
Парсинг сайтов без блокировок. Как лучше это делать? — Маркетинг на vc.ru
Меня зовут Максим Кульгин и моя компания xmldatafeed занимается парсингом сайтов в России. Ежедневно мы парсим более 500 крупнейших интернет-магазинов в России и на выходе мы отдаем данные в формате Excel/CSV и делаем готовую аналитику для маркетплейсов.
23 318 просмотров
Тема парсинга в последнее время становится все более востребованной, но развиваются и механизмы защиты от автоматизированного сбора данных.
Парсинг веб-сайтов, или автоматический сбор данных, — это процесс получения нужных вам данных со стороннего веб-сайта посредством скачивания и анализа HTML-кода. «Но для этого вы должны использовать API!», однако не всякий веб-сайт предоставляет API, а интересующие вас API не всегда дают доступ ко всей нужной вам информации. Поэтому зачастую единственное решение — извлекать данные из веб-сайта.
Парсинг веб-сайтов применяется в следующих случаях:
- Отслеживание цен на веб-сайтах электронной коммерции.

- Агрегация новостей.
- Лидогенерация.
- SEO (отслеживание поисковой выдачи).
- Агрегация банковских счетов (Mint в США, Bankin’в Европе).
- Исследователи-одиночки и ученые, создающие наборы данных, получить которые каким-либо другим путем невозможно.

Главная проблема заключается в том, что большинство администраторов или разработчиков веб-сайтов не хотят, чтобы кто-то собирал их данные. Они хотят предоставлять контент только реальным посетителям, использующим настоящие браузеры, за исключением Google, потому что поисковые системы индексируют веб-сайты.
Таким образом, если бы вы занимались парсингом, то вам бы не хотелось, чтобы вас приняли за робота. Есть два основных способа быть похожим на человека: использовать «человеческие» инструменты и имитировать поведение человека.
Этот пост познакомит вас со всеми инструментами, которые применяют веб-сайты для противодействия парсинга, а также со всеми способами обхода этих инструментов.
Имитация инструмента реального пользователя: Chrome в headless-режиме
Зачем использовать веб-браузер в headless-режиме?
Когда вы открываете свой браузер и заходите на веб-страницу, почти всегда это означает, что вы запрашиваете у HTTP-сервера определенный контент. Один из самых простых способов получения контента от HTTP-сервера — это использование традиционного инструмента командной строки наподобие cURL.
Дело в том, что если вы попытаетесь ввести команду «curl www.google.com», то у Google есть много способов узнать, что к веб-серверу обращается не человек, например с помощью просмотра заголовков. Заголовки — это небольшие фрагменты данных, которые входят в состав любого запроса, отправляемого на веб-серверы. Один из этих фрагментов данных точно описывает клиента, отправляющего запрос, — это пресловутый заголовок User-Agent. Только лишь глядя на заголовок User-Agent, Google знает, что вы используете cURL. Если вы хотите узнать больше о заголовках, то страница Википедии будет отличным источником.
Заголовки легко отредактировать с помощью cURL, и здесь могло бы помочь копирование заголовка User-Agent реального браузера. На практике вам понадобилось бы установить более одного заголовка. Но сегодня всё еще сложно искусственно подделать HTTP-запрос с помощью cURL или любой другой библиотеки, чтобы он выглядел в точности так же, как запрос, отправленный с помощью браузера. И все это знают. Таким образом, чтобы определить, используете ли вы настоящий браузер, веб-сайты проверят наличие возможности, которой не обладают cURL и программные библиотеки, — выполнение JavaScript кода.
Вы говорите на JavaScript?
Идея проста: веб-сайт встраивает фрагмент JavaScript-кода на свою страницу, который после своего выполнения «разблокирует» содержимое веб-страницы. Если вы пользуетесь настоящим браузером, то не заметите разницу. Если не пользуетесь, то получите HTML-страницу, содержащую непонятный JavaScript-код.
Реальный пример фрагмента такого кода
Опять же, это решение нельзя назвать идеальным, в основном потому что в наше время очень легко выполнять JavaScript-код вне браузера — с помощью Node.js. Однако Всемирная паутина видоизменилась в результате своего развития, и появились другие приемы для определения того, используете ли вы настоящий браузер.
Использование браузера в headless-режиме
Пытаться выполнять фрагменты JavaScript-кода вне браузера с помощью Node.js — затея сложная и ненадежная. И, что важнее, поскольку веб-сайты могут представлять собой большие одностраничные веб-приложения или включать в себя более сложные системы проверки, cURL и фиктивное выполнение JavaScript-кода с помощью Node.js становится бесполезным. Поэтому лучший способ сделать так, чтобы запрос на веб-сервер выглядел как запрос настоящего браузера — это, как ни странно, использовать настоящий браузер.
Браузеры в headless-режиме будут вести себя как и настоящие за исключением того, что вы легко сможете использовать их программно. Самый популярный из таких браузеров — «Chrome Headless», вариант браузера Chrome, который ведет себя как обычный Chrome, но не включает в себя пользовательский интерфейс, позволяющий обращаться к функциям браузера.
Самый популярный из таких браузеров — «Chrome Headless», вариант браузера Chrome, который ведет себя как обычный Chrome, но не включает в себя пользовательский интерфейс, позволяющий обращаться к функциям браузера.
Наиболее простым способом применения Headless Chrome считается обращение к драйверу, который предоставляет весь функционал браузера в виде удобного API. Selenium и Puppeteer — два наиболее известных программных решения.
Однако этого мало, поскольку веб-сайты обладают инструментами для обнаружения браузеров в headless-режиме. Эта «гонка вооружений» длится уже довольно давно.
