Используем rel=nofollow и noindex для Yandex » WPbloging
В апреле, поисковик Yandex, обрадовал рунетовских веб-мастеров, включением поддержки атрибута rel=»nofollow» в ссылках. Какую пользу это нам — блоггерам принесет? Как правильно прописать атрибут rel=»nofollow» в ссылках и что теперь будет с <noindex>?
Давайте попробуем разобраться в этих новинках Яндекса .
Небольшая предыстория атрибута rel=nofollow
Что такое rel=nofollow?
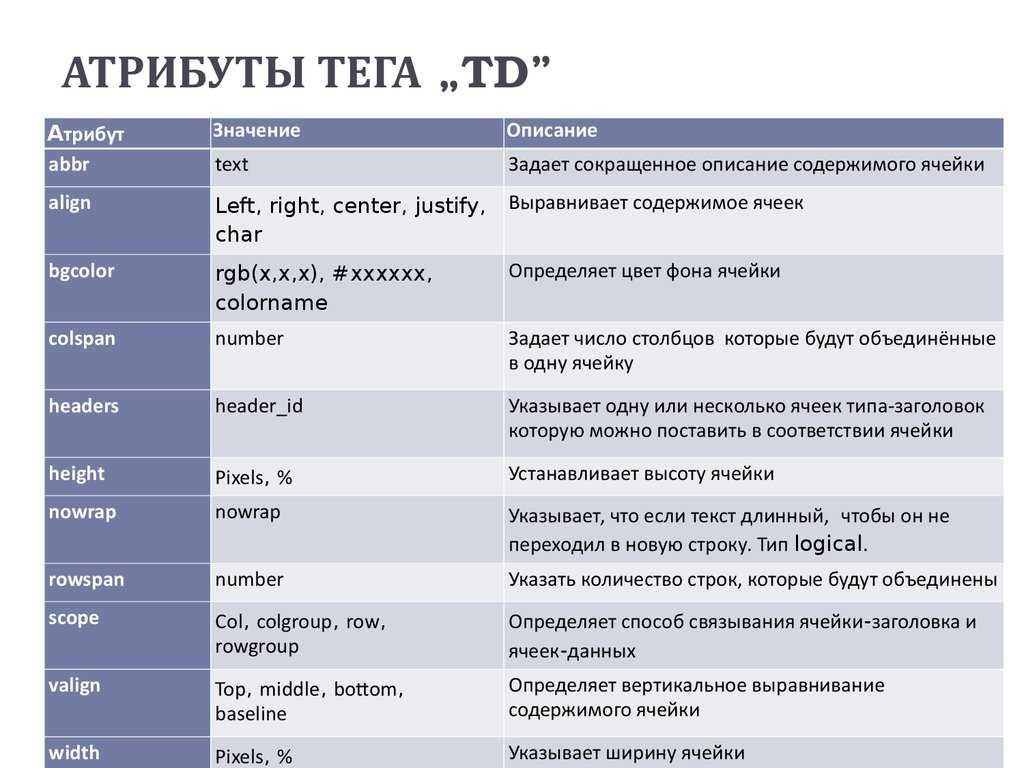
Rel=» « — атрибут в ссылке <a>, указывающий отношение ссылки к целевой странице. Также, есть еще атрибут Rev=» «, указывающий отношение целевой страницы к ссылке, например (ссылка с rev=»sponsor» указывает, что это спонсорская ссылка). Но об этом в следующей статье.
Nofollow — статус, говорящий о том,что вы не одобряете данную ссылку.
Исходя из вышесказанного:
Rel=nofollow — определяет отношение вашей ссылки к целевой странице как не одобряемое. Применительно к поисковикам, данный атрибут указывает индексирующим роботам, что по данной ссылке не следует переходить на целевую страницу.
Rel=nofollow был введен и стандартизирован в 2005 году, в ответ на многочисленный ссылочный спам, присутствующий в блогах. Инициатором введения была поисковая система Google, источник.
Google, встречая ссылку с данным атрибутом, не следует по данной ссылке и не передает вес PR целевым страницам. Также, данные ссылки не учитывались в расчетах распределения ссылочного веса по ссылкам страницы. Но, так было до 2010 года. На данный момент, Google, также не передает ссылочный вес и не следует по ссылкам с rel=»nofollow», но вот ссылочный вес, внутри страницы, стал распределятся и на эти ссылки но впустую. То есть, если у вашей страницы PR-10 и 10 ссылок на странице, где 5 из них закрыты, то каждая открытая ссылка передавала по 2PR на целевую страницу. Теперь каждая открытая ссылка будет передавать 1PR по открытым ссылкам и по 1PR в пустоту по закрытым. Но эта статья не о Google, вернемся к Яндексу.
Yandex, до апреля месяца 2010г., не учитывал данный статус. В рекомендациях Яндекса находим нашумевший тег <noindex>, который позволял сделать тоже самое и больше. Теперь там и nofollow.
В чем разница rel=nofollow и <noindex>
Так в чем же проблема? Зачем Яндексу понадобилось вводить поддержку rel=»nofollow»?
Все дело в том, что тег <noindex> это личная инициатива Yandex. Данный тег нигде в мире, кроме самого Яндекс, не поддерживается и не стандартизирован. При проверке ресурса на ошибки в коде и поддержке web-стандартов, веб-мастера всегда получали «не валидный» код. То есть, ваш ресурс содержит ошибки. Но, спешу вас успокоить, это не критическая ошибка и практически ни на что не влияет. Для тех кому важен валидный код, вот структура, рекомендованная самим Yandex для валидности вашего кода:
Еще одна проблема тега <noindex> в том, что зарубежные веб-мастера, не ведая о данном теге, не используют его в разработках своих плагинов к WordPress. Приходится данные плагины адаптировать под Яндексовскую реальность. Если в комментариях блога ссылки были закрыты атрибутом rel=»nofollow», то для Яндекса эти ссылки были открыты. Это означало, что роботу приходилось путешествовать по всем ссылкам указанным в комментариях.
Атрибут со статусом rel=»nofollow» стандартизирован и используется во всем мире для указания поисковикам, что ссылка не одобрена автором и по ней не нужно следовать. Например, если закрыть служебную страницу от индексации в robots.txt, а ссылку оставить открытой, робот проследует на данную страницу, но не проиндексирует ее. Зачем тогда тратить ресурсы робота на переходы по ненужным страницам? Еще есть один нюанс, если на вашу служебную страницу ведут открытые ссылки с других внешних источников, то ваша, как бы закрытая страница, попадет в поиск, даже если она закрыта в robots.txt. Об этом также расскажу в следующих статьях.
Исходя из всего этого, по многочисленным просьбам и жалобам веб-мастеров, Яндекс ввел поддержку стандартизированного W3C атрибута со статусом rel=»nofollow». Атрибут закрывает ссылки от переходов роботом и не передает вес. Теперь многое стало проще. Но есть один нюанс. Анкоры ссылок будут проиндексированы как текст.
Зачем нужен <noindex>?
Тег <noindex> очень важен, если вы хотите, чтобы часть текста, со всеми анкорами ссылок и т.д., не индексировалась и не попала в поисковую базу Yandex. Например, у вас на странице может быть служебная информация, или блок текста с сайта, который используется как негативный пример. Вы не хотите, чтобы поисковик связал ваш сайт с данным текстом или индексировал служебную информацию и сохранил у себя в базе. Для этого данный блок обрамляется тегом <noindex>.
К сожалению, такого инструмента для Google не существует. Вполне возможно, что Google или консорциум W3C в будущем обратят внимание на данный тег или придумают свой, и веб-мастера получат в свой инструментарий еще один полезный инструмент.
Как правильно прописать rel=nofollow и <noindex>
Для закрытия ссылок от индексации, с помощью rel=»nofollow», используется простая схема:
<a rel=»nofollow» href=»http://www. site.com» title=»Подсказка»>Ссылка на сайт</a> перехода по ссылке не будет.
