Как правильно использовать noindex и nofollow
Грамотное использование тегов noindex и nofollow — важная составляющая правильной seo-оптимизации страниц сайта.
Пренебрегать их использованием не стоит, так как ноуиндекс и ноуфоллоу играют важную роль в передачи веса сайта, а так же делают ваш ресурс более привлекательным в «глазах» как добавить сайт в сервис Яндекса и Google.
Noindex
Сразу стоит сказать, что теги <noindex></noindex> учитываются только поисковой системой яндекса, Гугл просто их не замечает. Ноуиндекс применяют для сокрытия от ян-са, а точнее для запрета индексации какого-то участка html- кода.
Помещённый текст между <noindex> и </noindex> не будет проиндексирован. Ссылки же и картинки закрыть не получится, с ними он не работает и они попадут в индекс.
Тег <noindex> считается не валидным и многие html-редакторы его просто выбрасывают. В таком случае его надо прописывать как <!— noindex —> и <!— /noindex —>, в этом виде он становиться вполне для них съедобен и валиден.
Весь текст после открывающего тега <noindex> не будет проиндексирован, поэтому (если есть необходимость) не забывайте нужные участки текста закрывать тегом </noindex>.
Ноуиндекс можно использовать, когда необходимо спрятать от яндекса ненужные «загрязняющие» страницы части html-кодов:
-
не уникальный или повторяющийся контент
-
вставленные цитаты с других источников
-
различные формы- рассылки, подписки, почта
-
закрыть ненужные неприличные слова
Nofollow – это атрибут тега <a>, запрещающий индексацию и передачу веса по ссылке поисковиком Google, и так же учитывается Яндексом. Хотя на счёт ян-кса существуют и другие мнения.
Пример написания ноуфоллоу в ссылке: <a href=»http://kakoyto.ru» rel=»nofollow»>текст ссылки</a>.
Nofollow применяют:
-
чтобы запретить передачу веса по ссылке на сайт с плохой репутацией у поисковиков
-
чтобы не переносить вес на не соответствующий тематике ресурс
-
для уменьшения общего количества исходящих ссылок со страницы
-
когда нежелательно передавать вес на супер-сайты с очень большим ТИЦ и PR
-
закрыть ссылки в комментариях, когда это не нужно
Некоторые оптимизаторы применяют совместное использование noindex и nofollow, заключая ссылки в оба тега. На мой взгляд это не эффективно, так как ноуфоллоу запрещает перенос веса, а добавление ноуиндекс закроет лишь текст ссылки — анкор от индексации яндексом, что не имеет никакого смысла.
На мой взгляд это не эффективно, так как ноуфоллоу запрещает перенос веса, а добавление ноуиндекс закроет лишь текст ссылки — анкор от индексации яндексом, что не имеет никакого смысла.
В заключении стоит сказать, что применение того или иного тега, не гарантирует, что поисковые системы полностью будут следовать этим указаниям. Хозяин — барин…
***
- < Назад
- Вперёд >
Как запретить индексирование сайта или страниц
Скрыть содержимое сайта от индексирования можно с помощью файла robots.txt, HTML-разметки или авторизации на сайте.
- Запретить индексирование сайта, раздела или страницы
- Запретить индексирование части текста страницы
- Скрыть от индексирования ссылку на странице
Если какие-то страницы или разделы сайта не должны индексироваться (например, со служебной или конфиденциальной информацией), ограничьте доступ к ним следующими способами:
В файле robots.
txt укажите директиву Disallow.
В HTML-коде страниц сайта укажите метатег robots с директивой noindex или none. Подробнее см. в разделе Метатег robots и HTTP-заголовок X-Robots-Tag.
Используйте авторизацию на сайте. Рекомендуем этот способ, чтобы скрыть от индексирования главную страницу сайта. Если главная страница запрещена в файле robots.txt, но на нее ведут ссылки с других сайтов, страница может попасть в результаты поиска.
Примечание. Чтобы неавторизованные пользователи не попадали на закрытые страницы, настройте для таких страниц HTTP-код ответа сервера 404 Not Found, 403 Forbidden или 410 Gone.
