
«Яндекс» закрывает рейтинги блогеров и блог-хостингов — РБК
adv.rbc.ru
adv.rbc.ru
adv.rbc.ru
Скрыть баннеры
Ваше местоположение ?
ДаВыбрать другое
Рубрики
Курс евро на 11 февраля
EUR ЦБ: 78,05
(-0,27)
Инвестиции, 10 фев, 19:31
Курс доллара на 11 февраля
USD ЦБ: 72,79
(-0,1)
Инвестиции, 10 фев, 19:31
Китай собрался сбить НЛО над Желтым морем Политика, 18:16
Число погибших после землетрясения в Турции превысило 29 тыс. человек
Общество, 18:11
человек
Общество, 18:11
Результаты ошеломительные: технологические прорывы и тренды 2022 года РБК и Omoda, 18:04
adv.rbc.ru
adv.rbc.ru
Бах отказался считать МОК «не на той стороне истории» из-за России Спорт, 17:51
«Роскосмос» показал фото турецкого аэропорта после землетрясения Общество, 17:42
CNN показал видео с «мини-припадком» Саакашвили в тюремной больнице Политика, 17:27
Как бизнесу возить грузы в городе: 5 фактов, которые вас удивят РБК и Газ, 17:18
Что подарить тем, у кого все есть?
Подписка РБК Pro – престижный подарок для тех, кто хочет принимать уверенные решения в бизнесе, карьере и финансах.
Купить сертификат
Захарова ответила на просьбу Дуды об оружии для Киева фразой «не поможет» Политика, 17:07
В бундестаге раскритиковали мирную инициативу по Украине Политика, 16:53
«Металлург» вышел в плей-офф КХЛ Спорт, 16:50
Собянин заявил о снижении числа угонов автомобилей в Москве на 93% Общество, 16:36
Школьное образование в Москве. Цифры, факты, инфографика Специальный проект, 16:32
Лавров заявил о признании США причастности к взрывам на Nord Stream Политика, 16:23
Правительство предложило изменить порядок расчета цены нефти для налогов Экономика, 16:15
adv. rbc.ru
rbc.ru
adv.rbc.ru
adv.rbc.ru
Сервис «Яндекса» по поиску информации в блогах (http://blogs.yandex.ru/) с сегодняшнего дня, 18 апреля, закрыл рейтинг блогов по количеству их читателей. Как уточнила компания, решение о закрытии части проекта планировалось давно, но последние законодательные инициативы ускорили его принятие.
Фото: ИТАР-ТАСС
«Если еще год или полгода назад приблизительная оценка, которую давал наш рейтинг, не могла никому навредить, то сегодня некорректные данные устаревшего рейтинга могут быть использованы против блогеров», — рассказали РБК в «Яндексе».
Сегодня депутаты Госдумы одобрили во втором чтении законопроект, который фактически приравнивает популярных блогеров к СМИ. Инициатива вносилась и рассматривалась в рамках пакета так называемых антитеррористических законов. По мысли разработчиков, каждый, «размещающий открытую для всеобщего доступа массовую информацию на персональном сайте или странице» с более чем 3 тыс. посещений, автоматически становится блогером.
посещений, автоматически становится блогером.
Сервис «Поиск по блогам» был запущен «Яндексом» в 2004г., но, по сути, он уже несколько лет заморожен: данные о количестве читателей в рейтинге могли отображаться неверно, говорится в официальном блоге компании.
adv.rbc.ru
«На эту весну в рамках «генеральной уборки» в сервисах «Яндекса» мы запланировали закрытие этой части поиска по блогам. Однако в связи с последними российскими законодательными инициативами, касающимся блогеров, мы решили сделать это сегодня, для того чтобы не дезориентировать почтенную публику», — сказано в сообщении.
adv.rbc.ru
По словам представителя «Яндекса» Аси Мелкумовой, рейтинг блогов никогда не мог быть использован для определения, кто именно из блогеров может быть приравнен к СМИ. «Мы и все крупные интернет-компании периодически проводим ревизию своих проектов, чтобы сконцентрироваться на самых важных и профильных для себя. Теперь пришло время закрыть сервис, который не отражает то, что на самом деле происходит вокруг», — отметила она.
Законопроект, который приравнивает популярных блогеров к СМИ, был принят 18 апреля уже во втором чтении.
Соответствующие поправки, внесенные председателем комитета Алексеем Митрофановым, а также членами фракции ЛДПР Андреем Луговым и Вадимом Деньгиным, были одобрены во вторник комитетом Госдумы по информационной политике, информационным технологиям и связи. Поправки к внесенному еще в январе под эгидой борьбы с терроризмом пакету законопроектов дают юридические определения понятий «блогер» и «организатор распространения информации в интернете» и устанавливают их ответственность.
Блогеров ждет деанонимизация. Законодатели оговаривают, что при публикации своих личных мнений популярные интернет-пользователи должны указывать свое имя или псевдоним. Требования же к личному сайту или странице несколько жестче: на них должны быть опубликованы фамилия и инициалы владельца, а также электронный адрес.
