
Правильный robots.txt для WordPress — 2019
Robots.txt – текстовой файл, который сообщает поисковым роботам, какие файлы и папки следует сканировать (индексировать), а какие сканировать не нужно.
Поисковые системы, такие как Яндекс и Google сначала проверяют файл robots.txt, после этого начинают обход с помощью веб-роботов, которые занимаются архивированием и категоризацией веб сайтов.
Файл robots.txt содержит набор инструкций, которые просят бота игнорировать определенные файлы или каталоги. Это может быть сделано в целях конфиденциальности или потому что владелец сайта считает, что содержимое этих файлов и каталогов не должны появляться в выдаче поисковых систем.

Если веб-сайт имеет более одного субдомена, каждый субдомен должен иметь свой собственный файл robots.txt. Важно отметить, что не все боты будут использовать файл robots.txt. Некоторые злонамеренные боты даже читают файл robots.txt, чтобы найти, какие файлы и каталоги Вы хотели скрыть. Кроме того, даже если файл robots.txt указывает игнорировать определенные страницы на сайте, эти страницы могут по-прежнему появляться в результатах поиска, если на них ссылаются другие просканированные страницы. Стандартный роботс тхт для вордпресс открывает весь сайт для интдекса, поэтому нам нужно закрыть не нужные разделы WordPress от индексации.
Оптимальный robots.txt
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # системная папка на хостинге, закрывается всегда Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # запрос поиска Disallow: *&s= # запрос поиска Disallow: /search/ # запрос поиска Disallow: /author/ # архив автора, если у Вас новостной блог с авторскими колонками, то можно открыть # архив автора, если у Вас новостной блог с авторскими колонками, то можно открыть Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads # Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent # не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже. Sitemap: http://site.ru/sitemap.xml Sitemap: http://site.ru/sitemap.xml.gz # Host прописывать больше не нужно.
Расширенный вариант (разделенные правила для Google и Яндекса)
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads User-agent: GoogleBot # правила для Google (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # от индексирования, а удалять параметры меток, # Google такие правила не поддерживает Clean-Param: openstat # аналогично # Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent # не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже. Sitemap: http://site.ru/sitemap.xml Sitemap: http://site.ru/sitemap.xml.gz # Host прописывать больше не нужно.
Оптимальный Robots.txt для WooCommerce
Владельцы интернет-магазинов на WordPress – WooCommerce также должны позаботиться о правильном robots.txt. Мы закроем от индексации корзину, страницу оформления заказа и ссылки на добавление товара в корзину.
User-agent: *
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Disallow: /cart/
Disallow: /checkout/
Disallow: /*add-to-cart=*
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Sitemap: https://site.ru/sitemap_index.xmlВопрос/ответ
Где находится файл robots.txt в вордпресс
Обычно robots.txt располагается в корне сайта. Если его нет, то потребуется создать текстовой файл и загрузить его на сайт по FTP или панель управления на хостинге. Если Вы не смогли найти роботс тхт в корне сайта, но при переходе по ссылке вашсайт.ру/robots.txt он открывается, значит какой то из SEO плагинов сам генерирует его.
К примеру плагин Yoast SEO создает виртуальный файл, которого нет в корне сайта.
Как редактировать robots.txt с помощью Yoast SEO
- Зайдите в админ панель сайта
Админа панель находится по следующему адресу вашсайт.ру/wp-admin/
- Слева в консоли наведите на кнопку SEO и в выпадающем окне выберите “Инструменты”
Перейдите в раздел, как указано на картинке.
- Зайдите в редактор файлов
Этот инструмент позволит быстро отредактировать такие важные для вашего SEO файлы, как robots.txt и .htaccess (при его наличии).
- Если файла Robots нет, нажмите на кнопку создать, либо вставьте нужный роботс и нажмите сохранить.
robots.txt для WordPress вы можете скопировать или скачать выше.



Чтобы установить плагин Yoast SEO воспользуйтесь данной статьей – ссылка.
Как проверить правильность robots.txt
У Google и Яндекс есть средства для проверки файла роботс.
Google – https://support.google.com/webmasters/answer/6062598?hl=ru
xn——6kcgnhys3cgg3ne.xn--p1ai
Правильный Robots.txt для WordPress
Всем привет! Сегодня статья о том, каким должен быть правильный файл robots.txt для WordPress. С функциями и предназначением robots.txt мы разбирались несколько дней назад, а сейчас разберём конкретный пример для ВордПресс.

