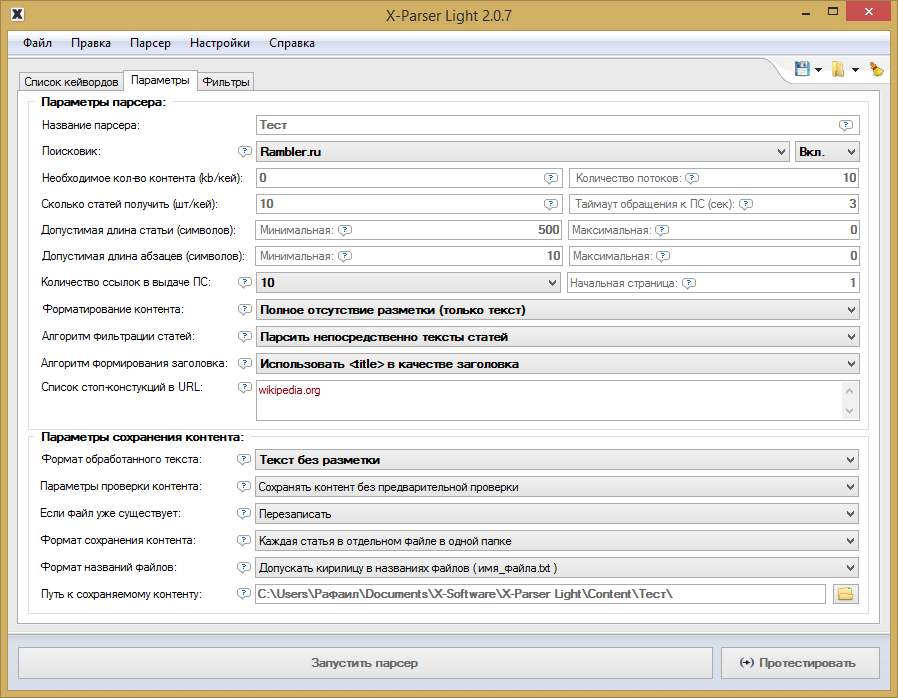
Возможно ли написать универсальный парсер сайтов? — Хабр Q&A
И да, и нет: у вас очень расплывчатая формулировка. Непонятно, насколько осмысленным и обработанным должен быть итоговый результат, насколько допустим мусор.
Скачать страницу, построить дерево документа и какими-то элементарными эвристиками вырезать ненужное (меню, сайдбары, подвалы, рекламу и т.п.) относительно просто, но результат будет довольно грубый с неудовлетворительным соотношением сигнал/шум.
Для повышения универсальности инструмента, потребуется увеличивать количество и сложность этих эвристик. А ещё можно подключить туда машинное обучение, чтобы они сами себя улучшали.
И вот вы уже хотите написать что-то вроде поискового паука. Представьте, сколько сил вложено в разработку паука Яндекса или Гугла. У вас есть такие возможности? А ведь мало его просто написать, надо поддерживать, следить за новыми стандартами…
Парсинг сайтов — это задача, которая легко решается людьми, но плохо даётся роботам.
Ответ написан
Очень сомневаюсь, что это возможно.
Вам же нужны структурированные данные, а не просто сплошной текст того, что есть на сайте/странице. А чтобы получить структурированные данные, необходимо знать и настроить структуру для парсера, чтобы он знал, что брать, а что пропускать.
Ну и curl — не панацея от всех проблем. Например, он не сможет получить данные, которые подгружаются на сайте, используя JavaScript (подсказка: в этом случае поможет только PhantomJS).
Ответ написан 
Этим поисковые системы уже второе десятилетие занимаются. Вроде получается, но оцените трудозатраты.
Ответ написан
Конечно, возможно, стандарт DOM предусматривает document.body.textContent как и у других DOM-элементов.
Ответ написан
Как вариант — можно уйти в сторону специализированных сервисов, наподобие https://lateral.io/docs/article-extractor
Ответ написан
Комментировать
Универсальный парсер для сбора данных в интернете
Автор: Parser | Декабрь 26, 2019
OutwitHub — это универсальный парсер данных, встроенный в веб-браузер для всех задач. Он обладает многими функциями распознавания данных, автономного их исследования, извлечения и экспорта для анализа.
