история проекта, и том как использовать архив веб-страниц
Веб-архив сайтов (The Wayback Machine): история проекта, и том как использовать архив веб-страницПодробная информация о сервисе
История интернет архива, описание проекта, награды и блокировка
The Wayback Machine — это архив интернета (Internet Archive). По сути это некоммерческая организация, которая была основана в 1996 году. Задачей данной организации является сбор и хранение всевозможной публичной информации собранной из интернета: веб-страницы, электронные книги, фото- и, видео материалы. Основные сервера расположены в Сан-Франциско. Размер архива на февраль 2017 года составляет 13 петабайт и включает в себя 525 миллиардов копий веб-страниц.
Краткая история Archive.org
Основателем является Брюстер Кейл, который основал организацию в 1996 году. В том же оду начал
процесс по архивации веб страниц. Проект назывался Wayback Machine. По сей день сохраненные копии
доступны любому пользователю посетившему сайт.
В том же оду начал
процесс по архивации веб страниц. Проект назывался Wayback Machine. По сей день сохраненные копии
доступны любому пользователю посетившему сайт.
Расширение организации в 1999 году, ознаменовалось хранением не только веб-страниц, но и видео, аудио, изображения и даже программное обеспечение.
Основные направления работы
Archive.org имеется два основных проекта
В интернете не существует аналогов данному проекту. База архива собиралась в общей сложности около 20 лет. При этом, можно смело заявить что проект является волантерским.
The Wayback Machine
Работает с 1996 года
Веб-сервис по сбору и хранению веб-страниц сайтов со всем их содержимым.
Open Library
Работает с 2005 года
Это общественный проект по сканированию всех книг в по всему миру. Проект имеет 13 центров оцифровки оцифровки книг в крупных библиотеках. Архив книг насчитывает более 1, миллионов книг, и коллекция постоянно растет.
Проблемы на законодательном уровне
На сервис не единожды подавались иски в суд за нарушение авторских прав. Поэтому по требованию правообладателей архив удаляет из публичного доступа соответствующие материалы.
Мануал: как пользоваться сайтом archive.org?
Открываем сайт по адресу — https://archive.
Как найти нужный сайт и восстановить копию из веб-архива?
Чтобы скачать страницы сайта, Вам необходимо использовать специализированные сервисы или соответствующее программное обеспечение. В открытом доступе такого программного обеспечения нет. Мы предлагаем Вам воспользоваться услугами сервиса — WEBARCHIVEORG.RU.
Почему именно мы?
Восстановленный сайт будет работать на простом движке. По качеству нет аналогов. Неограниченное количество страниц за фиксированную цену. Адекватная служба поддержки.
Инструкция по настройке https, и редиректа www на нашей платформе
Как настроить редиректы http и www на восстановленном из веб-архива сайте? Подробнее об этом читайте. ..
..Как установить счетчики, почистить и сделать замену участков кода?
Рассматриваем на примерах как самостоятельно отредактировать максимальное количество страниц с миним…
Руководство по установке сайта на ISPManager
Если на вашем хостинге установлена панель ISPManager, то данная инструкция поможет вам установить во…
Archivarix — Wayback Machine Downloader альтернативы и похожие программы
Загрузчик архива Wayway Machine онлайн — это сервис для воссоздания веб-сайтов с Wayback Machine web.archive.org
— Загрузка и обработка контента происходит на нашем сервере. Вам не нужно тратить на это время, мы вышлем вам готовый zip-архив со всем сайтом.
— Восстановленные файлы с текстом (html, css, js) находятся в отдельной папке, чтобы упростить поиск и замену. Внутренняя связь восстанавливается с помощью mod_rewrite в .htaccess
 Все битые файлы заменяются на фиктивные, которые вы можете редактировать. Все баннеры, счетчики и другие внешние скрипты удаляются с помощью базы данных AdBlock.
Все битые файлы заменяются на фиктивные, которые вы можете редактировать. Все баннеры, счетчики и другие внешние скрипты удаляются с помощью базы данных AdBlock. — И что самое важное, наш сервис оптимизирует восстановленный контент в соответствии с рекомендациями разработчиков Google. Файлы изображений сжимаются, и из них удаляются все файлы EXIF. Наш скрипт удаляет комментарии из html, оптимизирует css и js и делает намного больше, чтобы сделать сайт лучше, чем был.