С помощью этого файла у нас есть возможность задать основные правила индексации для различных поисковых систем, а также назначить права доступа для отдельных поисковых ботов. На примере я разберу как составить правильный robots.txt для WordPress. За основу возьму две основные поисковые системы — Яндекс и Google.
В узких кругах вебмастеров можно столкнуться с мнением, что для Яндекса необходимо составлять отдельную секцию, обращаясь к нему по User-agent: Yandex. Давайте вместе разберёмся, на чём основаны эти убеждения.
Яндекс поддерживает директивы Clean-param и Host, о которых Google ничего не знает и не использует при обходе.
Разумно использовать их только для Yandex, но есть нюанс — это межсекционные директивы, которые допустимо размещать в любом месте файла, а Гугл просто не станет их учитывать. В таком случае, если правила индексации совпадают для обеих поисковых систем, то вполне достаточно использовать User-agent: * для всех поисковых роботов.
При обращении к роботам по User-agent важно помнить, что чтение и обработка файла происходит сверху вниз, поэтому используя User-agent: Yandex или User-agent: Googlebot необходимо размещать эти секции в начале файла.
Пример Robots.txt для WordPress
Сразу хочу предупредить: не существует идеального файла, который подойдет абсолютно всем сайтам, работающим на ВордПресс! Не идите на поводу, слепо копируя содержимое файла без проведения анализа под ваш конкретный случай! Многое зависит от выбранных настроек постоянных ссылок, структуры сайта и даже установленных плагинов. Я рассматриваю пример, когда используется ЧПУ и постоянные ссылки вида /%postname%/.

WordPress, как и любая система управления контентом, имеет свои административные ресурсы, каталоги администрирования и прочее, что не должно попасть в индекс поисковых систем. Для защиты таких страниц от доступа необходимо запретить их индексацию в данном файле следующими строками:
Disallow: /cgi-bin
Disallow: /wp-Директива во второй строке закроет доступ по всем каталогам, начинающимся на /wp-, в их число входят:
- wp-admin
- wp-content
- wp-includes
Но мы знаем, что изображения по умолчанию загружаются в папку uploads, которая находится внутри каталога wp-content. Разрешим их индексацию строкой:
Allow: */uploadsСлужебные файлы закрыли, переходим к исключению дублей с основным содержимым, которые снижают уникальность контента в пределах одного домена и увеличивают вероятность наложения на сайт фильтра со стороны ПС. К дублям относятся страницы категорий, авторов, тегов, RSS-фидов, а также постраничная навигация, трекбеки и отдельные страницы с комментариями. Обязательно запрещаем их индексацию:
Disallow: /category/
Disallow: /author/
Disallow: /page/
Disallow: /tag/
Disallow: */feed/
Disallow: */trackback
Disallow: */commentsДалее хотелось бы уделить особое внимание такому аспекту как постоянные ссылки. Если вы используете ЧПУ, то страницы содержащие в URL знаки вопроса зачастую являются «лишними» и опять же дублируют основной контент. Такие страницы с параметрами следует запрещать аналогичным образом:
Disallow: */?Это правило распространяется на простые постоянные ссылки ?p=1, страницы с поисковыми запросами ?s= и другими параметрами. Ещё одной проблемой могут стать страницы архивов, содержащие в URL год, месяц. На самом деле их очень просто закрыть, используя маску 20*, тем самым запрещая индексирование архивов по годам:
Disallow: /20*Для ускорения и полноты индексации добавим путь к расположению карты сайта. Робот обработает файл и при следующем посещении сайта будет его использовать для приоритетного обхода страниц.
Sitemap: https:В файле robots.txt можно разместить дополнительную информацию для роботов, повышающую качество индексации. Среди них директива Host — указывает на главное зеркало для Яндекса:
Host: webliberty.ruПри работе сайта по HTTPS необходимо указать протокол:
Host: https:С 20 марта 2018 года Яндекс официально прекратил поддержку директивы Host. Её можно удалить из robots.txt, а если оставить, то робот её просто игнорирует.
Подводя итог, я объединил всё выше сказанное воедино и получил содержимое файла robots.txt для WordPress, который использую уже несколько лет и при этом в индексе нет дублей:
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-
Disallow: /category/
Disallow: /author/
Disallow: /page/
Disallow: /tag/
Disallow: */feed/
Disallow: /20*
Disallow: */trackback
Disallow: */comments
Disallow: */?
Allow: */uploads
Sitemap: https:Постоянно следите за ходом индексации и вовремя корректируйте файл в случае появления дублей.
