Индексирование сайтов с помощью Яндекс Вебмастер API на Python
Содержание:
Как использовать код из статьи
Я размещу код на Гитхабе в формате Jupyter Notebook – думаю, что так нагляднее.
Установите питон и сборку библиотек Anaconda.
Скачайте папку с Гитхаба. В ней будет:
файл yandex_webmaster_indexing.ipynb с кодом и комментариями,
таблица megaposm.xlsx, которая используется в качестве примера в первом скрипте,
папка result c вложенными отчетами, которые получаются в результате работы скриптов для получения страниц из поисковой базы Яндекса и дальнейшего сопоставления.
Регистрация приложения
Для работы необходимо зарегистрировать приложение и получить токен, который будет использоваться для всех сервисов Яндекса, с которыми вы будет взаимодействовать через программный интерфейс.
1. Перейти по ссылке https://oauth.yandex.ru/client/new.
2. Создать название, выбрать «Веб-сервисы», нажать ссылку «Подставить URL для разработки»:
3. Отметить данные, которые нужны – ВебМастер и Яндекс Метрика:
4. Нажать «Создать приложение».
5. Скопировать Client ID:
6. Подставить Client ID в ссылку https://oauth.yandex.ru/authorize?response_type=token&client_id=Client ID Произойдет редирект на страницу с токеном.
В ссылке указано время жизни токена в секундах – 180 дней:
7. Скопировать токен и использовать в своем коде.
8. Скопировать host проекта и использовать в коде:
Отправка списка страниц на индексирование в Яндекс Вебмастер
Импорт библиотек
import json
import requests
import pandas as pd
Настройки
TOKEN = 'y0_AgABCAAZqca9AAaElQAAAADKLs4Yq_tVuPHCZOKIQLy3rAYljzWccks'
User id
USERID_URL = 'https://api.webmaster.yandex.net/v4/user'
 webmaster.yandex.net/v4/user'
webmaster.yandex.net/v4/user'Отправка на переобход
RECRAWL_URL_TEMPLATE = 'https://api.webmaster.yandex.net/v4/user/{}/hosts/{}/recrawl/queue'Документация https://yandex.ru/dev/webmaster/doc/dg/reference/host-recrawl-post.html
Параметры проекта
host = 'https:megaposm.com:443'
project_name = 'megaposm'
Загрузка URL для индексирования
Файл в формате xlsx с названием поля «urls»:
table_with_urls_for_recrawl = pd.read_excel(f'{project_name}.xlsx')Отправка на индексирование
Авторизация
def get_auth_headers():
return {'Authorization': f'OAuth {TOKEN}'}
Получение user_id Яндекс Вебмастера
def get_user_id():
r = requests.get(USERID_URL, headers=get_auth_headers())
user_id = json.loads(r.text)['user_id']
return user_id
Отправка на индексирование
Функция принимает множество (set) url для отправки,
перебирает каждый url и отправляет его на переобход, пока будет получен ответ НЕ 202,
возвращает set отправленных url.
def send_urls_to_yandex_for_recrawl(data, user_id, host):
sent_urls_for_recrawl_set = set()
for url in data:
yandex_webmaster_recrawl_url = RECRAWL_URL_TEMPLATE.format(user_id, host)
url_for_recrawl = {'url': f'{url}'}
r = requests.post(yandex_webmaster_recrawl_url,
headers = get_auth_headers(),
json = url_for_recrawl
)
if r.status_code != 202:
break
sent_urls_for_recrawl_set.add(url)
sent_urls_set_len = len(sent_urls_for_recrawl_set)
print(json.loads(r.text))
print('На переобход отправлено:', sent_urls_set_len)
return sent_urls_for_recrawl_set
Удаление из списка и экспорт
Функция принимает set с со всеми адресами из загруженной таблицы и set отправленных url,
Из загруженной таблицы удаляются url, которые были отправлены. Это нужно для того, чтобы в следующий раз, когда обновится квота, эти же страницы не оправлялись на переобход.
Это нужно для того, чтобы в следующий раз, когда обновится квота, эти же страницы не оправлялись на переобход.
Экспорт
def export_data_to_excel(data):
project_report = pd.ExcelWriter(f'{project_name}.xlsx', engine='xlsxwriter')
data.to_excel(project_report, index=False)
project_report.save()
Удаление и экспорт
def delete_sent_urls_and_export_new_table(main_urls_set, sent_urls_for_recrawl_set):
main_urls_set_without_sent_urls = main_urls_set - sent_urls_for_recrawl_set
rest_urls_list = list(main_urls_set_without_sent_urls)
data = pd.DataFrame({'urls': rest_urls_list})
export_data_to_excel(data)
Главная функция
Принимает датафрейм, который был загружен в начале,
преобразует датафрейм в set,
отправляет на переобход,
удаляет из общего списка отправленные url и экспортирует датафрейм.
def main_send_pages_to_yandex_for_recrawl(data):
user_id = get_user_id()
main_urls_set = set(data['urls'].