Ссылки на официальные сайты
Официальный сайт Twitter Facebook
Теги
wayback-machine-downloader
wayback-machine
internet-archive
archives
archive. org
org
Официальный сайт
Wayback Machine Downloader by WebsiteDownloader.io
Wayback Machine Downloader позволяет загружать веб-сайты с archive.org на локальный жесткий диск вашего компьютера. Wayback Downloader упорядочивает загруженный сайт по исходной ссылочной структуре сайтов. Загруженный веб-сайт можно просмотреть, отк…
Бесплатно Web
Сохранить веб-страницу для автономного использования
Wayback Machine Downloader by Harator
wayback-machine-downloader — загрузите весь сайт с Wayback Machine.
 Он загрузит последнюю версию каждого файла, представленного на Wayback Machine, на ./websites/example.com/. Он также заново создаст структуру каталогов и автоматически создаст стран…
Он загрузит последнюю версию каждого файла, представленного на Wayback Machine, на ./websites/example.com/. Он также заново создаст структуру каталогов и автоматически создаст стран…Открытый исходный код Бесплатно Ruby Linux Windows
0
Wayback Machine Downloader by wayback2hosting
Что такое веб-архив? Веб-архив представляет собой всеобъемлющую резервную копию сети, которая выглядит так, как в разные периоды времени.
Задача веб-архива состоит в том, чтобы хранить Интернет целиком в разные моменты времени в течение последних 15…Платно Web
0
 Он загрузит последнюю версию каждого файла, представленного на Wayback Machine, на ./websites/example.com/. Он также заново создаст структуру каталогов и автоматически создаст стран…
Он загрузит последнюю версию каждого файла, представленного на Wayback Machine, на ./websites/example.com/. Он также заново создаст структуру каталогов и автоматически создаст стран… Задача веб-архива состоит в том, чтобы хранить Интернет целиком в разные моменты времени в течение последних 15…
Задача веб-архива состоит в том, чтобы хранить Интернет целиком в разные моменты времени в течение последних 15…[email protected]
Как восстановить ваш контент с Wayback Machine (Интернет-архив)
Обновлено Джоном-Полем Брионесом 16 мая 2022 г.
2 минуты 45 секунд на чтение
задача восстановления содержимого. Мы всегда рекомендуем делать регулярные резервные копии вашего сайта, но если они недоступны, у вас есть другой вариант.
Интернет-архив, также известный как Wayback Machine, периодически делает снимки многих сайтов в Интернете и может иметь копию вашего сайта. Итак, продолжайте, и мы научим вас, как искать архивы и восстановить ваш контент с Wayback Machine . Затем вы можете использовать эти части, чтобы восстановить свой сайт с нуля.
Создаете новый сайт? Мы рекомендуем использовать WordPress с BoldGrid. Он очень прост в использовании и включен в наши пакеты хостинга WordPress.
Поиск в архивах
- Посетите Wayback Machine по адресу https://archive.org/web.