Для закрытия блока текста тегом <noindex>, со всем содержимым, в том числе и с анкорами ссылок, используется схема: <!--noindex-->Блок вашего закрываемого текста<!--/noindex--> данный текстовый блок не будет проиндексирован в Яндекс, со всеми текстами ссылок.
Для закрытия блока текста тегом и ссылок в блоке, используется схема: <!--noindex-->Блок вашего закрываемого текста <a rel="nofollow" href="http://www.site.com" title="Подсказка">Текст анкор ссылки</a> Блок вашего закрываемого текста<!--/noindex--> данный блок не будет проиндексирован в Яндекс, со всеми ссылками содержащимся в данном блоке.
Что изменилось с вводом поддержки rel=nofollow?
Для тех, кто ведет ресурсы для людей и не использует спам-продвижения, почти ничего не изменится. Возможно некоторое уменьшение числа внешних ссылок, закрытых с rel=»nofollow».
Для тех, кто использовал в продвижении ссылочный спам (спам в комментариях, спам в форумах, соц. сетях, Википедии и т.д), и у кого основная ссылочная масса, дающая ТИЦ, состояла из таких ссылок, будет существенное снижение ТИЦ и как правило, проседание в поисковой выдаче Yandex.
Источник
Кратко, о новинках апреля 2010 года в Яндекс:
У страницы поисковой выдачи Яндекс теперь фиксированная ширина.
Появились в выдаче навигационные цепочки, у некоторых сниппетов и даты публикации.
Появился колдунщик видео.
В панели веб-мастера появилась возможность просмотра статистики по собственным ключевым словам.
P.S. Теперь осталось дождаться включения поддержки Яндексом канонического атрибута rel=»canonical», о котором я писал в статье о дублированном контенте, и многие блогеры вздохнут с облегчением. Хорошая новость, в конце мая 2011г. Яндекс стал учитывать атрибут rel=»canonical». Принесет это облегчение или нет, покажет время.
Нашел ошибку в тексте? Выдели ее мышкой и нажми
Noindex и nofollow — как исключить страницы из поиска Google?
Индексирование большого количества страниц в поисковых системах очень заманчиво для многих начинающих владельцев собственных сайтов.
Особенно если это новые сайты, и мы пытаемся как можно быстрее улучшить позиции нашего сайта.
Хотя это правда, что, публикуя больше страниц, релевантных заданному ключевому слову (при условии, что они также хорошего качества), мы способствуем улучшению позиции в рейтинге по выбранным ключевым фразам, иногда лучше держать некоторые страницы подальше от индекса поисковых систем.
Почему?
Я сейчас все объясню. В этой записи будут показаны некоторые ситуации, в которых лучше удалить данную подстраницу из индекса поисковой системы, и как именно это выглядит с технической точки зрения.
Почему вы должны исключить из индекса определенные подстраницы вашего сайта?
Существует ряд случаев, когда подстраница должна быть исключена из поисковой системы.
Основная причина использования noindex и nofollow — предотвращение индексации дублированного контента (ситуация, когда один и тот же текст находится на двух разных страницах).
Еще одна веская причина?
Например, подстраница благодарности. Обычно пользователь может увидеть его сразу после загрузки вашей электронной книги или подписки на рассылку.
Как владелец сайта, вы хотите, чтобы пользователь перешел на ваш сайт только в том случае, если он совершит какое-либо действие, например, подпишется на рассылку новостей. Вам не нужны прямые переходы из поисковой системы на страницы благодарности.
Почему?
Простой пример — если вы измеряете конверсии с помощью такой страницы, вы получите ложную информацию, потому что кто-то может зайти на такую подстраницу прямо из поисковой системы.
Другим примером может быть возможность скачать бесплатную электронную книгу в обмен на заполнение формы. После правильного завершения пользователь перенаправляется на подстраницу с благодарностью, где есть ссылка на обещанную электронную книгу.
Теперь представьте, что любой может попасть на эту подстраницу, набрав в поисковой системе фразу «e-book positioning».
На вашей подстранице появится благодарность и ссылка. Пользователь получил то, что хотел, а вы остались без информации и желанной электронной почты.
Кроме того, вы можете обнаружить, что подстраница с благодарностями занимает первое место в поисковой выдаче по вашему главному ключевому слову. В результате вы снова теряете множество незаполненных форм и информации.
Это довольно важные причины для использования тегов noindex и nofollow.
Итак, как отключить индексацию нежелательных страниц?
Есть два способа, поэтому перейдем к следующему пункту.
Способы не индексировать выбранные подстраницы сайта
1. Прикрепите файл robots.txt к вашему сайту.
Используйте файл robots.txt (прежде чем продолжить, я советую вам прочитать статью по ссылке), если вы хотите иметь больший контроль над тем, что должно быть проиндексировано, а что нет.
Внимание: если у вас нет базовых технических знаний, воспользуйтесь советом опытного специалиста, так как неправильная настройка файла robots.txt может полностью «отрезать» ваш сайт от любой поисковой системы.
В связи с этим одним из способов удаления конкретной подстраницы из результатов поиска является создание и добавление на ваш сайт файла robots.txt.
Преимущество этого метода заключается в том, что вы можете получить полный контроль над тем, что появляется в поисковой системе.
Внутри файла robots.txt вы сможете указать, хотите ли вы блокировать индексирующих роботов или нет.
Существует ряд правил. Вы можете исключить одну подстраницу, например, страницу благодарности, заблокировать весь каталог или даже избавиться от индексации одного изображения.
Недавно я также столкнулся с правилом, которое гласит, что вы не должны индексировать подстраницу, если Google AdSense еще не работает на данном сайте.
Если у вас нет технических знаний и вам не нужен полный контроль над тем, что появляется в результатах поисковых систем, есть гораздо более простой способ. ….
2. Добавьте теги noindex и nofollow к рассматриваемой подстранице.
Используйте теги noindex и nofollow как более простое решение для исключения нежелательной подстраницы из результатов поисковых систем.
Использование метатегов для предотвращения появления выбранной подстраницы является эффективным и простым.
На самом деле, это простое «копирование/вставка», если вы используете подходящую систему управления контентом (CMS).
Теги, которые позволят вам это сделать, называются noindex и nofollow.
Прежде чем объяснить, как правильно использовать noindex и nofollow, я объясню различия между этими двумя тегами.
Они выглядят похоже, но это две совершенно разные директивы. Их можно использовать вместе или по отдельности, но что они означают на самом деле?
Что такое тег noindex?
Когда вы добавляете тег noindex на веб-страницу, вы сообщаете поисковой системе, что она может индексировать эту страницу, но ни при каких обстоятельствах не может добавить ее в результаты поиска.
Что такое тег nofollow?
Когда вы добавляете тег nofollow на веб-страницу, вы запрещаете поисковым системам индексировать ссылки на этой странице. Это также означает, что авторитет страницы (авторитет страницы) не будет передан ни одной ссылке, которая находится на этой странице.
В связи с этим любые ссылки на странице с директивой ‘nofollow’ будут игнорироваться Google и другими поисковыми системами.
Когда использовать noindex и nofollow вместе, а когда по отдельности?
Вы можете использовать тег noindex отдельно или в сочетании с nofollow. Это правило также относится к директиве nofollow.
Добавьте один тег noindex, когда вы хотите, чтобы поисковая система не индексировала определенную подстраницу. Помните, что страница с директивой noindex будет исследована по всей длине и ширине страницы в поисках ссылок и получит часть своей силы от авторитетности подстраницы.
Добавьте один тег nofollow, когда вы хотите проиндексировать определенную подстраницу, но не хотите передавать авторитет подстраницы всем ссылкам на этой подстранице.
Существует не так много примеров добавления nofollow ко всей подстранице без одновременного добавления тега noindex.
Когда вы думаете о том, что добавить на ту или иную подстраницу, это скорее вопрос о том, что добавить: noindex или noindex и nofollow.
Добавьте тег noindex и nofollow, если вы не хотите, чтобы поисковая система индексировала выбранную подстраницу и передавала силу авторитета ссылкам внутри нее.