Ирина Юзбекова
Магазин исследований Аналитика по теме «Интернет»
Яндекс, поиск по блогам: цензуры нет, но она есть: vveshka — LiveJournal
? catIsShown({ humanName: ‘общество’ })» data-human-name=»общество»> Общество
catIsShown({ humanName: ‘общество’ })» data-human-name=»общество»> Общество- Cancel
искать среди десяти миллионов блогов мой жж, то находится только древний блог, заведенный на lj.rossia.org
А жжешного блога нет. Хотя несколько дней назад был.
Я это к тому, что сколько не давай ссылки на «обращение к петербуржцам», оно в топ не выйдет, пока эта проблема не решится (если я, конечно, все правильно понимаю).
Есть какие-нибудь соображения?
В техподдержку я уже написала.
UPD: И непосредственно перед митингом такое совпадение — не удивительно.
UPD 2: Техподдержка молчит, написала еще раз.
UPD3: в жж ecoist ситуация описана лучше:
«Удивительные совпадения все-таки случаются в жизни.
vveshka пишет пост — призыв придти на марш за сохранение Петербурга 10 октября.
На пост ссылается, кажется, половина блогосферы — а он все не в топе и не в топе. Как же так? А очень просто: Яндекс просто перестал обсчитывать блог vveshka
Просто нету теперь для Яндекса такого блога. Ссылки на него в других блогах — видит. А сам блог — в упор не замечает.»
А вот и ответ: «Яндекс не осуществляет отслеживание, контроль, премодерацию, цензуру индексируемых сайтов и результатов Поиска по блогам и форумам. …
Яндекс, не вступая в противоречие с вышесказанным, оставляет за собой право (но не обязанность) по своему усмотрению самостоятельно решать, какой сайт должен и какой не должен входить в поисковую базу, а равно вопросы об исключении сайта, страницы из поисковой базы.
Претензии по поводу отсутствия или наличия в поисковой базе страниц… не принимаются».
Subscribe
Календарь 2023
Не знаю, нужно ли было в этом году соблюдать традиции, но вот… Традиционный новогодний календарь.
 В здравый смысл верить все труднее, поэтому…
В здравый смысл верить все труднее, поэтому…Простые образовательные игры
Делаю маленькие игры для занятий с детьми. Буду сюда складывать. Накормите броненосца. Игра на быстрое чтение слов:…
Задания для тех, кто изучает русский язык
Дорогие друзья, я составила сборник своих заданий «Не фыр, а сыр!». Я готовила его для детей, изучающих русский как иностранный, но вы можете…
 В здравый смысл верить все труднее, поэтому…
В здравый смысл верить все труднее, поэтому…Photo
Hint http://pics.livejournal.com/igrick/pic/000r1edq
Календарь 2023
Не знаю, нужно ли было в этом году соблюдать традиции, но вот… Традиционный новогодний календарь. В здравый смысл верить все труднее, поэтому…
Простые образовательные игры
Делаю маленькие игры для занятий с детьми. Буду сюда складывать. Накормите броненосца. Игра на быстрое чтение слов:…
Задания для тех, кто изучает русский язык
Дорогие друзья, я составила сборник своих заданий «Не фыр, а сыр!».
Я готовила его для детей, изучающих русский как иностранный, но вы можете…
 Я готовила его для детей, изучающих русский как иностранный, но вы можете…
Я готовила его для детей, изучающих русский как иностранный, но вы можете…Две культуры программирования: почему обе важны | Энди Плахов | Яндекс | Февраль 2023 г.
В течение нескольких лет я наблюдал, что программисты и инструменты программирования делятся на две разные культуры:
Как человек, который изначально был частью первой культуры, я имел обыкновение отвергать вторую культуру как легкомысленную. Но несколько лет назад я наконец понял, как ошибался. Многие старые разработчики разделяют мою прежнюю точку зрения. В последние годы еще больше людей совершают ту же ошибку, но с противоположной стороны. Я понял, что понимание и знакомство с другой культурой сделает вас лучшим разработчиком.
Культура 1 : Значения больших проектов
Культура 2 : Значения короткие осмысленные фрагменты кода
Это различие, вероятно, диктует остальное. Молодые разработчики могут не в полной мере осознать масштабы проектов в первой культуре. Например, современная игра AAA, написанная на языке с синтаксисом, подобным C, может иметь миллионы строк кода, больше, чем кто-либо когда-либо мог прочитать. Еще более ярким примером является Linux с более чем 15 миллионами строк кода. Windows и macOS во много раз больше. Некоторые говорят, что производители автомобилей превзошли эти цифры: автомобиль Mercedes использует до 100 миллионов строк кода. Я не уверен, что это правда, но даже если это так, большинство этих строк, вероятно, избыточны. В любом случае, даже 100 миллионов — это ничто по сравнению с кодовой базой компании FAANG, которая может содержать буквально миллиарды строк кода.