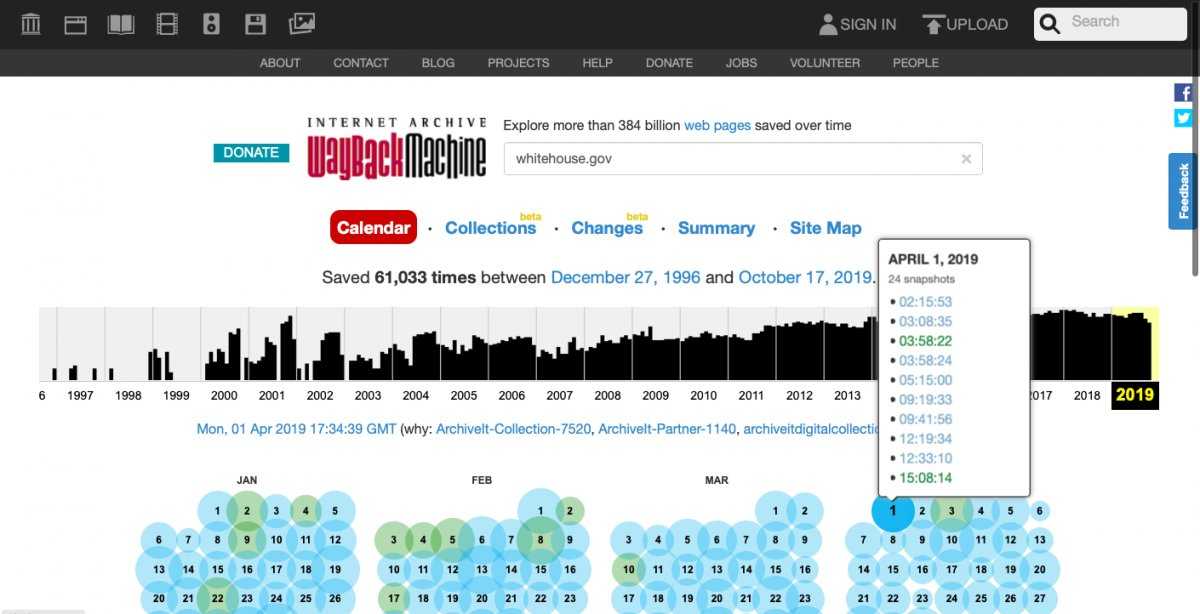
- Введите свой веб-адрес в поле поиска, затем нажмите кнопку Browse History . В нем будет указано, сколько раз ваш сайт был сохранен за определенный период времени. Например:
» Сохранено 34 раза в период с 9 ноября 2008 г. по 28 мая 2019 г. » - Вы также увидите временную шкалу и календарь. Нажмите на год , чтобы узнать, когда ваш сайт был заархивирован.
- Щелкните дату в календаре, чтобы просмотреть моментальный снимок того, что было сохранено. Вы можете попробовать перемещаться по сайту, чтобы просмотреть любой доступный контент. Имейте в виду, что он может не выглядеть точно так же, как ваш сайт, поскольку это зависит от того, что было заархивировано в то время.
- Рекомендую проверять каждые год и дата , чтобы убедиться, что вы найдете все содержимое.
Копирование содержимого вручную
Теперь, когда вы знаете, как искать и находить снимки своего веб-сайта, вы можете копировать текст и изображения на свой компьютер.
- Перейдите на каждую страницу сайта и скопируйте текст, затем вставьте его в текстовый редактор, такой как Notepad , Google Docs или MS Word .
- Посетите каждую страницу Интернет-архива, затем щелкните правой кнопкой мыши и сохраните любые изображения, которые вы хотите восстановить, в папку на вашем компьютере.
- В некоторых случаях вы можете восстановить часть кода веб-сайта. Щелкните правой кнопкой мыши , затем выберите Просмотреть исходный код страницы , чтобы получить доступ к коду сайта. Сохраните его в текстовом редакторе для дальнейшего использования.

Очистка содержимого интернет-архива
Если у вас нет времени вручную копировать каждую страницу восстанавливаемого веб-сайта, другой вариант — извлечь или очистить все содержимое сайта с помощью сценария. Ниже приведены некоторые из наиболее популярных доступных вариантов. Имейте в виду, что они часто кодируются третьими сторонами или отдельными лицами и могут потребовать тестирования и устранения неполадок, чтобы они работали успешно.
- Wayback Scraper
- Wayback Machine Scraper
- Hartator Wayback Machine Downloader (Ruby)
Сторонние услуги
Хотите сэкономить время? Вы можете заплатить стороннему сервису за очистку и восстановление вашего веб-сайта. Некоторые даже восстанавливают контент из CMS, таких как WordPress. Цены и объем услуг будут различаться в зависимости от сайта, поэтому мы рекомендуем проверить и сравнить их, чтобы увидеть, какой из них лучше всего соответствует вашим потребностям.
Некоторые даже восстанавливают контент из CMS, таких как WordPress. Цены и объем услуг будут различаться в зависимости от сайта, поэтому мы рекомендуем проверить и сравнить их, чтобы увидеть, какой из них лучше всего соответствует вашим потребностям.
- Загрузчик Wayback
- Загрузчик Wayback Machine
- Archivarix
Теперь, когда вы знаете, как найти и восстановить содержимое веб-сайта с Wayback Machine (Интернет-архив), вы можете приступить к восстановлению своего сайта. Надеюсь, ваш сайт вернет былую славу с помощью архивной копии. Мы рекомендуем заархивировать ваш веб-сайт с помощью Wayback Machine, чтобы у вас были обновленные снимки.