Страницы благодарности за подписку или заполненную форму — идеальные примеры такого рода ситуаций. Вы не хотите, чтобы браузеры индексировали такую подстраницу, и не хотите, чтобы они знали о ссылках, ведущих с нее на конкретное предложение или, например, на ссылку на электронную книгу.
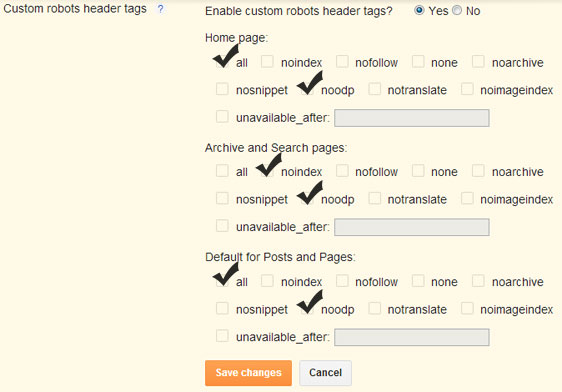
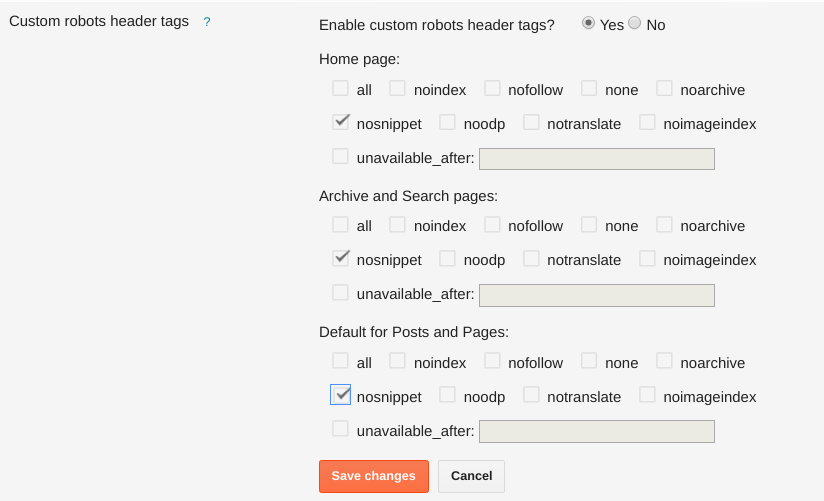
Как использовать теги noindex и nofollow?
Шаг 1: Скопируйте приведенный ниже код:
Для «noindex»:
<META NAME=»robots» CONTENT=»noindex»>
Для «nofollow»:
<META NAME=»robots» CONTENT=»nofollow»>
Для «noindex и nofollow»:
<META NAME=»robots» CONTENT=»noindex,nofollow»>
Шаг 2: Добавьте приведенный выше код в раздел head вашей подстраницы, которую вы хотите исключить.
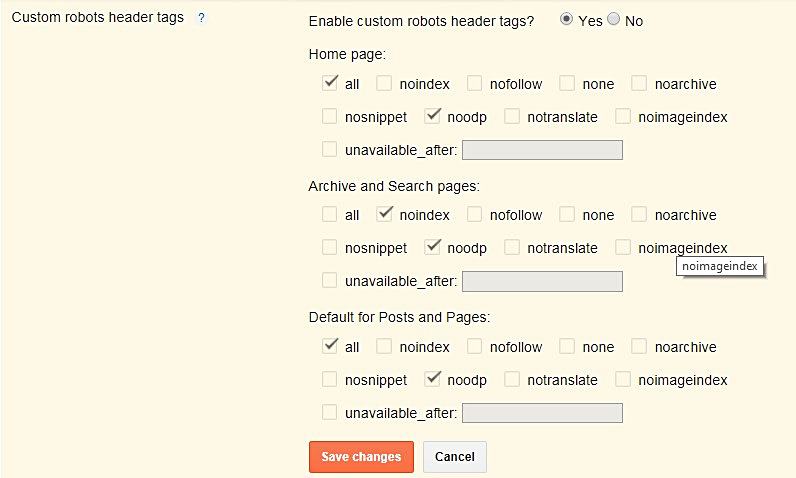
Если вы используете WordPress, самый простой способ — установить плагин Yoast SEO:
Если вы еще не знаете, что такое плагин Yoast SEO, приглашаю вас ознакомиться с нашей статьей о том, как оптимизировать пост с помощью плагина Yoast SEO. Если ваш сайт — это чистый HTML, то, к сожалению, все будет не так просто. Вам нужен доступ к хостингу или FTP.
Обратите внимание, что код должен быть размещен где-то между тегами <head> и </head>.
h3 hocus pocus, hocus mary — ваши подстраницы исчезли
Ваши исключенные подстраницы больше не будут появляться в результатах поисковых систем. Теперь вы можете снова приступить к захвату потерянных писем и ценной информации.
При этом следует помнить, что внесенные вами изменения будут видны не сразу. Это может занять даже несколько недель.
В связи с этим лучшим способом отслеживания изменений в индексе является изучение статистики в Google Search Console.
Если вы заметили, что выбранная вами страница по-прежнему отображается в результатах поиска, скорее всего, робот Google еще не посетил ваш сайт или директивы noindex и nofollow были использованы неправильно.
Случайно добавил тег nofollow, noindex, а потом… | SEO Форум
Ваш браузер не поддерживает JavaScript. В результате ваши впечатления от просмотра будут уменьшены, и вы будете переведены в режим только для чтения .
Загрузите браузер, поддерживающий JavaScript, или включите его, если он отключен (например, NoScript).
Дом
SEO-тактика
Средний и продвинутый SEO
org/ListItem»> Случайно добавил тег nofollow, noindex, а потом…
Эта тема была удалена. Его могут видеть только пользователи с правами управления вопросами.
Мой первый пост здесь и по иронии судьбы подчеркивает смехотворно глупую ошибку!
Хорошо, вот в чем дело…
Я начал создавать ссылки на одну из своих новых страниц на довольно хорошем старом сайте (DA = >35).
Прежде чем начать строить ссылки, я добавил свежий новый контент, и при этом я случайно добавил на страницу теги «nofollow» и «noindex»! Угадайте, что Google ДЕЙСТВИТЕЛЬНО деиндексировал страницу!
Итак, вопросы (и ДА, я изменил метатеги):
Будет ли Google переиндексировать страницу с хорошими ссылками?
Будет ли страница рассматриваться как новая, свежая, даже если она существовала более года?
Я уже начал создавать ссылки на эту страницу, и теперь технически ссылки указывают на страницу, которая не существует в индексе, поэтому, если она будет переиндексирована, пометит ли ее Google как имеющую слишком много ссылок?
Буду ли я ранжировать ее как новую страницу? Вернется ли его предыдущий рейтинг (по очень небольшому количеству ключевых слов)?
С уважением,
Амод
org/Comment»>
Абсолютно не проблема, о которой нужно беспокоиться по любому из тех вопросов, которые вы задали — просто удалите тег noindex и отправьте URL-адреса в WMT для Google, чтобы быстрее переназначить эти конкретные страницы, вы будете снова в рабочем состоянии. время.
Привет, Амод,
Я тоже столкнулся с этим, наш разработчик случайно разместил этот тег «nofollow» на всем веб-сайте.
Да, просто попросите Google получить ваши страницы с помощью инструментов для веб-мастеров.
№
№
4). Рейтинги вернутся, как заметил Мэтт, не о чем беспокоиться.
1. Да конечно гугл переиндексируем страницу. С «хорошей ссылкой» или без нее, в следующий раз, когда он будет сканировать страницу (и он будет делать это независимо от каких-либо новых действий по созданию ссылок), он увидит, что тег изменился, и снова включит его в индекс.
2. Нет, он будет знать о возрасте страницы.
3. Нет, Google уже проиндексировал все ссылки, ведущие на ваш сайт. Он не забудет об этом внезапно только потому, что вы добавили noindex на свою страницу. Это 2 отдельные сущности.
