
Описание отчета по атрибуту rel=»canonical»
rel=canonical — это атрибут, который применяется для указания поисковым системам канонической страницы.
Канонической называется та страница сайта, которая является предпочтительной для индексации в поисковых системах. То есть поисковый робот, обнаружив атрибут rel=canonical на какой-либо странице, будет индексировать вместо неё каноническую страницу, адрес которой указан в данном атрибуте. В отличие от редиректа, rel=canonical переадресует не пользователей, а только поисковые системы.
В каких случаях применяют этот атрибут?
Этот атрибут применяется в тех случаях, когда на сайте имеются страницы с идентичным или очень похожим контентом, находящиеся по разным адресам. Например, в интернет-магазине продаются футболки одного вида, отличающиеся только цветом или размером. Чтобы поисковая система не считала карточки таких товаров дублями, необходимо разместить на них ссылку на одну предпочтительную для индексации каноническую страницу.
Для чего нужно знать, на каких страницах сайта есть rel=canonical
Канонические страницы могут быть указаны неверно, что приведет к ошибкам в индексации. Например, на всех страницах сайта в атрибуте rel=canonical прописали главную, поэтому поисковые системы не могли проиндексировать все остальные страницы ресурса.
Почему это важно для поисковых систем
Атрибут rel=canonical позволяет поисковым системам определить среди страниц с дублирующим содержанием основную, которую нужно проиндексировать и вывести в результаты поиска.
Вы можете ознакомиться с рекомендациями от Яндекс по употреблению rel=»canonical» в разделе Яндекс Помощь.
Google также официально рекомендуют использовать rel=canonical для борьбы с повторяющимися URL. Об этом вы можете прочитать в руководстве Консолидация повторяющихся URL.
Содержание отчета «Страницы с rel=canonical»
- URL страницы, на которой найден атрибут
rel=canonical.
- URL, который прописан в атрибуте как канонический.
- Код ответа страницы, которая прописана в
rel=canonical— код 200 говорит об успешной обработке запроса (страница доступна). - Указано, разрешен ли канонический URL для индексации.

Сегментирование данных отчета по ошибкам
Проставив галочки около нужных пунктов в верхней части отчета, можно отфильтровать его содержимое так, чтобы отображались данные только по rel=canonical с выбранными параметрами. Тогда вы сможете проверить наличие конкретных ошибок в переадресации на каноническую страницу.
Страницы с несколькими rel=canonical
В случае нескольких объявлений rel=canonical Google, скорее всего, проигнорирует все указания rel=canonical.
Страницы с кросс-доменным rel=canonical
Вы можете использовать элемент rel=canonical в ссылке между доменами, чтобы указать точный URL, который предпочтительнее для индексации.
Ссылки с rel=canonical на несуществующие страницы
Страница, содержащая rel=canonical, ссылается на несуществующую страницу.
Канонический URL заблокирован для индексации
Это неэффективно расходует краулинговый бюджет и может быть ошибкой в указании данного URL. Если поисковый робот тратит слишком много времени на сканирование URL-адресов, которые не подходят для индекса, то у него может не остаться времени на просмотр остальной части вашего сайта.
В URL-адресе отсутствует префикс http или https
Абсолютные URL-адреса должны указывать полный путь к канонической странице, включая обозначение протокола, например http:// или https://.
rel = canonical найден в <body>
Атрибут rel=canonical должен быть только в теге <head>. Когда вы ставите rel=canonical в <body>, то он игнорируется.
Как прописать атрибут rel= «canonical» в коде страницы
Задается он с помощью тега LINK с атрибутом rel=canonical в HEAD страницы. Для этого необходимо поместить в блоке HEAD следующую запись:
Для этого необходимо поместить в блоке HEAD следующую запись:
<link rel=”canonical” href=”канонический URL” />
Где «канонический URL» – это полный адрес страницы, которую вы считаете предпочтительной для индексации. Пример употребления атрибута:
<link rel=”canonical” href=”http://site.ru/razdel/document/"/>
Обязательно нужно указывать абсолютный (полный) путь на страницу!
