заместитель генерального директора
Эй, это Тигран, могу я взять это — о, Грег, хочешь?
Грег Абовски — Главный операционный и финансовый директор
Нет, нет. Ничего страшного. Я думал, ты отключил Анну.
Тигран Худавердян — Заместитель генерального директора
Да, извините. Можно я возьму… извините. Хорошо. Могу я задать вопрос о SDC и службах мультимедиа? Что касается медиасервисов, мы будем продолжать инвестировать в контент. И в сервисе мы видим, что, особенно во время этой ситуации с COVID, он стал значительно привлекательнее, чем когда-либо. И эта служба является одним из бенефициаров этой ситуации — ситуации.
В SDC мы по-прежнему стремимся развивать эту технологию. Так что мы более или менее планируем продолжать увеличивать размер флота и размер команды. Так что — и в зависимости от доходов — какие доходы мы увидим от всего нашего бизнеса и как сложится наша ситуация к концу года, возможно, мы скорректируем наши планы. Но это долгосрочные инвестиции, и мы считаем, что в долгосрочной перспективе мы сможем предоставить полноценную технологию автономного вождения пятого уровня.
Грег Абовски — Главный операционный и финансовый директор
И затем — очевидно, в Media Services, я думаю, что это принесло большую пользу от этой пандемии. Кроме того, у нас есть некоторый контент, оригинальный контент, который мы разработали сами, который был выпущен на платформе совсем недавно. И это работает необыкновенно хорошо. И мы очень этому рады. И я думаю, что Медиасервисы, как часть этой большой экосистемы Яндекс.Плюс, являются для нас очень важным стратегическим активом.
И, наконец, в Яндекс.Маркете опять же очередной массовый бенефициар попутного ветра от пандемии. Поэтому мы продолжаем инвестировать в электронную коммерцию. И, очевидно, мы также инвестируем в «Яндекс.Лавку», которая не входит в состав совместного предприятия. Это было специально вырезано из совместного предприятия как модель гипер-локального магазина шаговой доступности. Там мы наблюдаем невероятный спрос, как я уже сказал, продажи в Лавке выросли примерно на 550% с декабря по апрель.
Оператор
Большое спасибо. Последний вопрос, который у нас сегодня есть, исходит от Владимира Беспалова из ВТБ Капитал. Пожалуйста продолжай.
Владимир Беспалов — ВТБ Капитал — Аналитик
Спасибо, что ответили на мой уточняющий вопрос. Я хотел бы спросить вас о структурной цене в вашем райдшеринговом бизнесе, чем она отличается от мировых аналогов, если мы посмотрим на ваших конкурентов? И будет ли эта структура способствовать быстрому восстановлению райдхейлинга после локдауна, там их просто сняли или еще, как вы здесь видите ситуацию? Спасибо.
Грег Абовски — Главный операционный и финансовый директор
Конечно. Ну, если вообще сравнивать с нашими глобальными коллегами, я думаю, во-первых, у нас относительно небольшая доля прав на аэропорты. Так, в Москве это средние однозначные числа и очень низкие однозначные числа по России в целом. И, конечно же, я говорю о доковидной ситуации. У нас нет услуг пула, которые в настоящее время не используются, предлагаемые Uber и нашими конкурентами.
И потом, просто чтобы знать, что прямо сейчас у нас. .. до карантинных ограничений у нас был очень быстрый рост использования наших премиальных тарифов, которые в настоящее время ограничены. Таким образом, в целом, с небольшой частью прав аэропорта, возвратом премиальных тарифов, я думаю, что у нас очень хорошие возможности для восстановления после снятия ограничений на блокировку. А также, я хочу подчеркнуть, что в любом другом бизнесе основные райдеры хайлинга, которые пользуются сервисом, часто генерируют значительную часть GMV, и как только карантинные ограничения будут ослаблены, мы увидим — мы увидим большинство этих райдеров. вернуться к своему обычному режиму использования. Итак [Наложение речи]
Владимир Беспалов — ВТБ Капитал — Аналитик
Большое спасибо.
Грег Абовски — Главный операционный и финансовый директор
Да.
Владимир Беспалов — ВТБ Капитал — Аналитик
Хорошо. Спасибо большое. Очень полезно.
Оператор
Большое спасибо. И больше никаких вопросов. И Юлия, вы хотите сделать вывод?
Юлия Герасимова — Начальник отдела по связям с инвесторами
Да. Большое спасибо. Спасибо всем за то, что присоединились к нашей сегодняшней телеконференции. Если у вас есть дополнительные вопросы, пожалуйста, свяжитесь с командой IR, мы будем рады помочь вам. И большое спасибо. Пока-пока.
Оператор
[Заключительное слово оператора]
Продолжительность: 65 минут
Участники звонка:
Юлия Герасимова — Глава по связям с инвесторами
Тигран Худавердиан — Заместитель главного исполнительного директора
Daniil Shuleyko — Главный исполнительный директор YANDEX.TAXI
333333333333333333333333333333333333333333333333333333333333333333333333333339. — Глав Финансовый директор Катя Жукова — Директор по связям с инвесторами
Евгений Сендеров — Финансовый директор Яндекс.
Реляционная СУБД
github.com/ydb-platform/ydb
ydb.tech
ydb.tech/en/docs
0.6, August 2022Поставщики предложений DBaaS, пожалуйста, свяжитесь с нами, чтобы получить список.
- Aiven для Apache Cassandra: полностью управляемая база данных NoSQL с открытым исходным кодом, специально разработанная для обеспечения высокой доступности, производительности и масштабируемости.
- Astra DB: Мультиоблачная DBaaS, построенная на Apache Cassandra.
Linux
OS X
Windows
поддержка структур данных XML и/или поддержка XPath, XQuery или XSLT.Thrift
C++
Clojure
Erlang
Go
Haskell
Java
JavaScript Node.js
Perl
PHP
Python
Ruby
Scala
Java
JavaScript (Node.js)
PHP
Python
Немедленная непротиворечивость может быть определена индивидуально для каждой операции записи
» подробнее
» подробнее
» подробнее
.. используется 40% компаний из списка Fortune 100. » подробнее
» подробнее
Блокчейн (данные) без боли
26 сентября 2022
Взлом ваших эмоций и общение во времена высоких ставок с Дженнифер Эдвардс
22 сентября 2022
Создание непобедимых приложений с помощью Temporal и Astra 2 2 сентября 290 Astra 2 290 Astra DB
Опыт документирования нового продукта
14 сентября 2022 г.
Узнайте, когда стоит рискнуть, а когда отказаться с помощью Kelly Battles
7 сентября 2022 г.
Мы приглашаем представителей поставщиков систем связаться с нами для обновления и расширения информации о системе,
и для отображения предоставленной поставщиком информации, такой как ключевые клиенты, конкурентные преимущества и рыночные показатели.
» Подробнее
Aiven для Apache Cassandra: действительно распределенная база данных, которая может обрабатывать большие объемы данных.
» подробнее
CData: подключение к большим данным и NoSQL через стандартные драйверы.
» подробнее
DataStax Cassandra: операции, настройка и управление без участия пользователя с настоящим автомасштабированием
» подробнее
Мы приглашаем представителей поставщиков сопутствующих товаров связаться с нами для предоставления информации о своих предложениях здесь.
Cassandra продолжает подниматься в рейтинге DB-Engines Ranking
3 мая 2016 г., Matthias Gelbmann
Oracle — СУБД года
5 января 2016 г. , Paul Andlinger, Matthias Gelbmann
Победители, проигравшие и привлекательный новичок в Ноябрь Рейтинг DB-Engines
2 Ноябрь 2015, Пол Андлингер
показать все
другие мероприятия DBMS
Cassandra Day London
Лондон, Великобритания, 11 октября 2022 г.
Почему стоит выбрать базу данных NoSQL? Есть много веских причин
23 сентября 2022 г., thenewstack.io
Что такое CRUD? Создание, чтение, обновление и удаление
21 сентября 2022 г., CrowdStrike
4 часто задаваемых вопроса об Apache Cassandra
14 сентября 2022 г., thenewstack.io
Связь с NoSQL в масштабе предприятия: уроки Amazon
9Сентябрь 2022 г., thenewstack.io
Основные угрозы безопасности баз данных и способы их предотвращения
26 сентября 2022 г., tripwire.com
предоставлено новостями Google
Узнать, что думают русские, не спрашивая их
22, 21 сентября 2020 г. Lawfare
Утечка из службы доставки еды Яндекса раскрыла личную информацию секретной полиции России
3 апреля 2022 г., Tech Times
предоставлено Google News
ИНЖЕНЕР ПО ДАННЫМ (M/F/X)
DHL, Бонн
Java-разработчик (редактор данных)
JetBrains, München
Java Backend-разработчик (м/ж/д)
sMeet Communications GmbH, Берлин
Databricks Engineer со Scala и Spark
версии 1, домашний офис
Ориентированный на клиента инженер — PostgreSQL/MySQL (EMEA-remote)
Айвен, Берлин
вакансий от
Слушайте шоу на (1) Spotify, (2) Apple Podcasts, (3) Google Podcasts, (4) TuneIn, (5) RadioPublic, (6) Stitcher и (7) iHeart Radio.
Я из мультикультурной семьи (мой отец африканец, а мама русская). Мне было очень интересно встречаться с людьми из разных культур, поэтому я выбрал второй вариант. Это лучшее решение в моей жизни . Я решил, что мне не хватает опыта в компьютерных науках и программировании, потому что я не участвовал ни в каких соревнованиях по программированию и не работал над какими-либо программными проектами. Поэтому я начал думать о том, чтобы получить больше опыта и стать лучшим инженером, чтобы хотя бы иметь шанс в Яндексе. Я подумал, что мне нужно сосредоточиться на инженерных курсах, поэтому я выбрал программу информатики.В конце концов я понял, что учиться на лету во время работы — это нормально. Если я хочу остаться в этой профессии надолго, мне нужно, чтобы мне было комфортно в этом процессе обучения.