4. Рейтинги вернутся, но на это потребуется время. Я читал сообщения в блогах об этом в прошлом, возможно, кто-то еще может дать оценку? Я предполагаю, что это зависит от силы страницы.
Спасибо,
Мэтт
У вас есть животрепещущий вопрос по SEO?
Подпишитесь на Moz Pro, чтобы получить полный доступ к вопросам и ответам, отвечать на вопросы и задавать свои.
Начать бесплатную пробную версию
Есть вопрос?
Просмотр вопросов
Посмотреть
Все вопросыНовые (нет ответов)ОбсуждениеОтветыПоддержка продуктаБез ответа
От
Все времяПоследние 30 днейПоследние 7 днейПоследние 24 часа
Сортировка по
Последние вопросыНедавняя активностьБольше всего лайковБольшинство ответовМеньше всего ответовСамые старые вопросы
С категорией
All CategoriesAffiliate MarketingAlgorithm UpdatesAPIBrandingCommunityCompetitive ResearchContent DevelopmentConversion Rate OptimizationDigital MarketingFeature RequestsGetting StartedImage & Video OptimizationIndustry EventsIndustry NewsIntermediate & Advanced SEOInternational SEOJobs and OpportunitiesKeyword ExplorerKeyword ResearchLink BuildingLink ExplorerLocal ListingsLocal SEOLocal Website OptimizationMoz BarMoz LocalMoz NewsMoz ProMoz ToolsOn-Page OptimizationOther SEO ToolsPaid Search MarketingProduct SupportReporting & AnalyticsResearch & TrendsReviews and RatingsSearch BehaviorSEO ТактикаТренды поисковой выдачиСоциальные сетиТехническое SEOВеб-дизайнБелое/черное SEO
Одна из наших ведущих органических целевых страниц была установлена как «NOINDEX,NOFOLLOW» по «ошибке». Мне потребовалось около недели, чтобы понять это после того, как я увидел падение трафика на этой странице. Я посмотрел в Google, чтобы узнать, был ли он проиндексирован, и мои опасения подтвердились!
Узнав, что он был переключен на «NOINDEX, NOFOLLOW», я снова переключил его на «INDEX, FOLLOW» и сделал запрос индекса в нашей консоли поиска Google.
Кто-нибудь еще сталкивался с подобной проблемой? Вы когда-нибудь снова индексировали страницу?
Средний и продвинутый SEO | | ФрэнкВиолетт
2
org/ListItem»> Нужно ли ставить канонический тег на странице, на которую я указываю?
Допустим, B i является дубликатом страницы A (главной страницы). Я понимаю, что мне нужно поместить канонический тег под B, чтобы указать на A. Нужно ли также размещать канонический тег под главной страницей A? Это необходимо? Я понимаю, что А затем сообщит Google, что это предпочтительная страница А? Это правильное понимание?
Средний и продвинутый SEO | | андыпаталак
0
Индексация результатов внутреннего поиска: канонизация или noindex?
Привет, Моззерс!
Впервые постер здесь, очень нравится сайт и инструменты. Я занимаюсь SEO для довольно крупного бренда электронной коммерции, и возникла проблема с результатами внутреннего поиска.
www.example.com/electronics/iphone/5s/ дает обзор списков конкретных моделей. Для некоторых моделей также есть списки цветов, но они не включены в структуру URL.
Вот что говорит Рэнд в Inbound Marketing & SEO: Insights From The Moz Blog
Фильтры поиска используются для сужения внутреннего поиска — это может быть цена, цвет, характеристики и т. д. Фильтры очень распространены на сайтах электронной коммерции, которые продают самые разные товары. Поисковый фильтр Во многих случаях URL-адреса очень похожи на поисковые сортировки: www.example.com/search.php?category=laptop www.example.com/search.php?category=laptop?price=1000 Решение здесь аналогично предыдущему — не индексировать фильтры. Пока Google имеет четкий путь к продуктам, индексация каждого варианта обычно приносит больше вреда, чем пользы.
Я считаю, что здесь подразумевается использование тега noindex. Допустим, вы хотите показать пользователям обзор предложений черных айфонов 5s. URL — это внутренний поисковый фильтр, который выглядит следующим образом:
www.example.com/electronics/apple/iphone/5s?search=black
Который вы хотите связать с якорным текстом «черный iphone 5s».
Поправьте меня, если я ошибаюсь, но если вы не проиндексируете поисковые фильтры черных 5s, вы потеряете эквити, пройденную по ссылке. Принимая во внимание, что если вы канонизируете /electronics/apple/iphone/5s, вы все равно будете использовать ссылочный вес и поможет вам ранжироваться для «черного iphone 5s». Не имеет ли тогда больше смысла использовать канонизацию?
Средний и продвинутый SEO | | Классический Драйвер
0
Почему Examiner. com не отслеживает мой рекомендуемый экспертный совет?
Привет, ребята, я недавно получил сообщение в прессе с советом, который я дал для статьи о маркетинге медицинской практики. Статья находится на examer.com, и мне интересно, по какой причине они могут не переходить по ссылкам в своих статьях… ttp://www.examiner.com/article/the-biggest-challenges-medical-marketing- и-как-преодолеть-их-1
Не поймите меня неправильно, я понимаю и взволнован внутренними преимуществами публикации в такой статье… просто интересно, почему за чем-то подобным не следят!
Хотелось бы услышать ваши мысли.
Спасибо,
Рики
Средний и продвинутый SEO | | РикиШокли
0
Ключевые слова контента и мета-теги инструментов для веб-мастеров
В инструментах для веб-мастеров ключевые слова контента дают представление о том, что Google думает о сайте. Этот сайт посвящен здоровью (интернет-покупки — пищевые добавки для здоровья ), но один из терминов, который, по его мнению, посвящен сайту, — «Доллар» . Я предполагаю, что это потому, что на каждой странице есть выбор валюты из нескольких валют.
Как сообщить Google, что эта часть страницы не имеет ничего общего с содержанием моего сайта?
Заранее спасибо за ответ!
Средний и продвинутый SEO | | s_EOgi_Bear
0
K3 дублирует содержимое страницы и теги заголовков
Я использую сайт Joomla, только что установил k2 в качестве платформы для ведения блога. Наш отчет о сканировании с SEOMOZ показывает много дублированного контента и дублирующихся тегов заголовков в нашем блоге K2. Мы установили sh504SEF.
Нужно ли будет заходить в sh504SEF каждый раз, когда мы создаем запись в блоге, чтобы указывать заголовки на один URL? Если есть что-то попроще, посоветуйте.
Спасибо,
Дон
Средний и продвинутый SEO | | Дональдмур
0
По каким типам ссылок следует переходить и nofollow внутри?
Мы отправили наш файл sitemap.xml в поисковые системы, так что теперь, когда они это сделали, должны ли мы использовать атрибут nofollow в файле sitemap. html? Нужен ли нам файл sitemap.html?
Для других ссылок на сайте, таких как:
Связаться с нами
О нас
Места
и другие фразы, по которым мы не пытаемся ранжироваться, должны ли мы установить для них значение nofollow?
Средний и продвинутый SEO | | SEOДинозавр
0
Рейтинги упали после изменения тега заголовка на сайте
Привет, ребята!
Один из наших клиентов — крупный бренд, но его бренд — домен ключевых слов.
После регистрации на seo moz и внесения рекомендуемых изменений в поисковую оптимизацию страницы произошло нечто радикальное.
Каждая страница сайта моих клиентов добавляла название сайта в конце тега title. Пример: <название>ключевое слово | ключевое слово 2 | ключевое слово доменного имени Я чувствовал, а также с отчетами semoz, что добавление основного ключевого слова в конец каждого тега заголовка было бы слишком спамным, и, как предположил seo moz, возможно, разные страницы борются за ранги по этой фразе.
Мы решили удалить домен с конца на всех заголовках страниц, и, поскольку Google повторно кэшировал сайт, рейтинг сильно упал. Сайт по-прежнему индексируется, так что это хорошо, но если учесть, что один лид стоит более 1000 фунтов стерлингов для моего клиента, а с 20-30 лидами в месяц он не слишком доволен.