sent_urls_for_recrawl_set = send_urls_to_yandex_for_recrawl(main_urls_set, user_id, host)
delete_sent_urls_and_export_new_table(main_urls_set, sent_urls_for_recrawl_set)
 to_list())
to_list())Запуск
main_send_pages_to_yandex_for_recrawl(table_with_urls_for_recrawl)
Получение списка проиндексированных страниц
Импорт библиотек
import json
import requests
import os
from datetime import datetime
from bs4 import BeautifulSoup
import pandas as pd
Настройки
TOKEN = 'y0_AgABCAAZqca9AAaElQAAAADKLs4Yq_tVuPHCZOKIQLy3rAYljzWccks'
User id
USERID_URL = 'https://api.webmaster.yandex.net/v4/user'
Получение статистики по проекту
HOST_STAT_URL_TEMPLATE = 'https://api.webmaster.yandex.net/v4/user/{}/hosts/{}/summary'Документация https://yandex.ru/dev/webmaster/doc/dg/reference/host-id-summary. html.
html.
Получение списка url в поисковой базе
INSEARCH_URL_TEMPLATE = 'https://api.webmaster.yandex.net/v4/user/{}/hosts/{}/search-urls/in-search/samples'Документация https://yandex.ru/dev/webmaster/doc/dg/reference/hosts-indexing-insearch-samples.html#hosts-indexing-insearch-samples.
Для получения списка страниц необходимо указать количество страниц, получаемое за одну итерацию, максимально можно указать 100.
YANDEX_PER_REQUEST_PAGE_LIMIT = 100
Параметры проекта
host = 'https:megaposm.com:443'
project_name = 'megaposm'
sitemap_path = 'https://megaposm.com/index.php?route=extension/feed/google_sitemap'
Директория для визуального отчета
YANDEX_VISUAL_REPORTS_DIR = 'results/visual_reports/yandex'
Директория для файлов со списком url на переобход
YANDEX_RECRAWL_BASES_DIR = 'results/recrawl_bases/yandex'
Получение списка страниц
Авторизация
def get_auth_headers():
return {'Authorization': f'OAuth {TOKEN}'}
Получение user_id Яндекс Вебмастера
def get_user_id():
r = requests.
user_id = json.loads(r.text)['user_id']
return user_id
 get(USERID_URL, headers=get_auth_headers())
get(USERID_URL, headers=get_auth_headers())Получение URL из поисковой базы
Функция принимает user id и хост,
получает число проиндексированных страниц — indexed_pages_quantity,
указаны параметры offset — смещение списка, т.е. с какой строки в списке будут получены url и limit — сколько страниц будет получено за один шаг — ранее был указан этот параметр в YANDEX_PER_REQUEST_PAGE_LIMIT,
запускается цикл while, который работает пока offser меньше числа проиндексированных страниц — indexed_pages_quantity,
запускается генератор множеств (set), в котороый добавляются полученные url,
полученный set с адресами объединяется с общим множеством indexed_pages,
к offset прибавляется число полученных url YANDEX_PER_REQUEST_PAGE_LIMIT,
функция возвращает множество indexed_pages.
def yandex_get_indexed_pages(user_id, host):
host_stat_url = HOST_STAT_URL_TEMPLATE.format(user_id, host)
insearch_url = INSEARCH_URL_TEMPLATE.format(user_id, host)
r = requests.get(host_stat_url, headers=get_auth_headers())
indexed_pages_quantity = json.loads(r.text)['searchable_pages_count']
print(f'В поисковой базе содержится {indexed_pages_quantity} страниц',)
indexed_pages = set()
params = {'offset': 0, 'limit': YANDEX_PER_REQUEST_PAGE_LIMIT}
while params['offset'] < indexed_pages_quantity:
r = requests.get(insearch_url, headers=get_auth_headers(), params=params)
current_urls = {element['url'] for element in json.loads(r.text)['samples']}
indexed_pages = indexed_pages.union(current_urls)
params['offset'] += YANDEX_PER_REQUEST_PAGE_LIMIT
return indexed_pages
Отмечу, что Яндекс Вебмастер предоставляет только 50 000 строк с url, которые хранятся в его базе. Если на сайте больше страниц, то дальнейшее сопоставление даст некорректные результаты.
Если на сайте больше страниц, то дальнейшее сопоставление даст некорректные результаты.
Сопоставление полученных url из Вебмастера с актуальными адресами на сайте
Функция yandex_get_indexed_pages возвращает set для удобного сопоставления с url, которые у вас на сайте.
Актуальный список url вы можете получить при парсинге краулером, например Comparser. Затем загрузите таблицу, например с названием поля ‘urls’, где будут перечислены адреса:
parsed_urls = pd.read_excel(f'{project_name}.xlsx')Конвертация в set:
site_pages = set(parsed_urls['urls'])
Далее для сопоставления я буду использовать адреса из sitemap.
