
Парсинг людей из строки поиска ВКонтакте
С помощью нашего Сервиса VK.BARKOV.NET вы сможете сделать парсинг людей из строки поиска ВКонтакте.Пройдите по ссылке и выберите инструмент, отвечающий вашему поисковому запросу.
Благодаря специальной функции (парсеру) вы сможете собрать пользователей по всему ВК, пользуясь инструментами расширенного поиска.
В этом случае парсинг будет выполняться с использованием мощностей наших сервером в облаке, а итоговый отчет будет в нужном вам формате данных.
Бесплатный парсинг людей работает в Классическом поиске в нижней части той же страницы Сервиса (с ограничение результатов до 1000).
Если вам нужно отфильтровать заранее подготовленный вами список людей из строки поиска ВКонтакте, воспользуйтесь «Фильтром пользователей по их данным» https://vk.barkov.net/filter.aspx
По указанному списку пользователей и критериям выбора парсер выдаст итоговый список под ваши требования.
Парсер просмотрит страницу каждого пользователя из вашего списка и сделает парсинг людей из строки поиска ВКонтакте под ваши настройки.
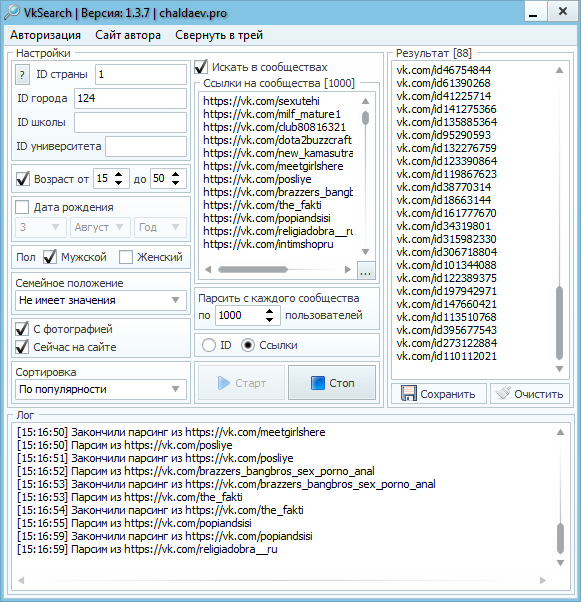
Если вам нужно парсить людей ВКонтакте по всему ВК, воспользуйтесь парсером расширенного поиска по ссылке https://vk.barkov.net/usersgeo.aspx вы сможете искать нужных вам пользователей по заданным критериям — пол, возраст, страна и город, дата рождения.
Поиск пользователей ВКонтакте с учетом семейного положения выполнит парсер https://vk.barkov.net/usersdetails.aspx
Запустить скрипт для решения вопроса
Полезный небольшой видеоурок по этой теме
О сервисе поиска аудитории ВКонтакте
vk.barkov.net — это универсальный набор инструментов, который собирает самые разнообразные данные из ВКонтакте в удобном виде.Каждый инструмент (скрипт) решает свою задачу:
Например, есть скрипт для получения списка всех подписчиков группы.
А вот тут лежит скрипт для сбора списка всех людей, поставивших лайк или сделавших репост к конкретному посту на стене или к любым постам на стене.
Ещё есть скрипт для получения списка аккаунтов в других соцсетях подписчиков группы ВКонтакте.И таких скриптов уже более 200. Все они перечислены в меню слева. И мы регулярно добавляем новые скрипты по запросам пользователей.

Запустить скрипт для решения вопроса
Полезные ответы на вопросы по этому же функционалу для сбора данных из ВКонтакте
Как спарсить веб страницу ВКонтакте?
Как собрать пользователей ВКонтакте из определенного города, отсортировав по своим критериям?
Поиск профилей Контакта
Парсер вконтакте скачать бесплатно
Собрать всех людей из ВК по каким-то ФИО и дате рождения
Искать девушек из России, у которых в интересах ВКонтакте указано «чтение»
Собрать данные ВКонтакте по конкретным городам женский пол и определенный возраст
Как собрать базу определенного города ВК?
Поиск людей по всему ВКонтакте
Найти людей ВКонтакте по ФИО и номеру телефона
Парсер вк онлайн
Как собрать ВКонтакте полный список ID по заданным критериям?
Как можно обойти ограничение ВК по количеству спарсенных пользователей?
Парсить поиск пользователей ВК
Спарсить список id и ссылок vk
Аккаунты ВК, у которых указаны соцсети
Парсинг поиска людей и групп ВК
Собрать базу людей Контакта по моим критериям
Как можно обойти лимит в 1000 ID ВКонтакте?