Но позже этот процесс стал более экспериментальным, и мне это нравилось. Очень важно знать, как решение влияет на реальных пользователей и согласуется с правильными показателями.Они пытались решить проблем прогнозирования/предотвращения оттока . Они разработали модель машинного обучения, чтобы предсказать, какие клиенты покинут сервис, чтобы сохранить их. Они хотели сравнить качество нашей модели со своими внутренними.
В то время я чувствовал, что должен участвовать в этом конкурсе, чтобы представлять Яндекс. Так что я потратил слишком много времени на этот проект. В итоге мы выиграли конкурс.
Я работал с инженерной компанией, которая пыталась решить проблему человеческих ресурсов. У них было много стажеров-инженеров, которые уходили менее чем через год. Но, конечно, компания потеряла довольно много денег на обучении этих стажеров, поэтому они определенно хотели бы сохранить их как можно дольше.
Они предоставили нам свои внутренние данные и попросили построить модели машинного обучения для прогнозирования увольнений. Вначале многие думали, что невозможно предсказать, кто покинет компанию, потому что может быть много разных мотивов. Поэтому я потратил много времени на изучение предметной области, просмотр различных версий наборов данных, изучение отдельных функций и т. д.
В самом конце, после 5-6 итераций, наша окончательная модель успешно предсказала 26 человек из 50 случаев в невидимом наборе данных. Это был огромный успех, и наш клиент был удивлен, что машинное обучение действительно работает.
Допустим, вы пытаетесь предсказать дефект стали на площади поверхности. В значительной степени данные, которые вы получили от некоторых датчиков в другом месте. Прямой связи между данными датчика и объектами нет. Вам нужно сделать много агрегаций (в большинстве случаев по времени), чтобы сделать эти ассоциации. Если вы потерпите неудачу на этом этапе, будет невозможно продолжить проект.
Таким образом, я считаю, что для промышленного ИИ; очень важно выучить данные наизусть — понять, как они были сгенерированы, как атрибуты связаны друг с другом, есть ли временные промежутки и т. д.
область. Без понимания того, как работает производство стали (например), невозможно сформулировать постановку задачи и начать проект.
coursera.org/lecture/big-data-essentials/meet-emeli-BxFP6Очень важно иметь толстую кожу. Когда вы публикуете что-то в Интернете, вы должны быть готовы получить обратную связь.
Поэтому мы настраиваем схему мониторинга с нуля для каждого проекта, потому что есть разные части решения, на которые нужно обращать внимание.В некоторых случаях нам нужно было контролировать наши источники данных, так как они были нестабильны из-за сломанных датчиков.
В других случаях нам нужно было контролировать наш конвейер, поскольку внутри конвейера данных были разные этапы разработки функций.
Таким образом, крайне важно отслеживать работоспособность службы, время отклика, использование памяти/графического процессора и т. д. не так с вашими моделями . Поэтому еще более важно контролировать входные данные. Важно проанализировать ваш конкретный случай, чтобы определить, где ваши модели могут сломаться, и использовать соответствующую стратегию мониторинга.Например, вы можете потерять доступ к данным (ваши источники данных могут быть повреждены), а ваши модели могут потерять очень важные сигналы.
Или, например, ваши модели машинного обучения могут использовать данные из системы CRM. Если пользователь CRM обновит данные, ваши модели сломаются, потому что они используют новую схему данных в качестве входных данных. Такие вещи часто случаются, особенно со сторонними источниками, поэтому для них вам нужен мониторинг целостности данных.
Но когда вы строите что-то публично, вы очень рано получаете обратную связь и можете быстро проверять гипотезы.
На самом деле ни у кого нет полной картины всех возможных проблем, которые могут возникнуть. Когда мы создаем общедоступный инструмент мониторинга, мы можем объединить опыт множества разных инженеров и бизнес-специалистов. Для нас это была главная причина, по которой мы создали Очевидно ИИ публично. Новый модуль🎙️#Datacast E66 включает @EmeliDral. Обсуждаем:
— Прикладное машинное обучение @YandexAI
— Преподавание @coursera
— Проблемы промышленного ИИ
— Мониторинг моделей с помощью @EvidentlyAI
Emeli создает инструменты с открытым исходным кодом, чтобы сделать мониторинг машинного обучения менее скучным. Наслаждаться! 👇https://t.co/5dTqVhQwFg
— Джеймс (@le_james94) 9 июня 2021 г.(02:07) Эмели поделилась своим образованием, получив степень в области прикладной математики и информатики в Российском университете дружбы народов в начале 2010-х.
(04:24) Эмели рассказала о своем опыте получения степени магистра в Школе анализа данных Яндекса.
(07:06) Эмели размышляет об уроках, извлеченных из ее первой работы после окончания университета, когда она работала разработчиком программного обеспечения в Рамблере, одном из крупнейших российских веб-порталов.
(09:33) Эмели провела свой первый год работы Data Scientist, разрабатывая рекомендательные системы электронной коммерции в Яндексе.
(13:38) Эмели рассказал об основных проектах, реализованных в качестве главного специалиста по анализу данных в Yandex Data Factory, комплексной платформе данных Яндекса.
(17:52) Эмели поделилась своими знаниями о переходе от IC к роли менеджера.
(19:21) Эмели упомянула ключевые составляющие успеха промышленного ИИ, учитывая, что она была соучредителем и главным специалистом по данным в Mechanica AI.
(22:40) Эмели рассказала о своих специализациях на Coursera — «Машинное обучение и анализ данных» и «Основы больших данных».
(26:14) Эмели рассказала о своей преподавательской деятельности в МФТИ, Школе анализа данных Яндекса, Harbour. Space и Высшей школе менеджмента — СПбГУ.
(30:12) Эмели поделился историей основания компании Evidently AI, которая создает человеческий интерфейс для машинного обучения, чтобы компании могли доверять своим решениям в области ИИ, отслеживать их и повышать их эффективность.
(32:32) Эмели объяснил концепцию модельного мониторинга и выявил пробелы в мониторинге на предприятии (читайте часть 1 и часть 2 серии «Мониторинг»).
(34:13) Emeli рассмотрел возможные проблемы с качеством и целостностью данных, предложив способы их отслеживания (см. части 3, части 4 и части 5 серии «Мониторинг»).
(36:47) Эмели рассказал о плюсах и минусах создания продукта с открытым исходным кодом.
(39:13) Эмели рассказал о том, как расставить приоритеты в планах развития продуктов для Evidently AI.
(41:24) Емели описал информационное сообщество в Москве.
(42:03) Заключительный сегмент.
Coursera
GitHub
Medium
Website
GitHub
Documentation
Мониторинг машинного обучения, часть 1: что это такое и чем оно отличается? (август 2020 г.)
Мониторинг отмывания денег, часть 2: кого это должно волновать и что нам не хватает? (август 2020 г.)
Мониторинг машинного обучения, часть 3: что может пойти не так с вашими данными? (сентябрь 2020 г.)
Мониторинг машинного обучения, часть 4: как отслеживать качество и целостность данных? (октябрь 2020 г.)
Мониторинг машинного обучения, часть 5: почему вас должны волновать отклонения данных и концепций? (ноябрь 2020 г. )
Мониторинг машинного обучения, часть 6: можно ли создать модель машинного обучения для мониторинга другой модели? (апрель 2021 г.)
«Машинное обучение и анализ данных»
«Основы больших данных»
Yann Lecun (профессор NYU, главный AI Scientist at Facebook)
Томас Микол (Создатель Facebook, Ex-Scistist stcistist stcistist x-stcistist xcient x-stcistist x xpcient xpecist x xpcient xpecient z-stcist x xpcient xpecient z-stcist x xpecist x x x xpcient x x x x xтечный )
Эндрю Нг (профессор Стэнфордского университета, соучредитель Google Brain, Coursera и Landing AI, бывший главный научный сотрудник Baidu)
com .Слушайте на Spotify
Прослушивание Apple Podcasts
Listen On Google Podcast
Источник: https://datacast.simplecast.com/episodes/emeli-dral
Tagged: Наука о данных, Мониторинг, Старт, Open Source, Россия, Рекомендательные системы, Преподавание, Информатика, Математика
Yandex N.V. (YNDX) Отчет о доходах за 1 квартал 2020 г.
Источник изображения: The Motley Fool.
Yandex N.V. (YNDX -6,79%)
Отчет о доходах за первый квартал 2020 г.
28 апреля 2020 г., , 8:00 по восточноевропейскому времени,
Содержание:
- Подготовленные замечания
- Вопросы и ответы
- Участники вызова
Подготовленные комментарии:
Оператор
Дамы и господа, спасибо за внимание и добро пожаловать в финансовые результаты за первый квартал 2020 года. [Инструкция оператору] Должен также сообщить вам, что звонок записывается сегодня, во вторник, 28 апреля 2020 года. Пожалуйста продолжай.
Юлия Герасимова — Начальник отдела по связям с инвесторами
Всем привет и добро пожаловать на звонок о доходах Яндекса за первый квартал 2020 года. Сегодня мы распространили отчет о доходах. Вы можете найти копию на нашем сайте IR, а также в службах Newswire.