Как избавиться от дублей в поиске Яндекс и Google
В данном материале мы рассмотрим все доступные методы борьбы с дублями для сайтов которые созданы в uCoz и uWeb. Будем избавляться от дублей страниц системного календаря, дублей переключателей страниц в модулях каталогах и других страниц которые портят вид сайта в лице поисковых систем.
Как избавиться от дублей на сайтах uCoz и uWeb ?
Избавляемся от дублей виджета календарь $CALENDAR$
На сайт где используются модули Блог и Новости и используется блок с календарем, в поиске могут возникнуть дубли с урл адресами подобно:
- http://ваш-сайт/news/2020-10-22
- http://ваш-сайт/news/2020-10-14
- http://ваш-сайт/blog/2020-10-22
- http://ваш-сайт/blog/2020-10-14
если материалов в модуле много, соответственно за каждую дату в календаре будут отметки и будет много урл дублей.
То есть, у вас может быть 1 — 2 тысячи новостей в модуле новости, новости добавлялись в разные дни, в итоге ожидайте 2 тыс урл адресов дублей, подобно примерам выше. Такие дубли не приносят никакой пользы, ниже будет описано решение как с ними бороться, чтобы такие дубли не индексировались, а если уже проиндексировались, чтобы удалились с поиска.
Для борьбы с такими дублями перейдите в модулях блог и новости в шаблон — Страница архива материалов
, далее в блоке хеад ( между тегов <head>сюда</head>) прописать следующее условие:<?if($PAGE_ID$=='day'||$PAGE_ID$=='month'||$PAGE_ID$=='year')?> <meta name="robots" content="noindex, nofollow"/> <?endif?>
сохраните изменения, далее ждите переиндексации в поисковиках и эти дубли начнут исчезать с поиска.
Избавляемся от дублей страниц пагинации в модулях Блог и Новости
Имея в модулях блог и новости много материалов, которые распределены по своих категориях или добавлены вне категорий, в модуле материалы разделяются на страницы, в результате всего этого если заранее не настроить борьбу с дублями переключателей страниц, в поиске будет много урл адресов подобно:
- http://ваш-сайт/?page2
- http://ваш-сайт/?page3
- http://ваш-сайт/?page4
- http://ваш-сайт/?page5
такие страницы никакой пользы в поиске не приносят.
Чтобы избавиться от таких страниц в поиске, нужно отредактировать ваш файл Robots.txt и удалить с него директиву:
Allow: /*?page
далее системно в роботсе останется директива:
Disallow: /*?
она должна быть, если у вас нет, нужно добавить. Далее при переиндексации такие страницы дубли как описаны в примере выше вылетят с поиска.
Запрещаем индексацию дублей страниц в категориях блога и новостей
Дополнительный метод борьбы с таким страницами в модулях блог и новости для категорий, в шаблоне Страница архива материалов, далее в блоке хеад ( между тегов <head>сюда</head>) прописать следующее условие:
<?if($PAGE_ID$='category')?> <?ifnot($CURRENT_PAGE$=='1')?> <meta name="robots" content="noindex, nofollow"/> <?endif?><?endif?>
так мы запретим индексацию страниц пагинации ( переключателей страниц ) в категориях кроме первой страницы.
То есть, мы сообщаем роботу поисковика, что в каждой из категорий модуля мы ему говорим, что нужно индексировать первую страницу категории.
Если в категории будет 5-10 и более страниц с материалами, данное условие позволит запретить их индексацию и в итоге поисковики не будут сообщать, что такие страницы являются не каноническими.
По сути поисковики на такие страницы ругаются, так как у них титл повторяется (дублируется).
Прописав это условие мы не навредим индексации материалов модуля и категорий, все будет индексироваться, мы лишь избавимся от страниц дублей (переключателей страниц).
Как избавиться от дублей переключателей страниц в Каталогах ?
В модулях Блог и Новости метод борьбы с дублями переключателей страниц один, в каталогах (файлов, статей, сайтов, объявлений и игр), метод немного отличается.
Перейти в шаблон Страница со списком материалов категории / раздела, далее в блоке хеад ( между тегов <head>сюда</head>) прописать следующее условие:
<?if($PAGE_ID$='category'||$PAGE_ID$='section')?> <?ifnot($CURRENT_PAGE$=='<span>1</span>')?> <meta name="robots" content="noindex, nofollow"/> <?endif?><?endif?>
этот способ решит проблему с дублями подобно как и в модулях блог и новости.