Как можно найти людей ВК по ключевым словам?
Документация | ОКТаргет
adminПарсер контактов ВК. Как собрать контакты людей из ВКонтакте
Как собрать контакты людей из ВКонтакте
В этой статье мы подробно расскажем о том, как пользоваться парсером для сбора контактов людей из социальной сети ВКонтакте.
Читать далее… adminПарсер пользователей Одноклассники, которые сейчас онлайн
05.01.2023 00:37Рассмотрим способ поиска пользователей социальной сети Одноклассники, которые находятся в сети (онлайн)…
Парсер пользователей ВКонтакте, которые сейчас онлайн
05. 01.2023 00:19
01.2023 00:19 Сегодня опишем работу с одной из возможностей нашего парсера «фильтрация аудитории ВК» для поиска тех, кто прямо сейчас онлайн…
Читать далее… adminПарсер Поиск людей Одноклассники
25.06.2020 14:19Обзор парсера Поиск людей Одноклассники. Как находить целевую аудиторию в Одноклассниках по различным параметрам…
Читать далее… adminПарсер Поиск людей ВКонтакте
18.06.2020 18:25Обзор парсера Поиск людей ВКонтакте. Как находить целевую аудиторию ВКонтакте по различным параметрам…
Как находить целевую аудиторию ВКонтакте по различным параметрам…
Парсер друзей Одноклассники
17.05.2020 23:24Обзор парсера друзей в Одноклассниках. Как им пользоваться и как с его помощью расширить целевую аудиторию.
Читать далее… adminПарсер друзей ВКонтакте
16.05.2020 18:35Как собрать друзей пользователей ВКонтакте с помощью ОкТаргет…
Читать далее… adminПарсер групп Одноклассники.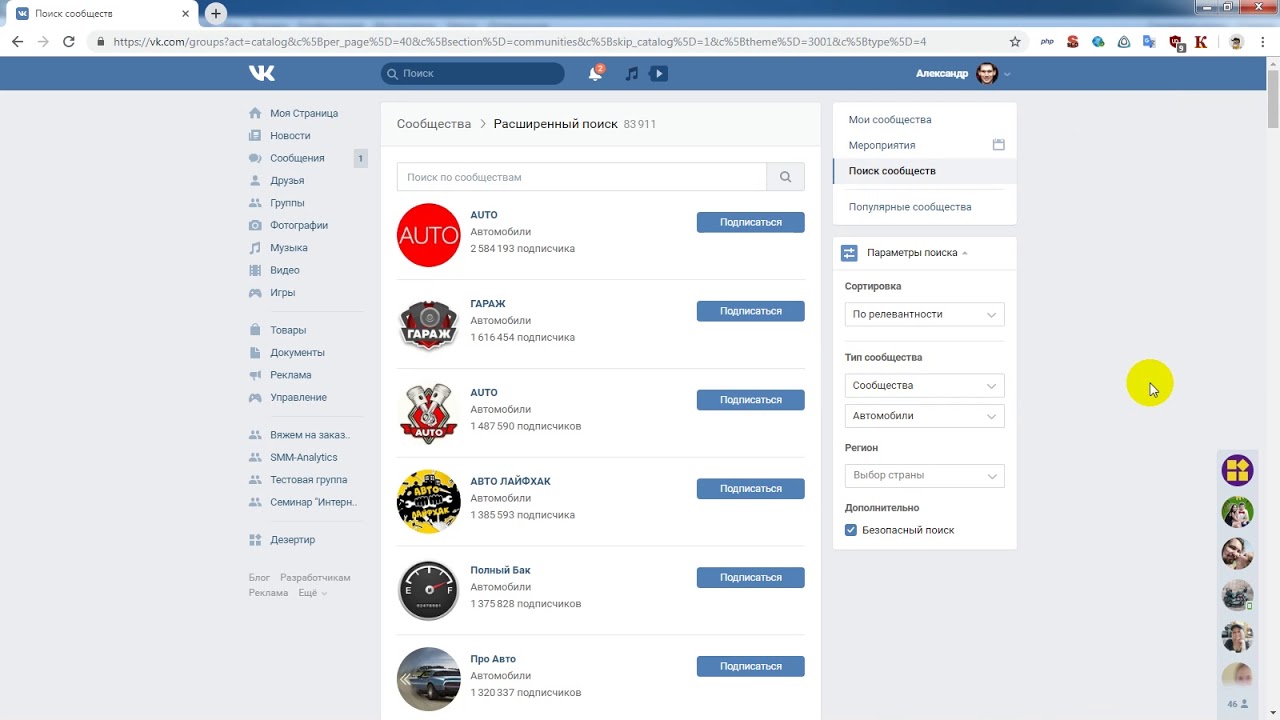 Поиск сообществ
Поиск сообществ
В этой статье речь пойдет о поиске сообществ (групп) в одноклассниках с помощью нашего парсера Поиск сообществ ОК…
Читать далее… adminПарсер групп ВКонтакте. Поиск сообществ
28.04.2020 10:37ОКТаргет позволяет парсить сообщества из ВКонтакте. Наш сервис парсит список групп, который можно получить с помощью поиска групп на сайте ВКонтакте…
Читать далее… adminПарсер номеров телефонов ВК по группам. Как собрать телефоны групп ВКонтакте
17.