От того правильно или нет составлен файл зависит очень многое, поэтому обратите особо пристальное внимание к его составлению, чтобы поисковики быстро и качественно индексировали сайт. Если у вас возникли вопросы — задавайте, с удовольствием отвечу!
webliberty.ru
Как сделать robots.txt для WordPress.Создаем правильный robots.txt для сайта на WordPress
Приветствую, друзья! В этом уроке мы поговорим о создании файла robots.txt, который показывает роботам поисковых систем, какие разделы Вашего сайта нужно посещать, а какие нет.
Фактически, с помощью этого служебного файла можно указать, какие разделы будут индексироваться в поисковых системах, а какие нет.
Создание файла robots.txt
1. Создайте обычный текстовый файл с названием robots в формате .txt.
2. Добавьте в него следующую информацию :
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= Host: site.com Sitemap: http://site.com/sitemap.xml
3. Замените в в текстовом файле строчку site.com на адрес Вашего сайта.
4. Сохраните изменения и загрузите файл robots.txt (с помощью FTP) в корневую папку Вашего сайта.
5. Готово.
Для просмотра и скачки примера, нажмите кнопку ниже и сохраните файл (Ctrl + S на клавиатуре).
Скачать пример файла robots.txtРазбираемся в файле robots.txt (директивы)
Давайте теперь более детально разберем, что именно и зачем мы добавили в файл robots.txt.
User-agent — директива, которая используется для указания названия поискового робота. С помощью этой директивы можно запретить или разрешить поисковым роботам посещать Ваш сайт. Примеры:
Запрещаем роботу Яндекса просматривать папку с кэшем:
User-agent: Yandex Disallow: /wp-content/cache
Разрешаем роботу Bing просматривать папку themes (с темами сайта):
User-agent: bingbot Allow: /wp-content/themes
Allow и Disallow — разрешающая и запрещающая директива. Примеры:
Разрешим боту Яндекса просматривать папку wp-admin:
User-agent: Yandex Allow: /wp-admin
Запретим всем ботам просматривать папку wp-content:
User-agent: * Disallow: /wp-content
В нашем robots.txt мы не используем директиву Allow, так как всё, что не запрещено боту с помощью Disallow — по умолчанию будет разрешено.
Host — директива, с помощью которой нужно указать главное зеркало сайта, которое и будет индексироваться роботом.
Sitemap — используя эту директиву, нужно указать путь к карте сайта. Напомню, что карта сайта является очень важным инструментом при продвижении сайта! Обязательно указывайте её в этой директиве!
Если остались какие-то вопросы — задавайте их в комментарий. Если же информации в этом уроке для Вас оказалось недостаточно, рекомендую почитать подробнее о всех директивах и способах их использования перейдя по этой ссылке.
Приветствую, друзья! В этом уроке мы поговорим о создании файла robots.txt, который показывает роботам поисковых систем, какие разделы Вашего сайта нужно посещать, а какие нет. Фактически, с помощью этого служебного файла можно указать, какие разделы будут индексироваться в поисковых системах, а какие нет. Создание файла robots.txt 1. Создайте обычный текстовый файл с названием robots в формате .txt. 2. Добавьте в него следующую информацию : User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes…
Создание и настройка robots.txt
Рейтинг: 4.49 ( 31 голосов ) 100wp-lessons.com
Правильный robots.txt для сайта wordpress, как закрыть ссылки от индексации
Индексация сайта представляет собой процесс, благодаря которому страницы вашего сайта попадают в поисковые системы.
Для того чтобы сайт индексировался хорошо, вам нужно создать правильный файл robots txt и вписать туда необходимые директивы.
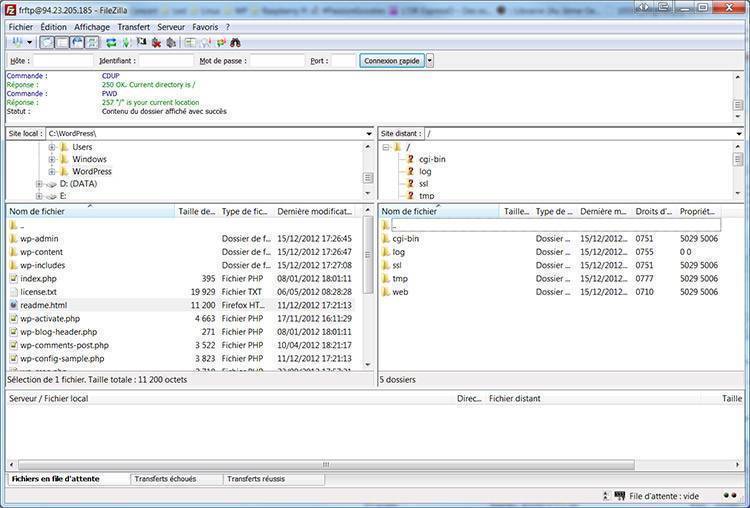
Файл можно создать в стандартной программе “Блокнот”, которая доступна абсолютно каждому пользователю ПК.