Он обладает многими функциями распознавания данных, автономного их исследования, извлечения и экспорта для анализа.
Мощный, многофункциональный инструмент парсинга для всех уровней:как любителей, так и профессионалов.
Программа охватывает широкий спектр потребностей, от простых до очень конкретных требований и очень больших объемов данных. Основное предназначение программы Outwit Hub, это сбор данных в автоматическом режиме из источников интернета. Программа проста и очень удобна в использовании, не требует от пользователя знаний программирования.
Парсер позволяет просматривать и захватывать информацию в интернете, собирать мультимедиа, контакты, телефоны и файлы из интернета в несколько кликов. Если ввести URL любого сайта, Outwit Hub отобразит страницу в своем окне вместе со всеми спецификациями страницы (количество ссылок, изображений, скриптов, даже время загрузки и прочее). В левой боковой панели можно просматривать каждую ссылку, изображение, документ и другие данные, которые появляются на странице.
- Парсит новости, статьи, пресс-релизы, RSS ленты;
- Парсинг контактов, емайл адресов и номеров телефонов;
- Парсинг работы, запросы предложений, возможности;
- Парсит SEO , ссылки, анализ страниц, мета данных, проверка источника, количество слов, фото. Мониторинг ключевых элементов в исходном коде сайтов;
- Мониторинг социальных сетей, форумов, комментариев, постов, твитов;
- Парсинг в электронной коммерции, каталоги товаров, списки, описания, артикулы, названия продуктов, мониторинг цен;
- Парсит объявления, расписание рейсов, недвижимость, ресурсы, онлайн сервисы сбора данных;
- Изображения, документы и загрузки;
- Поиск брендов, IP-наблюдение и защита;
- Экспорт данных в Excel, CSV, HTML, JSON, SQL…
Как пользоваться универсальным парсером OutWit Hub
Программа имеет интуитивный интерфейс с подробнейшим руководством по парсингу данных. Перед работой желательно изучить это руководство (переводчик от гугла в помощь). В новых версиях программы руководство вызывается из меню программы «Help» — поле «help».
В новых версиях программы руководство вызывается из меню программы «Help» — поле «help».
Работать с парсером просто. Вводим в адресную строку адрес нужного сайта и нажимаем поиск. После загрузки страницы сайта, в левой панели программы можно выбрать нужные данные и скачать или скопировать их.
Это бесплатное приложение позволит продвинутым пользователям создавать и распространять свои собственные оригинальные инструменты с их собственными пользовательскими интерфейсами, функциями, скриптами, макросами, парсерами и собственные мэшапы данных.
OutWit Hub существует как дополнение для Firefox до версии 42 и как отдельное приложение для Windows, Mac OS и Linux. Бесплатная и платная версии. В бесплатной версии есть ограничения, платная стоит 90$.
Универсальный парсер скачать можно на офф-сайте.
Скачать
Существует ли универсальный парсер веб-страниц?
Сегодня данные стали основой многих предприятий. Эпоха больших данных и машинного обучения создаст предприятия, использующие силу данных, и приведет к исчезновению тех, кто этого не делает. По этой причине предприятия по всему миру ищут инструменты для сбора данных, такие как веб-скраперы.
По этой причине предприятия по всему миру ищут инструменты для сбора данных, такие как веб-скраперы.
Долгое время любой, кому нужны данные со сторонних веб-сайтов, использовал официальные API для их извлечения. Веб-скраперы предлагают простой способ загрузки контента, программно выступая в качестве универсальных API. Компании не зависят от своих API, а также от своих веб-сайтов. Если вы сильно зависите от API для доступа к данным, вы часто будете получать не очень структурированные данные, поскольку веб-сайты больше заботятся о своем общедоступном сайте для посетителей.
Некоторые компании также склонны перемещать свои фиды или изменять свои API без предупреждения. Напротив, у них есть веб-мастера, которые следят за управлением и состоянием веб-сайтов. Они редко беспокоятся о своих автономных источниках структурированных данных.