Парсинг Sitemap
Можно указать user agent, чтобы парсер не получил ответ 403 из-за настроек сервера или CDN, например CloudFlare:
user_agent = {'User-agent': 'Mozilla/5.0'}Одна карта
Функция принимает адрес карты сайта,
парсит,
возвращает set с адресами из карты сайта.
def parse_sitemap_one_map(sitemap_path):
r = requests.get(sitemap_path, headers=user_agent)
soup = BeautifulSoup(r.text, 'xml')
url_set = {url.text for url in soup.find_all('loc')}
print('Количество страниц в Sitemap:', len(url_set))
return url_set
Мультакарта
Функция принимает адрес карты сайта,
парсит, получает список вложенных карт,
парсит по очереди вложенные карты,
возвращает set со всеми адресами из мультикарты.
def parse_sitemap_many_maps(sitemap_path):
r = requests.get(sitemap_path, headers=user_agent)
soup = BeautifulSoup(r.text, 'xml')
maps = [sitemap.text for sitemap in soup.find_all('loc')]
url_set = set()
for sitemap in maps:
r = requests.get(sitemap, headers=user_agent)
soup = BeautifulSoup(r.text, 'xml')
current_urls = {url.text for url in soup.find_all('loc')}
url_set = url_set.
print('Количество страниц в Sitemap:', len(url_set))
return url_set
 union(current_urls)
union(current_urls)Сопоставление адресов из базы Яндекса с адресами из Sitemap
Сопоставление
Функция принимает set с адресами из базы Яндекса и set с адресами из карты сайта,
в pages_is_sitemap_but_not_in_index записываются адреса, которые есть в карте сайта, но отсутствуют в поисковой базе,
оба отчета записываются в соседние колонки датафрейма для дальнейшего визуального сопоставления,
функция возвращает датафрейм.
def comapre_indexed_pages_with_pages_in_sitemap(indexed_pages, pages_in_sitemap):
pages_in_index_but_not_in_sitemap = indexed_pages - pages_in_sitemap
pages_is_sitemap_but_not_in_index = pages_in_sitemap - indexed_pages
pages_in_index_but_not_in_sitemap_df = pd.
pages_in_index_but_not_in_sitemap,
columns=['pages_in_index_but_not_in_sitemap']
)
pages_is_sitemap_but_not_in_index_df = pd.DataFrame(
pages_is_sitemap_but_not_in_index,
columns=['pages_is_sitemap_but_not_in_index']
)
df = pd.concat([pages_in_index_but_not_in_sitemap_df, pages_is_sitemap_but_not_in_index_df], axis=1)
return df
 DataFrame(
DataFrame(Создание визуального отчета в таблице
Функция с настройками для экспорта
def export_report_data_to_excel(data, path, filename):
os.makedirs(path, exist_ok=True)
project_report = pd.ExcelWriter(os.path.join(path, filename), engine='xlsxwriter')
data.to_excel(project_report, index=False)
project_report.save()
Экспорт визуального отчета
Функция принимает название проекта, путь, по которому будет лежать отчет, set с url в индексе, set url из карты сайта,
затем запускается функция сопоставления и запись датафрейма в data,
экспортируется файл, название которого состоит из названия проекта и даты отчета.
def make_visual_report_for_yandex(project_name, path, indexed_pages, pages_in_sitemap):
data = comapre_indexed_pages_with_pages_in_sitemap(indexed_pages, pages_in_sitemap)
current_date = datetime.now().strftime('%d_%m_%Y')
filename = f'{project_name}_{current_date}.xlsx'
export_report_data_to_excel(data, path, filename)
Экспорт визуального отчета для сайтов с мультикартой
def make_visual_report_for_yandex_for_many_maps(project_name, path, indexed_pages, pages_in_sitemap):
data = comapre_indexed_pages_with_pages_in_sitemap(indexed_pages, pages_in_sitemap)
current_date = datetime.now().strftime('%d_%m_%Y')
filename = f'{project_name}_{current_date}.csv'
data.to_csv(f'{path}/{filename}', index=False)
Модуль os создает директорию, которая была указана в настройках, если ее нет:
Отчет для визуального сопоставления содержит две колонки:
Страницы, которые есть в индексе, но отсутствуют в карте сайта – тут можно найти дубли, которые образованы параметрами, затем добавить параметры в robots. txt в Clean-param. Минусом парсинга карты сайта для сопоставления является возможное отсутствие в ней каких-нибудь побочных страниц (новости, контакты, информация о работе и т.д.) и пагинации, которую я рекомендую не закрывать от индексирования – подробнее. Так всегда будет несоответствие в отчете, но при быстром просмотре вы быстро распознаете «законное» несоответствие и реальные дубли.
txt в Clean-param. Минусом парсинга карты сайта для сопоставления является возможное отсутствие в ней каких-нибудь побочных страниц (новости, контакты, информация о работе и т.д.) и пагинации, которую я рекомендую не закрывать от индексирования – подробнее. Так всегда будет несоответствие в отчете, но при быстром просмотре вы быстро распознаете «законное» несоответствие и реальные дубли.
Страницы, которые если в карте сайта, но отсутствуют в индексе – эти страницы почему-то были не проиндексированы, нужно отправить на переобход.