Хотя вышеупомянутыми программными решениями легко пользоваться на своем локальном компьютере, организовать их работу в более широком масштабе, возможно, будет гораздо сложнее.
Считывание цифровых отпечатков браузера
Все, особенно фронтенд-разработчики, знают, что каждый браузер ведет себя по-разному. Иногда отличия связаны с отрисовкой CSS, иногда с выполнением JavaScript-кода, а иногда просто с внутренними свойствами браузера. Большая часть этих отличий хорошо известны, и сегодня есть возможность узнать, является ли браузер тем, за кого себя выдает. То есть веб-сайт «задается вопросом»: «Все ли свойства браузера и его поведение совпадают с тем, что мне известно о заголовке User-Agent, который отправил этот браузер?».
Большая часть этих отличий хорошо известны, и сегодня есть возможность узнать, является ли браузер тем, за кого себя выдает. То есть веб-сайт «задается вопросом»: «Все ли свойства браузера и его поведение совпадают с тем, что мне известно о заголовке User-Agent, который отправил этот браузер?».
Вот почему имеет место непрекращающаяся «гонка вооружений» между веб-парсерами, которые хотят выглядеть как настоящие браузеры, и веб-сайтами, желающими отделить браузеры в headless-режиме от остальных браузеров.
Но в этой гонке, как правило, у парсеров есть большое преимущество, и вот почему:
Скриншот предупреждения Chrome о вредоносном программном обеспечении (ПО)
Чаще всего JavaScript-код пытается определить, выполняется ли он в headless-режиме, тогда, когда вредоносное ПО пытается избежать проведения поведенческой цифровой «дактилоскопии». Это означает, что JavaScript будет вести себя хорошо в среде сканирования, и плохо в настоящих браузерах.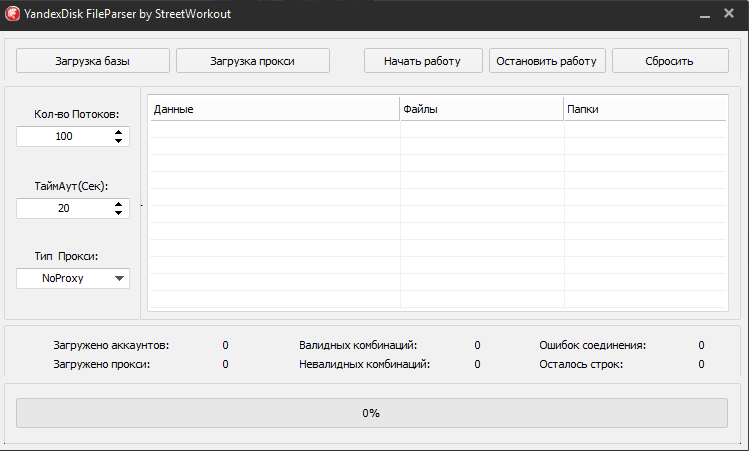
Кроме того, полезно знать, что хотя выполнение 20 параллельных процессов cURL — обычное дело, и пользоваться браузером Chrome в headless-режиме относительно несложно в случае небольших задач, более масштабный парсинг может оказаться проблематичным. Поскольку такой браузер использует много оперативной памяти, управление более чем 20 экземплярами браузера — задача не из легких.
Если вы хотите узнать больше о считывании цифровых отпечатков браузера, то взгляните на блог, который ведет Antoine Vastel и который целиком посвящен этой теме.
Это всё, что вам нужно знать о том, как имитировать использование настоящего браузера. Теперь давайте посмотрим, как имитировать поведение человека.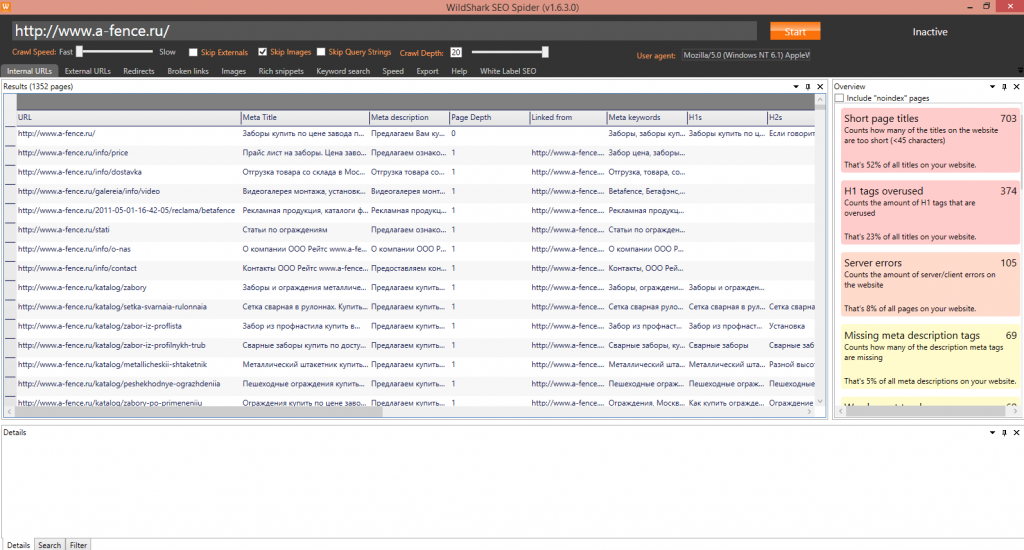
Считывание TLS-отпечатка
Что это за «зверь»?
TLS расшифровывается как «Transport Layer Security», то есть «безопасность транспортного уровня» и представляет собой преемника SSL, на использование которого, по сути, указывала буква S в HTTPS.