Сегодня на связи Тигран Худавердян, наш заместитель генерального директора; Даниил Шулейко, наш генеральный директор Яндекс.Такси; и Грег Абовски, наш главный операционный и финансовый директор. Аркадий Волож, наш основатель и генеральный директор; Вадим Марчук, наш вице-президент по корпоративному развитию; и Евгений Сендеров, финансовый директор Яндекс.Такси, примут участие в сессии вопросов и ответов. Звонок будет записан, и через несколько часов запись будет доступна на сайте IR. Как обычно, мы подготовили несколько дополнительных слайдов, которые сейчас доступны на сайте.
Теперь я быстро проведу вас через заявление о безопасной гавани. Различные замечания, которые мы делаем во время этой телеконференции о наших будущих ожиданиях, планах и перспективах, представляют собой прогнозные заявления. Наши фактические результаты могут существенно отличаться от указанных или предполагаемых в этих прогнозных заявлениях в результате различных важных факторов, включая влияние продолжающейся пандемии COVID-19, а также те, которые обсуждаются в разделе «Факторы риска» нашего годового отчета. в форме 20-F от 2 апреля 2020 г., которая хранится в SEC и доступна в Интернете. Кроме того, любые прогнозные заявления представляют наши взгляды только на сегодняшний день, и на них не следует полагаться как на представление наших взглядов на любую последующую дату. Хотя мы можем решить обновить эти прогнозные заявления в какой-то момент в будущем, мы специально отказываемся от каких-либо обязательств делать это, даже если наши взгляды изменятся. Таким образом, вы не должны полагаться на эти прогнозные заявления как на представление наших взглядов на любую дату после сегодняшнего дня.
Во время разговора мы будем ссылаться на определенные финансовые показатели, не относящиеся к GAAP. Эти финансовые показатели non-GAAP не подготовлены в соответствии с US GAAP. Сверка финансовых показателей, не относящихся к GAAP, с наиболее сопоставимыми показателями GAAP представлена в опубликованном нами сегодня отчете о прибылях и убытках.
А сейчас я перевожу звонок на Тиграна.
Тигран Худавердян — Заместитель генерального директора
Спасибо, Юла, и спасибо, что присоединились к нашему сегодняшнему разговору. Первая четверть началась для нас хорошо. Все наши предприятия демонстрировали стабильную производительность до середины марта, когда мы начали замечать неблагоприятное воздействие вспышки COVID. С тех пор нашим главным приоритетом было благополучие наших сотрудников, наших партнеров и наших пользователей. В то время как некоторые из наших предприятий, такие как реклама и такси, значительно пострадали от более строгих мер социального дистанцирования, введенных властями, спрос на технологии питания, электронную коммерцию, образование и медиа-услуги существенно увеличился.
Итак, позвольте мне перейти к краткому обзору тенденций первого квартала, прежде чем мы обсудим наши инициативы, связанные с COVID. Сегмент «Поиск и порталы» рос хорошо и превзошел наши внутренние ожидания в январе и феврале. Важно отметить, что мы получили очень сильный прирост доли поиска как на мобильных устройствах, так и на настольных компьютерах. В марте мы достигли рекордных 55,9% доли Android, увеличившись на 130 базисных пунктов с декабря и на 430 базисных пунктов с марта 2019 года. Наша общая доля продолжала активно расти и приблизилась к 60% в апреле.
Рост ядра поиска существенно ускорился в апреле до 40%, 45% в годовом исчислении с однозначных цифр в конце февраля. Важно отметить, что ключевым драйвером для этого стал рост молодой аудитории до 24 лет. Его доля в поисковом трафике увеличилась на 28% по сравнению с февралем, а доля школьников увеличилась на 56%. Трафик самой школьной аудитории за тот же период увеличился почти вдвое. В первом квартале наш мобильный поисковый трафик составил 59% от общего поискового трафика. Доходы от мобильной связи составили 50,4% наших доходов от услуг. Это был первый квартал, когда доходы от мобильного поиска превысили доходы от настольных компьютеров.
Обращение к дзен. Мы по-прежнему наблюдаем значительный рост числа пользователей: в марте число активных пользователей в день составило 14,6 миллиона человек, а в апреле количество активных пользователей Zen в день увеличилось до более чем 16 миллионов пользователей. Что касается вовлеченности, общее время, проведенное в марте, выросло на 56% по сравнению с аналогичным периодом прошлого года, а в апреле рост ускорился почти до 90%.
В сфере медиа-услуг общее число подписчиков достигло 4,3 миллиона в марте и продолжало расти в апреле. Количество ежемесячно просматривающих подписчиков на платформе «КиноПоиск АГ» превысило 1,5 миллиона человек.
А теперь позвольте мне рассказать вам о наших ключевых действиях в ответ на вспышку COVID. Во-первых, Яндекс — важный источник точной и достоверной информации для наших пользователей, включая все актуальные данные о COVID. Среди многочисленных инициатив публичного информирования мы представили индекс самоизоляции в режиме реального времени, доступный на главной странице Яндекса. Этот индекс показывает степень социального дистанцирования в разных городах путем сравнения анонимных данных о городской активности с нормализованной датой до пандемии. В настоящее время индекс доступен в 570 городах России, а также в восьми других странах.
Во-вторых, наши платформы, такие как Яндекс.Такси, Яндекс.Еда или Яндекс.Лавка, дают заработок сотням тысяч водителей и курьеров. Например, мы вложили значительные средства в расширение службы доставки, а также наших платформ доставки еды.
В-третьих, дистанционное обучение. Мы запустили Яндекс Школу как платформу, объединяющую все наши новые и существующие образовательные проекты, в том числе полноценную онлайн-школу для 5–11 классов по 15 предметам. В апреле ежедневное количество активных пользователей Яндекс.Учебника увеличилось в восемь раз по сравнению с серединой марта и превысило 1 млн пользователей.
И, наконец, наша социальная инициатива «Рука помощи». В рамках этого проекта мы перевозим врачей и доставляем лекарства, предоставляем наборы для тестирования на коронавирус и распределяем товары первой необходимости. Мы вложили в этот проект 250 миллионов рублей. В целом мы выделили около 1,5 млрд рублей на различные инициативы, включая фонд поддержки водителей такси и курьеров, рекламные кредиты для малого и среднего бизнеса и нашу образовательную деятельность. Полный список мер и инициатив намного длиннее. Наши собственные команды очень усердно работают над внедрением новых функций и услуг. Честно говоря, я думаю, что мы никогда не видели, чтобы инициативы и улучшения внедрялись такими быстрыми темпами.
Помимо пандемии, наш главный приоритет — обеспечить устойчивый долгосрочный рост. И я верю, что мы выйдем из этого кризиса сильнее, чем когда-либо. Нынешний спад в сочетании с изменением поведения потребителей предоставляет нам ряд привлекательных долгосрочных возможностей по многим вертикалям. В нашем основном рекламном бизнесе мы ожидаем получить выгоду от ускорения перехода от традиционной рекламы к онлайн-рекламе, увеличения потребления потокового видео в медиасервисах и цифрового контента в Zen.
Как корпорация мы считаем, что операционные модели, включающие больше сценариев удаленной работы, выиграют от более быстрого внедрения облачных сервисов. Есть также много привлекательных возможностей в области райдшеринговых и фуд-тек.
И с этим я передаю микрофон Даниилу.
Даниил Шулейко — Генеральный директор Яндекс.Такси
Спасибо, Тигран, и всем привет. Мы начали год в службе такси с хорошими показателями по всем нашим показателям. Поездки выросли на 40% по сравнению с аналогичным периодом прошлого года в первом квартале, а январь и февраль превзошли наши внутренние прогнозы. Мы начали наблюдать замедление во второй половине марта из-за распространения COVID-19.. В то время как в начале марта мы совершали почти 5 миллионов поездок в день. К концу марта это число значительно уменьшилось, что отрицательно сказалось на темпах роста в первом квартале.
Официальный карантин в Москве начался 30 марта, поэтому во втором квартале мы увидим гораздо большее влияние на наш бизнес. В Москве райдшеринг сильно пострадал. GMV Москвы снизилась примерно на 60% по сравнению с апрелем прошлого года и примерно на 70% по сравнению с началом марта. Наш общий показатель GMV по вызову пассажиров снизился меньше, чем в Москве, поскольку регионы, как правило, отстают от Москвы на несколько недель с точки зрения COVID-19.влияние. Мы вложили значительные средства в защиту водителей и курьеров. Мы предоставили сотни тысяч масок, огромный запас дезинфицирующих средств и усиленную дезинфекцию автомобилей [фонетическая].
Мы создали фонд в размере 500 миллионов рублей для поддержки пострадавших водителей и курьеров. Команда усердно работает над тем, чтобы предоставить водителям новые возможности получения дохода, включая доставку. Мы предоставляем транспортные услуги врачам и доставляем тесты на COVID и наборы питания в поликлиники и пенсионерам. Мы заключили партнерские отношения с крупными розничными компаниями, включая Леруа Мерлен, [Неразборчиво], Теле2, Азбука Вкуса и ВкусВилл, чтобы помочь им своевременно доставлять товары своим пользователям.
Что касается пищевых технологий, мы наблюдаем значительный рост спроса. Приток новых ресторанов через нашу платформу значительно увеличился, и мы упростили процесс регистрации новых ресторанов. На сегодняшний день к нашей платформе подключено более 20 000 ресторанов. Чтобы поддержать местные рестораны и действительно подключиться к нашей платформе, мы убрали для них условия.