Создание списка на переобход
Похожая функция как для сопоставления, которая принимает set с адресами из базы Яндекса и set с адресами из карты сайта,
в pages_in_index_but_not_in_sitemap записываются адреса, которые есть в поисковой базе, но отсутствуют в карте сайта,
в pages_is_sitemap_but_not_in_index записываются адреса, которые есть в карте сайта, но отсутствуют в поисковой базе,
оба отчета записываются в одну колонку для отправки на переобход,
функция возвращает датафрейм.
def get_recrawl_base_for_yandex(indexed_pages, pages_in_sitemap):
pages_in_index_but_not_in_sitemap = indexed_pages - pages_in_sitemap
pages_is_sitemap_but_not_in_index = pages_in_sitemap - indexed_pages
all_pages_to_recrawl = list(pages_in_index_but_not_in_sitemap.union(pages_is_sitemap_but_not_in_index))
data = pd.DataFrame(all_pages_to_recrawl, columns=['urls'])
return data
Экспорт таблицы со списком на переобход
def make_recrawl_base_for_yandex(project_name, path, indexed_pages, pages_in_sitemap):
data = get_recrawl_base_for_yandex(indexed_pages, pages_in_sitemap)
filename = f'{project_name}.xlsx'
export_report_data_to_excel(data, path, filename)
Экспорт таблицы со списком на переобход для сайтов с мультикартой
def make_recrawl_base_for_yandex_many_maps(project_name, path, indexed_pages, pages_in_sitemap):
data = get_recrawl_base_for_yandex(indexed_pages, pages_in_sitemap)
filename = f'{project_name}.
data.to_csv(f'{path}/{filename}', index=False)
 csv'
csv'Директория, которая указана в настройках, создается модулем os, если ее нет:
Список на переобход:В списке просто объединены url,которые содержатся в двух колонках в визуальном отчете.
Главная функция
def main_yandex_index_sitemap_compare():
user_id = get_user_id()
print(project_name)
indexed_pages = yandex_get_indexed_pages(user_id, host)
pages_in_sitemap = parse_sitemap_one_map(sitemap_path)
print('Подготовка визуального отчета')
make_visual_report_for_yandex(project_name, YANDEX_VISUAL_REPORTS_DIR, indexed_pages, pages_in_sitemap)
print('Подготовка таблицы со списком url на переобход')
make_recrawl_base_for_yandex(project_name, YANDEX_RECRAWL_BASES_DIR, indexed_pages, pages_in_sitemap)
Запуск
main_yandex_index_sitemap_compare()
Похожие статьи:
Автоматизaция — Индексирование сайтов с помощью Index Now на Python
Автоматизация — Индексирование сайтов с помощью Google Indexing API на Python
# Теги
Техническая оптимизация
Автоматизация SEO на Python
Василий Фокин
Работаю в агенстве Marronnier с 2015 года, занимаюсь продвижением сайтов в посковых системах.
Условия использования сервиса «API Яндекс.Вебмастер»
Общество с ограниченной ответственностью «ЯНДЕКС» (далее — «Яндекс») предлагает пользователю сети Интернет (далее — «Пользователь») использовать сервис «API Яндекс.Вебмастер» на условиях, изложенных в настоящем документе (далее — «Условия»).
1.1. Термины и определения
Клиентское приложение — уникальный идентификатор, выдаваемый Пользователю, позволяющий получить доступ к функциям Сервиса.
Данные — данные, поступающие от Сервиса, предназначенные для показа Конечным пользователям, о том, как индексируются поисковой машиной Яндекса сайты в сети Интернет, предоставляемые с помощью сервиса Яндекс.Вебмастер.
Расширенные Данные — данные, поступающие от Сервиса, предназначенные для показа Конечным пользователям, включая Данные, а также информацию о внешних ссылках на сайты Конечных Пользователей.
Сервис — сервис «API Яндекс.Вебмастер», представляющий собой программный интерфейс, который в онлайн режиме предоставляет доступ к части функциональных возможностей Яндекс. Вебмастера.
Вебмастера.
Сайт Пользователя — информационные ресурсы Пользователя в сети Интернет.
Программа Пользователя – программное обеспечение, создаваемое Пользователем с использованием Сервиса.
Конечные пользователи — лица, являющиеся посетителями информационных ресурсов в сети Интернет, в том числе лица, пользующиеся услугами и Сайтом Пользователя для осуществления хостинга сторонних информационных ресурсов в сети Интернет.
Яндекс.Вебмастер — размещенный в сети Интернет сервис Яндекса, предоставляющий возможность получать информацию о том, как индексируются сайты в сети Интернет поисковой машиной Яндекса, доступный в сети Интернет по адресу: http://webmaster.yandex.ru.
1.2. Использование Пользователем Сервиса регулируется настоящими Условиями, а также:
1.3. Начиная использовать Сервис или его отдельные функции, в том числе зарегистрировав Клиентское приложение, зарегистрировавшись на Сервисе, разместив код сервиса на своем Сайте или в Программе или воспользовавшись любой другой функциональной возможностью, предоставляемой Сервисом, Пользователь принимает настоящие Условия, а также условия всех указанных в п. 1.2 Условий документов, в полном объеме, без всяких оговорок и исключений, и обязуется соблюдать их. Использование Сервиса на иных условиях, чем условия указанных документов, возможно только по предварительному письменному согласию Яндекса. В случае несогласия Пользователя с какими-либо из условий указанных документов, Пользователь не вправе использовать Сервис.