Например, современная игра AAA, написанная на языке с синтаксисом, подобным C, может иметь миллионы строк кода, больше, чем кто-либо когда-либо мог прочитать. Еще более ярким примером является Linux с более чем 15 миллионами строк кода. Windows и macOS во много раз больше. Некоторые говорят, что производители автомобилей превзошли эти цифры: автомобиль Mercedes использует до 100 миллионов строк кода. Я не уверен, что это правда, но даже если это так, большинство этих строк, вероятно, избыточны. В любом случае, даже 100 миллионов — это ничто по сравнению с кодовой базой компании FAANG, которая может содержать буквально миллиарды строк кода.
Даже код, который может показаться «тупым», например обычная бизнес-логика, может стать сложным, когда он поступает в больших объемах. Это как писать роман; набирать слова легко, но они должны собраться вместе, чтобы создать последовательный, функционирующий сюжет с интересными персонажами. Без выяснения высокоуровневой структуры и принципов этого просто не произойдет. И то, что вы можете написать короткий рассказ, не означает, что вы можете написать книгу.
И то, что вы можете написать короткий рассказ, не означает, что вы можете написать книгу.
Для обслуживания большой базы кода требуются специальные инструменты навигации и рефакторинга. Эти инструменты легче использовать в одних языках, чем в других.
- В качестве примера возьмем простую функцию «перейти к определению» — возможность перейти к коду функции из того места, где она вызывается. Для кода, написанного на языках первой культуры, реализовать такую функцию несложно; синтаксис определения функции ясен, и их известное количество, поскольку функции обычно не могут каким-то образом появляться «на лету». Омонимы, если они есть, можно отличить с помощью формальной процедуры проверки типа и объема. Такие IDE, как VS Code, могут попытаться предложить «перейти к определению» в таких языках, как Python и JS. Однако это только имитация и до некоторой степени имитация: поскольку функции являются первоклассными объектами, между «именем функции» и «телом функции» существует отношение «многие ко многим».
- Или давайте рассмотрим управление доступом участников: частный/общедоступный. Вопреки тому, что вы могли бы подумать, эта функция не связана с безопасностью в традиционном смысле; это необходимо для выживания в крупных проектах. Эта функция позволяет вам определить границы, в которых вы можете определить API, взаимодействующий с конкретным фрагментом кода и поддерживающий все необходимые инварианты. За пределами этих границ вы можете взаимодействовать только с этим API без возможности случайного нарушения инвариантов. Без этого разделения доступа в проекте с миллионами строк кода любой код может непреднамеренно помешать работе другого, что сильно затруднит выживание.

Опять же, кто-то из первой культуры может подумать, что вторая культура — это детская игра. Но это было бы в корне неправильно.
В больших проектах единовременные накладные расходы незначительны, поэтому создатели языков программирования первой культуры не заботились об этих затратах. Например, неважно, сколько места занимает программа, которая печатает «Hello, World!». Программист на C++ запустит его с помощью команды
Программист на C++ запустит его с помощью команды #include , затем напишет еще несколько строк и не будет думать об этом. Java-разработчик должен сначала определить специальный класс. Программист Python посмотрит на них обоих как на сумасшедших: «Разве вы не можете просто написать print("Hello, World!") как у обычных людей?»
Этот принцип применим к любой ситуации, когда несколько строк кода должны нести смысл. REPL и первая культура вряд ли совместимы; например, блокноты Jupyter были бы невозможны на Java, несмотря на букву «J» в названии (теоретически можно было бы найти способы сделать это, но люди из первой культуры даже не подумали бы об этом).
Ту же функцию управления доступом, о которой говорилось выше, также трудно согласовать с концепцией, согласно которой объекты — это просто ящики с разнородными данными, которые могут появиться откуда угодно. Например, они могут появиться во время выполнения через «eval». Это делает систему удивительно управляемой и настраиваемой во время выполнения; вы можете исправить код во время отладки, заменить его на лету и продолжить выполнение или иметь конфигурацию системы на том же языке, на котором написана вся система.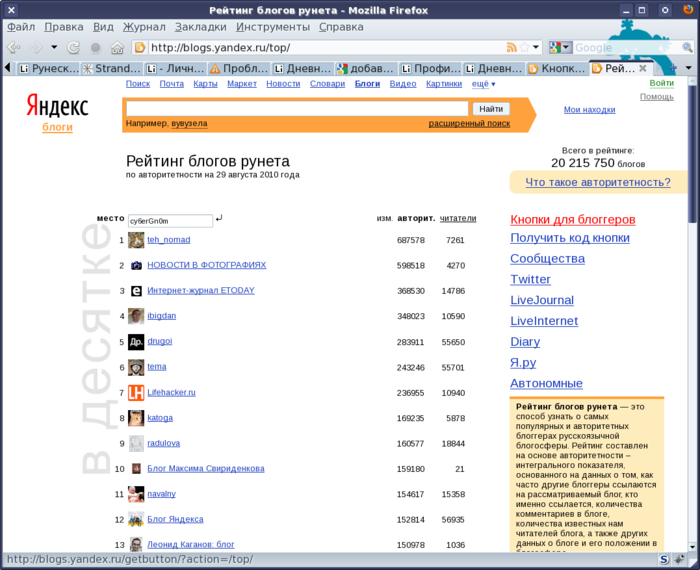
Для меня было огромным шоком узнать, что реализация нейросетей-трансформеров (великих и ужасных) занимает около 100 строк кода Python. Конечно, это очень высокоуровневый код, и без PyTorch, NumPy, CUDA и т. д. этих строк не бывает. Тем не менее такой компактный код немыслим в первой культуре.