Как собрать номера телефонов пользователе ВКонтакте по списку сообществ ВК…
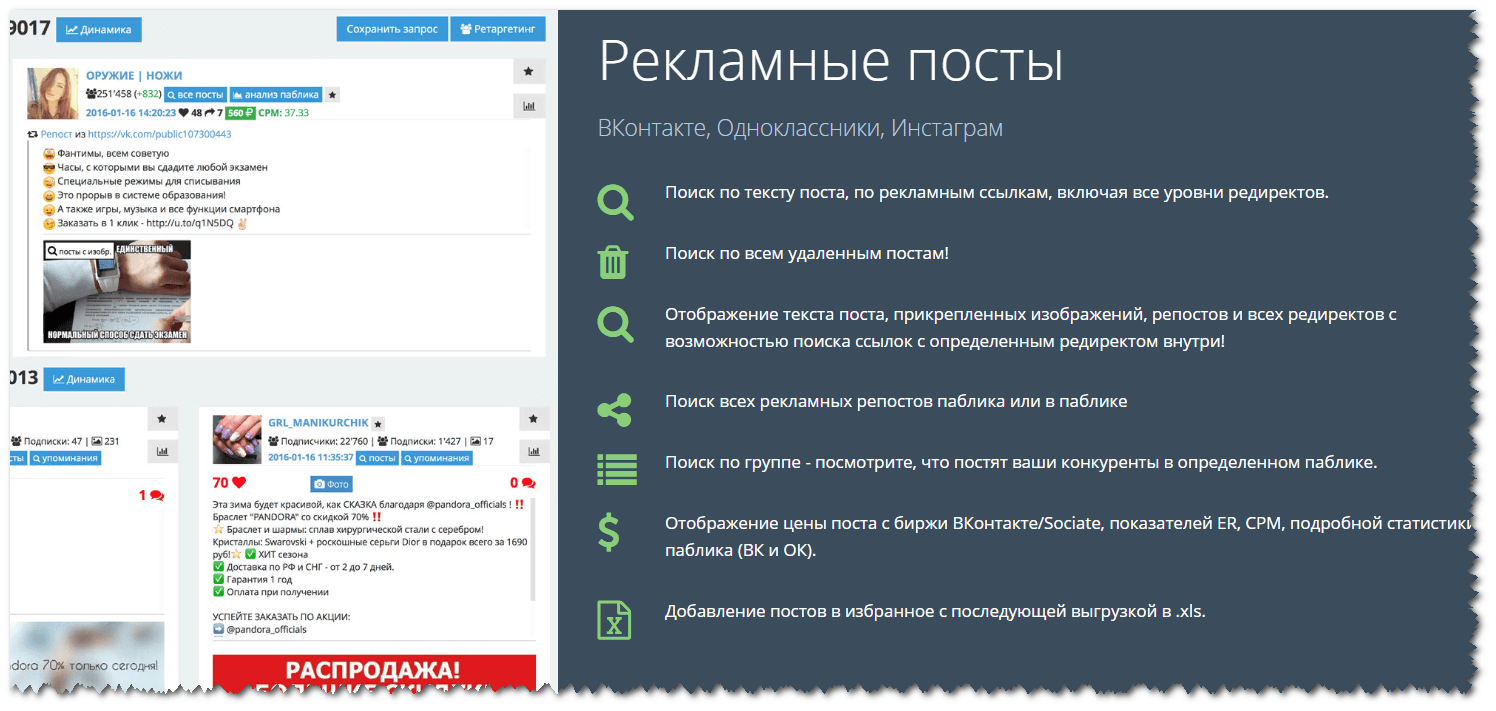
Читать далее…Интеграция vk API с Google Cloud API
Обзор/
Приложения/
vk/
Google CloudНастройте триггер vk API для запуска рабочего процесса, который интегрируется с Google Cloud API. Интеграционная платформа Pipedream позволяет удивительно быстро интегрировать vk и Google Cloud. Бесплатно для разработчиков.
