
Как найти и удалить дубли страниц на сайте
- SEO
- РАЗРАБОТКА
Дубль – страница, которая полностью или частично дублирует контент другой страницы. Одна из причин потери трафика из поисковых систем – наличие дублей страниц на сайте.
Подписаться
Дубль – страница, которая полностью или частично дублирует контент другой страницы. Одна из причин потери трафика из поисковых систем – наличие дублей страниц на сайте.
Одна из причин потери трафика из поисковых систем – наличие дублей страниц на сайте.
Принципы определения дублей поисковыми системами
Поисковые системы (далее «ПС») имеют свои алгоритмы проверки и определения дублей страниц.
Основные параметры, которые учитывают ПС при определении дублей:
- Мета-теги;
- Заголовки h2-H6;
- Текст страницы.
Способы определения дублей страниц на сайте
Статус «Дубль» присваивается поисковым роботом соответствующей поисковой системы при сканировании страниц сайта. Воспользуйтесь Вебмастерами поисковых систем, чтобы определить наличие дублей. Или воспользуйтесь специализированными программами для ручного поиска дублей.
Способ 1: Дубли страниц в Яндекс.Вебмастер
В поисковой системе Яндекс увидеть дубли страниц можно в Яндекс.Вебмастер, в разделе Индексирование → Страницы в поиске → Исключенные страницы → Статус «Дубль».
Способ 2: Дубли страниц в Google Search Console
В поисковой системе Google увидеть дубли страниц можно в Google Search Console, в разделе «Покрытие» → «Исключено».
Дубли страниц в Google Search ConsoleСпособ 3: Через программы для комплексного анализа сайтов
Поисковые системы не всегда корректно распознают дубли. Используя различные программы сканирования сайтов можно определить наличие дублей на сайте. Например, программа Screaming Frog позволяет это сделать.
Чтобы найти дубли с помощью Screaming Frog используйте те же самые основные параметры поиска:
-
Поиск одинаковых Title. Вкладка «Page Titles» → Filter «Duplicate»
-
Одинаковые заголовки h2, h3. Вкладка «h2» или «h3» → Filter «Duplicate»
Список страниц с одинаковыми h2 в программе Screaming Frog
Подобным образом можно найти дубли во вкладке Description, h3.
Способ 4: Ручной поиск – проверка типичных ошибок
Дубли сайта формируются на основании технических особенностей систем, на которых пишутся сайты.
Основные ручные проверки, которые необходимо провести:
- Доступность страницы с добавлением index.php / index.html / index.htm для каждой страницы после слеша. Например, есть страница https://site.ru, нужно проверить доступность страницы по адресам:
- https://site.ru/index.php
- https://site.ru/index.html
- https://site.ru/index.htm
- Доступность страницы по HTTP и HTTPS страницы: https://site.ru и http://site.ru. Если страница доступна по разным протоколам, то необходимо настроить 301 редирект с HTTP на HTTPS
- Доступность страницы по разным зеркалам. Адреса с «www» и без «www»:
- http://site.ru
- http://www.site.ru
- Доступность страницы с разным регистром в URL:
- http://site.
 ru/example/
ru/example/ - http://site.ru/EXAMPLE/
- http://site.
- Доступность одной и той же страницы по разным URL:
- http://site.ru/catalog/tovar1/
- http://site.ru/tovar1/
- Доступность страницы со слешами («/», «//», «///») и без них в конце:
- http://site.ru/example
- http://site.ru/example//
- http://site.ru///example/
- Доступность страницы-дубля через пагинацию:
- http://site.ru/catalog/
- http://site.ru/catalog/page1
 ru/example/
ru/example/Как избавиться от дублей страниц
- Установить тег canonical. Установить тег в head: link rel=»canonical» href=»ссылка на каноничную страницу»;
- Изменить контент страницы. Изменить мета-теги, заголовки h2-h6, текст, учитывая особенности контента, расположенного на странице. Используйте в случае необходимости индексирования страницы-дубля;
- Удалить страницу;
- Установить 301 редирект с дубля на оригинальную страницу. Попадая на страницу дубль, пользователь будет переадресован на нужную страницу;
- Запретить индексирование в robots.txt. Указать поисковому роботу, что добавлять в индекс такие страницы не нужно;
- Установить мета-тег noindex. Добавить в head: meta name=»robots» content=»noindex».
 Попадая на страницу дубль, пользователь будет переадресован на нужную страницу;
Попадая на страницу дубль, пользователь будет переадресован на нужную страницу;Влияние дублей страниц на поисковое продвижение
- Любой поисковая система имеет лимит на сканирование страниц для одного сайта. При появлении дублей, увеличивается общее количество страниц на сайте. При большом количестве страниц-дублей, поисковой робот может вовсе пропустить важные страницы;
- Изменение релевантности страницы. Поисковой робот может решить, что страница-дубль отвечает на запрос лучше, чем оригинальная страница и в поисковой выдаче будет показывать страницу-дубль;
- Потеря ссылочной массы оригинальной страницы и посетители станут попадать на страницы-дубли.
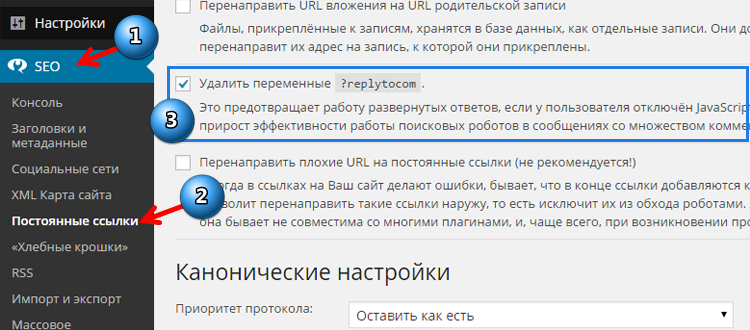
-
-
НОВОСТИ
Цифровой Элемент на Ecom Eхpo’22 -
РАЗРАБОТКА
Что такое 1С-Bitrix?
Все статьи
-
РАЗРАБОТКА
Как проверить и увеличить скорость загрузки сайта -
ИНТЕРНЕТ-РЕКЛАМА
Что такое контекстно-медийная реклама
Все статьи
-
РАЗРАБОТКА
Flutter или нативная разработка? -
ИНТЕРНЕТ-РЕКЛАМА
Что такое CTR в рекламе
Все статьи
#SEO
Микроразметка schema.org
Schema.org – микроразметка, позволяющая структурировать данные на сайте для поисковых систем. С ее помощью поисковые системы понимают, какие данные…
#ИНТЕРНЕТ-МАРКЕТИНГ
Как попасть на Яндекс.Карты, Google.Карты, 2GIS
Если ваша компания ведет бизнес офлайн, размещение на Яндекс.Картах и Google и 2GIS поможет рассказать об этом потенциальным клиентам. Присутствие…
#ДИЗАЙН
TОП-40 плагинов Figma
Для создания дизайнов и прототипов большинство современных дизайнеров использует Figma.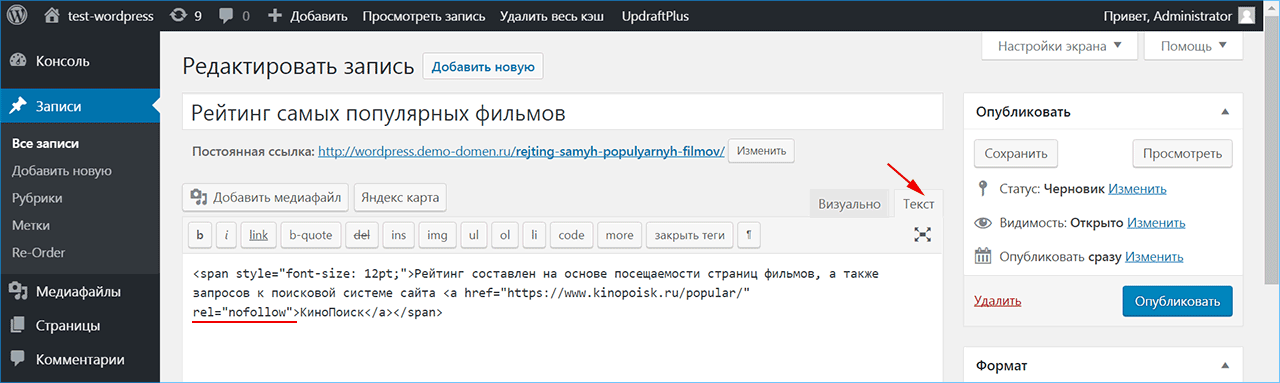 Его основное преимущество перед другими графическими прогр…
Его основное преимущество перед другими графическими прогр…
#SEO
404 ошибка – страница не найдена
404 ошибка (страница не найдена) – это ответ сервера, который возникает, когда сервер не может отобразить запрашиваемую страницу по указанному адре…
#SEO
Семантика сайта
Семантическое ядро – это набор фраз, соответствующих поисковым запросам пользователей в поисковых системах, которые характеризуют определенную тема…
#ИНТЕРНЕТ-РЕКЛАМА
Как предоставить гостевой доступ к Яндекс Директ и Google Adwords
Контекстная реклама — один из самых простых и быстрых способов увеличения посещений веб-сайта. Особенностью этого инструмента является понятность р…
#РАЗРАБОТКА
Как составить ТЗ на разработку сайта
ТЗ (техническое задание) – очень полезный документ, в котором описаны все разделы сайта, все элементы страницы и функциональность всех модулей. Пол…
Пол…
#SEO
Микроразметка Open Graph
Open Graph – стандарт микроразметки, который позволяет формировать превью сайта при публикации в социальных сетях. Стандарт Open Graph был р…
#ТЕХПОДДЕРЖКА
Сброс кеша DNS в Google Chrome
Для сброса кеша DNS в Google Chrome: Введите в адресной строке браузера chrome://net-internals/#dns и нажмите кнопку Clear host cache; Зат…
#ИНТЕРНЕТ-МАРКЕТИНГ
Анализ сайта с помощью Яндекс.Метрики
Яндекс.Метрика – инструмент анализа аудитории сайта. Метрика позволяет сегментировать данные, определять целевую аудиторию сайта, достигать целей и…
Заявка!
Для консультации или подготовки предложения.
Будьте всегда в курсе!
Подпишитесь на нашу рассылку
Ваш email
Ваш email
Я согласен(а) на получение сообщений по e-mail. Я уведомлен(а), что могу в любое время отказаться от их получения.
Ваш e-mail
Ваше имя
Контактный телефон
Эл. почта
Согласен на обработку персональных данных
Золотой партнер
1С-Битрикс
Сертифицированное агентство
Яндекс. Директ
Директ
Сертифицированное агентство
Google.AdWords
Региональный партнер
Ru-center
Золотой партнер
Битрикс24
Инструкция для новичков по удалению дублей страниц на сайте
140351 2432 2
| SEO | – Читать 14 минут |
Прочитать позже
Сергей Романов
Специалист по продвижению веб-проектов в Promodo
Дубли страниц очень опасны с точки зрения SEO. Они критично воспринимаются поисковыми системами и могут привести к серьезным потерям в ранжировании и даже к наложению фильтра. Чтобы этого избежать, важно вовремя находить и удалять такие дубли.
Содержание
- Дубликаты: в чем опасность?
- Какими бывают дубли?
- Полные дубликаты — откуда они берутся?
- Частичные дубликаты — что представляют из себя?
- C помощью каких инструментов искать дубли?
- Как побороть и чем?
- Как быстро найти дубли страниц на сайте с помощью Serpstat
Заключение
Дубликаты: в чем опасность?
Опасность возникновения дублей можно показать на простом отвлеченном примере: посмотрите на картинку справа и скажите, какой из 2-х изображенных плодов наиболее релевантен запросу «красное яблоко».
Сложно, не правда ли? Ведь оба плода на картинке — это яблоки, и оба они красные. То есть, они одинаково релевантны запросу, а выбрать нас просят один, максимально точно соответствующий.
Возвращаясь к сайтам: в той же ситуации оказывается и поисковая система, когда ей нужно выбрать из двух одинаковых страниц одну и показать ее в результатах выдачи.
Конечно, поисковик учитывает и другие параметры при ранжировании, такие как внешние и внутренние ссылки, поведение пользователей, но факт остается фактом: из 2-х одинаково красных яблок, Google или Yandex должны выбрать одно. В этом-то и состоит вся трудность.
Возникновение такой дилеммы может привести к различным негативным последствиям:
Снижению релевантности основной посадочной страницы, а, значит, и снижению позиций ключевых слов.
«Скачкам» позиций ключевых слов за счет постоянной смены релевантной привязки с одной страницы на другую.
Общему понижению в ранжировании, когда проблема приобретает масштабы не отдельных URL, а всего сайта.
Именно подобная опасность вынуждает SEO-оптимизаторов обращать особое внимание на поиск и устранение дублей на этапе внутренней оптимизации.
Какими бывают дубли?
Перед тем, как начать процесс поиска дублей, нужно определиться с тем, что они бывают 2-х типов, а значит, процесс поиска и борьбы с ними будет несколько отличным. Так, в частности, выделяют:
Полные дубли
Когда одна и та же страница размещена по 2-м и более адресам.
Частичные дубли
Когда определенная часть контента дублируется на ряде страниц, но они уже не являются полными копиями.
Как удалить пустые страницы на сайте
| Читать! |
Полные дубликаты — откуда они берутся?
Дубли главной страницы по адресам:
http://mysite. com/index,
com/index,
http://mysite.com/index/,
http://mysite.com/index.php,
http://mysite.com/index.php/,
http://mysite.com/index.html,
http://mysite.com/index.html/.
Один из этих URL может быть адресом главной страницы по умолчанию.
Дубли, сгенерированные реферальной ссылкой.
Когда пользователь приходит по URL адресу с параметром «?ref=…», должно происходить автоматическое перенаправление на URL без параметра, что, к сожалению, часто забывают реализовать разработчики.
Ошибки, связанные с иерархией URL, приводящие к возникновению дублей.
Так, например, один и тот же товар может быть доступен по четырем разным URL-адресам:
https://mysite.com/catalog/dir/tovar.php,
https://mysite.com/catalog/tovar.php,
https://mysite.com/tovar.php,
https://mysite.com/dir/tovar.php.
Некорректная настройка страницы 404 ошибки, приводящая к возникновению «бесконечных дублей» страниц вида:
http://mysite. com/olololo-test-olololo
com/olololo-test-olololo
где текст, выделенным красным — это любой набор латинских символов и цифр.