Этот протокол обеспечивает конфиденциальность и целостность данных, передаваемых между двумя приложениями — в нашем случае между браузером или скриптом и HTTP-сервером.
Подобно считыванию отпечатка браузера, цель считывания TLS-отпечатка — уникальным образом идентифицировать пользователей на основе того, как они используют TLS.
Работа этого протокола может быть разбита на две большие части.
Сначала, когда клиент подключается к серверу, осуществляется подтверждение, или «рукопожатие» TLS. В процессе этого подтверждения отправляется много запросов между сервером и клиентом, предназначенных для проверки, что каждый из них — действительно тот, за кого себя выдает.
Далее, если подтверждение было завершено успешно, протокол предписывает, как клиент и сервер должны безопасным образом шифровать и дешифровать данные. Если вам нужно более подробное объяснение, то ознакомьтесь вот с этим отличным вводным материалом от Cloudflare.
Если вам нужно более подробное объяснение, то ознакомьтесь вот с этим отличным вводным материалом от Cloudflare.
Большая часть значений, используемых для формирования цифрового отпечатка, берется из подтверждения TLS, и если вы хотите посмотреть, как выглядит цифровой TLS-отпечаток, то можете посетить вот эту прекрасную базу данных, доступную пользователям Всемирной паутины.
На этом веб-сайте вы можете видеть, что наиболее популярный цифровой отпечаток на прошлой неделе был использован в 22,19% случаях (на момент работы над данной статьей).
Цифровой TLS-отпечаток
Это очень внушительное число, и оно по меньшей мере на два порядка больше, чем у наиболее распространенного цифрового отпечатка браузера. И это логично, поскольку цифровой TLS-отпечаток вычисляется с использованием гораздо меньшего количества параметров по сравнению с отпечатком браузера.
Некоторые из этих параметров:
- Версия TLS.
- Версия механизма подтверждения.
- Поддерживаемый набор алгоритмов шифрования.
- Расширения.

Если вам интересно, как выглядит ваш TLS-отпечаток, то можете посетить этот веб-сайт.
Как изменить его?
Для повышения скрытности при парсинге веб-сайтов лучше всего будет менять свои параметры TLS. Однако такая процедура сложнее, чем кажется.
Во-первых, в мире не так много TLS-отпечатков, и простой произвольный перебор этих параметров не сработает. Ваш цифровой отпечаток будет настолько редким, что его мгновенно пометят как поддельный.
Во-вторых, параметры TLS обладают низкоуровневой природой, — они в значительной степени опираются на системные зависимости. Поэтому изменить эти параметры непросто.
Например, requests, известный модуль для Python, по умолчанию не поддерживает изменение TLS-отпечатка. Ниже представлено несколько информационных ресурсов на тему изменения своей версии TLS и набора алгоритмов шифрования с помощью разных языков программирования (возможно, среди них окажется ваш любимый язык):
- Python и requests.
- NodeJS и TLS package.
- Ruby и OpenSSL.
Учтите, что большинство из этих библиотек полагаются на реализации SSL и TLS вашей системы. OpenSSL — наиболее широко используемая библиотека, но вам, возможно, придется сменить ее версию, чтобы полностью поменять свой цифровой отпечаток.
Имитация человеческого поведения: прокси, решение капч и закономерности в отправке запросов на веб-сервер
Используйте прокси
Человек, использующий настоящий браузер, почти никогда не станет запрашивать 20 веб-страниц в секунду из одного и того же веб-сайта. Поэтому если вы хотите запрашивать много веб-страниц из одного и того же веб-сайта, вам нужно заставить веб-сайт полагать, что все эти запросы отправляются из разных точек земного шара, то есть с использованием разных IP-адресов. Другими словами, вам нужно использовать прокси-серверы.
Прокси-серверы не слишком дорогие — приблизительно один доллар за один IP-адрес.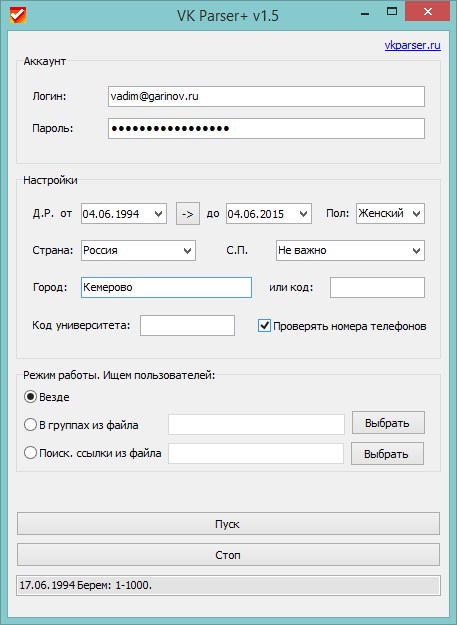 Однако если вам нужно отправлять более десяти тысяч запросов в день на один и тот же веб-сайт, то расходы могут быстро возрасти, и вам могут понадобиться сотни IP-адресов. При этом нужно учитывать, что IP-адреса прокси-серверов нужно постоянно отслеживать, чтобы выбрасывать те из них, которые больше не работают, и заменять их на другие.
Однако если вам нужно отправлять более десяти тысяч запросов в день на один и тот же веб-сайт, то расходы могут быстро возрасти, и вам могут понадобиться сотни IP-адресов. При этом нужно учитывать, что IP-адреса прокси-серверов нужно постоянно отслеживать, чтобы выбрасывать те из них, которые больше не работают, и заменять их на другие.
На рынке есть несколько поставщиков прокси-серверов, и вот наиболее популярные: Luminati Network, Blazing SEO и SmartProxy.