Условие выше запретит индексацию всех переключателей страниц в категориях и разделах каталогов кроме первой страницы.
Как избавиться от дублей подстраниц в Интернет-магазине ?
В модуле Интернет-магазин имеются свои подстраницы:
- Описание
- Спецификация
- Изображения
- Отзывы
По сути в поиске нужно оставить лишь первую вкладку «Описание«, которая отображает описание товара, другие вкладки нужны для отображения изображений товара и чтобы клиент имел возможность оставить отзывы.
Имея например на сайте 2 — 5 — 10 тыс товаров, на каждый товар прибавьте 3 страницы дубля, это тысячи страниц мусора, чтобы от него избавиться в роботс нужно прописать такие директивы:
Disallow: /shop/*comm Disallow: /shop/*spec Disallow: /shop/*imgs
вот так мы избавимся от возможных тысяч дублей в модуле Магазин.
Запрет индексации переключателей страниц модуля Магазин
В модуле магазин переключатели страниц работают по таким урл:
- /shop/all/1
- /shop/all/2
- /shop/all/3
- /shop/all/4
- /shop/all/5
Представьте ситуацию, когда в модуле 5-10 тыс товаров или больше, сколько у вас дублей переключателей страниц будет в поиске (такие дубли пользы не несут так как все они не уникальны и положительного влияния на покупки в магазине они не дают). Чтобы решить эту проблему, в файл robots.txt пропишите директиву:
Чтобы решить эту проблему, в файл robots.txt пропишите директиву:
Disallow: /shop/all/
эта директива решит проблему с переключателями страниц.
Избавляемся от дублей переключателей страниц в категориях Магазина
В категориях модуля магазин вы можете столкнуться с дублями подобно:
- http://site.net/shop/laminat;2
- http://site.net/shop/laminat;3
- http://site.net/shop/laminat;4
- http://site.net/shop/laminat;5
Для решения данной проблемы, в файл robots.txt нужно прописать директиву:
Disallow: /shop/*;
она решит проблему с такими дублями и не будет мешать индексации товаров.
Дополнительное средство защиты против дублей Canonical
Важно в каждом из модулей настроить для категорий, разделов и материалов Canonical, чтобы поисковики понимали какой урл является основным для индексации и не индексировали дубли.
Если у вас на сайте оплачивается платный тариф от Оптимального и выше на выбор, можно перейти в «Премиум настройки» Seo-модуля, далее отметить пункт — «Использовать атрибут rel=»canonical» для материалов«. После этих настроек достаточно пройтись по всем страницам шаблонам основных модулей и в блоке хеад ( между тегов <head>сюда</head>) прописать следующий код:
После этих настроек достаточно пройтись по всем страницам шаблонам основных модулей и в блоке хеад ( между тегов <head>сюда</head>) прописать следующий код:
<?$SEO_CANONICAL$?>
этого будет достаточно, чтобы поисковики понимали какая страница является канонической и не плодили дубли.
Как настроить Canonical если у вас на сайте нет оплаченного тарифа ?
В данной ситуации будет использовать каноникал с помощью внутренних операторов которые существуют в uCoz и uWeb.