Кто-нибудь испытал это раньше? Я предполагаю, что Google переоценивает рейтинг, чтобы отразить новые теги заголовков, и, таким образом, размещает сайт моих клиентов до тех пор, пока он не закончит обновление рейтинга и т. д.?
Любая помощь?
Спасибо
Средний и продвинутый SEO | | Глазго
0
Страницы NoIndex/NoFollow, отображаемые при поиске в Google с использованием параметра «Сайт:» | SEO Форум
Ваш браузер не поддерживает JavaScript. В результате ваши впечатления от просмотра будут уменьшены, и вы будете переведены в режим только для чтения .
Загрузите браузер, поддерживающий JavaScript, или включите его, если он отключен (например, NoScript).
Дом
SEO-тактика
Техническое SEO
Страницы NoIndex/NoFollow, отображаемые при выполнении поиска Google с использованием параметра «Сайт:»
Эта тема была удалена. Его могут видеть только пользователи с правами управления вопросами.
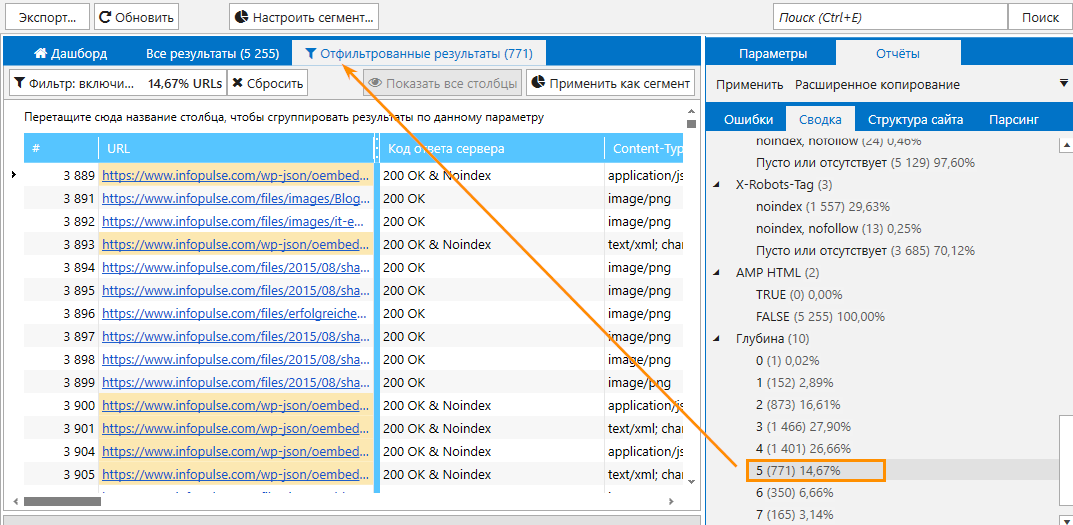
Недавно мы запустили бета-версию нашего нового веб-сайта в поддомене существующего сайта. Существующий сайт — www.fonts.com, а бета-версия — new.fonts.com. Мы не хотим, чтобы Google сканировал новый сайт, пока он не выйдет из бета-версии, поэтому мы добавили на все страницы следующее:
Однако один из членов нашей команды заметил, что Google отображает результаты с сайта new.fonts.com при выполнении » site:new.fonts.com» (см. прикрепленный скриншот). Возможно ли, что Google индексирует контент, несмотря на теги noindex, nofollow? Мы дважды проверили синтаксис, и он кажется правильным, за исключением завершающего «/». Я знаю, что Google по-прежнему сканирует непроиндексированные страницы, однако тот факт, что они отображаются в результатах поиска с использованием синтаксиса поиска по сайту, настораживает.
Будем признательны за любые мысли!
DyWRP.png
Спасибо, спасибо, что нашли время написать ответ!
Спасибо за ответ. Я передам эту информацию команде разработчиков!
Привет, Крис
Если Google увидит ссылку на страницу, он все равно может указать ее в своем индексе, даже если, когда они туда попали, они увидели тег noindex, поэтому они не просканировали ее.
Рациональное объяснение состоит в том, что они видят ссылку с вашего основного сайта с некоторым анкорным текстом и индексируют ссылку на основе анкорного текста, они не могут ее просканировать, потому что вы запрещаете это делать, но у них все еще есть некоторая информация о странице из вашего анкорного текста. текст.
Вот прямая цитата Мэтта Каттса:
» Нашим высшим долгом должны быть наши пользователи, а не отдельный веб-мастер. Когда пользователь делает навигационный запрос, и мы не возвращаем правильную ссылку из-за NOINDEX тег, это вредит пользовательскому опыту (к тому же это похоже на проблему Google). Если веб-мастер действительно хочет выйти из Google без единого следа, он может использовать инструмент Google для удаления URL. »
Вы можете заблокировать доступ к тестовому сайту (что мы и делаем) через htacess (если вы находитесь на Linux Server) и используйте Google Index Removal Tool, чтобы удалить проиндексированные в данный момент страницы.
Надеюсь, это поможет.
Если у вас есть nofollow на всех страницах, есть вероятность, что это вызвано тем, что Google не может переходить по ссылкам на ваши страницы, сканировать и обновлять их с помощью тега no-index.
Попробуйте изменить ссылки на noindex, следуйте.
У вас есть животрепещущий вопрос по SEO?
Подпишитесь на Moz Pro, чтобы получить полный доступ к вопросам и ответам, отвечать на вопросы и задавать свои.
Начать бесплатную пробную версию
Есть вопрос?
Просмотр вопросов
Посмотреть
Все вопросыНовые (нет ответов)ОбсуждениеОтветыПоддержка продуктаБез ответа
От
Все времяПоследние 30 днейПоследние 7 днейПоследние 24 часа
Сортировка по
Последние вопросыНедавняя активностьБольше всего лайковБольшинство ответовМеньше всего ответовСамые старые вопросы
С категорией
All CategoriesAffiliate MarketingAlgorithm UpdatesAPIBrandingCommunityCompetitive ResearchContent DevelopmentConversion Rate OptimizationDigital MarketingFeature RequestsGetting StartedImage & Video OptimizationIndustry EventsIndustry NewsIntermediate & Advanced SEOInternational SEOJobs and OpportunitiesKeyword ExplorerKeyword ResearchLink BuildingLink ExplorerLocal ListingsLocal SEOLocal Website OptimizationMoz BarMoz LocalMoz NewsMoz ProMoz ToolsOn-Page OptimizationOther SEO ToolsPaid Search MarketingProduct SupportReporting & AnalyticsResearch & TrendsReviews and RatingsSearch BehaviorSEO ТактикаТренды поисковой выдачиСоциальные сетиТехническое SEOВеб-дизайнБелое/черное SEO
Robots.txt и meta noindex — сайт по-прежнему отображается в поиске Google
Я настроил свой robots.txt следующим образом:
Пользователь-агент: * Запретить: /
и у меня есть этот метатег на моем сайте WordPress, настроенном с помощью SEO Yoast
name=»роботы» content=»noindex,follow»/>
Я сделал «Получить как Google» в своей консоли поиска Google.
Мой сайт все еще отображается в результатах поиска, и он говорит следующее:
«Описание этого результата недоступно из-за файла robots.txt этого сайта»
Этот сайт не появлялся в течение многих лет, и теперь он находится выше моего сайта, который я хочу ранжировать по этому ключевому слову. Как заставить Google игнорировать этот сайт? Это кажется действительно странным, и я не понимаю, как сайт с небольшим содержанием, который не обновлялся годами, может ранжироваться выше, чем сайт, который постоянно обновляется и улучшается.
Техническое SEO | | РоксБрок
1
Как заставить Google забыть мою старую, но все еще работающую страницу и перечислить мою новую полностью оптимизированную страницу по ключевому слову?
Привет!