В наши дни доставка продуктов питания стала неотъемлемой частью жизни людей, и мы явно выиграли от нашей модели доставки через гиперлокальный круглосуточный магазин Lavka. На сегодняшний день у нас более 100 аптек в Москве и Санкт-Петербурге, из которых наши курьеры доставляют в течение 10-15 минут, несмотря на значительный рост спроса. Недавно мы расширили зону обслуживания подключенными таксистами до Лавки. Сейчас он доступен примерно двум третям населения Москвы и более половины жителей Санкт-Петербурга. На данный момент количество пользователей нашей службы пищевых технологий выросло на 73% по сравнению с началом марта, и это на 130% больше, чем в прошлом году. Этому росту способствовало недавно запущенное приложение Supera [Phonetic]. В последние дни Lavka превысила треть своих заказов от Supera.
В целом, мы видим множество возможностей в будущем, кризисы ясно демонстрируют, что мы являемся одной из самых уникальных компаний в мире с невероятным сочетанием логистики, технологий и снабжения водителей и курьеров, чтобы мгновенно стать неотъемлемая часть жизни людей.
На этом я передаю микрофон Грегу, который расскажет вам о финансах.
Грег Абовски — Главный операционный и финансовый директор
Спасибо, Даниил, и спасибо всем за то, что присоединились к нашей сегодняшней телеконференции о доходах за первый квартал. Вы видели пресс-релиз со всеми нашими ключевыми финансовыми показателями, поэтому я не буду их повторять, а вместо этого позвольте мне сосредоточиться на производительности и текущих тенденциях в наших бизнес-подразделениях.
Поиск и портал. Search и Portal показали хорошие результаты, несмотря на жесткие ограничения и влияние COVID-19, начиная с середины марта. Выручка без учета TAC увеличилась на 14%, а рентабельность по скорректированному показателю EBITDA составила 48,7%, что на 130 базисных пунктов больше по сравнению с прошлым годом. Учитывая строго соблюдаемую политику изоляции по всей стране и ее влияние на деловую активность, снижение выручки от поиска и портала TAC в апреле находится на территории старшего подросткового возраста с начала месяца. Это было вызвано сочетанием таких факторов, как сокращение рекламных бюджетов, давление на динамику цены за клик и снижение доли коммерческих поисковых запросов. Важно отметить, что наши поисковые запросы в апреле растут самыми быстрыми темпами за последние пять лет, и рост числа кликов ускоряется. Динамика доходов от поисковой выдачи ex-TAC за последние несколько дней восстановилась до значительного снижения. По секторам ИТ и телекоммуникации, доставка еды и продуктов, здравоохранение, дом и сад показали относительно лучшие результаты, в то время как путешествия, одежда, недвижимость и автомобили находятся под большим давлением.
Тем не менее, я хотел подчеркнуть несколько моментов. Прежде всего, снижение явно вызвано внешними факторами, которые в значительной степени находятся вне нашего контроля. До COVID рост нашей выручки за январь и февраль по сравнению с TAC был на территории старшего подросткового возраста. Во-вторых, наша главная цель сейчас — увеличить нашу долю рынка и базу пользователей, чтобы, когда экономика восстановится, мы могли преобразовать это в рост доходов, и наш прогресс здесь впечатляет, особенно с более молодой аудиторией. В целом динамика выручки за весь год будет зависеть от продолжительности и строгости карантинных мер и экономического воздействия, а также от скорости восстановления, которые на данном этапе трудно предсказать.
Несколько слов о структуре затрат нашего бизнеса Search and Portal. Постоянные затраты составляют около половины общих денежных затрат в сегменте «Поиск и портал», где персонал является самым большим компонентом. Переменная часть включает TAC и себестоимость продаж.
Переход на такси. Доходы от такси выросли на 50% по сравнению с прошлым годом, в первую очередь за счет роста количества поездок на 40%, продолжающейся оптимизации стимулов в сфере такси, а также быстрого развития сервисов общественного питания. Нам удалось увеличить скорректированную маржу EBITDA без учета беспилотных автомобилей до 7,6% благодаря повышению прибыльности в сфере такси, компенсируемому нашими инвестициями в Lavka, а также общей слабости, которую мы наблюдали в конце марта. В райдшеринге переменные расходы составляют примерно две трети наших общих расходов, включая стимулы, а оставшаяся часть является фиксированной и состоит из расходов на персонал, аренды, определенной рекламы и маркетинга, а также других операционных расходов. Мы видим возможности для оптимизации затрат, в том числе на рекламу и маркетинг, затраты на приобретение товаров и некоторые накладные расходы.
В Яндекс.Еде мы увидели дальнейшее улучшение юнит-экономики, прежде всего в результате увеличения плотности заказов. Мы продолжаем инвестировать в Lavka, помня о влиянии этого бизнеса на общий показатель EBITDA такси.
Обращение к другим предприятиям. Медиа-сервисы продемонстрировали очень сильный рост выручки на 95% в годовом исчислении с улучшенной скорректированной маржой EBITDA как в годовом, так и в квартальном исчислении. В первом квартале доходы Media Services от подписки выросли на 152% по сравнению с аналогичным периодом прошлого года, и мы видим, что в апреле сохраняются сильные тенденции. Мы продолжаем инвестировать в бизнес, как и планировали, и сосредоточены на удержании новых пользователей.
Доходы от наших объявлений увеличились на 35% в первом квартале, рост за первые два месяца был очень сильным. Тем не менее, мы увидели, что в конце марта поток материалов замедлился после того, как автодилерам было приказано закрыться, что, очевидно, оказало очень существенное влияние на это бизнес-подразделение. Несмотря на то, что в апреле давление на доходы от объявлений продолжалось, трафик на нашей платформе остается устойчивым. Мы видим формирование отложенного спроса, который планируем монетизировать, как только деловая активность начнет восстанавливаться.
Наконец, о других ставках и экспериментах. Наша выручка почти удвоилась по сравнению с прошлым годом благодаря росту Яндекс.Драйва, Geo и Zen. Яндекс.Драйв, Cloud и Geo также стали ключевыми факторами нашего скорректированного убытка EBITDA в размере 1,9 млрд руб. Как упомянул Тигран, в апреле Zen продолжает показывать хорошие результаты, в то время как наш каршеринговый бизнес сильно пострадал, особенно после того, как 13 апреля сервисы каршеринга были приостановлены в Москве и Санкт-Петербурге. об оптимизации наших договоров аренды и размера автопарка с целью снижения скорости выгорания.
Руководство. Учитывая сложность прогнозирования того, как долго продлится пандемия, и неопределенность в отношении ее воздействия на экономику и наш бизнес, в настоящее время мы не можем надежно оценить влияние вспышки COVID-19 на наши будущие финансовые результаты. Таким образом, мы отзываем наши рекомендации на 2020 год, которые мы предоставили 14 февраля 2020 года.
Что мы делаем, чтобы смягчить влияние COVID-19 на нашу деятельность? Мы разработали различные стресс-тесты, которые помогли нам определить приоритеты, и эти приоритеты включают в себя инвестиции в бизнесы с повышенной активностью и более высокой социальной значимостью в текущих условиях, а также стратегические проекты для укрепления позиций Компании в долгосрочной перспективе. После адаптации около 1300 новых сотрудников в 2019 г., и еще 333 человека в 1 квартале 2020 года, мы решили замедлить темпы найма, учитывая текущие обстоятельства. Отчасти это связано с трудностями интеграции и обучения новых людей, пока мы все работаем удаленно. Но мы также хотим убедиться, что к 2021 году у нас будет соответствующий размер. стратегические приоритеты. Мы также приняли решение отказаться от денежных премий для высшего руководства в 2020 году. Кроме того, высшее руководство согласилось на добровольное сокращение заработной платы. Мы сокращаем несущественные расходы на маркетинг и строго контролируем наши накладные расходы. Мы считаем, что эти инициативы помогут нам уменьшить негативное влияние пандемии и макроэкономических факторов на нашу EBITDA в 2020 году.
В заключение хочу напомнить, что наш баланс крепкий. В настоящее время у нас есть 2,5 миллиарда долларов наличными, в том числе 390 миллионов долларов на балансе Taxi. Более двух третей этой наличности в долларах США.
Весь наш долг является долгосрочным и подлежит погашению в 2025 году. Мы уверены, что наша сильная позиция ликвидности поможет нам противостоять вызовам текущей ситуации, а также предоставит нам гибкость для продолжения инвестирования в долгосрочные стратегические проекты. .
На этом я переключаю микрофон на оператора для сеанса вопросов и ответов.
Вопросы и ответы:
Оператор
Большое спасибо. [Инструкции для оператора] Первый вопрос, который у нас есть сегодня, исходит от линии Cesar Tiron из Bank of America. Пожалуйста продолжай.
Сезар Тайрон — Bank of America Merrill Lynch — Аналитик
Да. Всем привет. Спасибо за звонок и спасибо за возможность задать вопросы. Так что у меня есть два, я буду только первый. Просто хотел проверить, можете ли вы объяснить значительный рост доли рынка за последние пару недель. Я думаю, что доля рынка смешанной продукции, о которой сообщалось в последний раз, составляет около 59.%. Что является ключевым фактором и видите ли вы увеличение доли рынка даже без помощи регулирования? Большое спасибо.
Грег Абовски — Главный операционный и финансовый директор
Привет, Цезарь. Это Грег. Вы меня слышите?
Сезар Тайрон — Bank of America Merrill Lynch — Аналитик
Да.
Грег Абовски — Главный операционный и финансовый директор
Идеально. Так что, я думаю, основные драйверы роста доли рынка как раз в том, что мы стали стандартом де-факто для получения большого количества знаний и информации о коронавирусе, а также предоставления множества различных вариантов развлечений и тому подобного. Мы запустили ряд инициатив, которые дают людям гораздо больше информации об этом. И я думаю, что по сравнению с нашими конкурентами широта информации намного богаче и гораздо больше адаптирована к местному содержанию — контексту. Вещи, которые мы запустили в сфере образования и тому подобное, также важны с точки зрения привлечения более молодой аудитории, о чем мы говорили в подготовленных комментариях. Итак, более молодая аудитория, которая исторически, вероятно, отклонялась от нас в сторону конкурентов, теперь переключилась на Яндекс, и это здорово.