Популярные триггеры vk и Google Cloud#
Новые сообщения Pub/Sub из Google Cloud API
Создать новую тему Pub/Sub в вашей учетной записи GCP. Сообщения, опубликованные в этой теме, отправляются из источника Pipedream.
Попробуйте
BigQuery — Новая строка из Google Cloud API
Генерация новых событий при добавлении новой строки в таблицу Google Cloud API
Выдавать новые события с результатами произвольного запроса
Попробовать
Popular vk и Google Cloud Actions#
Bigquery Insert Rows with Google Cloud API
Вставляет строки в таблицу BigQuery. См. документы и пример здесь.
См. документы и пример здесь.
Попробуйте
Создать корзину с помощью Google Cloud API
Создает корзину в Google Cloud Storage См. документацию
Получает корзину Google Cloud Storage метаданные. См. документы.
Попробуйте
Получить объект с помощью Google Cloud API
Загружает объект из корзины Google Cloud Storage, см. документацию
Попробуйте
Получение списка сегментов с помощью Google Cloud API
Получение списка сегментов Google Cloud Storage, см. документацию Вконтакте, популярный русский веб-сайт социальной сети
С помощью VK API разработчики могут создавать ряд приложений и сервисов
, которые могут взаимодействовать с пользователями и ресурсами ВКонтакте. С помощью VK API разработчики
может создавать различные сервисы, начиная от традиционных функций социальных сетей
и заканчивая более сложными приложениями и играми.
Вот некоторые вещи, которые можно создать с помощью VK API:
- Платформы социальных сетей: Дайте пользователям возможность устанавливать связи, отправлять сообщения,
обмениваться мультимедиа, а также создавать группы и события и управлять ими. Платформы потоковой передачи музыки и видео - : Создавайте платформы потоковой передачи музыки и видео
с поддержкой потоковой передачи популярного аудио- и видеоконтента из ВКонтакте. - Games: Реализуйте полнофункциональные игровые приложения, которые можно интегрировать с
VK для категорий лидеров, игровых сообществ и многого другого. - Чат-боты: Создайте своего личного чат-бота для пользователей ВКонтакте,
позволяя им общаться с другими пользователями ВКонтакте в автоматическом режиме. - Электронная коммерция: используйте VK API для создания онлайн-рынков и магазинов электронной коммерции
с интеграцией VK. - Услуги на основе определения местоположения: разработка приложений, которые можно использовать для определения местоположения и
делитесь событиями, локациями и достопримечательностями с пользователями ВКонтакте. - Аналитика и отслеживание: собирайте данные и внедряйте аналитические инструменты для пользователей и предприятий VK
. - Реклама и продвижение: разрабатывайте кампании и рекламные мероприятия с интеграцией
ВКонтакте. - Настройка: Позвольте пользователям настраивать свой опыт работы с ВКонтакте с помощью различных
методов, включая пользовательские скины, макеты страниц и многое другое.

Подключить vk#
1
2
3
4
5
6
7
8
9
9000 2 1011
12
13
14
15
16
17
18
19
20
21
import { axios } from "@pipedream/platform"
экспортировать по умолчанию defineComponent({
реквизит: {
вк: {
тип: "приложение",
приложение: "вк",
}
},
асинхронный запуск ({шаги, $}) {
возврат ожидания axios($, {
адрес: `https://api.vk.com/method/users. get`,
заголовки: {
Авторизация: `Bearer ${this.vk.$auth.oauth_access_token}`,
},
параметры: {
"в": `5.131`,
},
})
},
})
 get`,
заголовки: {
Авторизация: `Bearer ${this.vk.$auth.oauth_access_token}`,
},
параметры: {
"в": `5.131`,
},
})
},
})
get`,
заголовки: {
Авторизация: `Bearer ${this.vk.$auth.oauth_access_token}`,
},
параметры: {
"в": `5.131`,
},
})
},
})
Обзор Google Cloud#
Google Cloud API позволяет разработчикам получать доступ к различным службам Google Cloud
из их собственных приложений. Сервисы, к которым можно получить доступ, включают
Google Cloud Storage, Google Cloud Datastore, Google Cloud Functions и
Google Cloud Pub/Sub. С помощью Google Cloud API разработчики могут создавать различные
приложения, использующие преимущества сервисов Google Cloud.
Подключить Google Cloud#
1
2
3
4
5
6
7
8
9
10
900 02 1112
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2 7
28
29
30
31
32
33
34
модуль.