Джон-Пол Брионес Автор контента II
Джон-Пол — инженер-электронщик, который большую часть своей карьеры посвятил ИТ. Он был техническим писателем InMotion с 2013 года.
Другие статьи Джона-Пола
Какую часть Интернета действительно архивирует Wayback Machine?
 (AP Photo/Ben Margot)
(AP Photo/Ben Margot)Интернет-архиву в следующем году исполняется 20 лет, в нем хранится почти два десятилетия и 23 петабайта информации об эволюции Всемирной паутины. Тем не менее, на удивление мало известно о том, что именно находится в хваленой Wayback Machine Архива. Помимо того, что он заархивировал более 445 миллиардов веб-страниц, Архив никогда не публиковал список архивируемых веб-сайтов или алгоритмов, которые он использует для определения того, что и когда следует захватывать. Учитывая недавние заявления Архива о новых попытках сделать свой веб-архив доступным для научных исследований, крайне важно понять, что именно составляет этот 445-миллиардный архив страниц и как этот состав может повлиять на виды исследований, которые ученые могут проводить с ним. .
Постоянные пользователи Wayback Machine знакомы с бесчисленными странностями ее владений. Например, несмотря на то, что CNN.com был запущен в сентябре 1995 г., первый снимок домашней страницы Архива появился только в июне 2000 г. Напротив, веб-сайт BBC был заархивирован с декабря 1996 г., но количество снимков то убывало, то убывало. 2012. Чтобы по-настоящему понять Архив, очевидно, что мы должны перейти от случайных анекдотов к систематической оценке фондов коллекции.
Напротив, веб-сайт BBC был заархивирован с декабря 1996 г., но количество снимков то убывало, то убывало. 2012. Чтобы по-настоящему понять Архив, очевидно, что мы должны перейти от случайных анекдотов к систематической оценке фондов коллекции.
Поскольку Архив не публикует основной перечень доменов, сохраненных в Wayback Machine, был использован рейтинг Alexa одного миллиона самых популярных веб-сайтов в мире, составленный на основе активности просмотра в более чем 70 странах. Полная история всех моментальных снимков, когда-либо записанных Архивом для домашней страницы каждого веб-сайта, была запрошена с помощью API-интерфейса Wayback CDX Server до 5 ноября 2015 г. Хотя это отражает только моментальные снимки домашних страниц, а не сайтов в целом, ключевой показатель того, как часто Архив сканирует каждый сайт.
В этих данных можно увидеть огромные технические ресурсы, необходимые для сканирования и архивирования открытой сети. В целом, с 1996 года Интернет-архив сделал снимки домашних страниц одного миллиона самых популярных сайтов Alexa чуть более 240 миллионов раз. Для загрузки этих домашних страниц потребовалось чуть более 2 терабайт пропускной способности, при этом только в 2015 году потребовалось более 307 гигабайт.
Для загрузки этих домашних страниц потребовалось чуть более 2 терабайт пропускной способности, при этом только в 2015 году потребовалось более 307 гигабайт.
Если посмотреть на 2015 год, то топ-15 сайтов с наибольшим количеством снимков были seriesyonkis.sx (испанский сайт, предлагающий бесплатный доступ к телевидению и фильмам, который Chrome в настоящее время блокирует из-за угроз безопасности и который ранее был закрыт из-за предполагаемого пиратства фильмов), avtozapchasty.ru (российский сайт автозапчастей), savy.lt (литовский сайт кредитов), videox-amateur.org (порнографический сайт), most.bg (болгарский сайт компьютерных запчастей), fastpic.ru (российский хостинг изображений). сайт, на котором размещено большое количество порнографии), royalkona.com (гавайский курортный отель), trampolinepartsandsupply.com (веб-сайт запчастей для батутов), radikal.ru (еще один российский сайт для размещения изображений), youtube.com, zohraa.com (индийский сайт женской моды), arcelikal.com (турецкий веб-сайт бытовой техники и электроники), localiser-ip. com (поиск IP-адресов whois), jobsalibaba.com (веб-сайт онлайн-вакансий) и myspace.com.
com (поиск IP-адресов whois), jobsalibaba.com (веб-сайт онлайн-вакансий) и myspace.com.