Когда код наполнен смыслом, скорость разработки может резко возрасти в соответствующих ситуациях.
Культура 1 9″ неопределенный», «неопределенный» или «определенный реализацией», и эти три совершенно разные. «Неопределенное» поведение (наихудшее) означает, что программист допустил ошибку, но это не обязательно означает, что программа выдаст ошибку. Стандарт официально разрешает программе делать все, что она хочет, когда это происходит, буквально все, что угодно. Но зачем это кому-то нужно?
Многие из вас уже знают ответ: это позволяет компилятору выполнять различные низкоуровневые оптимизации. Например, если компилятор видит, что определение макроса или шаблона привело к выражению (x+1 > x), он может свободно заменить его на «true».
Если вы не программируете на C/C++, вы можете быть в шоке: «Люди действительно пишут такие программы?» Действительно, люди занимаются этим уже 50 лет, и все это время регулярно стреляют себе в ногу. Удобство компилятора стоит выше удобства программиста.
Напротив, в Python есть много примеров противоположного поведения. Начнем с простого:
>>> x = 2**32
>>> x*x
18446744073709551616
>>> x*x*x
79228162514264337593543950336Никакого переполнения и никаких связанных с этим проблем! Уму программиста легче: целое число — это просто целое число, и вам больше не нужно думать о INT_MAX.
Вот менее известный пример:
>>> 15 % 10
5
>>> -15 % 10
5Целочисленное деление в Python гарантирует, что остаток после деления на N всегда будет числом от 0 до N-1, даже для отрицательных чисел. С другой стороны, в C/C++ остаток после деления -15 на 10 равен -5. Опять же, первый подход экономит время и снижает когнитивную нагрузку на программиста. Например, при определении времени дня по метке времени программисту не нужно беспокоиться о том, старше ли метка времени 1970. Это не случайно — сам Гвидо ван Россум выбрал эту семантику, исходя из аналогичного хода мыслей. Последний подход лучше подходит для определенного оборудования и, таким образом, иногда на несколько пикосекунд быстрее.
Чтобы продемонстрировать степень беспокойства создателя Python подобными проблемами, вот последний пример: что вы ожидаете увидеть после запуска этого примера?
>>> круглый(1,5)
>>> круглый(2,5)
>>> круглый(3,5)
>>> круглый(4,5)Вот ответ.
Поверьте мне: это не ошибка, а именно так и было задумано. Попробуйте предположить (или поискать в Интернете), почему этот подход к округлению верен с точки зрения второй культуры, даже если это может потребовать дополнительных проверок в рамках реализации функции округления.
Наконец, интересно отметить, что при глубоком понимании обеих культур становится возможным найти компромисс между скоростью программы и скоростью программиста. Сложные вычисления можно выполнять с помощью библиотеки, написанной на C++ (иногда Fortran) с привязками к Python или Lua. Затем вы можете использовать эти библиотечные функции для создания сложных структур, таких как блоки Lego. Например, обучение и инференс больших нейронных сетей — одни из самых высоконагруженных ИТ-проектов на сегодняшний день — развиваются преимущественно в границах второй культуры. Программа для обработки чисел спрятана под капотом. Знать его особенности по-прежнему полезно, но эти знания уже не нужны даже для достижения результатов мирового уровня.
Культура 1 : Можно строго математически доказать, что код не содержит ошибок определенного типа скорость программы и скорость программиста, может показаться, что первая культура не заботится о безопасности и удобстве. Это обобщение совершенно неверно (как и любое чрезмерное обобщение). На самом деле программисты ценят, когда компилятор все проверяет за них. Идея «а что, если бы компилятор мог проверить все, что только возможно» лежит в основе Rust — всего языка, который быстро становится мейнстримом.
Как правило, программисты первой культуры используют статический подход к предотвращению ошибок. В эту группу входят проверки типов во время компиляции, проверка формальных спецификаций и использование инструментов анализа кода. Кроме того, аналогичные проверки могут также применяться к данным, когда они «скомпилированы» в двоичный формат, который используется кодом среды выполнения.
Программисты второй культуры, с другой стороны, стараются избегать ошибок, используя статистический подход.