Кроме того, есть много списков бесплатных прокси-серверов, но использовать их не рекомендуется, поскольку зачастую они медленные и ненадежные, а веб-сайты, размещающие эти списки, не всегда прозрачны в отношении того, где эти прокси-серверы расположены географически. Списки бесплатных прокси-серверов обычно общедоступны, и, как следствие, их IP-адреса будут автоматически блокироваться на большинстве веб-сайтов. Качество прокси имеет большое значение. Известно, что службы, противодействующие сбору данных, ведут свой список IP-адресов прокси-серверов, поэтому любые посетители с такими IP-адресами будут автоматически заблокированы. Будьте осторожны, выбирая поставщика прокси-серверов с хорошей репутацией. Вот почему рекомендуется использовать платную сеть прокси-серверов или создавать свою собственную.
Будьте осторожны, выбирая поставщика прокси-серверов с хорошей репутацией. Вот почему рекомендуется использовать платную сеть прокси-серверов или создавать свою собственную.
Другой тип прокси-серверов, который может вас заинтересовать, — это мобильные прокси-сервера с 3G или 4G. Они полезны для сбора данных на веб-сайтах, которые сложны для парсинга и ориентированы на мобильные устройства, например на веб-сайтах социальных медиа.
Для создания своего собственного прокси-сервера можете взглянуть на Scrapoxy, отличный API с открытым исходным кодом, позволяющий вам создать API прокси-серверов поверх различных поставщиков облачных технологий. Scrapoxy сформирует пул прокси-серверов посредством создания их экземпляров на инфраструктуре различных облачных поставщиков (AWS, OVH, Digital Ocean). Затем вы сможете настроить свой клиент таким образом, чтобы он использовал URL-адрес Scrapoxy в качестве основного прокси-сервера, и Scrapoxy будет автоматически предоставлять для использования прокси-сервер из пула прокси-серверов. Scrapoxy легко настроить под свои потребности (лимит скорости, черный список и прочее), но, возможно, немного проблематично подготовить к работе.
Scrapoxy легко настроить под свои потребности (лимит скорости, черный список и прочее), но, возможно, немного проблематично подготовить к работе.
Также вы могли бы использовать сеть TOR, которая расшифровывается как «The Onion Router». Это всемирная компьютерная сеть, созданная для маршрутизации трафика по множеству серверов для сокрытия его происхождения. Использование TOR сильно усложняет наблюдение за сетью или анализ трафика. Есть множество вариантов использования TOR, например обеспечение конфиденциальности, свобода слова, деятельность журналистов при диктаторском режиме и, разумеется, противозаконная деятельность. В контексте парсинга TOR может скрывать ваш IP-адрес и менять IP-адрес вашего бота каждые десять минут. IP-адреса выходных узлов TOR общедоступны. Некоторые веб-сайты блокируют трафик TOR, используя простое правило: если веб-сервер получает запрос от одного из общедоступных выходных узлов, то он блокирует такой запрос. Вот почему во многих случаях TOR не поможет вам в отличие от традиционных прокси-серверов. Кроме того, стоит заметить, что трафик, проходящий через TOR, заведомо гораздо более медленный из-за многоадресной маршрутизации.
Кроме того, стоит заметить, что трафик, проходящий через TOR, заведомо гораздо более медленный из-за многоадресной маршрутизации.
Капчи
Иногда прокси-серверов будет недостаточно. Некоторые веб-сайты с помощью так называемых капч систематически просят вас подтверждать, что вы — человек. Чаще всего капчи отображаются только для подозрительных IP-адресов, поэтому в таких случаях поможет смена прокси-сервера. В других случаях вам придется использовать сервис для решения капч, например 2Captchas или DeathByCaptchas.
Если некоторые капчи можно решить автоматически с помощью оптического распознавания символов (OCR), то новые капчи придется решать вручную.
Старая капча, которую можно решить программно
Google ReCaptcha V2
Если вы используете вышеупомянутые сервисы, то обращение к API подразумевает услуги сотен людей, решающих капчи всего лишь за 20 центов в час.
Но опять же, даже если вы решаете капчи или переключаетесь между прокси-серверами, как только замечаете капчу, веб-сайты всё еще могут обнаружить, что вы собираете данные.
Закономерность в отправке запросов
Другой продвинутый инструмент, используемый веб-сайтами для обнаружения парсинга, — это выявление закономерностей. Поэтому если вы планируете собирать каждый идентификационный номер в диапазоне от 1 до 10 000 на URL-адресе www.example.com/product/, постарайтесь не делать это последовательно или с постоянной частотой запросов. Вы могли бы, например, задать и использовать набор целых чисел от 1 до 10 000, в случайном порядке выбирать одно из них, а затем извлекать данные о товаре с таким номером.
Кроме того, некоторые веб-сайты ведут статистику по цифровым отпечаткам браузеров для каждой конечной точки обработки запросов. Это означает, что если вы не меняете какие-либо параметры в своем браузере в headless-режиме и отправляете запросы на одну и ту же конечную точку обработки запросов, то вас могут заблокировать.
Также веб-сайты отслеживают источник трафика, поэтому если вы хотите собирать данные на бразильском веб-сайте, то не пытайтесь делать это с использованием прокси-сервера, расположенного во Вьетнаме.
Но считается, что частота запросов — это наиболее важный фактор выявления закономерностей в осуществлении запросов, так что чем медленнее вы собираете данные, тем меньше вероятность, что вас обнаружат.
Имитация машинного поведения: обратный инжиниринг API
Иногда сервер ожидает, что клиентом будет машина (компьютер). В этих случаях скрыть себя гораздо проще.