Страницы с utm-метками и параметрами «gclid».
Данные метки нужны для того, чтобы передавать некоторые дополнительные данные в системы контекстной рекламы и статистики. Несмотря на то, что, по идее, они не должны индексироваться поисковыми системами, частенько можно встретить полный дубль страницы с utm-меткой в выдаче.
Полные дубли представляют серьезную опасность с точки зрения SEO, так как критично воспринимаются поисковыми системами и могут привести к серьезным потерям в ранжировании и даже к наложению фильтра, пессимизирующего весь сайт.
Хотите узнать, как с помощью Serpstat найти дубли страниц?
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! 😉
| Оставить заявку! |
Частичные дубликаты — что
представляют из себя?
Как и в случае с полными дублями, частичные возникают, в первую очередь, из-за особенностей CMS сайта, но значительно труднее обнаруживаются. Кроме того, от них сложнее избавиться, но об этом чуть ниже, а пока наиболее распространенные варианты:
Кроме того, от них сложнее избавиться, но об этом чуть ниже, а пока наиболее распространенные варианты:
Страницы пагинации, сортировок, фильтров
Как правило, каким-то образом меняя выводимый товарный ассортимент на странице категории магазина, страница изменяет свой URL (фактически все случаи, когда вывод не организован посредством скриптов). При этом SEO-текст, заголовки, часто и мета-данные — не меняются. Например:
http://mysite.com/catalog/category/ — стартовая страница категории товаров
http://mysite.com/catalog/category/?page=2 — страница пагинации
При том, что URL адрес изменился и поисковая система будет индексировать его как отдельную страницу, основной SEO-контент будет продублирован.
Страницы отзывов, комментариев, характеристик
Достаточно часто можно встретить ситуацию, когда при выборе соответствующей вкладки на странице товара, происходит добавление параметра в URL-адрес, но сам контент фактически не меняется, а просто открывается новый таб.
Версии для печати, PDF для скачивания
Данные страницы полностью дублируют ценный SEO-контент основных страниц сайта, но имеют упрощенную версию по причине отсутствия большого количества строк кода, обеспечивающего работу функционала. Например:
http://mysite.com/main/hotel/al12188 — страница отеля
http://mysite.com/main/hotel/al12188/print — ЧБ версия для печати
http://mysite.com/main/hotel/al12188/print?color=1 — Цветная версия для печати.
Выдача Google:
Выдача Yandex:
Html слепки страниц сайта, организованных посредством технологии AJAX
Найти их можно заменив в оригинальном URL-адресе страницы «!#» на «?_escaped_fragment_=». Как правило, в индекс такие страницы попадают только тогда, когда были допущены ошибки в имплементации метода индексации AJAX страниц посредством перенаправления бота на страницу-слепок и робот обрабатывает два URL-адреса: основной и его Html-версию.
Основная опасность частичных дублей в том, что они не приводят к резким потерям в ранжировании, а делают это постепенно и незаметно для владельца сайта. То есть найти их влияние сложнее и они могут систематически, на протяжении долгого времени «отравлять жизнь» оптимизатору.
C помощью каких инструментов искать дубли?
Существует несколько инструментов для поиска дублей:
Мониторинг выдачи посредством оператора «site:»
Отобразив на странице SERP все проиндексированные URL участвующие в поиске, можно визуально детектировать повторы и разного рода «мусор».
Десктопные программы-парсеры и сервисы
Могу порекомендовать три удобные и информативные программы: Screaming Frog Seo Spider, Netpeak Spider, Xenu. Запуская собственных ботов к вам на сайт, программы выгружают полный список URL-адресов, который можно отсортировать по совпадению тега «Title» или «Description», и таким образом, выявить возможные дубли.
В Serpstat также можно найти потенциальные дубли. Он находит страницы с дублирующимися Title и Description.
SEO-аудит сайта с помощью Serpstat: обзор инструмента
| Читать! |
Поисковая консоль Google
В Google Search Console во вкладке «Оптимизация Html» можно посмотреть список страниц с повторяющимися мета-описаниями, т.е. список потенциальных дублей.
Ручной поиск непосредственно на сайте
Опытные веб-мастера способны вручную выявить большинство дублей в течение пары минут, просто попробовав различные вариации URL-адресов в обозначенных выше проблемных местах.
Как побороть и чем?
Способов борьбы с дубликатами не так уж и много, но все они потребуют от вас привлечения специалистов-разработчиков, либо наличия соответствующих знаний. По факту же арсенал для «выкорчевывания» дублей сводится к:
По факту же арсенал для «выкорчевывания» дублей сводится к:
Их физическому удалению — хорошее решение для статических дублей.
Запрещению индексации дублей в файле «robots.txt» — подходит для борьбы со служебными страницами, частично дублирующими контент основных посадочных.
Настройке 301 редиректов в файле-конфигураторе «.htacces» — хорошее решение для случая с рефф-метками и ошибками в иерархии URL.
Установке тега «rel=canonical» — лучший вариант для страниц пагинации, фильтров и сортировок, utm-страниц.
Пример установки тега на странице пагинации:
Установке тега «meta name=»robots» content=»noindex, nofollow»» — решение для печатных версий, табов с отзывами на товарах.
Быстро проанализировать robots.txt, состояние тега canonical поможет:
Расширение для браузеров Serpstat Website SEO Checker
| Читать! |
Как быстро найти дубли страниц на сайте с помощью Serpstat
Чтобы быстро найти дубли страниц на сайте, можно воспользоваться «Аудитом сайта» от Serpstat.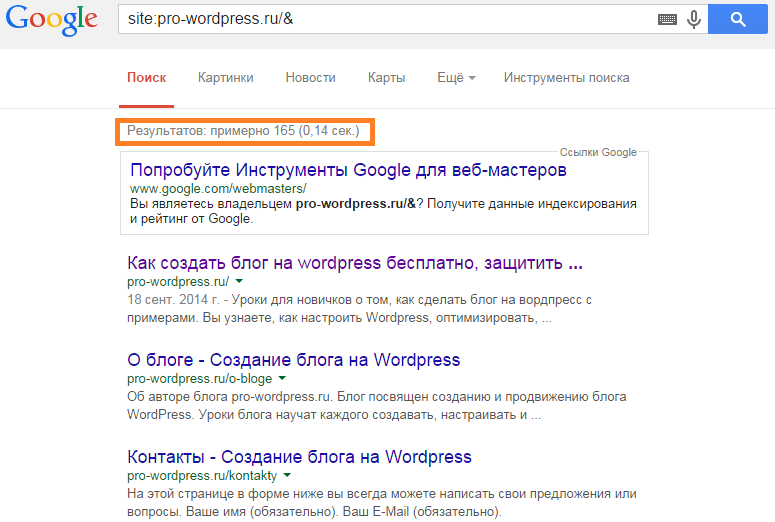 Это инструмент, который позволяет проанализировать сайт на наличие технических ошибок.
Это инструмент, который позволяет проанализировать сайт на наличие технических ошибок.
Аудит сайта Serpstat работает по тому же принципу, что и поисковый робот. Проверка укажет на слабые места вашего сайта, в которых он не соответствует требованиям поисковых систем, и предложит способы исправления этих ошибок. Также можно провести аудит одной страницы.
Для того, чтобы провести проверку сайта на ошибки, необходимо сначала создать проект и сделать соответствующие настройки. Подробнее об этом читайте в статье.
SEO-аудит сайта с помощью Serpstat: обзор инструмента
| Читать! |
После того как проверка будет произведена, вы получите подборную сводку по ошибкам. В ней все SEO-уязвимости будут распределены по приоритетам: от высокого — ошибок, которые угрожают позициям, до низкого — ошибок, которые опасны в меньшей мере, но требуют исправления и советов по улучшению, которые стоит внедрить, чтобы сайт выглядел привлекательнее в глазах поисковых роботов.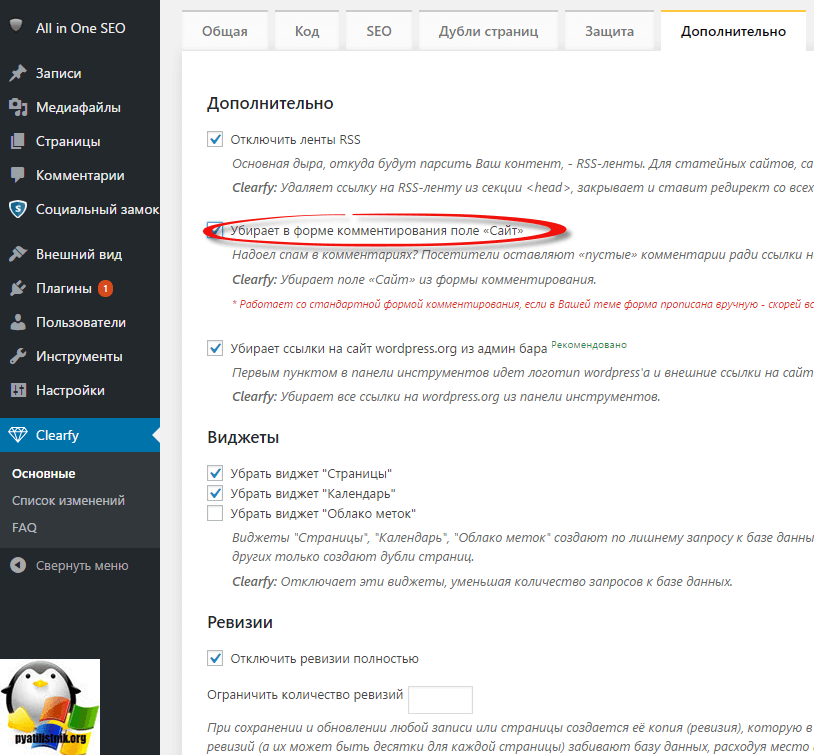
Чтобы найти дубли страниц, в сводке по ошибкам необходимо перейти в раздел «Метатеги» и найти пункт «Дублирующийся Title». Если возле него чек-бокс будет окрашен в серый цвет, значит на вашем сайте найдены такие неполадки.
Как видим, данная ошибка имеет высокий приоритет, так как метатег Title — это один из важнейших элементов, которые напрямую влияют на ранжирование. Кликните на название ошибки, чтобы увидеть ее описание, рекомендации к устранению и список URL, где она встречается.
Также косвенно можно найти дубли с помощью пункта «Дублирующийся Description» Следуйте рекомендациям и постарайтесь устранить ошибку как можно скорее.
Хотите узнать, как с помощью Serpstat сделать проверку сайта на дубли?
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! 😉
| Оставить заявку! |
| Узнать подробнее! |
Заключение
Часто решение проблемы кроется в настройке самого движка, а потому основной задачей оптимизатора является не столько устранение, сколько выявление полного списка частичных и полных дублей и постановке грамотного ТЗ исполнителю.
Запомните следующее:
Полные и частичные дубли могут понизить позиции сайта в выдаче не только в масштабах URL, а и всего домена.
Полные дубли — это когда одна и та же страница размещена по 2-м и более адресам.Частичные дубли — это когда определенная часть контента дублируется на ряде страниц, но они уже не являются полными копиями.
Полные дубликаты нетрудно найти и устранить. Чаще всего причина их появления зависит от особенностей CMS сайта и навыков SEO разработчика сайта.
Частичные дубликаты найти сложнее и они не приводят к резким потерям в ранжировании, однако делают это постепенно и незаметно для владельца сайта.
Чтобы найти частичные и полные дубли страниц, можно использовать мониторинг выдачи с помощью поисковых операторов, специальные программы-парсеры, поисковую консоль Google и ручной поиск на сайте.
Избавление сайта от дублей сводится к их физическому удалению, запрещению индексации дублей в файле «robots. txt», настройке 301 редиректов, установке тегов «rel=canonical» и «meta name=»robots» content=»noindex, nofollow»».
txt», настройке 301 редиректов, установке тегов «rel=canonical» и «meta name=»robots» content=»noindex, nofollow»».
Персональная демонстрация
Оставьте заявку и мы проведем для вас персональную демонстрацию сервиса, предоставим пробный период и предложим комфортные условия для старта использования инструмента.
Сэкономьте время на изучении Serpstat
Хотите получить персональную демонстрацию сервиса, тестовый период или эффективные кейсы использования Serpstat?
Оставьте заявку и мы свяжемся с вами 😉
Оцените статью по 5-бальной шкале
4.35 из 5 на основе 158 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
SEO
Петр Савинов
Как продвинуться в 2GIS: основные рекомендации
SEO +1
Daniel Ricardo
Как делать SEO-отчеты, которые впечатлят ваших клиентов: опыт Strategy Plus
SEO
Виталий Михейкин
Крауд-маркетинг своими руками: рекомендации для линкбилдинга
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
Как найти и удалить дубли страниц на сайте — Офтоп на vc.ru
{«id»:13623,»url»:»\/distributions\/13623\/click?bit=1&hash=626bd36534dece213f1f26a8750e63de3e475c69d0d206ab93e2c56faa7fda23″,»title»:»\u0418\u0449\u0435\u043c \u043a\u043e\u043c\u043c\u0435\u0440\u0447\u0435\u0441\u043a\u043e\u0433\u043e \u0440\u0435\u0434\u0430\u043a\u0442\u043e\u0440\u0430 \u0432 \u00ab\u041a\u043e\u043c\u0438\u0442\u0435\u0442\u00bb. \u042d\u0442\u043e \u043d\u0435 \u0432\u044b?»,»buttonText»:»\u042f!»,»imageUuid»:»1be73235-8504-513d-b994-f0b41ec0f080″,»isPaidAndBannersEnabled»:false}
Дубли страниц — документы, имеющие одинаковый контент, но доступные по разным адресам. Наличие таких страниц в индексе негативно сказывается на ранжировании сайта поисковыми системами.
Наличие таких страниц в индексе негативно сказывается на ранжировании сайта поисковыми системами.
2401 просмотров
Какой вред они могут нанести
- Снижение общей уникальности сайта.
- Затрудненное определение релевантности и веса страниц (поисковая система не может определить, какую страницу из дубликатов необходимо показывать по запросу).
- Зачастую дубли страниц имеют одинаковые мета-теги, что также негативно сказывается на ранжировании.
Как появляются дубликаты
Технические ошибки
К ним относят доступность страниц сайта:
- по www и без www;
- со слэшем на конце и без;
- с index.php и без него;
- доступность страницы при добавлении различных GET-параметров.