Как видите, четкой границы между двумя культурами нет. Некоторые программисты старой школы C++ могут также писать модульные тесты, а некоторые программисты Python могут создавать анализаторы кода. Однако каждая культура склонна использовать свой набор устоявшихся практик. Это верно и для всех других различий между двумя культурами.
Основное различие между двумя наборами практик заключается в уровне гарантии, которую они обеспечивают. Например, компилятор C++ или Java гарантирует, что объект «неправильного» типа не может быть передан в качестве параметра функции и что для объекта нельзя вызвать несуществующий метод. В Python эти проверки можно выполнять с помощью модульного, регрессионного и функционального тестирования, а также старого доброго способа «попробовать несколько раз и посмотреть, не сработает ли».
Конечно, это не математика, поэтому «доказательство» компилятора никогда не бывает полностью надежным. Например, сам компилятор теоретически может содержать редкий дефект. На практике, однако, эту возможность можно смело игнорировать по нескольким причинам:
- В среднем компиляторы во много раз надежнее обычных программ, и их поведение гораздо более строго регламентировано,
- Даже если компилятор не « заметить» ошибку, она будет обнаружена после небольшого изменения кода,
- Речь идет не об одном редком событии, а о совпадении двух маловероятных условий (компилятор не увидел ошибки программиста, и этот дефект тоже невероятно редкий),
- И так далее.
Большой пример
В течение многих лет при обсуждении этой темы я использовал этот пример. Давным-давно, когда я работал над игрой RTS для Nintendo DS, тестировщики обнаружили проблему рассинхронизации в многопользовательском режиме.
Это особенно неприятная ошибка. В нашей игре мультиплеер был организован peer-to-peer: разные DS-консоли только передавали пользовательский ввод между собой, а состояние мира вычислялось каждым устройством отдельно. Это идеально подходит для игр в реальном времени, поскольку обеспечивает многофункциональный игровой процесс, основанный на очень ограниченном канале передачи данных и минимальном обмене данными. Главный недостаток, однако, заключается в том, что вся игровая логика должна быть абсолютно детерминированной — это означает, что при одном и том же наборе входных данных результирующее состояние игрового мира всегда должно быть одинаковым. Не может быть никакой случайности, никакой зависимости от системного таймера, никакого округления битов, никаких неинициализированных переменных и тому подобного.
Как только происходит рассинхронизация, это фатально: любое несоответствие, даже если оно начинается с одного бита, быстро накапливается, и вскоре игроки видят совершенно разные картины происходящего. Естественно, оба игрока в конечном итоге «выигрывают» с огромным преимуществом. С помощью контрольных сумм можно приблизительно установить момент времени, когда произошла рассинхронизация. После этого требуется тщательное расследование. Исследование становится несколько проще, если вы можете позволить себе сериализовать все игровые данные с определенными аннотациями, а затем сравнить два дампа с разных устройств. К сожалению, такой возможности у нас не было: ведь мы работали с Nintendo DS, консолью с крошечным объемом памяти.
Вот описание ошибки, которое я получил от QA: «Иногда при неизвестных обстоятельствах происходит рассинхронизация. Точная причина неизвестна. Для воспроизведения: создайте игру на четверых и играйте до изнеможения, активно используя разных персонажей и способности.
А почему игра вообще рассинхронизируется? К счастью, неинициализированные переменные можно исключить: мы написали собственную систему управления памятью, а данные игрового процесса хранятся в отдельной локации, изначально заполненной нулями. Это гарантирует, что без рассинхронизации их состояния будут идентичны до бита, даже если будет несколько неинициализированных переменных. Это означает, что один из разработчиков должен был сделать что-то неожиданное, например, вызвать функцию, которая не обязана быть синхронной, например, обращение к пользовательскому интерфейсу, из логики игры. Технически это сделать непросто: как минимум нужно написать
#include <../../interface/blah-blah.h>в игровую логику без учета очевидных последствий этого. Простой поиск по регулярному выражению показал, что никто не был настолько глуп.Именно тогда я понял, что у меня на руках задание по проверке типов.
Все наши функции, методы класса и данные должны быть разделены на синхронные и асинхронные. Синхронные функции могут вызывать асинхронные (для побочных эффектов), но они не могут использовать возвращаемые им значения. Например, функция игрового процесса может сказать: «Интерфейс, покажи пользователю сообщение», но не может спросить: «Интерфейс, какое окно просмотра у пользователя?» И наоборот, асинхронные функции не могут вызывать синхронные функции с побочными эффектами, но могут свободно использовать возвращаемые им значения («Геймплей, какой процент здоровья у этого юнита?»).
Основные выводы:
• Код содержал некоторые нарушения этих правил; в противном случае ошибка рассинхронизации не возникнет.
• Не каждое такое нарушение привело бы к рассинхронизации, но если бы нарушений не было, то мы могли бы математически доказать, что рассинхронизации нет.