Обратный инжиниринг API
По сути, этот прием сводится к двум этапам:
- Анализ поведения веб-страницы с целью обнаружения примечательных обращений к API.
- Формирование этих обращений к API в своем коде.
Например, кто-то желает получить все комментарии из известной социальной сети. Можно заметить, что при клике на кнопку «загрузить больше комментариев» в браузерных инструментах разработчика происходит следующее:
Запрос, созданный и отправленный при клике на кнопку для отображения большего количества комментариев
Запрос, созданный и отправленный при клике на кнопку для отображения большего количества комментариев
Обратите внимание, что используется фильтрация — выводятся только запросы типа XHR.
Если посмотреть, какой запрос был отправлен и какой ответ мы получили, то… дело в шляпе!
Ответ на запрос
Теперь, если посмотреть на содержимое вкладки «Headers», у нас должно быть всё, что нужно для воспроизведения этого запроса и понимания смысла каждого из параметров. Это позволит нам отправить этот запрос из простого HTTP-клиента.
HTTP-ответ, отправленный клиенту и просматриваемый в Paw
Самая сложная часть этого процесса — понимание роли каждого параметра в этом запросе. Вы можете щелкнуть левой кнопкой мыши по любому запросу в инструментах разработчика в браузере Chrome, экспортировать его в формат HAR и затем импортировать его в свой любимый HTTP-клиент (например, Paw или PostMan).
Это позволит вам собрать все параметры работоспособного запроса и сделает ваш процесс экспериментирования более оперативным и увлекательным.
Представленный ранее запрос, импортированный в Paw
Обратный инжиниринг мобильных приложений
Те же принципы применимы при обратном инжиниринге мобильного приложения. Вам придется перехватить запрос, который интересующее вас мобильное приложение отправляет на сервер, и воспроизвести его с помощью своего кода.
Вам придется перехватить запрос, который интересующее вас мобильное приложение отправляет на сервер, и воспроизвести его с помощью своего кода.
Высокая сложность этой задачи обусловлена двумя причинами:
- Для перехвата запросов вам понадобится прокси-сервер типа «Man In The Middle», например прокси-сервер Charles.
- Мобильные приложения могут отследить цифровой отпечаток вашего запроса, и разработчикам мобильных приложений проще делать код более запутанным, чем разработчикам веб-приложений.
Например, когда несколько лет назад вышла Pokemon Go, масса людей смогли получить преимущество в игре нечестным путем после того, как осуществили обратный инжиниринг запросов, отправляемых этим мобильным приложением.
Но они не знали, что мобильное приложение отправляло секретный параметр, который скрипты, предназначенные для обмана игры, не отправляли. Таким образом, разработчикам, то есть компании Niantic, было несложно опознать читеров. Через несколько недель огромное количество игроков были отправлены в бан за читерство.
Через несколько недель огромное количество игроков были отправлены в бан за читерство.
Кроме того, есть интересный пример обратного инжиниринга API Starbucks.
Заключение
Сводка всех методов борьбы с ботами, которые были упомянуты в этой статье:
Сводка механизмов защиты
Надеемся, что этот обзор поможет вам понять парсинг веб-сайтов, и что вы многое из него узнали.
Парсинг сайта с JavaScript на Python
05.12.2021 | Категория Программирование
План статьи:
- Введение
- Почему пользователь видит всё корректно?
- Как устроены страницы с динамическим контентом.
- Библиотека Selenium. Эмуляция обычного браузера.
- Практика. Парсим новостной сайт.
 Парсим новостной сайт.
Парсим новостной сайт.Многие начинающие программисты на Python часто сталкиваются с проблемой: при парсинге сайта программа не находит элемент на сайте, хотя при его обычном посещении через браузер он присутствует. Оно и понятно, ведь вы, скорее всего, получаете HTML-документ через GET-запрос на сайт с помощью стандартной библиотеки requests.
- Почему пользователь видит всё корректно?
Но почему в браузере Вы видите весь контент, в отличии от Вашей программы? Дело в том, что при переходе на нужный домен браузер получает HTML-документ, CSS-стили и JavaScript. С первыми двумя, я думаю, всё понятно — они нужны для базовой отрисовки страницы. А вот JavaScript отличается от остальных. Это язык программирования, поддержка которого присутствует во всех браузерах. Чаще всего его применяют для добавления анимаций и расширения функций сайта с помощью изменения DOM-дерева.
- Как устроены страницы с динамическим контентом.

Сейчас набирает популярность создание своих SPA-приложений. Это так называемые одностраничные приложения (Single Page Application). Весь сайт отображается с помощью JavaScript, а в HTML-документе прописана лишь загрузка нужного JS-файла. Отключив JavaScript в своём браузере Вы, чаще всего, увидите пустую страницу с подобным текстом: “Для отображения сайта необходим JavaScript”..
Не сложно догадаться, что парсинг такого сайта через Python и библиотеку requests не получится. Перейдём к коду и практическим примерам.
- Библиотека Selenium. Эмуляция обычного браузера.
Для Python была разработана библиотека Selenium. Предназначена она для автоматизации действий в веб-браузере, выполнения рутинных задач и тестирования Web-приложений.
Давайте установим её:
pip3 install selenium
Для того, чтобы работать с библиотекой, нам также понадобится WebDriver. WebDriver нужен для эмуляции обычного браузера, который будет управляться через Selenium. Советую не заморачиваться и установить веб-драйвер для того браузера, который установлен у вас на ПК. В моём случае я использую ChromeDriver.
Советую не заморачиваться и установить веб-драйвер для того браузера, который установлен у вас на ПК. В моём случае я использую ChromeDriver.