И помните, предварительная установка никак не повлияла на увеличение доли рынка. Все эти увеличения доли рынка являются естественными и обусловлены качеством нашего поискового продукта и нашей платформы в целом. Предварительная установка теперь перенесена на январь 2021 года. Надеюсь, мы повлияем на результаты 2021 года. Но, очевидно, мы очень рады очень сильному увеличению доли рынка на Android и на настольных компьютерах. Фактически, в апреле наша доля рынка настольных компьютеров превысила 70%. А наша доля рынка на андроиде в апреле составляет 56%. Все это — я думаю, весьма впечатляющие показатели. Спасибо.
Сезар Тайрон — Bank of America Merrill Lynch — Аналитик
Грег, можно еще один вопрос? Просто хотел проверить, как повлияет отключение Диска, которое, как я понимаю, связано с нормативными требованиями. Что касается экспериментов с EBITDA за 2 квартал, можно ли предположить, что выручки нет, но вам все равно придется платить за лизинг автомобилей? Или как это будет работать? Спасибо.
Грег Абовски — Главный операционный и финансовый директор
Отличный вопрос. Таким образом, мы смогли пересмотреть наш лизинговый договор, чтобы существенно компенсировать последствия закрытия Яндекс.Драйва и других каршеринговых компаний в Москве. В результате вы абсолютно правы в том, что у нас не будет дохода, но и наша база затрат будет значительно снижена. Итак, я думаю, что еще слишком рано точно оценивать влияние, но мы чувствуем себя относительно комфортно, потому что это не просто черная дыра, в которую исчезнут деньги.
Вдобавок ко всему, я думаю, мы говорили об этом в последнем ежеквартальном звонке, мы уже предприняли шаги по оптимизации размера флота, чтобы лучше соответствовать спросу на услугу. И я думаю, что в целом мы все равно потеряем деньги в сегменте Яндекс.Драйва во втором квартале. Не то чтобы мы смогли полностью отсрочить все наши арендные платежи, но это не будет той черной дырой, о которой я говорил.
Сезар Тайрон — Bank of America Merrill Lynch — Аналитик
Большое спасибо. Очень полезно. Спасибо.
Оператор
Большое спасибо. Следующий вопрос сегодня с линии Ульяны Ленвальской из UBS. Пожалуйста продолжай.
Ульяна Ленвальская — UBS — Аналитик
Всем привет. Большое спасибо за презентацию. Мой первый вопрос будет по основному бизнесу. Не могли бы вы более подробно рассказать о категориях и эффективности рекламы, особенно о том, какие секторы способствуют восстановлению, о котором вы упоминали за последние пару дней? А можно ли раскрыть, каков вклад малого и среднего бизнеса в выручку на данный момент?
Грег Абовский — Главный операционный и финансовый директор
Конечно, Ульяна. Это Грег. Попробую ответить на них. Итак, дальше — сначала я отвечу на ваш второй вопрос, просто потому, что он простой. Наши малые и средние предприятия приносят примерно половину наших доходов от рекламы. И что интересно, за последние несколько недель мы фактически не видим существенной разницы в производительности сегмента малого и среднего бизнеса по сравнению с сегментом крупных предприятий в рамках рекламного бизнеса.
Важно помнить, что для малого и среднего бизнеса Яндекс, Яндекс.Поиск, Яндекс.Рекламная сеть часто представляют собой единственный канал продаж, который есть у этих предприятий. И, как мы видели в ходе предыдущих экономических спадов, это последнее, что люди отключают. Надеюсь, это ответ на вторую часть вопроса.
Что касается первой части вопроса, по категориям, то, что я сказал в подготовленных комментариях, очевидно, что мы видим силу в таких секторах, как ИТ и телекоммуникации, электронная коммерция, дом и сад. Что находится под давлением, так это то, что вы ожидаете, такие вещи, как путешествия, такие вещи, как автомобили. Помните, автосалонам приказали закрыться, по-моему, почти месяц назад. Так что, как и следовало ожидать, реклама там резко сократилась. Одежда была еще одной категорией — опять же, это не стало большим сюрпризом, — еще одной категорией, которая находилась под давлением.
С точки зрения того, что мы видим с точки зрения тенденций и того, что заставляет нас фактически видеть — потенциально видеть зеленые ростки, как я сказал, производительность в течение апреля отслеживалась вверх и вправо от первоначального шок. Мы видим лучшие результаты в области финансов и страхования. Мы видим лучшую производительность дома и в саду. Мы видим лучшую производительность в B2B. То, что в основном осталось без изменений — почти исчезло, — это такая категория, как путешествия. Еда вне дома как категория в основном плоская, ситуация не ухудшается, но и не улучшается. Улучшаются такие вещи, как здравоохранение, улучшаются информационные технологии и телекоммуникации, немного улучшаются услуги по строительству и ремонту. Надеюсь, этого цвета достаточно.
Ульяна Ленвальская — УБС — Аналитик
Ага. Большой. Спасибо. И второй вопрос будет о Такси. Предоставленные вами тренды GMV весьма полезны. Но не могли бы вы сначала прокомментировать ставки, особенно поощрения? Как это меняется в Москве и в бизнесе?
Грег Абовски — Главный операционный и финансовый директор
Да. Я позволю Даниилу взять его.
Даниил Шулейко — Генеральный директор Яндекс.Такси
Еще раз здравствуйте. Это Даниил. Вы меня слышите?
Ульяна Ленвальская — УБС — Аналитик
Да, да. Вперед, продолжать.
Даниил Шулейко — Генеральный директор Яндекс.Такси
Очень хорошо. Итак, вперед. Смотрите, сейчас наш валовой коэффициент продаж значительно ниже, чем у наших мировых аналогов. Например, наша смешанная эффективная доля дублей в первом квартале была ниже 10%. Значительную часть нашей комиссии за рост мы выплатили водителям в виде различных поощрений. Всего в 2019 г., выручка партнеров нашей райдшеринговой платформы составила 250 млрд рублей, тогда как в первом квартале она составляла примерно 75 млрд рублей. Наши главные приоритеты на сегодняшний день — сделать так, чтобы сотни тысяч водителей и курьеров, зарабатывающих на нашей платформе, чувствовали себя в безопасности, а также делаем все возможное, чтобы предоставить им дополнительные возможности заработка. Итак, мы вкладываем в это дело сотни миллионов рублей, и это лишь часть того, что мы делаем в целом для поддержки наших водителей. Наша команда также очень усердно работала над поиском новых способов предоставления водителям дополнительных поездок. Поэтому мы создаем и запускаем новые сервисы. Как я уже упоминал ранее, мы запустили другой тип партнерства с крупными игроками на этом рынке. Кроме того, всего пару часов назад мы объявили о нашем новом партнерстве с OZON для их доставки последней мили, и мы считаем, что это еще одно важное событие для нас.
Итак, прямо сейчас мы доставляем тесты, медицинские профессии и еще кучу всего. А с финансовой точки зрения, если вы посмотрите на все, что мы делаем вместе, это выходит за рамки того, что мы — влияние снижения комиссионных. Мы считаем, что создание новых возможностей для получения дохода — гораздо более эффективный и устойчивый способ поддержать наших водителей и общество, чем простое снижение комиссии.
Ленвальская Ульяна — УБС — Аналитик
Спасибо.
Оператор
Большое спасибо. Следующий вопрос сегодня с линии Вячеслава Дегтярева из Goldman Sachs. Пожалуйста продолжай.
Вячеслав Дегтярев — Goldman Sachs — Аналитик
Да. Большое спасибо за звонок. Первый вопрос касается полей поиска. Они были достаточно сильны в первом квартале.
Катя Жукова — Директор по связям с инвесторами
Вячеслав, извините. Вячеслав, извините.
Вячеслав Дегтярев — Goldman Sachs — Аналитик
Да?
Катя Жукова — Директор по связям с инвесторами
Просто — говорит Катя Жукова. Просто дайте нам секунду. У нас есть некоторые технические трудности.
Вячеслав Дегтярев — Goldman Sachs — Аналитик
Абсолютно.
Катя Жукова — Директор по связям с инвесторами
Повторное подключение. Хорошо. Пожалуйста продолжай.
Вячеслав Дегтярев — Goldman Sachs — Аналитик
Ага. Итак, мой первый вопрос был о полях поиска. Они были достаточно сильны в первом квартале. Мне интересно, насколько на это повлияли одноразовые факторы, если таковые имеются. Или есть какие-либо элементы слабой маржи в четвертом квартале, и насколько устойчивой была бы эта маржа, если бы не было последствий COVID в течение всего года?
Грег Абовский — Главный операционный и финансовый директор
Привет, Вячеслав, это Грег. Позвольте мне попробовать взять это. Итак, я… что касается разовых выплат, очевидно, решение, принятое высшим руководством отказаться от денежных премий, а также добровольно урезать свои зарплаты, окажет положительное влияние на прибыль в течение всего года, как и вы, очевидно, они начинают накапливаться с 1 января. Другое положительное влияние оказывается на спину TAC, и это конкретно некоторые TAC распределения. И если вы помните, это то, о чем мы говорили в отчете о прибылях и убытках за четвертый квартал, где мы сказали, что ожидаем увидеть преимущества от распределения TAC в 2020 году, и вы начинаете видеть, что это происходит.