Отлично, теперь мне пришлось взять на себя роль компилятора и переименовать все функции «doSmth» на границе между игровым миром, пользовательским интерфейсом и графикой либо в «doSmthSync», либо в «doSmthAsync», при этом отслеживая, какая из них вызывает какую . Менее чем за час все типографские ошибки были исправлены, и я смог восстановить цепочку событий, приведших к рассинхронизации.
Я нашел ошибку, при которой интерпретировалось падение наковальни (как мы все знаем, наковальня — это мультяшное супероружие). Для проверки того, что наковальня была брошена на пустое место или она была направлена на конкретного юнита, по ошибке была использована неверная функция:
isVisible(getCurrentPlayer())вместоisVisible(игрок шо бросает наковальню).Вот как воспроизвелся баг. Один игрок должен был построить Разведчика, сделать его невидимым и отправиться на базу противника. Второму игроку нужно было собрать Снайпера и использовать способность «Отбрасывание наковальни» в том месте, где стоит (или проходит) невидимый Разведчик — точнее, на его туловище.
Я не могу придумать ни одного модульного или любого другого теста, который смог бы обнаружить такое фантастическое совпадение. Чтобы такие баги не попадали в игру, вам нужны самоотверженные тестеры-люди. Крайне желательно также обеспечить математически строгий код.
Культура 1 : Проверка типов во время компиляции
Культура 2 : Утиный ввод
Вы можете понять, почему это так, из предыдущих разделов. Элементы одной культуры, примененные к другой, могут быть невероятно полезны в определенных ситуациях — если вы понимаете, что это не запрещено.
Культура 1 : «Я прочитал код всех библиотек, от которых зависит мой проект, и мне с ними комфортно».
Культура 2 : npm install left-pad
Новый код, который делает что-то новое, — это одновременно и благословение, и проклятие. Рассмотрим огромный проект, в котором каждые 10 000 строк кода реализуют свою функцию, строго определенную спецификациями (чтобы не наступил хаос и все не развалилось). В таком проекте каждая строчка кода, особенно если вы ее не писали сами, — болевая точка и потенциальная бомба замедленного действия. С другой стороны, иногда вам просто нужно загрузить изображение в формате PNG и определить, есть ли в нем хот-дог. Либо вы можете сделать это в четыре строчки, не слишком задумываясь, либо вы не можете — и люди второй культуры могут сделать это чаще, чем нет.
Культура 1 : Статическая сборка
Культура 2 : Динамическая сборка, включая загрузку библиотек из глубин интернета
В игре два вопроса:
- Могут ли вдруг сломать ваш продукт без посторонних действия с вашей стороны?
- Могут ли незнакомцы значительно улучшить ваш продукт без каких-либо действий с вашей стороны? (Например, залатать дыру в безопасности, о существовании которой вы даже не подозревали)
Как вы могли догадаться, ответы на эти два вопроса тесно связаны.
Культура 1 : Документация хранится локально
Культура 2 : Документация хранится в Интернете (на вашем веб-сайте, в GitHub, Read the Docs или Stack Overflow)
Такая мелочь, как вы могли подумать. Почему так важно, где вы храните что-то, что в основном представляет собой обычный текст (хорошо, может быть, гипертекст)? Но эта разница весьма показательна. В первом случае документация хранится на моем компьютере; он «мой», он определенно описывает версию, которую я использую, он не изменится, если я этого не захочу и т. д. Во втором случае я живу и развиваюсь вместе с окружающим миром, и у меня есть возможность учиться новые вещи об этой технологии, как только кто-то обнаружит их.
Культура 1 : Формальные языки, алгоритмы поиска, анализ конечных автоматов, сложные структуры данных
Культура 2 : Глубокое обучение
В каждой культуре есть свои герои и великие волшебники.
Во второй культуре герои — это люди, которые заставляют всех восхищаться тем, НА ЧТО теперь могут компьютеры. Часто эксперты могут предсказать, что это возможно, но это не умаляет достижения. Например, очевидно, что кто-то первым обучит диффузию генерировать качественное видео без всяких хаков, впритык. Скорее всего, это произойдет до конца 2023 года, но результат все равно будет потрясающим, а те, кто это сделает, будут прославлены как герои.
Средний возраст «передовой технологии» в первой культуре — 25 лет. Как правило, такая технология была создана одним из многих известных деятелей, таких как Керниган, Томпсон, Вирт, Хоар, Дейкстра или Торвальдс.
Напротив, средний возраст «передовых технологий» во второй культуре составляет всего один год. Например, многие из его создателей могут быть студентами Массачусетского технологического института. В этой культуре даже те, кто «играет с кубиками», могут собрать из них что-то новое и полезное, а бородатые гуру из первой культуры выясняют, что вызывает порчу памяти. Это не случайность, а следствие ряда фундаментальных и мудрых принципов. Например, «Производительность программиста почти всегда важнее, чем производительность программы». Или: «Технология не обязательно должна быть настолько сложной, чтобы вы должны были ее углубленно изучать или практиковать вуду для решения базовых задач». Именно на таких принципах построена эта культура. И вы тоже можете учиться у них.