Создаём Python-файл для будущего парсера. В директорию с ним переносим ранее установленный веб-драйвер.
- Практика. Парсим новостной сайт.
В качестве объекта для практики я выбрал новостной сайт Meduza. На сайте много информации, из-за чего процесс парсинга станет интересней. При парсинге через requests информация о новостях не отображается, ну и не должна):
Весь код будет написан в функциональном стиле. Для начала импортируем нужную библиотеку и инициализируем сам WebDriver:
from selenium.webdriver import Chrome
if __name__ == “__main__”:
driver = Chrome(executable_path="./chromedriver.exe")
Чтобы не добавлять ChromeDriver в переменные среды моей ОС я передал путь к драйверу в аргументе executable_path.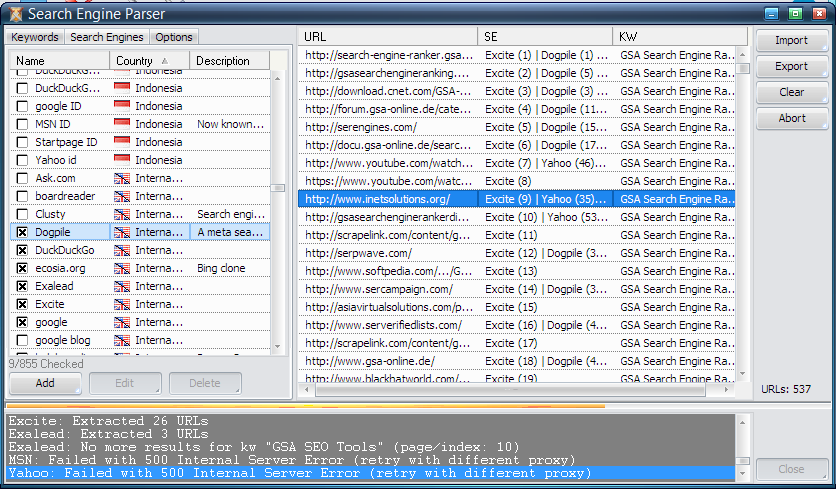
При запуске данного кода не произойдёт ничего необычного: у вас запустится окно браузера с базовым адресом “data:,”.
Для перехода по страницам в Selenium используется метод get у класса драйвера. Принимает всего лишь 1 аргумент — url. Поэтому напишем следующее:
driver.get(“https://meduza.io/”)
Сразу определимся с тем, что нам нужно. Мы будем парсить картинку, заголовок и дату публикации. Исходя из этого в нашей программе будет 4 функции для парсинга (get_news, get_image, get_title, get_date) и 1 для вывода.
Для карточки новости соответствует класс “RichBlock-root”:
Чтобы производить поиск по чему-либо необходимо импортировать класс By:
from selenium.webdriver.common.by import By
Напишем саму функцию:
def get_news():
news = [] news_elements = driver.find_elements(By.CLASS_NAME, "RichBlock-root")
for element in news_elements: data = {
"image": get_image(element),
"title": get_title(element), "date": get_date(element),
}
news. append(data)
append(data)
return news
Инициализируем пустой список и находим все элементы карточек новостей. Для каждой карточки мы получаем изображение, заголовок, дату и записываем это в переменную data. После всего этого мы добавляем данные в список, который мы возвращаем в конце функции.
Сейчас в значения для данных функции записываются несуществующие функции. Давайте исправим это. Создавать функции будем по порядку.
Чтобы получить картинку нам нужно выбрать класс “ImageElement-root”, а затем первый элемент с тегом “source”:
Но как мы видим, у “source” нет никакого текста, только атрибут srcset. Для получения атрибутов мы используем метод get_attribute на элементе.
def get_image(element):
images_element = element.find_element(By.CLASS_NAME, "ImageElement-root")
image_element = images_element.find_element(By.TAG_NAME, "source")
return "https://meduza.io" + image_element. get_attribute("srcset").strip()
get_attribute("srcset").strip()
Возвращаем абсолютную ссылку на картинку. При получении атрибута srcset в начале образовался отступ. Чтобы его убрать используем функцию strip.
Заголовок карточки помещён в тег a с классом “Link-root”.
Пишем функцию:
def get_title(element):
title_element = element.find_element(By.CLASS_NAME, "Link-root")
return title_element.text
Весь текст, который находится в этом элементе, получаем с помощью переменной text.
И, наконец, дата создания. В этом случае ищем элемент по классу “Timestamp-module_root__coOvT”
Создаём ещё одну функцию:
def get_date(element):
date_element = element.find_element(By.CLASS_NAME, "Timestamp-module_root__coOvT")
return date_element.text
Тут, я думаю, объяснять ничего не нужно.