 экспорт = определитьКомпонент({
реквизит: {
гугл_облако: {
тип: "приложение",
приложение: "google_cloud",
}
},
асинхронный запуск ({шаги, $}) {
// Требуемый обходной путь для получения пакета @google-cloud/storage
// правильно работает на Pipedream
требуют("@dylburger/umask")()
const { Storage } = require('@google-cloud/storage')
постоянный ключ = JSON.parse(this.google_cloud.$auth.key_json)
// Создает клиента из ключа сервисной учетной записи Google.
// См. https://cloud.google.com/nodejs/docs/reference/storage/1.6.x/global#ClientConfig
константное хранилище = новое хранилище ({
идентификатор проекта: key.project_id,
реквизиты для входа: {
client_email: key.client_email,
приватный_ключ: ключ.приватный_ключ,
}
})
// Раскомментируйте этот раздел и переименуйте его для своего сегмента перед запуском этого кода
// const BucketName = 'pipedream-test-bucket';
ожидайте storage.
экспорт = определитьКомпонент({
реквизит: {
гугл_облако: {
тип: "приложение",
приложение: "google_cloud",
}
},
асинхронный запуск ({шаги, $}) {
// Требуемый обходной путь для получения пакета @google-cloud/storage
// правильно работает на Pipedream
требуют("@dylburger/umask")()
const { Storage } = require('@google-cloud/storage')
постоянный ключ = JSON.parse(this.google_cloud.$auth.key_json)
// Создает клиента из ключа сервисной учетной записи Google.
// См. https://cloud.google.com/nodejs/docs/reference/storage/1.6.x/global#ClientConfig
константное хранилище = новое хранилище ({
идентификатор проекта: key.project_id,
реквизиты для входа: {
client_email: key.client_email,
приватный_ключ: ключ.приватный_ключ,
}
})
// Раскомментируйте этот раздел и переименуйте его для своего сегмента перед запуском этого кода
// const BucketName = 'pipedream-test-bucket';
ожидайте storage. createBucket(bucketName)
console.log(`Корзина ${bucketName} создана.`)
},
})
createBucket(bucketName)
console.log(`Корзина ${bucketName} создана.`)
},
})
Функциональный анализ строк в Swift с помощью Ogma: реализация поисковой системы Game of Thrones
— Знание Game of Thrones не требуется и БЕЗ спойлеров. Обещано. —Инженеры ежедневно решают множество вопросов: сложные потоки, условия гонки, общая обработка ошибок. Но одна проблема, которая всегда бросается в глаза, — это синтаксический анализ строк. В QuickBird Studios мы постоянно возвращаемся к этому.
Лично я всегда хотел создать свой собственный язык программирования и очень интересовался принципами и сложностями многих языков. Особенно Свифт.
Впечатляет, что парсеры строк играют такую важную роль в жизни всех разработчиков. Кажется, все мы слышали и поняли некоторые принципы их работы. И все же у меня такое чувство, что мы никогда не погружаемся в него достаточно глубоко. Мы всегда остаемся высоко на поверхности.
Поэтому я решил написать анализатор строк на Swift. Фактически, я написал библиотеку Swift с открытым исходным кодом под названием «Ogma», чтобы делать то же самое. Сегодня я хотел бы поделиться некоторыми мыслями и опытом, а также представить наше предложение о том, как реализовать чистую архитектуру Parser.
Фактически, я написал библиотеку Swift с открытым исходным кодом под названием «Ogma», чтобы делать то же самое. Сегодня я хотел бы поделиться некоторыми мыслями и опытом, а также представить наше предложение о том, как реализовать чистую архитектуру Parser.
В качестве примера для этого поста мы расширим возможности поиска по Вики популярного телешоу «Игра престолов». Мы собираемся добавить возможность добавления пользовательских фильтров в поисковый запрос.
(Результаты в видео произвольно фильтруются только по «Старку», просто чтобы убедиться, что мы не показываем здесь спойлеры)
Но прежде чем мы перейдем к коду, давайте начнем с очень простого вопроса:
Зачем мне когда-либо писать анализатор строк
Помимо возможностей обучения, существует множество вариантов использования собственного синтаксического анализатора:
- Парсеры строк часто необходимы при работе с такими форматами данных, как: JSON, yaml и xml.
- Возможно, эти конкретные уже хорошо зарекомендовали себя и имеют синтаксический анализатор почти на каждом языке. Тем не менее, всегда есть вероятность того, что новые форматы станут массовыми .