Особенности CMS
- страницы пагинации сайта;
- страницы сортировки, фильтрации и поиска товаров;
- передача лишних параметров в адресе страницы.

Важно! Также дубли страниц могут появляться за счет доступности первой страницы пагинации по двум адресам: http://site.ru/catalog/name/?PAGEN_1=1 и http://site.ru/catalog/name/.
Дубликаты, созданные вручную
Один из наиболее частых примеров дублирования страниц — привязка товаров к различным категориям и их доступность по двум адресам. Например: http://site.ru/catalog/velosiped/gorniy/stern-bike/ и http://site.ru/catalog/velosiped/stern-bike/.
Также страницы могут повторяться, если структура сайта изменилась, но старые страницы остались.
Поиск дублей страниц сайта
Существует большое количество методов нахождения дубликатов страниц на сайте. Ниже описаны наиболее популярные способы:
- программа Screaming Frog;
- программа Xenu;
- Google Webmaster: «Вид в поиске» -> «Оптимизация HTML»;
- Google Webmaster: «Сканирование» -> «Оптимизация HTML».

Для программы Screaming Frog и Xenu указывается адрес сайта, и после этого робот собирает информацию о нем. После того, как робот просканирует сайт, выбираем вкладку Page Title — Duplicate, и анализируем вручную список полученных страниц.
С помощью инструмента «Оптимизация HTML» можно выявить страницы с одинаковыми description и title. Для этого в панели Google Webmaster надо выбрать необходимый сайт, открыть раздел «Вид в поиске» и выбрать «Оптимизация HTML».
C помощью инструмента «Параметры URL» можно задать параметры, которые необходимо индексировать в адресах страниц.
Для этого надо выбрать параметр, кликнуть на ссылку «Изменить» и выбрать, какие URL, содержащие данный параметр, необходимо сканировать.
Также, найти все индексируемые дубли одной страницы можно с помощью запроса к поиску Яндекса. Для этого в поиске Яндекса необходимо ввести запрос вида site:domen.ru «фраза с анализируемой страницы», после чего проанализировать вручную все полученные результаты.
Как правильно удалить дубли
Чтобы сайт открывался лишь по одному адресу, например «http://www.site.ru/catalog/catalog-name/», а не по «http://site.ru/catalog/catalog-name/index.php», необходимо корректно настроить 301 редиректы в файле htaccess:
- со страниц без www, на www;
- со страниц без слэша на конце, на «/»;
- со страниц с index.php на страницы со слэшем.
Если вам необходимо удалить дубликаты, созданные из-за особенностей системы управления сайтом, надо правильно настроить файл robots.txt, скрыв от индексации страницы с различными GET-параметрами.
Для того чтобы удалить дублирующие страницы, созданные вручную, нужно проанализировать следующую информацию:
- их наличие в индексе;
- поисковый трафик;
- наличие внешних ссылок;
- наличие внутренних ссылок.
Если неприоритетный документ не находится в индексе, то его можно удалять с сайта.
Если же страницы находятся в поисковой базе, то необходимо оценить, сколько поискового трафика они дают, сколько внешних и внутренних ссылок на них проставлено. После этого остается выбрать наиболее полезную.
После этого необходимо настроить 301-редирект со старой страницы на актуальную и поправить внутренние ссылки на релевантные.
Ждите новые заметки в блоге или ищите на нашем сайте.
Дубли страниц на сайте, способовы поиска и методы устранения
К рамкам технической оптимизации относится поиск, выявление и удаление копий. Дубли — это страницы, которые обладают идентичным или частично совпадающим контентом, но доступ к ним можно получить по разным целевым.
Если такие разделы существуют на сайте, то системы поиска будут неправильно их ранжировать, а значит такой материал нужно как можно раньше выявить, а после удалить.
Как появляются
Бывают «полные» и «частичные» дубликаты или иногда их называют «явные» и «неявные». Первые полностью совпадают по всем показателям, а вторые совпадают лишь частично. Зачастую дубли страниц возникают на сайте из-за особенности работы CMS, некорректной настройки 301-редирект или ошибок в файле «robots.txt». Также копии могут появиться по следующим причинам:
Зачастую дубли страниц возникают на сайте из-за особенности работы CMS, некорректной настройки 301-редирект или ошибок в файле «robots.txt». Также копии могут появиться по следующим причинам:
- Доступ к сервису через префикс «www» или без него. Если не указать главную версию проекта, то произойдет конфликт с выбором главного зеркала сайта. А значит, что машины будут воспринимать ресурс с «www» и без него в качестве двух разных площадок. Зачастую такие случаи решают при помощи Google Search Console или Яндекс.Вебмастер.
- С протоколами http и https. Здесь происходит примерно такая же ситуация, как с «www». Если вовремя не настроить какая целевая будет главной, то произойдет появление зеркал. Это снижает уникальность контента, а также снижает позиции площадки в выдаче.
- Целевая может оканчиваться на слэш, а может быть без него. В таких ситуация создается полный дубликат. Поисковики индексируют оба раздела, которые наполнены идентичным контентом. По итогу вносят сайт в бан или понижают его вы выдаче по запросам. Какой вариант предпочтительнее (со слэшом или без него) решает веб-мастер: если больше проиндексировано материала без слэша, то лучше все страницы подвести под единое правило.
- Копии по ссылкам: http://site.com/index, http://site.com/index/, http://site.com/index.php, http://site.com/index.php/, а также другие похожие варианты. Одна из этих ссылок должна быть главной по умолчанию.
- Структура сайта изменилась, но сохранились старые страницы. Здесь ссылки могут не совпадать совершенно, но контент, мета-данные, товар остались таким же, как на новых. Это приводит к полному дубляжу материала.
- Ошибки, которые возникают при нарушении иерархии адреса. По примеру https://site.com/category/tovar/ и https://site.com/tover/category/. Дублируется часто полностью мета, контент, параметры.
- Страницы с utm-метками и параметрами «gclid». Метки нужны для передачи дополнительной информации в системы контекстной рекламы или статистики. Обычно они не должны индексироваться поисковиками, но бывают ситуации, когда удается встретить полный дубликат с utm-метками.
- Пагинация сайта, а также дубликаты, которые создаются фильтрами. В таких ситуациях выводится товарный ассортимент на странице «категория». При этом сам раздел меняет свой урл-адрес, но SEO-тексты, заголовки, мета-информация, весь прочий контент сохраняется. То есть происходит частичное копирование данных.
- Создание отдельных страниц для взаимодействия с блоками под комментарии, характеристики или отзывы. При выборе «оставить комментарий» или какого-либо тега с характеристиками происходит добавление параметра в адресную строку, но контент не меняется, то есть происходит частичное копирование.
- Версии для PDF-печати. Страницы для печатей копируют SEO-данные. Это приводит к снижению уникальности или даже бану. Также относятся к категории частичных дублей.
Какой вред наносят
Когда на платформе существует два идентичных макета, то системы не понимают что именно нужно выдавать по запросу, поэтому система ранжирования часто работает неправильно, а значит проект начнет со временем терять свои позиции в выдаче. Важно находить и удалять копии, а иначе можно столкнуться с рядом проблем:
- Понижение рейтинга площадки в целом, а не только его некоторых разделы.
Например, на проекте «site.com/catalog/phone» расположено большое количество товаров, вся необходимая информация, контент о них, включая мета-данные. В эту же страницу вкладывают деньги для продвижения и рекламы. По итогу она попадает в топ выдачи, а значит системы индексируют ее хорошо. Однако в какой-то момент ЦМС создает аналог «site.com/phone». Данная страница ранжируется плохо, привлекает мало пользователей, никаких действий для ее продвижения не ведется. После роботы для поиска по запросам видят, что происходит ухудшение просмотров, и значит начинают исключать из выдачи дубликат и оригинал. Роботы внимательнее относятся к остальному материалу и, если ситуация повторяется, то понижают рейтинг сервиса.
- Скачки в выдаче, так как поисковики все время меняют релевантность между одинаковыми материалами.
Это достаточно плохо для целевой. Во-первых, по ней начнут меньше переходить посетителей. Во-вторых, если вторая целевая частично дублирует материал, то на ее обнаружение уйдет больше времени, но когда ее найдут, то выяснить, какая из двух приносит больше трафика и что будет с посетителями с другой похожей страницей неясно, а значит выбрать что лучше и что нужно удалить будет сложнее. В-третьих, даже после удаления дубля, может быть так, что вернуть прежние показатели будет невозможно или очень трудно.
- Снижение уникальности работ на площадке.
Большинство маркетологов, контентщиков, аналитиков знает, что чем ниже уникальность работ, тем неохотнее системы выдают платформу в выдаче по запросам. При этом те ресурсы, которые предоставляют уникальную информацию и контент по ключевым словам почти всегда попадают в первые строки выдачи.
- Снижение позиций ключевых слов или фраз.
Похожая система со снижением уникальности. Ключевые слова и фразы просто перестают восприниматься поисковыми системами, так как материал с одинаковыми ключевиками встречаются на большом количестве страниц и внедрены они в неуникальный текст.
- Увеличение времени на индексацию.
На сканирование каждого ресурса у поисковых роботов есть краулинговый бюджет. Если дубликатов много, то робот может просто не добраться до нужной страницы. Такая проблема очень велика для крупных интернет-магазинов и холдингов, у которых тысячи или десятки тысяч разделов с похожим материалов, товарами или разделами.
- Бан от поисковых систем.
Здесь стоит отметить, что копии — это не повод наложения санкций со стороны поисковиков, но вот их большое количество воспринимается последними как намеренное решение, чтобы увеличить количество позиций в выдаче.
- Проблемы для веб-мастера.
Чем дольше откладывается работа по нахождению и устранению дублей, тем больше их накопится, а риск негативных последствий для ресурса также растет.
Стоит отметить, что полные копии с точки зрения SEO несут критическую и резкую опасность. Роботы воспринимают их враждебно, при этом не имеет значения, какой запрос был задан. Они вызывают потерю по ранжированию или даже наложению фильтра пессимизирующего всю площадку.
Частичные дубликаты не приводят к полной потери ранжирования резко или заметно для менеджеров, но делают это поступательно медленно, так, что владелец ресурса может этого до определенного момента даже не замечать. Это говорит о том, что найти их сложнее, а вред от них даже куда выше, чем от полных дублей.
Как найти дубли
Существует несколько способов обнаружения дублей. Чаще всего для этих целей используют:
- Мониторинг сайта через оператора «site». Часто используют для анализа проектов конкурентов. Чтобы проверить дубли страниц на сайте и провести анализа своей платформы онлайн в поисковой строке нужно ввести команду «site:site.com/catalog». Здесь можно увидеть перечень адресов всего проекта, включая те, которые дублируются. Также, если нужно проверить дубляж определенных страниц, для этого стоит в поисковой строке в ссылке добавить нужный запрос и проверить нет ли одинакового материала. Например, «site:site.com/catalog/белый телефон».
- Программы-парсеры: Screaming Frog, Xenu, PromoPult. Например, для работы с программой Screaming Frog вбивают ссылку, которая ведет на сайт, после запускают сканирование, где приложение собирает информацию о площадке. После запускают вкладку «Page Title→Duplicate» и происходит вывод страниц, которые нужно проанализировать вручную.
- Онлайн-платформы. Чтобы провести поиск дублей страниц сайта онлайн, можно использовать ApollonGuru. Работа с этим сервисом крайне простая, даже интуитивно понятная. В поле «Поиск дублей» вносят ссылки тех разделов, которые надо проверить. Сервис проводит анализ и выдает результат. Если напротив ссылки появляется значение «200», то их нужно брать в работу, так как они имеют полный или частичный скопированный материал.
- Google Webmaster: «Вид в поиске» → «Оптимизация HTML» или Google Webmaster: «Сканирование» → «Оптимизация HTML». Здесь инструменты помогают найти целевые с одинаковым Title и Description. Для работы с Вебмастером нужно указать ссылку сайта, открыть раздел «Вид в поиске» и выбрать «Оптимизация HTML». Инструмент «Параметры URL» позволяет задать параметры, которые нужно индексировать, сканировать. После анализа платформы, нужно выявить копии, а после заняться удалением.
- Яндекс.Вебмастер: «Индексирование» → «Страницы в поиске». Вебмастер от Яндекса работает похожим образом. Программа предоставляет также функции индексирования, сканирования проекта или отдельных макетов.
- Ручной поиск. Опытные веб-мастера способны уже предположить, где могут быть дубли, а также выявить большинство из них вручную. При этом они могут использовать дополнительные приложения, самописные программы и многое другое.
Как убрать дубли
Можно бороться с дублирующим материалом разными способами. Самыми популярными остаются те, которые вызывают большинство дубликатов: настройка 301 редирект, создание канонической страницы, директива Disallow в robots.txt.
301 редирект
Неплохое решение для случаев с рефф-метками и ошибками в иерархии адресов.
Если же CMS позволяет, то редиректы можно настраивать вручную даже без помощи программиста, например, UMI предоставляет такую возможность. Однако большинство площадок требуют вмешательства программиста с опытом работы в этой сфере.
Настраивают 301 редирект в файле htaccess. Например, для отдельной страницы используют: Redirect 301 %old_url% %new_url%
%old_url% — это старая ссылка страницы без домена
%new_url% — это новый адрес, где указывают домен.
При этом нужно запомнить, что поисковые системы не удаляют из индексации страницу, с которой происходит редирект, но и не добавляют в индекс страницу, которая получила редирект.
Каноническая страница
Использовать тег «rel-canonical» стоит. Он дает поисковикам понять, что перед ней именно та каноническая страница, которую нужно обрабатывать и выдавать.
Чтобы дать понять, что перед поисковиком такая страница, нужно на все копии добавить тег с ссылкой оригинальной страницы:
<link rel= “canonical” href= “http://www. site.com/original-page.html”>
Этот тег хорошо понимают машины. Кроме того, важно помнить, что добавлять такие теги можно и на посадочные страницы, которые являются основными для сайта с точки зрения SEO.
Чтобы на всех страницах прописать каноничность, то стоит использовать плагины. Например, для WordPress используют YoastSEO или AllinOneSEOPack.
С Bitrix ситуация сложнее. Для этой CMS нужно использовать язык программирования PHP в соответствующих файлах.
Директива Disallow в robots.txt.
Используют для борьбы со служебными страницами, которые частично или полностью дублируют контент посадочных. Часто сюда попадают адреса со слэшами и другими частями URL-адресов, которые создают копии.