Другие вещи, которые… мы будем компенсировать это будут инвестиции и такие вещи, как контент и так далее, как в сегменте поиска/портала. Помните, у нас есть контент и в Поиске/Портале, где мы показываем видео в сервисе Яндекс.Live.
Что касается маржи в целом, я думаю, что это во многом зависит от доходов, и их очень трудно предсказать на данный момент. И, очевидно, мы пытаемся сделать все возможное, чтобы изменить приоритеты проектов, чтобы сократить расходы там, где мы считаем это разумным, и перераспределить наши инвестиции в те вещи, которые, по нашему мнению, принесут наибольшую прибыль нашим акционерам.
Вячеслав Дегтярев — Goldman Sachs — Аналитик
Хорошо. Спасибо за это. И, во-вторых, можете ли вы описать конкурентные преимущества различных бизнес-подразделений? Может быть, вы заметили какие-либо возможности для доли рынка в определенных подсегментах? И вообще, предвидите ли вы кризис для создания таких возможностей? Можете ли вы уточнить это, пожалуйста?
Грег Абовски — Главный операционный и финансовый директор
Конечно, Вячеслав. Я думаю, я надеюсь, что это окажется настоящим скрытым благословением. Мы видим невероятную силу в плане завоевания доли практически в каждой вертикали, с которой мы конкурируем. Мы увеличили долю райдшеринга в первом квартале. Мы очень хорошо справились с доставкой еды. Мы добились большого успеха с нашей гиперлокальной продуктовой инициативой Яндекс.Лавка. Как я уже говорил, мы также получили значительную долю в поиске. И затем, если вы посмотрите на что-то вроде новостной ленты Яндекс.Дзен, то ясно, что она невероятно сильно растет. А на прошлой неделе мы дразнили нас 17 миллионами пользователей в день, что довольно много с декабря. И тенденции там очень сильные. Таким образом, я думаю, что хотя очевидно, что трудно предсказать, как все сложится, мы, безусловно, столкнемся с препятствиями в отношении доходов от рекламы и других вещей. Я думаю, что этот — этот кризис действительно продемонстрирует силу платформы, которую мы построили.
Вячеслав Дегтярев — Goldman Sachs — Аналитик
Хорошо. Большое спасибо, Грег.
Оператор
Большое спасибо. Кажется, мы потеряли очередь вопросов и ответов. [Инструкция оператору] Мы — я открываю линию Владимира Беспалова из ВТБ Капитал. Пожалуйста продолжай.
Владимир Беспалов — ВТБ Капитал — Аналитик
Здравствуйте. Поздравляю с числом и спасибо, что ответили на мои вопросы. Прежде всего, я хочу спросить у вас, какова тогда была доходность? В марте вы обычно приводите эти цифры. И я хотел бы также, возможно, уточнить тенденции в рекламе, поправьте меня, если я ошибаюсь. Но насколько я понял, Грег, вы упомянули, что видите некоторые улучшения в кликах. Но как насчет ценообразования и общей тенденции доходов? Если мы посмотрим на апрельскую ситуацию, как она развивается сейчас? Спасибо.
Грег Абовски — Главный операционный и финансовый директор
Здравствуйте, Владимир. На Дзене, поэтому пробег Дзена немного снизился по сравнению с декабрем. Годовая выручка в марте составила около 8 млрд рублей по сравнению с 8,8 млрд рублей в декабре. И это, очевидно, на фоне воздействия COVID-19. В то время как тенденции вовлеченности были чрезвычайно устойчивыми, общее время, проведенное в марте, выросло на 56%, а в апреле этот рост ускорился до 90%. И потом, люди проводят в апреле почти 13 миллионов часов в день с Яндекс.Дзен.
И затем в отношении кликов и цены за клик. Очевидно, что мы видим, что, несмотря на быстрый рост пиковых кликов, цены за клик снижаются. И эта тенденция, скорее всего, продолжится с ценой за клик, которая является просто результатом общей рекламы, которая в этом году стала слабее, чем в прошлом. И влияние этого на целый месяц, в отличие от двух недель, которые мы видели в первом квартале или около того. Но что важно иметь в виду, так это то, что я думаю, что сегодня поиск является амбаром на платформе с самой высокой рентабельностью инвестиций для рекламодателей. И в результате тенденции, которые мы наблюдаем в поиске, который восстанавливается быстрее, чем другие формы рекламы, я думаю, являются причиной этого. Это платформа с самой высокой окупаемостью инвестиций для рекламодателей, как для крупных корпоративных клиентов, так и для малого и среднего бизнеса, и поэтому они продолжают обращаться к ней.
Владимир Беспалов — ВТБ Капитал — Аналитик
Хорошо. Большое спасибо. Но вы не могли бы прокомментировать тенденции доходов прямо сейчас. Для рекламы непонятно.
Грег Абовски — Главный операционный и финансовый директор
Что ж, это именно то, что я сказал в подготовленных комментариях, а именно то, что в апреле общий спад рекламы достиг подросткового возраста. И затем, если вы посмотрите на последние несколько недель, спад, особенно в поиске, теперь сократился до высоких однозначных цифр. На самом деле, бывают дни, когда в апреле в поиске наблюдается прямая или слегка положительная динамика рекламы.
Владимир Беспалов — ВТБ Капитал — Аналитик
Хорошо. Спасибо. Может я пропустил это. И еще один вопрос по райдшеринговому бизнесу. Партнерские отношения, которые у вас есть в настоящее время со многими розничными торговцами, скажем, игроками электронной коммерции и тому подобными вещами. Являются ли эти партнерства и бизнес-модели, основанные на этом партнерстве, устойчивыми для развития этого бизнеса в будущем после окончания периода блокировки? Видите ли вы новые возможности в этой области? И какова рентабельность этого бизнеса, может, потенциального, если нет, то текущего? Спасибо.
Даниил Шулейко — Генеральный директор Яндекс.Такси
Здравствуйте, Владимир, это Даниил. Итак, смотрите, мы видим, что тенденции в целом в этом секторе будут меняться. А значит, люди начнут покупать онлайн намного чаще, чем это было раньше. Вот почему мы считаем, что это устойчивая бизнес-модель для нас в долгосрочной перспективе. Например, прямо сейчас мы оптимизируем нашу структуру затрат на эту доставку, чтобы в большинстве случаев в некоторых случаях выбор номер один с точки зрения затрат для компаний, с которыми мы подписали партнерские соглашения.
Владимир Беспалов — ВТБ Капитал — Аналитик
Хорошо. Большое спасибо.
Оператор
Большое спасибо. Следующий вопрос сегодня исходит от Мириам Адиса из Morgan Stanley. Пожалуйста продолжай.
Мириам Адиса — Morgan Stanley — Аналитик
Привет. Спасибо за звонок. Грег, я опираюсь на то, что вы только что сказали о том, что поиск является платформой с самой высокой окупаемостью инвестиций для рекламодателей. Просто интересно, что вы думаете о росте поиска по мере того, как вы выходите из режима самоизоляции и, возможно, впадаете в рецессию. Ходит много разговоров о том, что в этом году цифровые технологии могут впервые прийти в упадок. Согласны ли вы с такой оценкой? И что вы думаете о росте поиска в условиях рецессии, возможно, по сравнению с 2015 годом, потому что, очевидно, сейчас это самая высокая доля рынка? Так что просто интересно, как вы думаете о том, как бизнес работает в этой среде.
Грег Абовски — Главный операционный и финансовый директор
Привет, Мириам. Хотел бы я иметь хрустальный шар. Я не. Я не знаю, как будет работать цифровая реклама. Я думаю, вполне возможно, что цифровая реклама сократится в 2020 году. Но, прежде всего, цифровая реклама по-прежнему предлагает рекламодателям одну из самых высоких возможностей рентабельности инвестиций. И я думаю, что рекламодатели будут продолжать обращаться к нему раньше, чем к другим видам рекламы.
Очевидно, этот кризис отличается от кризиса 2009 года.. Это отличается от 2015 года. Цифровые технологии намного больше в процентах от общего пирога. Так что за ним стоит не вековой попутный ветер, а скорее вековой попутный ветер. Кроме того, вы получите сочетание COVID и сокращения ВВП из-за снижения цен на нефть и ослабления рубля. Таким образом, все, что мы пытаемся сделать и на чем мы сосредоточены, — это обеспечение высокой рентабельности инвестиций для наших рекламодателей, обеспечение кликов — высококачественных кликов для наших рекламодателей, разработка новых рекламных форматов для наших рекламодателей и предоставление им лучших инструментов, которые мы можем идти за своей аудиторией. Сейчас рано говорить о том, будет ли Search отключен или нет. Будет ли цифровая реклама отключена или нет, пока рано говорить, но мы, безусловно, моделируем всевозможные сценарии. И поэтому, когда мы запускаем различные симуляции и сценарии, мы думаем, что он может выйти из строя.
Мириам Адиса — Morgan Stanley — Аналитик
Хорошо. Это ясно. Спасибо. И затем мой второй вопрос только о марже Такси для основных поездок и доставки еды. Просто интересно, как мы должны думать о последовательном увеличении маржи во втором квартале, учитывая, я думаю, что вы оказываете большее влияние на Лавку.