1.2 Условий документов, в полном объеме, без всяких оговорок и исключений, и обязуется соблюдать их. Использование Сервиса на иных условиях, чем условия указанных документов, возможно только по предварительному письменному согласию Яндекса. В случае несогласия Пользователя с какими-либо из условий указанных документов, Пользователь не вправе использовать Сервис.
1.4. Пользователь самостоятельно несет ответственность за соблюдение им Законодательства при использовании Сервиса. Везде по тексту настоящих Условий, если явно не указано иное, под термином «Законодательство» понимается любое применимое законодательство, включая как законодательство Российской Федерации, так и законодательство места пребывания Пользователя или места совершения им юридически значимых действий в соответствии с настоящими Условиями. Если использование Пользователем какой-либо возможности, предоставляемой Сервисом, нарушает Законодательство, Пользователь обязуется воздержаться от использования Сервиса. Пользователь самостоятельно и за свой счет обязуется урегулировать все претензии и/или иски третьих лиц, связанные с действиями Пользователя при использовании Сервиса, а в случае если это повлекло убытки для Яндекса – возместить их в полном объеме.
1.5. К настоящим Условиям и отношениям между Яндексом и Пользователем, возникающим в связи с использованием Сервиса, подлежит применению право Российской Федерации.
2.1. В соответствии с настоящими Условиями, Пользователем может быть либо владелец Сайта, основным или одним из направлений деятельности которого является предоставление неограниченному кругу третьих лиц хостинг-услуг, в том числе размещение информационных ресурсов третьих лиц на серверах Пользователя с обеспечением доступа к ним в сети Интернет, либо разработчик программ для таких информационных ресурсов.
2.2. Пользователь с использованием Сервиса получает Данные (Расширенные Данные) о сайтах Конечных пользователей и отображает их на Сайте Пользователя или в Программе Пользователя, в порядке, определенном настоящими Условиями. Яндекс обеспечивает передачу Данных (Расширенных Данных) Пользователю, полученных с использованием технологий сервиса Яндекс.Вебмастер, при соблюдении условий и ограничений, предусмотренных настоящими Условиями. Пользователь отправляет запросы к Сервису в соответствии с техническими требованиями, определенными в документе «API Яндекс.Вебмастер Руководство разработчика», актуальная версия которого размещена по адресу: http://api.yandex.ru/webmaster.
Пользователь отправляет запросы к Сервису в соответствии с техническими требованиями, определенными в документе «API Яндекс.Вебмастер Руководство разработчика», актуальная версия которого размещена по адресу: http://api.yandex.ru/webmaster.
2.3. Пользователь предоставляет Конечным пользователям возможность доступа к Данным (Расширенным Данным) об их сайтах, полученным от Яндекса посредством Сервиса. Конечный пользователь, желающий воспользоваться указанной функциональностью, даёт свое согласие на загрузку Данных (Расширенных Данных) Пользователю посредством протокола OAuth. Пользователь не вправе загружать Данные (Расширенные Данные), если Конечный пользователь не дал на это своего согласия.
2.4. Яндекс самостоятельно определяет и изменяет состав и объем Данных (Расширенных Данных), а также принципы и условия использования Данных (Расширенных Данных) и/или их фрагментов Пользователем. Яндекс предоставляет Пользователю право использования Данных (Расширенных Данных) и/или их фрагментов в электронном виде путем их отображения на Сайте или в Программе Пользователя и сообщения исключительно Конечному пользователю, являющемуся владельцем информационных ресурсов, к которым такие Данные (Расширенные Данные) относятся. Предоставленное Пользователю разрешение действует без ограничения территории и до тех пор, пока Пользователь использует Сервис в полном соответствии с настоящими Условиями.
Предоставленное Пользователю разрешение действует без ограничения территории и до тех пор, пока Пользователь использует Сервис в полном соответствии с настоящими Условиями.
2.5. В случае если Пользователь желает получать от Сервиса Расширенные Данные, он обязан после регистрации Клиентского приложения идентифицировать себя, направив Яндексу уведомление, форма которого размещена по адресу: http://webmaster.yandex.ru/docs/uvedomlenie.pdf. Пользователь, не идентифицировавший себя и не направивший Яндексу уведомление, не вправе получать и каким-либо образом использовать Расширенные Данные. Указанная идентификация Пользователя является обязательным условием получения Расширенных Данных, но не является гарантией предоставления Яндексом Пользователю Расширенных Данных. Решение о предоставлении Пользователю возможности получения Расширенных Данных принимается исключительно Яндексом по собственному усмотрению. Яндекс вправе отказать любому Пользователю, в том числе идентифицировавшему себя, в получении Расширенных Данных без объяснения причин.
2.6. Перечень Сайтов и/или Программ Пользователя, где он желает использовать Расширенные Данные, должен быть указан Пользователем в уведомлении, направляемом Яндексу согласно п. 2.5 настоящих Условий. Пользователь вправе использовать Расширенные Данные только на тех Сайтах и/или Программах Пользователя, которые были письменно (включая электронную почту) подтверждены Яндексом.