Таким образом, из 15 лучших веб-сайтов с наибольшим количеством снимков, сделанных Архивом в этом году, один является предполагаемым бывшим пиратским сайтом фильмов, один — гавайским отелем, два — порнографическими сайтами и пять — сайтами онлайн-покупок. На втором месте по популярности — веб-сайт российских автозапчастей, а на восьмом — сайт поставщика запчастей для батутов.
При более подробном рассмотрении архива Wayback на сайте литовских кредитов savy.lt видно, что с 19 января Архив периодически сканировал сайт.99 по май 2003 г., после чего не возвращался более десяти лет. В 2015 году он сильно обползал его в конце марта и апреле, затем очень сильно в мае и июне, несколько раз 1 июля и ни разу в последующие четыре месяца. В общей сложности поисковые роботы Архива обращались к savy.lt в общей сложности 203 945 раз за этот период, в основном за один массивный цикл сканирования. Тем не менее, общедоступный профиль Wayback сайта утверждает, что он был просканирован всего 868 раз.
Причина этого в том, что общедоступный веб-сайт Wayback сообщает о количестве часов, в течение которых был сделан хотя бы один снимок, а не о фактическом общем количестве снимков, поэтому он сообщает максимум о 24 снимках в день, а не о тысячи захватов в день, которые он фактически видит для некоторых веб-сайтов. К сожалению, Архив не разъясняет это на своем веб-сайте, вместо этого небрежно ссылаясь на него в технической документации для своего API сервера CDX на GitHub.
Переранжирование одного миллиона лучших сайтов по количеству часов с хотя бы одним снимком за этот час и вычисление процента часов с 00:01 1 января 2015 года, с которого есть снимок, 15 лучших сайтов — это myspace.com ( 93%), yahoo.com (86%), cnn.com (80%), youtube.com (78%), msn.com (76%), twitter.com (76%), facebook.com (72% ), msnbc.com (70%), abcnews.go.com (70%), today.com (69%), nbcnews.com (67%), cbsnews.com (65%), infoseek.co.jp ( 65%), cnbc.com (63%) и tinypic.com (58%). Девять из 15 лучших веб-сайтов по почасовым снимкам являются новостными веб-сайтами, предлагающими более разумный рейтинг. Действительно, новостные веб-сайты составляют многие из доменов в топ-509.0003
Действительно, новостные веб-сайты составляют многие из доменов в топ-509.0003
Тем не менее, более пристальный взгляд на этот рейтинг также обнаруживает ряд аномалий. Сайт walb.com имеет рейтинг Alexa 100 803, но при этом занимает 24-е место по количеству часов со снимками, в то время как mountvernonnews.com занимает 363 013 место в Alexa и 43-е место по количеству часов снимков. Похоже, это общая тенденция, без заметной связи между рейтингом Alexa и количеством снимков домашней страницы веб-сайта или часов.
На самом деле общее количество снимков и общее количество часов хотя бы с одним снимком слабо коррелируют при r=0,35. Рейтинг Alexa и количество снимков не имеют значимой корреляции при r = -0,03, в то время как рейтинг Alexa и количество отдельных часов со снимками имеют обратную корреляцию при r = -0,15. Проще говоря, эти цифры означают, что количество снимков и количество часов с хотя бы одним снимком в значительной степени не связаны с его рейтингом Alexa. У более популярных сайтов не больше моментальных снимков, чем у менее популярных. С одной стороны, это может иметь смысл, поскольку популярность сайта не обязательно указывает на то, как часто он обновляется. Тем не менее, в Интернете около 2015 года очень популярные сайты, как правило, постоянно обновляются новым контентом — сайт, который обновляется раз в несколько лет, скорее всего, будет привлекать мало трафика. Таким образом, можно утверждать, что скорость обновления контента сайта и его популярность, по крайней мере, в некоторой степени связаны.
С одной стороны, это может иметь смысл, поскольку популярность сайта не обязательно указывает на то, как часто он обновляется. Тем не менее, в Интернете около 2015 года очень популярные сайты, как правило, постоянно обновляются новым контентом — сайт, который обновляется раз в несколько лет, скорее всего, будет привлекать мало трафика. Таким образом, можно утверждать, что скорость обновления контента сайта и его популярность, по крайней мере, в некоторой степени связаны.