Евгений Сендеров — Финансовый директор Яндекс.Такси
Привет, Мириам, это Евгений. Итак, давайте сначала поговорим о райдхейлинге. В первом квартале у нас был очень устойчивый рост, но в дальнейшем наш базовый сценарий предполагает пик спада и подъема во втором квартале. И, опять же, у меня тоже нет хрустального шара, как у Грега, но мы видим постепенное восстановление в третьем и четвертом квартале. Как мы упоминали ранее, переменные затраты в райдшеринге составляют две трети наших общих затрат, включая поощрения. А с точки зрения постоянных расходов, когда мы смотрим на наш бизнес в следующем квартале и до конца года, мы значительно сократили расходы, в первую очередь на рекламу и маркетинг, а также расходы на приобретение товаров и некоторые другие операционные расходы. расходы. И мы снижаем приоритеты или откладываем некоторые проекты, которые на данный момент не являются необходимыми. Очевидно, что у нас будут значительные дополнительные расходы, связанные с пандемией, в том числе наш фонд поддержки водителей в размере 500 млн рублей, а также расходы, связанные с приобретением различных масок и дезинфицирующих средств, расходы на транспорт медицинского персонала и тесты на COVID, которые мы делаем. А также поддержка новых ресторанов, где мы отказываемся от комиссий для новых ресторанов и у нас есть определенные инициативы.
Итак, на данный момент трудно делать какие-либо прогнозы, но для игры с цифрами, если у нас будет 60%-ное снижение GMV по сравнению с прошлым годом во втором квартале, у нас есть — скорее всего мы опубликуем убыток EBITDA в этом конкретном квартале. В случае, если наша консолидированная GMV по вызову такси снизится на 40% во втором квартале, я думаю, что мы будем безубыточны с текущей структурой затрат. И это структура затрат, направленная на быстрое восстановление и восстановление объемов после карантина. Итак, если мы сравним вторую половину 2020 года с первой половиной, мы ожидаем, что наш бизнес по вызову такси будет прибыльным в годовом исчислении.
И если вы посмотрите на Taxi в целом, то, конечно же, общие результаты будут зависеть от наших инвестиций в беспилотные автомобили и быстрорастущий бизнес в сфере пищевых технологий. Поэтому мы продолжим активно инвестировать в наш бизнес Eats. Мы видим некоторые улучшения в юнит-экономике, и мы уделяем особое внимание юнит-экономике бизнеса Eats. Таким образом, по итогам года мы ожидаем значительного улучшения убыточности EBITDA нашего Яндекс.Еда ближе к концу года.
И Lavka, наш гиперлокальный бизнес по доставке, находится на стадии инвестиций. Мы значительно увеличили «Лавку» с 50 магазинов в конце прошлого года до более 100 магазинов в настоящее время, как я уже упоминал, я думаю. Но наши средние ежедневные заказы выросли на 350% по сравнению с концом — по сравнению с декабрем прошлого года. А GMV вырос в этом году на 550%. А что касается Лавки, мы продолжим оценивать возможности роста, и интенсивность инвестиций будет зависеть от нашего успеха в этом формате до конца года. И мы продолжим инвестировать в SBC, потому что считаем, что это стратегически важное направление инвестиций для нас, для Компании.
И одна вещь, о которой я хотел бы упомянуть, уже упоминалась, но чтобы подчеркнуть, что у нас очень сильный баланс. У нас есть 393 миллиона долларов, большая часть которых в долларах США. Таким образом, мы думаем, что находимся в отличной форме, чтобы справиться с текущей ситуацией, и у нас есть хорошие возможности для продолжения роста, когда мы ее преодолеваем.
Мириам Адиса — Morgan Stanley — Аналитик
Отлично. Спасибо.
Оператор
Большое спасибо. Следующий вопрос сегодня исходит от линии Себастьяна Патулеа из Джеффриса. Пожалуйста продолжай.
Себастьян Патулеа — Джеффрис — Аналитик
Привет всем, и спасибо, что разрешили задавать вопросы. Поэтому я попрошу два, пожалуйста. Во-первых, кажется, что во время установки пользователи отказываются от маленьких экранов смартфонов и больше в пользу более крупных, таких как ноутбуки и настольные ПК. Вы тоже наблюдаете такое поведение в апреле? И следует ли нам ожидать в результате некоторого попутного ветра от этого эффекта?
А во-вторых, в период с марта по июнь этого года Яндекс появится в окне выбора поисковой системы по умолчанию в Эстонии, Колумбии [Фонетическая] и Латвии, опять же Польше. Не могли бы вы немного рассказать о первых результатах этой акции и некоторых тенденциях, которые вы здесь видите? Большое спасибо.
Грег Абовски — Главный операционный и финансовый директор
Привет, Себастьян. Что касается сочетания настольных компьютеров и мобильных устройств, я бы сказал, что оно не сильно изменилось. Я бы сказал, что в промежутке между днями состав немного изменился, так как, например, по выходным мы видим немного больше рабочих столов, чем обычно. Но я бы сказал, что это не очень большое изменение. Так что я бы не стал встраивать в ваши модели огромное влияние, так или иначе. И если вы посмотрите, где нас отслеживают с точки зрения процента поисковых запросов, поступающих с мобильных устройств, они все еще выше в первом квартале, верно? В четвертом квартале примерно 57,5% нашего поискового трафика приходилось на мобильные устройства. В первом квартале было 59%.
И затем в отношении экрана выбора Европейского Союза, который будет применяться к новым устройствам. Так что, если вы помните, это похоже на то, как это работало с антимонопольным элементом в России. Это влияет на новые устройства. Таким образом, требуется довольно много времени, чтобы количество устройств, содержащих экран выбора, действительно проникло в установленную базу. Таким образом, это то, что займет некоторое время, чтобы проявиться в данных.
Себастьян Патулеа — Джеффрис — Аналитик
Большое спасибо.
Грег Абовски — Главный операционный и финансовый директор
Спасибо.
Оператор
Большое спасибо. Следующий вопрос сегодня исходит от Ллойда Уолмсли из Deutsche Bank. Пожалуйста продолжай.
Ллойд Уолмсли — Дойче Банк — Аналитик
Хорошо, спасибо. Два, наверное, оба для Грега. Грег, я знаю, что вы больше не разделяете поиск и контекстно-медийную сеть, но не могли бы вы дать нам представление о том, как выглядят основные тенденции поиска по сравнению с медийной рекламой?
И тогда второй будет просто на ходу FX. Я думаю, что вы, ребята, перенесли наименьшую волатильность из отчета о прибылях и убытках в отчет о движении денежных средств. Но стоит ли ожидать каких-либо изменений в расходах на персонал из-за слабости валюты, учитывая глобальную конкуренцию за таланты? Все, что вы можете поделиться, было бы полезно.
Грег Абовски — Главный операционный и финансовый директор
Эй, Ллойд. Итак, вы правы, что мы не ломаем его. Но я мог бы просто дать вам немного цвета. Медийная реклама, безусловно, пользуется гораздо большим успехом, чем контекстная реклама и перформанс-реклама. Причина этого в том, что большинство покупателей медийной рекламы — это крупные предприятия, и именно они в большинстве — в самой жесткой форме — реагируют на внешние события быстрее всего. Таким образом, в первом квартале этот показатель снизился больше, чем в других формах рекламы, и мы ожидаем, что во втором квартале он ухудшится.
А что касается второго вопроса, напомните еще раз, что это было? Мне жаль.
Ллойд Уолмсли — Дойче Банк — Аналитик
Да. Повлиял ли обмен валюты на расходы на персонал или на другие области, за которыми мы должны следить?
Грег Абовски — Главный операционный и финансовый директор
А, да, и еще иммиграционная служба. Итак, учитывая, что большинство стран сейчас закрыты из-за COVID, пока мы не видим какого-либо значимого влияния девальвации иностранной валюты. То, как последствия повлияют на наши прибыли и убытки, сейчас не так велико, как во время последнего кризиса. Мы надеемся, что мы усвоили некоторые из наших уроков. Влияние будет отражено в отчете о движении денежных средств, где покупки серверов по-прежнему номинированы в долларах США, и нам все еще нужны эти серверы, поскольку мы продолжаем инвестировать в наши различные платформы. Итак, на данный момент мы перераспределяем приоритеты наших капиталовложений и пытаемся оптимизировать их таким образом, чтобы выраженная в рублях сумма совокупных капиталовложений в 2020 г. существенно не отличалась от нашего первоначального бюджета при предыдущем валютном режиме.
Ллойд Уолмсли — Deutsche Bank — Аналитик
Хорошо. Спасибо.
Грег Абовски — Главный операционный и финансовый директор
Спасибо.
Оператор
Большое спасибо. Следующий вопрос сегодня с линии Анны Куприяновой из Газпромбанка. Пожалуйста продолжай.
Анна Куприянова — Газпромбанк — Аналитик
Здравствуйте. Большое спасибо за презентацию и возможность задать вопрос. Мой вопрос касается вашей интернет-рекламы. Насколько я вижу, ваша доля TAC в затратах на интернет-рекламу свойств Яндекса снизилась. Сейчас это около 11%, если эта тенденция будет устойчивой. Кроме того, мой вопрос касается доли свойств Яндекса и онлайн-рекламы, могу ли я предположить, что она будет на том же уровне, что и сейчас, в первом квартале 20-го года? Спасибо.
Грег Абовски — Главный операционный и финансовый директор
Привет, Анна. Что касается TAC, мы, конечно же, ожидаем, что TAC по распределению должен быть чем-то вроде попутного ветра. Как мы уже говорили в отчете о прибылях и убытках за четвертый квартал, где мы сказали, что ожидаем, что TAC по дистрибуции будет расти существенно медленнее в 2021 г. по сравнению с — извините, в 2020 г. по сравнению с 2019 г. Таким образом, это дает ответ на вопрос о TAC по дистрибуции.
В партнерском TAC. Это все еще подлежит уточнению. Мы работаем с нашими партнерами по рекламной сети. И мы пытаемся найти, какая там оптимальная точка. Но вполне возможно, что и сократится.
И, наконец, ваш последний вопрос был о… напомните мне.