- Или кто знает? Возможно, вам придется иметь дело с нестандартной разновидностью JSON, которая ломает все парсеры строк, которые в настоящее время существуют в Swift 9.0092
- Или вы решили написать собственный формат для вашего приложения
- Возможно, эти конкретные уже хорошо зарекомендовали себя и имеют синтаксический анализатор почти на каждом языке.
- Иногда вы также получаете пользовательский ввод в своем приложении, которое вам нужно оценить или отобразить.
- Подобно Markdown или аналогичному языку разметки
- Возможно, вам нужно написать собственный анализатор поисковых запросов, такой как супер крутая функция поиска WolframAlpha. Как наш случай с Игрой Престолов .
- Или, может быть, вы действительно хотите написать свой собственный язык программирования, что ж, написание синтаксического анализатора строк — хорошее начало для этого.
 Тем не менее, всегда есть вероятность того, что новые форматы станут массовыми
Тем не менее, всегда есть вероятность того, что новые форматы станут массовымиИтак, теперь давайте углубимся в теорию работы синтаксического анализатора строк. А не ___ ли нам?!
Теория
Итак, здесь много теории, и я рискую показаться Википедией, объясняющей эти концепции. Люди, которые уже знакомы с контекстно-свободными грамматиками и стандартной архитектурой парсера, могут сразу перейти к следующему шагу.
Люди, которые уже знакомы с контекстно-свободными грамматиками и стандартной архитектурой парсера, могут сразу перейти к следующему шагу.
Я постараюсь быть кратким и понятным, так что этот раздел будет здесь на случай, если что-то из реализации будет неясным ;).
Что такое формальный язык?
Хорошо. Давайте поговорим о математике. В математике язык можно рассматривать как набор всех возможных слов, которые считаются допустимыми.
Например, если бы вы начали определять английский язык, вы бы перечислили каждое слово от A до Z и начали бы с написания первого слова в словаре: см. ниже). Затем вы будете продолжать печатать очень-очень долго, пока не перечислите все возможные английские слова. Когда дело доходит до английского, невозможно определить его, не записывая каждое возможное слово. Вот почему английский не является официальным языком.
Животное по имени Муравьед и первое слово в словаре
Формальный язык будет тогда определяться набором четких правил того, как мы можем проверить правильность слова.
Например, мы можем определить все возможные адреса электронной почты как формальный язык. Мы знаем, что [email protected] может быть действительным адресом электронной почты, но contactquickbirdstudios.com — нет, потому что мы ожидали, что @ разделит «локальную часть» и доменное имя.
В настоящее время существует множество способов определения формальных языков, в частности:
- Регулярные выражения: если вы не знакомы с регулярными выражениями, вы можете проверить множество ресурсов по этой теме. Мы предлагаем: «Введение в регулярные выражения»
- Контекстно-свободные грамматики
Что такое контекстно-свободная грамматика?
Контекстно-свободная грамматика — это способ описания правил формального языка. Точнее, контекстно-свободный язык (поймите!).
Например, давайте определим простую грамматику для калькулятора, где выражение, введенное в калькулятор, может быть числом, сложением или вычитанием:
ВЫРАЖЕНИЕ -> ЧИСЛО | ДОПОЛНЕНИЕ | ВЫЧИТАНИЕ ДОПОЛНЕНИЕ -> ВЫРАЖЕНИЕ + ВЫРАЖЕНИЕ ВЫЧИТАНИЕ -> ВЫРАЖЕНИЕ - ВЫРАЖЕНИЕ
Обратите внимание, что Дополнение содержит другое выражение. Таким образом, мы можем легко связать все больше и больше таких выражений вместе.
Таким образом, мы можем легко связать все больше и больше таких выражений вместе.
Вы также можете узнать больше о контекстно-свободных грамматиках на Tutorialspoint.
Что такое парсер?
Парсер — это программа, которая принимает строку в качестве входных данных, проверяет, является ли это правильным словом в языке, и выводит модель для нашей работы.
Хорошо! Кажется достаточно простым!
Хорошо? А как строятся парсеры?
Очень хороший вопрос! На практике вам нужно некоторое разделение задач внутри вашего синтаксического анализатора, чтобы избежать технического долга. Одним из распространенных способов является разделение модуля на:
- Lexer или Tokenizer: инструмент, который отвечает за предварительную классификацию множества символов в то, что мы называем токенами.
- Токены: промежуточное представление наших символов с добавлением к ним большего значения, такого как числа, запятые, открывающие и закрывающие скобки.
- Парсер или синтаксический анализатор: компонент, который превратит предварительно вычисленные токены в желаемую модель. Он пытается извлечь смысл из последовательности токенов в целом.