Скрыть от индексирования часть текста можно несколькими способами:
В HTML-код страницы добавьте элемент noindex. Например:
<noindex>текст, индексирование которого нужно запретить</noindex>
Элемент не чувствителен к вложенности — может находиться в любом месте HTML-кода страницы.
Если на странице отсутствует закрывающий тег, скрытым считается весь контент страницы. Не создавайте множественную вложенность тегов noindex — разметка будет учитываться только до первого закрывающего тега.При необходимости сделать код сайта валидным возможно использование тега в следующем формате:
<!--noindex-->текст, индексирование которого нужно запретить<!--/noindex-->
В HTML-код страницы добавьте элемент noscript. Например:
<noscript>текст, индексирование которого нужно запретить</noscript>
Элемент noscript, как и noindex, запрещает индексирование, но при этом скрывает содержимое сайта от пользователя, если его браузер поддерживает технологию JavaScript.
Примечание. JavaScript поддерживают все популярные браузеры, если эта функция не отключена пользователем специально.
Посмотреть отчет о наличии JavaScript можно в Яндекс Метрике .
 Если на странице отсутствует закрывающий тег, скрытым считается весь контент страницы. Не создавайте множественную вложенность тегов noindex — разметка будет учитываться только до первого закрывающего тега.
Если на странице отсутствует закрывающий тег, скрытым считается весь контент страницы. Не создавайте множественную вложенность тегов noindex — разметка будет учитываться только до первого закрывающего тега.Рекомендуем использовать атрибут rel. Разные значения атрибута указывают на тип ссылки, что помогает поисковой системе лучше распознавать содержимое сайта.
Разные значения атрибута указывают на тип ссылки, что помогает поисковой системе лучше распознавать содержимое сайта.
rel=»ugc». Используйте, если на вашем сайте есть форум или возможность оставить отзыв и вы не уверены в качестве ссылок, которые оставляют посетители.
rel=»sponsored». Используйте, если ссылка носит рекламный характер, указывает на рекламное место или размещение в рамках партнерской программы с другим сайтом.
rel=»nofollow». Указывайте, чтобы робот не проходил по ссылке, не зависимо от ее типа.
Можно комбинировать несколько значений. Пример:
<a href="url" rel="nofollow,sponsored">текст ссылки</a> или <a href="url" rel="nofollow sponsored">текст ссылки</a>
Значения атрибута rel воспринимаются роботом как рекомендация не принимать ссылку во внимание.
Чтобы скрыть от индексирования все ссылки на странице, укажите в HTML-коде страницы метатег robots с директивой nofollow. Робот не перейдет по ссылкам при обходе сайта, но может узнать о них из других источников. Например, на других страницах или сайтах.
Робот не перейдет по ссылкам при обходе сайта, но может узнать о них из других источников. Например, на других страницах или сайтах.
При использовании любого из перечисленных указаний ссылка может быть обработана роботом и отобразиться в Вебмастере как внутренняя или внешняя. Само отображение или отсутствие ссылки в Вебмастере не указывает на то, что поисковые алгоритмы учитывают ее.
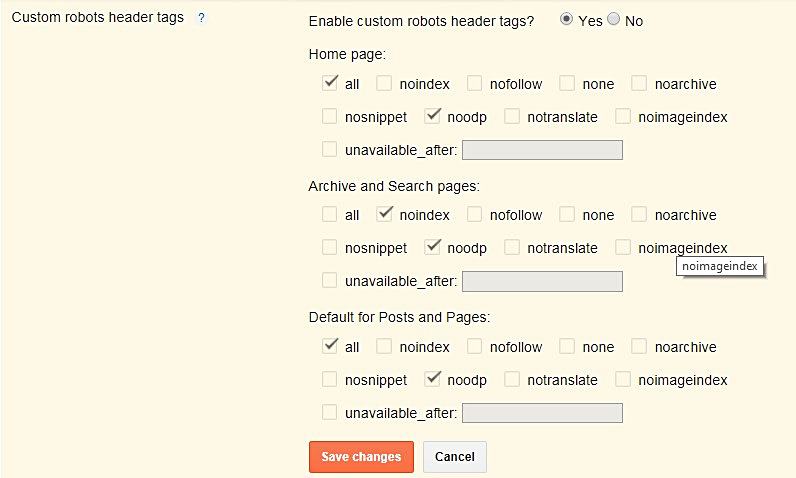
Директивы Noindex и Nofollow
Директивы Noindex и Nofollow
Содержание индекса Облако релевантности Coveo Разработчик Системный администратор Документация по продукту
В этой статье
- Добавление специальных директив Coveo
- Игнорировать директивы
- Что дальше?