Последняя функция в нашем коде — print_data_news:
def print_data_news():
news_items = get_news()
for news in news_items: print(f"""Изображение: {news['image']}Заголовок: {news['title']}Дата создание: {news['date']}""")
Осталось добавить в точку входа (после создания драйвера и перехода на страницу) вызов функции print_data_news().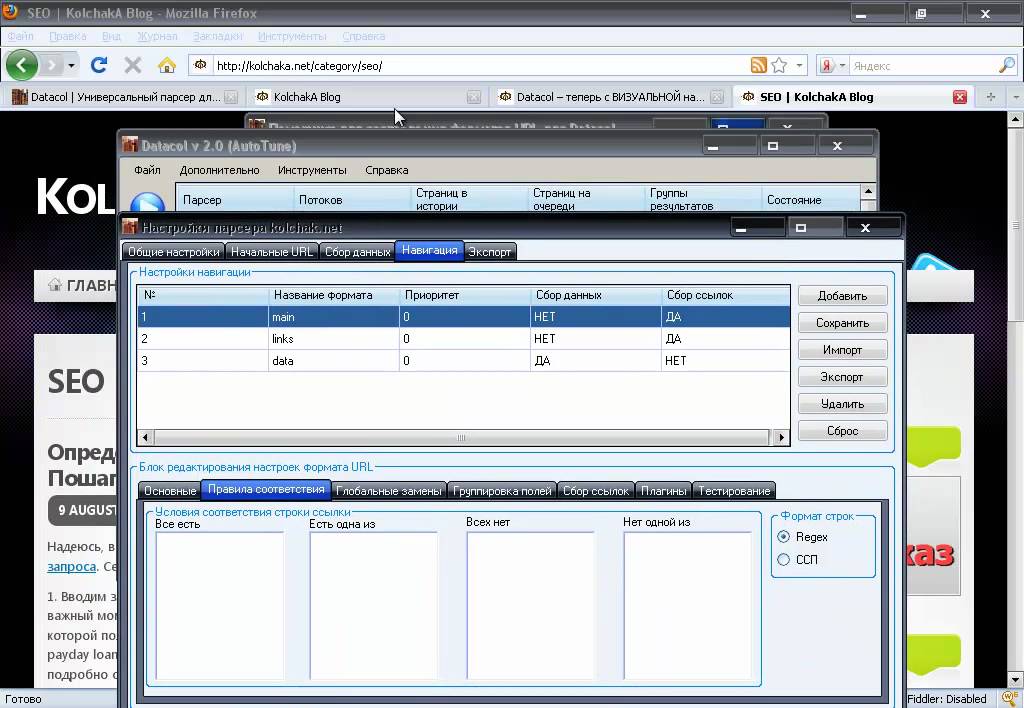
Наконец-то мы написали наш парсер динамической страницы. После запуска программа выдаёт следующее:
Это можно считать успехом, ведь все наши цели выполнены и мы можем спокойно отдохнуть
sjs-doc — Анализ работоспособности пакетов npm
sjs-doc — Анализ работоспособности пакетов npm Все уязвимости безопасности относятся к производственных зависимостей прямых и косвенных
пакеты.
Риск безопасности и лицензии для важных версий
Риск безопасности и лицензии для важных версий Все версии
9 02.2022 || Версия | Уязвимости | Лицензионный риск | |||
|---|---|---|---|---|---|
| 04/2015 | Популярный |
|
| ||
License ИСК Политика безопасности Нет Ваш проект подвержен уязвимостям?
Ваш проект подвержен уязвимостям? Сканируйте свои проекты на наличие уязвимостей. Быстро исправить с помощью автоматизированного
исправления. Начните работу со Snyk бесплатно.
Быстро исправить с помощью автоматизированного
исправления. Начните работу со Snyk бесплатно.
Начните бесплатно
Еженедельные загрузки (1)
Еженедельные загрузки (1) Скачать тренд
Звезды GitHub?Вилки?Авторы—
Популярность прямого использования
Популярность прямого использования Пакет npm sjs-doc получает в общей сложности
1 загрузка в неделю. Таким образом, мы забили
Уровень популярности sjs-doc будет ограничен.
На основе статистики проекта из репозитория GitHub для
npm package sjs-doc мы обнаружили, что он
снялся? раз.
Загрузки рассчитываются как скользящие средние за период из последних 12
месяцев, за исключением выходных и известных отсутствующих точек данных.
Частота фиксации
Частота фиксации Недоступные данные фиксации
Открытые проблемы?Открытый PR?Последняя версия8 лет назадПоследняя фиксациянеизвестный
Дальнейший анализ состояния обслуживания sjs-doc на основе
каденция выпущенных версий npm, активность репозитория,
и другие точки данных определили, что его обслуживание
Неактивный.
Важным сигналом обслуживания проекта, который следует учитывать для sjs-doc, является
это не видел никаких новых версий, выпущенных для npm в
за последние 12 месяцев и может считаться прекращенным проектом или проектом, который
получает мало внимания со стороны его сопровождающих.
За последний месяц мы не обнаружили никаких запросов на вытягивание или изменений в
статус issue был обнаружен для репозитория GitHub.
Совместимость с Node.jsне определено
Возраст8 летЗависимости0 ПрямыеВерсии2Установочный размер0 БРаспределенные теги1Количество файлов0Обслуживающий персонал1Типы TSНет
sjs-doc имеет более одного и последнего тега по умолчанию, опубликованного для
пакет нпм. Это означает, что для этого могут быть доступны другие теги.
пакет, например рядом, чтобы указать будущие выпуски, или стабильный, чтобы указать
стабильные релизы.
Это означает, что для этого могут быть доступны другие теги.
пакет, например рядом, чтобы указать будущие выпуски, или стабильный, чтобы указать
стабильные релизы.
Неправильный вывод
Неправильный вывод Ответы Lightrun были разработаны, чтобы уменьшить постоянное гугление, связанное с отладкой сторонних библиотек. Он собирает ссылки на все места, на которые вы могли бы обратить внимание, выискивая опасную ошибку.
И, если вы все еще застряли в конце, мы будем рады позвонить, чтобы узнать, как мы можем помочь.
См. исходную проблему GitHub
Описание проблемы
Описание проблемы Я пробовал это:
import wikipedia
печать(wikipedia.search("Ubuntu"))
Это дало мне это:
/home/sjs/.local/lib/python3.9/site-packages/wikipedia/wikipedia.py:389: GuessedAtParserWarning: парсер не был явно указан, поэтому я использую лучший доступный анализатор HTML для этой системы ("html5lib"). Обычно это не проблема, но если вы запустите этот код в другой системе или в другой виртуальной среде, он может использовать другой синтаксический анализатор и вести себя по-другому.