В разные годы корреляция рейтинга Alexa с часами и снимками удивительно постоянна с 2013 по 2015 год, варьируясь от -0,15 до -0,17 для часов и от -0,03 до -0,04 для снимков. Однако корреляция между часами и снимками значительно варьируется: от 0,35 в 2015 г. до 0,29 в 2014 г., 0,46 в 2013 г. и 0,38 в 2012 г. не учитывать популярность при сканировании. С другой стороны, значительное изменение корреляции общего количества снимков с количеством часов снимков предполагает, что поведение повторного сканирования Архива постоянно меняется, что окажет глубокое влияние на исследования, использующие Архив в качестве набора данных для изучения эволюции сети.
Новостные агентства представляют собой особый тип веб-сайтов, которые сочетают в себе высокую скорость обновления нового контента и значительную общественную значимость с точки зрения архивирования. Чтобы проверить, насколько хорошо Архив сохраняет онлайн-новости, были выбраны 20 000 лучших новостных веб-сайтов по объему, отслеживаемому проектом GDELT, и определена страна происхождения для каждого источника. Общее количество часов моментальных снимков было суммировано для всех новостных агентств в каждой стране за 2013, 2014 и 2015 годы и разделено на общее количество отслеживаемых СМИ в каждой стране, что дало следующие карты среднего количества часов моментальных снимков на новостное агентство. в каждой стране по годам.
Среднее количество часов с хотя бы одним снимком по СМИ для интернет-изданий по странам в… [+] 2013 (Фото: Kalev Leetaru)
Среднее количество часов с хотя бы одним снимком по СМИ для интернет-изданий по странам в… [+] 2014 (Фото: Kalev Leetaru)
Среднее количество часов с хотя бы одним снимком по СМИ для интернет-изданий по странам в. .. [+] 2015 (Фото: Kalev Leetaru)
.. [+] 2015 (Фото: Kalev Leetaru)
На этой последовательности карт отчетливо видна сильная централизация поисковых ресурсов Архива в отношении относительно небольшого числа стран с точки зрения часов снимка. В 2013 году было всего несколько выбросов, при этом в большинстве стран часы работы каждой точки были относительно одинаковыми. За три года произошла устойчивая переориентация в сторону более неравномерного распределения архивных ресурсов. Значительные географические изменения с течением времени добавляют еще одно свидетельство того, что поведение поисковых роботов Архива постоянно меняется глубокими и недокументированными способами.
В совокупности эти результаты показывают, что требуется гораздо более глубокое понимание Wayback Machine Интернет-архива, прежде чем его можно будет использовать для надежных научных исследований эволюции Интернета. Историческая документация по алгоритмам и входным данным его сканеров абсолютно необходима, особенно рабочие процессы и эвристики, которые сегодня контролируют его архивирование. Одна из возможностей заключается в том, чтобы Архив создал исторический архив, где он сохраняет каждую копию кода и рабочих процессов, приводящих в действие Wayback Machine с течением времени, что позволяет оглянуться назад на поисковые роботы с 19 года.97 и сравните их с 2007 и 2015 годами.
Одна из возможностей заключается в том, чтобы Архив создал исторический архив, где он сохраняет каждую копию кода и рабочих процессов, приводящих в действие Wayback Machine с течением времени, что позволяет оглянуться назад на поисковые роботы с 19 года.97 и сравните их с 2007 и 2015 годами.
Более подробные данные журналов также явно необходимы, особенно в отношении тех решений, которые приводят к таким ситуациям, как чрезвычайно резкое архивирование savy.lt или почему домашняя страница CNN.com не была заархивирована. до 2000 года. Если Архив просто откроет свои двери и выпустит инструменты, позволяющие анализировать данные своего веб-архива, не проводя такого рода исследования предвзятости коллекции, ясно, что результаты, полученные в результате, будут сильно искажены и во многих случаях не соответствуют действительности. точно отражают изучаемые явления.