Работает это следующим образом: Если на сайте есть копии, можно запретить их индексировать с помощью условия Disallow, который вписывают в файл «robots.txt». Например, в robots.txt прописать «Disallow:/tovar/whitephone/», после этого роботы поисковых систем не будут индексировать раздел с таким адресом.
Советы вместо заключения
- Старайтесь всегда создавать уникальный URL-адрес для каждой целевой.
- Указывайте, какая из страниц пагинации, фильтрации является целевой и рекламируйте ее.
- Выявляйте, какая из целевых приносит больше трафика, делайте ее главной, а копию или копии удаляйте.
- Если нет опыта поиска дубликатов и разбираться в том, как убрать дубли страниц на сайте нет времени, то можно нанять на работу сотрудников, которые разбираются в сфере, а значит смогут сделают работу за вас.
Хотите тоже написать статью для читателей Yagla? Если вам есть что рассказать про маркетинг, аналитику, бизнес, управление, карьеру для новичков, маркетологов и предпринимателей. Тогда заведите себе блог на Yagla прямо сейчас и пишите статьи. Это бесплатно и просто
Как найти и удалить дубли страниц на сайте
Здравствуйте!
Если Ваш сайт очень медленно растёт в поисковых системах, делает один шаг вперёд, а затем два назад, при постоянном изменении позиций, то одной из причин такой нестабильности могут быть дубли страниц на сайте. Это когда, страницы имеют разные адреса (url), но при этом содержат один и тот же контент, полностью или частично.
Чтобы вернуть сайту стабильность и поднять в ТОП, необходимо найти и удалить дубли страниц. О том, как это сделать, мы расскажем в сегодняшней публикации.
Чем опасны дубли страниц на сайте?
Но для лучшего понимания, зачем находить и удалять дубли страниц, мы расскажем о том, как вред может нанести сайту дублированный контент из-за которого и так снижается доверие поисковых систем к сайту:
- Некорректная индексации. Допустим, у Вас большой новостной портал, на котором ежедневно публикуются по 10 новостей и статей. Если для каждой страницы будет существовать хотя бы один дубль, то объём сайта вырасти вдвое, а значит и поисковикам придётся больше времени тратить на обход ресурса. А если таких дублей 4-5? Поисковая система будет удалять дубли страниц из поиска и занижать позиции сайта.
- Неправильное определение веса страниц. С помощью внутренней оптимизации сайта, без применения внешней, можно добиться значительных результатов, в том числе за счёт правильно поставленных внутренних ссылок, которые передают вес нужной странице, с товаром или услугой, или продвигаемой по ВЧ-запросам. Соответственно при наличии дублей страниц, передаваемый рейтинг будет распыляться, а значимость страницы для ПС будет падать.
- Показ в результатах поиска нерелевантной страницы. Так же одной из проблем, которой грозят дубли страниц является показ в результатах поиска нерелевантной страницы (например, вместо страницы услуги, показывается прайс, где эта услуга упоминается).
Таким образом, все усилия приложенные на продвижение определённой страницы (сюда относятся, как внешние, так и внутренние ссылки), пойдут к коту под хвост. Кроме того, в последствии поисковая система может ещё больше занизить рейтинг страницы, так как она нерелевантна запросу. - Потеря естественных ссылок. Пользователь, который был на Вашем сайте и захотел поделиться ссылкой на его страницу, может как раз поделиться ссылкой на дубль, а не на ту, которую нужно. В итоге, такие ценные для SEO-продвижения естественные ссылки будут вести на дубликаты, которые не индексируются.
Дубли могут быть полными (одна и та же страница, доступ по разным адресам) и частичными (фрагмент контента одной страницы дублируется на других).
Проверка сайта на дубли страниц
Ну, что? Убедились во вредности дубликатов страниц? Значит пора проверить свой сайт на дубли страниц! Есть несколько стандартных процедур, которые помогут выявить дубли страниц.
1. Search Console.
Или Google Webmaster. Это один из самых лёгких способов, для поиска дублей страниц. Заходим в сервис, далее идём в раздел «Вид в поиске» и выбираем вкладку «Оптимизация HTML».
Здесь нам необходимо обратить внимание на следующие строчки:
- «Повторяющееся метаописание» — страницы с одинаковыми описаниями Description;
- «Повторяющиеся заголовки (теги title)» — список страниц с одинаковыми Title.
Данный подход выявления дублей основывается на том, что страницах может совпадать не только содержание, но и мета-данные. Просмотрев страницы, которые показываются в данном отчёте, мы довольно-таки просто обнаружим страницы, которые являются дубликатами.
2. Яндекс Вебмастер.
Периодически Яндекс индексирует новые страницы сайта или какие-то удаляет. Эта информация отражается, как на главной странице сервиса, так и в разделе «Индексирование» — «Страницы в поиске». Зайдите туда прямо сейчас.
Рядом с удалёнными из поисковой выдачи страницами (они выделены синим), есть комментарий, говорящий о причине исключения. Одним из возможных вариантов является «Дубль».
В данном случае это страница категории, которая содержит часть контента из постов в виде анонсов. Поэтому поисковая система считает её дублем.
3. Просмотр поисковой выдачи.
Промониторьте выдачу, используя специальный оператор «site:».
Довольно часто причиной возникновения дублей страниц становятся несовершенства систем управлений сайтом (CMS). Например, WordPress грешен тем, что может автоматически генерировать дубли страниц или в рубриках публиковать анонсы с частичным содержанием текста из самой статьи.
Также причины дубликатов могут быть в присутствующих на сайте версиях для печати или ускоренных страниц (AMP), пагинация, страницы с utm-метками, динамические урлы, страницы тегов, не добавленные описания товаров в интернет-магазине, не прописанные мета-теги.
Как удалить дубли страниц на сайте?
- Если на сайте, есть две страницы, у которых совпадают мета-теги, но при этом разное содержание — нужно просто изменить мета-описание.
- Закрыть от индексации рубрики, категории и страницы тегов, с помощью параметра Disallow в robots.txt. Либо, если не хотите терять возможный трафик, который могут принести эти разделы сайта, придумайте способ их уникализировать. Например, сделать так, чтобы вместо анонса отображался только заголовок, который является ссылкой на статью.
- Для ускоренных страниц, страниц с utm-метками и версий для печати задайте в настройках канонический URL.
- Действительно есть две одинаковые страницы — удалите одну из них (ту, что не ранжируется поисковыми системами например).
- Настройте 301-редирект для удалённых страниц, чтобы заходя по старому адресу на сайт, пользователь не попал на 404-ую страницу.
что это, как влияет на SEO и как удалить из поисковой выдачи
Дублями называются веб-страницы, содержимое которых частично либо полностью совпадает. Дублирование приводит к тому, что сайт начинает терять трафик. Сегодня расскажем о том, как с этим бороться.
Как и почему дубли веб-страниц затрудняют SEO
Из-за дублирования поисковые системы не могут определить, какую именно из страниц, которые соответствуют релевантным запросам, необходимо показывать в выдаче. В результате поисковики снижают позиции сайта в ранжировании либо вообще банят его. По этой причине SEO-специалисты рекомендуют проверять продвигаемые ресурсы на наличие дубликатов.
Вопрос о том, почему дубли осложняют продвижение, можно рассмотреть на простом примере. На картинке ниже изображены три яблока.
Яблоки на картинке ничем не отличаются. Все они соответствуют запросу «красное яблоко», и выбрать фрукт, который больше других подходит под это определение, очень сложно.
С такими же затруднениями сталкиваются поисковые системы, если на сайте есть несколько частично похожих или полностью идентичных страниц.
Из-за наличия страниц-дубликатов возникают следующие проблемы:
- Снижение релевантности основной продвигаемой страницы и ее позиций по ключевым словам.
- Изменение страницы поисковыми системами для показа в выдаче, что также приводит к нестабильности позиций по ключевым словам.
- При наличии большого количества дублей — попадание под фильтры «Яндекса» и Google.
Виды дублей
Дубли бывают полные и частичные.
Полный дубль — страница, которую поисковые системы находят по разным адресам.
Причины появления полностью идентичных страниц:
- Отсутствие главного зеркала. Это одна из наиболее распространенных причин. Если разработчики забывают указать главное зеркало, то сайт может выходить в поиске в нескольких вариантах — с www и без него, с http и c https.
- Особенности CMS или действия разработчика. Например, главная страница может быть доступна со слешем в конце и без него, с добавлением слов start, php и т.д.
- Попадание в индекс страниц с динамичными адресами. Как правило, это происходит, если используются фильтры для сортировки и сравнения различных товаров.
-
Самогенерация дублей некоторыми движками — WordPress, Joomla, OpenCart, MODX. Например, в Joomla часть страниц автоматически отображается с разными URL —mysite.ru/catalog/25 и mysite. ru/catalog/25-article.html и т.п.
- Отслеживание сессий с помощью специальных идентификаторов, которые также могут индексироваться и создавать дубли.
- Добавление к адресам страниц UTM-меток. Они используются, чтобы отслеживать, насколько эффективно проходят рекламные кампании. Теоретически страницы с UTM-метками не должны индексироваться, но на практике они часто встречаются в выдаче.
Полные дубли легко обнаружить и удалить, в отличие от частичных.
Подпишитесь на нас в Telegram
Получайте свежие статьи об интернет-маркетинге и актуальные новости о наших готовых решениях
Рассмотрим причины, по которым появляются частичные дубли.
Пагинация страниц
С помощью пагинации можно упростить навигацию по сайту и одновременно осложнить продвижение.
Каждая страница пагинации представляет собой дубликат, часто — с такими же метаданными и SEO-текстом.
Например, адрес главной страницы — https://mysite.ru/women/clothes. При этом страница пагинации выглядит так: https://mysite.ru/women/clothes/?page=2. В результате появляются две страницы с разными адресами и практически одинаковым содержимым.
Блоки новостей, топовых статей и комментариев
Чтобы посетители как можно дольше оставался на сайте, ему предлагаются последние новости, популярные статьи и интересные комментарии. Их заголовки с частью содержимого обычно размещаются справа, слева или снизу от основного материала. Эти фрагменты не должны индексироваться, иначе поисковик обнаружит разные страницы с одинаковым контентом.
Как видно на картинке, внизу главной страницы находится три блока с новостями, последними статьями и новыми отзывами. Их текстовое содержимое можно найти в соответствующих разделах. При этом контент повторяется на главной странице, из-за чего создаются частичные дубли.
Наличие версий страниц для печати
Часть страниц сайта доступна в двух вариантах — обычном и для печати. Вторая версия отличается от основной адресом. Кроме того, в ее коде отсутствуют многие строки, поскольку странице для печати не требуется значительная часть функционала.
Чтобы понять разницу, можно сравнить адреса обычной страницы и версии для печати: https://my-site.ru/page и https://my-site.ru/page?print.
Применение технологии AJAX
Иногда на сайтах, при создании которых использовалась технология AJAX, появляются HTML-слепки. Они не представляют опасности для продвижения, если AJAX-страницы индексируются правильно. В противном случае поисковые боты выходят не на основную страницу, а на слепок. В результате одна страница индексируется по двум адресам — главному и HTML-слепка.
Чтобы найти слепок, нужно в основном адресе заменить «!#» на код «?_escaped_fragment_=».
Опасность частичных дублей заключается в том, что они не приводят к одномоментной значительной потере позиций, а незаметно ухудшают продвижение сайта.
Как искать дубликаты веб-страниц
Выявлять дубли можно вручную или с помощью специализированных программ или онлайн-сервисов.
Ручной способ
Найти дубликаты можно с помощью команды site. Ее нужно вставить в адресную строку и после нее ввести домен и часть текстового содержимого, чтобы Google выдал все существующие варианты.
Как видно на картинке, после команды site в адресную строку было введено первое предложение статьи. Поисковая система обнаружила, что основная страница с текстовым содержимым частично дублируется на главной.
Применение специализированных программ
Искать дубликаты можно с помощью различных программ, например, Xenu. Это бесплатный сервис. Еще одна программа — Screaming Frog. Ее стоимость составляет 149 фунтов в год. Также разработчики предлагают ограниченную бесплатную версию, функционала которой достаточно для решения большинства задач.
Применение Google Search Console и «Яндекс.Вебмастер»
Чтобы найти дубли с помощью Google Search Console, нужно проверить «Предупреждения» и «Покрытие». Там содержится информация о страницах, которые Google считает проблемными.
В «Яндекс.Вебмастере» данные о дублях находятся в разделе «Индексирование», где нужно зайти в «Страницы в поиске» и спуститься вниз. Далее следует выбрать справа формат файла — CSV либо XLS, скачать его и открыть документ. Все дубли в строке «Статус» должны быть помечены как DUPLICATE.
Как удалить дубли страниц
Рассмотрим способы удаления дубликатов.
С помощью noindex и nofollow
Проще всего закрыть страницу от индексации. Для этого метатег <meta name=”robots” content=”noindex,nofollow”/> нужно поставить в шапку между открывающим тегом <head> и закрывающим </head>. После этого поисковые системы перестанут индексировать страницу и учитывать те ссылки, которые на ней находятся.
Важно: при использовании метатега нельзя запрещать индексацию через robots.txt.
С помощью robots.txt
Индексацию дубликатов можно запретить в robots.txt через директиву Disallow. Для этого в файл нужно добавить такой код:
User-agent: *
Disallow: /dublictate.html
Host: mysite.ru
Запрет индексации через robots.txt часто используется для служебных страниц.
Такой способ становится альтернативным решением, если запрет через Disallow не работает.
С помощью canonical
Этот метатег сообщает поисковым роботам, что перед ними находится дубликат, а также указывает им на основную страницу. Сanonical нужно поместить между тегами <head> и </head>: <link rel=”canonical” href=”адрес основной страницы” />.
Как удалить дубли со страниц с пагинацией
Для сайтов с многостраничными каталогами типична ситуация, когда на второй и следующих за ней страницах появляются дубли.
Так выглядит первая страница каталога.
На второй и следующих за ней страницах дублируется текст и теги <title> и <description>.
SEO-специалист должен сделать так, чтобы текст отображался только на первой странице. Кроме того, нужно убрать дубли <title> и <description>. У каждой страницы должны быть уникальные теги. Также необходимо убедиться, что в адресах страниц пагинации отсутствуют динамические параметры.
Понимание того, что такое дубли страниц и как их устранить, поможет избежать попадания в индекс копий, которые осложняют продвижение сайта.