Canonical для страницы материала и комментариев
Для шаблона Страница материала и комментариев / Страница с полной фотографией и комментариями основных модулей (блог, новости, все каталоги файлов, статей, сайтов, объявлений, игр, видео и фотоальбомы), в блоке хеад ( между тегов <head>сюда</head>) прописать следующий код:
<link rel="canonical" href="$HOME_PAGE_LINK$<?substr($ENTRY_URL$,1)?>"/>
Canonical для страницы товара в Интернет-магазине
Для шаблона Страница товара в модуле Интернет-магазин, в блоке хеад ( между тегов <head>сюда</head>) прописать следующий код:
<link rel="canonical" href="$HOME_PAGE_LINK$<?substr($DESC_LINK$,1)?>" />
это решит вопрос с каноникалом для товаров.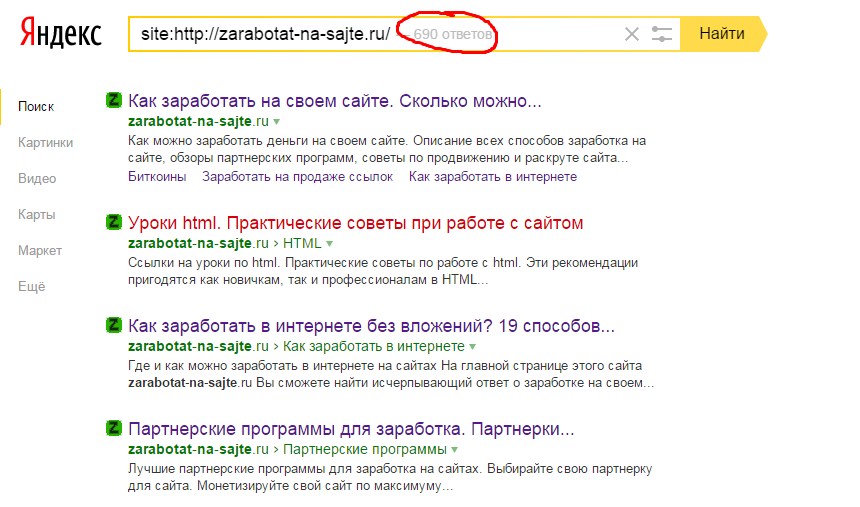
Canonical для страниц категории
Для шаблона Страница архива материала модулей (блог и новости), в блоке хеад ( между тегов <head>сюда</head>) прописать следующий код:
<?if($PAGE_ID$='category')?> <link rel="canonical" href="$HOME_PAGE_LINK$<?substr($REQUEST_URI$,1)?>" /> <?endif?>
Для шаблона Страница со списком материалов категории / Страница со списком фотографий альбома / Каталог товаров (каталогов файлов, статей, сайтов, объявлений, игр, видео, фотоальбома и магазина), в блоке хеад ( между тегов <head>сюда</head>) прописать следующий код:
<?if($CAT_URL$)?><link rel="canonical" href="$HOME_PAGE_LINK$<?substr($CAT_URL$,1)?>" /><?endif?>
Canonical для страниц раздела
Для шаблона Страница со списком материалов раздела / Страница со списком фотографий раздела (каталогов файлов, статей, сайтов, объявлений, игр и фотоальбома), в блоке хеад ( между тегов <head>сюда</head>) прописать следующий код:
<?if($SECTION_URL$)?><link rel="canonical" href="$HOME_PAGE_LINK$<?substr($SECTION_URL$,1)?>" /><?endif?>
Canonical для модуля Гостевая книга
Если у вас модуль гостевая используется, оставляются отзывы, тогда в данном модуле можно использовать в шаблоне Страница с сообщениями свой каноникал, в блоке хеад ( между тегов <head>сюда</head>) прописать следующий код:
<link rel="canonical" href="<?if($REQUEST_URI$="/gb/" or $REQUEST_URI$="/gb" or $REQUEST_URI$="/gb/1")?>https://ваш-сайт/gb<?else?>https://ваш-сайт/gb/<?substr($REQUEST_URI$,4)?><?endif?>" />
Canonical для модуля Форум
Если у вас модуль Форум используется, тогда в данном модуле можно использовать в шаблоне Общий вид страниц свой каноникал, в блоке хеад ( между тегов <head>сюда</head>) прописать следующий код:
<link rel="canonical" href="<?if($PAGE_ID$='main')?>$HOME_PAGE_LINK$forum<?endif?><?if($PAGE_ID$='category')?>$HOME_PAGE_LINK$<?substr($CUR_SECTION_URL$,1)?><?endif?><?if($PAGE_ID$='forum')?>$HOME_PAGE_LINK$<?substr($CUR_FORUM_URL$,1)?><?endif?><?if($PAGE_ID$='threadpage')?>$HOME_PAGE_LINK$<?substr($CUR_THREAD_URL$,1)?><?endif?>"/>
Примечание! Для подфорумов в модуле форум разграничить каноникал отдельный для форума и подфорума на уровне операторов слишком сложно, в связи с этим, для подфорумов используется урл корневого форума в который подформ добавлен.