Обновление ландшафта угроз
Группа анализа угроз
07 марта 2022 г.
мин. прочитано
Шейн Хантли
Директор группы анализа угроз
Онлайн-безопасность сейчас чрезвычайно важна для жителей Украины и близлежащих регионов. Правительственные учреждения, независимые газеты и поставщики государственных услуг нуждаются в нем для работы, а люди должны безопасно общаться. Группа анализа угроз Google (TAG) работает круглосуточно, уделяя особое внимание безопасности и безопасности наших пользователей и платформ, которые помогают им получать доступ и обмениваться важной информацией.
Эта работа является продолжением наших давних усилий по борьбе с угрозами в этом регионе. За последние 12 месяцев TAG выпустил сотни предупреждений об атаках, поддерживаемых правительством, для украинских пользователей, предупреждая их о том, что они стали целью поддерживаемого правительством взлома, в основном исходящего из России.
За последние две недели группа TAG наблюдала за активностью целого ряда субъектов угроз, которые мы регулярно отслеживаем и которые хорошо известны правоохранительным органам, включая FancyBear и Ghostwriter. Эта деятельность варьируется от шпионажа до фишинговых кампаний. Мы делимся этой информацией, чтобы повысить осведомленность сообщества безопасности и пользователей с высоким уровнем риска:
FancyBear/APT28, злоумышленник, приписываемый российскому ГРУ, провел несколько крупных фишинговых кампаний, нацеленных на пользователей ukr.net, UkrNet — украинская медиакомпания. Фишинговые электронные письма отправляются с большого количества скомпрометированных учетных записей (не Gmail/Google) и содержат ссылки на домены, контролируемые злоумышленниками.
В ходе двух недавних кампаний злоумышленники использовали недавно созданные домены Blogspot в качестве исходной целевой страницы, которая затем перенаправляла цели на фишинговые страницы с учетными данными.
Пример страницы фишинга учетных данных APT28
Примеры доменов фишинга учетных данных, наблюдаемых во время этих кампаний:
- id-unconfirmeduser[.]frge[.]io
- hatdfg-rhgreh684[.]-frge[.]io
- 4
ua Consumerpanel[.]frge[.]io- Consumerpanel[.]frge[.]io
Ghostwriter/UNC1151, , белорусский злоумышленник, на прошлой неделе проводил кампании по фишингу учетных данных против правительства и военных Польши и Украины. организации. TAG также выявила кампании, нацеленные на пользователей веб-почты следующих провайдеров:
- I.UA
- Meta.ua
- Rambler.ru
- UKR.NET
- WP.PL
- Yandex.RU
Пример платных доменов (
. Пример примерных доменов. secure-ua[.]веб-сайт
i[.]ua-паспорт[.]top логин[.]creditals-email[.]space post[.]mil-gov[. Verify[ .]rambler-profile[.]site Эти фишинговые домены были заблокированы с помощью Google Safe Browsing — службы, которая выявляет небезопасные веб-сайты в Интернете и уведомляет пользователей и владельцев веб-сайтов о потенциальном вреде.
Mustang Panda или Temp.Hex, базирующаяся в Китае организация, занимающаяся угрозами, нацелилась на европейские организации с приманками, связанными с украинским вторжением. TAG идентифицировал вредоносные вложения с такими именами файлов, как «Ситуация на границе ЕС с Украиной.zip». В zip-файле содержится исполняемый файл с тем же именем, который является базовым загрузчиком и при выполнении загружает несколько дополнительных файлов, которые загружают конечную полезную нагрузку. Чтобы уменьшить ущерб, TAG уведомила соответствующие органы о своих выводах.
Нацеливание на европейские организации представляет собой отход от регулярно наблюдаемых целей Mustang Panda в Юго-Восточной Азии.
DDoS-атаки
Мы продолжаем наблюдать попытки DDoS-атак на многочисленные украинские сайты, включая МИД, МВД, а также такие сервисы, как Liveuamap, которые призваны помочь людям найти информацию.
Project Shield позволяет Google поглощать плохой трафик при DDoS-атаке и действовать как «щит» для веб-сайтов, позволяя им продолжать работу и защищаться от этих атак. На сегодняшний день сервисом пользуются более 150 веб-сайтов в Украине, в том числе множество новостных организаций. Мы призываем все подходящие организации зарегистрироваться в Project Shield, чтобы наши системы могли блокировать эти атаки и поддерживать веб-сайты в сети.
Мы продолжим принимать меры, выявлять злоумышленников и делиться соответствующей информацией с другими представителями отрасли и правительств с целью повышения осведомленности об этих проблемах, защиты пользователей и предотвращения атак в будущем.