(я новичок в сео)
У меня есть динамические и статические страницы на нашем сайте. Я создал статическую страницу для определенного ключевого слова. Полностью оптимизировал его (h2, alt, metas и т. д., возможно, слишком оптимизирован). Моя проблема в том, что эта страница живет неделями, проверил ее в GWT и она есть в robots.txt, гугл ее видит, проиндексировал. НО всякий раз, когда я выполняю поиск по этому ключевому слову, мы по-прежнему появляемся с динамически созданной ссылкой в списках Google.
Как я мог «перенаправить» Google, если он выполняет поиск по этому ключевому слову, а не показывает нашу оптимизированную страницу? Есть ли инструмент для этого? Не могу удалить динамическую страницу…
Любые идеи?
Спасибо
Эндрю
Техническое SEO | | Некерманн
0
«Одна страница с двумя ссылками на одну и ту же страницу; мы засчитали первую ссылку» Это правда?
Я прочитал это сегодня http://searchengineland. com/googles-matt-cutts-one-page-two-links-page-counted-first-link-192718
Я подумал про себя, да, это то, что я читал в Moz в течение многих лет (жалко, Мэтт не мог подтвердить, что это все еще актуально для 2014 года)
Но, прочитав комментарии Майкла Мартинеса с сайта http://www.seo-theory.com/ , он заметил, что Мэт говорит: «…последний раз, когда я проверял, это было в 2009 году., а тогда — э-э, мы могли бы, например, выбрать только одну из ссылок с данной страницы .» Это означает, что это не означает, что это всегда первая ссылка.
Майкл продолжает: « Еще в 2008 году, когда Рэнд НЕПРАВИЛЬНО заявил, что Google считает только первую ссылку (я поделился результатами теста, в котором он прошел анкорный текст из ДВУХ ссылок на одной и той же странице )», затем продолжает: « На практике поисковая система иногда пропускала ссылки и брала якорный текст со второй или третьей ссылки вниз по странице. »
Для меня это существенно. Я знаю людей, у которых были «эксперты по SEO», которые рекомендовали им иметь блог, прикрепленный к сайту электронного стартапа, и публиковать сообщения в блогах (без реального интереса для читателей) с якорными текстовыми ссылками на ваши целевые страницы. Я думал, что публиковать сообщение в блоге только для анкорной текстовой ссылки было пустой тратой времени, если вы уже ссылаетесь на целевую страницу в основной навигации, поскольку Google сначала увидит эту ссылку. Но если Майкл прав, то посты в блогах такого типа имеют якорную текстовую ссылку.
Но кто прав, Рэнд или Майкл?
Техническое SEO | | Пэдди Дисплеи
0
Работает ли использование data-href=»» более эффективно, чем href=»» rel=»nofollow»?
Я видел в обзоре фрагмента Google, и он показывал фотографию профиля в поиске, но когда я вижу непосредственно на google.com, он не отображается там .. в чем проблема?
Техническое SEO | | эксплодегуру
0
org/ListItem»> Noindex,follow — связанные страницы не отображаются
У нас есть блог на нашем сайте, где главная страница и страницы категорий имеют «noindex,follow», но статьи имеют «index,follow».
Недавно мы заметили, что страницы статей больше не отображаются в поисковой выдаче Google (но они есть в Bing!) — это было сделано с помощью оператора поиска «сайт:».
Мы также перепроверили наш файл robots.txt на случай, если в него попала какая-то глупость, но так и должно быть…
Кто-нибудь еще замечал подобное поведение или мог бы предложить вещи, которые я мог бы проверить?
Спасибо!
Техническое SEO | | Никто15565114
0
org/ListItem»> С или без «/» в конце домена
Здравствуйте!
Клиентские домены иногда выглядят как www.domain.co.uk, а иногда как www.domain.co.uk/.
Я хочу разместить перенаправления с URL-адресов, содержащих такие строки, как /index.aspx?id=42, на главную страницу, но какой из них выбрать? С «/» или без?
Спасибо
Техническое SEO | | Давид Спивак
0
У меня 15000 страниц. Как заставить робота Google просканировать все страницы?

 Применительно к поисковикам, данный атрибут указывает индексирующим роботам, что по данной ссылке не следует переходить на целевую страницу.
Применительно к поисковикам, данный атрибут указывает индексирующим роботам, что по данной ссылке не следует переходить на целевую страницу.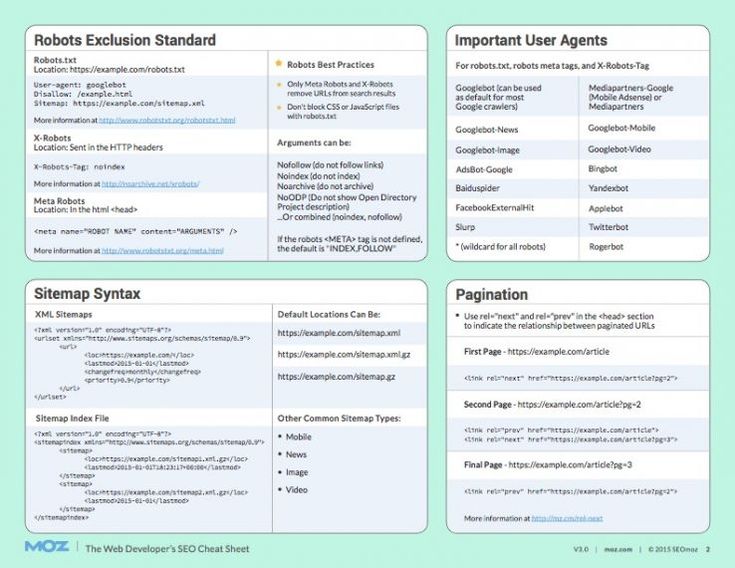 Но эта статья не о Google, вернемся к Яндексу.
Но эта статья не о Google, вернемся к Яндексу. Приходится данные плагины адаптировать под Яндексовскую реальность.
Приходится данные плагины адаптировать под Яндексовскую реальность. Атрибут закрывает ссылки от переходов роботом и не передает вес. Теперь многое стало проще. Но есть один нюанс. Анкоры ссылок будут проиндексированы как текст.
Атрибут закрывает ссылки от переходов роботом и не передает вес. Теперь многое стало проще. Но есть один нюанс. Анкоры ссылок будут проиндексированы как текст. site.com» title=»Подсказка»>Ссылка на сайт</a>
site.com» title=»Подсказка»>Ссылка на сайт</a> site.com» title=»Подсказка»>Ссылка на сайт</a>
site.com» title=»Подсказка»>Ссылка на сайт</a> Возможно некоторое уменьшение числа внешних ссылок, закрытых с rel=»nofollow».
Возможно некоторое уменьшение числа внешних ссылок, закрытых с rel=»nofollow».

 После правильного завершения пользователь перенаправляется на подстраницу с благодарностью, где есть ссылка на обещанную электронную книгу.
После правильного завершения пользователь перенаправляется на подстраницу с благодарностью, где есть ссылка на обещанную электронную книгу.
 ….
….


 org/ListItem»> Случайно добавил тег nofollow, noindex, а потом…
org/ListItem»> Случайно добавил тег nofollow, noindex, а потом… org/Comment»>
org/Comment»>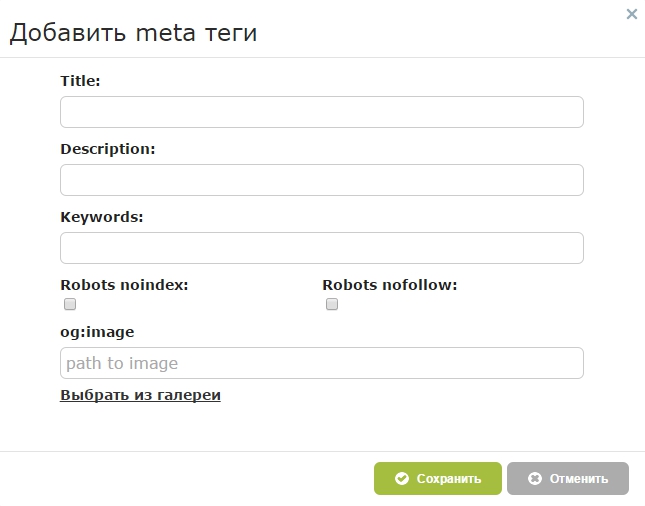 org/Comment»>
org/Comment»> 
 schema.org/ItemList» data-nextstart=»» data-set=»»>
schema.org/ItemList» data-nextstart=»» data-set=»»> org/ListItem»> Нужно ли ставить канонический тег на странице, на которую я указываю?
org/ListItem»> Нужно ли ставить канонический тег на странице, на которую я указываю?  Я занимаюсь SEO для довольно крупного бренда электронной коммерции, и возникла проблема с результатами внутреннего поиска.
www.example.com/electronics/iphone/5s/ дает обзор списков конкретных моделей. Для некоторых моделей также есть списки цветов, но они не включены в структуру URL.