Canonical для модуля Страницы / Редактор страниц
В данном модуле можно использовать в шаблоне Страницы сайта свой каноникал, в блоке хеад ( между тегов <head>сюда</head>) прописать следующий код:
<link rel="canonical" href="$HOME_PAGE_LINK$<?substr($REQUEST_URI$,1)?>" />
этого будет достаточно для данного модуля.
Canonical для модуля FAQ
В данном модуле можно использовать в шаблоне Общий вид страниц FAQ’a свой каноникал, в блоке хеад ( между тегов <head>сюда</head>) прописать следующий код:
<link rel="canonical" href="$HOME_PAGE_LINK$<?substr($REQUEST_URI$,1)?>" />
При необходимости, данный материал будет дополняться новыми решениями для борьбы с дополнительными дублями.
Избавляемся от дублей в модуле Фотоальбомы
Яндекс может ругаться на страницы фото с урл подобно:
- /photo/pozdravlenie_s_imeninami/1-0-66-3
- /photo/3-0-172-3
от таких страниц можно избавиться прописав роботс директиву:
Disallow: /photo/*-0-***-3
Установить Яндекс.
 Браузер на CentOS с помощью Snap Store Установить Яндекс.Браузер на CentOS с помощью Snap Store | Снапкрафт
Браузер на CentOS с помощью Snap Store Установить Яндекс.Браузер на CentOS с помощью Snap Store | СнапкрафтДругие популярные защелки…
Подробнее…Джами
Издатель: Savoir-faire Linux
Платформа голосовой связи, видео, чата и конференций, ориентированная на конфиденциальность, и SIP-телефон
Крита
Издатель: Stichting Krita Foundation Подтвержденный аккаунт
Цифровая живопись, свобода творчества
Тандерберд
Издательство: Canonical Подтвержденный аккаунт
Приложение электронной почты Mozilla Thunderbird
блокнотqq
Издатель: Даниэле Ди Сарли
Редактор наподобие Notepad++ для Linux.
почтальон
Издатель: Почтальон, Inc. Подтвержденный аккаунт
Среда разработки API
почтовая рассылка
Издатель: Mailspring Подтвержденный аккаунт
Лучшее почтовое приложение для людей и команд на работе
Spotify
Издатель: Spotify Подтвержденный аккаунт
Музыка для всех
Слабый
Издатель: Слэк Подтвержденный аккаунт
Командное общение для 21 века.
foobar2000 (ВИНО)
Издательство: Таки Раза
foobar2000 — это продвинутый бесплатный аудиоплеер.
Программа обработки изображений GNU
Издатель: Снапкрафтерс
Программа обработки изображений GNU
Хьюго
Издательство: Хьюго Авторс
Быстрый и гибкий генератор статических сайтов
Инкскейп
Издатель: Inkscape Project Подтвержденный аккаунт
Редактор векторной графики
Подробнее см. в избранном
в избранном
Больше дел…
Получить магазин оснастки
Просматривайте и находите моментальные снимки прямо на рабочем столе, используя снап-хранилище.
Узнайте больше о снимках
Хотите узнать больше о снэпах? Хотите опубликовать собственное приложение? Посетите snapcraft.io прямо сейчас.
docs/pre-signed-urls.md на master · yandex-cloud/docs · GitHub
Используя предварительно подписанные URL-адреса, веб-пользователи могут выполнять различные операции в {{ objstorage-name }}, например:
- Скачать объект
- Загрузить объект
- Создать ведро
Предварительно подписанный URL-адрес — это URL-адрес, в параметрах которого содержатся данные авторизации запроса. Предварительно подписанные URL-адреса могут быть созданы пользователями со статическими ключами доступа.
В этом разделе описаны общие принципы создания предварительно подписанных URL-адресов с помощью AWS Signature V4.
{% информация о примечании%}
Пакеты SDKдля различных языков программирования и другие инструменты для AWS S3 имеют готовые методы создания предварительно подписанных URL-адресов, которые также можно использовать для {{ objstorage-name }}.
{% примечание%}
Общий формат предварительно подписанного URL {#presigned-url-preview}
https://{{ s3-storage-host }}/<имя корзины>/<ключ объекта>?