Выполняя веб-скрапинг, майнеры данных могут получить анонимный доступ к данным без ограничения скорости. В отличие от API, которые заставляют своих пользователей регистрироваться для получения ключей, веб-скрапинг использует прокси-серверы, чтобы скрыть ваш IP-адрес. Поскольку веб-скрапинг можно выполнять на любом веб-сайте, вам не нужно ждать, пока интересующий веб-сайт создаст API данных. Просто просмотрите веб-сайт и изучите его шаблоны доступа, а затем отправьте свой парсер для работы.
Поскольку веб-скрапинг можно выполнять на любом веб-сайте, вам не нужно ждать, пока интересующий веб-сайт создаст API данных. Просто просмотрите веб-сайт и изучите его шаблоны доступа, а затем отправьте свой парсер для работы.
Есть универсальный скребок?
Раньше майнерам приходилось создавать свой код очистки с нуля. Они будут изучать веб-сайты, чтобы выяснить их веб-структуры, а затем писать для них код. В индустрии веб-скрапинга было много разработок, таких как универсальные инструменты для сбора данных, которые могут собирать данные с разных веб-сайтов.
Некоторые программисты создали веб-скраперы, которым для извлечения данных требуются только цели шаблона. Некоторые из универсальных фреймворков включают Selenium, Beautiful Soup и Scrapy. Например, Selenium широко используется для веб-тестирования и также может отображать файлы Javascript.
Если вы не являетесь программистом, вам не нужно нанимать профессиональных служб кодирования для ваших нужд по очистке веб-страниц. Просто получите доступ к универсальному парсеру из постоянно растущего списка визуальных инструментов веб-парсинга. Предприятиям, которым требуются мощные веб-скрейперы, следует обратиться к разработчикам инструментов для парсинга, которые могут предоставить специальные инструменты для парсинга.
Просто получите доступ к универсальному парсеру из постоянно растущего списка визуальных инструментов веб-парсинга. Предприятиям, которым требуются мощные веб-скрейперы, следует обратиться к разработчикам инструментов для парсинга, которые могут предоставить специальные инструменты для парсинга.
Типы универсальных инструментов для скребков
Выбор правильного типа инструментов для скребков может быть очень запутанным для нового пользователя. Ниже приведены различные типы инструментов веб-скрейпинга, каждый из которых имеет свои преимущества и недостатки.
1. Расширения браузера
Эти инструменты очистки идеально подходят для небольших операций по добыче данных. С помощью инструмента парсинга плагинов вы можете заниматься своими действиями в браузере во время парсинга. Расширения устанавливаются в веб-браузерах и в конце очистки загружают данные в удобочитаемом формате, таком как .CSV.
Эти универсальные скребки просты в использовании, но имеют свои ограничения. Например, они могут одновременно очищать только минимальный объем данных, а это означает, что если вам нужно очистить несколько страниц за раз, вам потребуется надежный инструмент для очистки.
Например, они могут одновременно очищать только минимальный объем данных, а это означает, что если вам нужно очистить несколько страниц за раз, вам потребуется надежный инструмент для очистки.
Возможности расширений браузера также ограничены. Если вам, например, нужно парсить данные с помощью ротационных пулов резидентных прокси, расширение для браузера вам не подойдет. Браузеры не предназначены для парсинга, поэтому они не будут легко интегрироваться с премиальными функциями парсинга.
2. Программные чистящие средства
Эти универсальные чистящие средства устанавливаются на жесткий диск компьютера. Большинство этих инструментов созданы для Windows, поэтому они совместимы с большинством компьютеров. После того, как программное обеспечение загружено и установлено, настройте его в соответствии с документацией и установите его для очистки.
Инструмент очистки будет загружать данные в таких форматах, как .CSV. Эти парсеры являются парсерами данных среднего веса и позволяют одновременно очищать больше, чем плагины. Они также позволяют использовать дополнительные функции, такие как фиксированные IP-сессии.
Они также позволяют использовать дополнительные функции, такие как фиксированные IP-сессии.