Вот что говорит Рэнд в Inbound Marketing & SEO: Insights From The Moz Blog
Фильтры поиска используются для сужения внутреннего поиска — это может быть цена, цвет, характеристики и т. д.
Я занимаюсь SEO для довольно крупного бренда электронной коммерции, и возникла проблема с результатами внутреннего поиска.
www.example.com/electronics/iphone/5s/ дает обзор списков конкретных моделей. Для некоторых моделей также есть списки цветов, но они не включены в структуру URL.
Вот что говорит Рэнд в Inbound Marketing & SEO: Insights From The Moz Blog
Фильтры поиска используются для сужения внутреннего поиска — это может быть цена, цвет, характеристики и т. д. 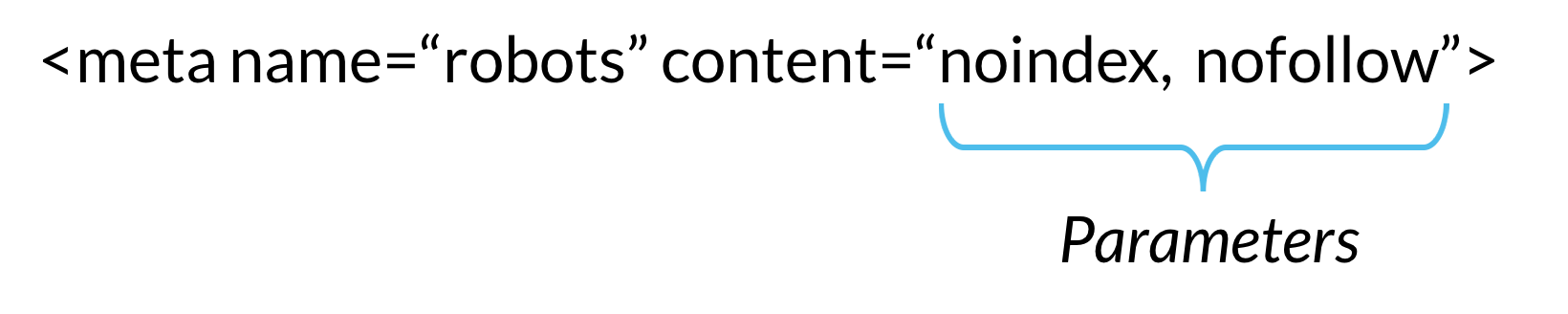 Допустим, вы хотите показать пользователям обзор предложений черных айфонов 5s. URL — это внутренний поисковый фильтр, который выглядит следующим образом:
www.example.com/electronics/apple/iphone/5s?search=black
Который вы хотите связать с якорным текстом «черный iphone 5s».
Поправьте меня, если я ошибаюсь, но если вы не проиндексируете поисковые фильтры черных 5s, вы потеряете эквити, пройденную по ссылке. Принимая во внимание, что если вы канонизируете /electronics/apple/iphone/5s, вы все равно будете использовать ссылочный вес и поможет вам ранжироваться для «черного iphone 5s». Не имеет ли тогда больше смысла использовать канонизацию?
Допустим, вы хотите показать пользователям обзор предложений черных айфонов 5s. URL — это внутренний поисковый фильтр, который выглядит следующим образом:
www.example.com/electronics/apple/iphone/5s?search=black
Который вы хотите связать с якорным текстом «черный iphone 5s».
Поправьте меня, если я ошибаюсь, но если вы не проиндексируете поисковые фильтры черных 5s, вы потеряете эквити, пройденную по ссылке. Принимая во внимание, что если вы канонизируете /electronics/apple/iphone/5s, вы все равно будете использовать ссылочный вес и поможет вам ранжироваться для «черного iphone 5s». Не имеет ли тогда больше смысла использовать канонизацию? com не отслеживает мой рекомендуемый экспертный совет?
com не отслеживает мой рекомендуемый экспертный совет?  Этот сайт посвящен здоровью (интернет-покупки — пищевые добавки для здоровья ), но один из терминов, который, по его мнению, посвящен сайту, — «Доллар» . Я предполагаю, что это потому, что на каждой странице есть выбор валюты из нескольких валют.
Как сообщить Google, что эта часть страницы не имеет ничего общего с содержанием моего сайта?
Заранее спасибо за ответ!
Этот сайт посвящен здоровью (интернет-покупки — пищевые добавки для здоровья ), но один из терминов, который, по его мнению, посвящен сайту, — «Доллар» . Я предполагаю, что это потому, что на каждой странице есть выбор валюты из нескольких валют.
Как сообщить Google, что эта часть страницы не имеет ничего общего с содержанием моего сайта?
Заранее спасибо за ответ!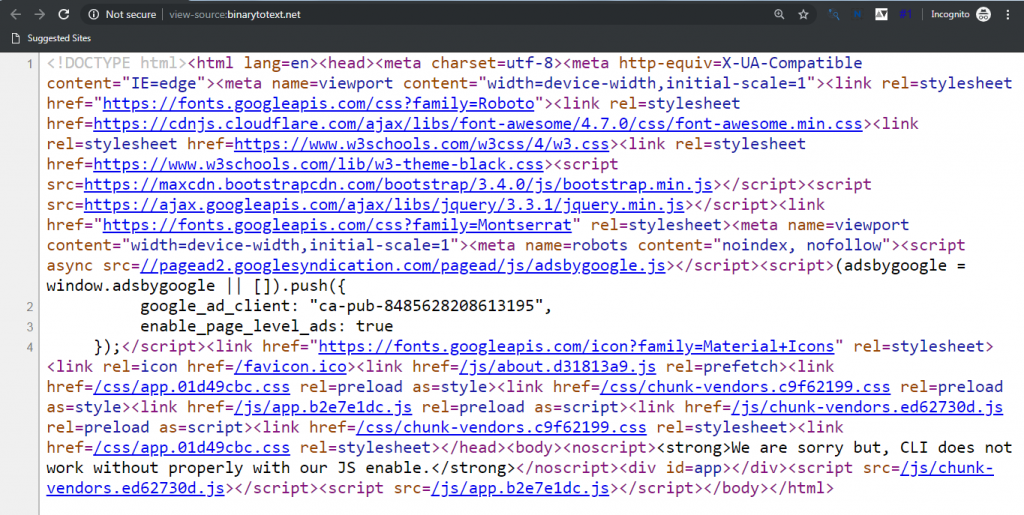 Наш отчет о сканировании с SEOMOZ показывает много дублированного контента и дублирующихся тегов заголовков в нашем блоге K2. Мы установили sh504SEF.
Нужно ли будет заходить в sh504SEF каждый раз, когда мы создаем запись в блоге, чтобы указывать заголовки на один URL? Если есть что-то попроще, посоветуйте.
Спасибо,
Дон
Наш отчет о сканировании с SEOMOZ показывает много дублированного контента и дублирующихся тегов заголовков в нашем блоге K2. Мы установили sh504SEF.
Нужно ли будет заходить в sh504SEF каждый раз, когда мы создаем запись в блоге, чтобы указывать заголовки на один URL? Если есть что-то попроще, посоветуйте.
Спасибо,
Дон html? Нужен ли нам файл sitemap.html?
Для других ссылок на сайте, таких как:
Связаться с нами
О нас
Места
и другие фразы, по которым мы не пытаемся ранжироваться, должны ли мы установить для них значение nofollow?
html? Нужен ли нам файл sitemap.html?