 Но что, если x == INT_MAX? Поскольку целочисленное переполнение является поведением undefined, компилятор оставляет за собой право игнорировать этот экзотический случай. В этом простом примере мы замечаем нечто пугающее: во время выполнения программы на самом деле нет момента, когда «возникает» неопределенное поведение; вы не можете «обнаружить» его, потому что он остался где-то в параллельной вселенной, но все еще влияет на нашу.
Но что, если x == INT_MAX? Поскольку целочисленное переполнение является поведением undefined, компилятор оставляет за собой право игнорировать этот экзотический случай. В этом простом примере мы замечаем нечто пугающее: во время выполнения программы на самом деле нет момента, когда «возникает» неопределенное поведение; вы не можете «обнаружить» его, потому что он остался где-то в параллельной вселенной, но все еще влияет на нашу. Конечно, это блаженство имеет свою цену: арифметика BigInt намного медленнее, чем встроенная арифметика.
Конечно, это блаженство имеет свою цену: арифметика BigInt намного медленнее, чем встроенная арифметика.

 Они полагаются на модульное и регрессионное тестирование, функциональное тестирование, ручное тестирование и другие, более экзотические методы, такие как фаззинг.
Они полагаются на модульное и регрессионное тестирование, функциональное тестирование, ручное тестирование и другие, более экзотические методы, такие как фаззинг. Оба подхода могут обеспечить надежность на практике и сделать всех счастливыми, но в этом и заключается принципиальное различие между ними: ни один тест не может охватывать все возможные ситуации одновременно. Всегда есть небольшой шанс, что пользователь программы сделает что-то неожиданное, что вызовет появление скрытой ошибки.
Оба подхода могут обеспечить надежность на практике и сделать всех счастливыми, но в этом и заключается принципиальное различие между ними: ни один тест не может охватывать все возможные ситуации одновременно. Всегда есть небольшой шанс, что пользователь программы сделает что-то неожиданное, что вызовет появление скрытой ошибки.

 Если игра завершится без проблем, повторите процесс. Ошибка появится в конце концов, будь то сразу или на следующий день».
Если игра завершится без проблем, повторите процесс. Ошибка появится в конце концов, будь то сразу или на следующий день». Меня интересовали не типы в смысле языка, а «логические типы» функций, так что это не типовая задача. Что-то вроде Haskell не делает различий между этими двумя понятиями, но мы говорим здесь о C++.
Меня интересовали не типы в смысле языка, а «логические типы» функций, так что это не типовая задача. Что-то вроде Haskell не делает различий между этими двумя понятиями, но мы говорим здесь о C++.
 На одном ДС эта команда означала «бросить наковальню на место за туловище Разведчика», а на другом — «бросить наковальню на Разведчика» (на место под его ноги). Также важно было не подходить слишком близко, чтобы Разведчика не «засекли» и не вывели из невидимости.
На одном ДС эта команда означала «бросить наковальню на место за туловище Разведчика», а на другом — «бросить наковальню на Разведчика» (на место под его ноги). Также важно было не подходить слишком близко, чтобы Разведчика не «засекли» и не вывели из невидимости.
 Они делают что-то настолько крутое и научное, что хочется быть на них похожими. В первой культуре эти люди являются создателями компиляторов и стандартных библиотек. Любой, кто читал «Книгу дракона», знает, что даже простой компилятор — невероятно сложная штуковина. Написать еще один контейнер данных на C++ очень просто, но сделать такой, который будут использовать другие, — само по себе искусство. Технологические достижения читаются как доказательство математической теоремы: «Таким образом, мы обнаружили, что существует структура данных с амортизированным временем поиска O(1) и временной сложностью O(In In N)».
Они делают что-то настолько крутое и научное, что хочется быть на них похожими. В первой культуре эти люди являются создателями компиляторов и стандартных библиотек. Любой, кто читал «Книгу дракона», знает, что даже простой компилятор — невероятно сложная штуковина. Написать еще один контейнер данных на C++ очень просто, но сделать такой, который будут использовать другие, — само по себе искусство. Технологические достижения читаются как доказательство математической теоремы: «Таким образом, мы обнаружили, что существует структура данных с амортизированным временем поиска O(1) и временной сложностью O(In In N)».

 Все известные домены Blogspot, контролируемые злоумышленниками, были отключены.
Все известные домены Blogspot, контролируемые злоумышленниками, были отключены. ]space
]space Мы расширили право на участие в Project Shield, нашей бесплатной защите от DDoS-атак, чтобы веб-сайты правительства Украины, посольства по всему миру и другие правительства, находящиеся в непосредственной близости от конфликта, могли оставаться в сети, защищать себя и продолжать предлагать свои важные услуги и обеспечивать доступ к информации. люди нуждаются.
Мы расширили право на участие в Project Shield, нашей бесплатной защите от DDoS-атак, чтобы веб-сайты правительства Украины, посольства по всему миру и другие правительства, находящиеся в непосредственной близости от конфликта, могли оставаться в сети, защищать себя и продолжать предлагать свои важные услуги и обеспечивать доступ к информации. люди нуждаются.