Однако их не так просто установить и настроить, как расширения. Они также будут использовать ресурсы вашего компьютера, что может значительно повлиять на скорость вашего ПК.
3. Облачные парсеры
Облачный парсер — это универсальное решение для парсинга веб-страниц. Эти инструменты очистки не затрагивают ресурсы вашего компьютера, поскольку инструмент размещен в облаке. Поэтому у вас не будет проблем с установкой или настройкой. Просто загрузите API парсера и получите парсинг.
Эти инструменты идеально подходят для крупных работ по очистке. Вы можете доверять им, чтобы надежно очищать огромные объемы данных за раз. Лучшие облачные парсеры не ограничивают объем извлекаемых данных, потому что у них есть несколько серверов, которые хорошо обслуживаются профессионалами.
Они обладают высокой степенью автоматизации и предлагают простую ротацию прокси-серверов, веб-сканирование, скрейпинг и процесс загрузки данных. Эти инструменты дороже других универсальных скребков.
Эти инструменты дороже других универсальных скребков.
Заключение
Сегодня на рынке представлены различные типы веб-скребков. Ваши потребности в очистке должны диктовать ваш выбор. Выберите лучший универсальный парсер для своего бизнеса и погрузитесь в мир использования больших данных.
Связанные элементы:Расширения для браузера, Облачные парсеры, MarTech, Программные парсеры, Универсальный веб-скрейпер
Зачем миру нужна универсальная библиотека веб-скрейпинга для JavaScript | Ян Чурн | HackerNoon.com
Опубликовано в
·
Чтение: 5 мин.
·
25 сентября 2018 г.
TL;DR: мы выпустили 9 0065 Apify SDK — Node.js с открытым исходным кодом библиотека для парсинга и веб-сканирования. Была одна для Python, но до сих пор не было такой библиотеки для JavaScript, языка Интернета.
В Python есть Scrapy, де-факто стандартный набор инструментов для создания парсеров и поисковых роботов. Но в JavaScript не было столь всеобъемлющей и универсальной библиотеки. Но это неправильно. Постоянно растущее число веб-сайтов использует JavaScript для получения и отображения пользовательского контента. Чтобы извлечь данные с этих веб-сайтов, вам часто потребуется использовать реальный веб-браузер для анализа HTML и запуска скриптов страниц, а затем внедрить свой код извлечения данных, который будет выполняться в контексте браузера, т. е. вам нужен JavaScript. Так какой смысл использовать другой язык программирования для управления «серверной частью» сканера?
Но в JavaScript не было столь всеобъемлющей и универсальной библиотеки. Но это неправильно. Постоянно растущее число веб-сайтов использует JavaScript для получения и отображения пользовательского контента. Чтобы извлечь данные с этих веб-сайтов, вам часто потребуется использовать реальный веб-браузер для анализа HTML и запуска скриптов страниц, а затем внедрить свой код извлечения данных, который будет выполняться в контексте браузера, т. е. вам нужен JavaScript. Так какой смысл использовать другой язык программирования для управления «серверной частью» сканера?
Давайте просто проигнорируем тот факт, что согласно опросу StackOverflow за 2018 год, JavaScript является наиболее широко используемым языком программирования в мире. Мы не будем упоминать этот факт в этом блоге.
Есть еще одна веская причина использовать JavaScript для просмотра веб-страниц. В апреле 2017 года Google запустил безголовый Chrome, а вскоре после этого выпустил Puppeteer — API Node.js для безголового Chrome. Это было не чем иным, как революцией в мире парсинга веб-страниц, потому что раньше единственными вариантами оснащения полнофункционального веб-браузера были использование PhantomJS, который сильно устарел, использование Splash, который основан на QtWebKit и имеет только Python SDK, или использовать Selenium, чей API ограничен необходимостью поддержки всех браузеров, включая Internet Explorer, Firefox, Safari и т. д. В то время как безголовый Chrome позволял запускать веб-браузеры на серверах без необходимости использования X Virtual Framebuffer (Xvfb), Puppeteer предоставил самый простой и мощный высокоуровневый API для веб-браузера, который когда-либо существовал.