Поиск и удаление дубликатов и почти дубликатов страниц PDF
Поиск и удаление дубликатов страниц PDF
- Введение
- В этом руководстве показано, как найти и при необходимости удалить похожие или повторяющиеся страницы в одном документе PDF с помощью подключаемый модуль AutoSplit™ для Adobe® Acrobat®. Эта операция обнаруживает похожие страницы и представляет их пользователю для просмотра. Пользователь может просмотреть результаты и выбрать/отменить выбор отдельных страниц из списка дубликатов для возможного удаление или извлечение. Вы можете выполнять следующие операции:
- Поиск дубликатов и почти дубликатов
- Добавление дубликатов страниц в закладки
- Извлечь дубликаты страниц в отдельный документ PDF
- Удалить дубликаты страниц из документа
- Сохранить отчет о сходстве страниц
- Подключаемый модуль предоставляет два разных метода обнаружения дубликатов или почти дубликатов страниц:
- Сравнить только текст страницы
- Используйте этот метод для сравнения текста страницы независимо от его внешнего вида. Он вычисляет сходство страниц
на основе текстового содержимого только и полностью игнорирует внешний вид текста, макет, изображения и графику
которые могут присутствовать на странице. Это лучший метод обнаружения дубликатов в большинстве типов документов.
- Сравните внешний вид страниц
- Этот метод сравнивает страницы «как изображения» и обнаруживает страницы, которые выглядят совершенно одинаково. Этот метод не сравнивает невидимый текст, который может присутствовать на странице. Не рекомендуется использовать этот метод для отсканированных бумажных документов.
- Использование отсканированных бумажных документов
- Довольно часто эта операция используется для поиска дубликатов страниц в отсканированных бумажных документах. Отсканированные документы необходимо подвергнуть распознаванию, прежде чем использовать их для какой-либо текстовой обработки.
OCR — это процесс распознавания текста в отсканированных документах и обеспечения возможности поиска по ним.
Важно понимать, что распознавание текста в отсканированных документах подвержено ошибкам и
это редко бывает на 100% точным. Количество ошибок зависит от разрешения сканирования и качества исходного документа.
В большинстве случаев отсканированная страница может содержать от 1 до 10 ошибок распознавания, где некоторые буквы
неправильно идентифицирован. Например, в зависимости от шрифта строчная буква l может выглядеть точно так же, как цифра 1.
. Заглавная буква O часто ошибочно принимается за цифру 0, заглавная буква S — за цифру 5 и т. д.
Поскольку многие буквенно-цифровые символы имеют схожие или идентичные физические характеристики, часто возникает необходимость их различения. вызов. Вот почему сравнение на основе подобия полезно для обнаружения небольших различий между страницами, которые
производится в процессе распознавания текста. Отсканированные документы низкого качества могут содержать большое количество ошибок, делающих их
непригоден для любого надежного текстового сравнения. См. следующий учебник о том, как распознавать отсканированные документы.
и оценивает их пригодность для текстовой обработки. .
- Предпосылки
- Для использования этого руководства вам потребуется копия Adobe® Acrobat® вместе с подключаемым модулем AutoSplit™, установленным на вашем компьютере. Вы можете загрузить пробные версии как Adobe® Acrobat®, так и подключаемого модуля AutoSplit™.
- Содержимое
- Сравнение только текста страницы
- Сравнить только внешний вид
- Сравнение нескольких документов
- Метод 1 — сравнение только текста страницы ↑обзор
- Этот метод сравнивает сходство страниц только на основе содержимого их страниц. Внешний вид, положение и порядок текста не имеют значения. Этот метод также игнорирует любые изображения и графику, присутствующие на страницах.
Метрика подобия модифицированного косинуса используется для расчета того, как
похожи две страницы на основе их текстового содержания.
- Шаг 1. Откройте файл PDF
- Запустите приложение Adobe® Acrobat® и откройте файл PDF с помощью меню «Файл > Открыть…».
- Шаг 2. Откройте диалоговое окно «Поиск повторяющихся страниц»
- Выберите «Подключаемые модули > Разделить документы > Найти и удалить повторяющиеся страницы…», чтобы открыть диалоговое окно «Найти повторяющиеся страницы».
- Шаг 3. Укажите параметры
- Установите флажок «Сравнять только текст страницы (игнорировать внешний вид страниц)».
- Использование предопределенных настроек
- Текстовый метод предоставляет ряд предопределенных наборов параметров, которые подходят для сравнения разных типов документов с разным количеством ошибок распознавания. Каждый предопределенный набор параметров обеспечивает различные условия для расчета подобия:
- Пользовательские настройки — все настройки задаются пользователем
- Отсканированный бумажный документ: высокое качество
- Отсканированный бумажный документ: среднее качество
- Факс: низкое качество
- Несканированный PDF: точное совпадение
- Неотсканированный PDF: нечеткое совпадение
- Точное совпадение (с порядком текста) — этот метод не использует косинусное сходство
- Настройки появляются под меню после выбора предопределенного набора параметров.
- Вот настройки, используемые предопределенными наборами:
- Нажмите «Изменить…», чтобы настроить параметры сходства страниц:
- Метод сравнения текста использует 3 параметра, чтобы ограничить, насколько разными могут быть две «похожие» страницы. Варьируя эти параметры, можно обнаружить страницы, имеющие разную степень сходства.
- Минимально допустимое сходство текста страницы (в процентах) — это значение метрики косинусного сходства, выраженное в процентах. Укажите минимально допустимое сходство текста страницы от 70 до 100 (в процентах).
- Максимально допустимая разница в длине страницы (в символах).
- Максимально допустимая разница текста страницы (в словах).
- Используйте эти настройки для экспериментов с настройками обработки, когда необходимо настроить алгоритм обработки для конкретного документа.
- Использовать образцы страниц
- При необходимости нажмите «Установить из образца страницы…», чтобы указать параметры схожести страниц на основе двух образцов страниц:
- Выберите две страницы, которые можно считать идентичными. Программное обеспечение автоматически рассчитает схожесть страниц, и статистика появится в левом нижнем углу диалогового окна.
- Нажмите «ОК», чтобы сохранить текущие настройки сходства.
- Укажите параметры фильтрации текста
- Существует несколько параметров, управляющих содержимым страницы, которое анализируется алгоритмом сравнения текста. Используйте эти параметры при сравнении отсканированных бумажных документов, которые могут содержать различные ошибки распознавания текста. Эти параметры исключают определенные виды символов из обработки. Во многих случаях это может помочь вычислить более точную метрику сходства.
- Игнорировать регистр — эта опция игнорирует регистр при сравнении текста.
- Игнорировать знаки препинания (,.!?-) — эта опция исключает из сравнения все знаки препинания.
- Игнорировать небуквенно-цифровые символы — этот параметр игнорирует все символы, кроме букв и цифр.
- Нажмите «ОК», чтобы сохранить настройки сходства страниц.
- Нажмите «ОК», чтобы начать поиск дубликатов страниц в текущем PDF-документе:
- Шаг 4. Проверка дубликатов страниц
- В диалоговом окне «Удалить повторяющиеся страницы» отображается список повторяющихся или почти повторяющихся страниц. Щелкните запись страницы, чтобы отобразить соответствующую страницу в средстве просмотра. Просмотрите страницы и выберите/отмените выбор страниц для удаления.
- При необходимости нажмите «Сохранить отчет…», чтобы создать отчет о схожести страниц в формате HTML. Или нажмите «Страницы закладок», чтобы создать закладки в PDF для выбранных дубликатов страниц.
- Плагин позволяет просматривать/сравнивать найденные дубликаты или почти дубликаты страниц. Сходство страниц (в %) и количество несовпадающие слова отображаются для каждой пары страниц. Вот примеры, рассчитанные для пары отсканированных бумажных документов:
- Обратите внимание, что внешний вид и расположение текста не влияют на результаты.
- Эти две страницы считаются идентичными, несмотря на разницу в цвете текста:
- Эти две страницы считаются идентичными, несмотря на разницу в расположении контента:
- Эти две страницы считаются на 94% похожими, несмотря на разницу в порядке текста, макете и отсутствии изображения:
- Шаг 5. Извлечение дубликатов страниц или добавление их в закладки
- При необходимости используйте кнопку «Закладка страниц», чтобы добавить в закладки все отмеченные страницы. Это полезно, если вы не планируете удалять найденные дубликаты страниц из документа. Используйте флажки перед страницами, чтобы выбрать или отменить их выбор в наборе обработки.
- Используйте кнопку «Извлечь страницы…», чтобы извлечь все отмеченные страницы в отдельный документ PDF. Эта операция не удалит страницы из текущего документа.
- Используйте кнопку «Сохранить отчет…», чтобы сохранить отчет о вычислении схожести страниц в файл HTML. Он содержит сведения о сходстве страниц, показывает различия между страницами и перечисляет пропущенные слова. Это может быть очень полезно для глубокого анализа.
- Шаг 6. Удаление повторяющихся страниц
- Используйте флажки перед страницами, чтобы выбрать/отменить выбор страниц для удаления. Нажмите кнопку «Удалить страницы» в диалоговом окне «Удалить дубликаты страниц», чтобы удалить все отмеченные страницы из текущего документа PDF:
- Нажмите кнопку «ОК» для подтверждения. Страницы будут удалены навсегда.
- Метод 2 — сравнение только внешнего вида ↑обзор
- Этот метод сравнивает страницы «как изображения» и обнаруживает страницы, которые выглядят совершенно одинаково. Этот метод не сравнивает невидимый текст, который может присутствовать на странице. Не рекомендуется использовать этот метод для отсканированных бумажных документов.
- Шаг 1. Откройте файл PDF
- Запустите приложение Adobe® Acrobat® и откройте файл PDF с помощью меню «Файл > Открыть…».
- Шаг 2. Откройте диалоговое окно «Поиск повторяющихся страниц»
- Выберите «Подключаемые модули > Разделить документы > Найти и удалить повторяющиеся страницы. ..», чтобы открыть диалоговое окно «Найти повторяющиеся страницы».
- Шаг 3. Укажите параметры
- Установите флажок «Сравнить внешний вид для точного соответствия (можно использовать для сравнения изображений)».
- Нажмите «ОК», чтобы начать поиск дубликатов страниц.
- Шаг 4. Проверка дубликатов страниц
- В диалоговом окне «Удалить повторяющиеся страницы» отображается список повторяющихся или почти повторяющихся страниц. Щелкните запись страницы, чтобы отобразить соответствующую страницу в параллельном представлении. Просмотрите страницы и выберите/отмените выбор страниц для возможного удаления.
- При необходимости нажмите «Сохранить отчет…», чтобы создать отчет о схожести страниц в формате HTML. Или нажмите «Страницы закладок», чтобы создать закладки в PDF для выбранных дубликатов страниц.
- Этот метод основан на создании уменьшенных (пробных) копий страниц и сравнении их «как изображения». В следующем примере показаны две идентичные страницы, которые содержат только графику и не содержат текст для поиска: .
- Если страницы визуально идентичны, то программа определяет их как дубликаты:
- Эти две страницы считаются разными из-за штампа «Утверждено» на одной из страниц:
- Эти две страницы считаются идентичными по этому методу:
- В отличие от текстового метода сравнения, если цвет или стиль текста отличаются, страницы не считаются идентичными:
- Шаг 5. Удаление повторяющихся страниц
- Нажмите «Удалить страницы» в диалоговом окне «Удалить повторяющиеся страницы», чтобы продолжить.
- Нажмите кнопку «ОК», чтобы удалить страницы из текущих документов PDF. Страницы будут удалены навсегда.
- Сравнение нескольких документов PDF
- Эту операцию можно использовать для поиска и удаления дубликатов страниц из нескольких документов PDF. Подход состоит в том, чтобы объединить один или несколько документов в один файл PDF и запустить «Найти и удалить дубликаты страниц».
операцию над результирующим файлом. По сути, это создаст один документ без каких-либо дубликатов. При желании можно извлечь все обнаруженные дубликаты страниц в отдельный PDF-документ.
- Шаг 1. Объединение нескольких PDF-документов ↑обзор
- Запустите приложение Adobe® Acrobat® и выберите «Инструменты» в меню. Выберите значок «Объединить файлы» в списке инструментов.
- Нажмите «Добавить файлы…» в меню «Объединить файлы» и выберите PDF-файлы для объединения для сравнения.
- Нажмите кнопку «Объединить» в меню, чтобы объединить выбранные файлы PDF.
- Шаг 2. Найдите дубликаты страниц
- На экране появится объединенный выходной PDF-файл. Если нет, откройте объединенный файл PDF.
- Выберите «Подключаемые модули > Разделить документы > Найти и удалить повторяющиеся страницы. ..», чтобы открыть диалоговое окно «Найти повторяющиеся страницы».
- Установите флажок «Сравнить внешний вид для точного соответствия (можно использовать для сравнения изображений)». Нажмите «ОК», чтобы начать поиск дубликатов страниц.
- Шаг 3. Извлечение дубликатов страниц
- В диалоговом окне «Удалить дубликаты страниц» будет показан список дубликатов или почти дубликатов страниц. Щелкните запись страницы, чтобы отобразить соответствующую страницу в средстве просмотра. Просмотрите страницы и выберите/отмените выбор страниц.
- Нажмите «Извлечь страницы…», чтобы извлечь выбранные дубликаты страниц в новый документ PDF.
- Укажите выходную папку и имя файла. Нажмите «Сохранить».
- Появится диалоговое окно, показывающее количество страниц, которые были извлечены в отдельный документ. Теперь вы сохранили все повторяющиеся страницы в отдельный файл PDF перед их удалением. Вы можете изучить эти страницы и использовать их позже, если это необходимо.
- Нажмите «ОК», чтобы закрыть диалоговое окно.
- Шаг 4. Удаление повторяющихся страниц
- Нажмите «Удалить страницы» в диалоговом окне «Удалить повторяющиеся страницы», чтобы продолжить.
- Нажмите «ОК» в диалоговом окне, чтобы удалить выбранные дубликаты страниц из текущего документа PDF.
- Выбранные повторяющиеся страницы будут навсегда удалены из документа PDF. Вам нужно будет использовать меню «Файл > Сохранить», чтобы сохранить измененный документ на диск.
- Щелкните здесь, чтобы просмотреть список всех доступных пошаговых руководств.
Удалить дубликаты страниц в PDF Online
«; ломать; case «limitationLimited»: e.innerHTML = «
Достигнуто ежедневное бесплатное использование. Go Pro или подождите 00:00:00, чтобы начать работу над другим файлом. Go Pro Now
«; ломать; случай «переподписаться»: е.innerHTML = «»; ломать; кейс «бесплатная пробная версия»: e.innerHTML = »
Начните бесплатную пробную версию
Разблокируйте функции Pro и выполняйте свою работу быстрее.
«; ломать; case «emailVerification»: e.innerHTML = «
Подтвердите свой адрес электронной почты
Возможности Smallpdf ограничены без подтвержденного адреса электронной почты
«; ломать; случай «ie11Offboard»: e.innerHTML = »
Прекращение поддержки IE11
Мы прекратили поддержку Internet Explorer. Используйте другой браузер.
«;
ломать;
случай «alipayNotSupported»:
e. innerHTML = »
Alipay больше не поддерживает
Обновите способ оплаты, чтобы продолжить использование Smallpdf Pro
«; ломать; } } }
HomeConvert & Compress
Compress PDF
PDF Converter
PDF Scanner
Split & Merge
Split PDF
Merge PDF
View & Edit
Edit PDF
PDF Reader
Number Pages
Delete PDF Pages
Rotate PDF
Convert from PDF
PDF в Word
PDF в Excel
PDF в PPT
PDF в JPG
0 Конвертировать в PDF10
Word to PDF
Excel to PDF
PPT to PDF
JPG to PDF
Sign & Security
eSign PDF
Unlock PDF
Защита PDF
Преобразование и сжатие
Сжатие PDF
Конвертер PDF3
12
PDF Scanner
Split & Merge
Split PDF
Merge PDF
View & Edit
Edit PDF
PDF Reader
Нумерация страниц
Удалить страницы PDF
Повернуть PDF
Преобразовать из PDF
1PDF для Excel
PDF до PPT
PDF в JPG
.
PDFJPG до PDF
1
PDF0003
Sign & Security
ESIGN PDF
Unlock PDF
- 111
PDF
- 1111110003
- Compress
- Преобразование
- Merge
- РЕДАКТИРОВАТЬ
- Знак
ПРЕИМУЩЕСТВА
«; ломать; } } }
Как удалить страницы PDF
by Hung Nguyen
Вы также можете прочитать эту статью на немецком, испанском, французском, индонезийском, итальянском и португальском языках.
Удалить дубликаты страниц из файла PDF онлайн бесплатно. Без водяных знаков и без регистрации!
Вы случайно объединили файлы PDF с одинаковыми страницами? Если это так, вы можете использовать инструмент Удалить страницы Smallpdf, чтобы удалить эти дубликаты страниц в одно мгновение. Этот инструмент можно использовать совершенно бесплатно — регистрация не требуется.
Как удалить дубликаты страниц в PDF онлайн бесплатно
Откройте инструмент «Удалить страницы» на нашем сайте.
Перетащите документ PDF в панель инструментов.
Наведите указатель мыши на повторяющиеся страницы и щелкните значок корзины, чтобы удалить их.
Нажмите «Применить изменения» и загрузите сохраненный файл.
Удалите дубликаты страниц из PDF-файла за один раз.
Удаление повторяющихся страниц
Масштабирование или поворот перед удалением
Пока вы используете инструмент для удаления дубликатов страниц в PDF-файле, вы также можете поворачивать или увеличивать масштаб, чтобы проверить содержимое каждой отдельной страницы, если это необходимо. Эти параметры перечислены рядом со значком удаления страниц, который отображается всякий раз, когда вы наводите курсор на миниатюры страниц. Масштабирование упрощает поиск дублирующегося содержимого в одном PDF-файле, чтобы убедиться, что вы удаляете правильные страницы.
Если вам нужно найти дубликаты страниц из нескольких PDF-файлов, вы всегда можете объединить их в один PDF-файл, используя наш инструмент слияния. Затем перейдите к инструменту «Удалить страницы», чтобы найти и удалить дубликаты.
Можно ли удалить дубликаты страниц PDF в автономном режиме?
Конечно! Вы можете использовать приложение Smallpdf Desktop для выполнения той же задачи полностью в автономном режиме. В отличие от онлайн-версии, для использования нашего настольного приложения требуется учетная запись Pro. Чтобы удалить дубликаты страниц в автономном режиме, следуйте приведенным ниже инструкциям:
- Откройте PDF-файл с помощью нашего настольного приложения.
- Щелкните правой кнопкой мыши миниатюру страницы, которую хотите удалить.
- Выберите «Удалить».
- Щелкните значок дискеты в верхней части страницы, чтобы сохранить изменения.
- Для пакетного удаления выделите несколько страниц и выполните те же действия.
Помимо пакетной обработки, вы также можете повернуть или даже вставить пустую страницу в файл PDF. Как всегда, перетаскивайте страницы, чтобы изменить порядок файлов, прежде чем сохранять их на свое устройство. Мы надеемся, что вам понравится редактировать ваши PDF-файлы так же, как нам понравилось создавать обе платформы.
Получить приложение Smallpdf Desktop
Бесплатно для использования на любом устройстве
Smallpdf — одно из самых посещаемых программ для работы с файлами PDF в Интернете, которым пользуются более 40 миллионов пользователей в месяц. Наша цель — упростить вашу работу с PDF-файлами, хотите ли вы удалить, изменить или добавить PDF-страницы — мы здесь, чтобы помочь! Наши онлайн-инструменты PDF бесплатны для всех с ограниченным использованием. Если вы являетесь частым пользователем, вы можете зарегистрировать учетную запись Pro, которая обеспечивает неограниченное использование, а также многие другие премиальные функции.
Наша команда верит в доступный доступ к программному обеспечению PDF для всех, поэтому наш сайт останется бесплатным для использования. Даже будучи обычным пользователем, вы можете получить подписку без дорогого ценника, который поставляется с другими программами PDF, например, с учетной записью Adobe Acrobat Pro.
Ознакомьтесь со многими другими онлайн-инструментами. Если вам нужно удалить страницы из цифрового документа в другом формате, помните, что вы всегда можете сначала преобразовать его в PDF, удалить страницы, а затем сохранить его обратно в исходную форму — все, что вам нужно, мы обеспечим!
Хунг Нгуен
Старший менеджер по маркетингу роста @Smallpdf
Как удалить дубликаты файлов PDF и удалить дубликаты страниц в PDF
Обновлено для удаления повторяющихся советов от Эми, 13 сентября 2022 г. | Одобрено Дженнифер Аллен
Дубликаты PDF-файлов затруднят управление документами, а дубликаты страниц в PDF-файлах будут мешать людям получать правильную информацию. В этой статье рассказывается, как удалить дубликаты PDF-файлов с помощью iBeesoft Duplicate File Finder и бесплатных программных инструментов для удаления дубликатов полей в PDF-файле.
Скачать бесплатно
PDF — это распространенный формат документов, позволяющий пользователям предоставлять важную информацию, особенно информацию, которую создатель документа не хочет изменять другими людьми. Однако с течением времени на вашем компьютере может быть сохранено много дубликатов PDF-файлов, занимающих слишком много места. А иногда по какой-то ошибке в файле PDF дублируется содержимое. Далее вы узнаете, как удалить дубликаты PDF-файлов и удалить повторяющийся контент в PDF-файле.
- Быстрая навигация
- Часть 1. Два способа удаления дубликатов PDF-файлов
- Часть 2. Как удалить повторяющиеся страницы в PDF
Часть 1. Два способа удаления дубликатов PDF-файлов
В этом разделе более подробно рассматривается вопрос о том, как удалить дубликаты PDF-файлов с компьютера. Есть две процедуры, которые вы можете использовать для выполнения задачи. Вы можете следовать методам в соответствии с вашими требованиями и удалить дубликаты PDF-файлов за несколько простых шагов.
Метод 1: Как вручную удалить дубликаты PDF-файлов?
Если вы хотите знать, как удалить дубликаты PDF-файлов с вашего компьютера, вы находитесь на правильном пути. Этот метод позволяет вам использовать приложение File Explorer, предоставляемое ОС Windows по умолчанию, для поиска дубликатов файлов.
С помощью приложения вы можете сортировать файлы PDF по имени, дате создания и времени. Вы можете использовать функцию поиска, чтобы уменьшить список, выбрать дубликаты файлов и продолжить удаление.
Шаги для завершения действия следующие:
1. Откройте приложение «Проводник», щелкнув значок «папка» на панели задач.
2. Вы увидите доступные разделы на жестком диске.
3. Если вы помните путь, по которому вы сохранили файлы PDF, перейдите по нему. Например, если файлы находятся в папке D:\PDF Files, перейдите к ней.
4. Вы увидите окно поиска для быстрого доступа к файлам в правом верхнем углу.
5. Вы можете ввести имя файла для поиска дубликатов или ввести .pdf и нажать клавишу Enter.
6. Функция поиска запустит процесс поиска всех файлов PDF, находящихся в выбранной папке, и перечислит их в окне.
7. Теперь вы можете искать дубликаты файлов вручную и удалять их один за другим.
Способ 2. Как удалить дубликаты PDF-файлов одним щелчком мыши?
Вы можете удалить дубликаты файлов PDF в одном с помощью удаления дубликатов файлов. На помощь приходит программа, в которой можно искать, отмечать нужные файлы и удалять их с компьютера в один клик. Удобно, когда на вашем компьютере хранится несколько PDF-файлов.
Рекомендуемым средством удаления дубликатов файлов для этого процесса является iBeesoft Duplicate File Finder. Программа является лучшим в своем классе средством поиска дубликатов файлов и помогает с легкостью удалить все идентичное содержимое. Этот процесс удалит ненужные файлы из системы, освободит место на жестком диске и поможет повысить производительность.
Что делает программное обеспечение уникальным по сравнению с другими в этой категории, так это возможность и гибкость, которые оно позволяет выбирать типы файлов. Например, вы можете выбрать, какой файл вы хотите удалить, размер файла, дату создания и так далее. Кроме того, вы можете выбрать интеллектуальный выбор, предоставляемый программным обеспечением, чтобы сделать весь процесс плавным, где вы можете быстро удалить файлы.
Ниже перечислены основные функции программного обеспечения iBeesoft Duplicate File Finder:
Руководство по удалению дубликатов PDF-файлов
Следующее руководство поможет вам научиться удалять дубликаты в PDF за несколько простых шагов. Однако, прежде чем приступить к упомянутым шагам, обязательно загрузите и установите пробную копию лучшего средства очистки от дубликатов, посетив официальный сайт.
1. После завершения установки программы дважды щелкните значок, появившийся на рабочем столе. Откроется главное окно программного обеспечения, где вы можете добавить место для сканирования PDF-файлов, имеющихся на вашем компьютере. Вы можете использовать символ «+», чтобы перейти к папке на вашем компьютере или перетащить папку в окно. В этом же окне можно добавить фильтры, где можно указать формат файла, например PDF. Кроме того, вы можете щелкнуть функцию «сканировать скрытые файлы», которая помогает программе сканировать папку на наличие скрытых файлов, которые вы не можете увидеть иначе. Нажмите «Установить ограничение размера файла», чтобы найти файлы PDF большого размера.
2. iBeesoft Duplicate File Finder начнет сканирование папки в соответствии с настройками. Время завершения процесса зависит от количества файлов, присутствующих в месте, и размера файла. Поэтому предпочтительнее оставаться терпеливым до завершения процесса. Тем временем iBeesoft будет отображать ход сканирования на экране. Вы также можете остановить сканирование с помощью кнопки «Остановить сканирование».
3. По завершении действия iBeesoft покажет вам все дубликаты PDF-файлов, имеющиеся в папке. У вас будет подробный обзор системы. Вы можете увидеть дублированные файлы, доступные в соответствии с форматом файла, установленным во время сканирования. Вы можете выбрать одинаковые файлы из списка и удалить их одним щелчком мыши. iBeesoft отправит файлы в «Корзину», откуда вы сможете удалить их навсегда.
Часть 2. Удаление повторяющихся страниц в PDF-файле
Единственный возможный способ удалить дубликаты страниц в PDF — с помощью программного обеспечения. Ниже приведены пять бесплатных онлайн-инструментов PDF, которые помогают удалить дубликаты страниц в файле PDF:
.№1. PDFResizer
Используйте этот бесплатный онлайн-инструмент для удаления дубликатов страниц вашего PDF-файла. Это быстро, легко и гибко. После удаления страниц вы можете воссоздать новый файл PDF, полностью удалив дубликаты.
№2. Online2pdf
Это еще одна онлайн-программа, позволяющая удалять дубликаты и ненужные страницы из файла PDF. Вы можете загрузить файл, выбрать нужный вариант и выполнить действие. После завершения вы можете сохранить новый файл в формате PDF для дальнейшего использования.
№3. Содаpdf
Sodapdf — это захватывающий бесплатный онлайн-редактор PDF. Вы можете использовать его в любом месте и на любом устройстве. Вы можете использовать различные бесплатные инструменты редактирования, предоставляемые программным обеспечением, для редактирования файла PDF, включая удаление дубликатов и ненужных страниц. Он также поддерживает облачные приложения, такие как Dropbox и Google Drive.
№4. Смоллpdf
Другим онлайн-инструментом, позволяющим удалять дубликаты страниц из PDF-файла, является Smallpdf. Весь процесс прост, так как вы можете загрузить файл, выбрать страницы для удаления и восстановить новый файл за несколько простых шагов. Инструмент не хранит документы, что делает их безопасными.
№5. Пдфзорро
Это самый простой и доступный онлайн-инструмент, который поможет вам удалить ненужные и повторяющиеся страницы из файла PDF. Вы можете загрузить файл или перетащить его, начать редактирование, удалить дубликаты страниц и сохранить новый файл.
Как видите, некоторые различные методы и инструменты помогают удалять дубликаты PDF-файлов и удалять дубликаты страниц из PDF-файла за несколько простых шагов. Используйте необходимую программу с умом и экономьте время и энергию.
Как найти и удалить дубликаты в Numbers на Mac
При работе с большим количеством данных в Apple Numbers на Mac вы можете столкнуться с ситуацией, когда у вас есть дубликаты. Это могут быть имена, адреса электронной почты, товары, цвета или что-то еще.
Если в электронной таблице много данных, поиск и удаление дубликатов может стать проблемой. В конце концов, в Numbers нет кнопки «удалить дубликаты».
Мы собираемся показать вам несколько различных методов, которые вы можете использовать, чтобы найти дубликаты, а затем либо пометить их, либо удалить, если хотите.
Поиск дубликатов в числах с помощью сортировки
Если в вашей электронной таблице не так много данных, вы можете отсортировать их и проверить на наличие дубликатов вручную. Этот метод может сэкономить вам время в долгосрочной перспективе, но только если у вас нет тысяч строк в таблице.
Сортировка по одному столбцу
Если вам нужно отсортировать только один столбец в электронной таблице, чтобы найти дубликаты, выполните следующие действия:
- Выберите таблицу данных, щелкнув в любом месте таблицы, а затем щелкнув кружок в левом верхнем углу. Это слева от столбца A.
- Наведите курсор на столбец, по которому вы хотите выполнить сортировку.
- Щелкните стрелку , которая отображается рядом с буквой столбца, и выберите либо Сортировка по возрастанию или Сортировка по убыванию в появившемся меню действий.
Сортировка по нескольким столбцам
Если вам нужно выполнить сортировку по нескольким столбцам, чтобы найти дубликаты в электронной таблице, используйте вместо этого следующие инструкции:
- Выполните те же действия, что и выше, но вместо выбора параметра «Сортировка» в меню действий щелкните «Показать параметры сортировки» .
- На правой боковой панели должно открыться меню Sort .
- Убедитесь, что Сортировать всю таблицу выбрано в первом раскрывающемся списке.
- В раскрывающемся списке Добавьте правило под заголовком Сортировка строк по нескольким столбцам и выберите первый столбец, по которому вы хотите выполнить сортировку. Ниже этого выберите «По возрастанию» или «По убыванию».
- Заголовок Sort rows теперь должен быть Sort by , а под первым должен появиться еще один раскрывающийся список Add a Rule . Выберите другой столбец из Добавить правило раскрывающийся список и выберите его порядок сортировки.
- Данные должны сортироваться автоматически, но если нет, нажмите кнопку Сортировать сейчас в верхней части боковой панели.
После того, как вы отсортируете свои данные, вам будет легче обнаружить дубликаты и пометить или удалить их по мере необходимости.
Поиск дубликатов в числах с функциями
В Numbers есть две встроенные функции, которые можно использовать для поиска дубликатов. Это функции ЕСЛИ и СЧЁТЕСЛИ. ЕСЛИ может отображать дубликаты как True или False или слово, которое вы назначаете. СЧЁТЕСЛИ покажет, сколько раз появляется элемент, указывающий на дубликаты.
Поиск дубликатов с помощью функции ЕСЛИ
Чтобы проиллюстрировать, как будет работать функция, данные нашего примера будут показывать названия продуктов в столбце A, а наша таблица имеет заголовки столбцов в строке 1. Чтобы это работало, вам нужно отсортировать строку. Просто выполните следующие действия для своей электронной таблицы:
- Добавьте еще один столбец или перейдите к пустому столбцу на листе, куда вы хотите добавить повторяющийся индикатор.
- Щелкните ячейку во второй строке нового или пустого столбца под заголовком и откройте Редактор функций, введя Знак равенства (=) .
- Введите IF(A2)=(A1),»Duplicate»,» » в редакторе. Это сравнит ячейку с ячейкой над ней и введет слово Duplicate, если это дубликат. Если это не дубликат, он войдет в пробел. Вы можете изменить A2 и A1 на B2 и B1 в зависимости от столбца, в котором вы хотите искать дубликаты.
- Щелкните галочку , чтобы применить формулу.
- Скопируйте формулу в последующие ячейки, щелкнув ячейку, в которой она находится, и перетащив ее вниз по столбцу, когда вы увидите желтый круг на границе.
Хотите, чтобы ячейки «Дубликаты» выделялись еще больше? Попробуйте использовать условное форматирование в Numbers, чтобы сделать их другого цвета, чтобы вы знали, какие строки удалять.
Если вы предпочитаете не использовать собственное слово, а просто отображать True для дубликатов и False для не дубликатов, вы можете просто ввести (A2)=(A1) в редакторе. Это работает без добавления IF перед ним.
Поиск дубликатов с помощью функции СЧЁТЕСЛИ
Мы будем использовать те же данные примера, что и выше, используя столбец A и наши заголовки столбцов. Вот как использовать функцию СЧЁТЕСЛИ для поиска дубликатов:
- Добавьте еще один столбец или перейдите к пустому столбцу на листе, где вы хотите дублировать индикатор.
- Щелкните ячейку во второй строке под заголовком нового или пустого столбца и откройте Редактор функций, введя знак равенства (=) .
- Введите СЧЁТЕСЛИ(A,A2) в редакторе. A — это столбец, а A2 — строка.
- Щелкните галочку , чтобы применить формулу.
- Скопируйте формулу в последующие ячейки так же, как в шаге 5 выше.
Теперь вы должны увидеть числа в этом новом столбце, показывающие, сколько раз появляется элемент в дублирующемся столбце. В нашем примере на снимке экрана выше вы можете видеть, что кепка появляется три раза, пальто один раз и перчатки дважды.
Удалить дубликаты из номеров
Вы можете удалить дубликаты при использовании функции ЕСЛИ или СЧЁТЕСЛИ вручную, найдя каждую ячейку, в которой указано «Дубликат», «Истина» или любое число больше 1, и удалив их одну за другой. Сортировка столбца формулы позволяет удалять дубликаты намного быстрее, но вы должны быть осторожны, чтобы не удалить оригиналы вместе с дубликатами.
Объединение и удаление дубликатов из номеров
Возможно, вы хотите удалить дубликаты, но при этом не хотите потерять данные. Например, у вас могут быть данные о запасах продуктов, как в нашем примере. Таким образом, вы хотите суммировать эти суммы, прежде чем удалять дубликаты. Для этого вам нужно сначала объединить данные. Для этой задачи вы будете использовать как формулу, так и функцию в Numbers.
Объединить данные
В нашем примере мы собираемся оставить столбец индикатора Duplicate, который мы использовали с функцией IF, потому что он понадобится нам позже. Затем мы собираемся добавить еще один столбец справа для наших итогов.
- Щелкните ячейку во второй строке нового столбца под заголовком и откройте Редактор функций, введя знак равенства (=) .
- Введите (B2)+IF(A2)=(A3),(D3),0 в редакторе. (Вы можете увидеть разбивку этих элементов формулы ниже.)
- Щелкните галочку , чтобы применить формулу.
- Скопируйте формулу в последующие ячейки.
Разбивка формулы:
- (В2) — это ячейка, содержащая нашу первую величину.
- + добавят это количество к следующему.
- ЕСЛИ(A2)=(A3) проверяет наличие дубликатов между двумя ячейками.
- (D3) — это место, где будет отображаться результат общего количества.
- 0 будет добавлено, если нет дубликатов.
После того, как вы закончите слияние данных, важно дважды проверить, чтобы убедиться, что все складывается правильно.
Удалить дубликаты
Чтобы удалить дубликаты после объединения данных, вы снова будете использовать действие сортировки. Но сначала вам нужно создать новые столбцы, чтобы скопировать и вставить результаты данных в виде значений, чтобы они больше не были формулами.
Используя тот же пример, мы скопируем и вставим столбцы Duplicate и Total:
- Выберите оба столбца и нажмите Изменить > Копировать в строке меню.
- Выберите новые столбцы, куда вы хотите их вставить, и нажмите Редактировать > Вставить результаты формулы из строки меню.
- Удалите столбцы с формулами, выбрав их еще раз и щелкнув правой кнопкой мыши или щелкнув стрелку заголовка столбца и выбрав Удалить выбранные столбцы .
Теперь вы можете сортировать по столбцу индикатора «Дублировать», который вы продолжаете, используя инструкции по сортировке в начале этого руководства. Вы должны увидеть все ваши дубликаты, сгруппированные вместе, чтобы вы могли удалить эти строки.
Затем вы также можете удалить исходные столбцы «Количество» и «Дублировать», которые вы использовали для функций и формул. Это оставит вас без дубликатов и объединенных данных.
Примечание: Опять же, прежде чем удалять столбцы, строки или другие данные из электронной таблицы, убедитесь, что все в порядке и что они вам больше не нужны.
Работа с дубликатами в числах
В ваших электронных таблицах Numbers легко появляются дубликаты, независимо от того, что вы вычисляете. Надеемся, что шаги, которые мы описали выше, помогут вам быстро определить любые дубликаты, объединить соответствующие данные о них и удалить их для очистки листа.
Мы также надеемся, что эти знания вдохновят вас на использование Numbers. Это отличная встроенная программа для Mac, которая способна на многое, если вы потратите время на ее изучение.
Подробное руководство по удалению дублированного контента с вашего сайта
В футболе судья показывает красную карточку, когда замечает пенальти. С Google штраф за дублированный контент может полностью разрушить вашу SEO-стратегию.
Большая часть вашего маркетингового успеха связана с вашими SEO стратегия .
Если вы подниметесь в рейтинге, ваш веб-сайт и бизнес выиграют от трафика, лидов и конверсий.
Если вы этого не сделаете, то вы либо посмотрите на другие маркетинговые методы , либо постараетесь усерднее.
Но, конечно же, вы не одиноки в своем желании попасть в первую десятку результатов Google.
Эти первые места представляют собой большой доход для вашего бизнеса. Итак, вы знаете, что они очень конкурентоспособны.
Это означает, что вам нужно использовать все возможные SEO-сигналы.
И ты знаешь, что не хочешь наказания. В спорте вам, возможно, придется просто посидеть несколько минут. Но в бизнесе штрафы могут снизить ваши шансы на привлечение клиентов.
Органический поисковый трафик встречается гораздо чаще, чем платный поиск , и Google находится на вершине рейтинга поисковых систем.
Другими словами, если вы действительно хотите извлечь выгоду из SEO, сосредоточьте свои усилия на Google.
К сожалению, сосредоточения внимания на Google недостаточно, чтобы автоматически поднять ваш рейтинг.
Помните, что почти каждый маркетолог, обладающий хоть малейшим знанием SEO, пытается повысить свой рейтинг.
Фактически, 78% маркетологов B2B регулярно используют SEO в качестве маркетинговой стратегии.
Это имеет смысл, если подумать. Преимущества SEO хорошо известны и широко распространены.
Каждый маркетолог пытается получить свой кусок пирога. Включая себя.
Это означает, что вы должны быть умнее, быстрее и лучше, чем они, чтобы победить.
Потому что этот круг включает 61 % более дешевых лидов и 70 % кликов по ссылкам.
Последнее, чего вы хотите, это отставать. Вы не хотите, чтобы все остальные веб-сайты в вашей отрасли вырвались вперед, пока вы отстаете от них.
Тогда все ваши конкуренты выигрывают SEO-потенциал — а вы проигрываете.
Это не рецепт успеха.
Какое отношение все это имеет к дублирующемуся контенту?
Дублированный контент может повредить вашему рейтингу, если вы его проигнорируете, и улучшить ваш рейтинг, если вы его исправите.
На самом деле дублированный контент может быть просто вашим билетом на вершину поисковой выдачи.
Что такое дублированный контент?Возможно, вы слышали, как ваши друзья говорили о дублирующемся контенте.
Или, может быть, вы впервые слышите об этом в этой статье.
Скорее всего, вы слышали этот термин, но все еще немного запутались. Это нормально. Я был немного смущен, когда впервые узнал о дублирующемся контенте несколько лет назад.
Так что потерпите, и я помогу вам понять, что такое дублированный контент и почему он вообще имеет значение.
По сути, дублированный контент — это именно то, на что он похож.
Это дубликат уже существующей страницы. И это сбивает с толку поисковые системы.
Когда поисковая система видит несколько страниц с дублирующимся содержимым, она должна решить, какую из них ранжировать .
Естественно, вы не хотите, чтобы он выбрал неправильно.
Каждый повторяющийся фрагмент контента имеет немного отличающийся URL-адрес. И даже если вы видите одно и то же, Google и другие поисковые системы видят несколько разных страниц.
Из-за этого у них разный рейтинг, SEO-составляющая и даже авторитет страницы .
Это не только выглядит беспорядочно, но и может навредить поисковой оптимизации страницы, которую вы хотите ранжировать.
Конечно, вы можете подумать, что попадание на несколько позиций в поисковой выдаче приносит вам пользу, но так ли это на самом деле?
Что, если, например, вы могли бы объединить SEO-сок этих двух страниц, чтобы ранжировать одну страницу еще выше?
Было бы здорово, правда?
Позже в этой статье я покажу вам, как это сделать.
Что такое дублированный контент, вот что сообщает Google :
«Дублированный контент обычно относится к существенным блокам контента внутри или между доменами, которые либо полностью совпадают с другим контентом, либо заметно похожи. В основном это не обманчивое происхождение».
И они определенно правы насчет отсутствия обмана.
Вы никого не пытаетесь обмануть дублирующимся контентом. Вы, вероятно, даже не знали, что на вашем сайте может быть дублированный контент.
Часто вы не создаете его намеренно, но он как бы создает сам себя.
Если вы хотите проверить свой домен на наличие дублирующегося контента, вы можете использовать этот инструмент для этого .
Просто введите URL-адрес, который вы хотите проверить, и нажмите «Выполнить проверку».
Затем на следующей странице будет показано, сколько существует дубликатов страниц с введенным вами URL-адресом.
Как вы можете видеть, в настоящее время в Интернете существует восемь повторяющихся фрагментов контента для введенного мной URL-адреса.
Теперь, когда вы понимаете, что такое дублированный контент и как его найти на своем веб-сайте, давайте поговорим о том, почему он существует и почему он появляется.
Почему он появляется?Возможно, самая запутанная часть дублированного контента — это то, почему он появляется в первую очередь.
В большинстве случаев вы не пытались намеренно создать копию одной из уже существующих страниц.
И тем не менее, многие веб-сайты имеют дублированный контент.
Так что же его создает и откуда оно берется?
Здесь я покажу вам несколько причин надоедливого дублированного контента.
Первый способ обнаружения дублированного контента — это когда веб-сайт использует систему URL-адресов, которая создает несколько версий одной и той же страницы.
Страница выглядит одинаково во всех ее вариантах, но URL-адрес немного отличается.
Вот так, например.
Другой пример, когда у вас есть один URL-адрес страницы, который является HTTPS, а другой — нет.
Эти страницы больше не одни и те же страницы, а дубликаты друг друга.
Этот выглядит как этот .
Другой способ, которым вы можете непреднамеренно создать дублированный контент, — это публикация печатной или HTML-версии уже существующей страницы.
Это отлично подходит для того, чтобы люди могли распечатать ваш контент, но не столько для SEO и предотвращения дублирования контента.
Конечно, это лишь несколько способов, которыми вы или ваша система создаете дублированный контент.
Однако это происходит по-разному.
Динамические URL-адреса, старые и забытые версии страниц, синдикация контента и идентификаторы сеансов — вот еще несколько причин, по которым эти страницы с дублированным контентом нашли свое место в цифровом мире .
Надеюсь, теперь у вас есть хорошее представление о том, что такое дублированный контент и что его создает.
А теперь обратим внимание на один из самых важных вопросов о дублирующемся контенте.
Почему это вызывает проблему и насколько она серьезна?
Почему это вызывает проблемы?Возможно, вы этого не знали. Но да, дублированный контент вызывает проблему.
Хотите верьте, хотите нет, но наличие дублированного контента на вашем сайте может повредить вашему SEO-рейтингу.
Но не напрямую. Google на самом деле сказал, что дублированный контент напрямую не влияет на рейтинг сайта. Но косвенно это вредит вашему рейтингу.
Поясню.
Представьте на мгновение, что у вас есть две страницы с одинаковым содержимым. У одного есть основной URL-адрес, а другой — дубликат.
Теперь, как и должно быть, обе страницы имеют свои собственные SEO-составляющие. Поскольку у них разные URL-адреса, они получили разные обратные ссылки и, следовательно, разные оценки авторитетности страницы.
В этом случае у вас есть два варианта.
Оставьте каждый в отдельности, чтобы ранжировать отдельно или комбинировать их ранжирующие сигналы.
Последнее почти всегда является лучшим вариантом, а первое почти всегда ухудшает общий рейтинг этой страницы.
Просто учтите, что 50% веб-сайтов имеют проблемы с дублированием контента, которые вредят их SEO.
Причина того, что дублированный контент вредит SEO, проста.
Когда вы оставляете каждую страницу в покое для ранжирования отдельно от ее копии, это похоже на отправку половины вашей армии на одну войну, а другую половину на другую войну.
Вместо этого вы могли бы объединить их силы и получить от этого больше пользы.
Если, например, одна страница имеет 3 балла по шкале от 1 до 10, а дубликат — 4, то их объединение даст 7.
Другими словами, целое гораздо мощнее, чем отдельные части .
Если вы предоставите решение о том, какие страницы ранжировать, а какие игнорировать, Google, то он может принять неправильное решение.
В идеале вы хотите сообщить Google, какой версии страницы отдать предпочтение, а затем отправить весь SEO-сопровождение с дубликатов страниц на эту каноническую страницу.
Как и в большинстве случаев в жизни, есть несколько разных способов сделать это.
Вот три способа, которые я рекомендую.
1. Тег rel=canonicalВ большинстве случаев тег rel=canonical — лучший способ перенести SEO-сопровождение с дублирующей страницы на другую страницу.
По сути, это тег HTML, который вы можете добавить к определенной странице, который затем сообщает поисковым системам, что именно эту страницу вы хотите проиндексировать в Google.
Затем, когда Google находит какие-либо дубликаты страницы, он приписывает все SEO-сопровождение этих дубликатов канонической странице.
Это означает, что ваш рейтинг повышается, и страница, которая действительно важна, побеждает.
Похож на редирект 301, но проще в реализации.
Плюс, при этом старая страница не исчезает. Google просто распознает его таким, какой он есть: дубликат другой страницы.
Иногда вы не хотите, чтобы старый дубликат исчезал. Вы просто хотите собрать все SEO-соки в одном месте.
Если, например, у вас есть HTML-версия страницы для печати, вы не хотите полностью удалять этот дубликат.
Но вы также не хотите, чтобы это ранжировалось.
Для этого отлично подходит тег rel=canonical.
Вот как это выглядит в коде вашего сайта.
И еще раз .
Если вы используете веб-сайт WordPress, добавить этот тег довольно просто.
Прежде всего, есть несколько плагинов, которые позволят вам сделать это с легкостью. Вы можете просмотреть некоторые из этих здесь .
Однако, если вы хотите сделать это вручную для своего основного домена, просто добавьте этот код в глава шаблона вашей темы .
Просто не забудьте заменить часть «bybe.net» своим собственным URL-адресом.
Тогда Google будет знать, на какую страницу отправить все эти повторяющиеся SEO-соки, и ваше ранжирование сразу выиграет.
2. 301 перенаправление Иногда вы не хотите, чтобы дубликат вашей веб-страницы оставался.
Возможно, вы хотите, чтобы существовала только основная версия страницы, а эти дубликаты просто загромождают ваше онлайн-пространство и настроение ваших посетителей.
Тем не менее, вы, вероятно, хотите, чтобы основная страница извлекала выгоду из SEO-сока своих дубликатов.
Возможно ли это? Убрать дубликаты страниц и при этом повысить SEO основной страницы?
Да. Да, это так.
И это возможно из-за 301 редиректа.
Эти щенки позволяют вам сообщать поисковым системам, что всякий раз, когда кто-то пытается посетить страницу A, вы хотите, чтобы они отправляли этих людей на страницу B вместо .
Однако переадресация 301 по-прежнему не удаляет страницу А. Вместо этого она просто перенаправляет всех посетителей на страницу Б.
Другими словами, никто никогда не увидит страницу А, но это все равно поможет странице Б ранжироваться выше.
Поскольку он не удаляется, все его SEO-соки автоматически относятся к странице, на которую он перенаправляется.
И поисковые системы точно знают, что делать, когда вы 301 перенаправляете страницу.
Однако будьте осторожны при использовании переадресации 302. Это только временные, тогда как 301 редиректы являются постоянными.
Вот как поисковая система вычисляет переадресацию 301.
Если вы решите, что перенаправление 301 является правильным выбором для вашей ситуации с дублированным контентом, то вот список различных плагинов WordPress , которые вы можете использовать для создания перенаправления.
Плагин для WordPress — самая безопасная и простая ставка.
3. Установите пассивные параметры в Google Search ConsoleК сожалению, иногда вы торопитесь.
Хотя я не рекомендую использовать пассивные параметры в долгосрочной перспективе, это может быть полезной краткосрочной стратегией.
Когда вы устанавливаете определенные URL-адреса как пассивные для Google, это указывает роботу сканирования Google в основном игнорировать этот URL-адрес.
Очевидно, что это может помочь удалить дублированный контент.
Если у вас есть несколько странных и загроможденных результатов, отображаемых в поисковой выдаче, вы можете просто быстро удалить некоторые из них.
Однако, возможно, ваша команда разработчиков слишком занята, чтобы просмотреть и добавить теги rel=canonical на сотни разных страниц, а затем указать им правильное направление.
В конце концов, это огромная работа, а ваша команда разработчиков уже достаточно занята.
Если вы хотите пометить некоторые страницы как пассивные, перейдите в Google Search Console и нажмите Параметры URL в левой части экрана.
Затем нажмите «Добавить параметр».
Введите URL-адрес страницы, которую вы хотите пометить как пассивную, а затем выберите «Нет: не влияет на содержимое страницы (например, отслеживает использование)».
Нажмите «Сохранить», и теперь этот URL будет помечен как пассивный в результатах поиска Google.
Это означает, что он не может отображаться, когда люди ищут ваш сайт.
Это может быть полезно, когда ваша команда разработчиков занята или когда вас не волнуют потенциальные преимущества SEO от ссылки на эту страницу с другим каноническим URL-адресом.
Это, конечно, провал этой стратегии.
URL-адрес, который вы храните, не получает никаких преимуществ SEO от дубликатов, которые в настоящее время существуют.
Однако это может быть не такой большой проблемой, если дубликаты, которые вы удаляете из глаз Google, являются новыми или имеют очень низкий авторитет страницы.
В этом случае это может быть одним из лучших решений для удаления дублирующегося контента из вашего домена.
Если, однако, это только временное решение, чтобы помочь занятой команде разработчиков, обязательно вернитесь и используйте тег rel=canonical или перенаправление 301, когда у вас будет время.
Вот так. Это было много.
Но теперь вы понимаете, что такое дублированный контент, почему он появляется, почему это проблема и даже как его можно безопасно удалить.
Потому что вот чего ты не хочешь, чтобы случилось.
Вы не хотите, чтобы весь этот дублированный контент наносил ущерб вашему SEO, и вы определенно не хотите удалять его неправильно и еще больше навредить вашему SEO.
При удалении повторяющегося контента помните о трех стратегиях, которые я упомянул здесь, и выберите ту, которая лучше всего соответствует вашим текущим потребностям.
Тег rel=canonical лучше всего подходит почти для всех случаев, но это может занять приличное количество времени, если вам нужно исправить много страниц.
Перенаправление 301 отлично подходит, если вы хотите, чтобы посетители не могли просматривать дублированный контент, но при этом получить преимущество основной страницы от SEO дубликатов.
Однако помните, что это решение займет у вас больше всего времени.
А пассивные параметры могут стать отличным краткосрочным решением, если у вас сейчас нет времени на настройку 301 редиректа или тегов rel=canonical.
Одно можно сказать наверняка.
Если вы не занимаетесь дублированием контента на своем веб-сайте, это может повредить вашему рейтингу и, следовательно, вашему бизнесу.
Не позволяй этому случиться.
Какую стратегию вы используете для удаления дублирующегося контента из вашего домена?
Посмотрите, как мое агентство может привлечь огромное количество трафика на ваш сайт Смотрите реальные результаты.
Закажите звонок
SEO: 2 хороших способа удалить повторяющийся контент и 8 плохих
Техническое SEO
26 мая 2022 г.
• Ann SmartyДублированный контент — это несколько страниц, содержащих одинаковый или очень похожий текст. Дубликаты существуют в двух формах:
- Внутренние: Когда в одном и том же домене размещено точное или похожее содержимое.
- Внешний: Когда вы синдицируете контент с других сайтов (или разрешаете синдикацию вашего контента).
Оба случая разделяют авторитет ссылок и, таким образом, снижают способность страницы ранжироваться в результатах обычного поиска.
Допустим, на веб-сайте есть две идентичные страницы, каждая из которых имеет 10 внешних входящих ссылок. Этот сайт мог бы использовать силу 20 ссылок для повышения рейтинга одной страницы. Вместо этого на сайте есть две страницы с 10 ссылками. Ни один из них не занял бы столь высокое место.
Дублированный контент также тратит впустую краулинговый бюджет и вынуждает Google выбирать страницу для ранжирования — редко хорошая идея.
Хотя Google утверждает, что штраф за дублирование контента не предусмотрен, избавление от такого контента — хороший способ укрепить ссылочный вес и повысить рейтинг.
Вот два хороших способа удалить повторяющийся контент из индексов поисковых систем — и восемь способов, которых следует избегать.
2 способа удаления
Чтобы исправить проиндексированный дублированный контент, объедините авторитет ссылок на одной странице и предложите поисковым системам удалить дубликат из их индекса. Есть два хороших способа сделать это.
- 301 редирект — лучший вариант. Они консолидируют авторитет ссылок, подсказывают деиндексацию и перенаправляют пользователей на новую страницу. Google заявил, что присваивает все полномочия по ссылкам новой странице с переадресацией 301.
- Канонические теги указывают поисковым системам на главную страницу, побуждая их перенести на нее ссылочный вес. Теги работают как подсказки поисковым системам, а не как команды вроде переадресации 301, и они не перенаправляют пользователей на главную страницу. Поисковые системы обычно уважают канонические теги для действительно дублированного контента (т. Е. Когда канонизированная страница имеет много общего с главной страницей). Канонические теги — лучший вариант для внешнего дублированного контента, например, для повторной публикации статьи с вашего сайта на такой платформе, как Medium.
8 Нерекомендуемые методы
По моему опыту, некоторые варианты, которые пытаются удалить повторяющийся контент из индексов поисковых систем, не рекомендуются.
- 302 перенаправляет сигнал о временном перемещении, а не о постоянном. Хотя Google заявил, что обрабатывает переадресацию 302 так же, как переадресацию 301, последняя является лучшим способом постоянной переадресации страницы.
- Перенаправления JavaScript действительны в соответствии с Google — после того, как прошло несколько дней или недель для завершения процесса рендеринга. Но нет особых причин использовать переадресацию JavaScript, если у вас нет доступа к серверу для 301-й.
- Мета-обновления (выполняемые веб-браузерами на стороне клиента) видны пользователям в виде короткого мигания на экране перед тем, как браузер загрузит новую страницу. Ваши посетители и Google могут быть сбиты с толку этими редиректами, и нет никаких причин предпочитать их 301. Коды ошибок
- 404 показывают, что запрошенный файл отсутствует на сервере, что побуждает поисковые системы деиндексировать эту страницу. Но ошибки 404 также удаляют связанный со страницей авторитет ссылок. Нет причин использовать 404, если вы не хотите стереть некачественные сигналы ссылок, указывающие на страницу.
- Мягкие ошибки 404 возникают, когда сервер 302 перенаправляет неверный URL-адрес на то, что выглядит как страница с ошибкой, которая затем возвращает ответ заголовка сервера 200 OK. Ошибки Soft 404 сбивают Google с толку, поэтому лучше их избегать.
- Инструменты поисковой системы. Google и Bing предоставляют инструменты для удаления URL. Однако, поскольку оба требуют, чтобы отправленный URL-адрес возвращал действительную ошибку 404, инструменты являются резервным шагом после удаления страницы с вашего сервера.
- Мета-теги robots noindex запрещают ботам индексировать страницу. Авторитет ссылок умирает из-за неспособности движков проиндексировать страницу. Более того, поисковые системы должны продолжать сканировать страницу, чтобы проверить атрибут noindex, что приводит к трате краулингового бюджета.
- Запрет Robots.txt не вызывает деиндексацию. Боты поисковых систем больше не сканируют запрещенные страницы, которые были проиндексированы, но страницы могут оставаться проиндексированными, особенно если на них указывают ссылки.
Предотвращение дублирования содержимого
В своей официальной документации Google рекомендует избегать дублирования контента:
- Сведение к минимуму повторяющихся шаблонов. Например, вместо того, чтобы повторять одни и те же условия обслуживания на каждой странице, опубликуйте их на отдельной странице и дайте ссылку на них по всему сайту.
- Не использовать заполнители, которые пытаются сделать автоматически созданные страницы более уникальными.