Чему мы можем научиться из всего этого? Возможно, самый важный урок заключается в том, что, подобно многим массивным архивам данных, которые определяют мир «больших данных», мы очень мало понимаем, что на самом деле содержится в данных, которые мы используем. Немногие исследователи останавливаются, чтобы задать такие вопросы, которые рассматриваются здесь, и еще меньшее количество архивов предоставляют какие-либо подробные статистические данные о своих владениях. Вместо этого эра «больших данных», к сожалению, все больше определяется захватывающими заголовками результатами, вычисленными на основе наборов данных, взятых с полки без особых попыток понять их внутренние предубеждения.
Немногие исследователи останавливаются, чтобы задать такие вопросы, которые рассматриваются здесь, и еще меньшее количество архивов предоставляют какие-либо подробные статистические данные о своих владениях. Вместо этого эра «больших данных», к сожалению, все больше определяется захватывающими заголовками результатами, вычисленными на основе наборов данных, взятых с полки без особых попыток понять их внутренние предубеждения.
Еще одна тема — неожиданные открытия. Первоначально этот анализ начинался как исследование практики архивирования новостей в Интернете в Интернет-архиве с целью выяснить, чаще ли он архивирует западные СМИ, чем в других странах. Первоначально ожидалось, что фонды Архива будут отражать популярность и скорость изменений, а язык и географическое положение будут основными отличительными чертами. Однако после изучения данных стало ясно, что архивный ландшафт Wayback Machine гораздо сложнее.
Интерфейсы, которые мы используем для доступа к этим обширным архивам, часто незаметно трансформируют их способами, которые не очевидны и не задокументированы, но могут оказать глубокое влияние на наше понимание результатов, которые мы получаем от них. Например, ни домашняя страница Wayback, ни подробные ответы на часто задаваемые вопросы не информируют пользователей о том, что подсчет снимка в веб-интерфейсе сообщает о количестве отдельных часов с хотя бы одним снимком, а не о фактическом количестве обходов страницы архивом. Этот факт доступен только глубоко внутри справочной страницы технического API на Github.
Например, ни домашняя страница Wayback, ни подробные ответы на часто задаваемые вопросы не информируют пользователей о том, что подсчет снимка в веб-интерфейсе сообщает о количестве отдельных часов с хотя бы одним снимком, а не о фактическом количестве обходов страницы архивом. Этот факт доступен только глубоко внутри справочной страницы технического API на Github.
В своем вступительном докладе на Генеральной ассамблее IIPC 2012 года в Библиотеке Конгресса я отметил, что для того, чтобы ученые могли использовать веб-архивы для исследований, нам нужно гораздо больше информации о том, как создаются эти архивы. Три с половиной года спустя несколько крупных веб-архивов подготовили такую документацию, особенно в отношении алгоритмов, которые контролируют, какие веб-сайты посещают их поисковые роботы, как они просматривают эти веб-сайты и как они решают, какие части бесконечной сети сохранить с их ограниченными ресурсами. . На самом деле совершенно неясно, как была построена Wayback Machine, учитывая невероятно неравномерный ландшафт, который она предлагает из миллиона лучших веб-сайтов даже за последний год.
Приведенные выше результаты показывают, насколько важным является такое понимание. При архивировании бесконечной сети с ограниченными ресурсами необходимо принимать бесчисленные решения относительно того, какие узкие фрагменты сети следует сохранить. На самом базовом уровне можно выбрать либо полностью случайное архивирование (выбор страниц без учета каких-либо других факторов), либо архивирование с приоритетом по скорости изменения (чаще архивирование страниц, которые чаще изменяются — хотя это имеет тенденцию подчеркивать динамически генерируемые сайты) , или в архиве с приоритетом популярности (при этом выделяются страницы, которые большинство людей используют сегодня, но есть риск не сохранить относительно неизвестные страницы, которые могут стать важными в будущем). Человеческий вклад также может сыграть решающую роль, как в случае со специализированной программой Archive-It.
Каждый подход имеет свои преимущества и риски. Можно разумно спросить: через 20 лет на что мы с большей вероятностью захотим оглянуться: на литовский кредитный веб-сайт, поставщика запчастей для батутов или на домашнюю страницу с последними новостями крупного новостного агентства, такого как CNN? Такие важные решения, как то, что сохранить для будущего, требуют гораздо большего участия сообщества, особенно ученых, которые полагаются на эти коллекции.