В код веб-страницы можно добавить директивы, чтобы указать роботам, как индексировать содержимое страницы.
В частности, 9Директива 0017 noindex предписывает сканерам не индексировать страницу, а директива nofollow запрещает им переходить по ссылкам на странице (см. спецификации метатега Robots и HTTP-заголовка X-Robots-Tag).
При индексировании содержимого веб-источника сканер Coveo может либо следовать, либо игнорировать эти директивы (см. Добавление или редактирование веб-источника).
спецификации метатега Robots и HTTP-заголовка X-Robots-Tag).
При индексировании содержимого веб-источника сканер Coveo может либо следовать, либо игнорировать эти директивы (см. Добавление или редактирование веб-источника).
При индексировании содержимого веб-сайта сканер Coveo учитывает следующие директивы.
Эти директивы не чувствительны к регистру и могут появляться как на странице HTML метатег или в HTTP-заголовке X-Robots-Tag .
 php" rel="nofollow">войти
php" rel="nofollow">войти Как правило, если не указано иное, эти директивы применяются ко всем роботам. Однако, если вы хотите, чтобы сканер Coveo соблюдал другие правила, у вас есть два варианта:
Если вы являетесь владельцем веб-сайта, который вы хотите сделать доступным для поиска, вы можете добавить директивы, специфичные для Coveo, в код, которому будет следовать сканер Coveo (см. Добавление директив, специфичных для Coveo).
Если вы не можете редактировать код веб-сайта, вы можете настроить свой веб-источник так, чтобы он игнорировал директивы
nofollow(см. Игнорировать директивы).
 Игнорировать директивы).
Игнорировать директивы).Добавить специальные директивы Coveo
Если вы являетесь владельцем веб-сайта, который вы хотите сделать доступным для поиска, вы можете добавить директивы индексации в код своей страницы, чтобы указать, какие элементы (т. е. страницы веб-сайта) разрешено сканировать роботам.
Мета-директивы с name="robots" и директивы заголовка ответа HTTP без указания имени искателя применяются ко всем искателям.
Однако если вы хотите, чтобы некоторые директивы применялись только к сканеру Coveo, вы можете использовать свойство name , чтобы указать coveobot .
В результате всякий раз, когда ваша страница содержит директивы, специально предназначенные для сканера Coveo, сканер следует этим инструкциям и игнорирует общие директивы для всех роботов.
Примеры
С метатегом следующая страница запрещается всем роботам индексировать страницу и переходить по ссылкам на ней, кроме
coveobotгусеничный:Со следующим HTTP-заголовком X-Robots-Tag всем роботам запрещено индексировать страницу и переходить по ссылкам в ней, кроме краулера
coveobot:HTTP/1.
1 200 ОК
Дата: пн, 29 апреля 2019 г., 15:08:11 по Гринвичу
(…)
X-Robots-Tag: nofollow, noindex, coveobot: все
(…)
 1 200 ОК
Дата: пн, 29 апреля 2019 г., 15:08:11 по Гринвичу
(…)
X-Robots-Tag: nofollow, noindex, coveobot: все
(…)
1 200 ОК
Дата: пн, 29 апреля 2019 г., 15:08:11 по Гринвичу
(…)
X-Robots-Tag: nofollow, noindex, coveobot: все
(…) Игнорировать директивы
В качестве альтернативы, особенно если вы не являетесь владельцем веб-сайта, который вы хотите сделать доступным для поиска, вы можете указать сканеру Coveo игнорировать директивы веб-сайта. Для этого на панели Добавить/редактировать веб-источник в разделе Настройки сканирования снимите соответствующий флажок (см. раздел Добавление или редактирование веб-источника).
Примечание Попробуйте уведомить владельца веб-сайта о том, что вы приказали сканеру Coveo игнорировать его указания. |
Что дальше?
Вы также можете настроить предельную скорость сканирования и дать указание сканеру Coveo обходить ограничения, указанные в файле robots.txt веб-сайта , если это еще не сделано (см. разделы Предельная скорость сканирования и Уважайте директивы robots. txt).
txt).