2.7. Для получения доступа к Сервису Пользователь обязан зарегистрировать Клиентское приложение по установленной форме https://oauth.yandex.ru/client/new. Яндекс вправе по своему усмотрению отказать в доступе к Сервису без объяснения причин. Пользователь не имеет права использовать любые программы, устройства или иные средства, позволяющие регистрировать Клиентские приложения автоматическим путем или иным образом с нарушением процедуры, установленной Яндексом.
2.8. Пользователь вправе использовать Сервис только в рамках интернет-сервисов/программ для ЭВМ, доступных для открытого использования неограниченным кругом лиц. Пользователь не имеет права использовать Сервис для проектов, в которых ограничен доступ к ним третьих лиц. Необходимость зарегистрироваться не считается ограничением доступа в рамках настоящего пункта.
Пользователь не имеет права использовать Сервис для проектов, в которых ограничен доступ к ним третьих лиц. Необходимость зарегистрироваться не считается ограничением доступа в рамках настоящего пункта.
2.9. При использовании Сервиса Пользователь обязан обеспечить указание на технологию Яндекса путем размещения на Сайте Пользователя или в Программе Пользователя в непосредственной близости от выводимых Данных, полученных с использованием Сервиса, логотипа Яндекса, текста «Данные предоставлены сервисом Яндекс.Вебмастер» с гиперссылкой на http://webmaster.yandex.ru в основе слов «Яндекс.Вебмастер», а также, что Данные хранятся на Ресурсах Яндекса. При использовании Сервиса пользователь не имеет права удалять, скрывать или модифицировать любые содержащиеся в Сервисе или полученных с его помощью данных товарные знаки, логотипы, ссылки или иные указания на Яндекс или иных лиц, равно как и любые другие уведомления и/или информацию, передаваемые Сервисом.
2.10. Пользователь не имеет права сохранять, обрабатывать, систематизировать, передавать третьим лицам и видоизменять Данные и Расширенные Данные, а также использовать иными способами, помимо разрешенных настоящими Условиями.
2.11. Пользователь не имеет права использовать Сервис для создания интернет-сервисов, программ для ЭВМ или иным образом, если такое использование влечет нарушение Законодательства, документов, указанных в п. 1.2 Условий, и/или прав и законных интересов третьих лиц.
2.12. Яндекс оставляет за собой право изменять, исправлять или обновлять Сервис в любой момент, без предварительного уведомления Пользователя. При выпуске очередной стабильной версии Яндекс сообщает о её выпуске на веб-страницах Сервиса. После выпуска новой версии Сервиса Яндекс не гарантирует стабильность и продолжительность работы его устаревших версий. Пользователь, не согласный использовать обновленную версию Сервиса, может либо продолжать на свой страх и риск использовать устаревшую версию Сервиса, либо прекратить использование Сервиса.
3.1. Исключительное право на Сервис принадлежит Яндексу. Исключительные права на Данные и Расширенные Данные принадлежат Яндексу или иным правообладателям. Настоящие Условия не дают Пользователю каких-либо прав на использование Сервиса или Данных помимо тех возможностей, которые предоставляются непосредственно в интерфейсе Сервиса в соответствии с настоящими Условиями.
3.2. Используя Сервис, Пользователь предоставляет Яндексу право использовать логотип, товарный знак и/или фирменное наименование Пользователя и/или сайта Пользователя в информационных, рекламных и маркетинговых целях без необходимости получения дополнительного согласия Пользователя и без выплаты ему какого-либо вознаграждения за такое использование.
4.1. Сервис (включая Данные и Расширенные Данные) предоставляется Яндексом «как есть». Яндекс не гарантирует соответствие Сервиса и Данных (Расширенных Данных) целям и ожиданиям Пользователя, бесперебойную и безошибочную работу Сервиса в целом и отдельных его компонентов и/или функций, а также не гарантирует достоверность, точность, полноту и своевременность Данных (Расширенных Данных). Яндекс не гарантирует бесперебойную и безошибочную работу сторонних программных продуктов и решений (в т.ч. библиотек), рекомендованных при использовании Сервиса в технических условиях и иной документации, связанной с его использованием. Яндекс не несет ответственности и не возмещает никакой ущерб, прямой или косвенный, причиненный пользователю Сервиса или третьим лицам в результате использования или невозможности использования Сервиса.
4.2. Пользователь самостоятельно и в полном объёме несёт ответственность за использование своего Клиентского приложения. Пользователь не имеет права регистрировать Клиентское приложение для третьих лиц, передавать или предоставлять его третьим лицам. Яндекс не несёт ответственности за несанкционированное использование Клиентского приложения третьими лицами. Все действия, совершенные на Сервисе с использованием принадлежащего Пользователю Клиентского приложения, считаются совершенными Пользователем.
5.1. Яндекс имеет право без уведомления по собственному усмотрению прекратить или приостановить доступ Пользователя к Сервису или к отдельным его функциям с использованием его учетной записи и/или Клиентского приложения, без объяснения причин, в том числе, в случае нарушения Пользователем требований настоящих Условий.