- Дерево синтаксического анализа: структурированный вывод синтаксического анализа.
Создание синтаксического анализатора строк с помощью Ogma
Как отмечалось в начале, этот пост публикуется вместе со Swift Open Source Framework под названием Ogma, предназначенным для создания синтаксических анализаторов так, как они предложены здесь. Основная идея: для программирования парсера строк в Swift, точно так же, как вы пишете контекстно-свободную грамматику.
Итак, вот процесс, который очень похож на описанный в нашем теоретическом разделе:
- Реализация модели: запишите ожидаемый результат. Это будет Parse Tree в конце.
- Реализовать лексер: Оценить, какие токены требуются для вашего синтаксиса, и сопоставить, как текст должен быть преобразован в эти токены. Не беспокойтесь, большинство кейсов уже реализовано за вас.
- Реализовать синтаксический анализ: сопоставить преобразование ваших токенов в вашу модель
 Не беспокойтесь, большинство кейсов уже реализовано за вас.
Не беспокойтесь, большинство кейсов уже реализовано за вас.Это может показаться большой работой, но будьте уверены, это намного проще, чем вы ожидали. Поэтому вместо того, чтобы болтать о том, что есть, давайте сразу перейдем к примеру.
Пример: давайте лучше найдем вики «Игра престолов»
По мере приближения финального сезона «Игры престолов» мы в офисе QuickBird Studios запоем просматриваем все это. К сожалению, в этом сериале слишком много персонажей. К счастью, есть Game of Thrones Wiki, отличный инструмент для отслеживания того, что происходит.
Однако вы, возможно, заметили, что их функция поиска требует немного любви.
Мне очень хотелось иметь возможность добавлять дополнительные фильтры с булевой логикой. Я хотел, чтобы в этой Вики появилась большая мощь поисковых запросов от Wolfram Alpha.
Оооооо, давай просто построим его – Садись, возьми попкорна и приступим!
О, и не беспокойтесь, если вы еще не смотрели «Игру престолов»: Этот пример не требует каких-либо знаний о сериале и не содержит спойлеров.
Наша цель состоит в том, чтобы найти способ запрашивать конкретную информацию и использовать очень простую логическую логику. Например, мы ищем людей…
- …из Дома Старков (в основном хороших парней)
- … кто еще жив
- … чья информация соответствует дополнительному произвольному запросу
случайный запрос #дом = Старк и #статус = жив
Если бы мы разобрали этот пример, наш идеальный вывод был бы структурирован следующим образом (извините за мой ужасный артистизм):
Наша грамматика
Давайте начнем с определения нашей контекстно-свободной грамматики для этого случая. Мы хотим, чтобы пользователь вводил обычный поисковый запрос, за которым следовали более конкретные фильтры. Итак, мы можем сказать, что наша грамматика примерно выглядит так:
- A
Запроспредставляет собой последовательность изключевых слов, за которыми следует необязательный фильтр . - A
Фильтрможет быть:- и
Проверка равенства(является ли свойство A равным B), - комбинация двух фильтров через вентиль
ИилиИЛИ, - или
Фильтрв скобках
- и
Записав на бумаге, мы могли бы определить его следующим образом:
ЗАПРОС -> КЛЮЧЕВОЕ СЛОВО* ФИЛЬТР? ФИЛЬТР -> РАВЕНСТВО | И_ФИЛЬТР | ИЛИ_ФИЛЬТР | (ФИЛЬТР) РАВЕНСТВО -> #СВОЙСТВО = ЗНАЧЕНИЕ AND_FILTER -> ФИЛЬТР и ФИЛЬТР OR_FILTER -> ФИЛЬТР или ФИЛЬТР
Записав нашу грамматику, мы можем начать с наших шагов:
1. Написание нашей модели
Как уже говорилось, наша модель — это в основном наше дерево разбора. Мы должны иметь возможность прочитать, что пользователь хочет от этой Модели.
Итак, мы начинаем с Запроса, примерно как описано выше:
Теперь мы можем смоделировать отдельные части, такие как Ключевые слова:
И структуру Фильтра:
Здесь в Фильтре мы упоминаем Равенство , который моделирует фильтр, который проверяет равенство между свойством и значением, например #дом = Старк в нашем исходном примере. Мы моделируем его с помощью структур:
Мы моделируем его с помощью структур:
В этом сценарии мы также используем BinaryOperation , структуру, уже включенную в Ogma, которая будет обрабатывать операции синтаксического анализа, а также приоритет операторов. Общий параметр для BinaryOperation просто означает, что с каждой стороны операции будет Filter .