Это было не чем иным, как революцией в мире парсинга веб-страниц, потому что раньше единственными вариантами оснащения полнофункционального веб-браузера были использование PhantomJS, который сильно устарел, использование Splash, который основан на QtWebKit и имеет только Python SDK, или использовать Selenium, чей API ограничен необходимостью поддержки всех браузеров, включая Internet Explorer, Firefox, Safari и т. д. В то время как безголовый Chrome позволял запускать веб-браузеры на серверах без необходимости использования X Virtual Framebuffer (Xvfb), Puppeteer предоставил самый простой и мощный высокоуровневый API для веб-браузера, который когда-либо существовал.
Хотя написать код извлечения данных для нескольких веб-страниц в Puppeteer несложно, все может оказаться сложнее. Например, когда вы пытаетесь выполнить глубокий обход всего веб-сайта, используя постоянную очередь URL-адресов, или просканировать список из 100 000 URL-адресов из CSV-файла. И здесь возникает потребность в библиотеке.
Apify SDK — это библиотека с открытым исходным кодом, которая упрощает разработку поисковых роботов, парсеров, средств извлечения данных и задач веб-автоматизации. Он предоставляет инструменты для управления и автоматического масштабирования пула безголовых экземпляров Chrome / Puppeteer, для поддержки очередей URL-адресов для сканирования, сохранения результатов сканирования в локальной файловой системе или в облаке, ротации прокси-серверов и многого другого. Библиотека доступна как 9Пакет 0081 apify на NPM. Его можно использовать либо автономно в ваших собственных приложениях, либо в акторах, работающих в облаке Apify.
Но в отличие от других библиотек веб-скрейпинга, таких как Headless Chrome Crawler, Apify SDK не привязан только к Puppeteer. Например, вы можете легко создавать поисковые роботы, использующие библиотеку синтаксического анализа HTML Cheerio или даже Selenium. Основные строительные блоки одинаковы для многих типов сканеров. Короче говоря, Apify SDK включает в себя уроки, которые мы в Apify извлекли из тысяч веб-сайтов за последние четыре года.
Ладно, хватит болтать, давайте взглянем на код. Для его запуска вам понадобится Node.js 8 или более поздняя версия, установленная на вашем компьютере. Во-первых, установите Apify SDK в свой проект, выполнив:
npm install apify --save
Теперь вы можете запустить этот пример сценария:
Пример Hello Crawler. Исходный код на GitHub Сценарий выполняет рекурсивное глубокое сканирование https://www.iana.org с помощью Puppeteer. Количество процессов и вкладок Puppeteer автоматически контролируется в зависимости от доступного процессора и памяти в вашей системе. Кстати, этот функционал выставлен отдельно как AutoscaledPool , чтобы можно было использовать его для управления пулом любых других ресурсоемких асинхронных задач.
Вот как это выглядит в терминале:
Рекурсивное сканирование https://www. iana.org с использованием Apify SDK — Терминальное представление
iana.org с использованием Apify SDK — Терминальное представлениеИ когда вы запустите сканирование в режиме headful, вы увидите, как Apify SDK автоматически запускает и управляет Браузеры и вкладки Chrome:
Рекурсивное сканирование https://www.iana.org с использованием Apify SDK — просмотр браузера ChromeApify SDK предоставляет ряд служебных классов, полезных для обычных задач веб-скрейпинга и автоматизации, например, для управления URL-адресами. для сканирования, хранения данных и различных скелетов краулеров. Чтобы получить лучшее представление, взгляните на Обзор компонентов.
Мы считаем, что каждый имеет право на доступ к общедоступной сети так, как он этого хочет, а не только так, как задумали авторы. Именно таким образом Интернет превратился в то, чем он является сегодня — позволяя людям творчески использовать то, что есть, и создавать новые слои поверх этого, независимо от того, для чего он был разработан. Вот почему веб-скрапинг важен, потому что он позволяет создавать ранее невообразимые инструменты или услуги поверх существующих и добавлять новый слой поверх Интернета.