5.2. Все вопросы и претензии, связанные с использованием/невозможностью использования Сервиса, должны направляться по адресу электронной почты webmaster-api@yandex-team. ru.
ru.
5.3. Яндекс вправе в любое время без уведомления Пользователя изменять текст настоящих Условий. Действующая редакция настоящих Условий размещается по адресу: https://yandex.kz/legal/webmaster_api. Новая редакция Условий вступает в силу с момента ее размещения в сети Интернет по указанному в настоящем абзаце адресу. Продолжение использования Сервиса после изменения Условий считается согласием с их новой редакцией. Пользователь обязан прекратить использование Сервиса, в случае если Яндексом были внесены какие-либо изменения в настоящие Условия, с которыми Пользователь не согласен.
Получение данных из API инструментов Bing для веб-мастеров
6 месяцев — столько времени назад вы можете получить доступ к данным поиска Bing. Сможете ли вы через год проанализировать, как изменились поисковые запросы Bing после интеграции ChatGPT?
Недавнее внимание к Bing после интеграции ChatGPT должно побудить предприятия пересмотреть свои конвейеры сбора данных Bing. В зависимости от темпов инноваций и различий между ChatGPT и Bard, впечатляющая доля рынка Google в 93% вскоре может быть оспорена.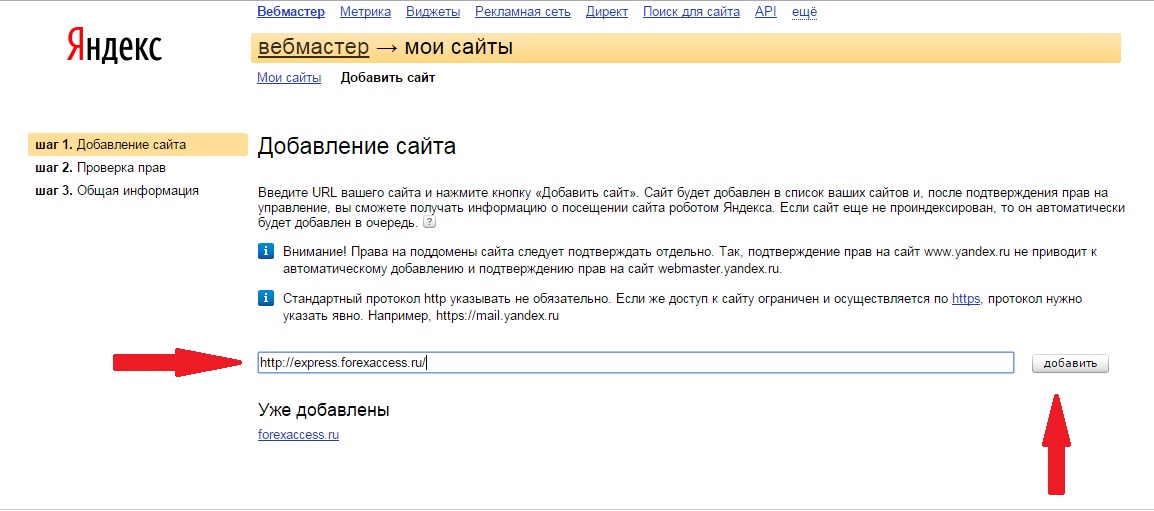 Более того, GPT4 вполне может усугубить отрыв Microsoft от Google в области искусственного интеллекта.
Более того, GPT4 вполне может усугубить отрыв Microsoft от Google в области искусственного интеллекта.
Учитывая сегодняшнее состояние рынка поисковых систем, предприятия, как и ожидалось, убрали приоритеты конвейеров данных Bing. Несмотря на то, что для расширенного поиска с помощью ИИ еще рано, доля Microsoft в OpenAI, вероятно, будет означать, что дальнейшие разработки ИИ и другие дополнительные услуги, вероятно, будут интегрированы в Bing. Это может означать повышенный интерес конечных пользователей к Bing, что напрямую приводит к необходимости для предприятий собирать и анализировать данные Bing.
Несмотря на то, что рынок вряд ли претерпит существенные изменения в ближайшем будущем, компании могут увидеть, что в ближайшие несколько лет трафик их поисковых систем станет более распределенным. Однако, если конвейеры данных Bing не настроены, ценные поисковые данные за месяцы или годы будут потеряны. Сегодня политика хранения данных Bing составляет шесть месяцев. Простой конвейер владения данными, внедренный сегодня, может оказаться бесценным через несколько лет.
К данным инструментов Bing для веб-мастеров можно получить программный доступ через Bing Webmaster API, а к данным Bingbot — через журналы веб-сервера.
Bing’s Webmaster API содержит исчерпывающий набор хорошо задокументированных конечных точек для пользовательского поиска и управления поисковой системой. API можно использовать для создания простых конвейеров, которые записывают данные поиска и индексирования в любую службу хранения. Этот подход предлагает предприятиям полный контроль над политиками хранения, а это означает, что они больше не будут зависеть от политик Bing. Настройка инфраструктуры для обеспечения более длительных политик хранения данных, пока это еще рано, обеспечит вам долгосрочную видимость, необходимую для анализа данных.