Была ли эта статья полезной?
Очень полезно Не совсем
Когда использовать NoIndex NoFollow в SEO
Термины NoIndex и NoFollow продолжают появляться при поисковой оптимизации. В этом посте я объясню на простом английском языке, как эти термины влияют на ваши результаты SEO.
Что такое NoIndex?
NoIndex — это так называемый метатег, который хранится в файле Robots.txt веб-сайта. Файл Robots.txt показывает поисковым системам, какие страницы сайта следует учитывать, а какие нет. Если на страницу добавлен тег NoIndex, это означает «запрет» в файле Robots.txt для сканирования страницы. Тогда поисковые системы будут игнорировать страницу.
Что означает NoFollow?
NoFollow означает, в отличие от NoIndex, что ссылка не считается переходом для поисковых систем.
Когда сканеры поисковых систем индексируют страницу, они «щелкают» и переходят по каждой ссылке — внутренней и внешней. С помощью атрибута ссылки NoFollow вы сигнализируете поисковым роботам не переходить по выбранной ссылке.
С помощью атрибута ссылки NoFollow вы сигнализируете поисковым роботам не переходить по выбранной ссылке.
Варианты использования NoIndex для SEO
SEO-маркетологи используют NoIndex для страниц, которые они хотят, чтобы поисковые системы игнорировали. NoFollow просто означает не переходить по ссылке и, таким образом, считать ее, например, обратной ссылкой.
Есть несколько причин, по которым страница должна быть удалена из индекса поисковых систем. Вот несколько примеров NoIndex:
- Дублированный контент на нескольких страницах
- Каннибализация ключевых слов из-за ранжирования одних и тех же ключевых слов на разных страницах
- Страница не используется в целях органического маркетинга, т.е. целевые страницы для PPC-кампаний
- Устаревшие посты в блогах, которые больше не актуальны, но все же не должны быть удалены — экономия краулерного бюджета
- Предотвращение ошибок SEO на сайте. Например, архивы могут вызвать технические ошибки SEO на сайте. Чтобы избежать этого, вы можете попросить поисковые системы игнорировать страницу.
- Страницы с благодарностью или ресурсом, на которые можно попасть только с помощью определенных действий пользователя, таких как форма или ворота контента. Это также могут быть страницы, созданные только для рассылок по электронной почте, участников мероприятий или аналогичных обязательных подписок.
- Внутренние результаты поиска страниц контента или интернет-магазинов. Отсутствие индексации может не только привести к дублированию контента, но и увеличить ваш SEO-инвентарь, что в данном случае было бы вредно. Усилия поисковых роботов будут слишком высокими и могут привести к тому, что релевантные страницы не будут проиндексированы.
 Например, архивы могут вызвать технические ошибки SEO на сайте. Чтобы избежать этого, вы можете попросить поисковые системы игнорировать страницу.
Например, архивы могут вызвать технические ошибки SEO на сайте. Чтобы избежать этого, вы можете попросить поисковые системы игнорировать страницу.Каковы причины использования тегов NoFollow?
Есть много причин, по которым SEO-специалисты присваивают атрибуту NoFollow метаинформацию о ссылке:
- Внешние ссылки, которые не следует считать обратными.
- Не следуйте рекламе. Медийные объявления обычно — если явно не указано иное — имеют атрибут NoFollow.
- Платные ссылки: в дополнение к внешним ссылкам и рекламным мероприятиям. Рекламные сообщения также могут иметь назначенный им тег NoFollow.
- Комментарии, форумы и пользовательский контент: когда пользователи могут сами размещать ссылки, этим часто злоупотребляют. Поэтому весь пользовательский контент должен иметь тег NoFollow.

Объяснение кодов NoIndex NoFollow
Это может немного сбить с толку. Существуют различные варианты использования и сочетания команд:
- NoIndex: поисковые системы не должны индексировать страницу (показывать ее в результатах поиска).
- NoFollow: ссылка не должна учитываться
- NoIndex, Follow: Страница не должна индексироваться, но следует переходить по ссылкам на странице.
- NoIndex, NoFollow: не индексировать страницу и не переходить по ссылкам на странице.