Для других ссылок на сайте, таких как:
Связаться с нами
О нас
Места
и другие фразы, по которым мы не пытаемся ранжироваться, должны ли мы установить для них значение nofollow? Пример: <название>ключевое слово | ключевое слово 2 | ключевое слово доменного имени Я чувствовал, а также с отчетами semoz, что добавление основного ключевого слова в конец каждого тега заголовка было бы слишком спамным, и, как предположил seo moz, возможно, разные страницы борются за ранги по этой фразе.
Мы решили удалить домен с конца на всех заголовках страниц, и, поскольку Google повторно кэшировал сайт, рейтинг сильно упал. Сайт по-прежнему индексируется, так что это хорошо, но если учесть, что один лид стоит более 1000 фунтов стерлингов для моего клиента, а с 20-30 лидами в месяц он не слишком доволен.
Кто-нибудь испытал это раньше? Я предполагаю, что Google переоценивает рейтинг, чтобы отразить новые теги заголовков, и, таким образом, размещает сайт моих клиентов до тех пор, пока он не закончит обновление рейтинга и т. д.?
Любая помощь?
Спасибо
Пример: <название>ключевое слово | ключевое слово 2 | ключевое слово доменного имени Я чувствовал, а также с отчетами semoz, что добавление основного ключевого слова в конец каждого тега заголовка было бы слишком спамным, и, как предположил seo moz, возможно, разные страницы борются за ранги по этой фразе.
Мы решили удалить домен с конца на всех заголовках страниц, и, поскольку Google повторно кэшировал сайт, рейтинг сильно упал. Сайт по-прежнему индексируется, так что это хорошо, но если учесть, что один лид стоит более 1000 фунтов стерлингов для моего клиента, а с 20-30 лидами в месяц он не слишком доволен.
Кто-нибудь испытал это раньше? Я предполагаю, что Google переоценивает рейтинг, чтобы отразить новые теги заголовков, и, таким образом, размещает сайт моих клиентов до тех пор, пока он не закончит обновление рейтинга и т. д.?
Любая помощь?
Спасибо В результате ваши впечатления от просмотра будут уменьшены, и вы будете переведены в режим только для чтения .
В результате ваши впечатления от просмотра будут уменьшены, и вы будете переведены в режим только для чтения .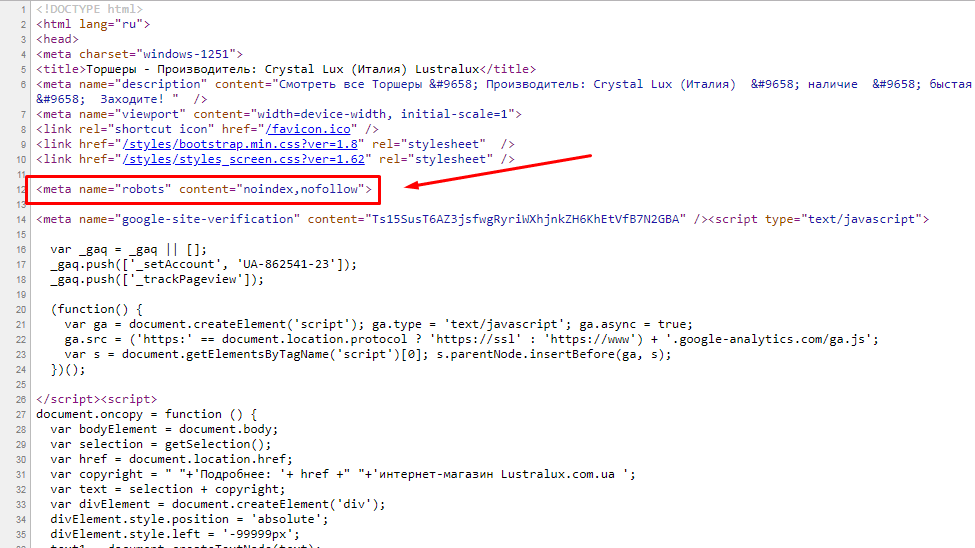


 schema.org/ItemList» data-nextstart=»» data-set=»»>
schema.org/ItemList» data-nextstart=»» data-set=»»> Как заставить Google игнорировать этот сайт? Это кажется действительно странным, и я не понимаю, как сайт с небольшим содержанием, который не обновлялся годами, может ранжироваться выше, чем сайт, который постоянно обновляется и улучшается.
Как заставить Google игнорировать этот сайт? Это кажется действительно странным, и я не понимаю, как сайт с небольшим содержанием, который не обновлялся годами, может ранжироваться выше, чем сайт, который постоянно обновляется и улучшается. Полностью оптимизировал его (h2, alt, metas и т. д., возможно, слишком оптимизирован). Моя проблема в том, что эта страница живет неделями, проверил ее в GWT и она есть в robots.txt, гугл ее видит, проиндексировал. НО всякий раз, когда я выполняю поиск по этому ключевому слову, мы по-прежнему появляемся с динамически созданной ссылкой в списках Google.
Как я мог «перенаправить» Google, если он выполняет поиск по этому ключевому слову, а не показывает нашу оптимизированную страницу? Есть ли инструмент для этого? Не могу удалить динамическую страницу…
Любые идеи?
Спасибо
Эндрю
Полностью оптимизировал его (h2, alt, metas и т. д., возможно, слишком оптимизирован). Моя проблема в том, что эта страница живет неделями, проверил ее в GWT и она есть в robots.txt, гугл ее видит, проиндексировал. НО всякий раз, когда я выполняю поиск по этому ключевому слову, мы по-прежнему появляемся с динамически созданной ссылкой в списках Google.
Как я мог «перенаправить» Google, если он выполняет поиск по этому ключевому слову, а не показывает нашу оптимизированную страницу? Есть ли инструмент для этого? Не могу удалить динамическую страницу…
Любые идеи?
Спасибо
Эндрю com/googles-matt-cutts-one-page-two-links-page-counted-first-link-192718
Я подумал про себя, да, это то, что я читал в Moz в течение многих лет (жалко, Мэтт не мог подтвердить, что это все еще актуально для 2014 года)
Но, прочитав комментарии Майкла Мартинеса с сайта http://www.seo-theory.com/ , он заметил, что Мэт говорит: «…последний раз, когда я проверял, это было в 2009 году., а тогда — э-э, мы могли бы, например, выбрать только одну из ссылок с данной страницы .»
com/googles-matt-cutts-one-page-two-links-page-counted-first-link-192718
Я подумал про себя, да, это то, что я читал в Moz в течение многих лет (жалко, Мэтт не мог подтвердить, что это все еще актуально для 2014 года)
Но, прочитав комментарии Майкла Мартинеса с сайта http://www.seo-theory.com/ , он заметил, что Мэт говорит: «…последний раз, когда я проверял, это было в 2009 году., а тогда — э-э, мы могли бы, например, выбрать только одну из ссылок с данной страницы .»  Я думал, что публиковать сообщение в блоге только для анкорной текстовой ссылки было пустой тратой времени, если вы уже ссылаетесь на целевую страницу в основной навигации, поскольку Google сначала увидит эту ссылку. Но если Майкл прав, то посты в блогах такого типа имеют якорную текстовую ссылку.
Но кто прав, Рэнд или Майкл?
Я думал, что публиковать сообщение в блоге только для анкорной текстовой ссылки было пустой тратой времени, если вы уже ссылаетесь на целевую страницу в основной навигации, поскольку Google сначала увидит эту ссылку. Но если Майкл прав, то посты в блогах такого типа имеют якорную текстовую ссылку.
Но кто прав, Рэнд или Майкл? otherodmain.com/» rel=»nofollow» target=»_blank»>
otherodmain.com/» rel=»nofollow» target=»_blank»> org/ListItem»> Noindex,follow — связанные страницы не отображаются
org/ListItem»> Noindex,follow — связанные страницы не отображаются  org/ListItem»> С или без «/» в конце домена
org/ListItem»> С или без «/» в конце домена 