Алгоритм X-Amz = AWS4-HMAC-SHA256
&X-Amz-Expires=<интервал времени в секундах>
&X-Amz-SignedHeaders=<список заголовков, разделенных ";">
&X-Amz-Signature=<подпись>
&X-Amz-Date=<время в ISO 8601>
&X-Amz-Credential=<идентификатор ключа доступа>%2F<ГГГГММДД>%2F{{ идентификатор региона }}%2Fs3%2Faws4_request
Параметры предварительно подписанного URL:
| Параметр | Описание |
|---|---|
X-Amz-алгоритм | Указывает версию подписи и алгоритм ее расчета. Значение: Значение: AWS4-HMAC-SHA256 . |
X-Amz-Истекает | Срок действия ссылки в секундах. Отправной точкой является время, указанное в X-Amz-Date . Максимальное значение — 2592000 секунд (30 дней). |
X-Amz-SignedHeaders | Заголовки запроса, который вы хотите подписать. Обязательно подпишите заголовок |
Подпись X-Amz | Подпись запроса. |
X-Amz-Date | Время в формате ISO8601, например, 20180719T000000Z . Указанная дата должна совпадать с датой в параметре X-Amz-Credential (по значению, а не по формату). |
X-Amz-Учетные данные | Идентификатор подписи. Это строка в формате |
Создание предварительно подписанных URL {#creating-presigned-url}
Чтобы получить предварительно подписанный URL-адрес, выполните следующие действия:
- Рассчитать подпись.
- Составьте строку для подписи.
- Рассчитать подпись, используя алгоритм строковой подписи.
- Создайте предварительно подписанный URL-адрес для вашего запроса.
Для создания предварительно подписанного URL-адреса необходимы статические ключи доступа.
Строка для подписи {#composing-string-to-sign}
Строка для подписи:
"AWS4-HMAC-SHA256" + "\n" + <отметка времени> + "\n" + <область> + "\n" + Hex(Hash-SHA256())
Где:
-
AWS4-HMAC-SHA256: Алгоритм хеширования. -
метка времени: Текущее время в формате ISO 8601, например,20190801T000000Z. Указанная дата должна совпадать с датой в области -
область действия:<ГГГГММДД>/{{ идентификатор региона }}/s3/aws4_request. -
CanonicalRequest: Канонический запрос. Чтобы включить запрос в строку, хешируйте его с помощью алгоритма SHA256 и преобразуйте в шестнадцатеричный формат.

Канонический запрос {#canonical-request}
Общий канонический формат запроса выглядит следующим образом:
\n <каноническийURL>\n <Каноническая строка запроса>\n <Канонические заголовки>\n <Подписанные заголовки>\n UNSIGNED-ПОЛЕЗНАЯ НАГРУЗКА
Канонический запрос всегда должен заканчиваться строкой UNSIGNED-PAYLOAD .
HTTPVerb {#http-глагол}
HTTPVerb обозначает метод HTTP, используемый для отправки запроса: GET , ПОСТАВИТЬ , ГОЛОВА или УДАЛИТЬ .
CanonicalURL {#канонический-url}
Канонический URL-адрес — это закодированный URL-адрес к ресурсу, например, / .
{% информация о примечании%}
Не нормализовать путь. Например, если объект имеет ключ some//strange//key//example , нормализация пути к / сделает его недействительным.
{% примечание%}
CanonicalQueryString {#canonical-query-string}
Каноническая строка запроса должна включать все параметры запроса целевого URL, кроме X-Amz-Signature . Параметры в строке должны быть закодированы в URL-адресе и отсортированы по алфавиту.
Пример:
X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=JK38EXAMPLEAKDID8%2F20190801%2F{{ идентификатор региона}}%2Fs3%2Faws4_request&X-Amz-Date=20190801T000000Z&X-Amz-Exp ires=86400&X-Amz-SignedHeaders= хозяин
CanonicalHeaders {#канонические заголовки}
В этом разделе содержится список заголовков запроса и их значений.
Требования следующие:
- Каждый заголовок должен быть разделен символом новой строки
\n. - Имена заголовков должны быть строчными.
- Заголовки должны быть отсортированы по алфавиту.
- Не должно быть лишних пробелов.
- Список должен содержать заголовок
hostи всеx-amz-*заголовки, используемые в запросе.
Вы также можете добавить любой заголовок запроса в список. Чем больше заголовков вы подписываете, тем безопаснее ваш запрос.