Журнал веб-сервера Процессы для некоторых предприятий полностью разработаны для Google и Googlebot. Они не учитывают Bing или другие поисковые системы, такие как Yahoo!, Yandex, Baidu или Naver. В этих случаях включение сбора данных Bingbot в процессе журнала сервера может повлечь за собой изменение всего базового процесса журнала сервера. Эти изменения могут принимать две возможные формы:
В этих случаях включение сбора данных Bingbot в процессе журнала сервера может повлечь за собой изменение всего базового процесса журнала сервера. Эти изменения могут принимать две возможные формы:
- Вставка Bingbot в существующую систему журналов сервера. Простое добавление Bingbot в систему журналов сервера вместе с Google может создать проблемы для инструментов аналитики нижестоящего уровня, если нижестоящие ожидают только данные робота Googlebot. Записи журнала должны быть помечены, чтобы различать записи, созданные Google и Bing.
- Создание отдельного конвейера Bingbot. Чтобы оставить систему журналов сервера Googlebot нетронутой, нам нужно создать отдельный конвейер Bingbot. Этот подход требует дополнительных предварительных усилий, но обеспечивает больший контроль и гибкость для независимого управления каждым конвейером журналов сервера поисковой системы.
Начало 2023 года может стать переломным моментом на рынке поиска. Возможность отслеживать изменения с этого момента может принести многочисленные долгосрочные преимущества. Однако все это зависит от наличия конвейеров сбора данных, чтобы получить право собственности на поисковые данные ваших веб-сайтов. Чтобы узнать больше о том, как Merj может помочь вам настроить конвейеры данных Bingbot, свяжитесь с нами сегодня.
Однако все это зависит от наличия конвейеров сбора данных, чтобы получить право собственности на поисковые данные ваших веб-сайтов. Чтобы узнать больше о том, как Merj может помочь вам настроить конвейеры данных Bingbot, свяжитесь с нами сегодня.
Инструменты Bing для веб-мастеров: руководство по подключению Supermetrics
Группа поддержки сайта SupermetricsДата изменения: Пт, 24 февраля 2023 г., 10:51
Следуйте этому руководству, чтобы подключить данные инструментов Bing для веб-мастеров к Supermetrics.
Если вам нужно подключить этот источник данных к одному из наших хранилищ данных или облачных хранилищ, изучите наши руководства по настройке хранилищ данных и облачных хранилищ.
Прежде чем начать
Чтобы подключить Supermetrics к инструментам Bing для веб-мастеров, веб-мастерам необходим ключ API . Следуйте инструкциям Microsoft, чтобы сгенерировать этот ключ API.
Следуйте инструкциям Microsoft, чтобы сгенерировать этот ключ API.
Инструкции
Перед подключением убедитесь, что вы установили надстройку Supermetrics.
- Откройте новый файл Google Sheets.
- Перейдите к Extensions → Supermetrics → Запустите боковую панель , чтобы открыть Supermetrics.
- Нажмите Создать новый запрос .
- В разделе Источник данных выберите Инструменты Bing для веб-мастеров .
- Введите ключ API и нажмите Пуск .
- В разделе «Выберите сайты» выберите сайты, которые вы хотите включить в отчет.
Узнайте о дополнительных настройках, рекомендациях и советах по устранению неполадок в Supermetrics для Google Таблиц.
Прежде чем выполнять следующие шаги, убедитесь, что вы подключили Supermetrics к Looker Studio.
- Откройте галерею источников данных Supermetrics Looker Studio.
- Перейдите к инструментам Bing для веб-мастеров и нажмите Начать бесплатную пробную версию .
- Вы увидите две кнопки с надписью Authorize . Если вы используете Supermetrics впервые, щелкните слева и войдите в учетную запись Google, которую вы используете с Supermetrics.
- После этого или, если вы уже делали это ранее, нажмите правую кнопку Авторизовать (в разделе «Инструментам для веб-мастеров Bing требуется авторизация для подключения к данным»).
- Выберите команду, у которой есть доступ к учетной записи, которую вы хотите подключить.
- Выберите, сделать это подключение общим или частным.
- Нажмите Пуск .
- Введите ключ API и нажмите Пуск .
- Выберите сайты, которые вы хотите включить в отчет.
- Прокрутите страницу вниз. Чтобы создать отчет с нашим шаблоном, выберите Использовать шаблон отчета для новых отчетов . Чтобы создать пустой отчет, снимите этот флажок.
- В правом верхнем углу панели нажмите Подключить .
- Нажмите Создать отчет .
- Нажмите Добавить в отчет .


Узнайте о дополнительных настройках, рекомендациях и советах по устранению неполадок в Supermetrics for Looker Studio.
Перед подключением убедитесь, что вы установили надстройку Supermetrics.
- Откройте файл Excel.
- Щелкните Данные → Показать суперметрики.
- В разделе Источник данных выберите Инструменты Bing для веб-мастеров .
- Выберите, сделать ли это подключение общим или частным.
- Введите ключ API и нажмите Пуск .
- В разделе «Выберите сайты» выберите сайты, которые вы хотите включить в отчет.