Добавляется файл robots txt в корневую папку сайта. Для того чтобы осуществить это действие, вам потребуется программа FileZilla или же обычный Total Commander при условии наличия FTP соединения. На некоторых хостингах есть возможность непосредственного добавления каких-либо файлов.
Что будет, если файл robots txt неправильно настроен
Чтобы ответить на данный вопрос, давайте представим, что сайт wordpress это офис, в который приходят клиенты. В вашем офисе есть как гостевые комнаты, так и служебные, вход в которые доступен только сотрудникам. На дверях служебных помещений обычно вешается табличка с надписью “вход воспрещен” или “вход только для сотрудников”. Таким образом, ваши клиенты будут понимать, что туда им лучше не соваться.
Теперь поговорим о сайте wordpress. Если придерживаться аналогии, то его гостевыми комнатами будут открытые к индексации страницы, а служебными — закрытые к индексации страницы. Клиенты же являются поисковыми роботами, которые посещают сайт и вносят в поисковый индекс определенные страницы.
После небольшого экскурса перейдем непосредственно к последствиям, которые могут возникнуть при неправильной настройке файла роботс. Если вы не впишите запрещающие директивы, то поисковый робот будет индексировать абсолютно все подряд, включая данные панели администратора сайта, тем, скриптов и так далее. Также в выдаче могут появиться страницы-дубли. Поисковый робот может запутаться и случайно проиндексировать одну и ту же страницу несколько раз. Бывают случаи, когда роботы вовсе не индексируют сайт из-за того, что директивы файла индексации неправильно настроены, но чаще всего такое последствие является санкцией, которая возлагается на сайт при продаже ссылок. Чтобы выяснить причину, вам нужно зайти в панель управления, которую предоставляют поисковые системы, которая отказывается индексировать сайт и обратить внимание на какие-либо оповещения.
Настройка robots txt
Запомните, что правильный файл robots txt состоит из 3 компонентов: выбор робота, которому вы задаете директивы; запрет на индексацию; разрешение индексации.
Для того чтобы указать конкретного робота, которому будут адресоваться правила, можно использовать директиву User-agent. Ниже представлены возможные примеры.
- User-agent: * (правила будут распространятся на всех поисковых роботов).
- User-agent: название поискового робота (правила будут распространятся только на тех роботов, которых вы впишете). В большинстве случаев сюда вписывают yandex и googlebot.
Чтобы запретить индексацию определенных разделов на wordpress, вам стоит использовать правильный комплекс директив Disallow. Помимо разделов вы можете также запретить индексировать какую-либо папку или файл. Итак, перейдем к примерам.
- Disallow: (на индексацию нет никаких запретов).
- Disallow: /file.pdf (закрыть файл file.pdf). Таким же образом можете попросить закрыть конкретные папки.
- Disallow: /nazvanie-razdela (закрыть страницы, которые находятся в разделе “nazvanie-razdela”).
- Disallow: */*slovo (закрыть страницы, ссылки на которые включают в себя “slovo”). Звездочки означают любой текст ссылки, который стоит перед или после указанного вами слова. При использовании такой комбинации символов поисковый робот будет считать, что звездочка находится и в конце. Поэтому, если хотите закрыть страницы, ссылки на которые заканчиваются определенным текстом, то вам стоит добавить еще “$” после директивы.
- Disallow: / (закрыть весь сайт).
Если же хотите разрешить индексирование конкретных файлов сайта, которые находятся в запрещенных для индексации разделах, то вам поможет директива Allow. Наглядный пример смотрите ниже.
адресуется поисковым роботам Google
User-agent: googlebot
закрыть страницы, которые находятся в разделе “nazvanie-razdela”
Disallow: /nazvanie-razdela
разрешено добавлять в индекс абсолютно все файлы с расширением txt, независимо от раздела сайта
Allow: *.txt$
В случае наличия XML карты сайта вы можете указать текст ее ссылки в директиву Sitemap. Она является неофициальной и поддерживается не всеми поисковыми роботами. Основными же (Yandex, Google, Bing и Yahoo) эта директива поддерживается. Если у сайта есть несколько XML карт, то вы можете указать все, используя ссылки на них. Никаких проблем не должно возникнуть. Основная ваша задача это правильно указать адрес ссылки каждой из них.
Sitemap: сайт.ru/название-карты-сайта.xml
Sitemap: сайт.ru/название-карты-сайта1.xml
У многих сайтов вордпресс есть зеркала. Чтобы указать основное, вам потребуется вписать адрес его ссылки в директиву Host. Ее понимают только поисковые роботы системы Yandex. Данную директиву можно вписать как под User-agent, так и в любое другое место роботс тхт. Обратите внимание, что адрес ссылки основного зеркала может содержать www. Если вы забудете его туда вписать, то тогда могут возникнуть проблемы.
Host: основное-зеркало.ru
Теперь, зная директивы, вы можете самостоятельно создать правильный файл роботс под любые поисковые системы. Для этого вам нужно в первую очередь проанализировать структуру сайта вордпресс и решить, что же закрыть от поисковиков, а что открыть. Если же вам лень этим заниматься, то можете использовать пример, который представлен ниже.
Для удобства вам рекомендуется использовать плагин wordpress All in One Seo Pack. Он содержит опцию, благодаря которой можно закрыть индексацию архивов, тегов и страниц поиска. Если у вас нет такого плагина, то вам стоит дописать в robots txt представленные ниже атрибуты после директивы Disallow.
- */20 – отвечает за архивы
- */tag – отвечает за теги
- *?s= – отвечает за страницы поиска
При прописывании директив обратите внимание на то, что все директивы, которые адресуются одному поисковому роботу, нужно прописывать без пробела между строками. В ином же случае вам этот пробел будет необходим.
Стоит отметить, что если вы прописали директивы для всех поисковых систем, не нужно их по 10 раз переписывать для каждой отдельно. Это будет лишней тратой времени. Директива User-agent универсальна, поэтому просто вписываете туда звездочку и никаких проблем не должно возникнуть.
Если вам лень прописывать полное название служебных разделов, то можете прописать директиву Disallow: /wp- при условии, что на вашем сайте wordpress нет страниц с таким названием, которые вы бы хотели добавить в индекс. Поэтому будьте внимательны при выборе названия для неслужебных разделов.
При изменении директив файла robots txt вам стоит помнить, что его индексация это не быстрый процесс. Иногда на это требуется не одна неделя. Чтобы проверить статус индексирования этого файла Яндексом, вам нужно перейти в панель вебмастера сервиса Яндекс, выбрать сайт и перейти в раздел “Настройка индексирования”. Потом вам нужно будет выбрать “Анализ robots txt”.
Чтобы проверить статус индексирования файла в Google, вам нужно перейти в раздел “Сканирование” и выбрать “Инструмент проверки robots txt”.
После того как настроите директивы, поисковики должны начать добавлять ваш сайт wordpress в индекс. Стоит отметить, что этот процесс может пойти не так гладко, как вы думаете. Многие вебмастера жалуются на Google из-за того, что он вопреки каким-либо запретам производит индексацию сайта так, как пожелает. Работники Google говорят, что файл роботс является не более, чем рекомендацией.
Даже если прописать запрещающие директивы отдельно для Google, то желаемый результат вы не факт, что получите. К тому же, из-за произвольной индексации роботов Google могут появиться страницы-дубли. Их количество со временем может увеличиться и сайт может попасть под фильтр. Чаще всего это Panda.
Чтобы справиться с этой проблемой, вы можете поставить пароль в панели управления wordpress на конкретный файл или же добавить атрибут noindex в метатеги страниц, на которые желаете наложить запрет индексации. Выглядеть это будет так.
<meta name="robots" content="noindex">
Альтернативой для атрибута noindex является атрибут nofollow. Разница между ними лишь в том, что они по-разному оцениваются поисковыми системами. В случае же с Google вам лучше использовать noindex. Если прислушаться к рекомендации, то вы добьетесь желаемого результата.
В справке сервиса Google можно более детально изучить особенности использования атрибута noindex.
Если вы не хотите вручную создавать роботс для своего wordpress, то можете воспользоваться плагином DL Robots.txt. Его можно установить прямо в панели администратора. Для этого вам нужно будет кликнуть по разделу “Плагины” и выбрать “Добавить новый”. Теперь вам останется лишь вписать название и кликнуть “Установить”, а затем “Активировать”. После этого в панели администратора должна появиться вкладка с названием плагина. Кликнув на нее, вы перейдете в настройки и сможете посмотреть обучающее видео. После проведения настройки вы получите адрес ссылки вашего роботс.
Альтернативами данного плагина wordpress являются PC Robots.txt и iRobots.txt. Они имеют свои особенности, но в целом похожи и являются легкими в настройке. Так что, если первый по каким-либо причинам не будет работать, вы всегда можете воспользоваться последними.
Несколько советов и примечаний
- Помните, что правильный файл роботс wordpress не должен занимать более 32 Кбайта дискового пространства. В противном случае могут возникнуть проблемы и индексацией. Чем меньше вес, тем быстрее обработка.
- Не желательно указывать несколько директив в одной строке.
- Не нужно добавлять в кавычки каждый атрибут директивы, который находится в роботс.
- При отсутствии файла роботс поисковики будут считать, что запрет на индексацию не установлен. Произвольная индексация может привести к фильтрации.
- Стоит отметить, что правильный роботс не должен содержать пробелы в начале каждой строки директивы.
wordpresslib.ru
И снова про robots.txt для WordPress (шпаргалка начинающим) / Habr
Перед каждым блогером (продвинутым, да) рано или поздно встает вопрос: «Чего бы такого написать в robots.txt, чтобы было все в шоколаде?»Совершенно естественно встал данный вопрос и передо мной, а написать хотелось грамотно и с пользой. Полез гуглить и все что нашел, были неуклюжие примеры robots.txt стянутые с официального сайта, которые некоторыми авторами выдавались за собственные поделки, продиктованные редкой музой веб-строительства.
Думаю не стоит и говорить, что такие примеры слабо подходили под наши с вами реалии (читай ПС Яндекс — прим. автора).
Поэтому собрав воедино всю информацию найденную в сети, а также собственные мысли и понимание того «как должно быть» написал следующий вариант.
Что имеем?
Во-первых что важно — разные конструкции для Гугла (и остальных) и для Яндекса.
Обусловлено следующим: Для Гугла в дубликатах прописывается мета-тег canonical (в шаблоне вручную, или при помощи многочисленных сео-плагинов), который должен решать проблему дублирующегося контента, а Яндекс пока этого не понимает, там другие штучки…
Во-вторых у Яндекса прописан Host — что в любом случае не помешает.
В-третьих задача разрешить как можно больше страниц для сапы не стояла, поэтому все лишнее закрыто.
В-четвертых используются более-менее принятые настройки ЧПУ и ссылок. Если у вас иерархия ЧПУ и ссылок другая (например изменены каким-либо плагином) — корректируйте исходя их своих настроек.
Основные ошибки виденные мной:
— зачастую для Яндекса прописывают только директива Host, оставляя Dissalow пустым, но такая конструкция дает право Яндексу опять индексировать все что угодно, несмотря на запреты в первой секции, что, впрочем, логично.
— закрывая категории не закрывают архивы по дате и архив автора.
— не закрывают системные адреса (трекбэки, вход и регистрацию)
Остальное я как мог вынес в комментарии, которые можно смело удалить, если вы со всем разобрались.
Не думаю что он универсален и идеален, но думаю послужит многим хорошей отправной точкой. robots.txt:
User-agent: *
Disallow: /cgi-bin
# запрещаем индексацию системных папок
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
# запрещаем индексацию страницы входа и регистрации
Disallow: /wp-login.php
Disallow: /wp-register.php
# запрещаем индексацию трекбеков, rss-ленты
Disallow: /trackback
Disallow: /feed
Disallow: /rss
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: /xmlrpc.php
# запрещаем индексацию архива автора
Disallow: /author*
# запрещаем индексацию постраничных комментариев
Disallow: */comments
Disallow: */comment-page*
# запрещаем индексацию результатов поиска и другого возможного "мусора"
Disallow: /*?*
Disallow: /*?
# разрешаем индексацию вложений, особо мнительным можно запретить папку wp-content целиком
Allow: /wp-content/uploads
User-agent: Yandex
Disallow: /cgi-bin
# запрещаем индексацию системных папок
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
# запрещаем индексацию категорий
Disallow: /category*
# запрещаем индексацию архивов по датам. Прописываем вручную актуальные года
Disallow: /2008*
Disallow: /2009*
# запрещаем индексацию архива автора
Disallow: /author*
# запрещаем индексацию страницы входа и регистрации
Disallow: /wp-login.php
Disallow: /wp-register.php
# запрещаем индексацию трекбеков, rss-ленты
Disallow: /trackback
Disallow: /feed
Disallow: /rss
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: /xmlrpc.php
# запрещаем индексацию постраничных комментариев
Disallow: */comments
Disallow: */comment-page*
# запрещаем индексацию результатов поиска и другого возможного «мусора»
Disallow: /*?*
Disallow: /*?