Пример:
хост: {{ s3-storage-host }}
x-amz-дата: 20190801T000000Z
SignedHeaders {#signed-headers}
Это список имен заголовков запросов в нижнем регистре, отсортированных по алфавиту и разделенных точкой с запятой.
Пример:
хост; x-amz-дата
URL-адреса с предварительной подписью {#composing-signed-url}
Чтобы создать предварительно подписанный URL-адрес, добавьте параметры, необходимые для авторизации запроса, включая параметр X-Amz-Signature с рассчитанной подписью, в URL-адрес ресурса {{ objstorage-name }}.
Пример составления предварительно подписанного URL для скачивания объекта {#example-for-object-download}
Вот пример создания подписанного URL-адреса для загрузки объекта object-for-share.txt из example-bucket , действительного в течение часа.
Статический ключ:
access_key_id = 'JK38EXAMPLEAKDID8' secret_access_key = 'ExamP1eSecReTKeykdokKK38800'
Канонический запрос:
ПОЛУЧИТЬ /example-bucket/object-for-share.txt Алгоритм X-Amz=AWS4-HMAC-SHA256&X-Amz-Credential=JK38EXAMPLEAKDID8%2F20190801%2F{{ идентификатор региона}}%2Fs3%2Faws4_request&X-Amz-Date=20190801T000000Z&X-Amz-Expires=360 0&X-Amz-SignedHeaders=хост хост: {{ s3-хост-хранения}} хозяин UNSIGNED-ПОЛЕЗНАЯ НАГРУЗКАСтрока для подписи:
AWS4-HMAC-SHA256 20190801T000000Z 20190801/{{ идентификатор региона }}/s3/aws4_request 2d2b4efefa9072d90a646afbc0fbaef4618c81396b216969ddfc2869db5aa356Ключ подписи:
знак (знак (знак (знак («AWS4» + «ExamP1eSecReTKeykdokKK38800», «20190801»), «{{ идентификатор региона }}»), «s3»), «aws4_request»)Здесь мы вводим функцию
signдля указания метода вычисления ключа, использующего алгоритм HMAC с SHA256.Подпись:
56bdf53a1f10c078c2b4fb5a26cefa670b3ea796567d85489135cf33e77783f0
Предварительно подписанный URL:
https://{{ s3-storage-host }}/example-bucket/object-for-share.txt?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=JK38EXAMPLEAKDID8%2F20190801%2F{{ идентификатор региона}}%2Fs3%2Faws4_request&X-Amz-Date=20190801T000000Z&X-Amz-Expires=3600&X-Amz-SignedHeaders=host&X-Amz-Signature=56bdf53a1f10c078c2b4fb5a26cefa670b3ea7 96567d85489135cf33e77783f0

Примеры получения предварительно подписанных ссылок в инструментах {{ objstorage-name }} {#example-for-getting-in-tools}
{% вкладок списка %}
Консоль управления
{% включает хранилище-получить ссылку для загрузки %}
Интерфейс командной строки AWS
Вы также можете использовать интерфейс командной строки AWS для создания ссылки для загрузки объекта.
Для этого выполните следующую команду:aws s3 presign s3://
/ --endpoint-url "https://{{ s3-storage-host }}/" [--expires-in ] Чтобы правильно сгенерировать ссылку, обязательно укажите параметр
--endpoint-url, указывающий на имя хоста {{ objstorage-name }}. Подробную информацию см. в этом разделе, посвященном особенностям интерфейса командной строки AWS.бото3
В приведенном ниже примере создается предварительно подписанный URL-адрес для загрузки объекта
для общего доступаиз корзиныс объектами. URL действителен в течение 100 секунд.# кодировка=utf-8 импорт бото3 из botocore.client импортировать конфигурацию ENDPOINT = "https://{{s3-storage-host}}" ACCESS_KEY = "JK38EXAMPLEAKDID8" SECRET_KEY = "ExamP1eSecReTKeykdokKK38800" сеанс = boto3.Session( aws_access_key_id=ДОСТУП_КЛЮЧ, aws_secret_access_key=SECRET_KEY, имя_региона="{{идентификатор региона}}", ) s3 = сеанс.
 Для этого выполните следующую команду:
Для этого выполните следующую команду: