Не все частотности одинаково полезны, или чем опасны «пустышки»
Знакома ситуация, когда «жирный» запрос, под который максимально оптимизирована страница, никак не попадает в ТОП-10 «Яндекса»? Или когда фраза приносит трафика на несколько порядков меньше, чем её частотка в Wordstat?
На самом деле, эти ситуации легко объяснить, если правильно проанализировать значения частотности ключевиков.
Сразу отметим, что в этой статье мы ответим на вопросы о самых важных для SEO параметрах запросов, не рассказывая подробно о том, что такое частотности вообще и какими они бывают. Кроме того, подразумевается, что анализ поисковой выдачи ведётся по нужному региону.
Какие частотности нужны?
По умолчанию Яндекс.Wordstat выдаёт базовую частотность. Она отображает сумму количества показов всех фраз, содержащих заданные слова в любой форме. Очевидно, что «база» будет особенно высокой у общих, имеющих несколько значений фраз. Многие из них могут не соответствовать в полной мере тематике сайта и не будут давать целевого трафика.
Сайт оптимизирован по «жирному» запросу, но не появился даже в ТОП-100
Поэтому в плане SEO интересна в первую очередь точная частотность — показывающая число запросов определённого набора слов в конкретной словоформе. В «Яндексе» она обозначается восклицательным знаком и кавычками, вот так: «! слово». Именно такая частотность наиболее точно соответствует потенциальному поисковому трафику по ключевику.
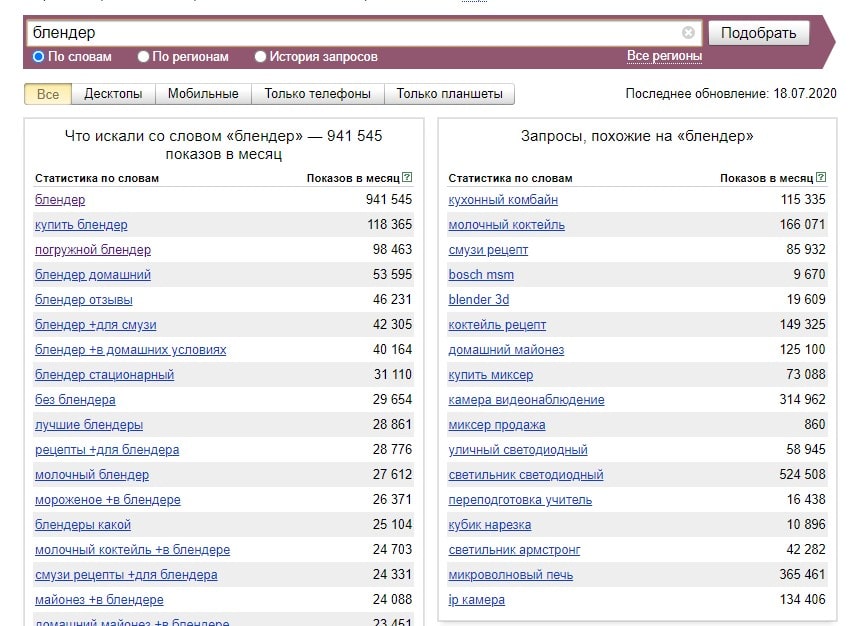
Например, количество показов по Самаре для основных фраз по тематике «пластиковые окна» выглядит таким образом:`
У запроса «окна» общая частотность в 6,5 раза выше, чем у «пластиковые окна», но точная — почти в 2 раза меньше. Аналогичное, хотя и не такое выраженное, различие можно заметить при сравнении по «базе» и точной частотности фраз:
«купить пластиковые окна» и «установка пластиковых окон»;
«купить пластиковые окна» и «купить пластиковые окна в самаре».


По статистике, на одну позицию в ТОП-10 приходится в среднем около 10% кликов. Так что поделив точную частоту на 10 можно примерно подсчитать, какое количество посетителей теоритически можно получить, выйдя на первую страницу выдачи по выбранному запросу.
Когда пригодится «база»?
Хотя точная частотность максимально полно отражает реальную популярность фразы, ориентироваться исключительно на неё тоже нельзя. Есть ключи, которых при внушительных значениях и базовой, и точной частотностей не будут давать значительного целевого трафика. В первую очередь это касается очень общих, многозначных слов и фраз. Такие запросы определяют по соотношению точной частотности к базовой: «! W»/W.
Этот показатель называют «полнотой» поисковой фразы. Запросы с околонулевым значением «полноты» SEO-специалисты часто называют «пустышками». В проектах, где достаточно высокочастотных запросов, можно отбирать как «пустышки» фразы, у которых соотношение точной и базовой частотностей меньше 5–7%.
Соотношение частот высчитывается многими SEO-сервисами или как KEI в KeyCollector
Наглядный пример «пустышки» — слово «окна». Его полнота при оценке по Самаре равна 96/81337 ≈ 0,001 = 0,1%. Продвигаться по нему бессмысленно — даже если удастся пробиться в топ, существенный целевой трафик будет низким, несмотря на огромное значение «базы».
Помимо излишней неконкретности, причиной низкой полноты запроса могут быть:
1. Неверный выбор словоформы — так, у «купить пластиковые окна самара» полнота всего 0,2%, а у такой же по смысловому содержанию, но написанной в правильной, устоявшейся форме «купить пластиковые окна в самаре» — вполне приличные 4,9%.
2. Наличие близких к исследуемой фразе запросов, отличающихся от неё, например, словоформами, предлогами — если все эти запросы тематичны, целесообразно использовать каждый из них, несмотря на небольшую полноту.
Так что при фильтрации по полноте, как и во всём SEO, стоит применять по возможности индивидуальный подход. Это касается и отбора по частотности — некоторые запросы с нулевой!”W» могут приносить неплохой целевой трафик, что легко отслеживается по «Яндекс.Метрике» и аналогичным сервисам.
Это касается и отбора по частотности — некоторые запросы с нулевой!”W» могут приносить неплохой целевой трафик, что легко отслеживается по «Яндекс.Метрике» и аналогичным сервисам.
Заключение
Правильное составления семантического ядра — один из ключевых факторов эффективного SEO-продвижения. Основные критерии для выбора запросов, по которым сайт сможет попасть в топ и которые будут приносить целевой поисковый трафик — это точная частотность и её отношение к «базе»
.При этом стоит помнить, что конечная цель SEO — это успешность продвигаемого проекта, а сам процесс продвижения — попытки угадать предпочтения поискового алгоритма. Поэтому применяя стандартные приёмы, можно и нужно экспериментировать. Именно так работает «Винтра».
P. S. Кстати, даже фразы с высокой точной частностью и хорошей полнотой могут быть бесполезными для продвижения, если у них неподходящие для проекта коммерциализация или локализация. Об этих параметрах мы расскажем в следующих статьях.
Частотность поисковых запросов — запросы делится на три категории «ВЧ» «СЧ» «НЧ»
Частотность поисковых запросов — параметр, отражающий популярность искомой фразы среди пользователей в определённой поисковой системе. Чаще всего ведется статистика по Яндекс и Google. Анализ запросов помогает узнать насколько востребован товар или услуга, предлагаемый сайтом. В соответствии с популярностью фраз, вбиваемых в поисковик, частотность поисковых запросов делится на три категории: «ВЧ» — высокочастотный, «СЧ» — среднечастотный и «НЧ» — низкочастотный. Для сбора данных используется инструмент Яндекс.Вордстат. С его помощью можно узнать: сколько человек в месяц интересуются конкретным запросом, в каком регионе эти люди живут и с каких устройств они заходят «компьютер», «мобильный телефон».
Отличие между видами поисковых запросов заключается не в цифрах. Например, фраза создать сайт ищется 180 000 раз в месяц. Купить клавиатуру — 73 000 в месяц, а смотреть фильмы — 34 000 000 раз. Но все они считаются высокочастотными запросами. Почему? Дело в том, что классификация запросов сложнее, чем кажется и происходит не только в количестве.
Но все они считаются высокочастотными запросами. Почему? Дело в том, что классификация запросов сложнее, чем кажется и происходит не только в количестве.
Все зависит от темы и ее распространенности, популярности у пользователей. В каждой тематике идут собственные высокочастотные, среднечастотные и низкочастотные запросы. Прежде, чем перейти к рассмотрению видов запросов, определимся с параметрами частотности. Их три: общая, точная и уточненная.
Общая частотность
Общая частотность – количество запросов определенного слова. Самый простой вид. В рассматриваемом примере это купить клавиатуру. Вводятся слова в соответствии с правилом русского языка, чаще всего в именительном падеже. Статистика будет размытой, обобщенной, поскольку включает не только высокочастотные запросы, но и все остальные.
Точная частотность
Точная частотность запросов помогает отсортировать статистику по конкретному запросу. Она скрывает остальные вариации вбиваемых в поиск слов. При ее расчете в Вордстат нужно вписать поисковой запрос в кавычках. На выходе отражается информация по числу поиска конкретной фразы, в том числе и ее склонений.
На выходе отражается информация по числу поиска конкретной фразы, в том числе и ее склонений.
Уточненная частотность
Уточненная частотность – показывает информацию только по введенной фразе, отсекая другие формы склонения, падежей и т.п. Иными словами, позволяет получить чистый поисковой запрос. Чтобы использовать уточненную частотность, нужно в запросе в кавычках добавить восклицательный знак перед каждым словом.
- Внимание!
- Далее вы увидите разницу между видами запросов на конкретных примерах.
Высокочастотные запросы
К высокочастотным запросам относятся те фразы и слова, которые пользователи ищут чаще всего. Это общий информационный запрос. Например, купить клавиатуру — обобщенное обращение к поисковику, поскольку клавиатуры бывают разными: для компьютеров, для ноутбуков, от разных производителей, с USB-разъемом или PS/2. Высокочастотные запросы состоят из 1-2 слов и имеют не узкую детальную направленность, а информационную. Цель ВЧ-запросов — дать простое представление по теме. Пользователи, делающие такой запрос только начинают разбираться в теме, они не углубляются в ее детали. Например, наши посетители из примера просто хотят увидеть магазины, в которых можно подобрать клавиатуру. Они еще не определились с брендом, они ищут обобщенную информацию.
Пользователи, делающие такой запрос только начинают разбираться в теме, они не углубляются в ее детали. Например, наши посетители из примера просто хотят увидеть магазины, в которых можно подобрать клавиатуру. Они еще не определились с брендом, они ищут обобщенную информацию.
К высокочастотным запросам относятся те фразы и слова, которые пользователи ищут чаще всего. Это общий информационный запрос. Например, купить клавиатуру — обобщенное обращение к поисковику, поскольку клавиатуры бывают разными: для компьютеров, для ноутбуков, от разных производителей, с USB-разъемом или PS/2. Высокочастотные запросы состоят из 1-2 слов и имеют не узкую детальную направленность, а информационную. Цель ВЧ-запросов — дать простое представление по теме. Пользователи, делающие такой запрос только начинают разбираться в теме, они не углубляются в ее детали. Например, наши посетители из примера просто хотят увидеть магазины, в которых можно подобрать клавиатуру. Они еще не определились с брендом, они ищут обобщенную информацию.
Среднечастотные запросы
Среднечастотные запросы – уточненные ВЧ-запросы. Они образуются при добавлении к ВЧ-запросу нескольких слов. На нашем примере таким будет купить клавиатуру для ноутбука. Среднечастотные запросы пользуются популярностью у интернет-магазинов для продвижения отдельных классификаций товаров. В первом случае пользователь искал самую общую информацию, не имея четкой цели. СЧ-запросы используют продвинутые в теме люди, конкретно знающие что хотят.
Низкочастотные запросы
К низкочастотным запросам относят наиболее точные фразы пользователей. Чаще всего низкочастотные запросы состоят из 4-7 слов. Здесь конкретика достигает максимума, пользователь абсолютно уверен в том, что хочет найти или купить. Вернемся к нашей клавиатуре. Примером низкочастотного запроса будет купить клавиатуру defender. Посетитель хочет девайс именно этого бренда, так как пользовался его аналогом и доверяет производителю. Посетитель ищет конкретные магазины, в которых может приобрести нужный товар по подходящей цене.
Конверсия низкочастотных запросов является самый высокой и эффективной. Конверсия – это отношения числа пользователей, купивших товар (или выполнивших другие действия, нужные сайту) к числу тех, кто просто зашел на сайт. Поглазеть в магазин заходят многие, но покупают не все. Иными словами, конверсия – это соотношение купивших к тем, кто просто зашел посмотреть. Опытные SEO-специалисты предпочитают использовать низкочастотные запросы, но в большом количестве. Это лучше, чем делать ставку на один популярный ВЧ-запрос.
Для получения максимальной конверсии рекомендуется использовать низкочастотные запросы. Они приводят основных посетителей и увеличивают доход сайта. Большинство же ВЧ-запросов ведут на порталы, давно обосновавшиеся в интернете и имеющие репутацию среди клиентов.
ФункцияЧАСТОТА — Служба поддержки Майкрософт
Excel
Формулы и функции
Дополнительные функции
Дополнительные функции
Функция ЧАСТОТА
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Дополнительно.
Функция ЧАСТОТА вычисляет, как часто значения встречаются в диапазоне значений, а затем возвращает вертикальный массив чисел. Например, используйте ЧАСТОТА, чтобы подсчитать количество результатов тестов, попадающих в диапазон значений. Поскольку ЧАСТОТА возвращает массив, его необходимо вводить как формулу массива.
ЧАСТОТА (массив_данных, массив_бинов)
Синтаксис функции ЧАСТОТА имеет следующие аргументы:
data_array Обязательный. Массив или ссылка на набор значений, для которых вы хотите подсчитать частоты. Если data_array не содержит значений, FREQUENCY возвращает массив нулей.
bins_array Обязательный.
Массив или ссылка на интервалы, в которые вы хотите сгруппировать значения в data_array. Если bins_array не содержит значений, функция FREQUENCY возвращает количество элементов в data_array.
 Массив или ссылка на интервалы, в которые вы хотите сгруппировать значения в data_array. Если bins_array не содержит значений, функция FREQUENCY возвращает количество элементов в data_array.
Массив или ссылка на интервалы, в которые вы хотите сгруппировать значения в data_array. Если bins_array не содержит значений, функция FREQUENCY возвращает количество элементов в data_array.Примечание. Если у вас установлена текущая версия Microsoft 365, вы можете просто ввести формулу в верхнюю левую ячейку выходного диапазона, а затем нажать ENTER , чтобы подтвердить формулу как формулу динамического массива. В противном случае формулу необходимо ввести как устаревшую формулу массива, сначала выбрав выходной диапазон, введя формулу в верхнюю левую ячейку выходного диапазона, а затем нажав 9.0018 CTRL+SHIFT+ENTER для подтверждения. Excel вставляет фигурные скобки в начале и в конце формулы. Дополнительные сведения о формулах массива см. в разделе Рекомендации и примеры формул массива.
Количество элементов в возвращаемом массиве на один больше, чем количество элементов в bins_array.
Дополнительный элемент в возвращаемом массиве возвращает количество любых значений выше максимального интервала. Например, при подсчете трех диапазонов значений (интервалов), введенных в три ячейки, обязательно введите ЧАСТОТА в четыре ячейки для результатов. Дополнительная ячейка возвращает количество значений в data_array, которые превышают значение третьего интервала.ЧАСТОТА игнорирует пустые ячейки и текст.
 Дополнительный элемент в возвращаемом массиве возвращает количество любых значений выше максимального интервала. Например, при подсчете трех диапазонов значений (интервалов), введенных в три ячейки, обязательно введите ЧАСТОТА в четыре ячейки для результатов. Дополнительная ячейка возвращает количество значений в data_array, которые превышают значение третьего интервала.
Дополнительный элемент в возвращаемом массиве возвращает количество любых значений выше максимального интервала. Например, при подсчете трех диапазонов значений (интервалов), введенных в три ячейки, обязательно введите ЧАСТОТА в четыре ячейки для результатов. Дополнительная ячейка возвращает количество значений в data_array, которые превышают значение третьего интервала.Пример
Нужна дополнительная помощь?
Вы всегда можете обратиться к эксперту в техническом сообществе Excel или получить поддержку в сообществе ответов.
python — Как получить точную частоту триграммы в текстовых данных?
Я хотел бы знать, как получить точную частоту триграмм. Я думаю, что функции, которые я использовал, больше нужны для того, чтобы получить «важность». Это вроде как частота, но не то же самое.
Это вроде как частота, но не то же самое.
Чтобы было понятно, триграмма — это 3 слова подряд. Знаки препинания не влияют на триграммы, по крайней мере, я не хочу.
И мое определение частоты таково: я хотел бы, чтобы количество комментариев, в которых присутствует триграмма, хотя бы один раз.
Вот как я получил свою базу данных с помощью парсинга:
импорт повторно
импортировать json
запросы на импорт
из запросов импортировать получить
из bs4 импортировать BeautifulSoup
импортировать панд как pd
импортировать numpy как np
импорт даты и времени
время импорта
импортировать случайный
root_url = 'https://fr.trustpilot.com/review/www.gammvert.fr'
urls = [ '{root}?page={i}'.format(root=root_url, i=i) для i в диапазоне (1807)]
связь = []
примечания = []
даты = []
для URL в URL:
результаты = запросы.get(url)
время сна(20)
суп = BeautifulSoup(results.text, "html.parser")
commentary = soap.find_all('раздел', class_='review__content')
для контейнера в комментарии:
пытаться:
comm = container. find('p', class_ = 'review-content__text').text.strip()
кроме:
comm = container.find('a', class_ = 'ссылка ссылка -- большая ссылка -- темная').text.strip()
comms.append(comm)
note = container.find('div', class_ = 'звездный рейтинг звездный рейтинг -- средний').find('img')['alt']
notes.append(примечание)
date_tag = container.div.div.find("div", class_="review-content-header__dates")
date = json.loads(re.search(r"({.*})", str(date_tag)).group(1))["дата публикации"]
date.append(дата)
данные = pd.DataFrame({
«связь»: связь,
«заметки»: заметки,
'даты': даты
})
данные['сообщения'] = данные['сообщения'].str.replace('\n', '')
данные ['даты'] = pd.to_datetime (данные ['даты']).dt.date
данные ['даты'] = pd.to_datetime (данные ['даты'])
data.to_csv('file.csv', sep=';', index=False)
 find('p', class_ = 'review-content__text').text.strip()
кроме:
comm = container.find('a', class_ = 'ссылка ссылка -- большая ссылка -- темная').text.strip()
comms.append(comm)
note = container.find('div', class_ = 'звездный рейтинг звездный рейтинг -- средний').find('img')['alt']
notes.append(примечание)
date_tag = container.div.div.find("div", class_="review-content-header__dates")
date = json.loads(re.search(r"({.*})", str(date_tag)).group(1))["дата публикации"]
date.append(дата)
данные = pd.DataFrame({
«связь»: связь,
«заметки»: заметки,
'даты': даты
})
данные['сообщения'] = данные['сообщения'].str.replace('\n', '')
данные ['даты'] = pd.to_datetime (данные ['даты']).dt.date
данные ['даты'] = pd.to_datetime (данные ['даты'])
data.to_csv('file.csv', sep=';', index=False)
find('p', class_ = 'review-content__text').text.strip()
кроме:
comm = container.find('a', class_ = 'ссылка ссылка -- большая ссылка -- темная').text.strip()
comms.append(comm)
note = container.find('div', class_ = 'звездный рейтинг звездный рейтинг -- средний').find('img')['alt']
notes.append(примечание)
date_tag = container.div.div.find("div", class_="review-content-header__dates")
date = json.loads(re.search(r"({.*})", str(date_tag)).group(1))["дата публикации"]
date.append(дата)
данные = pd.DataFrame({
«связь»: связь,
«заметки»: заметки,
'даты': даты
})
данные['сообщения'] = данные['сообщения'].str.replace('\n', '')
данные ['даты'] = pd.to_datetime (данные ['даты']).dt.date
данные ['даты'] = pd.to_datetime (данные ['даты'])
data.to_csv('file.csv', sep=';', index=False)
Вот функция, которую я использовал для получения моего comms_clean :
def clean_text(text):
текст = токенизатор. tokenize(текст)
текст = nltk.pos_tag(текст)
text = [дословно, pos в тексте if (pos == 'NN' или pos == 'NN' или pos == 'NNS' или pos == 'NNPS')
]
text = [слово в слово в тексте, если не слово в стоп_словах]
text = [слово в слово в тексте, если len(word) > 2]
final_text = ' '.join( [w вместо w в тексте, если len(w)>2] ) #удалить слово с одной буквой
вернуть окончательный_текст
data['comms_clean'] = данные['comms'].apply(лямбда x: clean_text(x))
данные['месяц'] = data.dates.dt.strftime('%Y-%m')
 tokenize(текст)
текст = nltk.pos_tag(текст)
text = [дословно, pos в тексте if (pos == 'NN' или pos == 'NN' или pos == 'NNS' или pos == 'NNPS')
]
text = [слово в слово в тексте, если не слово в стоп_словах]
text = [слово в слово в тексте, если len(word) > 2]
final_text = ' '.join( [w вместо w в тексте, если len(w)>2] ) #удалить слово с одной буквой
вернуть окончательный_текст
data['comms_clean'] = данные['comms'].apply(лямбда x: clean_text(x))
данные['месяц'] = data.dates.dt.strftime('%Y-%m')
tokenize(текст)
текст = nltk.pos_tag(текст)
text = [дословно, pos в тексте if (pos == 'NN' или pos == 'NN' или pos == 'NNS' или pos == 'NNPS')
]
text = [слово в слово в тексте, если не слово в стоп_словах]
text = [слово в слово в тексте, если len(word) > 2]
final_text = ' '.join( [w вместо w в тексте, если len(w)>2] ) #удалить слово с одной буквой
вернуть окончательный_текст
data['comms_clean'] = данные['comms'].apply(лямбда x: clean_text(x))
данные['месяц'] = data.dates.dt.strftime('%Y-%m')
А вот некоторые строки моей базы данных:
база данных
А вот функция, которую я использовал для получения частоты триграмм в моей базе данных:
def get_top_n_gram(corpus,ngram_range,n=None):
vec = CountVectorizer(ngram_range=ngram_range,stop_words = stop_words).fit(corpus)
bag_of_words = vec.transform (корпус)
сумма_слов = сумка_слов.сумма (ось = 0)
words_freq = [(word, sum_words[0, idx]) для слова, idx в vec.vocabulary_.items()]
words_freq = sorted (words_freq, key = lambda x: x[1], reverse = True)
вернуть слова_частота[:n]
процесс определения (корпус):
корпус = pd. DataFrame (корпус, столбцы = ['Текст', 'количество']).sort_values ('количество', по возрастанию = Истина)
вернуть корпус
 DataFrame (корпус, столбцы = ['Текст', 'количество']).sort_values ('количество', по возрастанию = Истина)
вернуть корпус
DataFrame (корпус, столбцы = ['Текст', 'количество']).sort_values ('количество', по возрастанию = Истина)
вернуть корпус
Вот результат с этой строкой кода:
trigram = get_top_n_gram(data['comms_clean'], (3,3), 10) триграмма = процесс (триграмма) trigram.sort_values («количество», по возрастанию = False, inplace = True) триграмма.голова(10)
триграмма
Позвольте мне показать вам, как это кажется непоследовательным, но в небольшом количестве. Я покажу 6 первую триграмму моего рисунка выше:
df = data[data['comms_clean'].str.contains('très bon état',regex=False, case=False, na=False)]
дф.форма
(150, 5)
df = data[data['comms_clean'].str.contains('оценка качества связи',regex=False, case=False, na=False)]
дф.форма
(148, 5)
df = data[data['comms_clean'].str.contains('très bien passé',regex=False, case=False, na=False)]
дф.форма
(129, 5)
Итак, с моей функцией у нас есть:
146 143 114
и когда я проверил номер комментария с этой триграммой в нем, я получил:
150 148 129
Это не так далеко, но у меня есть точное число.