# разрешаем индексацию вложений, особо мнительным можно запретить папку wp-content целиком
Allow: /wp-content/uploads
# прописываем директиву Host
Host: mysite.ru
User-agent: Googlebot-Image
Disallow:
Allow: /*
# разрешаем индексировать изображения
User-agent: YandexBlog
Disallow:
Allow: /*
# разрешаем индексировать rss-ленту
PS. Данный файл использую на своих блогах, валидность и правильность проверял в панели веб-мастера, добиваясь нужного мне результата. Поэтому если что-то не устраивает — проверяйте и дописывайте свое.
PPS. Я еще не матерый сеошник, посему где-то могу ошибаться. С robots.txt не ошибается тот, у кого такого файла вообще нет)
habr.com
Файл robot.txt | WordPress.org Русский
Спасибо за ответы, только у меня вопросов прибавилось((( Я НЕ специалист к сожалению((
Мой робот я сделала давно, тогда почему-то сайт долго индексировался и мне с яндекс вебмастера предложили закрыть лишнее, чтобы робот быстрей обходил, ну я и закрыла (в интернете день читала про все — так видимо и не поняла)
Я очень уважаю ваше мнение, но чем больше я смотрю файлов и сайтов, тем больше у меня вопросов ибо в каждом что-то разное — то стоит в конце /, то не стоит и прочие значки вот по ссылке, что прислал SeVlad я вообще ничего не поняла, так как это плюс еще очередной вариант на мою и без того запутанную чайниковую голову
Yui мне лучше совсем убрать то что Вы написали или добавить разрешение allow для моей темы Нирвана (у меня закачано еще три темы — хотела сменить дизайн посмотреть, чтобы не перегружать обходящего робота) Я ОЧЕНЬ боюсь испортить или открыть больше, чем нужно.
Могли бы вы подправить, исправить, проверить мой робот тхт или написать новый , чтобы он был правильным и в тоже время не замедлял обход сайта роботами гугла и яндекса.
User-agent: *
Allow: /wp-content/uploads
Allow: /wp-content/themes/nirvana/css
Disallow: /cgi-bin
Disallow: /wp-admin/
Disallow: /wp-content/cache
Disallow: /wp-login.php
Disallow: */attachment_id=*
Disallow: */trackback
Disallow: */feed/
Disallow: /?p=*
Disallow: *?s=
Disallow: /xmlrpc.php
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
Disallow: /wp-content/cache
Disallow: /wp-login.php
Disallow: *?replytocom=*
Disallow: */attachment_id=*
Disallow: */trackback
Disallow: */tag/*
Disallow: */feed/
Disallow: /?p=*
Disallow: *?s=
Disallow: /xmlrpc.php
Host: мойсайт.ru
Sitemap: http://мойсайт.ru/sitemap.xml
Sitemap: http://мойсайт.ru/sitemap.xml
Обязательно здесь ставить вторую строчку с gz в конце,
Грубо говоря — удаляете всё и следите за индексацией (метрика/вебмастер) и если если там появятся нежелательное — закрываете
Как я потом узнаю чем закрыть и что именно (куча значков то вначале, то в конце, то * то все вместе
Поэтому и спросила, что необходимо написать.
Тот пример который я приложила изобилует всякими функциями поэтому я и запуталась, а в моем случае многое закрыто, особенно этот css, который гугл так обожает
Заранее Спасибо за вашу помощь.Пустья покажусь бестолковой, но мне очень нужно, а может быть я даже что-то пойму на вашем примере.
ru.wordpress.org
Файл robots txt — основные директивы и инструкция по редактированию в Нубексе
Robots.txt — это текстовый файл, который содержит специальные инструкции для роботов-поисковиков, исследующих ваш сайт в интернете. Такие инструкции — они называются директивами — могут запрещать к индексации некоторые страницы сайта, указывать на правильное «зеркалирование» домена и т.д.
Для сайтов, работающих на платформе «Нубекс», файл с директивами создается автоматически и располагается по адресу domen.ru/robots.txt, где domen.ru — доменное имя сайта. Например, с содержанием файла для сайта nubex.ru можно ознакомиться по адресу nubex.ru/robots.txt.

Изменить robots.txt и прописать дополнительные директивы для поисковиков можно в админке сайта. Для этого на панели управления выберите раздел «Настройки», а в нем — пункт «SEO».

Найдите поле «Текст файла robots.txt» и пропишите в нем нужные директивы. Желательно активировать галочку «Добавить в robots.txt ссылку на автоматически генерируемый файл sitemap.xml»: так поисковый бот сможет загрузить карту сайта и найти все необходимые страницы для индексации.

Не забудьте сохранить страницу после внесения необходимых изменений.