Куприянова Анна — Газпромбанк — Аналитик
Речь идет о доле свойств Яндекса и онлайна.
Грег Абовски — Главный операционный и финансовый директор
Правильно. Таким образом, мы, безусловно, надеемся, что получим больше трафика и получим больше доходов от наших объектов. Мы вкладываем в них очень много. Я думаю, что качество нашей недвижимости растет. Мы лучше интегрируем их в наши продукты. Например, то, как мы интегрировали Дзен, я думаю, намного лучше в приложение «Поиск» и на главную страницу Яндекса. Итак, мы ожидаем, что свойства Яндекса должны хорошо расти и должны продолжать расти в процентах от общего числа.
Анна Куприянова — Газпромбанк — Аналитик
Большое спасибо. И очень быстрый дополнительный вопрос относительно вашего выкупа акций. Какие-нибудь изменения в планах выкупа, пожалуйста, сообщите нам?
Грег Абовски — Главный операционный и финансовый директор
Конечно. Итак, на сегодняшний день мы выкупили 4,5 миллиона акций. И мы потратили примерно половину из 300-миллионной программы обратного выкупа. Наше решение между обратным выкупом и инвестициями в бизнес будет зависеть от того, что принесет наибольшую прибыль акционерам. Итак, прямо сейчас нет каких-то конкретных обновлений, но мы будем — я ожидаю, что мы будем время от времени выкупать акции по привлекательным ценам, как мы это делали раньше.
Анна Куприянова — Газпромбанк — Аналитик
Большое спасибо.
Грег Абовски — Главный операционный и финансовый директор
Спасибо.
Оператор
Большое спасибо. Следующий вопрос поступает с линии Марии Сухановой из БКС. Пожалуйста продолжай.
Мария Суханова — BCS Global Markets — Аналитик
Да. Добрый день. Я хотел спросить о вашей деятельности по слияниям и поглощениям. Теперь, учитывая слабость макроэкономических показателей, мне интересно, следует ли нам ожидать от вас ускорения вашей деятельности по слияниям и поглощениям, особенно с учетом вашей кучи денег на балансе. А также второй, на Лавке, с прибавкой заказов, которую вы видели в последнее время. Есть ли какие-либо места, которые уже являются прибыльными, или что-то — или в экономике нужно улучшить дальше, чтобы места стали прибыльными?
Грег Абовски — Главный операционный и финансовый директор
Конечно, Мария. Евгений ответит про Лавку, а я постараюсь ответить про M&A активность. Таким образом, очевидно, что наличие сухого пороха на сумму около 2,5 миллиардов долларов чрезвычайно полезно в этой среде, потому что это дает нам стратегическую гибкость для заключения сделок по возможности. Итак, мы смотрим на различные активы и оцениваем их. Но вопрос в том, насколько они стратегические. Цена привлекательна? И это самая высокая доходность для наших акционеров?
Евгений, может Вы ответите на какие-то вопросы по Лавке?
Евгений Сендеров — Финансовый директор Яндекс.Такси
Мария, привет. Что ж, я бы не стал называть вам точную цифру, но да, у нас есть места, вклад которых в показатель EBITDA до накладных расходов положителен. Но мы — просто чтобы отметить, что мы не только увеличиваем выручку в Lavka, но и очень сосредоточены на улучшении картины маржи, которая на самом деле улучшается из месяца в месяц и, возможно, даже из недели в неделю. . Так что да, наша цель, конечно же, иметь прибыльные по EBITDA магазины, и мы наблюдаем значительный прогресс в этом направлении.
Мария Суханова — BCS Global Markets — Аналитик
Понятно. Спасибо.
Оператор
Большое спасибо. Следующий вопрос сегодня от Анны Курбатовой из Альфа-Банка. Пожалуйста продолжай.
Курбатова Анна — Альфа-Банк — Аналитик
Добрый день. Большое спасибо за презентацию. У меня есть два вопроса. В первую очередь о беспилотных автомобилях и инвестициях в СМИ, так что и проекты, и бизнес-направления находятся в активной инвестиционной стадии. Поэтому мне интересно, склонны ли вы в нынешних условиях придерживаться первоначального темпа инвестиций в беспилотные автомобили и медиаконтент, особенно видео. Или вы также внесли или собираетесь внести какие-то корректировки в бюджет во втором квартале или в будущем?
Второй вопрос по Яндекс.Маркету, было бы здорово понять, чтобы были какие-то указания от вас, вели ли вы переговоры с вашим партнером. Также есть коррективы в бюджете Яндекс.Маркета на этот год? Итак, какие есть тренды и события на Яндекс.Маркете?
Тигран Худавердян — Заместитель генерального директора
Эй, это Тигран, могу я взять это — о, Грег, хочешь?
Грег Абовски — Главный операционный и финансовый директор
Нет, нет. Ничего страшного. Я думал, ты отключил Анну.
Тигран Худавердян — Заместитель генерального директора
Да, извините. Можно я возьму… извините. Хорошо. Могу я задать вопрос о SDC и службах мультимедиа? Что касается медиасервисов, мы будем продолжать инвестировать в контент. И в сервисе мы видим, что, особенно во время этой ситуации с COVID, он стал значительно привлекательнее, чем когда-либо. И эта служба является одним из бенефициаров этой ситуации — ситуации.
В SDC мы по-прежнему стремимся развивать эту технологию. Так что мы более или менее планируем продолжать увеличивать размер флота и размер команды. Так что — и в зависимости от доходов — какие доходы мы увидим от всего нашего бизнеса и как сложится наша ситуация к концу года, возможно, мы скорректируем наши планы. Но это долгосрочные инвестиции, и мы считаем, что в долгосрочной перспективе мы сможем предоставить полноценную технологию автономного вождения пятого уровня.
Грег Абовски — Главный операционный и финансовый директор
И затем — очевидно, в Media Services, я думаю, что это принесло большую пользу от этой пандемии. Кроме того, у нас есть некоторый контент, оригинальный контент, который мы разработали сами, который был выпущен на платформе совсем недавно. И это работает необыкновенно хорошо. И мы очень этому рады. И я думаю, что Медиасервисы, как часть этой большой экосистемы Яндекс.Плюс, являются для нас очень важным стратегическим активом.
И, наконец, в Яндекс.Маркете опять же очередной массовый бенефициар попутного ветра от пандемии. Поэтому мы продолжаем инвестировать в электронную коммерцию. И, очевидно, мы также инвестируем в «Яндекс.Лавку», которая не входит в состав совместного предприятия. Это было специально вырезано из совместного предприятия как модель гипер-локального магазина шаговой доступности. Там мы наблюдаем невероятный спрос, как я уже сказал, продажи в Лавке выросли примерно на 550% с декабря по апрель.
Оператор
Большое спасибо. Последний вопрос, который у нас сегодня есть, исходит от Владимира Беспалова из ВТБ Капитал. Пожалуйста продолжай.
Владимир Беспалов — ВТБ Капитал — Аналитик
Спасибо, что ответили на мой уточняющий вопрос. Я хотел бы спросить вас о структурной цене в вашем райдшеринговом бизнесе, чем она отличается от мировых аналогов, если мы посмотрим на ваших конкурентов? И будет ли эта структура способствовать быстрому восстановлению райдхейлинга после локдауна, там их просто сняли или еще, как вы здесь видите ситуацию? Спасибо.
Грег Абовски — Главный операционный и финансовый директор
Конечно. Ну, если вообще сравнивать с нашими глобальными коллегами, я думаю, во-первых, у нас относительно небольшая доля прав на аэропорты. Так, в Москве это средние однозначные числа и очень низкие однозначные числа по России в целом. И, конечно же, я говорю о доковидной ситуации. У нас нет услуг пула, которые в настоящее время не используются, предлагаемые Uber и нашими конкурентами.
И потом, просто чтобы знать, что прямо сейчас у нас. .. до карантинных ограничений у нас был очень быстрый рост использования наших премиальных тарифов, которые в настоящее время ограничены. Таким образом, в целом, с небольшой частью прав аэропорта, возвратом премиальных тарифов, я думаю, что у нас очень хорошие возможности для восстановления после снятия ограничений на блокировку. А также, я хочу подчеркнуть, что в любом другом бизнесе основные райдеры хайлинга, которые пользуются сервисом, часто генерируют значительную часть GMV, и как только карантинные ограничения будут ослаблены, мы увидим — мы увидим большинство этих райдеров. вернуться к своему обычному режиму использования. Итак [Наложение речи]
Владимир Беспалов — ВТБ Капитал — Аналитик
Большое спасибо.
Грег Абовски — Главный операционный и финансовый директор
Да.
Владимир Беспалов — ВТБ Капитал — Аналитик
Хорошо. Спасибо большое. Очень полезно.
Оператор
Большое спасибо. И больше никаких вопросов. И Юлия, вы хотите сделать вывод?
Юлия Герасимова — Начальник отдела по связям с инвесторами
Да. Большое спасибо. Спасибо всем за то, что присоединились к нашей сегодняшней телеконференции. Если у вас есть дополнительные вопросы, пожалуйста, свяжитесь с командой IR, мы будем рады помочь вам. И большое спасибо. Пока-пока.
Оператор
[Заключительное слово оператора]
Продолжительность: 65 минут
Участники звонка:
Юлия Герасимова — Глава по связям с инвесторами
Тигран Худавердиан — Заместитель главного исполнительного директора
Daniil Shuleyko — Главный исполнительный директор YANDEX.TAXI
333333333333333333333333333333333333333333333333333333333333333333333333333339. — Глав Финансовый директорКатя Жукова — Директор по связям с инвесторами
Евгений Сендеров — Финансовый директор Яндекс.