Код, вызвавший это предупреждение, находится в строке 389.файла /home/sjs/.local/lib/python3.9/site-packages/wikipedia/wikipedia.py. Чтобы избавиться от этого предупреждения, передайте дополнительный аргумент 'features="html5lib"' конструктору BeautifulSoup.
lis = BeautifulSoup(html).find_all('li')
Traceback (последний последний вызов):
Файл "/home/sjs/msg/fbchat/wiki.py", строка 2, в
печать (wikipedia.summary ("Ubuntu"))
Файл "/home/sjs/.local/lib/python3.9/site-packages/wikipedia/util.py", строка 28, в __call__
ret = self._cache[key] = self.fn(*args, **kwargs)
Файл "/home/sjs/.local/lib/python3.9/site-packages/wikipedia/wikipedia.py", строка 231, резюме
page_info = страница (название, auto_suggest = auto_suggest, перенаправление = перенаправление)
Файл "/home/sjs/.local/lib/python3.9/site-packages/wikipedia/wikipedia.py", строка 276, на странице
вернуть страницу Википедии (название, перенаправление = перенаправление, предварительная загрузка = предварительная загрузка)
Файл "/home/sjs/. local/lib/python3.9/site-packages/wikipedia/wikipedia.py", строка 299, в __init__
self.__load(перенаправление=перенаправление, предварительная загрузка=предварительная загрузка)
Файл "/home/sjs/.local/lib/python3.9/site-packages/wikipedia/wikipedia.py", строка 39.3, в __load
поднять DisambiguationError(getattr(self, 'title', page['title']), may_refer_to)
wikipedia.exceptions.DisambiguationError: «банту» может означать:
языки банту
Народы банту
Банту узлы
Черная ассоциация за национализм через единство
Банту (группа)
Банту (альбом)
Банту ФК
Расширение банту
Бантустан
 Код, вызвавший это предупреждение, находится в строке 389.файла /home/sjs/.local/lib/python3.9/site-packages/wikipedia/wikipedia.py. Чтобы избавиться от этого предупреждения, передайте дополнительный аргумент 'features="html5lib"' конструктору BeautifulSoup.
lis = BeautifulSoup(html).find_all('li')
Traceback (последний последний вызов):
Файл "/home/sjs/msg/fbchat/wiki.py", строка 2, в
Код, вызвавший это предупреждение, находится в строке 389.файла /home/sjs/.local/lib/python3.9/site-packages/wikipedia/wikipedia.py. Чтобы избавиться от этого предупреждения, передайте дополнительный аргумент 'features="html5lib"' конструктору BeautifulSoup.
lis = BeautifulSoup(html).find_all('li')
Traceback (последний последний вызов):
Файл "/home/sjs/msg/fbchat/wiki.py", строка 2, в  local/lib/python3.9/site-packages/wikipedia/wikipedia.py", строка 299, в __init__
self.__load(перенаправление=перенаправление, предварительная загрузка=предварительная загрузка)
Файл "/home/sjs/.local/lib/python3.9/site-packages/wikipedia/wikipedia.py", строка 39.3, в __load
поднять DisambiguationError(getattr(self, 'title', page['title']), may_refer_to)
wikipedia.exceptions.DisambiguationError: «банту» может означать:
языки банту
Народы банту
Банту узлы
Черная ассоциация за национализм через единство
Банту (группа)
Банту (альбом)
Банту ФК
Расширение банту
Бантустан
local/lib/python3.9/site-packages/wikipedia/wikipedia.py", строка 299, в __init__
self.__load(перенаправление=перенаправление, предварительная загрузка=предварительная загрузка)
Файл "/home/sjs/.local/lib/python3.9/site-packages/wikipedia/wikipedia.py", строка 39.3, в __load
поднять DisambiguationError(getattr(self, 'title', page['title']), may_refer_to)
wikipedia.exceptions.DisambiguationError: «банту» может означать:
языки банту
Народы банту
Банту узлы
Черная ассоциация за национализм через единство
Банту (группа)
Банту (альбом)
Банту ФК
Расширение банту
Бантустан
Я установил этот пакет из pip: pip install wikipedia Версия Python: 3.9.1
Что не так?
Аналитика проблем
Аналитика проблем Состояние:Создано 2 года назадКомментарии:5
Лучшие результаты из Интернета
Лучшие результаты из Интернета Звук исходит из не того динамика на вашем ПК? Попробуйте…
Звук исходит не из того динамика на вашем ПК? Попробуйте это быстрое исправление · Быстро измените устройство вывода · Установите значение по умолчанию. ..
..
Подробнее >
Почему мой код Python выдает неверный вывод? — Quora
Таким образом, он всегда будет выполнять условие elif, потому что символ никогда не будет равен целому числу. Вы всегда получите counta = 0…
Подробнее >
Помогите мне! неправильный формат вывода Неожиданный конец файла — int32 …
В сообщении об ошибке жалуется, что в вашем выводе ожидается больше вещей (в частности, int32), но вместо этого обнаружено, что ваш вывод…
Подробнее >
Звук идет не с того устройства/не воспроизводится (2 аудиовыхода)
Звук идет не с того устройства/не воспроизводится (2 аудиовыхода) … Попробуйте установить динамик в качестве устройства вывода звука по умолчанию.
Подробнее >
Неверный вывод · Проблема № 137998 · Microsoft/vscode – GitHub
Выше приведен код для обращения числа, логика в полном порядке, но код vs возвращает неверный вывод, я попробовал.