Основные директивы для файла robots txt
Загружая robots.txt, поисковый робот первым делом ищет запись, начинающуюся с User-agent: значением этого поля должно являться имя робота, которому в этой записи устанавливаются права доступа. Т.е. директива User-agent — это своего рода обращение к роботу.
1. Если в значении поля User-agent указан символ «*», то заданные в этой записи права доступа распространяются на любых поисковых роботов, запросивших файл /robots.txt.

2. Если в записи указано более одного имени робота, то права доступа распространяются для всех указанных имен.

3. Заглавные или строчные символы роли не играют.

4. Если обнаружена строка User-agent: ИмяБота, директивы для User-agent: * не учитываются (это в том случае, если вы делаете несколько записей для различных роботов). Т.е. робот сначала просканирует текст на наличие записи User-agent: МоеИмя, и если найдет, будет следовать этим указаниям; если нет — будет действовать по инструкциям записи User-agent: * (для всех ботов).

Кстати, перед каждой новой директивой User-agent рекомендуется вставлять пустой перевод строки (Enter).
5. Если строки User-agent: ИмяБота и User-agent: * отсутствуют, считается, что доступ роботу не ограничен.

Запрет и разрешение индексации сайта: директивы Disallow и Allow
Чтобы запретить или разрешить поисковым ботам доступ к определенным страницам сайта, используются директивы Disallow и Allow соответственно.
В значении этих директив указывается полный или частичный путь к разделу:
- Disallow: /admin/ — запрещает индексацию всех страниц, находящихся внутри раздела admin;
- Disallow: /help — запрещает индексацию и /help.html, и /help/index.html;
- Disallow: /help/ — закрывает только /help/index.html;
- Disallow: / — блокирует доступ ко всему сайту.
Если значение Disallow не указано, то доступ не ограничен:
- Disallow: — разрешена индексация всех страниц сайта.
Для настройки исключений можно использовать разрешающую директиву Allow. Например, такая запись запретит роботам индексировать все разделы сайта, кроме тех, путь к которым начинается с /search:
User-agent: *
Allow: /search
Disallow: /
Неважно, в каком порядке будут перечислены директивы запрета и разрешения индексации. При чтении робот все равно рассортирует их по длине префикса URL (от меньшего к большему) и применит последовательно. То есть пример выше в восприятии бота будет выглядеть так:
User-agent: *
Disallow: /
Allow: /search
— разрешено индексировать только страницы, начинающиеся на /search. Таким образом, порядок следования директив никак не повлияет на результат.
Директива Host: как указать основной домен сайта
Если к вашему сайту привязано несколько доменных имен (технические адреса, зеркала и т.д.), поисковик может решить, что все это — разные сайты. Причем с одинаковым наполнением. Решение? В бан! И одному боту известно, какой из доменов будет «наказан» — основной или технический.

Чтобы избежать этой неприятности, нужно сообщить поисковому роботу, по какому из адресов ваш сайт участвует в поиске. Этот адрес будет обозначен как основной, а остальные сформируют группу зеркал вашего сайта.
Сделать это можно с помощью директивы Host. Ее нужно добавить в запись, начинающуюся с User-Agent, непосредственно после директив Disallow и Allow. В значении директивы Host нужно указать основной домен с номером порта (по умолчанию 80). Например:
User-Agent: *
Disallow:
Host: test-o-la-la.ru
Такая запись означает, что сайт будет отображаться в результатах поиска со ссылкой на домен test-o-la-la.ru, а не www.test-o-la-la.ru и s10364.nubex.ru (см. скриншот выше).
В конструкторе «Нубекс» директива Host добавляется в текст файла robots.txt автоматически, когда вы указываете в админке, какой домен является основным.
В тексте robots.txt директива host может использоваться только единожды. Если вы пропишите ее несколько раз, робот воспримет только первую по порядку запись.
Директива Crawl-delay: как задать интервал загрузки страниц
Чтобы обозначить роботу минимальный интервал между окончанием загрузки одной страницы и началом загрузки следующей, используйте директиву Crawl-delay. Ее нужно добавить в запись, начинающуюся с User-Agent, непосредственно после директив Disallow и Allow. В значении директивы укажите время в секундах.
User-Agent: *
Disallow:
Crawl-delay: 3
Использование такой задержки при обработке страниц будет удобным для перегруженных серверов.
Существуют также и другие директивы для поисковых роботов, но пяти описанных — User-Agent, Disallow, Allow, Host и Crawl-delay — обычно достаточно для составления текста файла robots.txt.
nubex.ru