Теперь определим операции. Для этого мы также должны реализовать MemberOfBinaryOperation 9.0306 , чтобы указать, что его можно использовать для двоичных операций:
Теперь мы предоставляем приоритет оператора через позицию в перечислении. Это означает, что и всегда предшествуют или . Действительно удобно, не так ли?
2. Реализация нашего лексера
Чтобы написать наш лексер, мы сначала должны решить, какие у нас токены. Судя по нашей грамматике, мы должны поддерживать:
- Одиночные слова
- #
- =
- круглая скобка
Мы также хотели бы поддерживать строковые литералы, если сравниваемое значение состоит из нескольких слов.
Например: #title = "Король Севера"
Таким образом, мы можем написать наш Token enum:
Лексер может быть создан с использованием того, что мы называем TokenGenerator s. Генератор токенов попытается сопоставить части строки с токеном . Нам понадобится:
-
WhiteSpaceTokenGenerator: это соответствует любому пробелу. Полезно для игнорирования пробелов. -
RegexTokenGenerator: сопоставляет регулярное выражение с токеном. -
StringLiteralTokenGenerator: соответствует строке внутри кавычек.
Таким образом, наш лексер может быть записан как:
3. Парсинг
Теперь, на заключительном этапе, мы просто соединяем точки. Мы должны объяснить, как мы ожидаем, что эти объекты будут составлены, и как отобразить результат от них. Мы делаем это, позволяя нашей модели реализовать Parsable , который определяет Парсер для каждого типа.
Начнем с написания двух хелперов для Token . Чтобы упростить получение слов и строковых литералов:
Теперь, когда это не так, мы можем смоделировать, как выглядит ключевое слово. Давайте вспомним, как это выглядело в нашем дереве:
Поскольку это просто слово, мы можем смоделировать его как синтаксический анализатор, который пытается потреблять свойство word из токена :
Функция , потребляющая , принимает KeyPath из Token , чтобы попытаться использовать его в качестве вывода. Мы можем сделать почти то же самое со свойством. Только на этот раз мы ожидаем # прямо перед ним:
С помощью оператора && мы создаем цепочку. Ожидается Token.hash , за которым следует слово.
Далее, для нашего значения это может быть просто слово или строковый литерал:
На этот раз мы используем || , чтобы сигнализировать о том, что мы хотим использовать первый удачный результат. Если это не голое слово, попробуйте строковый литерал.
Если это не голое слово, попробуйте строковый литерал.
Теперь наша структура Equality просто должна быть свойством, за которым следует = , за которым следует значение:
Обратите внимание, что мы просто связываем типы, которые, как мы ожидаем, будут там. И просто сопоставляем результат с нашей структурой.
Мы почти закончили с нашим фильтром :
Мы снова используем || оператора для объединения нескольких возможностей. Но на этот раз мы также используем фильтр для определения Фильтр снова в:
Это просто означает, что также разрешено снова иметь фильтр, но заключенный в круглые скобки, например так: (ФИЛЬТР)
Наконец, единственный тип, где мы должны реализовать Parsable , это наш запрос :
На этот раз с постфиксом * , чтобы указать, что это может произойти любое количество раз в последовательности, и с использованием фильтра ? , чтобы сигнализировать о том, что он необязателен и не должен выходить из строя, если его там нет.
Давайте проверим, что у нас получится!
И получаем на выходе:
{
ключевые слова = 2 значения {
[0] = "случайный"
[1] = "запрос"
}
фильтр = операция {
левая сторона = равенство = {
собственность = "дом"
значение = "Старк"
}
правая сторона = равенство = {
свойство = "статус"
значение = "живой"
}
оператор = и
}
}
Вот и все! Мы создали парсер для наших собственных поисковых запросов!!!
И только используя очень маленькие чистые функции 🤟🏼💪🏼😎.
Полную реализацию можно посмотреть здесь.
Завершение написания анализатора строк в Swift
Смотри! Написать надежное программное обеспечение сложно. И написание программного обеспечения, которое понимает текст, может быть одной из самых сложных задач. В большинстве случаев мы, разработчики, используем парсеры, созданные кем-то более опытным. Но, по нашему мнению, Ogma — это хороший способ создать собственный синтаксический анализатор, созданный в соответствии с вашими потребностями, если у вас:
- нет готового решения
- или хотите поддерживать дополнительные случаи, которые еще не являются стандартными (например, синтаксический анализ определенных поисковых запросов)
- или не хотите полагаться на чужую реализацию, которая тоже со временем может устареть
- или предпочтите гибкость, которую дает использование собственного синтаксического анализатора .
